一种基于经验模态分解动态优化的催化剂混合反应控制装置的制作方法
本发明涉及管式反应器生产控制领域,主要是一种基于经验模态分解动态优化的催化剂混合反应控制装置。能够对管式反应器内的催化剂混合比率进行自动控制,以提高目标产品的浓度。
背景技术:
催化剂混合反应系统广泛应用于石油化工、精细化工、农药等工业生产中。对于管长固定的管式反应器,当原料配额比、浓度等物料参数确定以后,在充分搅拌的条件下,影响产品产量的关键因素就是催化剂混合比率。由于不同产品的生产工艺要求不同,所以按生产工艺要求对管式反应器内的催化剂混合比率自动地进行最优控制是催化剂混合反应系统挖潜增效的关键。
当前国内管式反应器的控制方法中很少采用动态优化理论及对应方法,控制器中的参数往往凭已有经验设定。采用动态优化方法后的管式反应器装置的产品浓度可以进一步提高,实现挖潜增效。
技术实现要素:
为了提高催化剂混合反应器目标产品的浓度,本发明提供了一种基于经验模态分解动态优化的催化剂混合反应控制装置。
本发明的目的是通过以下技术方案来实现的:一种基于经验模态分解动态优化的催化剂混合反应控制装置,能够对管式反应器内催化剂混合比率自动控制,以提高目标产品的生产浓度。由管式反应器、混合比率传感器、模数转换器、现场总线网络、分散控制系统(dcs)、主控室混合比率与产品浓度状态显示、混合比率控制阀门端的数模转换器、混合比率控制阀门构成。所述控制装置的运行过程包括:
步骤1):控制室工程师指定管式反应器的长度、催化剂混合比率限制、反应器反应物的初始浓度状态、催化剂的初始混合比率信息,设定需要提高浓度的目标产品;
步骤2):dcs执行内部经验模态分解动态优化算法,获得使目标产品浓度最大的催化剂混合比率控制策略;
步骤3):dcs将得到的催化剂混合比率控制策略转换为混合比率控制阀门的开度指令,通过现场总线网络发送给混合比率控制阀门端的数模转换器,混合比率控制阀门根据收到的开度指令执行相应动作;
步骤4):混合比率传感器实时采集反应器反应物浓度,经过模数转换器后用现场总线网络回送给dcs,并在主控室内显示,使控制室工程师随时掌握生产过程。
所述的dcs,包括信息采集模块、初始化模块、动态优化求解模块、动态优化收敛性判断模块、经验模态分解模块、参数更新模块、控制指令输出模块。其中信息采集模块包括管式反应器管长采集、初始浓度和混合比率限制采集、目标产品参数采集三个子模块;动态优化求解模块包括微分代数方程组(ordinarydifferentialequations,简称ode)求解模块、梯度求解模块、非线性规划(nonlinearprogramming,简称nlp)问题求解模块三个子模块;nlp问题求解模块包括寻优方向求解、寻优步长求解、寻优校正、nlp收敛性判断四个子模块。
该管式反应器中目标产品的生产过程可以描述为:
其中t表示管长;u(t)表示催化剂的混合比率;x(t)是表示管式反应器中随管长变化的产品浓度,
要使管式反应器中目标产品的浓度最高,定义x3(t)为该目标产品随管长变化的浓度,则该问题的动态优化数学模型表达式为:
其中t0表示管长的起始端,tf表示管长的末端,x0表示管式反应器中各反应物的初始浓度,φ[u(t)]表示由控制变量即催化剂的混合比率u(t)决定的控制目标。
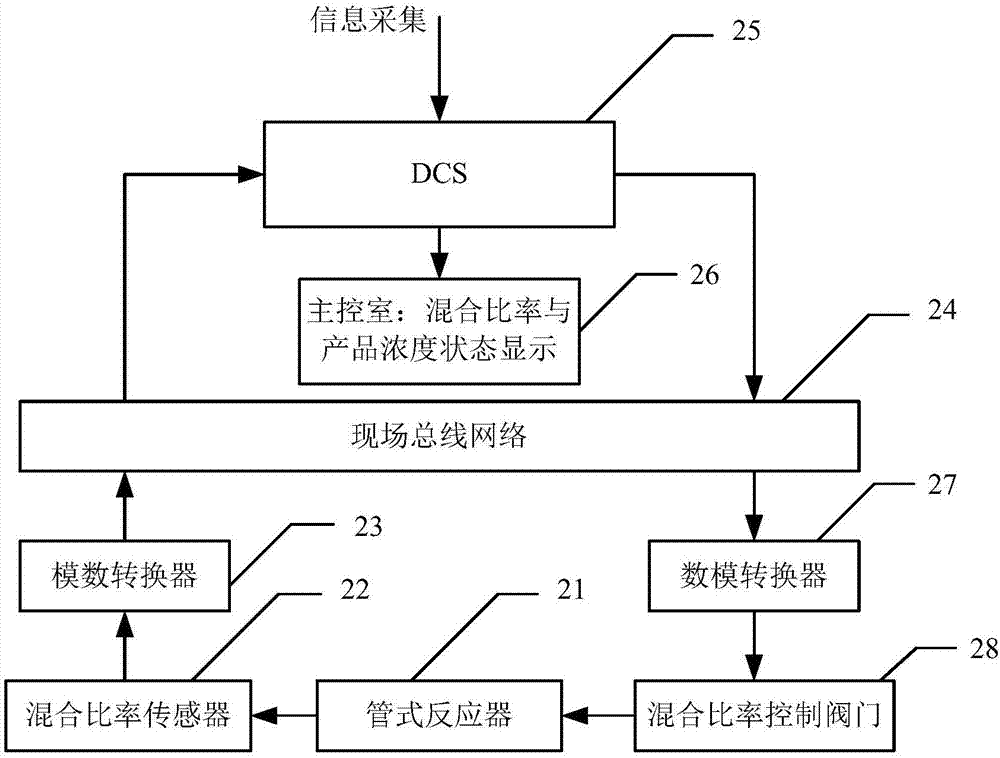
本发明解决其技术问题所采用的技术方案是:在分散控制系统(dcs)中集成了一种基于经验模态分解动态优化方法,并以此为基础构建了一套控制装置。所述装置的完整结构包括管式反应器21、混合比率传感器22、模数转换器23、现场总线网络24、dcs25、主控室催化剂混合比率与产品浓度状态显示26、混合比率控制阀门端的数模转换器27、混合比率控制阀门28。
