比特级信元的阵列、复合推进存储器和计算机系统的制作方法
本申请是申请号为201380005030.5、国际申请号为pct/jp2013/000760、申请日为2013年2月13日、发明名称为“没有存储器瓶颈的推进存储器、双向推进存储器、复合推进存储器和计算机系统”的发明专利申请的分案申请。
本发明涉及新存储器以及使用该新存储器的新计算机系统,其以低能耗高速操作。
背景技术:
自从冯·诺伊曼等人在60多年前开发出存储程序电子计算机之后,基本存储器存取原理一直没有改变。尽管对于整个范围的高性能计算(hpc)应用,计算机的处理速度多年来已显著增加,这或者通过器件技术,或者通过避免存储器存取的方案(例如,利用高速缓存)来实现。然而,存储器存取时间仍限制了性能。目前,计算机系统使用许多处理器11和许多大规模主存储器331,如图1所示。
图1所示的计算机系统包括处理器11、高速缓冲存储器(321a,321b)和主存储器331。处理器11包括:控制单元111,其具有被配置为产生时钟信号的时钟发生器113;算术逻辑单元(alu)112,其被配置为与时钟信号同步地执行算术和逻辑运算;指令寄存器文件(rf)322a,其连接到控制单元111;以及数据寄存器文件(rf)322b,其连接到alu112。高速缓冲存储器(321a,321b)具有指令高速缓冲存储器321a和数据高速缓冲存储器321b。主存储器331的一部分和指令高速缓冲存储器321a通过线和/或总线电连接,其限制了存储器存取时间(或者具有冯·诺伊曼瓶颈)351。主存储器331的剩余部分和数据高速缓冲存储器321b电连接以允许相似的存储器存取351。另外,实现存储器存取352的线和/或总线在数据高速缓冲存储器321b和指令高速缓冲存储器321a与指令寄存器文件322a和数据寄存器文件322b之间电连接。
尽管hpc系统预期以高速和低能耗操作,但是由于存储器存取瓶颈351、352,仍存在速度限制。瓶颈351、352归因于处理器11与主存储器331之间的布线,因为连线长度使对计算机的存取有所延迟,并且存在于线之间的杂散电容导致附加延迟。这种电容需要与11中的处理器时钟频率成比例的更多功耗。
目前,一些hpc处理器利用多个向量算术流水线来实现。该向量处理器使得存储器带宽被更好地使用,并且对于可以按照向量记法表示的hpc应用而言是上位机。向量指令得自源程序中的循环,这些向量指令中的每一个在向量处理器中的算术流水线或者并行处理器中的对应单元中执行。这些处理方案的结果给出相同的结果。然而,即使基于向量处理器的系统也在所有单元之间具有存储器瓶颈351、352。即使在具有大存储器和宽带宽的单系统中,也出现相同瓶颈351、352,并且如果系统像并行处理器中一样由许多相同的单元组成,则瓶颈351、352不可避免。
传统计算机系统中存在两个基本的存储器存取问题。第一个问题是布线不仅存在于存储器芯片与高速缓存之间或者甚至一个芯片上的这两个单元之间,而且存在于存储器系统内部。在芯片之间,这两个芯片/单元之间的布线由于容量和连线信号时间延迟而导致更多动态功耗。这扩展至与存取线路和剩余读/写线路有关的存储器芯片内的内部连线问题。因此,在存储器芯片之间和存储器芯片之内的布线中,存在由具有这些线的电容器引起的能耗。
第二个问题是处理器芯片、高速缓存和存储器芯片之间的存储器瓶颈351、352。由于alu可存取高速缓存或存储器的任何部分,所以存取路径351、352由长度较长的全局线组成。这些路径还在可用连线的数量方面受到限制。这种瓶颈似乎归因于诸如总线的硬件。特别是当存在高速cpu和大容量存储器时,这两者之间从根本上存在明显的瓶颈。
去除瓶颈的关键是具有与cpu相同的存储器时钟循环。首先,必须创建寻址进程来改进存储器存取。其次,必须在存储器内部和存储器外部均显著降低由较长的线引起的时间延迟。
通过解决这两个问题,实现了存储器与cpu之间的快速直接耦合,这使得计算机能够没有存储器瓶颈。处理器和处理器的外设由于这些问题而消耗总能量的70%,这分成用于提供指令的42%以及用于数据的28%,如图53所示。布线问题不仅产生功耗,而且产生信号的时间延迟。克服布线问题意味着消除限制数据/指令流的瓶颈351、352。如果我们可以去除芯片内/间的布线,则功耗、时间延迟和存储器瓶颈351、352的问题将被解决。
技术实现要素:
本发明的一方面涉及一种包括存储器单元阵列的推进存储器,各个存储器单元具有比特级信元序列以存储字节大小或字大小的信息,各个比特级信元包括:(a)传送晶体管,其具有通过第一延迟元件连接到时钟信号供应线的第一主电极以及通过第二延迟元件连接到设置在所述存储器单元阵列的输入侧的第一邻近比特级信元的输出端子的控制电极;(b)复位晶体管,其具有连接到所述传送晶体管的第二主电极的第一主电极、连接到所述时钟信号供应线的控制电极以及连接到地电势的第二主电极;以及(c)电容器,其被配置为存储比特级信元的信息,与所述复位晶体管并联连接,其中,连接所述传送晶体管的第二主电极与所述复位晶体管的第一主电极的输出节点用作比特级信元的输出端子,比特级信元的所述输出端子将存储在所述电容器中的信号输送至设置在所述存储器单元阵列的输出侧的第二邻近比特级信元。
这里,对于场效应晶体管(fet)、静电感应晶体管(sit)、高电子迁移率晶体管(hemt)等,第一主电极应该被指派为源极或漏极,并且如果第一主电极被指派为源极,则第二主电极是漏极。另选地,如果第一主电极被指派为fet、sit和hemt等的漏极,则第二主电极为源极。类似地,对于双极结型晶体管(bjt),第一主电极应该被指派为发射极或集电极,并且如果第一主电极被指派为发射极,则第二主电极是集电极。另选地,如果第一主电极被指派为bjt的集电极,则第二主电极是发射极。并且,控制电极对于fet、sit和hemt等是栅极,对于bjt是基极。
本发明的另一方面涉及一种包括存储器单元阵列的双向推进存储器,各个存储器单元具有比特级信元序列以存储字节大小或字大小的信息,各个比特级信元包括:(a)前向传送晶体管,其具有通过第一前向延迟元件连接到第一时钟信号供应线的第一主电极以及通过第二前向延迟元件连接到设置在所述存储器单元阵列的一侧的第一邻近比特级信元的前向输出端子的控制电极;(b)前向复位晶体管,其具有连接到所述前向传送晶体管的第二主电极的第一主电极、连接到所述第一时钟信号供应线的控制电极以及连接到地电势的第二主电极;(c)后向传送晶体管,其具有通过第一后向延迟元件连接到第二时钟信号供应线的第一主电极以及通过第二后向延迟元件连接到第二邻近比特级信元的后向输出端子的控制电极;(d)后向复位晶体管,其具有连接到所述后向传送晶体管的第二主电极的第一主电极、连接到所述第二时钟信号供应线的控制电极以及连接到地电势的第二主电极;(e)前向电容器,其被配置为存储比特级信元的信息,并且与所述前向复位晶体管并联连接;以及(f)后向电容器,其被配置为存储比特级信元的信息,并且与所述后向复位晶体管并联连接,其中,连接所述前向传送晶体管的第二主电极与所述前向复位晶体管的第一主电极的输出节点用作比特级信元的前向输出端子,比特级信元的所述前向输出端子将存储在所述前向电容器中的信号输送至设置在所述存储器单元阵列的另一侧的第二邻近比特级信元,连接所述后向传送晶体管的第二主电极与所述后向复位晶体管的第一主电极的输出节点用作比特级信元的后向输出端子,比特级信元的所述后向输出端子将存储在所述后向电容器中的信号输送至所述第一邻近比特级信元。
本发明的另一方面涉及一种包括存储器单元阵列的双向推进存储器,各个存储器单元具有比特级信元序列以存储字节大小或字大小的信息,各个比特级信元包括:(a)前向传送晶体管,其具有通过第一前向延迟元件连接到第一时钟信号供应线的第一主电极以及通过第二前向延迟元件连接到设置在所述存储器单元阵列的一侧的第一邻近比特级信元的前向输出端子的控制电极;(b)前向复位晶体管,其具有连接到所述前向传送晶体管的第二主电极的第一主电极、连接到所述第一时钟信号供应线的控制电极以及连接到地电势的第二主电极;(c)后向传送晶体管,其具有通过第一后向延迟元件连接到第二时钟信号供应线的第一主电极以及通过第二后向延迟元件连接到第二邻近比特级信元的后向输出端子的控制电极;(d)后向复位晶体管,其具有连接到所述后向传送晶体管的第二主电极的第一主电极、连接到所述第二时钟信号供应线的控制电极以及连接到地电势的第二主电极;以及(e)公共电容器,其被配置为存储比特级信元的信息,并且与所述前向复位晶体管和所述后向复位晶体管并联连接,其中,连接所述前向传送晶体管的第二主电极与所述前向复位晶体管的第一主电极的输出节点用作比特级信元的前向输出端子,比特级信元的所述前向输出端子将存储在所述公共电容器中的信号输送至设置在所述存储器单元阵列的另一侧的第二邻近比特级信元,连接所述后向传送晶体管的第二主电极与所述后向复位晶体管的第一主电极的输出节点用作比特级信元的后向输出端子,比特级信元的所述后向输出端子将存储在所述公共电容器中的信号输送至所述第一邻近比特级信元。
本发明的另一方面涉及一种包括空间部署的多个推进存储器块的复合推进存储器,各个推进存储器块包括存储器单元阵列,各个存储器单元具有被配置为存储字节大小或字大小的信息的比特级信元序列。这里,其中,各个存储器单元与cpu的时钟信号同步地从对应推进存储器块的输入侧朝着对应推进存储器块的输出侧逐步地传送,并且各个推进存储器块被随机存取,使得对象推进存储器块中的各个存储器单元可被随机存取。
本发明的另一方面涉及一种包括空间部署的多个推进存储器块的复合推进存储器,各个推进存储器块包括存储器单元阵列,各个存储器单元具有被配置为存储字节大小或字大小的信息的比特级信元序列。这里,各个存储器单元与第一时钟信号同步地从对应推进存储器块的第二边缘侧朝着对应推进存储器块的与所述第二边缘侧相对的第一边缘侧逐步地传送,并且另外,各个存储器单元与第二时钟信号同步地从所述第一边缘侧朝着所述第二边缘侧逐步地传送,并且各个推进存储器块被随机存取,使得对象推进存储器块中的各个存储器单元可被随机存取。
本发明的另一方面涉及一种包括处理器和推进主存储器的计算机系统,所述推进主存储器被配置为主动地并且顺序地向所述处理器提供存储的信息,使得所述处理器可利用所存储的信息执行算术和逻辑运算,另外,所述处理器中的处理结果被发送给所述推进主存储器,例外的是在指令移动的情况下,仅存在从所述推进主存储器至所述处理器的单向指令流,所述推进主存储器包括存储器单元阵列,各个存储器单元具有比特级信元序列以存储字节大小或字大小的信息,各个比特级信元包括:(a)传送晶体管,其具有通过第一延迟元件连接到时钟信号供应线的第一主电极以及通过第二延迟元件连接到设置在所述存储器单元阵列的输入侧的第一邻近比特级信元的输出端子的控制电极;(b)复位晶体管,其具有连接到所述传送晶体管的第二主电极的第一主电极、连接到所述时钟信号供应线的控制电极以及连接到地电势的第二主电极;以及(c)电容器,其被配置为存储比特级信元的信息,并且与所述复位晶体管并联连接,其中,连接所述传送晶体管的第二主电极与所述复位晶体管的第一主电极的输出节点用作比特级信元的输出端子,比特级信元的所述输出端子将存储在所述电容器中的信号输送至设置在所述存储器单元阵列的输出侧的第二邻近比特级信元。
本发明的另一方面涉及一种包括处理器和双向推进主存储器的计算机系统,所述双向推进主存储器被配置为主动地并且顺序地向所述处理器提供存储的信息,使得所述处理器可利用所存储的信息执行算术和逻辑运算,另外,所述处理器中的处理结果被发送给所述双向推进主存储器,例外的是在指令移动的情况下,仅存在从所述双向推进主存储器至所述处理器的单向指令流,所述双向推进主存储器包括存储器单元阵列,各个存储器单元具有比特级信元序列以存储字节大小或字大小的信息,各个比特级信元包括:(a)前向传送晶体管,其具有通过第一前向延迟元件连接到第一时钟信号供应线的第一主电极以及通过第二前向延迟元件连接到设置在所述存储器单元阵列的一侧的第一邻近比特级信元的前向输出端子的控制电极;(b)前向复位晶体管,其具有连接到所述前向传送晶体管的第二主电极的第一主电极、连接到所述第一时钟信号供应线的控制电极以及连接到地电势的第二主电极;(c)后向传送晶体管,其具有通过第一后向延迟元件连接到第二时钟信号供应线的第一主电极以及通过第二后向延迟元件连接到第二邻近比特级信元的后向输出端子的控制电极;(d)后向复位晶体管,其具有连接到所述后向传送晶体管的第二主电极的第一主电极、连接到所述第二时钟信号供应线的控制电极以及连接到地电势的第二主电极;以及(e)公共电容器,其被配置为存储比特级信元的信息,并且与所述前向复位晶体管和所述后向复位晶体管并联连接,其中,连接所述前向传送晶体管的第二主电极与所述前向复位晶体管的第一主电极的输出节点用作比特级信元的前向输出端子,比特级信元的所述前向输出端子将存储在所述公共电容器中的信号输送至设置在所述存储器单元阵列的另一侧的第二邻近比特级信元,连接所述后向传送晶体管的第二主电极与所述后向复位晶体管的第一主电极的输出节点用作比特级信元的后向输出端子,比特级信元的所述后向输出端子将存储在所述公共电容器中的信号输送至所述第一邻近比特级信元。
本发明的另一方面涉及一种包括处理器和双向推进主存储器的计算机系统,所述双向推进主存储器被配置为主动地并且顺序地向所述处理器提供存储的信息,使得所述处理器可利用所存储的信息执行算术和逻辑运算,另外,所述处理器中的处理结果被发送给所述双向推进主存储器,例外的是在指令移动的情况下,仅存在从所述双向推进主存储器至所述处理器的单向指令流,所述双向推进主存储器包括存储器单元阵列,各个存储器单元具有比特级信元序列以存储字节大小或字大小的信息,各个比特级信元包括:(a)前向传送晶体管,其具有通过第一前向延迟元件连接到第一时钟信号供应线的第一主电极以及通过第二前向延迟元件连接到设置在所述存储器单元阵列的一侧的第一邻近比特级信元的前向输出端子的控制电极;(b)前向复位晶体管,其具有连接到所述前向传送晶体管的第二主电极的第一主电极、连接到所述第一时钟信号供应线的控制电极以及连接到地电势的第二主电极;(c)后向传送晶体管,其具有通过第一后向延迟元件连接到第二时钟信号供应线的第一主电极以及通过第二后向延迟元件连接到第二邻近比特级信元的后向输出端子的控制电极;(d)后向复位晶体管,其具有连接到所述后向传送晶体管的第二主电极的第一主电极、连接到所述第二时钟信号供应线的控制电极以及连接到地电势的第二主电极;以及(e)公共电容器,其被配置为存储比特级信元的信息,并且与所述前向复位晶体管和所述后向复位晶体管并联连接,其中,连接所述前向传送晶体管的第二主电极与所述前向复位晶体管的第一主电极的输出节点用作比特级信元的前向输出端子,比特级信元的所述前向输出端子将存储在所述公共电容器中的信号输送至设置在所述存储器单元阵列的另一侧的第二邻近比特级信元,连接所述后向传送晶体管的第二主电极与所述后向复位晶体管的第一主电极的输出节点用作比特级信元的后向输出端子,比特级信元的所述后向输出端子将存储在所述公共电容器中的信号输送至所述第一邻近比特级信元。
本发明的另一方面涉及一种包括处理器和推进主存储器的计算机系统,所述推进主存储器被配置为主动地并且顺序地向所述处理器提供存储的信息,使得所述处理器可利用所存储的信息执行算术和逻辑运算,另外,所述处理器中的处理结果被发送给所述推进主存储器,例外的是在指令移动的情况下,仅存在从所述推进主存储器至所述处理器的单向指令流,所述推进主存储器包括空间部署的多个推进存储器块,各个推进存储器块包括存储器单元阵列,各个存储器单元具有被配置为存储字节大小或字大小的信息的比特级信元序列。这里,各个推进存储器块被随机存取,使得对象推进存储器块中的各个存储器单元可被随机存取。
本发明的另一方面涉及一种包括处理器和双向推进主存储器的计算机系统,所述双向推进主存储器被配置为主动地并且顺序地向所述处理器提供存储的信息,使得所述处理器可利用所存储的信息执行算术和逻辑运算,另外,所述处理器中的处理结果被发送给所述双向推进主存储器,例外的是在指令移动的情况下,仅存在从所述双向推进主存储器至所述处理器的单向指令流,所述双向推进主存储器包括空间部署的多个双向推进存储器块,各个双向推进存储器块包括存储器单元阵列,各个存储器单元具有比特级信元序列以存储字节大小或字大小的信息。这里,各个存储器单元与第一时钟信号同步地从对应推进存储器块的第二边缘侧朝着对应推进存储器块的与所述第二边缘侧相对的第一边缘侧逐步地传送,并且另外,各个存储器单元与第二时钟信号同步地从所述第一边缘侧朝着所述第二边缘侧逐步地传送,并且各个推进存储器块被随机存取,使得对象推进存储器块中的各个存储器单元可被随机存取。
附图说明
[图1]图1示出说明传统计算机系统的构造的示意性框图;
[图2]图2示出说明根据本发明的第一实施方式的计算机系统的基本构造的示意性框图;
[图3]图3示出实现根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的存储器单元阵列以及推进主存储器中的信息传送;
[图4]图4示出根据本发明的第一实施方式的计算机系统中所使用的推进主存储器中的信元阵列的晶体管层级表示的示例;
[图5]图5示出根据本发明的第一实施方式的计算机系统中所使用的推进主存储器中的信元阵列的放大的晶体管层级表示,其聚焦于四个邻近比特级信元;
[图6]图6示出根据本发明的第一实施方式的计算机系统中所使用的推进主存储器中的单个比特级信元的另一放大的晶体管层级表示;
[图7a]图7a示出晶体管对被配置为施加到根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的时钟信号波形的响应的示意性示例,其示出当从前一级传送来信号“1”时的情况;
[图7b]图7b示出晶体管对被配置为施加到根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的时钟信号波形的响应的另一示意性示例,其示出当从前一级传送来信号“0”时的另一情况;
[图7c]图7c示出晶体管对被配置为施加到根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的时钟信号波形的响应的实际示例;
[图8]图8示出根据本发明的第一实施方式的计算机系统的推进主存储器中所使用的比特级信元的详细示例;
[图9]图9示出实现图8所示的比特级信元的实际平面图的示例;
[图10]图10示出在图9所示的平面图中沿线a-a截取的截面图;
[图11]图11示出与单元间信元组合的单个比特级信元的另一放大的晶体管层级表示,所述单元间信元适用于根据本发明的第一实施方式的改型的计算机系统中所使用的推进主存储器;
[图12]图12示出实现图11所示的比特级信元的实际平面图的示例;
[图13]图13示出在根据本发明的第一实施方式的改型的计算机系统中所使用的推进主存储器中,与对应单元间信元组合的信元阵列的放大的晶体管层级表示,其聚焦于两个邻近比特级信元;
[图14]图14的(a)示出图13所示的比特级信元对时钟信号波形的响应的定时图,图14的(b)示出图13所示的下一比特级信元对时钟信号波形的下一响应的下一定时图。
[图15]图15示出晶体管对被配置为施加到根据本发明的第一实施方式的改型的计算机系统中所使用的推进主存储器的时钟信号波形的响应的实际示例;
[图16]图16的(a)-(d)分别示出在根据本发明的第一实施方式的改型的计算机系统中所使用的推进主存储器中,聚焦于图11和图13所示的比特级信元的信号传送操作的四种模式;
[图17]图17示出与单元间信元组合的单个比特级信元的另一放大的晶体管层级表示,所述单元间信元适用于根据本发明的第一实施方式的另一改型(第二改型)的计算机系统中所使用的推进主存储器;
[图18]图18示出在根据本发明的第一实施方式的第二改型的计算机系统中所使用的推进主存储器中,与对应单元间信元组合的信元阵列的放大的晶体管层级表示,其聚焦于两个邻近比特级信元;
[图19]图19示出与单元间信元组合的单个比特级信元的另一放大的晶体管层级表示,所述单元间信元适用于根据本发明的第一实施方式的另一改型(第三改型)的计算机系统中所使用的推进主存储器;
[图20]图20示出在根据本发明的第一实施方式的第三改型的计算机系统中所使用的推进主存储器中,与对应单元间信元组合的信元阵列的放大的晶体管层级表示,其聚焦于两个邻近比特级信元;
[图21]图21示出晶体管对被配置为施加到根据本发明的第一实施方式的第三改型的计算机系统中所使用的推进主存储器的时钟信号波形的响应的实际示例;
[图22]图22的(a)-(d)分别示出在根据本发明的第一实施方式的第三改型的计算机系统中所使用的推进主存储器中,聚焦于图20和图21所示的比特级信元的信号传送操作的四种模式;
[图23]图23示出图4所示的信元阵列的门层级表示;
[图24]图24示出实现根据本发明的第一实施方式的计算机系统中所使用的反向推进主存储器的存储器单元阵列以及该反向推进主存储器中的信息的反向传送;
[图25]图25的(a)示出实现图24所示的反向推进主存储器的第i行的信元阵列的晶体管层级电路配置的示例,图25的(b)示出晶体管对被配置为施加到图24所示的反向推进主存储器的时钟信号波形的响应的示例;
[图26]图26示出图25的(a)所示的实现反向推进主存储器中的第i行的信元阵列的门层级表示;
[图27]图27示出在根据本发明的第一实施方式的计算机系统中,推进主存储器中的存储器单元流处理时间与处理器(cpu)中的时钟循环之间的时域关系;
[图28]图28示意性地示出根据本发明的第一实施方式的计算机系统的构造,其中在根据本发明的第一实施方式的计算机系统中,在处理器(cpu)与包括推进主存储器的推进存储器结构之间存储器瓶颈消失;
[图29]图29的(a)示出在根据本发明的第一实施方式的计算机系统中,从包括推进主存储器的推进存储器结构流向处理器(cpu)的前向数据流以及从处理器(cpu)流向推进存储器结构的后向数据流,图29的(b)示出在推进存储器结构的存储器单元流处理时间等于处理器(cpu)的时钟循环的理想条件下,推进存储器结构与处理器(cpu)之间建立的带宽;
[图30]图30的(a)示意性地示出与图30的(b)所示的计算机系统相比的极高速磁带系统,其对应于根据本发明的第一实施方式的计算机系统;
[图31]图31的(a)示出在根据本发明的第一实施方式的计算机系统中,信息的推进行为(前向推进行为)的具象,其中在一维推进主存储器中信息朝着右手方向一起推进(移位),图31的(b)示出一维推进主存储器的停留状态,图31的(c)示出信息的反向推进行为(后向推进行为)的具象,其中在一维推进主存储器中信息朝着左手方向一起推进(移位);
[图32]图32示出在根据本发明的第一实施方式的计算机系统中的一维推进主存储器的晶体管层级电路配置的示例,该一维推进主存储器可实现图31的(a)-(c)所示的双向传送行为,被配置为存储并双向传送指令或标量数据;
[图33]图33示出在根据本发明的第一实施方式的计算机系统中在存储器单元之间包含隔离晶体管的一维推进主存储器的晶体管层级电路配置的另一示例,该一维推进主存储器可实现图31的(a)-(c)所示的双向传送行为,被配置为存储并双向传送指令或标量数据;
[图34]图34示出图32所示的一维推进主存储器的门层级电路配置的一般表示;
[图35]图35的(a)示出与处理器相邻的一维推进主存储器中的指令的双向传送模式,所述指令朝着处理器移动并且从布置在左手侧的下一存储器/向该下一存储器移动,图35的(b)示出与alu相邻的一维推进主存储器中的标量数据的双向传送模式,所述标量数据朝着alu移动并且从下一存储器/向下一存储器移动,图35的(c)示出与流水线相邻的一维推进主存储器中的向量/流数据的单向传送模式,所述向量/流数据朝着流水线移动并且从下一存储器移动;
[图36]图36的(a)与图36的(b)比较示出现有存储器的内部配置,其中各个存储器单元通过地址来标记,图36的(b)示出本发明的一维推进主存储器的配置,其中各个存储器单元的定位至少对于标识向量/流数据中的连续的存储器单元集合的起始点和结束点而言是必要的。
[图37]图37的(a)示出本发明的一维推进主存储器的内部配置,其中各个存储器单元的定位至少对于标识向量指令中的连续的存储器单元集合的起始点和结束点而言是必要的,图37的(b)示出对于标量数据的本发明的一维推进主存储器的内部配置。然而,图37的(c)示出本发明的一维推进主存储器的内部配置,其中位置索引至少对于标识向量/流数据中的连续的存储器单元集合的起始点和结束点而言是必要的;
[图38]图38的(a)示意性地示出在根据本发明的第一实施方式的计算机系统中,对于向量/流数据情况,通过多页实现的本发明的推进主存储器的总体配置的示例,图38的(b)示意性地示出对于向量/流数据情况,所述页中的一个页的配置的示例,各个页通过多个文件实现,图38的(c)示意性地示出对于向量/流数据情况,所述文件中的一个文件的配置的示例,各个文件通过多个存储器单元实现;
[图39]图39的(a)示意性地示出在根据本发明的第一实施方式的计算机系统中,对于程序/标量数据情况,通过多页实现的本发明的推进主存储器的总体配置的示例,其中各个页具有它自己的位置索引作为地址,图39的(b)示意性地示出对于程序/标量数据情况,所述页中的一个页的配置的示例以及该页使用二进制位的驱动位置,各个页通过多个文件实现,各个文件具有它自己的位置索引作为地址,图39的(c)示意性地示出对于程序/标量数据情况,所述文件中的一个文件的配置的示例以及该文件使用二进制位的驱动位置,各个文件通过多个存储器单元实现,其中各个存储器单元具有它自己的位置索引作为地址;
[图40]图40的(a)示意性地示出与根据本发明的第一实施方式的计算机系统中所使用的推进主存储器进行比较的现有存储器的速度/能力,图40的(b)示意性地示出与图40的(a)所示的现有存储器进行比较的推进主存储器的速度/能力;
[图41]图41的(a)示意性地示出对于标量指令,与根据本发明的第一实施方式的计算机系统中所使用的推进主存储器进行比较的现有存储器的最差情况的速度/能力,图41的(b)示意性地示出与图41的(a)所示的现有存储器的最差情况进行比较的推进主存储器的速度/能力;
[图42]图42的(a)示意性地示出对于标量指令,与根据本发明的第一实施方式的计算机系统中所使用的推进主存储器进行比较的现有存储器的典型情况的速度/能力,图42的(b)示意性地示出与图42的(a)所示的现有存储器的典型情况进行比较的推进主存储器的速度/能力;
[图43]图43的(a)示意性地示出对于标量数据情况,与根据本发明的第一实施方式的计算机系统中所使用的推进主存储器进行比较的现有存储器的典型情况的速度/能力,图43的(b)示意性地示出与图43的(a)所示的现有存储器进行比较的推进主存储器的速度/能力;
[图44]图44的(a)示意性地示出对于流数据和数据并行情况,与根据本发明的第一实施方式的计算机系统中所使用的推进主存储器进行比较的现有存储器的最佳情况的速度/能力,图44的(b)示意性地示出与图44的(a)所示的现有存储器的最佳情况进行比较的推进主存储器的速度/能力;
[图45]图45示出实现根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的二维存储器单元阵列的示例,各个存储器单元存储并传送数据或指令;
[图46]图46示出实现根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的二维存储器单元阵列的另一示例,各个存储器单元存储并传送数据或指令;
[图47]图47示出实现根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的二维存储器单元阵列的另一示例,各个存储器单元存储并传送数据或指令;
[图48]图48示出实现根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的二维存储器单元阵列的另一示例,各个存储器单元存储并传送数据或指令;
[图49]图49示出实现根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的二维存储器单元阵列的另一示例,各个存储器单元存储并传送数据或指令;
[图50]图50示出实现根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的二维存储器单元阵列的另一示例,各个存储器单元存储并传送数据或指令;
[图51]图51示出实现根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的二维存储器单元阵列的另一示例,各个存储器单元存储并传送数据或指令;
[图52]图52的(a)示出当前微处理器中的装置层级能耗,其分解为静态能耗和动态能耗,图52的(b)示出图52的(a)所示的动态能耗中的净功耗和开销,图52的(c)示出当前微处理器中的净能耗;
[图53]图53示出由dally估计的传统架构中的包括寄存器和高速缓存的处理器上的实际能耗分布;
[图54]图54的(a)示出传统基于高速缓存的架构中的能耗,高速缓冲存储器中的能耗分解为静态能耗和动态能耗,图54的(b)示出根据本发明的第三实施方式的计算机系统中的能耗,推进高速缓冲存储器中的能耗分解为静态能耗和动态能耗。
[图55]图55示出说明根据本发明的第二实施方式的计算机系统的构造的示意性框图;
[图56]图56示出说明根据本发明的第三实施方式的计算机系统的构造的示意性框图;
[图57]图57的(a)示出根据本发明的第三实施方式的计算机系统中的算术流水线与推进寄存器单元的组合,图57的(b)示出根据本发明的第三实施方式的计算机系统中的推进高速缓存单元阵列;
[图58]图58示出根据本发明的第三实施方式的改型的通过单个处理器核、推进高速缓冲存储器和推进寄存器文件的组合实现的计算机系统的构造的示意性框图;
[图59]图59示出根据本发明的第三实施方式的另一改型的通过单个算术流水线、推进高速缓冲存储器和推进向量寄存器文件的组合实现的计算机系统的构造的示意性框图;
[图60]图60示出根据本发明的第三实施方式的另一改型的通过多个处理器核、推进高速缓冲存储器和推进寄存器文件的组合实现的计算机系统的构造的示意性框图;
[图61]图61示出根据本发明的第三实施方式的另一改型的通过多个算术流水线、推进高速缓冲存储器和推进向量寄存器文件的组合实现的计算机系统的构造的示意性框图;
[图62]图62的(a)示出通过多个算术流水线、多个传统高速缓冲存储器、多个传统向量寄存器文件(rf)和传统主存储器的组合实现的传统计算机系统的构造的示意性框图,其中在传统高速缓冲存储器与传统主存储器之间形成瓶颈,图62的(b)示出根据本发明的第三实施方式的另一改型的通过多个算术流水线、多个推进高速缓冲存储器、多个推进向量寄存器文件和推进主存储器的组合实现的计算机系统的构造的示意性框图,其中没有形成瓶颈;
[图63]图63示出说明根据本发明的第四实施方式的高性能计算(hpc)系统的构造的示意性框图;
[图64]图64示出说明根据本发明的第五实施方式的计算机系统的构造的示意性框图;
[图65]图65的(a)示出根据本发明的第五实施方式的计算机系统中所使用的三维推进主存储器的截面图,图65的(b)示出根据本发明的第五实施方式的计算机系统中所使用的三维推进高速缓存的截面图,图65的(c)示出根据本发明的第五实施方式的计算机系统中所使用的三维推进寄存器文件的截面图;
[图66]图66示出根据本发明的第五实施方式的计算机系统中所使用的三维配置的立体图;
[图67]图67示出根据本发明的第五实施方式的计算机系统中所使用的另一三维配置的立体图;
[图68]图68示出图67所示的三维配置的截面图;
[图69]图69示出根据本发明的第五实施方式的计算机系统中所使用的另一三维配置的截面图;
[图70]图70通过在根据本发明的第五实施方式的计算机系统中表示控制路径,来示意性地示出执行控制处理的计算机系统的基本核的三维配置的截面图;
[图71]图71通过在根据本发明的第五实施方式的计算机系统中表示标量数据的数据路径,来示意性地示出执行标量数据处理的计算机系统的基本核的三维配置的截面图;
[图72]图72通过在根据本发明的第五实施方式的计算机系统中表示向量/流数据的数据路径,来示意性地示出执行向量/流数据处理的计算机系统的基本核的三维配置的截面图;
[图73]图73通过表示根据本发明的第五实施方式的计算机系统的标量数据路径和控制路径的组合,来示意性地示出被配置为执行计算机系统的标量数据部分的计算机系统的基本核的三维配置的截面图,其中多个处理单元(cpu)不仅执行标量数据,而且执行向量/流数据,并且流水线alu被包括在处理单元中;
[图74]图74示出misd架构中的标量/向量数据的比特级并行处理;
[图75]图75示出simd架构中的向量数据的并行处理;
[图76]图76示出向量处理中的典型链接;
