基于深度信念网络模型的水泥熟料游离钙含量预测方法与流程
本发明涉及水泥烧成系统熟料游离钙的预测领域,特别是涉及一种基于深度信念网络模型的水泥熟料游离钙含量预测方法。
背景技术:
水泥熟料游离钙(free calcium oxide in cement clinker,fCaO)是水泥生料经分解炉的预分解、回转窑高温煅烧,最后经篦冷机冷却而没有参加化学反应,以游离态存在于水泥熟料中的氧化钙。水泥熟料fCaO含量高低是影响水泥安定性的主要因素,能够直接反映物料在回转窑烧成带的烧成状况。如果水泥熟料fCaO含量过高,物料在回转窑煅烧的不充分,熟料强度低,水泥内部形成局部膨胀应力,使其变形或开裂,对水泥强度、安定性均有一定影响。反之,其含量过低时,熟料往往呈过烧状态,甚至是死烧,此时的熟料质量不仅缺乏活性,而且也造成了能源浪费,增加了水泥生产成本。目前,国内外关于水泥熟料fCaO含量的测量方法主要有在线分析仪测量方法和离线采样化验方法。在线分析仪测量的方法可以实现对水泥熟料游离钙含量实时检测,但设备成本较大,维护费用高,并且测量的准确性容易受到现场烟尘和实际工况的影响,精度也不高。离线采样化验方法需每隔1-2个小时现场取样离线化验得到水泥熟料fCaO的含量,由于水泥熟料烧成过程具有一定时间的延时,离线分析获得fCaO含量相对于指导烧成系统的控制具有很大的滞后性。因此,水泥熟料fCaO含量预测的实现对保证水泥熟料质量和实现水泥烧成系统节能减排具有重要意义。
众多国内外工艺、自控专家对此做了大量的研究工作,济南大学刘文光等针对水泥厂熟料质量指标游离钙含量难以在线测量的问题,提出一种基于最小二乘支持向量机(lssvm)的软测量建模方法,仿真实验研究表明,最小二乘支持 向量机建模具有良好的学习能力和泛化性能,且对数据样本的依赖程度低,是一种有效的软测量建模方法;沈阳理工大学王秀莲等在构建局部建模数据集时,同时考虑了数据样本之间的加权欧氏距离与向量的夹角,使得训练数据的选取更加具有实际意义,并建立基于局部pso-lssvm算法的软测量模型,计算得到当前fCaO含量值;合肥工业大学蒋妍妍等基于改进粒子群优化lssvm的水泥熟料fCaO软测量研究,利用改进的粒子群优化算法对最小二乘支持向量机模型的重要参数进行迭代寻优,解决了fCaO含量的测量问题提供了一些可行的方案。但是以往的算法泛化能力差、应用性不强、精度低。因此,有必要寻求一种精确度高、应用性强的预测方法实现对水泥熟料fCaO含量准确预测。
技术实现要素:
针对水泥水泥游离钙(fCaO)含量难以实时在线预测的问题,本发明提供一种基于深度信念网络模型(deep belief network,DBN)的水泥熟料fCaO含量预测方法。
为解决上述技术问题,本发明是通过以下方案实现的:
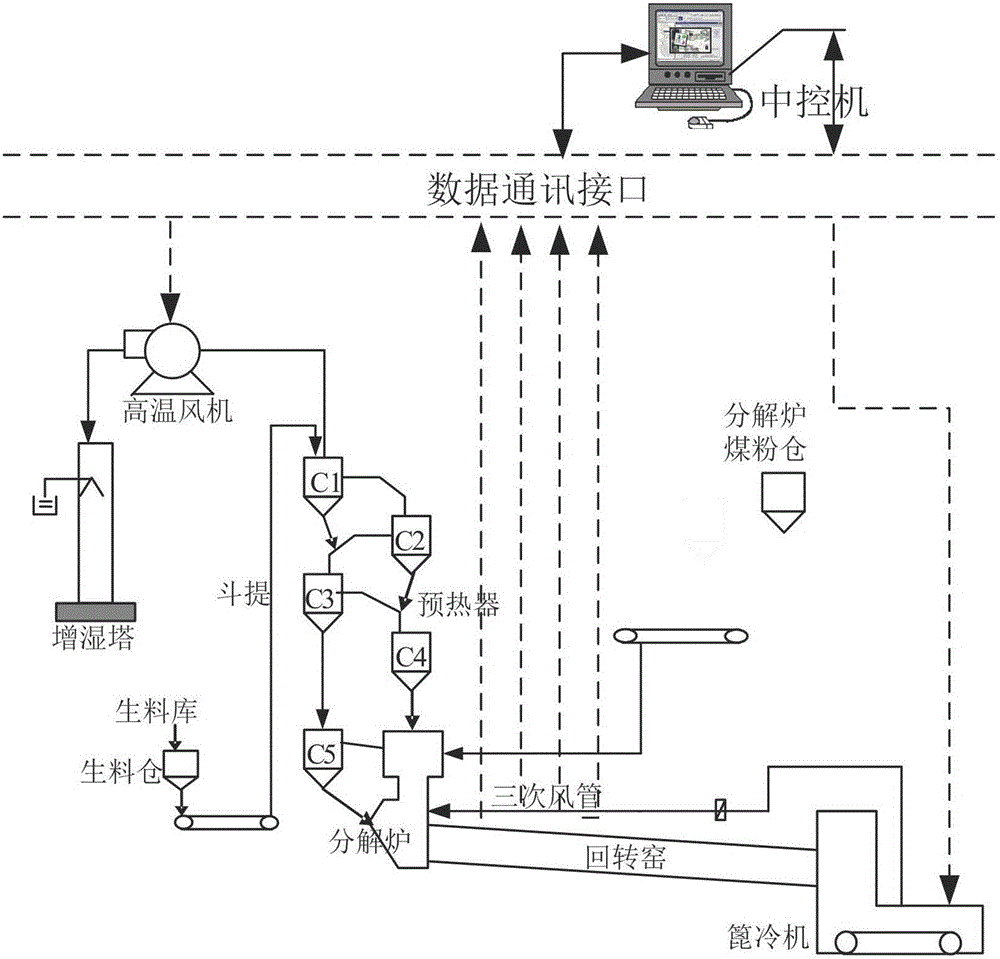
一种基于深度信念网络模型的水泥熟料游离钙含量预测方法,实现该方法所需设备包括测量仪表、数据通讯接口和中控机;
所述的测量仪表用于测量水泥熟料游离钙含量的辅助变量,即窑主机电流、二次风温、窑尾温度和烟室NOx;
所述的数据通讯接口用于将现场测量仪表测量的数据传输到中控机,所述的中控机用于运行深度信念网络的水泥熟料fCaO含量预测算法,根据水泥烧成系统的窑主机电流、二次风温、窑尾温度和烟室NOx,预测出输出变量水泥熟料fCaO含量;
该方法内容包括如下步骤:
