一种保持移动特征的车辆轨迹线数据压缩方法与流程
本发明属于地理信息技术领域,涉及一种车辆轨迹线数据的压缩方法,尤其涉及一种保持移动特征的车辆轨迹线数据压缩方法。
背景技术:
车辆轨迹线通常由一系列按时间序列组织的位置坐标组成,用以描述车辆在一定地理空间范围及时间周期内的时空运动状态。随着以全球卫星定位系统(GPS)、我国的北斗导航系统等为代表的定位导航技术的不断发展完善,以及车载/人载位置感知设备的普及,各种类型的车辆轨迹监测数据成为当前众源大数据的重要组成部分。这些轨迹监测数据对于城市群体\个体行为模式分析、交通信息实时监测表达、以及地理数据库更新等具有重要意义。然而,具备空间/时间高分辨率特点的车辆轨迹数据通常规模十分巨大。例如,车载GPS接收设备每10秒记录一次车辆当前的位置信息,一个中等规模城市的出租车单个工作日产生的轨迹线数据量将达到GB级别。一方面,这对存储设备空间、网络传输带宽以及后期分析的计算资源造成巨大压力;另一方面,轨迹数据本身包含大量冗余信息,浪费存储计算资源的同时也对分析处理及可视化表达造成负面干扰。解决上述问题的途径之一是研究高效的车辆轨迹线数据压缩方法,即在满足一定几何精度条件下删除冗余甚至信息量较小的轨迹点,从而压缩轨迹线数据规模。
目前,实施轨迹线压缩主要采用来自传统面向快照式静态地理数据的线目标压缩方法。它们的基本思想是从压缩精度控制出发,依据几何上的距离、角度、面积等指标参量评估线目标上每个点的重要性,保留重要特征点(如端点、局部极值点、拐点等)的同时删除其它次要的点。以应用中使用频率最高的Douglas-Peucker算法为例,通过相对当前基准线(首尾点连线)的最大偏移距离对原始线目标进行递归分段,当某一分段部分对应的最大偏移距离小于设定的几何化简精度ε,则将该分段部分拟合为对应的基准线。这类方法能够较好地保持原始线目标的空间形态结构,但是缺乏对时间维信息的考虑,应用到车辆时空轨迹线压缩中容易丢失速度、加速度、方向变化等移动特征。
技术实现要素:
针对上述存在的应用问题,本发明设计了一种新的保持移动特征的车辆轨迹线数据压缩方法。本发明的核心思想是依据速度、方向等移动特征相似性原则对原始轨迹线进行层次化剖分,使得几何精度控制下的轨迹点取舍决策尽量发生在移动模式均一的轨迹线片段内,从而缓解单纯考虑几何特征的压缩方法对原始轨迹线蕴含的移动特征的破坏。
本发明所采用的技术方案是:一种保持移动特征的车辆轨迹线数据压缩方法,其特征在于,包括以下步骤:
步骤1:按轨迹点产生的时间次序将原始轨迹线T组织为T={p1,p2,…,pn},每个轨迹点pi表示为三元组信息<xi,yi,ti>,xi和yi为轨迹点pi的空间位置坐标,ti表示pi产生的时间信息,n是包含的轨迹点数量,1≤i≤n;
步骤2:依次提取相邻两个轨迹点构成的轨迹直线段,组织为轨迹直线段集合E={e1,e2,…,en-1},计算每一条轨迹直线段ej对应区域内车辆的移动速度vj和移动方向θj,1≤j≤n-1;
步骤3:在拓扑连接关系约束下,基于速度、方向特征相似性原则对集合E中的轨迹直线段进行层次化聚类,并将聚类结果组织为层次二叉树结构;
步骤4:在压缩的几何精度阈值ε控制下,通过由上到下遍历层次二叉树结构的方式对原始轨迹线T实施分区处理,使得同一区域内轨迹线段的中间点距首尾基准线最大偏移距离小于ε;
步骤5:提取各分区内轨迹线片段的首尾点,按时间次序连接组织为压缩后的轨迹线T’。
本发明通过针对轨迹直线段的层次化聚类手段,将轨迹线隐含的速度、方向变化信息纳入到对局部轨迹点取舍决策中,使得移动特征变化上具有重要意义的轨迹点由于处在分区临界点而得以保留,从而使压缩结果达到更好地保持原始轨迹线移动特征这一目的。
附图说明
图1是本发明实施例的流程图;
图2是本发明实施例的车辆轨迹线初始化组织示意图;
图3是本发明实施例的车辆轨迹线直线段组织示意图;
图4是本发明实施例的轨迹直线段范围内车辆移动方向定义示意图;
图5是本发明实施例的轨迹线直线段层次化聚类方法示意图;