[图77]图77示出misd架构中的标量/向量数据的并行处理;
[图78]图78示出misd架构中的标量/向量数据的并行处理;
[图79]图79的(a)示出描绘于单个半导体芯片上的代表性传统dram的平面图,图79的(b)示出描绘于传统dram的同一单个半导体芯片上的复合推进存储器的示意性内部布局的对应平面图;
[图80]图80的(a)示出单个推进存储器块的外形,图80的(b)示出图80的(a)所示的推进存储器块的局部平面图,其具有一千列,其中推进存储器的存取时间(循环时间)被限定为单列,图80的(c)示出用于将内容写到传统dram的一个存储器元件中或从传统dram的一个存储器元件读出内容的传统dram的存储器循环;以及
[图81]图81示出复合推进存储器模块的示意性平面图。
具体实施方式
将参照附图描述本发明的各种实施方式。需要注意的是,贯穿附图,相同或相似的标号应用于相同或相似的部件和元件,相同或相似的部件和元件的描述将省略或简化。通常,并且如半导体器件的表示中惯常的,将理解的是,各个附图彼此未按比例绘制并且给定附图内也未按比例绘制,尤其是,层厚度被任意绘制以便于附图的阅读。在下面的描述中阐述了特定细节,例如特定材料、处理和设备,以便全面理解本发明。然而,对于本领域技术人员而言将明显的是,本发明可在没有这些特定细节的情况下实践。在其它情况下,公知的制造材料、处理和设备未详细阐述,以避免不必要地模糊本发明。诸如“上”、“上方”、“下”、“下方”和“垂直”的介词相对于基板的平坦表面定义,而与基板实际所保持的取向无关。层在另一层上,即使存在中间层。
尽管在图4、图5、图6、图8、图11、图13、图16-20、图22、图25和图32等中的比特级信元(bit-levelcell)的晶体管层级表示中,示出nmos晶体管作为传送晶体管和复位晶体管,但是如果采用相反极性的时钟信号,则pmos晶体管也可用作传送晶体管和复位晶体管。
--第一实施方式--
(计算机系统的基本构造)
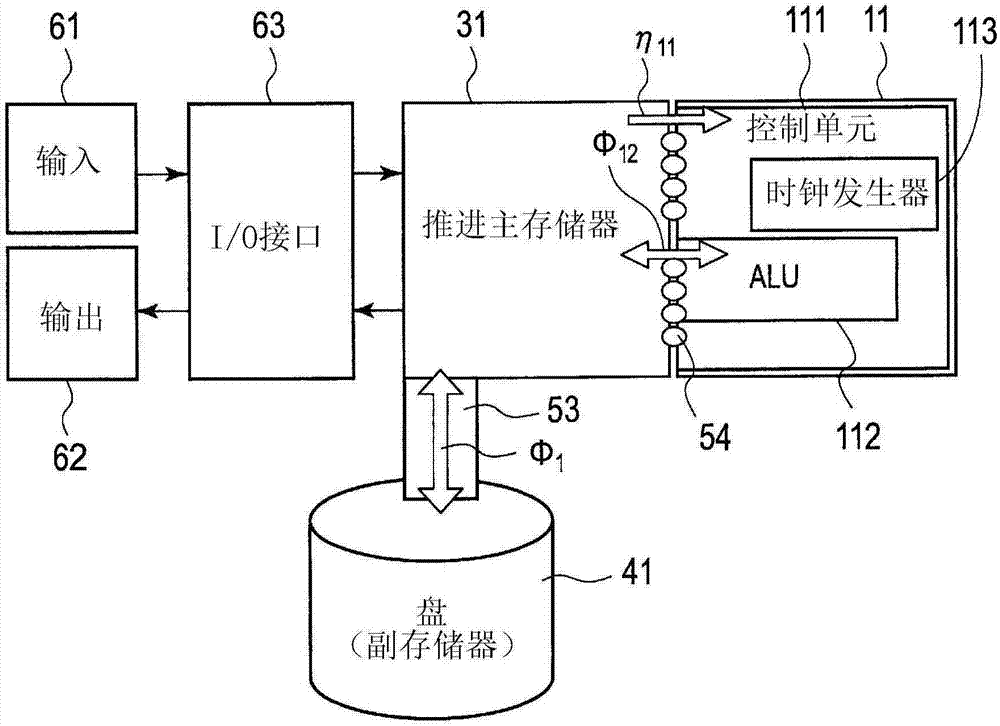
如图2所示,根据本发明的第一实施方式的计算机系统包括处理器11和推进主存储器31。处理器11包括控制单元111,控制单元111具有被配置为产生时钟信号的时钟发生器113以及被配置为与时钟信号同步地执行算术和逻辑运算的算术逻辑单元(alu)112。如图3所示,推进主存储器31包括存储器单元u1、u2、u3、......、un-1、un的阵列,存储器单元u1、u2、u3、......、un-1、un中的每一个具有单位信息,所述信息包括数据或指令的字大小、阵列的输入端子和阵列的输出端子。如图3所示,推进主存储器31将所述信息存储在存储器单元u1、u2、u3、......、un-1、un中的每一个中,并与时钟信号同步地逐步将所述信息朝着输出端子传送,以向处理器11主动地并且顺序地提供所存储的信息,使得alu112可利用所存储的信息执行算术和逻辑运算。
如图2所示,推进主存储器31和处理器11通过多个联接构件54电连接。例如,各个联接构件54可通过附着到推进主存储器31的第一端子引脚、附着到处理器11的第二端子引脚以及插入第一端子引脚和第二端子引脚之间的导电凸块实现。对于导电凸块的材料,焊球、金(au)凸块、银(ag)凸块、铜(cu)凸块、镍-金(ni-au)合金凸块或镍-金-铟(ni-au-in)合金凸块等是可接受的。alu112中的处理的所得数据通过联接构件54被发送给推进主存储器31。因此,如双向箭头phi(希腊字母)12所表示的,通过联接构件54在推进主存储器31与处理器11之间双向传送数据。相反,如单向箭头eta(希腊字母)11所表示的,对于指令移动,仅存在从推进主存储器31到处理器11的单向指令流。
如图2所示,根据本发明的第一实施方式的计算机系统的构造还包括外部副存储器41(例如,盘)、输入单元61、输出单元62和输入/输出(i/o)接口电路63。类似于传统冯·诺伊曼计算机,通过输入单元61接收信号或数据,从输出单元62发送信号或数据。例如,已知键盘和已知鼠标可被视作输入单元6,而已知监视器和打印机可被视作输出单元62。用于计算机之间的通信的已知装置(例如,调制解调器和网卡)通常用于为输入单元61和输出单元62二者服务。需要指出的是,将装置指定为输入单元61还是输出单元62取决于视角。输入单元61以人使用者提供的物理移动作为输入,并将其转换为根据第一实施方式的计算机系统能够理解的信号。例如,输入单元61将进入的数据和指令转换为根据第一实施方式的计算机系统能够理解的二进制码的电信号图案,输入单元61的输出通过i/o接口电路63被馈送给推进主存储器31。输出单元62以推进主存储器31通过i/o接口电路63提供的信号作为输入。然后,输出单元62将这些信号转换为人使用者能够看到或阅读的表示,从而与输入单元61的处理相逆,将数字化的信号转换为用户易懂的形式。每当处理器11驱动输入单元61和输出单元62时,需要i/o接口电路63。处理器11可通过i/o接口电路63与输入单元61和输出单元62通信。如果在交换不同格式的数据的情况下,i/o接口电路63将串行数据转换为并行形式,反之亦然。如果需要,存在产生中断和对应类型数的规定以便于处理器11的进一步处理。
副存储器41以比推进主存储器31更长期的方式存储数据和信息。尽管推进主存储器31主要涉及存储当前正在执行的程序以及当前正在使用的数据,副存储器41通常旨在存储需要保存的任何东西,即使计算机被关闭或者当前没有执行程序。副存储器41的示例是已知的硬盘(或硬盘驱动器)以及已知的外部介质驱动器(例如,cd-rom驱动器)。这些存储方法最常用于存储计算机的操作系统、用户的软件收集以及用户希望的任何其它数据。尽管硬盘驱动器用于以半永久性的方式存储数据和软件,外部介质驱动器用于保存其它数据,这种设置根据可用存储装置的不同形式以及各个存储装置的使用便利性而存在极大差异。如双向箭头phi(希腊字母)1所表示的,通过现有线连接53在副存储器41与推进主存储器31和处理器11之间双向传送数据。
尽管未示出,在图2所示的第一实施方式的计算机系统中,处理器11可包括多个算术流水线,该多个算术流水线被配置为通过输出端子从推进主存储器31接收所存储的信息,如双向箭头phi12所表示的,通过联接构件54在推进主存储器31与所述多个算术流水线之间双向传送数据。
在图2所示的第一实施方式的计算机系统中,不存在由数据总线和地址总线组成的总线,因为整个计算机系统即使在处理器11与推进主存储器31之间的任何数据交换中也不具有全局线,而所述线或总线在传统计算机系统中引起了所述瓶颈。仅在推进主存储器31内或者推进主存储器31与对应alu112的连接部分存在较短的局部线。由于不存在产生时间延迟以及这些线之间的杂散电容的全局线,所以第一实施方式的计算机系统可实现更高的处理速度和更低的功耗。
(实现推进主存储器的信元阵列的详细配置)
在最传统的计算机中,地址解析的单位是字符(例如,字节)或字。如果单位是字,则可利用给定大小的地址存取更大量的存储器。另一方面,如果单位是字节,则单独的字符可被寻址(即,在存储器操作期间被选择)。机器指令通常是架构的字大小的分数或倍数。这是自然选择,因为指令和数据通常共享相同的存储器子系统。图4和图5对应于实现图3所示的推进主存储器31的信元阵列的晶体管层级表示,图23对应于实现图3所示的推进主存储器31的信元阵列的门层级表示。
在图4中,m×n矩阵的通过信元m11、m21、m31、......、mm-1,1、mm1的垂直阵列实现的第一列表示图3所示的第一存储器单元u1。这里,“m”是由字大小确定的整数。尽管字大小的选择相当重要,当计算机架构被设计时,字大小自然是八比特的倍数,通常使用16、32和64比特。类似地,m×n矩阵的通过信元m12、m22、m32、......、mm-1,2、mm2的垂直阵列实现的第二列表示第二存储器单元u2,m×n矩阵的通过信元m13、m23、m33、......、mm-1,3、mm3的垂直阵列实现的第三列表示第三存储器单元u3,......,m×n矩阵的通过信元m1,n-1、m2,n-1、m3,n-1、......、mm-1,n-1、mm,n-1的垂直阵列实现的第(n-1)列表示第(n-1)存储器单元un-1,m×n矩阵的通过信元m1,n、m2,n、m3,n、......、mm-1,n、mm,n的垂直阵列实现的第n列表示第n存储器单元un,
即,如图4所示,字大小级别的第一存储器单元u1通过m×n矩阵的第一列中的比特级信元m11、m21、m31、......、mm-1,1、mm1的垂直阵列实现。第一列第一行上的信元m11包括:第一nmos晶体管q111,其具有通过第一延迟元件d111连接到时钟信号供应线的漏极以及通过第二延迟元件d112连接到第一比特级输入端子的输出端子的栅极;第二nmos晶体管q112,其具有连接到第一nmos晶体管q111的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c11,其被配置为存储信元m11的信息,并且与第二nmos晶体管q112并联连接,其中,连接第一nmos晶体管q111的源极和第二nmos晶体管q112的漏极的输出节点用作信元m11的输出端子,并且被配置为将存储在电容器c11中的信号输送给下一比特级信元m12。第一列第二行上的信元m21包括:第一nmos晶体管q211,其具有通过第一延迟元件d211连接到时钟信号供应线的漏极以及通过第二延迟元件d212连接到第二比特级输入端子的输出端子的栅极;第二nmos晶体管q212,其具有连接到第一nmos晶体管q211的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c21,其被配置为存储信元m21的信息,并且与第二nmos晶体管q212并联连接,其中,连接第一nmos晶体管q211的源极和第二nmos晶体管q212的漏极的输出节点用作信元m21的输出端子,并且被配置为将存储在电容器c21中的信号输送给下一比特级信元m22。第一列第三行上的信元m31包括:第一nmos晶体管q311,其具有通过第一延迟元件d311连接到时钟信号供应线的漏极以及通过第二延迟元件d312连接到第三比特级输入端子的输出端子的栅极;第二nmos晶体管q312,其具有连接到第一nmos晶体管q311的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c31,其被配置为存储信元m31的信息,并且与第二nmos晶体管q312并联连接,其中,连接第一nmos晶体管q311的源极和第二nmos晶体管q312的漏极的输出节点用作信元m31的输出端子,并且被配置为将存储在电容器c31中的信号输送给下一比特级信元m31。……第一列第(m-1)行上的信元m(m-1)1包括:第一nmos晶体管q(m-1)11,其具有通过第一延迟元件d(m-1)11连接到时钟信号供应线的漏极以及通过第二延迟元件d(m-1)12连接到第(m-1)比特级输入端子的输出端子的栅极;第二nmos晶体管q(m-1)12,其具有连接到第一nmos晶体管q(m-1)11的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c(m-1)1,其被配置为存储信元m(m-1)1的信息,并且与第二nmos晶体管q(m-1)12并联连接,其中,连接第一nmos晶体管q(m-1)11的源极和第二nmos晶体管q(m-1)12的漏极的输出节点用作信元m(m-1)1的输出端子,并且被配置为将存储在电容器c(m-1)1中的信号输送给下一比特级信元m(m-1)2。第一列第m行上的信元mm1包括:第一nmos晶体管qm11,其具有通过第一延迟元件dm11连接到时钟信号供应线的漏极以及通过第二延迟元件dm12连接到第m比特级输入端子的输出端子的栅极;第二nmos晶体管qm12,其具有连接到第一nmos晶体管qm11的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器cm1,其被配置为存储信元mm1的信息,并且与第二nmos晶体管qm12并联连接,其中,连接第一nmos晶体管qm11的源极和第二nmos晶体管qm12的漏极的输出节点用作信元mm1的输出端子,并且被配置为将存储在电容器cm1中的信号输送给下一比特级信元mm2。
并且,如图4所示,字大小级别的第二存储器单元u2通过m×n矩阵的第二列中的比特级信元m12、m22、m32、......、mm-1,2、mm2的垂直阵列实现。第二列第一行上的信元m12包括:第一nmos晶体管q121,其具有通过第一延迟元件d121连接到时钟信号供应线的漏极以及通过第二延迟元件d122连接到前一比特级信元m11的输出端子的栅极;第二nmos晶体管q122,其具有连接到第一nmos晶体管q121的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c12,其被配置为存储信元m12的信息,并且与第二nmos晶体管q122并联连接,其中,连接第一nmos晶体管q121的源极和第二nmos晶体管q122的漏极的输出节点用作信元m12的输出端子,并且被配置为将存储在电容器c12中的信号输送给下一比特级信元m13。第二列第二行上的信元m22包括:第一nmos晶体管q221,其具有通过第一延迟元件d221连接到时钟信号供应线的漏极以及通过第二延迟元件d222连接到前一比特级信元m21的输出端子的栅极;第二nmos晶体管q222,其具有连接到第一nmos晶体管q221的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c22,其被配置为存储信元m22的信息,并且与第二nmos晶体管q222并联连接,其中,连接第一nmos晶体管q221的源极和第二nmos晶体管q222的漏极的输出节点用作信元m22的输出端子,并且被配置为将存储在电容器c22中的信号输送给下一比特级信元m23。第二列第三行上的信元m32包括:第一nmos晶体管q321,其具有通过第一延迟元件d321连接到时钟信号供应线的漏极以及通过第二延迟元件d322连接到前一比特级信元m31的输出端子的栅极;第二nmos晶体管q322,其具有连接到第一nmos晶体管q321的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c32,其被配置为存储信元m32的信息,并且与第二nmos晶体管q322并联连接,其中,连接第一nmos晶体管q321的源极和第二nmos晶体管q322的漏极的输出节点用作信元m32的输出端子,并且被配置为将存储在电容器c32中的信号输送给下一比特级信元m33。……第二列第(m-1)行上的信元m(m-1)2包括:第一nmos晶体管q(m-1)21,其具有通过第一延迟元件d(m-1)21连接到时钟信号供应线的漏极以及通过第二延迟元件d(m-1)22连接到前一比特级信元m(m-1)1的输出端子的栅极;第二nmos晶体管q(m-1)22,其具有连接到第一nmos晶体管q(m-1)21的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c(m-1)2,其被配置为存储信元m(m-1)2的信息,并且与第二nmos晶体管q(m-1)22并联连接,其中,连接第一nmos晶体管q(m-1)21的源极和第二nmos晶体管q(m-1)22的漏极的输出节点用作信元m(m-1)2的输出端子,并且被配置为将存储在电容器c(m-1)2中的信号输送给下一比特级信元m(m-1)3。第二列第m行上的信元mm2包括:第一nmos晶体管qm21,其具有通过第一延迟元件dm21连接到时钟信号供应线的漏极以及通过第二延迟元件dm22连接到前一比特级信元mm1的输出端子的栅极;第二nmos晶体管qm22,其具有连接到第一nmos晶体管qm21的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器cm2,其被配置为存储信元mm2的信息,并且与第二nmos晶体管qm22并联连接,其中,连接第一nmos晶体管qm21的源极和第二nmos晶体管qm22的漏极的输出节点用作信元mm2的输出端子,并且被配置为将存储在电容器cm2中的信号输送给下一比特级信元mm3。
另外,如图4所示,字大小级别的第三存储器单元u3通过m×n矩阵的第三列中的比特级信元m13、m23、m33、......、mm-1,3、mm3的垂直阵列实现。第三列第一行上的信元m13包括:第一nmos晶体管q131,其具有通过第一延迟元件d131连接到时钟信号供应线的漏极以及通过第二延迟元件d132连接到前一比特级信元m12的输出端子的栅极;第二nmos晶体管q132,其具有连接到第一nmos晶体管q131的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c13,其被配置为存储信元m13的信息,并且与第二nmos晶体管q132并联连接,其中,连接第一nmos晶体管q131的源极和第二nmos晶体管q132的漏极的输出节点用作信元m13的输出端子,并且被配置为将存储在电容器c13中的信号输送给下一比特级信元。第三列第二行上的信元m23包括:第一nmos晶体管q231,其具有通过第一延迟元件d231连接到时钟信号供应线的漏极以及通过第二延迟元件d232连接到前一比特级信元m22的输出端子的栅极;第二nmos晶体管q232,其具有连接到第一nmos晶体管q231的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c23,其被配置为存储信元m23的信息,并且与第二nmos晶体管q232并联连接,其中,连接第一nmos晶体管q231的源极和第二nmos晶体管q232的漏极的输出节点用作信元m23的输出端子,并且被配置为将存储在电容器c23中的信号输送给下一比特级信元。第三列第三行上的信元m33包括:第一nmos晶体管q331,其具有通过第一延迟元件d331连接到时钟信号供应线的漏极以及通过第二延迟元件d332连接到前一比特级信元m32的输出端子的栅极;第二nmos晶体管q332,其具有连接到第一nmos晶体管q331的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c33,其被配置为存储信元m33的信息,并且与第二nmos晶体管q332并联连接,其中,连接第一nmos晶体管q331的源极和第二nmos晶体管q332的漏极的输出节点用作信元m33的输出端子,并且被配置为将存储在电容器c33中的信号输送给下一比特级信元。……第三列第(m-1)行上的信元m(m-1)3包括:第一nmos晶体管q(m-1)31,其具有通过第一延迟元件d(m-1)31连接到时钟信号供应线的漏极以及通过第二延迟元件d(m-1)32连接到前一比特级信元m(m-1)2的输出端子的栅极;第二nmos晶体管q(m-1)32,其具有连接到第一nmos晶体管q(m-1)31的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c(m-1)3,其被配置为存储信元m(m-1)3的信息,并且与第二nmos晶体管q(m-1)32并联连接,其中,连接第一nmos晶体管q(m-1)31的源极和第二nmos晶体管q(m-1)32的漏极的输出节点用作信元m(m-1)3的输出端子,并且被配置为将存储在电容器c(m-1)3中的信号输送给下一比特级信元。第三列第m行上的信元mm3包括:第一nmos晶体管qm31,其具有通过第一延迟元件dm31连接到时钟信号供应线的漏极以及通过第二延迟元件dm32连接到前一比特级信元mm2的输出端子的栅极;第二nmos晶体管qm32,其具有连接到第一nmos晶体管qm31的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器cm3,其被配置为存储信元mm3的信息,并且与第二nmos晶体管qm32并联连接,其中,连接第一nmos晶体管qm31的源极和第二nmos晶体管qm32的漏极的输出节点用作信元mm3的输出端子,并且被配置为将存储在电容器cm3中的信号输送给下一比特级信元。
另外,如图4所示,字大小级别的第n存储器单元u3通过m×n矩阵的第n列中的比特级信元m1n、m2n、m3n、......、mm-1,n、mmn的垂直阵列实现。第n列第一行上的信元m1n包括:第一nmos晶体管q1n1,其具有通过第一延迟元件d1n1连接到时钟信号供应线的漏极以及通过第二延迟元件d1n2连接到前一比特级信元m1(n-1)的比特级输出端子的栅极;第二nmos晶体管q1n2,其具有连接到第一nmos晶体管q1n1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c1n,其被配置为存储信元m1n的信息,并且与第二nmos晶体管q1n2并联连接,其中,连接第一nmos晶体管q1n1的源极和第二nmos晶体管q1n2的漏极的输出节点用作信元m1n的比特级输出端子,并且被配置为将存储在电容器c1n中的信号输送给第一比特级输出端子。第n列第二行上的信元m2n包括:第一nmos晶体管q2n1,其具有通过第一延迟元件d2n1连接到时钟信号供应线的漏极以及通过第二延迟元件d2n2连接到前一比特级信元m2(n-1)的比特级输出端子的栅极;第二nmos晶体管q2n2,其具有连接到第一nmos晶体管q2n1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c2n,其被配置为存储信元m2n的信息,并且与第二nmos晶体管q2n2并联连接,其中,连接第一nmos晶体管q2n1的源极和第二nmos晶体管q2n2的漏极的输出节点用作信元m2n的比特级输出端子,并且被配置为将存储在电容器c2n中的信号输送给第二比特级输出端子。第n列第三行上的信元m3n包括:第一nmos晶体管q3n1,其具有通过第一延迟元件d3n1连接到时钟信号供应线的漏极以及通过第二延迟元件d3n2连接到前一比特级信元m3(n-1)的比特级输出端子的栅极;第二nmos晶体管q3n2,其具有连接到第一nmos晶体管q3n1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c3n,其被配置为存储信元m3n的信息,并且与第二nmos晶体管q3n2并联连接,其中,连接第一nmos晶体管q3n1的源极和第二nmos晶体管q3n2的漏极的输出节点用作信元m3n的比特级输出端子,并且被配置为将存储在电容器c3n中的信号输送给第三比特级输出端子。……第n列第(m-1)行上的信元m(m-1)n包括:第一nmos晶体管q(m-1)n1,其具有通过第一延迟元件d(m-1)n1连接到时钟信号供应线的漏极以及通过第二延迟元件d(m-1)n2连接到前一比特级信元m(m-1)(n-1)的比特级输出端子的栅极;第二nmos晶体管q(m-1)n2,其具有连接到第一nmos晶体管q(m-1)n1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c(m-1)n,其被配置为存储信元m(m-1)n的信息,并且与第二nmos晶体管q(m-1)n2并联连接,其中,连接第一nmos晶体管q(m-1)n1的源极和第二nmos晶体管q(m-1)n2的漏极的输出节点用作信元m(m-1)n的比特级输出端子,并且被配置为将存储在电容器c(m-1)n中的信号输送给第(m-1)比特级输出端子。第n列第m行上的信元mmn包括:第一nmos晶体管qmn1,其具有通过第一延迟元件dmn1连接到时钟信号供应线的漏极以及通过第二延迟元件dmn2连接到前一比特级信元mm(n-1)的比特级输出端子的栅极;第二nmos晶体管qmn2,其具有连接到第一nmos晶体管qmn1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器cmn,其被配置为存储信元mmn的信息,并且与第二nmos晶体管qmn2并联连接,其中,连接第一nmos晶体管qmn1的源极和第二nmos晶体管qmn2的漏极的输出节点用作信元mmn的比特级输出端子,并且被配置为将存储在电容器cmn中的信号输送给第m比特级输出端子。
如图5所示,在根据本发明的第一实施方式的计算机系统中所使用的推进主存储器的代表性2×2信元阵列中,第i行第j列的比特级信元mij包括:第一nmos晶体管qij1,其具有通过第一延迟元件dij1连接到时钟信号供应线的漏极以及通过第二延迟元件dij2连接到前一比特级信元的输出端子的栅极;第二nmos晶体管qij2,其具有连接到第一nmos晶体管qij1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器cij,其被配置为存储比特级信元mij的信息,并且与第二nmos晶体管qij2并联连接,其中,连接第一nmos晶体管qij1的源极和第二nmos晶体管qij2的漏极的输出节点用作比特级信元mij的输出端子,并且被配置为将存储在电容器cij中的信号输送给下一比特级信元mi(j+1)。
第i行第(j+1)列的列比特级信元mi(j+1)包括:第一nmos晶体管qi(j+1)1,其具有通过第一延迟元件di(j+1)1连接到时钟信号供应线的漏极以及通过第二延迟元件di(j+1)2连接到前一比特级信元mij的输出端子的栅极;第二nmos晶体管qi(j+1)2,其具有连接到第一nmos晶体管qi(j+1)1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器ci(j+1),其被配置为存储比特级信元mi(j+1)的信息,并且与第二nmos晶体管qi(j+1)2并联连接,其中,连接第一nmos晶体管qi(j+1)1的源极和第二nmos晶体管qi(j+1)2的漏极的输出节点用作比特级信元mi(j+1)的输出端子,并且被配置为将存储在电容器ci(j+1)中的信号输送给下一信元。
并且,第(i+1)行第j列的比特级信元m(i+1)j包括:第一nmos晶体管q(i+1)j1,其具有通过第一延迟元件d(i+1)j1连接到时钟信号供应线的漏极以及通过第二延迟元件d(i+1)j2连接到前一比特级信元的输出端子的栅极;第二nmos晶体管q(i+1)j2,其具有连接到第一nmos晶体管q(i+1)j1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c(i+1)j,其被配置为存储比特级信元m(i+1)j的信息,并且与第二nmos晶体管q(i+1)j2并联连接,其中,连接第一nmos晶体管q(i+1)j1的源极和第二nmos晶体管q(i+1)j2的漏极的输出节点用作比特级信元m(i+1)j的输出端子,并且被配置为将存储在电容器c(i+1)j中的信号输送给下一比特级信元m(i+1)(j+1)。
另外,第(i+1)行第(j+1)列的比特级信元m(i+1)(j+1)包括:第一nmos晶体管q(i+1)(j+1)1,其具有通过第一延迟元件d(i+1)(j+1)1连接到时钟信号供应线的漏极以及通过第二延迟元件d(i+1)(j+1)2连接到前一比特级信元m(i+1)j的输出端子的栅极;第二nmos晶体管q(i+1)(j+1)2,其具有连接到第一nmos晶体管q(i+1)(j+1)1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器c(i+1)(j+1),其被配置为存储比特级信元m(i+1)(j+1)的信息,并且与第二nmos晶体管q(i+1)(j+1)2并联连接,其中,连接第一nmos晶体管q(i+1)(j+1)1的源极和第二nmos晶体管q(i+1)(j+1)2的漏极的输出节点用作比特级信元m(i+1)(j+1)的输出端子,并且被配置为将存储在电容器c(i+1)(j+1)中的信号输送给下一信元。
如图6所示,第i行上的第j比特级信元mij包括:第一nmos晶体管qij1,其具有通过第一延迟元件dij1连接到时钟信号供应线的漏极以及通过第二延迟元件dij2连接到前一信元的输出端子的栅极;第二nmos晶体管qij2,其具有连接到第一nmos晶体管qij1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器cij,其被配置为存储比特级信元mij的信息,并且与第二nmos晶体管qij2并联连接。
在图6所示的电路配置中,第二nmos晶体管qij2用作复位晶体管,其被配置为当高电平(或逻辑电平“1”)的时钟信号施加到第二nmos晶体管qij2的栅极时,使存储在电容器cij中的信号电荷复位,从而使已经存储在电容器cij中的信号电荷放电。
图7a和图7b示出图6所示的比特级信元mij对由虚线示出的时钟信号波形的晶体管层级响应的示意性示例,比特级信元mij是根据本发明的第一实施方式的计算机系统中所使用的比特级信元之一。由虚线示出的时钟信号按照时钟周期tau(希腊字母)clock周期性地在逻辑电平“1”和“0”之间摇摆。在图7a和图7b中,t1-t0(=t2-t1=t3-t2=t4-t3)被定义为时钟周期tauclock的四分之一(=tauclock/4)。
(a)如图7a(a)所示,在时间“t0”,尽管由虚线示出的高电平的时钟信号通过第一理想延迟元件dij1施加到第一nmos晶体管qij1的漏极并施加到第二nmos晶体管qij2的栅极,但在时间“t0”与时间“t1”之间,由于在第一nmos晶体管qij1的源极与第二nmos晶体管qij2的漏极之间连接的输出节点nout的电势应当为浮置状态,处于逻辑电平“0”与“1”之间,所以第二nmos晶体管qij2保持截止状态,直至在时间“t1”第一nmos晶体管qij1将建立导通状态为止。
(b)归功于第一理想延迟元件dij1,由于第一nmos晶体管qij1的导通被延迟了t1-t0=tauclock/4,所以在时间“t1”第一nmos晶体管qij1被激活成为传送晶体管,并且输出节点nout的电势变为逻辑电平“1”。这里,假设第一理想延迟元件dij1可实现tauclock/4的延迟,并且具有非常陡的前沿,使得可忽略上升时间。即,如图7a(a)中具有非常陡的前沿和非常陡的后沿的实线所示,在时间“t0”施加的时钟信号被延迟了t1-t0=tauclock/4。然后,如图7a(c)-(d)所示,如果存储在前一比特级信元mi(j-1)中的信号为逻辑电平“1”,则在时间“t2”,第二nmos晶体管qij2被激活成为复位晶体管,存储在电容器cij中的任何信号电荷被驱动以放电。
(c)第一nmos晶体管qij1在时间“t2”被激活成为传送晶体管,延迟了由第二理想延迟元件dij2确定的预定的延迟时间td2=t2-t0=tauclock/2。这里,假设第二理想延迟元件dij2可实现tauclock/2的延迟,并且具有非常陡的前沿,使得可忽略上升时间。然后,如果在时间“t2”,存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号从第i行上的前一比特级信元mi(j-1)被馈送至第一nmos晶体管qij1的栅极,则如图7a(b)所示,存储在电容器cij中的信号电荷被完全放电以建立逻辑电平“0”,并且如图7a(c)-(d)所示,第一nmos晶体管qij1开始将存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号传送给电容器cij,以执行推进与门运算。即,利用由时钟信号提供的输入信号“1”以及由前一比特级信元mi(j-1)提供的另一输入信号“1”,可执行传统2输入与运算:
1+1=1。
顺便说一下,如果存储在电容器cij中的信号电荷为逻辑电平“1”,则电容器cij可在时间“t0”开始放电,因为如果第二nmos晶体管qij2的操作没有延迟,则利用在时间“t0”施加到第二nmos晶体管qij2的栅极的由虚线示出的高电平的时钟信号,第二nmos晶体管qij2可被激活成为复位晶体管。
(d)另选地,如图7b(c)-(d)所示,如果存储在前一比特级信元mi(j-1)中的信号为逻辑电平“0”,则在任何时间“t0”、“t1”、“t2”和“t3”,第一nmos晶体管qij1保持截止状态。如上所述,如果存储在电容器cij中的信号电荷为逻辑电平“1”,则尽管第一nmos晶体管qij1保持截止状态,电容器cij也可在时间“t0”开始放电,因为第二nmos晶体管qij2可利用在时间“t0”施加到第二nmos晶体管qij2的栅极的由虚线示出的高电平的时钟信号而被激活成为复位晶体管,如图7a(c)-(d)所示,利用由时钟信号提供的输入信号“1”以及由前一比特级信元mi(j-1)提供的另一输入信号“0”,执行推进与门运算:
1+0=0。
