癌症中PD-L1启动子甲基化的制作方法
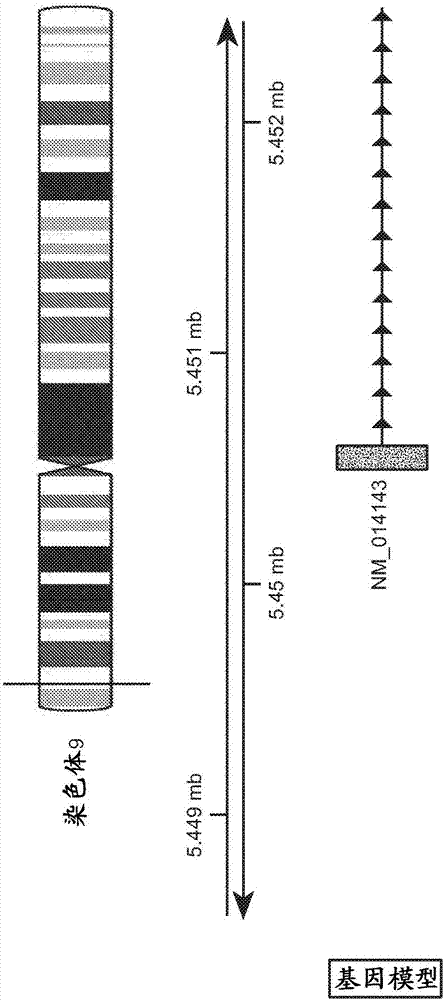
相关申请的交叉引用本申请要求于2015年5月29日提交的美国临时申请序号62/168,668的优先权,其全部内容通过引用并入本文。在ascii文本文件上提交序列表以下提交的ascii文本文件的内容通过整体引用并入本文:序列表的计算机可读形式(crf)(文件名:146392027040seqlist.txt,记录日期:2016年5月27日,大小:19kb)。本发明涉及分层采用抗pd-l1抗体治疗的癌症患者的方法,所述方法通过在含有来自患者的癌细胞的样品中测定pd-l1启动子区上游区和/或pd-l1内含子1中的一个或多个cpg位点上的甲基化水平进行。
背景技术:
:pd-l1在许多癌症中过表达,并且通常与不良预后相关(okazakit等人,intern.immun.200719(7):813)(thompsonrh等人,cancerres2006,66(7):3381)。有趣的是,大多数肿瘤浸润性t淋巴细胞主要表达pd-1,与正常组织中的t淋巴细胞和外周血t淋巴细胞相反,表明在肿瘤反应性t细胞上pd-1的上调可能导致损害抗肿瘤免疫应答(blood2009114(8):1537)。这可能是由于表达pd-l1的肿瘤细胞与表达pd-1的t细胞相互作用,介导pd-l1信号传导的利用,导致t细胞活化减弱和免疫监视的逃避(sharpe等人,natrev2002)(keirme等人,2008annu.rev.immunol.26:677)。因此,抑制pd-l1/pd-1相互作用可能增强cd8+t细胞介导的肿瘤杀伤作用。已经描述了抗pd-l1抗体及其在治疗恶性肿瘤中的用途(参见例如philips等人(2015)intimmunol27,39-461;herbst等人(2014)nature515,563-567)。某些患者对免疫检查点抑制剂具有原发抗性(参见,例如,taube等人(2012)scitranslmed.4,127;sznol等人(2014)clincancerres.19,1021-34;和gajewski等人(2011)curropinimmunol.23:286-92)。因此,仍然需要预测癌症患者对抗pd-l1抗体治疗的反应性。本文公开的所有参考文献、出版物和专利申请通过整体引用并入本文。技术实现要素:在某些实施方案中,本发明提供了治疗或延缓受试者中癌症进展的方法,所述方法包括向受试者施用有效量的抗pd-l1抗体,其中治疗(或延缓进展)基于在来自受试者的含有癌细胞的样品中受试者在pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化。在某些实施方案中,本发明提供了治疗或延缓受试者中癌症进展的方法,只要已发现在来自受试者的含有癌细胞的样品中受试者在pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化,该方法包括向受试者施用有效量的抗pd-l1抗体。在某些实施方案中,本发明提供了治疗或延缓癌症进展的方法,所述方法包括:(a)选择患有癌症的受试者,其中在来自受试者的含有癌细胞的样品中所述受试者在pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化;和(b)向由此选择的受试者施用有效量的抗pd-l1抗体。在某些实施方案中,本发明提供了一种预测癌症受试者是否可能对抗pd-l1抗体治疗反应的方法,所述方法包括在来自受试者的含有癌细胞的样品中测量pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平,其中在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上中等或低水平的甲基化表明该受试者可能对治疗反应。在某些实施方案中,提供了一种治疗受试者中癌症的方法,所述方法包括:(a)在来自受试者的含有癌细胞的样品中测量pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平;和(b)向已被确定为在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平甲基化的受试者施用有效量的抗pd-l1抗体。在某些实施方案中,本发明提供了鉴定可能对抗pd-l1抗体治疗反应的癌症受试者的方法,所述方法包括:(a)在来自受试者的含有癌细胞的样品中评估pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化;和(b)鉴定在样品中在pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平甲基化的受试者。在根据(或应用于)上述任何实施方案的一些实施方案中,所述方法还包括向所述受试者施用有效量的抗pd-l1抗体。在根据(或应用于)上述任何实施方案的一些实施方案中,受试者在pd-l1启动子区中的cpg1上和在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化。在根据(或应用于)上述任何实施方案的一些实施方案中,甲基化水平由亚硫酸氢盐测序确定。在根据(或应用于)上述任何实施方案的一些实施方案中,甲基化水平由亚硫酸氢盐次代测序确定。在根据(或应用于)上述任何实施方案的一些实施方案中,甲基化水平使用甲基化芯片阵列确定。在根据(或应用于)上述任何实施方案的一些实施方案中,来自受试者的样品显示免疫细胞浸润的证据。在根据(或应用于)上述任何实施方案的一些实施方案中,免疫细胞浸润的证据通过western印迹、elisa、流式细胞术、qpcr、qrt-pcr、转录组分析、微阵列分析或次代测序检测的cd8+淋巴细胞表示。在根据(或应用于)上述任何实施方案的一些实施方案中,由亚硫酸氢盐测序确定的中等水平的甲基化为约20%至约40%甲基化。在根据(或应用于)上述任何实施方案的一些实施方案中,由亚硫酸氢盐测序确定的低水平甲基化小于约20%甲基化。在根据(或应用于)上述任何实施方案的一些实施方案中,由亚硫酸氢盐次代测序确定的中等水平的甲基化为约5%至约60%甲基化。在根据(或应用于)上述任何实施方案的一些实施方案中,由亚硫酸氢盐次代测序确定的低水平甲基化小于约5%甲基化。在根据(或应用于)上述任何实施方案的一些实施方案中,由甲基化芯片阵列确定的中等水平的甲基化为约0.2至约0.3的β值。在根据(或应用于)上述任何实施方案的一些实施方案中,由甲基化芯片阵列确定的低水平甲基化为小于约0.2的β值在根据(或应用于)上述任何实施方案的一些实施方案中,癌症是肺癌、乳腺癌、膀胱癌或黑素瘤。在根据(或应用于)上述任何实施方案的一些实施方案中,癌症是肺癌,并且其中肺癌是非小细胞肺癌、肺鳞状细胞癌或肺腺癌。在根据(或应用于)上述任何实施方案的一些实施方案中,抗pd-l1抗体抑制pd-l1与pd-1的结合。在根据(或应用于)上述任何实施方案的一些实施方案中,抗pd-l1抗体抑制pd-l1与b7-1的结合。在根据(或应用于)上述任何实施方案的一些实施方案中,抗pd-l1抗体抑制pd-l1与pd-1和b7-1的结合。在根据(或应用于)上述任何实施方案的一些实施方案中,抗pd-l1抗体是单克隆抗体。在根据(或应用于)上述任何实施方案的一些实施方案中,抗pd-l1抗体是选自fab、fab'-sh、fv、scfv和(fab')2的抗体片段。在根据(或应用于)上述任何实施方案的一些实施方案中,抗pd-l1抗体是人源化抗体或人抗体。在根据(或应用于)上述任何实施方案的一些实施方案中,抗pd-l1抗体选自:yw243.55.s70、mpdl3280a、mdx-1105和medi4736。在根据(或应用于)上述任何实施方案的一些实施方案中,抗pd-l1抗体包含重链和轻链,所述重链包含seqidno:15的hvr-h1序列、seqidno:16的hvr-h2序列和seqidno:3的hvr-h3序列;和所述轻链包含seqidno:17的hvr-l1序列、seqidno:18的hvr-l2序列和seqidno:19的hvr-l3序列。在根据(或应用于)上述任何实施方案的一些实施方案中,抗pd-l1抗体包含包含seqidno:24的氨基酸序列的重链可变区和包含seqidno:21的氨基酸序列的轻链可变区。在一些实施方案中,本发明提供了一种制品,其包含一起包装的药物组合物和标签,所述药物组合物包含抗pd-l1抗体和药学上可接受的载体,所述标签指示抗pd-l1抗体或药物组合物指明用于治疗在来自受试者的含有癌细胞的样品中在pd-l1启动子区中的cpg1上和/或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平甲基化的癌症患者。在一些实施方案中,本发明提供了一种包含试剂和说明书的试剂盒,所述试剂用于在来自受试者的含有癌细胞的样品中测量pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平,和所述说明书用于将受试者分类为在pd-l1启动子区中的cpg1上和/或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低的甲基化水平。在根据(或应用于)上述任何实施方案的一些实施方案中,试剂盒或制品还包含抗pd-l1抗体和说明书,说明书用于说明如果受试者在pd-l1启动子区中的cpg1上和/或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低的甲基化水平,则向受试者施用抗pd-l1抗体。应当理解,本文所述的各种实施方案的一个、一些或全部性质可以组合以形成本发明的其它实施方案。本发明的这些和其它方面对于本领域技术人员将变得显而易见。通过下面的详细描述进一步描述本发明的这些和其它实施方案。附图说明图1显示91个非小细胞肺癌(nsclc)细胞系的pd-l1表达水平和pd-l1启动子甲基化热图。图2a显示在来自癌基因组图集的肺腺癌肿瘤集合中关联pd-l1rna表达和pd-l1启动子甲基化的分析的结果。图2b显示在来自癌基因组图集的肺鳞状细胞癌肿瘤集合中关联pd-l1rna表达和pd-l1启动子甲基化的分析的结果。图2c显示在来自癌基因组图集的乳腺癌肿瘤集合中关联pd-l1rna表达和pd-l1启动子甲基化的分析的结果。图2d显示在来自癌基因组图集的皮肤癌肿瘤集合中关联pd-l1rna表达和pd-l1启动子甲基化的分析的结果。图3显示在5种肺癌细胞系(即h661、lxfl529、a427、h2073、h322t和h1993)中进行的评估5aza-dc、tsa、ifng或5aza-dc+tsa+ifng处理对pd-l1rna表达的影响的实验结果。图4a显示在四种不同肺癌细胞系(a427、h292、h322t和h358)中进行的评估ifng处理对pd-l1蛋白和rna表达的影响实验的结果。图4b显示在a427、h292、h322t和h358细胞系中进行的测定30分钟ifng处理和24小时ifng处理对ifng/jak/stat信号通路的影响的实验结果。图4c显示在a427和h358中进行的测定ifng处理和/或stat1和stat3敲除对stat1、stat3和pd-l1表达的影响的实验结果。图5a显示对于外周血单核细胞亚型,将亚硫酸氢盐测序的数据叠印到可能的cpg甲基化位点的图上。图5b显示对于永生化正常肺细胞系和在pd-l1启动子区中具有高、中等或低甲基化水平的nsclc肺癌细胞系,将亚硫酸氢盐测序的数据叠印到可能的cpg甲基化位点的图上。图6a显示从nsclc细胞系的癌基因组计划(cgp)创建的散点图,其直接比较x轴上的平滑cpg1和cpg5甲基化(m值)和y轴上的pd-l1表达(rna-seq,log2-计数)。图6b显示进行的anova分析结果,该分析用来确定来自图6a的nsclc细胞系分类为3个甲基化水平组(即“低”、“中等”和“高”)的统计学相关性。图6c显示进行的anova分析结果,该分析用来确定来自图6a的nsclc细胞系中5aza-dc处理对pd-l1rna表达的影响的统计学相关性。图6d显示进行的以确定在关联的nsclc细胞系h1993和h2073中5aza-dc处理对pd-l1rna表达的影响的实验结果。图7a显示进行的anova分析结果,该分析用来确定在nsclc细胞系中t细胞浸润、cpg5(mut7)上的甲基化和pd-l1蛋白水平之间关系的统计学相关性。图7b显示进行的anova分析结果,该分析用来确定在nsclc细胞系中t细胞浸润、cpg5(mut7)上的甲基化和pd-l1转录水平之间关系的统计学相关性。图8提供了显示在igvintegratedgenomicsviewer(broadinstitute)中的.bed文件。.bed文件提供进行的chip-seq实验结果,该实验用来在a427和h358细胞系中确定stat1和/或stat3是否结合pd-l1的启动子区。具体实施方式i.一般技术本文描述或应用的技术或步骤是本领域技术人员通常能够很好地理解并使用常规方法应用的,如,例如,描述于sambrook等人,molecularcloning:alaboratorymanual第三版(2001)coldspringharborlaboratorypress,coldspringharbor,n.y.;currentprotocolsinmolecularbiology(f.m.ausubel等人编辑,(2003));theseriesmethodsinenzymology(academicpress,inc.):pcr2:apracticalapproach(m.j.macpherson,b.d.hames和g.r.taylor编辑(1995)),harlow和lane,编辑(1988)antibodies,alaboratorymanual,andanimalcellculture(r.i.freshney,编辑(1987));oligonucleotidesynthesis(m.j.gait编辑1984);methodsinmolecularbiology,humanapress;cellbiology:alaboratorynotebook(j.e.cellis,编辑,1998)academicpress;animalcellculture(r.i.freshney),编辑,1987);introductiontocellandtissueculture(j.p.mather和p.e.roberts,1998)plenumpress;cellandtissueculture:laboratoryprocedures(a.doyle,j.b.griffiths,和d.g.newell,编辑,1993-8)j.wiley和sons;handbookofexperimentalimmunology(d.m.weir和c.c.blackwell,eds.);genetransfervectorsformammaliancells(j.m.miller和m.p.calos,编辑,1987);pcr:thepolymerasechainreaction,(mullis等人编辑,1994);currentprotocolsinimmunology(j.e.coligan等人编辑,1991);shortprotocolsinmolecularbiology(wiley和sons,1999);immunobiology(c.a.janeway和p.travers,1997);antibodies(p.finch,1997);antibodies:apracticalapproach(d.catty.编辑,irlpress,1988-1989);monoclonalantibodies:apracticalapproach(p.shepherd和c.dean编辑,oxforduniversitypress,2000);usingantibodies:alaboratorymanual(e.harlow和d.lane(coldspringharborlaboratorypress,1999);theantibodies(m.zanetti和j.d.capra编辑,harwoodacademicpublishers,1995);以及cancer:principlesandpracticeofoncology(v.t.devita等人编辑,j.b.lippincottcompany,1993)中的广泛使用的方法。ii.定义如本文所用,术语“治疗”是指设计用来改变在临床病理过程中治疗的个体或细胞的天然过程的临床干预。治疗的期望效果包括降低疾病进展速率、减轻或缓和疾病状态、缓解或改善预后。例如,如果减轻或消除与癌症相关的一种或多种症状(包括但不限于减少(或破坏)癌细胞的增殖、减少由疾病引起的症状、增加患有疾病的那些人的生活质量、减少治疗疾病所需的其它药物的剂量和/或延长个体的生存),则个体被成功地“治疗”。如本文所用,“基于(basedupon)”包括(1)评估、确定或测量本文所述的患者特征(优选选择适合接受治疗的患者;和(2)施用如本文所述的治疗。用于治疗目的的“受试者”、“患者”或“个体”是指分类为哺乳动物的任何动物,包括人、家畜和农场动物、以及动物园、运动或宠物动物,例如狗、马、猫、牛等。优选地,哺乳动物是人。如本文所用,“延缓疾病的进展”意味着推迟、阻止、减慢、延迟、稳定和/或拖延疾病(如癌症)的发展。这种延缓可以是不同的时间长度,这取决于疾病的历史和/或被治疗的个体。如本领域技术人员显而易见的,足够或显著的延缓实际上可以包括预防,在这种情况下个体不发展疾病。例如,可能延缓晚期癌症,如转移的发展。“有效量”是实现可测量的特定疾患的改善或预防所需的至少最小量。本文的有效量可以根据如患者的疾病状态、年龄、性别和体重等因素以及抗体在个体中引起期望的反应的能力而变化。有效量也是治疗的有益效果超过任何治疗毒性或有害作用的量。对于预防用途,有益的或期望的结果包括如消除或降低风险、减轻严重性或延缓疾病发作的结果,包括疾病的生物化学、组织学和/或行为症状、其并发症和在疾病发展期间呈现的中间病理表型。对于治疗用途,有益的或期望的结果包括临床结果,如减少由疾病引起的一种或多种症状、增加患有疾病的那些患者的生活质量、降低治疗疾病所需的其它药物的剂量、增强其它药物的作用,如通过靶向、延缓疾病的进展和/或延长存活。在癌症或肿瘤的情况下,药物的有效量可具有以下作用:降低癌细胞的数量;降低肿瘤大小;抑制(即在一定程度上减慢或期望停止)癌细胞浸润到周围器官中;抑制(即在一定程度上减慢并期望停止)肿瘤转移;在一定程度上抑制肿瘤生长;和/或在某种程度上减轻与该疾患相关的一种或多种症状。有效量可以在一次或多次给药中施用。为了本发明的目的,药物、化合物或药物组合物的有效量是足以直接或间接地完成预防或治疗性治疗的量。如在临床情况中所了解的,药物、化合物或药物组合物的有效量可以或者可以不与另一种药物、化合物或药物组合物联合实现。因此,在施用一种或多种治疗剂的情况下可以考虑“有效量”,并且如果与一种或多种其它试剂联合,可以考虑单一试剂以有效量给予,可以或者实现期望的结果。术语“细胞增生性疾患”和“增生性疾患”是指与某种程度的异常细胞增殖相关的疾患。在一个实施方案中,细胞增生性疾患是癌症。在一个实施方案中,细胞增生性疾患是肿瘤。本文使用的“肿瘤”是指所有瘤细胞生长和增殖,无论是恶性还是良性,以及所有癌前和癌细胞和组织。术语“癌症”、“癌”、“细胞增生性疾患”、“增生性疾患”和“肿瘤”在本文中不是相互排斥的。术语“癌症”和“癌”是指或描述哺乳动物中通常以不受调节的细胞生长为特征的生理状况。癌症的实例包括但不限于癌、淋巴瘤、母细胞瘤、肉瘤、白血病或淋巴恶性肿瘤、鳞状细胞癌(例如上皮鳞状细胞癌)、腹膜癌、肝细胞癌、胃部的癌症或胃癌(如胃肠癌和胃肠道间质癌)、胰腺癌、胶质母细胞瘤、宫颈癌、卵巢癌、肝癌、膀胱癌、尿道癌、肝癌、结肠癌、直肠癌、结肠直肠癌(crc)、子宫内膜或子宫癌、唾液腺癌、肾或肾癌、前列腺癌、外阴癌、甲状腺癌、肝癌、肛门癌、阴茎癌、多发性骨髓瘤和b细胞淋巴瘤(如低级/滤泡型非霍奇金淋巴瘤(nhl)、小淋巴细胞(sl)nhl、中级/滤泡型nhl、中级弥漫性nhl、高级免疫母细胞nhl、高级淋巴母细胞nhl、高级小无裂细胞nhl、bulkydiseasenhl、外套细胞淋巴瘤、aids相关淋巴瘤和waldenstrom的巨球蛋白血症)、慢性淋巴细胞性白血病(cll)、急性淋巴母细胞性白血病(all)、毛细胞白血病、慢性成髓细胞白血病和移植后淋巴增生性疾患(ptld)、以及与斑痣性错构瘤病相关的异常血管增生、水肿(如与脑肿瘤相关的水肿)、meigs综合征、脑以及头颈癌、软组织肉瘤、卡波西肉瘤、类癌和间皮瘤、胶质母细胞瘤、神经母细胞瘤和相关转移。癌症的其它实例包括但不限于乳腺癌(如乳腺癌)、肺癌(如小细胞肺癌、非小细胞肺癌、肺腺癌和肺鳞状细胞癌)和皮肤癌(如黑素瘤、浅表性扩散性黑素瘤、恶性雀斑样黑素瘤、肢端的雀斑样黑素瘤、结节性黑素瘤和皮肤癌),包括这些癌症的转移形式。本文所用的“样品”是指获自或源自感兴趣受试者的组合物,其含有(例如基于物理、生物化学、化学和/或生理特征)待表征和/或鉴定的细胞和/或其它分子实体。例如,短语“疾病样品”及其变型是指从感兴趣受试者获得的任何样品,其预期或已知包含待表征的细胞和/或分子实体。样品可以是生物组织或流体的生物样品(如离体生物样品),其来自受试者的含有癌细胞和/或肿瘤细胞,可以从这些癌细胞和/或肿瘤细胞分离核酸(如多核苷酸,例如基因组dna和/或转录本)和/或多肽。这些样品通常来自人受试者,但包括从其它受试者分离的组织(如分类为哺乳动物的任何动物,如本文别处所述)。样品还可以包括如活组织检查和尸体解剖样品的组织切片、用于组织学目的的冷冻切片。样品可以包括来自受试者的新鲜样品或保存的组织样品,如福尔马林固定石蜡包埋(ffpe)的样品。样品还包括外植体和源自患者组织的原代和/或转化的细胞培养物。“组织或细胞样品”是指从受试者或患者的组织获得的相似细胞的集合。组织或细胞样品的来源可以是如来自新鲜的、冷冻的和/或保存的器官或组织样品或活组织检查或抽吸物的固体组织;血液或任何血液成分;体液如脑脊髓液、羊水、腹膜液或间质液;来自受试者妊娠或发育中任何时候的细胞。组织样品也可以是原代或培养的细胞或细胞系。任选地,组织或细胞样品从疾病组织/器官获得。组织样品可以含有与天然组织非天然混合的化合物,如防腐剂、抗凝剂、缓冲剂、固定剂、营养剂、抗生素等。本文所用的术语“细胞毒性剂”是指对细胞有害的任何试剂(例如引起细胞死亡、抑制增殖或以其它方式阻碍细胞功能)。细胞毒剂包括但不限于放射性同位素(例如at211、i131、i125、y90、re186、re188、sm153、bi212、p32、pb212和lu的放射性同位素);化疗剂;生长抑制剂;酶及其片段如溶核酶;和毒素,如细菌、真菌、植物或动物来源的小分子毒素或酶促活性毒素,包括其片段和/或变体。示例性细胞毒性剂可以选自抗微管剂、铂配位配合物、烷化剂、抗生素制剂、拓扑异构酶ii抑制剂、抗代谢类、拓扑异构酶i抑制剂、激素和激素类似物、信号转导通路抑制剂、非受体酪氨酸激酶血管发生抑制剂、免疫治疗剂、促凋亡剂、ldh-a抑制剂、脂肪酸生物合成抑制剂、细胞周期信号传导抑制剂、hdac抑制剂、蛋白酶体抑制剂和癌症代谢的抑制剂。在一个实施方案中,细胞毒性剂是紫杉烷。在一个实施方案中,紫杉烷是紫杉醇或多西紫杉醇。在一个实施方案中,细胞毒性剂是铂剂。在一个实施方案中,细胞毒性剂是egfr的拮抗剂。在一个实施方案中,egfr的拮抗剂是n-(3-乙炔基苯基)-6,7-双(2-甲氧基乙氧基)喹唑啉-4-胺(例如厄洛替尼)。在一个实施方案中,细胞毒性剂是raf抑制剂。在一个实施方案中,raf抑制剂是braf和/或craf抑制剂。在一个实施方案中,raf抑制剂是威罗菲尼。在一个实施方案中,细胞毒性剂是pi3k抑制剂。“化疗剂”是指可用于治疗癌症的化合物。化疗剂的实例包括厄洛替尼(genentech/osipharm.)、硼替佐米(millenniumpharm.)、双硫仑、表没食子儿茶素没食子酸酯、salinosporamidea、卡非佐米、17-aag(格尔德霉素)、根赤壳菌素、乳酸脱氢酶a(ldh-a)、氟维司群(astrazeneca)、sunitib(pfizer/sugen)、来曲唑(novartis)、甲磺酸伊马替尼(novartis)、finasunate(novartis)、奥沙利铂(sanofi)、5-fu(5-氟尿嘧啶)、甲酰四氢叶酸、雷帕霉素(sirolimus,wyeth)、拉帕替尼(gsk572016,glaxosmithkline)、lonafamib(sch66336)、索拉非尼(bayerlabs)、吉非替尼(astrazeneca)、ag1478、烷化剂如噻替派和环磷酰胺;烷基磺酸盐,如白消安、英丙舒凡和哌泊舒凡;氮丙啶如苯并多巴(benzodopa)、卡波醌、美妥替派(meturedopa),和乌瑞替派(uredopa);乙撑亚胺类(ethylenimines)和甲基蜜胺类(methylamelamines),包括六甲蜜胺、三亚乙基蜜胺、三亚乙基磷酰胺、三亚乙基硫代磷酰胺和三羟甲基三聚氰胺(trimethylomelamine);乙酰内酯类(acetogenins)(特别是bullatacin和bullatacinone);喜树碱(包括托泊替康和伊立替康)、苔藓抑素;callystatin;cc1065(包括其adozelesin、carzelesin和bizelesin合成类似物);cryptophycins(特别是cryptophycin1和cryptophycin8);肾上腺皮质类固醇(包括泼尼松和泼尼松龙);醋酸环丙孕酮;5α-还原酶,包括非那雄胺和度他雄胺);伏林司他、罗米地新、帕比司他、丙戊酸、莫西司他多拉司他汀;阿地白介素、滑石多卡米星(包括合成类似物,kw-2189和cb1-tm1);艾榴塞洛素;水鬼蕉碱;五加苷素;软海绵素(spongistatin);氮芥,如苯丁酸氮芥、氯罗沙嗪(chlomaphazine)、氯膦酰胺(chlomaphazine)、雌莫司汀、异环磷酰胺、二氯甲基二乙胺、盐酸甲氧化氮、美法仑、诺维生素、苯芥胆甾醇、泼尼莫司汀、曲磷胺、尿嘧啶氮芥;亚硝基脲如卡莫司汀、氯脲菌素、福莫司汀、洛莫司汀、尼莫司汀和雷尼地坦(ranimnustine);抗生素类如烯二炔类(enediyne)抗生素(例如加利车霉素,特别是加利车霉素γ1i和加利车霉素ω1i(angewchem.intl.ed.engl.199433:183-186);dynemicin,包括dynemicina;二膦酸盐,如氯膦酸盐;埃斯波霉素;以及新抑癌蛋白发色团和相关的发色蛋白烯二炔抗生素发色团)、aclacinomysins、放线菌素、authramycin、重氮丝氨酸、博莱霉素、放线菌素c、carabicin、caminomycin、嗜癌霉素(carzinophilin)、chromomycinis、更生霉素、柔红霉素、地托比星、6-重氮-5-氧代-l-正亮氨酸、(多柔比星)、吗啉代多柔比星、氰基吗啉代-多柔比星、2-吡咯啉-多柔比星和脱氧多柔比星)、表柔比星、依索比星、伊达比星、麻西罗霉素、丝裂霉素类如丝裂霉素c、霉酚酸、诺拉霉素、奥利菌素(olivomycins)、培洛霉素、普福霉素、嘌呤霉素、三铁阿霉素、罗多比星、链黑菌素、链脲霉素、杀结核菌素、乌苯美司、净司他丁、佐柔比星;抗代谢类如甲氨蝶呤和5-氟尿嘧啶(5-fu);叶酸类似物,如二甲叶酸、甲氨蝶呤、蝶呤素、三甲曲沙;嘌呤类似物如氟达拉滨、6-巯基嘌呤、硫咪嘌呤、硫鸟嘌呤;嘧啶类似物如安西他滨、阿扎胞苷、6氮尿苷(6-azauridine)、卡莫氟、阿糖胞苷、双脱氧尿苷、去氧氟尿苷、依诺他滨、氟尿苷;雄激素类如卡普睾酮、丙酸屈他雄酮、环硫雄醇、美雄烷、睾内酯;抗-肾上腺类如氨鲁米特、米托坦、曲洛司坦;叶酸补充剂如克罗来酸(frolinicacid);醋葡醛内酯;醛磷酰胺糖苷;氨基酮戊酸;恩尿嘧啶;安吖啶;bestrabucil;比山群;edatraxate;defofamine;秋水仙胺;地吖醌;elfomithine;依利醋铵;埃坡霉素;依托格鲁;硝酸镓;羟基脲;香菇多糖;lonidainine;美登素生物碱如美登素和美坦西醇;米托胍腙;米托蒽醌;mopidamnol;nitraerine;喷司他丁;蛋氨氮芥;吡柔比星;洛索蒽醌;鬼臼酸;2-ethylhydrazide;甲基苄肼;多糖复合物(jhsnaturalproducts,eugene,oreg.);雷佐生;根霉素;sizofuran;锗螺胺;替奴佐酸;2,2',2”-三氯三乙胺;单端孢霉烯族毒素类(特别是t-2毒素、verracurina、杆孢菌素a和anguidine);乌拉坦;长春地辛;达卡巴嗪;甘露莫司汀;二溴甘露醇;二溴卫矛醇;哌泊溴烷;gacytosine;阿糖胞苷(“ara-c”);环磷酰胺;塞替派;紫衫烷类,例如taxol(紫杉醇;bristol-myerssquibboncology,princeton,nj)、(无氢化蓖麻油)、紫杉醇的白蛋白工程化纳米颗粒制剂(americanpharmaceuticalpartners,schaumberg,ill.)