一种短期风速多步预测方法及装置与流程
本发明涉及风速预测技术领域,更具体地说,涉及一种短期风速多步预测方法及装置。
背景技术:
目前,短期风速预测对于风电场管理和电力系统运行具有重要的意义,但是风速的随机性、波动性和间歇性使风速预测的难度增加。近年来在风速预测领域提出的方法往往结构复杂且计算量大,且大部分研究都是离线模式,没法实时的追踪风速的变化。
因此,如何实时追踪风速的变化,是本领域技术人员需要解决的问题。
技术实现要素:
本发明的目的在于提供一种短期风速多步预测方法及装置,以实现实时追踪风速的变化,提高风速预测精度。
为实现上述目的,本发明实施例提供了如下技术方案:
一种短期风速多步预测方法,包括:
利用启发式分割算法bga将原始风速时间序列分割成多个平稳子序列;
利用自适应可变模式分解技术savmd将每个平稳子序列分解为一系列有限带宽的子模式;
通过基于cook距离的遗忘因子的鲁棒在线极限学习机λcdffos-orelm,对每个系列子模式建立基本预测模型,并采用带有自适应变异机制的纵横交叉优化算法cso-sam对预测模型进行参数优化;
利用在线集成学习和有序聚合技术oeoa,通过对多个λcdffos-orelm基本预测模型加权聚合获取最终预测值。
其中,所述利用启发式分割算法bga将原始风速时间序列分割成多个平稳子序列,包括:
确定所述原始风速时间序列中除起点和终点之外其他目标点的左平均值和右平均值,根据每个目标点的左平均值和右平均值确定每个目标点的统计值;
根据每个目标点的统计值计算每个目标点的统计显著性,将统计显著性大于预定阈值的目标点作为分割点,并利用所述分割点,对所述原始风速时间序列进行分割,形成多个平稳子序列。
其中,所述利用所述分割点,对所述原始风速时间序列进行分割之后,还包括:
判断分割后的左右两部分序列是否均大于最小分割长度;若否,则取消对所述原始风速时间序列的分割。
其中,所述利用自适应可变模式分解技术savmd将每个平稳子序列分解为一系列有限带宽的子模式,包括:
利用经验模态分解技术emd确定对目标平稳子序列进行分解的模态数k,并通过可变模式分解技术vdm将所述目标平稳子序列分解为k个模态;
通过消除趋势波动分析法dfa确定每个模态的波动参数,并根据每个模态的波动参数对所述目标平稳子序列进行去噪重构。
其中,所述通过基于cook距离的遗忘因子的鲁棒在线极限学习机λcdffos-orelm,对每个系列子模式建立基本预测模型,并采用带有自适应变异机制的纵横交叉优化算法cso-sam对预测模型进行参数优化,包括:
利用初始训练数据集创建初始预测模型,通过10折交叉验证法确定始预测模型隐含层节点个数,并计算模型参数;所述模型参数包括隐含层输出矩阵及初始输出权值;
计算cook距离,根据所述cook距离确定遗忘因子λ,通过所述遗忘因子λ更新模型参数,并通过带有自适应变异机制的纵横交叉优化算法cso-sam对模型参数进行优化,得到基本预测模型;所述基本预测模型包括与平稳子序列对应的多个预测模型。
其中,所述利用在线集成学习和有序聚合技术oeoa,通过对多个λcdffos-orelm基本预测模型加权聚合获取最终预测值,包括:
对每个平稳子序列对应的多个预测模型进行均方根误差更新,并根据更新结果选择预定数量个模型作为最优模型集合;
对所述最优模型集合中的每个预测模型分配权值,计算每个平稳子序列的预测值,并根据每个平稳子序列的预测值确定最终预测值。
其中,所述根据每个平稳子序列的预测值确定最终预测值之后,包括:
当获取到下一时刻的风速时间序列后,根据本时刻的真实值更新所述初始训练数据集,得到更新后的训练数据集;
根据本时刻的真实值,计算所述最优模型集合中的每个预测模型的预测误差,若存在预测误差大于误差阈值的预测模型,则通过所述更新后的训练数据集建立训练模型,替换所述最优模型集合中预测误差大于所述误差阈值的预测模型。
一种短期风速多步预测装置,包括:
平稳子序列分割模块,用于利用启发式分割算法bga将原始风速时间序列分割成多个平稳子序列;
