一种紫花苜蓿耐盐基因MsPIP2;2及其应用的制作方法
本发明属于生物技术领域,具体涉及一种紫花苜蓿耐盐基因mspip2;2及其应用。
背景技术:
土壤盐渍化是一个世界性的难题,全世界盐渍土面积约10亿hm2,其中,中国土地盐碱化大约占到全球盐碱土面积的1/10,主要分布在东北、华北、西北内陆地区以及长江以北沿海地带,盐碱化程度普遍较高。目前盐渍化已经是影响农业发展的一个重要因素,同时也对农牧业发展产生了严重的影响。近年来,关于植物对盐逆境适应能力的研究已成为全球关注的热点。土壤盐渍化造成的后果有植被密度减小、牧草产量和质量下降。农作物在盐碱地生长发育都会有一定的影响,但牧草较农作物具有更强的耐盐性,故应在改良盐碱地时完全将牧草较强的耐盐性考虑进去,这将会极大地促进盐碱地区的畜牧业发展。
紫花苜蓿(medicagosativa)是世界上利用最早、栽培最广的一种多年生豆科牧草。由于其产草量高、营养丰富,且具有良好的适口性,被誉为“牧草之王”,在我国畜牧业生产发展中发挥着重要的作用。此外,紫花苜蓿根系发达,并具有很强的非生物胁迫抗性并能够通过根瘤菌共生进行生物固氮等优点,对提高土壤肥力、促进粮草轮作等具有重要的意义。随着紫花苜蓿在我国大面积的栽培和集约化、商品化生产,对于优质高产高抗的新品种需求也越来越急迫。而传统的育种手段,如杂交育种、回交育种及综合品种选育等,所需时间长,并高度依赖广泛的种质资源,严重制约着苜蓿的育种进程,影响苜蓿产业的可持续发展。与传统的育种技术相比,转基因技术具有克服了有性杂交的弱点,可以在更远的亲缘关系间进行基因重组,目的性更明确,可以大大加速紫花苜蓿的育种进程。近年来,利用转基因手段进行苜蓿抗旱、抗寒等方面的研究也越来越多,为紫花苜蓿抗逆性的遗传研究提供了更大的便利,能够更快速的培育优质、高产、抗逆性强的苜蓿新品种,推动草畜业发展。
技术实现要素:
本发明的目的在于,提供一种紫花苜蓿耐盐基因mspip2;2,并验证其功能。
为了实现上述任务,本发明采取如下的技术解决方案:
一种紫花苜蓿耐盐基因mspip2;2,其特征在于,该紫花苜蓿耐盐基因mspip2;2编码区的核苷酸序列如下:
根据本发明,所述的紫花苜蓿耐盐基因mspip2;2编码区的氨基酸序列如下:
本发明进一步公开了该花苜蓿耐盐基因mspip2;2的克隆方法,其特征在于,包括如下步骤:
(1)苜蓿幼苗cdna合成:
提取苜蓿幼苗总rna,反转录得到第一链cdna;
(2)mspip2;2基因全长的克隆:
以苜蓿cdna为模板,根据ncbi上蒺藜苜蓿的pip2;2基因序列进行同源比对并设计引物p1和引物p2,进行pcr扩增,回收和纯化pcr扩增产物,并测序得到中间片段;再根据测序得到的序列设计5’race引物p3和3’
race引物p4,进行5’端序列和3’端序列的pcr扩增,回收和纯化pcr扩增产物,并测序;最终将中间序列,5’端序列和3’端拼接得到mspip2;2基因的全长序列,并用orffinder找到该基因的开放阅读框orf;其中:
引物p1序列为:5’-gatgctgaagaactcacaaaat-3’;
引物p2序列为:5’-aaaaggctccccctgtaacgaa-3’;
5’race引物p3为:
5’-gattacgccaagcttgtagaaggctgcaatggctgccccaa-3’;
3’race引物p4序列为:
5’-gattacgccaagcttttggggcagccattgcagccttctac-3’;
(3)在orf两端设计引物p5和p6并通过pcr扩增,将其产物进行纯化、载体连接、大肠杆菌转化,测序得到紫花苜蓿耐盐基因mspip2;2的编码区的核苷酸序列和氨基酸序列;其中:
