基于SVM的转炉炼钢钢水碳含量在线实时动态检测方法与流程
本发明的各个方面涉及转炉炼钢技术领域,尤其是转炉炼钢过程中钢水碳含量的实时监测,具体而言涉及基于SVM的转炉炼钢钢水碳含量在线实时动态检测方法。
背景技术:
现今世界上的主流炼钢技术就是转炉炼钢,其产量占钢铁总产量的70%以上。而在转炉炼钢过程中最重要的一环就是末期的终点控制,直接关系到最后钢水的质量。自从转炉炼钢方法出现以来,转炉炼钢的终点控制主要经历了人工经验控制、静态模型控制、动态模型控制和光信息控制四个发展阶段。
人工经验控制,即经验炼钢,利用热电偶测温定碳和炉前取样快速分析的手段,对正常吹炼条件下的转炉终点进行人工经验判断控制。碳氧反应速率是划分三个阶段的重要依据,而碳氧反应的剧烈程度及钢水的温度,都能够被炉口火焰反映出来。炼钢操作工人通过观察炉口火焰、火花和供氧时间来综合判断炼钢终点。然而,仅仅依靠操作工人的肉眼观察,存在终点命中率低、工人劳动强度大等问题。
静态模型控制就是根据统计学的原理,对以往转炉吹炼的初始数据进行统计分析,计算出吹炼所需要的初始条件,以此条件来进行吹炼过程。一般来说,静态模型控制相比人工经验控制能够更加有效地利用吹炼过程的初始条件进行定量计算和控制。静态模型控制能够依据原料条件寻找最佳原料配比,并根据实际配料确定冶炼方案,克服经验控制上的随机性和不一致性。现有的静态模型包括机理模型、统计模型和增量模型三种。而在实际应用中,常常以这三种模型相互结合来提高终点控制的精度。但是由于静态模型控制不考虑吹炼过程中的动态信息,不能进行在线跟踪和实时修正,因此准确性受到很大的限制。
动态模型控制主要是副枪动态控制方法,在静态模型的基础上利用副枪对转炉内的钢水进行检测,根据检测得到的结果,对初始参数加以修正,来得到精确的终点。尤其是近年来,随着人工神经网络的研究在动态模型控制方法上的应用,克服了传统静态模型控制忽视吹炼过程中动态信息的问题,进一步提高了检测的准确性,使终点检测结果的命中率得到了进一步的提升,同时使炼钢的自动化程度得到了极大的提高。但是它成本比较高,需要对转炉进行改造,故对一般的中小型转炉不太适用。
传统方法或对终点判断不准确,或成本高适应性受限,因此随着炼钢技术的发展和相关技术的进步,人们不断尝试在终点控制技术中应用更加有效和准确的方法。在20世纪80年 代,出现了利用转炉炉口光学信息对转炉炼钢终点判断的新型终点控制方法。诸如,利用红外激光穿透炉气时发生的变化情况来测量炉气成分来判断终点的光学探测器,该探测器通过检测穿过炉气激光发生的变化情况来判断终点,其主要原理是检测炉气中的一氧化碳的含量,根据炉气中的一氧化碳的成分变化来进行终点控制。在经验或者动态模型控制中,始终不可忽略的就是操作工人要从火焰的变化来获取不同程度的信息,这些信息其实就是火焰的光圈、光谱分布和火焰的图像信息。随着光电器件的不断发展,光学处理方法的不断成熟,光学探测技术得到了极大的发展,光学控制方法也应用到了转炉炼钢的终点控制中。诸如张金进、石彦杰等人提出的钢水辐射光谱信息探测法、美国伯利恒钢铁公司提出的炉口火焰光强信息探测法、卫成业、严建华等人提出的火焰图像信息探测法等。
虽然炼钢终点控制理论的研究不断深入,但这些方法所需的成本极高,探测和分析设备的造价都是极其昂贵的,而且安装和维护十分不便,仅仅在一些实力强大的钢铁企业中应用。在大多数中小钢铁企业中,还是以单一的经验控制或者静态模型控制为主。而最新的光信息控制方法虽然提供了一些有价值的思路和应用方向,但由于受到生产规模、生产条件的限制,尤其是复杂、恶劣的炼钢生产环境,在光信息采集方面,抗干扰能力弱,不能迅速连续的提取所需要的参数信息,因而很难为一些中小钢铁企业所接受。