然而,如果存储在电容器cij中的信号电荷为逻辑电平“0”,则由于第一nmos晶体管qij1和第二nmos晶体管qij2均保持截止状态,电容器cij在任何时间“t0”、“t1”、“t2”和“t3”均保持逻辑电平“0”,如图7a(c)-(d)所示,执行推进与门运算。连接第一nmos晶体管qij1的源极和第二nmos晶体管qij2的漏极的输出节点nout用作比特级信元mij的输出端子,比特级信元mij的输出端子将存储在电容器cij中的信号输送给第i行上的下一比特级信元。
另外,图7c示出对于如图8所示第一延迟元件dij1和第二延迟元件dij2均由r-c延迟电路实现的情况,对时钟信号波形的响应的实际示例。在推进存储器的正常操作中,存储在电容器cij中的信号电荷实际上为逻辑电平“0”或“1”,并且如果存储在电容器cij中的信号电荷为逻辑电平“1”,则尽管第一nmos晶体管qij1仍保持截止状态,电容器cij也可在时间“t0”开始放电,因为如果可逼近第二nmos晶体管qij2的没有延迟的理想操作,则当高电平的时钟信号施加到第二nmos晶体管qij2的栅极时,第二nmos晶体管qij2可被激活。因此,如果存储在电容器cij中的信号电荷实际上为逻辑电平“1”,则在高电平的时钟信号施加到第二nmos晶体管qij2的栅极并且存储在电容器cij中的信号电荷已放电之后,第一nmos晶体管qij1被激活成为传送晶体管(延迟了由通过r-c延迟电路实现的第一延迟元件dij1确定的预定延迟时间td1)。并且当存储在前一比特级信元mi(j-1)中的信号从第i行上的前一比特级信元mi(j-1)馈送至第一nmos晶体管qij1的栅极时,第一nmos晶体管qij1将存储在前一比特级信元mi(j-1)中的信号传送给电容器cij(进一步延迟了由第二延迟元件dij2确定的预定延迟时间td2)。连接第一nmos晶体管qij1的源极和第二nmos晶体管qij2的漏极的输出节点nout用作比特级信元mij的输出端子,并且比特级信元mij的输出端子将存储在电容器cij中的信号输送给第i行上的下一比特级信元。
如图7c所示,时钟信号按照预定时钟周期(时钟循环时间)tauclock周期性地在逻辑电平“1”与“0”之间摇摆,当时钟信号变为逻辑电平“1”时,第二nmos晶体管qij2开始将已经在前一时钟循环存储在电容器cij中的信号电荷放电。并且,在施加了逻辑电平“1”的时钟信号并且存储在电容器cij中的信号电荷完全放电至逻辑电平“0”的电势之后,第一nmos晶体管qij1被激活成为传送晶体管(延迟了由第一延迟元件dij1确定的预定延迟时间td1)。优选地,延迟时间td1可被设定为等于1/4tauclock。随后,当存储在第i行上的前一比特级信元mi(j-1)中的信号从前一比特级信元mi(j-1)馈送至第一nmos晶体管qij1的栅极时,第一nmos晶体管qij1将存储在前一比特级信元mi(j-1)中的信号传送给电容器cij(进一步延迟了由通过r-c延迟电路实现的第二延迟元件dij2确定的预定延迟时间td2)。
例如,如果存储在第i行上的前一比特级信元mi(j-1)中的逻辑电平“1”从前一比特级信元mi(j-1)馈送至第一nmos晶体管qij1的栅极,则第一nmos晶体管qij1变为导通状态,并且逻辑电平“1”被存储在电容器cij中。另一方面,如果存储在前一比特级信元mi(j-1)中的逻辑电平“0”从前一比特级信元mi(j-1)馈送至第一nmos晶体管qij1的栅极,则第一nmos晶体管qij1保持截止状态,并且电容器cij中维持逻辑电平“0”。因此,比特级信元mij可建立“推进与门”运算。延迟时间td2应该比延迟时间td1长,并且优选地,延迟时间td2可被设定为等于1/2tauclock。
由于时钟信号按照时钟周期tauclock周期性地在逻辑电平“1”与“0”之间摇摆,则时钟信号在时间前进1/2tauclock时变为逻辑电平“0”,连接第一nmos晶体管qij1的源极和第二nmos晶体管qij2的漏极的输出节点nout在时间前进1/2tauclock时无法将从前一比特级信元mi(j-1)传送来的信号进一步输送给下一比特级信元mi(j+1),因为信号被阻止延迟由第二延迟元件di(j+1)2确定的延迟时间td2=1/2tauclock传送至下一第一nmos晶体管qi(j+1)1的栅极。当时钟信号在时间前进tauclock时再次变为逻辑电平“1”时,连接第一nmos晶体管qij1的源极和第二nmos晶体管qij2的漏极的输出节点nout(用作比特级信元mij的输出端子)可在下一时钟循环将存储在电容器cij中的信号输送给下一比特级信元mi(j+1)。
回到图4,当图7a(a)或图7c所示的时钟信号变为逻辑电平“1”时,第一存储器单元u1中的第二nmos晶体管序列q112、q212、q312、......、qm-1,12、qm12分别开始将已经在前一时钟循环分别存储在第一存储器单元u1中的电容器c11、c21、c31、......、cm-1,1、cm1中的信号电荷放电。并且,在逻辑电平“1”的时钟信号分别施加到第二nmos晶体管序列q112、q212、q312、......、qm-1,12、qm12的栅极,并且存储在电容器c11、c21、c31、......、cm-1,1、cm1中的信号电荷分别完全放电至逻辑电平“0”的电势之后,第一nmos晶体管序列q111、q211、q311、......、qm-1,11、qm11分别延迟由第一延迟元件d111、d211、d311、......、dm-1,11、dm11确定的延迟时间td1被激活成为传送晶体管。随后,当字大小(八比特的倍数,例如16、32和64比特)信号序列输入到第一nmos晶体管序列q111、q211、q311、......、qm-1,11、qm11的栅极时,第一nmos晶体管序列q111、q211、q311、......、qm-1,11、qm11将该字大小信号序列分别传送给电容器c11、c21、c31、......、cm-1,1、cm1(延迟了由第二延迟元件d112、d212、d312、......、dm-1,12、dm12确定的延迟时间td2)。
当时钟信号在时间前进1/2tauclock时变为逻辑电平“0”时,连接第一nmos晶体管q111、q211、q311、......、qm-1,11、qm11的源极和第二nmos晶体管q112、q212、q312、......、qm-1,12、qm12的漏极的各个输出节点在时间前进1/2tauclock时无法将输入第一nmos晶体管q111、q211、q311、......、qm-1,11、qm11的栅极的信号进一步输送至下一比特级信元m12、m22、m32、......、mm-1,2、mm2,因为各个信号被阻止延迟由第二延迟元件d122、d222、d322、......、dm-1,22、dm22确定的延迟时间td2=1/2tauclock传送至下一第一nmos晶体管q121、q221、q321、......、qm-1,21、qm21的栅极。
并且,在时间前进tauclock时,当下一时钟信号再次变为逻辑电平“1”时,第二存储器单元u2中的第二nmos晶体管序列q122、q222、q322、......、qm-1,22、qm22分别开始将已经在前一时钟循环分别存储在第二存储器单元u2中的电容器c12、c22、c32、......、cm-1,2、cm2中的信号电荷放电。并且,在逻辑电平“1”的时钟信号分别施加到第二nmos晶体管序列q122、q222、q322、......、qm-1,22、qm22的栅极,并且存储在电容器c12、c22、c32、......、cm-1,2、cm2中的信号电荷分别完全放电至逻辑电平“0”的电势之后,第一nmos晶体管序列q121、q221、q321、......、qm-1,21、qm21分别延迟由第一延迟元件d121、d221、d321、......、dm-1,21、dm21确定的延迟时间td1被激活成为传送晶体管。随后,当存储在前一电容器c11、c21、c31、......、cm-1,1、cm1中的字大小信号序列被馈送至第一nmos晶体管序列q121、q221、q321、......、qm-1,21、qm21的栅极时,第一nmos晶体管q121、q221、q321、......、qm-1,21、qm21将该字大小信号序列传送给电容器c12、c22、c32、......、cm-1,2、cm2(延迟了由第二延迟元件d122、d222、d322、......、dm-1,22、dm22确定的延迟时间td2)。
当时钟信号在时间进一步前进至(1+1/2)tauclock时变为逻辑电平“0”时,连接第一nmos晶体管q121、q221、q321、......、qm-1,21、qm21的源极和第二nmos晶体管q122、q212、q322、......、qm-1,22、qm22的漏极的各个输出节点在时间前进(1+1/2)tauclock时无法将存储在前一比特级信元m11、m21、m31、......、mm-1,1、mm1中的信号进一步输送至下一比特级信元m12、m22、m32、......、mm-1,2、mm2,因为各个信号被阻止延迟由第二延迟元件d132、d232、d332、......、dm-1,32、dm32确定的延迟时间td2=1/2tauclock传送至下一第一nmos晶体管q131、q231、q331、......、qm-1,31、qm31的栅极。
并且,在时间进一步前进至2tauclock时,当下一时钟信号再次变为逻辑电平“1”时,第三存储器单元u3中的第二nmos晶体管序列q132、q232、q332、......、qm-1,32、qm32分别开始将已经在前一时钟循环分别存储在第三存储器单元u3中的电容器c13、c23、c33、......、cm-1,3、cm3中的信号电荷放电。并且,在逻辑电平“1”的时钟信号分别施加到第二nmos晶体管序列q132、q232、q332、......、qm-1,32、qm32的栅极,并且存储在电容器c13、c23、c33、......、cm-1,3、cm3中的信号电荷完全放电至逻辑电平“0”的电势之后,第一nmos晶体管序列q131、q231、q331、......、qm-1,31、qm31分别延迟由第一延迟元件d131、d231、d331、......、dm-1,31、dm31确定的延迟时间td1被激活成为传送晶体管。随后,当存储在前一电容器c12、c22、c32、......、cm-1,2、cm2中的字大小信号序列被馈送至第一nmos晶体管序列q131、q231、q331、......、qm-1,31、qm31的栅极时,第一nmos晶体管q131、q231、q331、......、qm-1,31、qm31将该字大小信号序列传送给电容器c13、c23、c33、......、cm-1,3、cm3(延迟了由第二延迟元件d132、d232、d332、......、dm-1,32、dm32确定的延迟时间td2)。
如图8所示,第一延迟元件dij1和第二延迟元件dij2中的每一个可通过已知的“电阻-电容延迟器”或“r-c延迟器”来实现。在rc电路中,时间常数(秒)的值等于电路电阻(欧姆)与电路电容(法拉)的乘积,即,td1,td2=r×c。由于rc电路的结构非常简单,所以对于第一延迟元件dij1和第二延迟元件dij2优选使用rc电路。然而,rc电路仅是示例,第一延迟元件dij1和第二延迟元件dij2可通过其它无源延迟元件或者各种有源延迟元件(可包括晶体管的有源元件等)来实现。
图9示出图8所示的第i行第j列的比特级信元mij的实际平面图案的俯视图的示例,比特级信元mij具有通过r-c延迟电路实现的第一延迟元件dij1和第二延迟元件dij2,图10示出沿图9的线a-a截取的对应截面图。如图9所示,第一延迟元件dij1通过导线的第一曲折线91实现,第二延迟元件dij2通过导线的第二曲折线97实现。
在图9中,第一nmos晶体管qij1具有经由接触插头96a连接到第一曲折线91的漏极区域93。第一曲折线91的与连接到第一nmos晶体管qij1的漏极区域93的末端相对的另一端连接到时钟信号供应线。漏极区域93通过n+半导体区域实现。第一nmos晶体管qij1的栅极通过第二曲折线97实现。第二曲折线97的与用作第一nmos晶体管qij1的栅极的末端相对的另一端连接到前一信元的输出端子。
第二nmos晶体管qij2具有:漏极区域,其通过公共n+半导体区域94实现,该区域也用作第一nmos晶体管qij1的源极区域;栅极98,其经由接触插头96a连接到时钟信号供应线;以及源极区域95,其经由接触插头96a连接到地电势。源极区域95通过n+半导体区域实现。由于公共n+半导体区域94是连接第一nmos晶体管qij1的源极区域和第二nmos晶体管qij2的漏极区域的输出节点,所以公共n+半导体区域94经由接触插头96d连接到表面布线92b。公共n+半导体区域94用作比特级信元mij的输出端子,并通过表面布线92b将存储在电容器cij中的信号输送给下一比特级信元。
如图10所示,漏极区域93、公共n+半导体区域94和源极区域95设置在p型半导体基板81的表面处上部中。代替p型半导体基板81,漏极区域93、公共n+半导体区域94和源极区域95可设置在p阱的上部或者在半导体基板上生长的p型外延层中。在p型半导体基板81上设置元件隔离绝缘体82,以将p型半导体基板81的有源区限定为设置在元件隔离绝缘体82中的窗口。并且,漏极区域93、公共n+半导体区域94和源极区域95设置在有源区中并被元件隔离绝缘体82包围。在有源区的表面上,设置栅绝缘膜83。并且,通过第二曲折线97实现的第一nmos晶体管qij1的栅极以及第二nmos晶体管qij2的栅极98设置在栅绝缘膜83上。
如图10所示,第一层间介质膜84设置在第二曲折线97和栅极98上。在第一层间介质膜84的一部分上设置有被配置为存储比特级信元mij的信息的电容器cij的底电极85。底电极85由导电膜制成,接触插头96c设置在第一层间介质膜84中以在底电极85与源极区域95之间连接。并且,在底电极85上设置有电容器绝缘膜86。
另外,在电容器绝缘膜86上设置有电容器cij的顶电极87,以占据底电极85的上部。顶电极87由导电膜制成。尽管图10所示的截面图中未示出,顶电极87电连接到公共n+半导体区域94,以建立电容器cij与第二nmos晶体管qij2并联连接的电路拓扑。各种绝缘体膜可用作电容器绝缘膜86。可能需要小型化的推进主存储器以占据与顶电极87相对的底电极85的小面积。然而,为了使得推进主存储器能够成功起作用,底电极85与顶电极87之间经由电容器绝缘膜86的电容需要维持恒定值。具体地讲,对于具有大约100nm或更小的最小线宽的小型化推进主存储器,考虑到底电极85与顶电极87之间的存储电容,优选使用介电常数er大于二氧化硅(sio2)膜的材料。然而,对于ono膜,例如,上层二氧化硅膜、中层氮化硅膜和下层二氧化硅膜的厚度之比是可选择的,可提供大约5至5.5的介电常数。另选地,可使用由er=6的氧化锶(sro)膜、er=7的氮化硅(si3n4)膜、er=8-11的氧化铝(al2o3)膜、er=10的氧化镁(mgo)膜、er=16-17的氧化钇(y2o3)膜、er=22-23的二氧化铪(hfo2)膜、er=22-23的氧化锆(zro2)膜、er=25-27的氧化钽(ta2o5)膜或者er=40的氧化铋(bi2o3)膜中的任一种制成的单层膜、或者包括这些膜中的至少两种的复合膜。ta2o5和bi2o3表现出在与多晶硅的界面处缺少热稳定性的缺点。另外,它可以是由二氧化硅膜与这些膜制成的复合膜。复合膜可具有三层或更多层的层叠结构。换言之,它应该是在至少一部分中包含相对介电常数er为5至6或更大的材料的绝缘膜。然而,在复合膜的情况下,优选选择导致有效相对介电常数ereff为5至6或更大(针对整个膜测得)的组合。另外,它还可以是由三元化合物的氧化物膜制成的绝缘膜,例如铝酸铪(hfalo)膜。
另外,第二层间介质膜87设置在顶电极87上。并且,第一曲折线91设置在第二层间介质膜87上。如图10所示,接触插头96a穿过第一层间介质膜84、电容器绝缘膜86和第二层间介质膜87设置,以在第一曲折线91与漏极区域93之间连接。
在图9和图10所示的拓扑中,r-c延迟器的电容c通过与第一曲折线91和第二曲折线97关联的杂散电容实现。由于r和c均与第一曲折线91和第二曲折线97的线长成比例,所以可通过选择第一曲折线91和第二曲折线97的线长来容易地设计延迟时间td1、td2。另外,我们可以设计第一曲折线91和第二曲折线97的厚度、横截面或电阻率以实现期望的值的延迟时间td1、td2。
例如,由于延迟时间td2应该是延迟时间td1的两倍,如果对于r-c延迟器(=r×c),我们针对第一曲折线91和第二曲折线97使用相同的厚度、相同的横截面以及具有相同的特定电阻率的材料,并且还针对实现杂散电容的绝缘膜使用相同的有效厚度和相同的有效介电常数,则第二曲折线97的线长可被设计为第一曲折线91的线长的21/2倍。然而,如果我们针对第一曲折线91和第二曲折线97使用不同的材料,则第一曲折线91和第二曲折线97的线长应该根据第一曲折线91和第二曲折线97的电阻率来确定,以实现所需值的延迟时间td1、td2。例如,在第二曲折线97由多晶硅形成,第一曲折线91由电阻率高于多晶硅的诸如钨(w)、钼(mo)、铂(pt)的耐火材料形成的情况下,第一曲折线91和第二曲折线97的线长根据第一曲折线91和第二曲折线97的电阻率来确定,以实现所需值的延迟时间td1、td2。
另外,尽管第一曲折线91和第二曲折线97示出于图9中,所示的电阻器r的曲折拓扑仅是示例,可根据电阻器r和电容c的所需值来使用其它拓扑,例如直线构造。在推进主存储器31的非常高速的操作中,如果寄生电阻(杂散电阻)和寄生电容(杂散电容)可实现所需的延迟时间td1、td2,则可省略描绘外在电阻器元件r。
在图4-6所示的配置中,尽管第i行上的第(j-1)比特级信元mij-1的信号存储状态与第i行上的第j比特级信元mij的信号存储状态之间的隔离可通过伴随第(j-1)比特级信元mij-1的输出端子与第j比特级信元mij的第一nmos晶体管qij1的栅极之间的信号传播路径的传播延迟来建立,所述传播延迟主要归因于第二延迟元件dij2的值,优选在第(j-1)比特级信元mij-1与第j比特级信元mij,之间插入单元间信元bij,如图11和图13所示。
尽管单元间信元bij被设置用于将第j存储器单元uj中的第j比特级信元mij的信号存储状态与第(j-1)存储器单元uj-1中的第(j-1)比特级信元mij-1的信号存储状态隔离,单元间信元bij按照通过时钟信号供应线供应的时钟信号所确定的所需定时将信号从第(j-1)比特级信元mij-1传送到第j比特级信元mij。由于第j存储器单元uj通过排列在第j存储器单元uj中的比特级信元序列来存储字节大小或字大小的信息,第(j-1)存储器单元uj-1通过排列在第(j-1)存储器单元uj-1中的比特级信元序列来存储字节大小或字大小的信息,所以与存储器单元uj-1和uj并行排列的单元间信元序列按照通过时钟信号供应线供应的时钟信号的控制传送字节大小或字大小的信息,使得字节大小或字大小的信息可沿着预定方向同时推进。如图11和图13所示,由于第i行上的第j比特级信元mij的输入端子连接到单元间信元bij,存储在第(j-1)比特级信元mij-1中的信号电荷按照所需定时通过单元间信元bij被馈送至第二延迟元件dij2,在除了所需定时之外的时间段,信号电荷的传送操作被截止。
在图11和图13中,尽管单元间信元bij的示例包括单个隔离晶体管qij3,其具有连接到第(j-1)比特级信元mij的输出端子的第一主电极、连接到第j比特级信元mij的输入端子的第二主电极以及连接到时钟信号供应线的控制电极,单元间信元bij的结构不限于图11和图13所示的配置。例如,单元间信元bij可通过具有多个晶体管的时钟电路来实现,其可按照时钟信号所确定的所需定时将信号从第(j-1)比特级信元mij-1传送至第j比特级信元mij。
类似于图5所示的配置,第j比特级信元mij包括:第一nmos晶体管qij1,其具有通过第一延迟元件dij1连接到时钟信号供应线的漏极以及通过第二延迟元件dij2连接到单元间信元bij的栅极;第二nmos晶体管qij2,其具有连接到第一nmos晶体管qij1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器cij,其被配置为存储比特级信元mij的信息,并且与第二nmos晶体管qij2并联连接。
图12示出除了图9已经示出的比特级信元mij的配置之外,包括nmos晶体管的单个隔离晶体管qij3的单元间信元bij的平面结构的示例。在比特级信元mij中,示出有:第一nmos晶体管qij1,其具有漏极区域93、经由接触插头96a连接到漏极区域93的第一曲折线91、实现第一nmos晶体管qij1的栅极的第二曲折线97;以及第二nmos晶体管qij3,其具有由用作比特级信元mij的输出端子的公共n+半导体区域94实现的漏极区域。
在图12中,单元间信元bij的隔离晶体管qij3具有通过n+半导体区域90的左侧实现的第一主电极区域、连接到时钟信号供应线的栅极99以及通过n+半导体区域90的右侧实现的第二主电极区域。第二主电极区域经由接触插头96e连接到与第二曲折线97的用作第一nmos晶体管qij1的栅极的一端相对的第二曲折线97的另一端,第一主电极区域经由接触插头96f连接到前一信元mij-1的输出端子。尽管未示出,类似于图10所示的结构,在设置在第二曲折线97上的层间介质膜上,例如,可设置被配置为存储比特级信元mij的信息的平行板结构的电容器cij,其与第二nmos晶体管qij2并联连接。
在图13中,除了图11所示的配置之外,在第(j-2)比特级信元mi(j-2)与第(j-1)比特级信元mi(j-1)之间设置另一单元间信元bi(j-1),其被配置为将第(j-1)存储器单元uj-1中的第(j-1)比特级信元mi(j-1)的信号存储状态与第(j-2)存储器单元uj-2中的第(j-2)比特级信元mi(j-2)的信号存储状态隔离,并且按照通过时钟信号供应线供应的时钟信号所确定的所需定时将信号从第(j-2)比特级信元mi(j-2)传送至第(j-1)比特级信元mi(j-1)。在图13中,由于第i行上的第(j-1)比特级信元mi(j-1)的输入端子连接到单元间信元bi(j-1),所以存储在第(j-2)比特级信元mi(j-2)中的信号电荷按照所需定时通过单元间信元bi(j-1)被馈送至第二延迟元件di(j-1)2,随后信号电荷的传送操作被截止。
在图13中,尽管单元间信元bi(j-1)的示例包括单个隔离晶体管qi(j-1)3,单个隔离晶体管qi(j-1)3具有连接到第(j-2)比特级信元mi(j-1)的输出端子的第一主电极、连接到第(j-1)比特级信元mi(j-1)的输入端子的第二主电极以及连接到时钟信号供应线的控制电极,单元间信元bi(j-1)的结构不限于图13所示的配置,单元间信元bi(j-1)可通过具有多个晶体管的时钟电路来实现,其可按照由时钟信号确定的所需定时将信号从第(j-2)比特级信元mi(j-2)传送至第(j-1)比特级信元mi(j-1)。
类似于第j比特级信元mij的配置,第(j-1)比特级信元mi(j-1)包括:第一nmos晶体管qi(j-1)1,其具有通过第一延迟元件di(j-1)1连接到时钟信号供应线的漏极以及通过第二延迟元件di(j-1)2连接到单元间信元bi(j-1)的栅极;第二nmos晶体管qi(j-1)2,其具有连接到第一nmos晶体管qi(j-1)1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器ci(j-1),其被配置为存储比特级信元mi(j-1)的信息,并且与第二nmos晶体管qi(j-1)2并联连接。
在图11和图13所示的电路配置中,比特级信元mij的第二nmos晶体管qij2用作复位晶体管,其被配置为当高电平(或逻辑电平“1”)的时钟信号施加到第二nmos晶体管qij2的栅极时将存储在电容器cij中的信号电荷复位,从而使已经存储在电容器cij中的信号电荷放电,比特级信元mi(j-1)的第二nmos晶体管qi(j-1)2用作复位晶体管,其被配置为当高电平(或逻辑电平“1”)的时钟信号施加到第二nmos晶体管qi(j-1)2的栅极时将存储在电容器ci(j-1)中的信号电荷复位,从而使已经存储在电容器ci(j-1)中的信号电荷放电。因此,尽管图11和图13将nmos晶体管的晶体管符号表示为隔离晶体管qi(j-1)3和qij3,但是隔离晶体管qi(j-1)3和qij3可以是可与第二nmos晶体管qi(j-1)2和qij2互补地操作的pmos晶体管。即,当第二nmos晶体管qi(j-1)2和qij2处于使存储在电容器ci(j-1)和cij中的信号电荷放电的导通状态时,隔离晶体管qi(j-1)3和qij3应该处于截止状态以建立存储器单元之间的隔离,当第二nmos晶体管qi(j-1)2和qij2处于截止状态时,隔离晶体管qi(j-1)3和qij3应该处于导通状态,以在存储器单元之间传送信号电荷。
另选地,如果如图11和图13所示的晶体管符号,隔离晶体管qi(j-1)3和qij3为nmos晶体管,则隔离晶体管qi(j-1)3和qij3应该是高速晶体管,其与具有与栅电路和栅结构关联的较大杂散电容和较大杂散电阻的第二nmos晶体管qi(j-1)2和qij2相比,具有较短的上升时间、较短的导通状态周期以及较短的下降时间,使得当第二nmos晶体管qi(j-1)2和qij2仍处于截止状态时,隔离晶体管qi(j-1)3和qij3非常快速地变为导通状态,以在存储器单元之间传送信号电荷,并且当第二nmos晶体管qi(j-1)2和qij2开始缓慢朝着使存储在电容器ci(j-1)和cij中的信号电荷放电的导通状态时,隔离晶体管qi(j-1)3和qij3继续非常快速地变为截止状态,以在存储器单元之间建立隔离。作为这些高速晶体管的候选,可使用常闭型mos静电感应晶体管(sit),其表现出类似三极管的i-v特性。n沟道mossit可被视作短沟道nmosfet的极端结构。归因于类似三极管的i-v特性,由于mossit的导通状态取决于栅电压以及第一主电极与第二主电极之间的电势差二者,可实现时间间隔非常短的导通状态。代替mossit,可使用任何常闭型开关装置,例如表现出类似狄拉克δ函数的非常短的导通状态的隧道sit。
图14的(a)示出图13所示的比特级信元mi(j-1)对时钟信号波形的响应的定时图,图14的(b)示出图13所示的下一比特级信元mij对时钟信号波形的下一响应的下一定时图。在图14的(a)和图14的(b)中,时钟信号应该按照时钟周期tau(希腊字母)clock周期性地在逻辑电平“1”与“0”之间摇摆,并且带有后向对角线阴影的矩形区域示出分别存储在电容器ci(j-1)和cij中的信号电荷的复位定时的方法,另外,带有前向对角线阴影的矩形区域示出分别存储在电容器ci(j-1)和cij中的信号电荷的电荷转移定时的方法。
即,如图14的(a)所示,在带有后向对角线阴影的矩形区域中,如果存储在电容器ci(j-1)中的信号电荷为逻辑电平“1”,则尽管第一nmos晶体管qi(j-1)1仍保持截止状态,存储在电容器ci(j-1)中的信号电荷被驱动以放电。在电容器ci(j-1)开始放电之后,在带有前向对角线阴影的矩形区域中,第一nmos晶体管qi(j-1)1被激活成为传送晶体管(延迟了由通过r-c延迟电路实现的第一延迟元件di(j-1)1确定的预定延迟时间td1)。并且,在带有前向对角线阴影的矩形区域中,当存储在前一比特级信元mi(j-2)中的信号通过单元间信元bi(j-1)馈送至第一nmos晶体管qi(j-1)1的栅极时,第一nmos晶体管qi(j-1)1将存储在前一比特级信元mi(j-2)中的信号传送至电容器ci(j-1)(进一步延迟了由第二延迟元件di(j-1)2确定的预定延迟时间td2)。
类似地,如图14的(b)所示,在带有后向对角线阴影的矩形区域中,如果存储在电容器中的信号电荷为逻辑电平“1”,则尽管第一nmos晶体管qij1仍保持截止状态,存储在电容器cij中的信号电荷被驱动以放电。在电容器cij开始放电之后,在带有前向对角线阴影的矩形区域中,第一nmos晶体管qij1被激活成为传送晶体管(延迟了由通过r-c延迟电路实现的第一延迟元件dij1确定的预定延迟时间td1)。并且,在带有前向对角线阴影的矩形区域中,当存储在前一比特级信元mi(j-1)中的信号通过单元间信元bij馈送至第一nmos晶体管qij1的栅极时,第一nmos晶体管qij1将存储在前一比特级信元mi(j-1)中的信号传送至电容器cij(进一步延迟了由第二延迟元件dij2确定的预定延迟时间td2)。
图15示出对于如图12所示,第一延迟元件di(j-1)1和第二延迟元件di(j-1)2均通过r-c延迟电路实现的情况,图13所示的比特级信元mi(j-1)对细实线所示的时钟信号波形的更详细的响应,比特级信元mi(j-1)是根据本发明的第一实施方式的计算机系统中所使用的比特级信元之一。由细实线所示的时钟信号按照时钟周期tauclock周期性地在逻辑电平“1”与“0”之间摇摆。在图15中,时间间隔tau1=tau2=tau3=tau4被限定为时钟周期tauclock的四分之一(=tauclock/4)。
在推进存储器的正常操作中,如图16的(a)-(d)所示,存储在电容器ci(j-1)中的信号电荷实际上为逻辑电平“0”或“1”。如图16的(c)和图16的(d)所示,如果存储在电容器ci(j-1)中的信号电荷为逻辑电平“1”,则尽管第一nmos晶体管qi(j-1)1仍保持截止状态,电容器ci(j-1)也可在时间间隔tau1的起点处开始放电,因为假设可逼近第二nmos晶体管qi(j-1)2的没有延迟的理想操作,则当高电平的时钟信号施加到第二nmos晶体管qi(j-1)2的栅极时,第二nmos晶体管qi(j-1)2被激活。因此,如果存储在电容器i(j-1)中的信号电荷实际上为逻辑电平“1”,则在高电平的时钟信号施加到第二nmos晶体管qi(j-1)2的栅极之后,如图15中的细实线所示,存储在电容器ci(j-1)中的信号电荷将放电,随后第一nmos晶体管qi(j-1)1被激活成为传送晶体管(延迟了由通过r-c延迟电路实现的第一延迟元件di(j-1)1确定的预定延迟时间td1)。在图15中,第一nmos晶体管qi(j-1)1的漏极处的电势变化由点划线示出。
并且,如图15中的粗实线所示,当存储在前一比特级信元mi(j-2)中的信号电平“1”从第i行上的前一比特级信元mi(j-2)通过单元间信元bi(j-1)馈送至第一nmos晶体管qi(j-1)1的栅极时,第一nmos晶体管qi(j-1)1将存储在前一比特级信元mi(j-2)中的信号电平“1”传送给电容器ci(j-1)(进一步延迟了由第二延迟元件di(j-2)2确定的预定延迟时间td2)。另选地,如图15中的虚线所示,当存储在前一比特级信元mi(j-2)中的信号电平“0”从前一比特级信元mi(j-2)馈送至第一nmos晶体管qi(j-1)1的栅极时,第一nmos晶体管qi(j-1)1将存储在前一比特级信元mi(j-2)中的信号电平“0”传送给电容器ci(j-1)(进一步延迟了预定延迟时间td2)。连接第一nmos晶体管qi(j-1)1的源极和第二nmos晶体管qi(j-1)2的漏极的输出节点nout用作比特级信元mi(j-1的输出端子,并且该输出端子将存储在电容器ci(j-1)中的信号输送给第i行上的下一比特级信元。
如图15中的细实线所示,当时钟信号变为逻辑电平“1”时,第二nmos晶体管qi(j-1)2开始将已经在前一时钟循环存储在电容器ci(j-1)中的信号电荷放电。并且,在施加了逻辑电平“1”的时钟信号并且存储在电容器ci(j-1)中的信号电荷完全放电至逻辑电平“0”的电势之后,第一nmos晶体管qi(j-1)1被激活成为传送晶体管(延迟了由第一延迟元件di(j-1)1确定的预定延迟时间td1)。优选地,延迟时间td1可被设定为等于1/4tauclock=tau1。
随后,如粗实线和虚线所示,当存储在第i行上的前一比特级信元mi(j-2)中的信号从前一比特级信元mi(j-2)通过单元间信元bi(j-1)馈送至第一nmos晶体管qi(j-1)1的栅极时,第一nmos晶体管qi(j-1)1将存储在前一比特级信元mi(j-2)中的信号传送至电容器ci(j-1)(进一步延迟了由通过r-c延迟电路实现的第二延迟元件di(j-1)2确定的预定延迟时间td2)。