分解模块,用于利用自适应可变模式分解技术savmd将每个平稳子序列分解为一系列有限带宽的子模式;
预测模型建立模块,用于通过基于cook距离的遗忘因子的鲁棒在线极限学习机λcdffos-orelm,对每个系列子模式建立基本预测模型,并采用带有自适应变异机制的纵横交叉优化算法cso-sam对预测模型进行参数优化;
预测模块,用于利用在线集成学习和有序聚合技术oeoa,通过对多个λcdffos-orelm基本预测模型加权聚合获取最终预测值。
其中,所述平稳子序列分割模块,包括:
统计值确定单元,用于确定所述原始风速时间序列中除起点和终点之外其他目标点的左平均值和右平均值,根据每个目标点的左平均值和右平均值确定每个目标点的统计值;
分割单元,用于根据每个目标点的统计值计算每个目标点的统计显著性,将统计显著性大于预定阈值的目标点作为分割点,并利用所述分割点,对所述原始风速时间序列进行分割,形成多个平稳子序列。
其中,所述预测模型建立模块,包括:
初始预测模型确定单元,用于利用初始训练数据集创建初始预测模型,通过10折交叉验证法确定始预测模型隐含层节点个数,并计算模型参数;所述模型参数包括隐含层输出矩阵及初始输出权值;
基本预测模型确定单元,用于计算cook距离,根据所述cook距离确定遗忘因子λ,通过所述遗忘因子λ更新模型参数,并通带有自适应变异机制的纵横交叉优化算法cso-sam对模型参数进行优化,得到基本预测模型;所述基本预测模型包括与平稳子序列对应的多个预测模型。
通过以上方案可知,本发明实施例提供的一种短期风速多步预测方法,包括:利用启发式分割算法bga将原始风速时间序列分割成多个平稳子序列;利用自适应可变模式分解技术savmd将每个平稳子序列分解为一系列有限带宽的子模式;通过基于cook距离的遗忘因子的鲁棒在线极限学习机λcdffos-orelm,对每个系列子模式建立基本预测模型,并采用带有自适应变异机制的纵横交叉优化算法cso-sam对预测模型进行参数优化;利用在线集成学习和有序聚合技术oeoa,通过对多个λcdffos-orelm基本预测模型加权聚合获取最终预测值。
可见,在本方案中,可通过基于cook距离的遗忘因子的鲁棒在线极限学习机根据风速的变化来更新模型,并使用有序聚合进行在线集成学习技术oeoa,通过对多个λcdffos-orelm加权聚合获取最终预测值,使多步预测精度有较大的提高;本发明还公开了一种短期风速多步预测装置,同样能实现上述技术效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例公开的一种短期风速多步预测方法流程示意图;
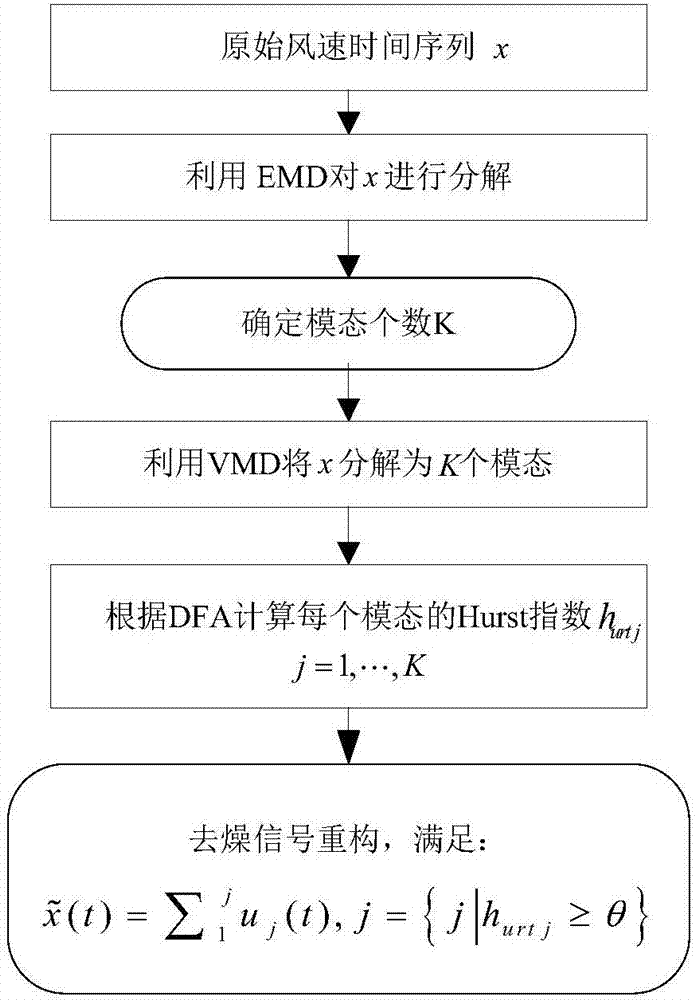
图2为本发明实施例公开的去噪流程示意图;
图3为本发明实施例公开的一种聚义的短期风速多步预测方法流程示意图;
图4为本发明实施例公开的一风速时间序列示意图;
图5为本发明实施例公开的另一风速时间序列示意图;
图6为本发明实施例公开的另一风速时间序列示意图;
图7为本发明实施例公开的另一风速时间序列示意图;
图8为本发明实施例公开的一预测结果示意图;
图9为本发明实施例公开的另一预测结果示意图;
图10为本发明实施例公开的另一预测结果示意图
图11为本发明实施例公开的一种短期风速多步预测装置结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种短期风速多步预测方法及装置,以实现实时追踪风速的变化,提高风速预测精度。
参见图1,本发明实施例提供的一种短期风速多步预测方法,包括:
s101、利用启发式分割算法bga将原始风速时间序列分割成多个平稳子序列;
其中,所述利用启发式分割算法bga将原始风速时间序列分割成多个平稳子序列,包括:
确定所述原始风速时间序列中除起点和终点之外其他目标点的左平均值和右平均值,根据每个目标点的左平均值和右平均值确定每个目标点的统计值;
