大规模输变电设备监测数据流的快速异常检测方法与流程
本发明涉及大规模输变电设备监测领域,尤指一种大规模输变电设备监测数据流的快速异常检测方法。
背景技术:
伴随智能电网建设的推进,电力系统的多个环节中都面临着大规模数据流快速分析的挑战。尤其在输变电设备在线监测系统中,随着监测范围扩大和深度的不断加强,众多量测和传感装置采集的大量多源异构监测数据以数据流的形式不断发送到监测中心,形成大规模监测数据流,而监测中心需要实时快速地处理这些流数据。
当前输变电设备检测数据分析的模式仍是以静态离线数据分析为主,这种方式存在与生产运行系统结合不紧密,不能快速反映系统运行状态和及时发现异常现象等问题。在很多场景下,输变电设备状态监测系统期望对实时到达的数据进行同步处理,从而有利于更快速发现和报警各种异常问题,快速诊断设备运行状况,提升系统运行的安全性。
但是,由于输变电设备状态监测普遍采用省电力公司集中部署方式,如果实时对到达的数据进行同步处理,需要面对以千万计的监测装置以固定的周期进行数据采集和各种异常上传任务,将面临大规模数据流的汇集和快速处理的挑战。
而应对大规模数据流的处理的挑战,传统处理方式显然无法达到所需要的处理能力,因而需要借助大数据处理技术。而在众多的现有的大数据处理技术中,流式计算技术是能够随着实时到达的数据,借助内存或内存集群进行快速分析,具有更好的实时性和处理速度。发明人认为流式计算技术如果与生产系统相结合,就能快速反映生产系统的运行状态,因此,可以用于处理用大规模输变电设备监测数据流。而传统以批处理为主的离线数据分析方式,由于性能和计算模式的问题,很难应对这种在线数据流的快速分析。
当前主流的流式计算平台包括storm、sparksteaming、flink、阿里云流计算等,这些平台均提供了分布式数据流处理框架。借助这些成熟的流式计算平台,可以使开发人员更多地关注业务处理逻辑,并拥有更好的可靠性和扩展性。其中sparksteaming是spark针对数据流处理的扩展,适合处理高可扩展性、高吞吐率和容错机制的实时数据流。sparksteaming目前广泛应用于多种实时数据流处理领域,包括点击流分析、商品推荐等,因此,发明人着手研发使用sparksteaming处理大规模输变电设备监测数据流的方法。
技术实现要素:
为解决上述技术问题,本发明目的在于提供一种能将流式计算技术与生产系统相结合,能快速反映生产系统的运行状态,以用于处理用大规模输变电设备监测数据流的大规模输变电设备监测数据流的快速异常检测方法。
为实现上述目的,本发明提供了一种大规模输变电设备监测数据流的快速异常检测方法,该方法借助使用dbscan算法对历史数据进行聚类和类别标记,并将标记后的样本发送至sparkstreaming集群,用于实时增量聚类;而前置机接收各种终端发送过来的数据流,并将数据流推送到sparksteaming集群处理,在sparksteaming集群上完成实时特征提取及归一化处理;然后进行实时聚类,以完成对新样本类别的判断。
其中,大规模输变电设备监测数据流的快速异常检测方法具体包含以下几个步骤:
(1)前置机接收各种终端发送过来的数据流,并将数据流推送到sparksteaming集群处理,利用streamingcontext的sockettextstream方法,在服务器指定端口接收数据流,并将接收的文本数据流转换为dstreams;
