一种基于经验模态分解的音频识别方法及系统与流程
本发明涉及音频识别领域,尤其涉及一种基于经验模态分解的音频识别方法及系统。
背景技术:
音频识别是指通过对音频信号进行频谱分析,获得音频信号的频谱,提取音频信号的特征值,构建模型或星座图,进行目标匹配、识别。主要技术包括短时傅氏变换、声谱图特征提取、特征模板生成等。
对一段原始音频或语音的具体处理大多经过如下步骤:预加重(Pre-emphasis)去噪、分帧、加窗处理、快速傅里叶转换(FFT)、滤波组处理(Mel-Filter Bank)、离散余弦转换DCT(计算倒谱参数)、对数能量、差量倒谱参数(向量形式、逆傅氏变换IFFT)、MFCC(梅尔频率倒谱系数---一帧音频的特征值)等,最终获得一段音频信号的一系列特征值,此系列特征值可充分、完全表征此段音频信号。
目前,主流音频信号的匹配识别算法主要是对声谱图(描述了特定频率的强度随着时间的变化)进行处理,包括比较时间、频率变化和不同或者寻找波峰。其中的一个主要技术实现方案为将频率转换为音符进行处理,每个音符对应一个音域,形成一个N维的特征向量,再经过过滤和标准化处理,获得特征声谱图,通过滑动子图的方法获得音频声纹,并针对声纹计算位错误率完成识别匹配。另一个主要技术方案为获取一段声谱图的一系列极大值点,获得此极大值点的所处的时间点和频率,基于多个极大值点构建星座图,依据星座图内两点的时间偏移和各自的频率强度生成此时间点上的哈希值,最终通过统计相同时间偏移的哈希值的个数完成目标的识别。
特征模型和星座图的构建相对复杂,不能有效的、完整的表征音频信号特征的变化,无法将特征的变化过程和趋势融入到特征值的生成,即形成的特征模板不能完整、充分表征音频信号。
因此,现有技术还有待于改进和发展。
技术实现要素:
鉴于上述现有技术的不足,本发明的目的在于提供一种基于经验模态分解的音频识别方法及系统,旨在解决现有的识别方法无法完整、充分表征音频信号的问题。
本发明的技术方案如下:
一种基于经验模态分解的音频识别方法,其中,包括步骤:
A、输入原始音频信号,对所述原始音频信号进行采样,然后依次进行去噪预处理、加汉明窗以及傅氏变换处理得到频谱数据,再依次连接每帧的频谱数据,获得声谱图;
B、获得所述声谱图各频率段的能量最大值所在点,并依次连接各频率段的能量最大值所在点生成时间-频率曲线;
C、将所述生成的时间-频率曲线进行经验模态分解,获得多个本征模函数;
D、通过获得的多个本征模函数结合相应的频率段以及时间帧,生成用于表征原始音频信号的多个特征值,并输出。
优选的,所述步骤D具体包括:
D1、对每一个本征模函数等间隔取样,获得一组相应的取样序列;
D2、在所述取样序列后追加所处的频率段序号;
D3、对追加后的取样序列进行处理获得一个哈希值;
D4、通过N组本征模函数获得N个哈希值,共同组成一组特征值。
优选的,所述步骤D之后还包括:
E、根据所述特征值获取时间偏移差的分布和数量,以表征原始音频信号。
优选的,所述步骤E具体包括:
E1、通过所述特征值在一数据库中进行搜索,获得与所述特征值相匹配的若干其他特征值所处的时间偏移构成的时间偏移组;
E2、将所述时间偏移组中各时间偏移与所述特征值所处的时间偏移分别求得时间偏移差,再通过这些时间偏移差的分布和数量,确定需识别的目标音频。
优选的,所述步骤D3中,对追加后的取样序列通过sha1哈希算法或Murmur哈希算法处理获得一个哈希值。
一种基于经验模态分解的音频识别系统,其中,包括:
