MYH9及CTLA4基因多态性位点在指导肾病综合征患儿使用他克莫司中的应用的制作方法
本发明涉及生物医学领域,具体而言,涉及myh9及ctla4基因多态性位点在指导肾病综合征患儿使用他克莫司中的应用。
背景技术:
他克莫司(fk506)是治疗儿童难治性肾病综合征的一线治疗药物。但是该药治疗窗窄(血药谷浓度需要控制在5~10ng/ml)、药动学个体差异大(口服生物利用度约为3%~77%,儿童半衰期约为8h~16.8h),给药剂量难以把握,一直是困扰fk506临床用药的关键问题。临床医生往往需要进行1~3个月的“试错型”摸索,才能使患儿的fk506谷浓度达到合适的治疗范围内,患儿的疗效才能得到保障。而在如此长的时间内,患儿可能延误治疗导致肾脏的进一步损害,甚至可能出现重症感染、肾衰等严重并发症,并蒙受经济、身体、精神损失。因此,找出影响fk506药动学个体差异大的真正原因,挖掘能够准确预测fk506稳态血药浓度的生物标志物,建立fk506的前瞻性浓度预测模型,做到患者给药前就明确合适的初始剂量,是实现fk506个体化给药急需解决的关键问题。
药物药动学个体差异产生的重要原因是编码相关药物代谢酶、转运体、药物靶点及相关表达调控因子的基因出现多态性所致。目前,国内外有关fk506个体化用药研究主要集中在器官、血液移植人群的药物代谢酶(cyp3a)、转运体(mdr1编码的p-gp)的基因多态性上。而对肾病综合征人群的研究很少,仅仅涉及到fk506的代谢酶编码基因cyp3a5*3、转运体编码基因mdr1c3435t、mdr11236c>t、mdr12677g>t/a等几个snps。而目前文献一致公认、且也获得器官移植指南推荐的仅是cyp3a5*3会显著影响fk506的血药浓度,其他snps对fk506的药动学的影响仍存在争议。而通过上述有限的几个snps并不能充分解释fk506的药动学个体差异。另外,肾病综合征是肾小球滤过膜通透性增加,血液中蛋白从尿中丢失从而导致血浆白蛋白降低、尿蛋白升高的综合征。而fk506是蛋白结合率约为99%的药物。因此,fk506在肾综人群中的药动学行为势必与健康人群、器官移植人群不同,fk506可能与血浆蛋白结合从损伤的肾小球滤过膜漏到尿液中,从而显著的改变了自身的药动学过程。那么肾小球滤过膜上相关蛋白的编码基因多态性是否会影响fk506的药动学呢?目前有文献报道了肾脏足细胞nphs2r229q多态性可能影响fk506的血药浓度。而尚未见肾小球其他足细胞相关蛋白编码基因多态性影响fk506的药动学的研究报道,也未见报道fk506代谢酶、转运体、靶蛋白的相关转录调控因子、炎症细胞因子的编码基因多态性对肾综患儿的fk506浓度的影响。因此,有必要挖掘上述snps对fk506血药浓度的影响,充分明确fk506药动学个体差异大的原因。
找到可能影响fk506血药浓度的生物标志物后,建立浓度预测模型,才能给医生、药师提供一种可靠、方便的用药决策支持。目前,国内外相关研究大多仍采用传统分析方法如多重线性回归建立浓度模型,但传统方法对于多维度复杂变量模型的拟合欠佳、模型泛化性差等。仅有的群体药动学模型纳入的影响因素太少,仅仅纳入了年龄、体重及一个药动学位点(cyp3a5*3),不足以解释实际临床浓度的个体差异。已有研究只用了传统的统计方法逻辑回归法来分析建模,而该方法不适用于一些复杂、多维、有相互作用的变量的建模,因而得到的模型拟合性能较差,存在欠拟合或过拟合的现象。此外群体药动学必须采集多个时间点的血标本,才能建立性能较佳的模型。这些临床结果或模型泛化性能差,难以推广。
故而通过现有技术难以分析得到哪些基因多态性位点是主要影响fk506药物给药剂量的位点,进而无法给出准确的用药指导建议。
技术实现要素:
传统的统计方法逻辑回归法来分析建模,而该方法不适用于一些复杂、多维、有相互作用的变量的建模。本发明首次采用机器学习算法建立并验证他克莫司稳定期稳态血药谷浓度的预测模型,该机器学习算法对数据进行更为合理的预处理和重要性排序,有效降低数据噪音;并且针对不同数据的特点将多种建模方法进行比对分析,从而找出在训练数据上表现优异(例如trainningerror足够小,且模型的vc维低、自由度适中)的机器学习模型。通过该方法,本发明首次能够对莫司药动学数据进行大规模复杂数据的高通量分析,并针对cyp3a5不同表达类型更为灵活、更有针对性地调整学习模型,从而首次实现较全面、精准地分析中国肾病综合征患儿的他克莫司药动学通路蛋白、药效学通路蛋白、肾病相关蛋白、转录调控因子等相关编码基因多态性与他克莫司稳定期血药谷浓度间的相关性,进而提供了一种肾病综合征患儿使用他克莫司的客观用药指导方法。
具体的,本发明涉及myh9和/或ctla4基因多态性位点的检测剂在制备用于肾病综合征患儿使用他克莫司的用药指导试剂盒中的应用;
所述myh9基因多态性位点为rs2239781,所述ctla4基因多态性位点为rs4553808。
myh9rs2239781和ctla4rs4553808位点与肾病综合征患儿的他克莫司药动学密切相关,且其检测属于外周血指标,可方便获取,方便将来推广使用。也可方便联合其它检测方式(例如本领域公认的cyp3a5*3基因位点的检测)以得出更可靠的结果。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
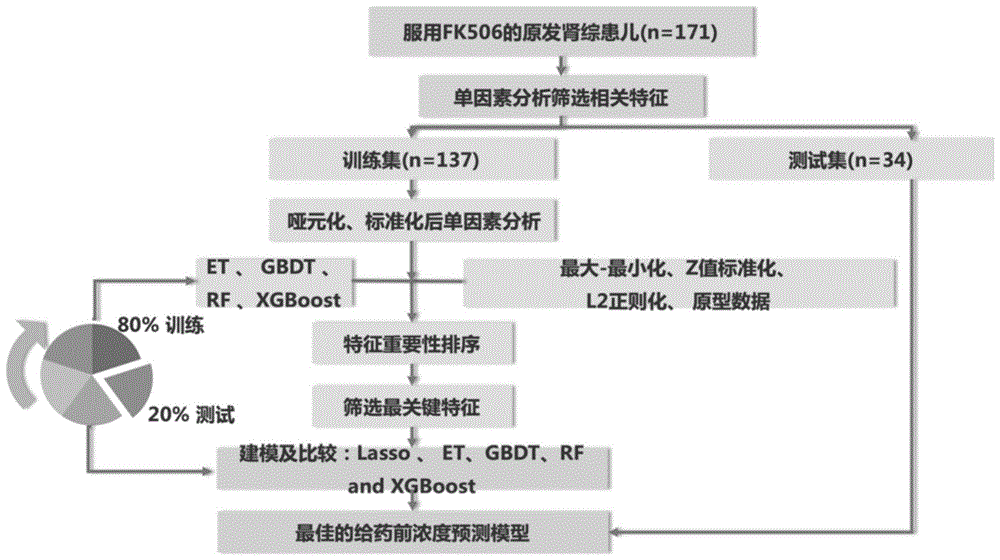
图1为本发明所用模型的构建和验证的流程示意图;
图2为本发明一个实施例中全体人群中cyp3a5*3/*3以及cyp3a5*1/*1+*1/*3基因型与cdr(他克莫司剂量校正谷浓度)之间的关系;
图3为本发明一个实施例中全体人群中myh9rs2239781不同基因型与cdr之间的关系;
图4为本发明一个实施例中全体人群中ctla4rs4553808不同基因型与cdr之间的关系;
图5为本发明一个实施例中根据训练集和测试集r2绘制的最佳特征变量图。
具体实施方式
现将详细地提供本发明实施方式的参考,其一个或多个实例描述于下文。提供每一实例作为解释而非限制本发明。实际上,对本领域技术人员而言,显而易见的是,可以对本发明进行多种修改和变化而不背离本发明的范围或精神。例如,作为一个实施方式的部分而说明或描述的特征可以用于另一实施方式中,来产生更进一步的实施方式。
因此,旨在本发明覆盖落入所附权利要求的范围及其等同范围中的此类修改和变化。本发明的其它对象、特征和方面公开于以下详细描述中或从中是显而易见的。本领域普通技术人员应理解本讨论仅是示例性实施方式的描述,而非意在限制本发明更广阔的方面。
本发明涉及myh9和/或ctla4基因多态性位点的检测剂在制备用于肾病综合征(ns)患儿使用他克莫司(fk506)的用药指导试剂盒中的应用;
所述myh9基因多态性位点为rs2239781,所述ctla4基因多态性位点为rs4553808。
“用药指导”在本发明中指本领域技术人员可根据myh9rs2239781和ctla4rs4553808位点调整他克莫司在肾病综合征患儿中的给药(给药量、给药间隔等)。在本发明所公开内容的基础上,本领域人员可以不付出创造性地获知这两个基因多态性位点与他克莫司的药物药动学密切相关。
肌球蛋白重链9(myh9)编码肌球蛋白iia重链,它参与许多细胞功能活动,包括细胞分裂,迁移和粘附。由myh9突变体引起的异常myh9表达或功能改变导致细胞骨架损伤,在某些情况下导致蛋白尿或肾衰竭。细胞毒性t淋巴细胞相关蛋白4(ctla4)是一种蛋白受体,其作为免疫检查点起作用并下调免疫应答。既往的研究中有发现ctla-4基因的多态性与自身免疫性疾病如自身免疫性甲状腺疾病和多发性硬化症有关,尽管这种关联通常很弱。
有文献已报道过myh9rs2239781和ctla4rs4553808位点与别的人群别的疾病之间的关系,但未发现与肾综人群的他克莫司浓度间的关系。本发明首次发现这两个基因位点的多态性与肾病综合征患儿对他克莫司的药动学密切相关。ctla4和myh9多态性的基因分型有助于更好地指导儿童ns患者的他克莫司剂量。
