基于PLS局部拟合的SCR反应器信息快速获取方法与流程
本发明属于工业脱销技术领域,具体涉及一种基于pls局部拟合的scr反应器信息快速获取方法。
背景技术:
由于国家新的排放政策的出台,对污染物的排放标准提出了新的要求。为了能够达到新的排放要求,各大电厂已基本完成脱硝系统改造任务。目前,电站锅炉中一般联合使用低nox燃烧技术和烟气脱硝技术来达到超低排放。选择性催化还原法(selectivecatalyticreduction,scr)烟气后处理技术以其脱硝效率高、技术成熟等优点,在各大电站脱硝系统中得到大规模的应用。scr脱硝技术是指在催化剂和氧气存在的条件下,在一定温度范围内,通过氨作为还原剂,有选择的与烟气中的nox反应生成无害的氮和水,从而除去烟气中的nox污染物,保证烟气达标排放甚至污染物零排放。影响scr脱硝效率的因素包括催化剂活性、浓度场分布、反应温度、空速、氨氮比等,还和喷氨格栅(ammoniainjectiongrid,aig)处及反应器内流场、浓度场有关。
现如今为了评估流场以及浓度场,许多学者采用cfd(计算流体动力学)对scr反应器进行建模分析,通过数值计算的方式得到scr催化剂层出口的nox浓度分布和氨逃逸分布。该方法一般能够较好的得出一般性结论,但该种方法存在着计算时间过长、变工况运行时误差较大、不便于实时在线监测等缺点。
技术实现要素:
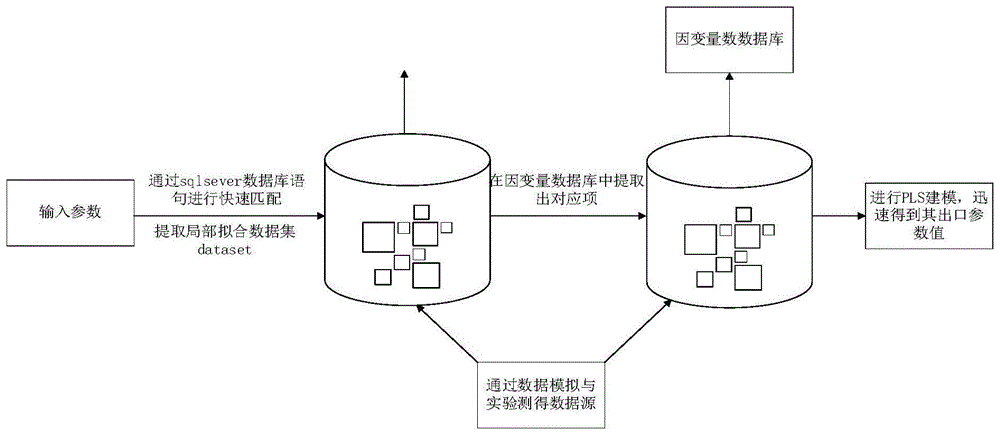
发明目的:为了克服现有技术中的不足,本发明提供一种基于pls局部拟合的scr反应器信息快速获取方法,在针对某一特定的scr脱硝系统基础之上,通过cfd软件和试验台得出宽负荷工况下的scr催化剂层的仿真数据和实验数据,并将其录入到sqlsever数据库中,当输入特定的入口参数之后,通过sql语句在方差最小化原则的基础上提取得到距离输入的入口参数最近的局部拟合数据集,并通过微软.net平台上采用偏最小二乘法(partialleast-squaremethod,pls)对其快速的进行局部拟合,并将其结果返回添加到原始数据库中,丰富并发展数据集,通过拟合能够得到催化剂层出口流场的分布情况,从而给电站脱硝系统运行人员提供运行指导意见。
技术方案:为解决上述技术问题,本发明提供一种基于pls局部拟合的scr反应器信息快速获取方法,包括如下步骤:
(1)建立自变量数据库和因变量数据库:根据scr新鲜、劣化催化剂化学反应实验,得出与化学反应速率常数相关参数:温度、指前因子以及活化能;建立化学反应速率常数与相关参数数据库,并把数据库以及scr脱硝反应模型带入到fluent中,得到关于数值模拟的数据库,并最终获取自变量数据库和因变量数据库,测量的点包括入口烟气速度、氨氮摩尔比nh3/no、入口烟气温度、入口no浓度、出口no浓度、氨逃逸率等测点数据,其中,自变量数据库包括入口烟气速度、氨氮摩尔比nh3/no、入口烟气温度和入口no浓度,因变量数据库包括出口no浓度和氨逃逸率,并将其录入到sql数据库中。
(2)任意输入一条参数后,通过sqlsever数据库中select语句快速查找并提取与所输入参数在方差最小化原则基础之上的距离输入参数最近的8个样本数据;
(2.1)获取标准化数据库:将步骤(2)中提取出每个队列数据进行标准化处理,减去自身的均值并除以其标准差,从而得到标准化数据库;
(2.2)将所输入的参数根据标准化数据库进行同样的标准化,得到标准化输入参数;
(2.3)建立局部拟合数据集dataset:将步骤(2.1)中快速提取出的数据建立一个局部拟合标准化数据集,并利用微软的.net技术对其进行进一步的处理;
(2.4)利用微软.net技术中的偏最小二乘法(pls)对局部拟合标准化数据集进行建模,并对输入参数进行回归,得到该输入参数下对应的输出值,将该输入参数与其对应的输出值分别加入到自变量数据库和因变量数据库,即进行步骤(3)。
