类几丁质酶基因序列、YKL‑40蛋白及制备方法与流程
本发明涉及生物技术领域,特别是涉及一种人工合成的类几丁质酶基因序列、YKL-40蛋白及制备方法。
背景技术:
类几丁质酶(YKL-40)是一种糖蛋白,最早是从人骨肉瘤细胞株MG63的体外培养物中分离出来的,该蛋白N端的三个氨基酸残基分别为酪氨酸(Y)、赖氨酸(K)和亮氨酸(L),分子量为40KD,故Johansen等将此蛋白命名为YKL-40,该蛋白又称几丁质酶-3样蛋白-1(Chtinase-3-like-1protein,CHI3L1)或人类软骨糖蛋白-39(Human cartilage glycoprotein-39,HCgp-39)。
YKL-40是近几年发现与新型心血管疾病发生关系最密切的血清炎性因子,参与内皮功能障碍和新生血管形成,具有极强的致动脉粥样硬化形成作用,其含量高低可用于预测心脑血管疾病发生风险。另外,多种恶性肿瘤患者血清中可检测到高水平的YKL-40,YKL-40可作为一种新兴的肿瘤标志物。YKL-40是肿瘤生长因子的一种,与肿瘤的发生、发展有着密不可分的联系。YKL-40在参与肿瘤细胞生存增殖浸润、保护细胞凋亡、刺激血管生成和肿瘤周围的炎症反应、重塑细胞外基质以及肿瘤转移等过程中发挥重要作用。
血清YKL-40已经成为心血管疾病和肿瘤血清学的强有力的生物标志物,YKL-40的表达水平对患者的病情与预后评估有重要价值。在检测YKL-40时,产品需要用到抗YKL-40的抗体,因此,稳定的、人源性的YKL-40蛋白对于制备抗YKL-40的抗体显得尤其重要。现有技术中,为了获得YKL-40蛋白,采用的方法是:根据基因库(GenBank)中YKL-40基因的序列,设计合成引物,应用聚合酶链式反应(Polymerase Chain Reaction,PCR)扩增YKL-40基因后,构建包含扩增后的YKL-40基因的表达载体,并表达获得YKL-40蛋白。
但是,上述采用PCR扩增所获得的YKL-40基因片段存在突变的因素,获得的YKL-40蛋白并不稳定,且表达量少、溶解性低、不容易纯化。
技术实现要素:
本发明主要解决的技术问题是提供一种人工合成的类几丁质酶(YKL-40)基因序列、YKL-40蛋白及制备方法,能够获得稳定的类几丁质酶蛋白,且表达量多、溶解性好、易纯化。
为解决上述技术问题,本发明采用的一个技术方案是:提供一种人工合成的YKL-40基因序列,所述YKL-40基因序列包括SEQ ID NO:1。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种YKL-40蛋白,所述YKL-40蛋白是通过人工合成的YKL-40基因序列表达而获得的,所述YKL-40基因序列包括SEQ ID NO:1。
其中,所述YKL-40蛋白是采用CHO细胞、对包含所述YKL-40基因序列的表达载体进行表达而获得的。
为解决上述技术问题,本发明采用的又一个技术方案是:提供一种YKL-40蛋白的制备方法,所述方法包括:人工合成YKL-40基因序列,其中,所述YKL-40基因序列包括SEQ ID NO:1;构建包含所述YKL-40基因序列的表达载体;表达包含所述YKL-40基因序列的表达载体,获得所述YKL-40蛋白。
其中,所述表达包含所述YKL-40基因序列的表达载体,获得所述YKL-40蛋白的步骤,包括:采用CHO细胞表达包含所述YKL-40基因序列的表达载体,获得所述YKL-40蛋白。
其中,所述表达载体为pCMV-EGFP质粒。
其中,所述表达包含所述YKL-40基因序列的表达载体,获得所述YKL-40蛋白的步骤之后,包括:采用镍琼脂糖凝胶Ni Sepharose亲和层析柱纯化所述YKL-40蛋白。
本发明的有益效果是:区别于现有技术的情况,本发明采用经过专门设计的、采用人工方式合成YKL-40基因序列,稳定性好;该基因序列删除原始序列上的跨膜区序列,使得YKL-40蛋白分泌到细胞溶液中,提高了溶解性;该基因序列设计有Kozak序列,能够促进表达,使得蛋白产量提高;该基因序列设计有纯化标签,有利于表达的YKL-40蛋白的纯化。
附图说明
图1是基因的酶切鉴定图谱;
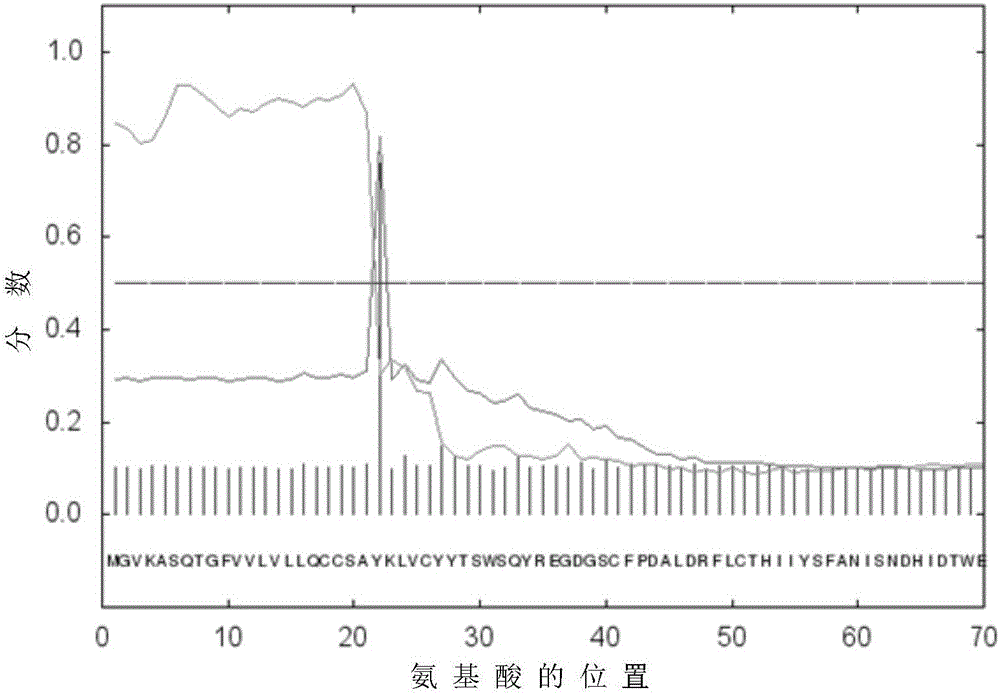
图2是推导YKL-40蛋白氨基酸信号肽的分析示意图;
图3是通过合成的YKL-40基因序列表达而获得的YKL-40蛋白的SDS电泳图谱示意图;
图4是转染细胞培养的荧光状况示意图。
具体实施方式
在详细说明本发明之前,先介绍一下与本发明相关的基本概念。
1993年Hakala等公布了人类软骨糖蛋白的完整氨基酸序列及cDNA序列(Genbank序列号为M80927),结果显示YKL-40是由383个氨基酸残基组成的长肽蛋白,分子量为40 476D;属于哺乳动物18糖基水解酶家族的几丁质类酶成员。1997年,德国学者Rehli首先分离鉴定了YKL-40基因,YKL-40由CHI3L1基因编码,其编码基因位于人类染色体1q31-1q32区域,基因含有10个外显子,长达8kb,共7948个碱基配对的基因组DNA组成,该研究还提示YKL-40基因可能有两个独立的转录本,启动子序列包括多种调节因子的结合位点。
