基于遗传算法的液压悬置参数辨识方法与流程
本发明涉及隔振装置参数辨识方法,具体涉及一种基于遗传算法的液压悬置参数辨识方法。
背景技术:
准确的液压悬置集总参数模型是进行液压悬置动特性性能预测、结构改进、动力学仿真的关键,而获得精确的液压悬置参数是液压悬置准确建模的基础。为此,有大量关于液压悬置参数辨识方法的研究。从已有的文献可知,液压悬置参数辨识方法主要有两大类,即试验法和流固耦合有限元法。试验法又可分为直接试验法和间接试验法。直接试验法是通过试验获取液压悬置的集总参数,这种方法在悬置开发前期未制作出样件时无法进行试验,且需要专门设计的工装设备和测量设备进行试验,成本高,周期长,但参数识别的精度高。而间接试验法是通过悬置动静特性试验,得到液压悬置的动特性曲线,根据该曲线的特征进行参数辨识。流固耦合有限元法参数辨识的精度直接依赖于液体、橡胶的材料特性的准确性,并且对有限元模型的精度要求较高,因此建模周期较长,人力成本较高,但是可以在开发前期预测液压悬置的参数。
间接试验法是液压悬置开发中后期进行参数辨识的主要手段,对间接试验法进行深入研究很有必要。特征点法和不动点法是目前最常用的两种液压悬置参数辨识的间接试验方法。特征点法是通过获取动刚度曲线上的高频稳定点动刚度、液柱共振段曲线斜率和滞后角曲线上的峰值点频率等特征点,从而对液压悬置进行参数识别。这种参数辨识方法只要进行一组固定振幅的动特性试验就可以进行参数辨识,因此,效率较高,但由于特征点的选取存在误差,且试验的频率步长精度为1Hz,频率取点误差较大,造成辨识精度较低。不动点法参数辨识通过多组不同位移幅值激励下的动特性试验,获得多组动特性曲线,通过确定这些曲线上固有的不动点进行参数辨识,这种参数辨识方法较特征点法参数辨识方法精度高,但试验次数多,导致成本高,且同样存在频率步长误差。
技术实现要素:
有鉴于此,本发明的目的是提供一种基于遗传算法的液压悬置参数辨识方法,使其具有辨识精度高、成本低、效率高及可操作性强的优点。
本发明通过以下技术手段解决上述问题:一种基于遗传算法的液压悬置参数辨识方法,包括以下步骤:
S1.进行液压悬置动静特性试验,获得液压悬置的动特性试验曲线,所述动特性指动刚度和滞后角;
S2.建立液压悬置的集总参数模型;
S3.确定所述集总参数模型中的橡胶主簧刚度Kr、上液室体积刚度K1、等效泵压面积Ap、惯性通道液感I和惯性通道液阻R的初始值,并将所述初始值作为遗传算法参数辨识的初始值;
S4.以液压悬置的动特性试验曲线与集总参数模型的动特性仿真曲线之间的误差数值的平方和作为遗传算法参数辨识的适应度函数;
S5.通过对所述适应度函数进行反复迭代以获得误差允许范围内的最优参数作为液压悬置参数辨识结果。
进一步地,所述Kr、K1、Ap、I和R的初始值经经验公式计算而得,其中,
上式中,η为橡胶主簧动静比,且η=1.2~1.6,△F为加载在橡胶主簧上的力,△x为加载在橡胶主簧上的力所产生的橡胶主簧位移;
上式中,ρ为液体密度,L为惯性通道长度,A为惯性通道截面积,μ为液体动力粘度,d为惯性通道水力直径;
上式中,D1、D2分别为橡胶主簧上、下锥台直径;
