用相控阵雷达测量高炉料面矿焦比来控制高炉气流分布的方法与流程
本发明属于高炉操作技术领域,特别是指一种用相控阵雷达测量高炉料面矿焦比来控制高炉气流分布的方法。
背景技术:
高炉作为一个多变量、大滞后、非线性的特大型铁水生产对流反应器,每天都要消耗极其巨大的物质、能量,以一个5000m3的大型现代化高炉为例,每天将生产12000吨左右的生铁,消耗20000吨左右的矿石,燃烧6000吨左右的燃料,产生4000吨左右的炉渣,产生25000吨左右的CO2,巨大的物质流、能量流都将在24小时内在高炉内完成,在高炉中如此巨大的物质、能量、信息交换一直以来是以人工的方式来完成的。目前世界上尚无以计算机来实现高炉冶炼控制的先例。
高炉炉料从上部装入,下部从风口鼓入1200℃左右的热风,热风将风口区的焦炭、煤粉燃烧,同时产生2300℃左右的高温煤气,煤气主要由CO、N2组成,燃料燃烧后会在高炉风口区形成空间,上面的炉料逐步下落,下面的还原气体逐渐上升,通过这种两相流动一方面加热炉料,另一方面利用还原气体实现炉料的还原。这样一来,高炉上部炉料的分布和风口区气流的分布状况就成了决定高炉冶炼顺利与否的关键因素,布料的目的主要是控制高炉上部气流分布,也就是说合理控制高炉上下部两股气流的分布状况成了维系高炉顺利冶炼的核心因素。由于高炉一旦进入冶炼状态,高炉下部在生产过程中不能做物理改变,也就是不能调整进风面积,风口尺寸,所以气流的调整主要由上部布料通过控制上部气流的分布来完成。
高炉操作的核心就是通过调节高炉下部的鼓风参数和上部的布料来控制高炉的稳定顺行,但高炉是一个特大型的高温密闭化学反应器,炉顶炉料的分布状况并不能直接进行测量,为了能够获取高炉炉顶的炉料分布进而精准控制气流分布,多年来高炉工作者进行了大量的卓有成效的工作,取得了一定的进展。
文献“刁日升,王戈,刘传胜,等.炉项红外摄像监控系统在攀钢高炉上的应用[J].钢铁钒钛,2002,23(3):54-58.”中讨论了利用炉顶红外图像对炉料分布状况进行评估的方法,这种技术通过直接测量布料过程中炉顶料面的温度变化来间接评估布料及气流分布状况,由于炉料表面温度依赖于炉内气流分布、下料速度、装入品种、装入量、下层的料面形状等因素,所以同一个布料矩阵所形成的料面形状测出的温度分布有时差异也比较大,单靠观测炉顶温度分布来直接评估气流分布误差较大。
文献“陈令坤,王志刚,赵思,于仲洁,基于图像处理的高炉煤气流评估系统的研究与应用,冶金工业出版社,2007-2007年中国钢铁年会(光盘)”中在炉顶红外测量的基础上提出了一种利用图像模式识别技术对观测图像进行处理的方法,该方法通过模式识别技术可以识别出外围条件相对稳定时的标准图像,由这些图像构成案例库,通过图像的匹配可以统计一定时间内各种图像出现的频率,进而评估高炉气流的变化,这种方法大大改善了炉顶红外图像的利用效率,在炉料条件变化不大、操作方针没有巨大变化时这种方法是可行的,但一旦高炉用料结构出现大的变化就会导致标准案例的变化,一旦处理不及时就会减低评估效果,同时由于炉内气流上升时夹杂着大量的粉尘,测量信号失真较大,并且测量信号采样口极易堆积灰尘,影响信号质量,所以这种方法也是一种间接测量方法,误差也同样不稳定。
文献“陈令坤,煤气流控制技术的开发及其在武钢5号高炉上的应用,炼铁,2011年,Vol.30.No.5,”中提出了直接利用炉顶4个上升管的温度测量数据来评判炉顶煤气流分布及其变化,该方法首先是通过模式识别技术来对炉顶4条上升管温度曲线进行分类,其次是通过模式匹配来评价立定气流分布,这种方法存在2个缺陷,一个是同一种炉顶温度曲线可能对应两种气流分布,也就是说标准案例库依赖于布料、原燃料质量、高炉操作状态的相对稳定,一旦出现原燃料等外部条件的剧烈波动就会引发案例库的变化,这将降低匹配识别精度,减少准确识别工艺状况的概率。