YKL-40蛋白是相对分子质量为40kDa的肝磷脂和壳质衔接的凝集素,编码的蛋白序列与糖基水解酶相似,属于进化保守的18糖基水解酶家族。因为其链上的一个起主要作用的谷氨酸被亮氨酸所替代,所以尽管YKL-40属于哺乳动物18家族的几丁质酶成员,却没有几丁质酶活性,导致其功能至今仍然难以明确。YKL-40由活化的巨噬细胞、中性粒细胞、关节软骨细胞、成纤维样滑膜细胞、血管平滑肌细胞及多种癌细胞分泌的,YKL-40,一方面通过上调单核细胞趋化蛋白-1(Monocyte chemoattractant protein-1,MCP-1)的表达,进而促使更多的单核细胞变成巨噬细胞,并与低密度脂蛋白结合形成泡沫细胞。另一方面,YKL-40也能加速血管平滑肌细胞增殖分化,可以引起内皮细胞功能失调,诱导血管平滑肌细胞迁移、重构,促进分支小血管形成参与各种炎症和肿瘤性疾病发病过程,YKL-40可能在细胞增殖、分化、有丝分裂、抑制凋亡、刺激血管形成及细胞外组织重塑中起重要作用。有临床数据显示,升高的YKL-40往往伴随着甘油三酯水平的增高,并且也能使脑梗死的风险增加两倍,推测有可能这些导致脑梗死高危因素是通过YKL-40途径发挥用作的。体外研究显示,YKL-40可以通过激活p38MAPK增加MMP-9的表达,导致多种蛋白的降解、纤维帽变薄、斑块稳定性降低。所以YKL-40可能会成为未来心血管治疗的新靶点,在心血管的早期诊断、治疗评估及预后监测等方面发挥重要作用。
在分子生物学领域,YKL-40已被证实是PI3K/AKT/MTOR通路的上游调控因子,YKL-40为成纤维细胞、软骨细胞的生长因子,并与胰岛素样生长因子-1起协同作用。YKL-40可启动成纤维细胞中丝裂原活化蛋白激酶(Mitogen-activated protein kinase,MAPK)和磷脂酰肌醇3激酶(Phosphatidylinositol 3kinase,PI3K)信号级联,使细胞外信号调节激酶(Extracellular signal-regulated kinase,ERK)-1/2、MAP激酶和蛋白激酶B(Protein kinase B,Akt)磷酸化,从而促进有丝分裂,并参与调控肿瘤细胞的增殖与凋亡等生物学行为。在血管形成方面,YKL-40也可以通过上调血管内皮生长因子(Vascular endothelial growth factor,VEGF)的表达,促进内皮细胞及平滑肌细胞的增生,能够促进血管内皮细胞及血管平滑肌细胞黏附、迁移及重组以形成病理性新生血管,这些因素直接关系到肿瘤细胞的恶性增殖与间质重塑,包括中溜溜周围血管分布密度变化、细胞连接的中断及细胞外基质降解等。Shao等报道,乳腺癌中YKL-40表达与血管密度相关,拥有广泛的血管生成表现,使用小干扰RNA基因阻断YKL-40的生成能够抑制肿瘤的血管生成,所以YKL-40可能会成为未来肿瘤治疗的新靶点,在肿瘤的早期诊断、治疗评估及预后监测等方面发挥重要作用,为肿瘤的防治提供新的思路和手段。
YKL-40与炎症及心血管疾病的检测意义:
YKL-40是近几年发现新型心血管疾病发生关系最密切的血清炎性因子,参与内皮功能障碍和新生血管形成,具有极强的致动脉粥样硬化形成作用,其含量高低可用于预测心脑血管疾病发生风险。动脉粥样硬化的病因包括内皮损伤、脂质代谢异常、血流动力学损伤、遗传、物理化学损伤等,而多种复杂因素作用于血管壁,其结果是血管壁的慢性炎症,是对血管壁损害的反应和修复过程。YKL-40作为细胞生长因子,血管生成因子,在心血管炎症反应过程中主要参与先天免疫系统的激活和有关细胞外基质的重塑,抗凋亡蛋白,促进组织纤维化等作用直接参与动脉粥样硬化,冠心病等心血管疾病。YKL-40是在多种复杂因素作用于血管壁时由局部活化巨噬细胞和中性粒细胞等颗粒细胞胞外分泌来释放;YKL-40属于局部炎症细胞分泌,所以在急、慢性炎症中的水平相对C反应蛋白等全身系统炎症标志物可以更快的达到高峰期;既往有研究表明在体内炎症环境的巨噬细胞中检测到大量的YKL-40,例如类风湿关节炎、动脉粥样硬化、巨细胞性关节炎和慢性阻塞性肺疾病。YKL-40高表达于动脉粥样硬化斑块中,与冠状动脉粥样斑块稳定性相关。高水平的YKL-40的表达与稳定性冠状动脉粥样硬化心脏病、老年人的死亡率有一定的相关性。因为它在亚临床疾病阶段容易被检测故它有助于疾病早期的筛选,而且也有可能成为心血管疾病发病和死亡率的预测指标。
YKL-40与肿瘤的检测意义:
多种恶性肿瘤患者血清YKL-40可检测到高水平的YKL-40,YKL-40可作为一种新兴的肿瘤标志物。YKL-40是肿瘤生长因子的一种,与肿瘤的发生、发展有着密不可分的联系。基因YKL-40在参与肿瘤细胞生存增殖浸润、保护细胞凋亡、刺激血管生成和肿瘤周围的炎症反应、重塑细胞外基质以及肿瘤转移等过程中发挥重要作用。抑制YKL-40基因的表达是肿瘤治疗的新方法。国内外研究表明,YKL-40在卵巢、子宫、乳房、胃肠道、肺、肝等多种肿瘤组织YKL-40高表达,YKL-40可作为这些高表达肿瘤诊断和处理的一个新指标。1)YKL-40可作为早期卵巢癌的诊断标志物及复发和生存预测的指标。卵巢癌是发生于卵巢组织的恶性肿瘤,病死率高居女性生殖系统肿瘤首位,其恶性程度最高,极易早期发生盆腔和腹腔的广泛转移。卵巢癌早期症状无异常,大多数患者发现时已是晚期,提高卵巢癌早期诊断及为重要。糖类抗原125(Carbohydrate antigen 125,CA125)是FDA批准的第一个卵巢上皮性癌生物标记物,CA125在80%的晚期卵巢癌患者中升高(>35U/mL),但在早期患者不足50%升高,其诊断的敏感性较高,但特异性较差。研究发现YKL-40对早期卵巢癌诊断灵敏度高于CA125,Zou L等研究显示YKL-40水平与卵巢癌的恶性程度成正相关,与患者的生存期呈负相关,血清YKL-40水平联合CA125水平检测在恶性卵巢癌的诊断等方面有较高的临床价值,可提高对卵巢癌诊断的灵敏度。2)在子宫内膜癌的研究中,Peng等研究表明血清YKL-40对子宫内膜癌患者的诊断和预后评估有重要价值,在子官内膜癌的组织和血清水平YKL-40均呈高表达,且组织中的阳性表达与肿瘤的组织学分级呈正相关,YKL-40可作为子宫内膜癌的诊断和或预后相关的分子标志物。3)在子宫颈癌的研究中,Palle C等对116例子宫颈癌患者血清YKL-40的浓度检测发现YKL-40血清浓度在子宫颈癌患者中最高,明显高于宫颈上皮内瘤变组和正常对照组,且随着临床期别的增高,YKL-40的水平越高,差异有统计学意义。4)YKL-40可反应复发性乳腺癌的侵袭性并作为其预后和转移位置的预测指标。5)YKL-40可由结直肠癌肿瘤细胞和肿瘤细胞旁的某些巨噬细胞与中性粒细胞所表达,高血清YKL-40是结直肠癌短的生存期的独立预测指标,在结直肠癌的侵袭中YKL-40可能发挥重要作用。6)小细胞肺癌患者血清YKL-40升高与其短的生存期相关。进一步研究发现基因YKL-40与肿瘤的预后密切相关,YKL-40的高表达与高分级的卵巢癌相关,与乳腺癌等的不良预后相关。癌前病变患者比健康对照组妇女YKL-40的表达水平更高。血清中基因YKL-40水平高的患者与正常水平患者相比,预后差且生存期短,说明基因YKL-40是一个新的预警指标,YKL-40已被作为一种潜在的肿瘤血清学标记物,可作为早期或晚期癌症的治疗及预后判断的新的标志物。
