基于IsolationForest的城市道路交通异常检测方法与流程
本发明属于智能交通领域,尤其涉及一种基于Isolation Forest的城市道路交通异常检测方法。
背景技术:
交通异常是指道路的实际运行特征偏离了它期望的运行特征,这在城市交通路网中广泛的存在。当发生重大交通事故、集会、施工以及交通管制等情况时,路网交通流会变得异常,影响出行时间、效率以及造成污染等,因此对于交通管理部门来说,检测城市路网中的异常十分重要。但是基于城市路网的复杂性,目前大多数的异常算法研究还只是基于高速公路和快速路而展开的,对于城市道路交通异常检测仍处于弱势。
城市道路交通异常的检测基于采集到的交通数据进行,本质上是一个模式识别或分类问题。根据所使用的数据源的不同,现有的交通异常检测方法可以分为两类:基于固定监测器的检测方法和基于浮动车的检测方法。
被广泛应用的基于固定监测器的交通异常检测算法有:基于模式识别的加利福尼亚算法、基于统计分析的标准偏差法等。加利福尼亚算法通过比较相邻检测站之间的占有率数据,对可能存在的交通异常进行判别。标准偏差法通过判断交通参数的变化率是否大于指定的阈值来实现对交通异常的判别。固定监测器大多是铺设在道路上的,数据精度较好,但是只能检测特定点的交通信息,难以检测路段的交通信息。
浮动车技术是发展比较新型的交通信息采集技术。浮动车是装备有GPS设备的车辆,具有应用方便、经济、覆盖范围广等特点,且采集到的是基于路段区间的数据(如路段的速度),能较为真实的反映道路的运行状况。
基于固定监测器数据的检测方法是直接检测道路相关参数的变化,而浮动车返回的数据是车辆行驶状态的参数,因此基于固定监测器的检测方法无法适用于浮动车数据。
基于浮动车数据的城市交通异常检测算法有两类:一类算法将地图划分为区域,用向量表示区域与区域之间车辆流动的变化,然后用KNN等方法检测异常,这些算法得到的是区域与区域之间的异常;另一类算法计算检测道路的异常,例如正态偏差检测算法,该算法假定道路在某个时间段内的交通值服从正态分布,如果某个时间段的交通流量超过了指定的阈值,则认为这条道路在这个时间段内是异常的,该方法需要计算所有道路在不同的时间段内分布值,当道路数量较多的时候计算量大。
Isolation Forest方法最初提出来是用于检测网络入侵数据等。它的基本思想是认为异常数据在整体数据里是孤立而且较少的,那么在对数据进行划分时,异常数据相对于正常的数据只需要很少的次数就能划分出来。Isolation Forest方法在对内存需求较低的情况下能保持线性时间复杂度,因为Isolation Forest方法通过采样数据集来训练异常树,因此在数据量较大的数据集以及高维数据集上也有很好的表现。
技术实现要素:
本发明提供一种基于Isolation Forest的城市道路交通异常检测方法。以道路为检测对象,根据道路在不同时段的平均运行速度划分不同类别数据集,基于每个数据集训练一个Isolation Forest,通过检测道路速度在Isolation Forest中到根节点的距离来判断道路是否异常。本发明提出的方法计算量小,不需要对每条道路都计算其分布。
为实现上述方法,本发明采用如下的技术方案:
一种基于Isolation Forest的城市道路交通异常检测方法包括以下步骤:
步骤1、以道路为检测对象,根据道路在不同时段的平均运行速度划分不同类别数据集;
步骤2、基于每个数据集训练一个Isolation Forest,通过检测道路速度在Isolation Forest中到根节点的距离来判断道路是否异常。
作为优选,步骤1具体为:
设城市路网用一个有向图G表示:
G=(V,E)
V是有向图的点集,每个点表示路网中的交叉口,由经度和纬度组成的两元组表示;E是有向图的边集,每条边表示路网中某条道路;
浮动车通过携带的GPS设备返回车辆状态,返回数据的形式如下:
record=[car ID,time,latitude,lontitude,speed,angel]
