一种基于可分割阵列的可重构加速器及其实现方法与流程
本发明是关于神经网络加速器技术,特别是关于一种基于可分割阵列的可重构加速器及其实现方法。
背景技术:
在过去的十年中,深度学习(deeplearning)技术促使人工智能技术飞速发展,基于深度学习的人工智能技术在图像识别、视频分析、语音识别与自然语义理解等领域取得了巨大的成功,在部分场景下甚至超越了人类智能。而基于深度学习的深度神经网络(deepneuralnetwork)是实现智能任务的核心技术。现阶段,一项智能任务往往由多个深度神经网络组成,当前主流的深度神经网络主要包括:深度卷积网络(deepconvolutionneuralnetwork,cnn),深度全连接网络(deepfullconnectionneuralnetwork)及深度递归网络(deeprecurrentneuralnetwork)。其中,卷积网络主要用于从二维信息中提取关键特征,主要包括了卷积层、池化层(poolinglayer)等;全连接网络主要擅长处理分类任务,主要包括全连接层;递归神经网络一般用来处理与上下文有关的时序信息,主要由全连接层组成。当前著名的图像分类器alexnet、resnet、googlenet以及视频分析网络lrcn等,均是采用混合神经网络架构。更有研究(pathnet)表明,通用人工智能都可以通过混合神经网络来实现。
在混合神经网络中大量的计算集中在了卷积网络,因此学术界与工业界的工作主要集中在了针对卷积神经网络的加速。基于阵列结构的卷积神经网络加速器由于其高性能与高能效比的特点,在卷积神经网络加速器当中尤为瞩目。因为智能任务均采用混合神经网络架构,很多研究工作为了实现混合神经网络的加速,将cnn中的卷积计算与fcn中的全连接计算用统一的计算形式表示,这些工作复用卷积神经网络加速器加速cnn与fcn。同时,由于混合神经网络采用级联结构组织不同的神经网络,因此上述研究工作分时复用加速器顺序加速混合神经网络中的cnn与fcn。
然而,混合神经网络中的多种神经网络具有不同的特点(如数据重用度、稀疏化等),因此采用卷积加速器在时间上分别加速不同的神经网络会导致加速器资源的浪费(内存带宽与计算资源)。这种浪费主要表现在两个方面:
第一,数据重用度不同导致的资源浪费。数据重用度主要是指数据从内存传到加速器内部直至数据不再参与运算,这段时间内所参与的运算次数。在混合神经网络中,卷积网络是计算密集型的网络,一次数据传输可以参与几十次(甚至几百次)的卷积运算,因此卷积网络仅需要一部分内存带宽就可以满足所有计算资源对数据的需求,导致内存带宽的利用率低。相反,全连接网络与递归网络是访存密集型的,一次数据传输仅参与一次运算,因此这两种网络利用所有的内存带宽也仅能为一部分计算资源提供数据,导致计算资源的利用率低。
第二,稀疏化导致的资源浪费。全连接网络具有非常高的稀疏度,因此采用稀疏计算的方式加速全连接网络可以很好的提高性能与能效比,但是现有的卷积加速器不能兼容稀疏网络计算,导致计算资源与带宽资源的同时浪费。
技术实现要素:
本发明实施例提供了一种基于可分割阵列的可重构加速器及其实现方法,以将两种神经网络的特点相互融合,提高芯片的计算资源与内存带宽利用率。
为了实现上述目的,本发明实施例提供了一种基于可分割阵列的可重构加速器,该可重构加速器包括:
便笺式存储器缓存区,用于实现卷积计算与稀疏化全连接计算的数据重用;
可分割计算阵列,包括多个可重构计算单元,所述可分割计算阵列分为被配置用于执行卷积计算的卷积计算阵列及用于执行稀疏化全连接计算的稀疏化全连接计算阵列;
