非免疫原性单结构域抗体的制作方法
相关申请
本申请要求于2015年1月21日提交的美国临时申请号62/106,035的权益,所述美国临时申请的内容通过引用以其整体并入本文。
发明领域
本发明一般地涉及在人或人源化单结构域抗体片段(sdab)内的修饰,所述修饰阻止通过预先存在的抗体的识别,涉及包括这些修饰的经分离的多肽及其方法和用途。
序列表的引入
于2016年1月20日创建且大小为10.0kb的名称为“inhi018001wo_st25”的文本文件的内容,通过引用以其整体并入本文。
发明背景
生物治疗剂的临床免疫原性可以限制功效并且促成不利事件。细胞和体液免疫原性两者在临床环境中都可以是有问题的。衍生自非人来源的抗体中最常观察到的免疫原性或其威胁已导致广泛的蛋白质工程和平台创新,以减轻潜在的免疫原性。这些包括人源化、人工程化(humaneering)、贴面化(veneering)和全人抗体平台的开发。然而,即使全人抗体和抗体片段也具有免疫原性的风险。免疫原性通常指向抗体的cdr区。相反,也观察到构架区定向的免疫原性,如单结构域抗体的情况。已注意到相当一部分人具有预先存在的针对单结构域抗体内的隐蔽表位的抗体。因此,存在生成非免疫原性单结构域抗体的需要。
发明概述
本发明的经修饰的单结构域抗体(sdab)片段可以衍生自许多来源,包括但不限于vhh、vnar、工程化vh或vk结构域。vhh可以由仅骆驼科重链抗体及其文库生成。vnar可以由仅软骨鱼类重链抗体及其文库生成。已实施了从常规异源二聚体vh和vk结构域生成单体sdab的各种方法,包括界面工程和特定种系家族的选择。在优选的实施方案中,本发明的经修饰的sdab是人或人源化的。
预先存在的抗人单结构域抗体(sdab)抗体(asda)最普遍以这样的形式观察到,其中sdab被定位使得其具有游离羧基末端。本发明提供了在人或人源化sdab区域内的突变,所述突变使asda识别失效。在本发明的一些实施方案中,sdab在构架1区(fw1)内被改变或修饰。在其他实施方案中,sdab在构架2区(fw2)内被改变或修饰。在其他实施方案中,sdab在构架3区(fw3)内被改变或修饰。在其他实施方案中,sdab在构架4区(fw4)内被改变或修饰。这些修饰包括突变、截短、延伸或其组合。在一些实施方案中,sdab在单个区域内被修饰。在其他实施方案中,sdab在多于一个区域处被修饰。例如,sdab可以在构架1和构架4内被修饰。本发明的sdab修饰使asda识别失效,而不显著降低蛋白质的结合亲和力、特异性、表达能力或稳定性。本文使用的所有编号均指kabat编号。
下文显示了与人vh羧基末端残基(leu/thr108、val109、thr110、val111、ser112、ser113;lvtvss)比对的sdab的构架4的示例性修饰:
108lvtvss113(天然人vh序列,seqidno:58)
108lveik112(seqidno:1)
108lvtve112(seqidno:2)
108lvtvse113(seqidno:3)
108lvtveg113(seqidno:4)
108lvtvseg114(seqidno:5)
108lvtvk112(seqidno:6)
108lvtvs112(seqidno:7)
108lvtvsk113(seqidno:8)
108lvtvkg113(seqidno:9)
108lvtvskg114(seqidno:10)
108lvtvskpg115(seqid:no30)
108lvtvskpgg116(seqid:no31)
108lvtvkp113(seqid:no32)
108lvtvkpg114(seqid:no33)
108lvtvkpgg115(seqid:no34)
108lvtvrp113(seqid:no35)
108lvtvrpg114(seqid:no36)
108lvtvrpgg115(seqid:no37)
108lvtvep113(seqid:no38)
108lvtvepg114(seqid:no39)
108lvtvepgg115(seqid:no40)
108lvtvdp113(seqid:no41)
108lvtvdpg114(seqid:no42)
108lvtvdpgg115(seqid:no43)
108evtvss113(seqidno:11)
108kvtvss113(seqidno:12)
108lvevss113(seqidno:13)
108lvkvss113(seqidno:14)
108evevss113(seqidno:15)
