NUDT15基因分型用的引物、试剂盒及方法与流程
本发明涉及分子生物学检测领域,尤其是涉及一种nudt15基因分型用的引物、试剂盒及方法。
背景技术:
咪唑硫嘌呤(azathioprine,aza)和6-巯基嘌呤(6-mercaptopurine,6-mp)等巯嘌呤类药物广泛用于治疗癌症、器官移植、自身免疫疾病或炎症性疾病,如炎症性肠病(ibd)。然而巯嘌呤类药物会导致白细胞减少症的发生,这种潜在危害在服用巯嘌呤类药物的欧洲人ibd人群中高达5%。硫嘌呤甲基转移酶(tmpt)突变与巯嘌呤类药物引起的白细胞减少症之间的关系已被证实,并且美国fda推荐在服用巯嘌呤类药物前进行tmpt检测。然而,服用巯嘌呤类药物引起白细胞减少症的ibd人群,仅有约1/4携带tpmt突变,提示存在其他因素导致该症状的发生,因此tpmt检测的有效性令人质疑。进一步研究表明,欧洲人群的tpmt突变比例(约10%)高于亚洲人群(约3%),但是,亚洲人群中巯嘌呤类药物引起的白细胞减少症的发生比例却远高于欧洲人群。最新研究表明,nudt15基因的突变与巯嘌呤类药物引起白细胞减少症的相关性远高于tmpt突变与该症状的相关性,nudt15基因是不同人群中巯嘌呤类药物引起白细胞减少症的重要遗传决定因素。
nudt15基因位于人第13号染色体,具体位置为chr13:48611703-48621358(hg19),基因全长9656bp。该基因共3个外显子,编码区长度为492bp,编码蛋白为nudix水解酶15(nudixhydrolase15)。nudt15基因的外显子第415位置(chr13:48619855(hg19))为一个snp位点,正常情况下,415处的碱基为c(胞嘧啶),415-417碱基cgt编码的氨基酸为arg(精氨酸);发生突变后,415处的碱基变为t(胸腺嘧啶),415-417碱基tgt编码的氨基酸变为cys(半胱氨酸)。nudt15c.415c>t突变为胚系突变,该突变在东亚人群最为常见(af=10.43%),其次是拉丁美洲和南亚、欧洲芬兰人,非洲人的突变频率最低。
由于nudt15基因c.415c>t(p.arg139cys)突变增强了巯基嘌呤药物诱导的白血球减少症的易感性,因此,对于急性淋巴细胞性白血病、自身免疫性疾病(如克罗恩病、类风湿性关节炎)和器官移植病人,在服用巯基嘌呤药物(thiopurine)前检测nudt15基因突变点,确定nudt15的基因型,有助于指导个体化用药治疗方案。
传统的基因分型的方法有一代测序法、片段长度多态性法(限制性内切酶)、高分辨率熔解曲线法(hrm)和其他基于qpcr的方法。其中,一代测序法测序准确,但是操作步骤多,实验周期长;片段长度多态性分析方法,需要酶切、电泳,容易造成样本污染或酶切不充分;高分辨率熔解曲线法对仪器的温度控制要求较高,适用性较低。尤其是目前市场上并没有nudt15基因分型的有效检测产品,因此,设计专门的检测nudt15基因型的检测产品具有十分重大的意义。
技术实现要素:
基于此,有必要提供一种检测效率高、特异性强且不易造成样本污染的nudt15基因分型用的引物、试剂盒和方法。
本发明解决上述技术问题的技术方案如下。
一种nudt15基因分型用的引物,选自如下三组引物中的至少一组:
第一组:序列如seqidno.1所示的正向引物、序列如seqidno.2所示的突变反向引物、以及序列如seqidno.3所示的野生反向引物;
第二组:序列如seqidno.1所示的正向引物、序列如seqidno.4所示的突变反向引物、以及序列如seqidno.5所示的野生反向引物;
第三组:序列如seqidno.1所示的正向引物、序列如seqidno.6所示的突变反向引物、以及序列如seqidno.7所示的野生反向引物。
在其中一个实施例中,所述pcr引物选自第三组引物,即序列如seqidno.1所示的正向引物、序列如seqidno.6所示的突变反向引物、以及序列如seqidno.7所示的野生反向引物。
在其中一个实施例中,所述nudt15基因分型用的引物还包括内参引物对,所述内参引物对用于扩增序列如seqidno.8所示的gapdh基因片段。
在其中一个实施例中,所述内参引物对的正向引物和反向引物的序列分别如seqidno.9和seqidno.10所示。
一种nudt15基因分型用的试剂盒,含有上述任一实施例所述的nudt15基因分型用的引物。