寄存器缓存区,由多块寄存器构成的存储区域,为卷积计算与稀疏化全连接计算提供输入数据、权重数据及对应的输出结果;所述卷积计算的输入数据及权重数据分别输入到所述卷积计算阵列,以得到卷积计算结果;所述稀疏化全连接计算的输入数据及权重数据分别输入到所述稀疏化全连接计算阵列,以得到稀疏化全连接计算结果。
一实施例中,用于执行卷积计算的配置信息及稀疏化全连接计算的配置信息通过配置通路加载至对应的每个可重构计算单元。
一实施例中,所述可重构计算单元包括:多组配置寄存器、乘法器、加法器、第一存储区域、第二存储区域、第三存储区域、第四存储区域、第五存储区域及多个选择器;
配置寄存器用于存储执行卷积计算的配置信息或稀疏化全连接计算的配置信息;
所述第一存储区域通过第一选择器连接至所述乘法器,所述第二存储区域连接至所述第一选择器的控制端;
所述第三存储区域通过第二选择器连接至所述乘法器,
所述第五存储区域通过第三选择器连接至所述加法器,所述第四存储区域连接至所述第三选择器的控制端;
所述乘法器通过第四选择器连接至所述加法器,所述加法器的乘加和写回所述第五存储区域。
一实施例中,在卷积计算模式下,所述第一存储区域用于存储卷积权重,所述第三存储区域用于存储卷积输入数据,所述第五存储区域用于存储加法器输出的卷积中间结果,所述第二存储区域及第四存储区域处于闲置状态;在执行卷积计算过程中,将所述第一存储区域中的卷积权重与所述第三存储区域中的卷积输入数据执行乘法操作,将乘法操作得到的乘积与所述第五存储区域中的卷积中间结果加和得到乘加和,所述乘加和存储至所述第五存储区域中。
一实施例中,在稀疏化全连接计算模式下,第一存储区域用于存储输入神经元,第五存储区域用于存储输出神经元,第三存储区域用于存储稀疏化权重,所述第二存储区域用于存储稀疏化权重对应的输入神经元索引,所述第四存储区域用于存储稀疏化权重对应的输出神经元索引;在执行稀疏化全连接计算过程中,从所述第三存储区域中选取一个稀疏化权重,从所述第二存储区域中读取与该稀疏化权重对应的输入神经元索引,从所述第四存储区域中读取与该稀疏化权重对应的输出神经元索引,根据读取的输入神经元索引从所述第一存储区域中读取输入神经元,根据读取的输出神经元索引从所述第五存储区域中读取输出神经元的中间结果,对读取的输入神经元与选取的稀疏化权重执行乘法操作,将乘法操作的乘积与输出神经元的中间结果加和得到乘加和,将所述乘加和根据读取的输出神经元索引写回所述第五存储区域。
一实施例中,所述输入数据包括输入图像矩阵,所述权重数据包括权重模板;针对卷积计算阵列,所述输入图像矩阵从所述卷积计算阵列的左侧与顶部输入,所述输入图像矩阵在所述卷积计算阵列中沿对角线方向由左上向右下传输;权重模板从所述卷积计算阵列的顶部输入,权重模板在所述卷积计算阵列中沿垂直方向由上向下传输;卷积计算阵列的加法器输出的中间结果在所述卷积计算阵列中沿水平方向从左向右传输并执行累加操作,最终累加和写入所述寄存器缓存区的卷积输出缓存中。
一实施例中,所述权重模板在所述输入图像矩阵中扫描移动,所述权重模板每次移动后与所述输入图像矩阵中的对应区域执行乘累加操作,得到二维输出图像的一个特征点,得到的所有特征点组成完整的二维输出图像。
一实施例中,所述输入数据包括输入向量,所述权重数据包括稀疏权重矩阵;针对稀疏化全连接计算阵列,输入向量从稀疏化全连接计算阵列的底部输入,并沿垂直方向由下向上传输;稀疏权重矩阵从稀疏化全连接计算阵列的左侧输入,并沿水平方向从左向右传输;稀疏化全连接计算阵列的加法器输出的中间结果在稀疏化全连接计算阵列中沿垂直方向从上向下传输并执行累加操作,最终累加和写入所述寄存器缓存区的稀疏全连接输出缓存中。
一实施例中,稀疏权重矩阵与输入向量进行矩阵乘操作,得到输出向量。
为了实现上述目的,本发明实施例还提供了一种基于可分割阵列的可重构加速器实现方法,该可重构加速器实现方法包括:
将所述可重构加速器的可分割计算阵列分割为被配置用于执行卷积计算的卷积计算阵列及用于执行稀疏化全连接计算的稀疏化全连接计算阵列,所述可分割计算阵列包括多个可重构计算单元;
将用于执行卷积计算的输入数据及权重数据分别输入到所述卷积计算阵列,并将用于执行稀疏化全连接计算的输入数据及权重数据分别输入到所述稀疏化全连接计算阵列,分别执行卷积计算及稀疏化全连接计算,输出卷积计算结果及稀疏化全连接计算结果;用于执行卷积计算的输入数据及权重数据、用于执行稀疏化全连接计算的输入数据及权重数据存储在所述可重构加速器的寄存器缓存区。
一实施例中,还包括:将用于执行卷积计算的配置信息及稀疏化全连接计算的配置信息通过配置通路加载至对应的每个可重构计算单元。
一实施例中,所述可重构计算单元包括:多组配置寄存器、乘法器、加法器、第一存储区域、第二存储区域、第三存储区域、第四存储区域、第五存储区域及多个选择器;
配置寄存器用于存储执行卷积计算的配置信息或稀疏化全连接计算的配置信息;
所述第一存储区域通过第一选择器连接至所述乘法器,所述第二存储区域连接至所述第一选择器的控制端;
所述第三存储区域通过第二选择器连接至所述乘法器,
所述第五存储区域通过第三选择器连接至所述加法器,所述第四存储区域连接至所述第三选择器的控制端;
所述乘法器通过第四选择器连接至所述加法器,所述加法器的乘加和写回所述第五存储区域。
一实施例中,在卷积计算模式下,所述第一存储区域用于存储卷积权重,所述第三存储区域用于存储卷积输入数据,所述第五存储区域用于存储加法器输出的卷积中间结果,所述第二存储区域及第四存储区域处于闲置状态;
对于卷积计算阵列中每个可重构计算单元,所述执行卷积计算,包括:
将所述第一存储区域中的卷积权重与所述第三存储区域中的卷积输入数据执行乘法操作;
将乘法操作得到的乘积与所述第五存储区域中的卷积中间结果加和得到乘加和;
将所述乘加和存储至所述第五存储区域中。
一实施例中,在稀疏化全连接计算模式下,第一存储区域用于存储输入神经元,第五存储区域用于存储输出神经元,第三存储区域用于存储稀疏化权重,所述第二存储区域用于存储稀疏化权重对应的输入神经元索引,所述第四存储区域用于存储稀疏化权重对应的输出神经元索引;
对于稀疏化全连接计算阵列中每个可重构计算单元,所述执行稀疏化全连接计算,包括:
从所述第三存储区域中选取一个稀疏化权重;
从所述第二存储区域中读取与该稀疏化权重对应的输入神经元索引;
从所述第四存储区域中读取与该稀疏化权重对应的输出神经元索引;
根据读取的输入神经元索引从所述第一存储区域中读取输入神经元;
根据读取的输出神经元索引从所述第五存储区域中读取输出神经元的中间结果;
对读取的输入神经元与选取的稀疏化权重执行乘法操作;
将乘法操作的乘积与输出神经元的中间结果加和得到乘加和;
将所述乘加和根据读取的输出神经元索引写回所述第五存储区域。
一实施例中,所述输入数据包括输入图像矩阵,所述权重数据包括权重模板;所述执行卷积计算,包括:
将所述输入图像矩阵从所述卷积计算阵列的左侧与顶部输入,所述输入图像矩阵在所述卷积计算阵列中沿对角线方向由左上向右下传输;
将所述权重模板从所述卷积计算阵列的顶部输入,权重模板在所述卷积计算阵列中沿垂直方向由上向下传输;
将卷积计算阵列的加法器输出的中间结果在所述卷积计算阵列中沿水平方向从左向右传输并执行累加操作,并将最终累加和写入所述寄存器缓存区的卷积输出缓存中。
一实施例中,所述执行卷积计算还包括:所述权重模板在所述输入图像矩阵中扫描移动,所述权重模板每次移动后与所述输入图像矩阵中的对应区域执行乘累加操作,得到二维输出图像的一个特征点,得到的所有特征点组成完整的二维输出图像。
