用于双样本共建测序文库的Y型接头和双样本共建测序文库的方法与流程
本发明涉及生物医学
技术领域:
,具体而言,涉及一种用于双样本共建测序文库的y型接头和双样本共建测序文库的方法。
背景技术:
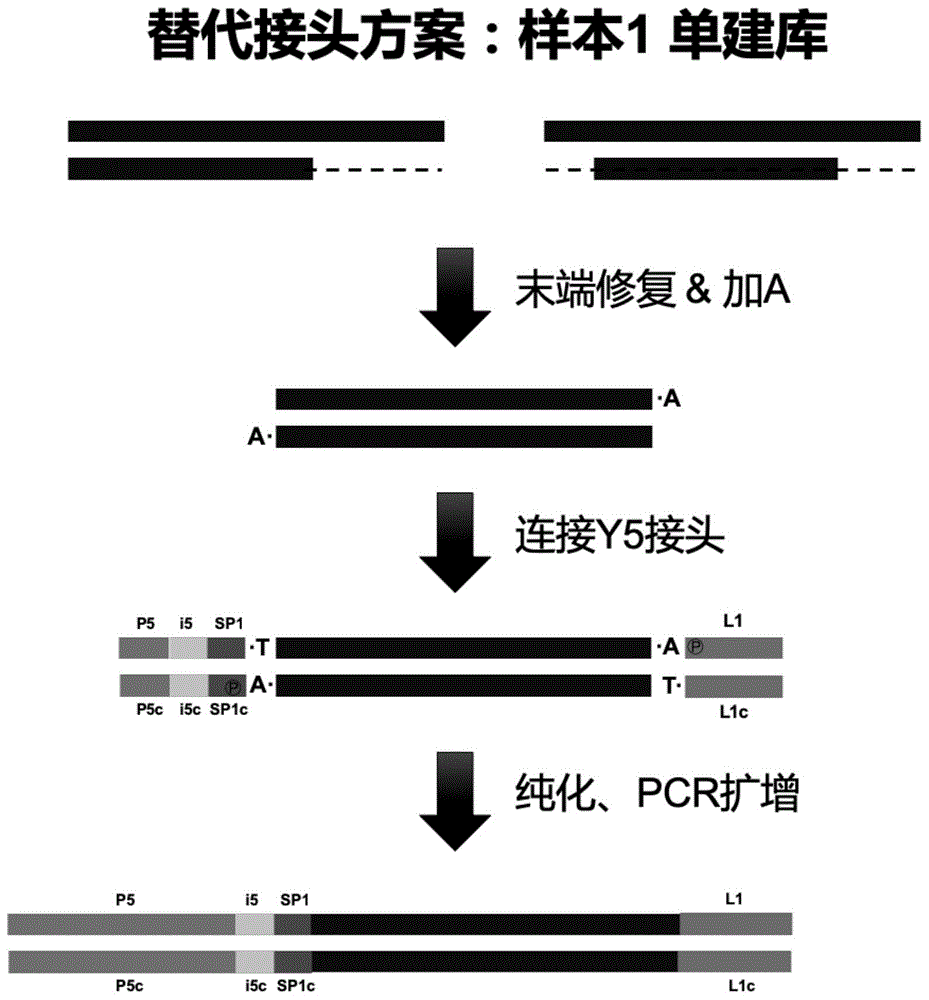
:作为基因检测临床转化最为成熟的项目,无创产前检测的方法多种多样:如ngs(nextgenerationsequencing)法、多重pcr法、探针法、数字pcr法和芯片法等等,其中多重pcr法、探针法、数字pcr法和芯片法等方法具有成本低、周期短、灵敏度高等优点,尤其是多重pcr法、芯片法和数字pcr法近年来在检测通量上有了很大提高,但仍无法达到ngs法检测的通量。目前关于这些方法的研究文章较多,也有一些专利文献,但尚未大规模应用。实际临床应用中,普遍采用的还是ngs法。其中,ngs法检测主要包含两个部分:文库构建和高通量测序。文库构建包括:对无创产前检测样本的游离dna(cfdna)进行末端修复得到末端被修复的cfdna,再通过加a反应在双链dna的3’端添加一个碱基a用于后续连接反应;接着对修复加a后的cfdna进行接头的连接,这一过程是为了将测序平台对应的接头添加到cfdna片段的两端便于后续测序;最后,再对连接产物进行扩增富集来达到检测量的需求。目前,对该常规建库流程的改进方法较多,主要集中于对单个样本建库方式(如接头方案、环化扩增等)的改进,目的是为了提高建库效率。高通量测序方面,无创产前样本目前主要采取的是se35、se50或se75策略,即单端35bp、50bp或75bp读长测序,数据量一般为5mreads,平均测序深度约为0.1×。然而,从测序成本方面考虑,单端测序的成本一般高于双端测序,且样本通量不高。以nextseq500为例,单次检测样本数量最高只有96个,在样本检测需求量大的应用场景中局限性较大。如果无创产前检测在较高通量的测序平台上(如illuminahiseqx-ten或novaseq6000)使用双端测序(pe测序),检测样本数量可以提高,单位数据量的成本也可以得到一定的降低,但同时由于分析只需要单端测序数据,造成了另一端数据的浪费。技术实现要素:本发明旨在提供一种用于双样本共建测序文库的y型接头和双样本共建测序文库的方法,以提高测序数据的利用率。为了实现上述目的,根据本发明的一个方面,提供了一种用于双样本共建测序文库的y型接头。该y型接头包括:第一y型接头和第二y型接头,其中,第一y型接头包括:第一序列,包括依次连接的p5、i5、sp1和n1序列,其中,依次连接的p5、i5和sp1即为illuminay型接头中包含p5的单链核苷酸序列;第二序列,包括依次连接的l1和n1c序列;第二y型接头包括:第三序列,包括依次连接的p7、i7、sp2和n2序列,其中,依次连接的p7、i7和sp2即为illuminay型接头中包含p7的单链核苷酸序列;第四序列,包括依次连接的l2和n2c序列;其中,l1、l2、n1、n1c、n2和n2c均与illumina接头序列及人基因组序列不同且不互补;n1与n1c互补,n2与n2c互补,且n1与n2和n2c不同且不互补;l1的3’端和l2的5’端序具有互补区域。进一步地,l1的3’端和l2的5’端序具有15~25bp的互补区域。进一步地,n1、n1c、n2和n2c的长度为10~20bp。进一步地,l1的3’端和l2的5’端序具有20bp的互补区域。进一步地,第一序列和第四序列的3’末端添加碱基t和硫代修饰,第二序列和第三序列的5’末端做磷酸化修饰。进一步地,第一序列具有如seqidno:1所示的核苷酸序列,第二序列具有如seqidno:2所示的核苷酸序列,第三序列具有如seqidno:3所示的核苷酸序列,以及第四序列具有如seqidno:4所示的核苷酸序列。根据本发明的另一个方面,提供一种双样本共建测序文库的方法。