在一些实施方式中,所述试剂盒中还含有可用于指导他克莫司用药的其他基因多态性位点的检测剂。
在一些实施方式中,所述其他基因多态性位点为cyp3a5*3/*3以及cyp3a5*1/*1+cyp3a5*1/*3的基因多态性位点。
在一些实施方式中,所述肾病综合征患儿的年龄在14岁以下。
在一些实施方式中,所述肾病综合征患儿的年龄在10岁以下。
在一些实施方式中,所述肾病综合征患儿为亚洲人种。
在一些实施方式中,所述肾病综合征患儿为中国人种。
在一些实施方式中,所述肾病综合征患儿的肝或肾功能基本正常。
在一些实施方式中,所述肾病综合征患儿为原发性肾病综合征患儿。
在一些实施方式中,所述肾病综合征患儿为难治性肾病综合征患儿。
在一些实施方式中,所述肾病综合征患儿来自于他克莫司慢代谢者与他克莫司快代谢者的总体人群。
在一些实施方式中,所述检测剂用于执行以下任一种方法:
限制性片段长度多态性法pcr-rflp、单链构象多态性法pcr-sscp、指竞争性等位基因特异性pcr(kompetitiveallelespecificpcr)、变性梯度凝胶电泳、等位基因特异性pcr(allelespecificpcr,aspcr)、dna测序法、dna分型芯片检测、飞行质谱仪(maldi-tofms)检测、变性高效液相色谱(dhplc)法、snapshot法、taqman探针法、生物质谱法以及hrm法。
上述方法均为本领域公知的基因多态性位点的检测方法,其所采用的试剂也为本领域技术人员所熟知。
在一些实施方式中,所述试剂盒中还包括dna提取试剂。
在一些实施方式中,所述dna提取试剂用于执行以下任一种方法:
酚氯仿法、naoh法、树脂提取法、盐析法、十六烷基三甲基溴化胺法、硅胶膜吸附法、fta卡法、硅珠法或磁珠提取法。
其中:
酚氯仿法通常是指通过酚氯仿混合物萃取dna溶液中的蛋白质类有机物质,保留dna于水相溶液中的dna提取方法。
naoh法一般是强碱溶解、变性蛋白质,破坏细胞膜及核膜,变性核酸酶,释放dna,naoh不破坏dna一级结构。
树脂提取法常用chelex100法,通过chelex螯合镁、钠和钾等离子,使降解dna的核酸酶失去活性的dna提取方法。
盐析法通常是将细胞破碎并离心后,用约6m的饱和nacl沉淀蛋白质,离心上清中dna用无水乙醇沉淀,用te溶解。
十六烷基三甲基溴化胺法通常是通过非离子型去污剂ctab破坏细胞壁和细胞膜及硬组织,并与dna形成复合物,分离dna与蛋白质及多糖类物质的dna提取方法。
硅胶膜吸附法通常指通过硅胶膜吸附细胞裂解液裂解后释放出dna,并经蛋白酶消化、漂洗液清洗除去蛋白质、脂质以及多糖等杂质的dna提取与纯化方法。
fta卡法通常指通过fta卡裂解细胞释放dna,从血液、口腔上皮细胞中获得dna的方法。
硅珠法通常是指在高浓度的硫氰酸胍存在的条件下,通过二氧化硅微粒特异捕获有机质溶液中dna分子的dna提取方法。
磁珠法通常是指在胍盐存在条件下,通过在硅胶外表涂上一层磁性树脂的磁珠,特异性的吸附细胞裂解液裂解后释放出dna的dna提取与纯化方法。
基于本发明,本领域技术人员容易想到本发明所提供的标记物myh9rs2239781和/或ctla4rs4553808位点也可用作药代动力学标记物。这里所用的“药代动力学标记物”是一个客观的生化标记物,其特异地与药物效应相关。药代动力学标记物的存在或数量并不与给予药物的疾病状况或病症相关;因此,药代动力学标记物的存在或数量可作为受试者的药物存在或活性的指标。例如,药代动力学标记物可指示生物组织中药物浓度,因为在该组织中标记物是相关于药物水平而被表达的或转录的,或是未被表达或转录的。以这种方式,用药代动力学标记物监测药物的分布或摄取。相似地,药代动力学标记物的存在或数量可以与药物代谢产物的存在或数量相关,以便标记物的存在或数量可指示体内的药物相对分解速度。药代动力学标记物尤其可应用于增加检测药物效应的灵敏度,尤其在以低剂量给予药物的时候。而且,由于标记物本身的性质使得标记物更容易检测;例如,利用在此所述的方法,在基于探针杂交或测序等方法可对上述标记物容易地进行检测。另外,应用药代动力学标记物可以提供以机理为基础的危险预测,所述危险是由于超出可能的直接观察范围之外的药物治疗。
