HDL相关蛋白质生物标记物组的检测的制作方法
本申请要求2016年7月21日提交的美国临时申请62/365,175的优先权,该申请全文以引用方式并入本文。
发明领域
本文提供了用于检测来自患有或怀疑患有心血管疾病(cvd)或其他hdl相关疾病的受试者的样品中的一种或多种hdl相关蛋白质(例如,apoc3;apoc3和apoa1;apoc3和saa1/2;或生物标记物组1-30中的蛋白质)的方法、系统和组合物。在某些实施方案中,此类方法、系统和组合物用于确定受试者的近似cvd(或其他疾病)风险,和/或样品的近似胆固醇流出能力(cec)。在特定实施方案中,所述系统和组合物由来自患有或怀疑患有cvd的受试者的样品和hdl相关结合剂或质谱标准品组成。
发明背景
尽管我们对心血管疾病的病理生理学的理解和对动脉粥样硬化斑块成像能力最近都取得了进展,但准确确定稳定心脏病患者的风险仍然是一项挑战。临床上未鉴定出的高风险患者是非常令人担忧的,所述临床上未鉴定出的高风险患者未经历侵袭性风险因子修改并且经历了主要不良心脏事件。同样,需要更准确地鉴定低风险受试者,以便将有限的医疗保健资源重聚焦于最能受益者。大多数目前的临床风险评定工具涉及根据对未经治疗的一级预防人群进行的基于流行病学的研究而开发的算法,并且在应用于较高风险和用药物治疗的心脏病门诊患者的背景下受到限制。尽管有相当大的兴趣,但是整合更全面的基于阵列的表型分析技术(例如,基因组学阵列、蛋白质组学阵列、代谢组学阵列、表达阵列)来改善心脏风险分层的努力仍处于起步阶段,并且尚未被转化为适用于临床实践高通量需求的高效和稳健的平台。
技术实现要素:
本文提供了用于检测来自患有或怀疑患有心血管疾病(cvd)或其他hdl相关疾病的受试者的样品中的一种或多种hdl相关蛋白质(例如,apoc3;apoc3和apoa1;apoc3和saa1/2;或生物标记物组1-30中的蛋白质)的方法、系统和组合物。在某些实施方案中,此类方法、系统和组合物用于确定受试者的近似cvd(或其他疾病)风险,和/或样品的近似胆固醇流出能力(cec)。在特定实施方案中,所述系统和组合物由来自患有或怀疑患有cvd的受试者的样品和hdl相关结合剂或质谱标准品组成。
在一些实施方案中,本文提供了方法,所述方法包括:检测来自受试者的样品中至少一种hdl相关蛋白质的水平,其中所述至少一种hdl相关蛋白包括apoc3,并且其中所述受试者患有或怀疑有心血管疾病。在某些实施方案中,样品是纯化的高密度脂蛋白样品。在其他实施方案中,所述样品选自由以下项组成的组:血清样品、血浆样品和血液样品。在另外的实施方案中,所述方法还包括:将至少一种hdl相关蛋白质的水平规一化至总hdl颗粒或apoa1或hdl-胆固醇的近似水平,以产生至少一种规一化的hdl蛋白质值。
在特定实施方案中,确定样品中总hdl颗粒或apoa1或hdl-胆固醇的近似水平包括确定加入到样品中的内标物的水平,其中所述内标物包括标记的hdl蛋白质。在一些实施方案中,检测至少一种hdl蛋白质的水平包括向样品中添加试剂,其中所述试剂消化样品中的hdl蛋白质(例如,lyc-c、胃蛋白酶、胰蛋白酶等)。在其他实施方案中,在没有事先消化的情况下检测到hdl相关蛋白质(例如,检测到完整的hdl相关蛋白质)。
在其他实施方案中,检测至少一种hdl相关蛋白质的水平包括对样品的至少一部分执行检测apoc3或apoc3的片段的测定。在某些实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apoc3蛋白质或蛋白质片段标准品,以及检测所述apoc3标准品。在其他实施方案中,apoc3标准品包含seqidno:11中所示的氨基酸序列或由其组成。在某些实施方案中,该测定是质谱测定或免疫测定。
在特定实施方案中,至少一种hdl相关蛋白质还包括血清淀粉样蛋白a1或2(saa1和/或saa2,本文称为“saa1/2”)。在其他实施方案中,检测至少一种hdl蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,和ii)saa1/2或saa1/2的片段。在另外的实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的saa1/2蛋白质或蛋白质片段标准品,以及检测所述saa1/2标准品。在某些实施方案中,saa1/2标准品包含seqidno:35中所示的氨基酸序列或由其组成。
在其他实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白1(apoa1)。在一些实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,和ii)apoa1或apoa1的片段。在其他实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)saa1/2或saa1/2的片段,和iii)apoa1或apoa1的片段。在某些实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apoa1蛋白质或蛋白质片段标准品,以及检测所述apoa1标准品。在其他实施方案中,apoa1标准品包含seqidno:1或seqidno:2中所示的氨基酸序列或由其组成。
在其他实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白c1(apoc1)。在一些实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,和ii)apoc1或apoc1的片段。在其他实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白c1(apoc2)。在一些实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,和ii)apoc1或apoc2的片段。在其他实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白c4(apoc4)。在一些实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,和ii)apoc1或apoc4的片段。在特定实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)apoa1或apoa1的片段,和iii)apoc1或apoc1的片段。在某些实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)apoa1或apoa1的片段,和iii)apoc2或apoc2的片段。
在一些实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白l1(apol1)和磷脂转移蛋白(pltp)。在其他实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)saa1/2或saa1/2的片段,iii)apol1或apol1的片段,和iv)pltp或pltp的片段。在其他实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apol1蛋白质或蛋白质片段标准品和/或标记的或未标记的pltp蛋白质或蛋白质片段标准品,以及检测所述apol1标准品和/或pltp标准品。在另外的实施方案中,apol1标准品包含seqidno:18或seqidno:19中所示的氨基酸序列或由其组成,并且其中pltp标准品包含seqidno:31或seqidno:32或由seqidno:31或seqidno:32组成。
在其他实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白e(apoe)。在其他实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)saa1/2或saa1/2的片段,iii)apol1或apol1的片段,iv)pltp或pltp的片段,和v)apoe或apoe的片段。在其他实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apoe蛋白质或蛋白质片段标准品,以及检测所述apoe标准品。在其他实施方案中,apoe标准品包含seqidno:15或seqidno:16中所示的氨基酸序列或由其组成。
在某些实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白a1(apoa1)和载脂蛋白d(apod)。在其他实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)saa1/2或saa1/2的片段,iii)apol1或apol1的片段,iv)pltp或pltp的片段,v)apoe或apoe的片段,vi)apoa1或apoa1的片段,和vii)apod或apod的片段。在一些实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apod蛋白质或蛋白质片段标准品,以及检测所述apod标准品。在特定实施方案中,apod标准品包含seqidno:13或seqidno:14中所示的氨基酸序列或由其组成。在其他实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apoa1蛋白质或蛋白质片段标准品,以及检测所述apoa1标准品。
在其他实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白m(apom)和磷脂转移蛋白(pltp)。在一些实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)saa1/2或saa1/2的片段,iii)apom或apom的片段,和iv)pltp或pltp的片段。在其他实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apom蛋白质或蛋白质片段标准品和/或标记的或未标记的pltp蛋白质或蛋白质片段标准品,以及检测所述apom标准品和/或pltp标准品。在另外的实施方案中,apom标准品包含seqidno:20中所示的氨基酸序列或由其组成,并且其中pltp标准品包含seqidno:31或seqidno:32中所示的氨基酸序列或由其组成。
在另外的实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白c1(apoc1)。在其他实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)saa1/2或saa1/2的片段,和iii)apoc1或apoc1的片段。在一些实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apoc1蛋白质或蛋白质片段标准品,以及检测所述apoc1标准品。在某些实施方案中,apoc1标准品包含seqidno:7或seqidno:8中所示的氨基酸序列或由其组成。
在另外的实施方案中,至少一种hdl相关蛋白质还包括载脂蛋白d(apod)。在其他实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)saa1/2或saa1/2的片段,和iii)apod或apod的片段。在其他实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apod蛋白质或蛋白质片段标准品,以及检测所述apod标准品。在一些实施方案中,apod标准品包含seqidno:13或seqidno:14中所示的氨基酸序列或由其组成。
在一些实施方案中,所述至少一种hdl相关蛋白还包括以下项或由以下项组成:选自由以下项组成的组的至少一种另外的蛋白质:clu、apoe、cetp、pon1、apoc1、apoa2、apoc2、apom、pltp,以及apol1。在其他实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)saa1/2或saa1/2的片段,和iii)至少一种另外的蛋白质或其片段。在特定实施方案中,检测至少一种hdl相关蛋白质的水平还包括加入对应于所述至少一种另外的蛋白质的标记的或未标记的蛋白质或蛋白质片段标准品,以及检测所述相应的标准品。在其他实施方案中,所述相应的标准品包含seqidno:23、seqidno:24、seqidno:15、seqidno:16、seqidno:21、seqidno:22、seqidno:33、seqidno:34、seqidno:7、seqidno:8、seqidno:3、seqidno:4、seqidno:9、seqidno:10、seqidno:20、seqidno:31、seqidno:32、seqidno:18和seqidno:19中所示的氨基酸序列或由其组成。
在某些实施方案中,至少一种hdl相关蛋白质还包括apoc1和apoc2。在其他实施方案中,检测至少一种hdl蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)apoc1或apoc1的片段,和iii)apoc2或apoc2的片段。在另外的实施方案中,检测至少一种hdl相关蛋白质的水平还包括向样品中加入标记的或未标记的apoc1蛋白质或蛋白质片段标准品和/或标记的或未标记的apoc2蛋白质或蛋白质片段标准品,以及检测所述apoc1标准品和/或apoc2标准品。在另外的实施方案中,apoc1标准品包含seqidno:7或seqidno:8中所示的氨基酸序列或由其组成,并且其中apoc2标准品包含seqidno:9或seqidno:10中所示的氨基酸序列或由其组成。在其他实施方案中,所述至少一种hdl相关蛋白质还包括载脂蛋白c1(apoc1)和选自由以下项组成的组的至少一种另外的蛋白质:apom、apoa1、apoc2、apoc4、clu、saa4、apol1、hp、c3和pltp。在其他实施方案中,检测至少一种hdl相关蛋白质的水平包括进行测定,所述测定检测:i)apoc3或apoc3的片段,ii)saa1/2或saa1/2的片段,iii)apoc1或apoc1的片段,和iv)至少一种另外的蛋白质或其片段。在其他实施方案中,检测至少一种hdl相关蛋白质的水平还包括加入标记的或未标记的apoc1蛋白质或蛋白质片段标准品和/或标记的或未标记的另外的蛋白质或蛋白质片段标准品,以及检测所述apoc1标准品和/或所述另外的蛋白质标准品。在其他实施方案中,apoc1标准品包含seqidno:7或seqidno:8中所示的氨基酸序列或由其组成,并且其中所述另外的蛋白标准品包含seqidno:23、seqidno:24、seqidno:9、seqidno:10、seqidno:20、seqidno:31、seqidno:32、seqidno:18、seqidno:19、seqidno:1、seqidno:2、seqidno:12、seqidno:36、seqidno:37、seqidno:27、seqidno:28、seqidno:25或seqidno:26中所示的氨基酸序列或由其组成。
在其他实施方案中,本文提供了方法,其包括:在来自受试者的样品中检测生物标记物组1-30中的至少一组中的每种hdl相关蛋白质的水平,其中所述生物标记物组1-26显示在表2中,并且其中生物标记物组27-30显示在表54中。在某些实施方案中,受试者是人(例如,人类男性或人类女性)。在某些实施方案中,所述人已被诊断为患有心血管疾病。
在一些实施方案中,本文提供了系统和组合物,所述系统和组合物包含:a)来自患有或怀疑患有心血管疾病的受试者的样品;和b)第一组分,其中所述第一组分包含:i)载脂蛋白c3(apoc3)结合剂,和/或ii)apoc3质谱标准品。
在某些实施方案中,所述系统和组合物还包含:c)第二组分,其包含含有可检测标记的hdl蛋白质的组合物,所述可检测标记的hdl蛋白质可用作校准物以将样品中的信号归一化至样品中存在的总hdl颗粒、apoa1或hdl-胆固醇的近似水平。在其他实施方案中,可检测标记的hdl蛋白质包括标记的apoa1(例如,同位素标记的)蛋白质或其片段。在某些实施方案中,所述样品选自由以下项组成的组:血清样品、血浆样品、血液样品和纯化的高密度脂蛋白(hdl)样品。在特定实施方案中,apoc3结合剂包括抗apoc3抗体或其结合部分,或抗apoc3核酸或蛋白质适体或其结合部分。在某些实施方案中,apoc3质谱标准品包括同位素标记的或未标记的apoc3蛋白质或蛋白质片段。在其他实施方案中,蛋白质片段包含seqidno:11中所示的氨基酸序列或由其组成。
在其他实施方案中,所述系统或组合物还包含:c)第二组分,其包含:i)血清淀粉样蛋白a1/2(saa1/2)结合剂,和/或ii)saa1/2质谱标准品。在特定实施方案中,saa1/2结合剂包括抗saa1/2抗体或其结合部分,或抗saa1/2核酸或蛋白质适体或其结合部分。在一些实施方案中,saa1/2质谱标准品包括标记的(例如,同位素标记的)或未标记的saa1/2蛋白质或蛋白质片段。在其他实施方案中,蛋白质片段包含seqidno:35中所示的氨基酸序列或由其组成。
在另外的实施方案中,所述系统或组合物还包含:d)第三组分,其包含:i)载脂蛋白a1(apoa1)结合剂,和/或ii)apoa1质谱标准品。在其他实施方案中,apoa1结合剂包括抗apoa1抗体或其结合部分,或抗apoa1核酸或蛋白质适体或其结合部分。在其他实施方案中,apoa1质谱标准品包括同位素标记的或未标记的apoa1蛋白质或蛋白质片段。在某些实施方案中,所述蛋白质片段包含seqidno:1或seqidno:2中所示的氨基酸序列或由其组成。
在另外的实施方案中,所述系统或组合物还包含:d)第三组分,其包含:i)载脂蛋白l1(apol1)结合剂,和/或ii)apol1质谱标准品;和e)第四组分,其包含:i)磷脂转移蛋白(pltp)结合剂,和/或ii)pltp质谱标准品。在其他实施方案中,apol1结合剂包括抗apoa1抗体或其结合部分,或抗apol1核酸或蛋白质适体或其结合部分,并且pltp结合剂包括抗pltp抗体或其结合部分,或抗pltp核酸或蛋白质适体或其结合部分。在某些实施方案中,apol1质谱标准品包括同位素标记的或未标记的apol1蛋白质或蛋白质片段,和/或pltp质谱标准品包括同位素标记的或未标记的pltp蛋白质或蛋白质片段。在其他实施方案中,apol1蛋白片段包含seqidno:18或seqidno:19中所示的氨基酸序列或由其组成,和/或pltp蛋白片段包含seqidno:31或seqidno:32中所示的氨基酸序列或由其组成。
在一些实施方案中,系统或组合物还包含第五组分,其包含:i)载脂蛋白e(apoe)结合剂,和/或ii)apoe质谱标准品。在其他实施方案中,apoe结合剂包括抗apoe抗体或其结合部分,或抗apoe核酸或蛋白质适体或其结合部分。在另外的实施方案中,apoe质谱标准品包括同位素标记的或未标记的apoe蛋白质或蛋白质片段。在其他实施方案中,apoe蛋白片段包含seqidno:15或seqidno:16中所示的氨基酸序列或由其组成。
在某些实施方案中,所述系统和组合物还包含:第六组分,其包含:i)载脂蛋白a1(apoa1)结合剂,和/或ii)apoa1质谱标准品。在其他实施方案中,所述系统还包含:d)第三组分,其包含:i)载脂蛋白m(apom)结合剂,和/或ii)apom质谱标准品;和e)第四组分,其包含:i)磷脂转移蛋白(pltp)结合剂,和/或ii)pltp质谱标准品。在某些实施方案中,apom结合剂包括抗apom抗体或其结合部分,或抗apom核酸或蛋白质适体或其结合部分。在特定实施方案中,apom质谱标准品包括同位素标记的或未标记的apom蛋白质或蛋白质片段。在其他实施方案中,apom蛋白片段包含seqidno:20中所示的氨基酸序列或由其组成。
在另外的实施方案中,所述系统和组合物还包含:d)第三组分,其包含:i)载脂蛋白c1(apoc1)结合剂,和/或ii)apoc1质谱标准品。在另外的实施方案中,apoc1结合剂包括抗apoc1抗体或其结合部分,或抗apoc1核酸或蛋白质适体或其结合部分。在其他实施方案中,apoc1质谱标准品包括标记的(例如,同位素标记的)或未标记的apoc1蛋白质或蛋白质片段。在某些实施方案中,apoc1蛋白片段包含seqidno:7或seqidno:8中所示的氨基酸序列或由其组成。
