一种GPU阵列计算系统的制作方法
本实用新型涉及图像处理硬件设备领域,尤其是一种GPU阵列计算系统。
背景技术:
信息科技经过60多年的发展,已渗透到各行业的方方面面。政治、经济活动中很大一部分的活动都与数据的创造、采集、传输和使用相关,随着网络应用日益深化,大数据应用的影响日益扩大。大数据可来自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章、购买交易记录、网络日志、病历、事监控、视频和图像档案及大型电子商务等。大数据指的是大小超出常规的数据工具获取、存储、管理和分析能力的数据集,通常是万亿或EB的大小。
图像大数据的一个大数据的一个重要组成部分。1999-2000 年间,计算机科学家,与诸如医疗成像和电磁等领域的研究人员,开始使用GPU( 图形处理器) 来运行通用计算应用程序。他们发现GPU( 图形处理器) 具备的卓越浮点性能可为众多科学应用程序带来显著的性能提升。这一发现掀起了被称作GPGPU( 图形处理器通用计算) 的浪潮。
GPU 的处理核心SP 基于传统的处理器核心设计,能够进行整数,浮点计算,逻辑运算等操作,从硬体设计上看就是一种完全为多线程设计的处理核心,拥有复数的管线平台设计,完全胜任每线程处理单指令的工作。
GPU 内的线程分成多种,包括像素、几何以及运算三种不同的类型,在三维图像处理模式下,大量的线程同时处理一个渲染以达到最大化的效率,所以像GTX 200 GPU的核心内很大一部分面积都作为计算之用,和CPU 上大部分面积都被缓存所占据有所不同,大约估计在CPU 上有20%的晶体管是用作运算之用的,而GTX200 GPU 上有80%的晶体管用作运算。GPU 处理的首要目标是运算以及数据吞吐量,而CPU 内部晶体管的首要目的是降低处理的延时以及保持管线繁忙,这也决定了GPU 在密集行计算比起CPU 来更有优势。
随着显卡的发展,GPU 越来越强大,而且GPU 为显示图像做了优化。在计算上已经超越了通用的CPU。如此强大的芯片如果只是作为显卡就太浪费了,因此,不少公司推出了新的GPGPU架构(如NVIDIA 公司推出的CUDA,美国SGI公司推出的OpenGL等),让显卡可以用于图像计算以外的目的,让显卡可以用于图像计算以外的目的。
目前淘宝等流行电子商务平台配备了专门的图像服务器来进行图像大数据处理,使得用户只需通过手机扫描实物以及将扫描的图片信息上传给图像服务器就能方便地找出相关联的类似图片,然而这类图像服务器的结构大多较为复杂,硬件成本较高,不适合小型商家使用,而且其处理速度有待进一步提升。
技术实现要素:
为解决上述技术问题,本实用新型的目的在于:提供一种硬件成本低且快速的GPU阵列计算系统。
本实用新型所采取的技术方案是:
一种GPU阵列计算系统,包括应用层、Mapreduce接口、API接口、云服务器和GPU阵列,所述GPU阵列由多个GPU并联而成,所述应用层分别与Mapreduce接口和API接口连接,所述API接口还与云服务器连接,所述云服务器和Mapreduce接口还均与GPU阵列连接。
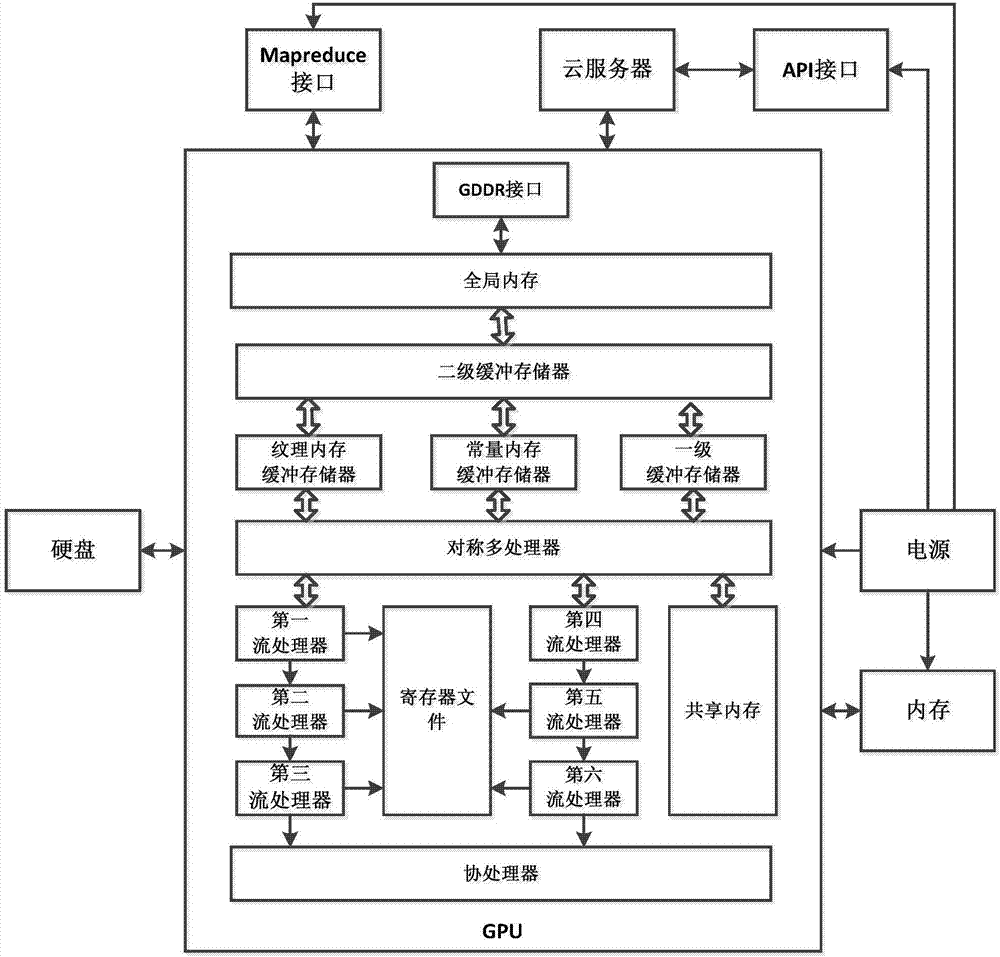