例如,如粗实线所示,如果存储在前一比特级信元mi(j-2)中的逻辑电平“1”从前一比特级信元mi(j-2)馈送至第一nmos晶体管qi(j-1)1的栅极,则第一nmos晶体管qi(j-1)1在时间间隔tau3的起点处变为导通状态,并且逻辑电平“1”被存储在电容器ci(j-1)中。另一方面,如虚线所示,如果存储在前一比特级信元mi(j-2)中的逻辑电平“0”从前一比特级信元mi(j-2)馈送至第一nmos晶体管qi(j-1)1的栅极,则第一nmos晶体管qi(j-1)1保持截止状态,并且电容器ci(j-1)中维持逻辑电平“0”。因此,比特级信元mi(j-1)可建立“推进与门”运算。延迟时间td2应该比延迟时间td1长,并且优选地,延迟时间td2可被设定为等于1/2tauclock。
如细实线所示,由于时钟信号按照时钟周期tauclock周期性地在逻辑电平“1”与“0”之间摇摆,则时钟信号在时间前进1/2tauclock时或者在时间间隔tau3的起点处变为逻辑电平“0”,如点划线所示,第一nmos晶体管qi(j-1)1的漏极处的电势开始衰落。如果插入当前比特级信元mi(j-1)和下一比特级信元mij之间的单元间信元bij通过nmos晶体管实现,则当前比特级信元mi(j-1)的输出端子与下一比特级信元mij的第一nmos晶体管qij1的栅极之间的路径由于施加到nmos晶体管的栅极的逻辑电平“0”的时钟信号而变为截止状态,因此,连接第一nmos晶体管qi(j-1)1的源极和第二nmos晶体管qi(j-1)2的漏极的输出节点nout在时间间隔tau3和tau4中无法将从前一比特级信元mi(j-2)传送来的信号像滚球戏(duckpins)一样进一步输送至下一比特级信元mij,信号被阻止多米诺式地传送至下一第一nmos晶体管qij1的栅极。由于在时间间隔tau3和tau4中第一nmos晶体管qi(j-1)1变为截止状态,所以输出节点nout处的电势保持在悬置状态,并且保持存储在电容器ci(j-1)中的信号状态。
如图15的下一列中的细实线所示,当时钟信号再次变为逻辑电平“1”时,因为单元间信元bij变为导通状态,连接第一nmos晶体管qi(j-1)1的源极和第二nmos晶体管qi(j-1)2的漏极的输出节点nout(用作比特级信元mi(j-1)的输出端子)可在下一时钟循环将存储在电容器ci(j-1)中的信号输送给下一比特级信元mij,第一nmos晶体管qi(j-1)1的漏极处的电势如点划线所示增大。
图16的(a)-(d)分别示出聚焦于图11和图13所示的比特级信元mij的信号传送操作的四种模式,比特级信元mij是顺序排列于第j存储器单元uj中的比特级信元之一,第j存储器单元uj通过顺序排列于第j存储器单元uj中的比特级信元序列来存储字节大小或字大小的信息。在根据本发明的第一实施方式的计算机系统中,顺序排列的字节大小或字大小的信息一起从前一存储器单元同时推进至下一存储器单元。在图16的(a)-(d)中,时钟信号由时钟信号供应线clock供应以按照时钟周期tauclock周期性地在逻辑电平“1”与“0”之间摇摆,同时时钟信号供应线clock用作电源线。
图16的(a)和图16的(b)示出当作为字节大小或字大小的信息中的信号之一,逻辑电平“0”通过前一时钟信号存储到电容器cij中时的情况,图16的(c)和图16的(d)示出当逻辑电平“1”通过前一时钟信号存储到电容器cij中时的情况。如图16的(a)所示,在先前存储在电容器cij中的信号电荷为逻辑电平“0”的情况下,如果在存储在电容器cij中的信号电荷保持逻辑电平“0”的同时,作为以协同方式传送的字节大小或字大小的信息中的信号之一,存储在前一比特级信元mi(j-1)中的逻辑电平“0”的信号从前一比特级信元mi(j-1)通过单元间信元bij(未示出)被馈送至第一nmos晶体管qij1的栅极,则因为第一nmos晶体管qij1保持截止状态,连接第一nmos晶体管qij1的源极和第二nmos晶体管qij2的漏极的输出节点nout将维持在电容器cij中的信号电平“0”输送给第i行上的下一比特级信元,以利用通过时钟信号提供的输入信号“1”执行0+1=0的推进与门运算。
类似地,如图16的(b)所示,在先前存储在电容器cij中的信号电荷为逻辑电平“0”的情况下,如果在存储在电容器cij中的信号电荷保持逻辑电平“0”的同时,存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号从前一比特级信元mi(j-1)通过单元间信元bij被馈送至第一nmos晶体管qij1的栅极,则第一nmos晶体管qij1开始导通以将存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号传送至电容器cij,使得逻辑电平“1”可被存储在电容器cij中,并且输出节点nout将存储在电容器cij中的信号电平“1”输送给第i行上的下一比特级信元,以利用通过时钟信号提供的输入信号“1”执行推进与门运算1+1=1。
相反,如图16的(c)所示,在先前存储在电容器cij中的信号电荷为逻辑电平“1”的情况下,如果在存储在电容器cij中的信号电荷完全放电以建立逻辑电平“0”之后,存储在前一比特级信元mi(j-1)中的逻辑电平“0”的信号从前一比特级信元mi(j-1)通过单元间信元bij被馈送至第一nmos晶体管qij1的栅极,则因为第一nmos晶体管qij1保持截止状态,输出节点nout将存储在电容器cij中的信号电平“0”输送给第i行上的下一比特级信元,以利用通过时钟信号提供的输入信号“1”执行0+1=0的推进与门运算。
类似地,如图16的(d)所示,在先前存储在电容器cij中的信号电荷为逻辑电平“1”的情况下,如果在存储在电容器cij中的信号电荷完全放电以建立逻辑电平“0”之后,存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号从前一比特级信元mi(j-1)通过单元间信元bij被馈送至第一nmos晶体管qij1的栅极,则第一nmos晶体管qij1开始导通以将存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号传送至电容器cij,使得逻辑电平“1”可被存储在电容器cij中,并且输出节点nout将存储在电容器cij中的信号电平“1”输送给第i行上的下一比特级信元,以利用通过时钟信号提供的输入信号“1”执行推进与门运算1+1=1。
类似于图11所示的配置,尽管单元间信元bij被插入在第(j-1)比特级信元mij-1与第j比特级信元mij之间,并且第j比特级信元mij包括:第一nmos晶体管qij1,其具有通过第一延迟元件dij1连接到时钟信号供应线的漏极以及通过第二延迟元件dij2连接到单元间信元bij的栅极;第二nmos晶体管qij2,其具有连接到第一nmos晶体管qij1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器cij,其被配置为存储比特级信元mij的信息,并且与第二nmos晶体管qij2并联连接,但是第一延迟元件dij1通过第一二极管d1a实现,第二延迟元件dij2通过第二二极管d2a与第三二极管d3a的串联连接来实现的特征可与图11所示的配置相区别。
尽管任何p-n结二极管可通过这样的等效电路来表示,该等效电路包括电阻器和电容器,所述电阻器包括诸如扩散电阻、引线电阻、欧姆接触电阻和扩展电阻等的串联电阻,所述电容器包括诸如结电容或扩散电容的二极管电容,但是单个二极管或二极管的串联连接可用作“电阻-电容延迟器”或“r-c延迟器”,因为可使“r-c延迟器”的值远小于通过特殊的专用r-c元件(例如图9和图12所示的第一曲折线91和第二曲折线97)实现的值,所以与通过图12所示的配置实现的操作相比,利用图17所示的单元间信元bij的第j比特级信元mij的操作可实现更优选的操作。即,利用图17所示的单元间信元bij的第j比特级信元mij的操作可逼近图7a和图7b所示的理想延迟性能,其中未示出任何上升时间和下降时间,并且脉冲波形由理想矩形形状示出。除了图11和图12所示的配置的性能之外,由于第二二极管d2a和第三二极管d3a的串联连接可有效阻止反向电流的流动,所以即使存储在前一比特级信元mi(j-1)中的低逻辑电平“0”的信号通过单元间信元bij被馈送至第一nmos晶体管qij1的栅极,通过第j比特级信元mij与图17所示的单元间信元bij的组合实现的配置也可在第(j-1)比特级信元mi(j-1)的信号存储状态与第j比特级信元mij的信号存储状态之间实现更好的隔离。
在图18中,除了图17所示的配置之外,另一单元间信元bi(j-1)被设置在第(j-2)比特级信元mi(j-2)与第(j-1)比特级信元mi(j-1)之间,并且被配置为将第(j-1)存储器单元uj-1中的第(j-1)比特级信元mi(j-1)的信号存储状态与第(j-2)存储器单元uj-2中的第(j-2)比特级信元mi(j-2)的信号存储状态隔离,并且按照由通过时钟信号供应线供应的时钟信号确定的所需定时将信号从第(j-2)比特级信元mi(j-2)传送至第(j-1)比特级信元mi(j-1)。在图18中,由于第(j-1)比特级信元mi(j-1)的输入端子连接到单元间信元bi(j-1),所以存储在第(j-2)比特级信元mi(j-2)中的信号电荷按照所需定时通过单元间信元bi(j-1)被馈送至第二延迟元件di(j-1)2,随后信号电荷的传送被截止。
类似于第j比特级信元mij的配置,第(j-1)比特级信元mi(j-1)包括:第一nmos晶体管qi(j-1)1,其具有通过第一延迟元件di(j-1)1连接到时钟信号供应线的漏极以及通过第二延迟元件di(j-1)2连接到单元间信元bi(j-1)的栅极;第二nmos晶体管qi(j-1)2,其具有连接到第一nmos晶体管qi(j-1)1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器ci(j-1),其被配置为存储比特级信元mi(j-1)的信息,并且与第二nmos晶体管qi(j-1)2并联连接。这里,第一延迟元件di(j-1)1通过第一二极管d1b实现,第二延迟元件di(j-1)2通过第二二极管d2b与第三二极管d3b的串联连接实现。
如上所述,由于单个二极管或二极管的串联可用作“电阻-电容延迟器”或“r-c延迟器”,利用图18所示的单元间信元bi(j-1)的第(j-1)比特级信元mi(j-1)的操作基本上与图13所示的配置的操作相同。除了图13所示的配置的性能之外,由于第二二极管d2b和第三二极管d3b的串联连接可有效阻止反向电流的流动,所以即使存储在前一比特级信元mi(j-2)中的低逻辑电平“0”的信号通过单元间信元bi(j-1)被馈送至第一nmos晶体管qi(j-1)1的栅极,通过第j比特级信元mi(j-1)与图18所示的单元间信元bi(j-1)的组合实现的配置也可在第(j-2)比特级信元mi(j-2)的信号存储状态与第(j-1)比特级信元mi(j-1)的信号存储状态之间实现更好的隔离。
在实际半导体器件中,由于固有地存在与布线、栅结构、电极结构和结结构关联的许多寄生电阻(杂散电阻)和许多寄生电容(杂散电容),在推进主存储器的非常高速的操作中,如果与推进主存储器的操作速度相比,寄生电阻和寄生电容可实现所需的延迟时间td1、td2,则可省略描绘外在电阻器元件和电容器元件。因此,在图11-13以及图16所示的配置中,可省略第一延迟元件di(j-1)1和dij1,如图19、图20和图22所示。
在图19所示的根据本发明的第一实施方式的计算机系统中所使用的比特级信元的其它示例之一中,尽管类似于图11所示的配置,第j比特级信元mij包括第一nmos晶体管qij1,但是所述第一nmos晶体管qij1具有直接连接到时钟信号供应线的漏极,省略了图11所示的配置中的第一延迟元件dij1。第一nmos晶体管qij1具有通过信号延迟元件dij(对应于图11所示的第二延迟元件dij2)连接到单元间信元bij的栅极,并且第二nmos晶体管qij2具有连接到第一nmos晶体管qij1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极,并且电容器cij被配置为存储比特级信元mij的信息并与第二nmos晶体管qij2并联连接的特征基本上与图11所示的配置相同。
在图19所示的根据第一实施方式的比特级信元的另一示例中,类似于图11-13以及图16所示的配置,还设置单元间信元bij以将第j存储器单元uj中的第j比特级信元mij的信号存储状态与第(j-1)存储器单元uj-1中的第(j-1)比特级信元mij-1的信号存储状态隔离。另外,单元间信元bij按照由通过时钟信号供应线供应的时钟信号确定的所需定时将信号从第(j-1)比特级信元mij-1传送至第j比特级信元mij。由于第j存储器单元uj通过排列于第j存储器单元uj中的比特级信元序列来存储字节大小或字大小的信息,并且第(j-1)存储器单元uj-1通过排列于第(j-1)存储器单元uj-1中的比特级信元序列来存储字节大小或字大小的信息,所以与存储器单元uj-1和uj并行排列的单元间信元序列按照通过时钟信号供应线供应的时钟信号的控制传送字节大小或字大小的信息,使得字节大小或字大小的信息可沿着预定方向同时推进。
如图19所示,由于第i行上的第j比特级信元mij的输入端子连接到单元间信元bij,所以存储在第(j-1)比特级信元mij-1中的信号电荷按照所需定时通过单元间信元bij被馈送至信号延迟元件dij,并且在除了所需定时外的时间段,信号电荷的传送操作被截止。
在图20中,除了图19所示的配置之外,另一单元间信元bi(j-1)被设置在第(j-2)比特级信元mi(j-2)与第(j-1)比特级信元mi(j-1)之间,并且被配置为将第(j-1)存储器单元uj-1中的第(j-1)比特级信元mi(j-1)的信号存储状态与第(j-2)存储器单元uj-2中的第(j-2)比特级信元mi(j-2)的信号存储状态隔离,并按照由通过时钟信号供应线供应的时钟信号确定的所需定时将信号从第(j-2)比特级信元mi(j-2)传送至第(j-1)比特级信元mi(j-1)。在图20中,由于第i行上的第(j-1)比特级信元mi(j-1)的输入端子连接到单元间信元bi(j-1),所以存储在第(j-2)比特级信元mi(j-2)中的信号电荷按照所需定时通过单元间信元bi(j-1)被馈送至信号延迟元件di(j-1),随后信号电荷的传送操作被截止。
类似于第j比特级信元mij的配置,第(j-1)比特级信元mi(j-1)包括:第一nmos晶体管qi(j-1)1,其具有直接连接到时钟信号供应线的漏极以及通过信号延迟元件di(j-1)连接到单元间信元bi(j-1)的栅极;第二nmos晶体管qi(j-1)2,其具有连接到第一nmos晶体管qi(j-1)1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器ci(j-1),其被配置为存储比特级信元mi(j-1)的信息,并且与第二nmos晶体管qi(j-1)2并联连接。
在图19和图20所示的电路配置中,作为根据第一实施方式的比特级信元的其它示例之一,比特级信元mij的第二nmos晶体管qij2用作复位晶体管,其被配置为当高电平(或逻辑电平“1”)的时钟信号施加到第二nmos晶体管qij2的栅极时,将存储在电容器cij中的信号电荷复位,从而使已经存储在电容器cij中的信号电荷放电,比特级信元mi(j-1)的第二nmos晶体管qi(j-1)2用作复位晶体管,其被配置为当高电平(或逻辑电平“1”)的时钟信号施加到第二nmos晶体管qi(j-1)2的栅极时,将存储在电容器ci(j-1)中的信号电荷复位,从而使已经存储在电容器ci(j-1)中的信号电荷放电。
在图19和图20中,隔离晶体管qi(j-1)3和qij3应该是高速晶体管,其与具有与栅电路和栅结构关联的较大杂散电容和较大杂散电阻的第二nmos晶体管qi(j-1)2和qij2相比,具有较短的上升时间、较短的导通状态周期以及较短的下降时间,使得当第二nmos晶体管qi(j-1)2和qij2仍处于截止状态时,隔离晶体管qi(j-1)3和qij3非常快速地变为导通状态以在存储器单元之间传送信号电荷,并且当第二nmos晶体管qi(j-1)2和qij2开始缓慢朝着使存储在电容器ci(j-1)和cij中的信号电荷放电的导通状态时,隔离晶体管qi(j-1)3和qij3继续非常快速地变为截止状态以在存储器单元之间建立隔离。
图21示出对于信号延迟元件di(j-1)通过r-c延迟电路实现的情况,图20所示的比特级信元mi(j-1)对虚实线所示的时钟信号波形的详细响应,比特级信元mi(j-1)是根据本发明的第一实施方式的计算机系统中所使用的比特级信元的其它示例之一。细实线所示的时钟信号按照时钟周期tauclock周期性地在逻辑电平“1”与“0”之间摇摆。在图21中,时间间隔tau1=tau2=tau3=tau4被限定为时钟周期tauclock的四分之一(=tauclock/4)。
在推进存储器的正常操作中,如图22的(a)-(d)所示,存储在电容器ci(j-1)中的信号电荷实际上为逻辑电平“0”或“1”。如图22的(c)和图22的(d)所示,如果存储在电容器ci(j-1)中的信号电荷为逻辑电平“1”,则尽管由于第一nmos晶体管qi(j-1)1的栅极的电势被信号延迟元件di(j-1)延迟,第一nmos晶体管qi(j-1)1仍保持截止状态,电容器ci(j-1)可在时间间隔tau1的起点处开始放电,因为假设可逼近第二nmos晶体管qi(j-1)2的没有延迟的理想操作,则当高电平的时钟信号施加到第二nmos晶体管qi(j-1)2的栅极时,第二nmos晶体管qi(j-1)2快速被激活。因此,如果存储在电容器i(j-1)中的信号电荷实际上为逻辑电平“1”,则在高电平的时钟信号施加到第二nmos晶体管qi(j-1)2的栅极之后,如图21中的细实线所示,存储在电容器ci(j-1)中的信号电荷将放电至逻辑电平“0”,并且几乎在同时,第一nmos晶体管qi(j-1)1准备被激活成为传送晶体管(延迟了由通过杂散电阻和杂散电容实现的寄生元件确定的可以忽略的短延迟时间)。在图21中,第一nmos晶体管qi(j-1)1的漏极处的电势变化由点划线夸大示出。
并且,如图21中的粗实线所示,当存储在前一比特级信元mi(j-2)中的信号电平“1”从前一比特级信元mi(j-2)通过单元间信元bi(j-1)馈送至第一nmos晶体管qi(j-1)1的栅极时,第一nmos晶体管qi(j-1)1导通,并且第一nmos晶体管qi(j-1)1将存储在前一比特级信元mi(j-2)中的信号电平“1”传送给电容器ci(j-1)(延迟了由信号延迟元件di(j-1)确定的预定延迟时间td2)。另选地,如图21中的虚线所示,当存储在前一比特级信元mi(j-2)中的信号电平“0”从前一比特级信元mi(j-2)馈送至第一nmos晶体管qi(j-1)1的栅极时,第一nmos晶体管qi(j-1)1保持截止状态。在这一刻,由于电容器ci(j-1)仍保持逻辑电平“0”,所以第一nmos晶体管qi(j-1)1等同于传送存储在前一比特级信元mi(j-2)中的信号电平“0”。用作比特级信元mi(j-1)的输出端子的输出节点nout将存储在电容器ci(j-1)中的信号输送给第i行上的下一比特级信元。
由于如细实线所示时钟信号按照时钟周期tauclock周期性地在逻辑电平“1”与“0”之间摇摆,所以时钟信号在时间前进1/2tauclock时或者在时间间隔tau3的起点处变为逻辑电平“0”,如由点划线夸大示出的,第一nmos晶体管qi(j-1)1的漏极处的电势开始快速衰落。如果插入在当前比特级信元mi(j-1)和下一比特级信元mij之间的单元间信元bij通过nmos晶体管实现,则当前比特级信元mi(j-1)的输出端子与下一比特级信元mij的第一nmos晶体管qij1的栅极之间的路径由于施加到nmos晶体管的栅极的逻辑电平“0”的时钟信号而变为截止状态,因此,输出节点nout在时间间隔tau3和tau4中无法将从前一比特级信元mi(j-2)传送来的信号像滚球戏一样进一步输送至下一比特级信元mij,信号被阻止多米诺式地传送至下一第一nmos晶体管qij1的栅极。由于在时间间隔tau3和tau4中第一nmos晶体管qi(j-1)1变为截止状态,所以输出节点nout处的电势保持在悬置状态,并且保持存储在电容器ci(j-1)中的信号状态。
如图21的下一列中的细实线所示,当时钟信号再次变为逻辑电平“1”时,因为单元间信元bij变为导通状态,所以连接第一nmos晶体管qi(j-1)1的源极和第二nmos晶体管qi(j-1)2的漏极的输出节点nout(用作比特级信元mi(j-1)的输出端子)可在下一时钟循环将存储在电容器ci(j-1)中的信号输送至下一比特级信元mij,第一nmos晶体管qi(j-1)1的漏极处的电势增大,如由点划线夸大示出的。
图22的(a)-(d)分别示出聚焦于图19和图20所示的比特级信元mij的信号传送操作的四种模式,比特级信元mij是顺序排列于第j存储器单元uj中的比特级信元之一,第j存储器单元uj通过顺序排列于第j存储器单元uj中的比特级信元序列来存储字节大小或字大小的信息。在根据本发明的第一实施方式的计算机系统中,顺序排列的字节大小或字大小的信息一起从前一存储器单元同时推进至下一存储器单元。在图22的(a)-(d)中,时钟信号由时钟信号供应线clock供应以按照时钟周期tauclock周期性地在逻辑电平“1”与“0”之间摇摆,同时时钟信号供应线clock用作电源线。
图22的(a)和图22的(b)示出作为字节大小或字大小的信息中的信号之一,当逻辑电平“0”通过前一时钟信号存储到电容器cij中时的情况,图22的(c)和图22的(d)示出当逻辑电平“1”通过前一时钟信号存储到电容器cij中时的情况。如图22的(a)所示,在先前存储在电容器cij中的信号电荷为逻辑电平“0”的情况下,如果作为以协同方式传送的字节大小或字大小的信息中的信号之一,存储在前一比特级信元mi(j-1)中的逻辑电平“0”的信号从前一比特级信元mi(j-1)通过单元间信元bij(未示出)被馈送至第一nmos晶体管qij1的栅极,则第一nmos晶体管qij1保持截止状态。在这一刻,由于电容器cij仍保持逻辑电平“0”,所以第一nmos晶体管qi(j-1)1等同于将逻辑电平“0”传送至电容器cij。然后,输出节点nout将维持在电容器cij中的信号电平“0”输送给下一比特级信元,如图22的(a)所示。
类似地,如图22的(b)所示,在先前存储在电容器cij中的信号电荷为逻辑电平“0”的情况下,如果在存储在电容器cij中的信号电荷保持逻辑电平“0”的同时,存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号从前一比特级信元mi(j-1)通过单元间信元bij被馈送至第一nmos晶体管qij1的栅极,则第一nmos晶体管qij1开始导通以将存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号传送至电容器cij,使得逻辑电平“1”可被存储在电容器cij中,并且输出节点nout将存储在电容器cij中的信号电平“1”输送至下一比特级信元,如图22的(b)所示。
相反,如图22的(c)所示,在先前存储在电容器cij中的信号电荷为逻辑电平“1”的情况下,如果在存储在电容器cij中的信号电荷完全放电以建立逻辑电平“0”之后,存储在前一比特级信元mi(j-1)中的逻辑电平“0”的信号从前一比特级信元mi(j-1)通过单元间信元bij被馈送至第一nmos晶体管qij1的栅极,则第一nmos晶体管qij1保持截止状态。然后,输出节点nout将存储在电容器cij中的信号电平“0”输送至下一比特级信元,如图22的(c)所示。
类似地,如图22的(d)所示,在先前存储在电容器cij中的信号电荷为逻辑电平“1”的情况下,如果在存储在电容器cij中的信号电荷完全放电以建立逻辑电平“0”之后,存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号从前一比特级信元mi(j-1)通过单元间信元bij被馈送至第一nmos晶体管qij1的栅极,则第一nmos晶体管qij1导通,并且第一nmos晶体管qij1将存储在前一比特级信元mi(j-1)中的逻辑电平“1”的信号传送至电容器cij。然后,输出节点nout将存储在电容器cij中的信号电平“1”输送至下一比特级信元,如图22的(d)所示。
如上所述,利用由时钟信号提供的输入信号“1”以及由前一比特级信元mi(j-1)提供的另一输入信号“1”或“0”,比特级信元mij可建立“推进与门”运算:
1+1=1
1+0=1,
并且利用由时钟信号提供的输入信号“0”以及由前一比特级信元mi(j-1)提供的另一输入信号“1”或“0”,比特级信元mij可建立“推进与门”运算:
0+1=0
0+0=0。
因此,在与图4所示的推进主存储器31对应的信元阵列的门层级表示中,如图23所示,分配于第一行的最左侧并且连接到输入端子i1的第一信元m11包括被配置为存储信息的电容器c11以及推进与门g11,所述推进与门g11的一个输入端子连接到电容器c11,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给第一行上的相邻第二信元m21的下一推进与门g21的一个输入端子。对时钟信号波形的响应的示例被示出于图7c中。当逻辑值“1”的时钟信号被馈送至推进与门g11的另一输入端子时,存储在电容器c11中的信息被传送至指派给相邻第二信元m12的电容器c12,电容器c12存储该信息。即,实现推进主存储器31的信元阵列的门层级表示的第一行上的第二信元m12包括电容器c12以及推进与门g12,所述推进与门g12的一个输入端子连接到电容器c12,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给第一行上的相邻第三信元m13的下一推进与门g13的一个输入端子。类似地,实现推进主存储器31的信元阵列的门层级表示的第一行上的第三信元m13包括被配置为存储信息的电容器c13以及推进与门g13,所述推进与门g13的一个输入端子连接到电容器c13,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给相邻第四信元的下一推进与门的一个输入端子(尽管第四信元未示出)。因此,当逻辑值“1”被馈送至推进与门g12的另一输入端子时,存储在电容器c12中的信息被传送至指派给第三信元m13的电容器c13,电容器c13存储该信息,并且当逻辑值“1”被馈送至推进与门g13的另一输入端子时,存储在电容器c13中的信息被传送至指派给第四信元的电容器。另外,实现推进主存储器31的信元阵列的门层级表示的第一行上的第(n-1)信元m1,n-1包括被配置为存储信息的电容器c1,n-1以及推进与门g1,n-1,所述推进与门g1,n-1的一个输入端子连接到电容器c1,n-1,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给相邻第n信元m1n(分配于第一行的最右侧并连接到输出端子o1)的下一推进与门g1n的一个输入端子。因此,信元m11、m12、m13、......、m1,n-1、m1n中的每一个存储信息,并与时钟信号同步地将信息朝着输出端子o1逐步传送,以主动地并且顺序地向处理器11提供所存储的信息,使得alu112可利用所存储的信息执行算术和逻辑运算。
类似地,在图23所示的实现推进主存储器31的信元阵列的门层级表示中,分配于第二行的最左侧并且连接到输入端子i2的第一信元m21包括电容器c21以及推进与门g21,所述推进与门g21的一个输入端子连接到电容器c21,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给第二行上的相邻第二信元m21的下一推进与门g21的一个输入端子。实现推进主存储器31的信元阵列的门层级表示的第二行上的第二信元m22包括电容器c22以及推进与门g22,所述推进与门g22的一个输入端子连接到电容器c22,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给第二行上的相邻第三信元m23的下一推进与门g23的一个输入端子。类似地,实现推进主存储器31的信元阵列的门层级表示的第二行上的第三信元m23包括电容器c23以及推进与门g23,所述推进与门g23的一个输入端子连接到电容器c23,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给相邻第四信元的下一推进与门的一个输入端子。另外,实现推进主存储器31的信元阵列的门层级表示的第二行上的第(n-1)信元m2,n-1包括电容器c2,n-1以及推进与门g2,n-1,所述推进与门g2,n-1的一个输入端子连接到电容器c2,n-1,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给相邻第n信元m1n(分配于第二行的最右侧并连接到输出端子o1)的下一推进与门g1n的一个输入端子。因此,第二行上的信元m21、m22、m23、......、m2,n-1、m2n中的每一个存储信息,并与时钟信号同步地将信息朝着输出端子o1逐步传送,以主动地并且顺序地向处理器11提供所存储的信息,使得alu112可利用所存储的信息执行算术和逻辑运算。
在第三行上,排列有分配于最左侧并连接到输入端子i3的第一信元m31、与第一信元m31相邻的第二信元m32、与第二信元m32相邻的第三信元m33、......、第(n-1)信元m3,n-1以及分配于第三行的最右侧并连接到输出端子o3的第n信元m3n。并且,第三行上的信元m31、m32、m33、......、m3,n-1、m3n中的每一个存储信息,并与时钟信号同步地将信息朝着输出端子o3逐步传送,以主动地并且顺序地向处理器11提供所存储的信息,使得alu112可利用所存储的信息执行算术和逻辑运算。
在第(m-1)行上,排列有分配于最左侧并连接到输入端子im-1的第一信元m(m-1)1、与第一信元m(m-1)1相邻的第二信元m(m-1)2、与第二信元m(m-1)2相邻的第三信元m(m-1)3、......、第(n-1)信元m(m-1),n-1以及分配于第(m-1)行的最右侧并连接到输出端子om-1的第n信元m(m-1)n。并且,第(m-1)行上的信元m(m-1)1、m(m-1)2、m(m-1)3、......、m(m-1),n-1、m(m-1)n中的每一个存储信息,并与时钟信号同步地将信息朝着输出端子om-1逐步传送,以主动地并且顺序地向处理器11提供所存储的信息,使得alu112可利用所存储的信息执行算术和逻辑运算。
在第m行上,排列有分配于最左侧并连接到输入端子im-1的第一信元mm1、与第一信元mm1相邻的第二信元mm2、与第二信元mm2相邻的第三信元mm3、......、第(n-1)信元mm(n-1)以及分配于第m行的最右侧并连接到输出端子om的第n信元mmn。并且,第m行上的信元mm1、mm2、mm3、......、mm(n-1)、mmn中的每一个存储信息,并与时钟信号同步地将信息朝着输出端子om逐步传送,以主动地并且顺序地向处理器11提供所存储的信息,使得alu112可利用所存储的信息执行算术和逻辑运算。
尽管图6中示出了推进与门gij的晶体管层级配置的示例之一,存在实现推进与门的各种电路配置,其可适用于实现根据本发明的第一实施方式的计算机系统中的推进主存储器31的信元阵列。可适用于实现推进主存储器31的信元阵列的推进与门gij的另一示例可以是包括cmos与非门以及连接到cmos与非门的输出端子的cmos反相器的配置。由于cmos与非门需要两个nmos晶体管和两个pmos晶体管,并且cmos反相器需要一个nmos晶体管和一个pmos晶体管,所以包括cmos与非门和cmos反相器的配置需要六个晶体管。另外,推进与门gij可通过诸如电阻器-晶体管逻辑的其它电路配置来实现,或者通过具有与逻辑的功能的各种半导体元件、磁性元件、超导元件或单量子元件等来实现。
如图23所示,实现推进主存储器31的信元阵列的门层级表示像dram的配置一样简单,其中各个比特级信元mij(i=1至m;j=1至n)由一个电容器和一个推进与门表示。实现第一存储器单元u1的推进与门垂直序列g11、g21、g31、......、gm-1,1、gm1中的每一个基于如图7c所示的时钟沿着行方向(或水平方向)使来自输入端子i1、i2、i3、......、in-1、in的信号序列向右移位。并且,实现第二存储器单元u2的推进与门垂直序列g12、g22、g32、......、gm-1,2、gm2中的每一个基于时钟沿着行方向使字大小的信号序列从左向右移位,实现第三存储器单元u3的推进与门垂直序列g13、g23、g33、......、gm-1,3、gm3中的每一个基于时钟沿着行方向使字大小的信号序列从左向右移位,......,实现第(n-1)存储器单元un-1的推进与门垂直序列g1,n-1、g2,n-1、g3,n-1、......、gm-1,n-1、gm,n-1中的每一个基于时钟沿着行方向使字大小的信号序列从左向右移位,实现第n存储器单元un的推进与门垂直序列g1,n、g2,n、g3,n、......、gm-1,n、gm,n中的每一个基于如图7c所示的时钟使字大小的信号序列从左向右移位至输入端子o1、o2、o3、......、on-1、on。特别是,各个推进与门gij(i=1至m;j=1至n)中的时间延迟td1、td2对于成功地在推进主存储器31中的每一个存储器单元中正确地执行推进移位动作而言具有重要意义。
