一种识别复配加料香精种类及浓度偏离的方法与流程
本发明涉及烟用香精分析领域,更具体地,涉及一种识别复配加料香精种类及浓度偏离的方法。
背景技术:
为了丰富卷烟的口味,会在卷烟生产的过程中在添加香精。香精根据添加的施加工艺不同,可以分为两种,第一类是在加料工艺中添加的,这类香精通常与水混合后添加到烟叶中,叶片迅速吸收料液,提高叶片含水率并改善烟叶品质,经过储叶柜2小时以上的平衡后,进行回潮、切丝和烘丝工序,并通过烘丝过程降低含水率,达到水分平衡;第二类是在加香工艺添加的,这类香精通常与挥发性溶剂(通常为乙醇)混合后添加到经过烘干的烟丝中,并不再进行溶剂的去除处理。在实际生产中发现,香精配方或浓度的轻微变化,都可能对烟丝口味改善效果发生明显影响,因此要求严格控制每批次的香精配方及浓度的一致性。然而现有对香精配方及浓度的控制,还是依赖人工进行为主,缺少一种科学的快速的识别方法;现有技术中有从用折光率等指标进行检测,但这些指标的适用性有限,未能实现对香精的种类和浓度进行精确检测。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种识别复配加料香精种类及浓度偏离的方法。经大量实验测试,该方法能迅速识别复配加料香精种类,并且能灵敏地判别复配加料香精是否与标准样品的浓度发生偏离。
本发明的上述目的通过如下技术方案予以实现:
一种识别复配加料香精种类及浓度偏离的方法,包括如下步骤:
S1.对待测复配加料香精样品进行近红外检测,获得近红外全波段光谱数据;
S2.对S1.所得全波段光谱数据进行数据处理:
选取6200~5500cm-1波段范围数据,并进行二阶导数处理;
S3.依据S2.处理后的数据与设定的标准样品的数据进行比较,判别待测复配加料香精样品的种类;以及换算待测复配加料香精样品数据与对应标准样品数据的马氏距离,判别待测复配加料香精样品的浓度与标准浓度样品浓度的差异程度;
S2.中,光程类型为SNV;
所述复配加料香精包括烟用香精成分和溶剂成分,所述溶剂为水。近红外透射光谱由于能采集较多的数据信息,已经有被报道用于烟用香精的品质控制中。但是现有的方法只能针对单一的烟用香精,并且采用全波段色谱数据。然而发明人发现,对于复配香精,由于为多种香精复配,其致香成分较单一香精更复杂,如果采用全波段的原光谱建立模型,一方面由于水分子的O~H键与香精中的致香成分如醇类、酚类、酸类等物质所含的强极性O~H键容易造成光谱重叠,另一方面复杂体系自身造成的光谱重叠使得这些波长处的光谱信息的测量选择性较差。因此复配香精的种类辨别难度较单一香精的辨别难度更大。并且,对于生产来说,不同品牌的香烟所用的复配香精的种类可能不同,因此,要求所建立的方法对多个不同种类的复配香精均有适用性。然而如果采用全波段的原光谱建立模型,不同种类的复配香精的主成分得分有重叠的现象,可见采用全波段的原光谱建立模型的辨别效果很不理想,即使采用导数处理,也不能将不同种类复配香精进行有效区分。
提取吸收较小的部分波段6200~5500cm-1进行建模时,同种类烟用复配加料香精的主成分得分较为分散,且不同种类烟用复配加料香精没有明显的距离,不能将不同种类烟用复配加料香精进行有效区分。
发明人发现,当同时选择吸收较小的部分波段6200~5500cm-1及其二阶导数处理的光谱进行建模时,同种样品的主成分得分分布相对集中,不同样品的主成分得分具有明显的距离。因此,通过对光谱数据进行合理的处理,可以建立具有较高识别效果的模型。如果对该测试样品数据进行一阶导数处理,也不能获得很好的识别效果。
光程类型对识别效果有影响,采用SNV模式下的光程类型,能够获得较高的识别效果。
另外,现有技术也有通过检测方法所计算的马氏距离判断样品浓度变化的方法,马氏距离的变化程度受样品种类的影响变化很大。对于某一样品,可能马氏距离变化很大,而对于另一样品来说,马氏距离变化很小,即对于不同的样品,区分度(灵敏度)可能会有明显差异。而通过对本领域的一些常用的复配加料香精样品进行反复测试,发现,上述方法对于常用的复配加料香精样品,均有较高的区分度,即对样品浓度偏离识别有高的灵敏度。
所述近红外检测的条件可以参照现有对烟用香精的检测条件。即,所述近红外检测的条件为:采集波数范围10000~4000cm-1,固定光程,以仪器内置背景为参比,样品和参比均使用32次扫描,分辨率8cm-1。
所述烟用香精成分为将两种以上香精混合后的烟用香精成分。
优选地,所述烟用香精成分为将两种香精混合后的烟用香精成分。
