一种混合存储阵列的构建方法与流程
本发明属于计算机存储技术领域,更具体地,涉及一种混合存储阵列的构建方法。
背景技术:
随着固态盘技术的发展,给整个存储领域的应用和研究带来了不小的影响。相对于机械磁盘,固态盘因其不需要磁头的寻道和旋转定位时间,有更好的随机访问性能,从而为从根本上解决传统磁盘低的随机访问性能问题提供了可能。此外作为电子器件的固态盘还具备功耗低、体积小、重量轻和抗震等优势。然而,由于价格、容量等方面的原因,在未来很长一段时间内固态硬盘仍然不可能在存储应用领域完全取代磁盘,因此利用磁盘和固态硬盘构建混合存储系统,充分利用两者各自的优势来提高存储系统的整体性能,成为目前主流的研究方向。
磁盘阵列(Redundant Arrays of Independent Disks,RAID),有“独立磁盘构成的具有冗余能力的阵列”之意。它是由很多价格较便宜的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。
现有的磁盘阵列分为三类:由硬盘驱动器(Hard Disk Drive,HDD)构建的传统RAID、由固态硬盘(Solid State Disk,SSD)构建的RAID以及由HDD和SSD混合的RAID。随着SSD价格的降低,由SSD组成大容量的阵列已经成为可能,并被越来越多的人所接受。但是正如之前提到的SSD在价格和容量上仍然和HDD有着较大的差距,况且其自身的擦写以及寿命问题,使得将SSD和HDD共同组成大容量、高性能、高可靠性的混合阵列成为一种理想的解决思路。
目前主要的混合阵列性能优化方法有以下几种:
HP公司提出了一种混合阵列AutoRAID。不过,AutoRAID做的是基于HDD的RAID1和SSD的RAID5的混合。AutoRAID提出了两层的存储架构,上层组建RAID1来存放active数据来保证高性能,而下层组建RAID5来存放inactive数据以性能换取冗余度,降低存储成本。其主要思路是利用active数据的规模小但访问频度高对性能要求高的特点,和inactive数据规模大但访问度低、只要保证可靠性的特点,分别采用不同级别的RAID方式组织数据,从而兼顾性能和存储成本,但是仅仅是在HDD级的混合。
谢涛等人提出了PEARL混合模型,在PEARL中,SSD和HDD一一对应组成混合磁盘对,所有HDD按某一RAID方式组织成阵列。PEARL将数据分为三类:读密集型、写密集型和读写混合型,写密集型放在HDD中,读密集型数据放在SSD,而读写混合型数据根据性能、能耗以及可靠性公式决定放在HDD还是SSD。该方案能够对性能、能耗和可靠性进行折衷考虑,但在性能优化上和很多方案一样忽略了SSD更好的随机读写性能优势。
毛波等人提出的HPDA将若干个SSD(数据盘)和一个HDD的部分空间(parity盘)组成RAID4,剩余的HDD空间和另一个HDD组成一个RAID1作为写buffer来优化对SSD阵列的小写。该方案利用HDD缓存一些随机小写请求来提高SSD阵列的写性能,但是为区分数据的冷热,所有数据的写操作都要进行两次。
因此,采用上述方式在提高混合存储阵列的性能方面存在一定的局限性。
技术实现要素:
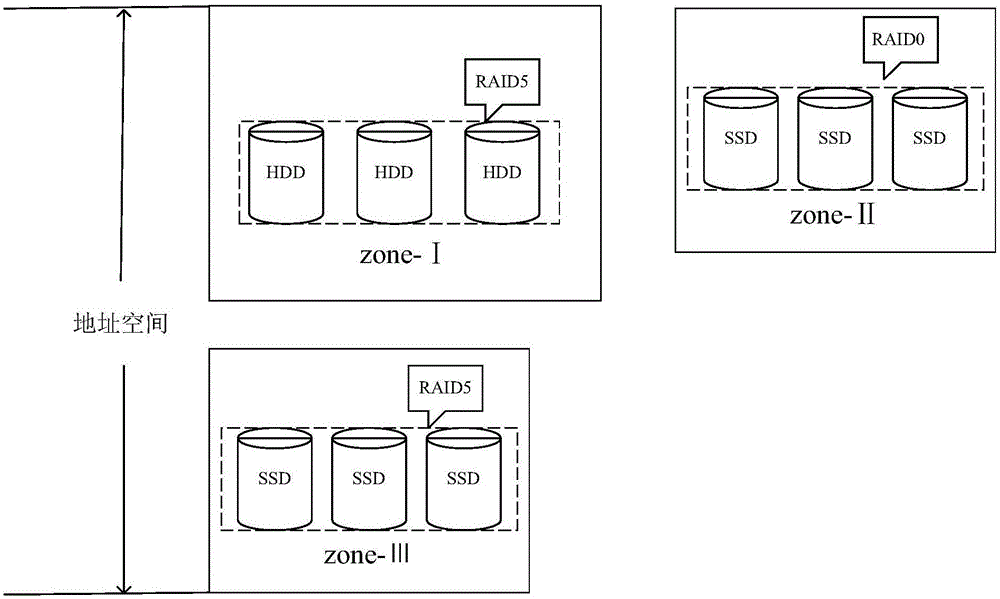
针对现有技术的以上缺陷,本发明提供了一种混合存储阵列的构建方法,其目的在于构建一种高性能的基于RAID5的混合阵列。通过将顺序读写请求数据放在zone-Ⅰ(一个HDD存储区域),将热的随机小读和小写请求分别放在zone-Ⅱ(SSD随机小读存储区域)和zone-Ⅲ(SSD随机小写存储区域),充分利用HDD高的顺序读写性能和SSD的随机读写性能来提高混合存储阵列的I/O性能,由此解决现有的提高混合存储阵列的性能存在一定局限性的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种混合存储阵列的构建方法,包括以下步骤:
S1:将混合阵列划分为三个区域zone-Ⅰ、zone-Ⅱ以及zone-Ⅲ,其中,zone-Ⅰ是由RAID5构成的一个HDD存储区域、zone-Ⅱ是由RAID0构成的一个SSD随机小读存储区域、zone-Ⅲ是由RAID5构成的一个SSD随机小写存储区域;
S2:利用参数request size、frequency以及seek distance计算出条带的性能收益值;
S3:计算条带在预设时间内的读写比例,根据读写比例以及条带的性能收益值将数据按条带分为三类S-Ⅰ、S-Ⅱ以及S-Ⅲ,其中S-Ⅰ表示冷数据以及顺序读写类型的热数据、S-Ⅱ表示随机小读类型的热数据、S-Ⅲ表示随机小写类型的热数据;
S4:按条带动态迁移数据,将S-Ⅰ类数据重定位到zone-Ⅰ,S-Ⅱ类数据重定位到zone-Ⅱ,S-Ⅲ重定位到zone-Ⅲ。
优选地,步骤S2具体包括以下子步骤:
S2-1:将文件系统下发的请求分为若干个物理地址连续的子请求;
S2-2:获取各子请求的request size和seek distance,利用公式:△P=(2Lp*[max(0,k-m)/k])*(1+t*S)计算出各子请求所涉及的条带的性能收益增量值△P,然后由公式P=P1+F*△P计算出各子请求所涉及的条带的性能收益值,其中,m表示request size,S表示seek distance,Lp、k和t分别为预设的参数,2Lp表示预设的P的最大增量,2k表示预设的最大请求大小,t为seek distance的权重因子,P1表示原始值,F表示访问频率frequency;
S2-3:更新各子请求涉及到的所有条带的性能收益值。
优选地,步骤S3具体包括以下子步骤:
S3-1:统计条带在预设时间内的读写比例,若读写比例大于预设读操作阈值,则确定该条带为读密集型,否则为写密集型;
S3-2:将性能收益值P低于第一预设值的条带作为S-Ⅰ类数据,将性能收益值P高于第一预设值的读密集型条带作为S-Ⅱ类数据,将性能收益值P高于第二预设值的写密集型条带作为S-Ⅲ类数据。
优选地,步骤S4具体包括以下子步骤:
S4-1:将zone-Ⅲ中的S-Ⅰ类和S-Ⅱ类数据迁往zone-Ⅰ;
S4-2:将zone-Ⅰ中的S-Ⅱ类数据采用拷贝式方式迁往zone-Ⅱ,S-Ⅲ类数据采用交换式方式迁往zone-Ⅲ;
S4-3:将zone-Ⅱ中的S-Ⅰ类数据迁回zone-Ⅰ,S-Ⅲ类数据迁往zone-Ⅲ。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,主要有以下的技术优点:
(1)采用request size、frequency和seek distance参数识别随机小请求数据,提高了识别的准确度,同时识别策略充分考虑到数据的条带性,更适合于混合阵列环境。
(2)通过数据分类识别,根据设备自身的性能特性合理对数据进行布局,充分利用存储资源,最大程度地优化了系统的I/O性能,做到对下层物理设备的感知存储。
(3)多种RAID模式混合,在保证可靠性的同时降低存储开销。将zone-Ⅰ和zone-Ⅲ上的数据按RAID5组织,而zone-Ⅱ按RAID0组织,其条带数据的可靠性需要配合该条带在zone-Ⅰ上的其他数据和parity来保证,因为zone-Ⅱ区域上的I/O多为读操作,所以很少会访问条带的其他数据和parity。
(4)将随机小请求数据分为读密集型和写密集型,并将其分别存放在不同的flash芯片上,既保证了性能和可靠性,又降低了成本。同时针对这两类数据的特性采用了不同的数据迁移策略,有效降低了迁移的开销。
附图说明