根据每个目标点的统计值计算每个目标点的统计显著性,将统计显著性大于预定阈值的目标点作为分割点,并利用所述分割点,对所述原始风速时间序列进行分割,形成多个平稳子序列。
其中,所述利用所述分割点,对所述原始风速时间序列进行分割之后,还包括:判断分割后的左右两部分序列是否均大于最小分割长度;若否,则取消对所述原始风速时间序列的分割。
具体的,在本实施例中利用bga(bernaolagalvanalgorithm)算法将风速时间序列分割成若干平稳子序列的具体步骤为:
11)对于一个含有n个点的风速时间序列xn={x1,...,xn},除起始点和终点两个点外,从左到右分别计算剩余点左边部分和右边部分的平均值ul和ur,用t检验的统计值ti来量化表示i点左右两部分均值的差异,计算如式(1):
ti=|(μl-μr)/sd|...................................................(1)
其中,合并方差
12)计算t中的最大值tmax的统计显著性p(tmax),如式(2)所示:
p(tmax)=prob(t≤tmax)...........................................(2)
其中,p(tmax)表示在随机过程中取到的t值小于tmax的概率。
13)如果这个显著性p(tmax)大于所选定的临界值,则于该点将风速时间序列切分为两段均值有明显差异的子序列,否则不分割;在本实施例中,p(tmax)可取95%。
14)为确保统计的有效性,检查分割后形成的左右两部分子序列的长度是否小于最小分割长度(l0),若其长度小于l0,则不再对其进行分割,否则按照上述方法对p(τ)≥p0的子序列继续进行分割,p(τ)可以通过蒙特卡洛模拟获取。
分割完成后,非平稳的风速时间序列被切分成多个有着不同均值的平稳子序列,使得相邻部分的均值差实现最大化,各个子序列的平稳性保证了更高的预测的精度。
s102、利用自适应可变模式分解技术savmd将每个平稳子序列分解为一系列有限带宽的子模式;
其中,所述利用自适应可变模式分解技术savmd将每个平稳子序列分解为一系列有限带宽的子模式,包括:
利用经验模态分解技术emd确定对目标平稳子序列进行分解的模态数k,并通过可变模式分解技术vdm将所述目标平稳子序列分解为k个模态;
通过消除趋势波动分析法dfa确定每个模态的波动参数,并根据每个模态的波动参数对所述目标平稳子序列进行去噪重构。
具体的,在本实施例中,利用savmd(self-adaptivevariationalmodedecomposition)技术将风速子序列分解为一系列有限带宽的子模式的具体步骤为:
21)利用经验模态分解(empericalmodedecomposition,emd)确定分解的模态数k,再通过vmd预设尺度对风速时间子序列信号x(t)进行分解,将子序列分解为k个中心频率为wk的子信号,由此得到k个模态函数uk,可变约束条件为:
式中,{uk}={u1,u2,......,uk}为各模态函数;{wk}={w1,w2,......,wk}为各中心频率;
22)式子(3)中的最小化问题,求解拉格朗日算子如下式:
式中,a是数据保真度的平衡参数,通过交替方向算子法(alternatedirectionmethodofmultipliers,admn)求解上式,得到的各参数最优值的迭代格式如下:
其中
23)通过消除趋势波动分析法(detrendedfluctuationanalysis,dfa)的波动参数hurt来检测含有噪声或者叠加有多项式趋势信号的风速时间子模式,hurt指数计算方法如下:
对于有n个点的风速时间序列{x(i),i=1,2,...,n},计算其累计离差:
对y(k)分别进行等长分割,以长度nn=n/n将序列分割成n个不重叠的区间,在每个区间用l次多项式进行拟合,本文取l=2,即得到
