基于多个基因诊断胃癌患者的检测试剂盒的制作方法
本发明涉及生物
技术领域:
,具体涉及一种基于多个基因诊断胃癌患者的检测试剂盒。
背景技术:
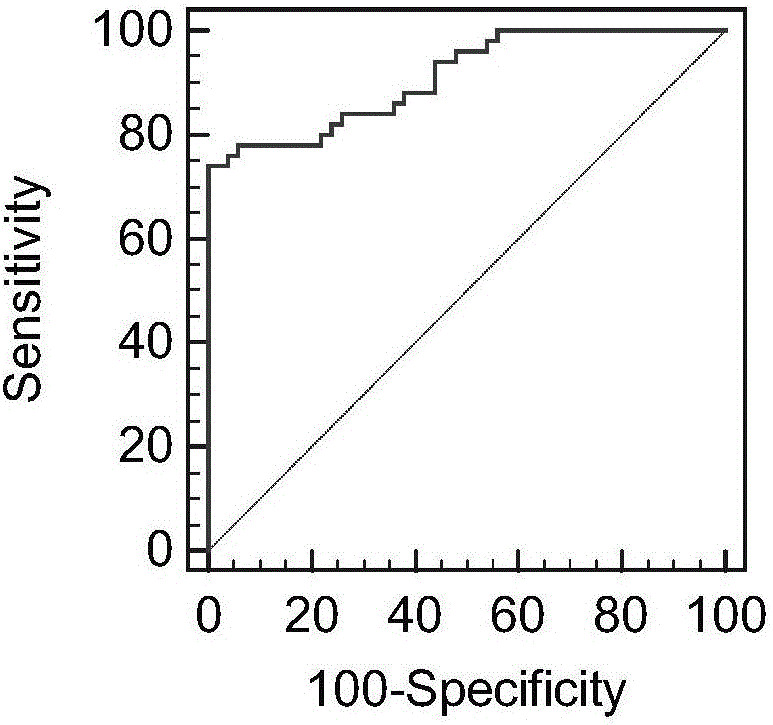
:在我国,消化道系统肿瘤的发病率排在第一位,其中最高的是胃癌。全球每年胃癌发病人数约为87万,我国就有30多万。1962年日本胃癌研究会正式提出早期胃癌(EGC)的概念,这是胃癌诊断和治疗一个里程碑的事件,由于早期胃癌概念的提出,使得胃癌达到临床治愈、获得长期存活成为可能。历经半个世纪的研究与诊治工作,对于早期胃癌的认识也逐步深入,对早期胃癌的诊断也得以逐渐精细,特别是近年来,对于早期胃癌治疗的指导思想由原来的片面追求根治效果延长生存期转变为不仅要求有长期的存活率,更要求在微创的情况下获得根治,保证术后病人有良好的生活质量,所以精准的早期诊断使其治疗手段也更趋于个体化。目前在我国早期胃癌的诊断率仍不足10%,而日本则高达50%~70%,开发胃癌早期诊断方法,提高早期胃癌的诊断率,使胃癌病人能够早期得到合适的治疗,是当前从事胃癌诊断产品开发企业的重要任务。目前,在包括体液如血液、尿液、唾液、支气管液、痰液、腹膜灌洗液和粪便等提取物在内的生物标本中的特异性癌症相关标记物的鉴定能提供有价值的癌症早期诊断方法,以便早期治疗并改善预后。特异性癌症标记物还能提供用于监测疾病进展的方法,从而能跟踪外科手术、放射治疗和化学治疗的功效。然而,对于许多主要癌症,可利用的标记物缺乏足够的敏感性和特异性。例如,用于胃癌的最常用标记物CA19-9、CA72-4和癌胚抗原(CEA)仅检测到大约15-50%的任何阶段的胃肿瘤,对于疾病早期的检测则降至大约2-11%。因此,出现假阴性检测的频率非常高,这导致患者和健康护理工作者认为不存在疾病,而事实上,患者可能患有严重的需要立即注意的癌症。而且,使用这些标记物可能对高达1/3的患有良性胃疾病个体给出假阳性信号。因此,有效的胃癌早期诊断生物标志物是迫切需要的。在散发性胃癌的发病中,表遗传学改变比遗传学改变占有更重要的地位。近20年的研究发现,作为表遗传学的重要组成部分,表观遗传学(epigenetics)是研究转录前基因在染色质水平的结构修饰对基因功能的影响,这种修饰可通过细胞分裂和增殖周期进行传递,并适当的调控基因转录表达,以保证细胞进行正常的增殖-分化-成熟-衰老的发育进程。长期以来,人们一直认为肿瘤的发生是基因突变累积的结果,然而近年随着表观遗传学的研究进展,已越来越清楚地发现表观遗传机制在肿瘤的发生中起着非常重要的作用。表观遗传修饰包括DNA甲基化修饰、组蛋白修饰和染色体印迹等。而DNA甲基化是肿瘤中最常见的分子改变之一,CpG岛甲基化导致抑癌基因失活是引起细胞恶化的重要步骤。以种系特异性基因为例:体细胞中需要保持永久关闭的关键基因在胚胎干细胞中被甲基化,然而一旦甲基化丢失则将导致细胞的去分化,并向着肿瘤相关的表型发展,如果抑癌基因再发生高甲基化或/和基因突变,则导致肿瘤的形成。DNA甲基化改变调控基因表达、与肿瘤的发生发展密切相关的概念是人类基因组计划完成之后,表观遗传学研究的一个重要的成果。DNA甲基化是基因表达调控的一种中间形式,最可能的调控作用是通过抑制关键基因的表达,从而决定该细胞的命运,如对于肿瘤细胞中DNA甲基化异常现象的研究已经在多种肿瘤中取得了许多重大的进展。哺乳动物中,甲基化仅影响DNA链上鸟嘌呤前的胞嘧啶(CpG)。正常细胞中CpG双核苷酸的甲基化分布并不均一,大约50%的基因在启动子区域有CpG集中分布的CpG岛存在,长度从0.5~2kb不等,该区域与基因的转录调控有着密切关系。人体某些基因调控区域的CpG岛甲基化在相关癌细胞组织中频繁出现,显示出与某些肿瘤的发病、病程进展和预后、用药敏感性等相关。迄今为止,已在大多数人类肿瘤中发现了基因甲基化异常。研究发现在癌细胞中表观遗传编码发生紊乱,首先表现在DNA甲基化水平紊乱,又称为甲基化重排,即促进增殖的基因低甲基化、高表达;促进细胞分化的基因高甲基化、低表达;DNA甲基化转移酶家族(DNMTfamily)高表达。癌症中甲基化重排涉及的基因包括:细胞周期调控基因、DNA修复基因、血管形成基因、细胞凋亡相关基因、细胞黏附迁移相关基因、激素受体基因、核转录因子、酶类等等。通过对DNA甲基化修饰的研究,有可能为肿瘤发病机制的阐明、肿瘤早期诊断和治疗开辟新的有效途径,达到肿瘤治疗的目的。由于CpG岛的局部高度甲基化早于细胞的恶性增生,因此,甲基化的诊断可以用于肿瘤发生的早期预测。技术实现要素:本发明的目的是提供一种检测p16、CDH1、MGMT、RARB和RNF180基因及其片段的甲基化的试剂盒,包括引物探针组合物甲、引物探针组合物乙、引物探针组合物丙、引物探针组合物丁和引物探针组合物戊;引物探针组合物甲包括特异性引物对甲、封闭引物甲和探针甲;引物探针组合物乙包括特异性引物对乙、封闭引物乙和探针乙;引物探针组合物丙包括特异性引物对丙、封闭引物丙和探针丙;引物探针组合物丁包括特异性引物对丁、封闭引物丁和探针丁;引物探针组合物戊包括特异性引物对戊、封闭引物戊和探针戊;引物探针组合物甲为第一引物探针组合物甲或第二引物探针组合物甲;第一引物探针组合物甲中:特异性引物对甲为序列表的序列6所示DNA和序列表的序列7所示DNA组成的引物对,封闭引物甲的核苷酸序列如序列表的序列8所示,探针甲的核苷酸序列如序列表的序列9所示;第二引物探针组合物甲中:特异性引物对甲为序列表的序列10所示DNA和序列表的序列11所示DNA组成的引物对,封闭引物甲的核苷酸序列如序列表的序列12所示,探针甲的核苷酸序列如序列表的序列13所示;引物探针组合物乙为第三引物探针组合物乙或第四引物探针组合物乙;第三引物探针组合物乙中:特异性引物对乙为序列表的序列14所示DNA和序列表的序列15所示DNA组成的引物对,封闭引物乙的核苷酸序列如序列表的序列16所示,探针乙的核苷酸序列如序列表的序列17所示;第四引物探针组合物乙中:特异性引物对乙为序列表的序列18所示DNA和序列表的序列19所示DNA组成的引物对,封闭引物乙的核苷酸序列如序列表的序列20所示,探针乙的核苷酸序列如序列表的序列21所示;引物探针组合物丙为第五引物探针组合物丙或第六引物探针组合物丙;第五引物探针组合物丙中:特异性引物对丙为序列表的序列22所示DNA和序列表的序列23所示DNA组成的引物对,封闭引物丙的核苷酸序列如序列表的序列24所示,探针丙的核苷酸序列如序列表的序列25所示;第六引物探针组合物丙中:特异性引物对丙为序列表的序列26所示DNA和序列表的序列27所示DNA组成的引物对,封闭引物丙的核苷酸序列如序列表的序列28所示,探针丙的核苷酸序列如序列表的序列29所示;引物探针组合物丁为第七引物探针组合物丁或第八引物探针组合物丁;第七引物探针组合物丁中:特异性引物对丁为序列表的序列30所示DNA和序列表的序列31所示DNA组成的引物对,封闭引物丁的核苷酸序列如序列表的序列32所示,探针丁的核苷酸序列如序列表的序列33所示;第八引物探针组合物丁中:特异性引物对丁为序列表的序列34所示DNA和序列表的序列35所示DNA组成的引物对,封闭引物丁的核苷酸序列如序列表的序列36所示,探针丁的核苷酸序列如序列表的序列37所示;引物探针组合物戊为第九引物探针组合物戊或第十引物探针组合物戊;第九引物探针组合物戊中:特异性引物对戊为序列表的序列38所示DNA和序列表的序列39所示DNA组成的引物对,封闭引物戊的核苷酸序列如序列表的序列40所示,探针戊的核苷酸序列如序列表的序列41所示;第十引物探针组合物戊中:特异性引物对戊为序列表的序列42所示DNA和序列表的序列43所示DNA组成的引物对,封闭引物戊的核苷酸序列如序列表的序列44所示,探针戊的核苷酸序列如序列表的序列45所示。