在其中一个实施例中,所述nudt15基因分型用的试剂盒还含有cc型基因型的阳性质控品和/或tt型基因型的阳性质控品。
在其中一个实施例中,所述nudt15基因分型用的试剂盒还含有内参模板,所述内参模板具有序列如seqidno.8所示的gapdh基因片段。
在其中一个实施例中,所述nudt15基因分型用的试剂盒还含有pcr反应缓冲液、taqdna热启动聚合酶、dntp、mgcl2、sybrgreeni荧光染料、以及roxreferencedye中的至少一种试剂。
一种nudt15基因分型方法,包括如下步骤:
获取待测样本的dna样本;
以获取的dna样本为模板,以所述nudt15基因分型用的引物作为pcr扩增引物,加入pcr反应缓冲液、taqdna热启动聚合酶、dntp、mgcl2、sybrgreeni荧光染料以及roxreferencedye,进行实时荧光pcr反应;
在实时荧光pcr反应过程中实时采集荧光信号。
在其中一个实施例中,实时荧光pcr反应的反应体系中各成分的终浓度如下:pcr反应缓冲液:1×、taqdna热启动聚合酶:0.05~0.1u/μl、dntp:0.1~1.0mm、mgcl2:0.3~3mm、sybrgreeni荧光染料:(0.2~1)×、roxreferencedye:0.1~1μm、各正向引物:0.1~1μm、各反向引物:0.1~1μm;
实时荧光pcr反应的条件是:94~95℃预变性5~15min;94~95℃、10~15s,58~63℃、30~40s、期间实时采集荧光信号,共35~45个循环;95℃、15s,60℃、60s,95℃、15s,并持续采集荧光信号。
上述nudt15基因分型用的引物、试剂盒及方法利用taq热启动dna聚合酶缺少3’-5’端外切酶活性的特点,当扩增引物的3’端碱基与模板碱基不互补时,会造成扩增产物的急剧减少,据此设计已知点突变的3条引物,其3’端碱基分别与突变型和野生型的模板碱基互补,从而可以将野生型和突变型基因区分开。
通过进一步研究发现,设计与突变型和野生型的模板碱基完全互补的引物虽然可以特异性扩增出所需的目的片段,但基因分型效果不好,探究其原因发现可能是非特异性的扩增而导致的,比如出现cc型引物不仅对cc基因型样本有扩增,对tt基因型样本也有扩增的情况,而tt型引物不仅对tt基因型样本有扩增,对cc基因型样本也有扩增。研究发现,引物的3’端碱基对dna聚合酶起始pcr扩增至关重要,但碱基对之间除了可以a-t、c-g互补配对外,往往还会出现碱基错配,如嘌呤碱基与嘌呤碱基错配、嘧啶碱基与嘧啶碱基错配或嘌呤碱基与嘧啶碱基错配,如g-a错配、t-c错配和g-t错配等,而错配碱基的结合力各不相同,故与突变型和野生型的模板碱基完全互补的引物虽然也可以分别匹配野生型、突变型的核酸模板,但不能完全区分基因分型。因而,在面对该技术难题时,本发明进一步通过在nudt15基因分型用的反向引物靠近3’端的位置主动引入错配碱基,并通过创造性地深入研究,发现引入的人工突变越多,分型效果越好,但扩增效率会下降,而引入人工突变越少,分型效果越差,但扩增效率升高,并且研究还发现,引入不同的错配碱基的结合能力不同,并且引物3’端不同位置的碱基引入错配后,与模板配对的能力也有所不同导致,最终筛选出几组反向引物,如上述第二组和第三组的反向引物,不仅可以实现正确的基因分型,并且扩增效率显著提高。
荧光定量pcr常用的荧光标记有荧光染料和taqman探针。taqman探针法虽然信号强度高,但对于本发明需要检测的nudt15基因,其用于基因分型的两种探针只有一个碱基的差异,因而需要进行繁杂的优化条件才可,不仅检测效率低,还容易造成错误扩增,产生假阳性或假阴性的结果。而本发明的nudt15基因分型方法通过使用特别设计的引物序列,结合荧光染料法,可以通过扩增曲线ct值有无实现基因分型,并且可结合熔解曲线tm值进一步判定是否为特异性扩增,可以得到基因分型的结果准确性和可靠性更高。
本发明的nudt15基因分型方法操作步骤简单、周期短,并且可以进行闭管式pcr扩增和实时荧光检测,后续无需开管进行电泳或酶切,可以有效降低实验污染的风险,进一步提高检测结果的准确性和可靠性。并且本发明的nudt15基因分型方法对检测设备的要求和温度等参数的控制精度的要求相对较低,仪器平台的适用性更为广泛。