血清YKL-40已经成为心血管疾病和肿瘤血清学的强有力的生物标志物,YKL-40的表达水平对患者的病情与预后评估有重要价值。
检测YKL-40,对应的产品需要用到抗YKL-40的抗体,因此,提供稳定的、人源性的YKL-40蛋白对于制备抗YKL-40的抗体显得尤其重要。现有技术为了获得YKL-40蛋白,采用的方法是:根据GenBank中YKL-40基因的序列,设计合成引物,应用PCR扩增YKL-40基因后,构建包含扩增后的YKL-40基因的表达载体,并表达获得YKL-40蛋白。但是,采用PCR扩增所获得的YKL-40基因片段存在突变的因素,获得的YKL-40蛋白并不稳定,且表达量少、溶解性低、不容易纯化。
本发明提供一种人工合成的类几丁质酶(YKL-40)基因序列、YKL-40蛋白及制备方法,采用经过专门设计的、采用人工方式合成YKL-40基因序列,稳定性好;该基因序列删除原始序列上的跨膜区序列,使得YKL-40蛋白分泌到细胞溶液中,提高了溶解性;该基因序列设计有Kozak序列,能够促进表达,使得蛋白产量提高;该基因序列设计有纯化标签,有利于表达的YKL-40蛋白的纯化。
下面结合附图和实施方式对本发明进行详细说明。
本发明提供一种人工合成的YKL-40基因序列,该YKL-40基因序列包括SEQ ID NO:1。
Genbank中定义的编码人YKL-40的cDNA的序列SEQ ID NO:2为:
(版本VERSION:EU831695.1,Genbank ID号GI:190689508,全长1195bp)
本发明实施方式中,SEQ ID NO:1的序列如下:
SEQ ID NO:1的氨基酸序列:
MGVKASQTGFVVLVLLQCCSAYKLVCYYTSWSQYREGDGSCFPDALDRFLCTHIIYSFANISNDHIDTWEWNDVTLYGMLNTLKNRNPNLKTLLSVGGWNFGSQRFSKIASNTQSRRTFIKSVPPFLRTHGFDGLDLAWLYPGRRDKQHFTTLIKEMKAEFIKEAQPGKKQLLLSAALSAGKVTIDSSYDIAKISQHLDFISIMTYDFHGAWRGTTGHHSPLFRGQEDASPDRFSNTDYAVGYMLRLGAPASKLVMGIPTFGRSFTLASSETGVGAPISGPGIPGRFTKEAGTLAYYEICDFLRGATVHRILGQQVPYATKGNQWVGYDDQESVKSKVQYLKDRQLAGAMVWALDLDDFQGSFCGQDLRFPLTNAIKDALAATHHHHHH*
比较上述的SEQ ID NO:1与SEQ ID NO:2,可以发现:相较于Genbank中定义的编码人YKL-40的cDNA的序列SEQ ID NO:2,在本发明的SEQ ID NO:1的序列中:
第一、SEQ ID NO:1人工合成而来,不是采用引物进行PCR反应而来,这样能够避免基因突变的问题,有助于编码蛋白YKL-40蛋白的稳定性。
第二、优化了SEQ ID NO:2中后面C端的编码跨膜区的序列。优化之后,SEQ ID NO:1编码的蛋白YKL-40蛋白可以直接分泌到细胞外的溶液中,这样可以提高编码蛋白YKL-40蛋白的溶解性;
第三、在C端的末端连接了用于纯化编码蛋白的6个组氨酸His标签:caccaccaccaccac,这样可以通过亲和层析柱纯化编码蛋白YKL-40蛋白;
第四、在N端连接了Kozak序列:gccaccatg,能够提高转录和翻译的效率,提高编码蛋白YKL-40蛋白的表达量。
第五、在N端设计了两个酶切位点,分别是Hand III(aagctt)和Sac I(gagctc),在C端设计了一个酶切位点Bam H I(ggatcc),这样方便在表达的时候,能够根据不同的需要,根据表达载体上的酶切位点,从而选择不同的表达载体。
第六、在N端具有引导表达的氨基酸信号肽的基因序列,氨基酸信号肽能够引导YKL-40蛋白分泌到细胞膜外,方便收集表达后的YKL-40蛋白。
本发明还提供一种类几丁质酶蛋白,该YKL-40蛋白是通过上述的YKL-40基因序列表达而获得的。
在实际应用中,人工合成上述的YKL-40基因序列后,可以通过现有的技术构建包含目的基因的表达载体,然后表达获得YKL-40蛋白。
其中,在一实施方式中,YKL-40蛋白是采用CHO细胞、对包含YKL-40基因序列的表达载体进行表达而获得的。
中国仓鼠卵巢细胞(Chinese Hamster Ovary,CHO),1957年美国科罗拉多大学Dr.Theodore T.Puck从一成年雌性仓鼠卵巢分离获得,为上皮贴壁型细胞,是生物工程上广泛使用的细胞系。该细胞具有不死性,可以传代百代以上。另外CHO细胞在基因工程使用中还有一个优点,该细胞属于成纤维细胞(Fibroblast),是一种非分泌型细胞,它本身很少分泌CHO内源蛋白,因此对目标蛋白分离纯化工作十分有利。可形成有活性的二聚体,具有糖基化的功能,CHO为表达复杂生物大分子的理想宿主。用CHO细胞表达重组的YKL-40基因序列,获得的YKL-40蛋白具有与人自然产生的蛋白完全相似的生物学特性。