上式中,hr1为橡胶主簧等效厚度,Er1为橡胶主簧弹性模量,ν为橡胶主簧泊松比,rd为解耦膜半径,hrd为解耦膜厚度,Erd为解耦膜橡胶弹性模量。
进一步地,所述适应度函数的取值为:
上式中,θ为集总参数模型的参数,即Kr、K1、Ap、I和R,Kd、分别为试验动刚度和阻尼滞后角,分别为集总参数模型计算得到的仿真动刚度和阻尼滞后角,ω1、ω2为权重系数,ω1、ω2分别代表了动刚度和阻尼滞后角在参数辨识中的重要程度,且ω1+ω2=1,△(θ)为动特性试验曲线与集总参数模型的动特性仿真曲线之间的相对误差的平方和。
进一步地,所述的遗传算法参数辨识过程包括对初始值的编码、选择操作、交叉操作、变异操作和计算适应度值,已编码的参数集称为种群,所述种群的大小取值为30~100。
进一步地,所述编码的方法为浮点数编码法。
本发明的有益效果:
1)本发明的悬置参数辨识方法精度比特征点法高,成本比不动点法低。
2)本发明的悬置参数辨识方法具有较强的抗干扰能力,鲁棒性强,在试验数据存在一定误差时,仍可以获得相对准确的参数辨识结果。
附图说明
图1为本发明的一种双模式半自动液压悬置的集总参数模型;
图2为半主动液压悬置静特性试验回复力和位移曲线;
图3为上液室等效几何简图;
图4为本发明的参数辨识方法原理图;
图5为本发明的参数辨识方法流程图;
图6为遗传算法参数辨识适应度函数随着进化次数的变化曲线;
图7为遗传算法参数辨识的变量与变量值图;
图8为遗传算法参数辨识结果动刚度仿真曲线和动刚度试验曲线对比图;
图9为遗传算法参数辨识结果滞后角仿真曲线和滞后角试验曲线对比图。
具体实施方式
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
目前汽车工业动力总成半主动悬置产品大都以双模式结构参数调节式为主,因此本发明结合一种双模式半主动液压悬置的参数辨识过程来进行详细说明。
首先进行半主动液压悬置动静特性试验,获得该液压悬置的动特性试验值,根据试验值建立动特性试验曲线,其中动特性指动刚度和滞后角。
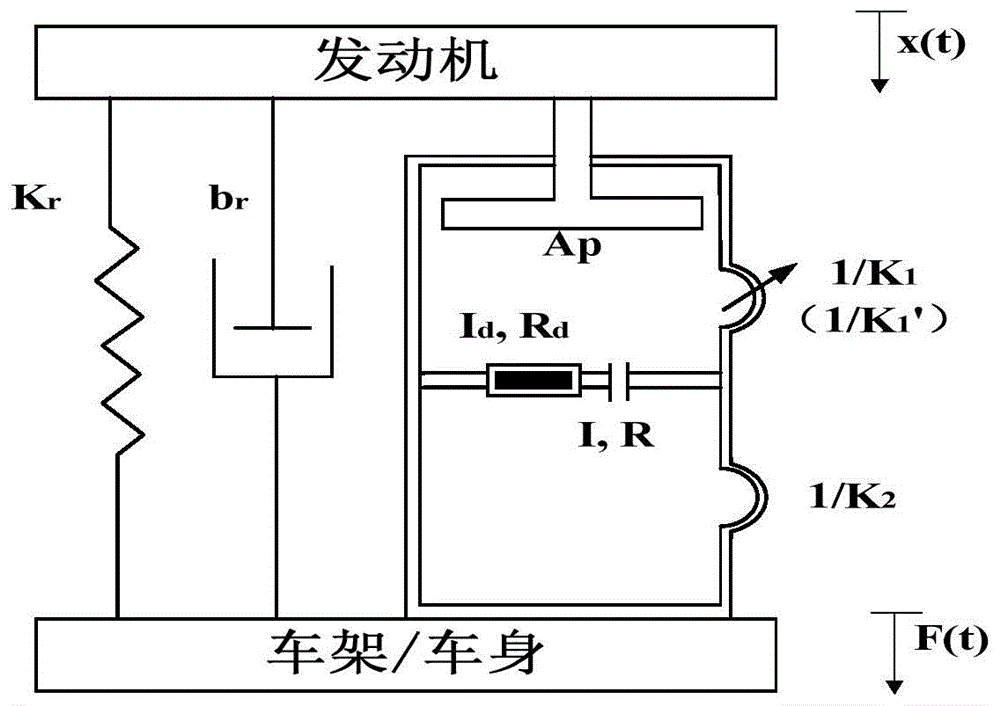
如图1所示,建立半自动液压悬置的集总参数模型(建立集总参数模型与进行半主动液压悬置动静特性试验并无先后顺序),该集总参数模型中的7个集总参数分别为橡胶主簧刚度Kr、橡胶主簧阻尼br、等效泵压面积Ap、上液室体积刚度K1、下液室体积刚度K2、惯性通道液感I和惯性通道液阻R,由于橡胶主簧阻尼br和下液室体积刚度K2对液压悬置动特性的影响较小,可忽略不计。因此半主动液压悬置参数辨识主要针对Kr、Ap、K1、I和R五个参数。
确定所述集总参数模型中的Kr、Ap、K1、I和R的初始值,并将所述初始值作为遗传算法参数辨识的初始值;由于遗传算法参数辨识对参数的初值要求高,参数初值的设定直接影响遗传算法参数辨识的准确性。因此为了获得较准确的初值,先采用经验公式对半主动液压悬置集总参数进行一次辨识。
橡胶主簧刚度Kr由半主动液压悬置静特性试验获得,如图2所示,在半主动液压悬置静特性试验回复力和位移曲线中,曲线斜率即为橡胶主簧刚度Kr,即