和(多西紫杉醇、多西他赛;sanofi-aventis);chloranmbucil;(吉西他滨);6-硫鸟嘌呤;巯基嘌呤;甲氨蝶呤;铂类似物如顺铂和卡铂;长春花碱;基于铂的药物,依托泊苷(vp-16);异环磷酰胺;卡培他滨;米托蒽醌;长春新碱;(长春瑞滨);novantrone;替尼泊苷;依达曲沙;柔红霉素;氨基喋呤;卡培他滨伊班膦酸钠;cpt-11;拓扑异构酶抑制剂rfs2000;二氟甲基鸟氨酸(dmfo);类维生素a如视黄酸;和上述任一项的药学上可接受的盐、酸和衍生物。该定义中还包括(i)用于调节或抑制激素对肿瘤的作用的抗激素剂,如抗雌激素和选择性雌激素受体调节剂(serm),包括例如他莫昔芬(包括他莫昔芬柠檬酸盐)、雷洛昔芬、屈洛昔芬、碘氧芬(iodoxyfene)、4-羟基他莫昔芬、曲沃昔芬、雷洛昔芬、ly117018、onapristone和(托瑞米芬柠檬酸盐);(ii)芳香酶抑制剂,其抑制在肾上腺中调节雌激素产生的芳香酶,例如4(5)-咪唑、氨鲁米特、(醋酸甲地孕酮)、(依马雌酮,pfizer)、福美斯汀(formestanie)、法倔唑、(vorozole)、(来曲唑,novartis)和(阿那曲唑;astrazeneca);(iii)抗雄激素如氟他胺、尼鲁替胺、比卡鲁胺、亮丙瑞林和戈舍瑞林;布舍瑞林、曲普瑞林(tripterelin)、醋酸甲羟孕酮、己烯雌酚、普雷马林、氟甲睾酮、全反式维甲酸、芬维a胺以及曲西他滨(1,3-二氧戊环核苷胞嘧啶类似物);(iv)蛋白激酶抑制剂;(v)脂质激酶抑制剂;(vi)反义寡核苷酸,特别是抑制涉及异常细胞增殖的信号通路中基因表达的那些,如,例如pkc-α、ralf和h-ras;(vii)核酶如vegf表达抑制剂(例如)和her2表达抑制剂;(viii)疫苗,如基因治疗疫苗,例如和ril-2;拓扑异构酶1抑制剂如rmrh;和(ix)上述任何一种的药学上可接受的盐、酸和衍生物。化疗剂还包括抗体,如阿仑单抗(campath)、贝伐单抗(bevacizumab)(genentech);西妥昔单抗(imclone);帕尼单抗(amgen)、利妥昔单抗(genentech/biogenidec)、帕妥珠单抗(2c4,genentech)、曲妥珠单抗(genentech)、托西莫单抗(bexxar,corixia)和抗体药物缀合物、吉妥珠单抗奥唑米星(wyeth)。作为与本发明化合物组合的试剂的具有治疗潜力的人源化单克隆抗体包括:阿泊珠单抗(apolizumab)、阿塞珠单抗(aselizumab)、阿替珠单抗(atlizumab)、bapineuzumab、bivatuzumabmertansine、莫坎妥珠单抗(cantuzumabmertansine)、西利珠单抗(cedelizumab)、赛妥珠单抗(certolizumabpegol)、cidfusituzumab、cidtuzumab、达克珠单抗(daclizumab)、依库珠单抗(eculizumab)、依法利珠单抗(efalizumab)、依帕珠单抗(epratuzumab)、erlizumab、felvizumab、芳妥珠单抗(fontolizumab)、吉妥珠单抗奥唑米星(gemtuzumabozogamicin)、英妥珠单抗奥佐米星(inotuzumabozogamicin)、伊匹木单抗(ipilimumab)、拉贝珠单抗(labetuzumab)、林妥珠单抗(lintuzumab)、马妥珠单抗(matuzumab)、美泊利单抗(mepolizumab)、莫维珠单抗(motavizumab)、motovizumab、那他珠单抗(natalizumab)、尼妥珠单抗(nimotuzumab)、nolovizumab、numavizumab、奥瑞珠单抗(ocrelizumab)、奥马珠单抗(omalizumab)、帕利珠单抗(palivizumab)、帕考珠单抗(pascolizumab)、pecfusituzumab、pectuzumab、培克珠单抗(pexelizumab)、ralivizumab、兰尼单抗(ranibizumab)、reslivizumab、瑞利珠单抗(reslizumab)、resyvizumab、罗维珠单抗(rovelizumab)、卢利珠单抗(ruplizumab)、西罗珠单抗(sibrotuzumab)、西利珠单抗(siplizumab)、索土珠单抗(sontuzumab)、他珠单抗(tacatuzumabtetraxetan)、他度珠单抗(tadocizumab)、他利珠单抗(talizumab)、tefibazumab、托珠单抗(tocilizumab)、toralizumab、tucotuzumabcelmoleukin、tucusituzumab、umavizumab、乌珠单抗(urtoxazumab)、优特克诺单抗(ustekinumab)、visilizumab和抗白细胞介素12(abt-874/j695,wyethresearchandabbottlaboratories),其是基因修饰的重组专用人序列全长igg1λ抗体,以识别白细胞介素-12p40蛋白。本文所用的“生长抑制剂”是指在体外或体内抑制细胞生长的化合物或组合物。在一个实施方案中,生长抑制剂是防止或减少表达抗体所结合抗原的细胞增殖的生长抑制性抗体。在另一个实施方案中,生长抑制剂可以是显著降低s期的细胞百分比的抑制剂。生长抑制剂的实例包括阻断细胞周期进展(在s期以外的时期),如诱导g1阻滞和m期阻滞的试剂。典型的m期阻断剂包括长春花(长春新碱和长春花碱)、紫杉烷类和拓扑异构酶ii抑制剂,如多柔比星、表柔比星、柔红霉素、依托泊苷和博来霉素。那些阻滞g1的试剂也会外溢至s期阻滞,例如dna烷化剂如他莫昔芬、泼尼松、达卡巴嗪、氮芥、顺铂、甲氨蝶呤、5-氟尿嘧啶和ara-c。更多的信息可以在mendelsohn和israel编辑,themolecularbasisofcancer,第一章题目为“cellcycleregulation,oncogenes,andantineoplasticdrugs”murakami等人(w.b.saunders,philadelphia,1995),例如第13页。紫杉烷(紫杉醇和多西紫杉醇)是源自紫杉树的抗癌药物。源自欧洲紫杉树的多西紫杉醇(rhone-poulencrorer)是紫杉醇(bristol-myerssquibb)的半合成类似物。紫杉醇和多西紫杉醇促进从微管蛋白二聚体组装微管,并通过防止解聚作用来稳定微管,这导致细胞中有丝分裂的抑制。本文的术语“抗体”以最广泛的含义使用,并且具体涵盖单克隆抗体、多克隆抗体、由至少两种完整抗体形成的多特异性抗体(例如双特异性抗体)和抗体片段,只要它们显示出所需的生物学活性。本文所用的术语“抗pd-l1抗体”是一种拮抗剂抗体,其指降低、阻断、抑制、废除或干扰由pd-l1与其一种或多种结合配偶体(如pd-1、b7-1)相互作用导致的信号转导。在一些实施方案中,抗pd-l1抗体是抑制pd-l1与其结合配偶体结合的抗体。在具体方面,抗pd-l1抗体抑制pd-l1与pd-1和/或b7-1的结合。在一些实施方案中,抗pd-l1抗体包括其抗原结合片段,所述抗原结合片段降低、阻断、抑制、废除或干扰由pd-l1与其一种或多种结合配偶体(如pd-1、b7-1)相互作用导致的信号转导。在一个实施方案中,抗pd-l1抗体减少由或通过t淋巴细胞(通过pd-l1介导信号传导)上表达的细胞表面蛋白介导的负性共刺激信号,以使功能失调的t细胞功能失调较少(例如增强效应子对抗原识别的反应)。在一个实施方案中,抗pd-l1抗体是本文所述的yw243.55.s70。在另一个实施方案中,抗pd-l1抗体是本文所述的mdx-1105。在另一个实施方案中,抗pd-l1抗体是本文所述的mpdl3280a。在另一个实施方案中,抗pd-l1抗体是本文所述的medi4736。“阻断”抗体或“拮抗剂”抗体是抑制或降低其结合的抗原的生物学活性的抗体。在一些实施方案中,阻断抗体或拮抗剂抗体基本上或完全抑制抗原的生物学活性。本发明的抗pd-l1抗体通过pd-1阻断信号传导。如本文所用,术语“结合”、“特异性结合”或“特异于”是指可测量和可重复的相互作用,如靶和抗体之间的结合,其决定于在存在包括生物分子在内的分子的异质群中靶的存在。例如,结合或特异性结合靶(其可以是表位)的抗体是以比其结合其它靶更高的亲和力、亲合性、更容易和/或更长的持续时间结合该靶的抗体。在一个实施方案中,抗体与无关靶结合的程度小于抗体与该靶结合的约10%,如,例如通过放射免疫测定法(ria)测量的。在某些实施方案中,特异性结合靶的抗体具有≤1μm、≤100nm、≤10nm、≤1nm或≤0.1nm的解离常数(kd)。在某些实施方案中,抗体特异性结合来自不同物种的蛋白质中保守的蛋白质上的表位。在另一个实施方案中,特异性结合可以包括排他性结合,但不是要求的。“抗体片段”包含完整抗体的一部分,优选包含其抗原结合区。抗体片段的实例包括fab、fab'、f(ab')2和fv片段;双体;线性抗体;单链抗体分子和由抗体片段形成的多特异性抗体。术语“全长抗体”、“完整抗体”和“整个抗体”在本文中可互换地用于表示以其基本完整形式存在的抗体,而不是如下文所定义的抗体片段。术语特别是指具有含fc区的重链的抗体。“分离的”抗体是已经从其天然环境的组分中鉴定和分离和/或回收的抗体。其天然环境的污染物组分是会干扰抗体的研究、诊断或治疗用途的物质,可以包括酶、激素和其它蛋白或非蛋白溶质。在一些实施方案中,抗体纯化(1)至大于抗体的95重量%,如通过例如lowry方法测定的,在一些实施方案中,大于99重量%;(2)至足以通过采用例如转杯式测序仪(spinningcupsequenator)得到n-末端或内部氨基酸序列的至少15个残基,或(3)至在还原或非还原条件下通过sds-page使用例如考马斯兰或银染色证实为均质。分离的抗体包括在重组细胞中的原位抗体,因为抗体天然环境中的至少一种组分将不存在。然而,通常通过至少一个纯化步骤制备分离的抗体。“天然抗体”通常是约150,000道尔顿的异四聚体糖蛋白,其由两条相同的轻(l)链和两条相同的重(h)链组成。每条轻链通过一个共价二硫键与重链连接,而二硫键连的数目在不同免疫球蛋白同种型的重链之间变化。每条重链和轻链也具有规则间隔的链内二硫桥。每条重链在一端具有可变结构域(vh),随后是多个恒定结构域。每条轻链在一端具有可变结构域(vl),在其另一端具有恒定结构域;轻链的恒定结构域与重链的第一个恒定结构域对齐,轻链的可变结构域与重链的可变结构域对齐。据信特定的氨基酸残基在轻链和重链可变结构域之间形成界面。术语“可变”是指在抗体之间可变结构域某些部分的序列广泛不同的事实,这些部分用于每种特定抗体对于其特定抗原的结合和特异性。然而,可变性不均匀地分布在抗体的整个可变结构域中。它集中在轻链和重链可变结构域中称为高变区的三个区段。可变结构域中更高度保守的部分称为框架区(fr)。天然重链和轻链的可变结构域各自包含四个fr,主要采用β片层构型,通过三个高变区连接,形成环连接,在某些情况下形成β片层结构的一部分。每条链中的高变区通过fr紧密地保持在一起,并且与来自另一条链的高变区帮助形成抗体的抗原结合位点(参见kabat等人,sequencesofproteinsofimmunologicalinterest,5thed.publichealthservice,nationalinstitutesofhealth,bethesda,md.(1991))。恒定结构域不直接参与抗体与抗原的结合,而是表现出各种效应功能,例如抗体参与的抗体依赖性细胞毒性(adcc)。抗体的木瓜蛋白酶消化产生两个相同的抗原结合片段,称为“fab”片段,每个具有单个抗原结合位点和残留的“fc”片段,其名称反映其容易结晶的能力。胃蛋白酶处理产生具有两个抗原结合位点并仍然能够交联抗原的f(ab')2片段。“fv”是含有完整的抗原识别和抗原结合位点的最小抗体片段。该区由紧密地、非共价连接的一条重链和一条轻链可变结构域的二聚体组成。在这种构型中,每个可变结构域的三个高变区相互作用以限定vh-vl二聚体表面上的抗原结合位点。总之,六个高变区赋予抗体抗原结合特异性。然而,即使是单个可变结构域(或仅包含特异于抗原的三个高变区的fv的一半)也具有识别和结合抗原的能力,尽管比完整结合位点的亲和力低。fab片段还包含轻链恒定结构域和重链第一恒定结构域(ch1)。fab'片段不同于fab片段,其在重链ch1结构域的羧基末端增加几个残基,包括来自抗体铰链区的一个或多个半胱氨酸。fab'-sh在文中命名为这样的fab',其中恒定结构域的半胱氨酸残基具有至少一个游离巯基。f(ab')2抗体片段最初作为fab'片段对产生,在fab'片段之间具有铰链半胱氨酸。抗体片段的其它化学偶联也是已知的。基于其恒定结构域的氨基酸序列,来自任何脊椎动物物种的抗体(免疫球蛋白)的“轻链”可被指定为两种明显不同的类型之一,称为κ和λ。根据其重链恒定结构域的氨基酸序列,抗体可被指定为不同的类别或同种型。完整抗体有五种主要类别:iga、igd、ige、igg和igm,其中几种可进一步分为亚类(同种型),例如igg1、igg2、igg3、igg4、iga和iga2。对应于抗体的不同类别,重链恒定结构域分别称为α、δ、ε、γ和μ。不同类别免疫球蛋白的亚基结构和三维构型是公知的,一般描述在例如abbas等人cellularandmol.immunology,第四版(w.b.saunders,co.,2000)中。抗体可以是抗体与一种或多种其它蛋白质或肽共价或非共价结合所形成的较大融合分子的一部分。“单链fv”或“scfv”抗体片段包含抗体的vh和vl结构域,其中这些结构域存在于单个多肽链中。在一些实施方案中,fv多肽进一步包含vh和vl结构域之间的多肽接头,使得scfv形成抗原结合所期望的结构。关于scfv的综述参见plückthun,thepharmacologyofmonoclonalantibodies,vol.113,rosenburg和moore编著,springer-verlag,newyork,pp.269-315(1994)。术语“双体抗体”是指具有两个抗原结合位点的小抗体片段,该片段包含与相同多肽链中的轻链可变结构域(vl)连接的重链可变结构域(vh)(vh-vl)。通过使用太短的接头不允许在相同链上的两个结构域之间的配对,所述结构域被迫与另一条链的互补结构域配对并产生两个抗原结合位点。双体抗体更全面地描述在例如ep404,097;wo93/11161和hollinger等人,proc.natl.acad.sci.usa,90:6444-6448(1993)。本文所用的术语“单克隆抗体”是指从基本上均质的抗体群获得的抗体,即群所包含的各抗体是相同的和/或结合表位相同,除了在单克隆抗体的制备过程中可能出现的变体之外,这些变体通常以少量存在。与通常包括针对不同决定簇(表位)的不同抗体的多克隆抗体制剂相反,各单克隆抗体针对抗原上的单一决定簇。除了它们的特异性之外,单克隆抗体的优点在于它们不被其它免疫球蛋白污染。修饰语“单克隆”表示抗体是从基本上同质的抗体群获得的特征,不应被解释为需要通过任何特定的方法生产抗体。例如,根据本发明使用的单克隆抗体可以通过首次由kohler等人nature,256:495(1975)描述的杂交瘤方法制备,或者可以通过重组dna方法制备(参见,例如美国专利号4,816,567)。也可以使用例如clackson等人nature,352:624-628(1991)和marks等人j.mol.biol.,222:581-597(1991)中描述的技术从噬菌体抗体文库中分离“单克隆抗体”。本文中的单克隆抗体具体包括“嵌合”抗体(免疫球蛋白),其中重链和/或轻链的一部分与源自特定物种或属于特定抗体类别或亚类的抗体中以及该抗体的片段中相应的序列相同或同源,而链的其余部分与源自另一物种或属于另一抗体类别或亚类的抗体以及该抗体的片段中相应的序列相同或同源,只要它们显示所期望的生物学活性(美国专利号4,816,567;morrison等人,proc.natl.acad.sci.usa,81:6851-6855(1984))。本文中感兴趣的嵌合抗体包括“灵长类”抗体,其包含源自非人灵长类(例如老世界猴(oldworldmonkey),如狒狒、恒河猴和食蟹猴)的可变结构域抗原结合序列和人恒定区序列(美国专利号5,693,780)。非人(例如,鼠)抗体的“人源化”形式是含有源自非人免疫球蛋白的最小序列的嵌合抗体。人源化抗体的大部分是人免疫球蛋白(受体抗体),其中来自受体高变区的残基被具有所期望的特异性、亲和力和能力的来自非人物种(供体抗体)(如小鼠、大鼠、兔或非人灵长类动物)的高变区替代。在一些情况下,人免疫球蛋白的框架区(fr)残基被相应的非人残基替代。此外,人源化抗体可以包含在受体抗体或供体抗体中未发现的残基。进行这些修饰以进一步改善抗体性能。通常,人源化抗体将基本上包含至少一个、通常为两个可变结构域的全部,其中高变环的全部或基本上全部对应于非人免疫球蛋白的那些高变环,以及fr的全部或基本上全部是人免疫球蛋白序列的那些fr,如上所述的fr取代除外。人源化抗体任选地还包含免疫球蛋白恒定区的至少一部分,通常是人免疫球蛋白的恒定区。更多细节见jones等人nature321:522-525(1986);riechmann等人nature332:323-329(1988);和presta,curr.op.struct.biol.2:593-596(1992)。“人抗体”是具有氨基酸序列的抗体,所述氨基酸序列对应于由人产生的抗体的氨基酸序列和/或使用本文所公开的制备人抗体的任何技术制备的氨基酸序列。人抗体的这种定义具体地排除包含非人抗原结合残基的人源化抗体。可以使用本领域已知的各种技术生产人抗体,包括噬菌体展示文库。hoogenboom和winter,j.mol.biol.,227:381(1991);marksetal.,j.mol.biol.,222:581(1991)。还可用于制备人单克隆抗体的方法是cole等人monoclonalantibodiesandcancertherapy,alanr.liss,p.77(1985);boerner等人j.immunol.,147(1):86-95(1991)。另见vandijk和vandewinkel,curr.opin.pharmacol.,5:368-74(2001)。可以通过将抗原施用给转基因动物来制备人抗体,所述转基因动物已被修饰以响应于抗原攻击而产生这样的抗体,但是所述转基因动物的内源性基因座已被失活,例如免疫异种小鼠(参见例如关于xenomousetm技术的美国专利号6,075,181和6,150,,584)。另见,例如,关于通过人b细胞杂交瘤技术产生人抗体的li等人proc.natl.acad.sci.usa,103:3557-3562(2006)。现在使用许多hvr的划定,其包涵在本文中。kabat互补决定区(cdr)基于序列变异性并且是最常用的(kabat等人,sequencesofproteinsofimmunologicalinterest,第五版publichealthservice,nationalinstitutesofhealth,bethesda,md.(1991))。chothia指代结构环的位置(chothia和leskj.mol.biol.196:901-917(1987))。abmhvr代表kabathvr和chothia结构环之间的折衷,并被oxfordmolecular的abm抗体建模软件使用。“contact”hvr基于对可用的复杂晶体结构的分析。来自这些hvr中的每一个的残基如下所述。hvr可以包括如下所示的“扩展hvr”:vl中的24-36或24-34(l1)、46-56或50-56(l2)和89-97或89-96(l3)以及vh中的26-35(h1)、50-65或49-65(h2)和93-102、94-102或95-102(h3)。根据kabat等人(同上),针对这些定义中的每一个对可变结构域残基进行编号。“框架”或“fr”残基是除本文定义的高变区残基之外的那些可变结构域残基。“裸抗体”是不与异源分子如细胞毒性部分或放射性标记缀合的抗体(如本文定义的)。本文所用的术语“约”是指本领域技术人员已知的相应值的通常误差范围。文中提及“约”某值或某参数包括(和描述)针对该值或参数本身的实施方案。例如,提及“约x”的描述包括“x”的描述。如本文和所附权利要求中所使用的,除非上下文另有明确规定,单数形式“a”、“或”和“该”包括复数指代。应当理解,本文描述的本发明的方面和变化包括“由方面和变化组成”和/或“基本上由方面和变化组成”。在详细描述本发明之前,应当理解,本发明不限于特定的组合物或生物系统,其当然可以变化。还应当理解,本文使用的术语仅用于描述特定实施方案的目的,而不是限制性的。iii.方法在一些实施方案中,提供治疗或延缓受试者中癌症进展的方法,所述方法包括向受试者施用有效量的抗pd-l1抗体,其中治疗基于在来自受试者的含有癌细胞的样品中受试者在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化。在一些实施方案中,提供治疗或延缓受试者中癌症进展的方法,只要已发现在来自受试者的含有癌细胞的样品中受试者在pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化,所述方法包括向受试者施用有效量的抗pd-l1抗体。在一些实施方案中,提供治疗或延缓癌症进展的方法,所述方法包括:(a)选择患有癌症的受试者,其中在来自受试者的含有癌细胞的样品中所述受试者在pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化;和(b)向所选择(例如步骤a)中所选择)的受试者施用有效量的抗pd-l1抗体。在一些实施方案中,提供一种预测癌症受试者是否可能对抗pd-l1抗体治疗反应的方法,所述方法包括在来自受试者的含有癌细胞的样品中测量pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平,其中样品中在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上中等或低水平的甲基化表明所述受试者可能对治疗反应。在一些实施方案中,提供一种治疗受试者中癌症的方法,所述方法包括:(a)在来自受试者的含有癌细胞的样品中测量pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平;和(b)向已被确定为在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平甲基化的受试者施用有效量的抗pd-l1抗体。在一些实施方案中,提供一种治疗受试者中癌症的方法,所述方法包括:(a)在来自受试者的含有癌细胞的样品中测量pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平;和(b)向如步骤a)测量的,在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平甲基化的受试者施用有效量的抗pd-l1抗体。在一些实施方案中,提供一种治疗受试者中癌症的方法,所述方法包括在来自受试者的含有癌细胞的样品中测量pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平;和如果受试者在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化,则向所述受试者施用有效量的抗pd-l1抗体。在一些实施方案中,提供鉴定可能对抗pd-l1抗体治疗反应的癌症受试者的方法,所述方法包括:(a)在来自受试者的含有癌细胞的样品中评估或测量pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平;和(b)鉴定在来自受试者的含有癌细胞的样品中在pd-l1启动子区中的cpg1上或pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平甲基化的受试者。在一些实施方案中,该方法进一步包括向受试者施用有效量的抗pd-l1抗体。在一些实施方案中,本文提供的方法包括评估在pd-l1启动子区中的cpg1上和pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平。pd-l1启动子区中的cpg1(本文中也称为mut2)的基因组坐标为hg19chr9:5449887-5449891。pd-l1基因内含子1中的一个或多个cpg位点(本文也称为cpg5或mut7)的基因组坐标为hg19chr9:5450934-5451072。这些坐标的序列可以在公共在线基因组数据库(如ucsc基因组浏览器(genome.ucsc.edu/))获得。cpg1的核酸序列是gctcg(seqidno:22)。