用于智能机器人的语音输出方法和装置与流程
本发明涉及智能机器人领域,尤其涉及一种用于智能机器人的语音输出方法和装置。
背景技术:
随着科学技术的不断发展,信息技术、计算机技术以及人工智能技术的引入,机器人的研究已经逐步走出工业领域,逐渐扩展到了医疗、保健、家庭、娱乐以及服务行业等领域。而人们对于机器人的要求也从简单重复的机械动作提升为具有拟人问答、自主性及与其他机器人进行交互的智能机器人,人机交互也就成为决定智能机器人发展的重要因素。
在机器人与用户进行语音交互时,表示机器人嘴部的输出设备通常是保持一定状态不变的,这样会导致给用户带来不好的交互体验,降低用户与机器人进行交互的意愿。而且,机器人的这种状态与其发展趋势——高度拟人存在较大差别,且智能性较差。
综上,需要提供一种能够提高机器人类人性和智能性的、使机器人在与用户进行语音交互时会带来更好的用户体验的方法。
技术实现要素:
本发明所要解决的技术问题之一是需要提供一种能够提高机器人类人性和智能性的、使机器人在与用户进行语音交互时会带来更好的用户体验的解决方案。
为了解决上述技术问题,本申请的实施例首先提供了一种用于智能机器人的语音输出方法,该方法包括:获取待输出的语音信息对应的文本信息;对所述文本信息进行分词;根据分词结果生成嘴部的张合次数与每次张合的时长,结合所述张合次数和所述时长控制执行语音输出。
优选地,在根据分词结果生成嘴部的张合次数与每次张合的时长的步骤中,进一步包括:根据所述分词结果中的词的数量确定所述嘴部的张合次数;基于所述文本信息计算进行语音信息输出所需的总时长,根据所述分词结果和总时长确定所述嘴部每次张合的时长。
优选地,在根据所述分词结果和总时长确定所述嘴部每次张合的时长的步骤中,进一步包括:根据所述分词结果中不同词在文本信息中所代表的成分结构,赋予各个词对应的权重;通过计算所述总时长与每个词对应权重的乘积值确定所述嘴部每次张合的时长。
优选地,该方法进一步还包括:对所述文本信息进行情绪分析,根据情绪分析结果控制进行语音输出时的嘴型状态。
优选地,在结合所述张合次数和所述时长控制执行语音输出的步骤中,进一步包括:上位机结合所述张合次数和所述时长,生成相应的下位机嘴部控制指令并发送给下位机;下位机结合所述嘴部控制指令控制嘴部动画,或者嘴部机械设备配合语音输出进行张合。
根据另一方面,本发明实施例还提供了一种用于智能机器人的语音输出装置,该装置包括:文本信息获取模块,其获取待输出的语音信息对应的文本信息;分词模块,其对所述文本信息进行分词;语音输出模块,其根据分词结果生成嘴部的张合次数与每次张合的时长,结合所述张合次数和所述时长控制执行语音输出。
优选地,所述语音输出模块进一步包括:张合次数确定子模块,其根据所述分词结果中的词的数量确定所述嘴部的张合次数;张合时长确定子模块,其基于所述文本信息计算进行语音信息输出所需的总时长,根据所述分词结果和总时长确定所述嘴部每次张合的时长。
优选地,所述张合时长确定子模块,其进一步根据所述分词结果中不同词在文本信息中所代表的成分结构,赋予各个词对应的权重,通过计算所述总时长与每个词对应权重的乘积值确定所述嘴部每次张合的时长。
优选地,该装置进一步还包括:嘴型状态控制模块,其对所述文本信息进行情绪分析,根据情绪分析结果控制进行语音输出时的嘴型状态。
优选地,所述语音输出模块进一步包括:控制指令发出子模块,其根据所述张合次数和所述时长,生成并发送相应的嘴部控制指令;嘴部控制子模块,其根据所述嘴部控制指令控制嘴部动画,或者嘴部机械设备配合语音输出进行张合。
与现有技术相比,上述方案中的一个或多个实施例可以具有如下优点或有益效果:
在智能机器人进行语音输出时,通过先获取待输出的语音信息对应的文本信息,然后对文本信息进行分词,根据分词结果生成嘴部的张合次数与每次张合的时长,能够结合张合次数和时长控制执行语音输出。因此,在机器人与用户进行交互时,机器人嘴部能够模仿人类在进行语音输出时嘴部的动作,提高机器人的智能性和类人性。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明的技术方案而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构和/或流程来实现和获得。
附图说明
附图用来提供对本申请的技术方案或现有技术的进一步理解,并且构成说明书的一部分。其中,表达本申请实施例的附图与本申请的实施例一起用于解释本申请的技术方案,但并不构成对本申请技术方案的限制。
图1为根据本发明第一实施例的用于智能机器人的语音输出方法的流程示意图。
图2为根据本发明第一实施例的用于智能机器人的语音输出方法的步骤S130的具体流程示意图。
图3为根据本发明第二实施例的用于智能机器人的语音输出方法的流程示意图。
图4为根据本发明第三实施例的用于智能机器人的语音输出装置300的结构示意图。
图5为根据本发明第四实施例的用于智能机器人的语音输出装置3000的结构示意图。
具体实施方式
以下将结合附图及实施例来详细说明本发明的实施方式,借此对本发明如何应用技术手段来解决技术问题,并达成相应技术效果的实现过程能充分理解并据以实施。本申请实施例以及实施例中的各个特征,在不相冲突前提下可以相互结合,所形成的技术方案均在本发明的保护范围之内。
另外,附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行。并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
随着智能机器人产品的普及,越来越多的家庭和商家都需要机器人为其服务。然而,现有技术中,仿真机器人与用户进行语音交互时,机器人嘴部要么保持不动仅输出语音信息,要么嘴部执行预先设定的、与发出的语音信息毫不匹配的嘴部动作,例如,在输出语音时,嘴部总是保持一定频率的一张一合的状态,这多少会给用户带来不好的体验,降低用户与机器人交互的兴趣。因此,亟需一种解决方案来解决上述问题。
本发明实施例的用于智能机器人的语音输出方法提高了机器人的智能性和类人性,使机器人在与用户进行语音交流的过程中,嘴部能够根据发出的语音信息来做出相应的张合动作,提高用户的体验感。具体来说,机器人在输出语音信息之前,对待输出语音信息的文本信息进行分词处理,然后根据分词结果生成嘴部的张合次数和每次张合的时长,并结合张合次数和时长控制执行语音输出,通过上面的方法能够使机器人在发出语音信息的同时保持嘴部的动作与语音信息匹配,使用户感受到机器人的趣味性和类人性。
另外,在本发明实施例中,机器人除了能够根据待输出语音信息的文本信息计算得到张合次数和每次张合的时长,还能够对文本信息进行情绪分析,并根据情绪分析结果控制进行语音输出时的嘴型状态,例如,在情绪分析结果为积极情绪时,则控制嘴部表现出嘴角上扬的状态,在情绪分析结果为消极情绪时,则控制嘴部表现出嘴角下垂的状态。这样能够进一步使机器人在语音输出的过程中,呈现出类人态的表现,提高用户体验。
在本发明实施例中,在计算嘴部的张合次数时,可以根据分词结果中的词的数量来确定;在计算每次张合的时长时,可以基于文本信息计算进行语音信息输出所需的总时长,然后根据分词结果和总时长来确定,更具体地,根据分词结果中不同词在文本信息中所代表的成分结构,赋予各个词对应的权重,通过计算总时长与每个词对应权重的乘积值确定所述嘴部每次张合的时长。由于根据词语的成分结构所对应的权重来计算每次张合的时长,因此机器人在对不同成分的词进行发音时会突出所要表达的重点内容,能够提高机器人的类人性以及用户与机器人的交互体验。
