用于C-kit基因突变检测的引物组合及其应用的制作方法
本发明属于基因工程技术领域,尤其是涉及用于c-kit基因突变检测的引物组合及其应用。
背景技术:
c-kit基因位于人染色体4q12-13,属于原癌基因,编码跨膜糖蛋白-酪氨酸激酶受体。c-kit是酪氨酸激酶受体蛋白家族的重要成员之一,其作为干细胞因子的受体,受干细胞因子激活后调节基因表达、控制细胞生长、增殖和分化。c-kit基因的突变可能与肿瘤的产生有一些关联。
胃肠道间质瘤(gist)是消化道最常见的间叶源性肿瘤。绝大部分的gist均表达c-kit基因编码的kit蛋白(cd117)。在分子层面上,大部分的gist均存在c-kit基因突变,从而导致kit蛋白的活化不需要配体scf参与就能刺激肿瘤细胞的持续增殖和抗凋亡信号的失控。
gist中c-kit基因突变率约为90%,且突变形式多样。其中位于11号外显子lys550-val560区段的变异最为常见(约占70-80%),位于9号外显子ala502-tyr503区段的6碱基重复突变约占5-10%。
格列卫(glivec)是一种酪氨酸激酶抑制剂,经fda批准可用于治疗c-kit阳性、不能手术切除和/或转移性的恶性gist,其临床疗效令人振奋。其作用机理在于药物结合于kit蛋白胞浆内酪氨酸激酶功能区的atp结合位点,阻断磷酸基团由atp向底物酪氨酸残基的转移,从而抑制细胞增殖并恢复细胞凋亡程序。
临床研究表明gist中c-kit基因的突变情况与格列卫分子靶向治疗的疗效相关:存在11号外显子突变患者的疗效最好,存在9号外显子突变的患者疗效次之,而野生型gist的疗效最差。另外,对于9号外显子突变的患者,提高用药剂量可显著提高疗效。检测c-kit基因突变对于指导gist患者的合理用药,具有重要的参考价值。
c-kit基因这些位点的突变可能与很多肿瘤的发生发展相关,包括胃肠道间质瘤、肥大细胞病、急性髓性白血病等,这些位点上的突变是细胞恶性转化及可能的肿瘤产生的预兆,应引起高度重视。因此,关于c-kit基因这些位点突变的检测有着非常重要的作用。
众所周知,高分辨熔解曲线(high-resolutionmelt,hrm)分析技术是近几年来在国外兴起的一种用于突变扫描和基因分型的最新遗传学分析方法。它是一种高效稳健的pcr技术,不受突变碱基位点与类型局限,无需序列特异性探针,在pcr(polymerasechainreaction)即聚合酶链式反应结束后直接运行高分辨熔解,即可完成对样品突变、单核苷酸多态性-snp、甲基化、配型等的分析。因操作简便快速,使用成本低,结果准确,实现了真正的闭管操作,hrm技术受到普遍关注。然而,高分辨率熔解曲线(hrm)是传统的熔解曲线分析的延伸,它要求特殊的荧光染料、高性能的荧光定量pcr与专门的分析算法;使我们可以不必测序直接筛查pcr扩增产物中是否存在遗传学变异(snps,mutations)。sybrtmgreeni对pcr扩增有毒性,因此必需使用低浓度的染料,又因为它是非饱和态结合,染料在熔解过程中可重新结合,使其无法适用于hrm。
与此同时,罗氏开发了一种新的适用于hrm的染料resolight或lcgreen,它有三个优点:1、饱和染料毒性低;2、浓度可以使dna达到饱和;3、降低了染料位置重组的可能。而,pcr(polymerasechainreaction)产物的高分辨率熔解曲线hrm的其他要求还包括:仪器:高分辨率高、均一性的仪器,确保结果差异仅受dna模板的影响;试剂:稳定可靠的pcr与hrm染料,确保获取高分辨率熔解曲线;软件:高分辨率熔解曲线分析专用软件。罗氏荧光定量pcr系统lightcyclernanosystem具有光源好、温控好、检测好、加热快的优点,完全能满足检测的要求,这台仪器也于近期通过了国家药监局的审批,适用于临床诊断检测。lightcyclernanosystem是lightcycler480system的缩小版,
目前常常使用测序法来检测是否存在突变,但是总结下来,现有的测序法有三个缺点:
第一:灵敏度不高,低比例突变(<20%)无法检测;
第二:耗时长,一般需要2-3天;
第三:成本高。
鉴于以上的问题,一种灵敏度高、耗时短、成本低、可操作性能更高的c-kit基因突变的快速检测方法,以及用于c-kit基因突变检测的引物组合开发是势在必行的。
技术实现要素:
本发明的目的就是为了提供一种用于c-kit基因突变检测的引物组合及其应用。基于本申请的用于c-kit基因突变检测的引物组合,可以进行c-kit基因突变的快速检测,以解决现有测序法存在的缺点:第一:灵敏度不高,低比例突变(<20%)无法检测;第二:耗时长,一般需要2-3天;第三:成本高。
本发明的目的可以通过以下技术方案来实现:
本发明首先提供用于c-kit基因突变检测的引物组合,包括c-kit第9号外显子(c-kit-e9)、第11号外显子(c-kit-e11)、第13号外显子(c-kit-e13)、第17号外显子(c-kit-e17)、第18号外显子(c-kit-e18)的野生型引物和突变型引物;
其中,第9号外显子的野生型引物的正向引物序列如seqidno.1所示,
第9号外显子的野生型引物的反向引物序列如seqidno.2所示,
第9号外显子的突变型引物的正向引物序列如seqidno.3所示,第9号外显子的突变型引物是指带有第9号外显子突变位点的突变引物,标记为c-kit-e9duplicationofa502-y503,
第9号外显子的突变型引物的反向引物序列如seqidno.4所示,
第11号外显子的野生型引物的正向引物序列如seqidno.5所示,
第11号外显子的野生型引物的反向引物序列如seqidno.6所示,
第11号外显子的突变型引物的正向引物序列如seqidno.7所示,第11号外显子的突变型引物是指带有第11号外显子突变位点的突变引物,标记为c-kit-e11v559d,
第11号外显子的突变型引物的反向引物序列如seqidno.8所示,
第13号外显子的野生型引物的正向引物序列如seqidno.9所示,
第13号外显子的野生型引物的反向引物序列如seqidno.10所示,
第13号外显子的突变型引物的正向引物序列如seqidno.11所示,第13号外显子的突变型引物是指带有第13号外显子突变位点的突变引物,标记为c-kit-e13k642e,
第13号外显子的突变型引物的反向引物序列如seqidno.12所示,
第17号外显子的野生型引物的正向引物序列如seqidno.13所示,
第17号外显子的野生型引物的反向引物序列如seqidno.14所示,
第17号外显子的突变型引物的正向引物序列如seqidno.15所示,第17号外显子的突变型引物是指带有第17号外显子突变位点的突变引物,标记为c-kit-e17n822i,
第17号外显子的突变型引物的反向引物序列如seqidno.16所示,
第18号外显子的野生型引物的正向引物序列如seqidno.17所示,
第18号外显子的野生型引物的反向引物序列如seqidno.18所示,
第18号外显子的突变型引物的正向引物序列如seqidno.19所示,第18号外显子的突变型引物是指带有第18号外显子突变位点的突变引物,标记为c-kit-e18a829t,
第18号外显子的突变型引物的反向引物序列如seqidno.20所示。
本发明还提供所述用于c-kit基因突变检测的引物组合在制备检测c-kit基因突变的检测试剂或检测c-kit基因突变的检测试剂盒中的应用。
本发明还提供所述用于c-kit基因突变检测的引物组合进行非诊断目的的c-kit基因突变的快速检测方法,包括如下步骤:
针对c-kit第9号外显子(c-kit-e9)、第11号外显子(c-kit-e11)、第13号外显子(c-kit-e13)、第17号外显子(c-kit-e17)、第18号外显子(c-kit-e18)突变位点两端分别设计一对野生型引物,并在突变位点上设计一对突变引物;