步骤一:根据水泥工艺初步选取能反映水泥熟料烧成情况的主要变量为辅助变量集合,预测变量为水泥熟料fCaO的含量;
在步骤一中,所述的辅助变量集合为:窑主机电流、二次风温、窑尾温度、烟室NOx、二室篦下压力、分解炉出口温度、窑头负压、烟室O2、烟室CO、窑转速、三次风温和预热器出口温度;由于初步选取的辅助变量集合维度高,故对辅助变量数据进行降维,以降低数据训练和预测的难度;
步骤二:数据采集及分类,通过现场仪表和操作员记录表分别采集各个辅助变量和水泥熟料fCaO含量的现场数据,采用灰色关联度分析方法对初始辅助变量集合降维;由于数据样本的单位不尽相同,故在训练之前对数据进行统一单位,对数据进行归一化处理,确保各权值的收敛速度大致相同,得到输入输出都在0到1之间,加快训练网络的收敛速度;
在步骤二中,所述采用灰色关联度分析方法对初始辅助变量集合降维,就是对初始辅助变量集合的数据进行灰色关联度计算,删除与游离钙灰色关联度小的变量,进而实现对初始辅助变量集合降维,获得最终的软测量模型输入辅助变量集合为:窑主机电流、二次风温、窑尾温度和烟室NOx,输出变量为水泥熟料fCaO含量;将最终的软测量模型输入辅助变量集合代入深度信念网络模型进行预训练,训练出水泥熟料fCaO含量的预测模型;
步骤三:根据深度信念网络的算法及样本数据量确定深度信念网络结构中的参数:学习率ε、权重wij、偏置和隐单元个数,将在步骤二中采集并归一化处理后的数据作为样本进行无监督训练,训练深度信念网络的参数,进而实现对整个网络权重和偏置的优化;
步骤四:采用反向传播算法对在步骤三中所确定的深度信念网络结构中的参数进行误差校正,对深度信念网络结构参数中隐含层偏置、输出层偏置和权 值矩阵进行全局搜索调整,进而确定水泥熟料fCaO含量的预测模型;
所述采用反向传播算法对在步骤三中所确定的深度信念网络结构中的参数进行误差校正,误差校正的过程是:由于步骤三的学习是一个无监督的学习过程,而使用反向传播算法对网络模型参数中隐含层偏置、输出层偏置和权值矩阵进行修正是一个有监督的学习过程;误差反传是采用从输出层到输入层逐层修正的方法,通过这种方法进行误差修正和模型微调,从而确定水泥熟料fCaO含量的预测模型;
步骤五:采集在步骤二中所得到辅助变量集合的实时数据,并将得到的辅助变量集合的实时数据进行3δ准则剔除误差;若当前时刻任一辅助变量被剔除,则一并删掉同一时刻其他辅助变量的数据,游离钙保持上一时刻的预测值;若没有辅助变量被删除,则将处理完的数据传输到步骤四得到的水泥熟料fCaO含量的预测模型算法的中控机中,进而预测出水泥熟料fCaO含量。
本发明具有以下有益效果:
1、根据水泥烧成系统工艺并结合灰色关联度分析方法选出辅助变量,准确地反应了水泥烧成系统实际运行状况,对保证水泥质量、节能降耗具有重要意义;
2、本发明建立的水泥熟料fCaO含量预测模型具有良好的泛化性能,能够对中控回转窑操作员的操作提供指导,有利于保证烧成系统平稳、安全运行;
3、本发明能够有效地对水泥熟料fCaO含量进行预测,进而对在线测量设备进行补充,甚至替代在线设备,有效地降低了硬件成本。
附图说明
图1为本发明提出的基于深度信念网络模型的水泥熟料游离钙含量预测系统的现场接线图;
图2为限制玻尔兹曼机示意图((Restricted Boltzmann Mzchine,RBM);
图3为本发明的用于水泥熟料游离钙含量预测的深度信念网络模型框图;