引物p5序列为:5’-atggcaaaggacgttgaag-3’;
引物p6序列为:5’-tcaaacagtagggttactcctg-3’。
根据申请人的实验表明,将该紫花苜蓿mspip2;2基因利用农杆菌介导的转基因技术,通过蘸花法将紫花苜蓿mspip2;2基因转入野生型拟南芥(col-0)中,使其在拟南芥中表达,获得mspip2;2转基因拟南芥植株。通过试验证明,相比于野生型植株,mspip2;2转基因植株耐盐性明显提高。说明该紫花苜蓿mspip2;2基因对提高植物的耐盐性具有重要作用。
与现有技术相比,本发明给出的紫花苜蓿耐盐基因mspip2;2,带来的有益的技术效果在于:
首次从紫花苜蓿中克隆出了与耐盐性相关的mspip2;2基因,获得了其完整的编码区的核苷酸序列和氨基酸序列。并通过转基因技术在拟南芥中验证了该紫花苜蓿耐盐基因mspip2;2基因的功能,并推测它对于提高苜蓿的耐盐能力也有重要的作用。
附图说明
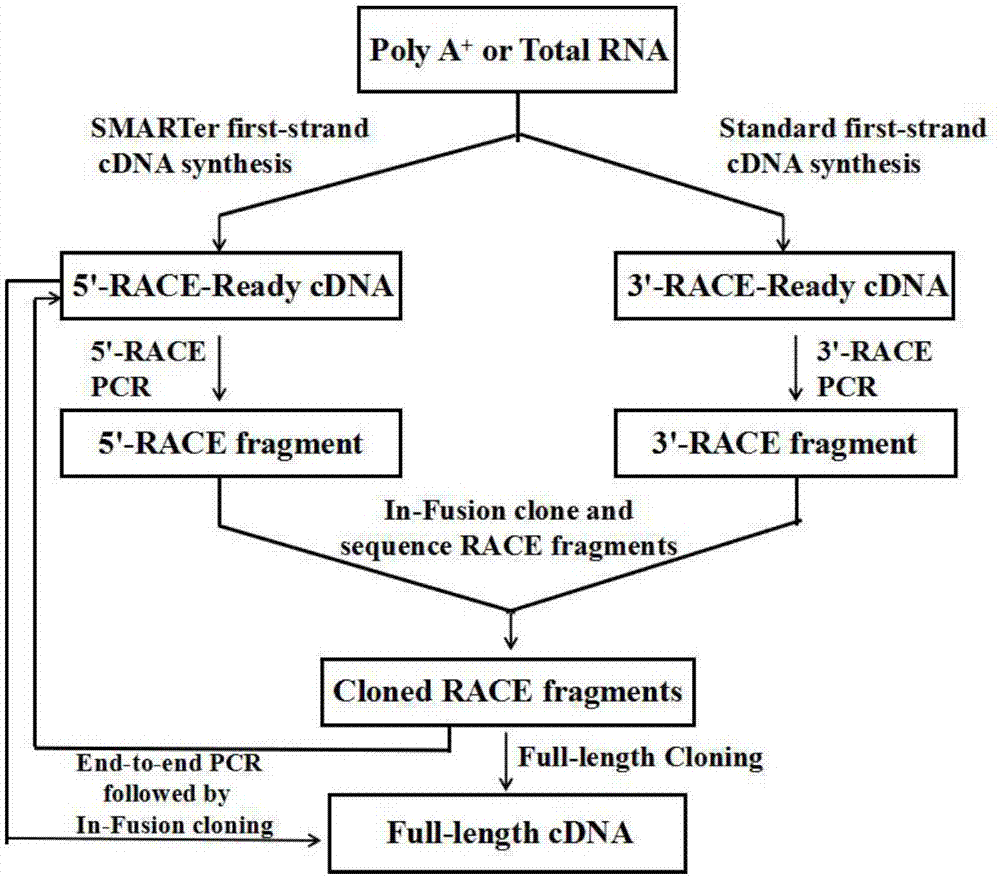
图1为race步骤概要图;
图2为紫花苜蓿mspip2;2基因获得技术路线图;
图3为紫花苜蓿rna提取质量图;
图4为5’race扩增图;
图5为3’race扩增图;
图6为紫花苜蓿mspip2;2基因编码区序列的扩增图;
图7为转基因植株的鉴定结果图;
图8为转基因植株的耐盐表型图;
图9为紫花苜蓿耐盐基因盐处理结果图。
下面结合附图和具体实施例对本发明作进一步详细说明。
具体实施方式
实施例1:紫花苜蓿mspip2;2基因编码区序列的获得
根据ncbi上蒺藜苜蓿的pip2;2基因序列进行同源比对并设计引物p1和引物p2,进行pcr扩增,回收和纯化pcr扩增产物,并进行载体连接、大肠杆菌转化并测序得到中间片段。
引物p1序列为:5’-gatgctgaagaactcacaaaat-3’;
引物p2序列为:5’-aaaaggctccccctgtaacgaa-3’;
race步骤概要图如图1所示:5’race引物p3和3’race引物p4设计按照clotech公司的
按照试剂盒说明书操作步骤完成race过程,分别扩增获得该基因的5’端序列和3’端序列。
5’race引物p3为:
5’-gattacgccaagcttgtagaaggctgcaatggctgccccaa-3’;
3’race引物p4序列为:
5’-gattacgccaagcttttggggcagccattgcagccttctac-3’;
紫花苜蓿mspip2;2基因获得方法技术路线图如2所示:用总rna提取试剂盒plantrnaextractionkit(takara)提取苜蓿幼苗总rna,操作步骤按提取试剂盒说明书进行。吸取2μl提取的总rna溶液用酶标仪进行测定,以无rnase的水为空白对照,测定溶液中rna浓度(ng/μl)。接着用cdna反转录试剂盒primescripttmii1ststrandcdnasynthesiskit(takara)按照操作步骤反转录为cdna。
紫花苜蓿rna提取质量图如图3所示:将提取的rna经1%琼脂糖凝胶电泳检测,结果表明所提rna完整性较好,可用于后续试验。
将克隆得到的5’端序列和3’端序列经测序后,利用dnaman软件将其与中间片段进行拼接获得基因的全长序列,再通过设计orf两端引物p5和引物p6,并利用高保真酶扩增得到该基因的全长cdna,将其产物进行纯化、载体连接、大肠杆菌转化并送去测序,得到紫花苜蓿耐盐基因mspip2;2的编码区的核苷酸序列和氨基酸序列,其中:
引物p5序列为:5’-atggcaaaggacgttgaag-3’;
引物p6序列为:5’-tcaaacagtagggttactcctg-3’。