分别扩增出野生型模板和突变型片段,再用野生型引物以两个突变片段为模板进行pcr扩增,得到突变型模板,扩增对应的突变型模板;
不同比例混合野生型模板和突变型模板,用hrm方法进行区分。
pcr产物的高分辨率熔解曲线基于hrm的基因分型-tm的不同,pcr产物的tm取决于gc含量。
高tmg:c>a:t>g:g>g:t=g:a>t:t=a:a>t:c>a:c>c:c低tm。
纯合子样品的扩增产物进行熔解曲线,得到相似峰形的熔解曲线,杂合子样品的扩增产物进行熔解曲线,得到不同峰形的熔解曲线;
其中,纯合子包括野生型纯合子或突变纯合子。
所述不同比例混合野生型模板和突变型模板是指:使突变型模板的含量为1/10、1/100、1/1000和0,最后用hrm方法进行区分。
其中,c-kit第9号外显子的野生型引物的正向引物序列如seqidno.1所示,
c-kit第9号外显子的野生型引物的反向引物序列如seqidno.2所示,
c-kit第9号外显子的突变型引物的正向引物序列如seqidno.3所示,
c-kit第9号外显子的突变型引物的反向引物序列如seqidno.4所示,
第11号外显子的野生型引物的正向引物序列如seqidno.5所示,
第11号外显子的野生型引物的反向引物序列如seqidno.6所示,
第11号外显子的突变型引物的正向引物序列如seqidno.7所示,
第11号外显子的突变型引物的反向引物序列如seqidno.8所示,
第13号外显子的野生型引物的正向引物序列如seqidno.9所示,
第13号外显子的野生型引物的反向引物序列如seqidno.10所示,
第13号外显子的突变型引物的正向引物序列如seqidno.11所示,
第13号外显子的突变型引物的反向引物序列如seqidno.12所示,
第17号外显子的野生型引物的正向引物序列如seqidno.13所示,
第17号外显子的野生型引物的反向引物序列如seqidno.14所示,
第17号外显子的突变型引物的正向引物序列如seqidno.15所示,
第17号外显子的突变型引物的反向引物序列如seqidno.16所示,
第18号外显子的野生型引物的正向引物序列如seqidno.17所示,
第18号外显子的野生型引物的反向引物序列如seqidno.18所示,
第18号外显子的突变型引物的正向引物序列如seqidno.19所示,
第18号外显子的突变型引物的反向引物序列如seqidno.20所示。
具体而言,包括以下步骤:
样本处理:取外周血2ml于edta抗凝管中,轻柔地颠倒混匀,4℃保存;
dna提取:取200μl抗凝血用试剂盒提取dna,采用电泳凝胶成像对dna纯度和浓度作检测;
qpcr-hrm检测,包括:对照孔的设立和检测重复孔;10μl反应体系构成;在八连管中依照次序加入各试剂,混合均匀;所有样本混合完后,将八连管置于罗氏荧光定量pcr系统仪器中进行程序性检测;
结果分析及判定:在高分辨率熔解曲线分析方法中,以阳性对照孔为分界线,样本孔与基线差异大于阳性对照孔的判定为突变型,差异小于阳性对照孔的判定为野生型。
所述qpcr-hrm检测的程序包括:95℃变性10分钟;95℃变性10秒钟;退火采用探底式,设置探底退火温度为55-65℃,每个循环降低1℃,时间为10秒钟;72℃延伸30秒钟;重复第2步到第四步45个循环;95℃变性60秒钟;40℃变性60秒钟;设置高分辨率熔解温度从60℃到95℃,缓变率是0.05℃/s。
获取c-kit-e9、c-kit-e11、c-kit-e13、c-kit-e17、c-kit-e18突变型模板,步骤包括:利用带有突变位点的突变引物获得突变位点前后两段突变片段;将这两段突变片段连接起来,构成c-kit-e9、c-kit-e11、c-kit-e13、c-kit-e17、c-kit-e18突变型模板。
获取c-kit-e9、c-kit-e11、c-kit-e13、c-kit-e17、c-kit-e18野生型模板,步骤包括:以已知未突变基因组为模板,分别以c-kit-e9、c-kit-e11、c-kit-e13、c-kit-e17、c-kit-e18的野生型引物进行实验,获得条带单一的特异性野生型模板;将野生型模板稀释至1万-10万倍,终浓度为10ng/l,作为检测野生型阴性对照模板用。