因此,迫切需要研制一种精确的,适用于中小钢铁企业,中小转炉的在线实时炼钢终点控制方案。
技术实现要素:
本发明目的在于提供一种基于SVM的转炉炼钢钢水碳含量在线实时动态检测方法,该方法基于支持向量机算法设计,具有碳含量检测精度高、非接触、抗干扰能力强、易于操作等优点,从而解决了当前转炉炼钢碳含量在线动态检测方面的问题。
本发明的上述目的通过独立权利要求的技术特征实现,从属权利要求以另选或有利的方式发展独立权利要求的技术特征。
为达成上述目的,本发明提出一种基于SVM的转炉炼钢钢水碳含量在线实时动态检测方法,该检测方法的实现包括:
根据转炉炼钢环境调节望远光学系统中的视场光栏,从而调节炉口火焰探测的视场使得炉口火焰的预设位置通过该望远光学系统成像,再经由一传输光纤将炉口火焰图像信息传输至一光谱仪;
光谱仪接收到像之后,进行光谱分析获取火焰光谱分布信息;
利用基于SVM终点控制方法根据火焰光谱分布信息进行转炉炼钢碳含量的实时检测,其中碳含量通过SVM碳含量动态检测模型来进行检测。
进一步的例子中,所述视场光栏为可变视场光栏。
进一步的例子中,所述转炉炼钢碳含量的实时检测通过运行存储在计算机系统中的程序来实现,包括以下过程:
接收火焰光谱信息并构建表征炉内碳含量变化的特征参量;
将表征炉内碳含量变化的特征参量输入一SVM碳含量动态检测模型进行检测;以及
输出碳含量的检测结果。
进一步的例子中,所述SVM碳含量动态检测模型为预先训练好的模型,其训练过程如下:
以实际钢水碳含量作为标准,通过反复训练、优化选择,确定SVM学习算法所涉及的各个参量,其具体包括:
由火焰光谱信息构建能够表征炉内碳含量变化的特征参量;
选定SVM学习算法的核函数;
优化控制参数核函数宽度δ和惩罚因子C;
选取模型训练样本,利用SVM学习算法对特征参量进行分类建模;
以测试样本输入所建立的模型,并分析误差和泛化性是否满足设计要求:如果满足,则输出模型,如果不满足,则返回所述步骤重新进行核函数宽度δ和惩罚因子C的选择以重新建模,直到满足要求。
进一步的例子中,所述模型训练过程中,按照下述方式构建特征参量:
波长600nm处光谱形状为凸起的尖峰,特征参量a1为此处的光强归一化值;
光谱形状在770nm处凸起的尖峰是双峰,特征参量a2为波长770nm和772nm处的光强归一化均值;
所述两个尖峰中间的连续光谱变化剧烈,将该段谱线平均分成三段,对每一段光强归一化后取平均值得到三个特征参量a3,a4,a5;以及
将光谱分布中光谱的峰值波长λ与所述光谱仪的探测范围最大值T max的比值作为第六个参量:a6。
进一步的例子中,所述模型训练过程中,所述的SVM学习算法的核函数选自线性核函数,多项式核函数,RBF核函数以及S型核函数中的一种。
进一步的例子中,在碳含量的检测过程中,在接收到在线实时采集的火焰光谱信息并构建特征参数后,首先通过所述SVM碳含量动态预测模型确定终点碳的类别,并基于终点碳的类别采用对应的终点拟合函数确定当前所采集火焰光谱信息对应的钢水的碳含量。
进一步的例子中,所述终点拟合函数包括了不同终点碳的类别各自所属的终点拟合函数,其中:
所述终点拟合函数表示为:
Y=f(X),
该公式表达了X与Y的映射关系,其中X是终点时刻火焰光谱中提取的特征变量,Y是终点碳值,该终点拟合函数使用MATLAB提供一个多项式拟合函数来对数据进行拟合,从而得到拟合函数。
应当理解,所述构思以及在下面更加详细地描述的额外构思的所有组合只要在这样的构思不相互矛盾的情况下都可以被视为本公开的发明主题的一部分。另外,所要求保护的主题的所有组合都被视为本公开的发明主题的一部分。
