基于高等真菌灵芝功能基因编辑的调节灵芝酸产量的方法与流程
本发明涉及的是一种生物工程领域的技术,具体涉及一种基于crispr-cas9实现高等真菌灵芝功能基因编辑,从而调节其灵芝酸发酵产量的方法,通过构建能在灵芝细胞内高效表达grna的质粒,在灵芝细胞中实现了对标记基因和功能基因的有效编辑。
背景技术:
目前从羊毛甾醇到灵芝酸的生物合成途径尚不清楚,而其中可能参与灵芝酸生物合成的细胞色素氧化酶p450s(cyp450s)的功能无法解析是其中的主要困境(xiaoh,zhongjj.trendsbiotechnol,2016,34(3):242-255.wangwf,xiaoh,zhongjj.biotechnol.bioeng,2018,115(7):1842-1854.)。
现有技术如中国专利文献号cn107779466a,公开了一种用于高等真菌基因中断的方法,通过将含有密码子优化的cas9基因的表达载体转入单倍体灵芝(ganodermalucidum,cgmccno.5.26)中,获得了可稳定表达cas9蛋白的灵芝菌株;然后将经体外转录的grna转入此表达cas9蛋白的灵芝菌株中,通过grna识别靶向基因,实现靶向基因的特定位点的中断,并以u6基因启动子介导grna内源转录,同样使靶向基因的特定位点中断。但该技术中断的基因仅限于ura3标记基因,并且其编辑效率比较低,107个原生质体只能获得0.1-0.9个突变体。显然,该基因编辑技术尚难以直接应用到功能基因的编辑。
技术实现要素:
本发明针对高等真菌灵芝基因编辑的上述不足之处,提出了一种基于高等真菌灵芝功能基因编辑的调节灵芝酸产量的方法,通过u6基因启动子pu6-3结合hdv核酶,构建了能在灵芝细胞内表达grna的crispr-cas9系统,能有效实现对灵芝的标记基因和功能基因的编辑。
本发明是通过以下技术方案实现的:
本发明涉及一种灵芝酸产量控制基因cyp5150l8,其核苷酸序列如seqidno.25所示。
本发明涉及一种灵芝u6-3基因的启动子pu6-3,如seqidno.1所示。
本发明涉及一种在灵芝细胞内表达grna的crispr-cas9系统,包括能够显著中断灵芝cyp5150l8功能基因的pu6-3-t2-grna-hdv质粒,该质粒通过以t2序列为靶序列、pu6-3-t1-grna-hdv质粒为pcr模板,经pcr扩增得到tl8-grna-hdv-glcas9序列和glcas9-tpdc-sdhb-pu6-3序列,将tl8-grna-hdv-glcas9序列和glcas9-tpdc-sdhb-pu6-3序列与线性化的pmd-glcas9质粒重组连接得到。
所述的t1为灵芝ura3标记基因的靶序列,如seqidno.22所示。
所述的t2序列即5’ggttgcgggaccataggtgt3’,具体如seqidno.23所示。
本发明涉及一种基于高等真菌灵芝功能基因编辑的调节灵芝酸产量的方法,通过构建pu6-3-t2-grna序列,并将其与hdv协同构建pu6-3-t2-grna-hdv质粒,与pcrdonor结合scr7实现了灵芝功能基因cyp5150l8的精确编辑,实现对灵芝酸的产量调节。
所述的hdv是用于割切grna尾部(gaoyb,zhaoyd.j.integr.plantbiol.,2014,56(4):343-349),保证grna长度一致性的核酶,如seqidno.2所示。
所述的pcrdonor,是指以质粒pmd-l8d为模板,pcr扩增得到的l8d片段,其序列如seqidno.24。
所述的质粒pmd-l8d,将通过pcr扩增与纯化得到的l8d序列(于cas9核酶在cyp5150l8基因的切割位点两侧各取1kb,并且切割位点附近的5’tccaacac3’序列被5’tga3’取代)重组连接至pmd-18t载体得到的质粒。
所述的scr7,为5,6-二(苄基氨基)-2-巯基嘧啶-4-醇,即5,6-bis(benzylideneamino)-2-mercapto-pyrimidin-4-ol。
所述的精确编辑是指:利用pcrdonor替换cyp5150l8基因序列上同源的序列。
所述的灵芝酸产量,通过发酵、灵芝酸提取以及高效液相色谱仪检测分析cyp5150l8突变体和野生型菌株的四种已知灵芝酸(ga-mk,ga-t,ga-s,ga-me)的含量。
所述的灵芝,采用中国微生物菌种保藏管理中心(cgmcc)中保藏编号为cgmcc5.616的灵芝。
所述的灵芝,其细胞的培养及筛选所采用的培养基包括:pda培养基、种子培养基、cym培养基、上层cym培养基和发酵培养基。
所述的马铃薯葡萄糖琼脂(pda培养基)(solarbio),其组分及含量为:葡萄糖20g/l,琼脂20g/l,马铃薯粉6g/l,ph5.4-5.8;其制备方法为:称取本品46.0克,加入1000ml蒸馏水中,115℃高压灭菌30分钟备用。
所述的发酵培养基,其组分及含量为:葡萄糖35g/l,蛋白胨5g/l,酵母膏5g/l,磷酸二氢钾1.0g/l,七水硫酸镁0.5g/l,维生素b10.05g/l。