进一步地,本发明还涉及一种受试者使用他克莫司的用药指导方法,所述方法包括:
a)获取含有受试者dna的样品;b)测量样品中的myh9rs2239781和/或ctla4rs4553808位点,c)任选地,测量样品中的一种或更多种可用于指导他克莫司用药的其他基因多态性位点;d)使用步骤b)的测量结果和任选的步骤c)的测量结果来指导他克莫司的药物用量。
在一些实施方式中,术语“受试者”为如上所述的“肾病综合征患儿”所定义。
在一些实施方式中,所述样品为所述受试者的体液,例如是血液、血清或血浆和脑脊髓液、组织或组织裂解液、细胞培养上清、精液、唾液样品、或其它适当的包含基因组dna的样品,优选外周血。
在一些实施方式中,步骤d可进一步包括:
d1)若所述患儿myh9rs2239781位点的基因型为tc,则相对于纯合子患者基因型需要增加他克莫司用药量;
若所述患儿myh9rs2239781位点的基因型为cc,则相对于其他基因型需要减少他克莫司用药量;
d2)若所述患儿ctla4rs4553808位点的基因型为aa,则相对于其他基因型需要增加他克莫司用药量。
下面将结合实施例对本发明的实施方案进行详细描述。
实施例
本实施例采用高级机器学习算法构建了给药前fk506在肾综患儿中的血药浓度预测模型。
一、材料与方法
1.患者与治疗
患者于2013年7月至2017年12月在广州市妇幼保健中心就诊。入选标准如下:14岁以前出现症状,临床诊断为难治性ns(包括激素依赖型ns,激素耐药性ns,频复发ns),并口服他克莫司至少三个月。排除接受除激素以外影响他克莫司血药水平的药物,如维拉帕米,酮康唑,伊曲康唑,红霉素,克拉霉素,地尔硫卓或某些传统中草药。继发性ns或肝或肾功能异常的患者也被排除在外。
所有患者均接受双重免疫抑制方案,包括他克莫司(prografttm,astellas,killorglin,ireland)和低剂量泼尼松(广东华南药业有限公司,中国东莞)。他克莫司的初始剂量以每天两次0.10~0.15mg/kg给予患者,随后调整剂量调整到他克莫司稳态浓度维持在5~10ng/ml。
患者的信息如表1所示
表1所有小儿原发性肾病综合征患者的人口统计学和临床特征(n=171)
2.数据采集
服用他克莫司三个月后,当持续达到稳态浓度时,获得体重,年龄,他克莫司剂量和全血谷浓度(c0)。在给予他克莫司早晨剂量之前收集静脉血样品。他克莫司的全血浓度通过酶联免疫分析技术(viva-e,西门子,德国)测定。cdr(即c0/d)是他克莫司谷浓度除以mg/kg体重表示剂量校正谷浓度。此外,还获取了相应的实验室参数,包括血清肌酐,丙氨酸氨基转移酶和天冬氨酸氨基转移酶。
3.dna提取和基因分型
在获得患者知情同意后,从患者中收集用于基因分型的静脉血样本(2ml)。使用genometiangen血液dna提取试剂盒(dp348,北京,中国)从外周血白细胞中提取总基因组dna。cyp3a4*1g(20230c>t),cyp3a5*3(6985a>g)和mdr1(1236c>t,2677g>t/a和3435c>t)多态性通过pcr-rflp方法测定。其余75个单核苷酸多态性(snp),包括actn4(rs62121818),actn4(rs56113315),actn4(rs3745859),ctla4rs4553808、nphs1(rs437168),nphs2(rs2274622),myh9(rs2239781),itgb4(rs871443),lamb2(yo11987e)(rs58948844),cd2ap(rs4711880),inf2(rs12147772),trpc6(rs10501986),plce1(rs17109671),wt1(rs1799925)、angptl4(rs2042899)等通过agenabioscience