108evkvss113(seqidno:16)
108kvkvss113(seqidno:17)
108kvevss113(seqidno:18)。
下文显示了与人vh羧基末端残基(leu/thr108、val109、thr110、val111、ser112、ser113;lvtvss)比对的对于sdab的示例性羧基末端延伸:
108lvtvss113(天然人vh序列,seqidno:58)
108lvtvssa114(seqidno:19)
108lvtvssg114(seqidno:20)
108lvtvssgg115(seqidno:21)
108lvtvssggg116(seqidno:22)
108lvtvssgggg117(seqidno:23)。
在一些实施方案中,sdab在构架1内的位置leu11处被修饰。例如,在位置leu11处的修饰是leu11lys(l11k)、leu11arg(l11r)、leu11glu(l11e)或leu11asp(l11d)。在一些实施方案中,sdab在位置leu11并且在其羧基末端区域内被修饰。例如l11k、l11r、l11e或l11d并且包含tve、tvse(seqidno:24)、tveg(seqidno:25)、tvseg(seqidno:26)、tvk、tvsk(seqidno:27)、tvkg(seqidno:28)、tvskg(seqidno:29)、tvskpg(seqidno:44)、tvskpgg(seqidno:45)、tvkp(seqidno:46)、tvkpg(seqidno:47)、tvkpgg(seqidno:48)、tvrp(seqidno:49)、tvrpg(seqidno:50)、tvrpgg(seqidno:51)、tvep(seqidno:52)、tvepg(seqidno:53)、tvepgg(seqidno:54)、tvdp(seqidno:55)、tvdpg(seqidno:56)、或tvdpgg(seqidno:57)的末端序列。
在一些实施方案中,sdab在位置11处被带正电荷的残基修饰(例如l11k或l11r),并且与在位置112或113处含有带负电荷的残基的羧基末端修饰配对。例如,l11k或l11r与tve、tvse(seqidno:24)、tveg(seqidno:25)、tvseg(seqidno:26)、tvep(seqidno:52)、tvepg(seqidno:53)、tvepgg(seqidno:54)、tvdp(seqidno:55)、tvdpg(seqidno:56)、或tvdpgg(seqidno:57)的羧基末端修饰配对。
在一些实施方案中,sdab在位置11处被带负电荷的残基修饰(例如l11e或l11d),并且与在位置112或113处含有带正电荷的残基的羧基末端修饰配对。例如,l11e或l11d与tvk、tvsk(seqidno:27)、tvkg(seqidno:28)、tvskg(seqidno:29)、tvskpg(seqidno:44)、tvskpgg(seqidno:45)、tvkp(seqidno:46)、tvkpg(seqidno:47)、tvkpgg(seqidno:48)、tvrp(seqidno:49)、tvrpg(seqidno:50)、或tvrpgg(seqidno:51)的羧基末端修饰配对。
在一些实施方案中,sdab在位置11处被带正电荷的残基修饰(例如l11k或l11r),并且与在位置112或113处含有带正电荷的残基的羧基末端修饰配对。例如,l11k或l11r与tvk、tvsk(seqidno:27)、tvkg(seqidno:28)、tvskg(seqidno:29)、tvskpg(seqidno:44)、tvskpgg(seqidno:45)、tvkp(seqidno:46)、tvkpg(seqidno:47)、tvkpgg(seqidno:48)、tvrp(seqidno:49)、tvrpg(seqidno:50)、或tvrpgg(seqidno:51)的羧基末端修饰配对。
在一些实施方案中,sdab在位置11处被带负电荷的残基修饰(例如l11e或l11d),并且与在位置112或113处含有带负电荷的残基的羧基末端修饰配对。例如,l11e或l11d与tve、tvse(seqidno:24)、tveg(seqidno:25)、tvseg(seqidno:26)、tvep(seqidno:52)、tvepg(seqidno:53)、tvepgg(seqidno:54)、tvdp(seqidno:55)、tvdpg(seqidno:56)、或tvdpgg(seqidno:57)的羧基末端修饰配对。