图1是本发明实施例公开的一种混合存储阵列的构建方法的流程示意图;
图2是本发明实施例公开的一种混合存储阵列的架构示意图;
图3是本发明实施例公开的一种数据类型识别方法的流程示意图;
图4是本发明实施例公开的一种将zone-Ⅰ中的S-Ⅱ类数据以及S-Ⅲ类数据进行迁移的示意图;
图5是本发明实施例公开的一种可选的按条带进行动态迁移数据的示意图;
图6是本发明实施例公开的另一种可选的按条带进行动态迁移数据的示意图;
图7是本发明实施例公开的一种数据迁移过程的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
图1为本发明实施例公开的一种混合存储阵列的构建方法的流程示意图,包括以下步骤:
S1:将混合阵列划分为三个区域zone-Ⅰ、zone-Ⅱ以及zone-Ⅲ,其中,zone-Ⅰ是由RAID5构成的一个HDD存储区域,zone-Ⅱ是由RAID0构成的一个SSD随机小读存储区域,zone-Ⅲ是由RAID5构成的一个SSD随机小写存储区域;
S2:利用参数request size、frequency和seek distance计算出条带的性能收益值;
S3:计算条带在预设时间内的读写比例,根据读写比例以及条带的性能收益值将数据按条带分为三类S-Ⅰ、S-Ⅱ以及S-Ⅲ,其中,S-Ⅰ表示冷数据以及顺序读写类型的热数据,S-Ⅱ表示随机小读类型的热数据,S-Ⅲ表示随机小写类型的热数据;
S4:按条带动态迁移数据,将S-Ⅰ类数据重定位到zone-Ⅰ,S-Ⅱ类数据重定位到zone-Ⅱ,S-Ⅲ重定位到zone-Ⅲ。
上述步骤S1中,区域的划分主要是依据具体存储设备的特性和数据访问的特点:
A、SSD和HDD在读写性能上存在很大差异。相比于HDD,SSD在顺序读写的情况下并没有明显的性能优势,甚至对于低端的SSD产品而言还没有HDD的顺序性读写性能高;但是对于随机访问负载而言,SSD比HDD表现出较为明显的性能优势。因此从I/O性能的角度出发,将随机读写请求定位到SSD区,将顺序读写请求定位到HDD区,能够提高系统的I/O带宽。
B、同时考虑到SSD的读写不平衡特性,将SSD区进一步分为读密集型区(zone-Ⅱ)和写密集型区(zone-Ⅲ),zone-Ⅱ由MLC型flash芯片构成RAID0,而zone-Ⅲ采用可擦除次数更高的SLC型flash芯片RAID5,这里zone-Ⅱ采用RAID0以节省存储空间,而其条带数据的可靠性需要配合该条带在zone-Ⅰ上的其他数据和奇偶校验位parity来保证。
如图2所示为本发明实施例公开的一种混合存储阵列的架构示意图,存储空间划分为三个区域zone-Ⅰ(HDD存储区域)、zone-Ⅱ(SSD随机小读存储区域)和zone-Ⅲ(SSD随机小写存储区域)。需要说明的是,整个地址空间由zone-Ⅰ和zone-Ⅲ构成,zone-Ⅱ作为预留空间用于存储迁移过来的随机小请求的读密集型数据。
在文件系统下发请求时,首先按照从低到高的顺序分配地址,然后在位图bitmap上标记该地址已经分配,同时完成数据项的初始化,记录从逻辑地址到物理地址的映射,接着向下转发请求。
该步骤给出的数据分布策略是根据设备自身的性能特性对混合阵列中的数据进行合理布局,充分利用存储资源最大程度地优化了系统的I/O性能,做到对下层物理设备的感知存储。
上述步骤S2中,计算条带的性能收益值的步骤如下:
将文件系统下发的请求按照物理地址,分为若干个地址连续的子请求q1,q2,q3…qn。其中每一个子请求还要满足只映射到一个zone。这里每一个zone可以看做是一个逻辑设备;
对每个子请求qi(i=1,2,3…n)获取其request size和seek distance参数,这里的request size以chunk为基本单位计算,表示请求指令请求访问的数据块的大小,而seek distance则以stripe为基本单位计算,表示请求指令访问的具体的数据块;