该方法包括以下步骤:分别采用不同的接头对两个待测样本进行单样本建库,得到第一测序文库和第二测序文库,其中,用于第一测序文库和第二测序文库构建的接头中具有能够通过pcr扩增将第一测序文库和第二测序文库连接在一起的序列;将第一测序文库和第二测序文库混合,通过pcr扩增将第一测序文库和第二测序文库连接在一起得到双样本测序文库。进一步地,用于第一测序文库和第二测序文库构建的接头中具有互补序列,通过重叠延伸pcr法将第一测序文库和第二测序文库连接在一起。进一步地,采用上述任一种用于双样本共建测序文库的y型接头进行双样本共建测序文库。进一步地,方法包括:s1,分别采用第一y型接头和第二y型接头对两个待测样本进行单样本建库,得到第一测序文库和第二测序文库;s2,将第一测序文库和第二测序文库混合,通过重叠延伸pcr法将第一测序文库和第二测序文库连接在一起得到双样本测序文库。进一步地,s1包括:接头连接步骤,对其中一个待测样本连接第一y型接头,对另一个待测样本连接第二y型接头;以及扩增步骤,采用具有p5和l1序列的引物对对连接有第一y型接头的待测样本进行扩增,得到第一测序文库,采用具有p7和l2序列的引物对对连接有第二y型接头的待测样本进行扩增,得到第二测序文库。进一步地,具有p5序列的引物具有如seqidno:5所示的核苷酸序列,具有l1序列的引物具有如seqidno:6所示的核苷酸序列,具有p7序列的引物具有如seqidno:7所示的核苷酸序列,具有l2序列的引物具有如seqidno:8所示的核苷酸序列。应用本发明的技术方案,可以构建一种双样本测序文库,使两个单独建库的样本连接到一起形成一个文库并正常测序,这样基于双端测序策略(如pe50、pe75、pe100等)的原理,合理利用双端测序数据,在相对较低的测序成本下,能够有效提高样本检测通量、进一步降低单个样本双端测序的成本,可应用于更为广泛的测序场景中。附图说明构成本申请的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:图1中的a示出了illuminay型接头,图1中的b和c示出了根据本发明一典型实施方式的用于双样本共建测序文库的y型接头结构示意图;图2a和图2b示出了根据本发明一典型实施方式的采用本发明的用于双样本共建测序文库的y型接头进行双样本分别构建测序文库的流程示意图;图3示出了根据本发明一典型实施方式的采用本发明的用于双样本共建测序文库的y型接头进行双样本共建测序文库的流程示意图;图4a和图4b示出了在本发明另一典型实施方式的用于双样本单建测序文库的接头结构示意图及建库流程示意图;图5示出了实施例1中y5接头单建库片段大小分布结果示意图;图6示出了实施例1中y7接头单建库片段大小分布结果示意图;以及图7示出了实施例1中y5和y7接头共建库片段大小分布结果示意图。具体实施方式需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。正如本发明
背景技术:
中记载的,现有nipt建库和测序技术存在成本较高且浪费测序数据和未能有效利用双端测序的数据的技术问题。为了解决这些技术问题,本发明提出了下列技术方案。根据本发明一种典型的实施方式,提供一种双样本共建测序文库的方法。该方法包括以下步骤:分别采用不同的接头对两个待测样本进行单样本建库,得到第一测序文库和第二测序文库,其中,用于第一测序文库和第二测序文库构建的接头中具有能够通过pcr扩增将第一测序文库和第二测序文库连接在一起的序列;将第一测序文库和第二测序文库混合,通过pcr扩增将第一测序文库和第二测序文库连接在一起得到双样本测序文库。应用本发明的技术方案,可以构建一种双样本测序文库,使两个单独建库的样本连接到一起形成一个文库并正常测序,这样基于双端测序策略(如pe50、pe75、pe100等)的原理,合理利用双端测序数据,在相对较低的测序成本下,能够有效提高样本检测通量、进一步降低单个样本双端测序的成本,可应用于更为广泛的测序场景中。