进一步,所述GPU包括全局内存、二级缓冲存储器、纹理内存缓冲存储器、常量内存缓冲存储器和一级缓冲存储器、对称多处理器、流处理器阵列、寄存器文件、共享内存和协处理器,所述全局内存分别与云服务器、Mapreduce接口和二级缓冲存储器连接,所述二级缓冲存储器还分别与纹理内存缓冲存储器、常量内存缓冲存储器和一级缓冲存储器连接,所述纹理内存缓冲存储器、常量内存缓冲存储器和一级缓冲存储器还均与对称多处理器连接,所述对称多处理器还分别与共享内存以及流处理器阵列连接,所述流处理器阵列的输出端分别与寄存器文件的输入端以及协处理器的输入端连接。
进一步,所述GPU还分别连接有硬盘和内存。
进一步,所述GPU还设有GDDR接口,所述GDDR接口与全局内存连接。
进一步,还包括电源,所述电源分别为Mapreduce接口、API接口、GPU和内存供电。
进一步,所述流处理器阵列包括第一流处理器、第二流处理器、第三流处理器、第四流处理器、第五流处理器和第六流处理器,所述第一流处理器和第四流处理器均与对称多处理器连接,所述第一流处理器的输出端依次通过第二流处理器和第三流处理器进而与协处理器的输入端连接,所述第四流处理器的输出端依次通过第五流处理器和第六流处理器进而与协处理器的输入端连接,所述第一流处理器的输出端、第二流处理器的输出端、第三流处理器的输出端、第四流处理器的输出端、第五流处理器的输出端和第六流处理器的输出端还均与寄存器文件的输入端连接。
进一步,所述第一流处理器与第四流处理器、第二流处理器与第五流处理器以及第三流处理器与第六流处理器均沿寄存器文件的两侧对称分布。
进一步,还包括CPU,所述CPU分别与Mapreduce接口以及云服务器连接。
本实用新型的有益效果是:包括应用层、Mapreduce接口、API接口、云服务器和GPU阵列,采用了GPU阵列来结合Mapreduce接口和API接口来处理应用层的图像数据,结构简单,硬件成本低,适合小型商家使用;GPU阵列由多个GPU并联而成,并增设了云服务器,进一步提升了系统的处理速度,更加快速。
附图说明
图1为本实用新型一种GPU阵列计算系统的整体功能模块框图;
图2为本实用新型GPU的结构框图。
具体实施方式
参照图1,一种GPU阵列计算系统,包括应用层、Mapreduce接口、API接口、云服务器和GPU阵列,所述GPU阵列由多个GPU并联而成,所述应用层分别与Mapreduce接口和API接口连接,所述API接口还与云服务器连接,所述云服务器和Mapreduce接口还均与GPU阵列连接。
参照图2,进一步作为优选的实施方式,所述GPU包括全局内存、二级缓冲存储器、纹理内存缓冲存储器、常量内存缓冲存储器和一级缓冲存储器、对称多处理器、流处理器阵列、寄存器文件、共享内存和协处理器,所述全局内存分别与云服务器、Mapreduce接口和二级缓冲存储器连接,所述二级缓冲存储器还分别与纹理内存缓冲存储器、常量内存缓冲存储器和一级缓冲存储器连接,所述纹理内存缓冲存储器、常量内存缓冲存储器和一级缓冲存储器还均与对称多处理器连接,所述对称多处理器还分别与共享内存以及流处理器阵列连接,所述流处理器阵列的输出端分别与寄存器文件的输入端以及协处理器的输入端连接。
参照图2,进一步作为优选的实施方式,所述GPU还分别连接有硬盘和内存。