据推测,在其中存在引入sdab的位置11和112或位置11和113内的带相反电荷的残基的实施方案中,新添加的负电荷和正电荷能产生许新的静电相互作用。据推测,在其中在位置11和112或位置11和113处引入的残基具有相同电荷的实施方案中,这些氨基酸的这些侧面的定位会彼此远离,然而,其仍能够阻断是经修饰的sdab的预先存在的asda识别的识别位点。
在一些实施方案中,sdab在构架3内的位置ala88处被修饰。例如,在位置ala88处的修饰是ala88glu(a88e)、ala88asp(a88d)、ala88lys(a88k)或ala88arg(a88r)。在一些实施方案中,sdab在位置ala88并且在其羧基末端区域内被修饰。例如a88e、a88d、a88k或a88r并且包含tve、tvse(seqidno:24)、tveg(seqidno:25)、tvseg(seqidno:26)、tvk、tvsk(seqidno:27)、tvkg(seqidno:28)、tvskg(seqidno:29)、tvskpg(seqidno:44)、tvskpgg(seqidno:45)、tvkp(seqidno:46)、tvkpg(seqidno:47)、tvkpgg(seqidno:48)、tvrp(seqidno:49)、tvrpg(seqidno:50)、tvrpgg(seqidno:51)、tvep(seqidno:52)、tvepg(seqidno:53)、tvepgg(seqidno:54)、tvdp(seqidno:55)、tvdpg(seqidno:56)、或tvdpgg(seqidno:57)的末端序列。
在一些实施方案中,sdab在leu11和ala88被修饰。例如,l11e/a88e、l11e/a88d、l11e/a88k、l11e/a88r、l11d/a88e、l11d/a88d、l11d/a88k、l11d/a88r、l11k/a88e、l11k/a88d、l11k/a88k、l11k/a88r、l11r/a88e、l11r/a88d、l11r/a88k或l11r/a88r。在一些实施方案中,sdab在位置leu11和ala88被修饰,并且与经修饰的羧基末端区域配对。例如,l11e/a88e、l11e/a88d、l11e/a88k、l11e/a88r、l11d/a88e、l11d/a88d、l11d/a88k、l11d/a88r、l11k/a88e、l11k/a88d、l11k/a88k、l11k/a88r、l11r/a88e、l11r/a88d、l11r/a88k或l11r/a88r并且包含tve、tvse(seqidno:24)、tveg(seqidno:25)、tvseg(seqidno:26)、tvk、tvsk(seqidno:27)、tvkg(seqidno:28)、tvskg(seqidno:29)、tvskpg(seqidno:44)、tvskpgg(seqidno:45)、tvkp(seqidno:46)、tvkpg(seqidno:47)、tvkpgg(seqidno:48)、tvrp(seqidno:49)、tvrpg(seqidno:50)、tvrpgg(seqidno:51)、tvep(seqidno:52)、tvepg(seqidno:53)、tvepgg(seqidno:54)、tvdp(seqidno:55)、tvdpg(seqidno:56)、或tvdpgg(seqidno:57)的末端序列。
附图简述
图1是vh结构域的结构模型的示意图,其将经修饰以阻止asda识别的示例性位置突出显示。
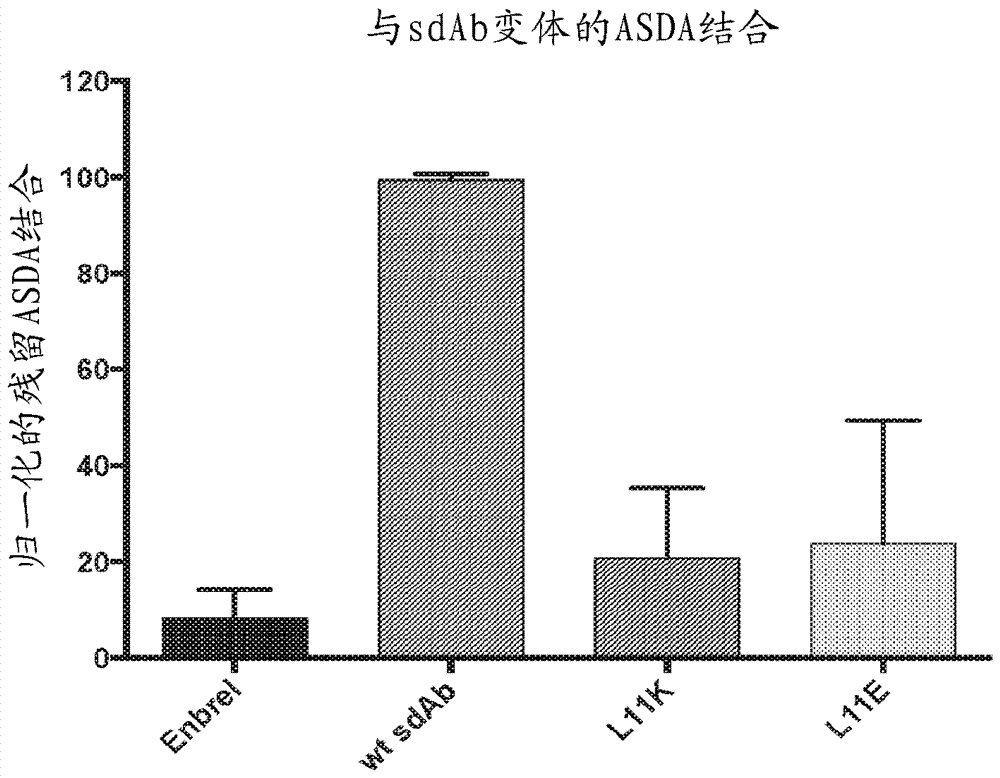
图2是asda测定的图,其证实免疫原性sdab的各种示例性修饰对asda识别的影响。包括enbrel(tnfr2-fc)作为非asda识别对照。c末端延伸由天然末端残基和延伸开始之间的“.”指示。c末端截短由在排除残基的位点处的“_”指示。
图3a和3b是asda测定的一系列图,其证实免疫原性sdab的各种修饰对asda识别的影响。包括enbrel(tnfr2-fc)作为非asda识别对照。
图4是asda测定的图,其证实asda识别中的免疫原性sdab的各种修饰的影响。包括enbrel(tnfr2-fc)作为非asda识别对照。本文构架1修饰与构架4修饰组合。
图5a和5b是间接asda测定的一系列图,其证实与在l11处未修饰并具有天然羧基末端序列tvss的人源化vhh相比,具有与羧基末端tvkpgg配对的l11e的人源化vhh的双重修饰的影响。