上式中,η为橡胶主簧动静比,且η=1.2~1.6,△F为加载在橡胶主簧上的力,△x为加载在橡胶主簧上的力所产生的橡胶主簧位移,
惯性通道液感I和惯性通道液阻R分别用以下公式计算:
上式中,ρ为液体密度,L为惯性通道长度,A为惯性通道截面积,μ为液体动力粘度,d为惯性通道水力直径;
橡胶主簧等效泵压面积Ap定义为橡胶主簧在单位位移内所压出的上液室液体体积量,如图3所示,根据上液室体积变形,由以下公式估算出等效泵压面积Ap:
上式中,D1、D2分别为橡胶主簧上、下锥台直径;
上液室体积刚度为:
上式中,hr1为橡胶主簧等效厚度,Er1为橡胶主簧弹性模量,ν为橡胶主簧泊松比,rd为解耦膜半径,hrd为解耦膜厚度,Erd为解耦膜橡胶弹性模量。
表1:半主动悬置集总参数一次辨识结果
基于遗传算法对半主动液压悬置集总参数进行二次辨识。
系统参数辨识通过确定系统数学模型的未知参数,使数学模型能够很好的模拟真实系统。对于半主动液压悬置而言,参数辨识就是通过确定半主动液压悬置集总参数模型中的关键参数,使集总参数模型的动特性仿真曲线与实际测试的动特性试验曲线取得一致。
遗传算法是一种随机优化与搜索算法,具有强大的并行搜索能力,应用于优化过程可得到较好的全局优化结果,且通过遗传算法可以很好的解决非线性函数的寻优问题。半主动液压悬置具有强非线性特征,采用遗传算法进行集总参数辨识,可以获得全局最优解。
遗传算法应用于半主动悬置参数辨识的基本原理如图4所示,以半主动液压悬置的试验动特性曲线与集总参数模型的动特性曲线之间的误差数值的平方和作为遗传算法参数辨识的适应度函数,半主动液压悬置的参数辨识问题就转化为在可行域内寻找一组最优参数使得动特性试验曲线和集总参数模型的动特性仿真曲线之间的误差最小化。
适应度函数的取值为:
上式中,θ为集总参数模型的参数,即Kr、K1、Ap、I和R,Kd、分别为试验动刚度和阻尼滞后角,分别为集总参数模型计算得到的动刚度和阻尼滞后角,ω1、ω2为权重系数,ω1、ω2分别代表了动刚度和阻尼滞后角在参数辨识中的重要程度,且ω1+ω2=1,△(θ)为动特性试验曲线与集总参数模型的动特性仿真曲线之间的相对误差的平方和。
由于橡胶主簧刚度Kr和惯性通道液感I容易确认,因此,本发明取θ=(Ap,K1,R,K'1),取ω1=ω2=0.5,取0<Ap/Ap0<2,0<K1/K10<2,0<R/R0<2,0<K1'/K'10<2,其中θ0=(Ap0,K10,R0,K'10)为集总参数初始值,取一次辨识结果为初始值,K1'为空气腔开放时的上液室体积刚度。
遗传算法的辨识流程如图5所示,包括对初始值的编码、选择操作、交叉操作、变异操作和计算适应度值等。遗传算法能够同时对已编码的参数集进行并行运算,这些已编码的参数集称为种群,一般情况下,种群大小取值为30~100,本发明取50,即θ=(Ap,K1,R,K'1)在大于0小于2θ0的范围内取值50组。
