一种渣油加氢处理装置的收率实时预测方法及其应用与流程
本发明涉及一种基于机理和运行特性的渣油加氢处理装置收率实时预测方法,该方法可以用于渣油加氢处理过程建模仿真、模型实时校正以及和PIMS生产计划优化模型/Orion调度优化模型实时构建的应用。
背景技术:
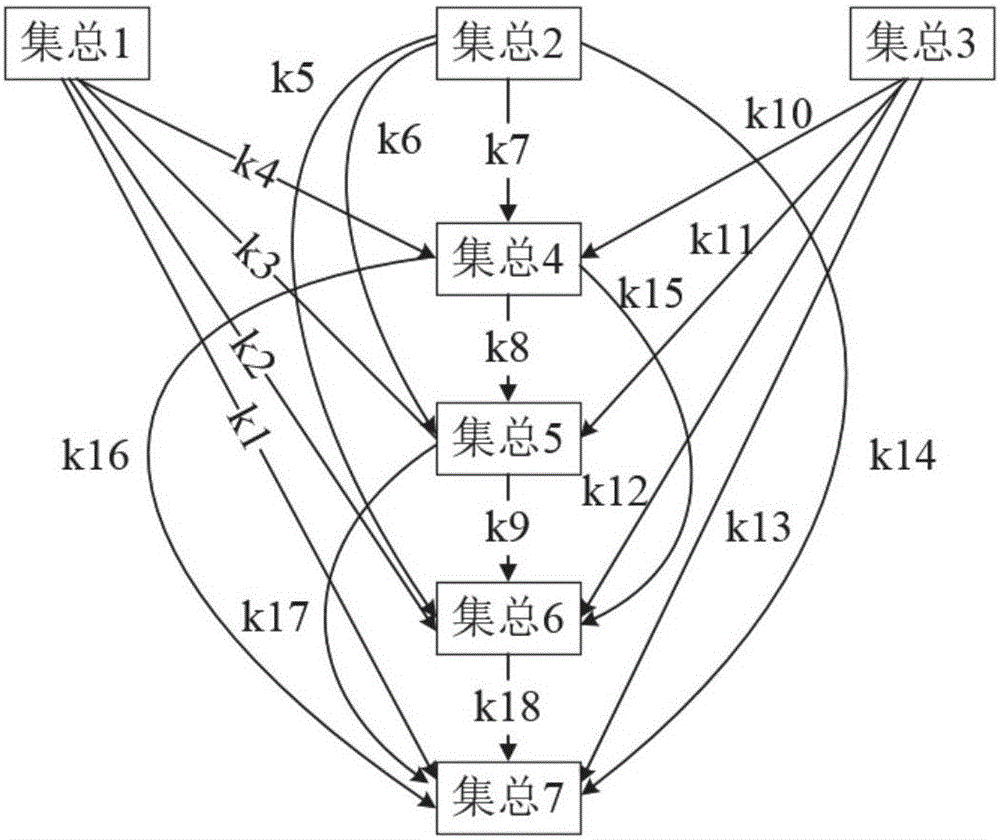
:炼油企业面临原油价格不断波动、原油重质化和劣质化(高硫、高酸等)、轻质油品需求量上升和燃油及环保标准更加严格的竞争压力,因此将更多的重质渣油转化为优质的轻质油品已成为炼油技术发展的主要方向,如经济环保的渣油加氢技术已受到企业的广泛关注。渣油加氢技术依据原料转化水平和生产目的分为加氢处理和加氢裂化两种,而按照反应器类型则主要分为固定床、移动床、沸腾床和浆态床。渣油固定床加氢处理技术是目前工业应用最多的渣油加氢技术,其加工能力约占85.5%。渣油固定床加氢处理技术主要用于催化裂化原料的加氢预处理,能够加工处理高硫渣油。相比于其它渣油加氢技术,固定床加氢处理技术的投资和操作费用低,运行安全简单,是迄今为止工业应用最多和技术最成熟的渣油加氢技术。渣油固定床加氢处理技术主要有Chevron公司的RDS/VRDS工艺、UOP公司的RCDUnionfining工艺、ExxonMobil公司的Residfining工艺、Shell公司的HDS工艺、Axens公司的Hyval技术、中国石化集团公司的S-RHT技术等。近年来,渣油固定床加氢处理技术围绕新型催化剂开发、催化剂级配等开展了系列研究。同时,随着轻质原油产量减少,炼厂渣油加工量不断增加等客观因素,渣油固定床加氢处理-催化裂化组合应用技术逐渐成为炼厂实现渣油轻质化生产清洁油品的重要手段,在相当长的时期内将是大多数炼厂尤其是加工重劣质原料炼厂的优选技术。渣油加氢处理过程中发生的反应主要是烃类的C-C键裂解加氢的反应,通过加氢裂化反应,大分子、高沸点烃类转化成小分子、低沸点的烃类。加氢过程中所发生的化学反应很多,也非常复杂,但主要发生加氢脱金属、加氢脱硫、加氢脱氮(HDN)、加氢脱残炭等加氢精制反应,同时还伴随芳烃加氢饱和反应、烯烃加氢饱和反应以及少量的加氢裂化反应,如加氢异构化和裂化(包括开环)反应。渣油中金属(主要是镍和钒)化合物在加氢反应中主要是通过加氢和氢解反应,最终以金属硫化物的形式沉积在催化剂上,造成孔口和孔径堵塞,导致催化剂中毒。渣油加氢脱硫的基本反应是含硫化合物中C-S键断裂的氢解反应,各种有机硫化物的加氢难易程度与分子大小和分子结构有关。渣油中氮化物主要是稠环杂环氮化物,杂环氮化物在C-N键氢解前,必须首先将含有氮原子的杂环加氢饱和,再C-N键氢解。残炭主要与原料中最不稳定的大分子有关,如胶质、沥青质和稠环芳烃等,在加氢反应过程中易缩合生成焦炭。对实际生产装置运行来说,影响产品收率的因素主要有原料油性质、反应压力、氢分压/氢耗、进料量、循环氢纯度与流量、反应温度等。原料油性质的变化对渣油加氢处理过程有重要的影响。原料油初馏点的升高将不利于加氢处理反应的进行。原料油中的铁化合物可以发生反应生成较大颗粒的固体物,降低床层孔隙率而引起过高的压降。原料中的镍和钒化合物的含量对催化剂的使用寿命有直接的重要影响。原料油的残炭含量对催化剂活性发挥不利。原料油粘度过高,对加氢处理反应不利。同时可能引起床层压降的脉动,给装置的安全操作带来危害。反应温度的升高,加氢过程脱硫率、脱氮率、脱残炭率和脱金属率均增加。循环氢可以限制催化剂床层的温升,也可以促使液体进料均匀分布在催化剂床层,还可以改善流体分布。循环氢纯度影响反应器的氢分压,当系统总压不变时,循环氢纯度越高,氢分压越高。