需要说明的是,引物探针组合物甲用于检测p16基因核酸序列的甲基化,引物探针组合物乙用于检测CDH1基因核酸序列的甲基化,引物探针组合物丙用于检测MGMT基因核酸序列的甲基化,引物探针组合物丁用于检测RARB基因核酸序列的甲基化,引物探针组合物戊用于检测RNF180基因核酸序列的甲基化,不同的引物探针组合物分别检测对应基因靶区域核酸序列中至少一段核酸序列的甲基化;其中,靶区域分别选自序列表的序列1所示、序列表的序列2所示、序列表的序列3所示、序列表的序列4所示和序列表的序列5所示的序列中的连续的至少15个碱基长度的片段;核酸序列分别等同、互补或杂交于上述靶区域。试剂盒中,每种引物探针组合物均可以单独包装。试剂盒还包括针对内参基因的内参引物和内参探针,内参基因为ACTB(NCBI基因库序列号:NM_001101.3)和/或GSTP1(NCBI基因库序列号:NM_000852.3)。内参基因ACTB的内参引物对为序列表的序列46所示DNA和序列表的序列47所示DNA组成的引物对;内参基因ACTB的内参探针的核苷酸序列如序列表的序列48所示;内参基因GSTP1的内参引物对为序列表的序列49所示DNA和序列表的序列50所示DNA组成的引物对;内参基因GSTP1的内参探针的核苷酸序列如序列表的序列51所示。本发明的目的还在于提供一种用于诊断胃癌患者的试剂盒,包括如下五个引物探针组合物中的至少一种:引物探针组合物甲、引物探针组合物乙、引物探针组合物丙、引物探针组合物丁和引物探针组合物戊,不同的引物探针组合物包括的引物对、封闭引物和探针分别同上述的引物探针组合物。也就是说,引物探针组合物甲、引物探针组合物乙、引物探针组合物丙、引物探针组合物丁和引物探针组合物戊可以分别检测p16、CDH1、MGMT、RARB和RNF180基因及其片段的甲基化,五种甲基化结果共同用于诊断是否为胃癌患者;当然,也可以挑选引物探针组合物甲、引物探针组合物乙、引物探针组合物丙、引物探针组合物丁和引物探针组合物戊中的一种、两种、三种或四种引物探针组合物分别检测对应的基因及其片段的甲基化,根据一种、两种、三种或四种甲基化结果来诊断是否为胃癌患者。本发明提供的引物探针组合物甲、引物探针组合物乙、引物探针组合物丙、引物探针组合物丁和引物探针组合物戊(对应十种引物探针组)分别对p16、CDH1、MGMT、RARB和RNF180基因及其片段的甲基化具有较高的特异性,只是五种引物探针组合物联合诊断时的灵敏度最高。试剂盒还包括针对内参基因的内参引物和内参探针,内参基因为ACTB和/或GSTP1,基因序列同上所述,内参基因ACTB和GSTP1的内参引物对同上所述。试剂盒还包括DNA提取试剂和亚硫酸氢盐试剂;DNA提取试剂包括裂解缓冲液、清洗缓冲液和洗脱缓冲液;其中,裂解缓冲液包括蛋白变性剂、去垢剂、pH缓冲剂和核酸酶抑制剂;清洗缓冲液分为清洗缓冲液A和清洗缓冲液B,清洗缓冲液A包括蛋白质变性剂、核酸酶抑制剂、pH缓冲剂、乙醇,清洗缓冲液B包括核酸酶抑制剂、pH缓冲剂、乙醇;洗脱缓冲液包括核酸酶抑制剂和pH缓冲剂;蛋白变性剂选自异硫氰酸胍、盐酸胍和尿素中的一种或几种;去垢剂选自Tween20、Tween40、TritonX-100、NP-40和SDS中的一种或几种;pH缓冲剂选自Tris、硼酸、磷酸盐、MES和HEPES中的一种或几种;核酸酶抑制剂选自EDTA、EGTA和DEPC中的一种或几种;亚硫酸氢盐试剂包括亚硫酸氢盐缓冲液和保护缓冲液;其中,亚硫酸氢盐缓冲液选自重亚硫酸钠、亚硫酸钠、亚硫酸氢钠、亚硫酸氢铵和亚硫酸铵中的一种或几种;保护缓冲液包括氧自由基清除剂,氧自由基清除剂选自对苯二酚、维生素E、维生素E衍生物、没食子酸、Trolox、三羟基苯甲酸和三羟基苯甲酸衍生物中的一种或多种。本发明还保护上述试剂盒在制备检测胃癌产品中的应用。本发明还保护试剂盒检测p16、CDH1、MGMT、RARB和RNF180基因及其片段的甲基化的方法,包括如下步骤:S1:采用DNA提取试剂提取人源样本的DNA;S2:将提取得到的DNA采用亚硫酸氢盐试剂进行处理;S3:以处理后的DNA为模板,采用引物探针组合物和内参基因的内参引物及内参探针进行PCR扩增。人源样本选自细胞系、组织切片、活检组织、石蜡包埋的组织、唾液、痰液、支气管液、胃液、体液、粪便、结肠流出物、尿、血浆、血清、全血和从血液中分离的细胞中的一种或多种。具体地,S1采用DNA提取试剂提取人源样本(如血浆)的DNA包括如下步骤:(1)取1~5ml血浆,加入相同体积的裂解缓冲液,再加入终浓度为10~500mg/L的蛋白酶K和0.01~10μg/mlCarrierRNA,震荡混匀,55℃温育10~30min;(2)加入100μl磁珠,振荡孵育0.5~1小时;(3)用磁分离器吸附磁珠,丢弃上清溶液;(4)加入0.5~2ml清洗缓冲液A重悬磁珠,震荡清洗1min;(5)用磁分离器吸附磁珠,丢弃上清;(6)加入0.5~2ml清洗缓冲液B重悬磁珠,震荡清洗1min;(7)用磁分离器吸附磁珠,丢弃上清溶液;(8)10000rpm快速离心1min,用磁分离器吸附磁珠,去除残余上清溶液;(9)将装有磁珠的离心管开盖放置在55℃的金属浴上,晾干3~10min;(10)加入50~500ul洗脱缓冲液重悬磁珠,放置在65℃金属浴上,震荡洗脱10min;(11)用磁分离器吸附磁珠,取出含有目的DNA的缓冲液,定量DNA,做好标记;(12)洗脱后的DNA存放于4℃冰箱待用,或者保存于-20℃冰箱长期保存。具体地,S2将提取得到的DNA采用亚硫酸氢盐试剂进行处理包括如下步骤:(1)配制亚硫酸氢盐缓冲液,用重亚硫酸钠、亚硫酸铵等配制1~12M缓冲液,根据DNA含量,可以选用不同浓度亚硫酸氢盐缓冲液;(2)配制保护缓冲液,用氧自由基清除剂的一种或者多种配制浓度0.01~5M保护缓冲液,浓度及组分取决于DNA含量及所用样本类型;(3)将100μlDNA溶液(DNA含量10pg~10μg)、200μl亚硫酸氢盐缓冲液和50μl保护液混合,震荡混合均匀;(4)热循环:95℃5min,50℃30min,95℃5min,50℃2h,95℃5min,50℃5h,4℃;(5)将0.5~5mlDNA结合缓冲液加入到亚硫酸氢盐处理后的DNA溶液中,再加入20~200μl磁珠,震荡孵育30min~1h;(6)用磁分离器吸附磁珠,丢弃上清溶液;(7)加入0.5~2ml清洗缓冲液A重悬磁珠,震荡清洗1min;(8)用磁分离器吸附磁珠,丢弃上清;(9)加入0.5~2ml清洗缓冲液B重悬磁珠,震荡清洗1min;(10)用磁分离器吸附磁珠,丢弃上清溶液。(11)10000rpm快速离心1min,用磁分离器吸附磁珠,去除残余上清溶液;(12)将装有磁珠的离心管放置在55℃的金属浴上,开盖晾干3~10min;(13)加入50~500μl洗脱缓冲液重悬磁珠,放置在65℃金属浴上,震荡洗脱10min;(14)用磁分离器吸附磁珠,取出含有目的DNA的缓冲液,定量DNA,做好标记。具体地,S3以处理后的DNA为模板,采用引物探针组合物和内参基因的内参引物及内参探针进行PCR扩增。检测基因为p16、CDH1、MGMT、RARB和RNF180基因,内参基因为ACTB和/或GSTP1。引物探针组合物甲用于检测p16基因核酸序列的甲基化,引物探针组合物乙用于检测CDH1基因核酸序列的甲基化,引物探针组合物丙用于检测MGMT基因核酸序列的甲基化,引物探针组合物丁用于检测RARB基因核酸序列的甲基化,引物探针组合物戊用于检测RNF180基因核酸序列的甲基化。DNA甲基化标志物基因(p16、CDH1、MGMT、RARB和RNF180基因)的探针和内参基因(ACTB、GSTP1基因)的探针5'端报告荧光基团为FAM、JOE、TET、HEX、Cy3、TexasRed、Rox和Cy5中的一种或多种;甲基化基因的探针和内参基因的探针3'端的猝灭基团为BHQ1、BHQ2、TAMRA、DABCYL中一种或多种;甲基化基因的封闭引物3'端修饰集团为C3Spacer、C6Spacer、inverted3'end中的一种或多种。