一种基于全息技术实时表演方法及其系统与流程
本发明涉及一种基于全息技术实时表演方法及其系统,属于信息采集领域。
背景技术:
“虚拟偶像”,可能是这些年来大家听到最多的一个词了。虚拟偶像凭借其新颖的表现形式,优美可人的人物形象,多才多艺载歌载舞的舞台风格,渐渐得到了大众广泛的欢迎。在日本,以初音为代表的虚拟偶像获得了巨大的成功。这些虚拟偶像也在一些国家举办过一些虚拟演唱会,但是都是采用录播的表现形式,缺少真人的不确定感,同时也缺少与真人互动的环节。
技术实现要素:
为解决上述问题,本发明的目的在于提供一种基于全息技术实时表演方法及其系统,通过制作三维虚拟偶像模型,捕捉待测对象的位置及动作获得动捕数据并生成三维骨骼模型和三维骨骼动作数据,将获得的三维骨骼模型与三维虚拟偶像模型进行绑定,根据获得的三维骨骼动作数据,与待测对象进行实时联动,并将三维虚拟偶像模型投影到指定区域,实现三维虚拟人物的全息互动展示。
本发明解决其问题所采用的技术方案一方面是:一种基于全息技术实时表演方法,其特征在于,所述方法包括以下步骤:制作三维虚拟偶像模型;捕捉待测对象的位置及动作获得动捕数据并生成三维骨骼模型和三维骨骼动作数据;将获得的三维骨骼模型与三维虚拟偶像模型进行绑定;三维虚拟偶像模型获取三维骨骼动作数据,根据获得的三维骨骼动作数据,与待测对象进行实时联动,并将三维虚拟偶像模型投影到指定区域。
进一步的,所述三维骨骼动作数据包括运动目标的三维空间坐标、人体关节的6自由度运动参数。
进一步的,所述三维骨骼模型与三维虚拟偶像模型包括人体骨骼节点信息。
进一步的,所述将获得的三维骨骼模型与三维虚拟偶像模型进行绑定,包括:将三维骨骼模型的人体骨骼节点信息与三维虚拟偶像模型的骨骼进行捆绑匹配。
进一步的,所述三维虚拟偶像模型获取三维骨骼动作数据,包括:使用基于xml的文件存储格式用于存储三维骨骼动作数据,并使用定制的基于tcp的专有应用层协议用于实时传输三维骨骼动作数据,三维虚拟偶像模型获取并存储三维骨骼动作数据。
进一步的,所述根据获得的三维骨骼动作数据,与待测对象进行实时联动,包括:根据获得的三维骨骼动作数据,执行三维虚拟偶像模型碰撞检测,包括虚拟偶像身体部位之间,虚拟偶像之间以及虚拟偶像与虚拟场景和物体之间的碰撞检测;在制定区域中创建三维虚拟偶像的活动场景,其中活动场景用于限制三维虚拟偶像的投影范围;三维虚拟偶像模型调用三维骨骼动作数据,用于驱动三维虚拟偶像模型执行对应动作,实现与待测对象的实时联动;将三维虚拟偶像模型投影到制定区域中的活动场景中。
本发明解决其问题所采用的技术方案另一方面是:一种基于全息技术实时表演系统,用于实现如权利要求1所述的方法,其特征在于,包括:三维建模模块,用于建立三维虚拟偶像模型;红外动作捕捉模块,用于捕捉待测对象的位置及动作获得动捕数据;骨骼模型建立模块,用于根据待测对象生成三维骨骼模型和根据动捕数据生成三维骨骼动作数据;骨骼绑定模块,用于将三维骨骼模型与三维虚拟偶像模型进行绑定匹配;联动模块,用于根据捕捉的动捕数据对三维虚拟偶像模型进行驱动,实现与待测对象进行实时联动;投影模块,用于将生成的三维虚拟偶像模型投影到制定区域;投影接收模块,用于接收投影模块发出的图像信号。
