一种汽车疲劳驾驶预测方法与流程
本发明涉及计算机视觉和图像处理领域,尤其涉及一种汽车疲劳驾驶预测方法。
背景技术:
随着经济的发展,汽车的拥有量急剧增长。据国务院发展研究中心课题组的方案预测结果,中国汽车保有量在2010年达到5669万辆,2016年达到19400万辆,2020年将超过2.5亿辆。高速公路里程日益增加,公路交通的平均车速有了很大提高,这无疑对经济的发展起到了促进作用。但同时交通事故也相应增多,给人民的生命和财产安全带来了极大威胁。据中国公安部交管部门提供的数据统计,2003年中国发生公路交通事故66.7万次。死亡10.44万人,直接经济损失达33.7亿元。美国汽车工程师协会统计,美国每年约有26万起交通事故。大量的疲劳驾驶公路交通事故对人们的生命和财产造成了难以估计的损失。疲劳驾驶检测系统能够检测驾驶员的疲劳状态,并提前给出预警,让存在疲劳状态的驾驶员在就近的服务区休息或紧急在安全区停车休息,避免各种交通意外事故的发生。这项技术涉及计算机视觉、图像处理、模式识别、人工智能、神经网络、机器学习等多个领域的技术。近年来,在疲劳检测方面,国内外的研究者从不同的角度出发提出了很多卓有成效的方法,根据出发点的不同,概括起来,其中代表性的方法大致可以分为两类:一类是基于特征的疲劳检测方法,如文献1:w.o.lee,e.c.lee,k.r.park,blinkdetectionrobusttovariousfacialposes,j.neurosci.methods193(2)(2010)356–372.文献2:k.arai,r.mardiyanto,realtimeblinkingdetectionbasedongaborfilter,int.j.hum.comput.interact.1(3)(2010)33–40.和文献3:l.lu,x.ning,m.qian,y.zhao,closeeyedetectedbasedonsynthesizedgrayprojection,in:advancesinmultimedia,softwareengineeringandcomputing,vol.2,2012,pp.345–351.所描述的,该类方法主要通过抽取虹膜和眼睑的形状特征或眼睛的灰度分布来判别是否疲劳,这类方法的有效性容易受定位的准确性及环境光照变化的影响。另一类是基于表观的疲劳检测方法,如文献4:y.wu,t.lee,q.wu,h.liu,aneyestaterecognitionmethodfordrowsinessdetection,in:proceedingsofvehiculartechnologyconference,2010,pp.1–5.文献5:l.zhou,h.wang,open/closedeyerecognitionbylocalbinaryincreasingintensitypatterns,in:proceedingsofieeeconferenceonrobotics,automationandmechatronics,2011,pp.7–11.所介绍的,该类方法通过抽取描述目标的形状和纹理的中层特征,如lbp、gabor特征等,并利用先进的机器学习工具,如svm、adaboost等,在良好的成像条件下获得了鲁棒性的结果。然而,上述两类方法容易受光照变化、图像模糊、眼睛被遮挡和眼睛定位的准确性的影响,所以它们不适合在挑战性的成像条件下的疲劳检测。
上世纪五十年代末,rosenblatt第一次提出了人工神经网络理论。1984年hopfield从图像碎片中提取出了完整的图像,从而激发了人工神经网络的研究热潮,随后研究者提出了许多神经网络模型,如bp、rbf、rnn等,到上世纪九十年代,人工神经网络在图像处理理论上有了很大发展,并结合其它数学工具如统计学、最优化理论、形态学等,形成了比较完整的理论体系。基于神经网络的图像处理方法有良好的数学基础,深厚的理论背景,在图像边缘检测、分割、修复、聚类、分类和预测等方面取得了一定的成果。
