话题检测方法及装置与流程
本申请涉及软件领域,具体而言,涉及一种话题检测方法及装置。
背景技术:
:话题检测,一般采用单一的关键词进行识别,即当关键词出现,则说明话题命中。但在话题检测的过程中只考虑单句的话题,并没有参考上下文的内容,容易导致话题识别不准确的问题。针对相关技术中话题检测准确率低的问题,目前尚未提出有效的解决方案。技术实现要素:本申请的主要目的在于提供一种话题检测方法,以解决话题检测准确率低的问题。为了实现上述目的,根据本申请的一个方面,提供了一种话题检测方法,其特征在于,用以检测文本内容中的话题,所述文本内容带有预设时间标签,所述方法包括:匹配所述文本内容中的话题词,所述话题词对应至少一个话题;确定每个时间片段上每个话题的基础分数;根据所述时间片段确定每个话题的衰减后分数;以及通过基础分数和衰减后分数计算得到当前话题的动态分数。进一步地,根据时间标签确定每个话题的衰减后分数包括:通过所述时间标签划分出时间片段;计算每个时间片段的话题基础分数;以及根据当前时间片段之前的所有时间片段的基础分数和时间间隔计算衰减后分数。进一步地,通过基础分数和衰减后分数计算得到当前时间片段的动态话题分数包括:根据所述预设时间标签和话题词权重计算所述文本的每个时间片段的基础话题分数,根据之前所有时间片段的基础话题分数计算时间维度上的衰减后分数;其中,动态话题分数=基础分数+衰减后分数。进一步地,通过基础分数和衰减后分数计算得到当前话题的动态话题分数之后还包括:抽取所述动态话题分数中的高分动态话题分数;判断所述高分动态话题分数是否满足预设条件;以及如果所述高分动态话题分数满足预设条件,则执行预设抽取操作。进一步地,所述判断所述高分动态话题分数是否满足预设条件包括执行以下任意一个或多个处理:动态话题分数是否达到该话题的触发阈值;是否在连续的时间片段上连续触发;在文本上是否属于同一场景;以及是否存在话题关键词。为了实现上述目的,根据本申请的另一方面,提供了一种话题检测装置,用以检测文本内容中的话题,所述文本内容带有预设时间标签,所述装置包括:匹配模块,用于匹配所述文本内容中的话题词;基础分数计算模块,用于确定每个时间片段上每个话题的基础分数;时间衰减模块,用于根据时间标签和之前所有时间片段的基础分数确定当前话题的衰减后分数;以及动态话题分数计算模块,用于根据基础分数和衰减后分数计算动态话题分数。进一步地,装置还包括:高分抽取模块,用于抽取所述动态话题分数中的高分动态话题分数;判断所述高分动态话题分数是否满足预设条件;以及如果所述高分动态话题分数满足预设条件,则执行预设抽取操作。进一步地,高分抽取模块,还用于执行以下任意一个或多个处理:动态话题分数是否达到该话题的触发阈值;是否在连续的时间片段上连续触发;在文本上是否属于同一场景;以及是否存在话题关键词。进一步地,所述基础分数计算模块,还用于通过所述时间标签划分出时间片段;计算每个时间片段的话题基础分数;所述时间衰减模块,还用于根据当前时间片段之前的所有时间片段的基础分数和时间间隔计算衰减后分数。进一步地,所述基础分数计算模块,还用于根据所述预设时间标签和话题词权重计算所述文本的每个时间片段的基础话题分数,根据之前所有时间片段的基础话题分数计算时间维度上的衰减后分数;其中,动态话题分数=基础分数+衰减后分数。在本申请实施例中,采用动态话题分数的计算方式,通过时间衰减,达到了高准确率的实时识别的目的,从而实现了更加准确识别话题的技术效果,进而解决了话题检测准确率低技术问题。附图说明构成本申请的一部分的附图用来提供对本申请的进一步理解,使得本申请的其它特征、目的和优点变得更明显。本申请的示意性实施例附图及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:图1是根据本申请第一实施例的话题检测方法流程示意图;图2是根据本申请第二实施例的话题检测方法流程示意图;图3是根据本申请第三实施例的话题检测方法流程示意图;图4是根据本申请第四实施例的话题检测方法流程示意图;图5是根据本申请第一实施例的话题检测装置示意图;以及图6是根据本申请第二实施例的话题检测装置示意图。具体实施方式为了使本
