使核酸分子同步化的方法与流程
本申请要求2015年8月13日提交的美国临时申请第62/204,942号、2015年11月3日提交的美国临时申请第62/250,362号以及2015年11月12日提交的美国临时申请第62/254,647号的权益,所述临时申请各自以引用的方式并入本文。
背景技术:
核酸测序对生物学研究、临床诊断学、个人化医学和医药开发以及许多其他领域有重要意义。有成本效益的、准确的和快速的测序为许多应用所需要,例如(但不限于)微生物或病原体检测和鉴定,以及受试者的遗传鉴定。例如,应用可包括但不限于亲子鉴定和在法医科学中(Reynolds等,Anal.Chem.,63:2-15(1991)),用于器官移植供体-受体匹配(Buyse等,Tissue Antigens,41:1-14(1993)和Gyllensten等,PCR Meth.Appl,1:91-98(1991)),用于遗传性疾病诊断、预后和产前咨询(Chamberlain等,Nucleic Acids Res.,16:11141-11156(1988)和L.C.Tsui,Human Mutat.,1:197-203(1992)),以及药物代谢和致癌突变的研究(Hollstein等,Science,253:49-53(1991))。另外,核酸分析(例如用于传染性疾病诊断)的成本效益直接随批量测试的多重规模而变化。许多的这些应用依靠在多个时常紧密间隔的多个基因座上辨别单碱基差异。
各种DNA杂交技术可用于在包含大量序列区的样品中检测一个或多个选定的多核苷酸序列的存在。在依赖片段捕获和标记的简单方法中,通过与固定探针杂交来捕获包含选定序列的片段。捕获片段可通过与包含可检测的报道基因部分的第二探针杂交而被标记。
另一种广泛使用的方法是Southern印迹法。在这种方法中,样品中的DNA片段混合物由凝胶电泳分离,并且然后固定在硝酸纤维素滤器上。通过使所述滤器与一个或多个标记的探针在杂交条件下反应,可鉴别出存在包含探针序列的条带。所述方法尤其用于鉴别在包含给定探针序列的限制性酶DNA消化物中的片段,以及用于分析限制性片段长度多态性(“RFLP”)。
另一种在多核苷酸样品中检测一个或多个给定序列存在的方法涉及通过聚合酶链式反应(美国专利第4,683,202号和R.K.Saiki等,Science230:1350(1985))来选择性扩增一个或多个序列。在这种方法中,与一个或多个选定序列的相反尾部互补的引物被用于与热循环协同来促进相继的引物引发的复制轮次。扩增的一个或多个序列可通过各种技术容易地鉴别。这种方法特别可用于在包含多核苷酸的样品中检测低拷贝序列的存在,例如用于在体液样品中检测病原体序列。
最近,已报道通过探针连接方法来鉴别已知靶序列的方法(美国专利第4,883,750号,D.Y.Wu等,Genomics 4:560(1989),U.Landegren等,Science 241:1077(1988)以及E.Winn-Deen等,Clin.Chem.37:1522(1991))。在一种被称为寡核苷酸连接反应测定法(“OLA”)的方法中,将跨越目标靶区的两个探针或探针元件与所述靶区杂交。在探针元件与相邻的靶碱基发生碱基配对的情况下,所述探针元件的对面末端可通过连接反应被联结,例如通过用连接酶处理。然后,测定连接的探针元件,以证明靶序列的存在。
在这种方法的变型中,连接的探针元件充当一对互补探针元件的模板。在多对探针元件存在下经过变性、杂交和连接反应的连续循环,将靶序列线性扩增,从而使极小量的靶序列被检测和/或扩增。这种方法被称为连接酶检测反应。当利用探针元件的两个互补对时,所述过程被称为连接酶链式反应,所述反应实现靶序列的指数扩增。F.Barany,Proc.Nat’l.Acad.Sci.USA,88:189-93(1991)和F.Barany,PCR Methods and Applications,1:5-16(1991)。.
另一种用于核酸序列差异的多重检测的方案公开于美国专利第5,470,705号中,其中序列特异性探针(其具有可检测标记以及电荷/平移摩擦拽力的特性比率)可与靶杂交并且连接在一起。这种技术在Grossman等,Nucl.Acids Res.22(21):4527-34(1994)中被用于囊性纤维病跨膜调节子基因的大规模多重分析。Jou等,Human Mutation 5:86-93(1995)涉及通常称作“空隙(gap)连接酶链式反应”的方法的使用,以扩增多个外显子的选定区,并且同时在免疫层析试纸条上读取扩增产物,所述免疫层析试纸条含有对每个外显子的探针上的不同半抗原具有特异性的的抗体。
等位基因特异性探针的连接一般已使用固相捕获(U.Landegren等,Science,241:1077-1080(1988);Nickerson等,Proc.Natl.Acad.Sci.USA,87:8923-8927(1990))或尺寸依赖性分离(D.Y.Wu等,Genomics,4:560-569(1989)和F.Barany,Proc.Natl.Acad.Sci,88:189-193(1991))以解析等位基因的信号,所述方法的后者因连接探针的窄尺寸范围而限于多重规模。此外,在多重格式中,连接酶检测反应不能单独地制得足够的产物来检测并且量化少量的靶序列。空隙连接酶链式反应过程需要额外的步骤—聚合酶延伸。针对更复杂的复合体使用具有电荷/平移摩擦拽力特性比率的探针会需要更长的电泳时间或者使用交替的检测形式。
需要有效地且准确地对更长核酸片段进行测序的方法。对例如用于床旁应用和病原体的野外检测的迅速、高通量和低成本测序技术存在巨大需求。本发明使用简单化学方式和低成本设备来允许对大量基因组进行测序,这导致显著的成本降低和速度提高,并且也导致其他相关的优点。
技术实现要素:
在一个方面中,提供一种边合成边测序(sequencing-by-synthesis,SBS)系统,其中所述系统被配置来产生大于至少300个碱基对且具有至少0.85或更大的纯洁度得分(chastity score)的测序读段(read)。所述系统可被配置来产生大于至少100kB且具有至少0.85或更大的纯洁度得分的测序读段。
在另一个方面中,提供一种用于序列测定的方法,所述方法包括:执行一种边合成边测序(SBS)反应以产生大于300个碱基对且具有至少0.85或更大的纯洁度得分的测序读段。所述方法可包括执行一种边合成边测序反应以产生大于至少100kB且具有至少0.85或更大的纯洁度得分的测序读段。
在另一个方面中,提供一种提高测序反应的纯洁度得分的方法,所述方法包括:对多个测序产物执行一个或多个同步化步骤,其中相对于在缺乏一个或多个同步化步骤的情况下执行的对应测序反应,纯洁度得分提高至少20%。在一些情况下,多个测序产物包括一个或多个非同步化测序产物。一个或多个同步化步骤中的每个可包括:在一组多达三种不同的核苷酸的存在下延伸多个测序产物。在一些情况下,所述多达三种不同的核苷酸选自由dATP、dCTP、dGTP、dTTP和dUTP组成的组。在一些情况下,所述多达三种不同的核苷酸包括至少一种天然核苷酸。所述方法可能还包括,在执行一个或多个同步化步骤之前,执行一个或多个相继的测序轮次,其中每个测序轮次包括:(i)在一个或多个标记的核苷酸的存在下使用多个靶核酸作为模板来延伸多个测序引物,以产生多个测序产物;以及(ii)针对多个测序产物中的每个来测定核酸序列。所述方法可能还包括,在执行一个或多个相继的测序轮次之前,将多个测序引物与多个靶核酸杂交。所述方法可能还包括,在执行一个或多个同步化步骤之后,一次或多次重复一个或多个测序轮次,接着是一个或多个同步化步骤。在一些情况下,在重复之后,测序反应具有至少0.85的纯洁度得分。所述提高纯洁度得分的方法可包括执行至少四个同步化步骤。所述提高纯洁度得分的方法可包括执行至少八个同步化步骤。一个或多个相继的测序轮次的执行可包括执行100至200个相继的测序轮次。在一些情况下,多个靶核酸经由捕获探针被固定至固体支撑物。所述方法可能还包括,在每个同步化步骤之后,(i)通过洗涤或(ii)通过使用核苷酸降解酶来除去所述组的多达三种不同的核苷酸。在一些情况下,延伸包括使用DNA聚合酶来延伸。