发明详述
单结构域抗体(sdab)是由能够选择性结合特异性抗原的单个单体可变抗体结构域组成的抗体片段。参见例如hamers-casterman,c.,等人,“naturallyoccurringantibodiesdevoidoflightchains,”naturevol.363:446-448(1993);nguyen,v.k.,等人,“camelheavy-chainantibodies:diversegermlinev(h)handspecificmechanismsenlargetheantigen-bindingrepertoire,”embo,第19卷:921-30(2000);achour,i.,等人,“tetramericandhomodimericcamelidiggsoriginatefromthesameighlocus,”j.immunol.,第181卷:2001–2009(2008);harmsen,等人,“llamaheavy-chainvregionsconsistofatleastfourdistinctsubfamiliesrevealingnovelsequencefeatures,”mol.immunol.,第37卷:579–590(2000);arbabighahroudi,m.,等人,“selectionandidentificationofsingledomainantibodyfragmentsfromcamelheavy-chainantibodies,”febslett.第414卷:521–526(1997);和vincke等人,“generalstrategytohumanizeacamelidsingle-domainantibodyandidentificationofauniversalhumanizednanobodyscaffold,”j.biol.chem.,第284(5)卷:3273-84(2009),其各自的内容在此通过引用以其整体并入本文)。
仅具有12-15kda的分子量,单结构域抗体比由两条重蛋白质链和两条轻链组成的一般抗体(150-160kda)小得多,并且甚至比fab片段(~50kda,一条轻链和一半重链)和单链可变片段(~25kda,两个可变结构域,一个来自轻链并且一个来自重链)更小。
单结构域抗体是其互补决定区是单结构域多肽的部分的抗体。实例包括但不限于重链抗体、天然缺乏轻链的抗体、衍生自常规4链抗体的单结构域抗体、工程抗体和除衍生自抗体的那些外的单结构域支架。单结构域抗体可以衍生自任何物种,包括但不限于小鼠、人、骆驼、美洲驼、山羊、兔和/或牛。在一些实施方案中,如本文使用的单结构域抗体是天然存在的单结构域抗体,称为缺乏轻链的重链抗体。出于清楚的原因,衍生自天然缺乏轻链的重链抗体的该可变结构域在本文中称为vhh,以将其与四链免疫球蛋白的常规vh区分开。这样的vhh分子可以衍生自骆驼科物种中产生的抗体,所述骆驼科物种例如骆驼、美洲驼、单峰骆驼、羊驼和原驼。除骆驼科之外的其他物种可以产生天然缺乏轻链的重链抗体;这样的vhh在本发明的范围内。
可以通过用所需抗原免疫单峰骆驼、骆驼、美洲驼、羊驼或鲨鱼,并且随后分离编码重链抗体的mrna,来获得单结构域抗体。通过逆转录和聚合酶链反应,产生了含有数百万个克隆的单结构域抗体的基因文库。筛选技术如噬菌体展示和核糖体展示帮助鉴定结合抗原的克隆。(参见例如,arbabighahroudi,m.;desmyter,a.;等人(1997).“selectionandidentificationofsingledomainantibodyfragmentsfromcamelheavy-chainantibodies”.febsletters414(3):521–526.)。
不同的方法使用来自未被预先免疫的动物的基因文库。这样的首次用于实验的文库通常仅含有对所需抗原具有低亲和力的抗体,使得有必要应用通过随机诱变的亲和力成熟作为附加步骤。(saerens,d.;等人(2008).“single-domainantibodiesasbuildingblocksfornoveltherapeutics”.currentopinioninpharmacology8(5):600–608.)。