声谱图获取模块,用于输入原始音频信号,对所述原始音频信号进行采样,然后依次进行去噪预处理、加汉明窗以及傅氏变换处理得到频谱数据,再依次连接每帧的频谱数据,获得声谱图;
时间-频率曲线生成模块,用于获得所述声谱图各频率段的能量最大值所在点,并依次连接各频率段的能量最大值所在点生成时间-频率曲线;
经验模态分解模块,用于将所述生成的时间-频率曲线进行经验模态分解,获得多个本征模函数;
特征值输出模块,用于通过获得的多个本征模函数结合相应的频率段以及时间帧,生成用于表征原始音频信号的多个特征值,并输出。
优选的,所述特征值输出模块具体包括:
取样单元,用于对每一个本征模函数等间隔取样,获得一组相应的取样序列;
追加单元,用于在所述取样序列后追加所处的频率段序号;
哈希处理单元,用于对追加后的取样序列进行处理获得一个哈希值;
向量组成单元,用于通过N组本征模函数获得N个哈希值,共同组成一组特征值。
优选的,所述音频识别系统还包括:
分布数量获取模块,用于根据所述特征值获取时间偏移差的分布和数量,以表征原始音频信号。
优选的,所述分布数量获取模块具体包括:
时间偏移组获取单元,用于通过所述特征值在数据库中进行搜索,获得与所述特征值相匹配的若干其他特征值所处的时间偏移构成的时间偏移组;
时间偏移差计算单元,用于将所述时间偏移组中各时间偏移与所述特征值所处的时间偏移分别求得时间偏移差,再通过这些时间偏移差的分布和数量,确定需识别的目标音频。
优选的,所述哈希处理单元中,对追加后的取样序列通过sha1哈希算法或Murmur哈希算法处理获得一个哈希值。
有益效果:本发明将EMD经验模态分解的方法引入到音频信号特征值的生成,从而将音频特征的变化趋势信息充分融合到特征值的生成,使生成的特征值更完整的表征音频信号。本发明可取代构建复杂的特征模型和星座图,并能够有效融合特征的变化过程信息,使得特征值对音频信号的表征更加充分、精确、有效。
附图说明
图1为本发明一种基于经验模态分解的音频识别方法第一实施例的流程图;
图2为本发明中经过短时傅里叶变换生成的声谱图;
图3为图1所示方法中步骤S104的具体流程图;
图4为本发明中经EMD分解后生成的5项IMF数据曲线;
图5为本发明一种基于经验模态分解的音频识别方法第二实施例的流程图;
图6为图5所示方法中步骤S105的具体流程图;
图7为本发明一种基于经验模态分解的音频识别系统第一实施例的结构框图;
图8为图7所示系统中特征值输出模块的具体结构框图;
图9为本发明一种基于经验模态分解的音频识别系统第二实施例的结构框图;
图10为图9所示系统中分布数量获取模块的具体结构框图。
具体实施方式
本发明提供一种基于经验模态分解的音频识别方法及系统,为使本发明的目的、技术方案及效果更加清楚、明确,以下对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
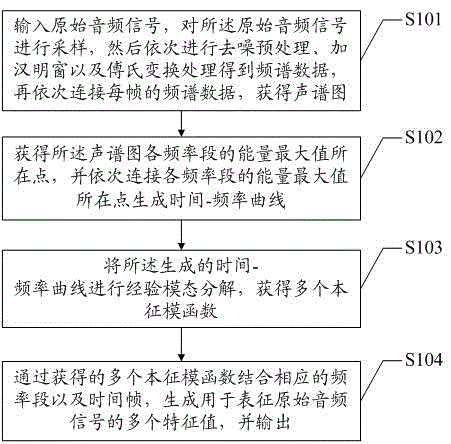
请参阅图1,图1为本发明一种基于经验模态分解的音频识别方法第一实施例的流程图,如图所示,其包括步骤:
S101、输入原始音频信号,对所述原始音频信号进行采样,然后依次进行去噪预处理、加汉明窗以及傅氏变换处理得到频谱数据,再依次连接每帧的频谱数据,获得声谱图;
S102、获得所述声谱图各频率段的能量最大值所在点,并依次连接各频率段的能量最大值所在点生成时间-频率曲线;