荧光定量PCR扩增反应体系的终浓度组成为:1~10×PCR缓冲液、0.1~1mMdNTPs、0.1~1μM目的基因检测引物、0.1~1μM目的基因荧光探针、0.1~1μM目的基因封闭引物、0.1~1μM内参基因引物、0.1~1μM内参基因荧光探针、0.001~2ng/μl模板DNA、0.01~0.10U/μl热启动TaqDNA聚合酶。dNTPs中包括10mMdATP、10mMdCTP、10mMdTTP和10mMdGTP,PCR缓冲液中包含Tris-HCl、氯化钾、硫酸铵和氯化镁。荧光定量PCR扩增反应的具体过程为:92~97℃预变性5~35分钟,再进行聚合酶链式反应扩增阶段,92~97℃变性10~30s,50~65℃退火延伸10~60s,并进行40~55个循环。p16、CDH1、MGMT、RARB和RNF180基因的甲基化情况是潜在的胃癌(尤其是早期胃癌)诊断、预后评估及疗效监测的有意义的临床指标。本发明对于深入了解早期胃癌的发病机制,认识其发生发展规律,提高我国早期胃癌诊治水平具有重要的价值,也为寻求新的早期胃癌靶向治疗策略奠定基础。本发明提供的试剂盒,可以应用于诊断胃癌,为多发性胃癌的诊断提供了一条快速、可靠、准确的新途径,为疗效观察、微小残留病的动态观察提供依据,本发明将在医学检测领域发挥重要作用。本发明的技术方案中,可以将p16、CDH1、MGMT、RARB或RNF180基因单独进行甲基化检测而进行胃癌筛查,也可以将p16、CDH1、MGMT、RARB和RNF180基因结合在一起进行胃癌筛查,通过将分别检测p16基因、CDH1基因、MGMT基因、RARB基因和RNF180基因及其片段的甲基化核酸序列联合使用,使得胃癌检测的灵敏度和特异性提高,尤其是灵敏度显著提高。单独检测p16的灵敏度为76%及以上、CDH1的灵敏度为77.67%及以上、MGMT的灵敏度为67.33%及以上、RARB的灵敏度为62%及以上,RNF180的灵敏度为72%及以上,当五个标志物基因联合检测时,灵敏度能提高到96%。本发明能够根据实时荧光定量PCR的循环阈值(Ct)来快速、便捷地判断样本是否阳性,提供了一种可以用于快速、准确的检测胃癌的试剂盒。本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。附图说明图1为本发明实施例五中检测血浆中p16基因的ROC曲线;图2为本发明实施例五中检测血浆中CDH1基因的ROC曲线;图3为本发明实施例五中检测血浆中MGMT基因的ROC曲线;图4为本发明实施例五中检测血浆中RARB基因的ROC曲线;图5为本发明实施例五中检测血浆中RNF180基因的ROC曲线;图6为本发明实施例五中检测血浆中联合检测p16、CDH1、MGMT、RARB和RNF180基因的ROC曲线;具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只是作为示例,而不能以此来限制本发明的保护范围。下述实施例中的实验方法,如无特殊说明,均为常规方法。以下实施例中的定量试验,均设置三次重复实验,数据为三次重复实验的平均值或平均值±标准差。下述实施例中所用的试验材料,如无特殊说明,均为自常规生化试剂商店购买得到的。实施例一:DNA提取DNA提取试剂由裂解缓冲液、清洗缓冲液和洗脱缓冲液组成,见表1;裂解缓冲液由蛋白变性剂、去垢剂、pH缓冲剂和核酸酶抑制剂组成;蛋白变性剂为:盐酸胍(购自sigma公司);去垢剂为:Tween20(购自sigma公司);pH缓冲剂为:Tris-HCl(购自阿拉丁公司);核酸酶抑制剂为:EDTA(购自sigma公司)。表1DNA提取所用试剂本实施例以血浆样本(购自北京301医院)为例,提取血浆循环肿瘤DNA,提取方法包括如下步骤:(1)取1ml血浆,加入相同体积的裂解缓冲液,再加入蛋白酶K和CarrierRNA,使其终浓度分别为100mg/L和1μg/ml,震荡混匀,55℃温育30min;(2)加入100μl磁珠,振荡孵育1小时;(3)用磁分离器吸附磁珠,丢弃上清溶液;(4)加入1ml清洗缓冲液A重悬磁珠,震荡清洗1min;(5)用磁分离器吸附磁珠,丢弃上清;(6)加入1ml清洗缓冲液B重悬磁珠,震荡清洗1min;(7)用磁分离器吸附磁珠,丢弃上清溶液;(8)10000rpm快速离心1min,用磁分离器吸附磁珠,去除残余上清溶液;(9)将装有磁珠的离心管开盖放置在55℃的金属浴上,晾干10min;(10)加入100ul洗脱缓冲液重悬磁珠,放置在65℃金属浴上,震荡洗脱10min;(11)用磁分离器吸附磁珠,取出含有目的DNA的缓冲液,定量DNA,做好标记;(12)洗脱后的DNA存放于4℃冰箱待用,或者保存于-20℃冰箱长期保存。实施例二:亚硫酸氢盐处理DNA亚硫酸氢盐处理DNA是采用亚硫酸氢盐试剂进行处理,亚硫酸氢盐试剂由亚硫酸氢盐缓冲液和保护缓冲液组成;亚硫酸氢盐缓冲液为亚硫酸氢钠(购自Sigma公司)和水的混合液体;保护缓冲液为氧自由基清除剂对苯二酚(购自sigma公司)和水的混合液体。蛋白变性剂为盐酸胍(购自sigma公司);pH缓冲剂为Tris-HCl(购自阿拉丁公司);核酸酶抑制剂为EDTA(购自sigma公司)。本实施例试剂配方见表2。表2亚硫酸氢盐处理DNA所用试剂本实施例二以实施例一提取得到的DNA为处理对象,采用亚硫酸氢盐处理DNA,具体方法包括:(1)配制亚硫酸氢盐缓冲液,称取1g亚硫酸氢钠粉末,加水配制成3M缓冲液。(2)配制保护缓冲液,称取1g对苯二酚试剂,加水配置成0.5M保护缓冲液。(3)将100μlDNA溶液(DNA含量100ng)、200μl亚硫酸氢盐缓冲液和50μl保护液混合,震荡混合均匀。(4)热循环:95℃5min,50℃30min,95℃5min,50℃2h,95℃5min,50℃5h,4℃。(5)将1mlDNA结合缓冲液加入到亚硫酸氢盐处理后的DNA溶液中,再加入50μl磁珠,震荡孵育1h。(6)用磁分离器吸附磁珠,丢弃上清溶液。(7)加入0.5ml清洗缓冲液A重悬磁珠,震荡清洗1min。(8)用磁分离器吸附磁珠,丢弃上清。(9)加入0.5ml清洗缓冲液B重悬磁珠,震荡清洗1min。(10)用磁分离器吸附磁珠,丢弃上清溶液。(11)10000rpm快速离心1min,用磁分离器吸附磁珠,去除残余上清溶液。(12)将装有磁珠的离心管放置在55℃的金属浴上,开盖晾干10min。(13)加入50μl洗脱缓冲液重悬磁珠,放置在65℃金属浴上,震荡洗脱10min。(14)用磁分离器吸附磁珠,取出含有目的DNA的缓冲液,定量DNA,做好标记。实施例三:荧光定量PCR检测DNA甲基化本实施例检测基因为p16、CDH1、MGMT、RARB和RNF180基因,内参基因为ACTB。内参基因ACTB的内参引物对为序列表的序列46所示DNA和序列表的序列47所示DNA组成的引物对;内参基因ACTB的内参探针的核苷酸序列如序列表的序列48所示。本实施例是采用实施例二经过亚硫酸氢盐处理后的DNA为模板进行PCR扩增。荧光定量PCR扩增反应体系的终浓度组成为:1×PCR缓冲液(购自NEB公司)、0.5mMdNTPs(购自NEB公司)、0.5μM目的基因检测引物、0.2μM目的基因荧光探针、1μM目的基因封闭引物、0.3μM内参基因引物、0.3μM内参基因荧光探针、2ng/μl模板DNA、0.10U/μl热启动TaqDNA聚合酶(购自NEB公司)。引物和探针均购自上海生工公司,dNTPs中包括10mMdATP、10mMdCTP、10mMdTTP和10mMdGTP,PCR缓冲液中包含50mMTris-HCl、20mM氯化钾、10mM硫酸铵和2mM氯化镁。荧光定量PCR扩增反应的具体过程为:95℃预变性10分钟,再进行聚合酶链式反应扩增阶段,95℃变性10s,60℃退火延伸60s,并进行50个循环。待测DNA样品、阴性质控品、阳性质控品和无模板对照均进行3个复孔(平行样)检测,PCR仪孔板加样布局见下表。