在其他实施方案中,所述系统和组合物还包含:d)第三组分,其包含:i)载脂蛋白d(apod)结合剂,和/或ii)apod质谱标准品。在一些实施方案中,apod结合剂包括抗apod抗体或其结合部分,或抗apod核酸或蛋白质适体或其结合部分。在其他实施方案中,apod质谱标准品包括标记的(例如,同位素标记的)或未标记的apod蛋白质或蛋白质片段。在其他实施方案中,apod蛋白片段包含seqidno:13或seqidno:14中所示的氨基酸序列或由其组成。
在某些实施方案中,所述系统组合物还包含:d)第四组分,其包含:i)另外的蛋白质结合剂,和/或ii)另外的蛋白质质谱标准品,其中所述另外的蛋白质选自由以下项组成的组:clu、apoe、cetp、pon1、apoc1、apoa2、apoc2、apom、pltp,以及apol1。在其他实施方案中,另外的蛋白质结合剂包括抗另外的蛋白质的抗体或其结合部分,或抗另外的蛋白质的核酸或蛋白质适体或其结合部分。在其他实施方案中,另外的蛋白质质谱标准品包括同位素标记的或未标记的另外的蛋白质或蛋白质片段。在其他实施方案中,另外的蛋白片段包含seqidno:23、seqidno:24、seqidno:15、seqidno:16、seqidno:21、seqidno:22、seqidno:33、seqidno:34、seqidno:7、seqidno:8、seqidno:3、seqidno:4、seqidno:9、seqidno:10、seqidno:20、seqidno:31、seqidno:32、seqidno:18和seqidno:19中所示的氨基酸序列或由其组成。
在一些实施方案中,所述系统和组合物还包含:c)第二组分,其包含:i)apoc1结合剂,和/或ii)apoc1质谱标准品,和d)第三组分,其包含:i)apoc2结合剂和/或ii)apoc2质谱标准品。在其他实施方案中,apoc1结合剂包括抗apoc1抗体或其结合部分,或抗apoc1核酸或蛋白质适体或其结合部分;并且其中apoc2结合剂包括抗apoc2抗体或其结合部分,或抗apoc2核酸或蛋白质适体或其结合部分。在其他实施方案中,apoc1质谱标准品包括同位素标记的或未标记的apoc1蛋白质或蛋白质片段,并且其中apoc2质谱标准品包括同位素标记的或未标记的apoc2蛋白质或蛋白质片段。
在特定实施方案中,所述系统和组合物还包含:d)第三组分,其包含:i)载脂蛋白c1(apoc1)结合剂,和/或ii)apoc1质谱标准品,和e)第四组分,其包含:i)另外的蛋白质结合剂,和/或ii)另外的蛋白质质谱标准品,其中所述另外的蛋白质选自由以下项组成的组:apom、apoa1、apoc2、apoc4、clu、saa4、apol1、hp、c3和pltp。在其他实施方案中,apoc1结合剂包括抗apoc1抗体或其结合部分,或抗apoc1核酸或蛋白质适体或其结合部分,并且其中另外的蛋白质结合剂包含抗另外的蛋白质的抗体或其结合部分,或抗另外的蛋白质的核酸或蛋白质适体或其结合部分。在一些实施方案中,apoc1质谱标准品包括同位素标记的或未标记的apoc1蛋白质或蛋白质片段,并且其中另外的蛋白质质谱标准品包括同位素标记的或未标记的另外的蛋白质或蛋白质片段。在其他实施方案中,apoc1蛋白片段包含seqidno:7或seqidno:8中所示的氨基酸序列或由其组成,并且其中另外的蛋白片段包含seqidno:23、seqidno:24、seqidno:9、seqidno:10、seqidno:20、seqidno:31、seqidno:32、seqidno:18、seqidno:19、seqidno:1、seqidno:2、seqidno:12、seqidno:36、seqidno:37、seqidno:27、seqidno:28、seqidno:25或seqidno:26中所示的氨基酸序列或由其组成。在特定实施方案中,受试者为人。在某些实施方案中,所述人已被诊断为患有心血管疾病。
在一些实施方案中,本文提供了确定近似心血管疾病(例如,cad、动脉粥样硬化疾病等)风险和/或近似逆向胆固醇转运能力的方法,其包括:a)在来自受试者的样品中检测生物标记物组1-30中的至少一个组中的每种hdl相关蛋白质的水平,其中生物标记物组1-26显示在表2中,并且其中生物标记物组27-30显示在表54中;以及b)确定受试者的近似心血管疾病(cvd)风险和/或样品的近似胆固醇流出能力(cec)。
在一些实施方案中,所述样品选自由以下项组成的组:血清样品、血浆样品、血液样品和纯化的高密度脂蛋白(hdl)样品。在其他实施方案中,所述确定包括采用第一算法来产生心血管疾病(cvd)风险评分或胆固醇流出能力(cec)评分,其中所述第一算法执行包括以下项的运算:i)将每个hdl相关蛋白质水平乘以预定系数以产生经相乘的值,以及ii)将所述经相乘的值相加,加上组特异性常数值,从而产生cvd风险评分或cec评分。在其他实施方案中,所述方法还包括:c)生成提供cvd风险评分和/或cec评分的报告。在某些实施方案中,该报告还包含hdl相关蛋白质水平中的至少一种hdl相关蛋白质水平。在其他实施方案中,确定还包括采用第二算法来产生cvd概率,其中所述第二算法将cvd风险评分应用于以下公式:cvd概率=1/(1+exp(-风险评分))或类似的公式。在其他实施方案中,所述方法还包括:c)生成提供cvd(例如,cad)概率的报告。在其他实施方案中,所述报告还包含hdl相关蛋白质水平中的至少一项hdl相关蛋白质水平。
在某些实施方案中,所述生物标记物组选自由以下项组成的组:组1、组2、组3、组4、组5、组6、组7、组8、组9、组10、组11、组12、组13、组14、组15、组16、组17、组18、组19、组20、组21、组22、组23、组24、组25、组26、组27、组28、组29或组30。在一些实施方案中,所述生物标记物组是生物标记物组编号18,其由hdl相关蛋白质apoa1、apoc1、apoc2、apoc3和apoc4组成。在其他实施方案中,所述生物标记物组是生物标记物组编号19,其由hdl相关蛋白质apoa2、apoc1、apoc2、apoc3、apod和saa1/2组成。在其他实施方案中,所述生物标记物组是生物标记物组编号5,其由hdl相关蛋白质apoa1、apoc2和apoc3组成。在另外的实施方案中,所述生物标记物组是生物标记物组编号4,其由hdl相关蛋白apoc1、apoc3、clu、pltp和saa4组成。在其他实施方案中,所述生物标记物组是生物标记物组编号28,其由hdl相关蛋白apoa1、apoa2、apoc1、apoc2、apoc3、apoc4、apod、apoe、apol1、apom、c3、clu、hp、saa1/2和saa4组成。在其他实施方案中,所述生物标记物组是生物标记物组编号30,其由hdl相关蛋白apoa1、apoa2、apoc3、apoc4、apod、apoe、apol1、apom、c3、hp、pltp、pon1和saa1/2组成。在一些实施方案中,cvd是冠状动脉疾病(cad)。在其他实施方案中,cec是全局cec。在其他实施方案中,cec是abca1cec。
在一些实施方案中,在步骤a)之后但在步骤b)之前,所述方法还包括使至少一个生物标记物组中的每种hdl相关蛋白质的水平归一化的步骤,其中所述归一化是归一化至样品中的总hdl颗粒或apoa1或hdl-胆固醇的近似水平,以产生归一化的hdl蛋白质值。在另外的实施方案中,所述方法还包括:确定样品中总hdl颗粒或apoa1或hdl-胆固醇的近似水平。在其他实施方案中,确定样品中总hdl颗粒或apoa1或hdl-胆固醇的近似水平包括确定加入到样品中的内标物的水平,其中所述内标物包括标记的hdl蛋白质。
在一些实施方案中,检测至少一个生物标记物组中每种hdl相关蛋白质的水平包括对样品的至少一部分执行测定,所述测定检测生物标记物组中的每种hdl相关蛋白质或其片段。在特定实施方案中,该测定是质谱测定或免疫测定。在其他实施方案中,检测至少一个生物标记物组中的每种hdl相关蛋白质的水平还包括向样品中加入对应于至少一种检测到的hdl相关蛋白质的标记的或未标记的蛋白质片段标准品,以及检测所述标准品。在其他实施方案中,受试者为人。在其他实施方案中,所述人已被诊断为患有心血管疾病。
在其他实施方案中,本文提供了系统和组合物,其包含:a)来自患有或怀疑患有心血管疾病的受试者的样品;b)以下项中的至少一者:i)用于生物标记物组1-30中的至少一个生物标记物组中的每种hdl相关蛋白质的结合剂,其中生物标记物组1-26显示在表2中,并且其中生物标记物组27-30显示在表54中;和/或ii)用于生物标记物组1-30中的至少一个生物标记物组中的每种hdl相关蛋白质的质谱标准蛋白质。
在特定实施方案中,所述系统还包括:c)报告,其提供样品中至少一个生物标记物组的hdl相关蛋白质的原始或归一化水平。在其他实施方案中,所述系统还包括:c)报告,其基于样品中至少一个生物标记物组的hdl相关蛋白质的水平来提供受试者的cvd风险评分和/或胆固醇流出能力(cec)。在其他实施方案中,所述系统还包括:c)报告,其提供受试者的cvd概率风险。在特定实施方案中,受试者为人。
在一些实施方案中,本文提供了用于报告受试者的cvd风险评分或胆固醇流出能力评分的方法,其包括:a)获得生物标记物组1-30中的至少一个生物标记物组中的每种hdl相关蛋白质的受试者值,其中生物标记物组1-26显示在表2中,并且其中生物标记物组27-30显示在表54中,b)用处理系统处理所述受试者值,从而确定受试者的cvd风险评分和/或胆固醇流出能力评分,其中所述处理系统包括:i)计算机处理器,以及ii)包括一个或多个计算机程序和数据库的非暂时性计算机存储器,其中所述一个或多个计算机程序包括:生物标记物组模型算法,并且其中所述数据库包括:i)所述至少一个生物标记物组中的每种hdl相关蛋白质的预定系数,和ii)所述至少一个生物标记物组的组特异性常数值;其中所述一个或多个计算机程序与所述计算机处理器一起被配置为应用所述生物标记物组模型算法以:i)将所述至少一个生物标记物组中的每种hdl相关蛋白质的水平乘以相应的预定系数以产生经相乘的值,以及ii)将所述经相乘的值加总在一起,加上组特异性常数值,从而产生受试者的cvd风险评分或胆固醇流出能力(cec)评分。
在某些实施方案中,所述方法还包括:c)报告由处理系统确定的受试者的cvd风险评分和/或cec评分。在一些实施方案中,cvd风险评分用于确定受试者的cvd风险的概率。在其他实施方案中,方法还包括:d)执行以下动作中的一种或多种动作:i)基于cvd风险概率为高而对受试者进行冠状动脉导管插入术,ii)基于cvd风险概率为高或中等而用心血管疾病(cvd)治疗剂(例如,他汀类、ace抑制剂、醛固酮抑制剂、血管紧张素ii受体阻滞剂、β受体阻滞剂、钙通道阻滞剂、降胆固醇药物、地高辛、利尿剂、钾、镁、血管扩张剂或华法林)治疗受试者,iii)基于cvd风险概率为高或中等而为受试者开具cvd治疗剂的处方,iv)基于cvd风险概率为中等或高而对受试者进行至少一次附加的诊断测试,v)基于cvd风险概率为高而将受试者收住入院和/或指示受试者住院,vi)基于cvd风险概率为中等或高而用一种或多种非生物标记物组cvd风险测定来检测来自受试者的样品,vii)基于cvd风险概率为低而让受试者从医疗机构出院,以及viii)基于cvd风险概率为中等或高而对受试者进行应激试验。
在某些实施方案中,所述方法还包括:d)执行以下动作中的一种或多种动作:i)将受试者的cvd风险概率传达给用户,ii)显示受试者的cvd风险概率,iii)生成提供受试者的cvd风险概率的报告,以及iv)准备和/或传输提供受试者的cvd风险概率的报告。在其他实施方案中,获得受试者值包括从测试实验室、从受试者、从分析测试系统和/或从手持或床旁测试装置接收受试者值。在一些实施方案中,处理系统还包括分析测试系统和/或手持或床旁测试装置。
在特定实施方案中,获得受试者值包括电子地接收受试者值。在其他实施方案中,获得受试者值包括用检测测定来测试来自受试者的样品。在其他实施方案中,检测测定包括免疫测定或质谱测定。在另外的实施方案中,处理系统还包括图形用户界面,并且所述方法还包括经由图形用户界面输入受试者值。在某些实施方案中,图形用户界面是选自以下项的装置的一部分:台式计算机、笔记本计算机、平板计算机、智能电话和床旁分析装置。
在另外的实施方案中,处理系统还包括样品分析仪。在其他实施方案中,计算机存储器的至少一部分位于样品分析仪内。在其他实施方案中,处理系统还包括实验室接口系统(lim)。在其他实施方案中,计算机存储器的至少一部分是lim的一部分。
在一些实施方案中,处理系统还包括选自由以下项组成的组的处理装置:台式计算机、笔记本计算机、平板计算机、智能电话和床旁分析装置。在另外的实施方案中,计算机存储器的至少一部分位于处理装置内。
在其他实施方案中,一个或多个计算机程序还包括cvd概率算法,并且其中一个或多个计算机程序与计算机处理器一起还被配置为应用cvd概率算法以:iii)将cvd风险评分应用于以下公式:cvd概率=1/(1+exp(-cvd风险评分)。在特定实施方案中,cvd是冠状动脉疾病(cad)。在其他实施方案中,cec是全局cec。在一些实施方案中,cec是abca1cec。
在另外的实施方案中,每种hdl相关蛋白质的受试者值是经归一化的水平(例如,关于样品中的总hdl颗粒或apoa1或hdl-胆固醇或样品中的一些其他蛋白质(诸如hsa)的近似水平归一化的水平)。在其他实施方案中,所述至少一个生物标记物组是生物标记物组编号18,其由hdl相关蛋白质apoa1、apoc1、apoc2、apoc3和apoc4组成。在其他实施方案中,所述至少一个生物标记物组是生物标记物组编号19,其由hdl相关蛋白质apoa2、apoc1、apoc2、apoc3、apod和saa1/2组成。在另外的实施方案中,所述至少一个生物标记物组是生物标记物组编号5,其由hdl相关蛋白质apoa1、apoc2和apoc3组成。在其他实施方案中,所述至少一个生物标记物组是生物标记物组编号4,其由hdl相关蛋白质apoc1、apoc3、clu、pltp和saa4组成。在其他实施方案中,所述至少一个生物标记物组是生物标记物组编号28,其由hdl相关蛋白质apoa1、apoa2、apoc1、apoc2、apoc3、apoc4、apod、apoe、apol1、apom、c3、clu、hp、saa1/2和saa4组成。在其他实施方案中,所述至少一个生物标记物组是生物标记物组编号30,其由hdl相关蛋白apoa1、apoa2、apoc3、apoc4、apod、apoe、apol1、apom、c3、hp、pltp、pon1和saa1/2组成。在其他实施方案中,受试者为人。在其他实施方案中,所述人已被诊断为患有心血管疾病。
在其他实施方案中,本文提供了处理系统,其包括:a)计算机处理器,和b)包含一个或多个计算机程序和数据库的非暂时性计算机存储器,其中所述一个或多个计算机程序包括:生物标记物组模型算法,并且其中所述数据库包括:i)生物标记物组1-30中的至少一个生物标记物组中的每种hdl相关蛋白质的受试者值,其中生物标记物组1-26显示在表2中,并且其中生物标记物组27-30显示在表54中,ii)生物标记物组1-30中的至少一个生物标记物组中的每种hdl相关蛋白的组特异性预定系数,和iii)至少一个生物标记物组的组特异性常数值;其中所述一个或多个计算机程序与所述计算机处理器一起被配置为应用所述生物标记物组模型算法以:i)将每种hdl相关蛋白质的受试者值乘以相应的组特异性预定系数以产生经相乘的值,以及ii)将经相乘的值加总在一起,加上组特异性常数值,从而产生受试者的cvd风险评分或胆固醇流出能力(cec)评分。
在某些实施方案中,一个或多个计算机程序还包括cvd概率算法,并且其中一个或多个计算机程序与计算机处理器一起还被配置为应用cvd概率算法以:iii)将cvd风险评分应用于以下公式:cvd概率=1/(1+exp(-cvd风险评分)。在一些实施方案中,cvd是冠状动脉疾病(cad)。在其他实施方案中,cec是全局cec。在其他实施方案中,cec是abca1cec。
在某些实施方案中,每种hdl相关蛋白质的受试者值是关于样品中总hdl颗粒或apoa1或hdl-胆固醇的近似水平归一化的水平。在其他实施方案中,系统还包括:c)hdl相关蛋白质分析测试系统和/或手持或床旁hdl相关蛋白质床旁测试装置。在特定实施方案中,hdl相关蛋白质分析测试系统包括质谱仪或光学检测器。在其他实施方案中,所述系统还包括:c)图形用户界面,其用于将每种hdl相关蛋白质的受试者值输入计算机存储器。在其他实施方案中,图形用户界面是选自以下项的装置的一部分:台式计算机、笔记本计算机、平板计算机、智能电话和床旁分析装置。
在一些实施方案中,系统还包括样品分析仪,其中计算机存储器的至少部分位于样品分析仪内。在特定实施方案中,系统还包括实验室接口系统(lim)的至少部分。在其他实施方案中,计算机存储器的至少一部分是lim的一部分。在其他实施方案中,所述系统还包括:c)选自由以下项组成的组的处理装置:台式计算机、笔记本计算机、平板计算机、智能电话和床旁分析装置。在其他实施方案中,计算机存储器的至少部分位于处理装置内。在另外的实施方案中,系统还包括显示部件,所述显示部件被配置为显示患者的cvd风险评分或cec评分。在其他实施方案中,显示部件选自计算机监视器、平板计算机屏幕、智能电话屏幕和床旁分析装置屏幕。
在一些实施方案中,所述至少一个生物标记物组是生物标记物组编号18,其由hdl相关蛋白质apoa1、apoc1、apoc2、apoc3和apoc4组成。在其他实施方案中,所述至少一个生物标记物组是生物标记物组编号19,其由hdl相关蛋白质apoa2、apoc1、apoc2、apoc3、apod和saa1/2组成。在其他实施方案中,所述至少一个生物标记物组是生物标记物组编号5,其由hdl相关蛋白质apoa1、apoc2和apoc3组成。在其他实施方案中,所述至少一个生物标记物组是生物标记物组编号4,其由hdl相关蛋白质apoc1、apoc3、clu、pltp和saa4组成。在一些实施方案中,所述至少一个生物标记物组是生物标记物组编号28,其由hdl相关蛋白质apoa1、apoa2、apoc1、apoc2、apoc3、apoc4、apod、apoe、apol1、apom、c3、clu、hp、saa1/2和saa4组成。在特定实施方案中,所述至少一个生物标记物组是生物标记物组编号30,其由hdl相关蛋白apoa1、apoa2、apoc3、apoc4、apod、apoe、apol1、apom、c3、hp、pltp、pon1和saa1/2组成。在其他实施方案中,受试者为人。在另外的实施方案中,所述人已被诊断为患有心血管疾病。
在一些实施方案中,本文提供了非暂时性计算机存储器部件,其包括:被配置为访问数据库的一个或多个计算机程序,其中所述一个或多个计算机程序包括:生物标记物组模型算法,并且其中所述数据库包括:i)生物标记物组1-30中的至少一个生物标记物组中的每种hdl相关蛋白质的受试者值,其中生物标记物组1-26显示在表2中,并且其中生物标记物组27-30显示在表54中,ii)生物标记物组1-30中的至少一个生物标记物组中的每种hdl相关蛋白的预定系数,和iii)至少一个生物标记物组的组特异性常数值;其中所述一个或多个计算机程序与所述计算机处理器一起被配置为应用所述生物标记物组模型算法以:i)将每种hdl相关蛋白质的受试者值乘以相应的预定系数以产生经相乘的值,以及ii)将经相乘的值加总在一起,加上组特异性常数值,从而产生受试者的cvd风险评分或胆固醇流出能力(cec)评分。
在其他实施方案中,使用选自由以下项组成的组的技术来执行hdl相关蛋白质的测定:质谱(ms)、色谱、lc-ms、等离子体共振,以及包括使用聚乙烯磺酸(pvs)和聚乙二醇-甲基醚(pegme)的测定。在某些实施方案中,通过将纯化的hdl样品注入到执行色谱法和质谱法的装置中来完成检测。在一些实施方案中,该装置是液相色谱-质谱(lc/ms)机器。