将两个样本的文库连接到一起,使之可以在illumina二代测序平台正常测序和分析,而将两个片段连接到一起的方案有很多种,比如直接连接法、pcr连接法和重组置换连接法等。优选的,用于第一测序文库和第二测序文库构建的接头中具有互补序列,通过重叠延伸pcr法将第一测序文库和第二测序文库连接在一起。通过重叠延伸pcr的方法来连接两个样本的文库,该方法具有操作简便、成本低等优点。典型的,本发明可以通过设计一种新的y型接头序列,作为桥梁来连接两个样本的测序文库,该接头需不影响文库的产量,不影响illumina二代测序平台的测序过程,不影响测序结果的分析过程。优选的,如图1所示(图1中第一个接头(a示出的接头)为illuminay型接头,第二、三个接头(b和c示出的接头)则分别为本发明的第一y型接头和第二y型接头),根据本发明一种典型的实施方式,提供一种用于双样本共建测序文库的y型接头。该y型接头包括第一y型接头和第二y型接头,其中,第一y型接头包括第一序列和第二序列,第一序列包括依次连接的p5、i5、sp1和n1序列,其中,依次连接的p5、i5和sp1即为illuminay型接头中包含p5的单链核苷酸序列;第二序列包括依次连接的l1和n1c序列;第二y型接头包括第三序列和第四序列,第三序列包括依次连接的p7、i7、sp2和n2序列,其中,依次连接的p7、i7和sp2即为illuminay型接头中包含p7的单链核苷酸序列;第四序列包括依次连接的l2和n2c序列;其中,l1、l2、n1、n1c、n2和n2c均与illumina接头序列及人基因组序列不同且不互补;n1与n1c互补,n2与n2c互补,且n1与n2和n2c不同且不互补;l1的3’端和l2的5’端序具有互补区域。上述方案的目的是将两个无创产前检测样本分别建库,使之分别带有p5和p7端的barcode,再连接到一起进行双端测序。这种使用双端barcode建库并结合上述双样本共建库的方法,可以有效利用双端测序的特点,使第一测序文库和第二测序文库的数据都能被用于无创产前检测的分析,增加一倍的可用数据;另外,使用双端barcode建库并结合上述双样本共建库的方法,可以将双端barcode分别标记两个样本,达到增加样本检测数量和节省barcode的目的。在上述技术方案中,为了实现p5端和p7端分别连接到不同样本的需求,本发明设计了两条新的序列:第二序列和第四序列。分别与第一序列(p5端接头序列)和第三序列(p7端接头序列)退火,形成“p5&l1”和“p7&l2”两种新的y型接头,为了后续描述方便,我们将退火后形成的新的y型接头简称为y5和y7接头(具体结构示意图见图1中b和c),采用该接头分别建库和共建库原理见图2a、图2b和图3。l1、l2、n1、n1c、n2和n2c均与illumina接头序列及人基因组序列不同且不互补,防止了共建库时造成非特异连接及对测序结果造成影响;l1的3’端和l2的5’端序列有15~25bp(优选20bp)的互补区域,用于两个样本文库的连接;n1和n2序列长度为10~20bp,n1与n1c互补,n2与n2c互补,且n1与n2和n2c不同且不互补,防止共建库时造成非特异连接。第一序列和第四序列的3’末端添加碱基t和硫代修饰,用来与加a后的dna片段配对连接,第二序列和第三序列的5’末端做磷酸化修饰,用来提高连接效率。