技术效果
与现有技术相比,本发明利用一个新的u6基因启动子和hdv核酶,构建了可以内源表达grna的crispr-cas9质粒,获得了更高的ura3标记基因的编辑效率,并首次在高等真菌灵芝内实现了功能基因的编辑。本发明只需要利用一次质粒转化与筛选,就可以实现crispr系统对目的基因的特定序列的编辑,此方法操作简单、成本比较低、节约时间,可以获得高达5.3个基因编辑的菌株/107个原生质体细胞,实现了功能基因的精准编辑,因此这种编辑方法具有推广性;该方法可以广泛用于各类高等真菌基因的编辑,为解析诸如灵芝酸等次生代谢物的生物合成途径奠定了基础,为高等真菌的遗传改造搭建了平台。
附图说明
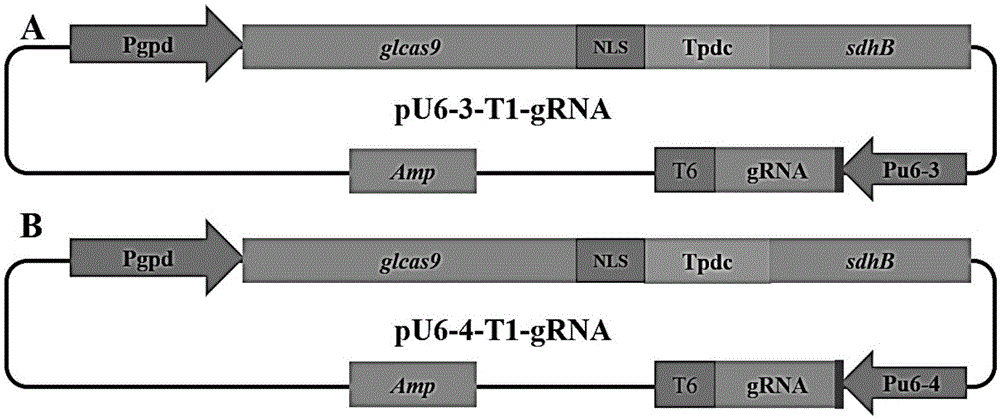
图1为内源表达grna的crispr-cas9质粒构建示意图,图a是用新发掘的u6基因启动子构建的质粒pu6-3-t1-grna和图b是用已报道的u6基因启动子构建的质粒pu6-4-t1-grna,黑色小方块代表t1;amp为氨苄抗性基因,pgpd是灵芝gpd基因的启动子,glcas9是灵芝密码子优化的cas9基因,tpdc是木霉pdc基因终止子,nls是sv40核定位序列,sdhb指carboxin抗性基因,t6是u6启动子终止序列tttttt(图4和图7中相应元件同此);
图2为pu6-3-t1-grna和pu6-4-t1-grna两个质粒对应的突变体的测序图,图a是pu6-3-t1-grna对应的三个随机的ura3基因中断菌株的测序图和图b是pu6-4-t1-grna对应的三个随机的ura3基因中断菌株的测序图;黑色三角形代表cas9切割位点,下划线标注的是pam序列,靶序列用长横线标注,虚线表示碱基缺失,箭头表示碱基插入;
图3为pu6-3-t1-grna和pu6-4-t1-grna基因编辑效率比较图;
图4为pu6-3-t1-grna-hdv质粒示意图,黑色小方块代表ura3靶序列t1;
图5为pu6-3-t1-grna-hdv质粒对应的三个随机的ura3基因中断菌株的结果测序图;黑色三角形代表cas9切割位点,下划线标注的是pam序列,靶序列用长横线标注,箭头表示碱基插入;
图6为pu6-3-t1-grna和pu6-3-t1-grna-hdv基因编辑效率比较图;
图7中断cyp5150l8的质粒:pu6-3-t2-grna-hdv示意图,黑色小方块代表靶序列t2;
图8为同源重组修复cyp5150l8基因的pcr模板:l8d
图9为pu6-3-t2-grna-hdv质粒对应的cyp5150l8基因编辑结果测序图;黑色三角形代表cas9切割位点,下划线标注的是pam序列,靶序列用长横线标注,虚线表示碱基缺失,箭头表示碱基插入;
图10为发酵第13天cyp5150l8基因中断菌株-no.16和野生型菌株的四种已知灵芝酸的含量。
具体实施方式
实施例1
pu6-3用于构建编辑标记基因和功能基因的质粒
1)pu6-3-t1-grna质粒和pu6-4-t1-grna质粒的构建:pu6-3-t1-grna序列和pu6-4-t1-grna序列均由上海睿勉生物科技有限公司合成,通过将现有技术cn107779466a中公开的pmd-glcas9质粒用限制性内切酶noti(货号r3189s,neb北京公司)线性化,回收并纯化线性化的质粒,分别将pu6-3-t1-grna序列和pu6-4-t1-grna序列通过trelieftmsosoocloningkit(货号tsv-s1,北京擎科新业生物技术有限公司)与线性化的pmd-glcas9质粒重组连接得到质粒pu6-3-t1-grna和质粒pu6-4-t1-grna。
本实施例的具体操作包括:根据真核生物u6基因的保守型,在ncbi数据库中调取人类的u6基因序列,然后在灵芝基因组中,通过同源比对发现了一个尚未报道的u6基因:u6-3,并调取其启动子序列用于内源表达grna。同时为了比较启动子的强弱,采用现有的u6-4启动子作为对照。
本实施例中pu6-3-t1-grna序列由引物对pu6-3-f:(seqidno.3)和grna-r:(seqidno.4)pcr扩增得到,pu6-4-t1-grna序列由引物对pu6-4-f:(seqidno.5)和grna-r:(seqidno.4)pcr扩增得到。
2)pu6-3-t1-grna-hdv质粒的构建:将pu6-3-t1-grna-hdv序列上海睿勉生物科技有限公司合成。pu6-3-t1-grna-hdv序列由引物对pu6-3-f:(seqidno.3)和hdv-r:(seqidno.6)pcr扩增并纯化得到,将pmd-glcas9质粒用限制性内切酶noti(货号r3189s,neb北京公司)线性化,回收并纯化线性化的质粒,将pu6-3-t1-grna-hdv序列通过trelieftmsosoocloningkit(货号tsv-s1,北京擎科新业生物技术有限公司)与线性化的pmd-glcas9质粒重组连接得到质粒pu6-3-t1-grna-hdv。
