基于强鲁棒自适应算法的采煤机故障诊断系统的制作方法
本发明涉及信号处理领域、自适应优化领域、机器学习领域、故障诊断领域,尤其涉及基于强鲁棒自适应算法的采煤机故障诊断系统。
背景技术:
煤炭作为工业动力燃料的主要原材料,是能源的主体,而且是全世界储量最大的化石燃料,使得煤炭资源的开采和使用成为全世界的关注点。由于煤矿安全问题严重,当前国家把煤矿安全作为突出任务,这种趋势下煤炭开采逐步机械化,并涌现出了很多大型复杂的机械化设备,其中,采煤机便是煤炭生产中的核心设备。其集机械、电子、电气、液压传动系统于一体,因此构成十分复杂,再加上其工作环境恶劣,在工作时会受到来自煤岩等巨大的冲击,还会受到煤尘、水雾等其它方面的污染,使得采煤机的油液经常遭受污染,导致采煤机的液压元件和机械零件过早磨损,造成采煤机过早损坏甚至故障,导致整个煤矿生产系统的瘫痪。因此对采煤机进行监测以提前预防故障的发生具有重要意义。
传统的采煤机故障诊断方法一般依赖于现场维修人员的专业知识和维修经验,具有效率低下、判断困难等弊端,而当前已经提出的采煤机故障自动诊断方案存在以下问题:①在复杂和陌生环境中的普适性问题亟待解决;②采煤机故障诊断系统数据库更新升级缓慢,难以维护;③随着系统的在线运行,模型失配严重甚至崩溃。以上问题导致传统的采煤机故障诊断方案准确度低、系统响应慢和可靠性差。
技术实现要素:
针对采煤机工作环境恶劣,对故障准确诊断需要的迫切需求,本发明的目的在于提供一种参数自适应、寻优效果好、识别精度高、普适性好的基于强鲁棒自适应算法的采煤机故障诊断系统。
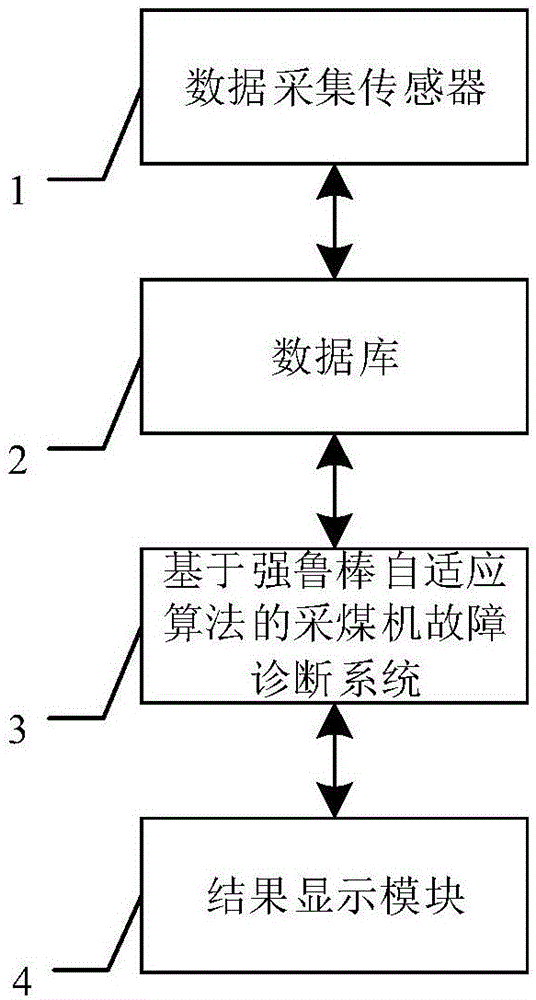
本发明解决其技术问题所采用的技术方案是:基于强鲁棒自适应算法的采煤机故障诊断系统,包括数据预处理模块、采煤机故障诊断模型建模模块、自适应寻优模块、采煤机故障诊断模块以及模型失配矫正模块。数据采集传感器、数据库、基于强鲁棒自适应算法的采煤机故障诊断系统以及结果显示模块依次相连,所述数据采集传感器对采煤机轴承温度、传动箱油温及油位、辅助系统压力、冷却水压力、液压系统进液流量及出液流量、冷却水流量、摇臂升起时间、电机电流及温度信息进行采集,并将采煤机信息储存到所述的数据库中,数据库中包含历史采煤机数据及其对应的故障类型标签,故障类型标签主要包含以下几种:轴承故障、主泵故障、补油泵故障、滤油器故障、辅助泵故障、液压马达故障、电机过载、冷却系统故障,数据库为基于强鲁棒自适应算法的采煤机故障诊断系统提供数据支持。基于强鲁棒自适应算法的采煤机故障诊断系统得到的故障诊断结果将通过结果显示模块输出显示。
进一步地,数据预处理模块用以进行采煤机数据预处理,采用如下过程完成:
(1)从数据库中采集一条采煤机数据,其特征分别为xj,j=1,2,…d,d为特征维度;
(2)对样本特征进行归一化处理,得到归一化特征值
进一步地,采煤机故障诊断模型建模模块,用以建立采煤机故障诊断模型,采用如下过程完成:
(1)从数据库中采集ns个采煤机数据xs及其所对应的故障类型标签ys作为训练集,采集nv个采煤机数据xv及其所对应的故障类型标签yv作为验证集;
(2)采用训练集进行监督训练,得到采煤机故障诊断模型:
y=f(x)。(2)
进一步地,自适应寻优模块,用以对重要参数——随机特征个数m,子样本个数即子决策树个数n进行优化。采用自适应群智能算法进行寻优,具体过程如下:
(1)随机产生初始粒子速度和位置;
(2)计算种群多样性指数d(t):