本发明的nudt15基因分型用的引物、试剂盒和方法检测流程简单、扩增效率高、特异性强,在分型检测过程中,可配合内参模板、内参引物对和阳性对照、阴性对照等,对实时荧光pcr过程进行全程监控,避免出现假阴性和假阳性的结果。
附图说明
图1为第一组引物中cc型引物对分别对cc型和tt型阳性质粒的扩增曲线和熔解曲线;
图2为第一组引物中tt型引物对分别对cc型和tt型阳性质粒的扩增曲线和熔解曲线;
图3为第二组引物中cc型引物对分别对cc型和tt型阳性质粒的扩增曲线和熔解曲线;
图4为第二组引物中tt型引物对分别对cc型和tt型阳性质粒的扩增曲线和熔解曲线;
图5为第三组引物中cc型引物对分别对cc型和tt型阳性质粒的扩增曲线及熔解曲线;
图6为第三组引物中tt型引物对分别对cc型和tt型阳性质粒的扩增曲线及熔解曲线;
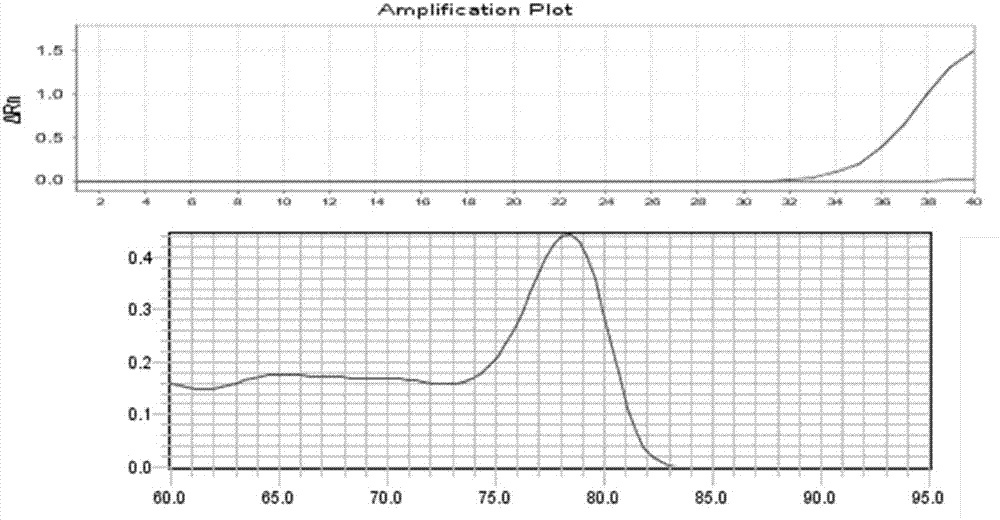
图7为实施例2中使用第三组引物和内参引物对对cc型待测样本和内参模板的扩增曲线及熔解曲线;
图8为实施例3中使用第三组引物和内参引物对对ct型待测样本和内参模板的扩增曲线及熔解曲线。
具体实施方式
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的较佳实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
针对nudt15基因的外显子第415位置(chr13:48619855(hg19)),即rs116855232位点,本实施方式设计出多组引物,通过对实时荧光pcr扩增过程中出现的诸多问题进行研究分析,如扩增效率低、特异性差等问题,在特定位点创造性的主动引入错配碱基,在保证特异性的前提下,显著提高了扩增效率。下表1为引物的详细信息,本实施方式的nudt15基因分型用的引物可选自表1中三组引物中的至少一组,如可以选自其中一组独立进行检测,也可以选自其中两组或三组配合进行多重检测,以多重验证分析,保证结果的准确性。
表1
各组引物中正向引物与突变反向引物构成tt型引物对,正向引物与野生反向引物构成cc型引物对。
优选的,在一个具体的实施例中,pcr引物独立选自第三组引物,即序列如seqidno.1所示的正向引物、序列如seqidno.6所示的突变反向引物、以及序列如seqidno.7所示的野生反向引物。
在一个实施例中,该nudt15基因分型用的引物还包括内参引物对,内参引物对用于扩增序列如seqidno.8所示的gapdh基因片段。内参引物对的正向引物和反向引物的序列可以是但不限于分别如seqidno.9(5’-ctttggtatcgtggaaggact-3’)和seqidno.10(5’-gtgagcttcccgttcagctc-3’)所示。gapdh基因片段:atggggaaggtgaaggtcggagtcaacggatttggtcgtattgggcgcctggtcaccagggctgcttttaactctggtaaagtggatattgttgccatcaatgaccccttcattgacctcaactacatggtttacatgttccaatatgattccacccatggcaaattccatggcaccgtcaaggctgagaacgggaagcttgtcatcaatggaaatcccatcaccatcttccaggagcgagatccctccaaaatcaagtggggcgatgctggcgctgagtacgtcgtggagtccactggcgtcttcaccaccatggagaaggctggggctcatttgcaggggggagccaaaagggtcatcatctctgccccctctgctgatgcccccatgttcgtcatgggtgtgaaccatgagaagtatgacaacagcctcaagatcatcagcaatgcctcctgcaccaccaactgcttagcacccctggccaaggtcatccatgacaactttggtatcgtggaaggactcatgaccacagtccatgccatcactgccacccagaagactgtggatggcccctccgggaaactgtggcgtgatggccgcggggctctccagaacatcatccctgcctctactggcgctgccaaggctgtgggcaaggtcatccctgagctgaacgggaagctcactggcatggccttccgtgtccccactgccaacgtgtcagtggtggacctgacctgccgtctagaaaaacctgccaaatatgatgacatcaagaaggtggtgaagcaggcgtcggagggccccctcaagggcatcctgggctacactgagcaccaggtggtctcctctgacttcaacagcgacacccactcctccacctttgacgctggggctggcattgccctcaacgaccactttgtcaagctcatttcctggtatgacaacgaatttggctacagcaacagggtggtggacctcatggcccacatggcctccaaggagtaa。
本实施方式还提供了一种nudt15基因分型用的试剂盒,其含有上述任一实施例的nudt15基因分型用的引物。
在一个实施例中,该nudt15基因分型用的试剂盒还含有cc型基因型的阳性质控品和/或tt型基因型的阳性质控品。各阳性质控品可以是含有相应基因型的基因片段的质粒,如含有一段nudt15cc型基因片段的t载体重组质粒、含有一段nudt15tt型基因片段的t载体重组质粒等。
在一个实施例中,该nudt15基因分型用的试剂盒还含有内参模板,内参模板具有序列如seqidno.8所示的gapdh基因片段。内参模板可以是但不限于为含有相应gapdh基因片段的t载体重组质粒等。
此外,该nudt15基因分型用的试剂盒还含有pcr反应缓冲液、taqdna热启动聚合酶、dntp、mgcl2、sybrgreeni荧光染料、以及roxreferencedye中的至少一种试剂。
在一个具体的实施例中,10×、ph8.3的pcr反应缓冲液的配方如下:
tris-hcl缓冲液(ph8.3):100mm;
kcl:500mm。
配制方法:以100ml10×的pcr反应缓冲液为例:称取tris1.21g、kcl3.73g至干净的烧杯,加去离子水溶解,调节ph至8.3并定容至100ml,使用0.2μm的滤膜过滤,存放至4℃。使用时稀释至1×即可。
进一步,本实施方式还提供了一种nudt15基因分型方法,其包括如下步骤:
获取待测样本的dna样本;
以获取的dna样本为模板,以nudt15基因分型用的引物作为pcr扩增引物,加入pcr反应缓冲液、taqdna热启动聚合酶、dntp、mgcl2、sybrgreeni荧光染料以及roxreferencedye,进行实时荧光pcr反应;
在实时荧光pcr反应过程中实时采集荧光信号。
在一个实施例中,实时荧光pcr反应的反应体系中各成分的终浓度如下:pcr反应缓冲液:1×;taqdna热启动聚合酶:0.05~0.1u/μl,优选为0.05u/μl;dntp:0.1~1.0mm,优选为0.2mm;mgcl2:0.3~3mm,优选为2mm;sybrgreeni荧光染料:(0.2~1)×,优选为1×;roxreferencedye:0.1~1μm,优选为0.5μm;各正向引物:0.1~1μm,优选为0.2μm;各反向引物:0.1~1μm,优选为0.2μm。此外,dna样本或阳性质控品的加入浓度是1~10ng/μl,优选1ng/μl。
在一个实施例中,实时荧光pcr反应的条件是:94~95℃预变性5~15min;94~95℃、10~15s,58~63℃、30~40s、期间实时采集荧光信号,共35~45个循环;95℃、15s,60℃、60s,95℃、15s,并持续采集荧光信号。优选的,实时荧光pcr反应的条件是:95℃预变性5min;95℃、10s,60℃、30s、期间实时采集荧光信号,共40个循环;95℃、15s,60℃、60s,95℃、15s,并持续采集荧光信号。
上述nudt15基因分型用的引物、试剂盒及方法利用taq热启动dna聚合酶缺少3’-5’端外切酶活性的特点,当扩增引物的3’端碱基与模板碱基不互补时,会造成扩增产物的急剧减少,据此设计已知点突变的3条引物,其3’端碱基分别与突变型和野生型的模板碱基互补,从而可以将野生型和突变型基因区分开。本发明的nudt15基因分型用的引物、试剂盒和方法检测流程简单、扩增效率高、特异性强,在分型检测过程中,可配合内参模板、内参引物对和阳性对照、阴性对照等,对实时荧光pcr过程进行全程监控,避免出现假阴性和假阳性的结果,分型结果准确可靠。
