一种适用于木聚糖酶氨基酸相互作用网络聚类的S‑FCM算法的制作方法
本发明公开了一种适用于木聚糖酶氨基酸相互作用网络聚类的s-fcm算法,属于计算机应用技术领域。具体的说就是在模糊c均值聚类算法(fcm算法)的基础上,引入了基于密度的数据预处理方法,同时在距离特征的基础上加入了氨基酸的序列特征,提高了聚类结果的稳定性和精确度,该方法为从社团的角度研究蛋白质热稳定性提供了一个新的途径。
背景技术:
木聚糖酶广泛分布于各种生物体内,其能够将木聚糖催化水解为五碳糖。现在耐热木聚糖酶因能在高温下保持活性而广泛应用于工业生产中:纸张漂白,农业饲料,生物转化等。研究耐热木聚糖酶热稳定性的作用机理必将产生显著的社会效益和经济效益。对蛋白质热稳定性的影响不只是单一氨基酸作用,而是多个氨基酸通过相互作用形成社团,在时间和空间上协调一致,来维持蛋白质热稳定性。将蛋白质编码成氨基酸相互作用网络,借助复杂网络社团结构分析方法,揭示氨基酸的内在联系,对于理解蛋白质的功能以及分析网络中氨基酸之间的行为具有重要的理论意义。因此,用聚类算法将蛋白质中氨基酸相互作用网络划分成簇,从社团的角度研究木聚糖酶的热稳定性是一条有效的途径。
rodrigueza(《clusteringbyfastsearchandfindofdensitypeaks》science,2014,344(6191):1492-1496)等提出了基于密度的方法,在网络中寻找高密段连通的子网络。作为寻找完全连通子图的最大团算法,它能从氨基酸相互作用网络中检测出那些高度连接的蛋白质,但是它不能对存在大量稀疏节点的网络进行分类。mayerb(《influenceofsolvationonthehelix-formingtendencyofnonpolaraminoacids》,journalofmolecularstructuretheochem,2000,532(1):213-226)提出的模糊c均值聚类方法属于划分的方法,该方法研究网络中所有孤立点的每个部分。该算法要找到一个最佳的划分使得所用的类的功能函数值之和最小。这个方法的最大的缺点就是要事先知道要划分的目标类的确定个数以及初始聚类中心。bhattacharjeen(《structuralpatternsinhelicesandsheetsinglobularproteins》,protein&peptideletters,2009,16(8):953-960)等发现了蛋白质中氨基酸社团与二级结构以及结构域之间有很好的对应关系,为分析社团对蛋白质热稳定性的影响提供了理论基础。
本发明提出的s-fcm算法是在引入了基于密度的数据预处理方法后,在fcm算法的距离特征的基础上加入了氨基酸的序列特征,从而提高了聚类结果的稳定性和精确度,已经成功应用在木聚糖酶氨基酸相互作用网络的聚类中。文献及专利中未见有人将基于密度的数据预处理方法引入fcm算法中,也未见在fcm算法中引入氨基酸序列特征作为分类标准。
技术实现要素:
有鉴于此,本发明的目的是在fcm算法的基础上,引入基于密度的数据预处理方法,获得初始聚类中心以及分类数目,同时在聚类标准中加入氨基酸的序列特征,提高聚类结果的稳定性和精确度。