根据本发明一种典型的实施方式,优选地,第一序列具有如seqidno:1(5’-aatgatacggcgaccaccgagatctacacccttgtagacactctttccctacacgacgctcttccgatctcataaatcaac*t-3’)所示的核苷酸序列,第二序列具有如seqidno:2(5’phos-gttgatttatgagatgcaggccaagcggtcttagtctgacagc-3’)所示的核苷酸序列,第三序列具有如seqidno:3(5’phos-caagcagaagacggcatacgagatccttggaagtgactggagttcagacgtgtgctcttccgatctccttggctcac-3’)所示的核苷酸序列,以及第四序列具有如seqidno:4(5’-gtgagccaaggagctgtcagactaagaccgcttggcctgcatc*t-3’)所示的核苷酸序列。根据本发明一种典型的实施方式,提供一种双样本共建测序文库的方法。该方法包括以下步骤:分别采用不同的接头对两个待测样本进行单样本建库,得到第一测序文库和第二测序文库,其中,用于第一测序文库和第二测序文库构建的接头中具有能够通过pcr扩增将第一测序文库和第二测序文库连接在一起的序列;将第一测序文库和第二测序文库混合,通过pcr扩增将第一测序文库和第二测序文库连接在一起得到双样本测序文库。在本发明一实施例中,具体的,s1包括:接头连接步骤,对其中一个待测样本连接第一y型接头,对另一个待测样本连接第二y型接头;以及扩增步骤,采用具有p5和l1序列的引物对对连接有第一y型接头的待测样本进行扩增,得到第一测序文库,采用具有p7和l2序列的引物对对连接有第二y型接头的待测样本进行扩增,得到第二测序文库。优选地,具有p5序列的引物具有如seqidno:5(5’-aatgatacggcgaccacc-3’)所示的核苷酸序列,具有l1序列的引物具有如seqidno:6(5’-caagcagaagacggcata-3’)所示的核苷酸序列,具有p7序列的引物具有如seqidno:7(5’-gctgtcagactaagaccg-3’)所示的核苷酸序列,具有l2序列的引物具有如seqidno:8(5-gtgagccaaggagctgtc-3’)所示的核苷酸序列。应用本发明的技术方案,可以构建一种双样本测序文库,使两个单独建库的样本连接到一起形成一个文库并正常测序,这样基于双端测序策略(如pe50、pe75、pe100等)的原理,合理利用双端测序数据,在相对较低的测序成本下,能够有效提高样本检测通量、进一步降低单个样本双端测序的成本,可应用于更为广泛的测序场景中。典型的,用于第一测序文库和第二测序文库构建的接头中具有互补序列,通过重叠延伸pcr法将第一测序文库和第二测序文库连接在一起。优选的,采用上述任一种用于双样本共建测序文库的y型接头进行双样本共建测序文库。在本发明一实施例中,双样本共建测序文库的方法包括:s1,分别采用第一y型接头和第二y型接头对两个待测样本进行单样本建库,得到第一测序文库和第二测序文库;s2,将第一测序文库和第二测序文库混合,通过重叠延伸pcr法将第一测序文库和第二测序文库连接在一起得到双样本测序文库。根据本发明一种典型的实施方式,将y型接头的两条单链分别用无核酸酶水稀释到100μm,按照如下表1所示比例配制退火反应液:表1试剂体积单链引物15μl单链引物25μlste缓冲液(品牌:solarbio货号:t1110))15μl总计25μl配制好的退火反应液涡旋10s,瞬时离心3s,置于pcr仪上,按照如下表2所示退火程序运行:表2温度时间降温速率95℃10min5%70℃10min5%65℃10min5%55℃10min5%50℃10min5%25℃10min退火后产物涡旋10s,瞬时离心3s,冻存于-20℃备用。·工作浓度退火后的接头母液为20μm,需稀释50倍后用于连接反应。本发明中用于实现单建库的接头采用了y型接头,y型接头的优势在于所有连接产物都可以被用来扩增富集;此y型接头也可以采用完全互补的两种双链接头代替,但是其连接产物中有效产物的量只有50%。典型的,在单建库时,每一个文库都需要使用两种序列完全互补的接头,如:完全互补的双链p5接头+完全互补的l1接头可以替代y5接头;完全互补的双链l2接头+完全互补的p7接头可以替代y7接头(见图4a和图4b)。