参见图1,图1是基因的酶切鉴定图谱,其中,第1道为DNA标准品DNA ladder,从上往下代表的DNA分子量大小分别是:5000bp、3000bp、2000bp、1000bp、750bp、500bp、250bp、100bp,第2道为连接上合成基因后的质粒未经过酶切的电泳图谱,第3道为连接上合成基因后的质粒经过酶切后的酶切电泳图谱。酶切结果显示,第3道的小基因片段大小为1.2kb左右(第3道从上往下箭头所指条带的位置),与目的基因大小相符。
参见图2,图2是推导YKL-40蛋白氨基酸信号肽的分析示意图,应用SignalP 4.1Server信号肽分析软件,将YKL-40基因序列推导出来的氨基酸序列的N端100个氨基酸输入序列框内,提交分析结果呈现,结果如图2所示,横坐标代表氨基酸的位置,纵坐标代表计算出来的分数,其中,分数大于0.5才可以被切割,分数越高切割就越好。从图2可知,YKL-40分子在第21-22之间被切割开。
参见图3,图3是通过上述合成的YKL-40基因序列表达而获得的YKL-40蛋白的SDS电泳图谱示意图(原始图片为彩色图片)。其中,第1道为纯化后的YKL-40蛋白的SDS电泳图谱,第2道为蛋白质分子量标准品Marker的SDS电泳图谱,从上往下代表的蛋白分子量大小分别是:230kD、150kD、100kD、80kD、46kD、30kD、23kD、17kD、7kD。SDS电泳图谱结果显示,纯化后只有一条带,大小约为50kD,与目的蛋白大小相同。
本发明还提供一种YKL-40蛋白的制备方法,该方法包括:
步骤一、人工合成YKL-40基因序列,其中,YKL-40基因序列包括SEQ ID NO:1;
步骤二、构建包含YKL-40基因序列的表达载体;
步骤三、表达包含YKL-40基因序列的表达载体,获得YKL-40蛋白。
本发明实施方式采用经过专门设计的、采用人工方式合成YKL-40基因序列,稳定性好;该基因序列删除原始序列上的跨膜区序列,使得YKL-40蛋白分泌到细胞溶液中,提高了溶解性;该基因序列设计有Kozak序列,能够促进表达,使得蛋白产量提高;该基因序列设计有纯化标签,有利于表达的YKL-40蛋白的纯化。
其中,步骤三具体可以是:采用CHO细胞表达包含YKL-40基因序列的表达载体,获得YKL-40蛋白。
用CHO细胞表达重组的YKL-40基因序列,获得的YKL-40蛋白具有与人自然产生的蛋白完全相似的生物学特性。
其中,表达载体为pCMV-EGFP质粒。
该表达载体包含增强绿色荧光蛋白(Enhanced Green Fluorescent Protein,EGFP)标签的融合蛋白。该质粒含有CMV启动子,可以高效启动目的基因在细胞中的表达。在多克隆位点的后面有一个EGFP的完整编码序列,因此在多克隆位点根据阅读框插入目的基因就可以表达含有EGFP标签的融合蛋白。利用EGFP的荧光特性可以比较容易地观察融合蛋白的表达水平和细胞内定位,也可以利用EGFP抗体来检测或免疫沉淀融合蛋白。该质粒为卡那霉素抗性。
在本发明实施方式中,将人工合成的YKL-40基因序列置于哺乳动物细胞表达的启动子下游,在转录起始点处添加用来增强真核基因的翻译效率的Kozak序列、YKL-40序列、纯化标签和终止密码,以Bgl II和BamH I为酶切位点,克隆至哺乳动物细胞表达载体pCMV-EGFP的多克隆位点(Multiple cloning site,MCS)内,后面连接了内部核糖体进入位点(int ernal ribosome entry site,IRES)和EGFP序列及SV40polyA,通过双酶切鉴定和测序鉴定证明pCMV-YKL-40-EGFP表达载体构建完全正确。
其中,步骤三之后,还可以包括:采用镍琼脂糖凝胶Ni Sepharose亲和层析柱纯化YKL-40蛋白。
下面通过具体的实验步骤来说明上述方法,需要说明的是,下述的步骤仅仅只是一个具体的实验步骤,并不用来限定本发明的方法,例如:表达载体、表达的宿主细胞、具体的实验条件等均可以采用现有技术中的其他表达载体、其他表达的宿主细胞、其他具体的实验条件等。
总体来说,本发明的方法具体包括如下步骤:
(1)YKL-40基因的克隆和序列分析
本发明应用的基因是根据Genbank中人源YKL-40分子序列分析比较后,对YKL-40信号肽序列、跨膜区序列、影响体内可溶性的膜内区、酶切位点、G+C含量和纯化标签等大量序列信息进行序列优化设计后,由南京金斯瑞公司直接合成YKL-40(质粒为6615BH190-1)。
Genbank中人源YKL-40序列为SEQ ID NO:2,优化设计后的YKL-40序列为SEQ ID NO:1。
(2)哺乳动物细胞表达载体的构建和鉴定
用无菌接种环直接从本实验室冻存的DH5α感受态细胞(Solarbio,C1100)在培养基表面划线,于37℃倒置培养16~20小时(h),挑取一个单菌落扩展培养制备实验所需的感受态细胞,将合成的含有目的基因的pUC57-YKL-40及pCMV-EGFP质粒,转化DH5α感受态细胞,从琼脂平板上挑取转化pUC57-YKL-40的一个单菌落,接种到含有氨苄青霉素的液体培养基中生长。同时挑取pCMV-EGFP的一个单菌落,接种到含有氨苄卡那霉素的液体培养基中生长,于37℃转速为180转每分钟(rpm)振荡培养扩增至一定密度,使用AxyPrep质粒DNA小量试剂盒(AP-MN-P-50)提取质粒,用Sac I和BamH I同时双酶切,使用AxyPrepDNA凝胶回收试剂盒(AP-GX-50),回收目的基因YKL-40基因和目的质粒pCMV-EGFP,使用T4噬菌体DNA连接酶于16℃温育12~16h,进行连接,将目的基因克隆到pCMV-EGFP多克隆位点Sac I和BamH I之间。将连接产物全部转化大肠杆菌感受态细胞,涂布含有卡那霉素的平板,于37℃过夜后,挑取5个菌落,置于5毫升(mL)含卡那霉素的LB培养基中培养16h,提取质粒。将质粒纯化后用Bgl II和BamH I双酶切,能够切得1200bp片段的克隆(如图1所示),进行序列测定,再次进行目的基因的确定。将测定的序列用DNAMANV6进行序列分析。