结合附图从下面的描述中可以更加全面地理解本发明教导的所述和其他方面、实施例和特征。本发明的其他附加方面例如示例性实施方式的特征和/或有益效果将在下面的描述中显见,或通过根据本发明教导的具体实施方式的实践中得知。
附图说明
附图不意在按比例绘制。在附图中,在各个图中示出的每个相同或近似相同的组成部分可以用相同的标号表示。为了清晰起见,在每个图中,并非每个组成部分均被标记。现在,将通过例子并参考附图来描述本发明的各个方面的实施例,其中:
图1是本发明所提出的基于SVM的转炉炼钢钢水碳含量在线实时动态检测系统的示意图。
图2是图1的检测方法中望远光学系统的示意图。
图3是基于图1所示检测系统实现的转炉炼钢钢水碳含量在线实时动态检测方法的流程示意图。
图4是本发明提出的SVM分类建模的流程示意图。
图5是本发明提出的数据选取范围示意图。
图6a-6b是惩罚因子C=30和核函数宽度δ=0.2时训练样本和测试样本的分类命中结果示意图。
图7a-8b是惩罚因子C=20和核函数宽度δ=0.8时训练样本和测试样本的分类命中结果示意图。
图8a-8b是惩罚因子C=20和核函数宽度δ=3时训练样本和测试样本的分类命中结果示意图。
图9a-9b是惩罚因子C=100和核函数宽度δ=0.06时训练样本和测试样本的分类命中结果 示意图。
图10是30个碳训练的分类模型结果示意图。
图11是最终训练的分类模型结果示意图。
图12是本发明所述图1所示的检测方法在实际启动后的工作流程示意图。
图13是本发明提出的碳含量检测流程示意图。
具体实施方式
为了更了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
在本公开中参照附图来描述本发明的各方面,附图中示出了许多说明的实施例。本公开的实施例不必定意在包括本发明的所有方面。应当理解,上面介绍的多种构思和实施例,以及下面更加详细地描述的那些构思和实施方式可以以很多方式中任意一种来实施,这是因为本发明所公开的构思和实施例并不限于任何实施方式。另外,本发明公开的一些方面可以单独使用,或者与本发明公开的其他方面的任何适当组合来使用。
本发明所提出的转炉炼钢钢水碳含量在线实时动态检测方法,总体来说,是通过望远系统来远距离地获取炉口火焰图像信息,并利用光谱仪对其进行分析得到火焰光谱信息,据此,从中提取有用的即能够表达碳含量的信息来构建特征参量,并对选取的训练样本进行SVM训练得到检测模型,最后利用检测模型来检测在线检测得到的样本数据,从而最终达到对炉内钢水碳含量的在线实时检测。
由于现在转炉炼钢一般是根据所炼钢种的不同来进行相应的转炉吹炼操作,根据要求所吹炼的钢种分为低碳钢(钢水中碳的含量低于1.5%),中碳钢(钢水中碳的含量在1.5%~3.0%)和高碳钢(钢水中碳的含量大于3.0%)三种,在本发明公开的内容中所提及的15个碳实际上是千分之15,即碳含量为1.5%,同样30个碳也是如此表示,下文所描述的30碳模型就是在碳含量为3.0%的若干转炉附近进行分类训练所得到的模型。
结合图1的基于SVM的转炉炼钢钢水碳含量在线实时动态检测系统,包括望远光学系统1、光谱仪2以及基于SVM的终点控制装置3。
望远光学系统1与光谱仪2之间通过光纤4连接。
望远光学系统1,被配置用于实时采集炼钢炉口的火焰图像信息。
光谱仪2,被配置通过光纤4接收来自望远光学系统1的火焰图像信息,并获取火焰图像信息的火焰光谱信息。
光谱仪2,在本例中选用了光栅光谱仪,诸如海洋光学的USB4000-VIS-NIR的微型CCD光栅光谱仪,其体积小、故障率低,且安装方便,与本例设计的望远光学系统配合可稳定获得炉口火焰的稳定光谱。