在另一个方面中,提供一种用于增加测序反应的测序读段中的准确碱基识别(call)的长度的方法,所述方法包括对多个测序产物执行一个或多个同步化步骤,由此增加测序反应的测序读段中的准确碱基识别的长度。在一些情况下,与在缺乏一个或多个同步化步骤的情况下执行的测序反应的测序读段中的准确碱基识别的长度相比,在测序反应的测序读段中的准确碱基识别的长度增加至少10个碱基对。在一些情况下,与在缺乏一个或多个同步化步骤的情况下执行的测序反应的测序读段中的准确碱基识别的长度相比,在测序反应的测序读段中的准确碱基识别的长度增加至少50个碱基对。在一些情况下,与在缺乏一个或多个同步化步骤的情况下执行的测序反应的测序读段中的准确碱基识别的长度相比,在测序反应的测序读段中的准确碱基识别的长度增加至少100至500个碱基对。一个或多个同步化步骤中的每个可包括在一组多达三种不同的核苷酸的存在下,延伸多个测序产物。在一些情况下,所述多达三种不同的核苷酸选自由dATP、dCTP、dGTP、dTTP和dUTP组成的组。在一些情况下,多个测序产物包括一个或多个非同步化测序产物。在一些情况下,在一个或多个同步化步骤之后,所述测序产物的纯洁度得分为至少0.85。在一些情况下,所述多达三种不同的核苷酸包括至少一种天然核苷酸。所述方法可能还包括,在执行一个或多个同步化步骤之前,执行一个或多个相继的测序轮次,其中每个测序轮次包括:(i)在一个或多个标记的核苷酸的存在下使用多个靶核酸作为模板来延伸多个测序引物,以产生多个测序产物;以及(ii)针对多个测序产物中的每个来测定核酸序列。所述方法可能还包括,在执行一个或多个相继的测序轮次之前,将多个测序引物与多个靶核酸杂交。所述方法可能还包括,在执行更多同步化步骤中的一个之后,一次或多次重复一个或多个测序轮次,接着是一个或多个同步化步骤。在一些情况下,在重复之后,测序反应具有至少0.85的纯洁度得分。在一些情况下,增加准确碱基识别的长度的方法可包括执行至少四个同步化步骤。在一些情况下,增加准确碱基识别的长度的方法可包括执行至少八个同步化步骤。在一些情况下,一个或多个相继的测序轮次的执行包括执行100至200个相继的测序轮次。在一些情况下,多个靶核酸经由捕获探针被固定至固体支撑物。所述方法可能还包括,在每个同步化步骤之后,(i)通过洗涤或(ii)通过使用核苷酸降解酶来除去所述组的多达三种不同的核苷酸。在一些情况下,延伸包括使用DNA聚合酶来延伸。
在又一个方面中,提供一种用于使一个或多个非同步化测序产物同步化的方法,所述方法包括:(a)对多个测序产物执行一个或多个同步化步骤,多个测序产物包括一个或多个非同步化测序产物,其中一个或多个同步化步骤中的每个包括:(i)将多个测序产物与第一组多达三种不同的核苷酸接触,所述多达三种不同的核苷酸选自由dATP、dTTP、dCTP、dGTP和dUTP组成的组;(ii)用DNA聚合酶来延伸多个测序产物;以及(iii)任选地,除去所述组的未标记的核苷酸,由此使一个或多个非同步化测序产物同步化。在一些情况下,一个或多个同步化步骤中的每个连续的同步化步骤包括:将多个测序产物与第二组多达三种不同的核苷酸接触,所述多达三种不同的核苷酸选自由dATP、dTTP、dCTP、dGTP和dUTP组成的组,其中第二组核苷酸与第一组核苷酸不同。所述方法可能还包括,在执行一个或多个同步化步骤之前:(b)将多个测序引物与多个靶核酸杂交;以及(c)执行一个或多个相继的测序轮次,每个测序轮次包括:(i)在一个或多个标记的核苷酸的存在下延伸多个测序引物,以产生多个测序产物;以及(ii)测定多个测序产物的核酸序列。在一些情况下,一个或多个相继的测序轮次的执行包括执行100至200个相继的测序轮次。所述方法可能还包括,在执行一个或多个同步化步骤之后,一次或多次重复一个或多个相继的测序轮次,接着是一个或多个同步化步骤。在一些情况下,所述组的多达三种不同的核苷酸还包括可逆终止子核苷酸。在一些情况下,在每个同步化步骤之后,可逆终止子核苷酸被去封闭,并且多个测序产物准备作进一步延伸。在一些情况下,可逆终止子核苷酸与每个组内的多达三种不同的核苷酸相比,具有不同的碱基。在一些情况下,使一个或多个非同步化测序产物同步化的方法包括执行至少四个同步化步骤。在一些情况下,使一个或多个非同步化测序产物同步化的方法包括执行至少八个同步化步骤。在一些情况下,执行一个或多个同步化步骤之后,至少95%的测序产物被同步化。在一些情况下,在执行一个或多个同步化步骤之后,测序产物具有至少0.85的纯洁度得分。在一些情况下,多个靶核酸经由捕获探针被附接至固体支撑物。所述方法可能还包括,在每个同步化步骤之后,(i)通过洗涤或(ii)通过使用核苷酸降解酶来除去所述组的多达三种不同的核苷酸。在一些情况下,所述组的多达三种不同的核苷酸包括天然核苷酸。在一些情况下,一个或多个标记的核苷酸包括一个或多个荧光标记的核苷酸。
在另一个方面中,提供一种用于对靶核酸分子进行测序的试剂盒,所述试剂盒包括:(a)可与靶核酸分子杂交的引物,(b)一个或多个标记的核苷酸;以及(c)一组或多组多达三种不同的核苷酸,所述多达三种不同的核苷酸选自由dATP、dTTP、dCTP、dGTP和dUTP组成的组。所述试剂盒可能还包括DNA聚合酶。所述试剂盒可能还包括焦磷酸酶。所述试剂盒可能还包括三磷酸腺苷双磷酸酶。在一些情况下,一个或多个标记的核苷酸包括一个或多个荧光标记的核苷酸。在一些情况下,一组或多组多达三种不同的核苷酸包括选自由以下组成的组的组中的至少一种:包括dATP、dCTP和dGTP的组;包括dATP、dTTP和dGTP的组;包括dCTP、dGTP和dTTP的组,包括dATP、dCTP和dTTP的组;以及它们的任何组合。在一些情况下,一组或多组多达三种不同的核苷酸还包括可逆终止子核苷酸。在一些情况下,可逆终止子核苷酸与每个组内多达三种不同的核苷酸相比,包括不同的碱基。
以引用的方式并入
本说明书中提及的所有出版物、专利和专利申请都以引用的方式并入本文,所述引用的程度就如同已特定地和个别地指示将各个别出版物、专利或专利申请以引用的方式并入一般。
附图说明
本发明的新型特征在随附权利要求中具体阐述。通过参考以下阐述利用了本发明的原理的说明性实施方案的详细描述及其附图将获得对本发明的特征和优点的更好理解:
图1描绘使用边合成边测序(SBS)方法的信号劣化。
图2描绘在150个SBS循环之后,最初同步的克隆簇的相位移后(dephasing)。
图3描绘一种使簇中的测序链重新同步化的计算方法。
图4描绘利用本公开的方法以用来使簇中的测序链重新同步化的实例。
图5描绘利用多个同步化循环以使簇中的测序链重新同步化的实例。
图6比较了多个同步化循环用以使簇中的测序链重新同步化的用途。
图7描绘将深色(dark)核苷酸组掺合入测序产物。
图8描绘适用于本文提供的方法的计算机系统的实例。
图9描绘利用本文所述的方法而增加的信号强度。
图10描绘利用本文所述的方法而使质量得分增加。
图11描绘利用本文所述的方法而使信号强度增加。
图12描绘利用本文所述的方法而使质量得分增加。
图13描绘利用本文所述的方法而使信号强度增加。
图14描绘利用本文所述的方法而使纯洁度得分增加。
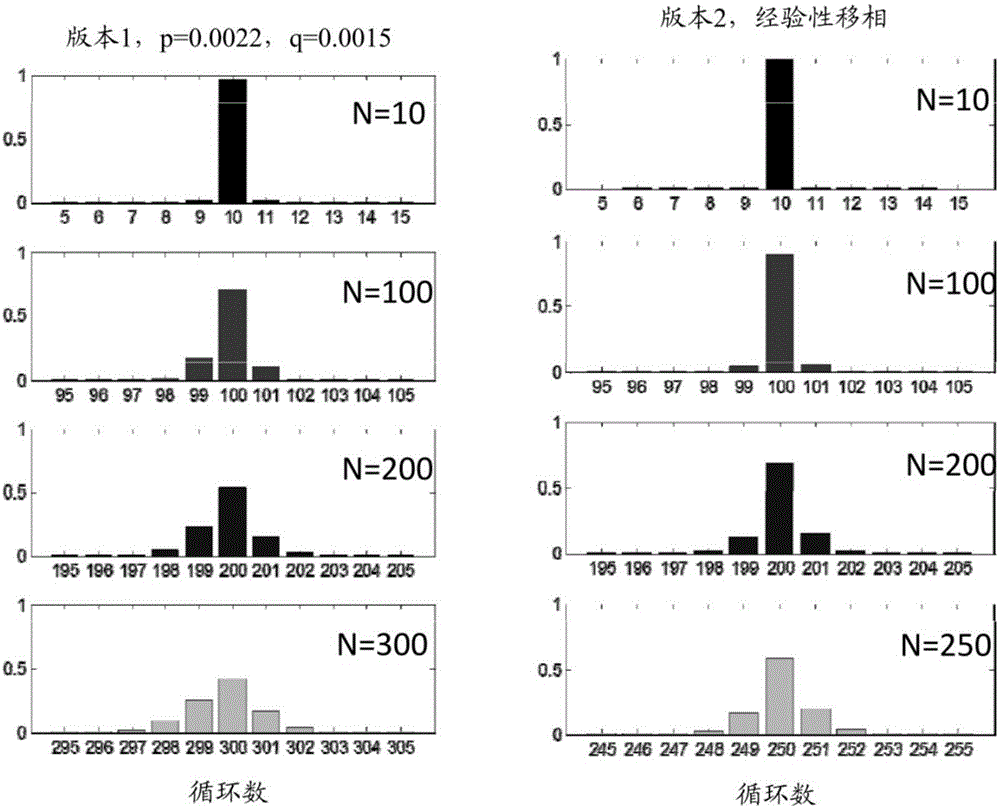
图15描绘一种对克隆群体进行测序的方法。
图16描绘对在长的读段中的移相(phasing)效应进行建模。
图17描绘对在长的读段中的移相效应进行建模。
图18描绘本文所述方法的实例。
图19描绘本文所述方法的实例。
图20描绘本文所述方法的实例。
图21描绘由执行本文所述方法获得的结果。
图22描绘由执行本文所述方法获得的结果。
图23描绘由执行本文所述方法获得的结果。
图24描绘本文所述方法的实例。
具体实施方式
除非另有定义,否则本文中使用的所有技术和科学术语具有与本发明所属领域的普通技术人员通常理解的含义相同的含义。虽然与本文中所述的那些方法和材料相似或相等的任何方法和材料也可用于实践或测试本发明,但是现在描述代表性例示方法和材料。此类常规的技术和说明可见于标准实验室手册中,例如Genome Analysis:A Laboratory Manual Series(第I-IV卷),Using Antibodies:A Laboratory Manual,Cells:A Laboratory Manual,PCR Primer:A Laboratory Manual,和Molecular Cloning:A Laboratory Manual(全部来自Cold Spring Harbor Laboratory Press);Stryer,L.(1995)Biochemistry(第4版)Freeman,New York;Gait,“Oligonucleotide Synthesis:A Practical Approach”1984,IRL Press,London,Nelson and Cox(2000),Lehninger,(2004)Principles of Biochemistry,第4版,W.H.Freeman Pub.,New York,N.Y.以及Berg等(2006)Biochemistry,第6版,W.H.Freeman Pub.,New York,N.Y.,所有这些文献出于所有目的而以引用的方式全文并入本文。
在本发明的一个方面中,提供用于对长核酸进行测序的方法、试剂盒、计算机软件产品。往往使用逐步法来对核酸进行测序,例如基于聚合酶延伸的测序或连接测序,其中为每个测序步骤读取一个或多个碱基。这种基于逐步的测序方法往往受其逐步低效率所限制,例如不完全掺合、不完全连接以及其他造成相位提前(prephasing)或相位移后的问题。逐步低效率可随读长积累,并且限制读长。
例如,基于可逆的终止子核苷酸的测序(可商购自Helicos公司、Illumina公司、Intelligent Biosystems公司/Azco Biotech公司得到,并且描述于供应商文献和其专利文档中,以及http://www.helicosbio.com,http://www.illumina.com,http://www.azcobiotech.com)受掺入的可逆终止子核苷酸的效率所限制,所述可逆终止子核苷酸在3'羟基基团处被修饰或以其他方式修饰,以中断通过聚合酶的进一步延伸。如果测序检测是基于用添加的可检测标记例如荧光基团来掺合修饰核苷酸,则掺合效率可能进一步降低。所述问题可通过将未标记的和标记的可逆终止子核苷酸混合而部分减轻。然而,即使化学性和效率有所增加,逐步低效率仍可显著限制在读段末端的读长和读取质量。