(反向推进主存储器)
尽管图3-图23示出在存储器单元u1、u2、u3、......、un-1、un中的每一个中存储信息并与时钟信号同步地将信息从输入端子朝着输出端子逐步传送的推进主存储器,但是图24示出另一推进主存储器。
在图24中,存储器单元u1、u2、u3、......、un-1、un中的每一个存储包括字大小的数据或指令的信息,并且与时钟信号同步地在朝着输出端子的相反方向上逐步传送信息,从处理器11向所述存储器单元提供alu112中执行的结果数据。
图25的(a)示出在图24所示的另一推进主存储器的信元层级表示中的m×n矩阵(这里,“m”是由字大小确定的整数)的第i行的阵列,其在各个信元mi1、mi2、mi3、......、mi,n-1、mi,n中存储比特级的信息,并与时钟信号同步地在图3-图23所示的推进主存储器的相反方向上(即,从输出端子out朝着输入端子in)逐步传送信息。
如图25的(a)所示,在反向推进主存储器中,分配于第i行的最右侧并连接到输入端子in的第i行第n列的比特级信元min包括:第一nmos晶体管qin1,其具有通过第一延迟元件din1连接到时钟信号供应线的漏极以及通过第二延迟元件din2连接到输入端子in的栅极;第二nmos晶体管qin2,其具有连接到第一nmos晶体管qin1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器cin,其被配置为存储比特级信元min的信息,并且与第二nmos晶体管qin2并联连接,其中,连接第一nmos晶体管qin1的源极和第二nmos晶体管qin2的漏极的输出节点用作比特级信元min的输出端子,并且被配置为将存储在电容器cin中的信号传送至下一比特级信元mi2。
如图25的(b)所示,时钟信号按照预定时钟周期tauclock周期性地在逻辑电平“1”与“0”之间摇摆,当时钟信号变为逻辑电平“1”时,第二nmos晶体管qin2开始使已经在前一时钟循环存储在电容器cin中的信号电荷放电。并且,在施加了逻辑电平“1”的时钟信号并且存储在电容器cin中的信号电荷完全放电以变为逻辑电平“0”之后,第一nmos晶体管qin1被激活成为传送晶体管(延迟了由第一延迟元件din1确定的预定延迟时间td1)。优选地,延迟时间td1可被设定为等于1/4tauclock。随后,当信号从输入端子in馈送至第一nmos晶体管qin1的栅极时,第一nmos晶体管qin1将存储在前一比特级信元mi2中的信号传送给电容器cin(进一步延迟了由第二延迟元件din2确定的预定延迟时间td2)。例如,如果逻辑电平“1”从输入端子in馈送至第一nmos晶体管qin1的栅极,则第一nmos晶体管qin1变为导通状态,并且逻辑电平“1”被存储在电容器cin中。另一方面,如果逻辑电平“0”从输入端子in馈送至第一nmos晶体管qin1的栅极,则第一nmos晶体管qin1保持截止状态,并且电容器cin中维持逻辑电平“0”。因此,比特级信元min可建立“推进与门”运算。延迟时间td2应该比延迟时间td1长,并且优选地,延迟时间td2可被设定为等于1/2tauclock。当时钟信号在时间前进1/2tauclock时变为逻辑电平“0”时,连接第一nmos晶体管qin1的源极和第二nmos晶体管qin2的漏极的输出节点在时间前进1/2tauclock时无法将进入第一nmos晶体管qin1的栅极的信号进一步输送至下一比特级信元mi2,因为信号被阻止延迟由第二延迟元件di22确定的延迟时间td2=1/2tauclock传送至下一第一nmos晶体管qi21的栅极。并且,在时间前进tauclock时,当下一时钟信号再次变为逻辑电平“1”时,第二nmos晶体管的序列
如图25的(a)所示,在反向推进主存储器中,分配于第i行的右侧第二位的第i行第(n-1)列的比特级信元mi(n-1)包括:第一nmos晶体管qi(n-1)1,其具有通过第一延迟元件di(n-1)1连接到时钟信号供应线的漏极以及通过第二延迟元件di(n-1)2连接到比特级信元min的输出端子的栅极;第二nmos晶体管qi(n-1)2,其具有连接到第一nmos晶体管qi(n-1)1的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器ci(n-1),其被配置为存储比特级信元mi(n-1)的信息,并且与第二nmos晶体管qi(n-1)2并联连接。当时钟信号变为逻辑电平“1”时,第二nmos晶体管qi(n-1)2开始使已经在前一时钟循环存储在电容器ci(n-1)中的信号电荷放电。并且,如图25的(b)所示,在电容器ci(n-1)中从时间“t”至时间“t+1”保持逻辑值“1”。在施加了逻辑电平“1”的时钟信号并且存储在电容器ci(n-1)中的信号电荷完全放电以变为逻辑电平“0”之后,第一nmos晶体管qi(n-1)1被激活成为传送晶体管(延迟了由第一延迟元件di(n-1)1确定的延迟时间td1)。随后,当信号从比特级信元min的输出端子馈送至第一nmos晶体管qi(n-1)1的栅极时,第一nmos晶体管qi(n-1)1将存储在前一比特级信元min中的信号传送给电容器ci(n-1)(进一步延迟了由第二延迟元件di(n-1)2确定的延迟时间td2)。当时钟信号在时间前进1/2tauclock时变为逻辑电平“0”时,连接第一nmos晶体管qi(n-1)1的源极和第二nmos晶体管qi(n-1)2的漏极的输出节点在时间前进1/2tauclock时无法将进入第一nmos晶体管qi(n-1)1的栅极的信号进一步输送至下一比特级信元mi(n-2),因为信号被阻止延迟由第二延迟元件di(n-2)2(未示出)确定的延迟时间td2=1/2tauclock传送至下一第一nmos晶体管qi(n-2)1(未示出)的栅极。
类似地,反向推进主存储器的第i行上的左侧第三个信元mi3包括:第一nmos晶体管qi31,其具有通过第一延迟元件di31连接到时钟信号供应线的漏极以及通过第二延迟元件di32连接到比特级信元mi4(未示出)的输出端子的栅极;第二nmos晶体管qi32,其具有连接到第一nmos晶体管qi31的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器ci3,其被配置为存储比特级信元mi3的信息,并且与第二nmos晶体管qi32并联连接。当时钟信号变为逻辑电平“1”时,第二nmos晶体管qi32开始使已经在前一时钟循环存储在电容器ci3中的信号电荷放电。在施加了逻辑电平“1”的时钟信号并且存储在电容器ci3中的信号电荷完全放电以变为逻辑电平“0”之后,第一nmos晶体管qi31被激活成为传送晶体管(延迟了由第一延迟元件di31确定的延迟时间td1)。随后,当信号从比特级信元mi4的输出端子馈送至第一nmos晶体管qi31的栅极时,第一nmos晶体管qi31将存储在前一比特级信元min中的信号传送给电容器ci3(进一步延迟了由第二延迟元件di32确定的延迟时间td2)。当时钟信号在时间前进1/2tauclock时变为逻辑电平“0”时,连接第一nmos晶体管qi31的源极和第二nmos晶体管qi32的漏极的输出节点在时间前进1/2tauclock时无法将进入第一nmos晶体管qi31的栅极的信号进一步输送至下一比特级信元mi2,因为信号被阻止延迟由第二延迟元件di22确定的延迟时间td2=1/2tauclock传送至下一第一nmos晶体管qi21的栅极。
并且,如图25的(a)所示,在反向推进主存储器中,第i行上左侧第二列的比特级信元mi2包括:第一nmos晶体管qi21,其具有通过第一延迟元件di21连接到时钟信号供应线的漏极以及通过第二延迟元件di22连接到比特级信元mi3的输出端子的栅极;第二nmos晶体管qi22,其具有连接到第一nmos晶体管qi21的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器ci2,其被配置为存储比特级信元mi2的信息,并且与第二nmos晶体管qi22并联连接。当时钟信号变为逻辑电平“1”时,第二nmos晶体管qi22开始使已经在前一时钟循环存储在电容器ci2中的信号电荷放电。在施加了逻辑电平“1”的时钟信号并且存储在电容器ci2中的信号电荷完全放电以变为逻辑电平“0”之后,第一nmos晶体管qi21被激活成为传送晶体管(延迟了由第一延迟元件di21确定的延迟时间td1)。随后,当信号从比特级信元mi3的输出端子馈送至第一nmos晶体管qi21的栅极时,第一nmos晶体管qi21将存储在前一比特级信元mi3中的信号传送给电容器ci2(进一步延迟了由第二延迟元件di22确定的延迟时间td2)。当时钟信号在时间前进1/2tauclock时变为逻辑电平“0”时,连接第一nmos晶体管qi21的源极和第二nmos晶体管qi22的漏极的输出节点在时间前进1/2tauclock时无法将进入第一nmos晶体管qi21的栅极的信号进一步输送至下一比特级信元mi1,因为信号被阻止延迟由第二延迟元件di12确定的延迟时间td2=1/2tauclock传送至下一第一nmos晶体管qi11的栅极。
如图25的(a)所示,在反向推进主存储器中,分配于第i行的最左侧并连接到输出端子out的第i行第一列的比特级信元mi1包括:第一nmos晶体管qi11,其具有通过第一延迟元件di11连接到时钟信号供应线的漏极以及通过第二延迟元件di12连接到比特级信元mi2的输出端子的栅极;第二nmos晶体管qi12,其具有连接到第一nmos晶体管qi11的源极的漏极、连接到时钟信号供应线的栅极以及连接到地电势的源极;以及电容器ci1,其被配置为存储比特级信元mi1的信息,并且与第二nmos晶体管qi12并联连接。当时钟信号变为逻辑电平“1”时,第二nmos晶体管qi12开始使已经在前一时钟循环存储在电容器ci1中的信号电荷放电。在施加了逻辑电平“1”的时钟信号并且存储在电容器ci1中的信号电荷完全放电以变为逻辑电平“0”之后,第一nmos晶体管qi11被激活成为传送晶体管(延迟了由第一延迟元件di11确定的延迟时间td1)。随后,当信号从比特级信元mi2的输出端子馈送至第一nmos晶体管qi11的栅极时,第一nmos晶体管qi11将存储在前一比特级信元mi2中的信号传送给电容器ci1(进一步延迟了由第二延迟元件di12确定的延迟时间td2)。连接第一nmos晶体管qi11的源极与第二nmos晶体管qi12的漏极的输出节点将存储在电容器ci1中的信号输送至输出端子out。
根据图24、图25的(a)和图25的(b)所示的第一实施方式的反向一维推进主存储器31,对各个存储器单元u1、u2、u3、......、un-1、un的寻址不复存在,所需信息朝着连接到存储器边缘的目的地单元进发。第一实施方式的反向一维推进主存储器31的存取机制确实是从寻址模式开始以读/写信息的现有存储器方案的替代方式。因此,根据第一实施方式的反向一维推进主存储器31,没有寻址模式的存储器存取比现有存储器方案简单很多。
如上所述,比特级信元mij可建立“推进与门”运算。因此,如图26所示,在与图25的(a)所示的反向推进主存储器31对应的信元阵列的门层级表示中,分配于第i行的最右侧并且连接到输入端子in的第n比特级信元mi,n包括被配置为存储信息的电容器cin以及推进与门gin,所述推进与门gin的一个输入端子连接到电容器cini,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给第i行上的相邻第(n-1)比特级信元mi,n-1的前一推进与门gin-1的一个输入端子。当逻辑值“1”被馈送至推进与门gn的另一输入端子时,存储在电容器cin中的信息被传送至指派给第i行上的相邻第(n-1)比特级信元mi,n-1的电容器ci,n-1,电容器ci,n-1存储该信息。即,反向推进主存储器的第i行上的第(n-1)比特级信元mi,n-1包括电容器ci,n-1以及推进与门gi,n-1,所述推进与门gi,n-1的一个输入端子连接到电容器ci,n-1,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给相邻第三比特级信元mi,n-2(未示出)的前一推进与门gi,n-2的一个输入端子。
类似地,反向推进主存储器的第i行上的第三比特级信元mi3包括被配置为存储信息的电容器ci3以及推进与门gi3,所述推进与门gi3的一个输入端子连接到电容器ci3,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给相邻第二比特级信元mi2的前一推进与门gi2的一个输入端子。因此,当逻辑值“1”被馈送至推进与门gi3的另一输入端子时,存储在电容器ci3中的信息被传送至指派给第二比特级信元mi2的电容器ci2,电容器ci2存储该信息。
另外,反向推进主存储器的第i行上的第二比特级信元mi3包括被配置为存储信息的电容器ci2以及推进与门gi2,所述推进与门gi2的一个输入端子连接到电容器ci2,另一输入端子被配置为被供应有时钟信号,输出端子连接到被指派给相邻第一比特级信元mi1(被分配于第i行的最左侧并连接到输出端子out)的前一推进与门gi1的一个输入端子。
根据本发明的第一实施方式的计算机系统中所使用的推进主存储器31的概念示出于图27中,这不同于现有计算机存储器,因为推进主存储器31被特意设计成具有通过推进主存储器31中的所有存储器单元u1、u2、u3、......、un-1、un存储和传输信息/数据的功能。推进存储器按照与处理器11相同的速度将信息/数据供应给处理器(cpu)11。如图9的时域关系所示,通过推进主存储器31中的一个存储器单元u1、u2、u3、......、un-1、un传送信息/数据所需的存储器单元流处理时间tmus等于处理器11中的时钟循环tcc。推进主存储器31将信息/数据存储在各个存储器单元u1、u2、u3、......、un-1、un中,并与时钟信号同步地朝着输出端子逐步传送,以向处理器11提供所存储的信息/数据,使得算术逻辑单元112可利用所存储的信息/数据执行算术和逻辑运算。
因此,如图28所示,推进存储器结构3包括本发明的第一实施方式的推进主存储器31。术语“推进存储器结构3”表示存储器结构的一般概念,除了根据本发明的第一实施方式的计算机系统中所使用的推进主存储器31之外,该存储器结构包括连接到alu112的推进指令寄存器文件(rf)22a和推进数据寄存器文件(rf)22b(将在下面的第二实施方式中进一步说明)以及推进指令高速缓冲存储器21a和推进数据高速缓冲存储器21b(将在下面的第三实施方式中进一步说明)。
图29的(a)示出从推进存储器结构3流向处理器11的前向数据流sf以及从处理器11流向推进存储器结构3的后向数据流(反向数据流)sb,图29的(a)示出假设推进存储器结构3中的存储器单元流处理时间tmus等于处理器11的时钟循环tcc,推进存储器结构3与处理器11之间建立的带宽。
推进主存储器31的方案可被视为类似于图30的(a)所示的磁带系统,其包括:磁带503、用于卷绕磁带503的卷带轮502、用于将磁带503退绕并释放的供带轮501、用于从磁带503读取信息/数据或者将信息/数据写到磁带503的读/写头504以及连接到读/写头504的处理器11。随着卷带轮502卷绕从供带轮501释放的磁带503,磁带503从供带轮501朝着卷带轮502高速移动,随着磁带503高速移动而传送的磁带503上所存储的信息/数据被读/写头504读取。并且,连接到读/写头504的处理器11可利用从磁带503读取的信息/数据执行算术和逻辑运算。另选地,处理器11中的处理结果通过读/写头504被发送给磁带503。
如果我们假定图30的(a)所示的磁带系统的架构通过半导体技术实现,即,如果我们想象如图30的(b)所示在半导体硅芯片上虚拟地建立极高速磁带系统,则图30的(a)所示的极高速磁带系统可对应于包括本发明的第一实施方式的推进主存储器31的净推进存储器结构3。图30的(b)所示的净推进存储器结构3将信息/数据存储在硅芯片上的各个存储器单元中,并且与时钟信号同步地朝着卷带轮502逐步传送,以便主动地并且顺序地向处理器11提供所存储的信息/数据,使得处理器11可利用所存储的信息/数据执行算术和逻辑运算,并且处理器11中的处理结果被发送给净推进存储器结构3。
(双向推进主存储器)
如图31的(a)-(c)所示,本发明的第一实施方式的推进主存储器31可实现信息/数据的双向传送。即,图31的(a)示出信息/数据的前向推进行为,其中在一维推进主存储器31中信息/数据朝着右手方向(前向方向)一起推进(移位),图31的(b)示出一维推进主存储器31的停留状态,图31的(c)示出信息/数据的反向推进行为(后向推进行为),其中在一维推进主存储器31中信息/数据朝着左手方向(反向方向)一起推进(移位)。
图32和图33分别示出在可实现图31的(a)-(c)所示的双向行为的双向推进主存储器31的信元阵列的晶体管层级表示中,m×n矩阵(这里,“m”是由字大小确定的整数)的第i行的代表性阵列的两个示例。双向推进主存储器31将比特级的信息/数据存储在各个信元mi1、mi2、mi3、......、mi,n-1、mi,n中,并与时钟信号同步地在第一i/o选择器512与第二i/o选择器513之间在前向方向和/或反向方向(后向方向)上逐步地双向传送信息/数据。
在图32和图33中,各个信元mi1、mi2、mi3、......、mi,n-1、mi,n分别被指派于存储器单元u1、u2、u3、......、un-1、un中。即,信元mi1被指派为第一存储器单元u1中的第一比特级信元,第一存储器单元u1通过排列于第一存储器单元u1中的比特级信元序列来存储字节大小或字大小的信息。类似地,信元mi2被指派为第二存储器单元u2中的第二比特级信元,信元mi3被指派为第三存储器单元u3中的第三比特级信元,......,信元mi,n-1被指派为第(n-1)存储器单元un-1中的第(n-1)比特级信元,信元mi,n被指派为第n存储器单元un中的第n比特级信元。并且,存储器单元u2、u3、......、un-1、un分别通过排列于存储器单元u2、u3、......、un-1、un中的比特级信元序列来存储字节大小或字大小的信息。因此,双向推进主存储器31将字节大小或字大小的信息/数据存储在各个信元u1、u2、u3、......、un-1、un中,并且同时与时钟信号同步地在第一i/o选择器512与第二i/o选择器513之间在前向方向和/或反向方向(后向方向)上双向传送字节大小或字大小的信息/数据。
时钟选择器511选择第一时钟信号供应线cl1和第二时钟信号供应线cl2。第一时钟信号供应线cl1驱动前向数据流,第二时钟信号供应线cl2驱动后向数据流,并且第一时钟信号供应线cl1和第二时钟信号供应线cl2中的每一个具有逻辑值“1”和“0”。
在图32所示的实现推进主存储器31的信元阵列的晶体管层级表示中,分配于第i行的最左侧的连接到第一i/o选择器512的第一比特级信元mi1包括:第一前向nmos晶体管qi11f,其具有通过第一前向延迟元件di11f连接到第一时钟信号供应线cl1的漏极以及通过第二前向延迟元件di12f连接到第一i/o选择器512的栅极;第二前向nmos晶体管qi12f,其具有连接到第一前向nmos晶体管qi11f的源极的漏极、连接到第一时钟信号供应线的栅极以及连接到地电势的源极;以及前向电容器ci1f,其被配置为存储信元mi1的前向信息/数据,并且与第二前向nmos晶体管qi12f并联连接,其中,连接第一前向nmos晶体管qi11f的源极和第二前向nmos晶体管qi12f的漏极的输出节点用作信元mi1的前向输出端子,并且被配置为将存储在前向电容器ci1f中的信号传送至下一比特级信元mi2。第一比特级信元mi1还包括:第一后向nmos晶体管qi11g,其具有通过第一后向延迟元件di11g连接到第二时钟信号供应线的漏极以及通过第二后向延迟元件di12g连接到比特级信元mi2的后向输出端子的栅极;第二后向nmos晶体管qi12g,其具有连接到第一后向nmos晶体管qi11g的源极的漏极、连接到第二时钟信号供应线的栅极以及连接到地电势的源极;以及后向电容器ci1g,其被配置为存储信元mi1的后向信息/数据,并且与第二后向nmos晶体管qi12g并联连接,其中,连接第一后向nmos晶体管qi11g的源极和第二后向nmos晶体管qi12g的漏极的输出节点用作信元mi1的后向输出端子,并且被配置为将存储在后向电容器ci1g中的信号传送至第一i/o选择器512。
分配于第i行的左侧第二位的连接到比特级信元mi1的第二比特级信元mi2包括:第一前向nmos晶体管qi21f,其具有通过第一前向延迟元件di21f连接到第一时钟信号供应线cl1的漏极以及通过第二前向延迟元件di22f连接到比特级信元mi1的前向输出端子的栅极;第二前向nmos晶体管qi22f,其具有连接到第一前向nmos晶体管qi21f的源极的漏极、连接到第一时钟信号供应线cl1的栅极以及连接到地电势的源极;以及前向电容器ci2f,其被配置为存储信元mi2的前向信息/数据,并且与第二前向nmos晶体管qi22f并联连接,其中,连接第一前向nmos晶体管qi21f的源极和第二前向nmos晶体管qi22f的漏极的输出节点用作信元mi2的前向输出端子,并且被配置为将存储在前向电容器ci2f中的信号传送至下一比特级信元mi3。第二比特级信元mi2还包括:第一后向nmos晶体管qi21g,其具有通过第一后向延迟元件di21g连接到第二时钟信号供应线cl2的漏极以及通过第二后向延迟元件di22g连接到比特级信元mi3的后向输出端子的栅极;第二后向nmos晶体管qi22g,其具有连接到第一后向nmos晶体管qi21g的源极的漏极、连接到第二时钟信号供应线cl2的栅极以及连接到地电势的源极;以及后向电容器ci2g,其被配置为存储信元mi2的后向信息/数据,并且与第二后向nmos晶体管qi22g并联连接,其中,连接第一后向nmos晶体管qi21g的源极和第二后向nmos晶体管qi22g的漏极的输出节点用作信元mi2的后向输出端子,并且被配置为将存储在后向电容器ci2g中的信号传送至下一比特级信元mi1。
分配于第i行的左侧第二位的连接到比特级信元mi2的第三比特级信元mi3包括:第一前向nmos晶体管qi31f,其具有通过第一前向延迟元件di31f连接到第一时钟信号供应线cl1的漏极以及通过第二前向延迟元件di32f连接到比特级信元mi2的前向输出端子的栅极;第二前向nmos晶体管qi32f,其具有连接到第一前向nmos晶体管qi31f的源极的漏极、连接到第一时钟信号供应线cl1的栅极以及连接到地电势的源极;以及前向电容器ci3f,其被配置为存储信元mi3的前向信息/数据,并且与第二前向nmos晶体管qi32f并联连接,其中,连接第一前向nmos晶体管qi31f的源极和第二前向nmos晶体管qi32f的漏极的输出节点用作信元mi3的前向输出端子,并且被配置为将存储在前向电容器ci3f中的信号传送至下一比特级信元mi4(未示出)。第三比特级信元mi3还包括:第一后向nmos晶体管qi31g,其具有通过第一后向延迟元件di31g连接到第二时钟信号供应线cl2的漏极以及通过第二后向延迟元件di32g连接到比特级信元mi4的后向输出端子的栅极;第二后向nmos晶体管qi32g,其具有连接到第一后向nmos晶体管qi31g的源极的漏极、连接到第二时钟信号供应线cl2的栅极以及连接到地电势的源极;以及后向电容器ci3g,其被配置为存储信元mi3的后向信息/数据,并且与第二后向nmos晶体管qi32g并联连接,其中,连接第一后向nmos晶体管qi31g的源极和第二后向nmos晶体管qi32g的漏极的输出节点用作信元mi3的后向输出端子,并且被配置为将存储在后向电容器ci3g中的信号传送至下一比特级信元mi2。
分配于第i行的左侧第二位的第(n-1)比特级信元mi(n-1)包括:第一前向nmos晶体管qi(n-1)1f,其具有通过第一前向延迟元件di(n-1)1f连接到第一时钟信号供应线cl1的漏极以及通过第二前向延迟元件di(n-1)2f连接到比特级信元mi(n-2)(未示出)的前向输出端子的栅极;第二前向nmos晶体管qi(n-1)2f,其具有连接到第一前向nmos晶体管qi(n-1)1f的源极的漏极、连接到第一时钟信号供应线cl1的栅极以及连接到地电势的源极;以及前向电容器ci(n-1)f,其被配置为存储信元mi(n-1)的前向信息/数据,并且与第二前向nmos晶体管qi(n-1)2f并联连接,其中,连接第一前向nmos晶体管qi(n-1)1f的源极和第二前向nmos晶体管qi(n-1)2f的漏极的输出节点用作信元mi(n-1)的前向输出端子,并且被配置为将存储在前向电容器ci(n-1)f中的信号传送至下一比特级信元min。第(n-1)比特级信元mi(n-1)还包括:第一后向nmos晶体管qi(n-1)1g,其具有通过第一后向延迟元件di(n-1)1g连接到第二时钟信号供应线cl2的漏极以及通过第二后向延迟元件di(n-1)2g连接到下一比特级信元min的后向输出端子的栅极;第二后向nmos晶体管qi(n-1)2g,其具有连接到第一后向nmos晶体管qi(n-1)1g的源极的漏极、连接到第二时钟信号供应线cl2的栅极以及连接到地电势的源极;以及后向电容器ci(n-1)g,其被配置为存储信元mi(n-1)的后向信息/数据,并且与第二后向nmos晶体管qi(n-1)2g并联连接,其中,连接第一后向nmos晶体管qi(n-1)1g的源极和第二后向nmos晶体管qi(n-1)2g的漏极的输出节点用作信元mi(n-1)的后向输出端子,并且被配置为将存储在后向电容器ci(n-1)g中的信号传送至下一比特级信元mi(n-2)(未示出)。
分配于第i行的最右侧的第n比特级信元min包括:第一前向nmos晶体管qin1f,其具有通过第一前向延迟元件din1f连接到第一时钟信号供应线cl1的漏极以及通过第二前向延迟元件din2f连接到比特级信元mi(n-1)的前向输出端子的栅极;第二前向nmos晶体管qin2f,其具有连接到第一前向nmos晶体管qin1f的源极的漏极、连接到第一时钟信号供应线cl1的栅极以及连接到地电势的源极;以及前向电容器cinf,其被配置为存储信元min的前向信息/数据,并且与第二前向nmos晶体管qin2f并联连接,其中,连接第一前向nmos晶体管qin1f的源极和第二前向nmos晶体管qin2f的漏极的输出节点用作信元min的前向输出端子,并且被配置为将存储在前向电容器cinf中的信号传送至第二i/o选择器513。第n比特级信元min还包括:第一后向nmos晶体管qin1g,其具有通过第一后向延迟元件din1g连接到第二时钟信号供应线cl2的漏极以及通过第二后向延迟元件din2g连接到第二i/o选择器513的栅极;第二后向nmos晶体管qin2g,其具有连接到第一后向nmos晶体管qin1g的源极的漏极、连接到第二时钟信号供应线cl2的栅极以及连接到地电势的源极;以及后向电容器cing,其被配置为存储信元min的后向信息/数据,并且与第二后向nmos晶体管qin2g并联连接,其中,连接第一后向nmos晶体管qin1g的源极和第二后向nmos晶体管qin2g的漏极的输出节点用作信元min的后向输出端子,并且被配置为将存储在后向电容器cing中的信号传送至下一比特级信元mi(n-1)。
当从第一时钟信号供应线cl1供应的时钟信号变为逻辑电平“1”时,第一存储器单元u1中的第二前向nmos晶体管qi12f开始使已经在前一时钟循环存储在第一存储器单元u1的前向电容器ci1f中的信号电荷放电。并且,在从第一时钟信号供应线cl1供应的逻辑电平“1”的时钟信号施加到第二前向nmos晶体管qi12f,并且存储在前向电容器ci1f中的信号电荷完全放电以变为逻辑电平“0”之后,第一前向nmos晶体管qi11f被激活成为传送晶体管(延迟了由第一前向延迟元件di11f确定的延迟时间td1)。随后,当比特级的信息/数据从第一i/o选择器512输入到第一前向nmos晶体管qi11f的栅极时,第一前向nmos晶体管qi11f将信息/数据传送至前向电容器ci1f(延迟了由第二前向延迟元件di12f确定的延迟时间td2)。当在时间前进1/2tauclock时从第一时钟信号供应线cl1供应的时钟信号变为逻辑电平“0”时,连接第一前向nmos晶体管qi11f的源极与第二前向nmos晶体管qi12f的漏极的输出节点在时间前进1/2tauclock时无法将从第一i/o选择器512输入到第一前向nmos晶体管qi11f的栅极的信息/数据进一步输送至下一比特级信元mi2,信息/数据被阻止延迟由第二前向延迟元件di22f确定的延迟时间td2=1/2tauclock传送至下一第一前向nmos晶体管qi21f的栅极。
当从第二时钟信号供应线cl2供应的时钟信号变为逻辑电平“1”时,第二后向nmos晶体管qi12b开始使已经在前一时钟循环存储在后向电容器ci1b中的信号电荷放电。在施加从第二时钟信号供应线cl2供应的逻辑电平“1”的时钟信号并且存储在后向电容器ci1b中的信号电荷完全放电以变为逻辑电平“0”之后,第一后向nmos晶体管qi11b被激活成为传送晶体管(延迟了由第一后向延迟元件di11b确定的延迟时间td1)。随后,当信息/数据从比特级信元mi2的后向输出端子被馈送至第一后向nmos晶体管qi11b的栅极时,第一后向nmos晶体管qi11b将存储在前一比特级信元mi2中的信息/数据传送至后向电容器ci1b(进一步延迟了由第二后向延迟元件di12b确定的延迟时间td2)。连接第一后向nmos晶体管qi11b的源极和第二后向nmos晶体管qi12b的漏极的输出节点将存储在后向电容器ci1b中的信息/数据输送至第一i/o选择器512。
并且,当从第一时钟信号供应线cl1供应的下一时钟信号变为逻辑电平“1”时,第二存储器单元u2中的第二前向nmos晶体管qi22f开始使已经在前一时钟循环存储在第二存储器单元u2的前向电容器ci2f中的信号电荷放电。并且,在从第一时钟信号供应线cl1供应的逻辑电平“1”的时钟信号施加到第二前向nmos晶体管qi22f,并且存储在前向电容器ci2f中的信号电荷完全放电以变为逻辑电平“0”之后,第一前向nmos晶体管qi2f1被激活成为传送晶体管(延迟了由第一前向延迟元件di21f确定的延迟时间td1)。随后,当存储在前一前向电容器ci1f中的比特级的信息/数据被馈送至第一前向nmos晶体管qi21f的栅极时,第一前向nmos晶体管qi21f将信息/数据传送至前向电容器ci2f(延迟了由第二前向延迟元件di22f确定的延迟时间td2)。当在时间前进1/2tauclock时从第一时钟信号供应线cl1供应的时钟信号变为逻辑电平“0”时,连接第一前向nmos晶体管qi21f的源极与第二前向nmos晶体管qi22f的漏极的输出节点在时间前进1/2tauclock时无法将输入到第一前向nmos晶体管qi21f的栅极的信息/数据进一步输送至下一比特级信元mi3,信息/数据被阻止延迟由第二前向延迟元件di32f确定的延迟时间td2=1/2tauclock传送至下一第一前向nmos晶体管qi31f的栅极。
当从第二时钟信号供应线cl2供应的时钟信号变为逻辑电平“1”时,第二后向nmos晶体管qi22b开始使已经在前一时钟循环存储在后向电容器ci2b中的信号电荷放电。在施加从第二时钟信号供应线cl2供应的逻辑电平“1”的时钟信号并且存储在后向电容器ci2b中的信号电荷完全放电以变为逻辑电平“0”之后,第一后向nmos晶体管qi21b被激活成为传送晶体管(延迟了由第一后向延迟元件di21b确定的延迟时间td1)。随后,当信息/数据从比特级信元mi3的后向输出端子被馈送至第一后向nmos晶体管qi21b的栅极时,第一后向nmos晶体管qi21b将存储在前一比特级信元mi3中的信息/数据传送至后向电容器ci2b(进一步延迟了由第二后向延迟元件di22b确定的延迟时间td2)。当在时间前进1/2tauclock时从第二时钟信号供应线cl2供应的时钟信号变为逻辑电平“0”时,连接第一后向nmos晶体管qi21b的源极与第二后向nmos晶体管qi22b的漏极的输出节点在时间前进1/2tauclock时无法将输入到第一后向nmos晶体管qi21b的栅极的信息/数据进一步输送至下一比特级信元mi1,信息/数据被阻止延迟由第二后向延迟元件di12b确定的延迟时间td2=1/2tauclock传送至下一第一后向nmos晶体管qi11b的栅极。