与现有技术相比,本发明的有益效果是:
本发明分别设计了c-kit第9号外显子(c-kit-e9)、第11号外显子(c-kit-e11)、第13号外显子(c-kit-e13)、第17号外显子(c-kit-e17)、第18号外显子(c-kit-e18)的野生型引物和突变型引物,分别扩增对应的野生型目的片段和突变型目的片段,不同比例混合这两种片段,使突变型目的片段的含量为1/10、1/100、1/1000和0,最后用hrm方法进行区分,采用了高分辨率熔解曲线法(hrm法);与其它方法相比,本发明的hrm法能检出0.1%的突变、检测时间只需要1小时、每样品试剂耗材成本<¥7.00,即,本发明方法具有高特异性、高灵敏度与方便快捷的优点;而且通量更高,单次成本更低。
附图说明
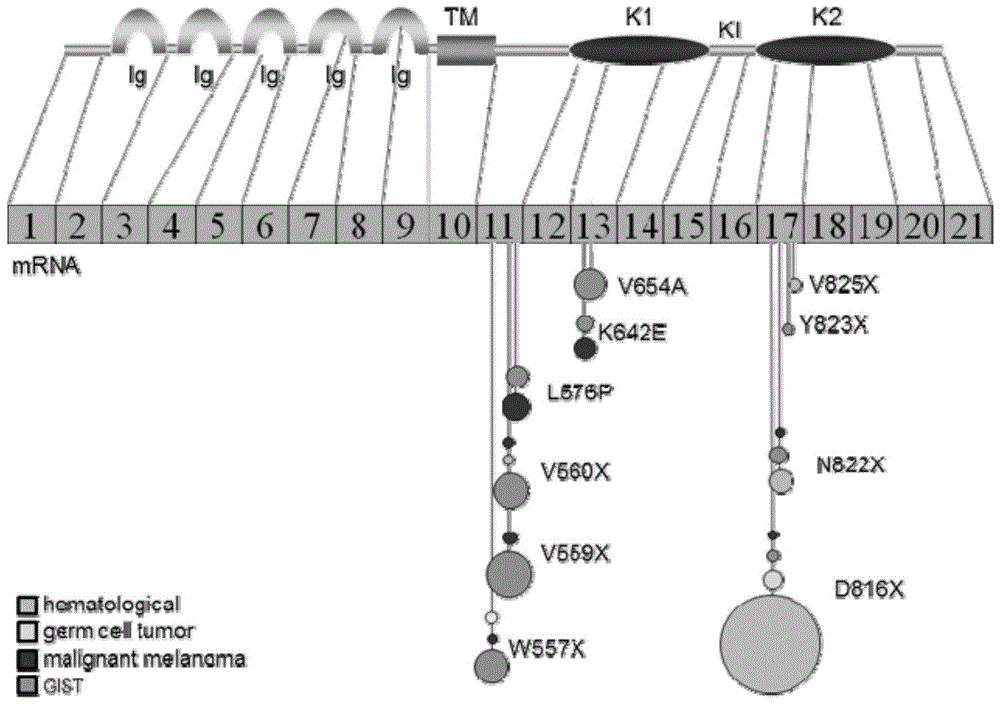
图1为本发明c-kit蛋白功能域及热点突变位点示意图;
图2为用野生型引物检测c-kit第9号外显子(c-kit-e9)1/10、1/100、1/1000突变型和野生型模板的hrm图;
图3为用野生型引物检测c-kit第11号外显子(c-kit-e11)1/10、1/100、1/1000突变型和野生型模板的hrm图;
图4为用野生型引物检测c-kit第13号外显子(c-kit-e13)1/10、1/100、1/1000突变型和野生型模板的hrm图;
图5为用野生型引物检测c-kit第17号外显子(c-kit-e17)1/10、1/100、1/1000突变型和野生型模板的hrm图;
图6为用野生型引物检测c-kit第18号外显子(c-kit-e18)1/10、1/100、1/1000突变型和野生型模板的hrm图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
实施例
本发明应用于生物技术和医学领域,尤其是分子生物学,分子诊断,实时定量pcr技术。
参考图1-图6,本发明分别设计了c-kit第9号外显子(c-kit-e9)、第11号外显子(c-kit-e11)、第13号外显子(c-kit-e13)、第17号外显子(c-kit-e17)、第18号外显子(c-kit-e18)的野生型引物和突变型引物,分别扩增对应的野生型目的片段和突变型目的片段,不同比例混合这两种片段,使突变型目的片段的含量为1/10、1/100、1/1000和0,最后用hrm方法进行区分。
下面以c-kit-e9为例,说明具体的操作,而第11号外显子(c-kit-e11)、第13号外显子(c-kit-e13)、第17号外显子(c-kit-e17)、第18号外显子(c-kit-e18)操作方法相同。
1、样本处理:取外周血2ml于edta抗凝管中,轻柔地颠倒混匀,4℃保存。
2、dna提取:取200μl抗凝血用qiampdnabloodminikit试剂盒提取dna。采用电泳凝胶成像对dna纯度和浓度作检测。
3、qpcr-hrm检测的体系:
1)对照的设立和检测重复孔
每个样本的检测必须同时设有对照实验,包括野生型阴性对照和m/w(突变/野生=1%)阳性对照。对照和样本均采用复孔。
2)10μl反应体系构成(引物序列见附表)
加样次序试剂体积(μl)
6hrmmix5
225mmmgcl21.2
3引物c-kit-e9f0.2
4引物c-kit-e9r0.2
5模板0.5
1h2o3.2
3)在八连管中依照次序加入各试剂,混合均匀,盖上八连管盖子。
4)所有样本混合完后,将八连管置于罗氏荧光定量pcr系统-lightcyclernano仪器中,注意仪器中a组与d组平衡,合上仪器盖子。
4、qpcr-hrm检测的程序:
1)95℃变性10分钟;
2)95℃变性10秒钟;