cpg5的核酸序列是cacgggtccaagtccaccgccagctgcttgctagtaacaigacttgtgtaagttatcccagctgcagcatctaagtaagtctcttcctgcgctaagcaggtccaggatccctgaacggaatttatttgctctgtccatt(seqidno:23)以下提供hg19chr9:5449887-5451072的序列(cpg1和cpg5带有下划线):gctcgggatgggaagttcttttaatgacaaagcaaatgaagtttcattatgtcgaggaactttgaggaagtcacagaatccacgatttaaaaatatatttcctattatacacccatacacacacacacacacctactttctagaataaaaaccaaagccatatgggtctgctgctgactttttatatgttgtagagttatatcaagttatgtcaagatgttcagtcaccttgaagaggcttttatcagaaagggggacgcctttctgataaaggttaaggggtaaccttaagctcttacccctctgaaggtaaaatcaaggtgcgttcagatgttggcttgttgtaaatttctttttttattaataacatactaaatgtggatttgctttaatcttcgaaactcttcccggtgaaaatctcatttacaagaaaactggactgacatgtttcactttctgtttcatttctatacacagctttattcctaggacaccaacactagatacctaaactgaaagcttccgccgatttcaccgaaggtcaggaaagtccaacgcccggcaaactggatttgctgccttgggcagaggtgggcgggaccccgcctccgggcctggcgcaacgctgagcagctggcgcgtcccgcgcggccccagttctgcgcagcttcccgaggctccgcaccagccgcgcttctgtccgcctgcaggtagggagcgttgttcctccgcgggtgcccacggcccagtatctctggctagctcgctgggcactttaggacggagggtctctacaccctttctttgggatggagagaggagaagggaaagggaacgcgatggtctagggggcagtagagccaattacctgttggggttaataagaacaggcaatgcatctggccttcctccaggcgcgattcagttttgctctaaaaataatttatacctctaaaaataaataagataggtagtataggataggtagtcattcttatgcgactgtgtgttcagaatatagctctgatgctaggctggaggtctggacacgggtccaagtccaccgccagctgcttgctagtaacatgacttgtgtaagttatcccagctgcagcatctaagtaagtctcttcctgcgctaagcaggtccaggatccctgaacggaatttatttgctctgtccatt(seoidno:30)测定甲基化水平的方法可以使用多种方法测定pd-l1启动子区的cpg1上和/或pd-l1内含子1中的一个或多个cpg位点上的甲基化程度。在某些实施方案中,通过亚硫酸氢盐dna测序测定pd-l1启动子区中的cpg1上或pd-l1内含子1中的一个或多个cpg位点上的甲基化程度。用亚硫酸氢盐处理的dna将胞嘧啶(“c”)残基转化成尿嘧啶(“u”),但不影响5-甲基胞嘧啶残基。因此,亚硫酸氢盐处理向dna序列中引入特异的变化,这样的变化依赖于各个胞嘧啶残基的甲基化状态,从而得到关于dna区段甲基化状态的单核苷酸解析信息。可以对改变的序列进行各种分析以检索该信息。在一些实施方案中,然后使用两组链特异性引物通过pcr扩增亚硫酸氢盐修饰的感兴趣序列(如pd-l1启动子区中的cpg1和/或pd-l1内含子1中的一个或多个cpg位点),产生一对片段,一个来自每条链,其中所有的尿嘧啶和胸腺嘧啶残基都被扩增为胸腺嘧啶,只有5-甲基胞嘧啶残基被扩增为胞嘧啶。可以直接测序pcr产物或可以克隆和测序pcr产物以提供单个dna分子的甲基化图谱(参见,例如frommer,等人proc.natl.acad.sci.89:1827-1831,1992)。在一些实施方案中,由亚硫酸氢盐测序确定的低水平甲基化是在cpg1上小于约20%的甲基化(如约19%、18%、17%、16%、15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%或小于约1%的甲基化中的任一个,包括在这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐测序确定的低水平甲基化是在pd-l1基因内含子1中的一个或多个cpg位点上小于约20%的甲基化(如约19%、18%、17%、16%、15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%或小于约1%的甲基化中的任一个,包括在这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐测序确定的低水平甲基化是在cpg1上小于约20%的甲基化(如约19%、18%、17%、16%、15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%或小于约1%的甲基化中的任一个,包括在这些值之间的任何范围)、以及在pd-l1基因内含子1中的一个或多个cpg位点上小于约20%的甲基化(如约19%、18%、17%、16%、15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%或小于约1%的甲基化中的任一个,包括在这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐测序确定的中等水平甲基化是在cpg1上约20%至约40%的甲基化(如约20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%或40%中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐测序确定的中等水平甲基化是在pd-l1基因内含子1中的一个或多个cpg位点上约20%至约40%的甲基化(如约20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%或40%中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐测序确定的中等水平甲基化是在cpg1上约20%至约40%的甲基化(如约20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%或40%中的任一个,包括这些值之间的任何范围)、以及在pd-l1基因内含子1中的一个或多个cpg位点上约20%至约40%的甲基化(如约20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%或40%中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐测序确定的高水平甲基化是在cpg1上大于约40%至约100%之间的甲基化(如约40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%的甲基化中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐测序确定的高水平甲基化是在pd-l1基因内含子1中的一个或多个cpg位点上大于约40%至约100%之间的甲基化(如约40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%的甲基化中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐测序确定的高水平甲基化是在cpg1上大于约40%至约100%之间的甲基化(如约40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%的甲基化中的任一个,包括这些值之间的任何范围)、以及在pd-l1基因内含子1中的一个或多个cpg位点上大于约40%至约100%之间的甲基化(如约40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%的甲基化中的任一个,包括这些值之间的任何范围)。在某些实施方案中,pd-l1启动子区中cpg1上和/或pd-l1内含子1中的一个或多个cpg位点上的甲基化程度由亚硫酸氢盐次代测序(bs-ngs)测定,其中使用高通量次代测序系统(如hiseqtm测序系统)分析亚硫酸氢盐处理的dna。关于亚硫酸氢盐次代测序的更多细节参见例如farlik等人(2015)cellreportsdoi:10.1016/j.celrep.2015.02.001;tiedemann等人(2014)cellreports.doi:10.1016/j.celrep.2014.10.013;fernandez等人(2015)genomeresearch.doi:10.1101/gr.169011.113;lim等人(2014)plosgenetics.doi:10.1371/journal.pgen.1004792。在一些实施方案中,由亚硫酸氢盐次代测序确定的低水平甲基化是在cpg1上小于约5%的甲基化(如约4%、约3%、约2%、约1%或小于约1%的甲基化,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐次代测序确定的低水平甲基化是在pd-l1基因内含子1中的一个或多个cpg位点上小于约5%的甲基化(如约4%、约3%、约2%、约1%或小于约1%的甲基化,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐次代测序确定的低水平甲基化是在cpg1上小于约5%的甲基化(如约4%、约3%、约2%、约1%或小于约1%的甲基化,包括这些值之间的任何范围)、以及在pd-l1基因内含子1中的一个或多个cpg位点上小于约5%的甲基化(如约4%、约3%、约2%、约1%或小于约1%的甲基化,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐次代测序确定的中等水平的甲基化是在cpg1上约5%至约60%之间的甲基化(如约5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%或小于约60%的甲基化中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐次代测序确定的中等水平甲基化是在pd-l1基因内含子1中的一个或多个cpg位点上约5%至约60%之间的甲基化(如约5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%或小于约60%的甲基化中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐次代测序确定的中等水平的甲基化是在cpg1上约5%至约60%之间的甲基化(如约5%、约10%、约15%、约20%、约25%、约30%、约35%、约40%、约45%、约50%、约55%或小于约60%的甲基化,包括这些值之间的任何范围)、以及在pd-l1基因内含子1中的一个或多个cpg位点上约5%至约60%之间的甲基化(如约5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%或小于约60%的甲基化中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐次代测序确定的高水平甲基化是在cpg1上约60%至约100%之间的甲基化(如约60%、65%、70%、75%、80%、85%、90%、95%、99%、大于约99%或约100%的甲基化中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐次代测序确定的高水平甲基化是在pd-l1基因内含子1中的一个或多个cpg位点上约60%至约100%之间的甲基化(如约60%、65%、70%、75%、80%、85%、90%、95%、99%、大于约99%或约100%的甲基化中的任一个,包括这些值之间的任何范围)。在一些实施方案中,由亚硫酸氢盐次代测序确定的高水平甲基化是在cpg1上约60%至约100%之间的甲基化(如约60%、大于约60%、约65%、约70%、约75%、约80%、约85%、约90%、约95%、约99%、大于约99%或约100%的甲基化,包括这些值之间的任何范围)、以及在pd-l1基因内含子1中的一个或多个cpg位点上约60%至约100%的甲基化(如约60%、65%、70%、75%、80%、85%、90%、95%、99%、大于约99%或约100%的甲基化中的任一个,包括这些值之间的任何范围)。在某些实施方案中,pd-l1启动子区中的cpg1上和/或pd-l1内含子1中的一个或多个cpg位点上的甲基化程度使用甲基化芯片阵列来确定,如来自的humanmethylation450beadchip阵列。简单地说,在用亚硫酸氢盐处理后,将基因组dna全基因组扩增(wga)、酶促片段化、纯化并加入到humanmethylation450barchips中,所述芯片包含485,512个探针,涵盖99%的refseq基因。探针探查19,755个独特的cpg岛(在岸区和mirna启动子中具有额外的覆盖率)以及3091个探针在非cpg位点。在杂交期间,亚硫酸氢盐处理的wga-dna分子退火至与单个珠类型连接的基因座特异性fna低聚物。两个珠类型对应于每个cpg基因座,即,一个对于甲基化(“c”)而另一个对应于所规定的无甲基化(“t”)。等位基因特异性引物退火之后是使用dnp-和生物素标记的ddntp进行的单碱基延伸。用于相同cpg基因座的两种珠类型将并入相同类型的标记核苷酸,由cpg基因座中探查的“c”之前的碱基所确定,并因此将在相同颜色的通道中检测。延伸后,阵列被荧光染色、扫描、并测量由无甲基化和甲基化珠类型产生的信号的强度。使用软件记录每个样品中每个基因座的dna甲基化值,描述为“β值”。dna甲基化β值是0和1之间的连续变量,代表甲基化珠类型强度与组合基因座强度的比值。描述humanmethylation450beadchip阵列和测定平台的进一步细节描述于例如morris等人(2015)methods72,3-8;sandoval等人(2011)epigenetics6,692-702;deruijter等人(2015)laboratoryinvestigationdoi:10.1038/labinvest.2015.53;lehne等人(2015)genomebiology16,37-49;和其它地方。在一些实施方案中,使用甲基化芯片阵列(如humanmethylation450beadchip阵列)确定的低水平甲基化是对于cpg1在约0至小于约0.2之间的β值(如约0、0.01、0.02、0.03、0.04、0.05、0.06、0.07、0.08、0.09、0.1、0.11、0.12、0.13、0.14、0.15、0.16、0.17、0.18和0.19中的任一个,包括这些值之间的任何范围)。在一些实施方案中,使用甲基化芯片阵列(例如humanmethylation450beadchip阵列)确定的低水平甲基化是对于pd-l1基因内含子1中的一个或多个cpg位点在约0至小于约0.2之间的β值(如约0、0.01、0.02、0.03、0.04、0.05、0.06、0.07、0.08、0.09、0.1、0.11、0.12、0.13、0.14、0.15、0.16、0.17、0.18和0.19中的任一个,包括这些值之间的任何范围)。在一些实施方案中,使用甲基化芯片阵列(如humanmethylation450beadchip阵列)确定的低水平甲基化是对于cpg1在约0至约小于约0.2之间的β值(如约0、0.01、0.02、0.03、0.04、0.05、0.06、0.07、0.08、0.09、0.1、0.11、0.12、0.13、0.14、0.15、0.16、0.17、0.18和0.19中的任一个,包括这些值之间的任何范围)、以及对于pd-l1基因内含子1中的一个或多个cpg位点在约0至小于约0.2之间的β值(如约0、0.01、0.02、0.03、0.04、0.05、0.06、0.07、0.08、0.09、0.1、0.11、0.12、0.13、0.14、0.15、0.16、0.17、0.18和0.19中的任一个,包括这些值之间的任何范围)。在一些实施方案中,使用甲基化芯片阵列(如humanmethylation450beadchip阵列)确定的中等水平甲基化是对于cpg1在约0.2至约0.3之间的β值(如约0.2、0.21、0.22、0.23、0.24、0.25、0.26、0.27、0.28或0.29中的任一个,包括这些值之间的任何范围)。在一些实施方案中,使用甲基化芯片阵列(如humanmethylation450beadchip阵列)确定的中等水平甲基化是对于pd-l1基因内含子1中的一个或多个cpg位点在约0.2至约0.3之间的β值(如约0.2、0.21、0.22、0.23、0.24、0.25、0.26、0.27、0.28或0.29中的任一个,包括这些值之间的任何范围)。在一些实施方案中,使用甲基化芯片阵列(如humanmethylation450beadchip阵列)确定的中等水平甲基化是对于cpg1在约0.2至约0.3之间的β值(如约0.2、0.21、0.22、0.23、0.24、0.25、0.26、0.27、0.28或0.29中的任一个,包括这些值之间的任何范围)、以及对于pd-l1基因内含子1中的一个或多个cpg位点在约0.2至约0.3之间的β值(如约0.2、0.21、0.22、0.23、0.24、0.25、0.26、0.27、0.28或0.29中的任一个,包括这些值之间的任何范围)。在一些实施方案中,使用甲基化芯片阵列(如humanmethylation450beadchip阵列)确定的高水平甲基化是对于cpg1在大于约0.3至约1.0之间的β值(如约大于0.3、0.35、0.4、0.45、0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95或1.0中的任一个,包括这些值之间的任何范围)。在一些实施方案中,使用甲基化芯片阵列(如humanmethylation450beadchip阵列)确定的高水平甲基化是对于pd-l1基因内含子1中的一个或多个cpg位点在大于约0.3至约1.0之间的β值(如约大于0.3、0.35、0.4、0.45、0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95或1.0中的任一个,包括这些值之间的任何范围)。在一些实施方案中,使用甲基化芯片阵列(如humanmethylation450beadchip阵列)确定的高水平甲基化是对于cpg1在大于约0.3至约1.0之间的β值(如约大于0.3、0.35、0.4、0.45、0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95或1.0中的任一个,包括这些值之间的任何范围)、以及对于pd-l1基因内含子1中的一个或多个cpg位点在大于约0.3至约1.0之间的β值(如约大于0.3、0.35、0.4、0.45、0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95或1.0中的任一个,包括这些值之间的任何范围)。在一些实施方案中,来自受试者的样品是生物组织或流体的生物样品(如离体生物样品),其来自受试者的含有癌细胞和/或肿瘤细胞,可以从这些癌细胞和/或肿瘤细胞中分离核酸(如多核苷酸,例如,基因组dna和/或转录本)和/或多肽。在一些实施方案中,样品包括组织的冷冻切片,如用于组织学目的那些切片。在一些实施方案中,样品取自活组织检查。在一些实施方案中,取自尸体解剖。在一些实施方案中,样品是冷冻组织样品。在一些实施方案中,样品是取自受试者的新鲜样品。在一些实施方案中,样品是保存的组织样品。在一些实施方案中,样品是福尔马林固定、石蜡包埋的(ffpe)样品。在一些实施方案中,样品是外植体或源自受试者组织的原代和/或转化的细胞培养物。在本文所述的任何方法的一些实施方案中,来自受试者的含有癌细胞的样品进一步显示免疫细胞浸润的证据。在某些实施方案中,在来自受试者的含有癌细胞的样品中存在cd16+、cd4+、cd3+、cd56+、cd45+、cd68+、cd20+、cd163+或cd8+淋巴细胞中的任一种或多种表示免疫细胞浸润。在某些实施方案中,在来自受试者的含有癌细胞的样品中存在cd8+淋巴细胞表明免疫细胞浸润。在某些实施方案中,使用本领域普通技术人员公知的且广泛使用的免疫组织化学(ihc)测定法在来自受试者的含有癌细胞的样品中检测cd16+、cd4+、cd3+、cd56+、cd45+、cd68+、cd20+、cd163+或cd8+淋巴细胞中的一种或多种的存在。这些方法包括但不限于例如western印迹、elisa和流式细胞术。在某些实施方案中,使用基因表达分析技术在来自受试者的含有癌细胞的样品中检测cd16+、cd4+、cd3+、cd56+、cd45+、cd68+、cd20+、cd163+或cd8+淋巴细胞中的一种或多种的存在,所述基因表达分析技术包括但不限于定量pcr(qpcr)、qrt-pcr、转录组分析(如rnaseq)、微阵列分析、次代测序等。这些服务由例如nanostring等提供。在某些实施方案中,如果来自受试者的含有癌细胞的样品在pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上具有中等水平甲基化和没有免疫细胞浸润的证据,则不用抗pd-l1抗体治疗受试者。在某些实施方案中,如果来自受试者的含有癌细胞的样品在pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上具有中等水平甲基化和具有免疫细胞浸润的证据,则用抗pd-l1抗体治疗受试者。癌症在本文所述的任何方法的一些实施方案中,癌症是癌、淋巴瘤、母细胞瘤、肉瘤、白血病或淋巴样恶性肿瘤。在本文所述的任何方法的一些实施方案中,癌症是癌、淋巴瘤、母细胞瘤、肉瘤、白血病或淋巴样恶性肿瘤。在一些实施方案中,癌症是鳞状细胞癌(例如上皮鳞状细胞癌)、腹膜癌、肝细胞癌、胃部的癌症或胃癌(如胃肠癌和胃肠道间质癌)、胰腺癌、胶质母细胞瘤、宫颈癌、卵巢癌、肝癌、膀胱癌、尿道癌、肝癌、结肠癌、直肠癌、结肠直肠癌(crc)、子宫内膜或子宫癌、唾液腺癌、肾或肾癌、前列腺癌、外阴癌、甲状腺癌、肝癌、肛门癌、阴茎癌、多发性骨髓瘤和b细胞淋巴瘤(如低级/滤泡型非霍奇金淋巴瘤(nhl)、小淋巴细胞(sl)nhl、中级/滤泡型nhl、中级弥漫性nhl、高级免疫母细胞nhl、高级淋巴母细胞nhl、高级小无裂细胞nhl、bulkydiseasenhl、外套细胞淋巴瘤、aids相关淋巴瘤和waldenstrom的巨球蛋白血症)、慢性淋巴细胞性白血病(cll)、急性淋巴母细胞性白血病(all)、毛细胞白血病、慢性成髓细胞白血病和移植后淋巴增生性疾患(ptld)、以及与斑痣性错构瘤病相关的异常血管增生、水肿(如与脑肿瘤相关的水肿)、meigs综合征、脑以及头颈癌、软组织肉瘤、卡波西肉瘤、类癌和间皮瘤、胶质母细胞瘤、神经母细胞瘤和相关转移。在某些实施方案中,适于通过本发明的方法治疗的癌症包括乳癌、肺癌和皮肤癌,包括那些癌症的转移形式。在某些实施方案中,乳癌是乳腺癌。在一些实施方案中,肺癌是小细胞肺癌、非小细胞肺癌、肺腺癌或肺鳞状细胞癌。在某些实施方案中,皮肤癌是黑素瘤、浅表性扩散性黑素瘤、恶性雀斑样黑素瘤、肢端的雀斑样黑素瘤、结节性黑素瘤、皮肤癌或膀胱癌。抗pd-l1抗体pd-l1(也称为“程序性死亡配体1”、pdcd1l1、pdcd1lg1、b7-h1、b7-h和cd274)是40kda的1型跨膜蛋白,其结合在活化的t细胞、b细胞和骨髓细胞上发现的受体pd-1。pd-l1与pd-1的结合传递抑制tcr介导的il-2产生的活化和t细胞增殖的信号。pd-l1/pd-1通路被认为是肿瘤逃逸免疫系统消除的主要机制(lipsonej等人,cancerimmunolres2013;1(1):54-63)。不受理论的约束,抗pd-l1抗体对pd-l1的抑制可能允许t细胞的活化,从而恢复其有效检测和攻击癌细胞和肿瘤细胞的能力。在本文提供的任何一种方法的某些实施方案中,抗pd-l1抗体(或其抗原结合片段)抑制pd-l1与其结合配偶体的结合。在具体方面,pd-l1结合配偶体是pd-1和/或b7-1。在某些实施方案中,抗pd-l1抗体(或其抗原结合片段)选自yw243.55.s70、mpdl3280a、mdx-1105、medi4736和msb0010718c。mdx-1105,也称为bms-936559,是wo2007/005874中描述的抗pd-l1抗体。抗体yw243.55.s70(重链和轻链可变区序列分别为seqidno:20和21所示)是wo2010/077634a1中描述的抗pd-l1抗体。medi4736是wo2011/066389和us2013/034559中描述的抗pd-l1抗体。可用于本文提供的方法的抗pd-l1抗体(或其抗原结合片段)及其制备方法的实例描述于pct专利申请wo2010/077634a1和us8,217,149中,其通过引用并入本文。在一些实施方案中,抗pd-l1抗体(或其抗原结合片段)能够抑制pd-l1和pd-1之间和/或pd-l1和b7-1之间的结合。在一些实施方案中,抗pd-l1抗体是单克隆抗体。在一些实施方案中,抗pd-l1抗体是选自fab、fab'-sh、fv、scfv和(fab')2片段的抗体片段。在一些实施方案中,抗pd-l1抗体是人源化抗体。在一些实施方案中,抗pd-l1抗体是人抗体。在一些实施方案中,抗pd-l1抗体包含含有seqidno:20的氨基酸序列的重链可变区和含有seqidno:21的氨基酸序列的轻链可变区。在一个实施方案中,抗pd-l1抗体包含重链可变区多肽,所述重链可变区多肽包含hvr-h1、hvr-h2和hvr-h3序列,其中:进一步地,其中:x1是d或g;x2是s或l;x3是t或s。在一个具体方面,x1是d;x2是s和x3是t。另一方面,多肽进一步包含可变区重链框架序列,其按照下列式并列在各hvr之间:(hc-fr1)-(hvr-h1)-(hc-fr2)-(hvr-h2)-(hc-fr3)-(hvr-h3)-(hc-fr4)。在另一方面,框架序列来自人共有框架序列。在进一步的方面,框架序列是vh亚组iii共有框架。