在某些实施方案中,hdl值是经归一化的值。在特定实施方案中,归一化是关于总hdl胆固醇或apoa1蛋白质或hdl颗粒的。总hdl的测定可以通过测量hdl胆固醇来执行,其通常使用“均相”测定法进行,所述“均相”测定法使用以特定顺序加入的选定试剂来“澄清”含有脂蛋白apob的ldl胆固醇颗粒的血清样品。随后,使用传统的酶偶联测定法来化学地确定hdl胆固醇。测量总hdl还可以利用用于hdl颗粒分离的物理方法来执行,所述物理方法通常是超速离心(例如,warnick等人,clinicalchemistry,2001年9月,第47卷,第91579-1596期,该文献以引用方式并入本文)。在一些实施方案中,可以将测量的hdl相关蛋白质的量与初始样品中天然apoa1的总量进行比较,以确定归一化的比率。apoa1是每种hdl颗粒的主要脂蛋白组分。虽然确定hdl胆固醇而不是apoa1已经成为心血管风险评定的主要支柱,但随着apoa1的测定在鉴定亚临床动脉粥样硬化中的使用,这种观点正在发生变化(florvall等人,journalofgerontology:biologicalsciences2006,第61a卷,第12期,1262-1266,该文献以引用方式并入本文)。通常使用广泛可用的免疫测定平台测定法来测量总apoa1。
在一些实施方案中,本文提供了方法,所述方法包括:检测来自受试者的样品中至少三种(或至少两种)hdl相关蛋白质(例如,选自表2和表54中列出的那些hdl相关蛋白质)的水平,并且其中所述受试者患有或怀疑患有心血管疾病。在特定实施方案中,样品是纯化的高密度脂蛋白样品。
在某些实施方案中,本文提供了确定近似心血管疾病风险和/或近似逆向胆固醇转运能力的方法,其包括:a)检测来自受试者的样品中至少三种(或至少两种)hdl相关蛋白质(例如,选自表2和表54中列出的那些hdl相关蛋白质)的水平;以及b)确定受试者的近似心血管疾病(cvd)风险和/或样品的近似胆固醇流出能力(cec)。
在一些实施方案中,本文提供了系统,其包含:a)来自患有或怀疑患有心血管疾病的受试者的样品;b)下列项中的至少一种:i)用于至少三种(或至少两种)hdl相关蛋白质(例如,选自表2和表54中列出的那些hdl相关蛋白质)中的每一种hdl相关蛋白质的结合剂;和/或ii)用于所述至少三种(或至少两种)hdl相关蛋白质中的每一种hdl相关蛋白质的质谱标准蛋白。
在其他实施方案中,本文提供了用于报告受试者的cvd风险评分或胆固醇流出能力评分的方法,其包括:a)获得至少三种(或至少两种)hdl相关蛋白质(例如,选自表2和表54中列出的那些hdl相关蛋白质)中的每一种hdl相关蛋白质的受试者值,b)用处理系统处理所述受试者值,使得所述受试者的cvd风险评分和/或胆固醇流出能力评分被确定,其中所述处理系统包括:i)计算机处理器,和ii)包括一个或多个计算机程序和数据库的非暂时性计算机存储器,其中所述一个或多个计算机程序包括:生物标记物算法,并且其中所述数据库包括:i)所述至少三种(或至少两种)hdl相关蛋白质中的每一种hdl相关蛋白质的预定系数,和ii)所述至少三种(或至少两种)hdl相关蛋白质的组合的组特异性常数值;其中所述一个或多个计算机程序与所述计算机处理器一起被配置为应用所述生物标记物算法以:i)将所述至少三种(或至少两种)hdl相关蛋白质中的每一种hdl相关蛋白质的水平乘以相应的预定系数以产生经相乘的值,以及ii)将所述经相乘的值加总在一起,加上所述组特异性常数值,从而产生所述受试者的cvd风险评分或胆固醇流出能力(cec)评分。
在一些实施方案中,本文提供了处理系统,其包括:a)计算机处理器,和b)包含一个或多个计算机程序和数据库的非暂时性计算机存储器,其中所述一个或多个计算机程序包括:生物标记物算法,并且其中所述数据库包括:i)至少三种(或至少两种)hdl相关蛋白质(例如,选自表2和表54中列出的那些hdl相关蛋白质)中的每一种hdl相关蛋白质的受试者值,ii)所述至少三种(或至少两种)hdl相关蛋白质中的每一种hdl相关蛋白质的组特异性预定系数,和iii)所述至少三种hdl相关蛋白质的组合的组特异性常数值;其中所述一个或多个计算机程序与所述计算机处理器一起被配置为应用所述生物标记物算法以:i)将所述至少三种(或至少两种)hdl相关蛋白质中的每一种hdl相关蛋白质的受试者值乘以相应的组特异性预定系数以产生经相乘的值,以及ii)将所述经相乘的值加总在一起,加上所述组特异性常数值,从而产生所述受试者的cvd风险评分或胆固醇流出能力(cec)评分。
在特定实施例中,本文提供了非暂时性计算机存储器组件,包括:被配置为访问数据库的一个或多个计算机程序,其中所述一个或多个计算机程序包括:生物标记算法,并且其中所述数据库包括:i)主题值至少三种(或至少两种)hdl相关蛋白中的每一种(例如,选自表2和54中列出的那些),ii)每种hdl相关蛋白的预定系数,和iii)小组特异性的至少三种(至少两种)hdl相关蛋白的组合的恒定值;其中,所述一个或多个计算机程序与所述计算机处理器一起被配置为应用所述生物标记算法:i)将每个hdl相关蛋白的主题值乘以相应的预定系数以产生相乘的值,ii)将相乘的值加在一起,加上小组特定的常数值,从而产生受试者的cvd风险评分或胆固醇外流能力(cec)评分。
在某些实施方案中,本文所述的生物标记物组用于诊断hdl相关疾病的风险,所述hdl相关疾病选自:心血管疾病、非酒精性脂肪性肝炎(nash)、红斑狼疮、肠易激综合征(ibs)、慢性肾病(ckd)、类风湿关节炎(ra)和阿尔茨海默病。
附图说明
图1示出了示例性工作流程,所述工作流程对应于下面关于组1的实施例1中描述的步骤。
图2:apoa-i相关血清级分的分离-apoa-i缔合蛋白质分离的概述示意图,所述apoa-i缔合蛋白质分离是通过以下方式进行的:将血清与his6apoa-i一起孵育,以及使用固定化金属亲和层析(imac)来靶向his-标签。
图3:apoa-i相关蛋白质组和hdl蛋白质组的重叠-维恩图,示出了在hdl蛋白质组监测列表的背景下,通过apoa-i亲和纯化鉴定的蛋白质与通过梯度超速离心制备的hdl的重叠。
图4:与基于细胞的胆固醇流出量测定的关联-从camp刺激的j774巨噬细胞测量的胆固醇流出能力(cec)与(a)基于对apoa-i相关血清蛋白的靶向分析使用6蛋白质组预测的cec以及(b)apoa-i、(c)hdl和(d)hscrp的血清浓度的相关性。
图5:预测的cec与cad的反向关联-通过靶向hdl蛋白质组分析预测的cec分布。总对照和cad患者群体(具有和没有mace)的比较。
图6:在apoa-i相关蛋白质的靶向mrm测量中观察到的内源性apoa-i与通过在参考临床实验室中进行免疫比浊分析而测量的血清apoa-i水平的相关性。
图7:根据对30个样品(n=15个对照,n=15个cad)的靶向hdl蛋白质组分析而预测的cec与通过对camp刺激的j774巨噬细胞中的相同样品集进行基于细胞的测定而测量的细胞胆固醇流出量的比较。
图8示出了来自实施例4的结果,比较跨群组的预测胆固醇流出量值揭示了相对于对照群组,cad群组的总体胆固醇流出量较低。
图9示出了来自实施例4的结果,所述实施例4为应用结果优化模型来根据生物标记物评分量表将患者分层,所述生物标记物评分量表与诊断为cad的风险相关。
定义
如本文所用,“高密度脂蛋白”或“hdl”是两亲性蛋白质的循环、非共价装配物,其使得如胆固醇和甘油三酯之类的脂质能够在基于水的血流中运输。hdl由按质量计约50%的两亲性蛋白质组成,所述两亲性蛋白质稳定化脂质乳剂,所述脂质乳剂由嵌入有游离胆固醇(约4%)以及甘油三酯(约3%)和胆固醇酯(约12%)核心的磷脂单层(约25%)组成。hdl的亚型包括hdl2和hdl3。hdl2颗粒较大且含有较高含量的脂质,而hdl3颗粒较小且含有较少的脂质。其他亚型从最大颗粒到最小颗粒包括hdl2b、hdl2a、hdl3a、hdl3b和hdl3c。
如本文所用,“脂蛋白”是指这样类型的蛋白质,一种或多种脂质分子附着或能够附着至所述蛋白质。在一些情况下,脂蛋白可以是“脂质贫乏的脂蛋白”,其中结合有四个或更少的磷脂分子。如本文所用,脂蛋白包括没有附着脂质但可以在hdl颗粒(例如载脂蛋白)中交换的蛋白质。
如本文所用,短语“逆向胆固醇转运”是指多步骤过程,所述多步骤过程导致胆固醇从外周组织通过血浆净移动回到肝脏。
如本文所用,短语样品的“胆固醇流出能力(cec)”是指样品中的hdl通过从负载脂质的巨噬细胞接受胆固醇来促进逆向胆固醇转运的能力。测量cec的方法包括但不限于delallera-moya等人,arteriosclerthrombvascbiol.2010年4月;30(4):796-801;sankaranarayanan等人,jlipidres.2011年12月;52(12):2332-40;和khera等人,nejm,364;2,2011,所有这些文献都以引用方式全文并入本文,并且包括它们所公开的测定。abca1cec特别地指由abca1转运蛋白特异性驱动的逆向胆固醇转运,该逆向胆固醇转运可以通过例如以下方式来测量:减去经试剂处理的(例如,经camp处理的)和未经试剂处理的巨噬细胞之间的cec差异,在所述未经试剂处理的巨噬细胞中所述巨噬细胞已经修饰为使得在处理试剂存在下abca1表达直接增加。
如本文所用,“血液样品”是指全血样品或来源于全血样品的血浆级分或血清级分。在某些实施方案中,血液样品是指人血液样品,诸如全血或来源于全血的血浆级分或血清级分。在一些实施方案中,血液样品是指非人哺乳动物(“动物”)血液样品,诸如全血或来源于全血的血浆级分或血清级分。
如本文所用,术语“全血”是指尚未分级并且含有细胞组分和液体组分两者的血液样品。
如本文所用,“血浆”是指全血的流体非细胞组分。取决于所用的分离方法,血浆可以完全不含细胞组分,或者可以含有不同量的血小板和/或少量其他细胞组分。因为血浆包含诸如纤维蛋白原之类的各种凝血因子,所以术语“血浆”与如下所述的“血清”不同。
如本文所用,术语“血清”是指哺乳动物全血清,诸如人全血清、来源于试验动物的全血清、来源于宠物的全血清、来源于家畜的全血清等。此外,如本文所用,“血清”是指已从中去除了凝血因子(例如,纤维蛋白原)的血浆。
如本文所用,短语“纯化的高密度脂蛋白样品”是指血液样品(例如,血清、或血浆、或全血样品),所述血液样品已经纯化(例如,通过超速离心或下文所述的apoa1交换方法)以产生纯化的样品,其中所述纯化的样品中所有蛋白质的至少90%(例如,至少90%......94%......98%......99%......或至少99.90%)是hdl脂蛋白。在一些实施方案中,所述纯化的样品中所有蛋白质的少于10%(例如,少于10%......5%......1%......0.2%)是非hdl脂蛋白。在某些实施方案中,非hdl脂蛋白主要或完全是血清白蛋白。
如本文所用,术语“心血管疾病”(cvd)或“心血管病症”是用于对影响身体的心脏、心脏瓣膜和脉管系统(例如,静脉和动脉)的许多病症进行分类的术语,并且涵盖包括但不限于以下项的疾病和病症:动脉硬化、动脉粥样硬化、心肌梗塞、急性冠状动脉综合征、心绞痛、充血性心力衰竭、主动脉瘤、主动脉夹层、髂动脉瘤或股动脉瘤、肺栓塞、原发性高血压、心房颤动、中风、短暂性脑缺血发作、收缩功能障碍、舒张功能障碍、心肌炎、房性心动过速、心室颤动、心内膜炎、动脉病、血管炎、动脉粥样硬化斑块、易损斑块、急性冠状动脉综合征、急性缺血性发作、心源性猝死、外周血管疾病、冠状动脉疾病(cad)、外周动脉疾病(pad)和脑血管疾病。
如本文所用,短语“怀疑患有cvd”是指具有至少一种与cvd相关的体征或症状的患者,所述体征或症状为例如极度疲劳、持续的头晕或头重脚轻、快速心率(例如,休息状态下超过每分钟100次心跳)、新的不规则心跳、活动中的胸痛或不适在休息时消失、在正常活动和休息期间呼吸困难、呼吸道感染或咳嗽变得恶化、躁动或混乱、睡眠模式改变,以及食欲不振或恶心。
如本文所用,术语“动脉粥样硬化性心血管疾病”或“病症”是指心血管疾病的子集,所述子集包括动脉粥样硬化作为特定类型的心血管疾病的组分或前体,并且包括但不限于cad、pad、脑血管疾病。动脉粥样硬化是一种慢性炎症反应,其发生在动脉血管壁上。它涉及动脉粥样斑块的形成,所述动脉粥样斑块可导致动脉变窄(“狭窄”),并且最终可导致动脉开口的部分或完全闭合和/或斑块破裂。因此,动脉粥样硬化疾病或病症包括动脉粥样硬化斑块形成和破裂的后果,包括但不限于动脉狭窄或变窄、心力衰竭、包括主动脉瘤在内的动脉瘤形成、主动脉夹层,以及诸如心肌梗塞和中风之类的缺血事件。在某些实施方案中,本文公开的方法、组合物和系统用于至少部分地诊断动脉粥样硬化cvd。
术语“个体”、“宿主”、“受试者”和“患者”在本文中可互换使用,并且通常是指哺乳动物,包括但不限于灵长类动物,包括猿猴和人类、马科动物(例如,马)、犬科动物(例如,狗)、猫科动物、各种驯养家畜(例如,有蹄类动物,诸如猪(swine/pig)、山羊、绵羊等),以及家养宠物和饲养在动物园内的动物。在一些实施方案中,受试者具体地为人类受试者。
具体实施方式
本文提供了用于检测来自患有或怀疑患有心血管疾病(cvd)或其他hdl相关疾病的受试者的样品中的一种或多种hdl相关蛋白质(例如,apoc3;apoc3和apoa1;apoc3和saa1/2;或生物标记物组1-30中的蛋白质)的方法、系统和组合物。在某些实施方案中,此类方法、系统和组合物用于确定受试者的近似cvd(或其他疾病)风险,和/或样品的近似胆固醇流出能力(cec)。在特定实施方案中,所述系统和组合物由来自患有或怀疑患有cvd的受试者的样品和hdl相关结合剂或质谱标准品组成。
本文提供了用于基于测量下表2和54中所示的一个或多个组中的蛋白质水平来确定预测心血管疾病和/或胆固醇流出的方法、组合物和试剂盒。在本公开案的实施方案的开发过程中进行的工作发现,单个蛋白质水平(例如,apoc3,即组10)或蛋白质组合(例如,组1-9和组11-30)可用于cvd和胆固醇流出量的潜在确定。下面描述的是使用生物标记物组对来自患有或怀疑患有心血管疾病的受试者的样品所采用的示例性、非限制性方法和系统。
在一些实施方案中,最初,具有心血管疾病症状(例如,胸痛)的受试者将在医院、诊所或其他医疗机构抽血。处理该血液样品以产生血清样品。然后使用用于纯化样品中hdl的方法来处理血清样品,诸如通过超速离心或标记的hdl结合颗粒纯化。然后用酶(例如,诸如lys-c)处理该纯化的血清样品,所述酶消化纯化样品中存在的hdl相关蛋白质。然后对该经消化的样品进行一种或多种检测测定(例如,质谱、免疫测定、适体结合测定),以检测在生物标记物组1-30中的一个或多个生物标记物组中发现的hdl相关蛋白质的水平。
在一些实施方案中,如果采用质谱法,则检测方案可以如下。将一部分经消化的hdl纯化的样品稀释并加载到lc柱上,然后使用三重四极质谱仪(例如,以动态mrm模式操作)来检测肽。用预定的“转换物”靶向肽,从而构成完整肽质量的预定m/z值(在仪器的q1中过滤)、完整肽在仪器的q2中经受的碰撞能量、以及肽片段的片段(m/z)值(在q3中过滤)。将转换物选择为对于样品中靶向的肽是唯一的。每个肽监测两种转换物(用于后续定量的“定量物”和用于质量控制的“定性物”),并且每种蛋白质靶向至多两种肽。肽靶标及其转换物的详细列表显示在下文实施例1的表1中。
通过整合每种肽的“定量”转换物的色谱峰来获得肽信号强度。通过以下方式来确定蛋白质强度:将每种蛋白质靶向肽的定量物峰面积相加,以及将其归一化至一种或多种hdl相关蛋白质的强度。
然后用多变量算法处理所选生物标记物组的hdl相关蛋白质的水平,以确定胆固醇流出量或cvd风险评分。该算法包括特定于每个组(并且特定于cvd风险评分或全局流出量或abca1流出量)的常数(i),以及特定于蛋白质和组的系数(c),所述系数(c)与检测到的特异性蛋白质的水平相乘。算法如下:
cvd风险评分/预测的全局胆固醇流出量=c1*p1+c2*p2...cn*pn+i
其中流出量或cvd风险通过以下方式确定:将系数(c)的加和组合乘以给定蛋白质的蛋白质水平(p)(例如,归一化的峰面积),加上常数(i)。下面的实施例1提供了每个组的每种蛋白质的系数和常数,以用于质谱确定的蛋白质值和以类推为依据的蛋白质值。实施例1还提供了这些数字中每一数字的95%置信区间。例如,当计算cvd风险评分和/或胆固醇流出量值时,可以使用该区间内任何地方的值作为(c)或(p)的值。
使用上述算法和下面实施例1中的值确定的cvd风险评分可以使用以下公式转换为概率(cvd风险百分比):
概率=1/(1+exp(-风险评分))。
然后可以将该概率值乘以100以给出cvd风险百分比。医疗保健人员可以采用风险评分或cvd风险概率或百分比来帮助确定怀疑患有心脏病的患者的治疗,或者将患者排除出需要治疗或监测。例如,一般来说,cad风险百分比低于10%的患者通常被认为是低风险(例如,患者可能被认为不需要心脏病治疗或监测),cad风险百分比在10-20%之间的患者通常被认为是中等风险(例如,可以监测患者的其他心脏病体征),cad风险百分比超过20%的患者通常被认为是高风险(例如,可立即用治疗剂或外科手术进行治疗)。
在某些实施方案中,在纯化的高密度脂蛋白样品中检测被检测作为组1-30的组成部分的一种或多种蛋白质。纯化的hdl样品可以通过任何合适的方法产生,包括超速离心或hdl结合肽方法。
例如,对于超速离心,可以在18℃下采用对密度为1.006kg/l的血清的超速离心(105,000xg)18小时,以去除干扰低密度脂蛋白以及锰和肝素的沉淀的极低密度脂蛋白。将足量的氯化锰和肝素加入底部级分中以获得0.0456mol的mn2+和183upsku/l的肝素的终浓度,这会使非hdl-c脂蛋白沉淀。在4℃下以1500xg离心30分钟后,然后使用溴化钾将所得上清液调节至≥1.21kg/l的密度。然后将经密度调节的溶液第二次离心(~105,000xg)24小时。离心后,可以小心地去除最上层以得到富含hdl的级分。
在某些实施方案中,使用经亲和标记的hdl结合肽(例如,apoa1)来纯化hdl。此类纯化方法描述于2015年5月15日提交的美国申请序列号14/713,046中,该申请以引用方式全文并入本文,如同在本文中完全阐述一样。简而言之,将经亲和标记的hdl结合肽(例如,apoa1)引入样品中。hdl颗粒包含所述结合颗粒中的一些结合颗粒。然后使用亲和标签纯化此类hdl颗粒,从而产生纯化的hdl样品。
本发明不受用于检测来自受试者样品的hdl相关肽(例如,apoc3、saa1/2、apoe、apol1等)的方法的限制。
在某些实施方案中,用选自以下项的检测方法来检测hdl相关蛋白质:免疫测定、表面等离振子共振、体外测定、活性测定、共免疫沉淀测定、质谱、荧光能量转移(fret)、生物发光能量转移(bret)、干涉测量、生物层干涉测量(bli)、双极化干涉测量(“dpi”)、椭圆偏振测量,以及石英晶体微天平。
实施例
实施例1
该实施例描述了使用各种全局胆固醇流出量和冠状动脉疾病风险算法测试单种和多种hdl蛋白质的26个组预测全局胆固醇流出量和心血管疾病风险的能力。hdl蛋白通过质谱测量。
hdl纯化
使用以下方案来纯化hdl。将12μl人血清与25μl的0.5mg/ml15n标记的经his标记的载脂蛋白a-i在1x磷酸盐缓冲盐水(pbs)ph7.4中的溶液合并。将血清-apoa-i混合物在37℃孵育15分钟,在此期间将his标记的apoa-i掺入血清样品中的hdl颗粒中。然后通过以移液管尖端形式进行固定化金属亲和层析来从混合物中纯化hdl,所述移液管尖端形式适合于高通量自动化液体处理平台。简言之,将血清-apoa-i混合物稀释至200μl,加入164μl结合缓冲液(5mm咪唑、50mm磷酸钠、300mm氯化钠,ph8.0)。将亲和柱尖端用400μl结合缓冲液平衡。然后使用亲和柱以200μl/分钟的流速在柱床上抽吸和分配180μl的血清/apoa-i混合物6次。然后通过抽吸和分配200μl结合缓冲液来洗涤柱床一次,接着用200μl强洗涤缓冲液(10mm咪唑、50mm磷酸钠、300mm氯化钠,ph8.0)进行第二次洗涤。然后通过抽吸和分配90μl洗脱缓冲液(300mm咪唑、50mmtris-hcl、25%甲醇,ph9.0)来洗脱结合的hdl颗粒。
hdl消化
然后将5μl的100mm二硫苏糖醇和10μl的50ng/μl内切蛋白酶lys-c加入到洗脱的hdl中,并在37℃下孵育4小时。lys-c在hdl相关蛋白质的序列中的赖氨酸氨基酸残基的c-末端处切割hdl相关蛋白质,从而产生可预测的靶肽以供用于lc-ms分析和定量。
hdl蛋白质组靶肽的lc-ms分析
将25μl的经lys-c消化的hdl在含有25%甲醇的洗脱缓冲液中的溶液注入,并使用混合三通在线稀释5倍,然后直接加载到lc柱上。使用通入到混合三通的样品加载泵(具有0.1%甲酸水溶液,以150μl/分钟运行)和二元泵(具有99%流动相a(0.1%甲酸水溶液)、1%流动相b(0.1%甲酸的乙腈溶液),以600μl/分钟运行)来完成稀释和加载。加载后,将二元泵直接与柱一起转向,并且将肽跨从1%至65%流动相b的5分钟线性梯度以500μl/min洗脱。使用在动态mrm模式下运行的agilent6490三重四极质谱仪来检测肽。动态mrm允许在预定的保留时间窗内对肽靶标进行靶向检测和定量。用预定的“转换物”靶向肽,从而构成完整肽质量的预定m/z值(在仪器的q1中过滤)、完整肽在仪器的q2中经受的碰撞能量、以及肽片段的片段(m/z)值(在q3中过滤)。将转换物选择为对于样品中靶向的肽是唯一的。每个肽监测两种转换物(用于后续定量的“定量物”和用于质量控制的“定性物”),并且每种蛋白质靶向至多两种肽。肽靶标及其转换物的详细列表显示在下表1中。应注意,除了所述肽序列之外,其他部分也可用于进行质谱测量。