基于SVM的终点控制装置3,该装置具有一运算单元31和控制运算单元运行的中央控制单元32,该运算单元被设置用于根据所述实时获取的火焰光谱信息通过SVM碳含量动态检测模型进行炼钢钢水中碳含量的实时检测。
本例中,基于SVM的终点控制装置构造为一个电路板。电路板上集成有作为运算单元的FPGA芯片和作为中央处理单元的微处理器,当然,电路板上还包括用于提供稳定电压供应的电源模块、串行接口、RS232接口等接口。
所述的SVM碳含量动态检测模型烧录在所述FPGA芯片中,并且在接收到火焰光谱信息后自动进行碳含量的检测。
当然,在另选的实施方式中,所述的运算单元还可以通过CPLD芯片来实现。
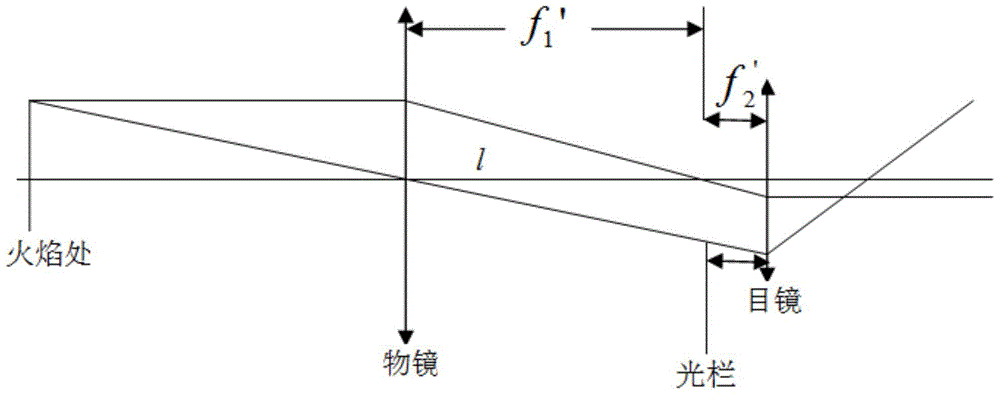
结合图2,所述望远光学系统1包括共光轴的物镜、目镜以及独立于物镜和目镜的视场光栏,该视场光栏配置在所述物镜、目镜所形成的光学成像通路中,用于调节炉口火焰探测的视场。
如图2所示,优选地,视场光栏设置在物镜于目镜之间,诸如位于所述物镜的焦平面上。
在另外的例子中,所述视场光栏位于所述目镜后方并贴近所述光纤。
作为可选的例子,所述物镜为双分离透镜,由一块正透镜和一块负透镜共光轴的分布而构成。
所述目镜为凯涅尔目镜,由一块单透镜和一块双胶合透镜共光轴的分布而构成。
优选地,所述视场光栏为可变视场光栏。
如图2所示,标号l表示物镜、目镜的光轴,f′1表示物镜的焦距,f′2表示目镜的焦距。
如前所述,所述基于SVM的终点控制装置3,其中的运算单元31通过FPGA、CPLD中的一种实现,SVM碳含量动态检测模型烧录在FPGA或CPLD中,并且在接收到火焰光谱信息后由中央控制单元32控制自动进行碳含量的检测。
本例中,所述SVM碳含量动态检测模型中包括:
用于根据输入的火焰光谱信息中构建表征炉内碳含量变化的特征参量的参量构建模块;
用于基于所述构建的特征参量进行碳含量检测的碳含量动态检测模块;以及
用于检测结果输出的输出模块。
结合图1、图2以及图3所示的流程图,根据本发明提出一种基于SVM的转炉炼钢钢水碳含量在线实时动态检测方法,该检测方法的实现包括:
根据转炉炼钢环境调节望远光学系统1中的视场光栏,从而调节炉口火焰探测的视场使得炉口火焰的预设位置通过该望远光学系统1成像,再经由传输光纤将炉口火焰图像信息传 输至一光谱仪2;
光谱仪2接收到像之后,进行光谱分析获取火焰光谱分布信息
利用基于SVM终点控制方法根据火焰光谱信息进行转炉炼钢碳含量的实时检测,其中碳含量通过SVM碳含量动态检测模型来进行检测。
优选地,前述用于调节炉口火焰探测的视场光栏为可变视场光栏。
本例中,结合图3所示,转炉炼钢碳含量的实时检测通过运行存储在计算机中的程序来实现,包括以下过程:
接收火焰光谱信息并构建表征炉内碳含量变化的特征参量;
将表征炉内碳含量变化的特征参量输入一SVM碳含量动态检测模型进行检测;以及
输出碳含量的检测结果。
SVM碳含量动态检测模型为预先训练好的模型,其训练过程如下:
以实际钢水碳含量作为标准,通过反复训练、优化选择,确定SVM学习算法所涉及的各个参量,其具体包括:
由火焰光谱信息构建能够表征炉内碳含量变化的特征参量;
选定SVM学习算法的核函数;
优化控制参数核函数宽度δ和惩罚因子C;
选取模型训练样本,利用SVM学习算法对特征参量进行分类建模;
以测试样本输入所建立的模型,并分析误差和泛化性是否满足设计要求:如果满足,则输出模型,如果不满足,则返回所述步骤重新进行核函数宽度δ和惩罚因子C的选择以重新建模,直到满足要求。