(2)在sparksteaming集群上,对监测数据进行归一化处理;
(3)使用dbscan算法对历史数据进行聚类和类别标记:
该步骤是在批量计算模式下,使用dbscan算法对历史数据进行聚类,从而形成初始类簇,其为每个类簇进行编号,并对每个数据点使用类簇编号进行标记;
(4)将重新标记和定义后的样本集发送至sparkstreaming平台,并且使用广播方式,将新样本集发送至集群所有数据节点,用于后续的增量聚类;
(5)对实时到达的监测数据,进行数据特征提取和归一化处理,形成可以用于参与增量聚类的数据样本m(m1,m2,..mn);
(6)对生成的数据样本m(m1,m2,..mn),在sparkstreaming平台上,执行增量dbscan算法,实时确定样本所属聚类。
其中较佳的,在步骤(2)中,较佳的是使用min-max离差标准化方法对原始采样数据data进行线性变换,使结果result映射到[0,1]之间,以消除量纲影响。
其映射公式为公式(1);
公式(1)中,datamax为样本数据最大值,datamin为样本数据最小值。在有新数据加入时,会实时更新datamax和datamin。
其中较佳的,在步骤(3)中,是使用三元组的格式重新定义每个数据样本,如公式为:
x=<(x1,x2,..xn),y,z>(2)
其中,公式(2)中,(x1,x2,..xn)为n维采样值,y为采样点所属类簇编号,z为数据点的类型,包括核心点、边缘点和异常点3种类型。
其中,该新样本m(m1,m2,..mn)的状态存在如下几种可能性:
d)m(m1,m2,..mn)是异常点;当新数据m在邻域内没有核心点时,将m标记为异常数据,这将引起报警事件,并发送至监测系统进行后续处理;
e)m(m1,m2,..mn)是一个新的核心点;使用增量dbscan算法,判断m(m1,m2,..mn)是否与现有类簇中的某个核心点密度可达,如果是,则将该点加入已有类簇;否则,生成新的类簇;
f)当数据点m(m1,m2,..mn)插入后,使不同聚类之间的核心点实现了密度可达,这时数据点m(m1,m2,..mn)和这些相邻的聚类合并,产生一个新的聚类。
较佳的,该方法还包括步骤:对步骤(6)中增量聚类的结果,使用广播方式,将新样本集发送至集群所有数据节点,进行类簇更新。
较佳的,该方法还包括步骤:定期将sparkstreaming平台上增量聚类的结果同步至后端hbase数据库,进行历史数据的持久化存储。
借助上述方法,本发明可以实现智能电网大规模数据流快速分析,及大规模输变电设备监测数据流的快速异常检测。
附图说明
图1本发明的监测数据流的异常检测平台架构;
图2本发明的异常检测方法的数据处理过程示意图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案做进一步具体的说明。
本发明是基于sparksteaming平台的大规模输变电设备监测数据流的异常检测方法,该方法设计实现了大规模输变电设备监测数据流的增量dbscan异常监测。如图1所示的监测数据流的异常检测平台架构,其为本发明监测数据流的异常检测方法所使用的平台架构。该平台架构包含获取监测数据流的前置机,sparkstreaming集群,历史数据存储单元及异常数据报警模块。本发明借助使用传统dbscan算法对历史数据进行聚类和类别标记,并将标记后的样本发送至sparkstreaming集群,用于实时增量聚类。而前置机接收各种终端发送过来的数据流,并将数据流推送到sparksteaming集群处理,在sparksteaming集群上完成实时特征提取及归一化处理,之后进行实时聚类,完成对新样本类别的判断。