所述系统的运行过程如下:
步骤1):控制室工程师指定管式反应器的长度、催化剂混合比率限制、反应器反应物的初始浓度状态、催化剂的初始混合比率信息,设定需要提高浓度的目标产品;
步骤2):dcs执行内部经验模态分解动态优化算法,获得使目标产品浓度最大的催化剂混合比率控制策略;
步骤3):dcs将得到的催化剂混合比率控制策略转换为混合比率控制阀门的开度指令,通过现场总线网络发送给混合比率控制阀门端的数模转换器,混合比率控制阀门根据收到的开度指令执行相应动作;
步骤4):混合比率传感器实时采集反应器物料浓度,经过模数转换器后用现场总线网络回送给dcs,并在主控室内显示,使控制室工程师随时掌握生产过程。
所述的dcs,包括信息采集模块、初始化模块、动态优化求解模块、经验模态分解模块、收敛性判断模块、参数更新模块、控制指令输出模块。其中信息采集模块包括管式反应器管长采集、初始浓度和混合比率限制采集、目标产品参数采集三个子模块;动态优化求解模块包括微分代数方程组(ordinarydifferentialequations,简称ode)求解模块、梯度求解模块、非线性规划(nonlinearprogramming,简称nlp)问题求解模块三个子模块;nlp问题求解模块包括寻优方向求解、寻优步长求解、寻优校正、nlp收敛性判断四个子模块。
所述dcs产生混合比率控制阀门开度指令的经验模态分解动态优化算法运行步骤如下:
步骤1):信息采集模块31获取工程师指定的管式反应器的长度、需要优化的目标产品参数以及初始浓度和混合比率限制;
步骤2):初始化模块32开始运行,将经验模态分解迭代次数l和nlp问题求解迭代次数k置零;采用分段常量参数化,设置反应器管长的分段数为ne、对应的控制网格为t(l)和催化剂混合比率控制策略的初始猜测值u(l),设定nlp问题的计算精度tol1,动态优化求解算法收敛精度tol2,动态优化最大迭代次数lmax;
步骤3):通过动态优化求解模块33获取第l次迭代的的控制策略u(l)和目标函数值φ[u(l)];
步骤4):如果l=0,直接转至步骤5);否则,采用动态优化收敛性判断模块34进行收敛性判断,如果φ[u(l)]与上一次迭代的目标函数值φ[u(l-1)]满足
则判断满足收敛条件,将第l次迭代得到的催化剂混合比率控制策略输出至控制指令输出模块37并转换为混合比率控制阀门开度指令输出;如果不满足,则继续执行步骤5);此外,如果l=lmax,无论φ[u(l)]是否满足公式(1),本次迭代得到的催化剂混合比率控制策略都将输出至控制指令输出模块37并转换为混合比率控制阀门开度指令输出;
步骤5):采用经验模态分解模块34对步骤3)中获得的控制策略u(l)进行经验模态分解,得到模态分解趋势项信息,根据得到的趋势项信息重构控制网格
步骤6):迭代次数l加1,结合重构后的控制网格
所述的动态优化求解模块,采用如下步骤实现:
步骤1):结合初始化模块32或参数更新模块36提供的参数信息,采用ode求解模块38获取本次迭代的状态信息x(k)(t)和目标函数值j(k)。
步骤2):通过梯度求解模块39获取本次迭代目标函数梯度信息dj(k);
步骤3):nlp问题求解模块40利用步骤1)和2)中获得的目标函数值和梯度信息,求解寻优方向和寻优步长,并进行寻优修正,获得比u(k-1)更优的控制策略u(k);
步骤4):nlp问题求解模块40运行,通过nlp收敛性判断模块进行收敛性判断,如果j(k)与上一次迭代的目标函数值j(k-1)的绝对值之差小于精度tol1,则判断收敛性满足,u(l)=u(k),φ[u(l)]=j(k),将本次迭代得到的控制策略u(l)和目标函数φ[u(l)]输出至动态优化收敛性判断模块34;如果收敛性不满足,则继续执行步骤5);