5’race扩增图如图4所示,目的条带长960bp。
3’race扩增图如图5所示,目的条带长430bp。
紫花苜蓿mspip2;2基因编码区序列的扩增图如图6所示:目的条带的全长为864bp。
综上,获得的紫花苜蓿耐盐基因mspip2;2编码区的核苷酸序列如下:
紫花苜蓿耐盐基因mspip2;2编码区的氨基酸序列如下:
实施例2:转基因拟南芥的获得及阳性苗的鉴定
构建以35s为启动子的mspip2;2过表达载体(35s:mspip2;2),利用拟南芥花序侵染的方法将紫花苜蓿耐盐基因mspip2;2转入到野生型拟南芥中,获得转基因拟南芥植株(basta抗性),并通过rt-pcr检测得到阳性转基因植株(图7),收取纯合种子,进行表型分析。
实施例3:转基因拟南芥对盐胁迫的抗性表型鉴定
将野生型拟南芥(col-0)与2个转基因株系l22和l25播种于装有蛭石的小盆中,置于光照培养间培养。生长2周后,用350mmnacl处理10天,观察植株表型并拍照记录。
表型分析结果表明,经盐胁迫处理10天后,转基因植株的生长状况明显优于野生型植株(图8)。表明花苜蓿耐盐基因mspip2;2可以提高拟南芥对盐胁迫的抗性。
实施例4:紫花苜蓿在盐(150mmnacl)处理下,分别在0,2,4,8和12h取样,用实时荧光定量pcr对mspip2;2基因的表达量进行检测,结果如图9所示。
由于紫花苜蓿组培生长周期较长,虽然尚未在紫花苜蓿植株中验证该基因的功能,但可以初步判定,该基因在苜蓿的抗盐过程也起到一定的调节作用,对于下一步研究转基因苜蓿的耐盐性具有重要意义。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的技术方案所作的任何修改、等同替换、改进等,均应视为本发明的保护范围。
核苷酸或氨基酸序列表
<110>西北农林科技大学
<120>一种紫花苜蓿耐盐基因mspip2;2及其应用
<160>
<210>1
<211>864
<212>dna
<213>核苷酸序列
<220>
<400>
atggcaaaggacgttgaagttgctgaacgtggctctttctctaacaaagactaccatgaccctccaccagcaccactcattgatgctgaagaactcacaaaatggtccttttatagggcccttattgctgagttcattgcaactttacttttcctttacgttactgttttgactgttattggttacagtatccaaactgatgttaaagctggtggtgatgcttgtggtggtgttggaattcttggtattgcttgggcttttggtggcatgatctttgtccttgtttactgcactgctggaatttcaggtggtcacattaacccagcagtgacatttgggctatttttggctcgtaaggtgtctttgatcagagcaattatgtacatggtggctcagtgtttaggggctattgctggagttgggttggttaaggcttttcaaagtgcttactttgatagatatggtggtggtgctaattttctccatgatggttacagtactggtgttggattaggtgctgagattgttggtacctttgttttggtttacaccgttttctctgctactgatcctaagagaagtgctagagattcacatgtgccggttttggcaccacttcccattggctttgctgtattcatggttcatttggcaaccatcccagtcactggcactggcatcaatcctgctagaagtcttggttctgctgttatctacaacaaagataagccctgggatgaccattggatcttttgggttggaccattcattggggcagccattgcagccttctaccatcaattcatcttaagagcaggtgctgttaaagctcttggatcattcaggagtaaccctactgtttga。