另外,需要说明的是,在机器人内部设置有上位机和下位机,在控制执行语音输出时,上位机结合张合次数和时长,生成相应的下位机嘴部控制指令并发送给下位机,下位机结合嘴部控制指令控制嘴部动画,或者嘴部机械设备配合语音输出进行张合。这样设置能够更好地分工操作,减轻上位机和下位机的数据处理负担。
如上段内容所述,在本发明实施例中,机器人的“嘴部”可以是以动画方式表示的虚拟嘴部,还可以是以机械结构的形式形成的真实的嘴部。
第一实施例
图1为根据本发明第一实施例的用于智能机器人的语音输出方法的流程示意图,该实施例的方法主要包括以下步骤。
首先,在步骤S110中,获取待输出的语音信息对应的文本信息。
需要说明的是,机器人可以自发地向用户发出语音信息,也可以通过与用户进行语音交互,并解析用户输入的语音信息来生成待输出的语音信息对应的文本信息。以语音交互为例,用户与机器人进行语音交互的过程中,用户向机器人发出语音信息,未知语音信号经麦克风、话筒之类的语音信号采集设备变换成电信号后输入到识别系统的输入端再进行处理。在接收到多模态输入信息后,响应该多模态输入数据生成对应的文本信息,然后根据该文本信息生成待输出给用户的语音信息对应的文本信息。
在对语音信息进行解析时,先进行例如去噪之类的预处理,然后将预处理后的语音信息进行语音识别的综合分析,生成与语音信息对应的文本信息。
例如,在对文本信息进行解析后得到用户输入的语音信息是“你今天过的怎么样啊”,生成的待输出的语音信息对应的文本信息可以为“我今天过的很好,你今天过的怎么样啊”。
接着,在步骤S120中,对文本信息进行分词。
“分词”是指以词为基本单位,将文本信息中的词逐个切分出来。以对中文语句进行分词为例,可以采用基于字符串匹配的分词方法、基于统计的分词方法和基于理解的分词方法。其中基于字符串匹配的分词方法分为最大匹配法、最小匹配法和全切分法。最大匹配法可以分为正向最大匹配法(由左到右的方向)、逆向最大匹配法(由右到左的方向)。
另外,在对文本信息进行分词的过程中,根据语法信息库对每个词在句子中的成分结构或词性(例如,主、谓、宾、名词、动词、形容词)进行确定。例如,文本信息“你今天过的怎么样啊”进行分词后的结果是:你(主)/今天(状)/过(谓)/的/怎么样(宾)/啊。
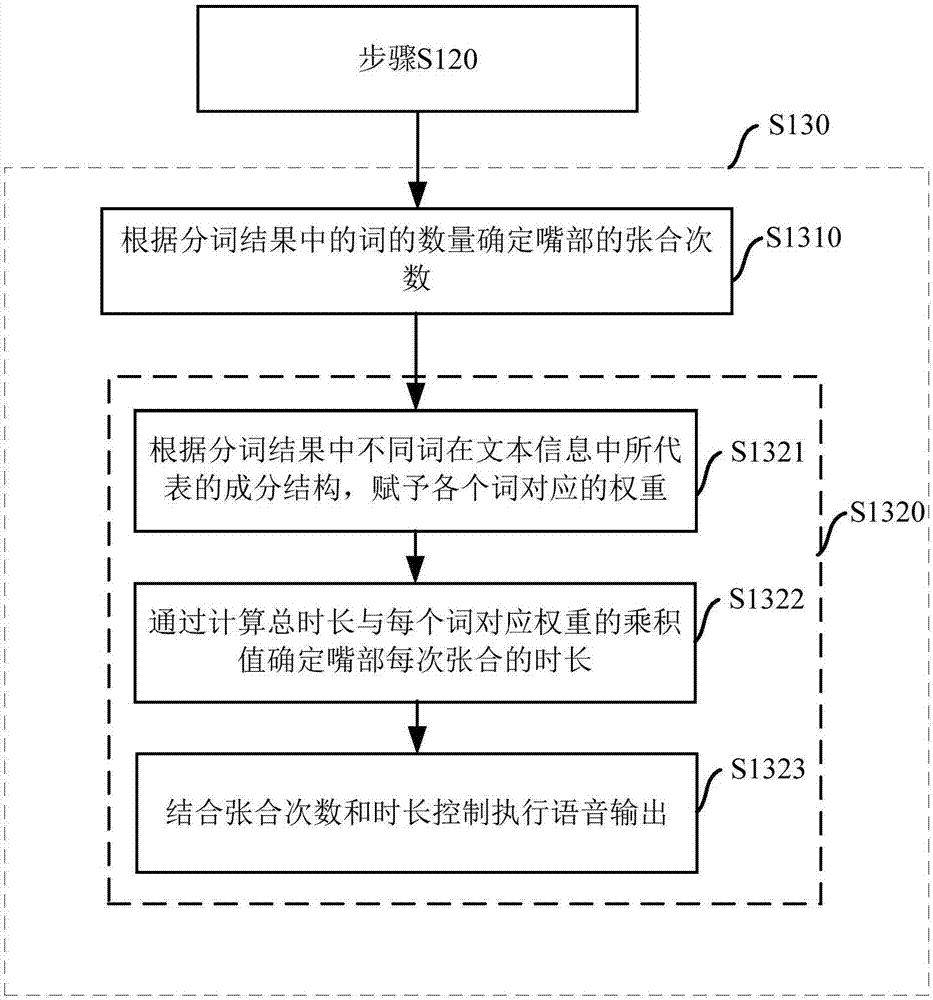
然后,在步骤S130中,根据分词结果生成嘴部的张合次数与每次张合的时长,结合张合次数和时长控制执行语音输出。图2是根据本发明第一实施例的步骤S130的具体流程示意图,下面参考图2详细说明步骤S130的各个子步骤。
在子步骤S1310中,根据分词结果中的词的数量确定嘴部的张合次数。
简而言之,在一个实施例中,可以认为机器人嘴部的张合次数与文本信息中所包含的词的数量一致,以上面例子来说,机器人输出“你今天过的怎么样啊”的语音信息时,由于该文本信息中包含的词的数量为6个,则机器人嘴部的张合次数为6次。当然,为了避免机器人嘴部张合次数过多,在其他实施例中,也可以设定机器人嘴部张合的次数等于分词结果中某些重要成分词的数量值,且对应输出这些重要成分词时嘴部进行张合操作。
在子步骤S1320中,基于文本信息计算进行语音信息输出所需的总时长,根据分词结果和总时长确定嘴部每次张合的时长,结合张合次数和时长控制执行语音输出。在子步骤S1320中,进一步优选地,还包括子步骤S1321、S1322和S1323。
在子步骤S1321中,根据分词结果中不同词在文本信息中所代表的成分结构,赋予各个词对应的权重。