3)退火采用探底式,设置探底退火温度为55-65℃,每个循环降低1℃,时间为10秒钟;
4)72℃延伸30秒钟;
5)重复第2步到第四步45个循环;
6)95℃变性60秒钟;
7)40℃变性60秒钟;
8)设置高分辨率熔解温度从60℃到95℃,缓变率是0.05℃/s)。
5、结果分析:
1)设置好样本名称、检测靶点和所使用的荧光染料。
2)通过各孔的熔解曲线图可以查看各孔pcr条带特异性;以野生型样品孔为基线,通过高分辨率熔解曲线,可以查看阳性对照孔与样本孔图谱。
3)结果判定
在高分辨率熔解曲线分析方法中,以阳性对照孔为分界线,样本孔与基线差异大于阳性对照孔的判定为突变型,差异小于阳性对照孔的判定为野生型(如图2、图3)。
4)获取结果图。
6、野生型目的片段的获取:
以已知未突变基因组为模板,c-kit-e9f+c-kit-e9r为引物进行实验,参照步骤3及步骤4的反应体系及程序,获得条带单一的特异性野生型目的片段。
将目的片段稀释至1万-10万倍,终浓度约为10ng/l,作为检测野生型阴性对照模板用。
7、c-kit-e9突变型目的片段的获取:
突变型目的片段的获取分为两步,第一步利用带有突变位点的突变引物(c-kit-e9duplicationofa502-y503f,c-kit-e9duplicationofa502-y503r)获得突变位点前后两段突变片段;第二步将这两段突变片段连接起来,构成c-kit-e9突变型目的片段。
1)突变第一步pcr
以稀释后的野生型目的片段为模板,分别以
c-kit-e9f+c-kit-e9duplicationofa502-y503r,c-kit-e9duplicationofa502-y503f+c-kit-e9r为引物进行两组实验,实验体系及程序参照步骤3及步骤4,获得两个条带单一的片段。
2)突变第一步产物稀释
将突变第一步获得的两段pcr产物稀释1万-10万倍,终浓度约为10ng/l。
3)突变第二步pcr
以稀释后的第一步两段产物为模板,以c-kit-e9f+c-kit-e9r为引物进行第二步pcr,实验体系及程序参照步骤3及步骤4,获得条带单一的片段。
4)突变第二步产物稀释
将突变第二步获得的pcr产物稀释1万-10万倍,终浓度约为10ng/l。
8、m/w=1/10、1/100、1/1000阳性对照模板的获取:
混合9μl野生型模板和1μl突变型模板,配制10μl突变型/野生型(m/w)=1/10的混合模板,作为检测用1/10阳性对照模板;将此模板用野生型模板作10倍稀释,分别获得突变型/野生型(m/w)=1/100、1/1000的混合模板,作为检测用1/100、1/1000阳性对照模板。
9、结果分析:
通过hrm方法,我们能区分含1/1000突变型的模板,证明了这个方法的高特异性和高灵敏度,而且,整个操作时间只需要1小时。
附表:c-kit-e9duplicationofa502-y503、c-kit-e11v559d、c-kit-e13k642e、c-kit-e17n822i、c-kit-e18a829t检测引物序列
与其它方法相比,本发明技术具有高特异性、高灵敏度与方便快捷的优点,而且通量更高,单次成本更低。
上述的对实施例的描述是为便于该技术领域的普通技术人员能理解和使用发明。熟悉本领域技术的人员显然可以容易地对这些实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,不脱离本发明范畴所做出的改进和修改都应该在本发明的保护范围之内。
序列表
<110>上海健康医学院
<120>用于c-kit基因突变检测的引物组合及其应用
<160>20
<170>siposequencelisting1.0
<210>1
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>1
gatgctctgcttctgtactg20
<210>2
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>2
