结核分枝杆菌核糖体蛋白S7的表达纯化、晶体结构及应用的制作方法
本发明属于生物技术领域,具体涉及一种来源于结核病致病菌结核分枝杆菌的核糖体蛋白的表达纯化、晶体结构及其在新型抗结核药物筛选中的应用。
背景技术:
结核病(Tuberculosis)在中医上称之为瘰疠,是一类由结核分枝杆菌(Mycobacterium tuberculosis)引起的传染性疾病,以肺部感染最为常见,身体的其它部位也会感染。大多数的结核病感染为潜伏性结核(latent tuberculosis),这类感染者仅携带结核分枝杆菌,并不会表现出任何症状。约有5-10%的潜伏性结核会转变为活动性结核(active tuberculosis)。结核病广泛分布于世界各地,据世界卫生组织统计,全球约有四分之一的人口患有潜伏性结核病。仅2017年,全球1000万例新生结核病患者,并导致了130万人死亡。结核病地区分布差异较大,大多来自发展中国家,其中印度、中国、印度尼西亚、菲律宾、巴基斯坦、尼日利亚、孟加拉国和南非这八个国家的新生病例占全球总数的三分之二左右。目前结核病的治疗主要依赖于抗生素,市面上最常用的抗结核药物为利福平(Rifampicin)和异烟肼(isoniazid),但普遍存在治疗周期长这一缺点,通常需要6个月以上才可能使患者转入稳定期。今年来,由于抗生素的滥用,使得很多致病菌具有多重耐药性,这类耐多药结核病只能通过二线抗结核药物进行治疗,具有很多局限性,如疗效差、副作用大及价格昂贵等,而且大多数情况下需要长期化疗(两年及两年以上)。由于部分广泛耐药结核病对最为有效地几种二线抗结核病药物具有抗性,目前没有很好的治疗方法,导致这类病人无药可医。中国是结核病高负担国及耐多药结核病最多的国家之一,面临着患病人数多、耐多药结核病发现率低、病原学确诊率低和耐药率高等挑战,急需补充药物对抗结核病。
核糖体(Ribosome)作为一种细胞器广泛存在于生命体中,是蛋白质合成的重要场所。蛋白质翻译过程主要可以分为起始、延伸、终止和再循环四个阶段,在这个过程中还需要很多调节因子的参与。尽管原核生物与真核生物核糖体都是由大小两个亚基及核糖体RNA组成,且具有相似的核心区域,但由于其整体结构及参与翻译的调节因子的动态调控机制不同,因此致病菌的核糖体经常用作抗菌药物筛选的直接或间接靶点。S7为核糖体小亚基的组成蛋白,其功能的缺失会直接影响到核糖体小亚基的装配及RNA识别。在之前的研究中发现,结核分枝杆菌的S7蛋白还与链霉素(streptomycin)的抗性有关。本发明通过异源表达及纯化获得了纯度及均一性较好的结核病致病菌Mycobacterium tuberculosis H37RvT的核糖体蛋白S7,并利用结晶的方法得到了S7的蛋白晶体并解析了其三维结构。核糖体蛋白S7的晶体结构可在抗结核药物筛选及新药开发等方面具有广泛的前景应用。
技术实现要素:
本发明的目的在于提供一种来源于结核病致病菌的核糖体蛋白的表达纯化方法、其晶体结构和应用。
本发明包括提供对来源于结核病致病菌Mycobacterium tuberculosis H37RvT的核糖体蛋白S7进行基因工程改造以获得在大肠杆菌中的高效表达、纯化和结晶的方法,以及所述核糖体蛋白S7的第1位到第156位氨基酸的三维晶体结构及其应用。
第一方面,本发明将来源于结核病致病菌Mycobacterium tuberculosis H37RvT的核糖体蛋白S7进行了基因工程改造,将其全长基因克隆在pSMT3的载体上。
本发明优先选择了使用大肠杆菌的原核细胞表达系统(但不排除其他的表达系统,如在其它细菌或者其他的真核生物细胞中进行表达);对以上所述蛋白以融合蛋白的方式进行表达,优先选择了His标签得到了可溶性表达(但不排除其它标签,如MBP或GST等标签也有可溶性表达)。