<210>2
<211>287
<212>
<213>氨基酸序列
<220>
<400>
metalalysaspvalgluvalalagluargglyserpheserasnlysasptyrhisaspproproproalaproleuileaspalaglugluleuthrlystrpserphetyrargalaleuilealaglupheilealathrleuleupheleutyrvalthrvalleuthrvalileglytyrserileglnthraspvallysalaglyglyaspalacysglyglyvalglyileleuglyilealatrpalapheglyglymetilephevalleuvaltyrcysthralaglyileserglyglyhisileasnproalavalthrpheglyleupheleualaarglysvalserleuileargalailemettyrmetvalalaglncysleuglyalailealaglyvalglyleuvallysalapheglnseralatyrpheaspargtyrglyglyglyalaasnpheleuhisaspglytyrserthrglyvalglyleuglyalagluilevalglythrphevalleuvaltyrthrvalpheseralathraspprolysargseralaargaspserhisvalprovalleualaproleuproileglyphealavalphemetvalhisleualathrileprovalthrglythrglyileasnproalaargserleuglyseralavaliletyrasnlysasplysprotrpaspasphistrpilephetrpvalglypropheileglyalaalailealaalaphetyrhisglnpheileleuargalaglyalavallysalaleuglyserpheargserasnprothrval。
<210>3
<211>22
<212>引物p1序列
<213>dna
<220>
<400>
5’-gatgctgaagaactcacaaaat-3’
<210>4
<211>22
<212>引物p2序列
<213>dna
<220>
<400>
5’-aaaaggctccccctgtaacgaa-3’
<210>5
<211>41
<212>5’race引物p3序列
<213>dna
<220>
<400>
5’-gattacgccaagcttgtagaaggctgcaatggctgccccaa-3’
<210>5
<211>41
<212>3’race引物p4序列
<213>dna
<220>
<400>
5’-gattacgccaagcttttggggcagccattgcagccttctac-3’
<210>6
<211>19
<212>引物p5序列
<213>dna
<220>
<400>
5’-atggcaaaggacgttgaag-3’
<210>7
<211>22
<212>引物p6序列
<213>dna
<220>
<400>
5’-tcaaacagtagggttactcctg-3’
- 还没有人留言评论。精彩留言会获得点赞!