(3)采用偏最小二乘法(pls)对所提取出的局部拟合数据集进行建模:
(3.1)设因变量组和自变量组的n次标准化观测数据阵分别记为f0、e0,f0是由输出参数出口no浓度和氨逃逸率组成的因变量矩阵,e0是由输入参数入口烟气速度、氨氮摩尔比、入口烟气温度以及入口no浓度组成的自变量矩阵(其中每一列代表一个样本),f0、e0的计算公式如下:
偏最小二乘法的回归分析建模的具体步骤如下:
(3.2)偏最小二乘法的基本做法是首先在自变量集中提出第一成分t1,t1是x1,x2,…xm的线性组合,且尽可能多地提取原自变量集中的变异信息;同时在因变量集中也提取第一成分u1,并要求t1和u1相关程度达到最大;然后建立因变量y1,y2,…yp与t1的回归,如果回归方程已达满意的精度,则算法中止;若最终对自变量集提取r个成分t1,t2,…tr,偏最小二乘回归将通过建立y1,y2,…yp与t1,t2,…tr的回归式,然后再表示为y1,y2,…yp与原自变量的回归方程式,具体展开如下所示:
(3.2.1)分别提取两变量组的第一对成分,并使之相关性达最大。
(3.2.2)假设从两组变量分别提取第一对t1和u1,t1是自变量集x=(x1,…xm)t的线性组合;t1=w11x1+…+w1mxm=w1tx,u1是因变量集y=(y1,...yp)t的线性组合;u1=v11y1+…+v1pyp=v1ty。为了回归分析的需要,需求t1和u1各自尽可能多地提取出所在变量组的变异信息且两者相关程度最大。
(3.2.3)由两组变量集的标准化观测数据阵e0和f0,可以计算第一对成分的得分向量,记为
第一对成分t1和u1的协方差cov(t1,u1)可用第一对成分的得分向量
w1tw=||w1||2=1,v1tv1=||v1||2=1公式六
利用lagrange乘数法,问题化为求单位向量w1和v1,使得
(3.2.4)建立y1,y2,…yp,对t1的回归及x1,x2,…,xm对t1的回归。
假定回归模型为:
其中,a1=(a11,…,a1m)t,β1=(β11,...β1p)t分别是多对一的回归模型中的参数向量,e1和f1是残差阵。回归系数向量a1,β1的最小二乘估计为:
称a1,β1为模型的效应负荷量。
(3.2.5)用残差阵e1和f1代替e0和f0重复以上步骤。
记
(3.2.6)设n×m数据阵e0的秩为r<=min(n-1,m),则存在r个成分t1,t2,…,tr,使得:
把tk=wk1x1+…+wkmxm(k=1,2,…,r),代入y=t1β1+...+trβr,即得p个因变量的偏最小二乘法回归方程式:yj=aj1x1+…+ajmxm,(j=1,2…,m)。
有益效果:本发明相对于现有技术而言,具有以下优点:
(1)依据cfd数值模拟的仿真数据与搭建试验台实验得出的测量数据建立起原始数据库模型,并将其分为自变量数据库、因变量数据库,能够建立起任何工况下的数据库,当随机输入任意工况参数时都能快速而准确的找到与其匹配的数据集。
(2)快速的从sql数据库中提取出对应的自变量数据和因变量数据,并通过基于微软的.net技术采用偏最小二乘法pls进行准确的建模,得出每一层催化剂出口的实时参数,同时可将所预测出的数据分别的添加到自变量数据库和因变量数据库中,丰富和发展了数据库的样本信息。
(3)通过实时预测催化剂层出口no浓度和氨逃逸率,可以快速的得到催化剂层出口浓度场和流场的分布情况,从而给电厂运行人员提供合理的运行指导。
附图说明
图1是本发明的流程图;
图2是本发明的pls算法流程图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
如图1-2所示,一种基于pls局部拟合的scr反应器信息快速获取方法,包括以下步骤:
(1)建立自变量数据库和因变量数据库:根据scr新鲜、劣化催化剂化学反应实验,得出与化学反应速率常数相关参数:温度、指前因子以及活化能。建立化学反应速率常数与相关参数数据库。并把数据库以及scr脱硝反应模型带入到fluent中,得到关于数值模拟的数据库,并最终获取自变量数据库和因变量数据库;
(2)在任意输入一条参数后,通过sql数据库中select语句快速查找并提取与所输入参数在方差最小化原则基础之上的距离输入参数最近的若干个样本数据,从而形成一个局部拟合数据集dataset;
(3)利用偏最小二乘法对局部拟合标准化数据集进行pls建模,得到该局部拟合标准化数据集的偏最小二乘回归方程,并对输入参数进行回归,得到该输入参数下对应的出口参数输出值,将该输入参数与其对应的输出值分别加入到自变量数据库和因变量数据库。
进一步的,步骤(2)的具体步骤为:
(2.1)在输入参数后,通过sql数据库中select语句提取得到距离输入样本最近的八个样本数据集;
(2.2)获取标准化数据库:将步骤(2.1)中提取的每个队列数据进行标准化处理,减去自身的均值并除以其标准差,从而得到标准化数据库;
(2.3)将所输入的参数根据标准化数据库进行同样的标准化,得到标准化输入参数;
(2.4)建立局部拟合数据集:将步骤(2.2)中获得的数据建立成一个局部拟合标准化数据集。
进一步的,步骤(3)的具体步骤为:
(3.1)设因变量组和自变量组的n次标准化观测数据阵分别记为f0、e0,f0是由输出参数出口no浓度和氨逃逸率组成的因变量矩阵,e0是由输入参数入口烟气速度、氨氮摩尔比、入口烟气温度以及入口no浓度组成的自变量矩阵,每一列代表一个样本,f0、e0的计算公式如下:
(3.2)偏最小二乘法的回归分析建模的具体步骤如下:
偏最小二乘法的基本做法是首先在自变量集中提出第一成分t1,t1是x1,x2,…xm的线性组合,且尽可能多地提取原自变量集中的变异信息;同时在因变量集中也提取第一成分u1,并要求t1和u1相关程度达到最大,然后建立因变量y1,y2,…yp与t1的回归,如果回归方程已达满意的精度,则算法中止,若最终对自变量集提取r个成分t1,t2,…tr,偏最小二乘回归将通过建立y1,y2,…yp与t1,t2,…tr的回归式,然后再表示为y1,y2,…yp与原自变量的回归方程式,即偏最小二乘回归方程式。
进一步的,步骤(3.2)中,偏最小二乘回归方程式的展开如下:
(3.2.1)分别提取两变量组的第一对成分,并使之相关性达最大;
(3.2.2)从两组变量分别提取第一对t1和u1,t1是自变量集x=(x1,...xm)t的线性组合,t1=w11x1+...+w1mxm=w1tx,u1是因变量集y=(y1,...yp)t的线性组合,u1=v11y1+...+v1pyp=v1ty,为了回归分析的需要,需求t1和u1各自尽可能多地提取出所在变量组的变异信息且两者相关程度最大;
(3.2.3)由两组变量集的标准化观测数据阵e0和f0,可以计算第一对成分的得分向量,记为
第一对成分t1和u1的协方差cov(t1,u1)可用第一对成分的得分向量
w1tw=||w1||2=1,v1tv1=||v1||2=1公式六
利用lagrange乘数法,问题化为求单位向量w1和v1,使得
(3.2.4)建立y1,y2,…yp,对t1的回归及x1,x2,…,xm对t1的回归;
假定回归模型为:
其中,a1=(a11,…,a1m)t、β1=(β11,...β1p)t分别是多对一的回归模型中的参数向量,e1和f1是残差阵;回归系数向量a1、β1的最小二乘估计分别为:
称a1,β1为模型的效应负荷量;
(3.2.5)用残差阵e1和f1代替e0和f0重复以上步骤;
记
进一步的,步骤(3.2.5)中,用残差阵e1和f1代替e0和f0重复以上步骤即得到:w2=(w21,…w2m)t;v2=(v21,…,v2m)t分别为第二对成分的权数,