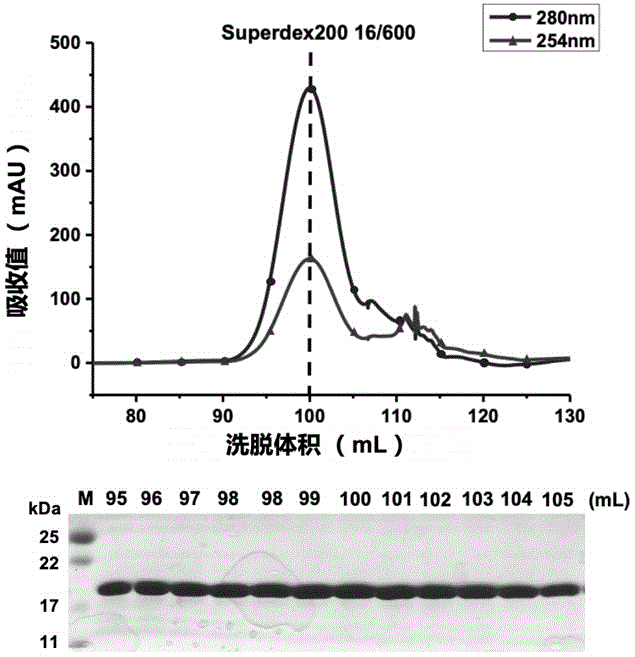
第二方面,本发明提供一种表达和纯化结核病致病菌Mycobacterium tuberculosis H37RvT的核糖体蛋白S7的方法,该方法包括:构建融合野生型mtb_rpsG全长基因的重组载体,用该载体转化大肠杆菌,从而表达带有标签His6-SUMO的融合蛋白,记为His6-SUMO-S7,将上述获得的蛋白通过特异性的与所述特异标签识别的方法,优选Ni-NTA亲和层析(分离原理为:低咪唑浓度缓冲液进行上样,高咪唑浓度缓冲液进行洗脱)分离目的蛋白,并使用ULP1酶切掉His6-SUMO标签,再通过凝胶过滤层析的方法得到高纯度的S7蛋白,如图1所示。所获得的目的蛋白溶液均一性较好,如图2所示。
其中,表达质粒为pSMT3,转化方法为CaCl2转化法,转化菌株为大肠杆菌DH5α,表达菌株为大肠杆菌Rosetta(DE3)。
其中,所述Ni-NTA亲和层析的平衡缓冲液优先选择50mM Tris(pH 8.0),1M NaCl,5%甘油,10mM咪唑,6mMβ-Me,0.2mM PMSF。所述Ni亲和层析洗脱缓冲液优先选择50mM Tris(pH 8.0),1M NaCl,5%甘油,250mM咪唑,6mMβ-Me;所述凝胶过滤层析的缓冲液优先选择20mM Tris(pH7.4),100mMNaCl,2mM DTT。
第三方面,本发明提供一种结晶上述得到的核糖体蛋白S7的方法,具体步骤为:将S7蛋白浓缩至浓度为5-20mg/ml,优先选择使用17mg/ml,使用结晶试剂盒(来自Hampton Research等公司的Crystal Screen Kit I/II,Index,Salt,PEG/Ion等)作为晶体生长的初筛条件,采用悬滴(或坐滴)气相扩散法进行结晶。温度为4-25摄氏度,优先选择使用18摄氏度。
采用悬滴气相扩散法进行结晶,结晶液滴中蛋白溶液与结晶试剂体积比在2:1至1:2的范围内,优选体积比为1:1,蛋白溶液中蛋白质浓度为5-20mg/ml,优先选择使用17mg/ml,结晶条件为5-25%PEG 3350(优先选择20%),5-15%Tacsimate(优先选择8%),pH 5.0-7.0(优先选择pH 6.0)。晶体培养在4至25摄氏度(优选18摄氏度)进行。晶体图片如图3所示。
第四方面,本发明还提供衍射性能良好的核糖体蛋白S7的蛋白晶体。
第五方面,本发明还提供核糖体蛋白S7的三维结构,该结构描述了S7蛋白的二级结构组成,肽链走向、组织模式以及三维分子构造。其中,针对S7蛋白进行X射线衍射,得到晶体衍射数据,以来源于细菌Geobacillus stearothermophilus的S7蛋白(PDB ID:1HUS)为模型进行结构解析,最终得到核糖体蛋白S7的三维结构。
在具体的实施方式中,提供了核糖体蛋白S7的晶体三维结构,其中所述晶体三维结构中的原子具有表1中所列的至少40%的原子坐标,或者任何与该坐标中至少40%氨基酸残基的主链碳骨架的原子三维坐标的平均根方差小于或等于的结构。
本发明获得的核糖体蛋白S7的晶体三维结构,分辨率为其晶体结构空间群为空间群:P212121,晶胞参数为:α=β=γ=90°。
本发明所述的核糖体蛋白S7或其可折叠部分的晶体结构,具有表1中列出的原子坐标(x,y,z)±(1.0,1.0,1.0)确定的三维结构。
在具体的实施方式中,所述的核糖体蛋白S7的三维结构在一个晶体学不对称单位内有两个蛋白分子。每个分子整体上由2个β折叠和6个α螺旋组成。