本实施例中pu6-3-t1-grna-hdv序列基于u6-3基因的启动子pu6-3与hdv核酶结合得到,由上海睿勉生物科技有限公司合成,启动子pu6-3的核苷酸序列如seqidno.1所示,hdv核酶的核苷酸序列如seqidno.2所示。
3)中断cyp5150l8功能基因的pu6-3-t2-grna-hdv质粒的构建:以pu6-3-t1-grna-hdv质粒为pcr模板,分别用引物cyp5150l8s-f(seqidno.7)/mglcas9-r(seqidno.8)、mglcas9-f(seqidno.9)/pu6-3-r(seqidno.10)pcr扩增并纯化得到tl8-grna-hdv-glcas9序列和glcas9-tpdc-sdhb-pu6-3序列,将tl8-grna-hdv-glcas9序列和glcas9-tpdc-sdhb-pu6-3序列通过trelieftmsosoocloningkit(货号tsv-s1,北京擎科新业生物技术有限公司)与线性化的pmd-glcas9质粒重组连接得到质粒pu6-3-t2-grna-hdv。
实施例2
内源表达grna的质粒用于ura3基因编辑。
本实施例通过以pu6-3-t1-grna质粒和pu6-4-t1-grna质粒用于灵芝细胞转化。
1)灵芝原生质体的制备和转化:用溶壁酶处理灵芝菌丝得到灵芝原生质体。将107个原生质体用160μlstc缓冲液(0.55m的山梨醇,0.1m的tris-hcl缓冲液,0.5m的氯化钙,ph为8.0)悬浮,加入20μg质粒dna、100μg肝素钠、500μg亚精胺、0.2μm金精三羧酸以及60μlptc缓冲液(60%peg3350(w/v),0.1m的tris-hcl缓冲液,1m的氯化钙,ph为8.0),冰浴30分钟,加入1mlptc缓冲液混匀,28℃放置30分钟,加入到1mlcym液体培养基中,30℃静置培养12小时,加入含有carboxin抗性的cym固体平板,随后加入含有carboxin抗性上层cym培养基,使carboxin终浓度为4mg/l,30℃放置20天后可见若干单菌落,这些单菌落称为转化子;生长出来的转化子转移到含有5-foa(终浓度为600mg/l)的cym培养基再次进行筛选,再次筛选得到的转化子进行鉴定与分析。
2)灵芝基因组dna的提取:称取约0.02g灵芝菌丝体(ganodermalucidum,cgmccno.5.616),转入1.5mlep管,每管加入10颗小磁珠磁珠(直径1mm,上海净信科技有限公司)和300μldesbuffer(1%sds,2%triton-100,0.372%edta-2na,0.585%nacl,10mmtris-hcl,ph8.0)和300μl酚:氯仿:异戊醇(24:25:1,ph8.0,北京鼎国生物科技有限公司)。放入研磨仪(型号-tissuelyser-24,上海净信科技有限公司),以60hz的频率研磨5分钟;然后在4℃下12000g离心10分钟,取上清液至一个新的离心管,加300μl异丙醇,-20℃放置30分钟;4℃下12000g离心10分钟,弃掉上清液,每管加300μl预冷的75%无水乙醇,充分悬起下层沉淀;4℃下12000g离心10分钟,去除上清后,50℃放置10分钟,溶于200μl去离子水,4度保存待用。
3)ura3突变体的鉴定。
以转化子的基因组dna为模板,使用ura3引物pcr扩增得到ura3基因序列,使用正向引物ura3-f对pcr产物进行测序,与野生型对比分析ura3基因序列的变化并统计相应质粒对应的基因编辑效率。
所述的正向引物ura3-f(seqidno.11):5'tcggttcatccgctagatctg3'
反向引物ura3-r(seqidno.12):5'actaacgggcatcgctgcaattt3'。
经过转化、筛选与鉴定后,pu6-3-t1-grna质粒的转化中得到51个转化子,其中13个基因编辑的转化子;pu6-4-t1-grna质粒的转化中得到66个转化子,其中8个基因编辑的转化子。测序验证的结果如图2所示,其中a是pu6-3-t1-grna质粒对应的3个随机的基因编辑转化子序列图,b是pu6-4-t1-grna质粒对应的3个随机的基因编辑转化子序列比对图。pu6-3-t1-grna质粒和pu6-4-t1-grna质粒对应的基因编辑效率比较如图3所示,pu6-3-t1-grna质粒的编辑效率显著高于pu6-4-t1-grna质粒的编辑效率。与已报道的基因编辑效率(0.1-0.9个突变体/107个原生质体)相比,pu6-3-t1-grna质粒的编辑效率更高(4.3个突变体/107个原生质体),因此,pu6-3能更有效地用于内源表达grna。
实施例3
本实施例采用与实施例2相同的转化步骤,以pu6-3-t1-hdv-grna和pu6-3-t1-grna两种质粒用于灵芝细胞转化,验证hdv核酶是否可以增强crispr系统的基因编辑效率。