而在模型训练过程中,按照下述方式构建特征参量:
波长600nm处光谱形状为凸起的尖峰,特征参量a1为此处的光强归一化值;
光谱形状在770nm处凸起的尖峰是双峰,特征参量a2为波长770nm和772nm处的光强归一化均值;
所述两个尖峰中间的连续光谱变化剧烈,将该段谱线平均分成三段,对每一段光强归一化后取平均值得到三个特征参量a3,a4,a5;以及
将光谱分布中光谱的峰值波长λ与所述光谱仪的探测范围最大值Tmax的比值作为第六个参量:a6。
所述的SVM学习算法的核函数选自线性核函数,多项式核函数,RBF核函数以及S型核函数中的一种。
在实际的模型生成时,通过将待测试训练分成三类,使得数据的碳值跨度范围缩小。
如前所述,在进行模型训练和建立时,即采用分类建模的方式进行。
本例中,结合图4所示,分类建模具体实现包括:
1)训练和测试样本的选取
从钢厂采集得到转炉炉口火焰的100个火焰光谱数据,对这100个光谱数据进行分类,将其分成碳含量C<15,15≤C<30,C≥30三大类,从SVM分类算法得知,对于多分类问题,可以将其转化成几个二分类问题,这样做简化了算法的难度,同时降低了多分类的时间复杂度。对本发明来说,很明显是多分类问题,因此可以用两个二分类模型来解决,在训练时只需在30个碳和15个碳附近训练两个模型即可达到将数据分成三类的目的。
示例性地,假设碳的范围为0~50之间,具体训练数据的选取如图5所示。
因此,对于30个碳分类模型的训练,它的两个类的范围分别是:0~30个碳之间和30个碳以上(测得的最大值在50个碳附近)。确定好两个类之后,再确定用于训练和测试的样本,训练样本和测试样本的个数一般按照2:1或者3:1的比例选择,最好不要个数持平,那样不利于模型的泛化性,训练样本的个数最好大于测试样本的个数。
同样对于15个碳模型的训练,它的两个类分别为:15~30个碳之间和15个碳以下,选择训练和测试样本的个数与30个碳模型选择规则是一样的。
在这里样本确定好之后,并不是一成不变的,有可能选择的样本在分类模型训练时,无论怎么做都达不到要求。这时就需要更改一下样本,将测试样本中没有命中的炉次放到训练样本中重新训练,这里需要说明一点,如果在此时刻改变了训练样本,那么下一时刻的模型训练,样本也跟着改变,也就是说不同时刻的训练样本是一致的。
2)特征变量的构建
炉口光强可以表征火焰的亮度,而炉口火焰的光谱信息可以表征转炉内的状态。在转炉炼钢过程中,炉内钢水的状态总是从一个状态向下一个状态变化,因此可以用一个量化的值来代表它,即可以用Yd来表示转炉内的状态信息,这个值包含了炉内的温度和成分信息。在这里Yd可以是离散的,也可以是连续的。在观察火焰光谱的变化趋势时,并没有发现光谱的异常突变,但是发现了光谱在某些波段上会发生轻微的变化,这种变化在吹炼末期会比较明显,可能会成为终点判断的标志。
因此,本例中利用M(λ)表示炉口火焰的光谱分布,并且认为Yd是一个连续变化的值,则可以用一个映射来将自变量(即M(λ)的值)转化为因变量(即Yd值),得到如下函数关系式:f(M(λ))=Yd。
钢水在吹炼过程中的状态与炉口火焰的光谱有关,即可以通过光谱的分布来检测炉内钢水的状态。因此要对光谱分布做预处理,忽略光谱强度的绝对值影响,仅仅考虑光谱分布的变化对钢水状态的影响。
对某一时刻的光谱数据而言,可以用如下公式处理:
在上式中,M(λi)代表在波长λi处光谱光强的绝对值,其作用是对光谱光强进行归一化处理,经过处理以后光谱分布的形状没有改变,但是在转炉整个吹炼过程中它的值在0~1之间。