所述的结构可分为两部分,一部分为由α螺旋1、α螺旋2、α螺旋3、α螺旋4和α螺旋5组成的α螺旋束结构,另一部分包括由β折叠1和β折叠2组成的β发卡结构以及α螺旋6,如图3所示;其中,α螺旋1,即含Gln21-Val30的氨基酸区段;α螺旋2,即含Lys36-Thr54的氨基酸区段;α螺旋3,即含Pro58-Val69的氨基酸区段;β折叠1,即含Leu73-Val80的氨基酸区段;β折叠2,即含Ala83-Glu90的氨基酸区段;α螺旋4,即含Pro93-Gln110的氨基酸区段;α螺旋5,即含Met116-Asn129的氨基酸区段;α螺旋6,即含Ala133-Asn148的氨基酸区段。
第六方面,本发明还提供核糖体蛋白S7的晶体结构在抗结核药物筛选及新药开发等方面的应用,即以该蛋白结构及其分子内的相互作用为理论依据,设计靶向药物对抗结核病。
附图说明
图1为结核病致病菌Mycobacterium tuberculosis H37RvT的核糖体蛋白S7的凝胶过滤层析(上)及SDS-PAGE(下)检测结果。所使用的层析柱为Superdex200 16/600(GE,美国)。
图2为结核病致病菌M.tuberculosis H37RvT的核糖体蛋白S7的动态光散射分析。溶液中半径为2.0nm的颗粒占总颗粒的100%,其%Pd值为7.9。
图3为结核病致病菌M.tuberculosis H37RvT的核糖体蛋白S7的晶体图片。
图4为结核病致病菌M.tuberculosis H37RvT的核糖体蛋白S7的三维结构示意图。(A)核糖体蛋白S7三维结构卡通示意图。α螺旋使用蓝色标示,β折叠使用黄色标记;(B)核糖体蛋白S7的表面电荷分布。红色代表分子表面带负电荷,蓝色代表分子表面带正电荷。
具体实施方式
下面采用具体实施例进一步说明本发明的内容。
以下内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
实施例1.核糖体蛋白S7的表达纯化
来源于结核病致病菌Mycobacterium tuberculosis H37RvT的核糖体蛋白S7,其氨基酸序列如SEQ.ID.NO1所示,核酸序列如SEQ.ID,NO2所示。
通过分子克隆技术将mtb_rpsG的全长基因克隆到pSMT3的载体上,用来表达氨基末端融合6个His以及SUMO标签的融合蛋白,将重组载体转化到大肠杆菌Rosetta(DE3)中,37℃振荡培养至OD600达到0.6-1.0(优先选择0.8)时加入终浓度为0.1-1.0mM(优先选择0.4mM)的IPTG进行诱导表达,表达条件为:16℃振荡培养20h或20℃振荡培养16h或25℃振荡培养8h。优先选择16℃,200rpm振荡培养。20小时后通过离心收集细菌,用于纯化。
将离心收集的表达菌以适量缓冲液(50mM Tris(pH 8.0),1M NaCl,5%甘油,10mM咪唑,6mMβ-Me,0.2mM PMSF)悬菌,使用低温超高压细胞破碎仪(广州聚能生物科技有限公司)裂解菌体,以18000rpm高速离心1h去除沉淀和其它颗粒状杂质。将离心后上清液与Ni-NTA亲和介质结合后,用50mM Tris(pH 8.0),1mM NaCl,5%甘油,50mM咪唑,6mMβ-Me的缓冲液冲洗介质,去除杂蛋白。最终用50mM Tris(pH 8.0),1M NaCl,5%甘油,250mM咪唑,6mMβ-Me的洗脱液将目的蛋白从亲和介质上洗脱下来,以10KDa截留的浓缩管将洗脱液浓缩。将浓缩后的蛋白溶液进一步用凝胶过滤层析(层析柱优先选择Superdex200,16/600)的方法纯化,使用的缓冲液为20mM Tris(pH7.4),100mMNaCl,2mM DTT。将洗脱下来的目的蛋白进行浓缩至浓度为5-20mg/ml,优先选择17mg/ml,于-80℃保存,用于结晶实验。