经过转化、筛选与鉴定后,pu6-3-t1-grna-hdv质粒的转化中得到50个转化子,其中16个基因编辑的转化子;图5是pu6-3-t1-grna-hdv质粒对应的3个随机的基因编辑转化子序列图,图6是pu6-3-grna-t1质粒和pu6-3-t1-grna-hdv质粒对应的基因编辑效率比较,pu6-3-t1-grna-hdv质粒的编辑效率显著高于pu6-3-t1-grna质粒的编辑效率,综合比较发现pu6-3-t1-grna-hdv这种质粒有最高的ura3基因的编辑效率,因此,此质粒结构可以用于编辑功能基因。
实施例4
功能基因cyp5150l8的精准编辑,具体包括以下步骤:
1)如图8所示,构建修复cyp5150l8基因的同源重组模板pcrdonor,具体为:以野生型灵芝(ganodermalucidumcgmccno.5.616)基因组dna为模板,采用l8d1引物pcr扩增与纯化得到左同源臂l8d1序列,再采用l8d2引物pcr扩增与纯化得到左同源臂l8d2序列,将l8d1序列、l8d2序列以及pmd-18t载体(takara大连公司)用trelieftmsosoocloningkit(货号tsv-s1,北京擎科新业生物技术有限公司)以及dl8引物重组连接得到质粒pmd-l8d,通过pcr扩增与纯化得到l8d序列。
所述的l8d1引物包括:正向引物l8d-f1(seqidno.13)
5'atgcctgcaggtcgacgattaggttgcgggaccgtaggtgttggcagtccatcacccttcc3'和反向引物l8d-r1(seqidno.14)
5'tcacacatgcctccaccagac3'。
所述的l8d2引物包括:用正向引物l8d-f2(seqidno.15)
5'gtctggtggaggcatgtgtgactatggtcccgcaaccaagt3'和反向引物l8d-r2(seqidno.16)
5'acccggggatcctctagagatggttgcgggaccgtaggtgttggggggcgttcatgttcg3'。
所述的dl8引物包括:正向引物dl8-f(seqidno.17)
5'cagtccatcacccttcctcc3'和反向引物dl8-r(seqidno.18)
5'ggggcgttcatgttcgattttact3'。
2)cyp5150l8基因的编辑:用溶壁酶处理灵芝菌丝得到灵芝原生质体。将107个原生质体用160μlstc缓冲液(0.55m的山梨醇,0.1m的tris-hcl缓冲液,0.5m的氯化钙,ph为8.0)悬浮,加入20μg质粒dna、3μgl8d、100μg肝素钠、500μg亚精胺、0.2μm金精三羧酸以及60μlptc缓冲液(60%peg4000(w/v),0.1m的tris-hcl缓冲液,1m的氯化钙,ph为8.0),冰浴30分钟后加入1mlptc缓冲液混匀,28℃放置30分钟,加入到1mlcym液体培养基中,加入scr7(终浓度20μm),30℃静置培养12小时,加入含有carboxin抗性的cym固体平板,随后加入含有carboxin抗性上层选择性培养基,使carboxin终浓度为4mg/l,30℃放置20天后可见若干单菌落,这些单菌落称为转化子;生长出来的转化子转移到含有carboxin(终浓度为4mg/l)的cym培养基再次进行筛选,再次筛选得到的转化子进行鉴定分析。
3)cyp5150l8突变体的鉴定:
3.1)以转化子的基因组dna为模板,使用cyp5150l8引物pcr扩增得到cyp5150l8基因序列,使用正向引物cyp5150l8-f对pcr产物进行测序,与野生型对比分析cyp5150l8基因序列的变化并统计相应质粒对应的基因编辑效率。
所述的cyp5150l8引物包括:正向引物cyp5150l8-f(seqidno.19):
5'agcggcgtacatcttttgg3'和反向引物cyp5150l8-r(seqidno.20):
5'tgggttggctcacatcaca3'。
经过转化、筛选与鉴定后,pu6-3-t2-grna-hdv质粒的转化中得到68个转化子,其中2个经测序确认为基因编辑了的转化子,但测序结果也表明这2个转化子的测序峰图是双峰,说明它们是杂合子。
3.2)为筛选得到纯合子,用上述两个突变体的菌丝体制备原生质体,每103个原生质体加入到1mlcym液体培养基中,30℃静置培养12小时,加入含有carboxin抗性(4mg/l)的cym固体平板,随后加入含有carboxin抗性上层选择性培养基,使carboxin终浓度为4mg/l。30℃培养7天后可见若干单菌落,随机挑取10个单菌,转移到cym固体平板(carboxin,4mg/l)再次筛选得到再生株。