在仍进一步的方面,框架序列中的至少一个如下:在另一方面,重链多肽进一步与包含hvr-l1、hvr-l2和hvr-l3的可变区轻链组合,其中:(a)hvr-l1序列是rasqx4x5x6tx7x8a(seqidno:8);(b)hvr-l2序列是sasx9lx10s,(seqidno:9);(c)hvr-l3序列是qqx11x12x13x14px15t(seqidno:10);进一步地,其中:x4是d或v;x5是v或i;x6是s或n;x7是a或f;x8是v或l;x9是f或t;x10是y或a;x11是y,g,f或s;x12是l,y,f或w;x13是y,n,a,t,g,f或i;x14是h,v,p,t或i;x15是a,w,r,p或t。在另一方面,x4是d;x5是v;x6是s;x7是a;x8是v;x9是f;x10是y;x11是y;x12是l;x13是y;x14是h;x15是a。在另一方面,轻链还包含可变区轻链框架序列,其按照下式并列在各hvr之间:(lc-fr1)-(hvr-l1)-(lc-fr2)-(hvr-l2)-(lc-fr3)-(hvr-l3)-(lc-fr4)。在另一方面,框架序列来自人共有框架序列。在另一方面,框架序列是vlκi共有框架。在另一方面,框架序列中的至少一个如下:在另一个实施方案中,提供了分离的抗pd-l1抗体或抗原结合片段,其包含重链和轻链可变区序列,其中:重链包含hvr-h1、hvr-h2和hvr-h3,其中进一步:和轻链包括hvr-l1、hvr-l2和hvr-l3,其中进一步:进一步地,其中:x1是d或g;x2是s或l;x3是t或s;x4是d或v;x5是v或i;x6是s或n;x7是a或f;x8是v或l;x9是f或t;x10是y或a;x11是y,g,f,或s;x12是l,y,f或w;x13是y,n,a,t,g,f或i;x14是h,v,p,t或i;x15是a,w,r,p或t。在具体方面,x1是d;x2是s和x3是t。在另一个方面,x4是d;x5是v;x6是s;x7是a;x8是v;x9是f;x10是y;x11是y;x12是l;x13是y;x14是h;x15是a。在另一个方面,x1是d;x2是s和x3是t,x4是d;x5是v;x6是s;x7是a;x8是v;x9是f;x10是y;x11是y;x12是l;x13是y;x14是h和x15是a。在另一方面,重链可变区包含并列在各hvr之间的一个或多个框架序列,如:(hc-fr1)-(hvr-h1)-(hc-fr2)-(hvr-h2)-(hc-fr3)-(hvr-h3)-(hc-fr4),并且轻链可变区包含并列在各hvr之间的一个或多个框架序列,如:(lc-fr1)-(hvr-l1)-(lc-fr2)-(hvr-l2)-(lc-fr3)-(hvr-l3)-(lc-fr4)。在另一方面,框架序列源自人共有框架序列。在另一方面,重链框架序列源自kabat亚组i、ii或iii序列。在另一方面,重链框架序列是vh亚组iii共有框架。在另一方面,一个或多个重链框架序列如下:在另一方面,轻链框架序列源自kabatκ1、ii、ii或iv亚组序列。在另一方面,轻链框架序列是vlκi共有框架。在另一方面,一个或多个轻链框架序列如下:在另一个具体方面,抗体还包含人或鼠恒定区。在另一方面,人恒定区选自igg1、igg2、igg2、igg3、igg4。在另一个具体方面,人恒定区是igg1。在另一方面,鼠恒定区选自igg1、igg2a、igg2b、igg3。在另一方面,鼠恒定区是igg2a。在另一个具体方面,抗体具有降低的或最小的效应功能。在另一个具体方面,最小效应功能来源于“效应子较少(effector-less)的fc突变”或无糖基化(aglycosylation)。在另一个实施方案中,效应子-较少的fc突变是恒定区中的n297a或d265a/n297a取代。在另一个实施方案中,提供了包含重链和轻链可变区序列的抗pd-l1抗体,其中:重链还包含分别与gftfsdswih(seqidno:15)、awispyggstyyadsvkg(seqidno:16)和rhwpggfdy(seqidno:3)具有至少85%序列相同性的hvr-h1、hvr-h2和hvr-h3序列,或轻链还包含分别与rasqdvstava(seqidno:17)、sasflys(seqidno:18)和qqylyhpat(seqidno:19)具有至少85%序列相同性的hvr-l1、hvr-l2和hvr-l3序列。在一个具体方面,序列相同性为86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。另一方面,重链可变区包含并列在各hvr之间的一个或多个框架序列,如:(hc-fr1)-(hvr-h1)-(hc-fr2)-(hvr-h2)-(hc-fr3)-(hvr-h3)-(hc-fr4),并且轻链可变区包含并列在各hvr之间的一个或多个框架序列,如:(lc-fr1)-(hvr-l1)-(lc-fr2)-(hvr-l2)-(lc-fr3)-(hvr-l3)-(lc-fr4)。在另一方面,框架序列源自人共有框架序列。在另一方面,重链框架序列源自kabat亚组i、ii或iii序列。在另一方面,重链框架序列是vh亚组iii共有框架。在另一方面,一个或多个重链框架序列如下:在另一方面,轻链框架序列源自kabatκi、ii、ii或iv亚组序列。在另一方面,轻链框架序列是vlκi共有框架。在另一方面,一个或多个轻链框架序列如下:在另一个具体方面,抗体还包含人或鼠恒定区。在另一方面,人恒定区选自igg1、igg2、igg2、igg3、igg4。在另一个具体方面,人恒定区是igg1。在另一方面,鼠恒定区选自igg1、igg2a、igg2b、igg3。在另一方面,鼠恒定区是igg2a。在另一个具体方面,抗体具有降低的或最小的效应功能。在另一具体方面,最小效应功能来自“效应子较少的fc突变”或无糖基化。在另一个实施方案中,效应子较少的fc突变是恒定区中的n297a或d265a/n297a取代。在另一个实施方案中,提供了分离的抗pd-l1抗体,其包含重链和轻链可变区序列,其中:(a)重链序列与以下重链序列具有至少85%的序列相同性:evqlvesggglvqpggslrlscaasgftfsdswihwvrqapgkglewvawispyggstyyadsvkgrftisadtskntaylqmnslraedtavyycarrhwpggfdywgqgtlvtvsa(seqidno:20),或(b)轻链序列与以下轻链序列具有至少85%的序列相同性:diqmtqspsslsasvgdrvtitcrasqdvstavawyqqkpgkapklliysasflysgvpsrfsgsgsgtdftltisslqpedfatyycqqylyhpatfgqgtkveikr(seqidno:21)。在具体方面,序列相同性为86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。另一方面,重链可变区包含并列在各hvr之间的一个或多个框架序列,如:(hc-fr1)-(hvr-h1)-(hc-fr2)-(hvr-h2)-(hc-fr3)-(hvr-h3)-(hc-fr4),并且轻链可变区包含并列在各hvr之间的一个或多个框架序列,如:(lc-fr1)-(hvr-l1)-(lc-fr2)-(hvr-l2)-(lc-fr3)-(hvr-l3)-(lc-fr4)。在另一方面,框架序列源自人共有框架序列。在另一方面,重链框架序列源自kabat亚组i、ii或iii序列。在另一方面,重链框架序列是vh亚组iii共有框架。在另一方面,一个或多个重链框架序列如下:在另一方面,轻链框架序列源自kabatκi、ii、ii或iv亚组序列。在另一方面,轻链框架序列是vlκi共有框架。在另一方面,一个或多个轻链框架序列如下:在另一个具体方面,抗体还包含人或鼠恒定区。在另一方面,人恒定区选自igg1、igg2、igg2、igg3、igg4。在另一个具体方面,人恒定区是igg1。在另一方面,鼠恒定区选自igg1、igg2a、igg2b、igg3。在另一方面,鼠恒定区是igg2a。在另一个具体方面,抗体具有降低的或最小的效应功能。在更进一步的具体方面,最小的效应功能来自原核细胞中的生产。在更进一步的具体方面,最小效应功能来自“效应子较少的fc突变”或无糖基化。在另一个实施方案中,效应子较少的fc突变是恒定区中的n297a或d265a/n297a取代。在另一个实施方案中,提供了分离的抗pd-l1抗体,其包含重链和轻链可变区序列,其中:(a)重链序列与以下重链序列具有至少85%的序列相同性:evqlvesggglvqpggslrlscaasgftfsdswihwvrqapgkglewvawispyggstyyadsvkgrftisadtskntaylqmnslraedtavyycarrhwpggfdywgqgtlvtvss(seqidno:24),或(b)轻链序列与以下轻链序列具有至少85%的序列相同性:diqmtqspsslsasvgdrvtitcrasqdvstavawyqqkpgkapklliysasflysgvpsrfsgsgsgtdftltisslqpedfatyycqqylyhpatfgqgtkveikr(seqidno:21)。在另一个实施方案中,提供了分离的抗pdl1抗体,其包含重链和轻链可变区序列,其中:(a)重链序列与以下重链序列具有至少85%的序列相同性:evqlvesggglvqpggslrlscaasgftfsdswihwvrqapgkglewvawispyggstyyadsvkgrftisadtskntaylqmnslraedtavyycarrhwpggfdywgqgtlvtvssastk(seqidno:28),或(b)轻链序列与以下轻链序列具有至少85%的序列相同性:diqmtqspsslsasvgdrvtitcrasqdvstavawyqqkpgkapklliysasflysgvpsrfsgsgsgtdftltisslqpedfatyycqqylyhpatfgqgtkveikr(seqidno:29)。在具体方面,序列相同性为86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。另一方面,重链可变区包含并列在各hvr之间的一个或多个框架序列,如:(hc-fr1)-(hvr-h1)-(hc-fr2)-(hvr-h2)-(hc-fr3)-(hvr-h3)-(hc-fr4),并且轻链可变区包含并列在各hvr之间的一个或多个框架序列,如:(lc-fr1)-(hvr-l1)-(lc-fr2)-(hvr-l2)-(lc-fr3)-(hvr-l3)-(lc-fr4)。在另一方面,框架序列源自人共有框架序列。在另一方面,重链框架序列源自kabat亚组i、ii或iii序列。在另一方面,重链框架序列是vh亚组iii共有框架。在另一方面,一个或多个重链框架序列如下:在另一方面,轻链框架序列源自kabatκi、ii、ii或iv亚组序列。在另一方面,轻链框架序列是vlκi共有框架。在另一方面,一个或多个轻链框架序列如下:在另一个具体方面,抗体还包含人或鼠恒定区。在另一方面,人恒定区选自igg1、igg2、igg2、igg3、igg4。在另一个具体方面,人恒定区是igg1。在另一方面,鼠恒定区选自igg1、igg2a、igg2b、igg3。在另一方面,鼠恒定区是igg2a。在另一个具体方面,抗体具有降低的或最小的效应功能。在另一具体方面,最小的效应功能来自在原核细胞中的生产。在更进一步的具体方面,最小效应功能来自“效应子较少的fc突变”或无糖基化。在另一个实施方案中,效应子较少的fc突变是恒定区中的n297a或d265a/n297a取代。在另一个实施方案中,抗pd-1抗体是mpdl3280a(cas登记号:1422185-06-5)。在另一个实施方案中,提供了分离的抗pd-1抗体,其包含重链可变区和/或包含轻链可变区,所述重链可变区包含来自seqidno:24的重链可变区氨基酸序列,所述轻链可变区包含来自seqidno:25的轻链可变区氨基酸序列。在另一个实施方案中,提供了包含重链和/或轻链序列的分离的抗pdl-1抗体,其中:(a)重链序列与以下重链序列具有至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%的序列相同性:evqlvesggglvqpggslrlscaasgftfsdswihwvrqapgkglewvawispyggstyyadsvkgrftisadtskntaylqmnslraedtavyycarrhwpggfdywgqgtlvtvssastkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqyastyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspg(seqidno:26),或(b)轻链序列与以下轻链序列具有至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%的序列相同性:diqmtqspsslsasvgdrvtitcrasqdvstavawyqqkpgkapklliysasflysgvpsrfsgsgsgtdftltisslqpedfatyycqqylyhpatfgqgtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec(seqidno:27)。在一些实施方案中,提供了编码抗pd-l1抗体的轻链或重链可变区序列的分离的核酸,其中:(a)重链还包含分别与gftfsdswih(seqidno:15)、awispyggstyyadsvkg(seqidno:16)和rhwpggfdy(seqidno:3)具有至少85%序列相同性的hvr-h1、hvr-h2和hvr-h3序列,和(b)轻链还包含分别与rasqdvstava(seqidno:17)、sasflys(seqidno:18)和qqylyhpat(seqidno:19)具有至少85%序列相同性的hvr-l1、hvr-l2和hvr-l3序列。在具体的方面,序列相同性为86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。在一方面,重链可变区包含并列在各hvr之间的一个或多个框架序列,如:(hc-fr1)-(hvr-h1)-(hc-fr2)-(hvr-h2)-(hc-fr3)-(hvr-h3)-(hc-fr4),轻链可变区包含并列在各hvr之间的一个或多个框架序列,如:(lc-fr1)-(hvr-l1)-(lc-fr2)-(hvr-l2)-(lc-fr3)-(hvr-l3)-(lc-fr4)。在另一方面,框架序列源自人共有框架序列。在另一方面,重链框架序列源自kabat亚组i、ii或iii序列。在另一方面,重链框架序列是vh亚组iii共有框架。在另一方面,一个或多个重链框架序列如下:在另一方面,轻链框架序列源自kabatκi、ii、ii或iv亚组序列。在另一方面,轻链框架序列是vlκi共有框架。在另一方面,一个或多个轻链框架序列如下:在另一个具体方面,本文所述的抗pd-l1抗体进一步包含人或鼠恒定区。在另一方面,人恒定区选自igg1、igg2、igg2、igg3、igg4。在另一个具体方面,人恒定区是igg1。在另一方面,鼠恒定区选自igg1、igg2a、igg2b、igg3。在另一方面,鼠恒定区是igg2a。在另一个具体方面,抗体具有降低的或最小的效应功能。在另一个具体方面,最小的效应功能来自原核细胞中的生产。在另一个具体方面,最小的效应功能来自“效应子较少的fc突变”或无糖基化。在另一方面,效应子较少的fc突变是恒定区中的n297a或d265a/n297a取代。在另一方面,本文提供了编码本文所述的任何抗体的核酸。在一些实施方案中,核酸还包括适于表达编码本文所述的任何抗pd-l1抗体的核酸的载体。在另一个具体方面,载体还包含适于表达核酸的宿主细胞。在另一个具体方面,宿主细胞是真核细胞或原核细胞。在另一特定方面,真核细胞是哺乳动物细胞,例如中国仓鼠卵巢(cho)。可以使用本领域已知的方法制备抗体或其抗原结合片段,例如通过以下方法,所述方法包括以适于表达的形式、在适于生产这样的抗体或片段的条件下,培养含有编码任何前述抗pd-l1抗体或抗原结合片段的核酸的宿主细胞,和回收抗体或片段。iv.抗体制备本文提供的方法、试剂盒和制品使用或并入结合pd-l1的抗体。用于产生和生产此类抗体的示例性技术描述如下。抗原制备pd-l1(如细胞外结构域)的可溶形式或其片段(任选地与其它分子缀合)可用作产生抗pd-l1抗体的免疫原和/或用于筛选抗pd-l1抗体。或者,表达pd-l1的细胞可用作免疫原或用于筛选。这样的细胞可源自天然来源(例如癌细胞系),或可以是通过重组技术转化的细胞,以表达跨膜分子。可用于制备和/或筛选抗pd-l1抗体的其它形式的pd-l1对于本领域技术人员将是显而易见的。多克隆抗体多克隆抗体优选通过相关抗原和佐剂的多次皮下(sc)或腹膜内(ip)注射而在动物体内产生。使用双功能或衍生试剂将相关抗原与在待免疫物种中是免疫原性的蛋白质缀合可能是有用的,所述蛋白质例如,钥匙孔血蓝蛋白、血清白蛋白、牛甲状腺球蛋白或大豆胰蛋白酶抑制剂,所述双功能或衍生试剂例如,马来酰亚胺基苯甲酰基磺基琥珀酰亚胺酯(通过半胱氨酸残基缀合)、n-羟基琥珀酰亚胺(通过赖氨酸残基)、戊二醛、琥珀酸酐、socl2或r1n=c=nr,其中r和r1是不同的烷基。通过将例如100μg或5μg的蛋白质或缀合物(分别用于兔或小鼠)与3体积的弗氏完全佐剂组合并将溶液在多点皮内注射,针对抗原、免疫原性缀合物或衍生物免疫动物。一个月后,通过在多点皮下注射弗氏完全佐剂中的原始量肽或缀合物的1/5至1/10,对动物加强免疫。7至14天后,将动物放血,测定血清中的抗体滴度。动物加强免疫直到滴度平台。在一些实施方案中,用相同抗原的缀合物加强免疫动物,但所述抗原与不同的蛋白质缀合和/或通过不同的交联剂缀合。缀合物也可以在重组细胞培养物中作为蛋白质融合物制备。此外,聚合剂如明矾适用于增强免疫应答。单克隆抗体单克隆抗体从基本上均质的抗体群获得,即群所包含的各抗体是相同的和/或结合表位相同,除在单克隆抗体的制备过程中可能出现的变体之外,这些变体通常以少量存在。因此,修饰语“单克隆”表示不是分立的混合物或多克隆抗体的抗体特征。例如,单克隆抗体可以使用首先由kohler等人,nature,256:495(1975)描述的杂交瘤方法制备,或者可以通过重组dna方法(美国专利号4,816,567)制备。在杂交瘤方法中,如本文所述免疫小鼠或其它合适的宿主动物如仓鼠,以引发产生或能够产生抗体的淋巴细胞,所述抗体将特异性结合用于免疫的蛋白质。或者,可以在体外免疫淋巴细胞。然后使用合适的融合剂如聚乙二醇将淋巴细胞与骨髓瘤细胞融合以形成杂交瘤细胞(goding,monoclonalantibodies:principlesandpractice,pp.59-103(academicpress,1986))。将如此制备的杂交瘤细胞接种并生长在合适的培养基中,该培养基优选含有抑制未融合的亲本骨髓瘤细胞生长或存活的一种或多种物质。例如,如果亲本骨髓瘤细胞缺乏次黄嘌呤鸟嘌呤磷酸核糖转移酶(hgprt或hprt),则用于杂交瘤的培养基通常包括次黄嘌呤、氨基蝶呤和胸苷(hat培养基),这些物质可以防止hgprt缺陷型细胞的生长。在一些实施方案中,骨髓瘤细胞是有效融合、支持所选的抗体产生细胞稳定、高水平地产生抗体、和对培养基如hat培养基敏感的那些细胞。其中,在一些实施方案中,骨髓瘤细胞系是鼠骨髓瘤细胞系,例如可从salkinstitutecelldistributioncenter,sandiego,californiausa获得的mopc-21和mpc-11小鼠肿瘤衍生的那些细胞系,以及可从americantypeculturecollection,rockville,marylandusa获得的sp-2或x63-ag8-653细胞衍生的那些细胞系。还描述了人骨髓瘤和小鼠-人杂合骨髓瘤细胞系用于生产人单克隆抗体(kozbor,j.immunol.,133:3001(1984);brodeur等人,monoclonalantibodyproductiontechniquesandapplications,pp.51-63(marceldekker,inc.,newyork,1987))。测定杂交瘤细胞在其中生长的培养基中针对抗原的单克隆抗体的产生。在一些实施方案中,通过免疫沉淀或通过体外结合测定法(例如放射免疫测定法(ria)或酶联免疫吸附测定法(elisa))测定由杂交瘤细胞产生的单克隆抗体的结合特异性。单克隆抗体的结合亲和力可以例如通过munson等人,anal.biochem.,107:220(1980)中的scatchard分析来测定。在鉴定了产生所期望的特异性、亲和力和/或活性的抗体的杂交瘤细胞之后,可以通过有限稀释步骤对克隆进行亚克隆,并通过标准方法生长(goding,monoclonalantibodies:principlesandpractice,pp.59-103(academicpress,1986))。用于该目的的合适的培养基包括例如d-mem或rpmi-1640培养基。此外,杂交瘤细胞可以在动物体内作为腹水肿瘤生长。通过常规的免疫球蛋白纯化步骤,例如蛋白质a-琼脂糖、羟基磷灰石色谱法、凝胶电泳、透析或亲和色谱法适当地从培养基、腹水或血清中分离由亚克隆分泌的单克隆抗体。使用常规步骤(例如,通过使用能够特异性结合编码鼠抗体的重链和轻链的基因的寡核苷酸探针)容易地分离和测序编码单克隆抗体的dna。在一些实施方案中,杂交瘤细胞用作这种dna的来源。一旦分离,可将dna置于表达载体中,然后将表达载体转染到宿主细胞如大肠杆菌细胞、猿猴cos细胞、中国仓鼠卵巢(cho)细胞或不另外产生免疫球蛋白蛋白的骨髓瘤细胞,获得重组宿主细胞中单克隆抗体的合成。关于编码抗体的dna在细菌中重组表达的综述文章包括skerra等人,curr.opinioninimmunol.,5:256-262(1993)和plückthun,immunol.revs.,130:151-188(1992)。文库衍生的抗体可以从使用mccafferty等人nature,348:552-554(1990)中描述的技术产生的抗体噬菌体文库中分离抗体或抗体片段。clackson等人nature,352:624-628(1991)和marks等人mol.biol.,222:581-597(1991)分别描述了使用噬菌体文库分离鼠和人抗体。随后的出版物描述了通过链改组生产高亲和力(nm范围)的人抗体(marks等人bio/technology,10:779-783(1992)),以及组合感染和体内重组作为构建非常大的噬菌体文库的策略(waterhouseetal.,nuc.acids.res.,21:2265-2266(1993))。因此,这些技术是用于分离单克隆抗体的传统单克隆抗体杂交瘤技术的可行替代方案。dna也可以被修饰,例如通过用人重链和轻链恒定结构域的编码序列代替同源鼠序列(美国专利号4,816,567;morrison等人,proc.natlacad.sci.usa,81:6851(1984)),或免疫球蛋白编码序列通过共价连接到全部或部分的非免疫球蛋白多肽的编码序列。通常,这种非免疫球蛋白多肽取代抗体的恒定结构域,或者取代抗体的一个抗原组合位点的可变结构域以产生嵌合二价抗体,其包含对抗原具有特异性的一个组合位点和对不同抗原具有特异性的另一抗原组合位点。可以通过筛选组合文库中具有所期望的一种或多种活性的抗体来分离本发明的抗体。例如,本领域已知多种方法用于产生噬菌体展示文库并筛选这样的文库中具有所期望的结合特征的抗体,如实施例3中所述的方法。其它方法如在hoogenboom等人,methodsinmolecularbiology178:1-37(o’brien等人编辑,humanpress,totowa,nj,2001)中综述了,进一步描述于例如,mccafferty等人nature348:552-554;clackson等人nature352:624-628(1991);marks等人j.mol.biol.222:581-597(1992);marks和bradbury,methodsinmolecularbiology248:161-175(lo,ed.,humanpress,totowa,nj,2003);sidhu等人j.mol.biol.338(2):299-310(2004);lee等人j.mol.biol.340(5):1073-1093(2004);fellouse,proc.natl.acad.sci.usa101(34):12467-12472(2004);和lee等人j.immunol.methods284(1-2):119-132(2004)。在某些噬菌体展示方法中,通过聚合酶链反应(pcr)分别克隆vh和vl基因谱系,并在噬菌体文库中随机重组,然后可筛选噬菌体文库中的抗原结合噬菌体,如winter等人ann.rev.immunol.,12:433-455(1994)所述。噬菌体通常展示作为单链fv(scfv)片段或fab片段的抗体片段。来自免疫源的文库提供对免疫原的高亲和力抗体,而不需要构建杂交瘤。或者,如griffiths等人emboj,12:725-734(1993)所述,可以克隆天然库(例如,来自人)以提供针对范围广泛的非自身以及自身抗原的单一来源的抗体,而无需任何免疫。最后,还可以通过从干细胞中克隆未重排的v-基因区段、并使用含有随机序列的pcr引物来编码高度可变的cdr3区并在体外完成重排,从而合成制备天然文库,如hoogenboom和winter,j.mol.biol.,227:381-388(1992)所述。描述人抗体噬菌体文库的专利文献包括例如:美国专利号5,750,373和美国专利公开号2005/0079574、2005/0119455、2005/0266000、2007/0117126、2007/0160598、2007/0237764、2007/0292936和2009/0002360。从人抗体文库分离的抗体或抗体片段在本文中被认为是人抗体或人抗体片段。嵌合和人源化抗体在某些实施方案中,本文提供的抗体是嵌合抗体。某些嵌合抗体描述于例如美国专利号4,816,567和morrison等人proc.natl.acad.sci.usa,81:6851-6855(1984)。在一个实例中,嵌合抗体包含非人可变区(例如,源自小鼠、大鼠、仓鼠、兔或非人灵长类动物如猴的可变区)和人恒定区。在另一个实例中,嵌合抗体是“类别转换”的抗体,其中类别或亚类已经从亲本抗体的类别或亚类改变。嵌合抗体包括其抗原结合片段。在某些实施方案中,嵌合抗体是人源化抗体。通常,非人抗体被人源化以降低对人的免疫原性,同时保留亲本非人抗体的特异性和亲和力。通常,人源化抗体包含一个或多个可变区,其中hvr,例如cdr(或其部分)源自非人抗体,而fr(或其部分)源自人抗体序列。人源化抗体任选还将包含人恒定区的至少一部分。在一些实施方案中,人源化抗体中的某些fr残基被来自非人抗体(例如hvr残基所来源的抗体)的相应残基取代,例如,以恢复或改善抗体特异性或亲和力。