参照图2,进一步作为优选的实施方式,所述GPU还设有GDDR接口,所述GDDR接口与全局内存连接。
参照图2,进一步作为优选的实施方式,还包括电源,所述电源分别为Mapreduce接口、API接口、GPU和内存供电。
参照图2,进一步作为优选的实施方式,所述流处理器阵列包括第一流处理器、第二流处理器、第三流处理器、第四流处理器、第五流处理器和第六流处理器,所述第一流处理器和第四流处理器均与对称多处理器连接,所述第一流处理器的输出端依次通过第二流处理器和第三流处理器进而与协处理器的输入端连接,所述第四流处理器的输出端依次通过第五流处理器和第六流处理器进而与协处理器的输入端连接,所述第一流处理器的输出端、第二流处理器的输出端、第三流处理器的输出端、第四流处理器的输出端、第五流处理器的输出端和第六流处理器的输出端还均与寄存器文件的输入端连接。
参照图2,进一步作为优选的实施方式,所述第一流处理器与第四流处理器、第二流处理器与第五流处理器以及第三流处理器与第六流处理器均沿寄存器文件的两侧对称分布。
参照图1,进一步作为优选的实施方式,还包括CPU,所述CPU分别与Mapreduce接口以及云服务器连接。
下面结合说明书附图和具体实施例对本实用新型作进一步解释和说明。
实施例一
针对现有图像服务器硬件成本高且速度不快的问题,本实用新型提出了一种新的GPU阵列计算系统。如图1所示,该GPU阵列计算系统主要包括应用层、Mapreduce接口、API接口、云服务器、GPU阵列、CPU、硬盘、电源和内存。
其中,应用层,用于将图像增强处理数据、图像目标搜索数据、公安行业数据、国防安全数据、平安城市数据、交通系统数据、救灾数据、卫星成像数据、信号处理数据、人脸识别数据、指纹识别数据、多路高清直播数据、智能视频监控数据等图像数据推送给Mapreduce接口和API接口。
Mapreduce接口,用于接收应用层推送的图像数据,并与GPU阵列通讯连接,以实现图像数据的并行化处理。本实用新型的Mapreduce接口可沿用现有的Mapreduce接口。
API接口,用于接收应用层推送的图像数据,并与云服务器通讯连接,以对图像数据进行更深层次的处理(如训练、学习和识别等)。本实用新型的API接口可沿用现有的API接口。
GPU阵列,由多个并联的GPU 组成,用于配合云服务器和Mapreduce接口完成图像数据的处理操作。如图2所示,本实用新型的GPU包括全局内存、二级缓冲存储器、纹理内存缓冲存储器、常量内存缓冲存储器和一级缓冲存储器、对称多处理器、流处理器阵列、寄存器文件、共享内存、协处理器和GDDR接口。流处理器阵列可进一步细分为第一流处理器、第二流处理器、第三流处理器、第四流处理器、第五流处理器和第六流处理器。本实用新型的GPU借鉴了CUDA框架的概念,并新建了如图2所示的硬件框架。下面对本实用新型的GPU的主要结构进行说明:
1)流处理器(Stream Processor,SP),是组成渲染管线的一部分,直接将多媒体等输入的图形数据流映射到流处理器上进行处理。
2)协处理器(Synergistic Processing Unit,SPU),是GPU专门用来运行一些计算任务的。二级缓冲存储器和一级缓冲存储器,是GPU内部的一些缓冲存储器,其作用跟内存一样。