一实施例中,所述输入数据包括输入向量,所述权重数据包括稀疏权重矩阵;所述执行稀疏化全连接计算,包括:
将所述输入向量从稀疏化全连接计算阵列的底部输入,并沿垂直方向由下向上传输;
将稀疏权重矩阵从稀疏化全连接计算阵列的左侧输入,并沿水平方向从左向右传输;
将稀疏化全连接计算阵列的加法器输出的中间结果在稀疏化全连接计算阵列中沿垂直方向从上向下传输并执行累加操作,并将最终累加和写入所述寄存器缓存区的稀疏全连接输出缓存中。
一实施例中,所述执行稀疏化全连接计算还包括:将稀疏权重矩阵与输入向量进行矩阵乘操作,得到输出向量。
本发明实施例中,利用了两种神经网络互补性的特点,采用可分割阵列将两种神经网络的特点相互融合,提高了芯片的计算资源与内存带宽利用率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例基于可分割阵列的可重构加速器的结构示意图;
图2为本发明实施例的可重构计算单元的结构示意图;
图3为本发明实施例卷积计算模式下可重构计算单元的结构示意图;
图4为本发明实施例稀疏化全连接计算模式下可重构计算单元的结构示意图;
图5为本发明一实施例的可分割阵列的数据流示意图;
图6a为本发明实施例的二维卷积计算示意图;
图6b为本发明实施例的卷积计算在3×3阵列的映射示意图;
图6c为本发明实施例中每一计算单元执行一维卷积计算的示意图;
图7a为本发明实施例的稀疏化全连接计算示意图;
图7b为本发明实施例的稀疏化全连接计算在3×3阵列的映射示意图;
图7c为本发明实施例中第二个计算单元执行稀疏化全连接计算的过程示意图;
图8为本发明实施例基于可分割阵列的可重构加速器实现方法流程图;
图9为本发明一实施例执行卷积计算流程图;
图10为本发明一实施例稀疏化全连接计算流程图;
图11为本发明一实施例卷积计算流程图;
图12为本发明一实施例稀疏化全连接计算流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本发明实施例基于可分割阵列的可重构加速器的结构示意图,如图1所示,该可重构加速器包括:便笺式存储器缓存区(scratch-pad-memorybuffer,简称spm缓存或spm缓存),寄存器缓存区及可分割计算阵列(计算阵列)。寄存器缓存区与计算阵列连接,便笺式存储器缓存区与寄存器缓存区通过加速器控制器(简称控制器)连接,实现数据双向通信,控制器还可以将可重构加速器的数据加载至spm缓存,实现内存访问。
spm缓存可以为统一(unified)spm缓存,用于实现卷积计算与稀疏化全连接计算的数据重用。一实施例中,spm缓存可以是一块由静态存储器(staticrandomaccessmemory,sram)构成的存储区域,大小为256kb,该spm缓存可以作为二级缓存使用,用来实现卷积计算与稀疏化全连接计算的数据重用。spm缓存可以通过内存控制器(doubledatarate,ddr)与片外实现数据通信。
计算阵列包括多个可重构计算单元(processingelement,pe),可分割计算阵列分为被配置用于执行卷积计算的卷积计算阵列及用于执行稀疏化全连接计算的稀疏化全连接计算阵列。卷积计算阵列及稀疏化全连接计算阵列分别包括其中的多个可重构计算单元。
一实施例中,计算阵列有16×16个可重构计算单元构成。如图1所示,计算阵列可分割成上下两个区域,上面的区域用来执行卷积计算,下面的区域用于执行稀疏化全连接计算。用于执行卷积计算的配置信息及稀疏化全连接计算的配置信息通过专用的配置通路(configuringpath)从可重构加速器外加载至计算阵列中对应的每个可重构计算单元。