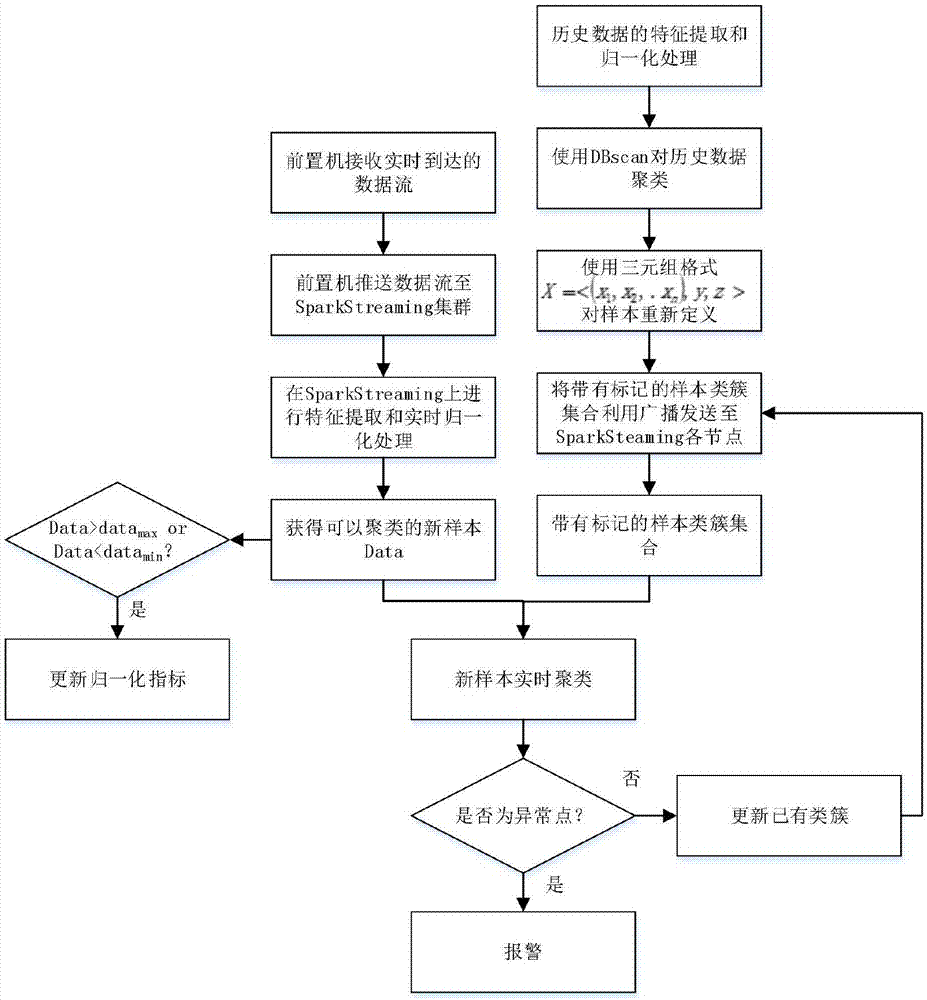
另请参阅图2,为本发明的大规模输变电设备监测数据流的增量dbscan异常检测方法的数据处理过程示意图,具体而言,本发明的监测数据流异常监测具体计算过程包含以下几个步骤:
(1)前置机接收各种终端发送过来的数据流,并将数据流推送到sparksteaming集群处理,利用streamingcontext的sockettextstream方法,在服务器指定端口接收数据流,并将接收的文本数据流转换为dstreams。
(2)在sparksteaming集群上,对监测数据进行归一化处理。使用min-max离差标准化方法对原始采样数据data进行线性变换,使结果result映射到[0,1]之间,以消除量纲影响。映射公式如公式(1)所示。
公式(1)中,datamax为样本数据最大值,datamin为样本数据最小值。在有新数据加入时,会实时更新datamax和datamin。
(3)在批量计算模式下,使用dbscan算法对历史数据进行聚类,从而形成初始类簇。为每个类簇进行编号,并对每个数据点使用类簇编号进行标记。使用三元组的格式重新定义每个数据样本,如公式(2)所示。
x=<(x1,x2,..xn),y,z>(2)
公式(2)中,(x1,x2,..xn)为n维采样值,y为采样点所属类簇编号,z为数据点的类型,包括核心点、边缘点和异常点3种类型。并且历史数据的选取应具有较好的代表性和较大的数据量。
(4)将重新标记和定义后的样本集发送至sparkstreaming平台,并且使用广播方式,将新样本集发送至集群所有数据节点,用于后续的增量聚类。
(5)对实时到达的监测数据,进行数据特征提取和归一化处理,形成可以用于参与增量聚类的数据样本m(m1,m2,..mn)。
(6)对生成的数据样本m(m1,m2,..mn),在sparkstreaming平台上,执行增量dbscan算法,实时确定样本所属聚类。新样本m(m1,m2,..mn)的状态存在如下几种可能性:
a)m(m1,m2,..mn)是异常点。当新数据m在邻域内没有核心点时,将m标记为异常数据,这将引起报警事件,并发送至监测系统进行后续处理;
b)m(m1,m2,..mn)是一个新的核心点。使用增量dbscan算法,判断m(m1,m2,..mn)是否与现有类簇中的某个核心点密度可达,如果是,则将该点加入已有类簇;否则,生成新的类簇。
c)当数据点m(m1,m2,..mn)插入后,使不同聚类之间的核心点实现了密度可达,这时数据点m(m1,m2,..mn)和这些相邻的聚类合并,产生一个新的聚类。
(7)对步骤(6)中增量聚类的结果,使用广播方式,将新样本集发送至集群所有数据节点,进行类簇更新。
(8)定期将sparkstreaming平台上增量聚类的结果同步至后端hbase数据库,进行历史数据的持久化存储。
以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解,依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!