一种高炉铁水质量预报方法及其系统与流程
本发明涉及高炉炼铁工业过程的自动控制领域,尤其涉及一种高炉铁水质量预报方法及其系统。
背景技术:
高炉炼铁是钢铁生产过程中重要环节,其为钢铁生产的上游工序,是钢铁生产过程中CO2排放的主要环节,同时也是能耗最大的工序,其存在着巨大的优化空间。控制高炉保持一个合理的炉温,维持高炉的长期稳定顺行是实现高炉生产高效、优质、低耗的关键所在。但是高炉是一个高温、高压、强腐蚀、强干扰、多物理场共存、化学反应与传递效应同时发生的环境,高炉炼铁过程则是具有时变、非线性、多尺度、大时滞特性的连续动态反应过程,我们很难直接获得高炉内部的炉况相关信息,这使得高炉的炉况极难控制。
高炉铁水中的硅含量反映了高炉内部的炉温变化和高炉炉缸位置的热状态,是高炉生产中的一个重要指标,在高炉的实际生产中是难以直接测得铁水中的硅含量的。故而众多学者都致力于铁水硅含量的软测量方法的研究,而由于高炉内部极为复杂的情况,高炉铁水硅含量的机理模型难以建立且效果较差,目前大部分都是采用数据驱动的方式建立铁水硅含量的软测量模型,实现对铁水硅含量的预测。
专利公开号CN104651559A公开了“一种基于多元在线序贯极限学习机的高炉铁水质量在线预报体系及预报方法”以炉腹煤气量、热风温度、热风压力、富氧率、鼓风湿度、喷煤量等变量的相关数据建立M-SVR软测量模型实现了对高炉铁水参数硅含量、磷含量、硫含量、铁水温度的预测。
专利公开号CN106096637A公开了一种“基于Elman-Adaboost强预测器的铁水硅含量预测方法”选择合适的输入变量训练K个Elman神经网络的弱预测器,并用Adaboost算法融合这K个弱预测器得到Elman-Adaboost强预测器对铁水硅含量进行预测。
专利公开号CN104915518A公开了“一种高炉铁水硅含量二维预报模型的构建方法及应用”将bootstrap预测区间发与基于BP神经网络的铁水硅含量预测方法相结合,构建出了高炉铁水硅含量的二维预报模型,在给出下一个时刻的铁水硅含量预测值的同时给出预测值的预测区间,以预测区间的宽度表征预测值的可信度。
上述专利的方法以及其相关的文献大多依凭经验人为选取或采用一些线性的相关性分析方法选取相关变量作为输入进行建模,若引入的变量对需要预测的铁水硅含量的影响不大,可能会带来一定程度的干扰,从而影响预测精度。并且上述专利及其相关文献中模型在训练完成之后模型中的各参数基本固定,随着运行时间的推移,样本发生变化,静态模型无法适应样本的变化,这可能会导致其预测精度出现一定程度的下降。综上所述,提出一种选取合适的变量构建高炉铁水质量动态预报方法和系统是非常有必要的。
技术实现要素:
有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供一种预测精度高,能够在高炉炼铁过程中指导现场工作人员的高炉铁水质量预报方法及系统。
为实现上述目的,本发明提供了一种高炉铁水质量预报方法,包括以下步骤:
步骤一、根据现有对铁水质量影响因素的研究,通过与现场技术人员交流以及现场数据的情况,以高炉的铁水硅含量作为铁水质量的主要表征参数,并从机理上分析出影响高炉铁水硅含量的参数,所述参数为影响变量X;
步骤二、在机理分析的基础上,通过现场数据库获得高炉炼铁过程中所产生的铁水硅含量以及所述影响变量的历史数据,使用最大信息系数对所述影响变量进行相关性分析;
步骤三、根据最大信息系数相关性分析的定义计算出所述影响变量X与铁水硅含量Y在不同时滞条件下与铁水硅含量的最大信息系数,记录并保存不同时滞条件下各个影响变量与铁水质量的最大信息系数所对应的数值和时滞大小;