其中波长λi的取值范围取决于光谱仪2的探测范围,本例中,所采用的光谱仪的探测范围是[350,1000]。
在研究过程中,火焰光谱分布中具有明显的两个凸起的尖峰,在多次研究中它们在整个吹炼过程中变化最有规律,尤其是在吹炼末期靠近终点时,它们的形状会在一定程度上代表炉内钢水的状态。其对应的波长分别为600nm和770nm、772nm,因此在在本发明中把这两处的光谱归一化值作为特征变量a1,a2。即a1=M'(600),由于在700nm处的尖峰是双峰,所以对其取平均值,即计算770nm和772nm处的光强归一化均值:
在多次研究的过程中还发现,两个尖峰中间的连续光谱变化也比较剧烈,这其中可以反映火焰亮度的变化,为了得到能够表征这一段谱线的特征变量,我们在本例中将这一段谱线平均分成三段,对每一段光强归一化值的取平均值,从而可以得到三个特征参量:a3,a4,a5。
光谱分布的峰值也可以反映一定的信息,但是峰值的光强归一化值已经在参量a4中得以反映,在选取参量时,首先要保证的是参量之间是相互独立的,不能存在其中两个参量可以反映另一参量,或者参量之间相互反映的情况,所以不需要重复选取。
对于这种情况,本例中,将光谱分布中光谱的峰值波长与所述光谱仪的探测范围最大值的比值作为第六个参量:a6。
因此,在本实施例中,所述参量构建模块被设置成按照下述方式构建特征参量:
波长600nm处光谱形状为凸起的尖峰,特征参量a1为此处的光强归一化值;
光谱形状在770nm处凸起的尖峰是双峰,特征参量a2为波长770nm和772nm处的光强归一化均值;
所述两个尖峰中间的连续光谱变化剧烈,将该段谱线平均分成三段,对每一段光强归一化后取平均值得到三个特征参量a3,a4,a5;
将光谱分布中光谱的峰值波长与所述光谱仪的探测范围最大值的比值作为第六个参量:a6。
通过上面的分析介绍,6个参量的值范围都在[0,1]之间,这样做是为了保持算法的稳健性。到这里光谱参量就已经选取完毕,参量都可以通过光谱计算而得到,对于N个训练样本,每一个训练样本都包含许多数据点xi=(a1,a2,a3,a4,a5,a6),i=1,...,N,每个数据点都含有6个参量,然后接下来就是导入样本参量,利用SVM进行分类模型的训练。
3)训练参数的选取
在这里对样本进行分类训练时,选取样本要遵循一个条件:样本是独立同分布的。经分析得,每一时刻光谱的信息是反映炉内的状态的,对于转炉吹炼过程来说,每一个状态是相互独立的,也就是说每一时刻火焰光谱信息也是相互独立的,它们之间是一种对应的关系,进而可得到每一个样本点之间是独立的。又因为每一时刻的光谱分布都是由同一介质燃烧得来,必定满足相同的物理特性,所以它们符合同一概率分布的。综上所述,可以认为选取的训练样本是独立同分布的。
SVM训练时不同的核函数对应不同的网格结构,本例中SVM学习算法的核函数选自线性核函数,多项式核函数,RBF核函数以及S型核函数中的一种。
线性核函数:K(x,x')=<x,x'>;
多相式核函数:K(x,x')=(<x,x'>+1)d其中d为正实数;
S型(sigmoid)核函数:K(x,x')=thanh(v<x,x'>+r)其中v和r为正常数。
高斯(径向基函数,RBF)核函数:K(x,x')=exp(-||x-x'||2/2σ2)其中σ为核宽,且为正整数。(参考:A Practical Guide to Support Vector Classi fication第2页,Hsu C W,Chang C C,Lin C J.A practical guide to support vector classification[J].2003.)