步骤5):nlp问题求解迭代次数k加1,利用步骤3)中得到的控制策略u(k)采用ode求解模块38重新求取状态信息x(k)(t)和目标函数值j(k),采用梯度求解模块39重新求解dj(k),执行步骤3)。
所述的ode求解模块,采用的是四级五阶龙格库塔方法,求解公式为:
其中,t表示管长,ti表示龙格库塔方法选择的积分节点,积分步长h为0.001,x(k)(ti)表示管式反应器反应物在第k次迭代中第ti节点的状态信息,f()是描述管式反应器中反应的状态微分方程函数,k1、k2、k3、k4分别表示龙格库塔法积分过程中的4个节点的函数值。
所述的梯度求解模块,采用灵敏度轨迹方程法:
步骤1):定义第k次迭代的灵敏度轨迹方程γ(k)(t)为:
γ(k)(t)的求解公式为:
其中,t表示反应器管长,
步骤2):采用四级五阶龙格库塔方法求解灵敏度轨迹方程γ(k)(t)在各积分时刻的值,求解公式为:
其中,t表示反应器管长,ti表示龙格库塔方法选择的控制过程中反应器长度节点,h为积分步长,x(k)(ti)表示反应器中反应物在第k次迭代中第ti节点的状态信息,s()是描述灵敏度方程的函数,q1、q2、q3、q4分别表示龙格库塔法积分过程中的4个节点的函数值。
步骤3):根据得到的状态信息x(k)(t)和灵敏度轨迹方程γ(k)(t),求解目标函数的梯度信息dj(k):
其中,φ(u(k),x(k)(t),tf)表示待优化的产品浓度目标函数。
所述的nlp问题求解模块,采用如下步骤实现:
步骤1):将初始化模块32或者参数更新模块36提供的催化剂混合比率控制策略u(k)作为初始值,u(k)是向量空间中的某个点,记作p1,p1对应的目标函数值就是j(k);
步骤2):从点p1出发,根据选用的nlp算法,根据ode求解模块38、梯度求解模块39得到的点p1处的目标函数梯度信息dj(k)和约束条件梯度信息g(k),构造向量空间中的一个寻优方向d(k)和步长α(k);
步骤3):通过式u(k+1)=u(k)+α(k)d(k)构造向量空间中对应u(k+1)的另外一个点p2;
步骤4):采用寻优校正u(k+1),得到校正后的点
步骤5):如果j(k+1)与上一次迭代的目标函数值j(k)的绝对值之差小于精度tol1,则判断收敛性满足,令φ[u(l)]=j(k+1),u(l)=u(k+1),将本次迭代得到的控制策略u(l)和目标函数φ[u(l)]输出至动态优化收敛性判断模块34;如果收敛性不满足,迭代次数k增加1,将u(k+1)设置为初始值,继续执行步骤2)。
所述的经验模态分解模块,采用如下步骤实现:
步骤1):对动态优化求解模块33得到的控制策略u(l)采用下式进行分解:
其中ci是u(l)的第i个固有模态函数,rn是u(l)的趋势项函数;
步骤2):根据步骤1)中得到的趋势项函数rn计算趋势变化信息,定义δj为向量rn的第j个元素的趋势变化值,用下式求解:
δk=rn,j+1-rn,j(10)
其中rn,j表示rn向量的第j个元素,rn,j+1表示rn向量的第j+1个元素;定义
其中,rn,j-1表示rn向量的第j-1个元素,rn,j表示rn向量的第j个元素,rn,j+1表示rn向量的第j+1个元素;
步骤3):根据步骤2)中得到的δj和
步骤4):根据控制网格重构结果得到重构后的控制网格
步骤5):将重构得到的控制网格
本发明的有益效果主要表现在:基于经验模态分解的催化剂混合控制装置,能够计算出催化剂混合问题的最优控制策略,可以适应问题的最优控制曲线,特别是找到问题的不连续点,因此能够获得较高的精度;采用自适应策略之后,下一次最优控制问题的初始估计值是当前迭代的最优曲线值,另一方面梯度求解模块给出了梯度的求解方法,由此可以获得较快的收敛速度,减少催化剂问题最优的控制策略的计算时间。本发明能够最大化目标产品的浓度,实现挖潜增效。
