高通量测序数据分析方法及装置与流程
本发明属于生物信息技术领域,尤其涉及高通量测序数据分析方法及装置。
背景技术:
高通量测序技术又称为下一代测序技术(nextgenerationsequencing,简称ngs),一次能并行对细胞基因组内的几十万至上千万条分子进行序列测定,因此在基因组研究中得到了广泛的应用。高通量测序能够对大量序列进行快速测序,能够用于不同个体如肿瘤患者的基因突变检测,为个体化治疗提供有益建议和指导。然而,高通量测序获得的大量初始数据常常包括例如实验操作等产生的低质量序列,严重影响测序数据的分析,并可能导致错误的分析结论。
目前用于高通量测序数据分析如肿瘤高通量测序变异分析的常见软件包括学术界的开源软件mutect,varscan,pindel等,也包括收费软件gatk,sentieon等。这些软件大多基于理论模型计算,在检测敏感性和特异性方面均不能满足临床的需求。本领域仍然亟需开发更加准确快速高效的高通量测序数据分析方法,获取更为精准的变异信息。
技术实现要素:
鉴于现有高通量测序数据分析方法如体细胞变异测序数据分析的方法存在无法准确分析出变异信息的缺陷,本发明提供一种高通量测序数据分析方法及装置。本发明的高通量测序数据分析方法及装置可以通过比较变异与背景的差异显著程度,针对变异测序数据检测分析噪点并进行过滤,提高了变异检测的准确性,同时也提高了分析速度。
在一些实施方案中,本发明提供一种高通量测序数据分析方法,其包括:
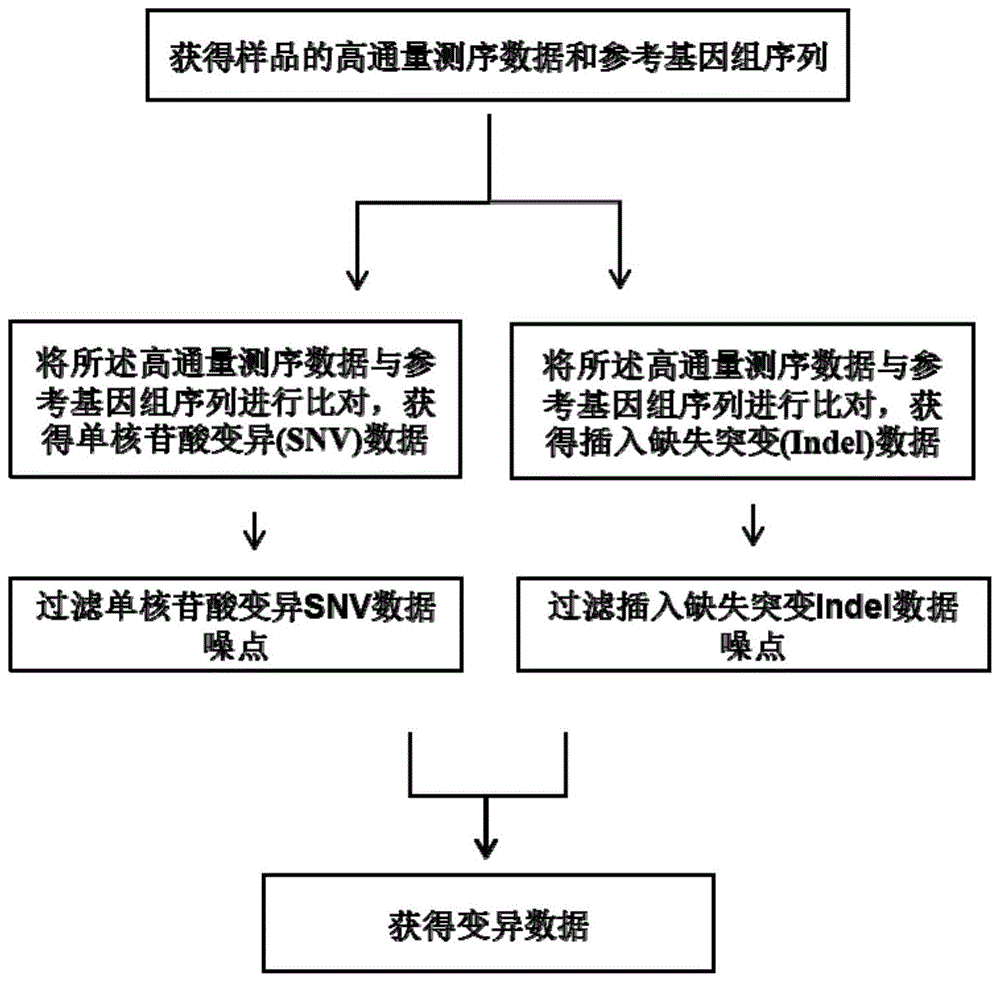
获得样本的高通量测序数据和参考基因组序列,
将所述高通量测序数据与参考基因组序列进行比对后,分别获得单核苷酸变异(snv)位点数据和插入缺失突变(indel)位点数据,和通过比较变异(snv变异和indel变异)与背景的差异显著程度分别过滤snv和indel数据噪点,由此获得变异数据。
在一些实施方案中,过滤单核苷酸变异snv数据噪点可以包括例如1)基于单样本不同变异背景错误率统计,比较单个变异与背景的差异显著程度,和/或2)基于单样本不同序列环境下变异背景错误率统计,比较单个变异与背景的差异显著程度。
在一些实施方案中,过滤插入缺失突变indel数据噪点可以包括例如1)基于单样本不同变异背景错误率统计,比较单个变异与背景的差异显著程度,和/或2)基于单样本str区域内不同长度重复单元发生的背景错误率,比较单个变异与背景的差异显著程度。
在一些实施方案中,已经发现通过对snv数据和indel数据分别进行比对和噪点过滤,能够显著改善高通量测序数据分析的结果,获得提高的灵敏度和特异性。在一些实施方案中,已经发现高通量测序过程中snv数据和indel数据的噪点可以具有不同来源,因此对于数据分析具有不同影响。在一些实施方案中,通过分别对高通量测序获得的snv数据和indel数据进行分类,具体分析各自测序过程中不同噪点产生原因,并针对性的进行噪点过滤,实现了对测序结果分析的改善,从而获得更加精准的变异信息。在一些实施方案中,通过比较各自的变异与背景的差异显著程度,对snv数据和indel数据分别进行比对和噪点过滤。在一些实施方案中,本发明的方法考虑从wet-lab到dry-lab过程中,各个环节可能引入的噪点,建立过滤器,训练阈值,并去除变异噪点。在一些实施方案中,本发明的方法尤其考虑具体单个样本的不同具体序列背景下在具体实验过程中(例如pcr扩增和测序过程中)产生噪点的不同,而非仅仅依据固定不变的理论模型对测序结果进行分析,从而显著提高了分析结果的准确性,降低分析错误率。在一些实施方案中,提供了一套基于临床检测数据训练学习后优化的流程,解决目前肿瘤体细胞变异检测数据分析时发现的问题,诸如:低质量dna样本引起的假阳性变异和测序错误率高导致的假阳性变异。