文献“姜慧研,许贵清,周建常.BP算法在高炉煤气流分布模式识别中的应用叨.东北大学学报:自然科学版,2000,21(2):144-146。”[4]中提供了利用炉顶十字测温装置来评价炉顶气流分布的方法,十字测温同样受布料、底层料面形状、炉料种类、布料批重、布料节奏等各种因素的影响,测量获得的温度分布并不是炉顶料面的温度分布,仅仅是测量杆的温度分布,由于测量杆为了烧损一般都带冷却,所以测量结果并不能反映炉顶料面温度的真实状况,测量结果只供布料及气流调剂时参考。
上世纪80年代中日本新日铁钢铁公司曾提供了一种利用机械料面探尺直接测量炉料分布的技术,该技术可以精确测定料面形状,但存在设备巨大,测量耗时长,装备防护差,易损坏等缺点,难以长时间稳定用于料面测量,这严重阻碍了该设备的推广及使用。
文献“Yaowei YU*and HenrikEffect of DEM Parameters on the Simulated Inter-particle Percolation of Pellets into Coke during Burden Descent in the Blast Furnace,ISIJ International,Vol.52(2012),No.5,pp.788–796。”提供了用颗粒流理论构建布料数学模型的方法,该方法可以计算布料后的料面形状,但由于炉料颗粒的真实滚动过程是难以模拟的,该方法只是一种示意性模型构建方法,作为科学研究是可以的,所以在实践中用处不大。
高炉上部控制气流的主要手段是调整布料,由于高炉一次布料量大,炉料在炉内的分布过程受炉料下降、底层料面形状、气流上升、热量传递、炉料滚动及滑落等种种因素的影响,布料形成过程相对复杂,不同的布料模式可以获得同样的料面形状,鉴于目前缺乏料面直接检测设备,难以获取炉料分布的详细信息,就给精准布料造成了很大的困难,目前通过布料来调剂气流分布仍然停留在经验阶段,尤其是精细调节更是如此。
技术实现要素:
本发明的目的在于,提供一种实现精准气流调节的用相控阵雷达测量高炉料面矿焦比来控制高炉气流分布的方法。
为实现上述目的,本发明所提供的用相控阵雷达测量高炉料面矿焦比来控制高炉气流分布的方法,包括如下步骤:
1)确定不同炉况下的目标O/C比分布曲线及建立气流调剂案例库
1.1)建立高炉相控阵雷达布料检测数据库:利用相控阵雷达对每批布料进行采样并记录每个测量点的布料检测数据,然后保存在布料检测数据库中;
1.2)根据布料检测数据库中的布料检测数据计算每批布料的O/C比分布曲面;
1.3)计算任意方向的O/C比分布曲线:每个O/C比分布曲面取一个方向的矿焦比分布得到一个O/C比分布曲线,然后将得到的所有O/C比分布曲线经离散后保存在离散数据库中;
1.4)建立O/C比分布曲线案例库:以预设时间段数据为案例空间,重复步骤1.1)~1.3)建立O/C比分布曲线案例库;
1.5)建立标准O/C比分布曲线案例库:利用k-means算法进行模式识别,对步骤1.4)中各种不同的O/C比分布曲线进行分类,获得M类分布模式,M类分布模式构成标准O/C比分布曲线案例库;
1.6)在标准O/C比分布曲线案例库中确定不同炉况下的目标O/C比分布曲线;
1.7)建立高炉气流分布检测数据:将影响高炉气流分布的因素进行采样并将采样的检测数据进行保存;