下面将结合实施例进一步说明本发明的有益效果,以下实施例中如果有没有明确描述的步骤或试剂,均可采用本领域的常规技术手段或常规试剂实现。实施例11.两个样本分别单独建库(单建库):为了实现双样本共建库,首先需要对两个样本(具体无创产前检测样本,即孕妇血浆游离dna),建库y型接头(y5接头:第一序列具有如seqidno:1所示的核苷酸序列,第二序列具有如seqidno:2所示的核苷酸序列;y7接头:第三序列具有如seqidno:3所示的核苷酸序列,第四序列具有如seqidno:4所示的核苷酸序列)进行单独建库,本实施例中单独建库使用的是kapahyperprepkit,流程如下:(1)末端修复&加a反应将末端修复缓冲液置于室温融化彻底后,涡旋10s,瞬时离心3s;按照下表3配制末端修复反应液:表3试剂体积dnasample(dna样本)50μlend-repair&a-tailingbuffer(末端修复&加a缓冲液)7μlend-repair&a-tailingenzymemix(末端修复&加a酶混合液)3μl总计60μl配好末端修复反应液后,涡旋10s,瞬时离心3s,放入pcr仪,按照下表4程序进行末端修复反应(pcr仪器热盖温度70℃);表4(2)接头连接末端修复反应结束后,从pcr仪中拿出样本,按紧pcr管盖,涡旋10s,瞬时离心3s;按下表5配制连接反应液:表5配制好的连接反应液涡旋10s,瞬时离心3s,置于pcr仪上,20℃温浴30min;注意:对于将要进行共建库的两个样本,分别使用y5和y7接头进行连接,y5和y7接头的barcode应选取一个udi接头中对应的两种barcodes;(3)连接产物纯化a.连接反应结束后,将连接产物转移到1.5ml的离心管中,加入0.8倍体积(88μl)的室温平衡30min的ampurexp磁珠,涡旋5s,室温放置5min;b.短时离心,将离心管置于磁力架上,静置3min直至溶液变澄清;c.小心吸取离心管中的上清并丢弃,枪头避免碰触磁珠;d.保持离心管在磁力架上,加入200μl80%乙醇;e.静置30s待磁珠沉降后,吸除乙醇;f.重复步骤d-e一次;g.室温晾干,直至离心管中残留的乙醇完全挥发;注意:磁珠不要过于干裂,否则易造成回收效率降低;h.加入22μlnuclease-freewater,votex混匀5s,室温放置5min;i.短时离心,将管子放在磁力架上,静置约2min至溶液变澄清;j.吸取20μl上清到一个新的pcr管中。(4)pcr扩增和纯化在上一步的pcr管中,按下表6配制pcr反应液:表6配好后涡旋10s,瞬时离心3s,放入pcr仪,按照下表7中的程序进行扩增:表7pcr反应结束后,按下述方案对pcr产物进行纯化:a.将pcr产物转移到1.5ml的离心管中,加入1倍体积(50μl)的室温平衡30min的ampurexp磁珠,涡旋5s,室温放置5min;b.短时离心,将离心管置于磁力架上,静置3min直至溶液变澄清;c.小心吸取离心管中的上清并丢弃,枪头避免碰触磁珠;d.保持离心管在磁力架上,加入200μl80%乙醇;e.静置30s待磁珠沉降后,吸除乙醇;f.重复步骤d-e一次;g.室温晾干,直至离心管中残留的乙醇完全挥发;注意:磁珠不要过于干裂,否则易造成回收效率降低;h.加入22μlnuclease-freewater,votex混匀5s,室温放置5min;i.短时离心,将管子放在磁力架上,静置约2min至溶液变澄清;j.吸取20μl上清到一个新的离心管中,标记好名称(y5/y7端,barcode编号等)。(5)单建库结果质检取1μl单建库结果用qubit3.0进行浓度测定,浓度大于等于5ng/μl视为建库合格,否则需重新建库;取适量文库用agilent2100或相似片段分析仪器进行文库大小质检,文库主峰应该在280-320bp左右。