进一步的,所述联动模块包括:存储模块,用于存储三维骨骼动作数据;骨骼匹配模块,用于根据三维骨骼动作数据驱动三维虚拟偶像模型,做出对应动作。
进一步的,所述联动模块包括:碰撞检测模块,用于根据获得的三维骨骼动作数据,执行三维虚拟偶像模型碰撞检测,包括虚拟偶像身体部位之间,虚拟偶像之间以及虚拟偶像与虚拟场景和物体之间的碰撞检测。
进一步的,所述投影接收模块为钢化玻璃反射膜金字塔幕;所述投影模块为激光距投影仪。
本发明的有益效果是:本发明采用的一种基于全息技术实时表演方法及其系统,使虚拟偶像真正的活了起来,而不仅仅是录好的视频,凭借这套系统,虚拟偶像将可以和台下观众进行互动,大大的提高了娱乐性和趣味性。
附图说明
图1所示为根据本发明的方法的总体流程图;
图2所示为根据本发明较佳实施例的系统模块框图;
图3所示为根据本发明的方法的较佳实施例的流程图。
具体实施方式
以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整的描述,以充分地理解本发明的目的、方案和效果。
需要说明的是,如无特殊说明,本公开中所使用的上、下、左、右等描述仅仅是相对于附图中本公开各组成部分的相互位置关系来说的。在本公开中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。此外,除非另有定义,本文所使用的所有的技术和科学术语与本技术领域的技术人员通常理解的含义相同。本文说明书中所使用的术语只是为了描述具体的实施例,而不是为了限制本发明。
本文所提供的任何以及所有实例或示例性语言(“例如”、“如”等)的使用仅意图更好地说明本发明的实施例,并且除非另外要求,否则不会对本发明的范围施加限制。
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
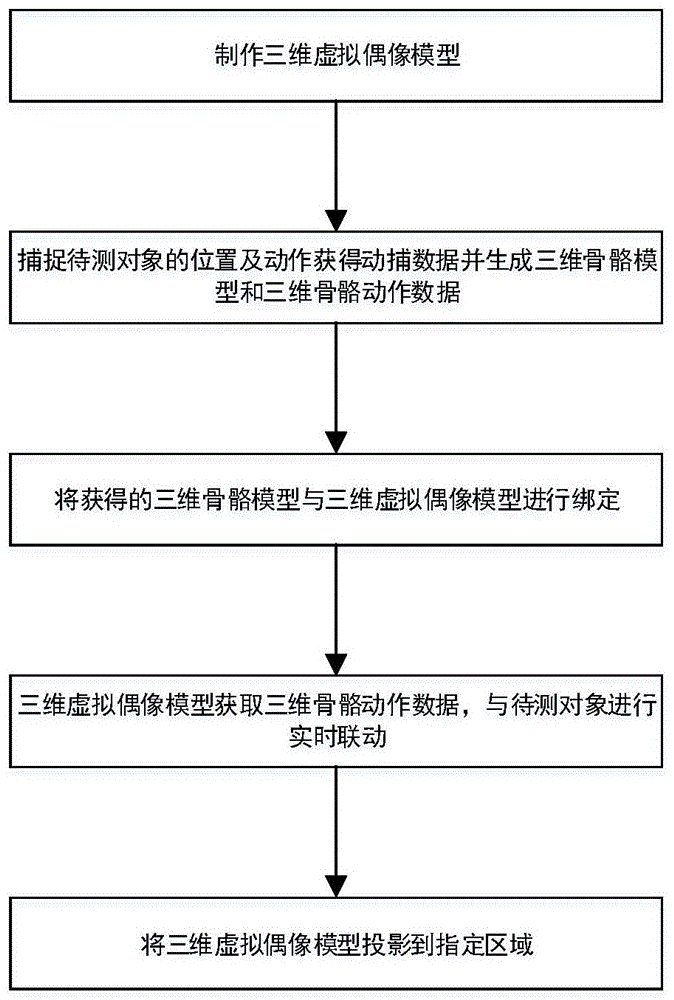
参照图1所示为根据本发明的方法的总体流程图,
制作三维虚拟偶像模型;
形状建模
要表现三维物体,最基本的是绘制出三维物体的轮廓,利用点和线来构建整个三维物体的外边界,即仅使用边界来表示三维物体。三维图形物体中运用边界表示的最普遍方式是使用一组包围物体内部的表面多边形来存储物体的描述,多面体的多边形表示精确的定义了物体的表面特征,但对其它物体,则可以通过把表面嵌入到物体中来生成一个多边形网格逼近,曲面上采用多边形网格逼近可以通过将曲面分成更小的多边形加以改进。由于线框轮廓能快速显示以概要的说明表面结构,因此,这种表示在设计和实体模型应用中普遍采用。通过沿多边形表面进行明暗处理来消除或减少多边形边界,以实现真实性绘制。
外观建模
对象的外表是一种物体区别于其它物体的质地特征,vr系统中虚拟对象的外表真实感主要取决于它的表面反射和纹理。一般来讲,只要时间足够宽裕,用增加物体多边形的方法可以绘制出十分逼真的图形表面。但是vr系统是典型的限时计算与显示系统,对实时性要求很高。因此,省时的纹理映射(texturemapping)技术在vr系统几何建模中得到广泛应用。用纹理映射技术处理对象的外表,一是增加了细节层次以及景物的真实感;二是提供了更好的三维空间线索;三是减少了视景多边形的数目,因而提高了帧刷新率,增强了复杂场景的实时动态显示效果。