逐步效率问题可用这样的情况例示,在所述情况中每个测序步骤具有约99%的恒定的掺合的逐步效率,并且在一簇中存在1,000个模板分子。在第一掺合步骤之后,10个测序引物不再延伸,并且被封端或以其他方式不再涉及测序。在这种情况下,在100个测序步骤之后,仅(0.99)100=36.6%或360个分子留在所述簇中以用于额外的测序。在第200步,仅(0.99)200=13.4%或134个分子留在所述簇中以用于额外的测序。如果效率降至98%,在第100个步骤处,仅留下13.4%的分子用于额外的测序反应,并且在第200个步骤处,仅有1.8%的分子可潜在地用于进一步测序。
对于核苷酸有限添加测序法而言,例如基于焦磷酸检测的测序(可商购自Roche/454,并且描述于供应商文献和专利文档中,以及http://www.454.com)或基于pH检测的测序(可商购自Ion Torrent公司/Life Technologies公司,并且描述于供应商文献和其专利文档中),效率可能受不完全掺合、错误掺合、结合聚合酶的损失(脱落)所限制。基于逐步连接的测序具有相似的效率问题,因逐步效率受例如连接反应的效率和标记的除去所限制。
另外,逐步测序方法可在测序链的簇内产生非同步化测序链。此问题可限制能实现的测序读段长度。随着簇中的测序产物被延伸,由于测序反应的低效率,簇中的一个或多个测序链可能变得与其他测序链不同步。图1强调了此问题。在测序反应的起始时,在测序引物的杂交之后,簇内100%的链被同步化。随着链被延伸,个别链可能较大多数链落后或更快延伸。同步化的这种损失随着测序轮次数的增加而被放大,并且最终,来自非同步化链的背景噪声变得太巨大以致不能准确地识别正确碱基。使用图1作为实例,簇可能以100%的链同步化起始101,但在150个SBS循环之后103,仅60%的链可能被同步化(即,仅60%的信号是正确的)105。在此实例中,一些链会落后(例如-1、-2等)并且一些链会提前(例如+1、+2等)。然后。本文提供的方法可适合于使链重新同步化(或重调),从而使得100%或接近100%的先前非同步化的链被同步化。在一些情况下,所述方法可适合于使测序链的簇重新同步化,从而使得80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或多于99%的先前非同步化的测序链被同步化。
使簇中的链重新同步化的当前方法一般例如通过软件(例如算法)经由电脑模拟来执行。例如,如图3中所描绘的,可利用计算法以使非同步化链的簇重新同步化。然而,所述方法有局限且可能仅约90%有效。所述方法以计算方式且未通过化学方式来执行,并且因而簇内的链并未实际同步化。本发明试图通过化学上使簇中的链重新同步化来解决此问题。在一些情况下,本文提供的方法涉及不使用计算机(即,通过化学方式)来使簇中的链重新同步化。然而,应理解本公开的任何步骤中皆可使用计算机,例如任何测序步骤、计算步骤(即,计算纯洁度得分)、成像步骤等等。
方法
本文提供的方法包括一个或多个同步化步骤来使簇中的多个非同步化链重新同步化或重调。在本发明的一些方面中,一个或多个同步化步骤包括一个或多个延伸步骤,其中多个测序产物在核苷酸的不完整组的存在下延伸。在一些情况下,核苷酸的不完整组包含多达三种不同的核苷酸。例如,所述组核苷酸包括四种类型的核苷酸中的一种至三种(例如,对于DNA聚合酶而言,四种核苷酸dATP、dCTP、dTTP和dGTP中的一种、两种或三种)。在一些情况下,所述组核苷酸可包括dUTP。在一些情况下,包含三种不同的核苷酸的反应将在与缺失核苷酸互补的模板碱基处停止。例如,对于具有dATP、dCTP和dGTP的反应而言,延伸停止在模板上的碱基“A”处,因为“A”与缺失核苷酸dTTP互补,由此限制测序产物的延伸。可用于执行本文所述方法的不完全核苷酸组的实例(也称缺失核苷酸)为dATP、dCTP和dGTP(-T);dCTP、dGTP和dTTP(-A);dATP、dCTP和dTTP(-G);以及dATP、dTTP和dGTP(-C)。或者,核苷酸组可使用包括三种天然未标记的核苷酸(“深色”核苷酸)和可逆终止子核苷酸。在此实例中,可逆终止子将是并非由三种天然核苷酸代表的核苷酸。将可逆终止子核苷酸添加至测序产物将防止测序产物的进一步延长,直至终止子被除去。
在本发明的一个方面中,提供了使簇内的多个链同步化的方法。所述方法包括一个或多个相继的测序轮次,其中核苷酸(例如借助于聚合酶)被掺合入生长的测序链。所述方法包括将测序引物与多个靶核酸杂交。靶核酸可被固定在固体支撑物上。所述方法进一步包括执行一个或多个相继的测序轮次。一个或多个相继的测序轮次步骤中的每个可包括在一个或多个标记的核苷酸的存在下延伸测序引物,以产生测序产物。所述方法可进一步包括测定测序产物的核酸序列。在一个或多个测序轮次之后,所述方法可能还包括执行一个或多个同步化步骤。一个或多个同步化步骤可包括在一组多达三种不同的核苷酸的存在下延伸测序产物,所述多达三种不同的核苷酸选自由dATP、dTTP、dCTP和dGTP组成的组。在一些情况下,所述组的多达三种不同的核苷酸是未标记的(例如天然核苷酸)。
在一个方面,本文提供的方法包括执行测序循环,接着是同步化循环。一个或多个测序轮次在本文中可统称为“测序循环”,而一个或多个同步化步骤在本文中可统称为“同步化循环”。例如,测序循环可包括一个或多个相继的测序轮次,在一些情况下包括100至200个测序步骤。同步化循环可包括一个或多个同步化步骤,在一些情况下包括四个至八个同步化步骤。在一些情况下,提供了用于执行一个或多个额外的测序循环接着一个或多个额外的同步化循环的方法。例如,所述方法包括执行额外的测序循环接着额外的同步化循环一次、二次、三次、四次、五次、六次、七次、八次、九次、10次或多于10次。每个同步化循环可使簇中的链重调或重新同步化。
在一些情况下,所述方法涉及一次或多次执行额外的测序循环接着是额外的同步化循环。在一些情况下,额外的测序和同步化循环与先前的测序和同步化循环不同(例如每个循环可包括不同的步骤数)。在其他情况下,额外的测序和同步化循环可与先前的测序和同步化循环相同(即,每个循环包括相同的步骤数)。每个同步化循环可使测序簇中的至少95%的测序产物重新同步化。在一个非限制性实例中,测序循环包括约150个测序步骤,并且同步化循环包括约八个同步化步骤。
图4以逐步的形式描绘本文提供的方法的一个实例。在此实例中,在第一步骤中(从顶部),靶核酸400可与捕获探针401杂交(例如在固体支撑物上)。测序引物403可与靶核酸401杂交,并且可执行测序循环以产生测序产物405。测序循环之后可执行同步化循环,以使测序产物407重新同步化。然后,执行额外的测序循环,以进一步延伸测序产物409并且产生测序读段。然后,额外的同步化循环接着为额外的测序循环,以使测序产物411重新同步化,接着是额外的测序循环413等等。额外的同步化循环接着额外的测序循环可按需要重复多次,以对整个靶核酸进行测序。测序循环中的测序轮次数可凭经验确定。在不希望由理论束缚的情况下,每个测序轮次一般导致轻微的信号强度损失,直至已执行了足够多测序轮次以使得信号强度的损失过大而不能准确识别正确碱基。此时,可能适合于执行同步化循环以使链重调或重新同步化,并且恢复信号的损失。虽然测序循环中的测序轮次的最佳数量会变化,但应考虑到将执行足够的测序轮次以在执行同步化循环之前导致测序链的同步化损失。测序链的同步化损失可能包括簇中的约50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、多达100%的非同步化链。在一些情况下,测序循环中的测序轮次数是50或更多。在一些实例中,测序循环中的测序轮次数是100或更多。非限制性实例包括测序循环中的约100个、约110个、约120个、约130个、约140个、约150个、约160个、约170个、约180个、约190个、约200个或多于200个测序轮次。在一些情况下,测序的轮次包括100至200个测序轮次。
同步化循环中的同步化步骤的数量也可凭经验确定。在一些情况下,同步化循环中的同步化步骤数可包括但不限于:一个、二个、三个、四个、五个、六个、七个、八个、九个、十个或更多个同步化步骤。在一些情况下,在同步化循环中执行一个或多个同步化步骤。在一些情况下,在同步化循环中执行四个或更多个同步化步骤。在其他情况下,在同步化循环中执行八个或更多个同步化步骤。在一些情况下,在同步化循环中执行四个至八个同步化步骤。
同步化步骤的次序也可凭经验确定。在一些情况下,各连续同步化步骤包括不同组的不完整核苷酸。例如,在缺乏dATP的情况下(“-A”;即,在dTTP、dCTP和dGTP的存在下)执行的同步化步骤可随后继以采用核苷酸组“-T”、“-C”或“-G”中的一个的同步化步骤。在一个非限制性实例中,同步化循环包括八个按以下次序执行的同步化步骤:“-A”、“-C”、“-G”、“-T”、“-G”、“-C”、“-A”、“-T”。同步化步骤可包括一组多达三种不同的核苷酸。多达三种不同的核苷酸可为未标记的核苷酸。未标记的核苷酸可为任何无可检测标记的核苷酸。在一些情况下,未标记的核苷酸为“深色”核苷酸(即,缺乏可检测的(例如荧光)标记)。在一些情况下,未标记的核苷酸为天然核苷酸,并且不包含任何修饰。在一些情况下,未标记的核苷酸为经修饰的核苷酸(例如包含可逆终止子)。
