一种代谢物批量定量软件系统的制作方法
本发明涉及计算机操作系统领域,具体涉及一种代谢物批量定量软件系统。
背景技术:
代谢组学是关于生物体内源性代谢物质的整体及其变化规律。其中超高液相色谱三重四级杆串联质谱仪广泛用于代谢组学,其具有分离效率高、分析速度快、应用范围广等特点。液相色谱-质谱检测时,样品中的分子经过色谱柱色谱分离后在色谱图上的不同时间出现,输出的总离子流图上的每个色谱峰都包含该物质信息(每个时间点所对应的质谱图和色谱峰的保留时间)和定量信息(峰高或峰面积)。现在最常用的超高效液相色谱三重四级杆串联质谱多是有相配套的软件用于实验数据的分析。但是其配套软件存在许多的弊端,一是软件使用过程繁琐,不容易操作。二是不同仪器的配套软件不同,各种软件参数优化的差异导致测试结果可比性较差。三是代谢物定量结果复杂,大部分需要用户手动逐个样本修改。四是输出结果的形式和格式不是常用的批量物质矩阵,必须经过大量人工调整后才能用于后续统计分析。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种代谢物批量定量软件系统,旨在对来自于不同平台的超高效液相色谱三重四级杆串联质谱系列仪器的测试数据,对多个样本中的多个目标代谢物进行批量预处理、峰提取、校正和定量,输出浓度值和基本配套信息,打通从测试图谱到统计分析的所有中间环节,提高工作效率、降低代谢组学中的数据处理的难度。
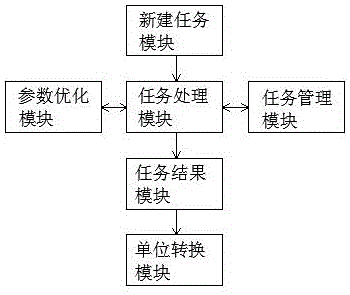
本发明的技术方案如下:一种代谢物批量定量软件系统,由新建任务模块、任务处理模块、任务管理模块、参数优化模块、任务结果模块和单位转换模块组成,所述新建任务模块、任务管理模块、任务结果模块和单位转换模块依次连接,所述任务管理模块、参数优化模块分别与所述任务处理模块连接;所述新建任务模块通过不同平台的超高效液相色谱三重四级杆串联质谱系列仪器测量得出原始数据表、样本信息配置表和物质信息配置表;所述任务处理模块通过导入原始数据表、样本信息配置表和物质信息配置表,完成多个样本中的多个目标代谢物的数据处理,并输出结果;所述任务管理模块,其用于查看现在和既往任务的状态和信息以及原始数据和处理结果的下载;所述参数优化模块,用于调整目标代谢物的参数,以重新进行代谢物的浓度计算,相应结果从所述任务结果模块中获得;所述单位转换模块,指定需要转换单位数据,选择该数据当前单位和期望转换的单位,对数据进行单位的转换。
进一步地,所述任务处理模块的数据处理包括数据预处理、峰识别和强度提取、校正、标准曲线构建以及目标物含量计算,所述任务处理模块的结果输出包括数据输出和图形输出,其中,数据输出包括目标物的强度值、浓度值、基本统计量和标准曲线的基本信息,图形输出包括每个物质在每个样本中的峰图、峰识别的结果、计算峰强度的区域和标准曲线。
进一步地,所述数据预处理包括平滑滤波、基线校正和噪音值的确定,其中,所述平滑滤波采用的是savitzky-golay滤波器,所述基线校正采用的是迭代加权最小二乘算法,所述噪音值的确定是通过从色谱数据中无放回的随机抽样1000次,每次选取10%的扫描点,计算多次抽样强度最小值的中位数。
进一步地,所述峰识别和强度提取是基于局部极值法。
进一步地,所述目标物含量计算是结合标准品的物质强度和浓度信息,通过回归建立强度变量与浓度变量的关系方程,将待测样品的物质强度代入方程,从而得到待测样品的物质浓度信息。
进一步地,所述原始数据表是txt格式的仪器测试文件,其通过不同平台的超高效液相色谱三重四级杆串联质谱和数据格式转换软件所获得。
进一步地,所述样本信息配置表包含了批次信息、文件名或样品名、样品类型和标准品浓度梯度信息,其中样品类型包含标准品和待测样品两种类型,标准品浓度梯度信息可为多组。
进一步地,所述物质信息配置表包括了索引编号、化合物名称、待测物质的通道编号、待测物质的分子量、目标峰所在的保留时间、允许偏离的保留时间左侧区间大小、允许偏离的保留时间右侧区间大小、确定目标峰的方法、峰强度的计算方法、是否进行内标校正、该物质对应的标准区线、标准曲线类型、标准曲线方程是否过原点、峰提取环节savitzky-golay滤波器滤波的窗口大小、峰提取环节savitzky-golay滤波器迭代次数、回归方程确定系数阈值、回归方程需要的最小标准点数量、lod值、loq值、构成一个可靠峰所需的左侧scan扫描点数量、构成一个可靠峰所需的右侧scan扫描点数量、峰面积计算环节savitzky-golay滤波器滤波的窗口大小、构建标准曲线初始点数量不足时,每次扩展,左侧扩张的标准点数量、构建标曲初始点数量不足时,每次扩展,右侧扩张的标准点数量、构建标曲初始点数量不足,两边扩展标准点。