表中PC代表阳性质控品(PositiveControl),NC代表阴性质控品(NegativeControl),NTC代表无模板对照(Notemplatecontrol),S代表检测样本(sample)。表3PCR反应加样布局表123456789101112APCPCPCS6S6S6BNCNCNCS7S7S7CNTCNTCNTCS8S8S8DS1S1S1S9S9S9ES2S2S2S10S10S10FS3S3S3S11S11S11GS4S4S4S12S12S12HS5S5S5S13S13S13实施例四:引物、探针封和闭引物筛选对于p16、CDH1、MGMT、RARB和RNF180基因,可以设计很多套引物和探针的组合,而每一套探针引物组合的性能可能存在差别,所以需要通过实验进行筛选。DNA甲基化标志物基因的探针和内参基因的探针5'端报告荧光基团为FAM、JOE、TET、HEX、Cy3、TexasRed、Rox、Cy5中的一种或多种;甲基化基因的探针和内参基因的探针3'端的猝灭基团为BHQ1、BHQ2、TAMRA、DABCYL中一种或多种。甲基化基因的封闭引物3'端修饰集团为C3Spacer、C6Spacer、inverted3'end中的一种或多种。本发明使用HeavyMethyl的方法检测基因甲基化,所以除了设计普通Taqman引物和探针外,还设计了封闭引物,封闭引物3’-OH引入化学修饰,DNA聚合酶无法扩增,因此用封闭引物结合到样本中没有发生甲基化的模板上,阻止其扩增,提高检测反应的特异性。本实施例中,用人工处理的甲基化和非甲基化模板对p16、CDH1、MGMT、RARB和RNF180基因的引物和探针进行筛选。具体步骤如下:设计p16、CDH1、MGMT、RARB和RNF180的各种引物和探针,只要其分别能等同于、互补于或杂交于序列表的序列1所示、序列表的序列2所示、序列表的序列3所示、序列表的序列4所示和序列表的序列5所示的序列的至少15个核苷酸及其互补序列;再用人工合成的甲基化和非甲基化核酸序列做为模板验证引物和探针的有效性;最后通过PCR扩增结果筛选出以下10套最佳的引物和探针组合:引物和探针组1(扩增甲基化p16基因)引物1:SEQIDNO6:5’-AGTAGCGTTCGTATTTTTTTTATTCG-3’引物2:SEQIDNO7:5’-AAAAACAACATAAAACCTTCGACT-3封闭引物:SEQIDNO8:5’-ATTTTTTTTATTTGATTTTGGGTTGTGGTTGTGGT-C3-3’探针:SEQIDNO9:FAM-5’-CTAACCACGACCGCGACCCGAAATCG-BHQ1-3’引物和探针组2(扩增甲基化p16基因)引物1:SEQIDNO10:5’-CGTCGTTCGTTGTTTGTTTTTT-3’引物2:SEQIDNO11:5’-AACTAACTAATCACCAAAA-3’封闭引物:SEQIDNO12:5’-GTTTGTTTTTTTTTTTTTTGTAGTTGTTGAGTGTATGTG-C3-3’探针:SEQIDNO13:FAM-5’-CGAACCGCGTACGCTCGACGACTACG-BHQ1-3’引物和探针组3(扩增甲基化CDH1基因)引物1:SEQIDNO14:5’-GTGGGCGGGTCGTTAGTTTC-3’引物2:SEQIDNO15:5’-CGCTAATTAACTAAAAATTCACCTACCG-3’封闭引物:SEQIDNO16:5’-AATTCACCTACCAACCACAACCAATCAACAACACAAA-C3-3’探针:SEQIDNO17:5’-JOE-TTCGCGTTGTTGATTGG-MGB-3’引物和探针组4(扩增甲基化CDH1基因)引物1:SEQIDNO18:5’-TTTTAGTTCGGTTCGATTCGATCG-3’引物2:SEQIDNO19:5’-CGGCTCCAAAAACCCATAACTAAC-3’封闭引物:SEQIDNO20:5’-TGATTTGATTGTATTTGGTGTTTGTTTTTGTTTGGTGTTTTTG-C3-3’探针:SEQIDNO21:5’-JOE-CGAAAACGCCGAACGAAAACAAACGCCG-BHQ1-3’引物和探针组5(扩增甲基化MGMT基因)引物1:SEQIDNO22:5’-GCGTTTCGACGTTCGTAGGT-3’引物2:SEQIDNO23:5’-CACTCTTCCGAAAACGAAACG-3’封闭引物:SEQIDNO24:5’-TGTTTGTAGGTTTTTGTGGTGTGTATTGTTTGTGAT-C3-3’探针:SEQIDNO25:5’-TexasRed-CGCAAACGATACGCACCGCGA-BHQ2-3’引物和探针组6(扩增甲基化MGMT基因)引物1:SEQIDNO26:5’-GGGTAGCGGCGTTGTCGGAGGATT-3’引物2:SEQIDNO27:5’-CGACGACGCCGAACCTAAAAC-3’封闭引物:SEQIDNO28:5’-TGTTGTTGGAGGATTAGGGTTGGTGTGTTGGTGTTTAGTG-C3-3’探针:SEQIDNO29:5’-TexasRed-CGCATCCTCGCTAAACGCCGACACGCCG-BHQ2-3’引物和探针组7(扩增甲基化RARB基因)引物1:SEQIDNO30:5’-ATGTCGAGAACGCGAGCGATTCG-3’引物2:SEQIDNO31:5’-GCAAAAAGCCTTCCGAATGCGTTC-3’封闭引物:SEQIDNO32:5’-CCAAATACATTCCAAATCCTACCCCAACAATACCCAA-C3-3’探针:SEQIDNO33:5’-Cy5-TTGGGTATCGTCGGGGTA-BHQ3-3’引物和探针组8(扩增甲基化RARB基因)引物1:SEQIDNO34:5’-GGCGAGGCGGTGGGCG-3’引物2:SEQIDNO35:5’-GCAAAAAGCCTTCCGAATGCGTTC-3’封闭引物:SEQIDNO36:5’-TGGTGGGTGGGAGGTGAGTGGGTGTAGGTGGAATATTG-C3-3’探针:SEQIDNO37:5’-Cy5-CGATATTCCGCCTACGCCCGCTCG-BHQ3-3’引物和探针组9(扩增甲基化RNF180基因)引物1:SEQIDNO38:5’-AGTTTTTAGAGTTTGGTTGTTGG-3’引物2:SEQIDNO39:5’-ACCTTTACCTATATCCACGTCC-3’封闭引物:SEQIDNO40:5’-GGTTGTTGGTGGTTGGGAGTGTTGGGATGGGGTGTGAAGTTG-C3-3’探针:SEQIDNO41:5’-FAM-CGACTTCGCGCCCCGTCCCGACGCTCCCG-BHQ1-3’引物和探针组10(扩增甲基化RNF180基因)引物1:SEQIDNO42:5’-CGAGTAGGGTCGTTGGTTGTGG-3’引物2:SEQIDNO43:5’-CGAACTATACCTACAACCCCGAC-3’封闭引物:SEQIDNO44:5’-TGTTGGTTGTGGTGGGTGAGTGTTGGGGTGTTATGTTTG-C3-3’探针:SEQIDNO45:5’-FAM-CGCGACCTCGAACGTAACGCCCCGACG-BHQ1-3’实验结果证明引物和探针的设计是合理的,10组引物和探针均能区分甲基化和非甲基化模板,分别可以作为检测p16、CDH1、MGMT、RARB和RNF180基因甲基化的引物和探针,检测Ct值见表4,其中“No”表示“NoCt”。虽然不同的引物和探针组合效果略有不同,但是以上引物和探针分别适用于p16、CDH1、MGMT、RARB和RNF180基因的甲基化检测。表4不同组合物检测甲基化和非甲基化模板的Ct值均值组1组2组3组4组5组6组7组8组9组10甲基化模板35.3235.7637.2836.7737.5637.9336.3436.8534.5434.77非甲基化模板NoNoNoNoNoNoNoNoNoNo采用不同癌症患者和正常人DNA作为模板进一步筛选引物和探针组合物。