如果进料性质及其他参数不变,则当进料量提高时,必须提高反应温度CAT以保证产品质量。此外,进料量的提高将加快催化剂失活,增加化学氢耗量,以及增加离开反应部分液体中的溶解氢数量。氢分压的提高一方面可抑制结焦反应,降低催化剂失活率,另一方面可提高杂质的脱除率,同时又可促进稠环芳烃加氢饱和反应。反应系统的压力对渣油加氢过程有重要的影响,压力越高,脱硫、脱氮、脱残炭和脱金属率越高。由此可见,原料性质和操作条件对渣油加氢过程的装置操作、产品分布和性质有较大影响。一项工艺参数的改变常常引发其他几个参数的调整,所以必须了解各种工艺参数之间的相互作用以及对产品收率和性质的影响。对渣油加氢处理装置来说,其关键产品如加氢石脑油、加氢柴油以及加氢重油的实际产量经常是波动的,与生产计划、调度计划预期值往往存在一定的偏差。究其原因,关键在于目前生产活动如生产计划编排中如PIMS模型、生产调度模型如ORION调度模型均采用固定收率,难以准确描述装置实际运行过程。因此,对渣油加氢装置进行流程模拟,建立一个能精确、定量实时预测渣油加氢装置的收率模型是提高当前炼油装置生产计划/调度模型准确性的关键。渣油加氢处理装置包括反应器和分馏塔,其中反应器为核心装置。精确收率模型的核心在于准确的反应机理动力学。目前的渣油加氢处理过程动力学建模主要包括以下几个方面:1)加氢脱金属反应动力学、2)加氢脱硫动力学模型、3)加氢脱氮动力学模型、4)加氢脱残炭动力学模型、5)渣油加氢处理动力学模型。目前关于渣油加氢动力学研究,国内外很多学者进行了许多开拓性的工作,并取得了较大的成果。如:不同分子量的分子加氢裂化规律,反应速率常数和烃类不同大小分子的关联,各集总裂化产物的分布函数,加氢裂化动力学模型建立方法。从最初探索过程机理、反应器放大,建模目的已拓宽至实际生产过程的仿真、预测和优化,模拟结果和实验数据也能较好的吻合。然而,也应看到,现有的加氢过程动力学成果,都只是在一定的程度上或者某些方面逐渐逼近加氢过程,离应用于实际生产过程、满足加氢装置灵活性的要求还有一定的距离,比如:以实验数据为建模的依据或以生产过程模拟优化为目标的模型,都是从实验装置上获得数据,通过回归得到动力学参数,然后用有限的工业数据进行校正。本发明综合考虑模型准确性和计算效率,采用从实际渣油加氢处理过程采集的数据,在加氢反应原理的基础上,基于加氢装置机理和运行特性,以数学方程模型为原理建立渣油加氢处理装置反应动力学及反应器模型,并根据实际工业装置数据,应用改进差分算法对渣油加氢机理模型进行实时校正,并以此为基础,针对关键操作/工艺条件开展操作特性分析,结合神经网络技术,建立代理模型,将操作条件与Delta-Base数据进行关联,实现渣油加氢装置收率的实时预测,为建立精确的计划优化PIMS模型/调度优化模型ORION等其他需要装置收率信息的系统或模型提供支撑。技术实现要素:鉴于上述问题,本发明提供了一种基于机理和运行特性的渣油加氢处理装置收率实时预测方法。基于加氢反应动力学模型和绝热径向反应器模型,根据实际工业装置数据,应用改进差分算法对机理模型进行实时校正,并以此为基础,针对关键操作/工艺条件开展操作特性分析,结合神经网络技术,建立代理模型,将原料性质和操作条件与与Delta-Base数据进行关联,实现渣油加氢处理装置收率的实时预测,为建立精确的计划优化PIMS模型/调度优化模型提供理论支撑。具体技术方案如下:一种渣油加氢处理装置的收率实时预测方法,包括以下步骤:1)利用.net接口技术建立现场实时数据库与渣油加氢处理装置之间的数据通信,实现渣油加氢处理装置运行数据的实时采集;结合现场情况和生产经验建立数据调和标准,剔除无用和错误的实时数据。