进一步地,所述任务管理模块内包含有密码修改模块,用于密码修改。
相对于现有技术,本发明的有益效果在于:1、与现有技术相比,本发明基于服务器-浏览器模式,网页界面友好,操作简单,实现了一键式快速分析;2、适用于不同平台的超高效液相色谱三重四级杆串联质谱;3、相对于现有技术,数据预处理、峰提取、校正、标准曲线确定和峰强度计算所采用的方法更科学,更高效;4、提供多种可调节参数,可根据需求进行个性化设置,有助于提高结果的准确性和可控性;5、精度更高,包含数据统计的准确度和检测的准确度。
附图说明
图1为本发明所提供的一种代谢物批量定量软件系统的系统框图;
图2为本发明所述任务处理模块的原理框图;
图3为本发明所提供的一种代谢物批量定量软件系统的原理框图;
图4为本发明输出的标准曲线图。
具体实施方式
以下结合附图和具体实施例,对本发明进行详细说明。
请参阅图1,本发明提供一种代谢物批量定量软件系统由新建任务模块、任务处理模块、任务管理模块、参数优化模块、任务结果模块和单位转换模块组成,所述新建任务模块、任务管理模块、任务结果模块和单位转换模块依次连接,所述任务管理模块、参数优化模块分别与所述任务处理模块连接。
所述新建任务模块通过不同平台的超高效液相色谱三重四级杆串联质谱系列仪器测量得出原始数据表、样本信息配置表和物质信息配置表。其中,所述不同平台包括,如沃特世、安捷伦等。
请参阅图2,所述任务处理模块通过导入原始数据表、样本信息配置表和物质信息配置表,完成多个样本中的多个目标代谢物的数据处理,并输出结果;其中,所述原始数据表是txt格式的仪器测试文件,其通过不同平台的超高效液相色谱三重四级杆串联质谱和数据格式转换软件所获得;所述样本信息配置表包含了批次信息、文件名或样品名、样品类型和标准品浓度梯度信息,其中样品类型包含标准品和待测样品两种类型,标准品浓度梯度信息可为多组;所述物质信息配置表包括了索引编号、化合物名称、待测物质的通道编号、待测物质的分子量、目标峰所在的保留时间、允许偏离的保留时间左侧区间大小、允许偏离的保留时间右侧区间大小、确定目标峰的方法、峰强度的计算方法、是否进行内标校正、该物质对应的标准区线、标准曲线类型、标准曲线方程是否过原点、峰提取环节s-g滤波器滤波的窗口大小、峰提取环节s-g滤波器迭代次数、回归方程确定系数阈值、回归方程需要的最小标准点数量、lod值、loq值、构成一个可靠峰所需的左侧scan扫描点数量、构成一个可靠峰所需的右侧scan扫描点数量、峰面积计算环节s-g滤波器滤波的窗口大小、构建标准曲线初始点数量不足时,每次扩展,左侧扩张的标准点数量、构建标曲初始点数量不足时,每次扩展,右侧扩张的标准点数量、构建标曲初始点数量不足,两边扩展标准点。
所述任务管理模块,其用于查看现在和既往任务的状态和信息以及原始数据和处理结果的下载。所述任务管理模块内包含有密码修改模块,用于密码修改。
所述参数优化模块,用于调整目标代谢物的参数,以重新进行代谢物的浓度计算,相应结果从所述任务结果模块中获得。
所述单位转换模块,输入待转换的xlsx格式的文件,指定所需要转换单位数据所在的行,选择该行数据的现单位和期望转换的单位,可以数据进行单位的转换,该模块提供20个浓度单位供用户选择。
请参阅图3,进一步地,所述任务处理模块的数据处理包括数据预处理、峰识别和强度提取、校正、标准曲线构建以及目标物含量计算,所述任务处理模块的结果输出包括数据输出和图形输出,所述数据输出包括目标物的强度值、浓度值、基本统计量和标准曲线的基本信息,图形输出包括每个物质在每个样本中的峰图、峰识别的结果、计算峰强度的区域和标准曲线。
进一步地,所述数据预处理包括平滑滤波、基线校正和噪音值的确定。平滑滤波采用的是savitzky-golay方法,savitzky-golay滤波器(通常简称为s-g滤波器)是一种在时域内基于局域多项式最小二乘法拟合的滤波方法,这种滤波器最大的特点在于在滤除噪声的同时可以确保信号的形状和宽度不变。基线校正采用的是迭代加权最小二乘算法,先递归的在二阶导数限制下采用最小二乘法进行基线的拟合,再将拟合出的基线信号从原始信号中扣除。噪音值的确定是通过从色谱数据中无放回的随机抽样,选取10%的扫描点(大于0),计算其强度最小值,以上过程重复1000次,得到1000个强度最小值。计算1000个强度最小值的中位数,将其作为色谱数据的噪音值。