步骤四、根据历史经验和数学统计方法分析,设定一个阈值作为选取影响变量和时滞的标准,根据设定的阈值标准,选取最大信息系数中大于该阈值所对应的影响变量作为高炉铁水硅含量预测模型的输入变量X1,X2,…Xn,在选定的输入变量中寻找不同时滞下所对应的最大信息系数最大的作为预测模型的输入变量时滞τ1,τ2,…τn;考虑自回归,利用最大信息系数相关性分析,确定铁水质量Y自身自回归的最佳时滞τ;
步骤五、根据步骤四中确定的输入变量X1,X2,…Xn和输入变量时滞τ1,τ2,…τn,以及铁水质量Y自身自回归的最佳时滞τ,确定具体的铁水质量预报模型为:
其中t为时间;
步骤六、根据设定好的影响高炉铁水硅含量的参数,通过所述参数的历史数据及对应炉次的铁水硅含量数据,对步骤五中的所述铁水质量预报模型进行训练、验证,直至得到误差在允许范围内的预测模型;
步骤七、利用步骤六中得到的误差在允许范围内的预测模型进行高炉炼铁过程中的铁水质量预测。
进一步地,所述最大信息系数相关性分析是指:对于给定的有序数据集D:(X,Y),把x-y平面划分为网格G,使数据集D中的所有点落入网格集G中,定义D|G为数据集D在网格集G上的分布,那么最大信息系数为其中G取可能划分的最大值,I(D|G)表示D|G的互信息;
所述互信息是指:针对两个时间序列X和Y,I(X|Y)=H(X)+H(Y)-H(X,Y);其中H(X),H(Y)分别为X,Y的信息熵,其求取公式为:H(X,Y)的求取公式为:
其中p(x,y)为随机变量X和Y的联合分布概率密度。
进一步地,所述影响高炉铁水硅含量的参数包括冷风流量、送风比、热风压力、炉顶压力、压差、顶压风量比、透气性、阻力系数、热风温度、富氧流量、富氧率、设定喷煤量、鼓风湿度、理论燃烧温度、标准风速、实际风速、鼓风动能、炉腹煤气量、炉腹煤气指数、顶温东北、顶温西南、顶温西北、顶温东南、软水温差。
进一步地,所述步骤六为:确定好影响变量的个数后,选取这些影响变量的历史数据和对应炉次的铁水硅含量数据,并进行归一化的预处理;随后将归一化后的数据作为动态神经网络的训练数据集,将处理过后与当次铁水硅含量对应的不同时滞条件下的变量数据作为输入,以当次铁水硅含量作为输出,对动态神经网络进行训练;随后选取在上述训练数据集以外的历史数据作为测试集,对训练的模型进行测试,若误差在一定范围内则可以使用,若误差超出误差允许范围则重新训练直至得到较好的预测模型,即所述误差在允许范围内的预测模型。
进一步地,所述步骤六中衡量误差范围的标准是以预测值与实际值之间的均方误差,即:
其中表示预测值,Y表示实际值。
根据上述方法,为了更好的应用到高炉炼铁过程中去,本发明还在上述铁水质量预测方法的基础上,利用LABVIEW、MATLAB以及数据库服务器等技术,采用LABVIEW与MATLAB混合编程,搭建一套铁水质量预报系统,该系统能够利用上述方法预判下一时刻的铁水质量值以及监控其他影响变量,以协助现场工人在高炉炼铁过程中更好的操作。
本发明基于上述方法构建了高炉铁水质量预报系统,所述的高炉铁水质量预报系统可用于预判下一时刻的铁水质量值以及监控其它影响变量,其包括:
登录模块,所述登录模块用于实现现场工人和管理员的登陆功能,根据预先存入的现场工人和管理员身份,通过身份对比验证登陆人员是否具有登陆预报系统的权限;
上位机模块,所述上位机模块与现场服务器和数据库相连,所述上位机模块包括所述高炉铁水质量预报系统的核心算法和界面,与现场服务器一起能够实现的功能包括:实现工人和管理员登录、显示铁水质量趋势、查看主要影响变量情况、记录并保存铁水质量和主要影响变量数据、监控高炉运行状态以及选择预测模型;所述上位机模块能够根据现场采集到的实时数据去预报下一批铁水质量,并对铁水质量以及相关的参数进行监控;