S103、将所述生成的时间-频率曲线进行经验模态分解,获得多个本征模函数;
S104、通过获得的多个本征模函数结合相应的频率段以及时间帧,生成用于表征原始音频信号的多个特征值,并输出。
本发明的方法将经验模态分解(EMD,Empirical Mode Decomposition)的方法引入到音频信号特征值的生成,由于EMD生成的本征模函数(IMF,Intrinsic Mode Function)项具有能够充分保留原始队列信号的特征、易于处理非平稳序列等优点,将经验模态分解的方法引入到特征值的生成,通过将声谱图生成的能量最大值所在点(tn, fn)构成为EMD分解的原始信号队列,对此原始信号队列进行EMD分解获得N个IMF项。本发明的方法可充分保留信号特征在频域随时间变化的趋势信息,使得特征值对音频信号的表征更加充分、精确、有效。
具体来说,在步骤S101中,原始音频信号(即模拟音频信号)通过麦克风输入后,通过A/D模数转换、采样(例如按照44100Hz的采样率采样),获得数字音频信号。
然后通过谱减法去噪,其主要利用音频信号的短时平稳特性,从带噪音频信号的短时谱值中减去噪声的短时谱,即消除信号内掺杂的随机环境噪声,从而得到纯净音频信号的频谱(即音频数据,将其缓存),达到语音增强的目的。在谱减法去噪之前,可对数字音频信号进行预加重处理。预加重处理其是利用信号特性和噪声特性的差别有效地对信号进行处理,在噪声引入之前采用预加重网络,减小噪声的高频分量,提高输出信噪比。
再对缓存内的音频数据进行分帧处理,每帧时长N毫秒,分帧后的每段音频数据都可以看成一段稳态信号。
再生成汉明窗,重叠加在音频数据上,重叠率为1/2,帧移为N/2毫秒;由于直接对信号截断会产生频率泄露,为了改善频率泄露的情况,加非矩形窗,例如加汉明窗,因为汉明窗的幅频特性是旁瓣衰减较大,主瓣峰值与第一个旁瓣峰值衰减可达40db。
再对每帧音频数据进行傅氏变换处理(即FFT快速傅里叶变换),获得频谱数据;关于傅氏变换处理的具体技术细节可参考现有技术的内容,在此不再详述。
依次连接每帧的频谱数据,以时间为横轴,以所处频率为纵轴,以颜色表征频谱振幅(能量)强度,绘制得到如图2所示的声谱图。
在步骤S102中,计算声谱图中每帧频谱数据上的各个频率段各个频率点的能量值,取得各频率段能量最大值;依次获得每个频率段能量最大值所在点所处的时间帧和频率段,将此时间帧和频率段作为新的点,依次连接各能量最大值所在点生成目标曲线,即时间-频率曲线。
例如,在声谱图中划分n段连续的频率段,各频率段的序号依次为id1,id2,...,idn, 在某个频率范围内(例如频率段idn,如图2中6kHz至9kHz)连接声谱图各能量最大值所在点,而未达到指定强度阈值的点归为此频率范围的下限值处理,形成一条以时间为横轴,以频率为纵轴的连续的动态变化曲线,即时间-频率曲线。
在所述步骤S103中,将生成的时间-频率曲线进行经验模态分解,获得能充分表征此曲线变化的多个本征模函数项,如获得N组(本曲线生成截止到12组)IMF本征模函数项(每项为时域的变化曲线)。
如图3所示,所述步骤S104具体包括:
S201、对每一个本征模函数等间隔取样,获得一组相应的取样序列;
S202、在所述取样序列后追加所处的频率段序号;
S203、对追加后的取样序列进行处理获得一个哈希值;
S204、通过N组本征模函数获得N个哈希值,共同组成一组特征值。