根据原料油性质的常规评价数据,如馏程、密度、残炭、硫、氮含量、金属含量(钠、镍、钒、铁)等分析数据(但不限于此),根据原料性质数据计算当前油品的特性,如虚拟组分含量、集总组分含量等;2)根据采集的渣油加氢处理装置实时数据,以反应器出口的模型预测值和实际值的平方差最小作为优化目标,利用改进后的差分进化算法进行求解,拟合模型参数,实现渣油加氢处理机理模型实时校正;3)基于校正后的模型,分析在不同原料品质、进料负荷和操作条件下的关键产品收率,建立产品收率分析数据库;4)利用产品收率分析数据库训练能够准确反映实际工况的神经网络代理模型,并将操作条件与Delta-Base数据进行关联,实现渣油加氢处理装置收率的实时预测。该实时预测可为建立精确的计划优化PIMS模型/调度优化ORION模型及时更新收率数据,提高模型的优化准确性。步骤(2)中所述实时数据选自原料油流量、原料油入反应器时温度、加热炉出口温度、进料压力、每一个反应器的入口温度和出口温度以及床层上中下三部位温度、每个反应器压降、循环氢纯度、循环氢温度及压力、压缩机出口压力和温度、富胺液出装置流量、装置外来新氢量、总冷氢量、加氢重油出装置流量、加氢石脑油流量、加氢柴油出装置流量、酸性气流量、加氢干气流量、分馏塔各点温度、分馏塔压力。步骤(2)中所述改进后的差分进化算法为带有三角变异的差分进化算法,并定义优化目标为:minf(X)=Σi=1(Cactuali-Cpredicti)2;]]>产品i收率实际值;产品i收率预测值。其中,决策变量X包括各个反应的指向因子和活化能。步骤(3)中所述关键产品选自渣油加氢酸性气、渣油加氢干气、渣油加氢石脑油、渣油加氢柴油、加氢重油。所述原料品质包括原料的密度、硫含量、氮含量、镍钒含量和残炭信息;所述进料负荷包括装置加工量;所述操作条件包括反应温度(催化剂床层加权平均温度)、反应压力和氢油比。步骤(4)中使用了神经网络装置代理模型来替代机理模型进行预测计算,从而满足实时计算对于模型计算效率的要求。所述神经网络模型采用反向传播(Backpropagation,BP)神经网络,选取7个输入变量:原料密度、原料残炭、原料氮含量、原料硫含量、进料负荷、催化剂床层加权平均温度、氢油比;5个输出变量:加氢酸性气、加氢干气、加氢石脑油、加氢柴油、加氢重油;隐含层设置为6层。本发明还提出了一种渣油加氢处理装置的收率实时预测方法用于渣油加氢处理过程建模仿真、模型实时校正以及和PIMS生产计划优化模型/Orion调度优化模型实时构建的应用。本发明的有益效果如下:基于加氢反应原理,完成渣油加氢处理装置的建模,结合实际运行数据对加氢装置模型参数进行校正,建立能良好描述实际运行工况的渣油加氢处理装置机理模型。根据影响趋势进行分段线性化,求解线性方程,获得相应的Delta-Base收率数据,结合神经网络建模技术,将操作条件与Delta-Base数据之间进行关联,建立收率代理模型,提高收率数据计算速度,实现渣油加氢装置产品收率实时预测,为建立其他需要更新收率的模型如计划优化PIMS模型、调度优化ORION模型提供支撑。附图说明图1是渣油加氢装置反应部分原则工艺流程图;图中:1-过滤后原料缓冲罐;2-原料泵;3-加热炉;4、5、6、7、8-加氢反应器;9-热高压分离器;10-冷高压分离器;11-热低压分离器;12-冷低压闪蒸罐;13-冷低压分离器;14-聚结器;15-循环氢脱硫塔;16-循环氢压缩机。图2是渣油加氢的7集总18反应网络图;图3是模型实时校正简化流程图;图4是多层前向神经网络结构示意图;图5是渣油加氢处理装置神经网络代理模型结构图。