GPU加速方法和装置与流程
本发明涉及硬件加速技术,尤其涉及一种GPU加速方法和装置。
背景技术:
图形加速结构(Ex-kaa aXeleration Architecture,EXA)驱动是Linux图形系统中显卡与X窗口系统的接口,是Linux图形系统实现GPU硬件加速的接口层,其工作在X窗口系统中的图形接口服务器Xserver之下、显卡的内核图形处理器(Graphics Processing Unit,GPU)驱动之上,X窗口系统通过EXA驱动实现所有Linux图形系统的2D显卡加速。
在目前的图形加速方案中,Xserver通过EXA驱动调用GPU执行一次加速操作前,会先在用户态空间为EXA驱动分配一段不连续的内存缓冲区来存储欲加速的数据,再通过EXA驱动调用GPU在独立显存中分配一段显存缓冲区,然后再调用memcpy函数将EXA驱动中的内存缓冲区数据复制到显存缓冲区中,通过GPU对数据进行加速操作。
现有的这种加速方案,在每次调用GPU进行加速操作前都要进行两次缓冲区分配操作和大量的memcpy操作,这样延迟了GPU加速操作的执行,使得GPU加速效率低下。
技术实现要素:
针对现有技术的上述缺陷,本发明提供一种GPU加速方法和装置,用于提高GPU加速效率。
本发明提供一种GPU加速方法,该方法包括:
通过图形加速结构EXA驱动中的连续物理内存分配函数调用内核中的图形处理器GPU驱动,控制GPU为EXA驱动分配一段物理地址连续的缓冲区,物理地址连续的缓冲区用于GPU调用以进行数据加速;
在物理地址连续的缓冲区中填写欲加速的数据;
通过EXA驱动将物理地址连续的缓冲区的物理地址和相应的加速指令提交给GPU驱动,控制GPU对数据进行加速处理。
在本发明的一实施例中,通过EXA驱动中的连续物理内存分配函数调用内核中的GPU驱动,控制GPU为EXA驱动分配一段物理地址连续的缓冲区,具体包括:
通过连续物理内存分配函数进行系统调用来调用GPU驱动,控制GPU从图形转换表GTT中分配一段物理地址连续的缓冲区;
在内核将物理地址连续的缓冲区映射到用户态空间后,存储内核返回的物理地址连续的缓冲区的物理地址和物理地址连续的缓冲区对应的用户态程序地址。
在本发明的一实施例中,物理地址连续的缓冲区的物理地址按照GPU硬件访问要求对齐,在物理地址连续的缓冲区中填写欲加速的数据,具体包括:根据用户态程序地址在对应的物理地址连续且首地址按照GPU硬件访问要求对齐的缓冲区中填写欲加速的数据。
在本发明的一实施例中,连续物理内存分配函数包括用于记录GPU驱动设备节点信息的参数、欲分配的缓冲区地址对齐要求的参数、欲分配的缓冲区大小的参数、欲分配的缓冲区类型的参数和分配的缓冲区首地址的参数。
在本发明的一实施例中,EXA驱动包括连续物理内存释放函数;该方法还包括:
通过连续物理内存释放函数进行系统调用来调用内核中的GPU驱动,控制GPU从GTT中释放缓冲区。
在本发明的一实施例中,连续物理内存释放函数包括用于记录GPU驱动设备节点信息的参数、分配的缓冲区大小的参数、分配的缓冲区类型的参数和分配的缓冲区首地址的参数。
本发明还提供一种GPU加速装置,包括:
分配模块,用于通过图形加速结构EXA驱动中的连续物理内存分配函数调用内核中的图形处理器GPU驱动,控制GPU为EXA驱动分配一段物理地址连续的缓冲区,物理地址连续的缓冲区用于GPU调用以进行数据加速;
填写模块,用于在物理地址连续的缓冲区中填写欲加速的数据;