在一些实施方案中,本发明的方法还包括:获取热点变异数据,例如疾病可用药位点变异数据,对于过滤单核苷酸变异snv数据噪点和/或过滤插入缺失突变indel数据噪点数据中热点变异区间回溯热点变异snv位点和/或indel位点。
在一些实施方案中,本发明的方法中过滤单核苷酸变异snv数据噪点还包括下述一种或多种:
3)比较支持变异的低质量碱基比例,与背景水平是否存在显著差异,
4)比较支持变异的低质量reads比例,与背景水平是否存在显著差异,
5)比较支持变异的reads比对质量,与背景水平是否存在显著差异,
6)比较单个变异与正常人数据集的基线水平的差异显著程度,
7)比较支持变异的链偏好性,与变异所处位置的背景水平是否存在显著差异。
在一些实施方案中,本发明的方法中过滤插入缺失突变indel数据噪点还包括下述一种或多种:
3)比较支持变异的reads比对质量,与背景水平是否存在显著差异,
4)比较单个变异与正常人数据集的基线水平的差异显著程度,
5)比较支持变异的链偏好性,与变异所处位置的背景水平是否存在显著差异。
在一些实施方案中,本发明的方法中的过滤通过估计单个样本中不同变异形式的背景错误率,利用二项分布概率统计模型,结合阈值进行判断,区分真实信号与低频背景噪音。
在一些实施方案中,本发明的方法还包括对多个连续点突变位点mnv和/或复杂indel变异进行校正,例如对mnv识别判断连续位置in-cis的snv并进行校正和对复杂indel进行重比对和识别校正。
在一些实施方案中,本发明的方法还包括根据人类基因组变异协会hgvs命名标准,对获得的变异数据命名,和/或针对目标检测范围roi,选择变异位点数据。
在一些实施方案中,本发明的方法还包括对变异信息注释和功能重要性过滤,例如通过下述一种或多种方式进行:
1)去除数据库中标记为commonsnp的变异,
2)去除数据库中maf>=0.015的变异,
3)除外显子边界2bp范围内的同义突变外,去除其余位置的同义突变,
4)除内含子边界2bp范围内的变异外,去除其余内含子区域变异,和
5)保留tert启动子区域内的变异,
在一些实施方案中,所述方法还包括获取热点变异数据,例如药物代谢相关变异数据,例如snp位点数据,和据此回溯过滤的变异数据。
在一些实施方案中,本发明的方法包括获取体细胞变异和胚系变异数据,和区分体细胞变异和胚系变异,例如通过下述方式对体细胞/胚系变异进行过滤:
1)对于体细胞变异,
a)对标记为hotspot的变异直接输出,
b)滤除40bp或以上的indel,
c)滤除germline变异,
2)对于胚系变异
a)滤除40bp或以上的indel
b)只输出germline基因列表范围内的变异。
在一些实施方案中,本发明的方法中过滤数据噪点的参数基于临床样本数据训练获得。
在一些实施方案中,本发明中可分析的样本没有特别限制。例如,所述样本可以包括来自患者和/或正常对照的样本,例如来自肿瘤患者的样本,例如ffpe样本、cfdna样本,ctdna样本、wbc样本,对照血样本,癌旁样本。
在一些实施方案中,本发明的方法中样本如疾病样本如肿瘤样本和正常对照如健康受试者样本同时平行进行高通量测序,并样本测序数据和参考基因测序数据进行比对。在一些实施方案中,通过对实验样本和对照样本平行进行同一次或同一批实验(例如pcr扩增、测序,优选采用同一批次实验试剂),并通过比对具体批次测序结果之间的差异,有效降低了系统误差,尤其是具体实验过程中产生噪点的不同,从而显著降低分析错误。