当已鉴定出最有效的克隆时,优化其dna序列,例如以改善其针对酶的稳定性。另一个目标是人源化以阻止人机体针对抗体的免疫反应。由于骆驼科vhh和人vh片段之间的同源性,人源化是没有问题的。(参见例如,saerens,等人,(2008).“single-domainantibodiesasbuildingblocksfornoveltherapeutics”.currentopinioninpharmacology8(5):600–608.)最后一步是在大肠杆菌(e.coli)、酿酒酵母(saccharomycescerevisiae)或其他合适的生物中翻译优化的单结构域抗体。
单结构域抗体片段也衍生自常规抗体。在一些实施方案中,单结构域抗体可以由具有四条链的常见鼠或人igg制备。(holt,l.j.;等人(2003).“domainantibodies:proteinsfortherapy”.trendsinbiotechnology21(11):484–490.)。该方法是相似的,包括来自免疫或首次用于实验供体的基因文库和展示技术用于鉴定最具特异性的抗原。这种方法的一个问题是一般igg的结合区由两个结构域(vh和vl)组成,由于其亲油性,所述结合区倾向于二聚化或聚集。单体化通常通过用亲水氨基酸代替亲脂氨基酸来实现,但通常导致对抗原的亲和力丧失。(参见例如,borrebaeck,c.a.k.;ohlin,m.(2002).“antibodyevolutionbeyondnature”.naturebiotechnology20(12):1189–90.)如果可以保留亲和力,则同样可以在大肠杆菌、酿酒酵母或其他生物中产生单结构域抗体。
不管生产方法如何,本文所述的人或人源化单结构域抗体片段内的修饰可用于任何单结构域抗体片段。
本发明提供了包含至少一种突变的单结构域抗体(sbab)或其抗原结合片段,所述至少一种突变阻止通过特异性识别单结构域抗体的抗体来识别sbab。在一些实施方案中,突变是构架区中的至少一种突变。
在一些实施方案中,突变是至少一种构架4突变。在一些实施方案中,构架4突变包含选自seqidno:1-18或30-43的氨基酸序列。
在一些实施方案中,突变是羧基末端氨基酸延伸。在一些实施方案中,羧基末端氨基酸延伸包含选自seqidno:19-23的氨基酸序列。
在一些实施方案中,突变是至少一种构架1突变。在一些实施方案中,构架1突变包含在位置leu11处的突变。在一些实施方案中,在位置leu11处的突变是leu11lys(l11k)、leu11arg(l11r)、leu11asp(l11d)或leu11glu(l11e)。在一些实施方案中,单结构域抗体进一步包含在羧基末端中的突变。在一些实施方案中,在羧基末端中的突变包含选自seqidno:24-29或30-43的氨基酸序列。在一些实施方案中,构架1区包含leu11lys(l11k),并且在羧基末端中的突变包含选自tve、tvse(seqidno:24)、tveg(seqidno:25)、tvseg(seqidno:26)、tvep(seqidno:52)、tvepg(seqidno:53)、tvepgg(seqidno:54)、tvdp(seqidno:55)、tvdpg(seqidno:56)、和tvdpgg(seqidno:57)的氨基酸序列。在一些实施方案中,构架1区包含leu11glu(l11e),并且在羧基末端中的突变包含选自tvk、tvsk(seqidno:27)、tvkg(seqidno:28)、tvskg(seqidno:29)、tvskpg(seqidno:44)、tvskpgg(seqidno:45)、tvkp(seqidno:46)、tvkpg(seqidno:47)、tvkpgg(seqidno:48)、tvrp(seqidno:49)、tvrpg(seqidno:50)、和tvrpgg(seqidno:51)的氨基酸序列。
在一些实施方案中,突变是至少一种构架3突变。在一些实施方案中,构架3突变包含在位置ala88处的突变。在一些实施方案中,在位置ala88处的突变是ala88glu(a88e)、ala88asp(a88d)、ala88arg(a88r)或ala88lys(a88k)。在一些实施方案中,单结构域抗体进一步包含在羧基末端中的突变。在一些实施方案中,在羧基末端中的突变包含选自seqidno:24-29和44-57的氨基酸序列。在一些实施方案中,构架3区包含ala88glu(a88e),并且在羧基末端中的突变包含选自tvk、tvsk(seqidno:27)、tvkg(seqidno:28)、tvskg(seqidno:29)、tvskpg(seqidno:44)、tvskpgg(seqidno:45)、tvkp(seqidno:46)、tvkpg(seqidno:47)、tvkpgg(seqidno:48)、tvrp(seqidno:49)、tvrpg(seqidno:50)、和tvrpgg(seqidno:51)的氨基酸序列。