图6是本发明实施例的利用二叉树表达轨迹直线段层次化聚类结果的示意图;
图7是本发明实施例的轨迹线分区结果示意图;
图8是本发明实施例的轨迹线压缩结果生成示意图;
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
请见图1,本发明提供的一种保持移动特征的车辆轨迹线数据压缩方法,包括以下步骤:
步骤1:按照车辆GPS轨迹线数据具体的文件格式读取数据后,进行数据的初始化组织。
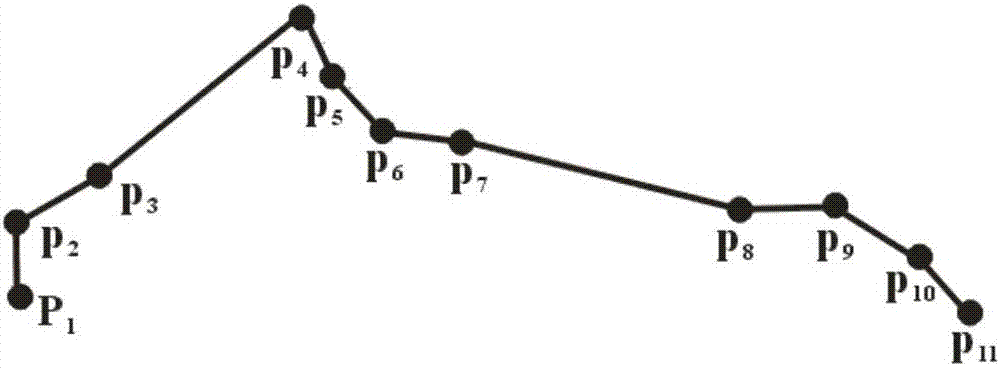
如图2所示的一条原始轨迹线T,该轨迹线按轨迹点产生的时间次序组织为T={p1,p2,…,p11},一共包含11个轨迹点,每个轨迹点pi表示为三元组信息<xi,yi,ti>,xi和yi为轨迹点pi的空间位置坐标,ti表示pi产生的时间信息,1≤i≤11;
步骤2:依次提取相邻两个轨迹点构成的轨迹直线段,组织为轨迹直线段集合E={e1,e2,…,en-1},计算每一条轨迹直线段ej对应区域内车辆的移动速度vj和移动方向θj,1≤j≤n-1;
图3是在图2所示的轨迹线基础上进一步提取轨迹直线段,共得到10条轨迹直线段,组织为集合E={e1,e2,…,e10}。
车辆运动是一种连续的状态,而轨迹线是对车辆运动位置状态的离散化描述模型,相邻轨迹点的中间状态无法获得精确的描述。因此,本发明忽略同一轨迹直线段内车辆的运动状态的变化,即认为同一轨迹直线段内车辆的运行速度及方向相同。基于这一前提条件,分别定义由相邻轨迹点pi,pi+1组成直线段ei范围内车辆的运动速度vi和移动方向θi如下:
(1)移动速度vi:定义为相邻轨迹点pi,pi+1间的欧式距离与两个轨迹点定位时间差的商。其中,d(pi,pi+1)表示轨迹点pi和pi+1间的欧式距离,ti和ti+1则分别是轨迹点pi和pi+1的定位时间。
(2)移动方向θi:定义为由正向X轴沿逆时针方向至有向线段形成的夹角(如图4所示),其中0≤θi<2π。
步骤3:提取轨迹直线段并计算相关速度、方向信息后,下一步在在拓扑连接关系约束下依据速度、方向相似性原则对集合E中的轨迹直线段进行层次化聚类,并将聚类结果组织为层次二叉树结构。
结合图5,实施例具体的实施过程说明如下:
(1)首先,将每条轨迹直线段映射为一个聚类单元。如图5a所示实例,该轨迹线共包含10条轨迹直线段,每条直线段独立构成一个聚类单元,表示为G1={e1}、G2={e2}、…、G10={e10}。
(2)在相邻聚类单元间定义连接边,并计算所有连接边的长度。连接边长度表示相邻两个聚类单元间移动特征(包括速度、方向)的差异性,如对于相邻的两个聚类单元Gi和Gj,连接边长度L(Gi,Gj)定义为:
其中,和分别表示Gi包含的轨迹直线段的平均速度值和平均方向值,和分别表示Gj包含的轨迹直线段的平均速度值和平均方向值,vmax和vmin则分别表示集合E包含的轨迹直线段的最大速度值和最小速度值,m1和m2分别表示速度差异和方向差异在连接边长度计算中的权值。m1和m2的具体取值需要考虑轨迹线自身特点和应用需求。例如对于沿城区道路行驶的车辆轨迹数据,车速特征相对方向特征变化更为频繁,m1取值应适当高于m2取值,如m1和m2分别取0.6和0.4。对于图5a所示实例,按上述方法首先计算相邻聚类单元间的连接边长度,包括L(G1,G2)、L(G2,G3)、L(G3,G4)、L(G4,G5)、L(G5,G6)、L(G6,G7)、L(G7,G8)、L(G8,G9)、L(G9,G10)。
(3)取当前长度值最小的连接边,将相连接的两个聚类单元合并为一个新的聚类单元,同时按式2计算新的聚类单元两侧的连接边长度。如图5b中,连接边长度L(G9,G10)最小,因此将聚类单元G9={e9}和G10={e10}组成更大的聚类单元G11={e9,e10};同时将原来G8和G9之间的连接边更新为G8和G11间的连接边,按照式2重新计算连接边长度L(G8,G11),更新后的连接边长度依次是L(G1,G2)、L(G2,G3)、L(G3,G4)、L(G4,G5)、L(G5,G6)、L(G6,G7)、L(G7,G8)、L(G8,G11)。