在同步化步骤期间未标记核苷酸的使用可导致在模板核酸上多个核苷酸位置的测序数据缺乏。每个同步化步骤可导致测序产物平均约延伸三个、四个、五个、六个、七个、八个、九个、十个或更多个核苷酸。在一些情况下,在每个同步化步骤中平均约四个核苷酸可被添加至测序产物。图7描绘使用多个同步化步骤来将“深色”(即,未标记的)核苷酸添加至测序产物的实例。在此实例中,每个同步化步骤可大致将七个未标记的核苷酸添加至测序产物,从而使得在12个同步化步骤之后,约102个未标记的核苷酸被添加至测序产物。可检测标记的缺乏会导致在测序产物上的未测序碱基的空隙。通过交错安排在同步化之前执行的测序步骤数(例如100个测序步骤与150个测序步骤),测序数据中的空隙可被填充。
在一些方面中,本文提供的方法可导致在执行同步化循环之后簇中多达100%的链的重新同步化。在一些情况下,重新同步化可能是90%、90.5%、91%、91.5%、92%、92.5%、93%、93.5%、94%、94.5%、95%、95.5%、96%、96.5%、97%、97.5%、98%、98.5%、99%、99.5%、99.9%或100%的簇内链。图5描绘在150个边合成边测序(SBS)轮次(60%的链同步化)501之后执行的四个同步化步骤的实例。在执行四个同步化步骤503之后,平均96.5%的链被重新同步化505。
同步化步骤的执行数可能进一步增加所述方法的效益。例如,在图6中,测定出在16个同步化步骤之后,平均97.3%的簇中链被重新同步化。
在一些情况下,大量的靶核酸(例如至少10、100、1,000、10,000、100,000或1,000,000)被同时测序。这些靶核酸可为DNA、RNA或经修饰的核酸。尽管它们可作为单分子被测序,但它们也可作为克隆或簇被测序。克隆或簇(例如在磁珠上)中的每一个皆衍生自单核酸分子。在本技术领域中用于对单分子或克隆分子簇或磁珠中大量靶核酸进行测序的方法是众所周知的。为了说明的简单性,一些实例可能使用单数术语例如“靶核酸”或“延伸引物”来描述,本领域技术人员将理解所述实施方案中的多个可用于同时地或顺序地对多个靶核酸进行测序,并且此类测序可对多个靶核酸的多个拷贝(多于10个、100个、1,000个、100,000个拷贝)执行。
靶或靶核酸
在一个方面,本发明提供用于对一个靶核酸分子或多个靶核酸的集合进行测序的方法。本文所用的“靶核酸分子”、“靶分子”、“靶多核苷酸”、“靶多核苷酸分子”或它们在语法上的等价物意指目标核酸。靶核酸例如可以是DNA或RNA或任何具有与DNA或RNA相似性质的合成结构。本文所用的测序指的是对靶核酸中至少单个碱基、至少2个连续的碱基、至少10个连续的碱基或至少25个连续的碱基的测定。测序精确度总体上或针对每个碱基可为至少65%、75%、85%、95%、99%、99.9%和99.99%。测序可直接对靶核酸执行或对衍生自靶核酸的核酸执行。在一些应用中,大量的靶核酸(例如至少1,000、10,000、100,000或1,000,000个靶核酸)被同时测序。
在一些情况下,靶核酸为衍生自特定生物的染色体中的遗传物质的基因组DNA,和/或非染色体遗传物质例如线粒体DNA。基因组克隆文库是克隆的集合,其由一组随机产生的重叠DNA片段制得,并且代表生物的整个基因组。基因组文库是生物的基因组DNA中的至少2%、5%、10%、30%、50%、70%、80%或90%的一个或多个序列的集合。
靶核酸包括自然出现的或基因改造的或合成制备的核酸(例如来自哺乳动物疾病模型的基因组DNA)。靶核酸可从实际上任何来源获得,并且可使用本领域已知的方法制备。例如,靶核酸可使用本领域已知方法来直接分离而不须扩增,包括但不限于从生物(例如细胞或细菌)中提取基因组DNA的片段以获得靶核酸。在另一个实例中,靶核酸还可使用本领域已知方法通过扩增来分离,包括但不限于聚合酶链式反应(PCR)、全基因组扩增(WGA)、多重置换扩增(MDA)、滚环扩增(RCA)、滚环扩增反应(RCA)以及其他扩增方法学。靶核酸还可通过克隆获得,包括克隆入例如质粒、酵母和细菌人工染色体的载体中。“扩增”指的是任何通过其使靶序列的拷贝数增加的过程。扩增可通过本领域已知的任何方式执行。靶多核苷酸的引物引导的扩增方法是本领域已知的,并且包括但不限于基于聚合酶链式反应(PCR)的方法。可使用的PCR技术的实例包括但不限于定量PCR、荧光定量PCR(QF-PCR)、荧光多重PCR(MF-PCR)、实时PCR(RTPCR)、单细胞PCR、限制性片段长度多态性PCR(PCR-RFLP)、PCK-RFLPIRT-PCR-IRFLP、热启动PCR、巢式PCR、原位polony PCR、原位滚环扩增(RCA)、桥式PCR、picotiter PCR和乳胶PCR。有利于靶序列扩增的PCR条件是本领域已知的,其可在所述方法中的各种步骤处优化,并且取决于反应中的要素特征,例如靶类型、靶浓度、待扩增的序列长度、靶和/或一个或多个引物的序列、引物长度、引物浓度、使用的聚合酶、反应体积、一个或多个要素比一个或多个其他要素的比率以及其他,可改变这些中的一些或所有。一般来说,PCR涉及以下步骤:待扩增靶的变性(如果是双链的),将一个或多个引物与靶杂交,以及由DNA聚合酶延伸引物,并且重复(或“循环”)所述步骤以便扩增靶序列。此方法中的步骤可针对各种结果而优化,例如来提高产率、减少假产物的形成,和/或提高或降低引物复性的特异性。优化的方法是本领域众所周知的,并且包括调整扩增反应中的要素的类型或量,和/或调整所述方法中给定步骤的条件,例如在特定步骤中的温度、特定步骤的持续时间和/或循环数。在一些情况下,扩增反应包括至少5个、10个、15个、20个、25个、30个、35个、50个或更多个循环。在一些情况下,扩增反应包括不超过5个、10个、15个、20个、25个、35个、50个或更多个的循环。循环可包含任何步骤数,例如1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个步骤。步骤可包括任何适合于实现给定步骤的目的的温度或温度梯度,所述给定步骤包括但不限于3’端延伸(例如衔接子填充)、引物复性、引物延伸和链变性。步骤可以是任何持续时间,持续时间包括但不限于约、小于约或多于约1秒、5秒、10秒、15秒、20秒、25秒、30秒、35秒、40秒、45秒、50秒、55秒、60秒、70秒、80秒、90秒、100秒、120秒、180秒、240秒、300秒、360秒、420秒、480秒、540秒、600秒或更多秒,包括无穷秒直至手动中断。包括不同步骤的任何数量的循环可以任何次序进行组合。在一些情况下,将包括不同步骤的不同循环进行组合,从而使得组合中的总循环数量为约、小于约或多于约5个、10个、15个、20个、25个、30个、35个、50个或更多个循环。其他合适的扩增方法包括连接酶链式反应(LCR)、转录扩增、自持续序列复制、靶多核苷酸序列的选择扩增、共有序列引物聚合酶链式反应(CP-PCR)、任意引物聚合酶链式反应(AP-PCR)、简并寡核苷酸引物PCR(DOP-PCR)和基于核酸的序列扩增(NABSA)。本文可使用的其他扩增方法包括在美国专利第5,242,794号、第5,494,810号、第4,988,617号和第6,582,938号中描述的那些。在一些情况下,扩增是在细胞内部执行。
在所述实例中的任一个中,扩增可在支撑物(例如磁珠或表面)上发生。在本文所述实例中的任一个中,靶可从单细胞的提取物中扩增。
靶核酸还可具有外源序列,例如在诸如文库制备期间经由连接或扩增过程被引入的通用引物序列或条形码序列。本文使用的术语“测序模板”指的是靶核酸自身,或是与靶核酸的片段的核苷酸序列或靶核酸的互补物相同或基本上相似的核苷酸序列。在一些情况下,靶核酸分子包括核糖核酸(RNA)。
在一些情况下,靶多核苷酸是基因组DNA或基因组DNA的一部分。尽管一些实例是用于对全基因组进行测序,例如以多于50%的覆盖率进行测序,但这些实例也适合于对例如涉及药物代谢的基因组区的靶区进行测序。在一个实例中,靶多核苷酸是人类基因组DNA。
本文所用的靶核酸也可指用于测序的核酸结构。此类结构通常包括在靶核酸序列的一端或两端上的衔接子序列。例如,由样品的基因组DNA衍生的或由样品的RNA分子衍生的序列可用扩增和/或一个或多个测序衔接子连接。文库构建方法是本领域众所周知的。核酸测序文库可在基质上使用桥式扩增、乳胶PCR扩增、滚环扩增或其他扩增方法以克隆形式扩增。此类过程可手动执行,或使用自动化设备例如cBot(Illumina公司)或OneTouchTM(Ion Torrent)来执行。