处理模块,用于通过EXA驱动将物理地址连续的缓冲区的物理地址和相 应的加速指令提交给GPU驱动,控制GPU对数据进行加速处理。
在本发明的一实施例中,分配模块,具体用于:
通过连续物理内存分配函数进行系统调用来调用GPU驱动,控制GPU从图形转换表GTT中分配一段物理地址连续的缓冲区;
在内核将物理地址连续的缓冲区映射到用户态空间后,存储内核返回的物理地址连续的缓冲区的物理地址和物理地址连续的缓冲区对应的用户态程序地址。
在本发明的一实施例中,物理地址连续的缓冲区的物理地址按照GPU硬件访问要求对齐,填写模块具体用于:根据用户态程序地址在对应的物理地址连续且首地址按照GPU硬件访问要求对齐的缓冲区中填写欲加速的数据。
在本发明的一实施例中,连续物理内存分配函数包括用于记录GPU驱动设备节点信息的参数、欲分配的缓冲区地址对齐要求的参数、欲分配的缓冲区大小的参数、欲分配的缓冲区类型的参数和分配的缓冲区首地址的参数。
在本发明的一实施例中,EXA驱动包括连续物理内存释放函数,装置还包括:释放模块,释放模块用于通过连续物理内存释放函数进行系统调用来调用内核中的GPU驱动,控制GPU从GTT中释放缓冲区。
在本发明的一实施例中,连续物理内存释放函数包括用于记录GPU驱动设备节点信息的参数、分配的缓冲区大小的参数、分配的缓冲区类型的参数和分配的缓冲区首地址的参数。
本实施例提供的GPU加速方法和装置,首先通过EXA驱动中的连续物理内存分配函数调用内核中的GPU驱动,控制GPU为EXA驱动分配一段物理地址连续的缓冲区,然后在缓冲区中填写欲加速的数据后,通过EXA驱动将缓冲区的物理地址和相应的加速指令提交给GPU,使GPU对数据进行加速处理,省去了一次缓冲区分配操作和大量的memcpy操作,有效的缩短了加速指令提交到GPU的时间,提高了GPU加速的效率。
附图说明
图1为本发明提供的GPU加速方法实施例一的流程示意图;
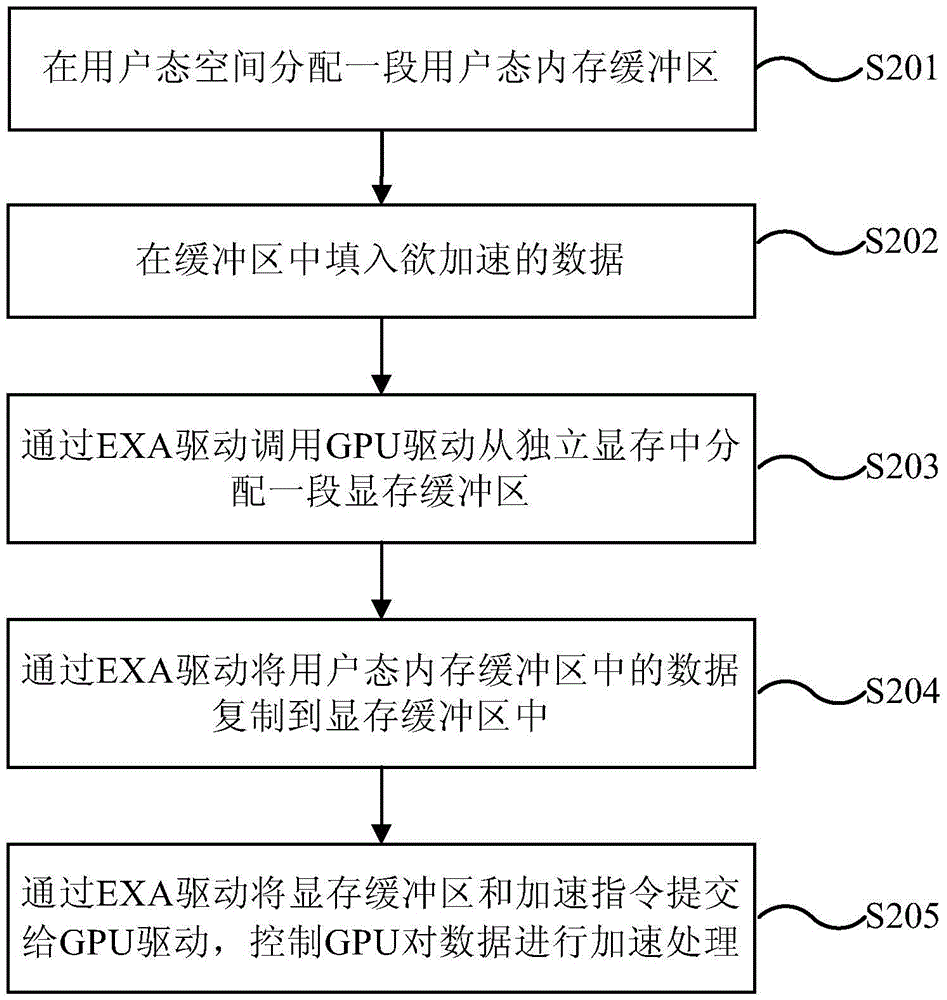
图2为现有技术中GPU加速方法的流程示意图;
图3为本发明提供的GPU加速方法实施例二的流程示意图;
图4为本发明提供的GPU加速装置的结构示意图。
附图标记说明:
10-分配模块;
20-填写模块;
30-处理模块;
40-释放模块。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例涉及的方法和装置可以应用于Linux图形系统以实现图形加速,其旨在解决现有技术中图形加速方案中GPU加速效率低的技术问题。
下面以具体地实施例对本发明的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
图1为本发明提供的GPU加速方法实施例一的流程示意图,该方法的执行主体可以是GPU加速装置,该装置可以集成在中央处理器(Central Processing Unit,CPU)中,实现CPU中Xserver的部分功能;也可以是独立的处理设备。如图1所示,本实施例的方法包括:
步骤S101、通过EXA驱动中的连续物理内存分配函数调用内核中的GPU驱动,控制GPU为EXA驱动分配一段物理地址连续的缓冲区。
具体的,在需要GPU进行图形加速时,CPU中的Xsever可以先调用EXA驱动,通过EXA驱动中的连续物理内存分配函数调用CPU内核中的GPU驱动,控制GPU为EXA驱动分配一段缓冲区,GPU可以直接访问该缓冲区以进行数据加速,其中,该缓冲区可以从共享显存或独立显存中分配,该缓冲区的物理地址连续且首地址按GPU硬件访问要求(如要求是64字节,则按照64字节)对齐,以保证GPU硬件访问物理地址时的正确性。