表1
具有特征肽和转换的靶蛋白质列表
26个hdl蛋白质组
表2中显示了蛋白质组合的26个组,所述组提供了测量hdl全局胆固醇流出量的良好结果。
表2
肽和蛋白质的定量和归一化
通过整合每种肽的“定量”转换物的色谱峰来获得肽信号强度。通过以下方式来确定蛋白质强度:将每种蛋白质靶向肽的定量物峰面积相加,以及将其归一化至一种或多种hdl相关蛋白质的强度。
用于流出能力和cad风险的算法
基于来自所测量蛋白质的归一化强度开发了用于流出能力(基于发现群组和新鲜对比冷冻群组)和cad风险(总体cad风险,具有事件的cad的风险,以及不具有事件的cad的风险)的多变量算法,并且使用所述多变量算法来产生与来源血清样品的胆固醇流出能力或cad风险相关的值。模型1是关于研究样品的全局胆固醇流出量;模型2是关于新鲜对比冷冻样品的全局胆固醇流出量;模型3是总冠状动脉疾病(cad)风险;模型4是具有事件的cad风险;并且模型5是不具有事件的cad风险。这些模型的一般形式如下所示:
模型1和模型2-预测的全局胆固醇流出量=c1*p1+c2*p2...cn*pn+i
模型3-5-cad(具有/不具有事件)风险评分=c1*p1+c2*p2...cn*pn+i
其中流出量是通过以下方式确定的:将系数(c)的加和组合乘以多种蛋白质的经归一化的峰面积(p),加上常数(i)。
统计分析
使用r(“www.”后接“r-project.org”)和bioconductor(“www.”后接“bioconductor.org”)对每个组的数据执行统计分析。将数据归一化至15napoa1蛋白质的总强度。对于通过mrm测量的具有两种肽的蛋白质,基于在所分析的大多数样品中具有最高强度的肽来计算所述蛋白质的水平。使用稳健的线性回归,计算每种蛋白质与全局胆固醇流出量的相关性。将最小绝对收值缩和选择算子(lasso)应用于所有蛋白质,并选择系数不等于0的特征。将逐步稳健线性回归应用于在70个研究样品中测量的所选特征。为每个组选择具有最低akaike信息准则(aic)的模型。
确定蛋白质的绝对摩尔量
为了获得摩尔值,构建包含表1中每种肽的测量信号范围的5点外部校准曲线,并使用合成肽标准品通过lc-ms来监测所述曲线。将校准曲线线性拟合并加权1/x,其中x为肽浓度。然后使用计算的摩尔值来计算摩尔量系数。
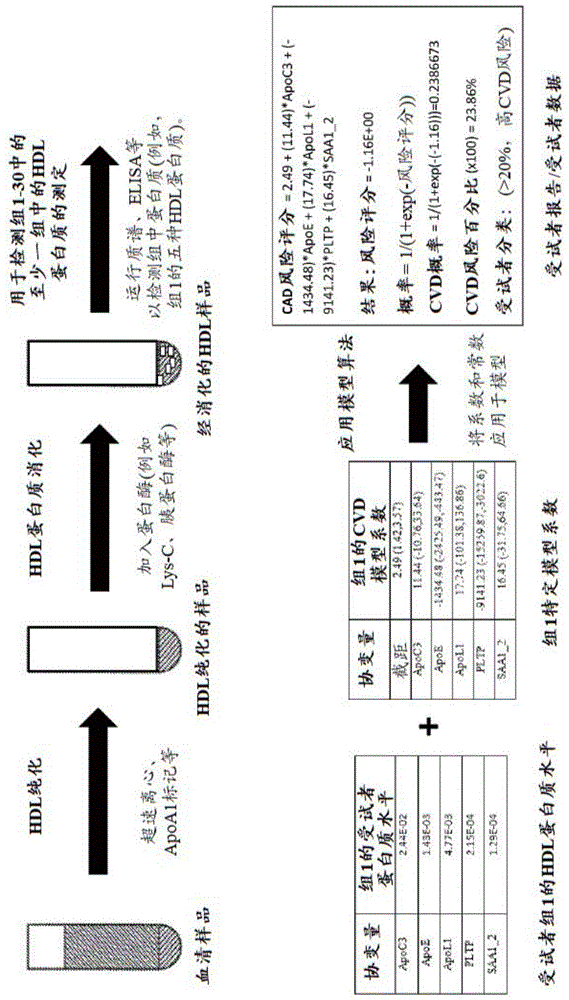
组1
将模型1和模型2开发用于预测组1的全局胆固醇流出量。这些模型如下所示:
模型1和模型2-预测的全局胆固醇流出量=(i)+(c1)*apoc3+(c2)*apoe+(c3)*apol1+(c4)*pltp+(c5)*saa1/2
模型1-5的值显示在下表3a中。例如,模型1将具有以下值:
模型1-预测的全局胆固醇流出量=9.25+(165.75)*apoc3+(-834.8)*apoe+(-144.26)*apol1+(-11548.33)*pltp+(-160.58)*saa1/2。
表3a
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.78。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)如上所示(表2),并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.52。例如,模型2将具有以下值:
模型2-预测的全局胆固醇流出量=5.27+(230.53)*apoc3+(4786.52)*apoe+(41.71)*apol1+(14368.89)*pltp+(-93.37)*saa1/2。
然后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者(模型3)拟合的模型的roc曲线下面积(auc)等于0.62。基于5倍交叉验证,与健康对照对比具有事件的cad患者(模型4)拟合的模型的roc曲线下面积(auc)等于0.64。基于5倍交叉验证,与健康对照对比不具有事件的cad患者(模型5)拟合的模型的roc曲线下面积(auc)等于0.66。三种模型的值如上表3a所示,并且等式如下所示。
cad(具有/不具有事件)风险评分=(i)+(c1)*apoc3+(c2)*apoe+(c3)*apol1+(c4)*pltp+(c5)*saa1/2
模型3-总cad风险评分=2.49+(11.44)*apoc3+(-1434.48)*apoe+(17.74)*apol1+(-9141.23)*pltp+(16.45)*saa1/2。
模型4-具有事件的cad的风险评分=2.42+(7.8)*apoc3+(-1597.95)*apoe+(-28)*apol1+(-9584.47)*pltp+(12.03)*saa1/2。
模型5-不具有事件的cad的风险评分=1.08+(13.1)*apoc3+(-1221.33)*apoe+(73.58)*apol1+(-8509.05)*pltp+(24.59)*saa1/2。
应注意,表3a中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
接下来,使用这些等式和值来计算三名患者(p1、p2和p3)的最终值。结果示出在下表3b中。
表3b
关于五个模型的三种样品的实例-等式结果
表3b中的风险评分结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。然后可以将该值乘以100以得出风险百分比。
例如,对于患者p1,表3a中的模型3的风险评分结果是-1.16。将其插入公式得出以下结果:1/(1+exp(-(-1.16)))=0.2386673。将结果乘以100给出患者p1的cad风险概率为23.8%。该相同的等式可以用于表3b中的所有模型和患者,以及下面针对该实施例以及进一步下面的实施例2中的其他组报告的结果。
医疗保健人员可以采用风险评分来帮助决定对怀疑患有心脏病的患者进行治疗,或者将患者排除出需要治疗或监测。例如,一般来说,cad风险百分比低于10%的患者通常被认为是低风险(例如,患者可能被认为不需要心脏病治疗或监测),cad风险百分比在10-20%之间的患者通常被认为是中等风险(例如,可以监测患者的其他心脏病体征),cad风险百分比超过20%的患者通常被认为是高风险(例如,可立即用治疗剂或外科手术进行治疗)。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表3c中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表3c
四个模型的系数(95%ci)(基于摩尔值)
应注意,表3c中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。例如,apoc3值,不是正好150.35,而是可以是109.91与190.8之间的任何值,并在所述模型中使用。
组2
将模型1-5开发用于预测组2的全局胆固醇流出量和cad风险。组2的模型1-5如下所示:
组2的模型1-5=(i)+(c1)*apoc2+((c2)*apoc3+((c3)*apoe+((c4)*apol1+((c5)*clu+((c6)*pltp
模型1-5的值显示在下表4中。
表4
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.77。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)的值显示在上表4中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.6。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.61。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.7。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.59。三种模型的值显示在表4中。应注意,表4中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名患者计算出的预测的胆固醇流出量和cad风险显示在下表5a中。
表5a
关于五个模型的三种样品的实例
表5a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表5b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表5b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表5b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组3
将模型1-5开发用于预测组3的全局胆固醇流出量和cad风险。组3的模型1-5如下所示:
组3的模型1-5=(i)+(c1)*apoc2+(c2)*apoc3+(c3)*apol1+(c4)*pltp
模型1-5的值显示在下表6中。
表6
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.73。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)显示在表6中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.5。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.61。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.68。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.61。三种cad模型显示在表6中。应注意,表6中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名患者计算出的预测的胆固醇流出量和cad风险显示在下表7a中。
表7a
关于五个模型的三种样品的实例
表7a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表7b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表7b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表7b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组4
将模型1-5开发用于预测组4的全局胆固醇流出量和cad风险。组4的模型1-5如下所示:
组4的模型1-5=(i)+(c1)*apoc1+(c2)*apoc3+(c3)*clu+(c4)*pltp+(c5)*saa4
模型1-5的值显示在下表8中:
表8
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.78。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型的值显示在上表8中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.68。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.72。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.8。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.66。三个模型的值显示在上表8中。应注意,表4中的值还包括95%置信度数字的区间。对于每个值,该区间的数字可以代入等式中。
基于五个模型和三名患者计算出的预测的胆固醇流出量和cad风险显示在表9a中。
表9a
关于五个模型的三种样品的实例
表9a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表9b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表9b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表9b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组5
将模型1-5开发用于预测组5的全局胆固醇流出量和cad风险。组5的模型1-5如下所示:
组5的模型1-5=(i)+(c1)*apoa1+(c2)*apoc1+(c3)*apoc3
模型1-5的值显示在下表10中。
表10
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.85。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)显示在上表10中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.53。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.75。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.81。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.68。三个cad模型的值显示在表10中。应注意,表10中的值还包括95%置信度数字的区间。对于每个值,该区间的数字可以代入等式中。
基于五个模型和三名患者计算出的预测的胆固醇流出量和cad风险显示在下表11a中。
表11a
关于五个模型的三种样品的实例
表11a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表11b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表11b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表11b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组6
将模型1-5开发用于预测组6的全局胆固醇流出量和cad风险。组6的模型1-5如下所示。
组6的模型1-5=(i)+(c1)*apoc3+(c2)*apol1+(c3)*pltp+(c4)*saa1/2
模型1-5的值显示在下表12中:
表12
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.74。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)显示在表12中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.49。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.6。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.63。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.64。三个cad风险模型(模型3-5)的值显示在表12中。应注意,表12中的值还包括95%置信度数字的区间。对于每个值,该区间的数字可以代入等式中。
基于五个模型和三名患者的预测的胆固醇流出量和cad风险显示在下表13a中。
表13a
关于五个模型的三种样品的实例
表13a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表13b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表13b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表13b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组7
将模型1-5开发用于预测组7的全局胆固醇流出量和cad风险。组7的模型1-5如下所示。
组7的模型1-5=(i)+(c1)*apoc1+(c2)*apoc3+(c3)*apom
模型1-5的值显示在下表14中。
表14
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.84。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)显示在表14中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.54。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.75。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.82。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.73。三个模型的值显示在上表14中。应注意,表14中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表15a中。
表15a
关于五个模型的三种样品的实例
表15a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表15b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表15b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表15b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组8
将模型1-5开发用于预测组8的全局胆固醇流出量和cad风险。组8的模型1-5如下所示。
组8的模型1-5=(i)+(c1)*apoc3+(c2)*saa1/2
模型1-5的值显示在下表16中。
表16
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.8。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用线性回归。模型(模型2)显示在表16中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.48。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.58。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.54。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.53。三个模型的值显示在上表16中。应注意,表16中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表17a中。
表17a
关于五个模型的三种样品的实例
表17a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表17b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表17b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表17b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组9