技术领域:
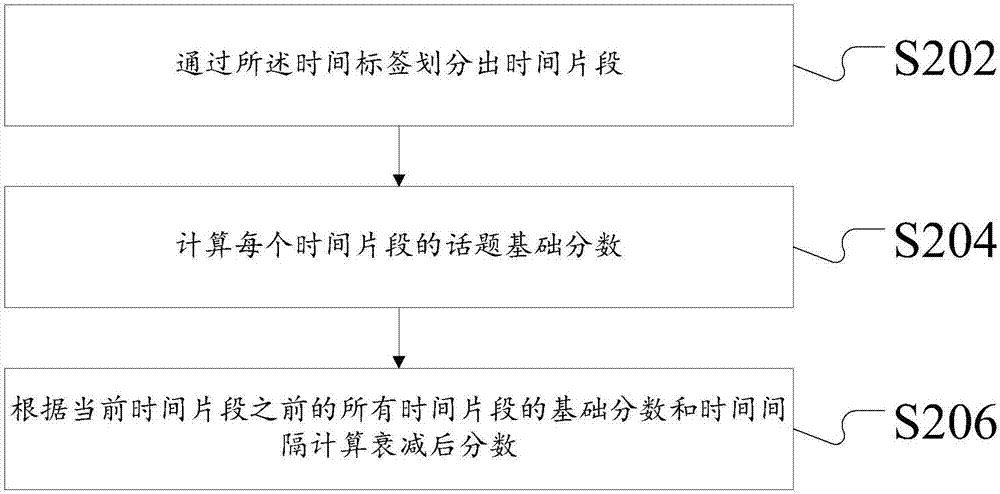
的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。此外,术语“安装”、“设置”、“设有”、“连接”、“相连”、“套接”应做广义理解。例如,可以是固定连接,可拆卸连接,或整体式构造;可以是机械连接,或电连接;可以是直接相连,或者是通过中间媒介间接相连,又或者是两个装置、元件或组成部分之间内部的连通。对于本领域普通技术人员而言,可以根据具体情况理解上述术语在本申请中的具体含义。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。本申请实施例中的话题检测方法,综合考虑上下文中多话题词的出现,每个话题词针对每个话题都有自己独特的权重值,并设置话题命中阈值,让识别更准确。此外,本申请实施例中还通过存储上下文的信息,进行更全局的考量。该方法可以实时进行话题识别,即对输入内容进行实时识别并立即返回结果,无需等到所有的文本全部输入并处理后统一返回。由于话题和话题词的设置具有很大的灵活性,可以针对不同主题类型的文本进行不同的设置,每个话题有大量的话题词且可以轻松的增删改,动态衰减因子也可灵活更改,给予使用者最大的灵活性和可调整性。如图1所示,该话题检测方法包括如下的步骤S102至步骤S108:步骤S102,匹配所述文本内容中的话题词,所述话题词对应至少一个话题;话题词可对应多个话题,同时话题也可包含多个话题词。在所述文本内容中带有预设时间标签是指,文本内容预设有时间戳。匹配文本内容的话题词采用聚类方式。例如,{"第一集":[{"end_id":210,"text":["洛杉矶也有一份不错的工作。","在洛杉矶,你就一直从事人物摄影有关的工作?","是。","我看过赵小姐的作品集,","你曾为很多好莱坞明星和国际名模拍照。","有这么好的工作机会,"],"start_time":"00:25:47.720","end_time":"00:26:15.500"}]}。则可知,时间标签为:"start_time":"00:25:47.720","end_time":"00:26:15.500"。文本内容预设有时间戳。步骤S104,确定每个时间片段上每个话题的基础分数;在开始时间戳和截止时间戳的基础上,划分出时间片段。时间片段由系统根据时间戳划出。基础分数可以是对根据预设的话题权重对话题打分。例如,"{第二集":[{"end_id":228,"text":["那你不吃饭吗?都已经快六点了。","还不饿。","那我等你。",″没你的世界好好坏坏只是无味空白″,″答应我哪天走失了人海″,"没有,主要是我现在也吃不下,还不如干脆等饿一点一会再吃呢"],"start_time":"00:25:47.720","start_id":223,"score":5.330011567936412,"end_time":"00:26:15.500","subject":"eating"}]},基础分数可以是对根据预设的话题权重对话题打分:5.330011567936412,时间戳即包括开始时间戳和结束时间戳。对话题的打分作为基础分数。步骤S106,根据所述时间片段确定每个话题的衰减后分数;衰减后分数是在时间维度对每个话题得到的分数。具体而言,是当前时间片段和之前所有时间片段的时间差值所产生的衰减。例如,{"text":["是不是我们该喝酒?","那这样吧。","这瓶酒你打算怎么喝?","先来俩?","干了它。","干了?错了。"],"start_time":"00:19:28.200","start_id":225,"score":8.2035550000000006,"end_time":"00:19:47.620","subject":"drinking"}上述时间片段内,话题为:喝酒,打分为:8.2035550000000006。{"text":["是不是我们该喝酒?","那这样吧。","这瓶酒你打算怎么喝?","干了它。","干了?