步骤S102、在物理地址连续的缓冲区中填写欲加速的数据。
在GPU为EXA驱动分配完缓冲区后,Xserver就可以将欲加速的数据填入该缓冲区中,以对这些数据进行加速处理。
步骤S103、通过EXA驱动将物理地址连续的缓冲区的物理地址和相应的加速指令提交给GPU驱动,控制GPU对数据进行加速处理。
Xserver填写完欲加速的数据后,可以再次通过EXA驱动将缓冲区的物理地址和相应的加速指令提交给GPU驱动,GPU可以根据该物理地址访问该缓冲区,然后再根据加速指令对缓冲区中欲加速的数据进行加速处理。
现有技术中,如图2所示,在需要GPU进行图形加速时,Xserver会先在用户态空间分配一段用户态内存缓冲区(步骤S201),该缓冲区的物理地址是不连续的,GPU无法访问,因此,Xserver在缓冲区中填入欲加速的数据后(步骤S202),会先通过EXA驱动调用GPU驱动从独立显存中分配一段GPU可以访问的物理地址连续的显存缓冲区(步骤S203);再通过EXA驱动调用memcpy函数将用户态内存缓冲区中的数据复制到显存缓冲区中(步骤S204);然后再通过EXA驱动将显存缓冲区和加速指令提交给GPU驱动,控制GPU对数据进行加速处理(步骤S205),这样延迟了GPU加速操作的执行,使得GPU加速效率低下,同时还增加了独立显存的需求和CPU的负担。本实施例中,Xsever直接通过EXA驱动调用内核中的GPU驱动,使GPU为EXA驱动分配一段物理地址连续的缓冲区,用该缓冲区替代现有的物理地址不连续的内存缓冲区,该缓冲区是GPU从显存中分配的,其可以直接访问,因而在Xsever向缓冲区中填入欲加速的数据后,无需再通过EXA驱动调用GPU驱动从独立显存中分配独立显存缓冲区,也不需要再通过memcpy函数进行数据复制操作,在EXA驱动向GPU驱动提交缓冲区和加速指令后,GPU就可以直接访问该缓冲区的物理地址,进行数据加速处理,从而有效的缩短了Linux图形系统加速指令提交到GPU的时间,提高了GPU加速的效率;此外,在分配缓冲区时,GPU可以从共享显存中分配,从而也减小了对独立显存的需求,同时,无需进行memcpy操作,也有效的减小了CPU的负担。
本实施例提供的GPU加速方法,首先通过EXA驱动中的连续物理内存分配函数调用内核中的GPU驱动,控制GPU为EXA驱动分配一段物理地址连续的缓冲区,然后在缓冲区中填写欲加速的数据后,通过EXA驱动将缓冲 区的物理地址和相应的加速指令提交给GPU,使GPU对数据进行加速处理,省去了一次缓冲区分配操作和大量的memcpy操作,有效的缩短了加速指令提交到GPU的时间,提高了GPU加速的效率。
图3为本发明提供的GPU加速方法实施例二的流程示意图,本实施例是上述图1所示实施例中步骤S101的具体实现方式。在图1所示实施例的基础上,如图3所示,本实施例中步骤S101通过EXA驱动中的连续物理内存分配函数调用内核中的GPU驱动,控制GPU为EXA驱动分配一段物理地址连续的缓冲区,具体包括:
步骤S301、通过连续物理内存分配函数进行系统调用来调用GPU驱动,控制GPU从GTT中分配一段物理地址连续的缓冲区。