yn(k)=ank2+bnk+cn...................................(9)
对n个等长度区间求均值并开方,计算得到dfa波动函数如下:
对dfa波动函数和n取双对数,hurt即为双对数坐标(ln(n),ln(f(n)))中的散点图,用最小二乘法对数据点进行拟合,其中直线部分的斜率即hurt指数,可通过式(11)得到:
ln(f(n))=hurtln(n)+c................................(11)
定义斜率的临界值θ=hurt+0.25(本文取hurt=0.5),当hurt参数小于θ时,将此风速时间子序列内模函数定义为噪音信号,作为独立的输入;当hurt指数大于θ时,定义为纯净的风速子序列内模函数,对其进行重构处理:
其中,hurtj代表第j个风速时间子序列内模函数的波动参数,其中1≤j≤k。
综上所述savmd-dfa的实现过程即:首先利用emd来确定vmd模态个数k,然后通过dfa计算每个模态的hurt指数来区分信号的随机成分,并对k个模态进行重构来最终确定模态的个数,其实现过程如图2所示。
s103、通过基于cook距离的遗忘因子的鲁棒在线极限学习机λcdffos-orelm,对每个系列子模式建立基本预测模型,并采用带有自适应变异机制的纵横交叉优化算法cso-sam对预测模型进行参数优化;
其中,所述通过基于cook距离的遗忘因子的鲁棒在线极限学习机λcdffos-orelm,对每个系列子模式建立基本预测模型,并采用带有自适应变异机制的纵横交叉优化算法cso-sam对预测模型进行参数优化,包括:
利用初始训练数据集创建初始预测模型,通过10折交叉验证法确定始预测模型隐含层节点个数,并计算模型参数;所述模型参数包括隐含层输出矩阵及初始输出权值;
计算cook距离,根据所述cook距离确定遗忘因子λ,通过所述遗忘因子λ更新模型参数,并通过带有自适应变异机制的纵横交叉优化算法cso-sam对模型参数进行优化,得到基本预测模型;所述基本预测模型包括与平稳子序列对应的多个预测模型。
具体的,在本实施例中,采用λcdffos-orelm(onlinesequentialorelmwithforgettingfactorbasedoncook’sdistance)对每个系列子模式建立基本预测模型,并采用cso-sam(crisscrossoptimizationalgorithmwithself-adaptivemutation)算法进行参数优化的具体步骤为:
31)初始化阶段。
模型利用初始训练数据集
则初始输出权值为
其中
32)在线序列学习阶段。当训练集d的第k+1个样本到来时,首先计算隐含层输出层矩阵
利用递归最小二乘法来更新输出权值,即
其中
33)计算新观察值的时变cook距离
m是输出参数β的长度,
其中,mk是有效样本数量,给定m0=0。
34)遗忘因子λk+1能够逐渐剔除旧的数据,保证利用最新的数据来建立模型,本文利用基于cook距离的遗忘因子(λcdff)来更新模型参数,当第k+1个样本到来时,求基于cook距离的遗忘因子:
ck=νdk.....................................................(21)
sk=p(χν>ck)(0<sk<1)..................................(22)
λk+1=λmin+(1-λmin)sk+1......................................(23)
式中,λmin为遗忘因子的最小值,sk+1为生存函数,其利用数理统计工具将cook距离转化为遗忘因子,其中ck服从自由度为ν的卡方分布:
35)以上基本预测模型的输入权值和隐含节点偏差需采用cso-sam算法来优化,具体步骤如下:
假定父代粒子x(i)和x(j)在第d维进行横向交叉,计算公式如下:
其中,r1和r2为均匀分布于[0,1]的随机数,c1和c2为均匀分布于[-1,1]的随机数,mshc(i,d)和mshc(j,d)是x(i,d)和x(j,d)交叉产生的子代。
36)将执行完横向交叉后更新的种群作为纵向交叉的父代种群,假定粒子x(i)在第d1和d2维进行纵向交叉,计算公式如下:
其中,r为均匀分布于[0,1]的随机数;d为粒子的维度总数;m是种群数量。将横向交叉与纵向交叉产生的中庸解与父代粒子进行竞争,得到最优的种群。
37)通过种群适应度值中的变量σ2来自动调整pvc,其中σ2的表达式如下:
其中fi为粒子i的适应度值,favg为此时所有适应度的平均值,n为粒子个数;
38)最后,利用公式(27)可以得到纵向交叉概率pvc的线性表达式:
其中,pvcmax和pvcmin是纵向交叉概率pvc的最大值和最小值;
39)λcdffos-orelm模型的训练误差将作为cso-sam算法的优化目标来确定orelm最优的输入权值和偏差,即
式中,
s104、利用在线集成学习和有序聚合技术oeoa,通过对多个λcdffos-orelm基本预测模型加权聚合获取最终预测值。
其中,利用在线集成学习和有序聚合技术oeoa,通过对多个λcdffos-orelm基本预测模型加权聚合获取最终预测值包括:
对每个平稳子序列对应的多个预测模型进行均方根误差更新,并根据更新结果选择预定数量个模型作为最优模型集合;
对所述最优模型集合中的每个预测模型分配权值,计算每个平稳子序列的预测值,并根据每个平稳子序列的预测值确定最终预测值。
其中,所述根据每个平稳子序列的预测值确定最终预测值之后,包括:
当获取到下一时刻的风速时间序列后,根据本时刻的真实值更新所述初始训练数据集,得到更新后的训练数据集;
根据本时刻的真实值,计算所述最优模型集合中的每个预测模型的预测误差,若存在预测误差大于误差阈值的预测模型,则通过所述更新后的训练数据集建立训练模型,替换所述最优模型集合中预测误差大于所述误差阈值的预测模型。
具体的,在本实施例中,利用λcdffos-orelm基本预测模型和oeoa(onlineensembleusingorderedaggregation)技术通过加权来得到风速点预测的具体步骤为:
41)多模型在线选择,oeoa利用初始训练数据集d0建立mmax个模型fm(m=1,…,mmax),形成模型集合ε。对于每个模型,在集成学习的过程中,训练均方根误差利用公式(29)进行更新。
其中,
根据每个模型训练得到的均方误差进行升序排序,自适应选取ε的前b个模型作为最优的子集,预测第t(t=t0+1,…,t)个样本数据xt对应的风速预测值。当第t+1个新样本到来时,第t个样本的真实值加入到训练数据集中,并将旧的数据样本
42)模型集成学习,oeoa从模型集合ε选择最优的b个模型来进行集成学习来对新的样本进行预测。在集成学习过程中,需要对b个模型分配权值,模型权值通过均方误差来计算获得,其计算公式如(31)所示。
其中,
最终,新样本数据的预测值为
43)模型更新,在对t+1时刻的样本进行预测之前,首先利用t时刻样本数据的真实值来校验模型的预测误差,通过设置误差阈值α来判断是否对此时的模型集合ε进行更新。当满足
时,根据公式(30)形成的新的训练集dt来建立新的训练模型fnew,并用fnew来替换ε预测误差最大的模型。当公式(33)不满足时,保持模型集合ε不变。
可见,在本方案考虑到原始风速时间序列的非平稳性,利用bga将原始风速分割为若干平稳风速子序列,每个子序列采用savmd进行信号分解和重构,形成一系列频率相近的子模式,再对每个子模式采用λcdffos-orelm-oeoa进行建模预测,模型参数通过cso-sam进行动态调整,以此得到短时风速多步预测模型。本预测方法与其他预测方法相比,本文方法在不同信号分解技术(savmd和eemd(ensembleempiricalmodedecomposition))下都表现出很好的预测性能,具体表现如下:
1)利用savmd技术对原始风速时间子序列进行分解,与vmd技术相比,savmd能够自适应确定子信号的个数;