将相关参数代入公式:△P=(2Lp*[max(0,k-m)/k])*(1+t*S),计算出各子请求所涉及的条带的性能收益增量值△P,然后由公式P=P1+F*△P计算出各子请求所涉及的条带的性能收益值,其中,m表示request size,S表示seek distance,Lp、k、t分别为预设的参数,2Lp表示预设的P的最大增量,2k表示预设的最大请求大小,t为seek distance的权重因子,P1表示原始值,F表示相应的条带被访问的频率frequency;
需要说明的是,性能收益值P表示将条带放在SSD上比放在HDD上访问I/O性能的提升程度。
更新该请求qi涉及到的所有条带的性能收益值。
例如,若q1=(R,D),其中R表示该请求为读操作,D代表要读的数据域,D=(chunck0,chunck1,chunck2,chunck3,chunck4),当前所在zone的条带数据长度为3个chunck,则请求q1涉及条带stripe0和条带strip1,因此将q1计算的P加到stripe0和strip1上。
若子请求为读操作,则所涉及到的所有条带的read_count值加1;否则write_count值加1。
该步骤给出的条带性能收益值的分析是以条带为单位,识别策略充分考虑到数据的条带性,与以往的分析方法相比,更适合于应用在阵列环境下的I/O行为分析。
上述步骤S3中,数据分类按照条带的性能收益值P以及读写比例将条带分为S-Ⅰ类、S-Ⅱ类和S-Ⅲ类。其中S-Ⅰ类适合于放在容量大、顺序访问性能高的HDD上,S-Ⅱ类和S-Ⅲ类适合于放在容量小、随机访问性能高的SSD上。
如图3所示为本发明实施例公开的一种数据类型识别方法的流程示意图,包括以下步骤:
301:将文件系统下发的请求Q分为若干个物理地址连续的子请求;
302:获取各子请求的request size、seek distance以及数据块的访问频率frequency;
303:计算各子请求所涉及的条带的性能收益值P;
304:统计条带在预设时间内的读写比例Rw,并更新子请求涉及到的条带的性能收益值;
305:判断条带qi的读写比例是否大于预设读操作阈值threshold-read,若是,则执行步骤306,否则执行步骤307;
306:判断条带qi的性能收益值P是否高于第一预设值Pii;若是,则执行步骤308,否则执行步骤309;
307:判断条带qi的性能收益值是否高于第二预设值Piii,若是,则执行步骤310,否则执行步骤309;
308:将该条带qi作为S-Ⅱ类数据;
309:将该条带qi作为S-Ⅰ类数据;
310:将该条带qi作为S-Ⅲ类数据;
311:检测是否完成所有条带的数据类型划分操作,若完成,则结束流程,否则执行步骤305。
上述步骤S4中,根据对数据分类的结果以条带为单位进行数据重分布。这里,我们重点讲将zone-Ⅰ上影响系统性能的数据迁到SSD区域进行优化。具体的,将zone-Ⅰ中的S-Ⅱ类数据采用拷贝式迁往zone-Ⅱ,将zone-Ⅰ中的S-Ⅲ类数据采用交换式迁往zone-Ⅲ。之所以采用两种不同的迁移方式,主要是考虑到了S-Ⅱ和S-Ⅲ类数据在访问特性上的本质区别。如图4所示,表示将zone-Ⅰ中的S-Ⅱ类数据以及S-Ⅲ类数据进行迁移的示意图。
图4的上面部分表示的是将读密集型S-Ⅱ型数据迁往zone-Ⅱ;下面部分表示将写密集型S-Ⅲ型数据迁往zone-Ⅲ。对于S-Ⅱ型数据A来说,将其迁往zone-Ⅱ后,因为进行的基本上都是读操作,数据不被修改的可能性很大,当数据A需要被迁出zone-Ⅱ时仅仅将脏数据部分写回即可,所以采用拷贝方式迁移数据,虽然造成了数据的冗余,增加了存储开销;但有效保存了源数据副本,降低了数据迁回的I/O开销。