其中car ID表示车辆的车牌号,time表示返回记录时的时间,latitude、lontitude表示返回记录时车辆所在位置的经度和纬度,speed表示车辆速度,angel表示车辆行驶角度;
首先,对浮动车返回的数据进行地图匹配,计算与浮动车返回数据(latitude、lontitude)最接近的道路上的点,即使浮动车数据与路段匹配的正确位置;
其次,将浮动车数据匹配后的道路数据进行分类,分类有时间和速度两个维度的标准:1)对每日06:00到21:00时间段以预设时间间隔进行划分;2)将每个时间段内道路速度按照城市道路交通评价指标体系分为四个速度区间,
然后对路网中所有道路按照时间段标记速度区间,即<e,t,s>表示在时间段t,道路e属于速度区间s,s∈{S1,S2,S3,S4},e∈E,其中s是n天内的时间段t道路e速度的均值;
根据道路标记的速度区间,将所有的道路数据分为四个数据集Di,i∈{1,2,3,4},如果<e,t,s>的分量s∈Si,则道路e在n天内的时间段t的记录<e,tj,speed>∈Di,j={1,2,……n}。
作为优选,步骤2具体包括以下步骤为:
步骤2.1、基于数据集Di构建Isolation Forest Fi={Tk|k=1,2,…,m}用于检测城市道路交通异常,Fi是包含m棵异常树的森林;
步骤2.2、检测一条道路记录<e,tj,speed>,即道路e在第j天的时间段t内的平均速度speed是否异常,先找到其所属的速度区间Si,即找到了对应的Isolation Forest Fi,然后计算道路记录在Fi中的平均深度;
步骤2.3、根据计算得到道路记录在Isolation Forest Fi中的平均深度,即道路记录距离根节点的期望长度为length,按照公式(1)计算异常值
c(ψ)由公式(2)计算。
H(ψ-1)=ln(ψ-1)+0.57721(欧拉常数)
其中,ψ为256,
如果记录的返回值s非常接近1,表明记录离根节点近,通过很少的划分便能隔离出来,则这条记录可以认为是异常的;
如果返回值远远小于0.5,说明记录距离根节点较远,需要多次划分才能将这条记录隔离出来,则这条记录可以认为是正常的。
附图说明
图1为Isolation Tree的结点结构;
图2异常路段数比例;
图3本方法检测到的异常路段;
图4 Isolation Forest与正态偏差检测算法训练所消耗的时间示意图。
图5本发明异常检测方法的流程图。
具体实施方式
如图5所示,本发明提供一种基于Isolation Forest的城市道路交通异常检测算法。以道路为检测对象,根据道路在不同时段的平均运行速度划分不同类别数据集,基于每个数据集训练一个Isolation Forest,通过检测道路速度在Isolation Forest中到根节点的距离来判断道路是否异常。本发明提出的方法计算量小,不需要对每条道路都计算其分布。
城市路网用一个有向图G表示:
G=(V,E)
V是有向图的点集,每个点表示路网中的交叉口,一般由经度和纬度组成的两元组表示。E是有向图的边集,每条边表示路网中某条道路。
浮动车通过携带的GPS设备返回车辆状态,返回数据的形式如下:
record=[car ID,time,latitude,lontitude,speed,angel]
其中car ID表示车辆的车牌号,time表示返回记录时的时间,latitude、lontitude表示返回记录时车辆所在位置的经度和纬度,speed表示车辆速度,angel表示车辆行驶角度。一般来说,每日21:00到次日6:00之间浮动车数量较少,返回的数据量不够,因此异常检测只考虑当日06:00到21:00时间段上的道路异常状态检测。
首先需要对浮动车返回的数据进行地图匹配,因为浮动车返回的经纬度信息存在偏差,需要计算与浮动车返回数据(latitude、lontitude)最接近的道路上的点,即使浮动车数据与路段匹配的正确位置,然后根据浮动车的速度计算出道路的平均速度。