在一些实施方案中,构架3区包含ala88lys(a88k),并且在羧基末端中的突变包含选自tve、tvse(seqidno:24)、tveg(seqidno:25)、tvseg(seqidno:26)、tvep(seqidno:52)、tvepg(seqidno:53)、tvepgg(seqidno:54)、tvdp(seqidno:55)、tvdpg(seqidno:56)、和tvdpgg(seqidno:57)的氨基酸序列。
在本说明书中提及的所有专利和出版物通过引用并入本文,其程度如同每个独立专利和出版物被特别且个别地指出通过引用并入。
定义
除非另有定义,否则与本发明结合的科学和技术术语应具有本领域普通技术人员通常理解的含义。此外,除非上下文另有要求,否则单数术语应包括复数,并且复数术语应包括单数。一般地,与本文所述的细胞和组织培养、分子生物学以及蛋白质和寡核苷酸或多核苷酸化学和杂交结合利用的命名法和技术是本领域众所周知和常用的那些。标准技术用于重组dna、寡核苷酸合成以及组织培养和转化(例如电穿孔、脂转染)。酶反应和纯化技术根据制造商的说明书、或者如本领域通常实现的或如本文所述的执行。前述技术和程序一般根据本领域众所周知的常规方法,并且如本说明书自始至终引用和讨论的各种一般和更具体的参考文献中所述的执行。参见例如sambrook等人molecularcloning:alaboratorymanual(第2版,coldspringharborlaboratorypress,coldspringharbor,n.y.(1989))。与本文所述的分析化学、合成有机化学以及药物和药物化学结合利用的命名法以及实验室程序和技术是本领域众所周知和通常使用的那些。标准技术用于化学合成、化学分析、药物制剂、制剂和递送以及患者的治疗。
如根据本发明利用的,除非另有说明,否则下述术语应理解为具有下述含义:
如本文使用的,“特异性结合”或“与……免疫反应”或“针对”意指抗体与所需抗原的一种或多种抗原决定簇反应,并且不与其他多肽反应或以低得多的亲和力结合(kd>10-6)。抗体包括但不限于多克隆、单克隆、嵌合、dab(结构域抗体)、单链、fab、fab'和f(ab’)2片段、fv、scfv、fab表达文库和单结构域抗体(sdab)片段,例如vhh、vnar、工程改造的vh或vk。
术语“抗原结合位点”或“结合部分”指参与抗原结合的免疫球蛋白分子的部分。抗原结合位点由重(“h”)和轻(“l”)链的n端可变(“v”)区的氨基酸残基形成。被称为“高变区”的重链和轻链的v区内的三个趋异段插入称为“构架区”或“fr”的更保守的侧翼段之间。因此,术语“fr”指在免疫球蛋白中的高变区之间天然发现且邻近高变区的氨基酸序列。在抗体分子中,轻链的三个高变区和重链的三个高变区在三维空间中相对于彼此排列,以形成抗原结合表面。抗原结合表面与结合抗原的三维表面互补,并且重链和轻链各自的三个高变区被称为“互补决定区”或“cdr”。对每个结构域的氨基酸指定根据kabatsequencesofproteinsofimmunologicalinterest(nationalinstitutesofhealth,bethesda,md.(1987和1991)),或chothia&leskj.mol.biol.196:901-917(1987),chothia等人nature342:878-883(1989)的定义。
如本文使用的,术语“表位”包括能够与免疫球蛋白或其片段或t细胞受体特异性结合/通过免疫球蛋白或其片段或t细胞受体特异性结合的任何蛋白质决定簇。术语“表位”包括能够与免疫球蛋白或t细胞受体特异性结合/通过免疫球蛋白或t细胞受体特异性结合的蛋白质决定簇。表位决定簇通常由分子例如氨基酸或糖侧链的化学活性表面分子基团组成,并且通常具有特定的三维结构特征以及特定的电荷特征。当解离常数≤1µm;例如≤100nm,优选≤10nm且更优选≤1nm时,抗体被视为特异性结合抗原。