具体实施方式下面通过实施例对本发明进行具体描述。有必要在此指出的是,以下实施例只用于对本发明作进一步说明,不能理解为对本发明保护范围的限制,该领域的专业技术人员根据本发明的内容作出的一些非本质的改进和调整,仍属于本发明的保护范围。实施例1下面结合图表具体介绍本发明的实现方法:1、渣油加氢处理装置机理建模渣油加氢装置反应部分原则工艺流程图见图1所示。反应部分设置串联的5台反应器,每台反应器都采用单床层。原料首先进入过滤器出去机械杂质,然后分两路进入反应器。其走向如下:原料油与经换热预热后的循环氢混合,再经换热后进入反应进料加热炉,加热到所需反应温度后进入第一反应器。第一反应器出口反应物先后通过串联的其余4个反应器,各反应器的温度通过反应器间的冷氢管注入冷氢加以调节。最后一个反应器出来的反应物经换热后进入热高压分离器进行气液分离,热高分气经换热、空冷后进入冷高压分离器,进行气、油、水三相分离。从热高压分离器底部出来的热高分油,混合后进入热低压分离器进行气、液分离,热低分油从底部排出后去分馏部分分馏。热低分气经换热冷却后进冷低压闪蒸罐进行气液分离,从下部出来的闪蒸液则进入冷低压分离器。从两冷高压分离器顶部出来的冷高分气体(循环氢)混合后进到循环氢脱硫塔,脱除硫化氢后进入循环氢压缩机进行循环。渣油加氢处理过程主要发生加氢脱金属、加氢脱硫、加氢脱氮及加氢脱残炭等加氢精制反应和加氢裂化反应。因此渣油加氢反应动力学模型包括渣油加氢精制动力学模型和渣油加氢反应动力学模型。建立适用于装置长期运转的渣油加氢精制动力学模型时做如下假设:(a)反应温度取反应器的一般平均温度的代数平均值。(b)反应过程中加氢脱硫、加氢脱氮、加氢脱镍、加氢脱钒和加氢脱残炭反应等各反应的动力学行为互不影响。(c)考虑催化剂时变失活因素。(d)各类型催化剂均匀混合填装于反应器。(e)氢压不变。(f)气、液两相按照平推流流动,发生拟均相反应。催化剂失活动力学形式拟以时变失活形式考虑,函数关系式如式(1)所示。式中:α:催化剂时变失活函数;t1:采集数据时装置运行的实际时间;T1:催化剂脱杂质功能活性时间(活性降为0.5的时间);β:催化剂脱杂质失活指数。将式(1)代入动力学模型积分方程(2),积分可得式(3)和式(4)。式中:R101:杂质的入口浓度,可以针对某一杂质具体化其入口浓度;R105:杂质的出口浓度,与R101所指杂质相对应;T2:反应温度,单位K;t2:原料在反应器中的停留时间,单位小时;n:反应级数,无因次;k0:反应指前因子,与R101杂质浓度相对应;E:反应活化能。渣油加氢集总动力学模型的集总划分如下:沥青质+胶质为集总1;芳香分为集总2;饱和分为集总3;加氢重油为集总4;加氢柴油为集总5;加氢石脑油为集总6;气体为集总7。建立渣油加氢反应动力学模型,作如下几条假设:(a)在实际反应过程中,重质组分的加氢反应和裂化反应是同时进行的,在反应网络中考虑重质组分的加氢反应和一次裂化反应,并考虑轻质组分的二次裂化反应。(b)所有反应均为一级不可逆反应;(c)各个反应遵循“互不作用”原理;(d)考虑催化剂时变失活、氢分压以及裂化因素的影响。含7集总18个反应的渣油加氢反应网络见图2。在以上的动力学基础上,结合装置实际运行特性,本发明收集渣油加氢处理装置信息如反应器直径、催化剂床层高度及原料结构性质如密度、残炭、馏程、粘度等、操作条件如原料预热温度、预热压力、各反应器中反应温度、反应压力、进料量、冷氢流量、循环氢纯度及流量、氢油比、关键产品如酸性气、加氢干气、加氢石脑油、加氢柴油、加氢重油等流量。