寄存器缓存区由多块寄存器构成的存储区域,为卷积计算与稀疏化全连接计算提供输入数据、权重数据及对应的输出结果;所述卷积计算的输入数据及权重数据分别输入到所述卷积计算阵列,以得到卷积计算结果;所述稀疏化全连接计算的输入数据及权重数据分别输入到所述稀疏化全连接计算阵列,以得到稀疏化全连接计算结果。
一实施例中,寄存器缓存区为由六块1kb大小的寄存器构成的存储区域。如图1所示,寄存器缓存区存储的卷积计算的输入数据、权重数据及对应的输出结果分别对应存储在卷积输入缓存、卷积权重缓存及卷积输出缓存中;寄存器缓存区存储的稀疏化全连接计算的输入数据、权重数据及对应的输出结果分别对应存储在稀疏化全连接输入缓寄存器存、稀疏化全连接权重寄存器缓存及稀疏化全连接输出寄存器缓存。
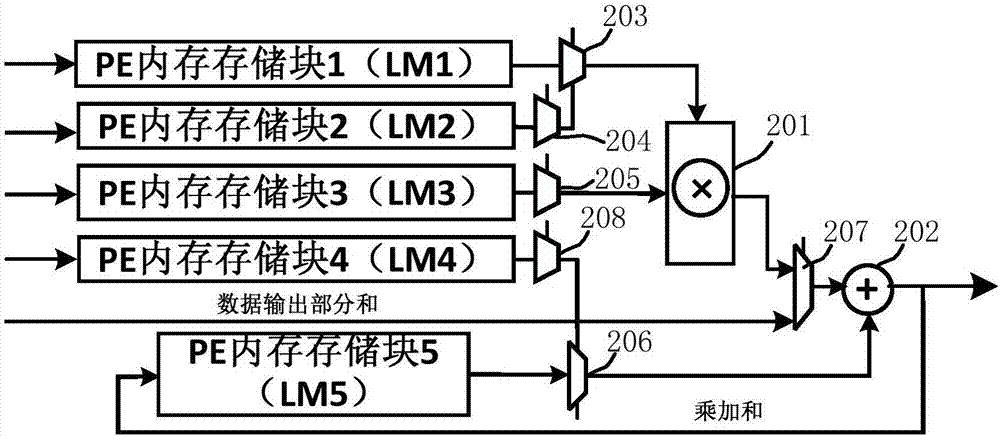
图2为本发明实施例的可重构计算单元的结构示意图,如图2所示,该可重构计算单元包括:多组配置寄存器(图中未示出)、乘法器201、加法器202、第一存储区域(pe内存存储块1,lm1)、第二存储区域(pe内存存储块2,lm2)、第三存储区域(pe内存存储块3,lm3)、第四存储区域(pe内存存储块4,lm4)、第五存储区域(pe内存存储块5,lm5)及多个选择器。
多组配置寄存器可以存储执行卷积计算的配置信息或稀疏化全连接计算的配置信息,根据该配置信息,可重构计算单元可以执行卷积计算或稀疏化全连接计算。
如图2所示,lm1通过选择器203连接至乘法器201,lm2通过选择器204连接至选择器203的控制端;lm3通过选择器205连接至乘法器201。
lm5通过选择器206连接至加法器202,lm4通过选择器208连接至选择器206的控制端。
乘法器201的输出端通过选择器207连接至加法器的202输入端,加法器202的乘加和写回lm5。
图3为本发明实施例卷积计算模式下可重构计算单元的结构示意图,如图3所示,在卷积计算模式下,lm1用于存储卷积权重,lm3用于存储卷积输入数据(输入图像数据),lm5用于存储加法器输出的卷积中间结果(输出图像部分和),lm2及lm4处于闲置状态。
在执行卷积计算过程中,从lm1中读取一个卷积权重,从lm3中读取一个输入数据,lm1中的卷积权重与lm3中的卷积输入数据执行乘法操作,将乘法操作得到的乘积与lm5中的卷积中间结果加和得到乘加和,乘加和返回,存储至lm5中。
图4为本发明实施例稀疏化全连接计算模式下可重构计算单元的结构示意图,如图4所示,在稀疏化全连接计算模式下,lm1用于存储输入神经元,lm5用于存储输出神经元,lm3用于存储稀疏化权重(非零权重),lm2用于存储稀疏化权重对应的输入神经元索引,lm4用于存储稀疏化权重对应的输出神经元索引。
在执行稀疏化全连接计算过程中,从lm3中选取一个稀疏化权重,从lm2中读取与该稀疏化权重对应的输入神经元索引,从lm4中读取与该稀疏化权重对应的输出神经元索引,根据读取的输入神经元索引从lm1中读取输入神经元,根据读取的输出神经元索引从lm5中读取输出神经元的中间结果,对读取的输入神经元与选取的稀疏化权重执行乘法操作,将乘法操作的乘积与输出神经元的中间结果加和得到乘加和,将乘加和根据读取的输出神经元索引写回lm5。
图5为本发明一实施例的可分割阵列的数据流示意图,如图5所示,以4x3的计算阵列为例展示了可分割阵列的数据流。在该实施例中,4x3的计算阵列被分割成上下两个区域:上面2x3区域的计算单元被配置成卷积模式来执行卷积操作,下面2x3区域的计算单元被配置成稀疏化全连接模式来执行稀疏化的全连接计算。