如本文使用的,术语“免疫结合”和“免疫结合性质”指在免疫球蛋白分子和免疫球蛋白对其特异性的抗原之间发生的非共价相互作用类型。免疫结合相互作用的强度或亲和力可以依据相互作用的解离常数(kd)表示,其中较小的kd代表更大的亲和力。可以使用本领域众所周知的方法来定量所选多肽的免疫结合性质。一种这样的方法需要测量抗原结合位点/抗原复合物形成和解离的速率,其中这些速率取决于复合配偶体的浓度、相互作用的亲和力以及同样影响在两个方向中的速率的几何参数。因此,“结合速率常数”(kon)和“解离速率常数”(koff)两者均可以通过计算浓度以及结合和解离的实际速率来确定。(参见nature361:186-87(1993))。koff/kon的比率使得能够消除与亲和力无关的所有参数,并且等于解离常数kd。(一般参见davies等人(1990)annualrevbiochem59:439-473)。如通过测定例如放射性配体结合测定、表面等离子体共振(spr)、流式细胞术结合测定或本领域技术人员已知的类似测定测量的,当平衡结合常数(kd)≤1μm,优选≤100nm,更优选≤10nm,且最优选≤100pm至约1pm时,本发明的抗体被视为特异性结合抗原。
如应用于多肽时,术语“基本同一性”意指当通过使用缺省缺口权重的程序gap或bestfit最佳比对时,两个肽序列共享至少80百分比的序列同一性,优选至少90百分比的序列同一性,更优选至少95百分比的序列同一性,且最优选至少99百分比的序列同一性。
优选地,不相同的残基位置因保守氨基酸取代而不同。
保守氨基酸取代指具有相似侧链的残基的可互换性。例如,具有脂肪族侧链的一组氨基酸是甘氨酸、丙氨酸、缬氨酸、亮氨酸和异亮氨酸;具有脂肪族-羟基侧链的一组氨基酸是丝氨酸和苏氨酸;具有含酰胺侧链的一组氨基酸是天冬酰胺和谷氨酰胺;具有芳香族侧链的一组氨基酸是苯丙氨酸、酪氨酸和色氨酸;具有碱性侧链的一组氨基酸是赖氨酸、精氨酸和组氨酸;并且具有含硫侧链的一组氨基酸是半胱氨酸和甲硫氨酸。优选的保守氨基酸取代基是:缬氨酸-亮氨酸-异亮氨酸、苯丙氨酸-酪氨酸、赖氨酸-精氨酸、丙氨酸缬氨酸、谷氨酸-天冬氨酸和天冬酰胺-谷氨酰胺。
如本文所讨论的,抗体或免疫球蛋白分子的氨基酸序列中的微小变化被视为由本发明包含,条件是氨基酸序列中的变化维持至少75%,更优选至少80%、90%、95%,且最优选99%。特别地,考虑了保守的氨基酸替代。保守替代是在其侧链中相关的氨基酸家族内发生的那些。遗传编码的氨基酸一般分成下述家族:(1)酸性氨基酸是天冬氨酸、谷氨酸;(2)碱性氨基酸是赖氨酸、精氨酸、组氨酸;(3)非极性氨基酸是丙氨酸、缬氨酸、亮氨酸、异亮氨酸、脯氨酸、苯丙氨酸、甲硫氨酸、色氨酸,以及(4)不带电的极性氨基酸是甘氨酸、天冬酰胺、谷氨酰胺、半胱氨酸、丝氨酸、苏氨酸、酪氨酸。亲水性氨基酸包括精氨酸、天冬酰胺、天冬氨酸、谷氨酰胺、谷氨酸、组氨酸、赖氨酸、丝氨酸和苏氨酸。疏水性氨基酸包括丙氨酸、半胱氨酸、异亮氨酸、亮氨酸、甲硫氨酸、苯丙氨酸、脯氨酸、色氨酸、酪氨酸和缬氨酸。氨基酸的其他家族包括(i)丝氨酸和苏氨酸,其为脂肪族-羟基家族;(ii)天冬酰胺和谷氨酰胺,其为含酰胺的家族;(iii)丙氨酸、缬氨酸、亮氨酸和异亮氨酸,其为脂肪族家族;和(iv)苯丙氨酸、色氨酸和酪氨酸,其为芳香族家族。例如,合理地预期亮氨酸由异亮氨酸或缬氨酸、天冬氨酸由谷氨酸、苏氨酸由丝氨酸的分开替代,或者氨基酸由结构相关氨基酸的类似替代不具有对所得到的分子的结合或性质的较大影响,尤其是如果替代不涉及构架位点内的氨基酸。氨基酸变化是否导致功能肽可以通过测定多肽衍生物的比活性来容易地确定。本文详细描述了测定。抗体或免疫球蛋白分子的片段或类似物可以由本领域普通技术人员容易地制备。片段或类似物的优选氨基和羧基末端在功能结构域的边界附近出现。可以通过核苷酸和/或氨基酸序列数据与公共或专有序列数据库的比较来鉴定结构和功能结构域。优选地,将计算机化比较方法用于鉴定在已知结构和/或功能的其他蛋白质中出现的序列基序或预测的蛋白质构象结构域。鉴定折叠成已知三维结构的蛋白质序列的方法是已知的。bowie等人science253:164(1991)。因此,前述实例证实本领域技术人员可以识别可用于限定根据本发明的结构和功能结构域的序列基序和结构构象。
优选的氨基酸取代是:(1)降低对蛋白水解的敏感性,(2)降低对氧化的敏感性,(3)改变用于形成蛋白质复合物的结合亲和力,(4)改变结合亲和力,和(4)赋予或修饰此类类似物的其他物理化学或功能性质的那些。类似物可以包括不同于天然存在的肽序列的序列的各种突变蛋白。例如,可以在天然存在的序列中(优选在形成分子间接触的结构域外的多肽部分中)进行单个或多个氨基酸取代(优选保守氨基酸取代)。保守氨基酸取代不应基本上改变亲本序列的结构特征(例如,替代氨基酸不应倾向于破坏在亲本序列中出现的螺旋,或破坏表征亲本序列的其他类型的二级结构)。本领域公认的多肽二级结构和三级结构的实例在proteins,structuresandmolecularprinciples(creighton,编辑,w.h.freemanandcompany,newyork(1984));introductiontoproteinstructure(c.branden和j.tooze,编辑,garlandpublishing,newyork,n.y.(1991));以及thornton等人nature354:105(1991)中描述。