3.3)按照本实施例的鉴定方法对上述再生株进行分析,极大部分(90%左右)的再生株的测序峰图为单峰,又继续了如下操作:用pclone007bluntsimplevectorkit(北京擎科新业生物技术有限公司)将相应转化子pcr扩增的cyp5150l8序列连接至pclone007载体,将重组的载体热激转化至dh5a,转移到luria-bertani(lb)培养基(100μg/mlampicillin)筛选单克隆,随机挑选10个单克隆用m13-f(seqidno.21)引物进行测序分析序列,所得序列与pcrdonor-l8d序列对比,全部单克隆的测序序列与l8d的序列都一致,则判断相应的突变体是纯合子。由此,经筛选,从突变体原生质体再生的菌株得到了2个纯合子;其序列比对如图9所示。
所述的m13-f(seqidno.21)引物为:5'tgtaaaacgacggccagt3'
实施例5
cyp5150l8纯合子灵芝酸含量分析。
1)cyp5150l8突变体和野生型发酵过程:先振荡培养、然后静置培养的两阶段发酵的操作具体按照文献fangqh,zhongjj.biotechnol.progr.,2002,18(1):51-54报道的过程进行。
2)在发酵的第6、8、11、13、15天等五个时间点进行取样,发酵的取样过程、灵芝酸的提取以及定量的操作具体按照文献fangqh,zhongjj.biotechnol.progr.,2002,18(1):51-54描述的方法进行。
3)cyp5150l8突变体和野生型四种已知灵芝酸含量比较:五个取样时间点与四种已知灵芝酸(ga-mk,ga-t,ga-s,ga-me)的含量比较可见,突变体的相应四种灵芝酸含量都比野生型的低;图10是发酵第13天的野生型和突变体的灵芝酸含量变化。cyp5150l8缺失出现明显的表型,四种灵芝酸的含量明显降低,证明cyp5150l8可能参与了灵芝酸的生物合成途径。
本发明以高等真菌为研究对象,选择灵芝作为模式物种,建立了内源表达grna的crispr-cas9系统,成功用于标记基因(ura3)和功能基因(cyp5150l8)的有效中断。首先,通过生物信息学分析与筛选,发掘了一个新的u6基因启动子可以使crispr-cas9系统获得较高的ura3基因编辑效率,可以得到4.3个阳性克隆/107原生质体,远高于现有技术;然后,在u6-3表达grna的基础上,hdv核酶添加到grna的3'端,进一步提高了ura3基因的编辑效率,效率为5.3个阳性克隆/107原生质体。hdv与u6-3启动子结合优化grna,成功用于cyp5150l8功能基因的中断,效率为0.7个阳性克隆/107原生质体。本发明的提高了基因编辑的效率,并且首次在高等真菌灵芝中实现了功能基因的中断。与现有高等真菌的基因中断技术相比,本技术操作简便、成本低、适用性广、效率更高,能有效用于功能基因的中断。此发明一方面为灵芝的代谢工程改造搭建了平台,为其他高等真菌功能基因编辑提供了重要的依据;另外一方面,本研究为解析高等真菌代谢途径奠定了重要的基础。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
序列表
<110>上海交通大学
<120>基于高等真菌灵芝功能基因编辑的调节灵芝酸产量的方法
<130>f-b449e
<141>2018-12-13
<160>25
<170>siposequencelisting1.0
<210>1
<211>197
<212>dna
<213>pu6-3启动子(ganodermalucidum)
<400>1
acctgtggatggcacagggaagtatcgagggcgggcgttgcttgcgcatgcggacattgt60
acttgatatgttttggccgcacttggactcggaagcgatgggggatcgagcgcccaaaga120
gatcgttgccgccaccccgcgagctgagcaaaaagcaaaactccggcggctgtaccccta180
agtccccctcaaccgtt197
<210>2
<211>68
<212>dna
<213>hdv核酶序列(人工序列)
<400>2
ggccggcatggtcccagcctcctcgctggcgccggctgggcaacatgcttcggcatggcg60
aatgggac68
<210>3
<211>46
<212>dna
<213>pu6-3-f引物(人工序列)
<400>3
tgcagcaatcgggaagagcagcggccacctgtggatggcacaggga46
<210>4
<211>44
<212>dna
<213>grna-r引物(人工序列)
<400>4
cggggatcctctagagatgcggccaaaaaaaaaagcaccgactc44
<210>5
<211>46
<212>dna
<213>pu6-4-f引物(人工序列)
<400>5
tgcagcaatcgggaagagcagcggccgagagtccaagcgccccgca46
<210>6