具体来说,通过对每一个IMF项进行等间隔取样(所有对IMF项的抽样处理间隔保持一致,并且间隔不可过大以保留曲线动态变化信息),如图4中的IMF C1,IMF C2, IMF C3,IMF C4和IMF C5曲线,获得一组相应的取样序列x1、x2...xn,将此取样序列后追加相应IMF项所处的频率段序号idn,对此追加后的取样序列通过sha1哈希算法或Murmur哈希算法获得一个32位或64位的哈希值,这样通过N组(即N个)IMF项获得N个哈希值组成一组特征值(也可称为一组特征向量)。同时保存此组特征值所处的时间偏移tm(即音频信号的起始帧所在时间轴上的位置)。
本发明的方法可将音频特征的变化趋势信息充分融合到特征值的生成,使生成的特征值更完整的表征音频信号。本发明将每帧生成特征值和局部时间段生成特征值结合,丰富了音频特征信息,即对每帧音频和对若干帧音频提取特征值分别进行EMD经验模态分解。本发明可取代构建复杂的特征模型和星座图,并能够有效融合特征的变化过程信息,使得特征值对音频信号的表征更加充分、精确、有效。
请参阅图5,图5为本发明本发明一种基于经验模态分解的音频识别方法第二实施例的流程图,其具体包括:
S101、输入原始音频信号,对所述原始音频信号进行采样,然后依次进行去噪预处理、加汉明窗以及傅氏变换处理得到频谱数据,再依次连接每帧的频谱数据,获得声谱图;
S102、获得所述声谱图各频率段的能量最大值所在点,并依次连接各频率段的能量最大值所在点生成时间-频率曲线;
S103、将所述生成的时间-频率曲线进行经验模态分解,获得多个本征模函数;
S104、通过获得的多个本征模函数结合相应的频率段以及时间帧,生成用于表征原始音频信号的多个特征值,并输出;
S105、根据所述特征值获取时间偏移差的分布和数量,以表征原始音频信号。
其与方法第一实施例不同的是,在步骤S104之后增加了步骤S105。步骤S105,其主要是利用前面生成的特征值,来获取时间偏移差的分布和数量,从而根据直观的表征音频信号。
具体来说,如图6所示,所述步骤S105具体包括:
S301、通过所述特征值在一数据库中进行搜索,获得与所述特征值相匹配的若干其他特征值所处的时间偏移构成的时间偏移组;
S302、将所述时间偏移组中各时间偏移与所述特征值所处的时间偏移分别求得时间偏移差,再通过这些时间偏移差的分布和数量,确定需识别的目标音频。
通过生成的若干特征值在数据库中进行搜索,每个特征值(即目标特征值)可获得与此特征值匹配的若干其他特征值向量所处的时间偏移t1、t2...tn,将这组时间偏移与此特征值(即目标特征值)所处的时间偏移tm分别求得时间偏移差td1、td2...tdn,依次,每平移一次(步长n帧)即可获得N组时间偏移差。
依次,直至处理完整个原始音频信号,最后再通过统计所有时间偏移差的分布和数目,确定目标,其中时间偏移差分布最集中的音频即为识别的目标音频。
为了适当增加所生成特征值的丰富性,通过若干帧(例如50帧)分块,求得每块的能量最大值,再进行如上S103~S105步骤,可获得更多的特征值和时间偏移差。这样,就可以充分捕捉较大范围特征变化信息,以加强整个音频信号的表征。
基于上述方法,本发明还提供一种基于经验模态分解的音频识别系统第一实施例,如图7所示,其包括:
声谱图获取模块100,用于输入原始音频信号,对所述原始音频信号进行采样,然后依次进行去噪预处理、加汉明窗以及傅氏变换处理得到频谱数据,再依次连接每帧的频谱数据,获得声谱图;
时间-频率曲线生成模块200,用于获得所述声谱图各频率段的能量最大值所在点,并依次连接各频率段的能量最大值所在点生成时间-频率曲线;