在一些实施方案中,本发明提供一种用于分析高通量测序数据的装置,包括处理器和存储器,其上存储有指令,所述指令在由所述处理器执行时使得所述处理器执行本发明所述的方法。
在一些实施方案中,本发明提供一种存储指令的计算机可读存储介质,所述指令在由处理器执行时使得所述处理器执行本发明所述的方法。
在一些实施方案中,可以利用计算机程序进行本文所述任何方法的一个或多个步骤。在一些实施方案中,本发明包括计算机程序执行的步骤。在一些实施方案中,本发明包括一种计算机可读存储介质,其上存储有可执行指令,所述指令在由一个或多个处理器执行时,可以使所述一个或多个处理器执行本发明方法的一步或多步操作。
在一些实施方案中,本发明提供一种用于进行高通量测序数据分析的设备,包括:存储器,用于存储高通量测序数据;处理器,用于对存储器中存储的测序数据进行如下处理:获得样本的高通量测序数据和参考基因组序列,将所述高通量测序数据与参考基因组序列进行比对后,分别获得单核苷酸变异(snv)位点数据和插入缺失突变(indel)位点数据,和通过比较变异(snv变异和indel变异)与背景的差异显著程度分别过滤snv和indel数据噪点,由此获得变异数据;以及显示器,用于呈现所述变异数据。因此,在一些实施方案中,本发明提供一种设备,包括:存储器,用于存储可执行指令;以及处理器,用于执行存储器中存储的可执行指令,以执行本发明所述方法的一步或多步操作。
本方法与现有方法相比,具有以下一种或多种优点:
1)噪点过滤方法考虑到实验环节各个步骤可能产生的噪音,可以根据实际生产数据以igv判读结果为标准来训练每个噪声来源的参数,通过实际临床样本数据训练后的评估结果,相对于目前常用的生信软件实现了点突变和插入缺失变异的精准计算。
2)mnv和complexindel的校正,变异hgvs命名完全标准化。
3)snv和indel变异检测速度快。
本发明的噪点过滤方法可广泛适用于各种样本,例如肿瘤ffpe样本、血浆cfdna样本以及对照血或癌旁样本的检测分析。本发明的方法适用于各种高通量测序获得的数据的处理,包括例如基于靶向区域捕获法基于illuminanextseq550机器测序等。本发明的方法可以用于检测肿瘤体细胞和胚系变异以及寻找临床可用药变异位点。本发明中所采用的方法也可以运用于其它样本类型,其它建库以及靶向区域富集方法,以及其它测序平台。
在一些实施方案中,本发明的高通量测序数据分析方法及装置包括针对变异测序数据检测分析噪点过滤方法,提高了变异检测的准确性,同时也提高了分析速度。
附图说明
图1是示例的本发明方法的分析流程图,图1a显示整体流程;图1b显示示例的snv/indel变异检测单样本(包括组织样本,对照样本或cfnda样本)分析流程图。
图2是示例的噪点过滤方法介绍。找寻噪点的特征,构建过滤器,基于训练数据集机器学习,确定阈值。
图3是示例的mnv和复杂indel变异示例图,图3a显示mnv变异形式图示以及具体命名示例;图3b显示复杂indel变异形式图示以及具体命名示例。
图4是针对配对样本进一步区分体细胞和胚系变异的分析流程图。
图5是可用于实施本发明的方法的示例硬件布置500的框图。
具体实施方式
为了使本发明的描述更易于理解,以下先对具体实施方式部分用到的专业术语进行解释说明。
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。
本发明应用于带有显示屏幕和输入设备的电子装置(如各种医疗检测设备)中。所述电子装置中运行有肿瘤样本捕获测序信息分析系统(以下也简称为“系统”),具体方法流程参阅图1至图5的描述。