<211>44
<212>dna
<213>hdv-r引物序列(人工序列)
<400>6
cggggatcctctagagatgcggccaaaaaagtcccattcgccat44
<210>7
<211>40
<212>dna
<213>cyp5150l8s-f引物序列(人工序列)
<400>7
ctaagtccccctcaaccgttggttgcgggaccgtaggtgt40
<210>8
<211>21
<212>dna
<213>mglcas9-r引物序列(人工序列)
<400>8
ccttgacgagctcgtcgacga21
<210>9
<211>21
<212>dna
<213>mglcas9-f引物序列(人工序列)
<400>9
tcgtcgacgagctcgtcaagg21
<210>10
<211>45
<212>dna
<213>pu6-3-r引物序列(人工序列)
<400>10
caaccaacggttgagggggacttaggggtacagccgccggagttt45
<210>11
<211>21
<212>dna
<213>ura3-f引物序列(人工序列)
<400>11
tcggttcatccgctagatctg21
<210>12
<211>23
<212>dna
<213>ura3-r引物序列(人工序列)
<400>12
actaacgggcatcgctgcaattt23
<210>13
<211>61
<212>dna
<213>l8d-f1引物序列(人工序列)
<400>13
atgcctgcaggtcgacgattaggttgcgggaccgtaggtgttggcagtccatcacccttc60
c61
<210>14
<211>21
<212>dna
<213>l8d-r1引物序列(人工序列)
<400>14
tcacacatgcctccaccagac21
<210>15
<211>41
<212>dna
<213>l8d-f2引物序列(人工序列)
<400>15
gtctggtggaggcatgtgtgactatggtcccgcaaccaagt41
<210>16
<211>60
<212>dna
<213>l8d-r2引物序列(人工序列)
<400>16
acccggggatcctctagagatggttgcgggaccgtaggtgttggggggcgttcatgttcg60
<210>17
<211>20
<212>dna
<213>dl8-f引物序列(人工序列)
<400>17
cagtccatcacccttcctcc20
<210>18
<211>24
<212>dna
<213>dl8-r引物序列(人工序列)
<400>18
ggggcgttcatgttcgattttact24
<210>19
<211>19
<212>dna
<213>cyp5150l8-f引物序列(人工序列)
<400>19
agcggcgtacatcttttgg19
<210>20
<211>19
<212>dna
<213>cyp5150l8-r引物序列(人工序列)
<400>20
tgggttggctcacatcaca19
<210>21
<211>18
<212>dna
<213>m13-f引物序列(人工序列)
<400>21
tgtaaaacgacggccagt18
<210>22
<211>20
<212>dna
<213>t1ura3基因的靶序列(ganodermalucidum)
<400>22
ggcctcttccgtgtatgagc20
<210>23
<211>20
<212>dna
<213>t2cyp5150l8基因的靶序列(ganodermalucidum)
<400>23
ggttgcgggaccataggtgt20
<210>24
<211>2000
<212>dna
<213>l8d片段(人工序列)
<400>24
cagtccatcacccttcctccgatgactgcgaacaatctacgactcgtgcatgtattacaa60
cagccctccgtttctagatgcacgcaaatgtcgtattgccggtcagcgtgcgaatgccgc120
aggcaagagaacagcgagtacgtttcttcaccgctcagtatccgcacattgacatagtct180
ctcaaacgggctcataggattctacctacgcatggcacgagcttacatgtatcatgtcca240
tgcaggtagacactagcgttatcagacaccagcacgcacgcatccgaacaagttatcaag300
gcgcgggggattaggcaattatagtaaccatgttgcaagttatctctacttttggcggtg360
agcaagtcgtcttcggccttcaaatgaagaggtactgacatgggtctgttgggcacaatg420