图4为本发明提出的基于深度信念网络模型预测水泥熟料游离钙系统流程的方框图;
图5为基于深度信念网络模型训练过程中的反向传播算法学习流程图。
具体实施方式
下面结合附图对本发明做进一步的详细描述。
一种基于深度信念网络模型的水泥熟料fCaO含量预测方法,图1所示为基于深度信念网络模型的水泥熟料游离钙预测系统的现场接线图,首先进行辅助变量的初步选取,将采集的数据与深度信念网络相结合,建立本发明的用于水泥熟料游离钙预测的深度信念网络模型,其框图如图3所示;本发明提出的基于深度信念网络模型预测水泥熟料游离钙系统的流程方框图如图4所示,采用反向传播算法对深度信念网络结构进进行误差修正,建立基于深度信念网络模型训练过程中的反向传播算法学习流程图如图5所示,实现水泥熟料fCaO预测模型的建立,其内容包括如下步骤:
步骤一 辅助变量选取
由水泥工艺可知,水泥熟料是以石灰石、粘土为主要原料,另加部分校正原料如铁粉等,按适当比例配制成的水泥生料,经分解炉的预分解、回转窑烧成带高温煅烧,最后经篦冷机冷却而获得的固体颗粒物料被称为水泥熟料。水泥熟料中没有参加化学反应,以游离态存在的氧化钙称为游离钙(fCaO)。水泥熟料fCaO含量对水泥的安定性有直接影响,且能间接反映物料在烧成带的烧成状况,对于指导回转窑的操作,实现对生产的优化控制具有重大意义。
根据水泥系统的工艺原理,确定辅助变量集合为:窑主机电流、二次风温、 窑尾温度、烟室NOx、二室篦下压力、分解炉出口温度、窑头负压、烟室O2、烟室CO、窑转速、三次风温和预热器出口温度。
根据水泥熟料煅烧工艺可知,窑主电机电流反映窑内窑皮的状况,可以间接反映窑内烧成带的温度;二次风主要将篦冷机的热风回收,用于提供煤粉燃烧用的空气,因此,二次风温能间接反映并影响窑烧成带的煅烧状况;窑尾温度为窑尾距窑烧成带最近的温度测点,同烧成带煅烧温度一起表征窑内各带热力分布状况;回转窑内NOx的生成过程主要产生于回转窑的烧成带,烧成带温度高,NOx浓度增加,反之降低,加之其为气体,可以在负压作用下迅速从烧成带区域移动到窑尾的烟室气体分析仪测量点,所以窑尾烟室所测量出的NOx含量可以较真实地反映出烧成带区域的NOx含量,进而反映出烧成带温度;篦冷机用于冷却水泥熟料,在篦速不变的条件下,烧成带煅烧温度越高,水泥熟料颗粒结构越致密,篦冷机二室压力越大;分解炉出口温度能反映水泥生料在分解炉的分解状况,分解的好坏对回转窑的煅烧有很大的影响;窑头保持负压状态是为了保持回转窑内通风流畅,负压大进风量大,窑内通风流畅,更利于回转窑内物料的煅烧;烟室O2含量高,窑内通风好;烟室CO含量高,窑内通风不畅不利于窑内物料煅烧;窑转速越快、窑内物料在窑内煅烧时间短,煅烧不充分;三次风是直接从篦冷机回收进分解炉的热风,三次风温度高能加速分解炉内物料的分解;预热器出口温度能够反映预热器内温度,温度越高,物料预热的越充分,更利于物料在预热器内预分解,减轻分解炉的负担。
步骤二 辅助变量数据采集及降维
由于初始辅助变量集合的数据维度大,故采用灰色关联度分析方法对初始辅助变量集合的数据进行灰色关联度计算,进而实现对初始辅助变量集合降维,获得最终的软测量模型输入辅助变量集合;
初始辅助变量集合:
Xi={Xi(k)|k=1,2…n},i=1,2…m (1)
熟料游离钙为:
Y={Y(k)|k=1,2…n} (2)
其中m为辅助变量的维数,n为一组辅助变量数据集的数据量。通过式(3)计算灰色关联系数,令Δi(k)=|y(k)-xi(k)|则:
计算灰色关联度
采用灰色关联度分析方法进行初始辅助变量降维,其中式(1)中Xi代表初始辅助变量集合,式(2)中Y代表初始fCaO集合。采用式(3)和式(4)对初始辅助变量集合的数据进行灰色关联度计算,设定灰色关联度阈值,删除与游离钙灰色关联度小的变量,进而实现对初始辅助变量集合降维,得到本次软测量模型输入辅助变量集合为:窑主机电流、二次风温、烟室温度、烟室NOx,输出变量为水泥熟料fCaO。
步骤三 基于深度信念网络的预测模型
1.深度信念网络预测模型的初步建立
深度信念网络预测模型构建可以看成有许多限制玻尔兹曼机(Restricted Boltzmann Mzchine,RBM)堆叠在一起,通过逐层训练限制玻尔兹曼机来实现网络的训练。用具体相应配置的深度信念网络初始化多层感知器权值时得到的结果,往往比随机权值初始化的表现好得多,因此用无监督的深度信念网络进行预训练学习,然后采用误差反向传播算法进行微调。根据深度信念网络的算法 及训练样本数据量确定深度信念网络结构,其具体参数设置规则如下:
(1)学习率ε
权值在每次循环学习中的变化受到学习率的影响较大。学习率小,学习时间长,收敛速度慢,不过能保证网络的误差值可以达到最终的极小点。系统的稳定性在学习率较大时可能会较差。通常倾向于选取较小的学习速率,其选取范围一般为0.001到0.10之间以保证系统的稳定性;
(2)权重wij
一般情况下,要取小的随机值,既保证各神经元的输入值较小,工作在激励函数斜率变化最大的区域,也防止某些权值的绝对值多次学习后不合理的无限增长。一般权重初始化来自正态分布的(0.001,1)的随机数。本发明在经过RBM预训练时采用该办法来初始权值。
(3)偏置
隐含层以及输出层单元偏置均初始置零。对于可见单元,由于可见单元在早期阶段容易利用隐含层单元使得第i个特征值以概率pi激活,所以这里可见单元偏置初时不为零,而是log(pi/(1-pi)),其中pi表示训练样本中第i个特征处于激活状态所占的概率。
(4)隐单元个数
如果不考虑计算复杂度,防止网络过拟合,可以提前预估隐含层单元个数。把模型描述一个样本数据需要的Bit数,乘以待学习样本的数目后,再降低一个数量级即为隐含层单元大概数目。本发明根据训练数据选择50个单元作为第一层隐含层,第二隐含层则均取20个单元。如果学习样本数量巨大,则隐含层单元数量可相对增加。
一个玻尔兹曼机是具有热力学能量函数定义的概率分布玻尔兹曼分布的, 一种基于能量理论的概率模型。设状态随机变量x,能量函数E(x)。一个典型的玻尔兹曼机是一个无项循环图,其能量定义为
E(x,h)=-b'x-c'h-x'Wh-x'Ux-h'Vh (5)
如果对玻尔兹曼机加以约束条件,层内无互联,可得到限制玻尔兹曼机(Restricted Boltzmann Mzchine,RBM),如图2所示。
如果一个限制玻尔兹曼机有n个可见节点和m个隐含层节点,用向量v表示可见节点状态,向量h表示隐含层节点,那么,对于一组给定的状态(v,h),限制玻尔兹曼机作为一个系统所具备的能量定义为:
式(6)中,θ={ai,bj,wij}是限制玻尔兹曼机的参数,其中ai表示可见节点i的偏置,bj表示隐含层节点j的偏置,wij为可见节点i与隐含层节点j之间的连接矩阵。当参数确定时,基于该能量函数可以得到联合概率分布:
其中Z(θ)为归一化因子,P(v/θ)称为似然函数。式(9)需要极其庞大的计算量,计算得到归一因子Z(θ),方能确定P(v/θ)的分布。