4.数据预处理
首先,去除缺失值占比大于10%的变量,进而采用单因素分析法分析每个变量与结局变量之间的相关性,剔除分析结果为阴性的变量(p值大于0.05);然后采用均值填补缺失的连续型变量;最后对连续型变量进行标准化,对分类变量进行哑元化。
5.特征提取
首先,对数据预处理后的变量进行单因素分析,筛选出与结局变量相关的初始特征变量(特征子集a),然后使用集成模型进一步选择恰当的特征变量子集,包括极端随机树(extremelyrandomizedtrees,et)、梯度提升决策树(gradientboostingdecisiontree,gbdt)、随机森林(randomforest,rf)以及极限梯度提升(extremegradientboosting,xgboost)四种算法:先对连续数据变量进行不同的数据变换,分别是最小-最大归一化(min-maxnormalization)、z-分数标准化(z-scorenormalization)、l2正则化以及保持原型不变,分别结合分类变量形成四种形式的变量数据集。然后采用上述四种算法分别对这四种形式变量建模,得到16种模型。每个模型都对数据变量进行重要性排序,一共得到16个变量重要性排名序列,取中位数重要性排名作为变量的最终重要排名。最后,选用五折交叉验证和xgboost方法,按照变量重要贡献度排名的顺序,从最重要的变量开始进行前向逐步建模,每次只添加一个变量并且重新建模和评估模型的r方,直到添加最后一个变量结束并根据r方确定最佳的变量个数,形成最终特征变量(特征子集b)。
6.模型构建
使用套索算法(leastabsoluteshrinkageandselectionoperator,lasso)分析特征子集a,实现特征选择和正则化并且构建多重线性回归模型;此外,使用lasso、et、gbdt、rf以及xgboost算法分析特征子集b并构建回归预测模型。所有模型构建过程中,训练集与测试集按8:2随机划分数据集,训练集在构建模型过程中采用五折交叉验证。建模和验模的流程图如图1所示。
二、实验结果
1.初始特征变量(特征子集a)的确定
将所有检测的特征变量包括给药前的临床特征和基因型总共118个变量,与剂量校正谷浓度(concentration/dose/normalizedbybodyweight,cdr)进行单因素分析,得到p<0.05的变量包括:给药前血白蛋白(alb0,p=0.032),cyp3a5*3(p<0.001),il2rars12722489(p=0.013),myh9rs4821478(p=0.008),myh9rs2239781(p=0.003),cyp3a4rs2242480(p<0.001),nphs2rs2274622(p=0.035),nphs2rs2274623(p=0.015),nfkb1rs230498(p=0.029),nfkb1rs230532(p=0.021),nfkb1rs3774959(p=0.029),nr1h4rs56163822(p=0.015),nphs2rs1410591(p=0.048),tnfrs1800610(p=0.034),il2rars2104286(p=0.002),ctla4rs4553808(p=0.017),lmx1brs71497630(p=0.007)。进一步将这些阳性分类变量进行哑元化,将哑元化后的变量再次进行单因素分析,得到p<0.05的阳性变量,包括cyp3a5*3rs776746_*1/*1(p=0.012),cyp3a5*3rs776746_*1/*3(p<0.001),cyp3a5*3rs776746_*3/*3(p<0.001),il2rars12722489_cc(p=0.036),il2rars12722489_ct(p=0.007),myh9rs4821478_aa(p=0.002),myh9rs2239781_tc(p=0.027),myh9rs2239781_cc(p=0.001),cyp3a4rs2242480