2)cso-sam具有很强的搜索能力,能够确定模型最优参数,以此来提高预测精度;
3)在线集成学习预测模型利用基于cook距离的遗忘因子实时跟踪风速变化来调整模型参数;并且利用oeoa技术来选择最优子模型,通过加权聚合来获得最终的预测值,进一步提高风速预测精度。
具体的,参见图3,图3为本实施例提供的一种基于在线鲁棒极限学习机自适应集成学习的短期风速多步预测方法实现流程图;为了对本方案进行详细的描述,提供一应用本方案的具体实施例:
选取nrel提供的某风电场2004年的实测风速时间序列作为研究对象,为了减少季节对风速预测的影响,选取四、七、十和一月份作为每个季节的典型月份,分别建立不同的预测模型。风速数据的采样频率10min,四个月份的样本点个数分别为4320,4464,4464和4464,其风速时间序列如图4-7所示,在实例分析中,分别进行短期风速单步、三步和五步预测。利用bga将原始的风速时间序列分割成多个子序列,其均值和方差如表1所示。
表12004年春季风速时间序列的分割结果
将每个风速子系列的后100个点作为验证集,其余部分作为训练集对风速模型进行训练。将此预测模型的预测结果与λcdffos-orelm-oeoa预测模型、λcdffos-orelm预测模型、bpnn、offline-elm、offline-orelm以及持久模型(persistencemodel,pm)的预测结果进行比较,同时分别建立基于savmd和eemd的上述预测模型,并将预测结果进行比较。
为了定性地评价预测模型的性能,引入平均绝对误差(meanabsoluteerror,mae),平均绝对百分比误差(meanabsolutepercentageerror,mape)和均方根误差(rootmean-squarederror,rmse)作为预测模型的性能评价指标:
上述式子中,
以2004年4月份的风速时间序列为例,利用bga将原始风速分割成9个子序列,各子序列风速的均值和方差见表1。选取第5个子序列(s5)进行分析,将前551个样本点作为训练数据集,后100个点作为验证样本集。
λcdffos-orelm-oeoa模型参数设置如下:初始训练集个数t0=20;误差阈值ρ=0.04;遗忘因子最小值λmin=0.6;mmin=10;mmax=15。
cso-sam参数设置如下:种群个数为20;最大迭代次数为100;根据经验值,纵向交叉概率的最大值和最小值分别取pvmax=0.8和pvmin=0.2。
savmd将s5原始子风速时间序列分解为5个子信号,eemd则把s5分解为8个子信号,按照上述的预测方法对每个子信号单独建立预测模型,最后对每个子信号的预测值求和,得到最终的风速预测值。s5没有经过信号分解后得出的多步误差评价指标如表2所示,经过savmd和eemd分解后的多步模型误差评价指标分别如表3和4所示。
表2未经信号分解风速预测结果
表3基于savmd技术的风速预测结果
表4基于eemd技术的风速预测结果
对比表2-表4可知:
(1)风速时间序列经过savmd和eemd技术处理后,各种预测模型的预测精度有大幅度的提高。以本文方法为例,采用信号分解技术后,单步预测emape分别提高了17.07%和9.76%;
(2)在所有预测模型中,本文提出模型的多步预测性能优于其他模型,其中pm模型的预测性能最差。
由以上数据进一步分析可知:
(1)cso-sam对orelm模型参数有较强的寻优能力;
(2)本文的在线预测模型与传统离线模型比较而言,在线模型可以实时改变参数来适应风速的变化,保证预测模型具有较强的鲁棒性;
(3)基于cook距离的遗忘因子(λcdff)在整个在线预测过程中,削弱旧数据样本的影响,利用新的数据样本来更新模型参数,提高预测模型的精度。