设n×m数据阵e0的秩为r<=min(n-1,m),则存在r个成分t1,t2,…,tr,使得:
把tk=wk1x1+…+wkmxm(k=1,2,…,r)代入y=t1β1+...+trβr,即得p个因变量的偏最小二乘法回归方程式:yj=aj1x1+…+ajmxm,(j=1,2…,m)。
进一步的,步骤(1)中,根据scr新鲜、劣化催化剂化学反应实验,得出与化学反应速率常数相关参数:温度、指前因子以及活化能。建立化学反应速率常数与相关参数数据库。并把数据库以及scr脱硝反应模型带入到fluent中,得到关于数值模拟的数据库,并最终获取自变量数据库和因变量数据库,测量的点包括入口烟气速度、氨氮摩尔比nh3/no、入口烟气温度、入口no浓度、出口no浓度、氨逃逸率等测点数据,其中,自变量数据库包括入口烟气速度、氨氮摩尔比nh3/no、入口烟气温度和入口no浓度,因变量数据库包括出口no浓度和氨逃逸率,并将其录入到sql数据库中。
实施例1
如图1-2所示,以某600mw燃煤机组的脱硝系统为例,建立其cfd数学模型并得出数值模拟数据,并通过试验台得到该机组催化剂层的单通道实验数据,且将其录入到sql数据库中,步骤如下:
(1)建立自变量数据库和因变量数据库:根据scr新鲜、劣化催化剂化学反应实验,得出与化学反应速率常数相关参数:温度、指前因子以及活化能;建立化学反应速率常数与相关参数数据库,并把数据库以及scr脱硝反应模型带入到fluent中,得到关于数值模拟的数据库,并最终获取自变量数据库和因变量数据库,测量的数据包括入口烟气速度、氨氮摩尔比nh3/no、入口烟气温度、入口no浓度、出口no浓度、氨逃逸率等测点数据,其中,自变量数据库包括入口烟气速度、氨氮摩尔比nh3/no、入口烟气温度和入口no浓度,因变量数据库包括出口no浓度和氨逃逸率,并将其录入到sql数据库(sqlsever数据库)中,总共1250条数据,测量得到的部分原始数据如表1所示。
表1
(2)在输入参数后,通过sql数据库中select语句快速的查找与输入参数在方差最小化原则基础之上的距离输入参数最近的8个样本数据,如输入参数为入口烟气速度5.5m/s、氨氮摩尔比0.86、入口烟气温度312℃、入口no浓度330mg/m3,则提取出数据为,表2为局部数据集dataset:
表2
(3)对每个队列数据进行标准化处理,即:减去自身的均值并除以其标准差,从而得到标准化数据库,即得到表3。
表3
(4)将输入参数进行如上的标准化步骤得到入口烟气速度0.25819、氨氮摩尔比-1.11837、入口烟气温度-0.77754、入口no浓度0.7610592。
(5)借助微软的.net技术对其进行进一步的处理,利用偏最小二乘法(pls)对局部拟合标准化数据集进行建模,该方法的建模思路如图2所示,并对输入参数进行回归预测,得到该输入参数下对应的输出值:出口no浓度为321.45mg/m3,氨逃逸率为121.956。
本发明实现了在通过cfd数值模拟计算与试验台实验测量得出的数据后并建立数据库,通过sql语句实现快速的在最小化方差的原则下提取出距离输入参数最短的局部拟合标准化数据集,并分别从因变量数据库和自变量数据库中提取出对应的数据,基于微软的.net平台并采用pls模型进行预测出在特定输入参数的条件下能够快速的得出催化剂出口no浓度以及氨逃逸率指标,从而能够快速而准确的得出催化剂层出口处的流场和浓度场分布情况,能够给电站脱硝系统运行人员提供运行意见。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明的原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!