_cc(p<0.001),cyp3a4rs2242480_ct(p=0.018),cyp3a4rs2242480_tt(p=0.001),nphs2rs2274622_ct(p=0.032),nphs2rs2274622_tt(p=0.010),nphs2rs2274623_tt(p=0.005),nfkb1rs230498_aa(p=0.008),nfkb1rs230532_tt(p=0.006),nfkb1rs3774959_aa(p=0.008),nr1h4rs56163822_gg(p=0.008),nr1h4rs56163822_gt(p=0.027),nphs2rs1410591_gc(p=0.047),nphs2rs1410591_cc(p=0.016),tnfrs1800610_gg(p=0.024),tnfrs1800610_ga(p=0.012),il2rars2104286_tt(p=0.036),il2rars2104286_tc(p=0.001),ctla4rs4553808_gg(p=0.043),ctla4rs4553808_aa(p=0.011)以及给药前标准化血白蛋白(alb0,p=0.032),即构成了初始特征变量(特征子集a)。将特征子集a的所有变量与cdr做图,其中全体人群中cyp3a5*3/*3以及cyp3a5*1/*1+*1/*3基因型与cdr之间的关系如图2所示,myh9rs2239781不同基因型与cdr之间的关系如图3所示,ctla4rs4553808不同基因型与cdr之间的关系如图4所示。
2.最佳特征变量(特征子集b)的确定
将上述特征子集a进行数据转换形成的4种变量子集采用4种机器学习算法建模得到16种模型,得到每个变量的16个重要贡献度,取每个变量的重要贡献度的中位数进行最终重要贡献度的排名,中位数值越小则该变量越重要。alb0、cyp3a5*3rs776746_*3/*3、myh9rs2239781_tc的重要性排在前列。进一步采用xgboost法(5折交叉验证)按照上述变量重要贡献度排名,从最重要的变量开始进行前向逐步建模,每次添加一个变量且重建和评估模型的r2,直到添加最后一个变量结束建模,得到根据训练集和测试集r2绘制的最佳特征变量图5。从图中可以看出,在一个一个加入变量达到第5个变量时,模型的训练集r2和测试集r2达到两者最佳r2值。因此,得到这5个变量(alb0、cyp3a5*3rs776746_*3/*3、myh9rs2239781_tc、myh9rs2239781_cc、ctla4rs4553808_aa)为最佳特征变量(特征子集b),进行最后浓度预测模型的建立和验证。
3.浓度预测模型的建立和验证
对上述最佳特征变量(特征子集b)采用5种机器学习算法进行建模和验证。包括xgboost、et、rf、gbdt和lasso回归分别建模和验证,得到5个浓度预测模型。5个模型的训练集和测试集预测性能(包括r2、均方误差、平均绝对误差、中值绝对误差)结果见表2~3。从表中可见,各个模型的训练集预测r2值大约为32.9%~46.7%,测试集预测r2值大约为37.6%~44.4%。其中gbdt算法建模得到的r2值最高,训练集和测试集r2分别为44.7%和44.4%,模型中变量重要贡献程度见表4。各项误差值都在可接受范围之内。
表2五组模型在全组人群训练集中的预测性能比较
表3五组模型在全组人群测试集中的预测性能比较
表4全组人群中五个模型进行特征筛选的重要性值
注:表4中的每行是某个模型所纳入的每个变量对于整个模型的贡献度。从每个变量的值的大小可以看出每个变量对于整个模型的贡献度。
从上面几个表格可知,gbdt模型最佳,因而可判断myh9rs2239781和ctla4rs4553808位点贡献度很高,与cyp3a5*3rs776746_*3/*3相当,说明二者对全组人群他克莫司药物代谢有重要的影响。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!