其次为了更加精确的检测到异常,需要将浮动车数据匹配后的道路数据进行分类,分类有时间和速度两个维度的标准:1)对每日06:00到21:00时间段以20分钟为间隔进行划分,即每天包含有45个时间段;2)将每个时间段内道路速度按照城市道路交通评价指标体系分为四个速度区间,对特定速度值speed来说
if speed>60km/h speed∈S1
else if speed≥40km/h speed∈S2
else if speed≥20km/h speed∈S3
else speed∈S4
然后对路网中所有道路按照时间段标记速度区间,即<e,t,s>表示在时间段t,道路e属于速度区间s,s∈{S1,S2,S3,S4},e∈E,其中s是n天内的时间段t道路e速度的均值。
根据道路标记的速度区间,将所有的道路数据分为四个数据集Di,i∈{1,2,3,4}。如果<e,t,s>的分量s∈Si,则道路e在n天内的时间段t的记录<e,tj,speed>∈Di,j={1,2,……n}。
接下来基于数据集Di构建Isolation Forest Fi={Tk|k=1,2,…,m}用于检测城市道路交通异常,Fi是包含m棵异常树的森林。
基于数据集D构建Isolation Forest F的算法如下:
异常树的构建算法如下:
检测一条道路记录<e,tj,speed>,即道路e在第j天的时间段t内的平均速度speed是否异常,先找到其所属的速度区间Si,即找到了对应的IsolationForest Fi,然后计算道路记录在Fi中的平均深度。
计算道路记录在Isolation Forest中的平均深度算法如下:
根据Algorithm 3可计算得到记录x在Isolation Forest Fi中的平均深度,即记录x距离根节点的期望长度为length,按照公式(1)计算异常值
c(ψ)由公式(2)计算。
H(ψ-1)=ln(ψ-1)+0.57721(欧拉常数)
本发明中ψ取值256。
s关于length单调递减,如果记录的返回值s非常接近1,表明记录离根节点近,通过很少的划分便能隔离出来,则这条记录可以认为是异常的。
如果返回值远远小于0.5,说明记录距离根节点较远,需要多次划分才能将这条记录隔离出来,则这条记录可以认为是正常的。
本发明对上述方法进行了实验,并得到了明显的效果。实验区域是在北京市五环内。我们用OpenStreeMap(OSM)数据来构建北京市的路网,剔除掉一些车辆无法通行的道路后,共有39951条路。出租车数据从2013年6月1日到2013年6月14日,剔除掉错误数据和不符合要求的数据后,每日的数据量约在1000万条以上。
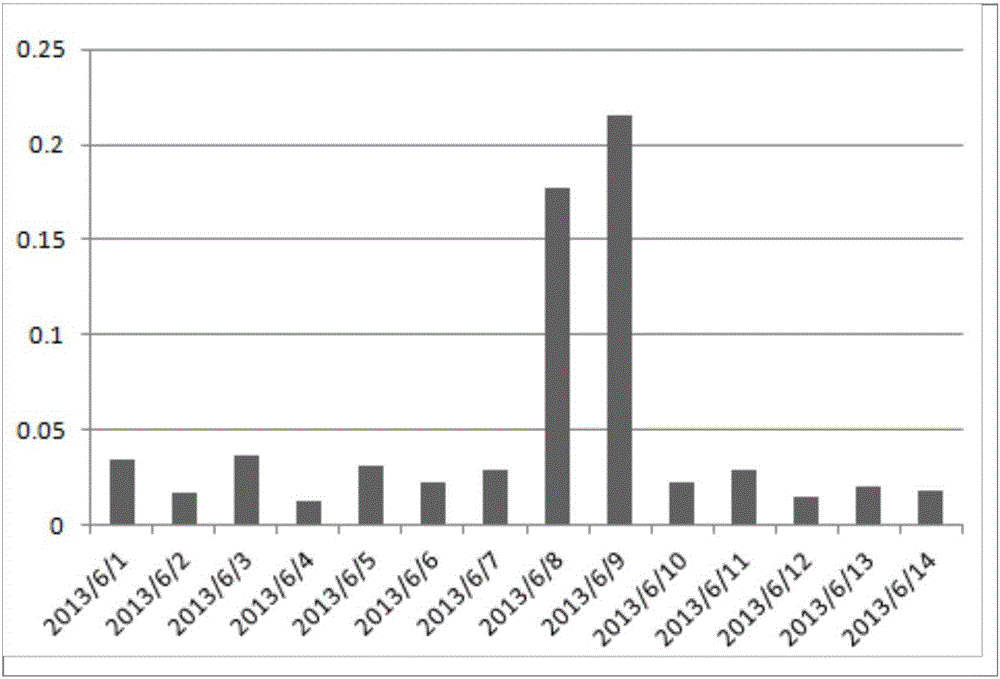
根据我们的方法计算14天中每天异常路段数占总体的比例,如图2所示,可以看出在2013年6月8日与6月9日异常路段数明显增多。而根据北京交通发展研究中心发布的北京市道路交通运行分析报告中指出,在2013年6月8日与6月9日适逢端午假期前不限行工作日、北京市高考以及降雨三因素叠加,道路交通拥堵情况突出,特别是6月9日高峰交通指数达到6月最高值8.4。
而北京市交通委发布的数据也显示6月8日与6月9日的道路交通指数明显要高于其它几天。表1为北京市交通委发布的道路交通指数。
表1 2013年6月北京市交通指数
图3为2013年6月8日18:20:00时的交通情况。其中黑线部分表示本方法检测到的异常路段。
而Isolation Forest在时间上也要优于基于道路的正态偏差检测算法。这两种算法在检测一条纪录是否异常所消耗的时间都在1ms左右,但是在训练过程中正态偏差算法所需的时间与道路数量成线性关系,道路数量越多,其训练需要的时间越长。而Isolation Forest算法因为是基于采样数据来构建异常树,因此训练所消耗的时间与道路数量无关。
图4为两种算法在训练上所消耗的时间。可以看出在道路数量较多时,Isolation Forest所消耗的时间要明显少于正态偏差检测算法。
- 还没有人留言评论。精彩留言会获得点赞!