以下为具体实施例部分。
实施例1
1、扩增效率和特异性分析
以上述表1三组引物作为实时荧光pcr扩增的引物,以cc型和tt型阳性质粒作为待测样本,采用无核酸的生理盐水作为阴性对照,验证扩增效率和特异性分析。
cc型和tt型阳性质粒的构建方法简述如下:
采用分子克隆的方法,以cc型基因型样本的核酸为模板,经扩增产生一段含有nudt15cc型基因型的核酸片段,与
以cc型基因型样本的核酸为模板,经重叠pcr的方法引入点突变,经扩增产生一段含有nudt15tt型基因型的核酸片段,与
扩增体系配制见下表2。
表2
注:对于待测样本的扩增体系,作为扩增模板的dna样本加入量为20ng。
扩增条件见下表3。
表3
*熔解曲线步骤:60℃~95℃持续采集荧光信号。
检测结果见下表4。
表4
结合表1中引物序列,由上表4可知,三组引物都可以区分不同的基因型,但是扩增效率不同。其中,如图1和图2所示,第一组引物:cc型引物对cc型阳性质粒有扩增且熔解曲线峰图单一,其对tt型阳性质粒无扩增;tt型引物对tt型阳性质粒有扩增且tm值峰图单一,其对cc型阳性质粒无扩增。第一组引物虽然可以区分cc型、tt型阳性质粒,但扩增效率相对较低。
如图3和图4所示,第二组引物:cc型引物对cc型阳性质粒有扩增且熔解曲线峰图单一,其对tt型阳性质粒无扩增;tt型引物对tt型阳性质粒有扩增且熔解曲线峰图单一,其对cc型阳性质粒有微弱扩增,但tm值为71.86℃,与正常扩增的tt阳性质粒tm值79.40℃相差巨大,故为非特异扩增,但不影响基因分型的效果。与第一组引物相比,第二组引物的扩增效率有所提高。
如图5、图6所示,第三组引物:cc型引物对cc型阳性质粒有扩增且熔解曲线峰图单一,其对tt型阳性质粒无扩增;tt型引物对tt型阳性质粒有扩增且tm值峰图单一,其对cc型阳性质粒无扩增。与第一组引物、第二组引物相比,第三组引物的扩增效率较高、分型效果良好,且无非特异扩增,更容易判定结果。
三组引物组合都可以独立使用,也可以组合使用,综合考虑,第三组引物的基因分型效果较优,尤其适合单独使用。
2、灵敏度验证
使用上述第三组的引物对进行灵敏度验证,并采用第二组引物作为对比。
将提取的人外周血dna,使用nanodrop测定浓度后,分别稀释至40ng/μl、20ng/μl、10ng/μl,采用与上述阳性质粒检测同样的实验条件进行验证。
结果表明:第二组引物在dna浓度为10ng/μl,仍然可以检测到扩增信号,但扩增ct值小于第三组引物。
将两种质粒cc型和tt型稀释至1×105copies/μl作为阳性质控,与样本同时扩增后观察样本的ct值和tm值,若无信号或ct>35,或tm值不符合,则认为该样本无扩增。结果表明,引物的检出率100%,区分度100%。
由此说明上述第二组引物和第三组引物检测符合率100%,特异性好,符合基因分型的要求。
实施例2
使用1例血液样本,提取dna后,nanodrop测定浓度,使用无菌水稀释至20ng/μl,作为扩增的模板。一代测序的结果表明,该样本为cc型。
如图7所示,采用上述表1中的第三组引物进行检测,检测结果表明,结果也为cc型,其ct值:27.48,tm值:79.82℃(与阳性质控符合),内参引物ct值:22.14,tm值:80.91℃。tt型引物对样本无扩增曲线、无熔解曲线。
实施例3
使用1例血液样本,提取dna后,nanodrop测定浓度,使用无菌水稀释至20ng/μl,作为扩增的模板。一代测序的结果表明,该样本为ct型。
如图8所示,采用上述表1中的第三组引物进行检测,检测结果表明,结果也为ct型,其中,cc型引物对的ct值:28.2、tm值:79.73℃(与cc型阳性质控符合),tt型引物对的ct值:31.12、tm值:77.81℃(与tt型阳性质控符合),内参引物对ct值:21.65,tm值:80.88℃。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
序列表
<110>广州迈景基因医学科技有限公司
<120>nudt15基因分型用的引物、试剂盒及方法
<160>10
<170>siposequencelisting1.0
<210>1
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>1
aagaactacctcccctgga19