(4)重复步骤3.3直至集合E中所有的轨迹直线段单元聚合为一个聚类单元Gf,即Gf={e1,e2,…,en-1}。例如图5c是在图5b表示的结果基础上进一步将连接边长度最小的两个聚类单元G4={e54}和G5={e5}组成更大的聚类单元G12={e4,e5},重新计算G12两侧的连接边长度,更新后的连接边长度依次是L(G1,G2)、L(G2,G3)、L(G3,G12)、L(G12,G6)、L(G6,G7)、L(G7,G8)、L(G8,G11);重复上述过程,直至得到最高级别的聚类单元G19={e1,e2,e3,e4,e5,e6,e7,e8,e9,e10}。图5d通过不同灰度的缓冲区记录了整个层次化聚类的过程及中间结果。
(5)将整个层次化聚类结果组织为层次二叉树结构,树的根结点对应最大的聚类单元(包含所有的轨迹直线段),叶子节点对应单条轨迹直线段构成的聚类单元,中间节点则对应由多条轨迹直线段构成的不同层次的聚类单元。图6表示了图5中层次化聚类结果的二叉树结构,二叉树的根结点对应于包含所有轨迹直线段的最高级别聚类单元G19={e1,e2,e3,e4,e5,e6,e7,e8,e9,e10},二叉树的叶子节点则分别是条轨迹直线段构成的聚类单元如G1={e1}、G2={e2}、…、G10={e10},中间结点由多条轨迹直线段构成的不同层次的聚类单元,不同结点间的分支关系则描述了层次化聚类的过程信息。由二叉树根结点到叶子结点,树节点对应的轨迹直线段间的移动特征(速度、方向)差异越来越小,为后面基于移动特征差异性的分区处理提供了结构化信息支撑。
步骤4:在压缩的几何精度阈值ε控制下,通过由上到下遍历层次二叉树结构的方式对原始轨迹线T实施分区处理,使得同一区域内轨迹线段的中间点距首尾基准线最大偏移距离小于ε;
实施例具体的实施过程说明如下:
以图6所示的层次化聚类结果二叉树结构为例,由根结点向叶子结点遍历构建的层次二叉树,每遍历一个树结点:
(1)提取该结点对应聚类单元包含的所有轨迹线直线段,按相邻关系组织为轨迹线片段。如图6中编号为2的二叉树结点对应的聚类单元为G16={e1,e2,e3},将G16包含的轨迹直线段按相邻关系连接后得到由轨迹点p1,p2,p3,p4构成的轨迹片段。
(2)以该轨迹线片段的首尾点构成的直线段为基准线,计算每一个中间点到基准线的偏移距离,记录其中的最大偏移距离dmax。例如图6中聚类单元G16对应的由轨迹点p1,p2,p3,p4构成的轨迹片段,分别计算中间轨迹点p2和p3到由首尾点p1,p4构成的基准线的偏移距离(即点p2(或p3)到直线段的最短距离),将其中的最大偏移距离记录为dmax。
(3)如果dmax≤ε,将该部分轨迹线片段划分为同一个区域,同时跳过该树结点的孩子结点;反之,则按照上述方法进一步考察该结点包含的孩子结点。以图6中编号为2的二叉树结点对应的聚类单元G16为例,如果dmax≤ε,则将由G16包含的轨迹直线段e1,e2,e3组成的轨迹线片段划分为同一个区域,,并且跳过对该树结点的孩子结点的考察;反之,如果dmax>ε,则进一步考察编号为7和12的孩子结点。
(4)按上述步骤完成对对二叉树结构的遍历后,原始轨迹线被分解为若干不同的区域(或若干不同的轨迹线片段)。图7是在图6所示的层次化聚类结果二叉树结构基础上,在压缩的几何精度阈值ε控制下基于上述步骤得到的分区结果,各分区的轨迹线片段分别表示为Seg1={e1,e2},Seg2={e3},Seg3={e4,e5,e6},Seg4={e7},Seg5={e8,e9,e10}。
步骤5:依次连接各分区内轨迹线段的首尾点并保存为最终的压缩结果T’。如图8所示,依次连接各分区内轨迹线片段的首尾点,然后组织为新的轨迹线T’={p1,p3,p4,p7,p8,p11}}导出作为压缩结果。
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!