受到大脑中深度层次结构的启发,以及对能够将特征抽取和分类这两个过程有机的结合的迫切需求,研宄者将深度学习的概念引入到人工神经网络的研究中,但计算机硬件的发展限制、大数据的出现及神经网络的局限性使这项工作变得异常困难。研究者在使用标准的随机初始化网络权重的情况下,通常都得到很差的训练和泛化结果,以至于得不到很好的深度网络结构。2006年,hinton等人采用逐层贪心算法和后向传播算法实现了一种叫做深信度网络(deepbeliefnetworks,dbns)的深度网络结构,取得了很好的实验结果。
现代生理学研究表明,人的视觉系统的理解和卷积神经网络中的图像处理过程相一致。lecun等人基于随机梯度下降算法设计并训练了深度卷积神经网络lenet,展现出了相对于其它方法的领先性能。2012年,hinton设计训练的深度卷积网络模型包含了6千万个参数,它从imagenet上学习得到的特征表示的分类能力远超人工设计的特征,具有非常强的泛化能力,并可以成功地应用到其它的数据集和任务中,如物体检测、跟踪和检索等等。
深度模型具有强大的学习能力,高效的特征表达能力,从像素级原始数据到抽象的语义概念逐层提取信息。这使得它在提取图像的全局特征和上下文信息方面具有突出的优势。这为解决计算机视觉问题如图像分割和关键点检测等带来了新的思路。以人脸的图像分割为例。为了预测每个像素属于哪个脸部器官(眼睛、鼻子、嘴、头发),通常的作法是在该像素周围取一个小的区域,提取纹理特征(例如局部二值模式),再基于该特征利用支持向量机等浅层模型分类。因为局部区域包含信息量有限,往往产生分类错误,因此要对分割后的图像加入平滑和形状先验等约束。事实上即使存在局部遮挡的情况下,人眼也可以根据脸部其它区域的信息估计被遮挡处的标注。这意味着全局和上下文的信息对于局部的判断是非常重要的,而这些信息在基于局部特征的方法中从最开始阶段就丢失了。深度学习可以学习针对人脸图像的分层特征表达,模型在高维数据转换过程中隐式地加入了形状先验。最底层可以从原始像素学习滤波器,刻画局部的边缘和纹理特征;通过对各种边缘滤波器进行组合,中层滤波器可以描述不同类型的人脸器官;最高层描述的是整个人脸的全局特征。在最高的隐含层,每个神经元代表了一个属性分类器。
针对基于深度学习的图像分类效果好,同时大数据和计算机硬件的飞速发展促进深度学习分类效果的事实,有研究者利用大数据进行人脸识别的方法,但由于眼睛的目标较小,涉及遮挡、表情变化、光线变化等复杂情况,所以目前这类方法无法适用眼睛的疲劳检测,尚没有看到基于多任务学习的级联深度卷积神经网络的疲劳检测方法。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种鲁棒高效、检测效果好的汽车疲劳驾驶预测方法。
本发明采用的技术方案是:
一种汽车疲劳驾驶预测方法,其包括以下步骤:
步骤1,对于训练数据集给定的任意一幅图像f(x,y),多尺度设定图像以构造图像金字塔并作为下面级联框架的输入;
步骤2,将多尺度训练图像集输入一级卷积神经网络cnn1,获得一级候选人脸窗口及其对应的一级包围盒回归向量;利用一级包围盒回归向量对一级候选窗口进行校正,并应用非极大值抑制nms合并高度重叠的一级候选窗口;
步骤3,将经过校正的一级候选窗口全部输入到二级卷积神经网络cnn2,获得二级候选人脸窗口及其对应的二级包围盒回归向量;将二级包围盒回归向量对二级候选窗口再次进行校正,并应用非极大值抑制nms合并重叠度高的二级候选窗口;