在为EXA驱动分配缓冲区时,具体可以修改Xserver的EXA接口结构体,在EXA驱动中增加连续物理内存分配函数,EXA驱动初始化时可以将该函数注册到Xserver中。Xserver需要GPU进行加速时,可以先调用该函数在图形转换表(Graphics Translation Table,GTT)中分配所需大小的缓冲区。
具体的,可以在Xserver代码目录下的exa/exa.h中,修改typedef struct_ExaDriver结构体,增加连续物理内存分配函数GPUSurfaceAlloc。
连续物理内存分配函数具体可以是:
BOOL GPUSurfaceAlloc(GPUPtr gpuctx,gctUINT alignedSize,gctUINT size,gctUINT surfaceMode,GenericSurfacePtr*surface)
其中,参数gpuctx记录GPU驱动设备节点信息,该设备节点信息作为GPU驱动的入口,用于EXA驱动访问GPU驱动;alignedSize记录欲分配的缓冲区地址对齐要求;size记录欲分配缓冲区大小;surfaceMode记录欲分配缓冲区类型(是从共享显存中分配还是从独立显存中分配);surface指针记录分配的缓冲区首地址。
用户态空间和内核态空间的交互可以通过系统调用实现,Xsever通过连续物理内存分配函数分配缓冲区时,该函数可以通过系统调用(例如调用ioctl函数)实现对GPU驱动的调用。
具体的,Xsever调用该函数分配缓冲区时,可以先向该函数传递参数gpuctx、alignedSize、size和surfaceMode的值,即确定欲分配的缓冲区的要 求和GPU驱动的访问入口信息;然后ioctl函数可以根据该入口信息调用GPU驱动,驱动GPU为EXA驱动分配满足上述要求的缓冲区。
步骤S302、在内核将缓冲区映射到用户态空间后,存储内核返回的缓冲区的物理地址和缓冲区对应的用户态程序地址。
GPU从GTT中分配完缓冲区后,内核则将缓冲区映射到用户态空间,以将缓冲区的物理地址映射为用户态程序可以识别的虚拟地址,在映射完成后即会产生一个用于用户态程序访问的用户态程序地址;分配的缓冲区的物理地址和用户态程序地址可以通过ioctl函数返回给物理内存分配函数,Xserver保存下来后,即可根据用户态程序地址访问分配的缓冲区,然后将欲加速的数据填入该缓冲区中,并且在进行GPU加速时,将保存缓冲区的物理地址提交给GPU,以使GPU访问该物理地址对应的缓冲区进行数据加速处理。
本实施例提供的GPU加速方法,通过改变EXA驱动的架构,在EXA驱动中增加连续物理内存分配函数,实现了在GTT中分配GPU可以直接访问的缓冲区,从而省去了一次缓冲区分配操作和大量的memcpy操作,有效的缩短了加速指令提交到GPU的时间,提高了GPU加速的效率。
在上述实施例的基础上,在本发明的另一实施例中,在GPU对数据进行加速处理后,还可以通过连续物理内存释放函数进行系统调用来调用内核中的GPU驱动,控制GPU从GTT中释放缓冲区。
GPU对数据进行加速处理后,程序返回到Xserver,Xsever可以再次通过EXA驱动调用GPU驱动,控制GPU释放上述分配的缓冲区。与上述步骤S301类似,可以在EXA驱动中增加连续物理内存释放函数,EXA驱动初始化时可以将该函数注册到Xserver中。Xserver需要释放缓冲区时,可以通过调用该函数实现。
具体的,可以在Xserver代码目录下的exa/exa.h中,修改typedef struct_ExaDriver结构体,增加连续物理内存释放函数GPUSurfaceFree。