实施例2.核糖体蛋白S7的结晶
将由上方法表达纯化好的核糖体蛋白S7浓缩至浓度约为17mg/ml,使用结晶试剂盒(来自Hampton Research等公司的Crystal Screen Kit I/II,Index,Salt,PEG/Ion等)作为晶体生长的初筛条件,采用悬滴(或坐滴)气相扩散法进行结晶。本发明在多个不同的结晶试剂条件下获得了初始晶体。通过后期的优化调整,优选20%PEG3350,8%Tacsimate(pH6.0)的缓冲液作为晶体生长条件,收集到一套分辨率为的X射线衍射数据。
实施例3.核糖体蛋白S7的衍射数据收集及结构解析
本发明将制备的晶体以25%的甘油作为防冻剂处理后,冻存于液氮中。晶体X射线衍射的数据收集在上海光源(SSRF)生物大分子晶体学光束线站(五线六站BL17U1)进行。数据处理使用HKL2000,结构解析以来源于细菌Geobacillus stearothermophilus的S7蛋白(PDB ID:1HUS)为模型,采用分子置换法,利用Refmac程序并辅以Coot软件做进一步修正,最终解析得到核糖体蛋白S7的蛋白晶体结构。本领域的普通技术人员可知,于其中所述晶体三维结构中的原子具有表1中所列的至少40%的原子坐标,或者3D蛋白的晶体三维结构中至少40%氨基酸的主链碳骨架的原子结构坐标与表1中的坐标的平均根方差小于或等于的原子坐标,均可被认为与3D蛋白具有雷同结构。
具体而言,所述的核糖体蛋白S7的晶体三维结构,一个晶体学不对称单位内有两个不对称分子。每个分子由2个β折叠和6个α螺旋组成。整个结构可分为两部分,一部分为由α螺旋1、α螺旋2、α螺旋3、α螺旋4和α螺旋5组成的α螺旋束结构,另一部分包括由β折叠1和β折叠2组成的β发卡结构以及α螺旋6;其中,α螺旋1,即含Gln21-Val30的氨基酸区段;α螺旋2,即含Lys36-Thr54的氨基酸区段;α螺旋3,即含Pro58-Val69的氨基酸区段;β折叠1,即含Leu73-Val80的氨基酸区段;β折叠2,即含Ala83-Glu90的氨基酸区段;α螺旋4,即含Pro93-Gln110的氨基酸区段;α螺旋5,即含Met116-Asn129的氨基酸区段;α螺旋6,即含Ala133-Asn148的氨基酸区段。
表1、S7蛋白晶体的原子坐标群如下:
晶体空间群:P212121
晶胞参数为:α=β=γ=90°。
I/σI:13.04
Rwork/Rfree分别为:0.1946和0.2171
分辨率范围41.31-1.80
数据完整性(%):99.95
PDB id:6JMK。
表1
序列表
<110> 复旦大学
<120> 结核分枝杆菌核糖体蛋白S7的表达纯化、晶体结构及应用
<130> 001
<160> 2
<170> SIPOSequenceListing 1.0
<210> 1
<211> 156
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 1
Met Pro Arg Lys Gly Pro Ala Pro Lys Arg Pro Leu Val Asn Asp Pro
1 5 10 15
Val Tyr Gly Ser Gln Leu Val Thr Gln Leu Val Asn Lys Val Leu Leu
20 25 30
Lys Gly Lys Lys Ser Leu Ala Glu Arg Ile Val Tyr Gly Ala Leu Glu