本领域已经描述了人源化非人抗体的方法。在一些实施方案中,人源化抗体具有引入的来自非人源的一个或多个氨基酸残基。这些非人氨基酸残基通常被称为“输入”残基,其通常来自“输入”可变结构域。人源化可以基本上基于winter和同事的方法(jones等人nature,321:522-525(1986);riechmann等人nature,332:323-327(1988);verhoeyen等人science,239:1534-1536(1988))、通过用高变区序列取代人抗体的相应序列进行。因此,这种“人源化”抗体是嵌合抗体(美国专利号4,816,567),其中实质上小于完整的人可变结构域被来自非人物种的相应序列取代。在实践中,人源化抗体通常是人抗体,其中一些高变区残基和可能的一些fr残基被来自啮齿动物抗体中类似位点的残基取代。选择用于制备人源化抗体的人轻链和重链可变结构域对于降低抗原性是非常重要的。根据所谓的“最佳拟合”方法,针对已知的人可变结构域序列的整个文库筛选啮齿动物抗体的可变结构域序列。然后接纳最接近啮齿动物序列的人序列作为人源化抗体的人框架区(fr)(sims等人,j.immunol.,151:2296(1993);chothia等人,jmol.biol.,196:901(1987))。另一种方法使用的特定框架区源自轻链或重链可变区特定亚组的所有人抗体的共有序列。相同框架可以用于几种不同的人源化抗体(carter等人,proc.natl.acad.sci.usa,89:4285(1992);presta等人,j.immunol.,151:2623(1993))。更重要的是,被人源化的抗体保留对抗原的高亲和力和其它有利的生物学性质。为了实现这一目的,在方法的一些实施方案中,通过使用亲本和人源化序列的三维模型分析亲本序列和各种概念性人源化产物的方法来制备人源化抗体。三维免疫球蛋白模型通常是可获得的并且是本领域技术人员所熟悉的。计算机程序可用于说明和展示所选候选免疫球蛋白序列的可能的三维构象结构。检查这些展示允许分析残基在候选免疫球蛋白序列功能中的可能作用,即分析影响候选免疫球蛋白结合其抗原能力的残基。以这种方式,可以从接受和输入序列中选择和组合fr残基,从而实现所期望的抗体特征,如增加的对靶抗原的亲和力。一般来说,高变区残基直接和最基本地参与影响抗原结合。上述cdr序列通常存在于人可变轻链和可变重框架序列中,如基本上存在于人轻链κ亚组i(vl6i)的人共有fr残基,以及基本上存在于人重链亚组iii(vhiii)的人共有fr残基。另见wo2004/056312(lowman等人)。在一些实施方案中,可变重区可以连接到人igg链恒定区,其中该区可以是例如igg1或igg3,包括天然序列和变体恒定区。在一些实施方案中,本文中的抗体还可包含改善adcc活性的fc区中至少一个氨基酸取代,如位于位置298、333和334中的氨基酸取代,优选s298a、e333a和k334a,使用重链残基的eu编号。另见美国专利号6,737,056b1,presta。这些抗体中的任何可以在fc区中包含改善fcrn结合或血清半衰期的至少一个取代,例如在重链位置434的取代,如n434w。另见美国专利号6,737,056b1,presta。这些抗体中的任何可以进一步在fc区中包含增加cdc活性的至少一个氨基酸取代,例如至少包含在位置326的取代,优选k326a或k326w的取代。另见美国专利号6,528,624b1(idusogie等人)。人抗体作为人源化的替代,可以生产人抗体。例如,现在可以生产在免疫后能够产生人抗体的完整谱系(repertoire)而不存在内源性免疫球蛋白产生的转基因动物(例如小鼠)。例如,已经描述了在嵌合和种系突变小鼠中抗体重链连接区(jh)基因的纯合缺失导致内源性抗体产生的完全抑制。在这样的种系突变小鼠中转移人种系免疫球蛋白基因阵列将导致抗原攻击后人抗体的产生。参见例如jakobovits等人proc.natl.acad.sci.usa,90:2551(1993);jakobovits等人nature,362:255-258(1993);bruggermann等人yearinimmuno.,7:33(1993);和美国专利号5,591,669、5,589,369和5,545,807。或者,可以使用噬菌体展示技术(mccafferty等人,nature348:552-553(1990))从来自未免疫供体的免疫球蛋白可变(v)结构域基因谱系中体外产生人抗体和抗体片段。根据该技术,将抗体v结构域基因框内克隆至丝状噬菌体如m13或fd的主要或次要外壳蛋白基因,并在噬菌体颗粒表面展示为功能性抗体片段。因为丝状颗粒含有噬菌体基因组的单链dna拷贝,所以基于抗体功能性质的选择也导致选择编码呈现这些性质的抗体的基因。因此,噬菌体模拟b细胞的一些性质。可以以各种形式进行噬菌体展示;他们的综述参见例如johnson,kevins.和chiswell,davidj.,currentopinioninstructuralbiology3:564-571(1993)。v基因区段的几个来源可用于噬菌体展示。clackson等人nature,352:624-628(1991)从源自免疫小鼠脾脏的v基因的小的随机组合文库中分离出抗恶唑酮抗体的不同阵列。可以构建来自未免疫人供体的v基因谱库,并且可以基本上按照marks等人j.mol.biol.222:581-597(1991)或griffith等人emboj.12:725-734(1993)描述的技术分离对不同阵列抗原(包括自抗原)的抗体。另见美国专利号5,565,332和5,573,905。也可以通过体外活化的b细胞产生人抗体(参见美国专利5,567,610和5,229,275)。抗体片段已经开发出多种用于生产抗体片段的技术。传统上,这些片段通过完整抗体的蛋白水解消化得到(参见例如morimoto等人journalofbiochemicalandbiophysicalmethods24:107-117(1992)和brennan等人science,229:81(1985))。然而,这些片段现在可以由重组宿主细胞直接产生。例如,可以从上述抗体噬菌体文库分离抗体片段。或者,fab'-sh片段可以直接从大肠杆菌回收并化学偶联形成f(ab')2片段(carter等人,bio/technology10:163-167(1992))。根据另一种方法,可以从重组宿主细胞培养物中直接分离f(ab')2片段。生产抗体片段的其它技术对于本领域技术人员将是显而易见的。在其它实施方案中,所选择的抗体是单链fv片段(scfv)。参见wo93/16185;美国专利号5,571,894;和美国专利号5,587,458。抗体片段也可以是“线性抗体”,例如美国专利5,641,870中描述的。这样的线性抗体片段可以是单特异性的或双特异性的。多特异性抗体多特异性抗体具有对至少两个不同表位的结合特异性,其中表位通常来自不同的抗原。虽然这样的分子通常仅结合两个不同的表位(即双特异性抗体,bsab),但是在文中使用时,该表达涵盖了具有额外特异性的抗体,如三特异性抗体。双特异性抗体可以制备为全长抗体或抗体片段(例如f(ab')2双特异性抗体)。制备双特异性抗体的方法是本领域已知的。全长双特异性抗体的传统产生是基于两个免疫球蛋白重链-轻链对的共表达,其中两条链具有不同的特异性(millstein等人nature,305:537-539(1983))。由于免疫球蛋白重链和轻链的随机分类,这些杂交瘤(四体瘤(quadromas))产生10种不同抗体分子的潜在混合物,其中只有一种具有正确的双特异性结构。通常通过亲和色谱法步骤进行正确分子的纯化,其相当麻烦,而且产物产率低。类似的步骤在wo93/08829和traunecker等人,emboj.,10:3655-3659(1991)中公开。一种本领域已知的用于制备双特异性抗体的方法是“杵-入-臼”或“突起-入-腔”的方法(参见例如美国专利号5,731,168)。在该方法中,两个免疫球蛋白多肽(例如,重链多肽)各自包含界面。一个免疫球蛋白多肽的界面与另一免疫球蛋白多肽上的相应界面相互作用,从而允许两个免疫球蛋白多肽结合。可以工程化这些界面使得位于一个免疫球蛋白多肽界面中的“杵”或“突起”(这些术语在本文中可互换使用)对应于位于另一免疫球蛋白多肽界面中的“臼”或“腔”(这些术语在本文中可互换使用)。在一些实施方案中,臼与杵具有相同或相似的尺寸和适当的定位,使得当两个界面相互作用时,一个界面的杵可定位在另一个界面的相应臼中。不希望束缚于理论,这被认为稳定异源多聚体,有利于比其它种类(例如同源多聚体)形成异源多聚体。在一些实施方案中,该方法可用于促进两种不同免疫球蛋白多肽的异源多聚化,产生包含对不同表位具有结合特异性的两种免疫球蛋白多肽的双特异性抗体。在一些实施方案中,可以通过用较大侧链代替小的氨基酸侧链来构建杵。在一些实施方案中,可以通过用较小的侧链代替大的氨基酸侧链来构建臼。杵或臼可存在于原始界面中,或者它们可以通过合成引入。例如,可以通过改变编码界面的核酸序列合成引入杵或臼,以用至少一个“输入”氨基酸残基代替至少一个“原始”氨基酸残基。用于改变核酸序列的方法可以包括本领域公知的标准分子生物学技术。各种氨基酸残基的侧链体积如下表所示。在一些实施方案中,原始残基具有小的侧链体积(例如丙氨酸、天冬酰胺、天冬氨酸、甘氨酸、丝氨酸、苏氨酸或缬氨酸),而用于形成杵的输入残基是天然存在的氨基酸,可以包括精氨酸、苯丙氨酸、酪氨酸和色氨酸。在一些实施方案中,原始残基具有大的侧链体积(例如精氨酸、苯丙氨酸、酪氨酸和色氨酸),而用于形成臼的输入残基是天然存在的氨基酸,可以包括丙氨酸、丝氨酸、苏氨酸和缬氨酸。表1:氨基酸残基的性质a氨基酸的分子量减去水的分子量。值来自第43版“化学与物理手册”,cleveland,chemicalrubberpublishingco.,1961。b值来自a.a.zamyatnin,prog.biophys.mol.biol.24:107-123,1972。c值来自c.chothia,j.mol.biol.105:1-14,1975。可及表面积定义在该参考文献的图6-20中。在一些实施方案中,基于异源多聚体的三维结构来鉴定形成杵或臼的原始残基。本领域已知的用于获得三维结构的技术可以包括x射线晶体学和nmr。在一些实施方案中,界面是免疫球蛋白恒定结构域的ch3结构域。在这些实施方案中,人igg1的ch3/ch3界面包括位于四个反平行β-链上每个结构域上的十六个残基。不希望受理论的束缚,突变的残基优选位于两个中心的反平行β-链上,以最小化杵被周围溶剂、而不是配偶体ch3结构域中的补偿臼容纳的风险。在一些实施方案中,在两个免疫球蛋白多肽中形成相应的杵和臼的突变对应于下表中提供的一个或多个对。表2:形成相应的杵和臼的突变的示例组突变由原始残基、随后是使用kabat编号系统的位置、和随后的输入残基(所有残基以单字母氨基酸代码给出)表示。多个突变被一个冒号分开。在一些实施方案中,免疫球蛋白多肽包含ch3结构域,所述ch3结构域包含上述表2中列出的一个或多个氨基酸取代。在一些实施方案中,双特异性抗体包含第一免疫球蛋白多肽和第二免疫球蛋白多肽,所述第一免疫球蛋白多肽包含含有表2的左列中列出的一个或多个氨基酸取代的ch3结构域,所述第二免疫球蛋白多肽包含含有表2的右列中列出的一个或多个相应的氨基酸取代的ch3结构域。在如上所述的dna突变之后,可以使用本领域已知的标准重组技术和细胞系统来表达和纯化编码用一个或多个相应的杵或臼形成突变修饰的免疫球蛋白多肽的多核苷酸。参见例如美国专利号5,731,168;5,807,706;5,821,333;7,642,228;7,695,936;8,216,805;美国公开号2013/0089553和spiess等人naturebiotechnology31:753-758,2013。可以使用原核宿主细胞如大肠杆菌或真核宿主细胞如cho细胞产生修饰的免疫球蛋白多肽。可以在宿主细胞中在共培养中表达带有相应的杵和臼的免疫球蛋白多肽,并作为异源多聚体一起纯化,或者其可以在单个培养中表达、分别纯化并在体外组装。在一些实施方案中,使用本领域已知的标准细菌培养技术共培养两种细菌宿主细胞的菌株(一种表达具有杵的免疫球蛋白多肽,另一种表达具有臼的免疫球蛋白多肽)。在一些实施方案中,两种菌株可以以特定比例混合,例如在培养物中达到相等的表达水平。在一些实施方案中,两种菌株可以以50∶50、60∶40或70∶30的比例混合。多肽表达后,细胞可以一起裂解,可以提取蛋白质。本领域已知的允许测量同质多聚体与异质多聚体种类丰度的标准技术可以包括尺寸排阻色谱法。在一些实施方案中,每个修饰的免疫球蛋白多肽使用标准重组技术分别表达,并且它们可以在体外组装在一起。例如可以通过纯化每个修饰的免疫球蛋白多肽、以相同质量混合并将其孵育在一起、还原二硫化物(例如通过用二硫苏糖醇处理)、浓缩和再氧化多肽来实现组装。可以使用包括阳离子交换色谱法的标准技术纯化形成的双特异性抗体,并使用包括尺寸排阻色谱法的标准技术进行测量。关于这些方法的更详细的描述,参见spiess等人natbiotechnol31:753-8,2013。在一些实施方案中,修饰的免疫球蛋白多肽可以在cho细胞中分别表达,并使用上述方法在体外组装。根据不同的方法将具有所期望的结合特异性的抗体可变结构域(抗体-抗原组合位点)与免疫球蛋白恒定区序列融合。融合体优选具有免疫球蛋白重链恒定结构域,其包含铰链、ch2和ch3区的至少一部分。典型地融合体(fusion)具有包含结合轻链所必需的位点的第一重链恒定区(ch1),所述位点存在于至少一个融合组件(fusions)中。将编码免疫球蛋白重链(如果需要编码免疫球蛋白轻链)各融合组件(fusions)的dna插入分开的表达载体,并共转染到合适的宿主生物体中。当在构建中使用的三种多肽链的不等比例提供最佳产率时,这提供了在实施方案中调整三种多肽片段相互比例的极大灵活性。然而,当至少两条多肽链以相等比例表达产生高产率或当这些比率没有特别意义时,可以在一个表达载体中插入两个或所有三个多肽链的编码序列。在该方法的一个实施方案中,双特异性抗体由在一个臂中具有第一结合特异性的杂合免疫球蛋白重链和在另一个臂中的杂合免疫球蛋白重链-轻链对(提供第二结合特异性)组成。发现这种不对称结构有助于期望的双特异性化合物从不想要的免疫球蛋白链组合中分离,因为仅在双特异性分子的一半中存在免疫球蛋白轻链提供了容易的分离方式。该方法在wo94/04690中公开。关于产生双特异性抗体的更多细节参见例如suresh等人methodsinenzymology,121:210(1986)。根据wo96/27011中描述的另一种方法,可以对一对抗体分子之间的界面进行工程化,以使从重组细胞培养物中回收的异源二聚体的百分比最大化。一个界面包括抗体恒定结构域的ch3结构域的至少一部分。在该方法中,来自第一抗体分子界面的一个或多个小氨基酸侧链被较大的侧链(例如酪氨酸或色氨酸)代替。通过用较小的氨基酸(例如丙氨酸或苏氨酸)代替大氨基酸侧链,在第二抗体分子的界面上产生与大侧链相同或相似尺寸的补偿性“腔”。这提供了一种相对于其它不想要的最终产物如同源二聚体,增加异源二聚体产率的机制。双特异性抗体包括交联或“异源缀合”抗体。例如,异源缀合物中的一种抗体可与抗生物素蛋白偶联,另一种与生物素偶联。例如,已经提出这样的抗体使免疫系统细胞靶向不想要的细胞(美国专利号4,676,980),用于治疗hiv感染(wo91/00360、wo92/200373和ep03089)。可以使用任何方便的交联方法制备异源缀合抗体。合适的交联剂是本领域公知的,在美国专利号4,676,980中公开了合适的交联剂以及一些交联技术。用于从抗体片段产生双特异性抗体的技术也已在文献中描述。例如,可以使用化学连接制备双特异性抗体。brennan等人science,229:81(1985)描述了完整抗体被蛋白水解切割以产生f(ab')2片段的方法。在二硫醇络合剂亚砷酸钠的存在下还原这些片段以稳定邻位二硫醇,防止分子间二硫键形成。然后将产生的fab'片段转化成硫代硝基苯甲酸(tnb)衍生物。然后通过用巯基乙胺还原将fab'-tnb衍生物之一再转化为fab'-硫醇,并与等摩尔量的其它fab'-tnb衍生物混合以形成双特异性抗体。所产生的双特异性抗体可用作选择性固定酶的试剂。最近的进展有助于从大肠杆菌直接回收fab'-sh片段,其可以化学偶联以形成双特异性抗体。shalaby等人,j.exp.med.,175:217-225(1992)描述了完全人源化的双特异性抗体f(ab')2分子的产生。每个fab'片段分别从大肠杆菌中分泌并在体外进行定向化学偶联以形成双特异性抗体。也已经描述了各种用于从重组细胞培养物中直接制备和分离双特异性抗体片段的技术。例如,使用亮氨酸拉链生产双特异性抗体。kostelny等人j.immunol.,148(5):1547-1553(1992)。来自fos和jun蛋白的亮氨酸拉链肽通过基因融合与两种不同抗体的fab'部分连接。在铰链区还原抗体同源二聚体以形成单体,然后再氧化形成抗体异源二聚体。该方法也可用于生产抗体同源二聚体。hollinger等人proc.natl.acad.sci.usa,90:6444-6448(1993)描述的“双体抗体”技术提供了制备双特异性抗体片段的替代机制。片段包含通过接头与轻链可变结构域(vl)连接的重链可变结构域(vh),该接头太短而不允许在相同链上的两个结构域之间配对。因此,一个片段的vh和vl结构域被迫与另一个片段的互补vl和vh结构域配对,从而形成两个抗原结合位点。还报道了通过使用单链fv(sfv)二聚体制备双特异性抗体片段的另一策略。参见gruber等人,j.immunol.,152:5368(1994)。用于制备双特异性抗体片段的另一技术是“双特异性t细胞衔接器”或方法(参见例如wo2004/106381、wo2005/061547、wo2007/042261和wo2008/119567)。该方法利用排列在单个多肽上的两个抗体的可变结构域。例如,单个多肽链包括两个单链fv(scfv)片段,每个具有被多肽接头分开的可变重链(vh)和可变轻链(vl)结构域,所述多肽接头的长度足以允许两个结构域之间的分子内结合。该单个多肽还包括两个scfv片段之间的多肽间隔序列。每个scfv识别不同的表位,并且这些表位可以特异于不同细胞类型,使得当每个scfv与其同源表位接合时,两种不同细胞类型的细胞被接近或拴系。该方法的一个具体实施方案包括识别由免疫细胞表达的细胞表面抗原(例如t细胞上的cd3多肽)的scfv与识别由靶细胞(例如恶性细胞或肿瘤细胞)表达的细胞表面抗原的另一scfv连接。由于其是单个多肽,所以可以使用本领域已知的任何原核或真核细胞表达系统例如cho细胞系来表达双特异性t细胞衔接器。然而,特异性纯化技术(参见例如ep1691833)可能是必需的,以将单体双特异性t细胞衔接器从其它多聚体物种分离,所述其它多聚体物种可具有除预期的单体活性之外的生物学活性。在一个示例性纯化方案中,首先对含有分泌多肽的溶液进行金属亲和色谱法,并用咪唑浓度梯度洗脱多肽。进一步使用阴离子交换色谱法纯化该洗脱液,并用氯化钠浓度梯度洗脱多肽。最后,将对该洗脱液进行尺寸排阻色谱法以从多聚体物种分离单体。hollinger等人proc.natl.acad.sci.usa,90:6444-6448(1993)描述的“双体抗体”提供了制备双特异性抗体片段的替代机制。片段包含通过接头与轻链可变结构域(vl)连接的重链可变结构域(vh),该接头太短而不允许在相同链上的两个结构域之间配对。因此,一个片段的vh和vl结构域被迫与另一个片段的互补vl和vh结构域配对,从而形成两个抗原结合位点。还报道了通过使用单链fv(sfv)二聚体制备双特异性抗体片段的另一策略。参见gruber等人j.immunol.,152:5368(1994)。考虑具有两个以上化合价的抗体。例如,可以制备三特异性抗体。tutt等人j.immunol.147:60(1991)。缀合或另外修饰的抗体用于本发明的方法中或包含在本发明的制品中的抗体任选地与细胞毒性剂缀合。例如,抗体可以与药物缀合,如wo2004/032828所述。上文已经描述了可用于产生这种抗体-细胞毒性剂缀合物的化疗剂。抗体和一种或多种小分子毒素如卡里奇霉素(calicheamicin)、美登素(maytansine)(美国专利号5,208,020)、单端孢霉烯(trichothene)和cc1065的缀合物也预期在本文中。在本发明的一个实施方案中,抗体与一个或多个美登素分子缀合(例如每抗体分子约1至约10个美登素分子)。例如,可以将美登素转化为may-ss-me,其可以被还原成may-sh3并与修饰的抗体反应(chari等人,cancerresearch52:127-131(1992)),以产生美登素生物碱-抗体缀合物。或者,抗体与一个或多个卡里奇霉素分子缀合。抗生素的卡里奇霉素家族能够以亚皮摩尔浓度产生双链dna断裂。可以使用的卡里奇霉素的结构类似物包括但不限于γ1i、α2i、α3i、n-乙酰基-γ1i、psag和θi1(hinman等人cancerresearch53:3336-3342(1993)和lode等人cancerresearch58:2925-2928(1998))。可以使用的酶活性毒素及其片段包括白喉a链、白喉毒素的非结合活性片段、来自绿脓假单胞菌(pseudomonasaeruginosa)的外毒素a链、蓖麻毒素a链、相思豆毒素a链、蒴莲根毒素a链、α-八叠球菌、油桐(aleuritesfordii)蛋白、石竹素蛋白、phytolacaamericana蛋白(papi、papii、pap-s)、苦瓜(momordicacharantia)抑制剂、麻风树毒蛋白、巴豆毒蛋白、肥阜草(sapaonariaofficinalis)抑制剂、白树毒素、mitogellin、局限曲菌素、酚霉素(phenomycin)、伊诺霉素(enomycin)和tricothecenes。参见例如1993年10月28日公布的wo93/21232。本发明进一步考虑与具有溶核活性的化合物(例如核糖核酶或dna内切酶,例如脱氧核糖核酶;dna酶)缀合的抗体。各种放射性同位素可用于生产放射性缀合的抗体。实例包括at211、i131、i125、y90、re186、re188、sm153、bi212、p32和lu的放射性同位素。可以使用各种双功能蛋白偶联剂制备抗体和细胞毒性剂的缀合物,所述双功能蛋白偶联剂如n-琥珀酰亚胺基-3-(2-吡啶基二硫醇)丙酸酯(spdp)、琥珀酰亚胺基-4-(n-马来酰亚胺基甲基)环己烷-1-羧酸酯、亚氨基噻吩(it)、亚氨基酯的双功能衍生物(如二甲基己二酰亚胺酯hcl)、活性酯(如二琥珀酰亚胺基辛二酸酯)、醛(如戊二醛)、双叠氮基化合物(如双(对叠氮苯甲酰基)己二胺)、双重氮衍生物(如双-(对重氮苯甲酰基)-乙二胺)、二异氰酸酯(如甲苯2,6-二异氰酸酯)和双活性氟化合物(如1,5-二氟-2,4-二硝基苯)。例如,可以如vitetta等人science238:1098(1987)所述制备蓖麻毒素免疫毒素。碳-14-标记的1-异硫氰酸苄基-3-甲基二亚乙基三胺五乙酸(mx-dtpa)是用于将放射性核苷酸与抗体缀合的示例性缀合剂。参见wo94/11026。接头可以是促进细胞毒性药物在细胞中释放的“可切割接头”。例如,可以使用酸不稳定接头、肽酶敏感接头、二甲基接头或含二硫键的接头(chari等人cancerresearch52:127-131(1992))。或者,例如可以通过重组技术或肽合成制备包含抗体和细胞毒性剂的融合蛋白。在另一个实施方案中,抗体可以与“受体”(如链霉亲和素)缀合用于肿瘤预靶向,其中将抗体-受体缀合物施用于患者,然后使用清洁剂从循环中除去未结合的缀合物,然后施用与细胞毒剂(例如放射性核苷酸)缀合的“配体”(例如抗生物素蛋白)。本发明的抗体还可以与将前药(例如肽基化疗剂,参见wo81/01145)转化成活性抗癌药物的前药活化酶缀合。参见例如wo88/07378和美国专利号4,975,278。这种缀合物的酶组分包括任何能够以这样的方式作用于前药的酶,以便将前药转化成其更有活性的细胞毒性形式。可用于本发明方法的酶包括但不限于用于将含磷酸盐的前药转化为游离药物的碱性磷酸酶;用于将含硫酸盐的前药转化为游离药物的芳基硫酸酯酶;用于将无毒的5-氟胞嘧啶转化成抗癌药物5-氟尿嘧啶的胞嘧啶脱氨酶;用于将含肽前药转化为游离药物的蛋白酶,如沙雷氏菌属(serratia)蛋白酶、嗜热菌蛋白酶、枯草杆菌蛋白酶、羧肽酶和组织蛋白酶(例如组织蛋白酶b和l);用于转化含有d-氨基酸取代的前药的d-丙氨酰羧肽酶;用于将糖基化前药转化为游离药物的碳水化合物切割酶如β-半乳糖苷酶和神经氨酸酶;用于将β-内酰胺衍生的药物转化为游离药物的β-内酰胺酶;和用于将在其胺氮分别用苯氧基乙酰基或苯乙酰基基团衍生的药物转化成游离药物的青霉素酰胺酶,如青霉素v酰胺酶或青霉素g酰胺酶。或者,具有酶活性的抗体(本领域也称为“抗体酶”)可用于将本发明的前药转化为游离活性药物(参见例如massey,nature328:457-458(1987))。可以如本文所述制备抗体-抗体酶缀合物用于将该酶递送至肿瘤细胞群。本发明的酶可以通过本领域熟知的技术共价结合抗体,如使用上述异源双功能交联剂。或者,可以使用本领域公知的重组dna技术构建融合蛋白,所述融合蛋白至少包含本发明抗体的抗原结合区,其至少与本发明酶的功能活性部分连接(参见例如neuberger等人nature,312:604-608(1984))。本文考虑抗体的其它修饰。例如,抗体可以连接多种非蛋白性聚合物之一,例如聚乙二醇(peg)、聚丙二醇、聚氧化烯或聚乙二醇和聚丙二醇的共聚物。在一些实施方案中,抗体片段如fab'与一个或多个peg分子连接。本文公开的抗体也可以配制成脂质体。含有抗体的脂质体通过本领域已知的方法制备,如epstein等人proc.natl.acad.sci.usa,82:3688(1985);hwang等人proc.natl.acad.sci.usa,77:4030(1980);美国专利号4,485,045和4,544,545;和1997年10月23日公开的wo97/38731。在美国专利号5,013,556中公开了具有延长的循环时间的脂质体。特别有用的脂质体可以使用含有磷脂酰胆碱、胆固醇和peg衍生的磷脂酰乙醇胺(peg-pe)的脂质组合物、通过反相蒸发法产生。脂质体通过限定孔径的过滤器挤出,得到具有期望直径的脂质体。如martin等人j.biol.chem.257:286-288(1982)所述的可以通过二硫化物交换反应将本发明抗体的fab'片段与脂质体缀合。化疗剂任选地包含在脂质体内。参见gabizon等人j.nationalcancerinst.81(19)1484(1989)。抗体变体考虑抗体的氨基酸序列修饰。例如,可能期望改善抗体的结合亲和力和/或其它生物学性质。通过将适当的核苷酸变化引入抗体核酸或通过肽合成来制备抗体的氨基酸序列变体。这些修饰包括,例如抗体氨基酸序列中的残基缺失和/或插入和/或取代。进行缺失、插入和取代的任何组合以获得最终构建体,只要最终构建体具有期望的特征。氨基酸变化也可能改变抗体的翻译后过程,如改变糖基化位点的数目或位置。