现场服务器与数据库,所述现场服务器与所述数据库相连,用于对高炉实时运行中高炉的上部调剂手段和相关数据、下部调剂手段和相关数据以及炉内可测量数据进行采集存储;其中,上部调剂的数据包括炉料的固有属性、一批料的批重、布料矩阵;下部调剂的数据包括喷煤量、冷风流量、富氧量;炉内可测量数据包括炉顶压力、炉顶温度、透气性。
进一步地,所述现场服务器从所述数据库中读取高炉炼铁现场所采集数据,然后将所需要的数据传到上位机模块从而实现对高炉运行状态的监控,实现对铁水质量和主要影响变量的查看、记录和保存。
进一步地,所述数据库包括高炉运行本身的数据、炉料供应系统的数据以及鼓风喷煤系统的数据;其中,所述高炉本身运行的数据包括炉温、铁水质量、铁水炉次和高炉顶压,所述炉料供应系统的数据包括炉料批次、炉料质量和炉料速度,所述鼓风喷煤系统的数据包括实际风速、鼓风量、富氧量、煤气利用率、炉腹煤气量、透气性、阻力系数和理论燃烧温度。
进一步地,所述铁水质量预报系统采用LABVIEW与MATLAB混合编程,完成铁水质量预报方法中预测模型的训练、验证与预测,从而能够实现铁水质量预测方法在铁水质量预报系统中的运用。
进一步地,所述铁水质量预报系统还包括选择和自建预测模型模块,所述选择和自建预测模型模块用于使任何具有权限使用铁水质量预报系统的人可以根据需要去实践自己的预测方法可行性;其中,所述根据需要是指高炉炼铁过程中高炉状况发生重大变化,或者有其它更好的铁水质量预测方法需要通过实践验证该预测方法的可行性。
本发明的铁水质量预报方法是基于最大信息系数与动态神经网络的预测方法,该方法首先利用最大信息系数研究对铁水质量的影响变量与铁水质量之间的非线性相关性进行研究,并基于上述相关性分析结果对铁水质量的影响变量进行筛选,并确定影响因素与铁水质量的时滞关系,通过从数据库中提取相应的历史数据作为预测模型的训练集,采用动态神经网络的方法对预测模型进行训练,以实现对模型的滚动优化,据此实现对铁水质量的预测。以上述预测方法为基础,本发明进一步利用LABVIEW与MATLAB混合编程,搭建了一套铁水质量预报系统,实现对铁水质量的预测以及铁水质量及其相关影响变量的监控,从而在高炉炼铁过程中对现场工作人员具体操作起一定指导作用。
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
图1为本发明的一个较佳实施例中的高炉本体结构示意图;
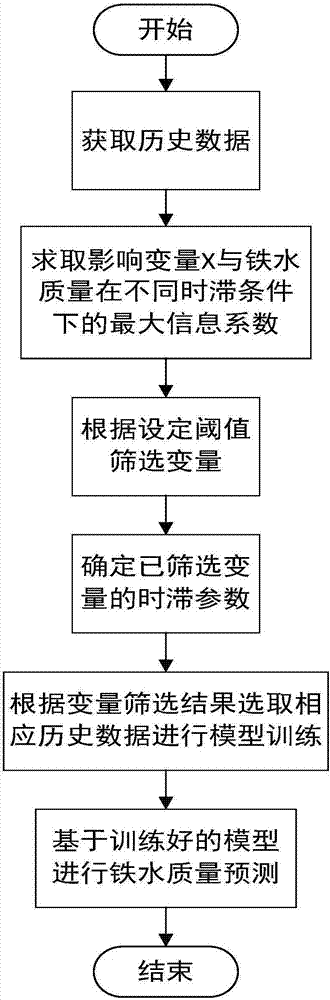
图2为本发明的一个较佳实施例的铁水质量预报系统的应用流程图;
图3为本发明的一个较佳实施例的铁水质量预报系统的结构框图;
图4为本发明的一个较佳实施例的铁水质量预报系统的登录界面;
图5为本发明的一个较佳实施例的铁水质量预报系统的监控界面;
图6为本发明的一个较佳实施例的铁水质量预报系统的监控参数设置界面;
图7为本发明的一个较佳实施例的铁水质量预报系统的预测模型选择界面。
具体实施方式
下面将结合附图与实例对本发明的具体实施方式做详细说明。
在本发明的一个较佳实施例中,提供了一种高炉铁水质量预报方法,采用该方法对高炉炼铁过程中的铁水质量进行预测。本实施例的高炉铁水质量预报方法包括以下步骤:
步骤一:结合某钢厂2号高炉的实际可测得或可计算得出的变量情况,进行机理分析,最终确定了24个与高炉铁水硅含量相关的影响变量:X1-冷风流量,X2-送风比,X3-热风压力,X4--炉顶压力,X5-压差,X6-顶压风量比,X7-透气性,X8-阻力系数,X9-热风温度,X10-富氧流量,X11-富氧率,X12-设定喷煤量,X13-鼓风湿度,X14-理论燃烧温度,X15-标准风速,X16-实际风速,X17-鼓风动能,X18-炉腹煤气量,X19-炉腹煤气指数,X20-顶温东北,X21-顶温西南,X22-顶温西北,X23-顶温东南,X24-软水温差。