在此基础上,结合设计工况数据,建立能够良好描述渣油加氢过程操作特性的工艺模型,根据实时运行数据,对渣油加氢过程进行模型参数在线校正,确保所建立的模型能够适应不同生产工况,实现实际工况的流程模拟。2、数据采集与调和由于工业现场情况复杂,生产过程受到多种因素的影响,完全依据实验报道的机理建立的渣油加氢处理装置模型无法准确模拟实际装置,因此需要结合现场装置实际运行特性来校正模型。首先是实现现场数据的采集和调和处理过程。1)现场数据采集:在实际生产过程中,大多数工厂都会使用实时数据库来记录装置的运行状况,并提供相应数据点的位号以便采集数据。本发明利用VB.net接口技术开发渣油加氢处理装置现场数据实时采集系统,可以实现将现场实时数据的读入,并储存到本地数据库中。需要采集的数据主要包括自原料油流量、原料油入反应器时温度、加热炉出口温度、进料压力、每一个反应器的入口温度和出口温度以及床层上中下三部位温度、每个反应器压降、循环氢纯度、循环氢温度及压力、压缩机出口压力和温度、富胺液出装置流量、装置外来新氢量、总冷氢量、加氢重油出装置流量、加氢石脑油流量、加氢柴油出装置流量、酸性气流量、加氢干气流量、分馏塔各点温度、分馏塔压力和产品的LIMS性质数据等信息。2)数据调和处理:受现场检测仪表可靠性的局限,直接从DCS上获取到的数据往往存在物料不平衡、热量不平衡等问题,因此不能直接用于建立装置模型。为了确保模型样本数据的准确性,有必要对实时采集的数据建立调和标准,具体使用以下几种方法:(1)采用天平均值来校正模型;(2)根据统计数据和生产经验确定数据的值域,依此判断数据的准确性,将错误数据从本地数据库中删除;(3)对于在特定期间内无法采集的数据,建立冗余的计算公式,通过采集其他数据来推导出这个点。3、渣油加氢处理装置机理模型实时校正这一步骤结合实际案例介绍渣油加氢处理装置机理模型的实时校正实现过程。模型实时校正可以归为参数估计问题,本发明首先将参数估计问题转化为最优化问题,即:其中,决策变量X包括各个反应的指向因子和活化能,和分别表示产品油各组分实际测量和预测的质量百分比。针对这种类型的优化目标,本发明使用改进的差分算法对问题进行求解。差分算法(differentialevolution,DE)是一种基于种群的的随机搜索算法,它具有结构简单、收敛速度快、鲁棒性高等特点。算法的变异机制,即生成子代的方法为:r′=r1+F*(r2-r3)(6)其中,r′是新生成的子代个体,r1,r2,r3是种群中随机选取的三个不同的父代个体,F为差分进化算子,一般为一个常数。由于该目标决策变量数目众多,导致算法求解时计算量很大,因此需要对算法进行改进,加快其收敛速度。本发明选择了带有三角变异的改进差分算法,该方法被证明在提高算法收敛速度方面具有显著成效,其改进的变异策略可以表示为:r′=(r1+r2+r3)/3+(p2-p1)(r1-r2)+(p3-p2)(r2-r3)+(p1-p3)(r3-r1)(7)其中p1=|f(r1)|/p′,p2=|f(r2)|/p′,p3=|f(r3)|/p′,p′=|f(r1)|+|f(r2)|+|f(r3)|模型实时校正的简化流程图如图3所示。本例选取某炼厂170万吨/年的渣油加氢处理装置,以20天的工况条件平均值进行模拟。