在步骤S120中通过对文本信息进行分词处理,能够获取每个词在文本中表示的成分结构,预先给不同成分结构赋予一定的权重比例(例如,百分比),设定所有词的总和为百分之百。例如,主语成分的词的权重为20%、谓语成分的词的权重为10%......,则上面例子中,各分词所占比例为:你(20%)/今天(20%)/过(10%)/的(10%)/怎么样(30%)/啊(10%)。或者,还可以根据分词结果中不同词在文本信息中的词性(例如,名词、动词、形容词)来赋予各个词对应的权重。
在子步骤S1322中,通过计算总时长与每个词对应权重的乘积值确定嘴部每次张合的时长。
具体地,可以通过如下表达式来得到嘴部每次张合的时长:总时长*每个词的权重。例如,“你今天过的怎么样啊”的TTS合成的音频总时长是4秒,通过利用上面表达式计算得到对应“你”字输出时,嘴部张合的时长是0.8秒、“今天”是0.8秒、“过”是0.4秒、“的”是0.4秒、“怎么样”是1.2秒、“啊”是0.4秒,总共4秒。
在子步骤S1323中,结合张合次数和时长控制执行语音输出。
具体地,机器人内部设置有上位机和下位机,为了更好地分工操作,减轻上位机和下位机的数据处理负担,上位机结合张合次数和时长,生成相应的下位机嘴部控制指令并发送给下位机,下位机结合嘴部控制指令控制嘴部动画,或者嘴部机械设备配合语音输出进行张合。具体来说,上位机发出的下位机嘴部控制指令中包括完成进行语音输出时嘴部张合次数,以及每次张合的时长。下位机在接收到嘴部控制指令后,控制嘴部配合语音输出进行张合。
本发明实施例在智能机器人进行语音输出时,使机器人通过先获取待输出的语音信息对应的文本信息,然后对文本信息进行分词,根据分词结果生成嘴部的张合次数与每次张合的时长,能够结合张合次数和时长控制执行语音输出。因此,在机器人与用户进行交互时,机器人嘴部能够模仿人类在进行语音输出时嘴部的动作,提高机器人的智能性和类人性。
第二实施例
图3为根据本发明第二实施例的用于智能机器人的语音输出方法的流程示意图,该实施例的方法主要包括以下步骤,其中,将与第一实施例相似的步骤以相同的标号标注,且不再赘述其具体内容,仅对区别步骤进行具体描述。
在步骤S110中,获取待输出的语音信息对应的文本信息。
在步骤S120中,对文本信息进行分词。
在步骤S130中,根据分词结果生成嘴部的张合次数与每次张合的时长,结合张合次数和时长控制执行语音输出。
在步骤S140中,对文本信息进行情绪分析,根据情绪分析结果控制进行语音输出时的嘴型状态。
除了获取嘴部的张合次数和每次张合的时长以外,为了更好地提高机器人的类人性,还需要对待输出语音信息对应的文本信息进行情绪分析。例如,可以根据情感词典来解析文本信息中每个词的情绪属性信息,若一句话中包含的某一类情感属性的词较多,则对应该情感属性输出用于控制机器人嘴型状态的控制指令。例如,若文本信息所呈现的情绪为高兴,则输出控制机器人嘴部的嘴角上扬的控制指令,若文本信息所呈现的情绪为悲伤,则输出控制机器人嘴部的嘴角下垂的控制指令。上位机发出嘴型状态的控制指令给下位机,下位机根据控制指令驱动控制构成嘴部的机械结构使嘴部呈现出相应的形态,或者在嘴部为虚拟图像时,下位机控制生成对应形态的虚拟嘴部图像显示在机器人的显示设备上。
需要说明的是,该步骤可以与步骤S130同时执行,也可以在步骤S130后执行,例如,在机器人输出语音信息后进行嘴部形态的控制,此处不做限定。
第三实施例
图4为根据本发明第三实施例的用于智能机器人的语音输出装置300的结构示意图。如图4所示,本实施例的语音输出装置300主要包括:文本信息获取模块310、分词模块320和语音输出模块330。
文本信息获取模块310,其获取待输出的语音信息对应的文本信息。