步骤4,将经过再次校正的二级候选窗口全部输入到三级卷积神经网络cnn3,利用人脸特征点标记信息预测图像中的人脸特征点,并输出人脸的5个特征点位置;
步骤5,根据5个人脸特征点中的2个人眼特征点位置,分割出以特征点为中心的24×24眼睛区域,将分割对齐的眼睛区域图像集输入到四级卷积神经网络cnn4中,使用睁眼和闭眼标记信息,通过随机梯度下降算法sgd得到人眼深度视觉特征模型;
步骤6,将摄像头采集的测试图像依次通过cnn1、cnn2、cnn3、cnn4,得到当前测试视频帧图像眼睛的闭合状态;
步骤7,计算驾驶员疲劳视觉评估参数perclos。首先根据摄像头采集速率获得3秒时间内视频包含的总帧数,接着按照步骤6计算3秒视频中包含的人眼闭合的帧数。perclose的计算公式为:
当perclos值大于40%时,则判定驾驶员开始疲劳或处于疲劳状态,输出报警状态。
进一步地,根据所述步骤2中一级卷积神经网络cnn1学习的目标函数被表示为两类分类问题,这两个类别分别是人类标记和非人脸标记;对于每个样本xi采用交叉熵损失作为目标函数:
其中,pi是神经网络产生的表示样本xi是人眼的概率,
进一步地,根据所述步骤3中二级卷积神经网络cnn2的学习目标表示为一个回归问题,对于每个样本xi采用欧氏损失作为目标函数:
其中,
进一步地,根据所述步骤4中三级卷积神经网络cnn3的学习目标表示为一个回归问题,对于每个样本xi采用欧氏损失作为目标函数:
其中,
进一步地,根据所述步骤5中使用基于度量学习的误差函数tripletloss作为神经网络的目标函数。设从训练数据集中随机选择一个样本作为anchor(记为
在方程(4)中,三元组分类损失对三个样本特征的梯度分别为:
其中,l表示三元组分类损失,
进一步地,步骤2、步骤3、步骤4和步骤5均使用随机梯度下降算法迭代学习目标函数以分类或预测人脸与非人脸候选窗口和包围盒回归向量、预测人脸特征点、判别眼睛的睁开闭合状态,通过前向传播得到网络各层的特征图、池化特征图和激活特征图;再利用后向传播算法更新网络各层的权重和偏置,直到网络收敛或终止。
进一步地,当随机梯度下降算法迭代学习目标函数方法应用于步骤2的一级卷积神经网络cnn1时,步骤2的对应卷积神经网络的输入为训练数据集的多尺度金字塔图像;
当随机梯度下降算法迭代学习目标函数方法应用于步骤3的二级卷积神经网络cnn2时,步骤3的对应卷积神经网络的输入为步骤2训练得到的多尺度人脸图像;
当随机梯度下降算法迭代学习目标函数方法应用于步骤4的三级卷积神经网络cnn3时,步骤4的对应卷积神经网络的输入为步骤3训练得到的多尺度人脸图像;
当随机梯度下降算法迭代学习目标函数方法应用于步骤5的四级卷积神经网络cnn4时,步骤5的对应卷积神经网络的输入为分割得到的眼睛图像和非眼睛图像组成三元组训练集
进一步地,当随机梯度下降算法迭代学习目标函数方法应用于步骤5的四级卷积神经网络cnn4时,步骤5获得输出层的激活值为对应三元组的激活值
所述步骤5具体计算过程为:对于输出层第nl层,按照公式(5)、(6)、(7)分别计算三元组分类损失对三元组的激活值的偏导数
进一步地,将摄像头采集的待测试图像输入步骤2、步骤3、步骤4、步骤5训练好的网络中,直接得到人眼的闭合分类信息。
本发明采用以上技术方案,与现有疲劳检测方法相比优点在于:检测精度高,实时性好,鲁棒性高,有效地克服了光线变化、天气变化等因素的影响。本发明的方法不仅能够检测正常光线下人的疲劳状态,而且还能够检测光线较暗及遮挡条件下人的疲劳状态。
附图说明
以下结合附图和具体实施方式对本发明做进一步详细说明;
图1为本发明一种汽车疲劳驾驶预测方法的流程示意图;
图2为本发明一种汽车疲劳驾驶预测方法的一级卷积神经网络cnn1的结构示意图;