装置的操作工况部分数据:原料汇总流量210.8t/h,原料经加热炉后的温度341.7℃;第一反应器入口温度344.4℃,反应床层上、中、下部温度分别为343.3℃、346.9℃、354.3℃,反应器出口温度354℃,催化剂床层平均温度346.5℃,床层温升9.6℃,反应器压降为0;第二反应器入口温度345.9℃,反应床层上、中、下部温度分别为346.9℃、355.0℃、357℃,反应器出口温度356.5℃,急冷氢量9920kNm3/h,催化剂床层平均温度351.5℃,反应床层温升8.9℃,床层压降0.583MPa;第三反应器入口温度353.6℃、反应床层上、中、下部温度分别为354.8℃、359.5、371.7℃,急冷氢量0,反应器出口温度369.6℃,催化剂床层平均温度359.4℃,反应床层温升12.1℃,床层压降0MPa,;第四反应器入口温度358.2℃、反应床层上、中、下部温度分别为359.1℃、366.4、369.5℃,反应器出口温度373.6℃,急冷氢量16912kNm3/h,催化剂床层平均温度362.7℃,反应床层温升8.8℃,床层压降0.881MPa;第五反应器入口温度363.2℃、反应床层上、中、下部温度分别为365.1℃、368.4、372.5℃,反应器出口温度376.6℃,急冷氢量10912kNm3/h,催化剂床层平均温度365.5℃,反应床层温升9.0℃,床层压降0.781MPa;反应器入口压力16.535MPa,反应器总压降1.005Mpa;急冷氢量36390kNm3/h,冷氢温度57.9℃,装置外来新氢量22167kNm3/h;分馏塔中段抽出温度189.2℃,塔底温度310.2℃,加氢重油流量194.6t/h,不稳定石脑油流量3.9t/h,柴油出装置流量7.42t/h,酸性气流量1137Nm3/h。原料性质数据:密度0.9506g/cm3,馏程数据:初馏点329℃、5%馏出点400℃、10%馏出点444℃、30%馏出点490℃50%馏出点540℃、90%馏出点720℃,总氮含量2800ppm、碱性氮903ppm,硫含量1.25%,粘度(100℃)62.7mm2/s,残炭9.87%,饱和烃31.92wt%、芳烃47.08wt%、胶质15.79wt%、沥青质5.20wt%;铁含量4.7mg/kg、镍含量24.3mg/kg、钠含量0.8mg/kg、钙含量钒含量12.6mg/kg等信息。4、渣油加氢装置产品收率分析通过以上步骤的实现,渣油加氢处理装置机理模型通过实时运行特性数据的校正已经可以准确反映渣油加氢处理装置的实际情况。利用校正的渣油加氢装置机理模型在针对不同性质原料和操作条件(比如残炭、硫含量、密度、各反应器床层平均温度、系统反应压力、新氢流量、各反应器冷氢量等,获取加氢处理装置的关键产品收率,其中关键产品主要包括酸性气、渣油加氢干气、加氢石脑油、加氢柴油、加氢重油等。并建立本地数据库存储收率数据,并能够实现数据的读写。表1为某工况下,渣油加氢处理装置模型关键产品预测值与实际的对比。表1某工况下渣油加氢处理装置模型关键产品预测值与实际的对比运行参数实际值,%模型预测值,%误差(%)气体(酸性气+干气)0.650.59-9.23渣油加氢石脑油1.521.637.24渣油加氢柴油7.717.932.85渣油加氢重油90.1289.85-0.30由此可知,本发明建立的模型能较好地模拟渣油加氢处理装置产品分布情况。5、渣油加氢处理装置产品收率实时预测渣油加氢处理装置收率实时预测技术要求机理模型有较高准确性的同时还对模型的计算效率提出了很高的要求。上文介绍的校正模型机理十分复杂,求解速度很慢,而且容易不收敛,显然无法满足实时预测的需要,因此亟需利用神经网络技术建立代理模型来实现装置收率的实时预测。本发明采用反向传播(Backpropagation,BP)神经网络,这是一种在过程控制中应用最广泛的神经网络结构。BP神经网络结构如图4和图5所示。