“核酸”或“寡核苷酸”或“多核苷酸”或语法上的等价物通常指的是共价连接到一起的至少两个核苷酸。本发明的核酸将一般包含磷酸二酯键,但在一些情况下,如下文概述(例如,在引物和探针(例如标记的探针)的构建中),包括了可能具有交替主链的核酸类似物,所述交替主链例如包含磷酰胺(例如参见Beaucage等,Tetrahedron 49(10):1925(1993);Letsinger,J.Org.Chem.35:3800(1970);Sprinzl等,Eur.J.Biochem.81:579(1977);Letsinger等,Nucl.Acids Res.14:3487(1986);Sawai等,Chem.Lett.805(1984),Letsinger等,J.Am.Chem.Soc.110:4470(1988);以及Pauwels等,Chemica Scripta 26:141(1986))、硫代磷酸酯(Mag等,Nucleic Acids Res.19:1437(1991);和美国专利第5,644,048号)、二硫代磷酸酯(例如参见Briu等,J.Am.Chem.Soc.111:2321(1989)),O-甲基亚磷酰胺键(例如参见Eckstein,Oligonucleotides and Analogues:A Practical Approach,Oxford University Press)和肽核酸(本文中也称作“PNA”)主链和键(例如参见Egholm,J.Am.Chem.Soc.114:1895(1992);Meier等,Chem.Int.Ed.Engl.31:1008(1992);Nielsen,Nature,365:566(1993);Carlsson等,Nature380:207(1996))。
其他核酸类似物包括具有二环结构的那些核酸类似物,所述核酸类似物包括本文中也称作“LNA”的锁核酸(例如参见Koshkin等,J.Am.Chem.Soc.120.13252 3(1998))、正电(positive)主链(Denpcy等,Proc.Natl.Acad.Sci.USA 92:6097(1995))、非离子主链(例如参见美国专利第5,386,023号、第5,637,684号、第5,602,240号、第5,216,141号和第4,469,863号;Kiedrowshi等,Angew.Chem.Intl.Ed.English 30:423(1991));Letsinger等,J.Am.Chem.Soc.110:4470(1988),Ed.Y.S.Sanghui和P.Dan Cook;Mesmaeker等,Bioorganic&Medicinal Chem.Lett.4:395(1994);Jeffs等,J.Biomolecular NMR 34:17(1994);Tetrahedron Lett.37:743(1996))和非核糖主链,并且所述非核糖主链包括那些在美国专利第5.235,033号和第5,034,506号以及ASC Symposium Series 580,“Carbohydrate Modifications in Antisense Research”,Ed.Y.S.Sanghui和P.Dan Cook的章6和章7中描述的那些。
包含一个或多个碳环糖类的核酸也包括在核酸的定义内(例如参见Jenkins等,Chem.Soc.Rev.(1995),第169 176页)。若干核酸类似物描述于Rawls,C&E News,1997年6月2日,第35页中。
根据指定,靶核酸可能是单链或双链的,或者可包含双链序列或单链序列的部分。根据应用,核酸可为DNA(包括基因组DNA和cDNA)、RNA(包括mRNA和rRNA)或混合物,其中核酸包含脱氧核糖核苷酸和核糖核苷酸的任何组合,和碱基的任何组合,所述碱基包括尿嘧啶、腺嘌呤、胸腺嘧啶、胞嘧啶、鸟嘌呤、肌苷、黄嘌呤、次黄嘌呤、异胞嘧啶、异鸟嘧啶等。
在一些情况下,本发明的所述方法包括靶多核苷酸的捕获。靶多核苷酸可来自基因组的已知区。在一些情况下,寡核苷酸探针可固定在磁珠上,并且这些便宜的和可再使用的寡核苷酸磁珠可用于捕获靶基因组多核苷酸。在其他情况下,微阵列被用于捕获靶多核苷酸。
在一些情况下,靶多核苷酸可被断裂为一个合适的长度或多个合适的长度,例如在长度上大约100-200个、200-300个、300-500个、500-1000个、1000-2000个或更多个碱基。
自然存在的靶可在细胞裂解液中、在核酸提取物中直接分析,或在小部分核酸部分纯化之后分析,以便将它们富集在目标靶中。在一个实例中,靶多核苷酸是人类基因组DNA。待检测的多核苷酸靶可为未修饰的或修饰的。有用的修饰包括但不限于放射性和荧光标记以及锚配体,例如生物素或地高辛。一个或多个修饰可布置在内部或在靶的5’或3’端。靶修饰可通过化学反应或通过酶促反应,例如连接或聚合酶辅助延伸,在合成后进行。或者,内部标记和锚配体可在酶促聚合反应期间通过使用少量的修饰NTP作为基质来直接掺合入扩增的靶或它的互补序列。
可将靶多核苷酸从受试者中分离。受试者不限于人类,而可也为其他生物,包括但不限于哺乳动物、植物、细菌、病毒或真菌。在一个实例中,靶多核苷酸为从人类提取的基因组DNA。
输入的核酸可为DNA,或复杂的DNA例如基因组DNA。输入的DNA也可为cDNA。cDNA可产生自RNA例如mRNA。输入的DNA可属于特定物种,例如人类、大鼠、小鼠、其他的动物、植物、细菌、藻类、病毒等等。输入的核酸也可来自例如寄主病原体、细菌种群等等的不同物种的基因组混合物。输入的DNA可为由不同物种的基因组混合物制得的cDNA。或者,输入的核酸可来自合成源。输入的DNA可为线粒体DNA。输入的DNA可为脱细胞DNA。脱细胞DNA可从例如血清或血浆样品获得。输入的DNA可包括一个或多个染色体。例如,如果输入的DNA来自人类,则DNA可包括1号、2号、3号、4号、5号、6号、7号、8号、9号、10号、11号、12号、13号、14号、15号、16号、17号、18号、19号、20号、21号、22号、X或Y染色体的一个或多个。DNA可来自线性或环状基因组。DNA可为质粒DNA、黏粒DNA、细菌人工染色体(BAC)或酵母人工染色体(YAC)。输入的DNA可来自多于一个个体或生物。输入的DNA可为双链或单链的。输入的DNA可为部分染色质。输入的DNA可与组蛋白缔合。本文描述的方法可应用于高分子量DNA,例如举例而言从组织或细胞培养物中分离的DNA,以及应用于高度降解的DNA,例如举例而言来自血液和尿液的脱细胞DNA,和/或提取自福尔马林固定的、石蜡包埋的组织的DNA。
衍生出靶多核苷酸的不同样品可包括来自相同个体的多个样品、来自不同个体的样品或它们的组合。在一些情况下,样品包括来自单个个体的多个多核苷酸。在一些情况下,样品包括来自两个或更多个个体的多个多核苷酸。个体为任何生物或它们的部分,从其可衍生出靶多核苷酸,个体的非限制性实例包括植物、动物、真菌、原生生物、原核生物、病毒、线粒体和叶绿体。样品多核苷酸可分离自受试者,例如由其衍生的细胞样品、组织样品或器官样品,包括例如培养的细胞系、活组织检查、血液样品或包含细胞的分泌液样品。受试者可为动物,包括但不限于例如牛、猪、小鼠、大鼠、小鸡、猫、狗等的动物,并且通常为哺乳动物,例如人类。样品也可人工衍生,例如通过化学合成。在一些情况下,样品包括DNA。在一些情况下,样品包括基因组DNA。在一些情况下,样品包括线粒体DNA、叶绿体DNA、质粒DNA、细菌人工染色体、酵母人工染色体、寡核苷酸标签,或它们的组合。在一些情况下,样品包括通过使用引物和DNA聚合酶的任何合适组合通过引物延伸反应来产生的DNA,所述引物延伸反应包括但不限于聚合酶链式反应(PCR)、反转录和它们的组合。在用于引物延伸反应的模板为RNA的情况下,反转录的产物被称作互补DNA(cDNA)。引物延伸反应中有用的引物可包含对一个或多个靶具有特异性的序列、随机序列、部分随机序列以及它们的组合。适合于引物延伸反应的反应条件是本领域已知的。一般来说,样品多核苷酸包含出现在样品中的任何多核苷酸,其可包含或可不包含靶多核苷酸。
测序
本文提供的方法适用于使用边合成边测序方法的测序技术和平台。全体此类方法涉及通过经由在核酸分子上测得的聚合反应来暂时添加碱基来对具有多个碱基的靶核酸分子进行测序,即在待测序的模板核酸分子上的核酸聚合酶的活性被实时跟踪。然后,可通过由核酸聚合酶在碱基添加的序列中在每个步骤中的催化活性来鉴定哪种碱基被掺合入靶核酸的生长互补链中而推导出序列。在靶核酸分子复合物上的聚合酶被提供合适的位置,以便沿靶核酸分子移动并且在活性位点延伸寡核苷酸引物。多种标记类型的核苷酸类似物被提供在紧邻活性位点处,并且每种可区别类型的核苷酸类似物在靶核酸序列中与不同的核苷酸互补。通过使用聚合酶来来以在活性位点将核苷酸类似物添加至核酸链,使生长的核酸链延伸,其中被添加的核苷酸类似物在活性位点与靶核酸的核苷酸互补。对因聚合步骤的结果而被添加至寡核苷酸引物的核苷酸类似物进行鉴定。重复提供标记的核苷酸类似物、使生长的核酸链聚合和鉴定所添加的核苷酸类似物的轮次,从而使得核酸链进一步延伸,并且靶核酸的序列被测定。可利用所述方法的测序平台的非限制性实例包括:来自Illumina的SBS平台,包括MiSeq系列、HiSeq系列、NextSeq系列和HiSeqX系列;IonTorrent(Life Technologies公司);以及454Pyrosquencing(454Life Sciences)。基本上任何使用模板扩增的SBS平台都可用于执行本公开所述的方法。