并且,当从第一时钟信号供应线cl1供应的下一时钟信号变为逻辑电平“1”时,第三存储器单元u3中的第二前向nmos晶体管qi32f开始使已经在前一时钟循环存储在第三存储器单元u3的前向电容器ci3f中的信号电荷放电。并且,在从第一时钟信号供应线cl1供应的逻辑电平“1”的时钟信号施加到第二前向nmos晶体管qi32f,并且存储在前向电容器ci3f中的信号电荷完全放电以变为逻辑电平“0”之后,第一前向nmos晶体管qi3f1被激活成为传送晶体管(延迟了由第一前向延迟元件di31f确定的延迟时间td1)。随后,当存储在前一前向电容器ci2f中的信息/数据被馈送至第一前向nmos晶体管qi31f的栅极时,第一前向nmos晶体管qi31f将信息/数据传送至前向电容器ci3f(延迟了由第二前向延迟元件di32f确定的延迟时间td2)。当在时间前进1/2tauclock时从第一时钟信号供应线cl1供应的时钟信号变为逻辑电平“0”时,连接第一前向nmos晶体管qi31f的源极与第二前向nmos晶体管qi32f的漏极的输出节点在时间前进1/2tauclock时无法将输入到第一前向nmos晶体管qi31f的栅极的信息/数据进一步输送至下一比特级信元mi4(未示出),信息/数据被阻止延迟由第二前向延迟元件di32f(未示出)确定的延迟时间td2=1/2tauclock传送至下一第一前向nmos晶体管qi41f(未示出)的栅极。
当从第二时钟信号供应线cl2供应的时钟信号变为逻辑电平“1”时,第二后向nmos晶体管qi32b开始使已经在前一时钟循环存储在后向电容器ci3b中的信号电荷放电。在施加从第二时钟信号供应线cl2供应的逻辑电平“1”的时钟信号并且存储在后向电容器ci3b中的信号电荷完全放电以变为逻辑电平“0”之后,第一后向nmos晶体管qi31b被激活成为传送晶体管(延迟了由第一后向延迟元件di31b确定的延迟时间td1)。随后,当信息/数据从比特级信元mi3的后向输出端子被馈送至第一后向nmos晶体管qi31b的栅极时,第一后向nmos晶体管qi31b将存储在前一比特级信元mi3中的信息/数据传送至后向电容器ci3b(进一步延迟了由第二后向延迟元件di32b确定的延迟时间td2)。当在时间前进1/2tauclock时从第二时钟信号供应线cl2供应的时钟信号变为逻辑电平“0”时,连接第一后向nmos晶体管qi31b的源极与第二后向nmos晶体管qi32b的漏极的输出节点在时间前进1/2tauclock时无法将输入到第一后向nmos晶体管qi31b的栅极的信息/数据进一步输送至下一比特级信元mi2,信息/数据被阻止延迟由第二后向延迟元件di22b确定的延迟时间td2=1/2tauclock传送至下一第一后向nmos晶体管qi21b的栅极。
并且,当从第一时钟信号供应线cl1供应的下一时钟信号变为逻辑电平“1”时,第三存储器单元u(n-1)中的第二前向nmos晶体管qi(n-1)2f开始使已经在前一时钟循环存储在第三存储器单元u(n-1)的前向电容器ci(n-1)f中的信号电荷放电。并且,在从第一时钟信号供应线cl1供应的逻辑电平“1”的时钟信号施加到第二前向nmos晶体管qi(n-1)2f,并且存储在前向电容器ci(n-1)f中的信号电荷完全放电以变为逻辑电平“0”之后,第一前向nmos晶体管qi(n-1)1f被激活成为传送晶体管(延迟了由第一前向延迟元件di(n-1)1f确定的延迟时间td1)。随后,当存储在前一前向电容器ci2f中的信息/数据被馈送至第一前向nmos晶体管qi(n-1)1f的栅极时,第一前向nmos晶体管qi(n-1)1f将信息/数据传送至前向电容器ci(n-1)f(延迟了由第二前向延迟元件di(n-1)2f确定的延迟时间td2)。当在时间前进1/2tauclock时从第一时钟信号供应线cl1供应的时钟信号变为逻辑电平“0”时,连接第一前向nmos晶体管qi(n-1)1f的源极与第二前向nmos晶体管qi(n-1)2f的漏极的输出节点在时间前进1/2tauclock时无法将输入到第一前向nmos晶体管qi(n-1)1f的栅极的信息/数据进一步输送至下一比特级信元min,信息/数据被阻止延迟由第二前向延迟元件din2f确定的延迟时间td2=1/2tauclock传送至下一第一前向nmos晶体管qin1f的栅极。
当从第二时钟信号供应线cl2供应的时钟信号变为逻辑电平“1”时,第二后向nmos晶体管qi(n-1)2b开始使已经在前一时钟循环存储在后向电容器ci(n-1)b中的信号电荷放电。在施加从第二时钟信号供应线cl2供应的逻辑电平“1”的时钟信号并且存储在后向电容器ci(n-1)b中的信号电荷完全放电以变为逻辑电平“0”之后,第一后向nmos晶体管qi(n-1)1b被激活成为传送晶体管(延迟了由第一后向延迟元件di(n-1)1b确定的延迟时间td1)。随后,当信息/数据从比特级信元mi(n-1)的后向输出端子被馈送至第一后向nmos晶体管qi(n-1)1b的栅极时,第一后向nmos晶体管qi(n-1)1b将存储在前一比特级信元mi(n-1)中的信息/数据传送至后向电容器ci(n-1)b(进一步延迟了由第二后向延迟元件di(n-1)2b确定的延迟时间td2)。当在时间前进1/2tauclock时从第二时钟信号供应线cl2供应的时钟信号变为逻辑电平“0”时,连接第一后向nmos晶体管qi(n-1)1b的源极与第二后向nmos晶体管qi(n-1)2b的漏极的输出节点在时间前进1/2tauclock时无法将输入到第一后向nmos晶体管qi(n-1)1b的栅极的信息/数据进一步输送至下一比特级信元mi(n-2)(未示出),信息/数据被阻止延迟由第二后向延迟元件di(n-2)2b(未示出)确定的延迟时间td2=1/2tauclock传送至下一第一后向nmos晶体管qi(n-2)1b(未示出)的栅极。
并且,当从第一时钟信号供应线cl1供应的下一时钟信号变为逻辑电平“1”时,第三存储器单元un中的第二前向nmos晶体管qin2f开始使已经在前一时钟循环存储在第三存储器单元un的前向电容器cinf中的信号电荷放电。并且,在从第一时钟信号供应线cl1供应的逻辑电平“1”的时钟信号施加到第二前向nmos晶体管qin2f,并且存储在前向电容器cinf中的信号电荷完全放电以变为逻辑电平“0”之后,第一前向nmos晶体管qin1f被激活成为传送晶体管(延迟了由第一前向延迟元件din1f确定的延迟时间td1)。随后,当存储在前一前向电容器ci2f中的信息/数据被馈送至第一前向nmos晶体管qin1f的栅极时,第一前向nmos晶体管qin1f将信息/数据传送至前向电容器cinf(延迟了由第二前向延迟元件din2f确定的延迟时间td2)。连接第一前向nmos晶体管qin1f的源极与第二前向nmos晶体管qin2f的漏极的输出节点将输入到第一前向nmos晶体管qin1f的栅极的信息/数据输送至第二i/o选择器513。
当从第二时钟信号供应线cl2供应的时钟信号变为逻辑电平“1”时,第二后向nmos晶体管qin2b开始使已经在前一时钟循环存储在后向电容器cinb中的信号电荷放电。在施加从第二时钟信号供应线cl2供应的逻辑电平“1”的时钟信号并且存储在后向电容器cinb中的信号电荷完全放电以变为逻辑电平“0”之后,第一后向nmos晶体管qin1b被激活成为传送晶体管(延迟了由第一后向延迟元件din1b确定的延迟时间td1)。随后,当信息/数据从第二i/o选择器513被馈送至第一后向nmos晶体管qin1b的栅极时,第一后向nmos晶体管qin1b将从第二i/o选择器513接收的信息/数据传送至后向电容器cinb(进一步延迟了由第二后向延迟元件din2b确定的延迟时间td2)。当在时间前进1/2tauclock时从第二时钟信号供应线cl2供应的时钟信号变为逻辑电平“0”时,连接第一后向nmos晶体管qin1b的源极与第二后向nmos晶体管qin2b的漏极的输出节点在时间前进1/2tauclock时无法将输入到第一后向nmos晶体管qin1b的栅极的信息/数据进一步输送至下一比特级信元mi(n-2)(未示出),信息/数据被阻止延迟由第二后向延迟元件di(n-2)2b(未示出)确定的延迟时间td2=1/2tauclock传送至下一第一后向nmos晶体管qi(n-2)1b(未示出)的栅极。
因此,在图32所示的双向推进主存储器中,双向推进主存储器的第i行上的各个信元mi1、mi2、mi3、......、mi,(n-1)、mi,n存储信息/数据,并且与从第一时钟信号供应线cl1和第二时钟信号供应线cl2分别供应的时钟信号同步地在第一i/o选择器512与第二i/o选择器513之间逐步地双向传送信息/数据。如已经说明的,由于各个信元mi1、mi2、mi3、......、mi,(n-1)、mi,n分别被指派于存储器单元u1、u2、u3、......、un-1、un中,并且存储器单元u2、u3、......、un-1、un分别通过排列于存储器单元u2、u3、......、un-1、un中的比特级信元序列来存储字节大小或字大小的信息,图32所示的双向推进主存储器31将字节大小或字大小的信息/数据存储在各个信元u1、u2、u3、......、un-1、un中,并与时钟信号同步地在第一i/o选择器512与第二i/o选择器513之间在前向方向和/或反向方向(后向方向)上同时将字节大小或字大小的信息/数据双向传送,以主动地并且顺序地向处理器11提供所存储的字节大小或字大小的信息/数据,使得alu112可利用所存储的信息/数据执行算术和逻辑运算。
如图33所示,前向隔离晶体管qi23f被设置用于将第二存储器单元un中的第二比特级信元mi2的信号存储状态与第一存储器单元u1中的第一比特级信元mi1的信号存储状态隔离,前向隔离晶体管qi23f按照由通过第一时钟信号供应线cl1供应的时钟信号确定的所需定时将信号从第一比特级信元mi1至第二比特级信元mi2前向传送。并且,后向隔离晶体管qi13b被设置用于将第一存储器单元u1中的第一比特级信元mi1的信号存储状态与第二存储器单元u2中的第一比特级信元mi2的信号存储状态隔离,后向隔离晶体管qi13b按照由通过第二时钟信号供应线cl2供应的时钟信号确定的所需定时将信号从第二比特级信元mi2至第一比特级信元mi1后向传送。然后,与存储器单元u1和u2并行排列的前向隔离晶体管的序列qi23f(i=1至m;“m”是与字节大小或字大小对应的整数)按照通过时钟信号供应线cl1供应的时钟信号的控制前向传送字节大小或字大小的信息,使得字节大小或字大小的信息可沿着前向方向同时推进。并且,与存储器单元u1和u2并行排列的后向隔离晶体管的序列qi13b(i=1至m)按照通过时钟信号供应线cl2供应的时钟信号的控制后向传送字节大小或字大小的信息,使得字节大小或字大小的信息可沿着后向方向同时推进。
并且,类似地,后向隔离晶体管qi23b被设置用于将第二存储器单元u2中的第二比特级信元mi2的信号存储状态与第三存储器单元u3中的第三比特级信元mi3(未示出)的信号存储状态隔离,后向隔离晶体管qi23b按照由通过第三时钟信号供应线cl2供应的时钟信号确定的所需定时将信号从第三比特级信元mi3至第二比特级信元mi2后向传送。并且,与存储器单元u2和u3并行排列的后向隔离晶体管的序列qi23b(i=1至m)按照通过时钟信号供应线cl2供应的时钟信号的控制后向传送字节大小或字大小的信息,使得字节大小或字大小的信息可沿着后向方向同时推进。
另外,如图33所示,前向隔离晶体管qi(n-1)3f被设置用于将第(n-1)存储器单元un-1中的第(n-1)比特级信元mi(n-1)的信号存储状态与第(n-2)存储器单元un-2(未示出)中的第(n-2)比特级信元mi(n-2)(未示出)的信号存储状态隔离,前向隔离晶体管qi(n-1)3f按照由通过第一时钟信号供应线cl1供应的时钟信号确定的所需定时将信号从第(n-2)比特级信元mi(n-2)至第(n-1)比特级信元mi(n-1)前向传送。然后,与存储器单元un-2和un-1并行排列的前向隔离晶体管的序列qi(n-1)3f(i=1至m)按照通过时钟信号供应线cl1供应的时钟信号的控制传送字节大小或字大小的信息,使得字节大小或字大小的信息可沿着前向方向同时推进。
并且,前向隔离晶体管qin3f被设置用于将第n存储器单元un中的第n比特级信元min的信号存储状态与第(n-1)存储器单元un-1中的第(n-1)比特级信元mi(n-1)的信号存储状态隔离,前向隔离晶体管qin3f按照由通过第一时钟信号供应线cl1供应的时钟信号确定的所需定时将信号从第(n-1)比特级信元mi(n-1)至第n比特级信元min前向传送。并且,后向隔离晶体管qin3b被设置用于将第(n-1)存储器单元un-1中的第(n-1)比特级信元min-1的信号存储状态与第n存储器单元un中的第n比特级信元min的信号存储状态隔离,后向隔离晶体管qin3b按照由通过第二时钟信号供应线cl2供应的时钟信号确定的所需定时将信号从第n比特级信元min至第(n-1)比特级信元min-1后向传送。然后,与存储器单元un-1和un并行排列的前向隔离晶体管的序列qin3f(i=1至m)按照通过时钟信号供应线cl1供应的时钟信号的控制传送字节大小或字大小的信息,使得字节大小或字大小的信息可沿着前向方向同时推进。并且,与存储器单元un-1和un并行排列的后向隔离晶体管的序列qin3b(i=1至m)按照通过时钟信号供应线cl2供应的时钟信号的控制传送字节大小或字大小的信息,使得字节大小或字大小的信息可沿着后向方向同时推进。
在图32和图33所示的双向推进主存储器的配置中,前向电容器cijf和后向电容器cij应该优选被合并为单个公共电容器,以实现具有高局部性(locality)的随机存取模式。图34示出在图31的(a)-(c)所示的双向行为中可实现随机存取模式的双向推进主存储器31的门层级表示中的m×n矩阵(这里,“m”是由字大小确定的整数)的第i行的阵列。
如图34所示,两种类型的推进与门被指派给第i行上的各个信元mi1、mi2、mi3、......、mi,(n-1)、mi,n以利用随机存取模式建立信息/数据的双向传送。双向推进主存储器31将比特级的信息/数据存储在各个信元mi1、mi2、mi3、......、mi,(n-1)、mi,n中,并与时钟信号同步地在第一i/o选择器512与第二i/o选择器513之间在前向方向和/或反向方向(后向方向)上逐步将信息/数据双向传送。
在图34所示的实现推进主存储器31的信元阵列的门层级表示中,分配于第i行的最左侧并连接到第一i/o选择器512的第一比特级信元mi1包括:公共电容器ci1,其被配置为存储信息/数据;前向推进与门gi1f,其一个输入端子连接到公共电容器ci1,另一输入端子被供应有第一时钟信号供应线cl1,输出端子连接到被指派给第i行上的相邻第二比特级信元m(i+1)1的下一前向推进与门g(i+1)1f的一个输入端子;以及后向推进与门gi1b,其一个输入端子连接到公共电容器ci1,另一输入端子被供应有第二时钟信号供应线cl2,输出端子连接到第一i/o选择器512。
通过时钟选择器511分别选择被配置为驱动前向数据流的第一时钟信号供应线cl1以及被配置为驱动后向数据流的第二时钟信号供应线cl2,第一时钟信号供应线cl1和第二时钟信号供应线cl2中的每一个具有逻辑值“1”和“0”。当第一时钟信号供应线cl1的逻辑值“1”被馈送至前向推进与门gi1的另一输入端子时,存储在公共电容器ci1中的信息/数据被传送至指派给相邻第二比特级信元mi2的公共电容器ci2,公共电容器ci2存储所述信息/数据。
双向推进主存储器31的第i行上的第二比特级信元mi2包括:公共电容器ci2,其被配置为存储信息/数据;前向推进与门gi2f,其一个输入端子连接到公共电容器ci2,另一输入端子被供应有第一时钟信号供应线cl1,输出端子连接到被指派给第i行上的相邻第三比特级信元mi3的下一前向推进与门g13的一个输入端子;以及后向推进与门gi2b,其一个输入端子连接到公共电容器ci2,另一输入端子被供应有第二时钟信号供应线cl2,输出端子连接到前一后向推进与门gi1的一个输入端子。
类似地,第i行上的第三比特级信元mi3包括:公共电容器ci3,其被配置为存储信息/数据;前向推进与门gi3f,其一个输入端子连接到公共电容器ci3,另一输入端子被供应有第一时钟信号供应线cl1,输出端子连接到被指派给相邻第四信元(尽管第四信元未示出)的下一前向推进与门的一个输入端子;以及后向推进与门gi3b,其一个输入端子连接到公共电容器ci3,另一输入端子被供应有第二时钟信号供应线cl2,输出端子连接到指派给相邻第二比特级信元mi2的前一后向推进与门gi2b的一个输入端子。因此,当第一时钟信号供应线cl1的逻辑值“1”被馈送至前向推进与门gi2f的另一输入端子时,存储在公共电容器ci2中的信息/数据被传送至指派给第三比特级信元mi3的公共电容器ci3,公共电容器ci3存储所述信息/数据,并且当第一时钟信号供应线cl1的逻辑值“1”被馈送至前向推进与门gi3f的另一输入端子时,存储在公共电容器ci3中的信息/数据被传送至指派给第四信元的电容器。
另外,第i行上的第(n-1)比特级信元mi,(n-1)包括:公共电容器ci,(n-1),其被配置为存储信息/数据;前向推进与门gi,(n-1)f,其一个输入端子连接到公共电容器ci,(n-1),另一输入端子被供应有第一时钟信号供应线cl1,输出端子连接到被指派给相邻第n比特级信元mi,n(被分配于第i行的最右侧并连接到第二i/o选择器513)的下一前向推进与门gi,nf的一个输入端子;以及后向推进与门gi,(n-1)b,其一个输入端子连接到公共电容器ci,(n-1),另一输入端子被供应有第二时钟信号供应线cl2,输出端子连接到指派给相邻第三比特级信元mi,(n-2)b(未示出)的前一后向推进与门gi,(n-2)b的一个输入端子。
最后,分配于第i行的最右侧并连接到第二i/o选择器513的第n比特级信元mi,n包括:公共电容器cin,其被配置为存储信息/数据;后向推进与门ginb,其一个输入端子连接到公共电容器cin,另一输入端子被配置为被供应有第二时钟信号供应线cl2,输出端子连接到指派给第i行上的相邻第(n-1)比特级信元mi,n-1的前一后向推进与门gi(n-1)b的一个输入端子;以及前向推进与门gi,nf,其一个输入端子连接到公共电容器ci,n-1,另一输入端子被配置为被供应有第一时钟信号供应线cl1,输出端子连接到第二i/o选择器513。
当第二时钟信号供应线cl2的逻辑值“1”被馈送至后向推进与门ginb的另一输入端子时,存储在公共电容器cin中的信息/数据被传送至指派给第i行上的相邻第(n-1)比特级信元mi,(n-1)的公共电容器ci,(n-1),公共电容器ci,(n-1)存储所述信息/数据。然后,当第二时钟信号供应线cl2的逻辑值“1”被馈送至后向推进与门gi3b的另一输入端子时,存储在公共电容器ci3中的信息/数据被传送至指派给第2比特级信元mi2的公共电容器ci2,公共电容器ci2存储所述信息/数据。另外,当第二时钟信号供应线cl2的逻辑值“1”被馈送至后向推进与门gi2b的另一输入端子时,存储在公共电容器ci2中的信息/数据被传送至指派给第二比特级信元mi1的公共电容器ci1,公共电容器ci1存储所述信息/数据,并且当第二时钟信号供应线cl2的逻辑值“1”被馈送至后向推进与门gi1b的另一输入端子时,存储在公共电容器ci1中的信息/数据被传送至第一i/o选择器512。
因此,双向推进主存储器的第i行上的各个信元mi1、mi2、mi3、......、mi,(n-1)、mi,n存储信息/数据,并且与从第一时钟信号供应线cl1和第二时钟信号供应线cl2分别供应的时钟信号同步地在第一i/o选择器512与第二i/o选择器513之间逐步地双向传送信息/数据。由于各个信元mi1、mi2、mi3、......、mi,(n-1)、mi,n分别被指派于存储器单元u1、u2、u3、......、un-1、un中,并且存储器单元u2、u3、......、un-1、un分别通过排列于存储器单元u2、u3、......、un-1、un中的比特级信元序列来存储字节大小或字大小的信息,图34所示的双向推进主存储器31将字节大小或字大小的信息/数据存储在各个信元u1、u2、u3、......、un-1、un中,并与时钟信号同步地在第一i/o选择器512与第二i/o选择器513之间在前向方向和/或反向方向(后向方向)上同时将字节大小或字大小的信息/数据双向传送,以主动地并且顺序地向处理器11提供所存储的字节大小或字大小的信息/数据,使得alu112可利用所存储的信息/数据执行算术和逻辑运算。
(位置指示策略)
图35的(a)示出与处理器相邻的一维推进主存储器中的指令的双向传送模式,其中指令朝着处理器移动,并且从下一存储器/向下一存储器移动。图35的(b)示出与alu112相邻的一维推进主存储器中的标量数据的双向传送模式,所述标量数据朝着alu移动,并且从下一存储器/向下一存储器移动。图35的(c)示出与流水线117(将在下面的第三实施方式中说明)相邻的一维推进主存储器中的向量/流数据的单向传送模式,所述向量/流数据朝着流水线117移动,并且从下一存储器移动。
根据第一实施方式的计算机系统中所使用的推进主存储器31使用定位来标识向量/流数据中的连续的存储器单元集合u1、u2、u3、......、un-1、un的起始点和结束点。另一方面,对于程序和标量数据,各个项必须具有类似于传统地址的位置索引。图36的(a)示出传统主存储器的配置,其中每一个存储器单元u1、u2、u3、......、un-1、un通过地址a1、a2、a3、......、an-1、an来标记,图36的(b)示出一维推进主存储器的配置,其中各个存储器单元u1、u2、u3、......、un-1、un的定位并不总是必要的,但是各个存储器单元u1、u2、u3、......、un-1、un的定位至少对于标识向量/流数据中的连续的存储器单元集合的起始点和结束点而言是必要的。
图37的(a)示出本发明的一维推进主存储器的内部配置,其中类似现有地址的位置索引对于标量指令is而言没有必要,但是各个存储器单元的定位至少对于标识向量指令iv中的连续的存储器单元集合的起始点和结束点而言是必要的,如带阴影线的圆所指示的。图37的(b)示出本发明的一维推进主存储器的内部配置,其中位置索引对于标量数据“b”和“a”而言没有必要。然而,如图37的(c)所示,位置索引至少对于标识向量/流数据中的连续的存储器单元集合“o”、“p”、“q”、“r”、“s”、“t”、......的起始点和结束点而言是必要的,如带阴影线的圆所指示的。
在除了根据本发明的第一实施方式的计算机系统中所使用的推进主存储器31之外,包括连接到alu112的推进指令寄存器文件22a和推进数据寄存器文件22b(将在下面的第二实施方式中说明)以及推进指令高速缓冲存储器21a和推进数据高速缓冲存储器21b(将在下面的第三实施方式中说明)的推进存储器族中,主存储器、寄存器文件和高速缓冲存储器之间的关系基于引用局部性的特性具有它们自己的位置指示策略。
图38的(a)示意性地示出对于向量/流数据情况,通过多页pi-1,j-1、pi,j-1、pi+1,j-1、pi+2,j-1、pi-1,j、pi,j、pi+1,j、pi+2,j实现的本发明的推进主存储器的总体配置的示例。图38的(b)示意性地示出对于向量/流数据情况,通过多个文件f1、f2、f3、f4实现的带阴影线的页pi,j的配置的示例,各个页pi-1,j-1、pi,j-1、pi+1,j-1、pi+2,j-1、pi-1,j、pi,j、pi+1,j、pi+2,j可用于第三实施方式中的推进高速缓冲存储器21a和21b。图38的(c)示意性地示出对于向量/流数据情况,带阴影线的文件f3的配置的示例,各个文件f1、f2、f3、f4通过多个存储器单元u1、u2、u3、......、un-1、un实现,各个文件f1、f2、f3、f4可用于第二实施方式中的推进寄存器文件22a和22b。
类似地,图39的(a)示意性地示出对于程序/标量数据情况,通过多页pr-1,s-1、pr,s-1、pr+1,s-1、pr+2,s-1、pr-1,s、pr,s、pr+1,s、pr+2,s实现的本发明的推进主存储器的总体配置的示例,其中各个页具有它自己的位置索引作为地址。图39的(b)示意性地示出对于程序/标量数据情况,带阴影线的页pr-1,s的配置的示例以及使用二进制位的页pr-1,s的驱动位置,各个页pr-1,s-1、pr,s-1、pr+1,s-1、pr+2,s-1、pr-1,s、pr,s、pr+1,s、pr+2,s通过多个文件f1、f2、f3、f4实现。各个页pr-1,s-1、pr,s-1、pr+1,s-1、pr+2,s-1、pr-1,s、pr,s、pr+1,s、pr+2,s可用于第三实施方式中的推进高速缓冲存储器21a和21b,其中各个文件f1、f2、f3、f4具有它自己的位置索引作为地址。图39的(c)示意性地示出对于程序/标量数据情况,带阴影线的文件f3的配置的示例以及使用二进制位0、1、2、3的文件f3的驱动位置,各个文件f1、f2、f3、f4通过多个存储器单元u1、u2、u3、......、un、un+1、un+2、un+3、un+4、un+5实现。各个文件f1、f2、f3、f4可用于第二实施方式中的推进寄存器文件22a和22b,其中各个存储器单元u1、u2、u3、......、un、un+1、un+2、un+3、un+4、un+5具有它自己的位置索引n+4、n+3、n+2、......、5、4、3、2、1、0作为地址。图39的(c)表示通过二进制位用于所有情况的位置指示策略。
如图39的(c)所示,在具有与推进寄存器文件的大小对应的等效大小的存储器结构中,n个二进制位分别在2n个存储器单元当中标识单个存储器单元。并且,如图39的(b)所示,一个页的结构具有与推进高速缓冲存储器的大小对应的等效大小,其由两位表示,这两位标识四个文件f1、f2、f3、f4,而如图39的(a)所示,一个推进主存储器的结构由三位表示,这三位标识推进主存储器中的八个页pr-1,s-1、pr,s-1、pr+1,s-1、pr+2,s-1、pr-1,s、pr,s、pr+1,s、pr+2,s。
(速度/能力)
传统计算机系统中的存储器存取时间与cpu循环时间之间的速度间隙为例如1:100。然而,在第一实施方式的计算机系统中,推进存储器存取时间的速度等于cpu循环时间。图40比较了没有高速缓存的传统计算机系统与被配置为用在根据本发明的第一实施方式的计算机系统中的推进主存储器31的速度/能力。即,图40的(b)示意性地示出通过一百个存储器单元u1、u2、u3、......、u100实现的推进主存储器31的速度/能力,并且与图40的(a)所示的现有存储器的速度/能力进行比较。在存在使用来自推进主存储器31的数据的必要处理单元的条件下,我们还可以支持推进主存储器31的99个附加同时存储器单元。因此,估计传统计算机系统中的一个存储器单元时间tmue等于一百个根据本发明的第一实施方式的推进主存储器31的存储器单元流处理时间tmus。
并且,图41比较了对于标量数据或程序指令,现有存储器的最差情况的速度/能力与被配置为用在根据本发明的第一实施方式的计算机系统中的推进主存储器31的速度/能力。即,图41的(b)的带阴影线部分示意性地示出通过一百个存储器单元u1、u2、u3、......、u100实现的推进主存储器31的速度/能力,并且与图41的(a)所示的现有存储器的最差情况的速度/能力进行了比较。在最差情况下,我们可读出推进主存储器31的99个存储器单元,但是它们由于标量程序的要求而不可用。
另外,图42比较了对于标量数据或程序指令,现有存储器的典型情况的速度/能力与被配置为用在根据本发明的第一实施方式的计算机系统中的推进主存储器31的速度/能力。即,图42的(b)示意性地示出通过一百个存储器单元u1、u2、u3、......、u100实现的推进主存储器31的速度/能力,并且与图42的(a)所示的现有存储器的典型情况的速度/能力进行了比较。在该典型情况下,我们可读出99个存储器单元,但是通过标量程序中的预测性数据准备,仅几个存储器单元可用,如现有存储器中的带阴影线的存储器单元所示。
图43比较了对于标量数据情况,现有存储器的典型情况的速度/能力与被配置为用在根据本发明的第一实施方式的计算机系统中的推进主存储器31的速度/能力。即,图43的(b)示意性地示出通过一百个存储器单元u1、u2、u3、......、u100实现的推进主存储器31的速度/能力,并且与图43的(a)所示的现有存储器的速度/能力进行了比较。类似于图34(a)-(b)所示的情况,在该典型情况下,我们可读出99个存储器单元,但是通过多线程并行处理中的标量数据或程序指令中的预测性数据准备,仅几个存储器单元可用,如现有存储器中的带阴影线的存储器单元所示。
图44比较了对于流数据、向量数据或程序指令情况,现有存储器的最佳情况的速度/能力与被配置为用在根据本发明的第一实施方式的计算机系统中的推进主存储器31的速度/能力。即,图44的(b)示意性地示出通过一百个存储器单元u1、u2、u3、......、u100实现的推进主存储器31的速度/能力,并且与图44的(a)所示的现有存储器的最佳情况的速度/能力进行了比较。在该最佳情况下,我们可理解,推进主存储器31的一百个存储器单元可用于流数据和数据并行。
(二维推进主存储器)
存储器单元可如图45-51所示在芯片上二维布置,使得可在没有开关/网络的情况下实现各种模式的操作。根据图45-51所示的第一实施方式的二维推进主存储器31,存储器单元u11、u12、u13、......、u1,v-1、u1v;u22、u22、u23、......、u2,v-2、u2v;......;uu1、uu2、uu3、......、uu,v-1、uuv不需要刷新,因为所有存储器单元u11、u12、u13、......、u1,v-1、u1v;u22、u22、u23、......、u2,v-2、u2v;......;uu1、uu2、uu3、......、uu,v-1、uuv通常由于信息移动方案(信息推进方案)而自动刷新。那么对各个存储器单元u11、u12、u13、......、u1,v-1、u1v;u22、u22、u23、......、u2,v-2、u2v;......;uu1、uu2、uu3、......、uu,v-1、uuv的寻址也不复存在,所需信息朝着其连接到存储器边缘的目的地单元进发。第一实施方式的二维推进主存储器31的存取机制确实是传统计算机系统中的从寻址模式开始以读/写信息的现有存储器方案的替代方式。因此,根据第一实施方式的二维推进主存储器31,第一实施方式的计算机系统中的没有寻址模式的存储器存取处理比传统计算机系统的现有存储器方案简单很多。
(能耗)
为了使根据本发明的第一实施方式的计算机系统的架构、设计和实现方式的改进之处清楚,将说明能耗方面的改进。图52的(a)示出微处理器中的能耗,其可分解为静态功耗和动态功耗。在图52的(a)所示的动态功耗中,图52的(b)中显著示出了功耗的净值和开销(overhead)。如图52的(c)所示,对于在计算机系统中进行给定作业而言,实际上仅净能量部分是必要的,因此这些纯能量部分构成运行计算机系统的最小能耗。这意味着通过图52的(c)所示的净能耗实现最短的处理时间。
即使对处理器的架构、设计和实现方式进行了一些努力,如图1所示在传统架构中仍存在瓶颈。在传统架构中,在冯·诺伊曼计算机中存在如下各种问题:
1)程序像数据一样存储在存储器中;
2)所有处理基本上在单处理器中顺序进行;
3)程序的操作是指令的顺序执行;
4)向量数据由cpu利用向量指令顺序处理;
5)流数据利用线程顺序处理;
6)程序,进而线程,顺序排列;
7)数据并行由作为向量的数据排列组成:以及
8)流数据是数据的流。
从传统计算机的特性,我们总结出,程序和数据的存储基本上是顺序排列的方式。这一事实意味着程序和对应数据中存在指令的规则排列。
在图2所示的根据本发明的第一实施方式的计算机系统中,推进主存储器31中的指令存取是不必要的,因为指令由它们自己主动存取至处理器11。类似地,推进主存储器31中的数据存取是不必要的,因为数据由它们自己主动存取至处理器11。