分词模块320,其与文本信息获取模块310连接,分词模块320对所述文本信息进行分词。
语音输出模块330,与分词模块320连接,语音输出模块330根据分词结果生成嘴部的张合次数与每次张合的时长,结合所述张合次数和所述时长控制执行语音输出。语音输出模块330进一步包括:张合次数确定子模块3310、张合时长确定子模块3320、控制指令发出子模块3330和嘴部控制子模块3340。
张合次数确定子模块3310,其根据所述分词结果中的词的数量确定所述嘴部的张合次数。张合时长确定子模块3320,其基于所述文本信息计算进行语音信息输出所需的总时长,根据所述分词结果和总时长确定所述嘴部每次张合的时长。张合时长确定子模块3320,其进一步根据所述分词结果中不同词在文本信息中所代表的成分结构,赋予各个词对应的权重,通过计算所述总时长与每个词对应权重的乘积值确定所述嘴部每次张合的时长。控制指令发出子模块3330,其根据所述张合次数和所述时长,生成并发送相应的嘴部控制指令。嘴部控制子模块3340,其根据所述嘴部控制指令控制嘴部动画,或者嘴部机械设备配合语音输出进行张合。
通过合理设置,本实施例的语音输出装置300可以执行第一实施例中涉及的语音输出方法的各个步骤,此处不再赘述。
第四实施例
图5为根据本发明第四实施例的用于智能机器人的语音输出装置3000的结构示意图。其中,将与第三实施例功能相似的模块以相同的标号标注,且不再赘述其具体内容,仅对区别模块进行具体描述。
如图5所示,本实施例的语音输出装置3000除了包括第三实施例中涉及的文本信息获取模块310、分词模块320和语音输出模块330以外,还包括嘴型状态控制模块340。嘴型状态控制模块330,其对所述文本信息进行情绪分析,根据情绪分析结果控制进行语音输出时的嘴型状态。
通过合理设置,本实施例的语音输出装置3000可以执行第二实施例中涉及的语音输出方法的各个步骤,此处不再赘述。
由于本发明的方法描述的是在计算机系统中实现的。该计算机系统例如可以设置在机器人的控制核心处理器中。例如,本文所述的方法可以实现为能以控制逻辑来执行的软件,其由机器人操作系统中的CPU来执行。本文所述的功能可以实现为存储在非暂时性有形计算机可读介质中的程序指令集合。当以这种方式实现时,该计算机程序包括一组指令,当该组指令由计算机运行时其促使计算机执行能实施上述功能的方法。可编程逻辑可以暂时或永久地安装在非暂时性有形计算机可读介质中,例如只读存储器芯片、计算机存储器、磁盘或其他存储介质。除了以软件来实现之外,本文所述的逻辑可利用分立部件、集成电路、与可编程逻辑设备(诸如,现场可编程门阵列(FPGA)或微处理器)结合使用的可编程逻辑,或者包括它们任意组合的任何其他设备来体现。所有此类实施例旨在落入本发明的范围之内。
应该理解的是,本发明所公开的实施例不限于这里所公开的特定结构、处理步骤或材料,而应当延伸到相关领域的普通技术人员所理解的这些特征的等同替代。还应当理解的是,在此使用的术语仅用于描述特定实施例的目的,而并不意味着限制。
说明书中提到的“一个实施例”或“实施例”意指结合实施例描述的特定特征、结构或特性包括在本发明的至少一个实施例中。因此,说明书通篇各个地方出现的短语“一个实施例”或“实施例”并不一定均指同一个实施例。
虽然本发明所公开的实施方式如上,但所述的内容只是为了便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属技术领域内的技术人员,在不脱离本发明所公开的精神和范围的前提下,可以在实施的形式上及细节上作任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!