将构建的载体进行序列测定,结果显示与设计的完全相符,应用DNAMAN6分析软件,与Genbank中登录的YKL-40基因序列进行了序列比对,结果显示完全相同。
(3)CHO细胞的转染
将(2)中构建的pCMV-YKL-40-EGFP,经过转化、细菌增殖和质粒的提取、核酸测定仪(Nanodrop One)测定浓度及纯度后,用TurboFect Transfection Reagent(Thermo)直接转染生长状态良好的用无血清培养基培养的CHO细胞中,置于37℃,5%CO2培养箱中培养6~8h后,将转染孔换成含有5%胎牛血清(Fetal Bovine Serum,FBS)的DMEM/F12(Dulbecco's Modified Eagle Media:Nutrient Mixture F-12)细胞生长液,继续培养观察荧光信号。转染36h后原培养基弃去,加CHO细胞无血清无蛋白化学培养基,继续观察荧光状况(参见图4,原始图片为彩色图片)。将需扩大培养或传代的转染细胞原孔中的培养基吸出,加入胰酶清洗一遍后再加入胰酶消化30秒(s),将胰酶吸弃,加入培养基吹散细胞,将细胞转入至T-75的培养瓶中,添适量CHO细胞无血清无蛋白化学培养基,置37℃,在5%CO2培养箱中培养扩增。
将构建的pCMV-YKL-40-EGFP载体转染CHO细胞后,48h后显微镜观察即可见荧光蛋白的表达,转染72h后显示50%以上的细胞有较强的绿色荧光,见图4所示。因为荧光蛋白基因和目的基因YKL-40在同一个开放阅读框(Open Reading Frame,ORF),只是用IRES将两者隔开,理论上位于GFP上游的YKL-40基因应该表达。
(4)重组YKL-40的纯化检验
由(3)转染的细胞转染后24h、48h、72h观察细胞生长状态和荧光蛋白表达强度,在转染后72h收集细胞上清,在转速为5000rpm,4于℃下离心15分钟(min)以上,弃掉细胞碎片后,上清液直接用Ni Sepharose亲和层析柱纯化表达的YKL-40蛋白,流速控制在15毫升每小时(mL/h)左右,收集纯化后的YKL-40蛋白进行SDS-PAGE电泳鉴定(如图3所示)。
在一实施方式中,具体的实验步骤和实验过程如下:
(一)YKL-40基因真核表达载体的构建
1.1DH5α感受态细胞的制备
用无菌接种环直接从冻存的DH5α感受态细胞在培养基表面划线,于37℃倒置培养16~20h,挑取一个单菌落于1mL LB(无抗生素)培养基中,制作2~3管,于37℃,转速为180rpm振荡使其分散,然后加入到30~100mL LB(无抗生素)培养基中稀释培养,于37℃,转速为200rpm下,培养大约2.5~3h,检测培养物的生长情况。取培养物置于40mL的灭菌的一次性的冰预冷的离心管中,冰浴10min,使培养物冷却至0℃,在转速4000rpm下,于4℃离心10min,弃上清。每50mL初始培养液重悬于30mL预冷的0.1mol/L CaCl2-MgCl2溶液(80mmol/L MgCl2,20mmol/L CaCl2)中,轻吹,冰浴10min,在转速4000rpm下,于4℃离心10min,弃上清。每50mL初始培养液重悬于2mL预冷的0.1mol/L CaCl2溶液,轻吹,每2mL重悬细胞液加70微升(μL)二甲基亚砜(Dimethyl Sulphoxide,DMSO),轻轻旋转混匀,将悬液置于冰上15min。每份悬液再加70μL DMSO,轻轻旋转混匀,将悬液置于冰上15min。迅速将悬液分装到预冷的无菌微量离心管中,封口,投入液氮中快速冰冻感受态细胞,于-70℃下保存,需要时从-70℃中取出。
1.2pCMV-YKL-40-EGFP载体的构建
将合成的含有目的基因的pUC57-YKL-40,转化DH5α感受态细胞,提取质粒,用Sac I和BamH I双酶切,回收目的基因,克隆到pCMV-EGFP多克隆位点Sac I和BamH I之间。
1.2.1pUC57-YKL-40转化DH5α感受态细胞
将感受态细胞(100μL)置于冰上融化。向感受态细胞悬液中加入需转化的pUC57-YKL-40,加入体积≤1μL。轻轻旋转离心管以混匀内容物,冰浴放置30min。将离心管置于42℃水浴中热冲击60~90s,不要摇动管,然后快速转移到冰浴中冷却2~3min,注意不要摇动离心管。向离心管中加入500μL无菌无抗生素的LB培养基,于37℃下,转速为180rpm振荡培养1h,取适量已转化的感受态细胞涂布含相应抗生素的LB平板,于37℃倒置培养12~16h。涂布剩余的菌液可4℃保存,如果次日的转化菌落数过少,可以将剩下的菌液再涂布新的平板。
1.2.2pUC57-YKL-40质粒的提取
从琼脂平板上挑取转化的pUC57-YKL-40的一个单菌落,接种到含有氨苄青霉素的液体培养基中,生长到对数晚期,就可以大量提纯质粒。使用AxyPrep质粒DNA小量试剂盒(AP-MN-P-50,包含Buffer S1、S2、S3、W1、W2)。取30mL在LB培养基中培养过夜的菌液(若使用丰富培养基,菌液体积应减半或更少),在离心力为12,000g下,离心1min,弃尽上清;加250μL Buffer S1悬浮细菌沉淀,悬浮需均匀,不应留有小的菌块;加250μL Buffer S2,温和并充分地上下翻转4~6次混合均匀使菌体充分裂解,直至形成透亮的溶液;加350μL Buffer S3,温和并充分地上下翻转混合6~8次,在离心力12,000g下,离心10min;吸取离心后的上清液并转移到制备管,在离心力12000g下,离心1min。加500μL Buffer W1,在离心力12000g下,离心1min,加700μL Buffer W2,在离心力12000g下,离心1min,以同样的方法再用700μL Buffer W2洗涤一次,弃滤液;在离心力12000g下,离心1min,将制备管移入新的1.5mL离心管中,加Eluent或去离子水60μL,室温静置1min,在离心力12000g下,离心1min收集,可得到极高纯度的质粒。