错了。","要问老婆该怎么喝。","该怎么喝?"],"start_time":"00:19:28.200","start_id":225,"score":3.8360704002872925,"end_time":"00:19:55.220","subject":"eating"}上述时间片段内,话题为:吃饭,打分为:3.8360704002872925,对每个话题得到的分数是衰减后分数是在时间维度上的计算。就会使得当前的时间片段的话题检测结果不仅依赖于当前的文本,还会受到之前所有的结果的影响,这种来自上下文的动态影响会让识别结果更加准确。步骤S108,通过基础分数和衰减后分数计算得到当前话题的动态分数。动态分数根据基础分数和衰减后分数进行累加得到。此时如果需要实时返回识别结果,则需要在步骤S108后可返回结果,从而获得实时查询结果。从以上的描述中,可以看出,本发明实现了如下技术效果:本申请的实施例,采用动态话题分数的计算方式,通过时间衰减,达到了高准确率的实时识别的目的,从而实现了更加准确识别话题的技术效果,进而解决了话题检测准确率低技术问题。图2是根据本申请第二实施例的话题检测方法流程示意图,优选地,根据时间标签确定每个话题的衰减后分数包括:S202,通过所述时间标签划分出时间片段;通过时间标签可划分出时间片段,得到的时间片段。在开始时间戳和截止时间戳的基础上,划分出时间片段。时间片段由系统根据时间戳划出。S204,计算每个时间片段的话题基础分数;S206,根据当前时间片段之前的所有时间片段的基础分数和时间间隔计算衰减后分数。图3是根据本申请第三实施例的话题检测方法流程示意图,优选地,通过基础分数和衰减后分数计算得到当前时间片段的动态话题分数包括:步骤S302,根据所述预设时间标签和话题词权重计算所述文本的每个时间片段的基础话题分数,步骤S304,根据之前所有时间片段的基础话题分数计算时间维度上的衰减后分数;其中,动态话题分数=基础分数+衰减后分数。具体地,每个时间片段对于每个话题有一个基础分数;每个时间片段之前的所有时间片段,都会对当前时间片段有一个时间维度上的衰减后分数;最后,基础分数+衰减后分数=动态分数。计算时还需考虑时间衰减因子:时间片段时间衰减因子1~2s0.92~4s0.854~8s0.88~16s0.716~20s0.620~30s0.430~60s0.260s0.1分数计算:p_score之前时间片段的分数FACTOR基础衰减因子(可配置)time_delta时间差time_factor时间衰减因子box_score当前基础分数decayed_score衰减后分数dynamic_score结果,动态分数计算公式:time_delta→time_factor映射decayed_score=p_score*FACTOR*time_factordynamic_score=box_score+decayed_score。图4是根据本申请第四实施例的话题检测方法流程示意图,优选地,通过基础分数和衰减后分数计算得到当前话题的动态话题分数之后还包括:步骤S402,抽取所述动态话题分数中的高分动态话题分数;步骤S404,判断所述高分动态话题分数是否满足预设条件;步骤S406,如果所述高分动态话题分数满足预设条件,则执行预设抽取操作。高分话题抽取,通过此步骤S402至步骤S406,能够有效的提高话题识别的准确性和话题命中时间段起止时间的准确性。所判断所述高分动态话题分数是否满足预设条件述包括执行以下任意一个或多个处理:动态话题分数是否达到该话题的触发阈值;是否在连续的时间片段上连续触发;在文本上是否属于同一场景;以及是否存在话题关键词。需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。根据本发明实施例,还提供了一种用于实施上述话题检测方法的话题检测装置,如图5所示,该装置包括:匹配模块10,用于匹配所述文本内容中的话题词;基础分数计算模块20,用于确定每个时间片段上每个话题的基础分数;时间衰减模块30,用于根据时间标签和之前所有时间片段的基础分数确定当前话题的衰减后分数;以及动态话题分数计算模块40,用于根据基础分数和衰减后分数计算动态话题分数。话题词可对应多个话题,同时话题也可包含多个话题词。