而对于S-Ⅲ型数据B来说,将其迁往zone-Ⅲ后,因为I/O中有很多写操作,数据不被修改的可能性很小,当数据需要被迁出zone-Ⅲ时,源数据等同于无效,此时数据的写回量等同于迁入的量,所以采用交换式的数据迁移方式,即迁移的源地址和目的地址的数据进行交换,而不保存源数据副本以节约存储空间。
另外,在数据进行重分布时,考虑到数据的条带性,迁移操作以条带为基本单位,也就是说要将整个条带的数据包括校验部分数据作为整体进行迁移。如图5所示,表示一种可选的按条带进行动态迁移数据的示意图。
图5中,条带stripe0被识别为S-Ⅱ型迁往zone-Ⅱ,条带stripe1被识别为S-Ⅲ型迁往zone-Ⅲ。现在假设D0、D1、D3和D4为热数据,而其他的为冷数据,因此对D2和D5的迁移并不是我们想要的。在图4的描述中对于S-Ⅲ型数据的迁移采用交换式迁移以节约存储空间。如果只迁移D3和D4,为了保证条带的可靠性,必须要重新计算P1,因为此时stripe1中的数据已经发生变化,这与迁移整个条带模式相比并不见得减少I/O开销,反而增加了迁移操作的复杂度。对于S-Ⅱ型数据的迁移我们可以采用copy-on-write方式解决条带中冷数据的迁移问题。具体来讲,可以将D2的迁移推迟到stripe0进行写操作的时候,在对条带进行读操作时通常并不会涉及到对条带中冷数据部分的操作,而只有在对条带进行写操作时才可能需要迁移条带剩余的冷数据部分:1)对于冷数据的写操作;2)对于热数据的写操作采用重构写。考虑到S-Ⅱ型数据的读操作比例很大,在数据迁回去之前很可能只会进行读取条带热数据的操作,并不需要将冷数据部分迁回,该策略可以有效降低了S-Ⅱ型数据的迁移开销,不过仍需要为条带中的冷数据预留空间,大大降低了zone-Ⅱ空间的利用率。
另一种方法是将zone-Ⅱ按RAID0组织数据。如图6所示,表示另一种可选的按条带进行动态迁移数据的示意图。
图6中stripe0和stripe2被识别为S-Ⅱ型,可以只将条带中的热数据部分D0、D1、D6和D7迁移到zone-Ⅱ,并以RAID0方式组成一个条带(条带内数据块的逻辑地址可以不连续)。相对于copy-on-write方式,该方法大大提高了SSD的空间利用率。由于条带stripe0的数据可靠性需要配合该条带在zone-Ⅰ上的其他数据和parity来保证,也就是说zone-Ⅰ上的D2和P0以及zone-Ⅱ上的D0和D1构成了一个逻辑上的stripe。当D0或D1执行写操作时,除了自身数据部分的修改,还要更新zone-Ⅰ上stripe0的P0,由于zone-I由HDD组成对于P0的更新可能会影响整个的写操作,但是考虑到zone-Ⅱ上数据为读密集型并不会经常涉及条带写操作,因此并不会对系统的写性能产生明显的影响。
具体来说,将zone-Ⅰ上的S-Ⅱ型数据采用拷贝式迁往zone-Ⅱ(减少迁回的开销),S-Ⅲ型数据采用交换式迁往zone-Ⅲ;将zone-Ⅱ的S-Ⅰ型数据迁回zone-Ⅰ,S-Ⅲ型数据迁往zone-Ⅲ;将zone-Ⅲ上S-Ⅰ型和S-Ⅱ型数据迁往zone-Ⅰ。注意到zone-Ⅲ上的数据只能迁往zone-Ⅰ而不能直接迁往zone-Ⅱ,这是为了zone-Ⅱ上的数据在zone-Ⅰ上均有副本以保证其可靠性,如图7所示,表示一种数据迁移过程的结构示意图。
该步骤给出的数据重分布策略根据不同类型数据的访问特性采用针对性的迁移方式,有效降低了迁移的开销;依据S-Ⅱ型数据的读密集型特性将zone-Ⅱ按RAID0组织数据,并采用部分条带迁移策略,在保证了性能和可靠性的同时提高了SSD的空间利用率。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!