附图说明
图1是本发明的功能示意图;
图2是本发明的结构示意图;
图3是本发明dcs内部模块结构图;
图4是对实施例1获得的催化剂混合比率控制策略图;
图5是图4中催化剂混合比率对应的产品浓度变化图。
具体实施方式
如图1所示,该管式反应器中目标产品的生产过程可以描述为:
其中t表示管长;u(t)表示催化剂的混合比率;x(t)是表示管式反应器中随管长变化的产品浓度,
要使管式反应器中目标产品的浓度最高,定义x3(t)为该目标产品随管长变化的浓度,则该问题的动态优化数学模型表达式为:
其中t0表示管长的起始端,tf表示管长的末端,x0表示管式反应器中各反应物的初始浓度,φ[u(t)]表示由控制变量即催化剂的混合比率u(t)决定的控制目标。
本发明解决其技术问题所采用的技术方案是:在分散控制系统(dcs)中集成了一种基于经验模态分解动态优化方法,并以此为基础构建了一套控制装置。所述装置的完整结构如图2所示,包括管式反应器21、混合比率传感器22、模数转换器23、现场总线网络24、dcs25、主控室催化剂混合比率与产品浓度状态显示26、混合比率控制阀门端的数模转换器27、混合比率控制阀门28。
所述系统的运行过程如下:
步骤1):控制室工程师指定管式反应器的长度、催化剂混合比率限制、反应器反应物的初始浓度状态、催化剂的初始混合比率信息,设定需要提高浓度的目标产品;
步骤2):dcs执行内部经验模态分解动态优化算法,获得使目标产品浓度最大的催化剂混合比率控制策略;
步骤3):dcs将得到的催化剂混合比率控制策略转换为混合比率控制阀门的开度指令,通过现场总线网络发送给混合比率控制阀门端的数模转换器,混合比率控制阀门根据收到的开度指令执行相应动作;
步骤4):混合比率传感器实时采集反应器物料浓度,经过模数转换器后用现场总线网络回送给dcs,并在主控室内显示,使控制室工程师随时掌握生产过程。
所述的dcs,包括信息采集模块、初始化模块、动态优化求解模块、经验模态分解模块、收敛性判断模块、参数更新模块、控制指令输出模块。其中信息采集模块包括管式反应器管长采集、初始浓度和混合比率限制采集、目标产品参数采集三个子模块;动态优化求解模块包括微分代数方程组(ordinarydifferentialequations,简称ode)求解模块、梯度求解模块、非线性规划(nonlinearprogramming,简称nlp)问题求解模块三个子模块;nlp问题求解模块包括寻优方向求解、寻优步长求解、寻优校正、nlp收敛性判断四个子模块。
所述dcs产生混合比率控制阀门开度指令的经验模态分解动态优化算法如图3所示,运行步骤如下:
步骤1):信息采集模块31获取工程师指定的管式反应器的长度、需要优化的目标产品参数以及初始浓度和混合比率限制;
步骤2):初始化模块32开始运行,将经验模态分解迭代次数l和nlp问题求解迭代次数k置零;采用分段常量参数化,设置反应器管长的分段数为ne、对应的控制网格为t(l)和催化剂混合比率控制策略的初始猜测值u(l),设定nlp问题的计算精度tol1,动态优化求解算法收敛精度tol2,动态优化最大迭代次数lmax;
步骤3):通过动态优化求解模块33获取第l次迭代的的控制策略u(l)和目标函数值φ[u(l)];
步骤4):如果l=0,直接转至步骤5);否则,采用动态优化收敛性判断模块34进行收敛性判断,如果φ[u(l)]与上一次迭代的目标函数值φ[u(l-1)]满足