在所述文本内容中带有预设时间标签是指,文本内容预设有时间戳。匹配文本内容的话题词采用聚类方式。例如,{"第一集":[{"end_id":210,"text":["洛杉矶也有一份不错的工作。","在洛杉矶,你就一直从事人物摄影有关的工作?","是。","我看过赵小姐的作品集,","你曾为很多好莱坞明星和国际名模拍照。","有这么好的工作机会,"],"start_time":"00:25:47.720","end_time":"00:26:15.500"}]}。则可知,时间标签为:"start_time":"00:25:47.720","end_time":"00:26:15.500"。文本内容预设有时间戳。在开始时间戳和截止时间戳的基础上,划分出时间片段。时间片段由装置根据时间戳划出。基础分数可以是对根据预设的话题权重对话题打分。例如,"第二集":[{"end_id":228,"text":["那你不吃饭吗?都已经快六点了。","还不饿。","那我等你。",″没你的世界好好坏坏只是无味空白″,″答应我哪天走失了人海″,"没有,主要是我现在也吃不下,还不如干脆等饿一点一会再吃呢"],"start_time":"00:25:47.720","start_id":223,"score":5.330011567936412,"end_time":"00:26:15.500","subject":"eating"}],基础分数可以是对根据预设的话题权重对话题打分:5.330011567936412,时间戳即包括开始时间戳和结束时间戳。对话题的打分作为基础分数。衰减后分数是在时间维度对每个话题得到的分数。具体而言,是当前时间片段和之前所有时间片段的时间差值所产生的衰减。例如,{"text":["是不是我们该喝酒?","那这样吧。","这瓶酒你打算怎么喝?","先来俩?","干了它。","干了?错了。"],"start_time":"00:19:28.200","start_id":225,"score":8.2035550000000006,"end_time":"00:19:47.620","subject":"drinking"}上述时间片段内,话题为:喝酒,打分为:8.2035550000000006。{"text":["是不是我们该喝酒?","那这样吧。","这瓶酒你打算怎么喝?","干了它。","干了?错了。","要问老婆该怎么喝。","该怎么喝?"],"start_time":"00:19:28.200","start_id":225,"score":3.8360704002872925,"end_time":"00:19:55.220","subject":"eating"}上述时间片段内,话题为:吃饭,打分为:3.8360704002872925,对每个话题得到的分数是衰减后分数是在时间维度上的计算。就会使得当前的时间片段的话题检测结果不仅依赖于当前的文本,还会受到之前所有的结果的影响,这种来自上下文的动态影响会让识别结果更加准确。动态分数根据基础分数和衰减后分数进行累加得到。此时如果需要实时返回识别结果,则需要在步骤S108后可返回结果,从而获得实时查询结果。如图6是根据本申请第二实施例的话题检测装置示意图,优选地,装置还包括:高分抽取模块50,用于抽取所述动态话题分数中的高分动态话题分数;判断所述高分动态话题分数是否满足预设条件;以及如果所述高分动态话题分数满足预设条件,则执行预设抽取操作。高分话题抽取,能够有效的提高话题识别的准确性和话题命中时间段起止时间的准确性。所判断所述高分动态话题分数是否满足预设条件述包括执行以下任意一个或多个处理:动态话题分数是否达到该话题的触发阈值;是否在连续的时间片段上连续触发;在文本上是否属于同一场景;以及是否存在话题关键词。优选地,高分抽取模块50,还用于执行以下任意一个或多个处理:动态话题分数是否达到该话题的触发阈值;是否在连续的时间片段上连续触发;在文本上是否属于同一场景;以及是否存在话题关键词。显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1