图53示出在传统架构中,包括寄存器和高速缓存的处理器上的实际能耗分布,其由williamj.dally等人在“efficientembeddedcomputing”(computer,第41卷,2008年第7期,第27-32页)中估计得到。在图53中,公开了仅在除了芯片之间的线之外的整个芯片上估计功耗分布。根据dally等人的研究,指令供应功耗被估计为42%,数据供应功耗被估计为28%,时钟和控制逻辑功耗被估计为24%,算术功耗被估计为6%。因此,我们可以理解,指令供应和数据供应功耗相对大于时钟/控制逻辑功耗和算术功耗,这归因于除了所有存储器、高速缓存和寄存器的不刷新之外,利用大量线的高速缓存/寄存器存取的低效率以及由这些高速缓存和寄存器的存取方式引起的一些软件开销。
由于指令供应功耗与数据供应功耗之比为3:2,时钟和控制逻辑功耗与算术功耗之比为4:1,依据图2所示的根据本发明的第一实施方式的计算机系统,我们可以至少部分地利用推进主存储器31来容易地将数据供应功耗降低至20%,使得指令供应功耗变为30%,同时我们可将算术功耗增大至10%,使得时钟和控制逻辑功耗变为40%,这意味着可使指令供应功耗与数据供应功耗之和为50%,并且可使时钟和控制逻辑功耗与算术功耗之和为50%。
如果我们将数据供应功耗降低至10%,则指令供应功耗变为15%,如果我们将算术功耗增大至15%,则时钟和控制逻辑功耗将变为60%,这意味着可使指令供应功耗与数据供应功耗之和为35%,同时可使时钟和控制逻辑功耗与算术功耗之和为75%。
传统计算机系统如图54的(a)所示耗散能量,花费相对大的平均有效时间来寻址并读/写存储器单元,并且伴随有线延迟时间,而本发明的计算机系统如图54的(b)所示耗散较少的能量,因为本发明的计算机系统通过推进存储器而具有较短的平均有效平滑时间,并且我们可利用较少能量比传统计算机系统更快地处理相同的数据。
--第二实施方式--
如图55所示,根据本发明的第二实施方式的计算机系统包括处理器11和推进主存储器31。处理器11包括:控制单元111,其具有被配置为产生时钟信号的时钟发生器113;算术逻辑单元(alu)112,其被配置为与时钟信号同步地执行算术和逻辑运算;推进指令寄存器文件(rf)22a,其连接到控制单元111;以及推进数据寄存器文件(rf)22b,其连接到alu112。
尽管未示出,但是非常类似于图3-图24、图25的(a)、图25的(b)、图26以及图45-图51所示的推进主存储器31,推进指令寄存器文件22a具有:指令寄存器单元阵列;第三阵列的指令寄存器输入端子,其被配置为从推进主存储器31接收所存储的指令;以及第三阵列的指令寄存器输出端子,其被配置为将指令存储在各个指令寄存器单元中,并且与时钟信号同步地从与指令寄存器输入端子相邻的指令寄存器单元朝着与指令寄存器输出端子相邻的指令寄存器单元周期性地依次将各个指令寄存器单元中存储的指令传送至相邻指令寄存器单元,以通过指令寄存器输出端子主动地并且顺序地将通过所存储的指令实现的指令提供给控制单元111,使得控制单元111可利用所述指令执行操作。
还类似于图3-图24、图25的(a)、图25的(b)、图26以及图45-图51所示的推进主存储器31,推进数据寄存器文件22b具有:数据寄存器单元阵列;第四阵列的数据寄存器输入端子,其被配置为从推进主存储器31接收所存储的数据;以及第四阵列的数据寄存器输出端子,其被配置为将数据存储在各个数据寄存器单元中,并且与时钟信号同步地从与数据寄存器输入端子相邻的数据寄存器单元朝着与数据寄存器输出端子相邻的数据寄存器单元周期性地依次将各个数据寄存器单元中存储的数据传送至相邻数据寄存器单元,以通过数据寄存器输出端子主动地并且顺序地将数据提供给alu112,使得alu112可利用所述数据执行操作,但是推进数据寄存器文件22b未详细示出。
如图55所示,推进主存储器31的一部分与推进指令寄存器文件22a通过多个联接构件54电连接,推进主存储器31的剩余部分与推进数据寄存器文件22b通过另外多个联接构件54电连接。
alu112中的处理的结果数据被发送给推进数据寄存器文件22b。因此,如双向箭头phi(希腊字母)24所示,数据在推进数据寄存器文件22b与alu112之间双向传送。另外,存储在推进数据寄存器文件22b中的数据通过联接构件54被发送给推进主存储器31。因此,如双向箭头phi23所示,数据通过联接构件54在推进主存储器31与推进数据寄存器文件22b之间双向传送。
相反,如单向箭头eta(希腊字母)22和eta23所示,对于指令移动,仅存在从推进主存储器31到推进指令寄存器文件22a以及从推进指令寄存器文件22a到控制单元111的单向指令流。
在图55所示的第二实施方式的计算机系统中,不存在由数据总线和地址总线组成的总线,因为即使在推进主存储器31与推进指令寄存器文件22a之间、推进主存储器31与推进数据寄存器文件22b之间、推进指令寄存器文件22a与控制单元111之间以及推进数据寄存器文件22b与alu112之间的任何数据交换中整个计算机系统也没有线,而这些线或总线在传统计算机系统中形成瓶颈。由于不存在产生时间延迟以及这些线之间的杂散电容的全局线,所以第二实施方式的计算机系统可实现更高的处理速度和更低的功耗。
由于根据第二实施方式的计算机系统的其它功能、配置以及操作方式基本上类似于已经在第一实施方式中说明的功能、配置、操作方式,所以可省略重复或多余的描述。
--第三实施方式--
如图56所示,根据本发明的第三实施方式的计算机系统包括处理器11、推进高速缓冲存储器(21a,21b)和推进主存储器31。类似于第二实施方式,处理器11包括:控制单元111,其具有被配置为产生时钟信号的时钟发生器113;算术逻辑单元(alu)112,其被配置为与时钟信号同步地执行算术和逻辑运算;推进指令寄存器文件(rf)22a,其连接到控制单元111;以及推进数据寄存器文件(rf)22b,其连接到alu112。
推进高速缓冲存储器(21a,21b)包括推进指令高速缓冲存储器21a和推进数据高速缓冲存储器21b。尽管未示出,但是非常类似于图3-图24、图25的(a)、图25的(b)、图26以及图45-图51所示的推进主存储器31,推进指令高速缓冲存储器21a和推进数据高速缓冲存储器21b中的每一个具有:高速缓冲存储器单元阵列,其位于与单位信息对应的位置处;阵列的高速缓存输入端子,其被配置为从推进主存储器31接收所存储的信息;以及阵列的高速缓存输出端子,其被配置为将信息存储在各个高速缓冲存储器单元中,并且与时钟信号同步地将各个信息逐步传送至相邻高速缓冲存储器单元,以主动地并且顺序地将所存储的信息提供给处理器111,使得alu112可利用所存储的信息执行算术和逻辑运算。
如图56所示,推进主存储器31的一部分与推进指令高速缓冲存储器21a通过多个联接构件52电连接,推进主存储器31的剩余部分与推进数据高速缓冲存储器21b通过另外多个联接构件52电连接。另外,推进指令高速缓冲存储器21a与推进指令寄存器文件22a通过多个联接构件51电连接,并且推进数据高速缓冲存储器21b与推进数据寄存器文件22b通过另外多个联接构件51电连接。
alu112中的处理的结果数据被发送给推进数据寄存器文件22b,如双向箭头phi(希腊字母)34所示,数据在推进数据寄存器文件22b与alu112之间双向传送。另外,存储在推进数据寄存器文件22b中的数据通过联接构件51被发送给推进数据高速缓冲存储器21b,如双向箭头phi33所示,数据通过联接构件51在推进数据高速缓冲存储器21b与推进数据寄存器文件22b之间双向传送。另外,存储在推进数据高速缓冲存储器21b中的数据通过联接构件52被发送给推进主存储器31,如双向箭头phi32所示,数据通过联接构件52在推进主存储器31与推进数据高速缓冲存储器21b之间双向传送。
相反,如单向箭头eta(希腊字母)31、eta32和eta33所示,对于指令移动,仅存在从推进主存储器31到推进指令高速缓冲存储器21a、从推进指令高速缓冲存储器21a到推进指令寄存器文件22a以及从推进指令寄存器文件22a到控制单元111的单向指令流。
在图56所示的第三实施方式的计算机系统中,不存在由数据总线和地址总线组成的总线,因为即使推进主存储器31与推进指令高速缓冲存储器21a之间、推进指令高速缓冲存储器21a与推进指令寄存器文件22a之间、推进主存储器31与推进数据高速缓冲存储器21b之间、推进数据高速缓冲存储器21b与推进数据寄存器文件22b之间、推进指令寄存器文件22a与控制单元111之间以及推进数据寄存器文件22b与alu112之间的任何数据交换中整个计算机系统也没有全局线,而这些线或总线在传统计算机系统中形成瓶颈。由于不存在产生时间延迟以及这些线之间的杂散电容的全局线,所以第三实施方式的计算机系统可实现更高的处理速度和更低的功耗。
由于根据第三实施方式的计算机系统的其它功能、配置以及操作方式基本上类似于已经在第一实施方式和第二实施方式中说明的功能、配置、操作方式,所以可省略重复或多余的描述。
如图57的(a)所示,第三实施方式的计算机系统中的alu112可包括多个算术流水线p1、p2、p3、......、pn,这些算术流水线p1、p2、p3、......、pn被配置为通过推进寄存器单元r11、r12、r13、......、r1n;r22、r22、r23、......、r2n接收所存储的信息,其中数据与算术流水线p1、p2、p3、......、pn的排列方向平行地移动。在存储向量数据的情况下,可使用推进向量寄存器单元r11、r12、r13、......、r1n;r22、r22、r23、......、r2n。
另外,如图57的(b)所示,多个推进高速缓存单元c11、c12、c13、......、c1n;c21、c22、c23、......、c2n;c31、c32、c33、......、c3n并行排列。
如图58所示,第三实施方式的计算机系统中的alu112可包括单个处理器核116,并且如交叉箭头所示,信息可从推进高速缓冲存储器21移动至推进寄存器文件22,并且从推进寄存器文件22移动至处理器核116。处理器核116中的处理的结果数据被发送给推进寄存器文件22,使得数据在推进寄存器文件22与处理器核116之间双向传送。另外,存储在推进寄存器文件22中的数据被发送至推进高速缓冲存储器21,使得数据在推进高速缓冲存储器21与推进寄存器文件22之间双向传送。在指令移动的情况下,不存在沿着待处理信息的相反方向的流。
如图59所示,第三实施方式的计算机系统中的alu112可包括单个算术流水线117,如交叉箭头所示,信息可从推进高速缓冲存储器21移动至推进向量寄存器文件22v,并且从推进向量寄存器文件22v移动至算术流水线117。算术流水线117中的处理的结果数据被发送给推进向量寄存器文件22v,使得数据在推进向量寄存器文件22v与算术流水线117之间双向传送。另外,存储在推进向量寄存器文件22v中的数据被发送至推进高速缓冲存储器21,使得数据在推进高速缓冲存储器21与推进向量寄存器文件22v之间双向传送。在指令移动的情况下,不存在沿着待处理信息的相反方向的流。
如图60所示,第三实施方式的计算机系统中的alu112可包括多个处理器核116-1、116-2、116-3、116-4、......、116-m,如交叉箭头所示,信息可从推进高速缓冲存储器21移动至推进寄存器文件22,并且从推进寄存器文件22移动至处理器核116-1、116-2、116-3、116-4、......、116-m。处理器核116-1、116-2、116-3、116-4、......、116-m中的处理的结果数据被发送给推进寄存器文件22,使得数据在推进寄存器文件22与处理器核116-1、116-2、116-3、116-4、......、116-m之间双向传送。另外,存储在推进寄存器文件22中的数据被发送至推进高速缓冲存储器21,使得数据在推进高速缓冲存储器21与推进寄存器文件22之间双向传送。在指令移动的情况下,不存在沿着待处理信息的相反方向的流。
如图61所示,第三实施方式的计算机系统中的alu112可包括多个算术流水线117-1、117-2、117-3、117-4、......、117-m,如交叉箭头所示,信息可从推进高速缓冲存储器21移动至推进向量寄存器文件22v,并且从推进向量寄存器文件22v移动至算术流水线117-1、117-2、117-3、117-4、......、117-m。算术流水线117-1、117-2、117-3、117-4、......、117-m中的处理的结果数据被发送给推进向量寄存器文件22v,使得数据在推进向量寄存器文件22v与算术流水线117-1、117-2、117-3、117-4、......、117-m之间双向传送。另外,存储在推进向量寄存器文件22v中的数据被发送至推进高速缓冲存储器21,使得数据在推进高速缓冲存储器21与推进向量寄存器文件22v之间双向传送。在指令移动的情况下,不存在沿着待处理信息的相反方向的流。
如图62的(b)所示,第三实施方式的计算机系统中的alu112可包括多个算术流水线117-1、117-2、117-3、117-4、......、117-m,多个推进高速缓冲存储器21-1、21-2、21-3、21-4、......、21-m电连接到推进主存储器31。这里,第一推进向量寄存器文件22v-1连接到第一推进高速缓冲存储器21-1,第一算术流水线117-1连接到第一推进向量寄存器文件22v-1。并且,第二推进向量寄存器文件22v-2连接到第二推进高速缓冲存储器21-2,第二算术流水线117-2连接到第二推进向量寄存器文件22v-2;第三推进向量寄存器文件22v-3连接到第三推进高速缓冲存储器21-3,第三算术流水线117-3连接到第三推进向量寄存器文件22v-3;......;第m推进向量寄存器文件22v-m连接到第m推进高速缓冲存储器21-m,第m算术流水线117-m连接到第m推进向量寄存器文件22v-m。
信息并行地从推进主存储器31移动至推进高速缓冲存储器21-1、21-2、21-3、21-4、......、21-m,并行地从推进高速缓冲存储器21-1、21-2、21-3、21-4、......、21-m移动至推进向量寄存器文件22v-1、22v-2、22v-3、22v-4、......、22v-m,并且并行地从推进向量寄存器文件22v-1、22v-2、22v-3、22v-4、......、22v-m移动至算术流水线117-1、117-2、117-3、117-4、......、117-m。算术流水线117-1、117-2、117-3、117-4、......、117-m中的处理的结果数据被发送给推进向量寄存器文件22v-1、22v-2、22v-3、22v-4、......、22v-m,使得数据在推进向量寄存器文件22v-1、22v-2、22v-3、22v-4、......、22v-m与算术流水线117-1、117-2、117-3、117-4、......、117-m之间双向传送。另外,存储在推进向量寄存器文件22v-1、22v-2、22v-3、22v-4、......、22v-m中的数据被发送给推进高速缓冲存储器21-1、21-2、21-3、21-4、......、21-m,使得数据在推进高速缓冲存储器21-1、21-2、21-3、21-4、......、21-m与推进向量寄存器文件22v-1、22v-2、22v-3、22v-4、......、22v-m之间双向传送,并且存储在推进高速缓冲存储器21-1、21-2、21-3、21-4、......、21-m中的数据被发送给推进主存储器31,使得数据在推进主存储器31与推进高速缓冲存储器21-1、21-2、21-3、21-4、......、21-m之间双向传送。在指令移动的情况下,不存在沿着待处理信息的相反方向的流。
相反,如图62的(a)所示,在包括多个算术流水线117-1、117-2、117-3、117-4、......、117-m的传统计算机系统的alu112中,多个传统高速缓冲存储器321-1、321-2、321-3、321-4、......、321-m通过形成冯·诺伊曼瓶颈325的线和/或总线电连接到传统主存储器331。然后,信息通过冯·诺伊曼瓶颈325并行地从传统主存储器331移动至传统高速缓冲存储器321-1、321-2、321-3、321-4、......、321-m,并行地从传统高速缓冲存储器321-1、321-2、321-3、321-4、......、321-m移动至传统向量寄存器文件(rf)322v-1、322v-2、322v-3、322v-4、......、322v-m,并且并行地从传统向量寄存器文件322v-1、322v-2、322v-3、322v-4、......、322v-m移动至算术流水线117-1、117-2、117-3、117-4、......、117-m。
在图62的(b)所示的第三实施方式的计算机系统中,不存在由数据总线和地址总线组成的总线,因为即使在算术流水线117-1、117-2、117-3、117-4、......、117-m与推进主存储器31之间的任何数据交换中整个计算机系统也没有全局线,而如图62的(a)所示,这些线或总线在传统计算机系统中形成瓶颈。由于不存在产生时间延迟以及这些线之间的杂散电容的全局线,所以图62的(b)所示的计算机系统可实现更高的处理速度和更低的功耗。
--第四实施方式--
如图63所示,第四实施方式的计算机系统包括传统主存储器31s、连接到传统主存储器31s的母推进主存储器31-0以及多个处理单元12-1、12-2、12-3、......,这些处理单元被配置为与母推进主存储器31-0通信,以实现高性能计算(hpc)系统,该hpc系统可用于基于图形处理单元(gpu)的通用计算。尽管未示出,第四实施方式的hpc系统还包括控制单元111,控制单元111具有:时钟发生器113,其被配置为产生时钟信号;以及现场可编程门阵列(fpga),其被配置为对多个处理单元12-1、12-2、12-3、......的操作进行开关控制,通过并行运行来优化处理计算流,进行构造以帮助管理并组织带宽消耗。本质上,fpga是针对给定任务本身可重写的计算机芯片。fpga可利用诸如vhdl或verilog的硬件描述语言编程。
第一处理单元12-1包括第一分支推进主存储器31-1、分别电连接到第一分支推进主存储器31-1的多个第一推进高速缓冲存储器21-11、21-12、......、21-1p、分别电连接到第一推进高速缓冲存储器21-11、21-12、......、21-1p的多个第一推进向量寄存器文件22v-11、22v-12、......、22v-1p、分别电连接到第一推进向量寄存器文件22v-11、22v-12、......、22v-1p的多个第一算术流水线117-11、117-12、......、117-1p。
类似于图3-图24、图25的(a)、图25的(b)、图26以及图45-图51等中所示的配置,由于母推进主存储器31-0、第一分支推进主存储器31-1、第一推进高速缓冲存储器21-11、21-12、......、21-1p以及第一推进向量寄存器文件22v-11、22v-12、......、22v-1p中的每一个包括存储器单元阵列、阵列的输入端子和阵列的输出端子,其被配置为将信息存储在各个存储器单元中并且与时钟信号同步地从输入端子一侧朝着输出端子逐步传送。
由于母推进主存储器31-0、第一分支推进主存储器31-1、第一推进高速缓冲存储器21-11、21-12、......、21-1p以及第一推进向量寄存器文件22v-11、22v-12、......、22v-1p的操作由fpga控制,所以信息从母推进主存储器31-0移动至第一分支推进主存储器31-1,并行地从第一分支推进主存储器31-1移动至第一推进高速缓冲存储器21-11、21-12、......、21-1p,并行地从第一推进高速缓冲存储器21-11、21-12、......、21-1p移动至第一推进向量寄存器文件22v-11、22v-12、......、22v-1p,并且并行地从第一推进向量寄存器文件22v-11、22v-12、......、22v-1p移动至第一算术流水线117-11、117-12、......、117-1p。第一算术流水线117-11、117-12、......、117-1p中的处理的结果数据被发送给第一推进向量寄存器文件22v-11、22v-12、......、22v-1p,使得数据在第一推进向量寄存器文件22v-11、22v-12、......、22v-1p与第一算术流水线117-11、117-12、......、117-1p之间双向传送。另外,存储在第一推进向量寄存器文件22v-11、22v-12、......、22v-1p中的数据被发送给第一推进高速缓冲存储器21-11、21-12、......、21-1p,使得数据在第一推进高速缓冲存储器21-11、21-12、......、21-1p与第一推进向量寄存器文件22v-11、22v-12、......、22v-1p之间双向传送,并且存储在第一推进高速缓冲存储器21-11、21-12、......、21-1p中的数据被发送给第一分支推进主存储器31-1,使得数据在第一分支推进主存储器31-1与第一推进高速缓冲存储器21-11、21-12、......、21-1p之间双向传送。然而,fpga控制指令的移动,使得不存在沿着将要在第一处理单元12-1中处理的信息的相反方向的流。
第二处理单元12-2包括第二分支推进主存储器31-2、分别电连接到第二分支推进主存储器31-2的多个第二推进高速缓冲存储器21-21、21-22、......、21-2p、分别电连接到第二推进高速缓冲存储器21-21、21-22、......、21-2p的多个第二推进向量寄存器文件22v-21、22v-22、......、22v-2p、分别电连接到第二推进向量寄存器文件22v-21、22v-22、......、22v-2p的多个第二算术流水线117-21、117-22、......、117-2p。类似于第一处理单元12-1,母推进主存储器31-0、第二分支推进主存储器31-2、第二推进高速缓冲存储器21-21、21-22、......、21-2p以及第二推进向量寄存器文件22v-21、22v-22、......、22v-2p中的每一个包括存储器单元阵列、阵列的输入端子和阵列的输出端子,其被配置为将信息存储在各个存储器单元中并且与时钟信号同步地从输入端子一侧朝着输出端子逐步传送。由于母推进主存储器31-0、第二分支推进主存储器31-2、第二推进高速缓冲存储器21-21、21-22、......、21-2p以及第二推进向量寄存器文件22v-21、22v-22、......、22v-2p的操作由fpga控制,信息从母推进主存储器31-0移动至第二分支推进主存储器31-2,并行地从第二分支推进主存储器31-2移动至第二推进高速缓冲存储器21-21、21-22、......、21-2p,并行地从第二推进高速缓冲存储器21-21、21-22、......、21-2p移动至第二推进向量寄存器文件22v-21、22v-22、......、22v-2p,并且并行地从第二推进向量寄存器文件22v-21、22v-22、......、22v-2p移动至第二算术流水线117-21、117-22、......、117-2p。第二算术流水线117-21、117-22、......、117-2p中的处理的结果数据被发送给第二推进向量寄存器文件22v-21、22v-22、......、22v-2p,使得数据在第二推进向量寄存器文件22v-21、22v-22、......、22v-2p与第二算术流水线117-21、117-22、......、117-2p之间双向传送。另外,存储在第二推进向量寄存器文件22v-21、22v-22、......、22v-2p中的数据被发送给第二推进高速缓冲存储器21-21、21-22、......、21-2p,使得数据在第二推进高速缓冲存储器21-21、21-22、......、21-2p与第二推进向量寄存器文件22v-21、22v-22、......、22v-2p之间双向传送,并且存储在第二推进高速缓冲存储器21-21、21-22、......、21-2p中的数据被发送给第二分支推进主存储器31-2,使得数据在第二分支推进主存储器31-2与第二推进高速缓冲存储器21-21、21-22、......、21-2p之间双向传送。然而,fpga控制指令的移动,使得不存在沿着将要在第二处理单元12-2中处理的信息的相反方向的流。
例如,产生自源程序中的循环的向量指令从母推进主存储器31-0并行地传送至第一处理单元12-1、第二处理单元12-2、第三处理单元12-3、......,使得可由第一处理单元12-1、第二处理单元12-2、第三处理单元12-3、......中的每一个中的算术流水线117-11、117-12、......、117-1p、117-21、117-22、......、117-2q、......执行这些向量指令的并行处理。
尽管目前由fpga控制的hpc系统需要大量布线资源,这些布线资源产生时间延迟以及这些线之间的杂散电容,从而造成瓶颈,但是在图63所示的第四实施方式的hpc系统中,由于对于第一推进向量寄存器文件22v-11、22v-12、......、22v-1p与第一算术流水线117-11、117-12、......、117-1p之间、第一推进高速缓冲存储器21-11、21-12、......、21-1p与第一推进向量寄存器文件22v-11、22v-12、......、22v-1p之间、第一分支推进主存储器31-1与第一推进高速缓冲存储器21-11、21-12、......、21-1p之间、第二推进向量寄存器文件22v-21、22v-22、......、22v-2p与第二算术流水线117-21、117-22、......、117-2p之间、第二推进高速缓冲存储器21-21、21-22、......、21-2p与第二推进向量寄存器文件22v-21、22v-22、......、22v-2p之间、第二分支推进主存储器31-2与第二推进高速缓冲存储器21-21、21-22、......、21-2p之间、母推进主存储器31-0与第一分支推进主存储器31-1之间、母推进主存储器31-0与第二分支推进主存储器31-2之间的任何数据交换,不存在诸如数据总线和地址总线的总线,所以与目前由fpga控制的hpc系统相比,图63所示的由fpga控制的hpc系统可实现更高的处理速度和更低的功耗。通过增加处理单元12-1、12-2、12-3、......的数量,根据第四实施方式的由fpga控制的hpc系统可以按照非常高的速度同时执行(例如)上千线程或更多线程,从而实现在大量数据上的高计算吞吐量。
--第五实施方式--
如图64所示,根据本发明的第五实施方式的计算机系统包括:处理器11;推进寄存器文件22-1、22-2、22-3、......的堆栈,其实现连接到处理器11的三维推进寄存器文件;推进高速缓冲存储器21-1、21-2、21-3、......的堆栈,其实现连接到三维推进寄存器文件(22-1、22-2、22-3、......)的三维推进高速缓冲存储器;以及推进主存储器31-1、31-2、31-3、......的堆栈,其实现连接到三维推进高速缓存(21-1、21-2、21-3、......)的三维推进主存储器。处理器11包括:控制单元111,其具有被配置为产生时钟信号的时钟发生器113;算术逻辑单元(alu)112,其被配置为与时钟信号同步地执行算术和逻辑运算。
在三维推进寄存器文件(22-1、22-2、22-3、......)中,第一推进寄存器文件22-1包括连接到控制单元111的第一推进指令寄存器文件22a-1以及连接到alu112的第一推进数据寄存器文件22b-1,第二推进寄存器文件22-2包括连接到控制单元111的第二推进指令寄存器文件以及连接到alu112的第二推进数据寄存器文件,第三推进寄存器文件22-3包括连接到控制单元111的第三推进指令寄存器文件以及连接到alu112的第三推进数据寄存器文件,以及......。在三维推进高速缓存(21-1、21-2、21-3、......)中,第一推进高速缓冲存储器21-1包括第一推进指令高速缓冲存储器21a-1和第一推进数据高速缓冲存储器21b-1,第二推进高速缓冲存储器21-2包括第二推进指令高速缓冲存储器和第二推进数据高速缓冲存储器,第三推进高速缓冲存储器21-3包括第三推进指令高速缓冲存储器和第三推进数据高速缓冲存储器,以及......。
尽管未示出,非常类似于图45-图51所示的推进主存储器31,各个推进主存储器31-1、31-2、31-3、......具有存储器单元的二维阵列(各自具有单位信息)、主存储器阵列的输入端子以及主存储器阵列的输出端子,各个推进主存储器31-1、31-2、31-3、......将信息存储在各个存储器单元中并且与时钟信号同步地朝着主存储器阵列的输出端子逐步传送,以主动地并且顺序地向三维推进高速缓存(21-1、21-2、21-3、......)提供所存储的信息,各个推进高速缓冲存储器21-1、21-2、21-3、......具有高速缓冲存储器单元的二维阵列、被配置为从三维推进主存储器(31-1、31-2、31-3、......)接收所存储的信息的推进高速缓存阵列的高速缓存输入端子以及推进高速缓存阵列的高速缓存输出端子,各个推进高速缓冲存储器21-1、21-2、21-3、......将信息存储在各个高速缓冲存储器单元中并且与时钟信号同步地将信息逐步传送至相邻高速缓冲存储器单元,以主动地并且顺序地将所存储的信息提供给三维推进寄存器文件(22-1、22-2、22-3、......),并且各个推进寄存器文件22-1、22-2、22-3、......具有寄存器单元的二维阵列(各自具有单位信息)、被配置为从三维推进高速缓存(21-1、21-2、21-3、......)接收所存储的信息的寄存器阵列的输入端子以及寄存器阵列的输出端子,各个推进寄存器文件22-1、22-2、22-3、......将信息存储在各个寄存器单元中并且与时钟信号同步地朝着寄存器阵列的输出端子逐步传送,以主动地并且顺序地向处理器11提供所存储的信息,使得处理器11可利用所存储的信息执行算术和逻辑运算。
各个推进主存储器31-1、31-2、31-3、......通过描绘在半导体芯片的表面处的存储器单元的二维阵列实现,多个半导体芯片如27a所示垂直层叠,使得在所述多个半导体芯片之间夹有散热板58m-1、58m-2、58m-3、......,以实现三维推进主存储器(31-1、31-2、31-3、......)。优选的是,散热板58m-1、58m-2、58m-3、......由具有高热导率的材料(例如金刚石)制成。类似地,各个推进高速缓冲存储器21-1、21-2、21-3、......通过描绘在半导体芯片的表面处的存储器单元的二维阵列实现,多个半导体芯片如27b所示垂直层叠,使得在所述多个半导体芯片之间夹有散热板58c-1、58c-2、58c-3、......,以实现三维推进高速缓存(21-1、21-2、21-3、......),并且各个推进寄存器文件22-1、22-2、22-3、......通过描绘在半导体芯片的表面处的存储器单元的二维阵列实现,多个半导体芯片如27c所示垂直层叠,使得在所述多个半导体芯片之间夹有散热板58r-1、58r-2、58r-3、......,以实现三维推进寄存器文件(22-1、22-2、22-3、......)。优选的是,散热板58c-1、58c-2、58c-3、......、58r-1、58r-2、58r-3、......由具有高热导率的材料(例如金刚石)制成。由于在图65的(a)-(c)以及图66所示的三维配置中半导体芯片的表面内部不存在互连,所以很容易将散热板58c-1、58c-2、58c-3、......、58c-1、58c-2、58c-3、......、58r-1、58r-2、58r-3、......插入半导体芯片之间,图65的(a)-(c)以及图66所示的配置可扩展至具有任何数量的半导体芯片的层叠结构。在传统架构中,基本上,当传统半导体芯片直接层叠时,就热问题而言,对层叠的半导体芯片的数量有限制。在第五实施方式的计算机系统中,图65的(a)-(c)以及图66所示的夹心结构适合于更有效地建立从有效计算半导体芯片穿过散热板58c-1、58c-2、58c-3、......、58c-1、58c-2、58c-3、......、58r-1、58r-2、58r-3、......至外部系统的热流。因此,在第五实施方式的计算机系统中,这些半导体芯片可与系统规模成比例地层叠,并且如图65的(a)-(c)以及图66所示,由于合并有推进主存储器31-1、31-2、31-3、......、推进高速缓冲存储器21-1、21-2、21-3、......以及推进寄存器文件22-1、22-2、22-3、......的多个半导体芯片可容易地层叠以实现三维配置,所以可容易地构造可扩展计算机系统,从而保持系统的温度更低。