在一个情况下,可用标记的核苷酸例如具有标记的dNTP来进行测序。碱基可通过以下方式检测,在聚合酶的存在下经由将杂交复合物顺序地与标记的dATP、dCTP、dGTP和dTTP中的一个接触来延伸递增的片段,并且检测标记的dATP、dCTP、dGTP和dTTP的掺合,以获得每个反应的序列读段。
在一个实例中,使用标记的dATP、dCTP、dGTP和dTTP的混合物。一般而言,由于修饰的dNTP(例如标记的dNTP)的普遍的低掺合效率,仅前几个碱基被延伸以产生强信号。“连缀”延伸的概率相当低,并且使用本文提供的或本领域已知的方法,由此类“连缀”延伸产生的信号可作为噪声被过滤掉。在一个实例中,使用标记的ddATP、ddCTP、ddGTP和ddTTP的混合物,并且不允许“连缀”延伸。在一个实例中,仅一个涵盖所有四种可能碱基的询问轮次被运用于每个递增的片段。例如,每个询问轮次中依次添加一个标记的dNTP提供了每次(即,在每个基质上)添加一个可检测碱基的可能。这一般导致每个轮次可组装的短读段(例如一个碱基或几个碱基)。在另一个实例中,使用多于一个的询问轮次产生长读段。
在另一个实例中,添加标记的ddATP、ddCTP、ddGTP和ddTTP的混合物和少量(<10%(例如5、6、7、8或9%)或<20%(例如10、11、12、13、14、15、16、17、18或19%)的天然dATP、dCTP、dGTP和dTTP。
在一些情况下,标记的核苷酸为可逆终止子。可通过信号强度检测多个碱基,或就可逆终止子而言,通过碱基添加检测来检测。核苷酸可逆终止子是核苷酸类似物,其用封端3'-OH基团的可逆化学部分来修饰,以暂时终止聚合酶反应。这样一来,一般将仅一个核苷酸掺合入生长的DNA链中,即使是在同聚区中。例如,3'端可用氨基-2-羟丙基基团封端。烯丙基或2-硝基苄基基团也可用作可逆部分,以封端四种核苷酸的3'-OH。可逆终止子的实例包括但不限于3'-O-修饰的核苷酸,例如3'-O-烯丙基-dNTP和3'-O-(2-硝基苄基)-dNTP。
在一些情况下,在检测溶液探针上存在的切割位点之后,引物延伸产物的3'-OH通过不同的脱保护方法再生。DNA延伸产物的3'-OH上的封端部分可在由化学方法、酶促反应或光分解作用检测切割位点之后有效除去,即将从切割位点切下封端物。为了对DNA进行测序,在一些情况下,将包含同聚区的模板固定在琼脂糖珠上,并且然后通过在DNA珠上使用核苷酸可逆终止子来进行延伸-信号检测-脱保护循环,以清楚地译码DNA模板的序列。在一些情况下,这种可逆-终止子-测序方法被用于受试者方法,以准确测定DNA序列。(在本文中所述封端物可被称作“保护基团”。)
在一些情况下,本发明的多核苷酸可被标记。在一些情况下,分子或化合物含有至少一个附接的可检测标记(例如同位素或化合物),以允许化合物的检测。一般来说,本发明中使用的标记包括但不限于同位素标记(其可为放射性或重同位素)、磁性标记、电性标记、热标记、有色和发光染料、酶以及磁性颗粒。标记可还包括金属纳米颗粒,例如重元素或大原子序数元素,其在电子显微技术中提供高对比度。本发明中使用的染料可为生色团、磷光体或荧光染料,由于它们的强信号,可提供用于解码的良好信噪比。
在一些情况下,标记可包括荧光标记的使用。本发明中使用的合适的染料包括但不限于荧光的镧系元素复合物(包括铕和铽的复合物)、荧光素、罗丹明(rhodamine)、四甲基罗丹明、伊红、赤藓红、香豆素、甲基香豆素、芘、孔雀绿、均二苯乙烯、荧光黄(Lucifer Yellow)、级联蓝(Cascade Blue)、德克萨斯红(Texas Red),以及在Richard P.Haugland的Molecular Probes Handbook第11版中描述的其他染料,所述文献特此明白地以引用的方式全文并入。可商购的易于掺合入标记的寡核苷酸的荧光性核苷酸类似物包括,例如,Cy3-dCTP、Cy3-dUTP、Cy5-dCTP、Cy5-dUTP(GE Healthcare),荧光素-12-dUTP、四甲基罗丹明-6-dUTP、Texas-5-dUTP、Cascade-7-dUTP、FL-14-dUTP、R-14-dUTP、TR-14-dUTP、Rhodamine GreenTM-5-dUTP、Oregon488-5-dUTP、Texas-12-dUTP、630/650-14-dUTP、650/665-1 4-dUTP、Alexa488-5-dUTP、Alexa532-5-dUTP、Alexa568-5-dUTP、Alexa594-5-dUTP、Alexa546-1 4-dUTP、荧光素-12-UTP、四甲基罗丹明-6-UTP、Texas-5-UTP、Cascade-7-UTP、FL-14-UTP、TMR-14-UTP、TR-14-UTP、Rhodamine GreenTM-5-UTP、Alexa488-5-UTP以及Alexa546-1 4-UTP(Invitrogen)。其他合成后附接可用的荧光团包括,尤其有,Alexa350、Alexa532、Alexa546、Alexa568、Alexa594、Alexa647、BODIPY 493/503、BODIPY FL、BODIPY R6G、BODIPY 530/550、BODIPY TMR、BODIPY 558/568、BODIPY 558/568、BODIPY 564/570、BODIPY 576/589、BODIPY 581/591、BODIPY 630/650、BODIPY 650/665、Cascade Blue、Cascade Yellow、Dansyl、丽丝胺罗丹明B、Marina Blue、Oregon Green 488、Oregon Green514、Pacific Blue、罗丹明6G、罗丹明绿、罗丹明红、四甲基罗丹明、Texas Red(可从Invitrogen得到)以及Cy2、Cy3.5、Cy5.5和Cy7(GE Healthcare)。
用于信号检测和强度数据处理的方法和装置公开于例如美国专利第5,143,854号、第5,547,839号、第5,578,832号、第5,631,734号、第5,800,992号、第5,834,758号;第5,856,092号、第5,902,723号、第5,936,324号、第5,981,956号、第6,025,601号、第6,090,555号、第6,141,096号、第6,185,030号、第6,201,639号、第6,218,803号和第6,225,625号、第7,689,022号中以及WO99/47964中,这些中的每个也特此出于所有目的以引用的方式全文并入。用于DNA序列分析和读段解读的荧光成像和软件程序或算法是本领域普通技术人员已知的,并且公开于Harris TD等“Single-Molecule DNA Sequencing of a Viral Genome”Science,2008年4月4日:第320卷,第5872期,第106-109页中,其以引用的方式全文并入本文。在一些情况下,Phred软件被用于DNA序列分析。Phred读取DNA测序仪踪迹数据、识别碱基、对碱基赋予质量值,并且将碱基识别和质量值写入至输出文件。Phred是广泛使用的用于碱基识别的DNA测序踪迹文件的程序。Phred能从SCF文件和ABI型号373和377的DNA测序仪的chromat文件读取踪迹数据,并且自动检测文件格式。在识别碱基之后,Phred将序列以FASTA格式(适合于XBAP的格式)、PHD格式或SCF格式写入至文件。碱基的质量值被写入至FASTA格式文件或PHD文件,所述值能被phrap序列组装程序使用,以便提高组装序列的精确度。质量值是对数转换的误差概率,明确来说Q=-10log10(Pe),其中Q和Pe分别是质量值和特定碱基识别的误差概率。Phred质量值已对准确性和功率两者作了彻底测试,以辨别正确与错误的碱基识别。Phred能使用质量值来执行序列整理。
基于DNA聚合酶的测序反应一般具有效率问题。与非天然核苷酸(例如标记的核苷酸或可逆终止子)的低掺合效率相比,天然核苷酸可以相对高的效率掺合。因此,在核苷酸延伸反应的生长链中,延长的可能性随着延伸长度的变化而降低。因此,即使在单核苷酸掺合效率中轻微的差异也能随着反应继续进行而导致显著的差异。降低的掺合效率导致增加的错误率,并且因此降低沿生长链的序列信息质量。所得序列信息由相对短的序列读段组成,所述读段由于低到不能接受的正确序列信号而已终止。本发明提供在测序反应中克服这种问题的方法和组合物。
固定靶
在一些情况下,将核酸靶附接至基质或固定在基质上。基质可为磁珠、平坦基质、流动池或其他合适的表面。在一些情况下,基质包括玻璃。
在一些情况下,将靶核酸经由捕获探针附接或固定至基质。捕获探针为寡核苷酸,其附接至基质表面,并且能够与测序模板结合。捕获探针可为各种长度,例如18个碱基至100个碱基,例如20个碱基至50个碱基。
在一些情况下,捕获探针含有与测序模板互补的序列。例如,如果本方法用于对至少部分序列已知的基因组进行测序,则捕获探针可设计为与已知序列互补。在一些情况下,捕获探针与经由例如特异性连接作为PCR反应引物的一部分添加至测序模板的“条形码”或“识别符”序列互补。在此类反应中,将测序模板特异性引物和包括唯一条形码的引物用于扩增,因此所有具有相同序列的靶分子含有相同的附接条形码。