用于鉴定作为诱变的优选位置的抗体的某些残基或区的有用方法被称为“丙氨酸扫描诱变”,如cunningham和wellsscience,244:1081-1085(1989)所述。在这里,鉴定残基或靶残基的组(例如,带电残基如arg、asp、his、lys和glu),并由中性或带负电荷的氨基酸(最优选丙氨酸或聚丙氨酸)替代以影响氨基酸与抗原的相互作用。然后通过在取代位点或对取代位点引入进一步的或其它变体来精修那些对取代显示功能敏感性的氨基酸位置。因此,尽管引入氨基酸序列变异的位点是预先确定的,然而突变本身的性质不需要预先确定。例如,为了分析在给定位点的突变性能,在靶密码子或区进行ala扫描或随机诱变,并筛选表达的抗体变体以获得所期望的活性。氨基酸序列插入包括长度从一个残基到含有一百个或更多个残基的多肽的氨基和/或羧基末端融合,以及单个或多个氨基酸残基的序列内插入。末端插入的实例包括具有n-末端甲硫氨酰残基的抗体或与细胞毒性多肽融合的抗体。抗体分子的其它插入变体包括向抗体的n-或c-末端的酶的融合、或增加抗体的血清半衰期的多肽的融合。另一种类型的变体是氨基酸取代变体。这些变体在抗体分子中具有至少一个被不同残基取代的氨基酸残基。对抗体的取代诱变最感兴趣的位点包括高变区,但也考虑fr的变化。保守取代在表3中显示在“优选取代”的标题下。如果这种取代导致生物学活性的变化,那么可以引入更实质性的变化,即表3中所称的“示例性取代”,并筛选产物。表3:保持性氨基酸取代通过选择在维持(a)取代区中多肽骨架的结构,例如片层或螺旋构象、(b)分子在靶位点上的电荷或疏水性、或(c)侧链的体积的作用中差异显著的取代来实现对抗体生物学性质的实质性修饰。氨基酸可以根据其侧链性质的相似性分组(在a.l.lehninger,biochemistry,第二版,pp.73-75,worthpublishers,newyork(1975)中):(1)非极性:ala(a)、val(v)、leu(l)、ile(i)、pro(p)、phe(f)、trp(w)、met(m)(2)不带电荷、极性:gly(g)、ser(s)、thr(t)、cys(c)、tyr(y)、asn(n)、gln(q)(3)酸性:asp(d)、glu(e)(4)碱性:lys(k)、arg(r)、his(h)或者,天然存在的残基可以基于共同的侧链性质分组:(1)疏水性:正亮氨酸、met、ala、val、leu、ile;(2)中性亲水性:cys、ser、thr、asn、gln;(3)酸性:asp、glu;(4)碱性:his、lys、arg;(5)影响链方向的残基:gly、pro;(6)芳香族:trp、tyr、phe。非保守性取代将需要将这些类别中的一类的成员换成另一类的成员。不参与维持抗体正确构象的任何半胱氨酸残基通常也可以被丝氨酸取代,以改善分子的氧化稳定性并防止异常交联。相反,可以向抗体中添加半胱氨酸键以提高其稳定性(特别是当抗体是抗体片段如fv片段时)。取代变体的特别优选的类型包括取代亲本抗体的一个或多个高变区残基。通常,选择用于进一步开发的所得变体相对于产生其的亲本抗体将具有改善的生物学性质。产生这种取代变体的便捷方法是使用噬菌体展示的亲和力成熟。简言之,将几个高变区位点(例如6-7位点)突变以在每个位点产生所有可能的氨基取代。由此产生的抗体变体以从单价形式丝状噬菌体颗粒展示为与每个颗粒内包装的m13的基因iii产物的融合体。然后如本文公开的筛选噬菌体展示变体的生物学活性(例如结合亲和力)。为了鉴定用于修饰的候选高变区位点,可以进行丙氨酸扫描诱变以鉴定对抗原结合显著贡献的高变区残基。或者,或另外地,分析抗原-抗体复合物的晶体结构以鉴定抗体和抗原之间的接触点可能是有益的。这种接触残基和相邻的残基是根据本文详述的技术进行取代的候选。一旦产生了这样的变体,则如本文所述筛选变体组,并且可以选择在一个或多个相关测定法中具有优异性质的抗体用于进一步开发。另一种类型的抗体的氨基酸变体改变了抗体的原始糖基化模式。这种改变包括删除在抗体中发现的一个或多个碳水化合物部分,和/或添加一个或多个不存在于抗体中的糖基化位点。多肽的糖基化通常是n-连接或o-连接。n-连接是指碳水化合物部分与天冬酰胺残基的侧链附着。三肽序列天冬酰胺-x-丝氨酸和天冬酰胺-x-苏氨酸(其中x是除脯氨酸以外的任何氨基酸)是将碳水化合物部分酶促附着到天冬酰胺侧链的识别序列。因此,多肽中存在这些三肽序列的任一个产生潜在的糖基化位点。o-连接的糖基化是指n-乙酰基半乳糖胺、半乳糖或木糖中的一种糖与羟基氨基酸附着,最常见的羟基氨基酸为丝氨酸或苏氨酸,但是也可以使用5-羟基脯氨酸或5-羟基赖氨酸。通过改变氨基酸序列使得其含有一个或多个上述三肽序列(对于n-连接的糖基化位点),可方便地实现向抗体添加糖基化位点。也可以通过向原始抗体的序列添加一个或多个丝氨酸或苏氨酸残基或用一个或多个丝氨酸或苏氨酸残基取代(对于o-连接的糖基化位点)来进行改变。当抗体包含fc区时,可以改变与其附着的碳水化合物。例如,美国专利申请号2003/0157108a1(presta,l.)中描述了具有成熟碳水化合物结构的抗体,其缺乏附着于抗体fc区的岩藻糖;另见涉及cd20抗体组合物的us2004/0093621a1(kyowahakkokogyoco.,ltd.)。在附着于抗体fc区的碳水化合物中具有二等分的n-乙酰葡糖胺(glcnac)的抗体参见wo03/011878、jean-mairet等人和us专利号6,602,684,umana等人。在wo97/30087(patel等人)中报道了附着于抗体fc区的寡糖中具有至少一个半乳糖残基的抗体;也参见wo98/58964(raju,s.)和wo99/22764(raju,s.),其涉及具有附着于抗体fc区的改变的碳水化合物的抗体。在一些实施方案中,本文的糖基化变体包含fc区,其中附着于fc区的碳水化合物结构缺乏岩藻糖。这样的变体具有改善的adcc功能。任选地,fc区还包含其中的一个或多个进一步改善adcc的氨基酸取代,例如fc区的位置298、333和/或334上的取代(残基的eu编号)。与“去岩藻糖基化”或“岩藻糖缺乏”抗体相关的出版物的实例包括:美国专利申请号us2003/0157108a1,presta,l;wo00/61739a1;wo01/29246a1;us2003/0115614a1;us2002/0164328a1;us2004/0093621a1;us2004/0132140a1;us2004/0110704a1;us2004/0110282a1;us2004/0109865a1;wo03/085119a1;wo03/084570a1;wo2005/035778;wo2005/035586(描述了岩藻糖基化的rna抑制(rnai));okazaki等人j.mol.biol.336:1239-1249(2004);yamane-ohnuki等人biotech.bioeng.87:614(2004)。产生去岩藻糖基化抗体的细胞系的实例包括岩藻糖基化蛋白缺乏的lec13cho细胞(ripka等人arch.biochem.biophys.249:533-545(1986);美国专利申请号us2003/0157108a1,presta,l;和wo2004/056312a1,adams等人,特别是实施例11)和敲除细胞系,例如α-1,6-岩藻糖基转移酶基因,fut8敲除的cho细胞(yamane-ohnuki等人biotech.bioeng.87:614(2004))。通过本领域已知的多种方法制备编码抗体氨基酸序列变体的核酸分子。这些方法包括但不限于从天然来源(在天然存在氨基酸序列变体的情况下)的分离或通过寡核苷酸介导的(或定点的)诱变、pcr诱变和早期制备的变体或抗体的非变体形式的盒诱变制备。可能期望在效应功能方面修饰本发明的抗体,例如,以增强抗体的抗原依赖性细胞介导的细胞毒性(adcc)和/或补体依赖性细胞毒性(cdc)。这可以通过在抗体的fc区中引入一个或多个氨基酸取代来实现。或者或另外地,可以将半胱氨酸残基引入fc区,从而允许在该区形成链间二硫键。由此产生的同源二聚体抗体可具有改善的内化能力和/或增加的补体介导的细胞杀伤和抗体依赖性细胞毒性(adcc)。参见caron等人j.expmed.176:1191-1195(1992)和shopes,b.j.immunol.148:2918-2922(1992)。也可以使用如wolff等人cancerresearch53:2560-2565(1993)所述的异源双功能交联剂来制备具有增强的抗肿瘤活性的同源二聚体抗体。或者,抗体可被工程化成具有双fc区,并且因此可以具有增强的补体裂解和adcc能力。参见stevenson等人anti-cancerdrugdesign3:219-230(1989)。wo00/42072(presta,l.)描述了在人效应细胞存在下具有改善的adcc功能的抗体,其中抗体在其fc区中包含氨基酸取代。在一些实施方案中,具有改善的adcc的抗体包含在fc区位置298、333和/或334上的取代。在一些实施方案中,改变的fc区是人igg1fc区,其包含这些位置中的一个、两个或三个位置上的取代,或由其组成。在wo99/51642、美国专利号6,194,551b1、美国专利号6,242,195b1、美国专利号6,528,624b1和美国专利号6,538,124(idusogie等人)中描述了具有改变的c1q结合和/或补体依赖性细胞毒性(cdc)的抗体。这些抗体包含其fc区的氨基酸位置270、322、326、327、329、313、333和/或334中的一个或多个位置上的氨基酸取代。为了增加抗体的血清半衰期,可以将补救受体结合表位并入抗体(特别是抗体片段)中,例如,如在美国专利5,739,277中所述。如本文所用,术语“补救受体结合表位”是指igg分子(例如,igg1、igg2、igg3或igg4)fc区的表位,其负责增加igg分子的体内血清半衰期。在wo00/42072(presta,l.)中还描述了在其fc区中具有取代并且具有增加的血清半衰期的抗体。也考虑了具有三个或更多(优选四个)功能性抗原结合位点的工程化抗体(美国专利号us2002/0004587a1,miller等人)。可以进一步修饰本发明的抗体以含有本领域已知并且易于获得的其它非蛋白质部分。在某些实施方案中,适于抗体衍生化的部分是水溶性聚合物。水溶性聚合物的非限制性实例包括但不限于聚乙二醇(peg)、乙二醇/丙二醇的共聚物、羧甲基纤维素、葡聚糖、聚乙烯醇、聚乙烯吡咯烷酮、聚-1,3-二氧戊环、聚-1,3,6-三氧杂环己烷、乙烯/马来酸酐共聚物、聚氨基酸(均聚物或无规共聚物)和葡聚糖或聚(n-乙烯吡咯烷酮)聚乙二醇、丙二醇均聚物、聚环氧丙烷/环氧乙烷共聚物、聚氧乙烯多元醇(例如甘油)、聚乙烯醇及其混合物。聚乙二醇丙醛由于其在水中的稳定性而具有制造优点。聚合物可以是任何分子量的,并且可以是支链或非支链的。附着到抗体上的聚合物数量可以变化,并且如果附着多于一个聚合物,它们可以是相同或不同的分子。通常,用于衍生化的聚合物数量和/或类型可以基于以下考虑来确定,包括但不限于待改善抗体的特定性质或功能、抗体衍生物是否用于限定的条件下治疗等。载体、宿主细胞和重组方法还可以使用重组方法产生抗体。为了重组生产对抗抗原的抗体,分离编码抗体的核酸并将其插入到可复制的载体中用于进一步克隆(dna的扩增)或用于表达。可以使用常规步骤(例如,通过使用能够特异性结合编码抗体的重链和轻链的基因的寡核苷酸探针)容易地分离编码抗体的dna并进行测序。许多载体是可用的。载体组分通常包括但不限于以下的一个或多个:信号序列、复制起点、一个或多个标记基因、增强子元件、启动子和转录终止序列。信号序列组分本发明的抗体不仅可以直接地重组产生,而且还可以作为与异源多肽的融合多肽产生,所述异源多肽优选是在成熟蛋白或多肽的n末端具有特异性切割位点的信号序列或其它多肽。所选择的异源信号序列优选是被宿主细胞识别和加工(例如被信号肽酶切割)的信号序列。对于不识别和加工天然抗体信号序列的原核宿主细胞,信号序列被选自例如碱性磷酸酶、青霉素酶、lpp或热稳定的肠毒素ii前导序列(leader)的原核信号序列替代。对于酵母分泌,天然信号序列可以被例如酵母转化酶前导序列、因子前导序列(包括酿酒酵母属(saccharomyces)和克鲁维酵母属(kluyveromyces)α因子前导)或酸性磷酸酶前导序列、白色念珠菌(c.albicans)葡糖淀粉酶前导序列或描述于wo90/13646中的信号序列取代。在哺乳动物细胞表达中,哺乳动物信号序列以及病毒分泌前导序列,例如单纯疱疹病毒gd信号序列是可获得的。复制起点表达和克隆载体都含有能够使载体在一个或多个所选择的宿主细胞中复制的核酸序列。通常,在克隆载体中,该序列是能够使载体独立于宿主染色体dna而复制的序列,并且包括复制起点或自主复制序列。针对各种细菌、酵母和病毒的这些序列是众所周知的。质粒pbr322的复制起点适用于大多数革兰氏阴性细菌,2μ质粒起点适用于酵母,各种病毒起点(sv40、多瘤病毒、腺病毒、vsv或bpv)可用于在哺乳动物细胞中克隆载体。通常,哺乳动物表达载体不需要复制起点组分(通常可使用sv40起点仅仅是由于其含有早期启动子。选择基因组分表达和克隆载体可以含有选择基因,也称为选择标记物。典型的选择基因编码以下蛋白:(a)赋予抗生素或其它毒素抗性的蛋白,例如氨苄青霉素、新霉素、甲氨蝶呤或四环素,(b)补充营养缺陷型缺陷的蛋白,或(c)提供不能从复合培养基获得的重要营养物质,用于芽孢杆菌的编码d-丙氨酸消旋酶的基因。选择方案的一个实例利用药物来阻滞宿主细胞的生长。用异源基因成功转化的那些细胞产生赋予耐药性的蛋白,从而在选择方案中存活。这种优势选择的实例使用药物新霉素、霉酚酸和潮霉素。用于哺乳动物细胞的合适的选择标记物的另一个实例是能鉴定细胞能够吸收编码抗体的核酸的那些选择标记物,如dhfr、谷氨酰胺合成酶(gs)、胸苷激酶、金属硫蛋白-i和-ii(优选灵长类金属硫蛋白基因)、腺苷脱氨酶、鸟氨酸脱羧酶等例如,通过在含有甲氨蝶呤(mtx)(一种dhfr的竞争性拮抗剂)的培养基中培养转化体来鉴定用dhfr基因转化的细胞。在这些条件下,dhfr基因与任何其它共转化的核酸一起被扩增。可以使用缺乏内源性dhfr活性的中国仓鼠卵巢(cho)细胞系(例如,atcccrl-9096)。或者,通过在含有l-甲硫氨酸亚砜亚胺(msx)(一种gs抑制剂)的培养基中培养转化体来鉴定用gs基因转化的细胞。在这些条件下,gs基因与任何其它共转化的核酸一起被扩增。可以组合使用gs选择/扩增系统与上述dhfr选择/扩增系统。或者,可以通过在含有针对选择标记物的选择剂如氨基糖苷类抗生素(例如卡那霉素、新霉素或g418)的培养基中生长细胞来选择用编码感兴趣抗体的dna序列、野生型dhfr基因和另一选择标记物如氨基糖苷3'-磷酸转移酶(aph)转化或共转化的宿主细胞(特别是含有内源性dhfr的野生型宿主)。参见美国专利号4,965,199。用于酵母中的合适的选择基因是存在于酵母质粒yrp7中的trp1基因(stinchcomb等人,nature,282:39(1979))。trp1基因提供针对在色氨酸中缺乏生长能力的酵母突变菌株(例如atccno.44076或pep4-1)的选择标记物。jones,genetics,85:12(1977)。然后酵母宿主细胞基因组中trp1损害的存在为在不含色氨酸时的生长提供了检测转化的有效环境。类似地,leu2缺陷型酵母菌株(atcc20,622或38,626)由携带leu2基因的已知质粒补充。此外,源自1.6μm环形质粒pkd1的载体可用于转化克鲁维酵母属。或者,报道了在乳酸克鲁维酵母(k.lactis.)中用于大规模生产重组小牛凝乳酶的表达系统。vandenberg,bio/technology,8:135(1990)。还公开了用于由克鲁维酵母属的工业菌株分泌成熟的重组人血清白蛋白的稳定的多拷贝表达载体。fleer等人bio/technology,9:968-975(1991)。启动子组分表达和克隆载体通常含有被宿主生物体识别并与编码抗体的核酸可操纵地连接的启动子。适用于原核宿主的启动子包括phoa启动子、β-内酰胺酶和乳糖启动子系统、碱性磷酸酶启动子、色氨酸(trp)启动子系统、以及如tac启动子的杂合启动子。然而,其它已知的细菌启动子是合适的。用于细菌系统的启动子还含有与编码抗体的dna可操纵地连接的shine-dalgarno(s.d.)序列。真核细胞的启动子序列是已知的。几乎所有的真核生物基因都具有位于转录起始位点上游约25至30个碱基处的富含at的区。许多基因的转录起始上游70至80个碱基处发现的另一序列是cncaat区,其中n可以是任何核苷酸。大多数真核生物基因的3'末端是aataaa序列,其可能是将polya尾添加到编码序列的3'末端的信号。将所有这些序列适当地插入到真核表达载体中。用于酵母宿主的合适的启动子序列的实例包括3-磷酸甘油酸激酶或其它糖酵解酶的启动子,如烯醇酶、甘油醛-3-磷酸脱氢酶、己糖激酶、丙酮酸脱羧酶、磷酸果糖激酶、葡萄糖-6-磷酸异构酶、3-磷酸甘油酸变位酶、丙酮酸激酶、磷酸丙糖异构酶、磷酸葡萄糖异构酶和葡糖激酶。其它酵母启动子(是具有通过生长条件控制转录的另外的优点的诱导型启动子)是用于醇脱氢酶2、异细胞色素c、酸性磷酸酶、与氮代谢相关的降解酶、金属硫蛋白、甘油醛-3-磷酸脱氢酶和负责麦芽糖和半乳糖利用的酶的启动子区域。用于酵母表达中的合适的载体和启动子进一步描述于ep73,657中。酵母增强子也有利地与酵母启动子一起使用。在哺乳动物宿主细胞中从载体的抗体转录可以例如通过从病毒基因组获得的启动子来控制,如多瘤病毒、禽痘病毒、腺病毒(如腺病毒2)、牛乳头瘤病毒、禽肉瘤病毒、巨细胞病毒、逆转录病毒、乙型肝炎病毒、猿猴病毒40(sv40)或来自异源哺乳动物的启动子,例如肌动蛋白启动子或免疫球蛋白启动子、来自热休克的启动子,只要这些启动子与宿主细胞系统相容即可。sv40病毒的早期和晚期启动子可作为sv40限制性片段方便地获得,其还含有sv40病毒复制起点。人巨细胞病毒的即时早期启动子作为hindiiie限制性片段方便地获得。使用牛乳头瘤病毒作为载体在哺乳动物宿主中表达dna的系统公开在美国专利号4,419,446。该系统的修饰在美国专利号4,601,978中描述。还参见reyes等人nature297:598-601(1982),其关于在单纯疱疹病毒的胸苷激酶启动子控制下在小鼠细胞中表达人β-干扰素cdna。或者,rous肉瘤病毒长末端重复可用作启动子。增强子元件组分将增强子序列插入载体中通常增加由高等真核生物转录的编码本发明抗体的dna。现在已知许多增强子序列来自哺乳动物基因(珠蛋白、弹性蛋白酶、白蛋白、甲胎蛋白和胰岛素)。然而,通常会使用来自真核细胞病毒的增强子。实例包括复制起点后侧的sv40增强子(bp100-270)、巨细胞病毒早期启动子增强子、复制起点后侧的多瘤病毒增强子和腺病毒增强子。参见yaniv,nature297:17-18(1982),其关于真核启动子活化的增强元件。增强子可以在抗体编码序列的5'或3'位置处被剪接到载体中,但优选位于启动子的5'位点。转录终止组分在真核宿主细胞(酵母、真菌、昆虫、植物、动物、人或其它多细胞生物体的有核细胞)中使用的表达载体也将含有终止转录和稳定mrna所需的序列。这些序列通常可从真核或病毒dna或cdna的5'、但是偶尔也从3'非翻译区获得。这些区含有在mrna编码抗体的非翻译部分中转录为多聚腺苷酸化片段的核苷酸区段。一种有用的转录终止组分是牛生长激素多聚腺苷酸化区。参见wo94/11026及其中公开的表达载体。宿主细胞的选择和转化用于在本文的载体中克隆或表达dna的合适的宿主细胞是上述原核细胞、酵母或高级真核细胞。用于此目的的合适的原核细胞包括真细菌,如革兰氏阴性或革兰氏阳性生物体,例如肠杆菌科(enterobacteriaceae)如埃希氏杆菌属(escherichia)例如大肠杆菌,肠杆菌属(enterobacter),欧文氏菌属(erwinia),克雷伯杆菌属(klebsiella),变形杆菌属(proteus),沙门氏菌属(salmonella)例如鼠伤寒沙门氏菌(salmonellatyphimurium),沙雷氏菌属(serratia)例如粘质沙雷氏菌(serratiamarcescans)和志贺氏菌属(shigella),以及芽胞杆菌属(bacilli)如枯草芽孢杆菌(b.subtilis)和地衣芽孢杆菌(b.licheniformis)(例如1989年4月12日公布的dd266,710中公开的地衣芽孢杆菌41p),假单胞菌属(pseudomonas)如铜绿假单胞菌(p.aeruginosa)和链霉菌属(streptomyces)等。一个优选的大肠杆菌克隆宿主是大肠杆菌294(atcc31,446),尽管其它菌株如大肠杆菌b、大肠杆菌x1776(atcc31,537)和大肠杆菌w3110(atcc27,325)也是合适的。这些例子是说明性的而不是限制性的。全长抗体、抗体融合蛋白和抗体片段可以在细菌中产生,特别是当不需要糖基化和fc效应功能时,如当治疗性抗体与细胞毒性剂(例如毒素)缀合时,所述细胞毒性剂本身就显示肿瘤细胞破坏的有效性。全长抗体在循环中具有更长的半衰期。在大肠杆菌中的生产更快、成本效率更好。对于在细菌中表达抗体片段和多肽,参见例如美国专利号5,648,237(carter等人)、美国专利5,789,199(joly等人)、美国专利号5,840,523(simmons等人),其描述了用于优化表达和分泌的翻译起始区(tir)和信号序列。参见charlton,methodsinmolecularbiology,vol.248(b.k.c.lo,ed.,humanapress,totowa,n.j.,2003),第245-254页,其描述了在大肠杆菌中表达抗体片段。表达后,抗体可以从大肠杆菌细胞糊中以可溶性级分分离,并且可以根据同种型通过例如蛋白a或g柱纯化。可以类似于纯化例如cho细胞中表达的抗体的方法进行最终纯化。除了原核生物之外,真核微生物如丝状真菌或酵母是用于编码抗体的载体的合适的克隆或表达宿主。酿酒酵母或普通烘焙酵母是低级真核宿主微生物中最常使用的。然而,通常可获得许多其它属、种和菌株,并且在本文中是有用的,如粟酒裂殖酵母(schizosaccharomycespombe);克鲁维酵母属宿主如,例如乳酸克鲁维酵母、脆弱克鲁维酵母(k.fragilis)(atcc12,424)、保加利亚克鲁维酵母(k.bulgaricus)(atcc16,045)、威克克鲁维酵母(k.wickeramii)(atcc24,178)、瓦尔提克鲁维酵母(k.waltii)(atcc56,500)、k.drosophilarum(atcc36,906)、k.thermotolerans和马克斯克鲁维酵母(k.marxianus);耶氏酵母属(yarrowia)(ep402,226);毕赤酵母(pichiapastoris)(ep183,070);念珠菌属(candida);瑞氏木霉(trichodermareesia)(ep244,234);粗糙脉孢菌(neurosporacrassa);许旺酵母属(schwanniomyces)如西方许旺酵母(schwanniomycesoccidentalis)和丝状真菌,如脉孢菌属(neurospora)、青霉属(penicillium)、弯颈霉属(tolypocladium)和曲霉属(aspergillus)宿主如构巢曲霉(a.nidulans)和黑曲霉(a.niger)。关于讨论酵母和丝状真菌用于生产治疗性蛋白的综述,参见例如gerngross,nat.biotech.22:1409-1414(2004)。可以选择某些真菌和酵母菌株,其中糖基化通路已被“人源化”,导致产生具有部分或完全人糖基化模式的抗体。参见,例如li等人nat.biotech.24:210-215(2006)(描述了毕赤酵母中糖基化通路的人源化);和gerngross等人,同上。用于表达糖基化抗体的合适的宿主细胞也源自多细胞生物体(无脊椎动物和脊椎动物)。无脊椎动物细胞的实例包括植物和昆虫细胞。已经鉴定了许多杆状病毒菌株和变体以及来自以下宿主的相应许可的昆虫宿主细胞:如草地贪夜蛾(spodopterafrugiperda)(毛虫)、埃及伊蚊(aedesaegypti)(蚊子)、白纹伊蚊(aedesalbopictus)(蚊子)、黑腹果蝇(drosophilamelanogaster)(果蝇)和家蚕(bombyxmori)。用于转染的多种病毒株可公开获得,例如苜蓿银纹夜蛾(autographacalifornica)npv的l-1变体和家蚕npv的bm-5株,这些病毒在文中可用作根据本发明的病毒,特别是用于转染草地贪夜蛾细胞。棉花、玉米、马铃薯、大豆、矮牵牛、番茄、浮萍(leninaceae)、苜蓿(m.truncatula)和烟草的植物细胞培养物也可用作宿主。参见,例如美国专利号5,959,177、6,040,498、6,420,548、7,125,978和6,417,429(描述了用于在转基因植物中产生抗体的plantibodiestm技术)。脊椎动物细胞可以用作宿主,并且脊椎动物细胞在培养(组织培养)中的繁殖已经成为常规步骤。有用的哺乳动物宿主细胞系的实例是由sv40(cos-7,atcccrl1651)转化的猴肾cv1系;人胚胎肾细胞系(293或293细胞亚克隆用于在悬浮培养中生长,graham等人,j.genvirol.36:59(1977));幼仓鼠肾细胞(bhk,atccccl10);小鼠支持细胞(tm4,mather,biol.reprod.23:243-251(1980));猴肾细胞(cv1atccccl70);非洲绿猴肾细胞(vero-76,atcccrl-1587);人宫颈癌细胞(hela,atccccl2);犬肾细胞(mdck,atccccl34);大鼠(buffalorat)肝细胞(brl3a,atcccrl1442);人肺细胞(w138,atccccl75);人肝细胞(hepg2,hb8065);小鼠乳腺肿瘤(mmt060562,atccccl51);tri细胞(mather等人,annalsn.y.acad.sci.383:44-68(1982));mrc5细胞;fs4细胞;和人肝癌细胞系(hepg2)。其它有用的哺乳动物宿主细胞系包括中国仓鼠卵巢(cho)细胞,包括dhfr-cho细胞(urlaub等人,proc.natl.acad.sci.usa77:4216(1980));和骨髓瘤细胞系如ns0和sp2/0。对于适用于抗体生产的某些哺乳动物宿主细胞系的综述,参见例如yazaki和wu,methodsinmolecularbiology,第248卷(b.k.c.lo编辑,humanapress,totowa,n.j.,2003),第255-268页。用上述用于抗体产生的表达或克隆载体转化宿主细胞,并在常规营养培养基中培养,所述培养基经修饰适于诱导启动子、选择转化体或扩增编码所期望序列的基因。培养宿主细胞用于产生本发明抗体的宿主细胞可以在各种培养基中培养。市售的培养基如ham'sf10(sigma)、minimalessentialmedium((mem)(sigma)、rpmi-1640(sigma)和dulbecco'smodifiedeagle'smedium((dmem),sigma)适于培养宿主细胞。