经验模态分解模块300,用于将所述生成的时间-频率曲线进行经验模态分解,获得多个本征模函数;
特征值输出模块400,用于通过获得的多个本征模函数结合相应的频率段以及时间帧,生成用于表征原始音频信号的多个特征值,并输出。
本发明的系统将经验模态分解引入到音频信号特征值的生成,由于EMD生成的本征模函数项具有能够充分保留原始队列信号的特征、易于处理非平稳序列等优点,将经验模态分解引入到特征值的生成,通过将声谱图生成的能量最大值所在点(tn, fn)构成为EMD分解的原始信号队列,对此原始信号队列进行EMD分解获得N个IMF项。本发明的系统可充分保留信号特征在频域随时间变化的趋势信息,使得特征值对音频信号的表征更加充分、精确、有效。
具体来说,在声谱图获取模块100中,原始音频信号(即模拟音频信号)通过麦克风输入后,通过A/D模数转换、采样(例如按照44100Hz的采样率采样),获得数字音频信号。
然后通过谱减法去噪,其主要利用音频信号的短时平稳特性,从带噪音频信号的短时谱值中减去噪声的短时谱,即消除信号内掺杂的随机环境噪声,从而得到纯净音频信号的频谱(即音频数据,将其缓存),达到语音增强的目的。在谱减法去噪之前,可对数字音频信号进行预加重处理。预加重处理其是利用信号特性和噪声特性的差别有效地对信号进行处理,在噪声引入之前采用预加重网络,减小噪声的高频分量,提高输出信噪比。
再对缓存内的音频数据进行分帧处理,每帧时长N毫秒,分帧后的每段音频数据都可以看成一段稳态信号。
再生成汉明窗,重叠加在音频数据上,重叠率为1/2,帧移为N/2毫秒;由于直接对信号截断会产生频率泄露,为了改善频率泄露的情况,加非矩形窗,例如加汉明窗,因为汉明窗的幅频特性是旁瓣衰减较大,主瓣峰值与第一个旁瓣峰值衰减可达40db。
再对每帧音频数据进行傅氏变换处理(即FFT快速傅里叶变换),获得频谱数据;关于傅氏变换处理的具体技术细节可参考现有技术的内容,在此不再详述。
依次连接每帧的频谱数据,以时间为横轴,以所处频率为纵轴,以颜色表征频谱振幅(能量)强度,绘制得到如图2所示的声谱图。
在所述时间-频率曲线生成模块200中,计算声谱图中每帧频谱数据上的各个频率段各个频率点的能量值,取得各频率段能量最大值;依次获得每个频率段能量最大值所在点所处的时间帧和频率段,将此时间帧和频率段作为新的点,依次连接各能量最大值所在点生成目标曲线,即时间-频率曲线。
例如,在声谱图中划分n段连续的频率段,各频率段的序号依次为id1,id2,...,idn, 在某个频率范围内(例如频率段idn,如图2中6kHz至9kHz)连接声谱图各能量最大值所在点,而未达到指定强度阈值的点归为此频率范围的下限值处理,形成一条以时间为横轴,以频率为纵轴的连续的动态变化曲线,即时间-频率曲线。
在所述经验模态分解模块300中,将生成的时间-频率曲线进行经验模态分解,获得能充分表征此曲线变化的多个本征模函数项,如获得N组(本曲线生成截止到12组)IMF本征模函数项(每项为时域的变化曲线)。
进一步,如图8所示,所述特征值输出模块400具体包括:
取样单元410,用于对每一个本征模函数等间隔取样,获得一组相应的取样序列;
追加单元420,用于在所述取样序列后追加所处的频率段序号;
哈希处理单元430,用于对追加后的取样序列进行处理获得一个哈希值;
向量组成单元440,用于通过N组本征模函数获得N个哈希值,共同组成一组特征值。