3)GPU实际上是一个对称多处理器SM的阵列,每个SM包含若干个核(G80和GT200中有8个核,费米架构中有32~48个核,开普勒架构中至少再增加8个核)。一个GPU设备中包含一个或多个SM,这是处理器具有可扩展性的关键因素。如果向设备中增加更多的SM,GPU就可以在同一时刻处理更多的任务,或者对于同一任务,如果有足够的并行性的话,GPU可以更快地完成它。
4)每个SM都需要访问寄存器文件(register File),这是一组能够以与SP相同速度工作的存储单元,所以访问这组存储单元几乎不需要任何等待时间。不同型号的GPU中,寄存器文件的大小可能是不同的。它用来存储SP上运行的线程内部活跃的寄存器。另外,本实用新型还有一个只供每个SM内部访问的共享内存(shared memory),该共享内存可以用作高速缓存。
5)对于纹理内存(texture memory)缓冲存储器、常量内存(constant memory)缓冲存储器和全局内存(global memory)来说,每一个SM都分别设置有独立访问它们的总线。其中,纹理内存是针对全局内存的一个特殊视图,用来存储插值(interpolation)计算所需的数据,例如,显示2D或3D图像时需要的查找表。它拥有基于硬件进行插值的特性。常量内存用于存储那些只读的数据,所有的GPU卡均是对其进行缓存。与纹理内存一样,常量内存也是全局内存建立的一个视图。全局内存,即普通的显存,整个网格中的任意线程都能读写全局存储器的任意位置。本实用新型GPU的一级缓冲存储器数据量不够时会将先数据存储到全局内存,而GPU在查找数据时先去一级缓冲存储器查找,一级缓冲存储器找不到时再通过全局内存去共享内存查找。
6)图形卡通过GDDR(Graphic Double Data Rate)接口访问全局内存。GDDR是DDR(Double Data Rate)内存的一个高速版本,其内存总线宽度最大可达512位,提供的带宽是CPU对应带宽的5~10倍,在费米架构GPU中最高可达190GB/s。
CPU,用于辅助GPU进行图像数据处理,以提高处理速度。
硬盘和内存,用于存储图像处理结果数据。
电源,用于为Mapreduce接口、API接口、GPU和内存供电。
本实用新型的工作过程如下:
S1、应用层将图像增强处理数据、图像目标搜索数据、公安行业数据、国防安全数据、平安城市数据、交通系统数据、救灾数据、卫星成像数据、信号处理数据、人脸识别数据、指纹识别数据、多路高清直播数据、智能视频监控数据等图像数据推送给Mapreduce接口和API接口。
S2、通过MapReduce k接口来并行处理图像数据;
S3、通过API接口直接与云服务器通信,将直接图像数据提交到云服务器,利用云服务器的快速运算能力进行快速处理。
S4、云服务器与GPU阵列的CPU进行通信,以完成图像数据的处理工作。
本实用新型的云服务器、GPU和CPU虽然涉及数据处理的内容,但其均可采用现有的技术手段来实现,在此不再重复描述。
以上是对本实用新型的较佳实施进行了具体说明,但本实用新型并不限于所述实施例,熟悉本领域的技术人员在不违背本实用新型精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!