同理,表1中经bga切割后形成的其他子序列均可采用上述方法进行预测,其预测结果如图8-10所示。由图8-10的误差评价指标可知,经bga算法分割后的子序列预测精度比完整的序列更高,即表明数据预处理时利用bga的有效性。将本文的λcdffos-orelm-oeoa模型应用在2004年的4个季节,得到的模型单步误差评价指标如表5所示。
表5本文方法得到的不同季节预测结果
由表5可知,每个季节的单步误差评价指标值相差不大,春季的预测性能较其它季节略差,说明本文的模型是能够反应季节变化引起的风速变化,反映了风速预测的季节特性。
下面对本发明实施例提供的短期风速多步预测装置进行介绍,下文描述的短期风速多步预测装置与上文描述的短期风速多步预测方法可以相互参照。
参见图11,本发明实施例提供的一种短期风速多步预测装置,包括:
平稳子序列分割模块100,用于利用启发式分割算法bga将原始风速时间序列分割成多个平稳子序列;
分解模块200,用于利用自适应可变模式分解技术savmd将每个平稳子序列分解为一系列有限带宽的子模式;
预测模型建立模块300,用于通过基于cook距离的遗忘因子的鲁棒在线极限学习机λcdffos-orelm,对每个系列子模式建立基本预测模型,并采用带有自适应变异机制的纵横交叉优化算法cso-sam对预测模型进行参数优化;
预测模块400,用于利用在线集成学习和有序聚合技术oeoa,通过对多个λcdffos-orelm基本预测模型加权聚合获取最终预测值。
基于上述实施例,所述平稳子序列分割模块100,包括:
统计值确定单元,用于确定所述原始风速时间序列中除起点和终点之外其他目标点的左平均值和右平均值,根据每个目标点的左平均值和右平均值确定每个目标点的统计值;
分割单元,用于根据每个目标点的统计值计算每个目标点的统计显著性,将统计显著性大于预定阈值的目标点作为分割点,并利用所述分割点,对所述原始风速时间序列进行分割,形成多个平稳子序列。
其中,平稳子序列分割模块100还包括:
判断模块,用于判断分割后的左右两部分序列是否均大于最小分割长度;
所述分割单元,用于在分割后的左右两部分序列均大于最小分割长度时,对原始风速时间序列进行分割;否则,取消对所述原始风速时间序列的分割。
基于上述实施例,所述分解模块200包括:
模态分解模块,用于利用经验模态分解技术emd确定对目标平稳子序列进行分解的模态数k,并通过可变模式分解技术vdm将所述目标平稳子序列分解为k个模态;
去噪重构模块,用于通过消除趋势波动分析法dfa确定每个模态的波动参数,并根据每个模态的波动参数对所述目标平稳子序列进行去噪重构。
基于上述实施例,所述预测模型建立模块300,包括:
初始预测模型确定单元,用于利用初始训练数据集创建初始预测模型,通过10折交叉验证法确定始预测模型隐含层节点个数,并计算模型参数;所述模型参数包括隐含层输出矩阵及初始输出权值;
基本预测模型确定单元,用于计算cook距离,根据所述cook距离确定遗忘因子λ,通过所述遗忘因子λ更新模型参数,并通过带有自适应变异机制的纵横交叉优化算法cso-sam对模型参数进行优化,得到基本预测模型;所述基本预测模型包括与平稳子序列对应的多个预测模型。
基于上述实施例,预测模块400包括:
最优模型集合确定模块,用于对每个平稳子序列对应的多个预测模型进行均方根误差更新,并根据更新结果选择预定数量个模型作为最优模型集合;
最终预测值确定模块,用于对所述最优模型集合中的每个预测模型分配权值,计算每个平稳子序列的预测值,并根据每个平稳子序列的预测值确定最终预测值。
其中,预测模块400包括:
更新模块,用于当获取到下一时刻的风速时间序列后,根据本时刻的真实值更新所述初始训练数据集,得到更新后的训练数据集;
最优模型更新模块,用于根据本时刻的真实值,计算所述最优模型集合中的每个预测模型的预测误差,若存在预测误差大于误差阈值的预测模型,则通过所述更新后的训练数据集建立训练模型,替换所述最优模型集合中预测误差大于所述误差阈值的预测模型。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!