将模型1-5开发用于预测组9的全局胆固醇流出量和cad风险。组9的模型1-5如下所示。
组9的模型1-5=(i)+(c1)*apoc1+(c2)*apoc3
模型1-5的值显示在下表18中。
表18
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.85。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用线性回归。模型(模型2)显示在表18中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.54。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.7。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.77。与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.68。三个模型的值显示在上表18中。应注意,表18中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表19a中。
表19a
关于五个模型的三种样品的实例
表19a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表19b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表19b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表19b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组10
将模型1-5开发用于预测组10的全局胆固醇流出量和cad风险。组10的模型1-5如下所示。
组10的模型1-5=(i)+(c1)*apoc3
模型1-5的值显示在下表20中。
表20
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.8。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用线性回归。模型(模型2)显示在表20中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.48。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.56。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.58。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.49。三个模型的值显示在上表20中。应注意,表20中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表21a中。
表21a
关于五个模型的三种样品的实例
表21a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。可以将该概率乘以100以得到cad风险百分比。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表21b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表21b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表21b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组11
将模型1-5开发用于预测组11的全局胆固醇流出量和cad风险。组11的模型1-5如下所示。
组11的模型1-5=(i)+(c1)*apoc3+(c2)*apol1+(c3)*saa1/2
模型1-5的值显示在下表22中。
表22
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.8。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)显示在表22中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.48。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.54。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.53。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.48。三个模型的值显示在上表22中。应注意,表22中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表23a中。
表23a
关于五个模型的三种样品的实例
表23a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表23b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表23b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表23b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组12
将模型1-5开发用于预测组12的全局胆固醇流出量和cad风险。组12的模型1-5如下所示。
组12的模型1-5=(i)+(c1)*apoa1+(c2)*apoc1+(c3)*apoc3+(c4)*clu
模型1-5的值显示在下表24中。
表24
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.86。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)显示在表24中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.61。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.75。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.82。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.63。三个模型的值显示在上表24中。应注意,表24中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表25a中。
表25a
关于五个模型的三种样品的实例
表25a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表25b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表25b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表25b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组13
将模型1-5开发用于预测组13的全局胆固醇流出量和cad风险。组13的模型1-5如下所示。
组13的模型1-5=(i)+(c1)*apoc1+(c2)*apoc3+(c3)*apol1+(c4)*hp+(c5)*pltp
模型1-5的值显示在下表26中。
表26
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.74。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)显示在表26中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.54。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.7。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.79。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.68。三个模型的值显示在上表14中。应注意,表26中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表27a中。
表27a
关于五个模型的三种样品的实例
表27a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表27b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表27b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表27b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组14
将模型1-5开发用于预测组14的全局胆固醇流出量和cad风险。组14的模型1-5如下所示。
组14的模型1-5=(i)+(c1)*apoc3+(c2)*apod+(c3)*saa1/2
模型1-5的值显示在下表28中。
表28
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.8。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用线性回归。模型(模型2)显示在表28中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.48。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.68。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.71。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.65。三个模型的值显示在上表28中。应注意,表28中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表29a中。
表29a
关于五个模型的三种样品的实例
表29a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表29b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表29b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表29b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组15
将模型1-5开发用于预测组15的全局胆固醇流出量和cad风险。组15的模型1-5如下所示。
组15的模型1-5=(i)+(c1)*apoa2+(c2)*apoc2+(c3)*apoc3+(c4)*apod+(c5)*clu+(c6)*saa1/2
模型1-5的值显示在下表30中。
表30
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.73。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用部分线性回归。模型(模型2)显示在表20中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.57。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.61。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.7。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.6。三个模型的值显示在上表30中。应注意,表30中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表31a中。
表31a
关于五个模型的三种样品的实例
表31a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表31b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表31b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表31b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组16
将模型1-5开发用于预测组16的全局胆固醇流出量和cad风险。组16的模型1-5如下所示。
组16的模型1-5=(i)+(c1)*apoa2+(c2)*apoc2+(c3)*apoc3+(c4)*apod+(c5)*apom+(c6)*saa1/2
模型1-5的值显示在下表32中。
表32
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.65。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用部分线性回归。模型(模型2)显示在表32中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.51。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.65。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.74。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.65。三个cad模型的值显示在上表32中。应注意,表32中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表33a中。
表33a
关于五个模型的三种样品的实例
表33a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表33b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表33b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表33b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组17
将模型1-5开发用于预测组17的全局胆固醇流出量和cad风险。组17的模型1-5如下所示。
组17的模型1-5=(i)+(c1)*apoc1+(c2)*apoc2+(c3)*apoc3
模型1-5的值显示在下表34中。
表34
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.81。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用弹性网模型。模型(模型2)显示在上表34中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.53。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.74。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.78。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.72。三个模型的值显示在上表34中。应注意,表34中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表35a中。
表35a
关于五个模型的三种样品的实例
表35a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表35b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表35b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表35b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组18
将模型1-5开发用于预测组18的全局胆固醇流出量和cad风险。组18的模型1-5如下所示。
组18的模型1-5=(i)+(c1)*apoa1+(c2)*apoc1+(c3)*apoc2+(c4)*apoc3+(c5)*apoc4
模型1-5的值显示在下表36中。
表36
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.86。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用线性回归。模型(模型2)显示在表36中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.55。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.77。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.81。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.72。三个cad模型的值显示在上表36中。应注意,表36中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表37a中。
表37a
关于五个模型的三种样品的实例
表37a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表37b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表37b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表37b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组19
将模型1-5开发用于预测组19的全局胆固醇流出量和cad风险。组19的模型1-5如下所示。
组19的模型1-5=(i)+(c1)*apoa2+(c2)*apoc1+(c3)*apoc2+(c4)*apoc3+(c5)*apod+(c6)*saa1/2
模型1-5的值显示在下表38中。
表38
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.71。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用部分线性回归。模型(模型2)的值显示在表38中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.51。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.74。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.79。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.73。三个cad模型的值显示在上表38中。应注意,表38中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表39a中。
表39a
关于五个模型的三种样品的实例