其中,gbest(t)是整个群在第t次迭代时到达过的全局最优解,表示f(gbest(t))对应的适应度值,m是群规模,ri(t)是第i个粒子在第t次迭代时的位置,f(ri(t))表示ri(t)对应的适应度值,适应度选择错误率的相反数。
(3)更新学习速率参数μ(t):
(4)更新粒子的速度和位置,产生新的群体;
其中,α1=0.5是个体加速度参数,α2=0.35是全局加速度参数,
(5)判断是否符合算法终止条件——连续五次迭代全局最优解不变,若符合,输出全局最优粒子及其代表的最优解,并结束迭代;否则返回0继续迭代;
(6)重复以上步骤,将优化好的模型在验证集上进行测试,选取训练集验证集上正确率最高的模型作为最优模型。
进一步地,采煤机故障诊断模块用以利用训练好的最优采煤机故障诊断模型对新采集的采煤机数据进行识别以判断采煤机当前是否故障以及故障类型。采用如下过程完成:
(1)对新采集到的采煤机数据xt进行预处理:
(2)利用自适应寻优模块优化后的最优模型对采煤机故障进行诊断:
其中,fopt为优化后的最优模型,
进一步地,模型失配矫正模块考虑到由于采煤机工作环境恶劣,负载变化大,一些核心部位在工作时很容易发生过载,导致老化或损坏甚至故障,而且采煤机自身的组成结构复杂,产生故障的原因也非常复杂而导致的固定采煤机故障数据库得到的模型对新故障的诊断能力有限,即对未知故障会导致模型失配,从而引起诊断效果变差甚至崩溃的弊端,更进一步提出模型失配矫正策略,以期突破在复杂和陌生环境下新故障所导致的模型失配问题,进一步提升采煤机故障诊断模型的鲁棒性(即普适效果)和置信度,并大幅度提高不同采煤机工作环境下的模型适应性,从而得到基于强鲁棒自适应算法的采煤机故障最优诊断模型。采用如下过程完成:
(1)时刻t采集得到的采煤机数据的标签可能在未来的t+n时刻得到,由此可以判断模型诊断值的准确性。将判断错误的采煤机数据作为“难”样本点加入训练集;
(2)自适应寻优模块重新在线优化参数得到新的采煤机故障最优诊断模型,以解决采煤机在复杂和陌生工作环境下的模型失配问题,提高模型的适应性和鲁棒性。
进一步地,采煤机故障诊断模块得到的故障诊断结果将通过结果显示模块输出显示。
本发明的技术构思为:本发明对采煤机数据进行预处理,并对预处理后的数据进行非线性拟合,引入参数自适应方法,并于在线运行过程中不断矫正模型失配问题,从而建立基于强鲁棒自适应算法的采煤机故障诊断系统。
本发明的有益效果主要表现在:1、建立了采煤机故障诊断模型,可以在线诊断采煤机故障;2、引入参数自适应算法,寻优效果好,从而避免了人为参数设定的随机性导致的置信度和准确度的下降;3、通过不断地模型在线矫正,解决复杂和陌生环境下的模型失配问题,进一步提高了模型的鲁棒性。
附图说明
图1基于强鲁棒自适应算法的采煤机故障诊断系统的基本硬件结构图;
图2基于强鲁棒自适应算法的采煤机故障诊断系统的功能模块图;
图3自适应群智能算法流程图;
图4模型失配校正策略流程图。
具体实施方式
下面根据附图具体说明本发明。
实施例1
参考图1、图2、图3、图4,基于强鲁棒自适应算法的采煤机故障诊断系统,包括数据预处理模块5、采煤机故障诊断模型建模模块6、自适应寻优模块7、采煤机故障诊断模块8以及模型失配矫正模块9。数据采集传感器1、数据库2、基于强鲁棒自适应算法的采煤机故障诊断系统3以及结果显示模块4依次相连,所述数据采集传感器1对采煤机轴承温度、传动箱油温及油位、辅助系统压力、冷却水压力、液压系统进液流量及出液流量、冷却水流量、摇臂升起时间、电机电流及温度信息进行采集,并将采煤机信息储存到所述的数据库2中,数据库2中包含历史采煤机数据及其对应的故障类型标签,故障类型标签主要包含以下几种:轴承故障、主泵故障、补油泵故障、滤油器故障、辅助泵故障、液压马达故障、电机过载、冷却系统故障,数据库2为基于强鲁棒自适应算法的采煤机故障诊断系统3提供数据支持。基于强鲁棒自适应算法的采煤机故障诊断系统3得到的故障诊断结果将通过结果显示模块4输出显示。