此外,ham等人meth.enz.58:44(1979),barnes等人anal.biochem.102:255(1980),美国专利号4,767,704;4,657,866;4,927,762;4,560,655或5,122,469;wo90/03430;wo87/00195;或美国专利re.30,985中描述的任何培养基可以用作宿主细胞的培养基。任何这些培养基可以根据需要补充激素和/或其它生长因子(如胰岛素、转铁蛋白或表皮生长因子)、盐(如氯化钠、钙、镁和磷酸盐)、缓冲液(如hepes)、核苷酸(如腺苷和胸苷)、抗生素(如gentamycintm药物)、微量元素(定义为通常以微摩尔浓度的最终浓度存在的无机化合物)和葡萄糖或等效能量源。任何其它必需的补充剂也可以以本领域技术人员已知的适当浓度包括在内。培养条件如温度、ph等是先前与选择用于表达的宿主细胞一起使用的,对于本领域普通技术人员将是显而易见的。抗体纯化当使用重组技术时,可以在细胞内、周质空间中产生抗体,或直接将抗体分泌到培养基中。如果抗体在细胞内产生,则作为第一步,例如通过离心或超滤除去宿主细胞或裂解片段的颗粒碎片。carter等人,bio/technology10:163-167(1992)描述了分离分泌到大肠杆菌周质空间中的抗体的方法。简言之,在乙酸钠(ph3.5)、edta和苯甲基磺酰氟(pmsf)存在下,将细胞糊融解约30分钟。可以通过离心去除细胞碎片。当抗体分泌到培养基中时,来自这种表达系统的上清液通常首先使用市售的蛋白浓度过滤器,例如amicon或milliporepellicon超滤单元进行浓缩。任何前述步骤中可包括蛋白酶抑制剂如pmsf以抑制蛋白水解,并且可以包括抗生素以防止外来污染物的生长。从细胞制备的抗体组合物可以使用例如羟基磷灰石色谱法、疏水相互作用色谱法、凝胶电泳、透析和亲和色谱法纯化,其中亲和色谱法是通常优选的纯化步骤之一。蛋白a作为亲和配体的适用性取决于存在于抗体中的任何免疫球蛋白fc结构域的种类和同种型。蛋白a可用于纯化基于人γ1、γ2或γ4重链的抗体(lindmark等人j.immunol.meth.62:1-13(1983))。蛋白g被推荐用于所有小鼠同种型和人γ3(guss等人emboj.5:15671575(1986))。亲和配体所附着的基质最常见是琼脂糖,但是其它基质是可用的。机械稳定的基质如可控孔的玻璃或聚(苯乙烯二乙烯基)苯允许比琼脂糖实现更快的流速和更短的加工时间。当抗体包含ch3结构域时,bakerbondabxtm树脂(j.t.baker,phillipsburg,n.j.)可用于纯化。也可以根据待回收的抗体使用用于蛋白质纯化的其它技术,如离子交换柱上的分级、乙醇沉淀、反相hplc、二氧化硅色谱法、在阴离子或阳离子交换树脂(如聚天冬氨酸柱)上的肝素sepharosetm色谱上的色谱法、色谱聚焦、sds-page和硫酸铵沉淀。一般来说,制备用于研究、测试和临床的抗体的各种方法在本领域中是很好地确定的,与上述方法一致和/或被本领域技术人员认为适用于特定的感兴趣的抗体。选择生物学活性抗体可以对如上述产生的抗体进行一种或多种“生物学活性”测定,以从治疗角度选择具有有益特性的抗体或选择保留抗体生物学活性的制剂和条件。可以测试抗体与产生其的抗原的结合能力。例如,可以使用本领域已知的方法(例如elisa,westernblot等)。例如,对于抗pdl1抗体,可以在检测结合pdl1的能力的测定法中评估抗体的抗原结合性质。在一些实施方案中,可以通过例如饱和结合、elisa和/或竞争测定法(例如ria's)来测定抗体的结合。此外,例如,还可对抗体进行其它生物学活性测定,以评价其作为治疗剂的有效性。这些测定法是本领域已知的,并且取决于靶抗原和抗体的预期用途。例如,可以在cd8+t细胞、淋巴细胞性脉络丛脑膜炎病毒(lcmv)小鼠模型和/或同基因肿瘤模型中(例如美国专利8,217,149中所述)评估抗体阻断pd-l1的生物学效应。为了筛选结合感兴趣的抗原上特定表位的抗体(例如,阻断本实施例的抗pdl1抗体与pd-l1的结合的抗体),可进行如antibodies,alaboratorymanual,coldspringharborlaboratory,edharlowanddavidlane(1988)中所述的常规交叉阻断测定法。或者,可以进行例如,如champe等人j.biol.chem.270:1388-1394(1995)所述的表位作图,以确定抗体是否结合感兴趣的表位。v.药物制剂通过将具有所期望纯度的抗体与任选的药学上可接受的载体、赋形剂或稳定剂(remington'spharmaceuticalsciences第16版,osol,a.编辑(1980))混合以冻干制剂或水溶液的形式来制备根据本发明使用的抗体的用于储存的治疗制剂。可接受的载体、赋形剂或稳定剂在使用的剂量和浓度下对受体无毒,并且包括缓冲液(如磷酸盐、柠檬酸盐和其它有机酸);抗氧化剂(包括抗坏血酸和甲硫氨酸);防腐剂(如十八烷基二甲基苄基氯化铵;氯化六烃季铵;苯扎氯铵、苄索氯铵;酚醇、丁基或苄基醇;对羟基苯甲酸烷基酯,如对羟基苯甲酸甲酯或对羟基苯甲酸丙酯;儿茶酚;间苯二酚;环己醇;3-戊醇;间甲酚);低分子量(小于约10个残基)多肽;蛋白质(如血清白蛋白、明胶或免疫球蛋白);亲水性聚合物(如聚乙烯吡咯烷酮);氨基酸(如甘氨酸、谷氨酰胺、天冬酰胺、组氨酸、精氨酸或赖氨酸);单糖、二糖和其它碳水化合物(包括葡萄糖、甘露糖或糊精);螯合剂(如edta);糖(如蔗糖、甘露糖醇、海藻糖或山梨糖醇);盐形成抗衡离子如钠;金属络合物(例如zn-蛋白络合物);和/或非离子表面活性剂如tweentm、pluronicstm或聚乙二醇(peg)。美国专利号6,267,958(andya等人)中描述了适于皮下施用的冻干制剂。这样的冻干制剂可以用合适的稀释剂重构形成高蛋白浓度,并且重构的制剂可以皮下施用于待治疗的哺乳动物。也考虑了抗体或抗体的结晶形式。参见,例如us2002/0136719a1(shenoy等人)。在一些实施方案中,本文的制剂还可以包含对于所治疗的具体适应症而言所必需的多于一种的活性化合物,那些活性化合物具有不会不利地影响彼此的互补活性。例如,可能期望进一步在制剂中提供细胞毒性剂;化疗剂;免疫抑制剂;细胞因子;细胞因子拮抗剂或抗体;生长因子;激素;整联蛋白;整联蛋白拮抗剂或抗体(例如lfa-1抗体,如可从genentech购得的依法珠单抗/raptiva,或α4整联蛋白抗体,如可从biogenidec/elanpharmaceuticals,inc.获得的那他珠单抗/);干扰素类药物如ifnβ-1a(和)或ifnβ-1b寡肽如醋酸格拉替雷细胞毒性剂如米托蒽醌甲氨蝶呤、环磷酰胺、苯丁酸氮芥或硫唑嘌呤;静脉注射免疫球蛋白(γ球蛋白);淋巴细胞消耗性药物(例如米托蒽醌、环磷酰胺、campath、抗cd4或克拉屈滨);非淋巴细胞消耗性免疫抑制药物(例如麦考酚酸酯(mmf)或环孢菌素);“他汀类”类降胆固醇药物;雌二醇;睾酮;激素替代疗法、治疗ms继发或相关症状的药物(例如痉挛、失禁、疼痛、疲劳);tnf抑制剂;改善疾病的抗风湿药(dmard);非甾体抗炎药(nsaid);皮质类固醇(例如甲基泼尼松龙、泼尼松、地塞米松或糖皮质激素);左旋甲状腺素;环孢菌素a;生长抑素类似物;细胞因子拮抗剂;抗代谢药;免疫抑制剂;整联蛋白拮抗剂或抗体(例如lfa-1抗体,如依法珠单抗或α4整联蛋白抗体,如那他珠单抗);或另一种b细胞表面拮抗剂/抗体等。这样的其它试剂的类型和有效量取决于例如制剂中存在的抗体的量、待治疗的多发性硬化症的类型和患者的临床参数。这些试剂通常以与上述使用相同的剂量和施用途径使用,或者约占在这之前使用剂量的1至99%。还可以将活性成分包埋在例如通过凝聚技术或通过界面聚合制备的微胶囊中,分别例如在胶体药物递送系统(例如,脂质体、白蛋白微球、微乳液、纳米颗粒和纳米胶囊)中的羟甲基纤维素或明胶微胶囊和在大量乳液(macroemulsions)中的聚(甲基丙烯酸甲酯)微胶囊。这种技术在remington'spharmaceuticalsciences第16版,osol,a.编辑中公开了(1980年)。可以制备持续释放的制剂。持续释放的制剂的合适实例包括含有抗体的固体疏水性聚合物的半渗透性基质,该基质为成形制品的形式,例如,薄膜或微胶囊。持续释放的基质的实例包括聚酯、水凝胶(例如,聚(2-羟乙基-甲基丙烯酸酯)或聚(乙烯醇))、聚乳酸(美国专利号3,773,919)、l-谷氨酸和γ-乙基-l-谷氨酸酯的共聚物、不可降解的乙烯-乙酸乙烯酯、可降解的乳酸-乙醇酸共聚物如luprondepottm(由乳酸-乙醇酸共聚物和醋酸亮丙瑞林组成的可注射微球)和聚-d-(-)-3-羟基丁酸。用于体内施用的制剂必须是无菌的。这通过无菌过滤膜过滤容易地实现。vi.施用在一些实施方案中,抗pd-l1抗体通过静脉内、肌肉内、皮下、局部、口服、经皮、腹膜内、框内、通过植入、通过吸入、鞘内、心室内或鼻内施用。可以施用有效量的抗pd-l1抗体来预防或治疗疾病。抗pd-l1抗体的适当剂量可以基于待治疗疾病的类型、抗pd-l1抗体的类型、疾病的严重性和病程、个体的临床状况、个体的临床病史和对治疗的反应、以及主治医师的判断确定。作为通常的主张,施用于人的抗体的治疗有效量可以在约0.01至约50mg/kg患者体重的范围内,无论是通过一次或多次施用。在一些实施方案中,所使用的抗体例如每天施用约0.01至约45mg/kg、约0.01至约40mg/kg、约0.01至约35mg/kg、约0.01至约30mg/kg、约0.01至约25mg/kg、约0.01至约20mg/kg、约0.01至约15mg/kg、约0.01至约10mg/kg、约0.01至约5mg/kg、或约0.01至约1mg/kg。在一些实施方案中,抗体以15mg/kg施用。然而,其它剂量方案可能是有用的。在一个实施方案中,本文所述的抗pdl1抗体以约100mg、约200mg、约300mg、约400mg、约500mg、约600mg、约700mg、约800mg、约900mg、约1000mg、约1100mg、约1200mg、约1300mg或约1400mg,在21天周期的第1天施用于人。剂量可以以单次剂量或多次剂量(例如2或3次剂量)施用,例如输注。与单次治疗相比,组合治疗中施用的抗体剂量可以减少。通过常规技术容易地监测该疗法的进展。在一些实施方案中,方法还可以包含另外的治疗。另外的疗法可以是放疗、手术(例如乳房肿瘤切除术和乳房切除术)、化疗、基因治疗、dna治疗、病毒治疗、rna治疗、免疫治疗、骨髓移植、纳米治疗、单克隆抗体治疗或上述组合。另外的治疗可以是佐剂或新辅助治疗的形式。在一些实施方案中,另外的治疗是施用小分子酶抑制剂或抗转移剂。在一些实施方案中,另外的治疗是施用副作用限制剂(例如,旨在减轻治疗副作用的发生和/或严重性的试剂,如抗恶心剂等)。在一些实施方案中,另外的疗法是放疗。在一些实施方案中,另外的疗法是手术。在一些实施方案中,另外的治疗是放疗和手术的组合。在一些实施方案中,另外的治疗是γ照射。在一些实施方案中,另外的治疗是靶向pi3k/akt/mtor通路、hsp90抑制剂、微管蛋白抑制剂、凋亡抑制剂和/或化学预防剂的治疗。另外的治疗可以是本文所述的一种或多种化疗剂。组合疗法在某些实施方案中,抗pd-l1抗体与另一种抗癌剂或癌症治疗联合施用。“联合”是指除了另一种治疗方式之外还施用的一种治疗方式。因此,“联合”是指在向个体施用另一种治疗方式之前、期间(如同时或同时)或之后施用一种治疗方式。在一些实施方案中,抗pd-l1抗体可以与化疗或化疗剂联合施用。在一些实施方案中,抗pd-l1抗体可以与放疗或放疗剂联合施用。在一些实施方案中,抗pd-l1抗体可以与靶向治疗或靶向治疗剂联合施用。在一些实施方案中,抗pd-l1抗体可以与免疫治疗或免疫治疗剂(例如单克隆抗体)联合施用。不希望束缚于理论,认为通过促进活化性共刺激分子或通过抑制阴性共刺激分子来增强t细胞刺激可以促进肿瘤细胞死亡,从而治疗或延缓癌症的进展。在一些实施方案中,抗pd-l1抗体可以与针对活化性共刺激分子的激动剂联合施用。在一些实施方案中,活化性共刺激分子可以包括cd40、cd226、cd28、ox40、gitr、cd137、cd27、hvem或cd127。在一些实施方案中,针对活化性共刺激分子的激动剂是结合cd40、cd226、cd28、ox40、gitr、cd137、cd27、hvem或cd127的激动剂抗体。在一些实施方案中,抗pd-l1抗体可以与针对抑制性共刺激分子的拮抗剂联合施用。在一些实施方案中,抑制性共刺激分子可以包括ctla-4(也称为cd152)、pd-1、tim-3、btla、vista、lag-3、b7-h3、b7-h4、ido、tigit、mica/b或精氨酸酶。在一些实施方案中,针对抑制性共刺激分子的拮抗剂是结合ctla-4、pd-1、tim-3、btla、vista、lag-3、b7-h3、b7-h4、ido、tigit、mica/b或精氨酸酶的拮抗剂抗体。在一些实施方案中,抗pd-l1抗体可以与针对ctla-4(也称为cd152)的拮抗剂(例如阻断抗体)联合施用。在一些实施方案中,抗pd-l1抗体可以与伊匹木单抗(ipilimumab)(也称为mdx-010、mdx-101或)联合施用。在一些实施方案中,抗pd-l1抗体可以与曲美木单抗(tremelimumab)(也称为ticilimumab或cp-675,206)联合施用。在一些实施方案中,抗pd-l1抗体可以与针对b7-h3(也称为cd276)的拮抗剂(例如阻断抗体)联合施用。在一些实施方案中,抗pd-l1抗体可以与mga271联合施用。在一些实施方案中,抗pd-l1抗体可以与针对tgfβ的拮抗剂(例如,metelimumab(也称为cat-192)、fresolimumab(也称为gc1008)或ly2157299)联合施用。在一些实施方案中,抗pd-l1抗体可以与包括过继转移表达嵌合抗原受体(car)的t细胞(例如,细胞毒性t细胞或ctl)的治疗联合施用。在一些实施方案中,抗pd-l1抗体可以与包括过继转移包含显性抑制的(dominant-negative)tgfβ受体(例如显性抑制的tgfβ2型受体)的t细胞的治疗联合施用。在一些实施方案中,抗pd-l1抗体可以与包含hercreem方案的治疗联合施用(参见例如clinicaltrials.govidentifiernct00889954)。在一些实施方案中,抗pd-l1抗体可以与针对cd137(也称为tnfrsf9、4-1bb或ila)的激动剂(例如活化抗体)联合施用。在一些实施方案中,抗pd-l1抗体可以与urelumab(也称为bms-663513)联合施用。在一些实施方案中,抗pd-l1抗体可以与针对cd40的激动剂(例如活化抗体)联合施用。在一些实施方案中,抗pd-l1抗体可以与cp-870893联合施用。在一些实施方案中,抗pd-l1抗体可以与针对ox40(也称为cd134)的激动剂(例如活化抗体)联合施用。在一些实施方案中,抗pd-l1抗体可以与抗ox40抗体(例如,agonox)联合施用。在一些实施方案中,抗pd-l1抗体可以与针对cd27的激动剂(例如活化抗体)联合施用。在一些实施方案中,抗pd-l1抗体可以与cdx-1127联合施用。在一些实施方案中,抗pd-l1抗体可以与针对吲哚胺-2,3-双加氧酶(ido)的拮抗剂联合施用。在一些实施方案中,ido拮抗剂是1-甲基-d-色氨酸(也称为1-d-mt)。在一些实施方案中,抗pd-l1抗体可以与抗体-药物缀合物联合施用。在一些实施方案中,抗体-药物缀合物包括mertansine或单甲基澳瑞他汀e(mmae)。在一些实施方案中,抗pd-l1抗体可以与抗napi2b抗体-mmae缀合物(也称为dnib0600a或rg7599)联合施用。在一些实施方案中,抗pd-l1抗体可以与trastuzumabemtansine(也称为t-dm1、ado-trastuzumabemtansine或genentech)联合施用。在一些实施方案中,抗pd-l1抗体可以与dmuc5754a联合施用。在一些实施方案中,抗pd-l1抗体可以与靶向内皮素b受体(ednbr)的抗体-药物缀合物联合施用,例如针对ednbr的抗体与mmae缀合。在一些实施方案中,抗pd-l1抗体可以与血管生成抑制剂联合施用。在一些实施方案中,抗pd-l1抗体可以与针对vegf的抗体(例如vegf-a)联合施用。在一些实施方案中,抗pd-l1抗体可以与贝伐单抗(bevacizumab)(也称为genentech)联合施用。在一些实施方案中,抗pd-l1抗体可以与针对血管生成素2(也称为ang2)的抗体联合施用。在一些实施方案中,抗pd-l1抗体可以与medi3617联合施用。在一些实施方案中,抗pd-l1抗体可以与抗肿瘤剂联合施用。在一些实施方案中,抗pd-l1抗体可以与靶向csf-1r(也称为m-csfr或cd115)的试剂联合施用。在一些实施方案中,抗pd-l1抗体可以与抗csf-1r(也称为imc-cs4)联合施用。在一些实施方案中,抗pd-l1抗体可以与干扰素(例如干扰素α或干扰素γ)联合施用。在一些实施方案中,抗pd-l1抗体可以与roferon-a(也称为重组干扰素α-2a)联合施用。在一些实施方案中,抗pd-l1抗体可以与gm-csf(也称为重组人粒细胞巨噬细胞集落刺激因子rhugm-csf、沙莫司亭或)联合施用。在一些实施方案中,抗pd-l1抗体可以与il-2(也称为阿地白介素或)联合施用。在一些实施方案中,抗pd-l1抗体可以与il-12联合施用。在一些实施方案中,抗pd-l1抗体可以与靶向cd20的抗体联合施用。在一些实施方案中,靶向cd20的抗体是奥妥珠单抗(obinutuzumab)(也称为ga101或)或利妥昔单抗。在一些实施方案中,抗pd-l1抗体可以与靶向gitr的抗体联合施用。在一些实施方案中,靶向gitr的抗体是trx518。在一些实施方案中,抗pd-l1抗体可以与癌症疫苗联合施用。在一些实施方案中,癌症疫苗是肽癌疫苗,在一些实施方案中其是个体化肽疫苗。在一些实施方案中,肽癌疫苗是多价长肽、多肽、肽混合物、杂合肽或肽脉冲树突状细胞(peptide-pulseddendriticcell)疫苗(参见例如yamada等人cancersci,104:14-21,2013)。在一些实施方案中,抗pd-l1抗体可以与佐剂联合施用。在一些实施方案中,抗pd-l1抗体可以与包含tlr激动剂(例如poly-iclc(也称为)、lps、mpl或cpgodn)的治疗联合施用。在一些实施方案中,抗pd-l1抗体可以与肿瘤坏死因子(tnf)α联合施用。在一些实施方案中,抗pd-l1抗体可以与il-1联合施用。在一些实施方案中,抗pd-l1抗体可以与hmgb1联合施用。在一些实施方案中,抗pd-l1抗体可以与il-10拮抗剂联合施用。在一些实施方案中,抗pd-l1抗体可以与il-4拮抗剂联合施用。在一些实施方案中,抗pd-l1抗体可以与il-13拮抗剂联合施用。在一些实施方案中,抗pd-l1抗体可以与hvem拮抗剂联合施用。在一些实施方案中,抗pd-l1抗体可以与icos激动剂联合施用,例如通过施用icos-l或针对icos的激动性抗体。在一些实施方案中,抗pd-l1抗体可以与靶向cx3cl1的治疗联合施用。在一些实施方案中,抗pd-l1抗体可以与靶向cxcl9的治疗联合施用。在一些实施方案中,抗pd-l1抗体可以与靶向cxcl10的治疗联合施用。在一些实施方案中,抗pd-l1抗体可以与靶向ccl5的治疗联合施用。在一些实施方案中,抗pd-l1抗体可以与lfa-1或icam1激动剂联合施用。在一些实施方案中,抗pd-l1抗体可以与selectin激动剂联合施用。在一些实施方案中,抗pd-l1抗体可以与靶向治疗联合施用。在一些实施方案中,抗pd-l1抗体可以与b-raf的抑制剂联合施用。在一些实施方案中,抗pd-l1抗体可以与威罗菲尼(也称为)联合施用。在一些实施方案中,抗pd-l1抗体可以与达拉菲尼(也称为)联合施用。在一些实施方案中,抗pd-l1抗体可以与厄洛替尼(也称为)联合施用。在一些实施方案中,抗pd-l1抗体可以与mek的抑制剂如mek1(也称为map2k1)或mek2(也称为map2k2)联合施用。在一些实施方案中,抗pd-l1抗体可以与cobimetinib(也称为gdc-0973或xl-518)联合施用。在一些实施方案中,抗pd-l1抗体可以与曲美替尼(也称为)联合施用。在一些实施方案中,抗pd-l1抗体可以与k-ras的抑制剂联合施用。在一些实施方案中,抗pd-l1抗体可以与c-met的抑制剂联合施用。在一些实施方案中,抗pd-l1抗体可以与onartuzumab(也称为metmab)联合施用。在一些实施方案中,抗pd-l1抗体可以与alk的抑制剂联合施用。在一些实施方案中,抗pd-l1抗体可以与af802(也称为ch5424802或阿雷替尼)联合施用。在一些实施方案中,抗pd-l1抗体可以与磷脂酰肌醇3-激酶(pi3k)的抑制剂联合施用。在一些实施方案中,抗pd-l1抗体可以与bkm120联合施用。在一些实施方案中,抗pd-l1抗体可以与idelalisib(也称为gs-1101或cal-101)联合施用。在一些实施方案中,抗pd-l1抗体可以与哌立福辛(也称为krx-0401)联合施用。在一些实施方案中,抗pd-l1抗体可以与akt的抑制剂联合施用。在一些实施方案中,抗pd-l1抗体可以与mk2206联合施用。在一些实施方案中,抗pd-l1抗体可以与gsk690693联合施用。在一些实施方案中,抗pd-l1抗体可以与gdc-0941联合施用。在一些实施方案中,抗pd-l1抗体可以与mtor的抑制剂联合施用。在一些实施方案中,抗pd-l1抗体可以与西罗莫司(也称为雷帕霉素)联合施用。在一些实施方案中,抗pd-l1抗体可以与西罗莫司脂化物(也称为cci-779或)联合施用。在一些实施方案中,抗pd-l1抗体可以与依维莫司(也称为rad001)联合施用。在一些实施方案中,抗pd-l1抗体可以与地磷莫司(也称为ap-23573、mk-8669或deforolimus)联合施用。在一些实施方案中,抗pd-l1抗体可以与osi-027联合施用。在一些实施方案中,抗pd-l1抗体可以与azd8055联合施用。在一些实施方案中,抗pd-l1抗体可以与ink128联合施用。在一些实施方案中,抗pd-l1抗体可以与双重pi3k/mtor抑制剂联合施用。在一些实施方案中,抗pd-l1抗体可以与xl765联合施用。在一些实施方案中,抗pd-l1抗体可以与gdc-0980联合施用。在一些实施方案中,抗pd-l1抗体可以与bez235(也称为nvp-bez235)联合施用。在一些实施方案中,抗pd-l1抗体可以与bgt226联合施用。在一些实施方案中,抗pd-l1抗体可以与gsk2126458联合施用。在一些实施方案中,抗pd-l1抗体可以与pf-04691502联合施用。在一些实施方案中,抗pd-l1抗体可以与pf-05212384(也称为pki-587)联合施用。试剂盒和制品本发明还提供了含有根据本文所述的方法用于治疗癌症的材料的试剂盒和制品。在一些实施方案中,本发明提供了一种制品,其包含一起包装的药物组合物和药学上可接受的载体以及标签,所述药物组合物包含抗pd-l1抗体(或其抗原结合片段),所述标签指示抗pd-l1抗体(或其抗原结合片段)或药物组合物指明用于治疗在来自受试者的含有癌细胞的样品中在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低的甲基化水平的癌症患者。在一些实施方案中,制品还包括说明书,所述说明书用于说明向癌症受试者施用抗pd-l1抗体(或其抗原结合片段)或药物组合物,所述癌症受试者在来自受试者的含有癌细胞的样品中在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低的甲基化水平。在一些实施方案中,本发明提供了一种制品,其包含一起包装的药物组合物和药学上可接受的载体以及标签,所述药物组合物包含抗pd-l1抗体(或其抗原结合片段),所述标签指示抗pd-l1抗体(或其抗原结合片段)或药物组合物的施用是基于在来自受试者的含有癌细胞的样品中在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化的患者。在一些实施方案中,制品还包括说明书,所述说明书用于说明向癌症受试者施用抗pd-l1抗体(或其抗原结合片段)或药物组合物,所述癌症受试者在来自受试者的含有癌细胞的样品中在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低的甲基化水平。在一些实施方案中,本发明提供了一种制品,其包含一起包装的药物组合物和药学上可接受的载体以及标签,所述药物组合物包含抗pd-l1抗体(或其抗原结合片段),所述标签指示抗pd-l1抗体(或其抗原结合片段)或药物组合物施用给所选择的患者,其中发现受试者在来自受试者的含有癌细胞的样品中在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化。在一些实施方案中,制品还包括说明书,所述说明书用于说明向癌症受试者施用抗pd-l1抗体(或其抗原结合片段)或药物组合物,所述癌症受试者在来自受试者的含有癌细胞的样品中在pd-l1启动子区中的cpg1上或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低的甲基化水平。在一些实施方案中,本发明提供了一种包含试剂和说明书的试剂盒,所述试剂用于在来自受试者的含有癌细胞的样品中测量pd-l1启动子区中的cpg1上和/或pd-l1基因内含子1中的一个或多个cpg位点上的甲基化水平,和所述说明书用于将受试者分类为在pd-l1启动子区中的cpg1上和/或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低的甲基化水平。在一些实施方案中,试剂盒还包含抗pd-l1抗体和说明书,说明书用于说明如果受试者在pd-l1启动子区中的cpg1上和/或在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低的甲基化水平,则向受试者施用抗pd-l1抗体。在本文描述的任何试剂盒或制品的一些实施方案中,发现受试者在来自受试者的含有癌细胞的样品中在pd-l1启动子区中的cpg1上和在pd-l1基因内含子1中的一个或多个cpg位点上具有中等或低水平的甲基化。在本文所述的任何试剂盒或制品的一些实施方案中,标签指示在pd-l1启动子区中的cpg1上或pd-l1内含子1中的一个或多个cpg位点上的甲基化程度由亚硫酸氢盐dna测序确定。在本文所述的任何试剂盒或制品的一些实施方案中,标签指示在pd-l1启动子区中的cpg1上或pd-l1内含子1中的一个或多个cpg位点上的甲基化程度由亚硫酸氢盐次代测序确定。在本文所述的任何试剂盒或制品的一些实施方案中,标签指示在pd-l1启动子区中的cpg1上或pd-l1内含子1中的一个或多个cpg位点上的甲基化程度由甲基化芯片阵列(如humanmethylation450beadchip阵列)确定。在一些实施方案中,本文提供的试剂盒或制品包含用于在来自受试者的含有癌细胞的样品中检测免疫细胞浸润的试剂。