表39a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表39b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表39b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表39b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组20
将模型1-5开发用于预测组20的全局胆固醇流出量和cad风险。组20的模型1-5如下所示。
组20的模型1-5=(i)+(c1)*apoa2+(c2)*apoc3+(c3)*apod+(c4)*apoe+(c5)*apol1+(c6)*pltp+(c7)*saa1/2
组20的模型1-5的值显示在下表40中。
表40
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.8。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用弹性网模型。模型(模型2)显示在上表40中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.52。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.64。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.68。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.66。三个cad模型的值显示在上表40中。应注意,表40中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算的预测的胆固醇流出量和cad风险显示在下表41中。
表41
关于五个模型的三种样品的实例
表41a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表41b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表41b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表41b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组21
将模型1-5开发用于预测组21的全局胆固醇流出量和cad风险。组21的模型1-5如下所示。
组21的模型1-5=(i)+(c1)*apoc3+(c2)*apom+(c3)*pltp+(c4)*saa1/2
组21的模型1-5的值显示在下表42中。
表42
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.76。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)如上表42所示,并且预测的胆固醇流出量与实验室测量的胆固醇流出量的相关性为0.5。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.65。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.71。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.68。三个cad模型的值显示在上表42中。应注意,表42中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表43a中。
表43a
关于五个模型的三种样品的实例
表43a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表43b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表43b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表43b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组22
将模型1-5开发用于预测组22的全局胆固醇流出量和cad风险。组22的模型1-5如下所示。
组22的模型1-5=(i)+(c1)*apoc3+(c2)*apod+(c3)*pltp+(c4)*saa1/2
模型1-5的值显示在下表44中。
表44
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.79。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)显示在上表44中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.5。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.65。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.71。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.66。三个cad模型的值显示在上表44中。应注意,表44中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表45a中。
表45a
关于五个模型的三种样品的实例
表45a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表45b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表45b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表45b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组23
将模型1-5开发用于预测组23的全局胆固醇流出量和cad风险。组23的模型1-5如下所示。
组23的模型1-5=(i)+(c1)*apoa2+(c2)*apoc3+(c3)*apod+(c4)*apol1+(c5)*apom+(c6)*pltp+(c7)*saa1/2
模型1-5的值显示在下表46中。
表46
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.79。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用弹性网模型。模型(模型2)如上表46所示,并且预测的胆固醇流出量与实验室测量的胆固醇流出量之间的相关性为0.5。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.65。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.7。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.67。三个cad模型的值显示在上表46中。应注意,表46中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表47a中。
表47a
关于五个模型的三种样品的实例
表47a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表47b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表47b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表47b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组24
将模型1-5开发用于预测组24的全局胆固醇流出量和cad风险。组24的模型1-5如下所示。
组24的模型1-5=(i)+(c1)*apoc1+(c2)*apoc3+(c3)*saa1/2
模型1-5的值显示在下表48中。
表48
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.85。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用线性回归。模型(模型2)显示在上表48中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.53。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.7。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.75。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.67。三个cad模型的值显示在上表48中。应注意,表48中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表49a中。
表49a
关于五个模型的三种样品的实例
表49a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表49b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表49b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表49b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组25
将模型1-5开发用于预测组25的全局胆固醇流出量和cad风险。组25的模型1-5如下所示:
组25的模型1-5=(i)+(c1)*apoc1+(c2)*apoc3+(c3)*c3+(c4)*pltp
模型1-5的值显示在下表50中。
表50
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.79。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用稳健线性回归。模型(模型2)显示在表50中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.56。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.74。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.8。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.7。三个cad模型的值显示在上表50中。应注意,表50中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表51a中。
表51a
关于五个模型的三种样品的实例
表51a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表51b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表51b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表51b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组26
将模型1-5开发用于预测组26的全局胆固醇流出量和cad风险。组26的模型1-5如下所示。
组26的模型1-5=(i)+(c1)*apoa2+(c2)*apoc2+(c3)*apoc3+(c4)*apod+(c5)*apoe+(c6)*apol1+(c7)*apom+(c8)*cetp+(c9)*clu+(c10)*pltp+(c11)*pon1+(c12)*saa1/2
模型1-5的值如下表52所示。
表52
五个模型的系数(95%ci)
接下来,在35个平行测定样品中测试该模型。预测的胆固醇流出量与实验室中测量的胆固醇流出量的相关性为0.78。然后,在由76个新鲜和冷冻样品(40个新鲜样品和36个冷冻样品)组成的另一样品群组中对该组中的蛋白质应用弹性网模型。模型(模型2)显示在上表52中,并且预测的胆固醇流出量与在实验室中测量的胆固醇流出量的相关性为0.62。
最后,在由74名健康对照和157名cad患者(83名具有事件,和74名不具有事件)组成的另一样品群组中对该组中的蛋白质应用逻辑回归。基于5倍交叉验证,与健康对照对比cad患者拟合的模型的roc曲线下面积(auc)等于0.63。基于5倍交叉验证,与健康对照对比具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.71。基于5倍交叉验证,与健康对照对比不具有事件的cad患者拟合的模型的roc曲线下面积(auc)等于0.6。三个cad模型的值显示在上表52中。应注意,表52中的值还包括95%置信度数字的区间。对于等式中的每个值,该区间的数字可以代入等式中。
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表53a中。
表53a
关于五个模型的三种样品的实例
表53a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表53b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表53b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表53b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
实施例2
该实施例描述了使用各种abca1胆固醇流出量和冠状动脉疾病风险算法测试单种和多种hdl蛋白质的5个组预测全局abca1胆固醇流出量(而不是全局胆固醇流出量)和心血管疾病风险的能力。对于上面讨论的五个组,如上文实施例1中那样测量相同的测定和样品。五个组是组27-30和组10,如下表54所示。
表54
组27
将模型1-5开发用于预测组27的abca1胆固醇流出量和cad风险。组27的模型1-5如下所示。
组27的模型1-5=预测的abca1胆固醇流出量=(i)+(c1)*apoc3+(c2)*apoe+(c3)*apol1+(c4)*hp+(c5)*pltp
模型1-5的值如下表55所示。
表55
五个模型的系数(95%ci)
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表56a中。
表56a
关于五个模型的三种样品的实例
表56a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上文实施例1中所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表56b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表56b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表56b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组28
将模型1-5开发用于预测组28的abca1胆固醇流出量和cad风险。组28的模型1-5如下所示。
组28的模型1-5-预测的abca1胆固醇流出量=(i)+(c1)*apoa1+(c2)*apoa2+(c3)*apoc1+(c4)*apoc2+(c5)*apoc3+(c6)*apoc4+(c7)*apod+(c8)*apoe+(c9)*apol1+(c10)*apom+(c11)*c3+(c12)*clu+(c13)*hp+(c14)*saa1/2+(c15)*saa4
模型1-5的值如下表57所示。
表57
五个模型的系数(95%ci)
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表58a中。
表58a(分为2部分)
关于五个模型的三种样品的实例
(续表)
表58a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上文实施例1中所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表58b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表58b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表58b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组29
将模型1-5开发用于预测组29的abca1胆固醇流出量和cad风险。组29的模型1-5如下所示。
组29的模型1-5-预测的abca1胆固醇流出量=(i)+(c1)*apoa1+(c2)*apoc3+(c3)*apod+(c4)*apoe+(c5)*apol1+(c6)*apom+(c7)*hp+(c8)*pltp+(c9)*pon1+(c10)*saa1/2
模型1-5的值如下表59所示。
表59
五个模型的系数(95%ci)
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表60a中。
表60a(分为2部分)
关于五个模型的三种样品的实例
(续表)
表60a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上文实施例1中所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表60b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表60b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表60b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组30
将模型1-5开发用于预测组30的abca1胆固醇流出量和cad风险。组30的模型1-5如下所示。
组30的模型1-5-预测的abca1胆固醇流出量=(i)+(c1)*apoa1+(c2)*apoa2+(c3)*apoc3+(c4)*apoc4+(c5)*apod+(c6)*apoe+(c7)*apol1+(c8)*apom+(c9)*c3+(c10)*hp+(c11)*pltp+(c12)*pon1+(c13)*saa1/2
模型1-5的值如下表61所示。
表61
五个模型的系数(95%ci)
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表62a中。
表62a(分为2部分)
关于五个模型的三种样品的实例
(续表)
表62a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上文实施例1中所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表62b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表62b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表62b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
组10
将模型1-5开发用于预测组10的abca1胆固醇流出量和cad风险。组10的模型1-5如下所示。
组10的模型1-5-预测abca1胆固醇流出量=(i)+(c1)*apoc3
模型1-5的值如下表63所示。
表63
五个模型的系数(95%ci)
基于五个模型和三名特定患者计算出的预测的胆固醇流出量和cad风险显示在下表64a中。
表64a