对于卷积计算阵列,输入数据为输入图像矩阵,权重数据为权重模板。如图5所示,针对卷积计算阵列,输入图像矩阵从卷积计算阵列的左侧与顶部输入,输入图像矩阵在卷积计算阵列中沿对角线方向由左上向右下传输;权重模板从卷积计算阵列的顶部输入,权重模板在卷积计算阵列中沿垂直方向由上向下传输;卷积计算阵列的加法器输出的中间结果在卷积计算阵列中沿水平方向从左向右传输并执行累加操作,最终累加和写入寄存器缓存区的卷积输出缓存中。
对于稀疏权重矩阵,输入数据为输入向量,权重数据为稀疏权重矩阵。如图5所示,针对稀疏化全连接计算阵列,输入向量从稀疏化全连接计算阵列的底部输入,并沿垂直方向由下向上传输;稀疏权重矩阵从稀疏化全连接计算阵列的左侧输入,并沿水平方向从左向右传输;稀疏化全连接计算阵列的加法器输出的中间结果在稀疏化全连接计算阵列中沿垂直方向从上向下传输并执行累加操作,最终累加和写入寄存器缓存区的稀疏全连接输出缓存中。
为了更清楚的说明卷积计算及稀疏化全连接计算,下面结合具体的实施例进行说明。
首先说明卷积计算,图6a至图6c展示了一个二维卷积在阵列上的计算过程,图6a为本发明实施例的二维卷积计算示意图,图6b为本发明实施例的卷积计算在3×3阵列的映射示意图,图6c为本发明实施例中每一计算单元执行一维卷积计算的示意图。
如图6a所示,二维输入图像(input)大小为5x5,二维权重模板(又称为卷积模板)大小为3x3,二维输出图像大小为3x3。权重模板在输入图像矩阵中扫描移动,权重模板每次移动后,与二维输入图像中一块3x3的区域执行乘累加操作,可以得到二维输出图像中的一个特征点(图6a中等号右侧的粗黑框)。通过卷积模板在二维输入图像上扫描移动,可以得到完整的二维输出图像。
如图6b所示,三行权重(w-row1/2/3)分别从卷积计算阵列顶部由上向下输入到卷积计算阵列的不同列中;输入图像的前三行(in-row1/2/3)从卷积计算阵列顶部延对角线输入到卷积计算阵列中,输入图像的后两行(in-row4/5)从卷积计算阵列左侧沿对角线输入到卷积计算阵列中;卷积计算的中间结果沿水平方向由左向右传输,在传输过程中与所经过的计算单元(pe1、pe2、pe3、pe4、pe5、pe6、pe7、pe8、pe9)的中间结果实现累加,并将最终累加和送出卷积计算阵列。该计算分成三步完成:
第一步,计算单元pe1、pe2、pe3分别收到w-row3/in-row3,w-row2/in-row2,w-row1/in-row1,三个计算单元pe1、pe2、pe3分别基于w-row与in-row执行一维卷积,产生三行部分和,然后从左向右传递执行累加操作(将计算单元pe1、pe2、pe3得到一维卷积累加),得到out-row1的输出结果。
第二步,计算单元pe4、pe5、pe6分别收到w-row3/in-row4,w-row2/in-row3,w-row1/in-row2,三个计算单元pe4、pe5、pe6分别基于w-row与in-row执行一维卷积,产生三行部分和,然后从左向右传递执行累加操作(将计算单元pe4、pe5、pe6得到一维卷积累加),得到out-row1的输出结果。
第三步,pe7、pe8、pe9分别收到w-row3/in-row5,w-row2/in-row4,w-row1/in-row3,三个计算单元pe7、pe8、pe9分别基于w-row与in-row执行一维卷积,产生三行部分和,然后从左向右传递执行累加操作(将计算单元pe7、pe8、pe9得到一维卷积累加),得到out-row1的输出结果。
如图6c所示,一维卷积利用一行图像输入(in-row)与一行权重(w-row)计算一行中间结果输出(out-row)。一行权重与一行输入分别保存在计算单元的lm1与lm3中,一行中间结果输出保存在lm5中。一行权重与对应位置的输入数据执行卷积操作,可以得到输出图像的一个元素,通过将一行卷积模板在一行输入图像上移动并执行卷积操作,最终可以得到一行输出图像。