捕获探针可在5'端或3'端附接至基质。在一些情况下,捕获探针附接在5'端附接至基质,并且捕获探针的3'端可通过掺合如本文描述的核苷酸来延伸,以产生递增的延伸片段,可接着通过进一步掺合标记的核苷酸对所述片段进行测序。在其他情况下,捕获探针在3'端附接至基质,并且捕获探针的5'端不能通过核苷酸的掺合来延伸。第二探针(或测序引物)与测序模板杂交,并且它的3'端通过如本文描述的核苷酸掺合来延伸,以产生递增的延伸片段,可接着通过进一步掺合标记的核苷酸对所述片段进行测序。在这种情况下,延伸朝向捕获探针的方向。一般来说,测序引物与引入至直接从基因组DNA产生或从亲本靶分子产生的测序模板末端的接头杂交。因此,为“通用引物”的种子(seed)/测序引物可用于对不同的靶分子进行测序。在一些情况下,使用对靶分子具有特异性的测序引物。
在一些情况下,捕获探针在与测序模板结合之前固定在固体支撑物上。在一些情况下,捕获探针的5'端附接至固体表面或基质。捕获探针可通过本领域已知的各种方法固定,包括但不限于共价交联至表面(例如以光化学方法或以化学方法)、通过锚配体与相应受体蛋白的相互作用(例如生物素-链霉亲和素或地高辛-抗地高辛抗体)非共价附接至表面,或通过于锚核酸或核酸类似物杂交。锚核酸或核酸类似物具有对于测序模板充足的互补性(即,形成的双链具有充足地高Tm),从而使得锚-测序模板-探针复合物将经受住用以除去未结合靶和探针的严格洗涤,但它们不重叠于与探针反义序列互补的靶位点。
在一些情况下,使用捕获模板或靶核酸作为桥式扩增的模板。在此类情况下,使用两种或更多种不同的固定探针。在一些情况下,使用单分子模板以在基质上通过桥式扩增产生核酸簇。在一些情况下,核酸簇中的每个包含大致相同(>95%)的核酸类型,因为它们衍生自仅一个模板核酸。这种簇通常被称作单分子簇。此类具有单分子簇的基质可通过使用例如描述于Bently等,Accurate whole human genome sequencing using reversible terminator chemistry,Nature 456,53-59(2008)中的方法来生产,或使用可商购自例如Illumina公司(San Diego,CA)的试剂盒和仪器来生产。
然后,固定或附接的靶核酸可与一个引物(或多个引物)杂交。然后,添加处于适合缓冲液中的聚合酶,以与固定或附接的模板或靶核酸接触。所述引物可直接作为测序引物使用。
测序系统
在另一个方面,本发明提供一种用于测序的系统。在一些情况下,通过系统执行本文公开的一个或多个测序方法,例如由用户控制的自动化测序系统仪器(例如图8中用示意性示出)。在一些情况下,用户控制可操作各种本发明的仪器装置、液体处置设备或分析步骤的计算机。在一些情况下,使用计算机控制收集、处理或分析系统来控制、激活、开始、继续或终止如本文描述的方法的任何步骤或过程。在一些情况下,使用计算机设备来控制、激活、开始、继续或终止进入和通过如本文描述的系统或装置的流体或试剂的处置和/或运动、一个或多个试剂至一个或多个储筒中的一个或多个腔室或多个腔室的处置或运动、数据的获得或分析等。在一些情况下,将测序反应的芯片布置在一个或多个储筒中的一个或多个腔室/流动池或多个腔室/流动池中。芯片可包括提供用于测序反应的位点的基质。
在一些情况下,计算机是任何类型的计算机平台,例如工作站、个人计算机、服务器或任何其他现在的或未来的计算机。计算机通常包括已知部件,例如处理器、操作系统、系统存储器、存储器存储设备,和输入-输出控制器、输入-输出设备,以及显示设备。此类显示设备包括提供视觉信息的显示设备,这种信息通常可逻辑上和/或物理上组织为像素阵列。在一些情况下,包括了图形用户界面(GUI)控制器,所述控制器包括各种用于提供图形输入和输出界面的已知的或未来的软件程序中的任一种。在一些情况下,GUI给用户提供一个或多个图形表示,并且被允许使用相关技术领域的普通技术人员已知的选择或输入的方式经由GUI来处理用户输入。
有关技术领域的普通技术人员将理解存在计算机部件的许多可能配置,并且未描述一些可能通常包括于计算机中的部件,例如高速缓冲存储器、数据备份单元和许多其他设备。在本实例中,每个执行核心可作为允许多个线程并行执行的独立处理器来执行。
在一些情况下,处理器执行操作系统,所述操作系统例如来自Microsoft公司的WINDOWSTM类型的操作系统(例如WINDOWSTM XP)、来自Apple Computer公司的Mac OS X操作系统(例如7.5Mac OS X v10.4“Tiger”或7.6Mac OS X v10.5“Leopard”操作系统)、可从许多厂商得到的或被称作开源的UNIXTM或Linux类型的操作系统,或它们的组合。操作系统以众所周知的方式与固件和硬件进行交互,并且有利于处理器协调和执行可能以各种程序语言编写的各种计算机程序的功能。操作系统通常与处理器合作来协调和执行其他计算机部件的功能。操作系统还提供调度、输入-输出控制、文件和数据管理、存储器管理和通信控制以及相关服务,所有服务都根据已知的技术。
在一些情况下,系统存储器是各种已知的或未来的存储器存储设备。实例包括任何通常可用的随机存取存储器(RAM)、磁性介质例如驻留硬盘或磁带、光学介质例如读取和写入压缩盘或其他存储器存储设备。存储器存储设备可为各种已知的或未来的设备中的任一种,包括压缩盘驱动器、磁带驱动器、可移动硬盘驱动器、USB或闪存驱动器、或软盘驱动器。所述类型的存储器存储设备通常从程序存储介质(未示出)读取和/或写入,例如分别读取和/或写入光盘、磁带、可移动硬盘、USB或闪存驱动器或软盘。
在一些情况下,计算机程序产品据描述包括具有存储于其中的控制逻辑(计算机软件程序,包括程序代码)的计算机可用介质。所述控制逻辑在由处理器执行时使处理器执行本文所述的功能。在其他实施方案中,一些功能主要被实施于使用例如硬件状态机的硬件中。对有关技术领域的技术人员而言,用于执行本文所述功能的硬件状态机的实施方法将是显而易见的。
在一些情况下,输入-输出控制器包括各种用于接受和处理来自用户的信息的已知设备中的任一种,无论所述用户是人还是机器、无论是本地的还是远程的。此类设备包括例如调制解调卡、无线网卡、网络接口卡、声卡或其他类型的针对各种已知输入设备中的任一种的控制器。输入-输出控制器的输出控制器可包括针对各种用于将信息呈现给用户的已知显示设备中的任一种的控制器,无论所述用户是人还是机器、无论是本地的还是远程的。在一些情况下,计算机的功能元件经由系统总线与彼此通信。在替代性实例中,这种通信中的一些可使用网络或其他类型的远程通信来完成。
在一些情况下,应用与一个或多个服务器、一个或多个工作站和/或一个或多个仪器的一个或多个元件或进程通信,并且接收来自所述一个或多个元件的指令或信息,或者控制所述一个或多个元件。在一些情况下,具有存储于其上的应用的具体实施方案的服务器或计算机位于本地或远程,并且与一个或多个额外的服务器和/或一个或多个其他计算机/工作站或仪器通信。在一些情况下,应用能够有数据加密/解密功能性。例如,出于数据安全性和机密性的目的,可能期望对数据、文件、与GUI相关的信息或其他可沿网络传输至一个或多个远程计算机或服务器的信息进行加密。
在一些情况下,应用包括仪器控制特征,其中将个别类型或特定仪器(例如温度控制设备、成像设备或流体处置系统)的控制功能针对应用而组织为插入型模块。在一些情况下,仪器控制特征包括对一个或多个仪器的一个或多个元件的控制,例如,所述元件包括流体处理仪器、温度控制设备或成像设备的元件。在一些情况下,仪器控制特征能够从一个或多个仪器接收信息,所述信息包括实验或仪器状态、处理步骤或其他有关信息。在一些情况下,仪器控制特征处于所述应用的界面的元件的控制下。在一些情况下,经由GUI中的一个,用户输入期望的控制命令和/或接收仪器控制信息。
在一些情况下,自动化测序系统由第一用户控制,进行本文所述的测序方法,分析如本文所述的原始数据,组装如本文所述的序列读段,并且然后将测序信息发送至处在位置不同于第一用户的远程第二用户。
数据处理与数据分析
在一些情况下,用计算机进行对靶多核苷酸序列的鉴定和对用以组装基因组信息的序列的整合。在一些情况下,本发明包括被设计成经由本发明所述方法来分析和组装获得的序列信息的计算机软件或算法。
按照用于原位阵列的序列读段解读,在阵列特征中的读段对应于映射感兴趣基因座的X-Y坐标。“读段”通常指的是衍生自原始数据的观测序列,例如对应于个别核苷酸的循环添加的检测信号的次序。在一些情况下,为了质量控制,在10-bp基因座处针对预期参考基因组序列检查读段。参考序列允许使用短的读长。然后,将通过质量控制检查的读段进行组合以在每个基因座产生共有序列。在一个实例中,每个感兴趣基因座减去任何未通过质量控制检查的读段存在10个唯一的探针。
按照用于“草坪(lawn)”方法的序列读段解读,所述读段在表面(例如流动池)上处于随机定位。在一些情况下,为了质量控制,在目标基因座处对照预期参考基因组序列的子集检查读段。将通过质量控制检查的读段映射至单个目标基因座。然后,将对应于每个基因座的读段进行组合以产生共有序列。在一些情况下,每10-bp基因座存在多于3,000个读段。
序列读段组装