整个结构由L层神经元组成,第一层为输入层,最后一层为输出层,其它层为隐层,可以得到每个神经元的模型为:式中:ypjk:j层中第k各神经元在第p组样本状态下的和输出;Xpjk:j层中第k个神经元在第p组样本状态下的和函数输出;Wpjk:j-1层中第i个神经元到j层中第p个神经元的链接权值。其中Wpjo定义为j层第k个神经元的阀值。f(y):神经元的非线性激活函数。神经网络学习的目的是找出一系列权值,使样本的每组输入向量作用于网络后,其网络的实际输出向量与样本的期望输出向量一致,整个学习过程是调整网络中各神经元之间的连接权值,使下述网络的误差能量函数达到最小:其中:Opk:第p组样本输入向量作用于网络后,网络输出层中第k个神经元的函数输出的期望值。BP算法用来解决上述多层前向网络的学习问题,该学习算法由信号正向传播和误差反向传播组成。传统的BP算法可以概括地总结如下。其中:式中:δpjk:第p组样本输入向量作用于网络后,j层中第k个神经元函数输出的误差信息;t:学习时间;f′(y):神经元激活函数的一阶导函数。式(11)-(12)是BP网络中权值的学习规则,式中学习速率和势态项系数一般是由经验确定,在传统BP算法中它们不能与网络结构、网络状态以及外部学习环境自动匹配,网络训练时需要人为进行调整。根据上述神经网络结构,选取神经网络输入7个:原料密度、原料残炭、原料氮含量、原料硫含量、进料负荷、催化剂床层加权平均温度、氢油比;5个输出变量:加氢酸性气、加氢干气、加氢石脑油、加氢柴油、加氢重油;隐含层设置为6层。原料性质/操作变量影响下的渣油加氢处理装置关键产品收率呈现非线性的趋势。本发明利用神经网络代理预测模型计算,将非线性对象进行分段线性化处理,产生相应的Delta-Base数据,实现收率实时预测。计算结果可用于建立PIMS模型/ORION模型等,提高模型的精度。在某基准工况下,利用神经网络代理模型计算部分性质变化时,装置关键产品收率的Delta-Base数据如表2所示:表2装置实时收率预测Delta-base值其计算过程分为两步:第一步:根据给定的性质计算出渣油加氢处理装置各项关键产品的预测收率作为Base数据;第二步:根据设定的自由变量,自动计算该变量在给定值邻域内变化下的产品收率预测数据,并计算出单位变量改变下收率的变化量,该变化量即作为装置收率预测的Delta数据,计算公式如下:其中,Val表示指定的自由变量(如硫含量,残炭、氮含量、密度等,但不限于此),ykeyproduct表示关键产品预测收率。表2是分别以硫含量、残炭、密度为自由变量,获得的Delta_Base数据,其中BA表示相应产品收率的Base数据,自由变量值表示变化量,NA表示变量变化下相应的关键产品收率的变化情况,即为产品收率的Delta数据。关键产品收率的计算公式如下:Yproduct=Cproduct/CInlet(17)其中,Yproduct表示产品收率,Cproduct表示产品的质量流量,CInlet表示原料进料的质量流量。通过以上步骤的进行,本发明可以实现基于机理和运行特性的渣油加氢处理装置收率的实时预测。该方法以7集总反应动力学模型为理论基础,利用实际工业数据对渣油加氢处理装置机理模型进行实时校正,并通过计算校正模型获得的分析数据来训练神经网络代理模型,克服了渣油加氢机理模型计算速度慢的局限。利用神经网络代理模型计算渣油加氢处理装置关键产品的收率,实现原料性质/操作条件与Delta-Base数据的关联,达到渣油加氢处理装置收率的实时预测的效果。此发明可实时方便快捷地更新计划模型、调度模型渣油加氢处理装置数据,提高计划/调度模型如PIMS模型/Orion模型的优化精度。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1