gcctaaacatccccttaaattgg23
<210>3
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>3
gacttctgcctatgcctattttaactttgc30
<210>4
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>4
gcaaagttaaaataggcataggcagaagtc30
<210>5
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>5
ctctccagagtgctctaatgac22
<210>6
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>6
agcccctgtttcatactgacc21
<210>7
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>7
gtacagtggaaggatgttgaggag24
<210>8
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>8
ctcctcaacatccttccactgtac24
<210>9
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>9
cggccatgactgtcgctgtaa21
<210>10
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>10
ctccaatggtgcaggctccaa21
<210>11
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>11
catgtctgaactcgaagtcctgag24
<210>12
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>12
ctcaggacttcgagttcagacatg24
<210>13
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>13
tctcctccaacctaatagtg20
<210>14
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>14
ggactgtcaagcagagaat19
<210>15
<211>27
<212>dna
<213>人工序列(artificialsequence)
<400>15
gaatgattctatttatgtggttaaagg27
<210>16
<211>27
<212>dna
<213>人工序列(artificialsequence)
<400>16
cctttaaccacataaatagaatcattc27
<210>17
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>17
ctccacatttcagcaacagcagca24
<210>18
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>18
tcccataggaccagacgtcact22
<210>19
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>19
gcttctattacagactcgactacc24
<210>20
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>20
ggtagtcgagtctgtaatagaagc24
- 还没有人留言评论。精彩留言会获得点赞!