捕捉待测对象的位置及动作获得动捕数据并生成三维骨骼模型和三维骨骼动作数据;
首先,动捕演员进入布置了红外光学定位装置的动捕房间中,由动捕设备进行动作捕捉,,并连接至系统,然后动捕演员开始按照剧本进行表演,动捕设备将采集的动捕数据实时传输至系统中,骨骼模型建立模块利用这些动捕数据生成三维骨骼动作数据并建立三维骨骼模型,同时场景绘制控制器采集动捕演员的头部运动和眼睛运动从而判断动捕演员视线方向和景深以便实时绘制模块绘制出相应的三维场景,获得三维虚拟偶像模型动画和实时三维场景后,渲染模块将其结合起来进行渲染。
将获得的三维骨骼模型与三维虚拟偶像模型进行绑定;
将三维骨骼模型的人体骨骼节点信息与三维虚拟偶像模型的骨骼进行捆绑匹配,保证三维虚拟偶像模型根据三维骨骼动作数据做出的动作与动捕演员的实际表演的契合度,不至于太过于违和。
三维虚拟偶像模型获取三维骨骼动作数据,根据获得的三维骨骼动作数据,与待测对象进行实时联动,并将三维虚拟偶像模型投影到指定区域。
使用基于xml的文件存储格式用于存储三维骨骼动作数据,并使用定制的基于tcp的专有应用层协议用于实时传输三维骨骼动作数据,三维虚拟偶像模型获取并存储三维骨骼动作数据,根据获得的三维骨骼动作数据,执行三维虚拟偶像模型碰撞检测,包括虚拟偶像身体部位之间,虚拟偶像之间以及虚拟偶像与虚拟场景和物体之间的碰撞检测;在制定区域中创建三维虚拟偶像的活动场景,其中活动场景用于限制三维虚拟偶像的投影范围;三维虚拟偶像模型调用三维骨骼动作数据,用于驱动三维虚拟偶像模型执行对应动作,实现与待测对象的实时联动;将三维虚拟偶像模型投影到制定区域中的活动场景中,由联动模块实时驱动远程舞台中间的玻璃金字塔中的虚拟偶像。完成表演
参照2所示为根据本发明较佳实施例的系统模块框图,包括:
三维建模模块,用于建立三维虚拟偶像模型;
红外动作捕捉模块,用于捕捉待测对象的位置及动作获得动捕数据;
骨骼模型建立模块,用于根据待测对象生成三维骨骼模型和根据动捕数据生成三维骨骼动作数据;骨骼绑定模块,用于将三维骨骼模型与三维虚拟偶像模型进行绑定匹配;联动模块,用于根据捕捉的动捕数据对三维虚拟偶像模型进行驱动,实现与待测对象进行实时联动;投影模块,用于将生成的三维虚拟偶像模型投影到制定区域;投影接收模块,用于接收投影模块发出的图像信号。联动模块包括:存储模块,用于存储三维骨骼动作数据;骨骼匹配模块,用于根据三维骨骼动作数据驱动三维虚拟偶像模型,做出对应动作;碰撞检测模块,用于根据获得的三维骨骼动作数据,执行三维虚拟偶像模型碰撞检测,包括虚拟偶像身体部位之间,虚拟偶像之间以及虚拟偶像与虚拟场景和物体之间的碰撞检测。
投影接收模块可为钢化玻璃反射膜金字塔幕;所述投影模块可为激光距投影仪。
参照图3所示为根据本发明的方法的较佳实施例的流程图,
虚拟人脸袋惰的运动踉踪
关键技术有三点:获取人人险的运动数据、驱动稠密网络模型以及实现非特定人的人脸险动画。可以针对不同的应用场景,能够自适应地使用相应的技术,来跟踪人体骨骼节点的数据和人脸表面的稠密网络数据。比如在单人近距坐姿的场景下,只要跟踪上半身骨骼节点的姿态,重点在于双手和人脸表情。
虚拟人物的三维建模技术
三维虚拟偶像的视觉效果由unity3d构建,虚拟偶像的动作和表情的控制来源为动捕数据,需要包括几个功能:
a)人体骨骼节点信息与虚拟人骨骼的捆绑。
b)人脸表情信息与虚拟人脸的捆绑。
c)虚拟人在虚拟场景中的3d位置信息,特别是虚拟物体之间相对于虚拟摄像机的遮挡关系。
d)碰撞检测,包括虚拟偶像身体部位之间,虚拟偶像之间,虚拟偶像与虚拟场景和物体之间的碰撞检测。
虚拟人物在虚拟环境场集中的交互
虚拟场景和物体大部分为静止或哥王先设定好的动作,而通过识别被摄人体的姿势可以用来控制虚拟物体(比如虚拟屏幕或虚拟道具等)。
系统需要设定一套姿势标准,让被摄人能与虚拟物体进行交互,比如在做出来一种姿势后,当检测并识别出为标准中设设虚拟屏幕开始播放vcr视额的姿势后,联动模块开始驱动虚拟偶像表演。
传统和基于深度图像的运动捕捉技术
目前虚拟人物动作仿真通常所采用的方法主要
有.角色动画软件(如autodesk公司的motionbuilder角色动画软件}、视频动作提取以及传感器硬件运动捕获等方法。传统的运动捕捉技术有如下几种:
电磁式运动捕捉系统
机械式运动捕捉系统
声学式运动捕捉系统
光学式运动捕捉系统
目前光学式运动捕捉系统应用较为普遍,它所跟踪的对象身上佩戴一标记点(marker),在专门的场地中标定一些摄像机的物理参数。当捕捉软件从图像序列中识别出其中的标记点后,通过所拍摄的图像和参数生确定这一时刻该点在空间中的位置,连续拍摄就可以得到该点的运动轨迹。
总体来说,传统的运动捕捉技术在操作上比较复杂,寻求更自然的人体姿态跟踪方式是目前业界研究的重点。通过深度信息米获取人体的姿态跟踪(skeletontracking)不需要过多的准备工作,降低了对设备和人员的要求。
人体骨髓节点运动状态的实时分析
得到了三维场景的深度数据后,可以通过机器学习的方法从深度数据中槌取出人物’商俯节点的运动状态数据,并用于驱动虚拟角色模型。
传送和储存人体信息的协议
编制一种基于tcp之上的专有应用层协议和基于xml的文件储存格式,用于实时传送和储存人体骨骼节点和人脸表情信息,这些数据被录制下来,当没有真是的人用于动作捕捉时,可以直接用这些数据来创建虚拟偶像的运动动作。
虚拟人物的三维建模技术
虚拟人的三维建模技术相对比较成熟,可以用商业软件来生,比如poser是一款三维人体造型软件,内置了丰富的模型,这些模型以库形式存放在资料板中。构成模型的各个组成部分都可以通过控制参数来修改造型,如人的头部、手部和脚部等,调整参数盘的设置可以方便随意地调整模型的体态,从而建立出一个特定角色的体态特征造型。
虚拟人脸表情的运动模拟
按照人脸建模所采用的方法不同,人脸建模可以大体分为四类:参数模型、生理肌肉模型、基于图像的视觉模型以及基于人脸库的组合模型。
虚拟人物在座拟环镜场景中的交互
对手势和姿态识别技术进行研究,可以用来控制虚拟物体如虚拟屏幕或虚拟道具,通过利用某两个关节点之间的欧氏距离,以及通过计算领域连接关节点连线之间的角度来进行特定姿势的识别,方便于虚拟物体id交互,还应建立标准的手势和姿态库。
以上所述,只是本发明的较佳实施例而已,本发明并不局限于上述实施方式,只要其以相同的手段达到本发明的技术效果,都应属于本发明的保护范围。在本发明的保护范围内其技术方案和/或实施方式可以有各种不同的修改和变化。
- 还没有人留言评论。精彩留言会获得点赞!