1.2.3载体酶切、片段回收
将提取的含有目的基因的质粒pUC57-YKL-40和表达质粒pCMV-EGFP按照下列体系分别酶切:
37℃酶切2h后电泳,在紫外灯下切下含有目的DNA的琼脂糖凝胶,分别回收pUC57-YKL-40中1200bp和pCMV-EGFP的5320bp的片段。使用AxyPrepDNA凝胶回收试剂盒(AP-GX-50,包含Buffer DE-A、DE-B、W1、W2),用纸巾吸尽凝胶表面液体并切碎。计算凝胶重量(提前记录1.5mL离心管重量),该重量为一个凝胶体积(如100mg=100μL体积)。加入3个凝胶体积的Buffer DE-A,混合均匀后于75℃加热,间断混合,直至凝胶块完全熔化(约6~8min)。加0.5个Buffer DE-A体积的Buffer DE-B,混合均匀。转DNA制备管,在离心力12000g下,离心1min。加500μL Buffer W1,在离心力12000g下,离心30s,加700μL Buffer W2,在离心力12000g下,离心30s,以同样的方法再用700μL Buffer W2洗涤一次,弃滤液;在离心力12000g下,离心1min,将制备管移入新的1.5ml离心管中,加Eluent或去离子水15μL,室温静置1min,12000g,离心1min收集。
1.2.4片段的连接、转化和鉴定
将2μL回收酶切的pCMV-EGFP载体DNA片段及回收的YKL-40基因片段转移到无菌微量离心管中。加水5μL,于45℃加温5min以使粘端解链,将混合物冷却到0℃。加入10xT4噬菌体DNA连接酶缓冲液2μL、1μL T4噬菌体DNA连接酶0.1Weiss单位、5mmol/L ATP 1μL,然后于16℃温育1~4h。将连接产物全部转化大肠杆菌感受态细胞,涂布含有卡那霉素的平板,37℃过夜后,挑取5个菌落于5mL含卡那霉素的LB培养基中培养16h,提取质粒。将质粒纯化后用Sac I和BamH I双酶切,能够切除1200bp片段的克隆,进行序列测定。
(二)细胞转染
2.1配制转染试剂
每孔加入100μL DMEM/F12、2微克(μg)pCMV-YKL-40-EGFP质粒及4μL转染试剂,缓慢吸打混匀,室温静置20min。
2.2处理细胞板
用24孔CHO细胞板长满70~80%时进行转染,pCMV-YKL-40-EGFP质粒转2孔,先用500μL无血清DMEM洗2个细胞孔,每孔洗两次,为待转染孔,每个待转染孔加入300μL无血清DMEM备用。
2.3CHO细胞的转染
将静置好的转染复合物缓慢吸打1~2次后取100μL/孔均匀滴加至待转染孔中,将24孔板置于37℃,5%CO2培养箱中培养6~8h后将转染孔换细胞生长液DMEM/F12含5%FBS,继续培养观察荧光信号。转染36h后原培养基弃去,加CHO细胞无血清无蛋白化学培养基,继续观察荧光状况。
2.4转染细胞传代、换液:
将需扩大培养或传代的转染细胞原孔中的培养基吸出,加入胰酶清洗一遍后再加入胰酶消化30s,将胰酶吸弃,加入培养基吹散细胞,将细胞转入至T-75的培养瓶中,添适量CHO细胞无血清无蛋白化学培养基,置37℃,5%CO2培养箱中培养。
(三)重组YKL-40的纯化
3.1细胞上清的收集和保存
将转染pCMV-YKL-40-EGFP的CHO细胞用无血清无蛋白化学培养基的培养72h,收集细胞上清,5000rpm/min,4℃离心15min以上。取上清,置于冰上备用或-20℃保存。
3.2层析
将NTA树脂装入合适的层析柱,层析用10倍NTA体积的NTA-0Buffer洗。将样品加到NTA层析柱中,流速控制在15mL/h左右,收集穿透部分,用于SDS-PAGE分析蛋白质的结合情况。层析用5倍NTA体积的NTA-0Buffer洗,流速控制在30mL/h左右。分别用5倍NTA体积的NTA-20,NTA-40,NTA-60,NTA-80,NTA-100,NTA-200,NTA-1000Buffer洗脱,流速控制在15mL/h左右,收集洗脱液,每管收集一个NTA体积。确定目标蛋白质在洗脱液中的分布情况,然后用SDS-PAGE分析蛋白质的分布。
其中,层析溶液配方如下:
NTA-0Buffer:20mM Tris-HCl,pH为7.9,0.5M NaCl,10%Glycerol;
NTA-20Buffer:20mM Tris-HCl,pH为7.9,0.5M NaCl,10%Glycerol,20mM咪唑(Imidazole);
NTA-40Buffer:20mM Tris-HCl,pH为7.9,0.5M NaCl,10%Glycerol,40mM Imidazole;
NTA-60Buffer:20mM Tris-HCl,pH为7.9,0.5M NaCl,10%Glycerol,60mM Imidazole;
NTA-80Buffer:20mM Tris-HCl,pH为7.9,0.5M NaCl,10%Glycerol,80mM Imidazole;
NTA-100Buffer:20mM Tris-HCl,pH为7.9,0.5M NaCl,10%Glycerol,100mM Imidazole;
NTA-200Buffer:20mM Tris-HCl,pH为7.9,0.5M NaCl,10%Glycerol,200mM Imidazole;
NTA-1000Buffer:20mM Tris-HCl,pH为7.9,0.5M NaCl,10%Glycerol,1000mM Imidazole。
以上所述仅为本发明的实施方式,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