将5例胃癌、5例肺癌、2例肝癌和5例正常人的血浆样本(购自北京301医院)采用实施例一的DNA提取方法提取DNA,然后采用实施例二的方法,采用亚硫酸氢盐处理DNA模板,利用上述10组引物和探针,采用实施例三的方法进行荧光定量PCR实验。分别测得癌症样本和正常人样本的各种甲基化基因Ct值,具体见表5。表5不同组合物检测癌症和正常人样本的Ct值组1组2组3组4组5组6组7组8组9组10胃癌136.5636.7839.2338.4938.7938.7740.7140.7236.1538.8胃癌237.1337.3138.9939.4138.4238.0840.7139.7737.5837.26胃癌337.2337.4540.1139.5938.738.6539.6940.0138.6338.53胃癌436.2236.5938.4539.3939.1838.2240.2740.8538.6737.59胃癌536.8337.0239.7338.5538.3439.8340.8840.8338.1736.22肺癌143.6545.8846.8647.7447.56NoNo47.14No44.66肺癌246.12No46.43NoNo43.35NoNo47.51No肺癌347.544.4244.1445.7546.2745.3749.4648.35No42.25肺癌4No43.63NoNo43.94No44.61No45.92No肺癌547.6148.944.2244.96No45.06No45.01No43.07肝癌148.3243.6348.38No49.09No44.31No44.77No肝癌247.6148.9No48.23No45.7NoNoNo45.77正常人1No47.56No47.23NoNoNo49.23No47.77正常人2NoNo47.12NoNo48.34NoNo47.81No正常人346.89NoNo49.12NoNo48.23NoNo49.25正常人4No48.65NoNo49.01NoNo47.89NoNo正常人5NoNo48.88NoNo48.36NoNo48.23No从以上癌症患者和正常人样本的p16、CDH1、MGMT、RARB和RNF180基因甲基化检测的Ct值可以看出,以上10组引物和探针对胃癌甲基化DNA有高度扩增,其它癌症和正常人无扩增或者扩增Ct值大于45。虽然不同组的引物和探针对胃癌样本的扩增Ct值有些差异,但都明显区别于其它癌症很正常人样本,因此以上引物组均适用于胃癌早期检测。在实际应用中可采用单组引物和探针检测目的基因甲基化,也可以两组或两组以上联合使用。实施例五:试剂盒检测胃癌、正常人血浆的灵敏度和特异性本实施例采用300例正常人和300例胃癌患者的血浆样本(购自北京301医院)为检测对象测试我们的胃癌检测试剂的灵敏度和特异性。采用实施例一的DNA提取方法提取DNA,然后采用实施例二的方法,采用亚硫酸氢盐处理DNA模板,利用实施例四的探针引物组,采用实施例三的内参基因ACTB的内参引物和相关方法进行荧光定量PCR实验,检测p16、CDH1、MGMT、RARB和RNF180基因和内参基因ACTB,最后得出正常人和胃癌患者样本的Ct值。检测p16基因采用的是引物和探针组1,检测CDH1基因采用的是引物和探针组4,检测MGMT基因采用的是引物和探针组5,检测RARB基因采用的是引物和探针组7,检测RNF180基因采用的是引物和探针组10,内参基因ACTB的内参引物对为序列表的序列46所示DNA和序列表的序列47所示DNA组成的引物对;内参基因ACTB的内参探针的核苷酸序列如序列表的序列48所示。根据p16、CDH1、MGMT、RARB和RNF180各自的ROC曲线,见图1-5所示,确定各自的Cutoff值为37.4、40.64、40.12、41.07和38.89,即样本Ct值小于Cutoff值为阳性,样本Ct值大于Cutoff值为阴性,在此判定标准下单标志物的灵敏度最高。将五个标志物组合在一起来检测胃癌,只要有一个基因为阳性,即判定该样本为阳性,其它视为阴性,ROC曲线见图6。根据上述判定标准以及表6的检测结果,p16的灵敏度为76%、CDH1的灵敏度为77.67%、MGMT的灵敏度为67.33%、RARB的灵敏度为62%,RNF180的灵敏度为72%,五个标志物联合检测时,灵敏度提高到96%,特异性为80%。表6检测p16、CDH1、MGMT、RARB和RNF180基因甲基化诊断胃癌灵敏度和特异性为了达到不同的预期用途和目的,本发明提供的检测试剂盒,可以通过调整Cutoff值达到不同的灵敏度和特异性指标。在实施例五中,为了提高灵敏度,设定Cutoff值并不代表本发明仅能用此为Cutoff值,可以根据本发明提供的ROC曲线,选取不同的Cutoff值作为判定标准。本发明提供的技术方案,通过联合利用分别用于检测p16、CDH1、MGMT、RARB和RNF180基因及其片段的甲基化的核酸序列,使得胃癌检测的灵敏度和特异性得到了提高,从而保证了检测结果的正确性和可靠性。并且,通过利用实时PCR分析血浆样本中的DNA的方法,能方便地实现针对p16、CDH1、MGMT、RARB和RNF180这五个生物标记物的同时检测,并且能根据实时PCR的循环阈值(Ct)值来快速、便捷地判断样本是否呈阳性,提供了一种用于无创性的快速癌症的检测方法的试剂盒。最后,本申请还公开了至少一组的效果较好的、设计达到最优化的用于检测p16、CDH1、MGMT、RARB和RNF180基因及其片段是否甲基化的引物和探针组合及其筛选方法,确保检测效果达到最优化。需要注意的是,除非另有说明,本申请使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对步骤、数字表达式和数值并不限制本发明的范围。在这里示出和描述的所有示例中,除非另有规定,任何具体值应被解释为仅仅是示例性的,而不是作为限制,因此,示例性实施例的其他示例可以具有不同的值。最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。SEQUENCELISTING<110>北京艾克伦医疗科技有限公司<120>基于多个基因诊断胃癌患者的实时定量PCR检测试剂盒<130>1<160>51<170>PatentInversion3.3<210>1<211>2861<212>DNA<213>人(HomoSapiens)<400>1aatttttctctctctctttctctctttctttctttcgacaaagtctcactctgtcaccca60ggctggagtgaagtggctccatctcgctgttcactacaacctcagcctcccgggttcaag120cgattctcctgcctcaacctcccgagtagctgggattacaggcgcctgccaccacccccg180gctactttttgtatttttagtagaggcgaggtttcacctgttggccaggctggtctcgaa240ctcccgacctcaggtgattccccccgccttgatctcccaaagtgaagggattacaaggcg300tgaggcaccgcgcccggccgcttctgaataatttcgatcaaaatttatattcgatattta360ttccaacatacaccacagatttccactgataatccctcctagtaagaaagataagctcca420tccaggtatctgtgaattggaggctaagtagtcccagcacatcttacatttctttaagac480tccctttttatcccaaacgttcgtaaattttgtatctgataaagagcatacttccatcta