进一步地,所述峰识别和强度提取是基于局部极值法,其流程为:根据nups4pp(minimumnumberofincreasingstepsbeforeapeakisreached,构成一个可靠峰所需的左侧scan扫描点数量)和ndowns4pp(minimumnumberofdecreasingstepsafterthepeak,构成一个可靠峰所需的右侧scan扫描点数量)这两个参数,在指定保留时间和保留时间窗口范围内通过极值(一阶导数)找峰。通过极大值确定峰顶点,极小值确定两侧峰边界,计算得到对应的保留时间。计算每个峰的峰高,过滤峰高低于snr*noise的峰(snr为用户指定的信噪比参数,noise表示根据数据自动确定的噪音的大小)。
进一步地,标准曲线的确定,采用自创的动态递归算法并充分考虑样本的浓度范围。首先,采用动态算法,通过待测样品的强度分布,选取最合适的标准点参与标准曲线的绘制。其次,在回归方差的求取过程,采用自适应算法动态删除标准点,得到最佳的标准曲线。最后,借助一系列参数可控制高/低浓度点在标准曲线构建中的权重以及标准曲线的点数等性质。
具体地,请参阅图4,图中两根竖线分别对应待测样品的强度的最小值和最大值。意味着,待测样品在这两条线对应的区间内。标准品的点用实心圆点表示,待测样品的点用x符号表示。
其具体步骤如下:(1)对于待测物质,所有样品(包括标准品和待测样品)均经过处理后,得到对应的强度值检测结果;(2)以待测样品强度值的最小值和最大值作为区间,求出强度落入区间内的标准品。这些标准品对应的点称为构建标曲初始点。如遇极端情况,区间内找不到标准品,取最近的一个标准品对应的点作为构建标曲初始点;(3)检查构建标曲初始点数量,如果大于等于mp4e参数值,则直接进行回归。否则,往两边扩展,直至标准点的数量大于等于mp4e的参数值时停止。扩展规则依赖于lp4e和rp4e的参数值,每一轮扩展,往坐标轴左侧扩张lp4e个点的同时,往右侧扩张rp4e个点。建议lp4e设为2,rp4e设为1,优先增加更多的低浓度点【1】;(4)通过步骤(3),得到用于构建标准曲线的标准点进行回归分析,建立强度(x)与浓度(y)的回归方程;(5)检测步骤(4)得到的回归方程回归系数,如果大于rs4rs的参数值,则停止回归,将该方程作为标准曲线。否则,删除标准点,再次执行步骤(4);(6)循环执行步骤(4)和步骤(5),删除其中1个标准点、2个标准点、3个标准点....,直至回归方程的确定系数大于rs4rs的参数值。遍历所有情况,直至剩下的标准点数量等于mp4rs的参数值。如果遍历所有情况后,回归方程的回归系数r2仍然不满要求,则取所有情况中,r2最大的回归方程作为标准曲线【2】;
(7)将待测样品的强度信息代入标准曲线,得到对应的物质浓度结果输出。同时,也会将标准品的强度信息代表标准曲线,求出相应的浓度推断值。
参数说明:leftpointsforextending,建议设为2,构建标曲初始点数量不足时,每次扩展,左侧扩张的标准点数量。lp4e为2,rp4e为1,这样设置侧重于优先加入更多的低浓度点。
rp4e:rightpointsforextending,建议设为1,构建标曲初始点数量不足时,每次扩展,右侧扩张的标准点数量。lp4e为2,rp4e为1,这样设置侧重于优先加入更多的低浓度点。
mp4e:minimumpointsforextending,构建标曲初始点数量不足,两边扩展标准点,直至大于等于mp4e参数要求时停止。
rs4rs:rsquareforregressionstop,回归方程回归系数的阈值,在迭代过程中,回归方程r2满足要求则退出迭代,具体参考上方的算法说明。
mp4rs:minimumpointsforregressionstop,回归方程需要的最小标准点数量,迭代达到最小标准点数量则退出循环,参考上方的算法说明。
需要注意的是:如果该物质为内标化合物,那么在每个样品(标准品+待测样品)中,浓度值固定。这时,内标化合物将采用如下固定方法进行特殊处理(参数设置无效),以所有点(标准品+待测样品),直接拟合一条过原点的直线,该直线作为内标化合物的强度与浓度关系曲线,用于得到内标化合物在每个样品中的浓度推断值。
所述目标物含量计算,其过程为同一个测试组内内部包含待测样品和标准品,并且已知标准品对应的相应的浓度梯度,结合标准品的物质强度和浓度信息,通过回归建立强度变量与浓度变量的关系方程。将待测样品的物质强度代入方程,从而得到待测样品的物质浓度信息。
以上仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!