本发明的技术方案:s-fcm算法及在木聚糖酶氨基酸相互作用网络中的应用,采用了下列步骤:
(1)基于密度的数据预处理方法选定初始聚类中心以及分类数目
使用基于密度的聚类算法思想,确定氨基酸相互作用网络中每个氨基酸节点的局部密度以及距离。找出的聚类中心被具有较低局部密度的邻居点包围,且与更高密度的其他点有相对较大的距离。通过该算法对数据进行预处理,可以获得反映数据空间密度分布特征的代表点。同时可以根据聚类中心的数目确定分类数目。
(2)加入氨基酸序列特征作为分类标准
在蛋白质中,氨基酸形成二级结构具有倾向性。序列上相邻的氨基酸,可能在同一个二级结构中,也可能在不同的二级结构中,氨基酸形成二级结构的倾向性受到周围氨基酸的影响。所以在距离特征的基础上加入序列特征后进行模糊聚类。
(3)构建目标函数方程
基于距离特征与序列特征建立目标函数方程,根据已经确定好的初始聚类中心以及分类数目计算目标函数的极小值。得到隶属度矩阵,确定聚类结果。
所述的适用于氨基酸相互作用网络聚类的s-fcm算法,其特征在于用基于密度的数据预处理方法确定初始聚类中心以及分类数目。然后将氨基酸序列特征加入到模糊c均值聚类算法中,使聚类结果的可靠性增加,并同时提高了聚类结果精确度。
基于密度的数据预处理思想,就是找到那些局部密度较大,同时聚类中心之间的距离也较大的节点即聚类中心。聚类中心被具有较低局部密度的邻居点包围,且与更高密度的其他点有相对较大的距离,这些节点可以反映出数据空间密度分布特征。
fcm算法是用隶属度确定每个数据点属于某个类的程度的一种聚类算法。它的思想是:被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。这是对隶属度函数求极小值的问题。在数据挖掘,图像处理,蛋白质相互作用网络聚类上都有广泛的应用。
针对fcm算法的缺点,引入了基于密度的数据预处理机制,同时加入了氨基酸之间的序列特征,对木聚糖酶氨基酸相互作用网络进行聚类分析。
待聚类的数据集
数据点i的局部密度ρi定义为:
dij代表节点的欧几里得距离,dc表示截断距离,dc的选取在算法描述中详细介绍。
数据点i的距离δi为:
其中,数据集
预处理算法描述如下:
1.从数据集s中获取节点的位置信息,计算出距离矩阵dij。
2.对距离矩阵进行升序排列,选取前1%个距离设定为截断距离dc。
3.根据公式2,3计算出每个节点的ρi和δi。
基于步骤3中的结果,把局部密度和距离都较大的“离群点”作为s-fcm算法的初始聚类中心,初始聚类中心的数目作为分类数目。
确定数据集s和分类数目c,以及初始聚类中心后,fcm算法是下列目标函数求极小值问题,函数如下:
公式中(3)j为待聚类节点数量;i为分类数目;uij为第j个节点属于第i个聚类中心的隶属度;ci为第i个社团的聚类中心;d为节点间的欧几里得距离。显然,fcm算法没有考虑到样本不同属性对分类贡献的差异,在蛋白质中,氨基酸形成二级结构是有倾向性的,序列上相邻的氨基酸可能在同一个二级结构中,也可能在不同的二级结构中,氨基酸形成二级结构的倾向性受到周围氨基酸的影响。所以,本发明在考虑距离的基础上,加入了氨基酸的序列特征,将序列特征引入目标函数。那么,对氨基酸相互作用网络聚类的问题可以表示为公式(4)目标函数求极小值的问题。