通常地,所述烟用香精成分占复配加料香精重量的8~15 %。
与现有技术相比,本发明具有以下优点:
本发明公开的方法能够快速识别复配加料香精的种类,除了定性分析外,还能灵敏辨别复配加料香精样品与标准样品的浓度偏离程度,并且适用性广,对多种复配加料香精,均有很好的预测效果,能实现生产中对复配加料香精的准确识别。
附图说明
图1 实施例1采用(10000~4000)cm-1范围,不进行导数处理的数据建模的主成分得分图。
图2 实施例1采用(10000~4000)cm-1范围,一阶导数处理的数据建模的主成分得分图。
图3 实施例1采用(10000~4000)cm-1范围,二阶导数处理的数据建模的主成分得分图。
图4 实施例1采用(9000~7200)cm-1范围,不进行导数处理的数据建模的主成分得分图。
图5实施例1采用(9000~7200)cm-1范围,一阶导数处理的数据建模的主成分得分图。
图6 实施例1采用(9000~7200)cm-1范围,二阶导数处理的数据建模的主成分得分图。
图7实施例1采用(6200~5500)cm-1范围,不进行导数处理的数据建模的主成分得分图。
图8实施例1采用(6200~5500)cm-1范围,一阶导数处理的数据建模的主成分得分图。
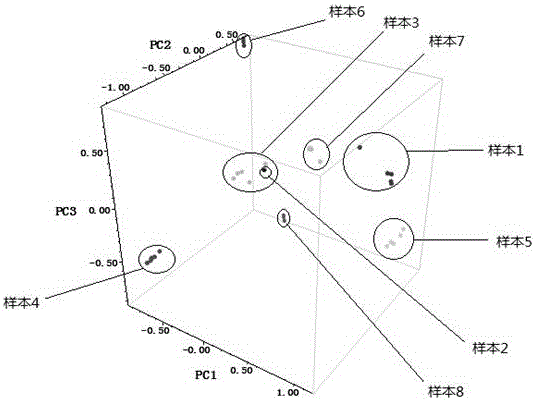
图9实施例1采用(6200~5500)cm-1范围,二阶导数处理的数据建模的主成分得分图。
具体实施方式
下面结合具体实施例进一步详细说明本发明。除非特别说明,本发明采用的试剂、设备和方法为本技术领域常规市购的试剂、设备和常规使用的方法。
实施例中所用的香精均为市售香精。
挑选常用的较有代表性的8种复配加料香精作为标准样品,具体如下:
试样1的标准样品:辛甜型香精、酒香型香精和水按2%、8%、90%重量比例混合。所述辛甜型香精为茴香香精,所述酒香型香精为白酒香精。
另外,再往上述标准样品中加入水,将上述样品稀释为原来的95%、90%、85%、80%的浓度(即对应为分别配制水重量比为90.5%、91%、91.5%、92%的偏差试样溶液。)
试样2的标准样品:酸甜型香精、果香型香精和水按3%、6%、91%重量比例混合。所述酸甜型香精为发酵型草莓香精,所述果香型香精为圆柚香精。
另外,再往上述标准样品中加入水,将上述样品稀释为原来的95%、90%、85%、80%的浓度(即对应为分别配制水重量比为91.45%、91.9%、92.35%、92.8%的偏差试样溶液。)
试样3的标准样品:烟草香型香精、膏甜型香精和水按10%、5%、85%重量比例混合。所述烟草香型香精为白肋烟提取物,所述膏甜型香精为秘鲁浸膏。
另外,再往上述标准样品中加入水,将上述样品稀释为原来的95%、90%、85%、80%的浓度(即对应为分别配制水重量比为85.75%、86.5%、87.25%、88%的偏差试样溶液。)
试样4的标准样品:发酵酸香型香精、果甜型香精和水按4%、6%、90%重量比例混合。所述发酵酸香型香精为果类发酵酸香香精,所述果甜型香精为偏果甜型的梅子香精。
另外,再往上述标准样品中加入水,将上述样品稀释为原来的95%、90%、85%、80%的浓度(即对应为分别配制水重量比为90.5%、91%、91.5%、92%的偏差试样溶液。)
试样5的标准样品:药香型香精、烟草香型香精和水按6%、2%、92%重量比例混合。所述药香型香精为冬青精油,所述烟草香型香精为津巴布韦烤烟提取物。
另外,再往上述标准样品中加入水,将上述样品稀释为原来的95%、90%、85%、80%的浓度(即对应为分别配制水重量比为92.4%、92.8%、93.2%、93.6%的偏差试样溶液。)
试样6的标准样品:药香型香精、焦甜型香精和水按2%、8%、90%重量比例混合。所述药香型香精为葫芦巴浸膏,所述焦甜型香精为偏烘焙香的麦芽香精。
另外,再往上述标准样品中加入水,将上述样品稀释为原来的95%、90%、85%、80%的浓度(即对应为分别配制水重量比为90.5%、91%、91.5%、92%的偏差试样溶液。)
试样7的标准样品:甜香型香精、辛香型香精和水按9%、6%、85%重量比例混合。所述甜香型香精为偏甜香的热带水果香精,所述辛香型香精为偏辛香味的丁香香精。
另外,再往上述标准样品中加入水,将上述样品稀释为原来的95%、90%、85%、80%的浓度(即对应为分别配制水重量比为85.75%、86.5%、87.25%、88%的偏差试样溶液。)