图3为本发明一种汽车疲劳驾驶预测方法的二级卷积神经网络cnn2的结构示意图;
图4为本发明一种汽车疲劳驾驶预测方法的三级卷积神经网络cnn3的结构示意图;
图5为本发明一种汽车疲劳驾驶预测方法的四级卷积神经网络cnn4的结构示意图。
具体实施方式
如图1-5之一所示,本发明公开了一种汽车疲劳驾驶预测方法,其包括以下步骤:
步骤1,对于训练数据集给定的任意一幅图像f(x,y),多尺度设定图像以构造图像金字塔并作为下面级联框架下神经网络的输入;
本发明中,产生多尺度图像金字塔的尺度因子为1.2,、1.0、0.8。利用尺度因子可产生三个尺度的训练和测试图像集。它们分别作为训练学习和测试时的网络输入。
本发明中,训练数据集由正例(人脸)、负例(非人脸)、部分人脸和特征脸图像按3:1:1:2比例组成。负例:与基准测试人脸图像交并比小于0.3的图像区域。正例:与基准测试人脸图像交并比大于0.65的图像区域。部分人脸:与基准测试人脸图像交并比在0.4-0.65之间的图像区域。特征脸:包含5个特征点的人脸。
步骤2,将多尺度训练数据集输入卷积神经网络cnn1中,获得候选人脸窗口及其对应的包围盒回归向量;然后使用估计的包围盒回归向量对上述候选窗口进行校正,并应用非极大值抑制nms合并高度重叠的候选窗口;
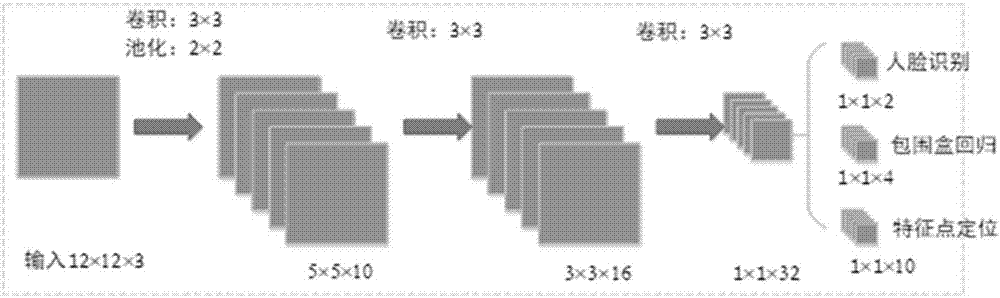
进一步地,所述步骤2中卷积神经网络cnn1是根据人脸识别的特点设计的。cnn1的体系结构如图2所示。输入图像的大小为12×12,神经网络的第一层10个滤波器的大小为3×3,学习率为0.0001,衰减为0.01,步长为1,滤波器权重参数利用"xavier"算法获得,该层网络偏置为0,10个滤波器分别与输入图像按式(13)卷积,得到10个特征图;利用最大池化方法对上述特征图进行池化,池化窗口大小为2×2,步长为1,得到10个新特征图;然后使用prelu激活函数将这些特征图激活为10个特征图。神经网络的第二个卷积层将激活的10个特征图与16个3×3滤波器卷积,得到16个特征图;使用prelu激活函数激活上述特征图得到16个新特征图。在神经网络的第三个卷积层,将新激活的16个特征图与32个3×3滤波器卷积,得到32个特征图,使用prelu激活函数激活它们,得到32个激活特征图。最后,32个激活特征图与2个1×1滤波器卷积,得到候选人眼窗口,softmax分类器识别候选窗口为人脸区域和非人脸区域。同时,将32个激活特征图再次与4个1×1滤波器卷积,得到包围盒对应的回归向量。将32个激活特征图与10个1×1滤波器卷积得到5个特征点的坐标。
步骤3,将经过校正的上述候选窗口全部输入到卷积神经网络cnn2,获得二级候选人脸窗口及其对应的二级包围盒回归向量;使用二级包围盒回归向量对二级候选窗口再次进行校正,并应用非极大值抑制nms合并重叠度高的二级候选窗口;
步骤3中卷积神经网络cnn2的体系结构如图3所示。将步骤2得到的经过校正的候选窗口重新调整为大小24×24的输入图像,输入到卷积神经网络cnn2中。神经网络的第一层28个滤波器的大小为3×3,学习率为0.0001,衰减为0.01,步长为1,滤波器权重利用"xavier"算法获得,该层网络偏置为0,该层28个滤波器分别与输入图像按式(13)卷积,得到28个特征图;然后利用最大池化方法对上述特征图进行池化,池化窗口大小为3×3,步长为2,得到28个新特征图;接着使用prelu激活函数激活上述特征图得到28个激活特征图。在网络模型第二个卷积层,首先将这28个激活特征图与48个3×3滤波器卷积,得到48个特征图;其次利用最大池化方法对上述特征图进行池化,池化窗口大小为3×3,步长为2,得到48个新特征图;再次使用prelu激活函数得到48个激活特征图。