上述某钢厂2号高炉模型如图1所示,其中,1-高炉布料溜槽,2-高炉炉顶部分,3-高炉炉喉部分,4-高炉炉身部分,5-高炉冷却壁,6-高炉炉腰部分,7-高炉炉腹部分,8-高炉炉缸部分,9-热风炉,10-高炉喷吹罐。该钢厂2号高炉的炉容为2600m3,其中有效容积为2000m3,高炉主体部分高约50m,炉顶结构为串罐式无料钟式。
步骤二:在机理分析的基础上,从现场服务器数据库中提取出上述24个影响变量X以及硅含量Y(铁水质量参数之一)在某一段时间内的历史数据M。步骤三:根据最大信息系数相关性分析的定义,将上述所提出的历史数据M,利用MATLAB计算上述各影响变量X与铁水硅含量Y在不同时滞条件下与铁水硅含量的最大信息系数,保存并记录所得计算得到的最大信息系数表格如下:
步骤四:根据历史经验和数学统计方法分析,设定一个阈值A作为选取影响变量和时滞的标准,根据设定阈值A,选取上述最大信息系数中大于A所对应的的影响变量作为高炉铁水硅含量预测模型输入变量(根据实验结果选取X1-冷风流量,X2-送风比,X3-热风压力,X4--炉顶压力作为输入变量,注该处为假设选取),在选定的输入变量中寻找不同时滞下所对应的最大信息系数最大的作为预测模型的输入变量时滞τ1,τ2,…τn;考虑自回归,利用最大信息系数相关性分析,确定铁水质量Y自身自回归的最佳时滞τ;时滞τ的选取过程如图2中选取部分所示。
步骤五、根据步骤四中确定的输入变量X1,X2,…Xn和输入变量时滞τ1,τ2,…τn,以及铁水质量Y自身自回归的最佳时滞τ,确定具体的铁水质量预报模型为:
其中t为时间。
步骤六:根据设定好的影响高炉铁水硅含量的参数,通过所述参数的历史数据及对应炉次的铁水硅含量数据,对步骤五中的所述铁水质量预报模型进行训练、验证,直至得到误差在允许范围内的预测模型。具体为,在MATLAB中设定铁水质量预测模型参数,将历史数据M的一部分作为该铁水预测模型训练集,一部分作为该铁水质量预测模型验证集,通过神经网络训练、验证并得到误差在允许范围内的铁水质量预测模型Model。
步骤七:将步骤六所得到的Model保存到现场服务器中。
步骤八:利用步骤六中得到的误差在允许范围内的预测模型进行高炉炼铁过程中的铁水质量预测。
本实施例还提供了一种使用上述方法的高炉铁水质量预报系统,其整体架构如图3所示,该系统包括登录模块、上位机模块、现场服务器与数据库。其中登录模块用于实现现场工人和管理员的登陆功能,根据预先存入的现场工人和管理员身份,通过身份对比验证登陆人员是否具有登陆预报系统的权限。上位机模块与现场服务器和数据库相连,上位机模块包括本实施例的高炉铁水质量预报系统的核心算法和界面(如图4~7所示),与现场服务器一起能够实现的功能包括:实现工人和管理员登录、显示铁水质量趋势、查看主要影响变量情况、记录并保存铁水质量和主要影响变量数据、监控高炉运行状态以及选择预测模型。上位机模块能够根据现场采集到的实时数据去预报下一批铁水质量,并对铁水质量以及相关的参数进行监控。
现场服务器与数据库相连,用于对高炉实时运行中高炉的上部调剂手段和相关数据、下部调剂手段和相关数据以及炉内可测量数据进行采集存储;其中,上部调剂的数据包括炉料的固有属性、一批料的批重、布料矩阵;下部调剂的数据包括喷煤量、冷风流量、富氧量;炉内可测量数据包括炉顶压力、炉顶温度、透气性。现场服务器从数据库中读取高炉炼铁现场所采集数据,然后将所需要的数据传到上位机模块从而实现对高炉运行状态的监控,实现对铁水质量和主要影响变量的查看、记录和保存。数据库包括高炉运行本身的数据、炉料供应系统的数据以及鼓风喷煤系统的数据;其中,所述高炉本身运行的数据包括炉温、铁水质量、铁水炉次和高炉顶压,所述炉料供应系统的数据包括炉料批次、炉料质量和炉料速度,所述鼓风喷煤系统的数据包括实际风速、鼓风量、富氧量、煤气利用率、炉腹煤气量、透气性、阻力系数和理论燃烧温度。