然后说明卷积计算,图7a至图7c展示了一个稀疏化全连接计算在计算阵列上的执行过程,图7a为本发明实施例的稀疏化全连接计算示意图,图7b为本发明实施例的稀疏化全连接计算在3×3阵列的映射示意图,图7c为本发明实施例中第二个计算单元执行稀疏化全连接计算的过程示意图。
如图7a所示,本实施例中,稀疏权重矩阵(sparsefcweightmatrix)大小为6x6,其中仅有9个有效权重(w1~w9),其余权重均为零;三组输入向量(in1/2/3),每个输入向量长度为6;三组输出向量(out1/2/3),每个输出向量长度为6。
如图7b所示,输入向量从稀疏化全连接计算阵列(如图7b右侧所示)底部由下向上输入到稀疏化全连接计算阵列中,同一列的计算单元复制相同的输入数据;稀疏的权重矩阵平均分成三组,从稀疏化全连接计算阵列的左侧从左向右输入到稀疏化全连接计算阵列中;全连接计算的中间结果,延垂直方向由上向下传输,在传输过程中实现输出向量的累加操作,并将最终的累加和送出稀疏化全连接计算阵列。
如图7c所示,以第二行的第二个计算单元为例,该计算单元基于输入向量2(in2)与稀疏权重(w2/5/8)计算输出向量2(out2)。输入向量2(in2)与输出向量2(out2)分别保存在计算单元的lm1与lm5中,稀疏权重(w2/5/8)、其输入索引(5/0/4)、其输出索引(0/3/4)分别缓存在计算单元的lm2/3/4中。以权重w5的计算为例,权重w5利用输入索引编号0读取输入向量0号位置的数据in[0],利用输出索引编号3读取输出向量3号位置的数据out[3],实现计算out[3]+=in[0]*w5,并将w5参与计算结果写回输出向量的3输出索引号位置。
本发明实施例中,利用了两种神经网络互补性的特点,采用可分割阵列将两种神经网络的特点相互融合,提高了芯片的计算资源与内存带宽利用率。
图8为本发明实施例基于可分割阵列的可重构加速器实现方法流程图,该可重构加速器实现方法可以应用于如图1所示的可重构加速器。该可重构加速器实现方法可以基于与上述可重构加速器相同的发明构思,如下面实施例所述。由于该可重构加速器实现方法解决问题的原理与可重构加速器相似,因此该可重构加速器实现方法的实施可以参见可重构加速器的实施,重复之处不再赘述。
如图8所示,该可重构加速器实现方法包括:
s801:将所述可重构加速器的可分割计算阵列分割为被配置用于执行卷积计算的卷积计算阵列及用于执行稀疏化全连接计算的稀疏化全连接计算阵列,所述可分割计算阵列包括多个可重构计算单元;
s802:将用于执行卷积计算的输入数据及权重数据分别输入到所述卷积计算阵列,并将用于执行稀疏化全连接计算的输入数据及权重数据分别输入到所述稀疏化全连接计算阵列,分别执行卷积计算及稀疏化全连接计算,输出卷积计算结果及稀疏化全连接计算结果;用于执行卷积计算的输入数据及权重数据、用于执行稀疏化全连接计算的输入数据及权重数据存储在所述可重构加速器的寄存器缓存区。
一实施例中,该可重构加速器实现方法还可以包括:将用于执行卷积计算的配置信息及稀疏化全连接计算的配置信息通过配置通路加载至对应的每个可重构计算单元。
如图3所示,lm1用于存储卷积权重,lm3用于存储卷积输入数据(输入图像数据),lm5用于存储加法器输出的卷积中间结果(输出图像部分和),lm2及lm4处于闲置状态。对于卷积计算阵列中每个可重构计算单元,如图9所示,执行卷积计算,包括:
s901:将lm1中的卷积权重与lm3中的卷积输入数据执行乘法操作;
s902:将乘法操作得到的乘积与lm5中的卷积中间结果加和得到乘加和;