则判断满足收敛条件,将第l次迭代得到的催化剂混合比率控制策略输出至控制指令输出模块37并转换为混合比率控制阀门开度指令输出;如果不满足,则继续执行步骤5);此外,如果l=lmax,无论φ[u(l)]是否满足公式(1),本次迭代得到的催化剂混合比率控制策略都将输出至控制指令输出模块37并转换为混合比率控制阀门开度指令输出;
步骤5):采用经验模态分解模块34对步骤3)中获得的控制策略u(l)进行经验模态分解,得到模态分解趋势项信息,根据得到的趋势项信息重构控制网格
步骤6):迭代次数l加1,结合重构后的控制网格
所述的动态优化求解模块,采用如下步骤实现:
步骤1):结合初始化模块32或参数更新模块36提供的参数信息,采用ode求解模块38获取本次迭代的状态信息x(k)(t)和目标函数值j(k)。
步骤2):通过梯度求解模块39获取本次迭代目标函数梯度信息dj(k);
步骤3):nlp问题求解模块40利用步骤1)和2)中获得的目标函数值和梯度信息,求解寻优方向和寻优步长,并进行寻优修正,获得比u(k-1)更优的控制策略u(k);
步骤4):nlp问题求解模块40运行,通过nlp收敛性判断模块进行收敛性判断,如果j(k)与上一次迭代的目标函数值j(k-1)的绝对值之差小于精度tol1,则判断收敛性满足,u(l)=u(k),φ[u(l)]=j(k),将本次迭代得到的控制策略u(l)和目标函数φ[u(l)]输出至动态优化收敛性判断模块34;如果收敛性不满足,则继续执行步骤5);
步骤5):nlp问题求解迭代次数k加1,利用步骤3)中得到的控制策略u(k)采用ode求解模块38重新求取状态信息x(k)(t)和目标函数值j(k),采用梯度求解模块39重新求解dj(k),执行步骤3)。
所述的ode求解模块,采用的是四级五阶龙格库塔方法,求解公式为:
其中,t表示管长,ti表示龙格库塔方法选择的积分节点,积分步长h为0.001,x(k)(ti)表示管式反应器反应物在第k次迭代中第ti节点的状态信息,f(·)是描述管式反应器中反应的状态微分方程函数,k1、k2、k3、k4分别表示龙格库塔法积分过程中的4个节点的函数值。
所述的梯度求解模块,采用灵敏度轨迹方程法:
步骤1):定义第k次迭代的灵敏度轨迹方程γ(k)(t)为:
γ(k)(t)的求解公式为:
其中,t表示反应器管长,
步骤2):采用四级五阶龙格库塔方法求解灵敏度轨迹方程γ(k)(t)在各积分时刻的值,求解公式为:
其中,t表示反应器管长,ti表示龙格库塔方法选择的控制过程中反应器长度节点,h为积分步长,x(k)(ti)表示反应器中反应物在第k次迭代中第ti节点的状态信息,s()是描述灵敏度方程的函数,q1、q2、q3、q4分别表示龙格库塔法积分过程中的4个节点的函数值。
步骤3):根据得到的状态信息x(k)(t)和灵敏度轨迹方程γ(k)(t),求解目标函数的梯度信息dj(k):
其中,φ(u(k),x(k)(t),tf)表示待优化的产品浓度目标函数。
所述的nlp问题求解模块,采用如下步骤实现:
步骤1):将初始化模块32或者参数更新模块36提供的催化剂混合比率控制策略u(k)作为初始值,u(k)是向量空间中的某个点,记作p1,p1对应的目标函数值就是j(k);
步骤2):从点p1出发,根据选用的nlp算法,根据ode求解模块38、梯度求解模块39得到的点p1处的目标函数梯度信息dj(k)和约束条件梯度信息g(k),构造向量空间中的一个寻优方向d(k)和步长α(k);
步骤3):通过式u(k+1)=u(k)+α(k)d(k)构造向量空间中对应u(k+1)的另外一个点p2;
步骤4):采用寻优校正u(k+1),得到校正后的点