1.8)根据步骤1.7)中高炉气流分布检测数据建立气流分布数据库;
1.9)以不同炉况下对应的目标O/C比分布曲线为基准对气流控制模式和范围进行分类:炉况的标准包括四种,如炉温波动,炉型波动,炉缸堆积,透气性、顺行恶化;
1.10)构建不同炉况下利用O/C比控制气流的气流调剂案例库:
(1)炉温波动状况下利用O/C比控制气流的气流调剂案例库;
(2)炉型波动状况下利用O/C比控制气流的气流调剂案例库;
(3)炉缸堆积状况下利用O/C比控制气流的气流调剂案例库;
(4)透气性、顺行恶化状况下利用O/C比控制气流的气流调剂案例库;
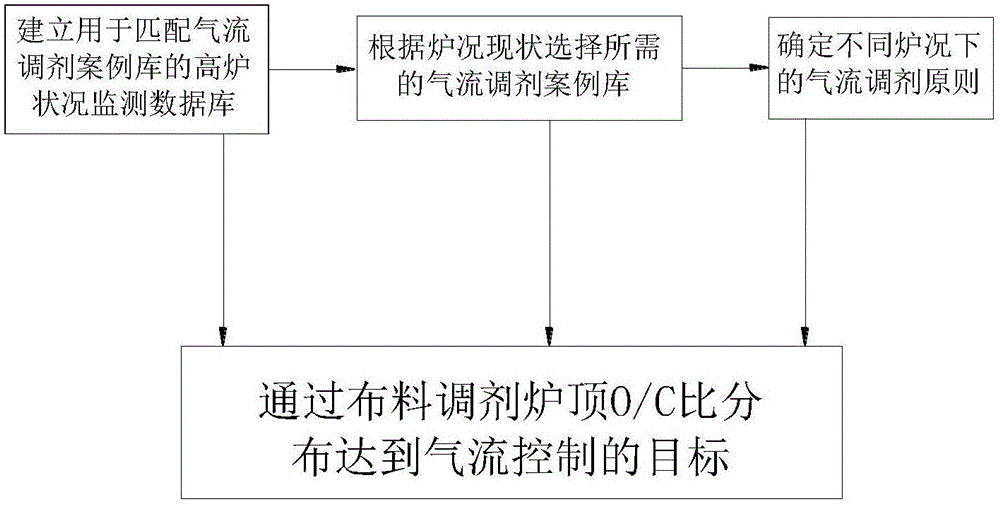
2)选择气流调剂案例库及确定调剂原则:
2.1)建立用于匹配气流调剂案例库的高炉状况监测数据库:将用于描述高炉状况的监测数据保存在高炉状况监测数据库;
2.2)根据炉况现状选择所需的气流调剂案例库;
2.3)确定不同炉况下的气流调剂原则;
2.4)通过布料调剂炉顶O/C比分布达到气流控制的目标:利用相控阵雷达计算出实际O/C比分布曲线,从相应气流调剂案例库中进行曲线匹配,判断当前实际O/C比分布曲线是否处在最佳状态,如果不是,则在气流调剂案例库中选择目标O/C比分布曲线,计算两种O/C比分布曲线的差异,给出布料调剂的原则,从而实现对气流分布的控制。
进一步地,所述步骤1.2)的具体过程为:根据计算沿每批布料不同直径位置的下料速度,计算每批布料中每个测量点焦炭下落后的位置坐标信息及同时计算当前计算时所对应时间段的矿石料层的三维坐标位置信息,从而计算每批布料的O/C比分布曲面,并将所有的O/C比分布曲面保存在O/C比分布曲面数据库中。
进一步地,所述步骤1.6)的具体过程为:以煤气利用率、利用系数及高炉顺行指标为标准,对标准O/C比分布曲线案例库中的O/C比分布曲线进行评判,确定在不同炉况下的目标O/C比分布曲线,并且不同炉况对应着不同的特征炉况参数。
进一步地,所述步骤1.7)中影响气流分布的因素包括原料质量及性能、高炉冷却壁温度状况、高炉布料矩阵中涉及的布料信息、高炉鼓风参数、下料时间、风压变化、炉顶压力、炉身静压力变化值、炉缸及炉底温度信息、出渣出铁信息,其中高炉布料矩阵中涉及的布料信息包括入炉原料的种类、数量、布料料线深度设定、布料次序、角位及环数。
进一步地,所述步骤1.8)的具体过程为:将步骤1.7)中检测数据通过建表的形式保存在气流分布数据库中,并且一类数据建立一个表。
进一步地,所述步骤2.2)的具体过程为:根据影响气流分布的特征因素集识别特征炉况参数,根据特征炉况参数启用对应的气流调剂案例库;并按照“炉缸堆积状况→炉温波动状况→炉型波动状况→透气性、顺行恶化状况”调剂的次序依次进行处理。
进一步地,所述步骤2.3)气流调剂原则具体为:炉温波动状况的气流调剂原则为通过炉料负荷来调节炉温走向;炉型波动状况的气流调剂原则为通过调整边缘、中心两股气流来进行调节;炉缸堆积状况的气流调剂原则为用打通中心气流的方式来活跃炉缸;透气性、顺行恶化状况的气流调剂原则为通过调整边缘、中心两股气流的方式进行调节。
本发明的有益效果是:在考虑炉料下降、底层料面形状的影响、及炉料塌落影响的前提下,直接计算炉顶布料的O/C比分布状况,通过比较布料和气流分布之间的对应关系,通过有针对性的布料来控制炉顶气流分布,从而实现精准的气流调节,将经验型的高炉炉顶气流控制提升到量化的层次,实现高炉的稳定顺行。
附图说明
图1为本实施例步骤1)的流程示意图;
图2为本实施例步骤2)的流程示意图。
具体实施方式
下面通过具体实施例对本发明作进一步的详细说明。