进一步地,数据预处理模块5用以进行采煤机数据预处理,采用如下过程完成:
(1)从数据库中采集一条采煤机数据,其特征分别为xj,j=1,2,…d,d为特征维度;
(2)对样本特征进行归一化处理,得到归一化特征值
进一步地,采煤机故障诊断模型建模模块6,用以建立采煤机故障诊断模型,采用如下过程完成:
(1)从数据库2中采集ns个采煤机数据xs及其所对应的故障类型标签ys作为训练集,采集nv个采煤机数据xv及其所对应的故障类型标签yv作为验证集;
(2)采用训练集进行监督训练,得到采煤机故障诊断模型:
y=f(x)。(2)
进一步地,参考图3,自适应寻优模块7用以对重要参数——随机特征个数m,子样本个数即子决策树个数n进行优化。采用自适应群智能算法进行寻优,具体过程如下:
(1)随机产生初始粒子速度和位置;
(2)计算种群多样性指数d(t):
其中,gbest(t)是整个群在第t次迭代时到达过的全局最优解,表示f(gbest(t))对应的适应度值,m是群规模,ri(t)是第i个粒子在第t次迭代时的位置,f(ri(t))表示ri(t)对应的适应度值,适应度选择错误率的相反数。
(3)更新学习速率参数μ(t):
(4)更新粒子的速度和位置,产生新的群体;
其中,α1=0.5是个体加速度参数,α2=0.35是全局加速度参数,
(5)判断是否符合算法终止条件——连续五次迭代全局最优解不变,若符合,输出全局最优粒子及其代表的最优解,并结束迭代;否则返回0继续迭代;
(6)重复以上步骤,将优化好的模型在验证集上进行测试,选取训练集验证集上正确率最高的模型作为最优模型。
进一步地,采煤机故障诊断模块8用以利用训练好的最优采煤机故障诊断模型对新采集的采煤机数据进行识别以判断采煤机当前是否故障以及故障类型。采用如下过程完成:
(1)对新采集到的采煤机数据xt进行预处理:
(2)利用自适应寻优模块7优化后的最优模型对采煤机故障进行诊断:
其中,fopt为优化后的最优模型,
进一步地,参考图4,模型失配矫正模块9考虑到由于采煤机工作环境恶劣,负载变化大,一些核心部位在工作时很容易发生过载,导致老化或损坏甚至故障,而且采煤机自身的组成结构复杂,产生故障的原因也非常复杂而导致的固定采煤机故障数据库得到的模型对新故障的诊断能力有限,即对未知故障会导致模型失配,从而引起诊断效果变差甚至崩溃的弊端,更进一步提出模型失配矫正策略,以期突破在复杂和陌生环境下新故障所导致的模型失配问题,进一步提升采煤机故障诊断模型的鲁棒性(即普适效果)和置信度,并大幅度提高不同采煤机工作环境下的模型适应性,从而得到基于强鲁棒自适应算法的采煤机故障最优诊断模型。采用如下过程完成:
(1)时刻t采集得到的采煤机数据的标签可能在未来的t+n时刻得到,由此可以判断模型诊断值的准确性。将判断错误的采煤机数据作为“难”样本点加入训练集;
(2)自适应寻优模块7重新在线优化参数得到新的采煤机故障最优诊断模型,以解决采煤机在复杂和陌生工作环境下的模型失配问题,提高模型的适应性和鲁棒性。
进一步地,采煤机故障诊断模块8得到的故障诊断结果将通过结果显示模块4输出显示。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!