尽管未示出,三维推进主存储器(31-1、31-2、31-3、......)与三维推进高速缓存(21-1、21-2、21-3、......)通过多个联接构件电连接,三维推进高速缓存(21-1、21-2、21-3、......)与三维推进寄存器文件(22-1、22-2、22-3、......)通过多个联接构件电连接,并且三维推进寄存器文件(22-1、22-2、22-3、......)与处理器11通过另外多个联接构件电连接。
alu112中的处理的结果数据通过联接构件被发送给三维推进寄存器文件(22-1、22-2、22-3、......),使得数据在三维推进寄存器文件(22-1、22-2、22-3、......)与alu112之间双向传送。另外,存储在三维推进寄存器文件(22-1、22-2、22-3、......)中的数据通过联接构件被发送给三维推进高速缓存(21-1、21-2、21-3、......),使得数据在三维推进高速缓存(21-1、21-2、21-3、......)与三维推进寄存器文件(22-1、22-2、22-3、......)之间双向传送。另外,存储在三维推进高速缓存(21-1、21-2、21-3、......)中的数据通过联接构件被发送给三维推进主存储器(31-1、31-2、31-3、......),使得数据在三维推进主存储器(31-1、31-2、31-3、......)与三维推进高速缓存(21-1、21-2、21-3、......)之间双向传送。
相反,仅存在从三维推进主存储器(31-1、31-2、31-3、......)至三维推进高速缓存(21-1、21-2、21-3、......)、从三维推进高速缓存(21-1、21-2、21-3、......)至三维推进寄存器文件(22-1、22-2、22-3、......)以及从三维推进寄存器文件(22-1、22-2、22-3、......)至控制单元111的单向指令流。例如,产生自源程序中的循环的向量指令从三维推进主存储器(31-1、31-2、31-3、......)通过三维推进高速缓存(21-1、21-2、21-3、......)通过三维推进高速缓存(21-1、21-2、21-3、......)和三维推进寄存器文件(22-1、22-2、22-3、......)传送至控制单元111,使得这些向量指令中的每一个可由控制单元111中的算术流水线执行。在图64所示的第五实施方式的计算机系统中,在三维推进主存储器(31-1、31-2、31-3、......)与三维推进高速缓存(21-1、21-2、21-3、......)之间、三维推进高速缓存(21-1、21-2、21-3、......)与三维推进寄存器文件(22-1、22-2、22-3、......)之间以及三维推进寄存器文件(22-1、22-2、22-3、......)与处理器11之间的任何数据交换中不存在诸如数据总线和地址总线的总线,而这些线或总线在传统计算机系统中形成瓶颈。由于不存在产生时间延迟以及这些线之间的杂散电容的全局线,所以与传统计算机系统相比,第五实施方式的计算机系统可实现更高的处理速度和更低的功耗,并且通过采用由具有高热导率的材料(例如金刚石)制成并设置在半导体芯片之间的散热板58c-1、58c-2、58c-3、......、58c-1、58c-2、58c-3、......、58r-1、58r-2、58r-3、......,可将计算机系统的温度保持在比传统计算机系统更低的温度,以实现“清凉计算机”。根据第五实施方式的清凉计算机不同于现有计算机,因为清凉计算机被特意构造并设计为(例如)能耗平均降低30%并且尺寸减小10000%,以获得高100倍的速度。
由于根据第五实施方式的计算机系统的其它功能、配置、操作方式基本上类似于已在第一实施方式至第三实施方式中说明的功能、配置、操作方式,所以可省略重复或多余的描述。
(各种三维配置)
图64、图65的(a)、图65的(b)和图65的(c)所示的三维配置仅是示例,存在各种方式和组合以实现有利于可扩展计算机系统的构造的三维配置。
例如,如图66所示,合并有多个算术流水线117和多个推进寄存器文件22的第一芯片(顶部芯片)、合并有推进高速缓冲存储器21的第二芯片(中间芯片)以及合并有推进主存储器31的第三芯片(底部芯片)可垂直层叠。各个算术流水线117可包括向量处理单元,各个推进寄存器文件22可包括推进向量寄存器。在第一芯片与第二芯片之间插入多个联接构件55a,在第二芯片与第三芯片之间插入多个联接构件55b。例如,联接构件55a和55b中的每一个可通过导电凸块(例如焊球、金(au)凸块、银(ag)凸块、铜(cu)凸块、镍-金(ni-au)合金凸块或镍-金-铟(ni-au-in)合金凸块)实现。尽管未示出,类似于图65的(a)-(c)和图66所示的配置,散热板可插入第一芯片与第二芯片之间以及第二芯片与第三芯片之间,以实现“清凉芯片”。
另选地,如图67和图68所示,包括第一顶部芯片、第一中间芯片和第一底部芯片的第一三维(3d)叠层以及包括第二顶部芯片、第二中间芯片和第二底部芯片的第二3d叠层可二维地设置在同一基板或同一电路板上,以利用多个处理器实现并行计算,其中第一3d叠层和第二3d叠层通过桥59a和59b连接。
在第一3d叠层中,合并有多个第一算术流水线117-1和多个第一推进寄存器文件22-1的第一顶部芯片、合并有第一推进高速缓冲存储器21-1的第一中间芯片以及合并有第一推进主存储器31-1的第一底部芯片垂直地3d层叠。各个第一算术流水线117-1可包括向量处理单元,各个第一推进高速缓存文件22-1可包括推进向量寄存器。在第一顶部芯片与第一中间芯片之间插入多个联接构件55a-1,在第一中间芯片与第一底部芯片之间插入多个联接构件55b-1。例如,联接构件55a-1和55b-1中的每一个可通过导电凸块(例如焊球、金(au)凸块、银(ag)凸块、铜(cu)凸块、镍-金(ni-au)合金凸块或镍-金-铟(ni-au-in)合金凸块)实现。类似地,在第二3d叠层中,合并有多个第二算术流水线117-2和多个第二推进寄存器文件22-2的第二顶部芯片、合并有第二推进高速缓冲存储器21-2的第二中间芯片以及合并有第二推进主存储器31-2的第二底部芯片垂直地3d层叠。各个第二算术流水线117-2可包括向量处理单元,各个第二推进高速缓存文件22-2可包括推进向量寄存器。在第二顶部芯片与第二中间芯片之间插入多个联接构件55a-2,在第二中间芯片与第二底部芯片之间插入多个联接构件55b-2。例如,联接构件55a-2和55b-2中的每一个可通过导电凸块(例如焊球、金(au)凸块、银(ag)凸块、铜(cu)凸块、镍-金(ni-au)合金凸块或镍-金-铟(ni-au-in)合金凸块)实现。尽管未示出,类似于图65的(a)-(c)和图66所示的配置,散热板可插入第一顶部芯片与第一中间芯片之间、第一中间芯片与第一底部芯片之间、第二顶部芯片与第二中间芯片之间以及第二中间芯片与第二底部芯片之间,以实现“清凉芯片”。
类似于第四实施方式的计算机系统,现场可编程门阵列(fpga)可通过第一算术流水线117-1和第二算术流水线117-2上的线程的行进或向量处理的链接对第一3d叠层和第二3d叠层的操作进行开关控制,从而实现可用于基于gpu的通用计算的hpc系统。
另选地,如图69所示,合并有多个算术流水线117的第一芯片(顶部芯片)、合并有多个推进寄存器文件22的第二芯片、合并有推进高速缓冲存储器21的第三芯片、合并有第一推进主存储器31-1的第四芯片、合并有推进主存储器31-2的第五芯片以及合并有第三推进主存储器31-3的第六芯片(底部芯片)可垂直层叠。各个算术流水线117可包括向量处理单元,各个推进寄存器文件22可包括推进向量寄存器,使得产生自源程序中的循环的向量指令可在向量处理单元中执行。第一散热板58-1插入第一芯片与第二芯片之间,第二散热板58-2插入第二芯片与第三芯片之间,第三散热板58-1插入第三芯片与第四芯片之间,第四散热板58-4插入第四芯片与第五芯片之间,第五散热板58-5插入第五芯片与第六芯片之间,以实现“清凉芯片”。由于在图69所示的三维配置中这些清凉芯片的表面内部不存在互连,所以很容易将诸如金刚石芯片的散热板58-1、58-2、58-3、58-4、58-5交替插入这六个芯片之间。
图69所示的清凉芯片配置不限于六个芯片的情况,而是可扩展至具有任何数量的芯片的三维层叠结构,因为图69所示的夹心结构适合于更有效地建立从有效计算芯片穿过散热板58-1、58-2、58-3、58-4、58-5至清凉计算机系统外部的热流。因此,第五实施方式的计算机系统中的清凉芯片的数量可与计算机系统的规模成比例地增加。
图70-图72示出实现根据本发明的第五实施方式的计算机系统的基本核的一部分的三维(3d)叠层的各种示例,各个3d叠层包括利用散热板58(例如金刚石板)的冷却技术,所述散热板被插入半导体存储器芯片3a与3b之间,所述半导体存储器芯片中合并有被分类到推进存储器族中的至少一个推进存储器,除了推进主存储器31(在本发明的第一实施方式中进行说明)之外,术语“推进存储器族”包括连接到alu112的推进指令寄存器文件22a和推进数据寄存器文件22b(在第二实施方式中进行说明)以及推进指令高速缓冲存储器21a和推进数据高速缓冲存储器21b(在第三实施方式中进行说明)。
即,如图70所示,实现根据本发明的第五实施方式的计算机系统的基本核的一部分的3d叠层包括:第一半导体存储器芯片3a,其合并有推进存储器族中的至少一个推进存储器;散热板58,其设置在第一半导体存储器芯片3a下面;第二半导体存储器芯片3b,其设置在散热板58下面,并且合并有推进存储器族中的至少一个推进存储器;以及处理器11,其设置在散热板58的一侧。这里,在图70中,由于作为示例之一示出处理器11的位置,根据3d叠层的设计选择,处理器11可被设置在3d叠层的配置中的任何所需或适当的位置或者3d叠层的外部。例如,处理器11可被分配在与第一半导体存储器芯片3a相同的水平面处,或者分配在第二半导体存储器芯片3b的水平面处。合并在第一半导体存储器芯片3a上的推进存储器和合并在第二半导体存储器芯片3b上的推进存储器分别存储程序指令。在图70所示的第一半导体存储器芯片3a、散热板58和第二半导体存储器芯片3b垂直层叠的3d配置中,第一控制路径设置在第一半导体存储器芯片3a与处理器11之间,第二控制路径设置在第二半导体存储器芯片3b与处理器11之间,以方便利用处理器11执行控制处理。另外的数据路径可设置在第一半导体存储器芯片3a与第二半导体存储器芯片3b之间,以方便第一半导体存储器芯片3a与第二半导体存储器芯片3b之间的程序指令的直接通信。
并且,如图71所示,实现根据本发明的第五实施方式的计算机系统的基本核的一部分的另一3d叠层包括:第一半导体存储器芯片3a,其合并有推进存储器族中的至少一个推进存储器;散热板58,其设置在第一半导体存储器芯片3a下面;第二半导体存储器芯片3b,其设置在散热板58下面,并且合并有推进存储器族中的至少一个推进存储器;以及alu112,其设置在散热板58的一侧。alu112的位置不限于图71所示的位置,根据3d叠层的设计选择,alu112可被设置在3d叠层的配置中的任何所需或适当的位置或者3d叠层的外部,例如,被分配在与第一半导体存储器芯片3a相同的水平面处或者分配在第二半导体存储器芯片3b的水平面处。合并在第一半导体存储器芯片3a上的推进存储器和合并在第二半导体存储器芯片3b上的推进存储器分别读/写标量数据。在图71所示的第一半导体存储器芯片3a、散热板58和第二半导体存储器芯片3b垂直层叠的3d配置中,第一数据路径设置在第一半导体存储器芯片3a与alu112之间,第二数据路径设置在第二半导体存储器芯片3b与alu112之间,以方便利用alu112执行标量数据处理。另外的数据路径可设置在第一半导体存储器芯片3a与第二半导体存储器芯片3b之间,以方便第一半导体存储器芯片3a与第二半导体存储器芯片3b之间的标量数据的直接通信。
另外,如图72所示,实现根据本发明的第五实施方式的计算机系统的基本核的一部分的另一3d叠层包括:第一半导体存储器芯片3a,其合并有推进存储器族中的至少一个推进存储器;散热板58,其设置在第一半导体存储器芯片3a下面;第二半导体存储器芯片3b,其设置在散热板58下面,并且合并有推进存储器族中的至少一个推进存储器;以及算术流水线117,其设置在散热板58的一侧。类似于图62和图63所示的拓扑,算术流水线117的位置不限于图72所示的位置,算术流水线117可被设置在任何所需或适当的位置。合并在第一半导体存储器芯片3a上的推进存储器和合并在第二半导体存储器芯片3b上的推进存储器分别读/写向量/流数据。在图72所示的第一半导体存储器芯片3a、散热板58和第二半导体存储器芯片3b垂直层叠的3d配置中,第一数据路径设置在第一半导体存储器芯片3a与算术流水线117之间,第二数据路径设置在第二半导体存储器芯片3b与算术流水线117之间,以方便利用算术流水线117执行向量/流数据处理。另外的数据路径可设置在第一半导体存储器芯片3a与第二半导体存储器芯片3b之间,以方便第一半导体存储器芯片3a与第二半导体存储器芯片3b之间的向量/流数据的直接通信。
如图73所示,根据第五实施方式的3d混合计算机系统包括:第一左侧芯片(顶部左侧芯片)3p-1,其合并有推进存储器族中的至少一个推进存储器;第二左侧芯片3p-2,其合并有推进存储器族中的至少一个推进存储器;第三左侧芯片3p-3,其合并有推进存储器族中的至少一个推进存储器;第四左侧芯片3p-4,其合并有推进存储器族中的至少一个推进存储器;第五左侧芯片3p-5,其合并有推进存储器族中的至少一个推进存储器;以及第六左侧芯片(底部左侧芯片)3p-6,其合并有推进存储器族中的至少一个推进存储器,这些芯片垂直层叠。第一左侧散热板58a-1插入第一左侧芯片3p-1与第二左侧芯片3p-2之间,第二左侧散热板58a-2插入第二左侧芯片3p-2与第三左侧芯片3p-3之间,第三左侧散热板58a-1插入第三左侧芯片3p-3与第四左侧芯片3p-4之间,第四左侧散热板58a-4插入第四左侧芯片3p-4与第五左侧芯片3p-5之间,并且第五左侧散热板58a-5插入第五左侧芯片3p-5与第六左侧芯片3p-6之间,以实现“清凉左侧芯片”。并且,合并有推进存储器族中的至少一个推进存储器的第一右侧芯片(顶部右侧芯片)3q-1、合并有推进存储器族中的至少一个推进存储器的第二右侧芯片3q-2、合并有推进存储器族中的至少一个推进存储器的第三右侧芯片3q-3、合并有推进存储器族中的至少一个推进存储器的第四右侧芯片3q-4、合并有推进存储器族中的至少一个推进存储器的第五右侧芯片3q-5以及合并有推进存储器族中的至少一个推进存储器的第六右侧芯片(底部右侧芯片)3q-6垂直层叠。第一右侧散热板58b-1插入第一右侧芯片3q-1与第二右侧芯片3q-2之间,第二右侧散热板58b-2插入第二右侧芯片3q-2与第三右侧芯片3q-3之间,第三右侧散热板58b-1插入第三右侧芯片3q-3与第四右侧芯片3q-4之间,第四右侧散热板58b-4插入第四右侧芯片3q-4与第五右侧芯片3q-5之间,并且第五右侧散热板58b-5插入第五右侧芯片3q-5与第六右侧芯片3q-6之间,以实现“清凉右侧芯片”。
第一处理单元11a设置在第一左侧散热板58a-1与第一右侧散热板58b-1之间,第二处理单元11b设置在第三左侧散热板58a-3与第三右侧散热板58b-3之间,第三处理单元11c设置在第五左侧散热板58a-5与第五右侧散热板58b-5之间,并且流水线alu分别包括在处理单元11a、11b、11c中。
在第一左侧芯片3p-1与第二左侧芯片3p-2之间建立标量数据路径和控制路径,在第二左侧芯片3p-2与第三左侧芯片3p-3之间建立标量数据路径和控制路径,在第三左侧芯片3p-3与第四左侧芯片3p-4之间建立标量数据路径和控制路径,在第四左侧芯片3p-4与第五左侧芯片3p-5之间建立标量数据路径和控制路径,在第五左侧芯片3p-5与第六左侧芯片3p-6之间建立标量数据路径和控制路径,在第一右侧芯片3q-1与第二右侧芯片3q-2之间建立标量数据路径和控制路径,在第二右侧芯片3q-2与第三右侧芯片3q-3之间建立标量数据路径和控制路径,在第三右侧芯片3q-3与第四右侧芯片3q-4之间建立标量数据路径和控制路径,在第四右侧芯片3q-4与第五右侧芯片3q-5之间建立标量数据路径和控制路径,在第五右侧芯片3q-5与第六右侧芯片3q-6之间建立标量数据路径和控制路径。通过计算机系统的标量数据路径和控制路径的组合,图73所示的3d计算机系统不仅可执行标量数据,而且可执行向量/流数据。
由于在图73所示的3d配置中这些清凉芯片的表面内部不存在互连,所以很容易将诸如金刚石左侧芯片的散热板58a-1、58a-2、58a-3、58a-4、58a-5交替插入这六个左侧芯片之间,并且将诸如金刚石右侧芯片的散热板58b-1、58b-2、58b-3、58b-4、58b-5交替插入这六个右侧芯片之间。
--其它实施方式--
本领域技术人员在接受本公开的教导之后,在不脱离其范围的情况下,各种改型将变得可能。
在图4、图5、图6、图8、图11、图13、图16-20、图22、图25和图32中,尽管在比特级信元的晶体管层级表示中,nmos晶体管分别被指派为传送晶体管和复位晶体管,由于图4、图5、图6、图8、图11、图13、图16-20、图22、图25和图32中的图示仅为示意性示例,所以如果采用相反极性的时钟信号,则pmos晶体管可用作传送晶体管和复位晶体管。另外,mis晶体管或绝缘栅晶体管(具有由氮化硅膜、ono膜、sro膜、al2o3膜、mgo膜、y2o3膜、hfo2膜、zro2膜、ta2o5膜、bi2o3膜、hfalo膜以及其它膜制成的栅绝缘膜)可用于传送晶体管和复位晶体管。
存在多种不同形式的并行计算,例如比特级、指令级、数据和任务并行计算,也称为“费林分类法”,程序和计算机根据它们是使用单个指令集还是多个指令集进行操作、那些指令是否使用单个数据集合或多个数据集合来进行分类。
例如,如图74所示,可包括推进寄存器文件、推进高速缓冲存储器和推进主存储器(已经在第一实施方式至第五实施方式中进行了讨论)的推进存储器可按照多指令单数据(misd)架构实现标量/向量数据的比特级并行处理,通过该架构,垂直提供给第一处理器11-1、第二处理器11-2、第三处理器11-3、第四处理器11-4、......的许多独立指令流利用处理器11-1、11-2、11-3、11-4的脉动阵列一次在单个水平数据流上并行操作。
另选地,如图75所示,可利用单指令多数据(simd)架构通过可包括推进寄存器文件、推进高速缓冲存储器和推进主存储器(已经在第一实施方式至第五实施方式中进行了讨论)的推进存储器建立算术级并行计算,通过该架构,单个指令流被提供给第一处理器11-1、第二处理器11-2、第三处理器11-3和第四处理器11-4,使得该单个指令流可利用处理器11-1、11-2、11-3、11-4的阵列一次在多个垂直数据流上操作。
另选地,如图76所示,可包括推进寄存器文件、推进高速缓冲存储器和推进主存储器(已经在第一实施方式至第五实施方式中进行了讨论)的推进存储器可利用被分别提供有第一指令i1、第二指令i2、第三指令i3和第四指令i4的第一处理器11-1、第二处理器11-2、第三处理器11-3和第四处理器11-4来实现向量处理中的典型链接。
另外,如图77所示,可包括推进寄存器文件、推进高速缓冲存储器和推进主存储器(已经在第一实施方式至第五实施方式中进行了讨论)的推进存储器可利用第一处理器11-1、第二处理器11-2、第三处理器11-3和第四处理器11-4以misd架构实现单个水平标量/向量数据流的并行处理。
另外,如图78所示,可包括推进寄存器文件、推进高速缓冲存储器和推进主存储器(已经在第一实施方式至第五实施方式中进行了讨论)的推进存储器可利用被配置为执行乘法的第一处理器11-1、被配置为执行加法的第二处理器11-2、被配置为执行乘法的第三处理器11-3以及被配置为执行加法的第四处理器11-4以misd架构实现单个水平标量/向量数据流的并行处理。
另外,对于进程级并行处理,可利用可包括推进寄存器文件、推进高速缓冲存储器和推进主存储器(已经在第一实施方式至第五实施方式中进行了讨论)的推进存储器实现单线程流和单数据流架构、单线程流和多数据流架构、多线程流和单数据流架构以及多线程流和多数据流架构。
参照图41,我们已经对于标量数据或程序指令比较了现有存储器的最差情况的速度/能力与推进主存储器31的速度/能力,图41的(b)的带阴影线部分示意性地示出通过一百个存储器单元u1、u2、u3、......、u100实现的推进主存储器31的速度/能力,并且与图41的(a)所示的现有存储器的最差情况的速度/能力进行了比较。在最差情况下,我们已讨论了我们可读出推进主存储器31的99个存储器单元,但是它们由于标量程序的要求而不可用。然而,通过图79的(b)所示的“复合推进存储器”方案,我们可改进对于标量数据或程序指令,推进存储器的速度/能力,其中多个推进存储器块mm11、mm12、mm13、......、mm16;mm21、mm22、mm23、......、mm26;mm31、mm32、mm33、......、mm36;......;mm51、mm52、mm53、......、mm56被二维部署并被合并在单个半导体芯片66上,并且类似于动态随机存取存储器(dram)架构中所采用的随机存取方法,可从所述多个推进存储器块mm11、mm12、mm13、......、mm16;mm21、mm22、mm23、......、mm26;mm31、mm32、mm33、......、mm36;......;mm51、mm52、mm53、......、mm56随机存取指定的推进存储器块mmij(i=1至5;j=1至6)。
如图79的(a)所示,在传统dram中,存储器阵列区域661、用于行解码器662的外围电路、用于感测放大器(senseamplifier)663的外围电路以及用于列解码器664的外围电路被合并在单个半导体芯片66上。多个存储器信元按照行和列的阵列排列在存储器阵列区域661中,使得各行存储器信元共享公共“字”线,而各列信元共享公共“位”线,阵列中的存储器信元的位置被确定为“字”线与“位”线的交叉点。在“写”操作期间,在“位”线处从列解码器664提供待写数据(“1”或“0”),而从行解码器662确定“字”线,以使存储器信元的存取晶体管导通,并根据位线的状态允许电容器充电或放电。在“读”操作期间,也从行解码器662确定“字”线,其可使存取晶体管导通。被使能的晶体管允许感测放大器663通过“位”线读取电容器上的电压。感测放大器663可通过将所感测的电容器电压与阈值进行比较来确定存储器信元中存储的是“1”还是“0”。
尽管为了避免使附图散乱,6×5=30个推进存储器块mm11、mm12、mm13、......、mm16;mm21、mm22、mm23、......、mm26;mm31、mm32、mm33、......、mm36;......;mm51、mm52、mm53、......、mm56部署在半导体芯片66上,但是该图示是示意性的,实际上,如果排列了单向推进存储器,并且如果假设512mbdram芯片技术作为图79的(b)所示的复合推进存储器方案的制造技术,则具有256kb容量的一千个推进存储器块mmij(i=1至s;j=1至t;s×t=1000)可部署在同一半导体芯片66上。即,作为用于将具有256kb容量的各个推进存储器块mmij整体集成在半导体芯片66上的区域,需要512kbdram块的等效区域,因为如图4-图6所示,各个单向推进存储器块通过由两个晶体管和一个电容器组成的比特级信元实现,而dram存储器信元仅由与电容器配对的单个晶体管组成。另选地,对于双向推进存储器的阵列,具有128kb容量的一千个推进存储器块mmij可部署在512mbdram芯片的同一半导体芯片66上。即,作为用于将具有128kb容量的各个推进存储器块mmij整体集成的区域,需要512kbdram块的等效区域,因为如图32所示,双向推进存储器块通过由四个晶体管和两个电容器组成的比特级信元实现,而dram存储器信元仅由单个晶体管和单个电容器组成。如果假设1gbdram芯片,则具有256kb容量的一千个双向推进存储器块mmij可部署在同一dram芯片66上,以实现256mb推进存储器芯片。
因此,一千个推进存储器块mmij或一千个推进存储器核可整体地集成在半导体芯片66上,如图79的(b)所示。单个推进存储器块mmij或“单个推进存储器核”可包括(例如)一千个推进存储器列或一千个推进存储器单元uk(k=1至1000),其具有基于1000×32字节的地址,其中一个存储器单元uk具有256个比特级信元。即,利用具有一千个推进存储器块mmij的复合推进存储器芯片,可允许在一个传统dram存取循环中存取32字节(或256比特)的一千个推进存储器单元uk(k=1至1000)。
图80的(a)和图80的(b)示出单个256kb推进存储器块mmij的示例,其具有32字节(或256比特)的一千个推进存储器单元uk(k=1至n;n=1000)。在复合推进存储器方案中,如图80的(b)所示,分别在各个推进存储器单元uk上标记位置索引tk(k=1至1000)或位置标签作为各个列uk的令牌,其表示列字节的第一地址。在图80的(b)中,图7c所示的时钟周期(时钟循环时间)tau(希腊字母)clock被描述为“推进存储器的存储器循环tm”。
鉴于以上在第一实施方式至第五实施方式中的讨论,由于我们可利用传统dram与推进存储器之间那么大的速度差异,如图80的(c)所示,对于写或读传统dram的一个存储器元件的内容的传统dram的存储器循环tc,我们可估计:
tc=1000tm............(1)。
因此,对于图79的(b)所示的复合推进存储器方案,我们可改进推进存储器对于标量数据或程序指令的速度/能力,其中类似于dram架构中所采用的随机存取方法,可从一千个推进存储器块随机存取指定的推进存储器块mmij(i=1至s;j=1至t;s×t=1000)。
尽管图79的(b)中未示出,多个256kb的推进存储器块mmij可按照二维矩阵形式排列在半导体芯片66上,使得推进存储器块mmij的各个水平阵列共享公共水平核线,而推进存储器块mmij的各个垂直阵列共享公共垂直核线,二维矩阵中的指定的推进存储器块mmij的位置作为水平核线与垂直核线的交叉点利用双层级结构来存取。在双层级结构中,在低层级利用地址存取每一列的对象推进存储器块mmij,在高层级利用各个推进存储器块mmij自己的地址直接存取每一推进存储器块mmij。
另选地,虚拟存储机制可用于复合推进存储器的存取方法。在虚拟存储机制中,就像虚拟存储器中的页一样调度要使用的推进存储器块mmij(i=1至s;j=1至t)或推进存储器核。调度在编译运行(如果有的话)时决定。例如,在多级高速缓存架构中,多级高速缓存通常通过首先检查最低级(l1)高速缓存来工作,如果l1高速缓冲命中,则处理器高速前进。如果较低的l1高速缓存失败,则检查下一个较高的高速缓存(l2),以此类推,直至检查外部存储器。对于复合推进存储器的存取方法,类似l2高速缓存的存储器可支持虚拟编索引机制,因为l2高速缓存的大小对应于复合推进存储器的大小,并且推进存储器块mmij的大小对应于最低l1高速缓存的大小。
然后,由于包括一千个推进存储器块或一千个内核的复合推进存储器的实现如上所述相对容易,并且在复合推进存储器中,即使在最差情况下,在cpu时钟频率下任何列的存取也基本上可行,复合推进存储器的速度保持传统dram的速度。
另外,尽管电路板未示出,多个复合推进存储器芯片或多个宏复合推进存储器块mmm1、mmm2、......、mmmk可被安装在具有外部链接引脚p1、p2、......、ps-1、ps(“s”可以是由字节单位或字大小确定的任何整数)的第一电路板上,以如图81所示实现复合推进存储器的多芯片模块或“复合推进存储器模块”。在宏复合推进存储器块mmm1、mmm2、......、mmmk的混合组装中,例如,第一宏复合推进存储器块mmm1可在第一半导体芯片上整体集成一千个推进存储器块mm111、mm121、mm131、......、mm1(t-1)1、mm1t1;mm211、......、;mm(s-1)11......;mms11、mms21、......、mms(t-1)1、mmst1,第二宏复合推进存储器块mmm2可在第二半导体芯片上整体集成一千个推进存储器块mm112、mm122、mm132、......、mm1(t-1)2、mm1t2;mm212、......、;mm(s-1)12......;mms12、mms22、......、mms(t-1)2、mmst2,......,第k宏复合推进存储器块mmmk可在第k半导体芯片上整体集成一千个推进存储器块mm11k、mm12k、mm13k、......、mm1(t-1)k、mm1tk;mm21k、......、;mm(s-1)1k......;mms1k、mms2k、......、mms(t-1)k、mmstk,......。并且,混合地组装宏复合推进存储器块mmm1、mmm2、......、mmmk的第一复合推进存储器模块可通过外部链接引脚p1、p2、......、ps-1、ps连接到在第二电路板上混合地组装宏复合推进存储器块mmmk+1及其它的第二复合推进存储器模块。这里,例如,宏复合推进存储器块mmmk+1可在半导体芯片上整体地集成一千个推进存储器块mm11(k+1)、mm12(k+1)、mm13(k+1)、......、mm1(t-1)(k+1)、mm1t(k+1);mm21(k+1)、......、;mm(s-1)1(k+1)......;mms1(k+1)、mms2(k+1)、......、mms(t-1)(k+1)、mmst(k+1)。另外,如果我们实现宏复合推进存储器块的双线混合组装,则我们可建立复合推进存储器的双在线模块。
在图81所示的复合推进存储器模块的配置中,利用三层级结构,在最低层级利用地址存取每一列的对象推进存储器块mmiju(u=1至k;“k”为大于或等于2的任何整数),在中间层级利用各个推进存储器块mmiju自己的地址来存取每一推进存储器块mmiju,在最高层级可利用它自己的地址直接存取每一宏推进存储器块mmmu(u=1至k),这有利于针对标量数据或程序指令存取远处列的推进存储器。
另选地,非常类似于包括对存储器中的命令以锁步方式工作的一组dram芯片的dram排(rank)架构(其中相同排内的dram芯片被同时存取),多个宏复合推进存储器块mmm1、mmm2、......、mmmk可被同时随机存取,并且利用上述双层级结构方法,在低层级利用地址存取每一列的对象推进存储器块mmiju(u=1至k),在高层级利用各个推进存储器块mmiju自己的地址直接存取每一推进存储器块mmiju。
另选地,虚拟存储机制可用于复合推进存储器的存取方法,其中就像虚拟存储器中的页一样调度要使用的推进存储器核。调度在编译运行(如果有的话)时决定。
由于推进主存储器31与处理器11之间的数据传送非常高速地实现,所以不需要传统计算机系统中所采用的高速缓冲存储器,可省略高速缓冲存储器。然而,类似于图56所示的构造,通过复合推进存储器方案实现的推进数据高速缓冲存储器21b可与更多更小尺寸的推进存储器块或更多更小尺寸的推进存储器核一起使用。例如,具有1kb、512比特或256比特容量的多个推进存储器核可部署在半导体芯片上,以实现推进数据高速缓冲存储器21b,而具有256kb容量的多个推进存储器核mmij(i=1至s;j=1至t;s×t=1000)可部署在半导体芯片66上,以实现推进主存储器31。并且,例如,通过虚拟存储机制,各个推进存储器核可被随机存取。
另选地,垂直部署在半导体芯片上的推进存储器块或推进存储器核的一维阵列可实现推进高速缓冲存储器。这里,各个推进存储器核包括存储器单元的单个水平阵列,水平部署的存储器单元的数量小于推进主存储器31的推进存储器核中所采用的存储器单元的数量。并且,例如,利用虚拟存储机制,各个推进存储器核可被随机存取。
另外,多个推进存储器块或多个推进存储器核可垂直部署在半导体芯片上,各个推进存储器块由单个存储器单元组成,各个存储器单元具有被配置为存储字节大小或字大小的信息的比特级信元的序列,以通过复合推进存储器方案实现推进寄存器文件。
在缩放推进存储器核的极端情况下,可以考虑具有最小尺寸(或一比特容量)的多个推进存储器核可通过复合推进存储器方案部署在半导体芯片上,其可对应于传统sram的结构。因此,类似于图55和图56所示的构造,通过一比特推进存储器核实现的推进数据寄存器文件22b可连接到alu112。然后,非常类似于sram的操作,各个一比特推进存储器核可被随机存取。
因此,本发明当然包括以上未详述的各种实施方式和改型等。因此,本发明的范围将在所附权利要求中限定。
[工业实用性]
本发明可适用于需要更高速度和更低功耗的各种计算机系统的工业领域。
- 还没有人留言评论。精彩留言会获得点赞!