在网络结构的第三个卷积层,首先将获取的48个激活特征图与64个2×2滤波器卷积,得到64个特征图;接着使用prelu激活函数激活它们,得到64个激活特征图。在模型第四个卷积层,将上一层64个激活特征图与128个1×1滤波器卷积,得到128内积值。使用prelu激活函数激活它们得到128个激活的内积值。在神经网络第五个卷积层,128个激活特征与2个1×1滤波器卷积,得到候选人脸窗口。最后,这些候选人脸窗口通过softmax分类器被识别为人脸和非人脸区域。同时,将128个激活特征与4个1×1滤波器卷积得到包围盒对应的回归向量。将128个激活特征图与10个1×1滤波器卷积得到5个特征点的坐标。
步骤4,将经过校正的二级候选窗口全部输入到三级卷积神经网络cnn3,利用人脸特征点标记预测图像中的人脸特征点,并输出人脸的5个特征点位置;
步骤4中三级卷积神经网络cnn3的体系结构如图4所示。将步骤3得到的经过校正的二级候选窗口重新调整为大小48×48的输入图像,输入到另一个卷积神经网络cnn3中。cnn3的第一层32个滤波器的大小为3×3,学习率为0.0001,衰减为0.1,步长为1,滤波器权重系数利用"xavier"算法获得,该层网络偏置为0。该层32个滤波器分别与上述输入图像按式(13)卷积,得到32个特征图;然后利用最大池化方法对上述特征图进行池化,池化窗口大小为3×3,步长为2,得到32个新特征图;接着使用prelu激活函数激活上述池化后的特征图得到32个激活特征图。在cnn3的第二个卷积层,将这32个激活的特征图与64个3×3滤波器卷积,得到64个特征图;利用最大池化方法对上述特征图进行池化,池化窗口大小为3×3,步长为2,得到64个池化特征图;然后使用prelu激活函数激活上述池化特征图得到64个激活特征图。在cnn3的第三个卷积层,将上述64个激活特征图与64个3×3滤波器卷积,得到64个特征图;利用最大池化方法对上述特征图进行池化,池化窗口大小为2×2,步长为2,得到64个池化特征图;接着使用prelu激活函数激活它们,得到64个激活特征图。在cnn3的第四个卷积层,将64个激活特征图与128个2×2滤波器卷积,得到128特征图;然后使用prelu激活函数激活它们得到128个激活的特征图。在cnn3的第五个卷积层,将上述128个激活特征图与256个3×3滤波器卷积,得到256个特征图。为了防止过拟合,提高模型的泛化能力,这一层在训练时采用了dropout技术,每次训练都抛弃25%的隐层节点进行训练。然后使用prelu激活函数激活它们得到256个激活的特征图。在cnn3的第六个卷积层,将256个激活的特征图与2个1×1滤波器进行内积,得到候选人脸窗口。最后,将候选人脸窗口输入softmax分类器被识别为人脸和非人脸区域。同时将256个激活特征图与4个1×1滤波器卷积得到包围盒对应的回归向量。将256个激活特征图与10个1×1滤波器卷积得到5个特征点的坐标。
步骤5,根据步骤4检测的人脸的2个人眼特征点位置,分割出以人眼特征点为中心的24×24眼睛区域,将分割对齐的眼睛区域图像输入到四级卷积神经网络cnn4,通过深度学习算法训练人眼深度视觉特征模型;
步骤5中,四级卷积神经网络cnn4的体系结构如图5所示。将步骤4得到的2个人眼特征点位置,分割出以人眼特征点为中心的24×24眼睛区域。将人眼区域重新调整为大小48×48的输入图像,输入到四级卷积神经网络cnn4中。cnn4的第一层96个滤波器的大小为5×5,步长为1,滤波器权重利用"xavier"算法获得,该层网络偏置为0,96个滤波器分别与输入图像按式(13)卷积,得到96个特征图;将计算得到的得到96个特征图分别与96个大小为1×1的滤波器卷积,卷积步长为1,再次得到96个特征图;然后利用最大池化方法对上述特征图进行池化,池化窗口大小为3×3,步长为2,得到96,个池化特征图;再使用prelu激活96个池化特征图,得到96个激活特征图。