在实际应用中,通常要根据问题的具体情况选择合适的核函数和参数。为找到不同转炉对应的最合适的SVM模型核函数,可以分别对不同转炉的样本光谱数据采用以上4种核函数训练,然后选择训练结果最好的核函数作为该转炉SVM模型核函数
SVM分类就是在选定核函数之后,在核函数空间中寻找拥有最大间隔的超平面。
本例中,利用的是LS_SVM算法进行分类模型的训练,得到原问题的优化定义为:
Subject to:yi(<ω·xi>+b)≥1-ξi,i=1,...,l[备注:支持向量机导论第91页]
上式中,C是需要给定的值,它是样本误差的惩罚因子。
接下来的工作就是训练模型,具体的步骤是:按时间顺序导入训练样本的光谱信息,也就是每一炉的光谱参量。在这里所选的训练规则是从终点往前训练,即选取末尾100帧训练一个模型,然后继续往前推100帧再训练一个模型。
首先对一段时间内的炉次进行训练,比如对训练样本选取它们倒数200帧至300帧之间的100帧数据训练模型,这里100帧数据的提取对所有训练样本是一致的。
以30碳的分类模型为例,在确定了核函数后,接下来控制的参数主要是:核函数宽度δ和惩罚因子C。
调参方法主要包括:智能微粒群(PSO)算法(如Eberhart R C,Kennedy J.A new optimizer using particle swarm theory[C]//Proceedings of the sixth international symposium on micro machine and human science.1995,1:39-43.)、遗传(GA)算法(如雷剑.基于SVM和遗传算法的建模与全局寻优方法[J].科技广场,2008(5):120-122.)、网格搜索法(如王健峰,张磊,陈国兴,等.基于改进的网格搜索法的SVM参数优化[J].应用科技,2012,39(3):28-31.)等,可以分别用以上不同方法进行调参,结合样本的命中率和模型的泛化性,选择最优的核函数宽度δ和惩罚因子C。
下面依然以30碳的分类模型为例简单介绍调参过程:
首先,随意选择一对惩罚因子C=30和核函数宽度δ=0.2的参数,利用SVM训练就可以得到一个分类器即超平面,它自身的训练精度和测试样本精度如图6a、6b所示,星号表示的是实际的碳值,圆圈表示的未命中的炉次,也就是分类错误的炉次。
如图6a、6b所示,对于训练样本和测试样本的分类命中情况,图6a、6b可以看出模型对训练样本的分类效果非常好,能够全部分类正确,在这种参数下训练样本全部是支持向量的。但是对于测试样本来说,有4个炉次的碳没有正确分类,如果不考虑其它参数情况的话,认为这种情况是可以接受的,但是实际上需要尝试大量的参数来寻找合适的模型。前面已经说过在选择模型时主要考虑的是样本的命中率和模型的泛化性,泛化性则是由测试数据的分类情况看出。
接下来考虑在参数C=20和δ=0.8条件下的分类情况,训练和测试样本的命中率如图7a、7b所示。
从图6a、6b,图7a、7b可以看出,在这两组参数下,训练样本和测试样本的命中率是一样的,但是在参数C=20和δ=0.8的情况下,训练样本的分类精度降低,样本支持向量的数目减少,模型的泛化性比前者要好,对新的测试数据准确性要优于前者。所以在这种情况下, 相比而言选择后面一对参数所训练的模型较为合适。
前面已经介绍过,最大间隔的超平面在N个随机样本S中的误差是以概率1-δ不大于:
在上式中,d=#sv就表示支持向量的个数,上面的公式表明支持向量的个数越少,其泛化能力就越强。通过分析得到,调整δ的值可以改变支持向量的数目,进而改变分类模型的泛化性,在一定情况下,δ的值越大,支持向量的数目越少,泛化性越好,这一点在SVM回归拟合时,会表现的更为明显。但是并不是δ越大越好,当δ增大到一定程度时,模型的泛化性并没有得到改善,有可能还会变坏,甚至训练样本的命中率也有可能会变差,如图8a、8b所示为参数C=20,δ=3时训练样本和测试样本的分类命中结果。
由图8a、8b可以看出,这时就需要调节一下惩罚因子C的值,C的值表示对超过目标的惩罚因子。虽然前面支持向量的数目是减少了,但是参数C的约束能力相对于训练向量来说减小了,造成了不是支持向量的训练结果超出了泛化误差界一定范围,因而影响了其命中率。所以这两个参数都是需要调节的,并不是一个参数固定,只改变另一个参数来寻找合适的分类模型即可,而是两个参数都要改变来选择分类模型。通过尝试大量的参数,最终选择了C=100和δ=0.06的参数组合下的分类模型,它用来对样本分类的命中率如图9a、9b所示。