SEQUENCE LISTING
<110> 奥普金生物科技(深圳)有限公司
<120> 类几丁质酶基因序列、YKL-40蛋白及制备方法
<160> 3
<210> 1
<211> 1200
<212> DNA
<213> 人工序列
<220>
<221> misc_difference
<222> (1)…(1200)
<400> 1
cccaagcttg agctcgccac catgggtgtg aaggcgtctc aaacaggctt tgtggtcctg 60
gtgctgctcc agtgctgctc tgcatacaaa ctggtctgct actacaccag ctggtcccag 120
taccgggaag gcgatgggag ctgcttccca gatgcccttg accgcttcct ctgtacccac 180
atcatctaca gctttgccaa tataagcaac gatcacatcg acacctggga gtggaatgat 240
gtgacgctct acggcatgct caacacactc aagaacagga accccaacct gaagactctc 300
ttgtctgtcg gaggatggaa ctttgggtct caaagatttt ccaagatagc ctccaacacc 360
cagagtcgcc ggactttcat caagtcagta ccgccatttc tgcgcaccca tggctttgat 420
gggctggacc ttgcctggct ctaccctgga cggagagaca aacagcattt taccacccta 480
atcaaggaaa tgaaggccga atttataaag gaagcccagc cagggaaaaa gcagctcctg 540
ctcagcgcag cactgtctgc ggggaaggtc accattgaca gcagctatga cattgccaag 600
atatcccaac acctggattt cattagcatc atgacctacg attttcatgg agcctggcgt 660
gggaccacag gccatcacag tcccctgttc cgaggtcagg aggatgcaag tcctgacaga 720
ttcagcaaca ctgactatgc tgtggggtac atgttgaggc tgggggctcc tgccagtaag 780
ctggtgatgg gcatccccac cttcgggagg agcttcactc tggcttcttc tgagactggt 840
gttggagccc caatctcagg accgggaatt ccaggccggt tcaccaagga ggcagggacc 900
cttgcctact atgagatctg tgacttcctc cgcggagcca cagtccatag aatcctcggc 960
cagcaggtcc cctatgccac caagggcaac cagtgggtag gatacgacga ccaggaaagc 1020
gtcaaaagca aggtgcagta cctgaaggac aggcagctgg cgggcgccat ggtatgggcc 1080
ctggacctgg atgacttcca gggctccttc tgcggccagg atctgcgctt ccctctcacc 1140
aatgccatca aggatgcact cgctgcaacg caccaccacc accaccacta aggatccgcg 1200
<210> 2
<211> 1195
<212> DNA
<213> human
<220>
<221> gene
<222> (1)…(1195)
<400> 2
gtacaaaaaa gcaggctcca ccatgggtgt gaaggcgtct caaacaggct ttgtggtcct 60
ggtgctgctc cagtgctgct ctgcatacaa actggtctgc tactacacca gctggtccca 120
gtaccgggaa ggcgatggga gctgcttccc agatgccctt gaccgcttcc tctgtaccca 180
catcatctac agctttgcca atataagcaa cgatcacatc gacacctggg agtggaatga 240
tgtgacgctc tacggcatgc tcaacacact caagaacagg aaccccaacc tgaagactct 300
cttgtctgtc ggaggatgga actttgggtc tcaaagattt tccaagatag cctccaacac 360
ccagagtcgc cggactttca tcaagtcagt accgccattt ctgcgcaccc atggctttga 420
tgggctggac cttgcctggc tctaccctgg acggagagac aaacagcatt ttaccaccct 480
aatcaaggaa atgaaggccg aatttataaa ggaagcccag ccagggaaaa agcagctcct 540
gctcagcgca gcactgtctg cggggaaggt caccattgac agcagctatg acattgccaa 600
gatatcccaa cacctggatt tcattagcat catgacctac gattttcatg gagcctggcg 660
tgggaccaca ggccatcaca gtcccctgtt ccgaggtcag gaggatgcaa gtcctgacag 720