步骤5):如果j(k+1)与上一次迭代的目标函数值j(k)的绝对值之差小于精度tol1,则判断收敛性满足,令φ[u(l)]=j(k+1),u(l)=u(k+1),将本次迭代得到的控制策略u(l)和目标函数φ[u(l)]输出至动态优化收敛性判断模块34;如果收敛性不满足,迭代次数k增加1,将u(k+1)设置为初始值,继续执行步骤2)。
所述的经验模态分解模块,采用如下步骤实现:
步骤1):对动态优化求解模块33得到的控制策略u(l)采用下式进行分解:
其中ci是u(l)的第i个固有模态函数,rn是u(l)的趋势项函数;
步骤2):根据步骤1)中得到的趋势项函数rn计算趋势变化信息,定义δj为向量rn的第j个元素的趋势变化值,用下式求解:
δk=rn,j+1-rn,j(21)
其中rn,j表示rn向量的第j个元素,rn,j+1表示rn向量的第j+1个元素;定义
其中,rn,j-1表示rn向量的第j-1个元素,rn,j表示rn向量的第j个元素,rn,j+1表示rn向量的第j+1个元素;
步骤3):根据步骤2)中得到的δj和
步骤4):根据控制网格重构结果得到重构后的控制网格
实施例1
管式反应器中发生并行可逆反应:
其中,t表示管长,x1(t)是a的浓度,x2(t)是b的浓度,x3(t)表示c的浓度,x1(0)表示a的初始浓度系数,x2(0)表示b的初始浓度系数,反应速率常数k1=k3=1,k2=10。
dcs运行内部经验模态分解动态优化算法,其运行过程如图3所示,执行步骤为:
步骤1):信息采集模块31开始运行,工程师设置管式反应器的长度为12m,需要优化的目标产品为x3(12),初始各反应物浓度系数为x1(0)=1、x2(0)=0,混合比率限制为0≤u(t)≤1;
步骤2):初始化模块32开始运行,设置经验模态分解迭代次数l和nlp问题求解迭代次数k为0;分段常量参数化的分段数为ne=6、对应的初始控制网格为t(0)=[0,2,4,6,8,10,12],催化剂混合比率控制策略的初始猜测值u(0)=0.5,设定nlp问题的计算精度tol1=10-6,动态优化求解算法收敛精度tol2=0.001,动态优化最大迭代次数lmax=5;
步骤3):通过动态优化求解模块33获取第l次迭代的的控制策略u(l)和目标函数值φ[u(l)];
步骤4):如果l=0,直接转至步骤5);否则,采用动态优化收敛性判断模块34进行收敛性判断,如果φ[u(l)]与上一次迭代的目标函数值φ[u(l-1)]满足
则判断满足收敛条件,将第l次迭代得到的催化剂混合比率控制策略u(l)输出至控制指令输出模块37并转换为混合比率控制阀门开度指令输出;如果不满足,则继续执行步骤5);此外,如果l=lmax,无论φ[u(l)]是否满足公式(1),本次迭代得到的催化剂混合比率控制策略都将输出至控制指令输出模块37并转换为混合比率控制阀门开度指令输出;
步骤5):采用经验模态分解模块34对步骤3)中获得的控制策略u(l)进行经验模态分解,得到模态分解趋势项信息,根据得到的趋势项信息重构控制网格
步骤6):迭代次数l加1,结合重构后的控制网格
催化剂混合比率控制策略结果如图4所示,图5是图4中催化剂混合比率策略对应的产品浓度变化图,可以看出在沿着管长方向,目标产品c的浓度不断增加,物料a的浓度不断减少,达到了最优控制生产要求,而且在生产过程结束时催化剂的混合比率满足0≤u(t)≤1的生产限制要求。
最后,dcs将获得的催化剂混合比率控制策略作为混合比率控制阀门开度指令经过现场总线网络输出到混合比率控制阀门端的数模转换器,使混合比率控制阀门根据收到的控制指令相应动作,同时用混合比率传感器实时采集管式反应器的当前混合比率与产品浓度,经模数转换器、现场总线网络回送到dcs,并在主控室内显示。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!