关于五个模型的三种样品的实例
表64a中的结果可用于基于以下公式产生cad概率:概率=1/(1+exp(-风险评分))。
如上文实施例1中所述,使用内标物的绝对量来确定每种蛋白质的绝对摩尔量。然后使用这些摩尔量来确定表64b中的模型1、3、4和5的系数。这些系数当为摩尔量形式时可以用于模型中,其中通过任何类型的检测测定(例如,elisa、质谱等)来确定蛋白质值。
表64b
四个模型的系数(95%ci)(基于摩尔值)
应注意,表64b中的值还包括95%置信度数字的区间。对于等式(模型)中的每个值,该区间的数字可以代入等式中。
实施例3
载脂蛋白a-i相关蛋白质组与胆固醇流出能力和冠状动脉疾病相关
本实施例在胆固醇流出上下文中探讨了apoa-i相关血清蛋白质组以及其与hdl功能的关系。此外,本研究旨在建立预测胆固醇流出能力(cec)的方法。对与his标记的重组apoa-i相关的血清蛋白质级分进行数据依赖性蛋白质组学分析,在此基础上开发针对与逆向胆固醇转运和/或冠状动脉疾病(cad)相关的21种蛋白质的靶向定量蛋白质组学方法。将这种靶向方法与基于细胞的cec测量值(n=105)进行比较从而推导出预测性蛋白质组学算法,将该算法在健康(n=74)和具有(n=83)和不具有(n=74)主要不良心血管事件的cad样本的病例/对照研究中进行评价。观察到apoa-i相关血清蛋白质组与在hdl中观察到的蛋白质之间存在显著的重叠。由apoa-ii、apoc-i、apoc-ii、apoc-iii、apod和血清淀粉样蛋白a组成的预测性蛋白质组学算法(组19)与基于细胞的cec测定结果强相关(r=0.77)。病例/对照群组中的蛋白质组预测的cec测量值证明cec诊断与cad诊断之间存在显著负相关(p=0.0032),其中在对照和不具有mace的cad样本之间观察到了显著较低的cec(p=0.04),其中在具有mace的cad样本中观察到了进一步降低的cec。
材料和方法:
所有研究方法均视情况经地方伦理审查委员会批准。除非另有说明,否则所有试剂均以最高可用质量从sigma-aldrich(st.louis,mo)或thermofisher购买。本研究中使用的样本从供应汇集的血清样品的goldenwestbiologicals获得。通过免疫亲和耗竭(immunoaffinitydepletion)制备的无脂蛋白血清购自genwaybio(sandiego,ca),另外,使用来自clevelandheartlab的其余样品。代表冠状动脉疾病病例和对照的临床样本从fairbanksinstituteforhealthycommunities获得。
富集apoa-i相关血清级分
将24μl0.5mg/ml重组表达且纯化的15n标记的his6标记载脂蛋白a-i(15n-his6apoa-i)(genscript,piscataway,nj)在1xpbs,ph7.4中的溶液加入到12μl人血清中。将15n-his6apoa-i/血清混合物在37℃下孵育30分钟。孵育后,将样品在5mm咪唑、20mm磷酸钠、150mm氯化钠,ph8.0中稀释至200μl的总体积,然后根据制造商的方案,使用配备有装有5μlni-ntahisbindsuperflow固定相的phytips(phynexus,sanjose,ca)的tecanfreedomevo自动化液体处理器(liquidhandler)(tecan,
通过纳米lc-ms进行数据依赖性蛋白质组学分析
除了500ng内切蛋白酶lysc(wakochemicalsusa,richmond,va)之外,还将二硫苏糖醇以5mm的最终浓度加入到富集的apoa-i相关血清级分中。将样品在eppendorfpcr热循环仪上于37℃消化4小时,然后保持在4℃以停止内切蛋白酶活性。使用watersnanoacquity超高压lc系统(waters,inc.,milford,ma)分离得到的肽混合物。在反相symmetryc18捕集柱(180μm内径×20mm,5μm颗粒)(waters,inc)上将含有500ng总肽材料的10μl体积注入,加以捕集,并用流动相a(0.1%甲酸、2%乙腈的水溶液)以10μl/min洗涤4分钟。然后在填充有1.7μmbeh130c18固定相的nanoacquity柱(75μm内径×250mm)上使用2%至50%的流动相b(0.1%甲酸、2%水的乙腈溶液)的梯度以300nl/min洗脱肽达210分钟,然后增加至100%流动相b洗脱达15分钟,然后在2%流动相b下再平衡15分钟。利用在轨道阱以120,000分辨率进行的m/z350-1800的前体离子扫描,接着利用使用碰撞诱导的解离在离子阱中得到的25个数据依赖性ms/ms事件,在ltq-orbitrapvelos质谱仪(thermofisherscientific,waltham,ma)上检测肽。将前体以2.5m/z的分离宽度分离,并用35%的归一化碰撞能量片段化20ms。启用单同位素前体选择,并且将带有1+和未分配的电荷态的前体从针对ms/ms的选择中排除。在正或负10ppm质量排斥窗口中利用前体的动态排除达60秒。将离子阱和轨道阱中的自动增益控制极限分别设置为1×104和1×106。处理raw格式的质谱仪数据文件,以便在maxquant(版本1.4.1.2)14中使用集成的andromeda搜索算法15进行蛋白质鉴定。除了常见的污染物数据库外,还对uniprot人类数据库(2013年10月14日从欧洲生物信息学研究所(europeanbioinformaticsinstitute)下载并且由88,304个条目组成)进行搜索。使用土7ppm前体质量公差和0.6da片段质量公差进行搜索。将lysc设定为切割酶,并且允许含有至少6个氨基酸和至多2个错误切割的肽用于分析。允许甲硫氨酸氧化作为可变修饰。将蛋白质和肽的错误发现率设定为1%。将蛋白质鉴定进一步精确为具有至少2种已鉴定的肽。
靶向的蛋白质组学分析
将还原剂(5μl的100mm二硫苏糖醇)和蛋白酶(10μl的50ng/μl内切蛋白酶lysc(wako))加入到85μl富集的apoa-i相关血清级分中,并在37℃下孵育4小时,此时将温度降至4℃。将5μl定义的13c6、15n2-赖氨酸标记的内标肽的混合物加入到75μl蛋白质消化物中,随后注入25μl用于液相色谱-多重反应监测质谱(lc-mrm)分析。将注入的样品加载到柱上并在柱上洗涤1.25分钟,然后用线性梯度的流动相b以500μl/min洗脱。使用在动态mrm模式下运行的agilent6490三重四极质谱仪检测肽,从而允许在预定的保留时间窗口内靶向检测肽靶标。对转换物进行选择、优化并确定所述转换物对于样品内被靶向的肽是唯一的。每种肽监测两种转换物,并且每种蛋白质监测至多两种肽。肽靶标及其转换物的详细列表在上表1中给出,并且组19的肽靶标及其转换物的详细列表在下表67中给出:
表67.用于cec预测的生物标记物组
经由使用masshunter定量分析软件(agilent)对定量转换物的色谱峰进行积分来获得肽信号强度。使用定性物的离子比和内标物的峰来手动检查所有峰。
通过超速离心来分离hdl
使用稍作修改的brewer方法16来分离来自汇集的血清的hdl(1.063g/ml<ρ<1.21g/ml)。
胆固醇流出能力的基于细胞评估
人血清样品是ldl耗竭的,vascularstrategies,inc.,(plymouthmeeting,pa)使用delallera-moya描述的方法17在外部执行基于细胞的测定以测量来自j774巨噬细胞的3h标记的胆固醇的流出量。所有测量值均以归一化的流出量值报告。
用于cec算法开发的样本
用于流出量相关模型开发的血清样品取自在chl处分两批、间隔6周收集的反鉴定的(de-identified)剩余样本,以分别提供训练集和测试集。ldl-c、hdl-c、apoa、apob、甘油三酯和高灵敏度c反应蛋白(hscrp)的定量分析用来指导用于每个集合的候选样品的选择,最终产生匹配良好的样本集(表65)。
表65.流出量相关样品群组的描述
针对105个样本以及作为质控物(qualitycontrolmaterial)的高度表征的血清汇集物收集定量apoa-i相关蛋白质组分析值和cec测量值。
用于临床验证的样本
样本选自fairbanksinstituteforhealthycommunitiesbiobank,所述样本由1500名年龄在22至87岁的男性和女性的血清样品组成;750名被记录为经由冠状动脉造影而诊断为cad(≥50%闭塞),并且750名对照受试者没有关于cad、阳性应激测试、糖尿病、高血压或异常脂质(ldl-c≥130mg/dl,hdl-c≤40mg/dl,总胆固醇≥240mg/dl或甘油三酯≥200mg/dl)的阳性发现。根据研究sop收集空腹血样并随后储存在-80℃。评价诊断为cad的受试者以建立两个组,即病例组和具有事件的病例组。针对有关主要不良心血管事件(mace),心肌梗塞(410)、冠状动脉分流术或血管成形术(36.1,45.82)或中风(434.91)的icd-9代码,对所有cad患者进行过滤。为了根据icd9筛查确认心肌梗塞,检查记录以选择具有以下三项中的两项的患者的病史:缺血性疼痛、ecg异常、肌钙蛋白异常。总共选择了74名不具有事件的cad受试者和83名具有mace事件的cad受试者(表66)。
表66.fairbanks研究群组的描述
还选择了一组74个匹配对照。
靶向算法开发
在计算分析之前,将每种靶肽的峰面积丰度以富集过程中使用的15n-his6apoa-i的强度作归一化。对于通过lc-ms/ms测量的具有两种或更多种肽的蛋白质,使用在所分析的大多数样品中具有最高强度的肽建立蛋白质的相对量。将蛋白质水平数据用于统计分析。将包括一系列连续的特征选择步骤的分析管线(pipeline)应用于归一化的蛋白质水平数据,以搜寻与cec相关的蛋白质18。对于单变量分析,将稳健的线性回归应用于每种蛋白质从而对70个训练样品预测cec,并选择p值<0.1的蛋白质。使用弹性网模型来进行进一步过滤。对于多变量分析,使用偏最小二乘回归在过滤的蛋白质上建立生物标志物组。为了评估生物标记物组的性能,计算预测的cec和测量的cec之间的斯皮尔曼相关性(spearmancorrelation)和中值绝对差(成本(cost))。最初,使用未校准的lc-ms峰强度来开发生物标记物组。随后改进蛋白质组学方法以提供经校准的绝对摩尔量,并且使用偏最小二乘回归在经校准的mrm数据上精修组系数。最后,使用35个验证样品来测试所述组。为了评估预测性cec生物标记物组是否可以区分具有和不具有cad的受试者,我们测试了74名健康对照和157名cad患者中的生物标记物蛋白质。使用r第3.2.3版(rcoreteam(2013).r:alanguageandenvironmentforstatisticalcomputing,rfoundationforstatisticalcomputing,vienna,austria)来执行数据统计分析。使用kolmogorov-smirnov(k-s)检验来执行对累积患者群组分布的比较。
结果:
快速apoa-i亲和汇集物制备
设计快速亲和富集策略,以以便于使用基于质谱的蛋白质组学来对无脂质apoa-i相关蛋白质进行精确、高通量分析。该策略使用his标记的apoa-i和固定化的金属亲和层析(图2)。将具有n-末端多组氨酸标签的重组无脂质apoa-i(his6apoa-i)加入人血清中并在37℃下孵育。然后使样品通过镍-nta固定相从而使his6apoa-i和相关蛋白质结合。在用低浓度的咪唑洗涤固定相以减少非特异性结合的蛋白质后,将复合的蛋白质和过量的his6apoa-i在期望的含有高浓度咪唑的回收缓冲液中洗脱。然后使洗脱的样品经受标准酶促消化工作流程,以供用于最终的液相色谱质谱(lc-ms/ms)分析。我们使用15n标记的his6apoa-i(15n-his6apoa-i)从而使得外源apoa-i的特异性测量值能够与属于待分析样本的内源蛋白质区分开。
无脂质apoa-i亲和汇集物的数据依赖性蛋白质组学分析
早期数据依赖性实验表明,在无脂质apoa-i亲和级分中鉴定的大多数蛋白质已知为hdl相关的。我们试图通过对使用传统超速离心而分离的hdl与使用商购可得的400名男性供体的血清汇集物而获得的apoa-i相关血清级分进行定性蛋白质组比较,来进一步阐明该观察结果。对每种富集技术执行三个过程平行测定。总体而言,在通过超速离心纯化的hdl中鉴定出了91种蛋白质,并且在无脂质apoa-i亲和汇集物中鉴定出了162种蛋白质,其中两种制备方法之间共享78种蛋白质(参见图3)。
我们将我们实验中鉴定的蛋白质与hdl蛋白质组监测列表进行了比较,所述hdl蛋白质组监测列表汇总了17项已公布的hdl蛋白质组研究的结果。该列表包括229种蛋白质,其中在3项或更多项研究中鉴定出或通过其他分子生物学技术验证出了95种蛋白质。在蛋白质组监测列表中的所有229种蛋白质中,80种是在通过超速离心制备的hdl中鉴定出的,并且86种是在我们的亲和纯化汇集物中鉴定出的,其中两种制备方法之间共享72种(不包括常见污染物,诸如角蛋白)(77%重叠)(图3)
通过多重反应监测质谱法进行靶向定量
为了探索apoa-i亲和汇集物与胆固醇流出能力(cec)之间的关系,我们试图使用基于液相色谱-多重反应监测(lc-mrm)的精确定量方法。基于文献检索和我们的数据依赖性lc-ms结果,将21种已知与脂质转运、逆向胆固醇转运和/或心血管疾病有关的蛋白质选择用于开发(脂质代谢(载脂蛋白a-i、a-ii、a-iv、c-i、c-ii、c-iii、c-iv、d、e、f、j、l-i、m)、酶(磷脂转移蛋白-pltp、胆固醇酯转移蛋白-cetp、卵磷脂胆固醇酰基转移酶-lcat、对氧磷酶1-pon1),以及急性期响应蛋白(补体c3、触珠蛋白、血清淀粉样蛋白a1和2-saa1/2,以及saa4))。鉴定出来自每种蛋白质的两种肽(如果可能的话)以供用于测定开发,并且优化整个工作流程。获得使所有蛋白质在4小时内都产生稳定肽丰度的消化条件。来自纯净血清的天然apoa-i的回收率据估计为约55%,并且与通过免疫测定法测定的血清中的apoa-i水平强相关(pearsonr=0.84,附图6)。相比之下,无脂质15n-his6apoa-i从pbs缓冲液中的平均回收率为85%,并且从抽提的血清中的平均回收率为72%。
用于cec预测的多元算法的开发与验证
通过使用无脂质apoa-i亲和富集技术,我们分析了一组血清样品,以探讨亲和富集的蛋白质与cec之间是否存在关系。不考虑任何疾病诊断地随机选择一组70个训练样品和35个独立测试样品(表65),但在脂蛋白测量值上进行仔细匹配。测定每个样本的归一化的cec和21种蛋白质的补体的归一化质谱数据。部署包括单变量和多变量统计方法的多步骤信息学管线来开发将相对蛋白质丰度与基于细胞的cec相关联的生物标记物组18。在单变量分析后,通过稳健线性回归鉴定出了p值<0.1的9种蛋白质(载脂蛋白a-i、a-ii、c-i、c-ii、c-iii、c-iv、d、cetp和saa)。随后的弹性网回归选择出了6种蛋白质(apoa-ii、apoc-i、apoc-ii、apoc-iii、apod和saa),对这6种蛋白质应用部分线性回归以建立最终预测模型。
鉴于在cec测量中所测量的不精确性,预测组表现良好(训练集的斯皮尔曼r=0.63,p<0.001;验证集的斯皮尔曼r=0.70,p<0.001)。蛋白质组预测的cec算法在整个开发样品集中的表现如图4a所示(pearsonr=0.77)。检查通过基于细胞的测定和蛋白质组学估计确定的cec与其他临床测量值(总胆固醇、hdl-c、ldl-c、非hdl-c、甘油三酯、apoa-i、apob和hscrp)之间的关联。与基于细胞的cec最显著的关联是apoa-i(pearsonr=0.57,图4b)和hdl-c(pearsonr=0.45,图4c),与先前的报告11,12一致。我们还观察到cec和hscrp之间的显著负相关(pearsonr=-0.23,图4d)。预测的cec在总胆固醇方面表现相似,但由于在蛋白质组的组中包含apoa-i,因此未计算与apoa-i和hdl-c的关系。
预测的cec与cad负相关
假设预测的cec应该与基于细胞的cec测量值所报告的心血管疾病具有相似的负相关,我们使用我们的多变量组来预测157名cad患者(74名无主要不良心血管事件(mace),83名具有mace)和74名年龄和性别明显匹配的健康对照的cec(表66)。
图5a中示出了所有这些群组中的预测的cec的分布。我们发现cad患者具有较低的预测cec中值(9.54%流出量/4小时;对照为9.98%流出量/4小时;p=0.0032)。当cad病例被分成不具有mace和特定不良事件的患者时,我们观察到相对于对照,不具有mace的cad患者具有显著较低的预测cec(p=0.04)。经历血运重建的cad患者(n=29)显示出比不具有mace的cad患者更低的预测cec(相对于对照,p=0.027,p=0.0003)。经历过心肌梗塞(n=38)或中风(n=16)的cad患者,虽然显示出较低的预测cec中值,但是与不具有mace的cad患者没有显著差异。6周后进行年龄和性别匹配的对照与cad样品的重复比较,并证实确认在初始分析中观察到的趋势。我们还在一小部分具有临床结果的样品中对预测的cec和基于细胞的cec测量值的表现进行了比较。在对照群组和cad群组中分别鉴定出15个最高和最低预测cec值后,获得了基于细胞的cec测量值。如附图7所示,cad样本子集具有显著较低的cec,如通过蛋白质组预测的cec测量值和基于细胞的cec测量值所确定的(p值<0.001)。另外,当在预测的测量值和基于细胞的测量值中比较相同的结果子集时,没有显著差异(对于对照为p=0.39,对于cad为p=0.08)。
经由基于细胞的测定法的cec测定在胆固醇代谢的问诊中无疑是非常有效的,并且越来越多的研究已证明基于血清的cec测量值是心血管风险的独立预测因子。不幸的是,劳动强度、工作流程复杂性和方法的相对不精确性损害了该技术向临床实验室的转化,在临床实验室中规模、产量(throughput)、精确度、校准以及最终的分析验证是必要的成就。
蛋白质组预测的cec表现
蛋白质组预测的cec在测试集中的表现(r=0.71)是令人鼓舞的,并且揭示了除apoa-i之外的蛋白质在调节胆固醇流出量中的关键作用。使用荧光标记的胆固醇来展开基于经修饰细胞的测定的cec最新临床研究发现了重要预测值,其中与使用预测放射性同位素测定法的归一化流出量的一致性(agreement)适中(r=0.54)的12。已经鉴定出与流出量相关的其他相关因素。正如预期的那样,在许多研究中已经报道了与apoa-i的单变量正相关(positiveunivariateassociation),范围是r=0.22至0.64(在本研究中r=0.57)11,19。在高hdl-c(>68mg/dl)样本中,鞘磷脂/磷酸乙醇胺比被证实与流出量显著相关(r=0.64),但在正常hdl-c水平下无相关性。还已知流出量依赖于hdl亚类,进一步揭示了一组复杂的结构和功能相互作用20。这些因素的多样性仍有待完全阐明,但提供了将另外的生化和生物物理数据整合到可以改善cec预测的模型中的机会。
对cec-预测性组蛋白质的机制见解
在我们的研究中得出的cec的蛋白质组预测因子由与胆固醇转运机械相关的蛋白质(载脂蛋白a-ii、c-i、c-ii、c-iii、d和saa;组19)组成。对于与流出量正相关的蛋白质,apoa-i和apoa-ii充当细胞胆固醇的主要受体1,21。apoc-i同样是一种次要但有效的胆固醇受体,并且还激活在hdl成熟中起作用的卵磷脂-胆固醇酰基转移酶lcat22。apoc-ii和apoc-iii调节参与hdl重塑的脂蛋白脂肪酶,并且apod在pre-β3-hdl的形成中发挥作用,pre-β3-hdl是hdl的一种有效的细胞胆固醇接受形式22,23。血清淀粉样蛋白a(saa)是一种急性期响应蛋白,并且已广泛表征为通过从hdl置换apoa-i而对胆固醇流出能力具有负面影响24,25。我们还注意到saa在调节流出量方面的功能作用反映为流出量与hscrp之间的负相关,-hscrp是另一种常见测量的全身炎症生物标记物(但在本研究中未被鉴定为apoa-i相关)。有趣的是,如由蛋白质组学分析所揭示的无脂质apoa-i与血清蛋白质之间的相互作用显示出与在蛋白质组监测列表中编目的典型hdl蛋白质组的高度重叠。
本实施例的参考文献:
1.kontusha,chapmanmj.high-densitylipoproteins:structure,metabolism,function,andtherapeutics.johnwiley&sons,inc;2012.