如本文使用的,术语“多肽片段”指具有氨基末端和/或羧基末端缺失的多肽,但其中剩余氨基酸序列与例如从全长cdna序列推导的天然存在序列中的相应位置相同。片段通常长至少5、6、8或10个氨基酸,优选长至少14个氨基酸,更优选长至少20个氨基酸,通常长至少50个氨基酸,且甚至更优选长至少70个氨基酸。
在本发明中,“包含(comprises)”、“包含(comprising)”、“含有”、“具有”等等可以具有美国专利法中的含义,并且可以意指“包括(includes)”、“包括(including)”等等;术语“基本上由……组成”或“基本上组成”同样具有美国专利法中的含义,并且这些术语是开放性的,允许多于所述的那种的存在,只要所列举的基本的或新颖的特征不被多于所列举的存在改变,但排除现有技术实施例。
“片段”意指多肽或核酸分子的一部分。该部分优选含有参考核酸分子或多肽的整个长度的至少10%、20%、30%、40%、50%、60%、70%、80%或90%。片段可以含有10、20、30、40、50、60、70、80、90、或100、200、300、400、500、600、700、800、900或1000个核苷酸或氨基酸。
本文提供的范围被理解为在该范围内的所有值的速记。例如,1至50的范围被理解为包括由1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49或50组成的任何数目、数目组合或子范围。
除非明确说明或由上下文显而易见,否则如本文使用的,术语“一个”、“一种”和“该/所述”被理解为单数或复数。除非明确说明或由上下文显而易见,否则如本文使用的,术语“或”被理解为包含性的。
除非明确说明或由上下文显而易见,否则如本文使用的,术语“约”被理解为在本领域的正常容许范围内,例如在平均值的2个标准差内。约可以理解为在所述值的10%、9%、8%、7%、6%、5%、4%、3%、2%、1%、0.5%、0.1%、0.05%或0.01%内。除非由上下文显而易见,否则本文提供的所有数值均由术语“约”修饰。
实施例
直接抗单结构域抗体(asda)检测测定可用于确定来自人供体的血清中的预先存在的asda。一般地,可以通过elisa鉴定人血清内的预先存在的抗体,其中将sdab固定在平板上并且用bsa阻断。然后使人血清(纯的或在pbs+0.01%tween-20中稀释的)与板结合的sdab一起温育。洗掉未结合的血清igg,并且使用抗人igκ和抗人igλhrp缀合的抗体两者检测针对sdab的任何剩余抗体。
间接asda测定可用于分析给定sdab的多种变体,以便测量sdab特异性血清抗体反应性。间接asda涉及sdab的固定并且用bsa阻断。然后使人血清(纯的或在pbs+0.01%tween-20中稀释的)与可溶性sdab(相同的sdab或具有本发明修饰[突变、截短或延伸]的亲本sdab的变体)一起预温育,然后加入与板结合的sdab中。可溶性sdab变体阻断固定化sdab的asda识别的能力指示可溶性sdab被asda识别,并且因此是预先存在的asda应答的间接测量。相反,可溶性sdab不能阻止固定化sdab的asda识别指示可溶性sdab变体是非免疫原性的,或以其他方式未被预先存在的asda识别。一般地,使用先前确定为含有asda的分开供体的血清平行进行8-16个测定。
在本文提供的研究中,使用asda测定评估免疫原性sdab的各种示例性修饰。有时包括enbrel(tnfr2-fc)和bsa作为非asda识别的对照。在一些实验中,将纯化的血清igg包被作为第二抗体的阳性对照。c末端延伸由天然末端残基和延伸开始之间的“.”指示。c末端截短由在排除残基的位点处的“_”指示。结果显示于图2-4中。
间接asda测定证实与在l11处未修饰并具有天然羧基末端序列tvss的人源化vhh相比,具有与羧基末端tvkpgg配对的l11e的人源化vhh的双重修饰的影响(图5a-5b)。
其他实施方案
虽然本发明已与其详细描述结合进行描述,但前述描述预期举例说明而不是限制由所附权利要求的范围限定的本发明的范围。其他方面、优点和修饰在下述的范围内。
- 还没有人留言评论。精彩留言会获得点赞!