至此,对于30个碳的分类模型来说,在倒数100至200帧之间的分类模型就训练完成,按照同样的寻优原则,可以找到直至倒数1500帧的15个分类模型,全部的模型训练情况。当实际检测火焰光谱数据时,从光谱仪采集到的炉口火焰光谱数据首先进入第15个模型,然后依次进入第14、13、...、2、1个分类模型,如图10所示。到每一个分类模型时都会得出一个标签值,这个结果值就表示模型的分类情况,即属于哪一个类。
在这里需要明确的一点就是:吹炼前期采集的光谱数据进入模型后得到的检测结果是不准确的,因为本发明的分类模型是根据吹炼后期的光谱数据来训练的,只有转炉吹炼进入后期以后,分类模型才开始真正发挥作用,这和钢厂工人的经验控制是相一致的,工人也是在到吹炼末期时才开始真正的终点控制,前期和中期只是按照长期以来的经验在进行。
同样,对于15个碳的分类模型也是如此,以100帧为准依次训练,等30个碳分类模型和15个碳的分类模型全部训练完成之后,实际光谱的模型检测流程可以表示为图11所示,在每一时刻段都会有两个分类模型在工作,经过模型检测后会确切的知道碳含量是属于高、中、低哪一个大类,进而利用已知的拟合曲线来检测出实际的碳值。
结合图12所示,本发明所提出的碳含量在线实时动态检测方法在启动后,进行现场测试时,训练的分类模型也随之开始进行分类,它会实时的给出一个分类结果,这个结果表明此 时的碳是属于高、中、低中的哪一个类。显然,在确定终点碳的类别之后,接下来的工作过程就是得出此时实际的碳值,所以就需要终点拟合曲线的帮助才可以实现。
如图12所示,本发明所提出的检测方法中,所述基于SVM的终点控制装置3,诸如检测板等,可通过数据线与一上位工控机连接,以接收和发送数据信息,实现对整个检测方法的调试、控制以及数据的上传、显示、存储和后续分析等,诸如将在线实时采集的光谱信息显示在工控机的显示屏上,和/或,将检测出的碳含量结果实时地显示或者以曲线表达的形式通过显示屏表征给操作者。
在碳含量的检测过程中,在接收到在线实时采集的火焰光谱信息并构建特征参数后,首先通过所述SVM碳含量动态预测模型确定终点碳的类别,并基于终点碳的类别采用对应的终点拟合函数确定当前所采集火焰光谱信息对应的钢水的碳含量。
所述终点拟合函数包括了不同终点碳的类别(例如低碳钢、中碳钢、高碳钢)各自所属的终点拟合函数,其中:
所述终点拟合函数表示为:
Y=f(X),
该公式表达了X与Y的映射关系,其中X是终点时刻火焰光谱中提取的特征变量,Y是终点碳值,该终点拟合函数使用MATLAB提供一个多项式拟合函数来对数据进行拟合,从而得到拟合函数。
本例中,也就是说,结合图1所示,运算单元在接收到在线实时采集的火焰光谱信息并构建特征参数后,首先通过所述SVM碳含量动态检测模型确定碳的类别,即确定所吹炼的钢种属于低碳钢、中碳钢还是高碳钢,并基于碳的类别采用对应的终点拟合函数确定当前所采集火焰光谱信息对应的钢水的碳含量。
本例中,终点拟合函数包括了低碳钢、中碳钢、高碳钢的各自分别所属的终点拟合函数。也即,将炉次按照碳含量分成高、中、低三类,对每一个类的样本分别进行拟合,得出一个拟合函数,也就是最终会得到高、中、低三条拟合曲线。
所述终点拟合函数Y=f(X),实际上是表达了X与Y的映射关系,其中X是终点时刻火焰光谱中提取的特征变量,Y是终点碳值。例如,使用MATLAB提供一个多项式拟合函数来对数据进行拟合,得到拟合函数。
下面给出一个以多项式拟合函数进行数据拟合的示例。
多项式拟合函数如下公式:
[p,s]=polyfit(X,Y,N)
拟合的准则是最小二乘法,即寻找使得最小的f(x)。式中的N表示拟合的阶数,p表示多项式的系数向量,s表示生成检测值的误差估计。
对于选取拟合函数的评价标准,主要是拟合的精度,即在误差范围之内拟合值与实际值的差值。为了考虑拟合曲线在实际应用中的识别性和观察性,还要考虑拟合曲线的下降趋势情况。
在成功的训练出所需要的分类模型和终点碳拟合函数后,正如以上所提出的,当转炉炼钢吹炼到末期时,分类模型开始发挥其真正的作用,对钢水中的碳含量进行实时的分类检测,如图13所示,利用拟合函数得到确切的碳值,为炼钢厂提供实时碳含量的调控依据。
经过试验,通过现场检测40个转炉的炉口火焰光谱数据,得到终点碳的检测结果,分析其命中情况和误差分布,得出本发明研究的终点碳分类检测方法命中率可达85%以上,完全满足钢厂的实际需求。
虽然本发明已以较佳实施例揭露如上,然其并非用以限定本发明。本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视权利要求书所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!