2.drewetal.,high-densitylipoproteinandapolipoproteinaiincreaseendothelialnosynthaseactivitybyproteinassociationandmultisitephosphorylation.procnatlacadsci.2004;101(18):6999-7004.
3.anselletal.inflammatory/antiinflammatorypropertiesofhigh-densitylipoproteindistinguishpatientsfromcontrolsubjectsbetterthanhigh-densitylipoproteincholesterollevelsandarefavorablyaffectedbysimvastatintreatment.circulation.2003;108(22):2751-2756.
4.gaidukovl,tawfikds.highaffinity,stability,andlactonaseactivityofserumparaoxonasepon1anchoredonhdlwithapoa-i.biochemistry.2005;44(35):11843-11854.
5.huangetal.myeloperoxidase,paraoxonase-l,andhdlformafunctionalternarycomplex.jclininvest.2013;123(9):3815-3828.
6.cavigiolioetal.,exchangeofapolipoproteina-ibetweenlipid-associatedandlipid-freestates:apotentialtargetforoxidativegenerationofdysfunctionalhighdensitylipoproteins.jbiolchem.2010;285(24):18847-18857.
7.fredolinietal.immunocapturestrategiesintranslationalproteomics.expertrevproteomics.2016;13(1):83-98.
8.gavinetal.functionalorganizationoftheyeastproteomebysystematicanalysisofproteincomplexes.nature.2002;415(6868):141-147.
9.gundryetal.,investigationofanalbumin-enrichedfractionofhumanserumanditsalbuminome.proteomics-clinappl.2007;1(1):73-88.
10.poulsenetal,serumamyloidpcomponent(sap)interactomeinhumanplasmacontainingphysiologicalcalciumlevels.biochemistry.2017;56(6):896-902.
11.khera,etal.cholesteroleffluxcapacity,high-densitylipoproteinfunction,andatherosclerosis.nengljmed.2011;364(2):127-135.
12.rohatgietal.hdlcholesteroleffluxcapacityandincidentcardiovascularevents.nengljmed.2014;317(25):2383-2393.
13.modyetal.,beyondcoronarycalcification,familyhistory,andc-reactiveprotein.jamcollcardiol.2016;67(21):2480-2487.
14.coxj,mannm.maxquantenableshighpeptideidentificationrates,individualizedp.p.b.-rangemassaccuraciesandproteome-wideproteinquantification.natbiotechnol.2008;26(12):1367-1372.
15.coxetal.,apeptidesearchengineintegratedintothemaxquantenvironment.jproteomeres.2011;10(4):1794-1805.
16.duvergeretal.,biochemicalcharacterizationofthethreemajorsubclassesoflipoproteina-ipreparativelyisolatedfromhumanplasma.biochemistry.1993;32(46):12372-12379.
17.delallera-moyaetal,theabilitytopromoteeffluxviaabca1determinesthecapacityofserumspecimenswithsimilarhigh-densitylipoproteincholesteroltoremovecholesterolfrommacrophages.arteriosclerthrombvascbiol.2010;30(4):796-801.
18.sinetal.,biomarkerdevelopmentforchronicobstructivepulmonarydisease.fromdiscoverytoclinicalimplementation.amjrespircritcaremed.2015;192(10):1162-1170.
19.saleheenetal.associationofhdlcholesteroleffluxcapacitywithincidentcoronaryheartdiseaseevents:aprospectivecase-controlstudy.lancetdiabetes&endocrinol.2015;3(7):507-513.
20.duetal.hdlparticlesizeisacriticaldeterminantofabca1-mediatedmacrophagecellularcholesterolexport.circres.2015;116(7):1133-1142.
21.rotllanetal.,overexpressionofhumanapolipoproteina-iiintransgenicmicedoesnotimpairmacrophage-specificreversecholesteroltransportinvivo.arteriosclerthrombvascbiol.2005;25(9).
22.voneckardsteina,noferj-r,assmanng.highdensitylipoproteinsandarteriosclerosis:roleofcholesteroleffluxandreversecholesteroltransport.arteriosclerthrombvascbiol.2001;21(1):13-27.
23.franconeol,fieldingcj.initialstepsinreversecholesteroltransport:theroleofshort-livedcholesterolacceptors.eurheartj.1990;11(supple).
24.vaisaretal.inflammatoryremodelingofthehdlproteomeimpairscholesteroleffluxcapacity.jlipidres.2015;56(8):1519-1530.
25.bankaetal.,serumamyloida(saa):influenceonhdl-mediatedcellularcholesterolefflux.jlipidres.1995;36(5):1058-1065.
实施例4
该实施例将组18(apoa1、apocl、apoc2、apoc3和apoc4)应用于fairbanksinstituteforhealthycommunitities的样品和abcodiabiobank的子集。
fairbanksinstituteforhealthycommunities(fairbanksinstitute)已经为假设驱动的研究创建了广泛注释的生物样本库。这些生物样品与来自全州电子临床数据库indiananetworkforpatientcare(inpc)的纵向临床和疾病特定健康记录信息相关联。所使用的fairbanksinstitute的cad集合包括来自诊断为冠状动脉疾病的个体以及匹配的对照的血清和血浆。使用该样品集,将基于通过质谱法测量的摩尔蛋白质量的胆固醇流出预测模型(表37b,模型1)应用于由健康患者(对照)(n=74)或已被诊断为冠状动脉疾病(cad)的患者(n=157)组成的样品集。比较这些群组的预测胆固醇流出量值显示,cad群组相对于对照群组的整体胆固醇流出量较低(mann-whitney检验的p=0.03),如图8所示。对组18的蛋白质组分执行逻辑回归以优化临床结果的分离(对照对比cad),得到表37中模型3的参数。当应用于fairbanks临床集时,我们观察到了改善的基于结果的患者群组分层。结果优化模型的应用根据生物标记物评分量表对患者进行分层,所述生物标记物评分量表与诊断为cad的风险相关,如图9所示。在此,cad群组显示出相对于对照组显著升高的生物标记物评分(mann-whitney检验的p<0.0001)。
我们还将来自组18的模型应用于abcodiabiobank的子集,该子集由200,000名50-74岁的绝经后妇女组成,这些妇女中的50,000名在几年的时间内纵向取样。在这项研究中,对照患者按照取样位置、年龄、及取样日期和时间来与鉴定为非致命性心肌梗塞的病例相匹配。模型1和模型3(表37b)均表现为,在事件发生之前0-8年范围内这些群组之间存在持久和统计学上显著的分离。
表68
本申请中提及的所有出版物和专利均以引用方式并入本文。在不脱离本发明的范围和精神的情况下,对本发明所述方法和组合物进行的各种修改和变化对本领域的技术人员来说是显而易见的。虽然已结合具体优选实施方案描述了本发明,但应理解的是,要求保护的本发明不应不适当地局限于所述具体实施方案。事实上,对于相关领域技术人员来说显而易见的用于进行本发明的描述的模式的各种修改旨在处于以下权利要求书的范围内。
序列表
<110>clevelandheartlab,inc.
<120>hdl相关蛋白质生物标记物组的检测
<130>chl-34474/wo-1/ord
<150>us62/365,175
<151>2016-07-21
<160>37
<170>patentin第3.5版
<210>1
<211>11
<212>prt
<213>智人
<400>1
alathrgluhisleuserthrleuserglulys
1510
<210>2
<211>14
<212>prt
<213>智人
<400>2
leuleuaspasntrpaspservalthrserthrpheserlys
1510
<210>3
<211>8
<212>prt
<213>智人
<400>3
gluglnleuthrproleuilelys
15
<210>4
<211>9
<212>prt
<213>智人
<400>4
serprogluleuglnalaglualalys
15
<210>5
<211>14
<212>prt
<213>智人
<400>5
leuvalprophealathrgluleuhisgluargleualalys
1510
<210>6
<211>9
<212>prt
<213>智人
<400>6
valasnserphepheserthrphelys
15
<210>7
<211>9
<212>prt
<213>智人
<400>7
alaarggluleuileserargilelys
15
<210>8
<211>7
<212>prt
<213>智人
<400>8
glnsergluleuseralalys
15
<210>9
<211>11
<212>prt
<213>智人
<400>9
gluserleusersertyrtrpgluseralalys
1510
<210>10
<211>9
<212>prt
<213>智人
<400>10
thrtyrleuproalavalaspglulys
15
<210>11
<211>7
<212>prt
<213>智人
<400>11
asptyrtrpserthrvallys
15
<210>12
<211>7
<212>prt
<213>智人
<400>12
alatrppheleugluserlys
15
<210>13
<211>11
<212>prt
<213>智人
<400>13
asnileleuthrserasnasnileaspvallys
1510
<210>14
<211>10
<212>prt
<213>智人
<400>14
tyrleuglyargtrptyrgluileglulys
1510
<210>15
<211>20
<212>prt
<213>智人
<400>15
leuglugluglnalaglnglnileargleuglnalaglualaphegln
151015
alaargleulys
20
<210>16
<211>20
<212>prt
<213>智人
<400>16
sergluleuglugluglnleuthrprovalalaglugluthrargala
151015
argleuserlys
20
<210>17
<211>11
<212>prt
<213>智人
<400>17
aspalaasnileserglnprogluthrthrlys
1510
<210>18
<211>9
<212>prt
<213>智人
<400>18
leuasnileleuasnasnasntyrlys
15
<210>19
<211>13
<212>prt
<213>智人
<400>19
trptrpthrglnalaglnalahisaspleuvalilelys
1510
<210>20
<211>20
<212>prt
<213>智人
<400>20
glupheprogluvalhisleuglyglntrptyrpheilealaglyala
151015
alaprothrlys
20
<210>21
<211>13
<212>prt
<213>智人
<400>21
leupheleuserleuleuasppheglnilethrprolys
1510
<210>22
<211>12
<212>prt
<213>智人
<400>22
proalaleuleuvalleuasnhisgluthralalys
1510
<210>23
<211>10
<212>prt
<213>智人
<400>23
gluileglnasnalavalasnglyvallys
1510
<210>24
<211>18
<212>prt
<213>智人
<400>24
leupheaspseraspproilethrvalthrvalprovalgluvalser
151015
arglys
<210>25
<211>14
<212>prt
<213>智人
<400>25
alapheseraspargasnthrleuileiletyrleuasplys
1510
<210>26
<211>9
<212>prt
<213>智人
<400>26
thrglyleuglngluvalgluvallys
15
<210>27
<211>12
<212>prt
<213>智人
<400>27
aspilealaprothrleuthrleutyrvalglylys
1510
<210>28
<211>10
<212>prt
<213>智人
<400>28
valthrserileglnasptrpvalglnlys
1510
<210>29
<211>19
<212>prt
<213>智人
<400>29
aspargpheileaspglypheileserleuglyalaproglnglygly
151015
serilelys
<210>30
<211>11
<212>prt
<213>智人
<400>30
thrtyrservalglutyrleuaspserserlys
1510
<210>31
<211>8
<212>prt
<213>智人
<400>31
glyleuarggluvalileglulys
15
<210>32
<211>22
<212>prt
<213>智人
<400>32
glngluglyleuargpheleugluglngluleugluthrilethrile
151015
proaspleuargglylys
20
<210>33
<211>9
<212>prt
<213>智人
<400>33
serpheasnproasnserproglylys
15
<210>34
<211>11
<212>prt
<213>智人
<400>34
tyrvaltyrilealagluleuleualahislys
1510
<210>35
<211>12
<212>prt
<213>智人
<400>35
tyrphehisalaargglyasntyraspalaalalys
1510
<210>36
<211>9
<212>prt
<213>智人
<400>36
alagluglutrpglyargserglylys
15
<210>37
<211>12
<212>prt
<213>智人
<400>37
aspproaspargpheargproaspglyleuprolys
1510
- 还没有人留言评论。精彩留言会获得点赞!