35 40 45
Gln Ala Arg Asp Lys Thr Gly Thr Asp Pro Val Ile Thr Leu Lys Arg
50 55 60
Ala Leu Asp Asn Val Lys Pro Ala Leu Glu Val Arg Ser Arg Arg Val
65 70 75 80
Gly Gly Ala Thr Tyr Gln Val Pro Val Glu Val Arg Pro Asp Arg Ser
85 90 95
Thr Thr Leu Ala Leu Arg Trp Leu Val Gly Tyr Ser Arg Gln Arg Arg
100 105 110
Glu Lys Thr Met Ile Glu Arg Leu Ala Asn Glu Ile Leu Asp Ala Ser
115 120 125
Asn Gly Leu Gly Ala Ser Val Lys Arg Arg Glu Asp Thr His Lys Met
130 135 140
Ala Glu Ala Asn Arg Ala Phe Ala His Tyr Arg Trp
145 150 155
<210> 2
<211> 471
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 2
atgccacgca aggggcccgc gcccaagcgt ccgttggtca acgacccggt ctacggatcg 60
cagttggtca cccagttggt gaacaaggtt ctgttgaagg ggaaaaaatc gctggccgag 120
cgcattgttt atggtgcgct tgagcaagct cgcgacaaga ccggcaccga tccggtgatc 180
accctcaagc gggctctcga caatgtcaaa cccgccctgg aggtgcgcag ccgtcgcgtc 240
ggcggcgcga cctatcaggt gcctgtcgag gtgcgccccg accggtcgac cacgctggcg 300
ctgcgctggc tcgtcggcta ctcgcggcaa cgccgtgaga agacgatgat cgagcgcctg 360
gcaaatgaga tcctggatgc cagcaatggc cttggggcct ccgtcaagcg gcgtgaggac 420
acccacaaga tggccgaggc gaaccgagcc tttgcgcatt atcgctggtg a 471
- 还没有人留言评论。精彩留言会获得点赞!
- 一种敲除c‑di‑AMP分解酶的重组耻垢分枝杆菌株及其应用的制造方法与工艺
- 检测结核分枝杆菌感染的抗原多肽池及其应用的制造方法与工艺
- 一种猕猴桃分枝定位器的制造方法与工艺
- 一种xanthone类化合物及其单晶的制备方法与作为抗海分枝杆菌药物的应用与制造工艺
- 一种糖肽类抗生素耐药基因检测试剂盒的制造方法与工艺
- 分枝杆菌快速分离培养方法与制造工艺
- 一种用于检测潜在结核的特异性标志物及其应用的制造方法与工艺
- 结核分枝杆菌抗原蛋白Rv2941及其T细胞表位肽的应用的制造方法与工艺
- 一种微流控芯片上基于荧光量子点磁性富集并分离结核分枝杆菌TB的方法及装置与制造工艺
- 二肽meso‑DAP‑D‑Ala和/或四肽L‑Ala‑D‑Glu‑L‑Lys‑D‑Ala的新用途的制造方法与工艺