cnn4的第二个卷积层,将上述96个激活特征图与256个3×3滤波器卷积,得到256个特征图;将计算得到的得到256个特征图分别与256个大小为1×1的滤波器卷积,卷积步长为1,再次得到256个特征图;利用最大池化方法对上述特征图进行池化,池化窗口大小为3×3,步长为2,得到256个池化特征图;接着使用prelu激活函数得到256个激活特征图。在cnn4的第三个卷积层,将激活的256个特征图与384个3×3滤波器卷积,得到384个特征图;将计算得到的得到384个特征图分别与384个大小为1×1的滤波器卷积,卷积步长为1,再次得到384个特征图;利用最大池化方法对上述特征图进行池化,池化窗口大小为2×2,步长为2,得到384个池化特征图;然后使用prelu激活函数激活它们,得到384个激活特征图。在cnn4的第四个卷积层,384个激活特征图与128个3×3滤波器卷积,得到128特征图;将计算得到128个特征图分别与128个大小为1×1的滤波器卷积,卷积步长为1,再次得到128个特征图;利用平均池化方法对上述特征图进行池化,池化窗口大小为4×4,步长为2,得到128个池化特征图;然后使用prelu激活函数激活它们得到128个激活的特征图。在cnn4的第五个卷积层,128个激活特征图与256个1×1滤波器卷积得到256个特征图,并用prelu激活函数激活它们得到256个激活特征图。为了防止过拟合,提高模型的泛化能力,这一层在训练时采用了dropout技术,每次训练都抛弃25%的隐层节点进行训练。使用prelu激活函数激活它们得到256个激活的特征图。256个激活的特征图与128个1×1滤波器进行内积,得到128维特征向量。在cnn4的训练中,学习率设置为0.005,间隔α设置为0.2。我们使用具有标准后向传播的随机梯度下降sgd和adagrad训练cnn4。
步骤6,将摄像头采集的测试图像依次通过cnn1、cnn2、cnn3、cnn4,得到测试视频帧图像眼睛的闭合状态;
步骤7,计算驾驶员疲劳视觉评估参数perclos。首先根据摄像头采集速率获得3秒时间内视频包含的总帧数,接着计算3秒视频中包含的人眼闭合的帧数。perclose的计算公式为:
当perclos值大于40%时,则判定驾驶员开始疲劳或处于疲劳状态,输出报警状态。
本发明采用以上技术方案,与现有疲劳检测方法相比优点在于:本发明的方法不仅能检测正常光照、姿态、表情条件下驾驶员的疲劳状态,还能够检测光照条件变化、姿态及表情变化等条件下的驾驶员疲劳状态,检测结果鲁棒性高,有效地克服了光照、姿态、表情等因素对驾驶员疲劳检测的影响。
本发明公开一种汽车疲劳驾驶预测方法,构建依次设置一至四级的卷积神经网络,输入图像由一级卷积神经网络获得候选人脸窗口及其对应的包围盒回归向量,再经过一二级卷积神经网络合并高度重叠的候选窗口;剩余的候选窗口经过三级卷积神经网络并利用人脸特征点信息预测人脸特征点,输出5个人脸特征点位置;再用5个人脸特征点中的2个人眼特征点为中心分割眼睛区域并由四级卷积神经网络通过深度学习算法训练眼睛图像的深度视觉特征模型;将摄像头采集的测试图像依次通过cnn1、cnn2、cnn3、cnn4,得到测试视频帧图像眼睛的闭合状态;反复计算3秒时间内视频中驾驶员疲劳视觉评估参数perclos,当perclos值大于40%时,则判定驾驶员开始疲劳或处于疲劳状态,输出报警状态。本发明的方法不仅能检测各种光照、姿态、表情条件下驾驶员的疲劳状态,检测结果鲁棒性高,有效地克服了光照、姿态、表情等因素对驾驶员疲劳检测的影响。
- 还没有人留言评论。精彩留言会获得点赞!