s903:将乘加和存储至lm5中。
结合图4所示,在稀疏化全连接计算模式下,lm1用于存储输入神经元,lm5用于存储输出神经元,lm3用于存储稀疏化权重(非零权重),lm2用于存储稀疏化权重对应的输入神经元索引,lm4用于存储稀疏化权重对应的输出神经元索引。
对于稀疏化全连接计算阵列中每个可重构计算单元,如图10所示,执行稀疏化全连接计算,包括:
s1001:从lm3中选取一个稀疏化权重;
s1002:从lm2中读取与该稀疏化权重对应的输入神经元索引;
s1003:从lm4中读取与该稀疏化权重对应的输出神经元索引;
s1004:根据读取的输入神经元索引从lm1中读取输入神经元;
s1005:根据读取的输出神经元索引从lm中读取输出神经元的中间结果;
s1006:对读取的输入神经元与选取的稀疏化权重执行乘法操作;
s1007:将乘法操作的乘积与输出神经元的中间结果加和得到乘加和;
s1008:将所述乘加和根据读取的输出神经元索引写回lm5。
对于卷积计算阵列,输入数据为输入图像矩阵,权重数据为权重模板。输入数据包括输入图像矩阵,所述权重数据包括权重模板。如图11所示,执行卷积计算包括:
s1101:将所述输入图像矩阵从所述卷积计算阵列的左侧与顶部输入,所述输入图像矩阵在所述卷积计算阵列中沿对角线方向由左上向右下传输;
s1102:将所述权重模板从所述卷积计算阵列的顶部输入,权重模板在所述卷积计算阵列中沿垂直方向由上向下传输;
s1103:将卷积计算阵列的加法器输出的中间结果在所述卷积计算阵列中沿水平方向从左向右传输并执行累加操作,并将最终累加和写入所述寄存器缓存区的卷积输出缓存中。
一实施例,所述执行卷积计算还包括:所述权重模板在所述输入图像矩阵中扫描移动,所述权重模板每次移动后与所述输入图像矩阵中的对应区域执行乘累加操作,得到二维输出图像的一个特征点,得到的所有特征点组成完整的二维输出图像。为了更清楚的说明卷积计算,图6a至图6c展示了一个二维卷积在阵列上的计算过程,具体请参见如图6a至图6c所示。
对于稀疏权重矩阵,输入数据为输入向量,权重数据为稀疏权重矩阵。如图12所示,执行稀疏化全连接计算包括:
s1201:将所述输入向量从稀疏化全连接计算阵列的底部输入,并沿垂直方向由下向上传输;
s1202:将稀疏权重矩阵从稀疏化全连接计算阵列的左侧输入,并沿水平方向从左向右传输;
s1203:将稀疏化全连接计算阵列的加法器输出的中间结果在稀疏化全连接计算阵列中沿垂直方向从上向下传输并执行累加操作,并将最终累加和写入所述寄存器缓存区的稀疏全连接输出缓存中。
一实施例,所述执行稀疏化全连接计算还包括:将稀疏权重矩阵与输入向量进行矩阵乘操作,得到输出向量。为了更清楚的说明稀疏化全连接计算,图7a至图7c展示了一个二维卷积在阵列上的计算过程,具体请参见如图7a至图7c所示。
本发明提供了基于可分割阵列结构的可重构混合神经网络加速器。该加速器的计算单元可以重构,配置成不同的计算模式,包括:卷积神经计算模式(用于卷积神经网络加速)、稀疏化全连接计算模式(用于稀疏的全连接网络与稀疏的递归网络加速)。该加速器的计算阵列可以配置成上下两部分,分别用于加速卷积网络与稀疏全连接网络(或稀疏递归网络)。由于混合神经网络中的不同网络在数据重用度上不仅存在差异,同时存在互补性,因此可分割阵列将两种神经网络的特点相互融合,可以提高芯片的计算资源与内存带宽利用。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
本发明中应用了具体实施例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!