在一些实施方案中,试剂包括以下一种或多种:抗cd16抗体、抗-cd4抗体、抗cd3抗体、抗cd56抗体、抗cd45抗体、抗cd68抗体、抗cd20抗体、抗cd163抗体或抗cd8抗体。在一些实施方案中,试剂是抗cd8抗体。在一些实施方案中,本文提供的试剂盒或制品还包括用于进行免疫组织化学测定法(包括但不限于westernblot、elisa或流式细胞术)的说明书,以便在来自受试者的含有癌细胞的样品中检测免疫细胞浸润。在一些实施方案中,本文提供的试剂盒或制品还包括用于进行基因表达分析测定法(包括但不限于定量pcr(qpcr)、qrt-pcr、转录组分析(如rnaseq)、微阵列分析、次代测序等)的说明书。在本文提供的任何试剂盒或制品的一些实施方案中,癌症是乳癌、肺癌或皮肤癌,包括那些癌症的转移形式。在某些实施方案中,乳癌是乳腺癌。在一些实施方案中,肺癌是小细胞肺癌、非小细胞肺癌、肺腺癌或肺鳞状细胞癌。在某些实施方案中,皮肤癌是黑素瘤、浅表性扩散性黑素瘤、恶性雀斑样黑素瘤、肢端的雀斑样黑素瘤、结节性黑素瘤或皮肤癌。在任何试剂盒或制品的一些实施方案中,试剂盒或制品中包含的抗pd-l1抗体(或其抗原结合片段)是本文所述的抗pd-l1抗体。在任何试剂盒或制品的一些实施方案中,抗pd-l1抗体(或其抗原结合片段)选自yw243.55.s70、mpdl3280a、mdx-1105和medi4736。可以包括在本文提供的制品中或包括在本文提供的制品或试剂盒中的其它示例性抗pd-l1抗体(或其抗原结合片段)描述于wo2010/077634、wo2007/005874、wo2011/066389和us2013/034559中,其各自通过引用整体并入本文。通常,试剂盒或制品包含容器和在容器上或与容器相关的标签或包装插页。合适的容器包括例如瓶、小瓶、注射器等。容器可以由各种材料如玻璃或塑料制成。容器容纳或含有有效治疗癌症的抗pd-l1抗体(或其抗原结合片段)或药物组合物,并且可具有无菌进入口(例如,该容器可为静脉内溶液袋或具有通过皮下注射针可刺穿的塞子的小瓶)。组合物中至少一种活性剂是抗pd-l1抗体。标签或包装插页指示组合物用于治疗患有癌症的患者中的癌症,其具有针对提供的抗体和任何其它药物的给药量和给药间隔的具体指导。制品可进一步包括第二容器,其包含药学上可接受的稀释缓冲液,如用于注射的抑菌水(bwfi)、磷酸盐缓冲盐水、林格氏溶液和葡萄糖溶液。制品可以进一步包括从商业和用户观点期望的其它材料,包括其它缓冲剂、稀释剂、过滤器、针和注射器。任选地,本文的制品还包含容器,其包含不同于用于治疗的抗体的试剂,并且还包含关于用所述试剂治疗患者的说明书,所述试剂是例如化疗剂(如本文别处所述的化疗剂)、细胞毒性剂(如本文别处所述的细胞毒性剂)等。通过以下非限制性实施例说明本发明的进一步的细节。说明书中所有引用的公开内容通过引用明确地并入本文。实施例实施例纯粹旨在是本发明的示例,并且因此不应被认为以任何方式限制本发明,其还描述和详细描述了以上讨论的本发明的各方面和各实施方案。上述实施例和详细描述通过说明而非限制的方式提供。实施例1:材料和方法以下材料和方法在以下实施例2中使用。细胞系和培养条件从美国典型细胞培养物(atcc)或学术来源获得nsclc细胞系,并在补充有10%胎牛血清(fbs)和2mml-谷氨酰胺的rpmi1640培养基中培养。在pbs洗涤和用accutase分离培养基(sigma)孵育后,分离细胞以进行分开和/或实验分析。用0.1mm曲古抑菌素a(“tsa”,sigma)和/或1ng/ml干扰素γ(ifnγ)处理细胞24小时和1mm5-阿扎胞苷-dc(5-aza-dc,sigma)处理3天qd(即每天一次)或6天q2d(即每隔一天一次)。肿瘤样品来自nsclc患者的肿瘤标本档案从irb批准的供应商集团获得,所述供应商集团来自themtgroup,cureline,inc,cambridgebiosource,tristartechnologygroupllc或clinpathadvisors。dna/rna分析使用缓冲液rltplus(qiagen)裂解细胞,使用allprepdna/rnaminikit(qiagen)从相同裂解物进行rna和dna提取。通过asuragen,inc的genechiphumangenomeu133plus2.0array(affymetrix)上的微阵列和使用taqmangeneexpressionassays(lifetechnologies)的qpcr分析rna表达。使用genomicssuite(partek)、spotfire(tibco)、jmp(sas)和ipa(ingenuity)分析数据。在humanmethylation450beadchip(illumina)上分析dna。使用zymodnagold甲基化试剂盒(zymoresearch)对dna进行亚硫酸氢盐修饰,并用靶向cd274启动子区的亚硫酸氢盐特异性测序引物扩增。使用标准方法(abi)对pcr产物进行ta亚克隆和测序。使用biqanalyzer软件(c.bock)分析abi序列文件。蛋白质分析使用补充有sigmafast蛋白酶抑制剂片剂(sigma)和磷酸酶抑制剂混合物1和2(sigma)的细胞提取缓冲液(lifetechnologies)生成蛋白质裂解物。裂解物在4℃下以20,000×g离心10分钟,然后移除上清液用于westernblot(wb)的分析。样品用nupagenovexlds和sra缓冲液(lifetechnologies)处理,并与seeblueplus2分子量标准(lifetechnologies)并排加载到bis-tris凝胶(lifetechnologies)上。将凝胶转移到使用iblot系统(lifetechnologies)的硝酸纤维素膜上,然后在室温下用odyssey封闭缓冲液(li-cor)封闭1小时。凝胶用在odyssey封闭缓冲液+0.01%tween-20中稀释的针对人pd-l1(内部制备)、β-肌动蛋白(sigma);p/tstat1、p-stat3-y705、p-stat3-s727和t-stat3(所有的细胞信号传导)的抗体染色。检测一抗,在odyssey封闭缓冲液+0.01%tween-20+0.001%sds中的二抗来自li-cor,并在odysseyclx系统(li-cor)上进行分析。对于facs分析,分离细胞,然后在fbs染色缓冲液(bdbiosciences)中洗涤两次。然后用pe-缀合的抗人pd-l1或同种型对照(bdbiosciences)染色细胞,然后洗涤并在facscantoii分析仪(bdbiosciences)上分析。如herbst等人(2014)nature515,563-574的描述进行免疫组织化学(ihc)分析。染色质免疫沉淀(chip,活性基序)使nsclc细胞系生长至适当融合,并用1%甲醛固定处理的细胞15分钟,并用0.125m甘氨酸淬灭。通过加入裂解缓冲液以及用dounce匀浆器破碎分离染色质。将裂解物超声处理,并将dna剪切至平均长度为300-500bp。通过用rna酶、蛋白酶k和用于去交联的加热处理染色质的等分试样,来制备基因组dna(输入)。处理后进行乙醇沉淀。将基因组dna的颗粒重新悬浮,并在nanodrop分光光度计上定量得到的dna。原始染色质体积的外推法允许定量总染色质的产率。用蛋白a琼脂糖珠(invitrogen)预先清洗染色质等份试样(30μg)。使用4μg针对stat1(santacruz,cat#sc-345)和stat3(santacruz,sc-482)的抗体分离感兴趣的基因组dna区。洗涤复合物,用sds缓冲液从珠洗脱,并进行rnase和蛋白酶k处理。通过在65℃过夜孵育去交联,通过苯酚-氯仿提取和乙醇沉淀纯化染色质免疫沉淀(chip)dna。使用针对候选stat1和stat3对照位点的引物、通过qpcr测定chip富集的质量。使用sybrgreensupermix(bio-rad)一式三份进行qpcr反应。通过使用输入dna对每个引物对进行qpcr,针对引物效率将所得信号标准化。chip测序(illumina,活性基序)通过末端削平、da添加和接头连接的标准连续的酶促步骤从chip和输入dna制备illumina测序文库。在最终的pcr扩增步骤后,将得到的dna文库在hiseq2500或nexseq500上进行定量和测序。使用bwa算法将序列(50nt读数、单末端或75nt读数、单末端)与人基因组(hg19)比对。在计算机上使比对的序列各自在其3'末端延伸至200bp的长度,即尺寸选择文库中的平均基因组片段长度,并分配至沿着基因组的32-nt的箱(bin)。得到的直方图(基因组“信号图”)存储在bigwig文件中。使用macs算法(v1.4.2.)、p值=1×10-7的截止值来确定峰值位置。信号图和峰值位置被用作活性基序专有分析程序的输入数据,该程序创建excel表格,其中含有样品比较、峰度量(metrics)、峰位置和基因注释的详细信息。亚硫酸氢盐次代测序(亚硫酸氢盐ngs,活性基序)通过chip-seq分析的nsclc细胞系也通过亚硫酸氢盐次代测序(ngs)对pd-l1启动子的甲基化状态进行分析。使用methprimer软件(world-wide-web.urogene.org/cgi-bin/methprimer/methprimer.cgi)设计靶区(正链)的pcr引物。引物用于从亚硫酸氢盐转化的基因组dna扩增靶区。对于6个样品中的每一个,将大约相等量的9个pcr的产物合并、连环化(concatemerized)、超声处理至150-300个碱基对的平均片段长度,并加工成标准的,标有条形码的illumina测序文库。在nextseq500中对illumina测序文库进行测序。使用bismark比对程序(v0.7.7)(world-wide-web.bioinformatics.babraham.ac.uk/projects/bismark/)分析测序读数。人chr6和chr9(hg19组装)用作参考序列。bismark比对报告在文件“2674genentechbismarkreports.xlsx”中编译。每个样品分析510万到740万个读数。实施例2:pd-l1甲基化和表达的分析从91个nsclc细胞系中提取rna和dna,并测试pd-l1表达水平(rna-seq,log2-计数)和启动子甲基化(阵列)。五个cpg位点(即cpg1-cpg5)中的两个显示与pd-l1rna表达成反向关联的差异甲基化模式。参见图1。第一个cpg位点,即cpg1,在图1中表示为最左侧的cpg位点,发现该位点位于tss上游预测的pd-l1启动子位点。第二个cpg位点,即cpg5,在图1中表示为最右侧的cpg位点,位于内含子1内。绘制cpg1-5中每个的平均β值相对于其在cd274转录本nm_014143中位置的热图,其伴随的表达热图位于基因座9p24.1中pd-l1启动子图的右侧。图1显示了测试的每个细胞系的pd-l1启动子区表达和甲基化热图。热图通过pd-l1rna表达由高(红色)至低(绿色)分选。发现具有高pd-l1表达的细胞系甲基化较低(蓝色)。分析来自癌基因组图集(tcga3.0)的肿瘤数据,以进一步研究pd-l1表达(rna-seq,log2-计数)与dna甲基化(阵列,平均m值cpg1&cpg5)之间的相关性。包括四个集合的肿瘤:肺腺癌(luad)、肺鳞状细胞癌(lusc)、乳腺癌(brca)和皮肤癌(skcm)。在这些患者肿瘤分析中也观察到rna表达与甲基化之间的反向关联:luad=-0.33,lusc=-0.38,brca=-0.4,skcm=-0.25。将肿瘤样品进一步分亚组并通过cd8a表达(rna-seq,中位数截止值)着色,以便通过每个肿瘤中免疫浸润的量进一步解析pd-l1表达。具有较高cd8a表达的肿瘤倾向于具有较高的pd-l1表达和较低的pd-l1启动子甲基化。参见图2a(肺腺癌)、2b(肺鳞状细胞癌)、2c(乳腺癌)和2d(皮肤癌)。进一步分析了检测pd-l1表达水平和启动子甲基化(参见图1)的选择数量的nsclc细胞系,以研究体外pd-l1启动子甲基化与pd-l1表达之间的关系。基于cpg1和cpg5的平均甲基化水平选择用于进一步分析的细胞系。细胞系h661、lxfl529和a427被分类为在cpg1和cpg5具有高的平均甲基化水平;细胞系h2073和h322t被分类为在cpg1和cpg5具有中等的平均甲基化水平;细胞系h1993被分类为在cpg1和cpg5具有低的平均甲基化水平。来自每个细胞系的细胞暴露于以下五种情况之一:(1)无处理;(2)用1mm5-阿扎胞苷-dc(5-aza-dc,dna去甲基化剂)处理;(3)用0.1mm曲古抑菌素a(tsa,i类和ii类哺乳动物组蛋白脱乙酰酶)处理;(4)用1ng/ml干扰素γ(ifng)处理;或(5)用5-aza-dc、tsa和ifng的组合处理。然后通过qrt-pcr测量pd-l1rna表达。如图3所示,在5-aza-dc处理3天后,h661、lxfl529、a427和h322t中pd-l1rna表达增加。只有h322t表现出在tsa处理后pd-l1rna表达的增加。使用5-aza-dc、tsa和ifng的组合处理导致在除了h1993(即在cpg1和cpg5具有低的平均甲基化水平的细胞系)以外的所有系中pd-l1表达增加。h1933已经表现出高水平的基线pd-l1表达。选择四种细胞系,即a427(其中cpg1和cpg5具有高水平的甲基化);h322t(其中cpg1和cpg5具有中等水平的甲基化,且其中pd-l1表达可通过用ifng处理诱导;h292(其中cpg1和cpg5具有低水平的甲基化);和h358(其中cpg1和cpg5具有低水平的甲基化)用于实验,以进一步研究在存在和不存在ifng时pd-l1rna和蛋白表达的关系。当用ifng刺激时,a427、h322t、h292和h358表现出pd-l1rna诱导增加,这与其原始的基础表达无关。参见图4a。在不存在ifng时以低水平表达pd-l1rna的a427和h292显示对ifng刺激的反应不同,其中a427保持低水平(在0.0122-dct),而h292显示增加的rna水平(0.1022-dct)。在h322t细胞系中观察到pd-l1rna表达的最大变化,从0.018增加到1.3562-dct。已经显示高水平的基线pd-l1表达和在cpg1和cpg5上低的甲基化水平的h358细胞系,在刺激后rna表达没有显著变化。在细胞系的该亚型中,在基线和ifng刺激后,pd-l1蛋白表达与rna表达的关系不密切。通过facs分析,a427仍然几乎没有显示高于背景的表达,其中标准化的中位荧光强度(nmfi)为20。h322t也显示低水平的pd-l1表达(nmfi为107)。参见图4a。h292显示显著更高的蛋白表达,其中nmfi为1580,h358表现出最高的基线表达(nmfi为4204)。在ifng处理后,所有四种细胞系显示增加的表面pd-l1蛋白水平。在a427细胞系中,pd-l1蛋白表达仍然低。在h292和h358细胞系中,pd-l1蛋白表达增加了3-4倍,而在h322t中,与基线水平相比,pd-l1蛋白表达增加了48倍以上。相比之下,ifng处理后a427中的pd-l1蛋白水平增加至h322t中见到的处理前水平。h322t中ifng处理显示pd-l1蛋白表达是高度可诱导的。如上所述,h322t中pd-l1蛋白的基线水平低。相比之下,ifng处理后h322t中的pd-l1蛋白水平与ifng处理后的h292和h358中的pd-l1蛋白水平相当。接下来,在a427、h322t、h292和h358中进行westernblot以确定ifng/jak/stat信号传导通路在ifng介导的pd-l1转录本和蛋白质水平的诱导中是否起作用。简言之,来自a427、h322t、h292和h358的细胞或者(a)未经处理;(b)用ifng处理30分钟;或者(c)用ifng处理24小时。然后将细胞加工成蛋白质裂解物并在凝胶上电泳,用以下抗体印迹和检测:(1)抗磷酸化stat1;(2)抗全stat1;(3)抗磷酸化stat3-y705;(4)抗磷酸stat3-s727;(5)抗全stat3;和(6)β-肌动蛋白(加载对照)。所有四种细胞系显示出ifng刺激后强的p-stat1活化,仅在h358中观察到基础p-stat1。参见图4b。p-stat3-y705是stat3的初始活化位点,其在h292(ifng处理30分钟后)和h358中被组成型活化,但在h358中在ifng刺激24小时后消失。stat3被在s727的mtor和mapk通路进一步活化。在所有细胞系中在24小时均观察到jak/stat信号传导通路的活化,除了h358细胞,其在刺激之前和之后的早期和晚期时间点上均未显示p-stat3-s727活化。这些结果表明jak/stat通路(包括stat1通路)在所有测试的四种细胞系中均有活性。接下来,使用sirna在a427和h358中研究了pd-l1启动子甲基化与ifng/jak/stat通路之间的关系。如上所述,cpg1和cpg5在a427中具有低水平的甲基化,并且a427在基线和ifng刺激后显示低至无的pd-l1蛋白表达。相比之下,cpg1和cpg5在h358中具有低水平的甲基化,且h358在基线时表现出高的pd-l1蛋白表达,ifng刺激后增加。为了确定在甲基化背景下哪个stat对pd-l1表达最为重要,给予来自每个细胞系的细胞(1)无sirna;(2)加扰对照;(3)sistat1;(4)sistat3;(5)ifng或(6)sistat1、sistat3和ifng。a427显示出与处理无关的无pd-l1表达,尽管用ifng刺激后强烈诱导了活化的stat1和stat3。参见图4c。无甲基化的h358细胞显示出基础组成型pd-l1表达,其被ifng刺激进一步诱导。sistat3进一步降低pd-l1的基础表达。sistat1和sistat3都敲低了pd-l1表达,使其接近基线,而ifng和两种sirna的组合显示出最少的pd-l1表达量,尽管用sirna干扰同时进行刺激。这些结果表明,尽管ifng/jak/stat1或ifng/jak/stat3活化,pd-l1启动子的甲基化阻断了pd-l1表达。这些结果还表明,stat1和stat3都是ifng刺激的pd-l1表达所必需的,stat3也似乎对于pd-l1基础表达是部分必需的。接下来,将亚硫酸氢盐测序数据叠加到代表所有三种pd-l1启动子甲基化类型(即,高、中等、低甲基化水平)的外周血单核细胞(pbmc)亚型、永生化正常肺细胞系和nsclc肺细胞系的可能cpg甲基化位点的图上。在图5a和5b中,mut2/cpg1和mut7/cpg5在红色框内。在肿瘤患者中作为免疫浸润被发现的各种pbmc亚组中看到很少至无甲基化。参见图5a。正常肺细胞系在这些位点也没有显示甲基化。参见图5a和5b。在高水平表达pd-l1的细胞系h358和h1993在cpg1和5处没有显示甲基化。参见图5b。显示低的但可诱导的基线pd-l1表达的细胞系h322t和h2073在两个cpg位点显示出部分甲基化。参见图5b。显示具有低的基线pd-l1表达的a427在cpg1和cpg5上表现出高水平的甲基化。因为在pbmc亚型和正常肝细胞系中在cpg1和cpg5上很少或没有甲基化,因此在患者的全肿瘤样品中检测到的pd-l1启动子区的甲基化应主要来自肿瘤细胞,而不是来自任何样品中的其它细胞亚型。使用来自癌基因组计划(cgp)的nsclc细胞系产生直接比较x轴上的平滑cpg1和cpg5甲基化(m值)和y轴上的pd-l1表达(rna-seq,log2-计数)的散点图。如图6a所示,数据具有高度反向相关的关系,pearson相关系数为-0.7。这些细胞系中的pd-l1基线表达受到启动子甲基化水平的高度影响。然后将图6a中分析的cgp细胞系分为三个甲基化组:(1)低(即在cpg1和cpg5上均为低至无甲基化)、(2)中等(即cpg1或cpg5位点甲基化)或(3)高的(cpg1和cpg5二者上的甲基化)。将这些组绘制在x轴上,通过rna-seq的基础pd-l1表达绘制在y上并显示每组的表达中位数。anova分析显示针对各组在pd-l1表达上高度的统计学相关性。组(1)(即低的)具有最高的pd-l1表达中位数,其中组(2)(即中等)和组(3)(即高的)甲基化组显示较低的pd-l1表达中位数。参见图6b。这些数据表明基础pd-l1表达由cpg1或cpg5上的启动子甲基化水平反向调节,也由甲基化的cpg位点数反向调节。然后用5-aza-dc处理cpgnsclc细胞系组中的细胞系,以使全面去甲基化在具有更多数量细胞系的数据集中对pd-l1表达具有影响。pd-l1表达显著诱导。只有组(3)(即高的)细胞系显示显著诱导甲基化抑制的pd-l1表达。参见图6c。另外,已知在该组中的两个细胞系,h1993(低的)和h2073(中等的),是从一个患者的两个分开的样品中获得的。在5-aza-dc处理后,h1993显示pd-l1表达没有显著变化,而h2073在pd-l1启动子去甲基化后显示出显著的pd-l1表达诱导。参见图6d。这些结果表明,pd-l1甲基化可能是影响pd-l1表达的驱动因素,因为在cpg1和cpg5上具有不同甲基化模式的不同细胞系源自相同的患者。适应性免疫是一种过程,通过该过程免疫浸润通过从活化的t细胞释放的ifng和其它因子活化和上调肿瘤中的免疫检查点蛋白(如pd-l1)。上述实验的结果表明,该pd-l1活化在具有cpg1和/或cpg5上高水平的甲基化的细胞系中被阻断。分析了人nsclc肿瘤样品的集合,以检测活化的t细胞浸润(cd8a基因表达,fluidigm)和肿瘤细胞在cpg5上的pd-l1启动子甲基化(也称为mut7)。如图7a和7b所示,仅具有低cpg5/mut7甲基化的高度浸润的肿瘤样品通过ihc(蛋白质,参见图7a)和通过qrt-pcr(rna,参见图7b)显示高的pd-l1肿瘤细胞表达。低或无浸润的肿瘤或具有高cpg5甲基化的肿瘤均显示低的pd-l1蛋白和rna表达。在这些nsclc患者的肿瘤样品中,通过活化的t细胞浸润上调的肿瘤细胞pd-l1仍被cpg5上的启动子甲基化阻断。接下来,进行实验以确定cpg1和cpg5上的cpg甲基化是否可以物理阻断stat1和/或stat3与pd-l1启动子区(cpg1)和内含子1(cpg5)的结合。在pd-l1启动子中的cpg1附近已知有两个stat结合基序。如上所述,将上述a427(即甲基化的)和h358(即无甲基化的)细胞系生长几乎至融合,然后用对照缓冲液或ifnγ刺激。第二天早晨,将细胞分成两个等分试样,第一个用于亚硫酸氢盐测序,第二个用于chip-seq以评估stat1和stat3结合。亚硫酸氢盐测序证实了两种细胞系的甲基化状态,在两种细胞系之间观察到差异的结合模式,如通过macspeakcalling的显著峰分析所表示的。chip-seq实验的结果作为.bed文件示于图8,其显示在igv整合基因组查看器(broadinstitute)中。在图8中,顶部的bed文件包含在pd-l1启动子区和内含子1中发现的cpg坐标。cpg1和cpg5被标记。第二bed文件包含pd-l1启动子区中已知stat结合基序的坐标。第三bed文件包含pd-l1/cd274的hg19序列和基因结构。第4-11bed文件(编号1-8)是在nsclc细胞系a427和h358中、从stat1和stat3的chip-seq实验下游产生的macs显著结合文件。有或没有ifnγ刺激,甲基化的a427细胞系均显示不结合任一stat蛋白。参见表4。这些结果表明,a427中cpg1和可能的cpg5的甲基化完全阻断了stat1和stat3与pd-l1启动子中cpg1附近的stat结合基序的结合。无刺激的h358显示不结合stat1,但是在ifnγ刺激后stat1显示与pd-l1启动子结合。参见表4。h358细胞系与刺激无关地结合stat3。参见表4。如前所述,h358已经具有非常高的基础水平的pd-l1rna表达,这些结果表明stat3转录因子可能是该细胞系中高水平基础pd-l1表达的驱动。表4:pd-l1启动子中cpg1附近的stat1和stat3的结合样品#细胞系pd-l1启动子上的甲基化刺激chip结合1a427高对照stat1不结合2a427高ifnγstat1不结合3a427高对照stat3不结合4a427高ifnγstat3不结合5h358低对照stat1不结合6h358低ifnγstat1结合7h358低对照stat3结合8h358低ifnγstat3结合提供前述实施例仅用于说明目的,并不意图以任何方式限制本发明的范围。除了本文所示和所述之外,从前述描述中本发明的各种修改对于本领域技术人员而言将变得显而易见,并且落在所附权利要求的范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- Sept9基因启动子甲基化检测引物探针体系及其试剂盒的制作方法
- Tmem176a基因启动子区dna甲基化检测的制作方法
- 类固醇生成因子1sf-1启动子区高甲基化作为宫内发育迟缓的分子标记及其应用
- 可用于检测与2型糖尿病相关的ptpn1基因启动子区甲基化程度的试剂盒及其应用
- 可用于检测与2型糖尿病相关的glud1基因启动子区甲基化程度的试剂盒及其应用
- 基于焦磷酸测序技术的mgmt基因启动子甲基化检测的制作方法
- 一种用于分析dna样本中mlh1启动子甲基化状态的试剂盒、方法和引物的制作方法
- Mgmt基因启动子甲基化检测试剂和方法
- 基因启动子甲基化的检测方法
- 抑癌基因启动子甲基化检测在口腔白斑癌变评估中的应用的制作方法
- Mlh1基因启动子甲基化检测引物探针体系及其试剂盒的制作方法
- Sept9基因启动子甲基化检测引物探针体系及其试剂盒的制作方法
- Tmem176a基因启动子区dna甲基化检测的制作方法
- 一种检测转基因CaMV35S启动子的电极的制备方法及用图
- 类固醇生成因子1sf-1启动子区高甲基化作为宫内发育迟缓的分子标记及其应用
- 可用于检测与2型糖尿病相关的ptpn1基因启动子区甲基化程度的试剂盒及其应用
- 可用于检测与2型糖尿病相关的glud1基因启动子区甲基化程度的试剂盒及其应用
- 基于焦磷酸测序技术的mgmt基因启动子甲基化检测的制作方法
- 一种用于分析dna样本中mlh1启动子甲基化状态的试剂盒、方法和引物的制作方法
- Mgmt基因启动子甲基化检测试剂和方法
- Mgmt基因启动子甲基化检测引物探针体系及其试剂盒的制作方法
- Tmem176a基因启动子区dna甲基化检测的制作方法
- 可用于检测与喉癌相关的shisa3基因启动子区甲基化程度的试剂盒及其应用
- 可用于检测与喉癌相关的esrrg基因启动子区甲基化程度的试剂盒及其应用
- 用于检测与肺癌相关的shox2基因启动子区甲基化程度的试剂盒的制作方法
- 可用于检测与2型糖尿病相关的ptpn1基因启动子区甲基化程度的试剂盒及其应用
- 可用于检测与2型糖尿病相关的glud1基因启动子区甲基化程度的试剂盒及其应用
- 基于焦磷酸测序技术的mgmt基因启动子甲基化检测的制作方法
- 一种用于分析dna样本中mlh1启动子甲基化状态的试剂盒、方法和引物的制作方法
- 一种检测癌症相关dna甲基化的试剂盒及应用