由限制玻尔兹曼机层内有连接,层外无连接的特殊结构可知,给定某层节点状态时,另一层节点状态之间的状态条件分布相互独立,即
当给定可见节点状态时,此时第j个隐含层节点的激活概率为:
在式(12)中,σ(·)为sigmoid激活函数,定义σ(x)=1/(1+exp(-x))。
求得所有的隐含层节点后,基于限制玻尔兹曼机的对称结构,可见节点的激活概率为:
假设有一个训练学习样本,分别用data和model来简记P(h/v(t),θ)和P(v,h/θ)这两个概率分布,对数似然函数关于连接矩阵wij可见层节点偏置和隐含层节点偏置的偏导数分别为:
限制玻尔兹曼机的快速学习算法,就是对比散度算法,该算法通过预训练学习数据,获得v0初值后,然后只需吉布斯采样一到两次,就能完成最后的概率近似。给定学习数据v0,计算出所有隐含节点j的二元状态,待隐含层节点全部求出时,反过来确定可见节点vi二值状态,进而产生可见层的一个重构,使用随机梯度上升法最大化对数似然函数在训练数据上的值时,各参数更新准则为:
ΔWij=ε(<vihj>data-<vihj>model) (17)
Δai=ε(<vi>data-<vi>model) (18)
Δbj=ε(<hj>data-<hj>model) (19)
式中,ε为学习效率,<~>recon表示一部重构后模型定义的分布。
2.深度信念网络预测模型的训练
采集水泥生产过程中水泥熟料游离钙预测的辅助变量数据,然后筛选出具有代表性的500组数据,将其代入深度信念网络进行预训练,训练出水泥熟料fCaO的预测模型。
深度信念网络可以看成有许多RBM堆叠在一起,通过逐层训练RBM来实现:底层的RBM以原始输入数据训练,顶部的RBM将底部RBM提取的特征作为输入,通过由底层到高层逐层训练这些限制玻尔兹曼机来实现。本发明建立的水泥熟料游离钙预测的深度信念网络模型框图,如图3所示。
限制玻尔兹曼机作为一个系统所具备的能量如式(6)所示,深度信念网络以似然函数P(v/θ)为目标,根据式(7)和式(8)能求出式(9)的联合概率分布。将步骤二得到的数据样本代入深度信念网络的结构中,并进行吉布斯采样得到式(14)—式(16),采用梯度下降法,进而得到各参数跟新准则如式(17)—式(19)所示,这样就为深度信念网络的微调初始化了权重和偏置;其具体步骤如下:
(1)首先充分训练第一个RBM。当给定可见节点状态时,此时第j个隐含层节点的激活概率为:
其中,σ(.)为sigmoid激活函数,定义σ(x)=1/(1+exp(-x))。求得所有的隐含层节点后,基于限制玻尔兹曼机的对称结构,可见节点的激活概率为:
(2)固定第一个RBM的权重和偏移量,然后使用其隐性神经元的状态,作为第二个RBM的输入向量,训练过程和第一个RBM相同。
(3)充分训练第二个RBM后,将第二个RBM堆叠在第一个RBM的上方。
(4)重复以上三个步骤任意多次,这样就实现了层数很多的深度信念网络的预训练过程,以上深度信念网络的预训练过程能实现对整个网络权重和偏置的初始化。
步骤四 误差修正及模型微调
人工神经网络的种类很多,选择何种网络类型,需要根据实际问题确定。本发明采用反向传播算法对步骤三训练的深度信念网络进行微调。本发明的基于深度信念网络模型训练过程中的反向传播算法学习流程图,如图5所示,具体步骤如下:
如当神经元为第一层隐含层单元时:
Netkj=∑iWjiXKI-θj (22)
Netkj为隐含层第j个神经元的状态;
Wji=Wij为输入层第i个神经元与本层隐含层第j个神经元之间的权值;
θj为隐含层第j个神经元的阈值;
计算可得Okj=Sj(Netkj)其中S(x)为S形函数;
Okj是隐含层第j个神经元的输出;
反向传播算法的学习规则是基于最小均方误差,一个样本输入网络产生输出时,均方误差为:
Tk为第K个样本的期望输出向量:
ΔWji设为网络中一个连接权值,根据梯度下降法,权值修正应为:
则得到下式:
ΔkWji=ηδkjOki (25)
η为学习率,不宜过高,0<η<1;
求各层的反传误差,假设S函数中的增益为1;
求得
输出层:
隐含层:
在步骤三中对层数很多的深度信念网络的预训练过程,实现对整个网络权重和偏置的初始化,然后采用反向传播算法进行微调,通过式(25)—式((27)对权重和偏置进行微调,这样就实现了对深度信念网络预测模型的建立。
步骤五 游离钙的预测输出
将现场测量仪表采集到的辅助变量的数据传输到用于运行深度信念网络的水泥熟料游离钙预测算法的中控机中,根据水泥烧成系统的窑主机电流、二次风温、窑尾温度、烟室NOx预测出输出变量为水泥熟料fCaO;
现场采集到的数据可能由于受到外界干扰出现大的波动,采用3δ准则剔除这些数据。设辅助变量序列为X1,···,Xn,据式(28)和式(29)分别计算器算术平均值t和标准偏差δ:
将现场测量仪表采集到的一段时间的辅助变量分别采用式(28)和式(29)进行算术平均值t和标准偏差δ计算,判断当前时刻辅助变量的数据Xi是否为粗大误差。若|Xi-t|≥3δ,则Xi为含有粗大误差的坏值,则删除同一时刻各个辅助变量 的数值,用上一时刻的测量值预测熟料fCaO含量。
综上所述,一种基于深度信念网络的水泥熟料fCaO含量预测方法步骤总结如下:
步骤一:控制变量初步选取Xi,对烧成过程影响的主要变量是窑主机电流、二次风温、窑尾温度、烟室NOx、二室篦下压力、分解炉出口温度、窑头负压、烟室O2、烟室CO、窑转速、三次风温、预热器出口温度,被控变量是熟料中游离氧化钙含量Y;
步骤二:数据采集及分类,通过中控机的数据通讯接口采集步骤一所述各辅助变量式(1)中的Xi和熟料游离钙的现场数据式(2)中的Y;采用式(3)和式(4)对初始辅助变量集合的数据进行灰色关联度计算,删除与游离钙灰色关联度小的变量,进而实现对初始辅助变量集合降维,获得最终输入变量集为:窑主机电流、二次风温、烟室温度、烟室NOx,输出变量为熟料fCaO含量;由于数据样本的单位不尽相同,故在进行数据建模之前要对数据进行统一单位,从而确保各权值的收敛速度大致相同;针对这种情况采用Sigmoid函数对步骤三的数据集合归一化处理,进而得到输入输出都在0到1之间;
步骤三:将步骤二得到的数据作为样本进行训练深度信念网络,通过对一些参数的调整,为深度信念网络优化了权重和偏置;
步骤四:采用反向传播算法对步骤三建立的深度信念网络模型进行误差校正与微调,进而确定出满足预测要求的深度信念网络模型;采用反向传播算法进行微调,通过式(25)—式(27)对权重和偏置进行微调,这样就实现了对深度信念网络预测模型的建立;
步骤五:采集步骤二得到的辅助变量的实时数据,并将其通过数据通信接口传输到在运行步骤四训练得到的水泥熟料fCaO的预测模型算法的中控机中, 进而预测出水泥熟料fCaO含量。
- 还没有人留言评论。精彩留言会获得点赞!