本发明中模糊参数m取2.其中sq表示节点间的序列特征,定义参数α>0是定义序列特征所占的权重,当α增加,序列特征的影响大于距离特征。
算法评价分为内部评价和外部评价,内部评价是模块度,外部评价是二级结构准确率。
模块度:
m表示在整个网络中边的数量;avw表示网络中节点形成的实际边数,
二级结构准确率:
w表示蛋白质中二级结构的个数,tij表示在第i个社团中出现在第j个二级结构中氨基酸的数目,tj表示第j个二级结构中氨基酸总数目。整个木聚糖酶氨基酸相互作用网络的二级结构准确率acc是社团二级结构准确率的平均值。
算法如下:
1.数据集预处理,通过预处理算法处理待分类的木聚糖酶氨基酸相互作用网络,依据氨基酸的实际分布情况,获得s-fcm算法所需要的初始聚类中心以及分类数目。
2.根据算法新的目标函数公式4计算目标函数的值,同时计算隶属度矩阵u,并确定新的聚类中心。
3.多次迭代,重复步骤2,用一个矩阵范数比较两次迭代之间隶属度矩阵,如果||u(k+1)-uk||<=ε,则停止迭代。得到最终的聚类中心和节点对于各个社团的隶属度值。
4..利用内部评价标准和外部评价标准对聚类结果进行评价。
本发明的有益效果:本发明公开了一种适用于木聚糖酶氨基酸相互作用网络聚类的s-fcm算法。本发明方法是针对fcm算法的参数依赖性强,并对初始聚类中心敏感的缺陷作出改进。s-fcm算法首先引入了基于密度的数据预处理方法,使其可以根据输入的木聚糖酶氨基酸相互作用网络自身的密度特性来获取初始聚类中以及分类数目,保证聚类结果的可靠性。其次,考虑氨基酸序列特征对聚类结果的影响,从而在距离特征的基础上加入了氨基酸序列特征,提高了聚类的准确度。本发明方法在fcm算法的基础上,针对该算法的一些缺陷做出改进,并对木聚糖酶氨基酸相互作用网络进行聚类,为从社团的角度研究蛋白质的稳定性提供了一个新的途径。
具体实施方式
(1)本文选择来自streptomyceslividans(s.lividans,简写为s.liv)的常温木聚糖酶分子动力学模拟的构象数据作为算法输入。数据集中包括了在300k温度下的20个常温木聚糖酶s.liv的构象信息。二级结构的信息是从pdb数据库中得到的(http://www.rcsb.org/pdb/home/home.do)。
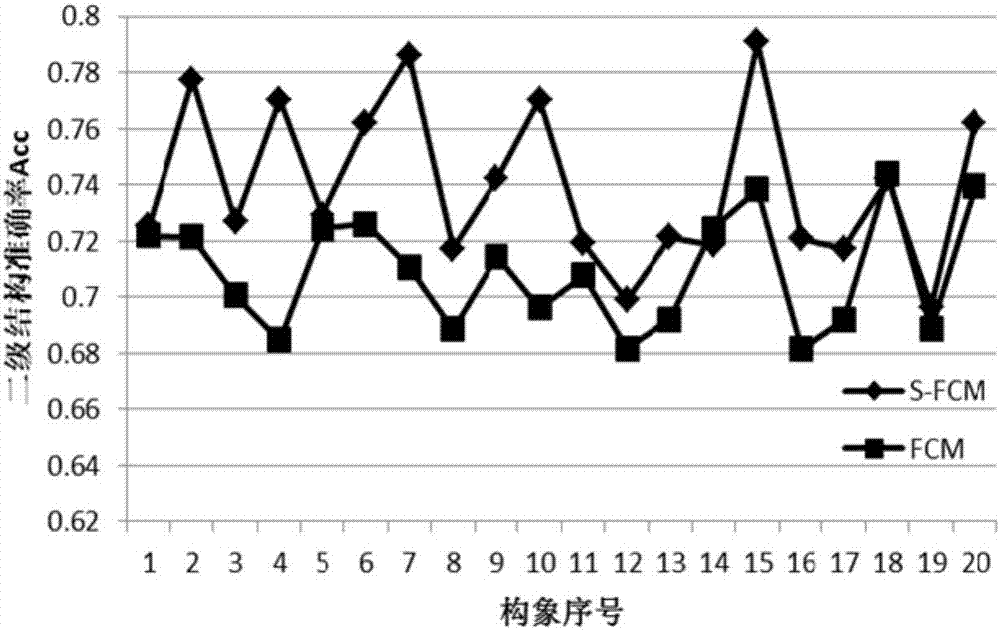
(2)分别用fcm算法和s-fcm算法对20个s.liv构象数据集进行聚类,比较两种算法的模块度和二级结构准确率,如附图说明中的图1,图2所示:
附图说明:
图1:fcm算法和s-fcm算法对常温木聚糖酶20个构象聚类后的模块度q的比较结果;
图2:fcm算法和s-fcm算法对常温木聚糖酶20个构象聚类后的二级结构准确率acc的比较
用本发明提出的预处理算法可以使聚类结果稳定可靠。再由图1和图2可见,考虑到氨基酸序列特征对分类结果的影响,加入序列特征,使s-fcm算法比fcm算法的聚类准确度得到提高。
- 还没有人留言评论。精彩留言会获得点赞!