<210>2
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>2
gccttgttcttttaaacatca21
<210>3
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>3
gccttgttcttttaaacaaag21
<210>4
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>4
gccttgttcttttaaacagca21
<210>5
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>5
gccttgttcttttaaacagcg21
<210>6
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>6
gccttgttcttttaaacacca21
<210>7
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>7
gccttgttcttttaaacatcg21
<210>8
<211>1008
<212>dna
<213>人工序列(artificialsequence)
<400>8
atggggaaggtgaaggtcggagtcaacggatttggtcgtattgggcgcctggtcaccagg60
gctgcttttaactctggtaaagtggatattgttgccatcaatgaccccttcattgacctc120
aactacatggtttacatgttccaatatgattccacccatggcaaattccatggcaccgtc180
aaggctgagaacgggaagcttgtcatcaatggaaatcccatcaccatcttccaggagcga240
gatccctccaaaatcaagtggggcgatgctggcgctgagtacgtcgtggagtccactggc300
gtcttcaccaccatggagaaggctggggctcatttgcaggggggagccaaaagggtcatc360
atctctgccccctctgctgatgcccccatgttcgtcatgggtgtgaaccatgagaagtat420
gacaacagcctcaagatcatcagcaatgcctcctgcaccaccaactgcttagcacccctg480
gccaaggtcatccatgacaactttggtatcgtggaaggactcatgaccacagtccatgcc540
atcactgccacccagaagactgtggatggcccctccgggaaactgtggcgtgatggccgc600
ggggctctccagaacatcatccctgcctctactggcgctgccaaggctgtgggcaaggtc660
atccctgagctgaacgggaagctcactggcatggccttccgtgtccccactgccaacgtg720
tcagtggtggacctgacctgccgtctagaaaaacctgccaaatatgatgacatcaagaag780
gtggtgaagcaggcgtcggagggccccctcaagggcatcctgggctacactgagcaccag840
gtggtctcctctgacttcaacagcgacacccactcctccacctttgacgctggggctggc900
attgccctcaacgaccactttgtcaagctcatttcctggtatgacaacgaatttggctac960
agcaacagggtggtggacctcatggcccacatggcctccaaggagtaa1008
<210>9
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>9
ctttggtatcgtggaaggact21
<210>10
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>10
gtgagcttcccgttcagctc20
- 还没有人留言评论。精彩留言会获得点赞!