试样8的标准样品:酸香型香精、烘烤香型香精和水按5%、3%、92%重量比例混合。所述酸香型香精为酱类发酵酸香香精,所述烘烤香型香精为愈创木树脂香型香精。
另外,再往上述标准样品中加入水,将上述样品稀释为原来的95%、90%、85%、80%的浓度(即对应为分别配制水重量比为92.4%、92.8%、93.2%、93.6%的偏差试样溶液。)
实施例1 种类判别
S1.配制上述试样1~8的标准样品分别各5个,各平衡标准样品采用折光率检测确认均为合格的标准样品,分别进行近红外检测,获得近红外全波段光谱数据;
所述近红外检测的条件为:采集波数范围10000~4000cm-1,固定光程,以仪器内置背景为参比,样品和参比均使用32次扫描,分辨率8cm-1。
S2.对S1.所得全波段光谱数据进行数据处理:设定光程类型为SNV,分别以采用10000~4000 cm-1、9000~7300cm-1、6200~5500cm-1波段范围,及不进行导数处理、进行一阶或二阶导数处理;分别建立模型,并进行内部检验,内部检验沿用建模样品。共40个样品。检验结果如表1所示。
图1~9分别反映了不同波段范围及是否进行导数处理,对模型构建的影响。图1~3可以看出,对于采用全波段(10000~4000 cm-1)范围,无论是否进行导数处理,平衡样之间的得分较为分散,因此在检测时,错误率较高。
从图4~5可以看出,采用(9000~7200 cm-1)范围,如果不进行导数处理或仅进行一阶导数处理,虽然部分平衡样之间得分较集中,但各试样之间的差异小,部分平衡样得分较分散,难以做出准确预测。从图6可以看出,采用(9000~7200 cm-1)范围,进行二阶导数处理会有相对较好的结果,但对于部分样品,例如样品3,平衡样得分还是不够集中,存在错判风险。
从图7~8可以看出,即使采用较小的波段(6200~5500 cm-1)范围,如果不进行导数处理或仅进行一阶导数处理,其平衡样之间的得分依然较为分散。存在错判的风险。
从图9可以看出,采用较小的波段(6200~5500 cm-1)范围,并经过二阶导数处理,各个试样的平衡样的得分很集中,不同试样之间的差异较大,因此可以较准确的进行预判。
表1
尽管从内部检验来看,(9000~7300cm-1)范围与(6200~5500cm-1)范围仅在原光谱数据的检测结果上有差异,但从模型构建的图形来看,不同条件下构建的模型差异性较大,因此还需要结合实际预测来验证模型的准确性。
实施例2
S1. 对上述试样1~8的4个浓度分别进行近红外检测,获得近红外全波段光谱数据;
所述近红外检测的条件为:采集波数范围10000~4000cm-1,固定光程,以仪器内置背景为参比,样品和参比均使用32次扫描,分辨率8cm-1。
S2.对S1.所得全波段光谱数据进行数据处理:
选取6200~5500cm-1波段范围数据,设定光程类型为SNV,并进行二阶导数处理;
S3.依据S2.处理后的数据与设定的标准样品的数据进行比较,判别待测样品的种类;以及换算待测样品数据与对应标准样品数据的马氏距离,判别待测样品的浓度与标准浓度样品浓度的差异程度;并计算区分度。区分度的计算方式为:
区分度== 80%稀释样品离标准样品的马氏距离/95%稀释样品距标准样品的马氏距离。
浓度偏离的检测结果:
当选用实施例2所述条件处理时,各偏差试样的区分度如表2所示:
表2
对比例
选取9000~7300cm-1波段范围并采用二阶导数数据处理,其余与实施例2相同,比较波段范围对区分度的影响,各偏差试样的区分度如表3所示:
表3
从表2可以看出,对于多种不同配方复配成的复配加料香精,所述的识别方法均具有良好的区分度。并且即使香精浓度发生细微的变化(约0.5%),也依然能够灵敏地反映浓度偏离。从表3可以看出,当选取的波段范围不在本发明所述范围内时,灵敏度明显出现下降。
应用例:
利用建立起来的近红外分析模型,跟踪分析生产配制的复配加料香精样品共71个,运用定性判别模型进行双喜品牌复配加料香精的规格识别、规格匹配度的判定,各样品经过折光密度检测值均确认为合格样品(实际配制合格样品允许偏差1%,即,如标准样品的浓度为100%,那么在该浓度的99-101%范围内,均可判定为合格样品),不同的方法构建的模型的判定结果如表4所示。从表4可以看出,仅在(6200~5500cm-1)范围,并对数据进行二阶导数处理建立的模型,才能达到100%的预测准确率。证明了本发明构建的近红外分析模型能在实际生产中持续应用,并作为常规折光密度检测手段的补充。
表4 近红外跟踪分析复配加料香精
- 还没有人留言评论。精彩留言会获得点赞!