将该方法实施于内容积5000m3的高炉,该高炉二级机安装有两套Oracle数据库系统,使用C++编程语言,包括四套与布料、喷煤控制有关的PLC系统,两套用于布料控制,一套用于炉缸炉底检测与控制,一套用于煤粉喷吹控制,一套DCS系统,用于鼓风参数的调节等,建立两个数据库系统。
用相控阵雷达测量高炉料面矿焦比来控制高炉气流分布的方法其步骤如下:
1)确定不同炉况下的目标O/C比分布曲线及建立气流调剂案例库,如图1所示,
1.1)建立高炉相控阵雷达布料检测数据库:
以5000m3大型高炉为例,在高炉炉顶齿轮箱下部,炉顶锥台上部开孔,安装相控阵雷达设备,只要保证测量点离布料垂直距离超过4.5米,就可以保证采用一台设备测量到整个布料。利用相控阵雷达对每批布料进行采样并记录每个测量点的布料检测数据,然后保存在布料检测数据库中。相控阵雷达采样信息及采样频率如表1
表1
1.2)根据布料检测数据库中的布料检测数据计算每批布料的O/C比分布曲面:一批布料包括焦炭和矿石,只有在一批布料种的矿石布完后才进行O/C比分布曲面的计算;根据计算沿每批布料不同直径位置的下料速度,计算每批布料中每个测量点焦炭下落后的位置坐标信息及同时计算当前计算时所对应时间段的矿石料层的三维坐标位置信息,在考虑15%左右的焦炭层塌落修正后,从而计算每批布料的O/C比分布曲面,并将所有的O/C比分布曲面保存在O/C比分布曲面数据库中。
1.3)计算任意方向的O/C比分布曲线:鉴于正常布料是沿圆周对称的,为简便起见,这里只考虑一个方向的矿焦比分布,将O/C比分布曲面转化为曲线来考虑,每个O/C比分布曲面取一个方向的矿焦比分布得到一个O/C比分布曲线,每条曲线包括30个左右的数据,然后将得到的所有O/C比分布曲线经离散后保存在离散数据库中。
1.4)建立O/C比分布曲线案例库:以一年时间段数据为案例空间,建立O/C比分布曲线案例库。5000m3高炉每天入炉原料批次在160~180批左右,重复步骤1.1)~1.3),每天可以获得160~180个O/C比分布曲线案例,一年的案例量在7~8万个左右;
1.5)建立标准O/C比分布曲线案例库:利用k-means算法进行模式识别,对步骤1.4)中各种不同的O/C比分布曲线进行分类,获得36类分布模式,36类分布模式构成标准O/C比分布曲线案例库;
1.6)在标准O/C比分布曲线案例库中确定不同炉况下的目标O/C比分布曲线:以煤气利用率、利用系数及高炉顺行指标为标准,并结合当时的风量、压差,对标准O/C比分布曲线案例库中的O/C比分布曲线进行评判,确定在不同炉况下的目标O/C比分布曲线,并且不同炉况对应着不同的特征炉况参数。5000m3高炉判断依据如表2:
表2
1.7)建立高炉气流分布检测数据:将影响高炉气流分布的因素进行采样并将采样的检测数据进行保存,其中,影响气流分布的因素包括原料质量及性能、高炉冷却壁温度状况、高炉布料矩阵中涉及的布料信息、高炉鼓风参数、下料时间、风压变化、炉顶压力、炉身静压力变化值、炉缸及炉底温度信息、出渣出铁信息,其中高炉布料矩阵中涉及的布料信息包括入炉原料的种类、数量、布料料线深度设定、布料次序、角位及环数。各种检测数据的数量及采样频率如表3:
表3
1.8)根据步骤1.7)中高炉气流分布检测数据建立气流分布数据库:将步骤1.7)中检测数据通过建表的形式保存在气流分布数据库中,并且一类数据建立一个表。如表4;
表4
1.9)以不同炉况下对应的目标O/C比分布曲线为基准对气流控制模式和范围进行分类:炉况的标准包括四种,如炉温波动,炉型波动,炉缸堆积,透气性、顺行恶化;即如下四种:
O/C比分布曲线+炉温波动;
O/C比分布曲线+炉型波动;
O/C比分布曲线+炉缸堆积;
O/C比分布曲线+透气性、顺行恶化。
分类时将每种情况的相关数据构成数据样本,代表气流分布的一种状态,待样本整理完成后对样本库进行自动分类,所分类别即是每种情况对应的分类结果。
另外,不同炉况对应着不同的特征炉况参数如表5
表5
1.10)构建不同炉况下利用O/C比控制气流的气流调剂案例库:
(1)炉温波动状况下利用O/C比控制气流的气流调剂案例库;对于5000m3高炉而言,该案例库中包括16种案例;
(2)炉型波动状况下利用O/C比控制气流的气流调剂案例库;对于5000m3高炉而言,该案例库中包括14种案例;
(3)炉缸堆积状况下利用O/C比控制气流的气流调剂案例库;对于5000m3高炉而言,该案例库中包括8种案例;
(4)透气性、顺行恶化状况下利用O/C比控制气流的气流调剂案例库;对于5000m3高炉而言,该案例库中包括22种案例。
2)选择气流调剂案例库及确定调剂原则:如图2所示,
2.1)建立用于匹配气流调剂案例库的高炉状况监测数据库:
在步骤1)中完成了各种炉况下的气流调剂案例库的建立,确定了炉型异常、炉温异常、炉缸工作状况异常、高炉下料不好时的气流调剂案例库,这些案例库中包含了各特定炉况的O/C比分布曲线、表征特定炉况的特征参数。要利用这些调剂不同炉况下气流分布的案例库,就需要找出启动案例库的触发数据,也就是判断当前的炉况是否落入了这些特殊炉况中,这种判断是基于高炉过程检测数据的,这些数据描述了高炉状况,需要事先计算出来,并保存在数据库中。如表6:
表6
2.2)根据炉况现状选择所需的气流调剂案例库:根据影响气流分布的特征因素集识别特征炉况参数,根据特征炉况参数启用对应的气流调剂案例库;有时候四种炉况是单独出现,有时候是集中出现,在集中出现时由于各种炉况下的布料调剂各有特点,有时甚至会出现相互之间有矛盾的现象,这种情况下就需要根据炉况相互之间的因果关系,确定优先调剂的炉,。这里根据影响因素的状态识别出需要处理的炉况,按照“炉缸堆积状况→炉温波动状况→炉型波动状况→透气性、顺行恶化状况”调剂的次序依次进行处理。特征炉况参数如表7,即参数的具体化:
表7
2.3)确定不同炉况下的气流调剂原则:气流调剂原则具体为:炉温波动状况的气流调剂原则为通过炉料负荷来调节炉温走向;炉型波动状况的气流调剂原则为通过调整边缘、中心两股气流来进行调节;炉缸堆积状况的气流调剂原则为用打通中心气流的方式来活跃炉缸;透气性、顺行恶化状况的气流调剂原则为通过调整边缘、中心两股气流的方式进行调节。
2.4)通过布料调剂炉顶O/C比分布达到气流控制的目标:利用相控阵雷达计算出实际O/C比分布曲线,从相应气流调剂案例库中进行曲线匹配,判断当前实际O/C比分布曲线是否处在最佳状态,如果不是,则在气流调剂案例库中选择目标O/C比分布曲线,计算两种O/C比分布曲线的差异,给出布料调剂的原则,从而实现对气流分布的控制。
由于O/C比分布曲线是经过离散化后存入数据库中的,对于两种曲线的比较就转换成了厚度的比较。用目标O/C比分布曲线厚度减去实际O/C比分布曲线厚度,通过观察差值的特征确定布料调剂方向,生成新的布料矩阵。例如边缘区域为正值则加重边缘,中心区域为正值则加重中心。
3)将步骤2.4)生成的布料矩阵,通过控制槽下配料的PLC系统,及控制炉顶布料的PLC系统,实现新布料矩阵的实施,通过不断地匹配、调整达成炉况调整目标,从而实现炉缸、炉型、炉温、透气性、顺行调整的目标。
- 还没有人留言评论。精彩留言会获得点赞!