具体来说,通过对每一个IMF项进行等间隔取样(所有对IMF项的抽样处理间隔保持一致,并且间隔不可过大以保留曲线动态变化信息),如图4中的IMF C1,IMF C2, IMF C3,IMF C4和IMF C5曲线,获得一组相应的取样序列x1、x2...xn,将此取样序列后追加相应IMF项所处的频率段序号idn,对此追加后的取样序列通过sha1哈希算法或Murmur哈希算法获得一个32位或64位的哈希值,这样通过N组(即N个)IMF项获得N个哈希值组成一组特征值(也可称为一组特征向量)。同时保存此组特征值所处的时间偏移tm(即音频信号的起始帧所在时间轴上的位置)。
本发明的系统可将音频特征的变化趋势信息充分融合到特征值的生成,使生成的特征值更完整的表征音频信号。本发明将每帧生成特征值和局部时间段生成特征值结合,丰富了音频特征信息,即对每帧音频和对若干帧音频提取特征值分别进行EMD经验模态分解。本发明可取代构建复杂的特征模型和星座图,并能够有效融合特征的变化过程信息,使得特征值对音频信号的表征更加充分、精确、有效。
本发明还提供一种基于经验模态分解的音频识别系统第二实施例,如图9所示,其包括:
声谱图获取模块100,用于输入原始音频信号,对所述原始音频信号进行采样,然后依次进行去噪预处理、加汉明窗以及傅氏变换处理得到频谱数据,再依次连接每帧的频谱数据,获得声谱图;
时间-频率曲线生成模块200,用于获得所述声谱图各频率段的能量最大值所在点,并依次连接各频率段的能量最大值所在点生成时间-频率曲线;
经验模态分解模块300,用于将所述生成的时间-频率曲线进行经验模态分解,获得多个本征模函数;
特征值输出模块400,用于通过获得的多个本征模函数结合相应的频率段以及时间帧,生成用于表征原始音频信号的多个特征值,并输出;
分布数量获取模块500,用于根据所述特征值获取时间偏移差的分布和数量,以表征原始音频信号。
其与系统第一实施例不同的是,增加了分布数量获取模块500。所述分布数量获取模块500其主要是利用前面生成的特征值,来获取时间偏移差的分布和数量,从而根据直观的表征音频信号。
进一步,如图10所示,所述分布数量获取模块500具体包括:
时间偏移组获取单元510,用于通过所述特征值在数据库中进行搜索,获得与所述特征值相匹配的若干其他特征值所处的时间偏移构成的时间偏移组;
时间偏移差计算单元520,用于将所述时间偏移组中各时间偏移与所述特征值所处的时间偏移分别求得时间偏移差,再通过这些时间偏移差的分布和数量,确定需识别的目标音频。
通过生成的若干特征值在数据库中进行搜索,每个特征值(即目标特征值)可获得与此特征值匹配的若干其他特征值向量所处的时间偏移t1、t2...tn,将这组时间偏移与此特征值(即目标特征值)所处的时间偏移tm分别求得时间偏移差td1、td2...tdn,依次,每平移一次(步长n帧)即可获得N组时间偏移差。
依次,直至处理完整个原始音频信号,最后再通过统计所有时间偏移差的分布和数目,确定目标,其中时间偏移差分布最集中的音频即为识别的目标音频。
为了适当增加所生成特征值的丰富性,通过若干帧(例如50帧)分块,求得每块的能量最大值,再执行经验模态分解模块300、特征值输出模块400、分布数量获取模块500,可获得更多的特征值和时间偏移差。这样,就可以充分捕捉较大范围特征变化信息,以加强整个音频信号的表征。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!