连续物理内存释放函数具体可以是:
BOOL GPUSurfaceFree(GPUPtr gpuctx,gctUINT size,gctUINT surfaceMode,GenericSurfacePtr*surface)
其中,参数gpuctx记录GPU驱动设备节点信息;size记录分配的缓冲区 大小;surfaceMode记录分配的缓冲区类型;surface指针记录分配的缓冲区首地址。
Xsever通过连续物理内存释放函数释放缓冲区时,该函数可以通过系统调用(例如调用ioctl函数)实现对GPU驱动的调用。具体的,Xsever调用该函数分配缓冲区时,可以根据保存的缓冲区的物理地址先向该函数传递参数gpuctx、size、surfaceMode和surface的值,即确定欲释放的缓冲区信息和GPU驱动的访问入口信息;然后ioctl函数可以根据该入口信息调用GPU驱动,驱动GPU释放所分配的缓冲区。
本实施例提供的GPU加速方法,通过改变EXA驱动的架构,在EXA驱动中增加连续物理内存释放函数,实现了在GTT中释放GPU分配的缓冲区,从而提高了GTT中缓冲区的利用率。
图4为本发明提供的GPU加速装置的结构示意图,本实施例的装置可以集成在CPU中,也可以是独立的处理设备。如图4所示,本实施例的装置包括:分配模块10、填写模块20和处理模块30,其中,
分配模块10,用于通过EXA驱动中的连续物理内存分配函数调用内核中的GPU驱动,控制GPU为EXA驱动分配一段物理地址连续的缓冲区,物理地址连续的缓冲区用于GPU调用以进行数据加速;
填写模块20,用于在物理地址连续的缓冲区中填写欲加速的数据;
处理模块30,用于通过EXA驱动将物理地址连续的缓冲区的物理地址和相应的加速指令提交给GPU驱动,控制GPU对数据进行加速处理。
本实施例提供的GPU加速装置,可以执行上述方法实施例,其实现原理和技术效果类似,此处不再赘述。
在上述实施例的基础上,在本发明的一实施例中,物理地址连续的缓冲区的物理地址首地址按照GPU硬件访问要求对齐,分配模块10,具体用于:
通过连续物理内存分配函数进行系统调用来调用GPU驱动,控制GPU从GTT中分配一段物理地址连续的缓冲区;
在内核将物理地址连续的缓冲区映射到用户态空间后,存储内核返回的物理地址连续的缓冲区的物理地址和物理地址连续的缓冲区对应的用户态程序地址。
填写模块20,具体用于根据所述用户态程序地址在对应的物理地址连续且首地址按照GPU硬件访问要求对齐的缓冲区中填写欲加速的数据。
其中,连续物理内存分配函数可以包括用于记录GPU驱动设备节点信息的参数、欲分配的缓冲区地址对齐要求的参数、欲分配的缓冲区大小的参数、欲分配的缓冲区类型的参数和分配的缓冲区首地址的参数。
另外,EXA驱动还可以包括连续物理内存释放函数,本实施例的装置还可以包括:释放模块40,用于通过连续物理内存释放函数进行系统调用来调用内核中的GPU驱动,控制GPU从GTT中释放缓冲区。
其中,连续物理内存释放函数可以包括用于记录GPU驱动设备节点信息的参数、分配的缓冲区大小的参数、分配的缓冲区类型的参数和分配的缓冲区首地址的参数。
本实施例提供的GPU加速装置,可以执行上述方法实施例,其实现原理和技术效果类似,此处不再赘述。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!