编码是遗传算法的解的遗传表示,它是遗传算法求解问题的第一步。本发明的优化问题为多维、高精度要求的连续函数优化问题,利用二进制编码存在诸多不便,而采用浮点数编码方法可以提高运算效率,便于在较大空间进行遗传搜索。因此,本发明采用浮点数编码法进行编码。浮点数编码法是指个体的每个基因值用某一范围内的一个浮点数表示,个体的编码长度取决于决策变量的位数。
选择又称复制,是在群体中选择生命力强的个体产生新的群体的过程。本发明采用随机遍历抽样(SUS)进行选择。随机遍历抽样是具有零偏差和最小个体扩展的单状态抽样算法。
交叉又称重组,是按较大的概率从群体中选择两个个体,交换两个个体的某个或某些位。与自然进化一样,交叉产生的新个体具有父母双方的一部分遗传物质。本发明采用均匀交叉算子进行交叉运算。均匀交叉是指两个配对个体的每个基因座上的基因都以相同的交叉概率进行交换,从而形成两个新的个体。均匀交叉实际上可归属于多点交叉的范围,其具体运算可通过设置一屏蔽字来确定新个体的各个基因如何由哪一个父代个体来提供。
变异是以较小的概率对个体编码串上的某个或某些位值进行改变。交叉运算是产生新个体的主要方法,它觉得了遗传算法的全局搜索能力;而变异算子是产生新个体的辅助方法,它决定了遗传算法的局部搜索能力。本发明采用均匀变异算子。所谓均匀变异操作是指分别用符合某一范围内均匀发布的随机数,以较小的概率来替换个体编码串中各个基因座上的原有基因值。
本发明通过对适应度函数进行反复迭代以获得误差允许范围内的最优参数作为液压悬置参数辨识结果,在本发明的计算中,种群大小为50,终止进化代数为100,交叉概率为0.9,变异概率为0.1。
图6为遗传算法参数辨识的适应度值随进化代数的变化曲线。由图6可知,遗传算法运行到40代以后,适应度值逐渐收敛,半主动悬置集总参数模型的参数已经趋于最优结果。
图7为遗传算法辨识得到的四个参数值。由图7可知,四个参数的辨识结果都未达到约束的上下限,说明遗传算法优化的结果是有效的。
为了证明本发明所用的液压悬置动特性参数辨识方法的优越性,使用特征点法对K1、K1'、R和Ap四个参数进行辨识。
特征点法参数辨识的流程如下:
液压悬置液柱共振圆频率为:
液柱阻尼比为:
最大阻尼角所在频率对应的动刚度曲线上点的斜率为:
动刚度曲线达到的稳定值为:
则K1=ωn2I,K1'=ωn'2I,
由此可计算得到半主动悬置特征点法参数辨识的结果,与本发明方法获得的参数值列于表2。从表2中可以看出,特征点法与本发明方法所获得的参数之间相对误差较大,说明特征点法在选取动特性曲线上的特征点时取点误差较大,操作较为困难。因此,使用遗传算法能够以较快的速度获得高精度的参数辨识结果。
表2 半主动液压悬置参数辨识结果对比
为验证参数辨识结果的准确性,分别将遗传算法参数辨识结果和特征点法参数辨识结果用于半主动液压悬置的集总参数模型中,并与试验动特性结果进行对比。由图8、9中的数据可知,用遗传算法参数辨识结果建立的集总参数模型与试验结果的吻合程度高于特征点法,因此,遗传算法参数辨识方法的精度高于特征点法。图8、9中,硬模式指空气腔开放时的模式,软模式指空气腔关闭时的模式。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!