acaccgaagcctatctatctccccatggcatgggcgatgcttgatggcgcattggttcaa480
tcctttttgtgaggacacctcaaatttcgccgatgctggcagccacgtcgtacgtcagcg540
gttagtcttattcggcttccctcacggatcggcgactaatgagcagtcctaagcatgata600
catccacagtacagacgacggatagcaaatcgcttcagagcccagagacattaagtttaa660
cgccggtattctgaagaggtctataaaccttcgctttcttcagcatgatgaatcgctatg720
ggcccactcccctgaaatttcaagcagaacgcctgcatcatgcccgactcttctctcgtc780
ctcgtggccatcgccggagcggcgtacatcttttggctggtgttccatcgttatctcgtg840
cggtcacctttggacaacctcccaagcccgcctagctctccattcctgggtatgtcacat900
cagtgttgaacaacgacccgaccgcgaacattccgtctttttaggaaaccttcccgacat960
tgtccatcgccaaagccacgtctggtggaggcatgtgtgactatggtcccgcaaccaagt1020
tgactgcgtttttcggcgtgcgtgattcttattctcgtgtcgaggtcgactgacatggac1080
acatcccatccagatacaaatgctatacacattcgaccccaaagcgatgtacagcattct1140
cgtcaaggacacggaactatacccgaagaagaccgccgcgtacgagttgagtagccgatc1200
cagacagcgtctccccatcgcgctaacaggcgtttcgcaagcgacttcactctgttcatc1260
gggcccggccttctcttcgccgagggcgcacaacatcgccggcaacgcaagtggctcaac1320
cccgtcttttctgtcgcccagctgcgcgatgtctcgcacgtcttctacggcgtcgcatac1380
aaggtccgtcccgcactgcctgctgcaggacacttcagtgacggtgctgcccagcttgag1440
gaggcgatccgaaaccgcgtcggcgcccaatcccaaaacctagatgtgaacggctggatg1500
gcgcgtacgacgttggagatgctcggccaggcgggcctcggatactcgttcgacaagttc1560
acggaggactcgacggattcgtacggagaggccctcaagtcgttcttgtacgttcctcgc1620
ttttcgttcaggcccagcagcagtggttgagcatctccgcgatcgtagtcccgttatcaa1680
ccacgttcccttgctaaacctcttcgtcatgaccctcgccaaccacatcccgaagtggct1740
catgcgccgagtccttcggctagccgttccgttcccccatgtccttcgcctcctaaggat1800
ctcagagaccatgcagaagcgttcgtcggagatcatccagcagaagaagactgccttgca1860
aaagggcgacaaggcactcatacatcaagtcggcgaggggaaagacatcatgagcgtcct1920
gtgtatgtcccgtggcaggccgatctctgttcatacatcgctaatcgcagacgtacagta1980
aaatcgaacatgaacgcccc2000
<210>25
<211>2259
<212>dna
<213>cyp5150l8基因(ganodermalucidum)
<400>25
atgcccgactcttctctcgtcctcgtggccatcgccggagcggcgtacatcttttggctg60
gtgttccatcgttatctcgtgcggtcacctttggacaacctcccaagcccgcctagctct120
ccattcctgggtatgtcacatcagtgttgaacaatgacccgaccgcgaatattccgtctt180
ttaggaaaccttcccgacattatccatcgccaaagccacctctggtggaggcatgtgtcc240
aacacctacggtcccgcaaccaagttgactgcgtttttcggcgtgcgtgattcttattct300