540atacaaatatgttccccccttcagatcttctcagcattcgagagatctgtacgcgcgtgg600ctcctcattcctcttccttggcttcccaagcccccagggcgtcgccaggaggaggtctgt660gattacaaaccccttctgaaaactccccaggaagcctcccctttttccggagaatcgaag720cgctacctgattccaattcccctgcaaacttcgtcctccagagtcgcccgccatcccctg780ctcccgctgcagaccctctacccacctggatcggcctccgaccgtaactattcggtgcgt840tgggcagcgcccccgcctccagcagcgcccgcacctcctctacccgaccccgggccgcgg900ccgtggccagccagtcagccgaaggctccatgctgctccccgccgccggctccatgctgc960tccccgccgcccgctgcctgctctccccctctccgcagccgccgagcgcacgcggtccgc1020cccaccctctggtgaccagccagcccctcctctttcttcctccggtgctggcggaagagc1080cccctccgaccctgtccctcaaatcctctggagggaccgcggtatctttccaggcaaggg1140gacgccgtgagcgagtgctcggaggaggtgctattaactccgagcacttagcgaatgtgg1200cacccctgaagtcgccccaggttgggtctcccccgggggcaccagccggaagcagccctc1260gccagagccagcgttggcaaggaaggaggactgggctcctccccacctgccccccacacc1320gccctccggcctccctgctcccagccgcgctcccccgcctgccagcaaaggcgtgtttga1380gtgcgttcactctgttaaaaagaaatccgcccccgccccgtttccttcctccgcgataca1440accttcctaactgccaaattgaatcggggtgtttggtgtcatagggaaagtatggcttct1500tcttttaatcataagaaaaagcaaaactattctttcctagttgtgagagccccaccgaga1560atcgaaatcacctgtacgactagaaagtgtccccctaccccctcaacccttgattttcag1620gagcgcggggttcactaagtcagaaaccctagttcaaaggattccttttggagagtcgga1680ctgctctctccttcccctccccttcccctcctgcgtgtaaaacggctgtctggggcaagg1740gtttctcagacgtgtacattgcctggtataagagcagactctgaaaagatgaggtttatt1800taatacggacgggggagaattctgcctgtaggcagataggaaaatggggagggagtcatt1860ggaaggacggactccattctcaaagtcataattcctagaccagaaaaagtgctcagtgtt1920ctagaagcagagttgcacagtgatccaaagaccagcttcaaatactgtcctgtctccttc1980acacttctcacatttctctttcctactgaaaataccttgcatttttcgtaattataaagg2040gggaagggaatatgagtgccccctgctttataggggttgttgtgagtttaaatgatgtat2100taatacatataagccttaagaacagtgccacacatcctaagctaatacctgttagctctt2160gaattatccgctttgaggactggcttgcaatcttgttttgaggcatagaaagaaaatgct2220ttggagcaggacgcggtggctcacacctgtaatcccagcactttgggaagccgaggcggg2280cagatcacctgaggtcaggagttcgaggccagcttggccaaaatggtgacaccccgtctc2340tactaaaaatacaaaaattagctggccatggtggcgcacgtgtgtaattccagctactca2400ggaggctgaggcaggagaatcgcttgaacccgggaggcagaggttgcagtaagccgagat2460cgcgccaccaccctccagcctgggtgacagaatgagactccgactcaaaaaaaaaaaaaa2520aaatgctttggatagaattatcactattacataaaaggaaagtccggatgcggtggctca2580cgtctataatcccagcattctgggaggccgagacaggcggatcacctgaggccaggagtt2640cgagacaagcctgaccaacatggcgaaaccctgtctctactaaaaaatacaaaattagcg2700gggcttggtggcgcatgcctgtaatcccagctactcggaggctgatgtaggagaatcgct2760tgaacccaggagaaggcggaggttgcagtgagccgagatcgcgccattgcactccagcct2820gggagacaagagcgaaacttggtctcaagaaaaaaagaaag2861<210>2<211>1310<212>DNA<213>人(HomoSapiens)<400>2cgcgtctatgcgaggccgggtgggcgggccgtcagctccgccctggggaggggtccgcgc60tgctgattggctgtggccggcaggtgaaccctcagccaatcagcggtacggggggcggtg120cctccggggctcacctggctgcagccacgcaccccctctcagtggcgtcggaactgcaaa180gcacctgtgagcttgcggaagtcagttcagactccagcccgctccagcccggcccgaccc240gaccgcacccggcgcctgccctcgctcggcgtccccggccagccatgggcccttggagcc300gcagcctctcggcgctgctgctgctgctgcaggtaccccggatcccctgacttgcgaggg360acgcattcgggccgcaagctccgcgccccagccctgcgccccttcctctcccgtcgtcac420cgcttcccttcttccaagaaagttcgggtcctgaggagcggagcggcctggaagcctcgc480gcgctccggaccccccagtgatgggagtggggggtgggtggtgaggggcgagcgcggctt540tcctgccccctccagcgcagaccgaggcgggggcgtctggccgcggagtccgcggggtgg600gctcgcgcgggcggtgggggcgtgaagcggggtgtagggggtggggtgtggagaaggggt660gccctggtgcaagtcgagggggagccaggagtcgtggggacgatcttcgagggaaggaga720ggggcatccgtagaaataaaggcacctgccatgccaagaaaggtcgtaaataggagtgag780ggtcccggggataagaaagtgaggtcggaggaggtgggagcgcccctcgctctgaggagt840ggtgcattcccggtctaaggaaagtggggtactggagaataaagacatctccaataaaat900gagaaaggagactgaaagggaacggtgggctaggtcttgagggggtgactcggcggcccc960ctcccgggagttcctgggggctcggcggccgtaggtttcggggtgggggagggtgacgtc1020gctgcccgcccgtcccggggctgcgggctggggtcctcccccaatcccgacgccgggagc1080gagggaggggcggcgctgttggtttcggtgagcaggagggaaccctccgagtcacccggt1140tccatctacctttcccccaccccaggtctcctcttggctctgccaggagccggagccctg1200ccaccctggctttgacgccgagagctacacgttcacggtgccccggcgccacctggagag1260aggccgcgtcctgggcagaggtgagggcgcgctgccggtgtccctgggcg1310<210>3<211>762<212>DNA<213>人(HomoSapiens)<400>3cgcgctccgggctcagcgtagccgccccgagcaggaccgggattctcactaagcgggcgc60cgtcctacgacccccgcgcgctttcaggaccactcgggcacgtggcaggtcgcttgcacg120cccgcggactatccctgtgacaggaaaaggtacgggccatttggcaaactaaggcacaga180gcctcaggcggaagctgggaaggcgccgcccggcttgtaccggccgaagggccatccggg240tcaggcgcacagggcagcggcgctgccggaggaccagggccggcgtgccggcgtccagcg300aggatgcgcagactgcctcaggcccggcgccgccgcacagggcatgcgccgacccggtcg360ggcgggaacaccccgcccctcccgggctccgccccagctccgcccccgcgcgccccggcc420ccgcccccgcgcgctctcttgcttttctcaggtcctcggctccgccccgctctagacccc480gccccacgccgccatccccgtgcccctcggccccgcccccgcgccccggatatgctggga540cagcccgcgcccctagaacgctttgcgtcccgacgcccgcaggtcctcgcggtgcgcacc600gtttgcgacttggtgagtgtctgggtcgcctcgctcccggaagagtgcggagctctccct660cgggacggtggcagcctcgagtggtcctgcaggcgccctcacttcgccgtcgggtgtggg720gccgccctgacccccacccatcccgggcgagctccaggtgcg762<210>4<211>1380<212>DNA<213>人(HomoSapiens)<400>4gcaaacgagtgcagtcaattcagccaggggcttgcaagagggagaaagagaaaaagactg60tggaatggaaagtttcccaacccaagcctttcccaaggggtagccattctctgttctaca120gtttagggcttgcatgtgctttttctggagtggaaaaatacataagttataaggaattta180acagacagaaaggcgcacagaggaatttaaagtgtgggctggggggcgaggcggtgggcg240ggaggcgagcgggcgcaggcggaacaccgttttccaagctaagccgccgcaaataaaaag300gcgtaaagggagagaagttggtgctcaacgtgagccaggagcagcgtcccggctcctccc360ctgctcattttaaaagcacttcttgtattgtttttaaggtgagaaataggaaagaaaacg420ccggcttgtgcgctcgctgcctgcctctctggctgtctgcttttgcagggctgctgggag480tttttaagctctgtgagaatcctgggagttggtgatgtcagactagttgggtcatttgaa540ggttagcagcccgggtagggttcaccgaaagttcactcgcatatattaggcaattcaatc600tttcattctgtgtgacagaagtagtaggaagtgagctgttcagaggcaggagggtctatt660ctttgccaaaggggggaccagaattcccccatgcgagctgtttgaggactgggatgccga720gaacgcgagcgatccgagcagggtttgtctgggcaccgtcggggtaggatccggaacgca780ttcggaaggctttttgcaagcatttacttggaaggagaacttgggatctttctgggaacc840ccccgccccggctggattggccgagcaagcctggaaaatggtaaatgatcatttggatca900attacaggcttttagctggcttgtctgtcataattcatgattcggggctgggaaaaagac960caacagcctacgtgccaaaaaaggggcagagtttgatggagttgggtggacttttctatg1020ccatttgcctccacacctagaggataagcacttttgcagacattcagtgcaagggagatc1080atgtttgactgtatggatgttctgtcagtgagtcctgggcaaatcctggatttctacact1140gcgagtccgtcttcctgcatgctccaggagaaagctctcaaagcatgcttcagtggattg1200acccaaaccgaatggcagcatcggcacactgctcaatgtaggtttatttttttcccttct1260tctaccaagaaaaaaaaaattgtctctcttgcatgcaataaagacgttggaaataaactg1320cattggtagcaagacaaaggatttaatgatttaatgctgaaggggtgtgatatgctggca1380<210>5<211>658<212>DNA<213>人(HomoSapiens)<400>5cggttccgtctggcccgcggcgcttgtctgcctgcgcggggtcaaagcccggcgccgccc60acgcgcggctcgggtgggaacccgcagacgtggggcgagcagggccgctggctgtggcgg120gcgagcgccggggcgccacgtccgaggccgcggggtcggggctgcaggcacagctcgagc180gctttccgcggggtttggctcctgtcgcttcccgtctcgccgaaccggcatcgccgccgc240cggagccgcagcgagtcctcagagcctggctgctggcggccgggagcgccgggacggggc300gcgaagccggaggctccgggacgtggatacaggtaaaggccggcgggtcggagtcgggcg360gggcgcggcggcggcgcctctcggagggacctggcctcggccgggccctacccagccgcg420gtggcccgggcccccacgttggcccaggcggggacgtgccaaggggctgggctagggttg480ccgctggcctggccgcctctcgcccggcgggcctcaggtgacgcggccgcggcttaactt540tcgcacctgaggctctcggagcggcctcggggcgcgcccacctggaggttggaattacac600agggtcgaaaaagctgagtcctggaggcgaggcgctgtaggtgtggcggaggaggccg658<210>6<211>26<212>DNA<213>人工序列<400>6agtagcgttcgtattttttttattcg26<210>7<211>24<212>DNA<213>人工序列<400>7aaaaacaacataaaaccttcgact24<210>8<211>35<212>DNA<213>人工序列<400>8attttttttatttgattttgggttgtggttgtggt35<210>9<211>26<212>DNA<213>人工序列<400>9ctaaccacgaccgcgacccgaaatcg26<210>10<211>22<212>DNA<213>人工序列<400>10cgtcgttcgttgtttgtttttt22<210>11<211>19<212>DNA<213>人工序列<400>11aactaactaatcaccaaaa19<210>12<211>39<212>DNA<213>人工序列<400>12gtttgttttttttttttttgtagttgttgagtgtatgtg39<210>13<211>26<212>DNA<213>人工序列<400>13cgaaccgcgtacgctcgacgactacg26<210>14<211>20<212>DNA<213>人工序列<400>14gtgggcgggtcgttagtttc20<210>15<211>28<212>DNA<213>人工序列<400>15cgctaattaactaaaaattcacctaccg28<210>16<211>37<212>DNA<213>人工序列<400>16aattcacctaccaaccacaaccaatcaacaacacaaa37<210>17<211>17<212>DNA<213>人工序列<400>17ttcgcgttgttgattgg17<210>18<211>24<212>DNA<213>人工序列<400>18ttttagttcggttcgattcgatcg24<210>19<211>24<212>DNA<213>人工序列<400>19cggctccaaaaacccataactaac24<210>20<211>43<212>DNA<213>人工序列<400>20tgatttgattgtatttggtgtttgtttttgtttggtgtttttg43<210>21<211>28<212>DNA<213>人工序列<400>21cgaaaacgccgaacgaaaacaaacgccg28<210>22<211>20<212>DNA<213>人工序列<400>22gcgtttcgacgttcgtaggt20<210>23<211>21<212>DNA<213>人工序列<400>23cactcttccgaaaacgaaacg21<210>24<211>36<212>DNA<213>人工序列<400>24tgtttgtaggtttttgtggtgtgtattgtttgtgat36<210>25<211>21<212>DNA<213>人工序列<400>25cgcaaacgatacgcaccgcga21<210>26<211>24<212>DNA<213>人工序列<400>26gggtagcggcgttgtcggaggatt24<210>27<211>21<212>DNA<213>人工序列<400>27cgacgacgccgaacctaaaac21<210>28<211>40<212>DNA<213>人工序列<400>28tgttgttggaggattagggttggtgtgttggtgtttagtg40<210>29<211>28<212>DNA<213>人工序列<400>29cgcatcctcgctaaacgccgacacgccg28<210>30<211>23<212>DNA<213>人工序列<400>30atgtcgagaacgcgagcgattcg23<210>31<211>24<212>DNA<213>人工序列<400>31gcaaaaagccttccgaatgcgttc24<210>32<211>37<212>DNA<213>人工序列<400>32ccaaatacattccaaatcctaccccaacaatacccaa37<210>33<211>18<212>DNA<213>人工序列<400>33ttgggtatcgtcggggta18<210>34<211>16<212>DNA<213>人工序列<400>34ggcgaggcggtgggcg16<210>35<211>24<212>DNA<213>人工序列<400>35gcaaaaagccttccgaatgcgttc24<210>36<211>38<212>DNA<213>人工序列<400>36tggtgggtgggaggtgagtgggtgtaggtggaatattg38<210>37<211>24<212>DNA<213>人工序列<400>37cgatattccgcctacgcccgctcg24<210>38<211>23<212>DNA<213>人工序列<400>38agtttttagagtttggttgttgg23<210>39<211>22<212>DNA<213>人工序列<400>39acctttacctatatccacgtcc22<210>40<211>42<212>DNA<213>人工序列<400>40ggttgttggtggttgggagtgttgggatggggtgtgaagttg42<210>41<211>29<212>DNA<213>人工序列<400>41cgacttcgcgccccgtcccgacgctcccg29<210>42<211>22<212>DNA<213>人工序列<400>42cgagtagggtcgttggttgtgg22<210>43<211>23<212>DNA<213>人工序列<400>43cgaactatacctacaaccccgac23<210>44<211>39<212>DNA<213>人工序列<400>44tgttggttgtggtgggtgagtgttggggtgttatgtttg39<210>45<211>27<212>DNA<213>人工序列<400>45cgcgacctcgaacgtaacgccccgacg27<210>46<211>24<212>DNA<213>人工序列<400>46gtgatggaggaggtttagtaagtt24<210>47<211>25<212>DNA<213>人工序列<400>47ccaataaaacctactcctcccttaa25<210>48<211>30<212>DNA<213>人工序列<400>48accaccacccaacacacaataacaaacaca30<210>49<211>20<212>DNA<213>人工序列<400>49ggagtggaggaaattgagat20<210>50<211>22<212>DNA<213>人工序列<400>50ccacacaacaaatactcaaaac22<210>51<211>33<212>DNA<213>人工序列<400>51tgggtgtttgtaatttttgttttgtgttaggtt33当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1