2.两个样本文库的连接(共建库)(1)pcr连接&扩增取准备共建库的两个单建库样本文库各50ng,建库y型接头(y5接头:第一序列具有如seqidno:1所示的核苷酸序列,第二序列具有如seqidno:2所示的核苷酸序列;y7接头:第三序列具有如seqidno:3所示的核苷酸序列,第四序列具有如seqidno:4所示的核苷酸序列),按照下表8配制共建库反应液:表8试剂体积2×kapahifihotstartreadymix25μlkapaprimermix5μl单文库150ng单文库250ng无核酸酶水to50μl总计50μl配好后涡旋10s,瞬时离心3s,放入pcr仪,按照下表9中的程序进行扩增:表9(2)扩增产物纯化pcr反应结束后,按下述方案对pcr产物进行纯化:a.将pcr产物转移到1.5ml的离心管中,加入0.7倍体积(35μl)的室温平衡30min的ampurexp磁珠,涡旋5s,室温放置5min;b.短时离心,将离心管置于磁力架上,静置3min直至溶液变澄清;c.小心吸取离心管中的上清并丢弃,枪头避免碰触磁珠;d.保持离心管在磁力架上,加入200μl80%乙醇;e.静置30s待磁珠沉降后,吸除乙醇;f.重复步骤d-e一次;g.室温晾干,直至离心管中残留的乙醇完全挥发;注意:磁珠不要过于干裂,否则易造成回收效率降低;h.加入22μlnuclease-freewater,votex混匀5s,室温放置5min;i.短时离心,将管子放在磁力架上,静置约2min至溶液变澄清;j.吸取20μl上清到一个新的离心管中,标记好共建库信息。本实施例中的两个样本分别使用y5和y7接头进行单建库和共建库,上机测序,对测序结果的r1和r2数据(ngs双端测序数据包括两部分,分别是r1(reads1)端数据和r2(reads2)端数据)分别分析并计算z值。单建库结果见表10,图5和图6:表10样本编号起始量接头pcr循环数文库产量t15ngy58432ngt25ngy78386ng共建库结果见表11和图7:表11样本编号起始量pcr循环数文库产量t1&t2各50ng71880ng分析结果见表12和13:表12样本数据q30gc%r1(t1)94.6%40.79%r2(t2)93.8%41.19%r1和r2数据均可以正常拆分,且质控(q30和gc%)合格,计算z值也正常。表13从以上的描述中,可以看出,本发明上述的实施例实现了如下技术效果:1)设计了一种新的成对的接头y5和y7,可以分别用于两个样本的单文库构建,同时建好的文库可以用过y5和y7接头中的l1和l2序列进行连接,形成双样本文库;2)建立了一种通过pcr连接两个文库的方法,实验操作简便,成本较低;3)双样本共建库后,每个样本对应标记了双端barcode中的一种barcode,可以有效利用双端测序的优势,使测序结果中r1和r2的reads都可以被有效利用,节省了测序成本;4)novaseq6000等高通量测序平台单条lane数据产量约为800-10000g,如将来获批用于检测无创产前样本这种数据需求较小(约1-3g)的文库,barcode数量可能不够,本发明将用于一个样本的双端barcode(udi)分别标记两个样本,在增加样本检测数量的同时,提高了barcode的利用率。以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。序列表<110>北京科迅生物技术有限公司<120>用于双样本共建测序文库的y型接头和双样本共建测序文库的方法<130>pn115044yxyx<160>8<170>siposequencelisting1.0<210>1<211>82<212>dna<213>人工序列(artificialsequence)<220><221>primer_bind<222>(1)..