attcagcaac actgactatg ctgtggggta catgttgagg ctgggggctc ctgccagtaa 780
gctggtgatg ggcatcccca ccttcgggag gagcttcact ctggcttctt ctgagactgg 840
tgttggagcc ccaatctcag gaccgggaat tccaggccgg ttcaccaagg aggcagggac 900
ccttgcctac tatgagatct gtgacttcct ccgcggagcc acagtccata gaatcctcgg 960
ccagcaggtc ccctatgcca ccaagggcaa ccagtgggta ggatacgacg accaggaaag 1020
cgtcaaaagc aaggtgcagt acctgaagga caggcagctg gcgggcgcca tggtatgggc 1080
cctggacctg gatgacttcc agggctcctt ctgcggccag gatctgcgct tccctctcac 1140
caatgccatc aaggatgcac tcgctgcaac gaagcttgac ccagctttct tgtac 1195
<210> 3
<211> 389
<212> PRT
<213> 未知
<220>
<221> VARIANT
<222> (1)…(389)
<400> 3
Met Gly Val Lys Ala Ser Gln Thr Gly Phe Val Val Leu Val Leu
1 5 10 15
Leu Gln Cys Cys Ser Ala Tyr Lys Leu Val Cys Tyr Tyr Thr Ser
20 25 30
Trp Ser Gln Tyr Arg Glu Gly Asp Gly Ser Cys Phe Pro Asp Ala
35 40 45
Leu Asp Arg Phe Leu Cys Thr His Ile Ile Tyr Ser Phe Ala Asn
50 55 60
Ile Ser Asn Asp His Ile Asp Thr Trp Glu Trp Asn Asp Val Thr
65 70 75
Leu Tyr Gly Met Leu Asn Thr Leu Lys Asn Arg Asn Pro Asn Leu
80 85 90
Lys Thr Leu Leu Ser Val Gly Gly Trp Asn Phe Gly Ser Gln Arg
95 100 105
Phe Ser Lys Ile Ala Ser Asn Thr Gln Ser Arg Arg Thr Phe Ile
110 115 120
Lys Ser Val Pro Pro Phe Leu Arg Thr His Gly Phe Asp Gly Leu
125 130 135
Asp Leu Ala Trp Leu Tyr Pro Gly Arg Arg Asp Lys Gln His Phe
140 145 150
Thr Thr Leu Ile Lys Glu Met Lys Ala Glu Phe Ile Lys Glu Ala
155 160 165
Gln Pro Gly Lys Lys Gln Leu Leu Leu Ser Ala Ala Leu Ser Ala
170 175 180
Gly Lys Val Thr Ile Asp Ser Ser Tyr Asp Ile Ala Lys Ile Ser
185 190 195
Gln His Leu Asp Phe Ile Ser Ile Met Thr Tyr Asp Phe His Gly
200 205 210
Ala Trp Arg Gly Thr Thr Gly His His Ser Pro Leu Phe Arg Gly
215 220 225
Gln Glu Asp Ala Ser Pro Asp Arg Phe Ser Asn Thr Asp Tyr Ala
230 235 240
Val Gly Tyr Met Leu Arg Leu Gly Ala Pro Ala Ser Lys Leu Val
245 250 255
Met Gly Ile Pro Thr Phe Gly Arg Ser Phe Thr Leu Ala Ser Ser
260 265 270
Glu Thr Gly Val Gly Ala Pro Ile Ser Gly Pro Gly Ile Pro Gly
275 280 285
Arg Phe Thr Lys Glu Ala Gly Thr Leu Ala Tyr Tyr Glu Ile Cys
290 295 300
Asp Phe Leu Arg Gly Ala Thr Val His Arg Ile Leu Gly Gln Gln
305 310 315
Val Pro Tyr Ala Thr Lys Gly Asn Gln Trp Val Gly Tyr Asp Asp
320 325 330
Gln Glu Ser Val Lys Ser Lys Val Gln Tyr Leu Lys Asp Arg Gln
335 340 345
Leu Ala Gly Ala Met Val Trp Ala Leu Asp Leu Asp Asp Phe Gln
350 355 360
Gly Ser Phe Cys Gly Gln Asp Leu Arg Phe Pro Leu Thr Asn Ala
365 370 375
Ile Lys Asp Ala Leu Ala Ala Thr His His His His His His
380 385 389
- 还没有人留言评论。精彩留言会获得点赞!