本实施例的铁水质量预报系统还可以包括选择和自建预测模型模块,该选择和自建预测模型模块用于使任何具有权限使用铁水质量预报系统的人可以根据需要去实践自己的预测方法可行性;其中,根据需要是指高炉炼铁过程中高炉状况发生重大变化,或者有其它更好的铁水质量预测方法需要通过实践验证该预测方法的可行性。
以下步骤是针对铁水质量预报系统的操作实例。
步骤九:打开铁水质量预报系统,在登陆界面根据用户身份选择相应的登录界面,并输入相应的用户名和登录密码,图4中11-普通用户的登陆界面,经过身份验证之后即可进入图5所示的铁水质量预报系统的主界面中,同时系统将用户信息和登录时间记入后台数据库中。
步骤十:主界面中系统从数据库中读取前几个时刻的铁水质量的历史数据以及相应的预测数据,并以折线图的形式展示在铁水质量走势图中;走势图中纵坐标为铁水质量数据,横坐标为时间轴,实线表示铁水质量的实测值,虚线表示铁水质量的预测值。并于走势图下方列出本炉次实际值、本炉次预测值、实际预测差值、本炉次预测趋势、下炉次预测值、下炉次预测趋势。其中预测趋势以斜向上或者斜向下箭头表示;实际预测差值则为实际值减去预测值。
步骤十一:结合专家经验知识和理论数据分析结果,系统设定了默认的铁水质量正常区间范围,该区间范围可由有相应修改权限的用户根据实际情况对其进行修改。系统会根据本炉次的实际值和下炉次的预测值对铁水质量进行监控预警,当本炉次实际值在正常区间外时,图5中实际异常处呈现红色高亮提示状态;当下炉次预测值在正常区间外时,图5中预测异常处呈现黄色高亮提示状态;当上述两者都不存在异常时,图5中正常运行处会处于绿色高亮状态。
步骤十二:主要参数监控模块主要是对上述使用最大信息系数方法所筛选出的变量选取用户所关心的变量进行监控,用户点击图5中的12-参数设置按钮会弹出图6所示的参数设置界面,这里可选参数均为经过筛选的变量,结合专家经验知识和理论数据分析结果,系统给出默认的正常区间上下限,有权限的用户可以根据实际情况进行修改;用户可以勾选其所关心的参数,(图6中假定勾选为参数2、3、5、8)点击确认后,即在主界面中显示,系统则会每一个通信时刻读取现场服务器中相应的参数的数值,并显示出具体数值,给出参数的状态以及相应的调节指导建议。数据保存按钮是将当前时刻主要参数监控界面下所有的监控参数按照既定的格式保存到用户指定目录下。
步骤十三:该铁水质量预报系统支持多种预测模型,点击主界面右下方的预测模型选择则会弹出如图7所示的模型选择界面,已默认设有6个可直接使用的模型,选中模型点击模型简介会给出该模型特性的简要的文字描述,点击模型分析则会使用近期的历史数据对模型进行测试并给出一个模型预测精度,选中预设模型之后点击确认模型,便会在将该模型应用实时预测中去。图7中还有其他模型和自建模型两个选项,其中其他模型为导入按既定格式存储好参数的模型,自建模型则是用来当用户对选中的预设模型的预测精度不满意时,对模型进行重新训练以获得更适合当前情况模型参数,从而适应环境变化提高预测精度。
步骤十四:点击重启按钮将会将所有设置都重置为默认设置。
步骤十五:点击退出按钮,系统将会退出主界面完成账户注销,将用户信息的退出时间记入后台数据库,并将界面返回至图4的用户登录界面。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!