(82)<223>第一序列<220><221>modified_base<222>(82)..(82)<223>硫代修饰<400>1aatgatacggcgaccaccgagatctacacccttgtagacactctttccctacacgacgct60cttccgatctcataaatcaact82<210>2<211>43<212>dna<213>人工序列(artificialsequence)<220><221>primer_bind<222>(1)..(43)<223>第二序列<220><221>modified_base<222>(1)..(1)<223>磷酸化修饰<400>2gttgatttatgagatgcaggccaagcggtcttagtctgacagc43<210>3<211>77<212>dna<213>人工序列(artificialsequence)<220><221>primer_bind<222>(1)..(77)<223>第三序列<220><221>modified_base<222>(1)..(1)<223>磷酸化修饰<400>3caagcagaagacggcatacgagatccttggaagtgactggagttcagacgtgtgctcttc60cgatctccttggctcac77<210>4<211>44<212>dna<213>人工序列(artificialsequence)<220><221>primer_bind<222>(1)..(44)<223>第四序列<220><221>modified_base<222>(44)..(44)<223>硫代修饰<400>4gtgagccaaggagctgtcagactaagaccgcttggcctgcatct44<210>5<211>18<212>dna<213>人工序列(artificialsequence)<220><221>primer_bind<222>(1)..(18)<223>具有p5序列的引物<400>5aatgatacggcgaccacc18<210>6<211>18<212>dna<213>人工序列(artificialsequence)<220><221>primer_bind<222>(1)..(18)<223>具有l1序列的引物<400>6caagcagaagacggcata18<210>7<211>18<212>dna<213>人工序列(artificialsequence)<220><221>primer_bind<222>(1)..(18)<223>具有p7序列的引物<400>7gctgtcagactaagaccg18<210>8<211>18<212>dna<213>人工序列(artificialsequence)<220><221>primer_bind<222>(1)..(18)<223>具有l2序列的引物<400>8gtgagccaaggagctgtc18当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 一种构建Hi‑C高通量测序文库的方法与制造工艺
- 桑葚病原菌高通量鉴定及种属分类方法及其应用与制造工艺
- 基于高通量测序技术检测乳腺癌/卵巢癌易感基因的多重PCR特异性引物、试剂盒及方法与制造工艺
- 基于高通量测序检测人EGFR基因变异的质控方法及试剂盒与制造工艺
- 基于高通量测序技术的小麦病原微生物检测方法及其应用与制造工艺
- 一种基于二代高通量测序技术的地中海贫血症的基因检测试剂盒的制造方法与工艺
- 一种基于集群的高通量数据分析方法与制造工艺
- 高通量双折射干涉成像光谱仪装置及其成像方法与制造工艺
- 高通量测序检测人循环肿瘤DNA EGFR基因的捕获探针及试剂盒的制造方法与工艺
- 一种高通量测序检测无创亲子鉴定的方法与制造工艺