在一些情况下,本发明提供一种用于通过从基质中的每个来组装序列读段以获得靶分子序列信息的方法。由于例如上文所述的使用相同靶分子的相同捕获探针的不同碱基延伸,序列读段可通过一系列具有不同长度的多核苷酸的碱基延伸来获得。因而,它们代表靶分子序列的连续片段,并且可被组装以提供靶分子的连续序列。
可使用计算机程序以在用于组装的不同基质上跟踪从相同捕获探针获得的序列读段。
在一些情况下,使用模板的唯一标识符(例如模板定位或标签序列)来鉴定起源于单个模板的测序信息。重叠的序列信息可被缝合在一起,以产生来自单个模板的更长的序列信息。在一些情况下,模板的互补物也被测序。在一些情况下,使用产生自模板和其互补物两者的测序读段来将测序信息缝合在一起。
性能
本文公开的方法、试剂和试剂盒能改善核酸测序反应的性能。在特定实例中,性能的改善涉及在测序反应期间核酸分子同步化的改善。同步化的改善可涉及测序读段质量的改善。
测序反应中的核酸分子同步化可由纯洁度得分来度量。纯洁度得分由以下公式定义:纯洁度=I1/(I1+I2),其中I1是最强信号的强度(即,掺合的正确碱基),并且I2是第二强信号的强度(即,掺合的错误碱基)。因此,纯洁度得分是对在给定时间点掺合至生长的测序产物的正确碱基的量比掺合至生长的测序产物的正确碱基的量和错误碱基的量的总和的比率的度量。纯洁度得分是对于新生测序产物的簇来进行计算的,并且是对发生于所述簇的相位移后/相位提前的程度的度量。纯洁度得分可涉及测序循环的特定步骤,并且可根据测序反应的持续时间而改变。例如,纯洁度得分可在若干测序步骤之后例如在50个、100个、150个、200个或更多个测序步骤之后对于新生测序产物的簇进行计算。纯洁度得分一般将随着测序产物变得更长(即,更多测序产物变得脱离相位)而降低。本文提供的方法、试剂和试剂盒可通过改善生长链的同步化来提高测序产物的簇的纯洁度得分。在一些情况下,在执行本公开的方法之后,纯洁度得分将为0.8、0.85、0.9、0.95、0.99,至多1.0。在一个实例中,在执行如整个公开内容中所述的同步化循环之后,执行本文所述方法之后的纯洁度得分将为至少0.85或更高。一般而言,纯洁度得分将在同步化循环之后提高。在执行同步化循环之后,纯洁度得分可提高10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、100%或大于100%。在一些情况下,纯洁度得分至少提高20%。在其他情况下,纯洁度得分至少提高35%。在其他情况下,纯洁度得分至少提高50%。图9描绘通过执行本文提供的方法改善纯洁度的实例。在同步化循环之前,链平均具有约0.7的纯洁度得分,而在同步化循环(例如8个同步化步骤)之后,平均纯洁度得分为约0.85。
在一些方面中,本文提供的方法和系统适用于增加靶核酸序列的测序读段长度。在一些情况下,在执行同步化循环之后,靶核酸序列的测序读段长度有所增加。相对于不利用本文所述的同步化方法的测序方法而言,测序读段长度可能有所增加。在一些情况下,测序读段长度是通过产生具有更大精确度的更长的测序读段来增加。在一些情况下,所述方法和系统产生约300个、400个、500个、600个、700个、800个、900个、1000个或更多个碱基对的更长的测序读段。在一些情况下,读段错误率降低约50%、55%、60%、65%、70%、75%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。
在一个方面中,边合成边测序(SBS)系统被配置来产生大于300个碱基对并且具有至少0.85或更大的纯洁度得分的测序读段。在另一个方面中,提供一种用于序列测定的方法,其中所述方法包括执行边合成边测序(SBS)反应以产生大于300个碱基对并且具有至少0.85或更大的纯洁度得分的测序读段。在另一个方面中,提供一种提高测序反应的纯洁度得分的方法,其中纯洁度得分至少提高20%。在一些情况下,所述方法不涉及软件。
试剂盒
进一步提供试剂盒和试剂来执行本文所述的方法。在一些情况下,提供用于靶核酸分子测序的试剂盒。所述试剂盒可包括一个或多个测序引物。一个或多个测序引物可与靶核酸分子杂交。在一些情况下,一个或多个测序引物可与出现在靶核酸上的一个或多个衔接子、索引或条形码序列发生复性。在其他情况下,一个或多个测序引物可直接与靶核酸序列发生复性。所述试剂盒可还包括一个或多个标记的核苷酸。一个或多个标记的核苷酸已在上文中描述,并且可利用其执行所述方法的一个或多个测序循环。在一些情况下,一个或多个标记的核苷酸是荧光标记的核苷酸。所述试剂盒可还包括一组或多组多达三种不同的核苷酸,所述多达三种不同的核苷酸选自由dATP、dTTP、dCTP和dGTP组成的组。在一些情况下,dUTP也可包括于所述组中。在一些情况下,所述组核苷酸是未标记的核苷酸。一组或多组未标记的核苷酸已在上文中描述,并且可利用其执行所述方法的一个或多个同步化步骤。在一些情况下,一组或多组未标记的核苷酸包括天然核苷酸。试剂盒可包括一个或多个以下组的未标记核苷酸:dATP、dCTP和dGTP(“-T”),dATP、dTTP和dGTP(“-C”),dCTP、dGTP和dTTP(“-A”),以及dATP、dCTP和dTTP(“-G”)。替代地或另外,试剂盒可包括多组核苷酸,所述组核苷酸包括可逆终止子核苷酸和三种未标记核苷酸(例如dATP、dCTP、dGTP和可逆终止子dTTP)。
试剂盒可还包括以下中的一个或多个:聚合酶(例如DNA聚合酶)、焦磷酸酶、三磷酸腺苷双磷酸酶、缓冲液或任何额外的适用于执行本文所述方法的试剂。所述试剂盒可还包括描述试剂使用和如何执行上文所述方法的说明书。
实施例
给出以下实施例,目的在于例示本发明的各种实施方案,并且不意在以任何方式限制本发明。所述实施例与本文所述方法目前代表优选实施方案,是示例性的并且不旨在限制本发明的范围。本领域的技术人员将想到在由权利要求书的范围所定义的本发明的精神内所涵盖的变化和其他用途。
实施例1-在SBS测序的100个轮次之后Inline+S同步化使测序链重调。
图10和11描绘同步化方案的结果。简单地说,边合成边测序(SBS)反应在MiSeq测序系统(Illumina)上执行。在SBS测序的100个轮次之后,所述反应被去封闭,用三磷酸腺苷双磷酸酶引发所述反应,接着在37℃下进行混合。接下来,8个inline+S同步化步骤如下述执行以使测序链重调:(-A、-C、-G、-T、-G、-C、-A、-T)。同步化方案后接着是另一100个测序轮,接着是额外的8个inline+S同步化步骤,以及额外的25个测序轮。图10描绘在每个步骤(x轴)针对每个核苷酸(y轴)测得的强度信号。第一inline+S方案导致平均10.2%的强度提高(A:11%、C:8.8%、G:11.7%和T:9.4%),而第二inline+S方案导致平均12.3%的强度提高(A:18.6%、C:13.2%、G:19.5%和T:10.8%)。图11描绘在每个步骤(x轴)中测序读段的质量得分(y轴)。图11对通过算法计算的所报道Illumina质量得分(黑色线)与通过将数据与参考序列对齐计算的质量得分(灰色线)进行了比较。
实施例2-在SBS测序的110个轮次之后Inline+S同步化使测序链重调
图12和13描绘同步化方案的结果。简单地说,边合成边测序(SBS)反应在MiSeq测序系统(Illumina)上执行。在SBS测序的110个轮次之后,所述反应被去封闭,并且用三磷酸腺苷双磷酸酶引发所述反应,接着在37℃进行混合。接下来,8个inline+S同步化步骤如下述执行以使测序链重调:(-A、-C、-G、-T、-G、-C、-A、-T)。同步化方案后接着是40个测序轮。然后,从测序产物的相反末端开始重复测序和同步化方案。图12描绘在每个步骤(x轴)针对每个核苷酸(y轴)测得的强度信号。第一inline+S方案导致平均12.2%的强度提高(A:15.0%、C:8.2%、G:17.0%和T:7.5%),而第二inline+S方案导致平均11.5%的强度提高(A:15.5%、C:4.6%、G:20.0%和T:6.0%)。图13描绘在每个步骤(x轴)中测序读段的质量得分(y轴)。图13对通过算法计算的所报道Illumina质量得分(黑色线)与通过将数据与参考序列对齐计算的质量得分(灰色线)进行了比较。
实施例3-Inline+S同步化降低SBS测序的错误率
图14描绘在实施同步化方案之后错误率的降低。简单地说,在PhiX测序控制器上的边合成边测序(SBS)反应使用MiSeq测序系统(Illumina)执行。在SBS测序的110个轮次之后,所述反应被去封闭,并且用三磷酸腺苷双磷酸酶引发所述反应,接着在37℃进行混合。接下来,8个inline+S同步化步骤如下述执行以使测序链重调:(-A、-C、-G、-T、-G、-C、-A、-T)。同步化方案后接着是40个测序轮。然后,从测序产物的相反末端开始重复测序和同步化方案。
尽管本文已示出和描述了本发明的优选实施方案,但对于本领域技术人员来说将显而易见,此类实施方案仅作为实例提供。在不脱离本发明的情况下,本领域技术人员现将会想到众多的变化、改变和替代。应理解,本文所述的本发明的实施方案的各种替代方案可用于实行本发明。意图在于,上文的权利要求书定义本发明的范围,并且因此可涵盖处于这些权利要求范围内的方法和结构以及其等效物。
- 还没有人留言评论。精彩留言会获得点赞!