cgtgtcgaggtcgactgacatggacacatcccatccagatacaaatgctatacacattcg360
accccaaagcgatgtacagcattctcgtcaaggacacggagctatacccgaagaagaccg420
ccgcgtacgagttgagtagccgatccagacagcgtctccccattgtgctcacaggtgttt480
cgcagcgacttcactctgttcatcgggcccggccttctcttcgccgagggcgcgcaacat540
cgccggcaacgcaagtggctcaaccccgtcttttctgtcgcccagctgcgcgatgtctcg600
cacgtcttctacggcgtcgcatacaaggtccgtcccgcactgcctgctgcaagacacttt660
cagtgacagtgctgcccagcttgaggaggcgatccgaaaccgcgtcggcgcccaatccca720
aaacctagatgtgaacggctggatggcgcgtacgacgttggagatgctcggccaggcggg780
cctcggatactcgttcgacaagttcacggaggactcgacggattcgtacggagaggccct840
caagtcgttcttgtacgttcctcgcttttcgttcaggcccagcagcagtggttgagcatc900
tccgcgatcgtagtcccgttatcaaccacgttcccttgctaaacctcttcgtcatgaccc960
tcgccaaccacatcccgaagtggctcatgcgccgagtccttcggctagccgttccgttcc1020
cccatgtccttcgcctcctaaggatctcagagaccatgcagaagcgttcgtcggagatca1080
tccagcagaagaagactgccttgcaaaagggcgacaaggcactcatacatcaagtcggcg1140
aggggaaagacatcatgagcgtcctgtgtatgtcccgtggcaggccgatctctgttcata1200
catcgctaatcgcagacgtacagtaaaatcgaacatgaacgcccccagcgactcggaaaa1260
gcttcctgacgaggagcttctcgcacagatgtcgtaagtgactggccggtcatggccgca1320
tcgatgctgagccccccgctagcacattcatcctcgccgggatggacaccacatcgaacg1380
ccctgtcgcgcatcctccacctcctcgcggagcacccggacgtgcaagagaagctgcggc1440
acgagctctcggaggcgcgcgagatcgtcgggaacggcaaggacgtcccctacgacgacc1500
tcgtcaagctcccgtacctcgacgccgtctgccgcgagaccctgcggctccacccgccgc1560
tcaacctgatcggccggaggtacgcacggaagcacctgacacggacgcgcgatctgacgc1620
cgactcggttgacactggcagggcagcgaaggacatggtcgtgccgctgtcgtccccggt1680
gcgcggcagggacgggacgctcgtcaacgaggtcacgctcccgaaggacacgttcgtcct1740
cctcgggctgcaggcgtgcaacacgaacaagaagctgtggggcgaggacgcgtacgagtg1800
gaagccggagcgctggctgcagccgctcccttccatgctcgaggaggcacgggtgcctgg1860
ggtgtattcgaacttgtaagatcgtcgcttttcctccgtcatcaccgtacttacgcacct1920
ccgacgcaggatgtccttcagtggcggggtccgttcgtgcatgtaagtcttgtcgccgat1980
ttgatgaggcatagcaatgctgactgtcgtttgccagcgggttcaaattctcccaactcg2040
agatgagtaagcacatcgccgttggggcagccatgttcgccattattgaccgcggccgtt2100
tctgcagaggtcctgttgaccatcctcttgccggcgttttcgttcgagttgacggagaag2160
cccatcttctggaacaccagcgccgtttcgtatcctaccatggacaaagacagcacgcgg2220
ccggagatgttgttgaaggtcaaggcgttggcttgctga2259
- 还没有人留言评论。精彩留言会获得点赞!