在一些实施方案中,本发明的信息分析流程可以包括:
1)去除接头污染和低质量数据;
2)比对,产出数据的统计和质控结果
3)snv/indel变异检出和噪点的去除;
4)mnv/complexindel的校正和变异hgvs信息生成;
5)变异临床信息注释和功能重要性过滤;
6)体细胞/胚系变异过滤。
图1是发明突变检测分析流程图。图1a示例了整体流程。在图1b中,可以包括下述步骤:
步骤s1,输入数据:包括1)比对后dedup.bam文件,例如,可以使用已知数据库的参考序列,例如使用人类参考基因组hg19版本,基于fastq文件,使用bwa工具的bwa-mem模式完成样本测序所得序列与hg19基因组的比对,生成sam格式比对结果;使用picard的sortsam功能完成比对结果的排序,并将sam格式文件转换为bam格式文件;使用picard的markduplicates功能标记并去除样本中的冗余片段,并生成去冗余后的bam格式文件。2)捕获探针目标区域bed文件。
步骤s2,使用并行化遍历方法,找出所有reads与参考基因组野生型等位基因不一致的点突变位点;
步骤s3,使用噪点过滤方法,过滤噪音突变位点,产生噪点包括:1)样本连接接头前,由于各种外部因素引入的dna损伤积累;
2)扩增过程中,由于聚合酶的碱基错误整合引起的错误碱基引入;
3)测序仪前期准备过程中,在经历clusteramplification、cyclesequencing和图像信号处理过程中引入的测序错误;
4)下机后的数据预处理过程中出现的错误。
在一些实施方案中,具体过滤器可以如图2和表一所示。在一些实施方案中,可以估计单个样本中不同变异形式的背景错误率,利用统计模型如二项分布概率统计模型,结合给定的阈值进行判断,区分真实信号与低频背景噪音。
表一snv检测的过滤器
步骤s4,针对癌症相关的可用药位点突变采取了独立的补救措施,对mapq过滤器中热点变异区间回溯热点变异snv位点;
步骤s5,使用并行化遍历方法,找出所有reads与参考基因组野生型等位基因不一致的插入缺失位点;
步骤s6,使用噪点过滤方法,过滤噪音突变的插入缺失位点,产生噪点的来源和snv近似,但具体过滤器可以有所不同,如表二所示。在一些实施方案中,可以估计单个样本中不同变异形式的背景错误率,利用统计模型如二项分布概率统计模型,结合给定的阈值进行判断,区分真实信号与低频背景噪音。
在一些实施方案中,snv过滤器可以包括下述一个或多个步骤:
1)目标区域分块:对提供的目标区域文件进行分块。在一些实施方案中,若存在多个目标区域,则可以一行存储一个。在一些实施方案中,块大小(blocksize)可以进行适当设置,例如可以默认最大不超过300bp。若单个目标区域不足300bp,则不进行分块。在一些实施方案中,在一些实施方案中,也可自行设计块大小,例如范围为:100bp、200bp、300bp、400bp、500bp……直至染色体长度。
2)目标区域内的遍历:以块为单位,对块内所有位置进行snv遍历并提取以下一种或多种信息:
a)统计每个基因组位置上a、g、c、t出现的频数。在一些实施方案中,若样本使用umi方法生成consensusreads,则额外统计每个基因组位置上,有consensusreads支持的a、g、c、t出现的频数。
b)统计每个基因组位置上,各个测序碱基的碱基测序质量。
c)统计每个基因组位置上,各个测序碱基离reads末端(包括5’端和3’端)的最近距离。
d)统计每个基因组位置上,各个测序碱基对应reads的比对质量。
e)统计每个基因组位置上,各个测序碱基对应reads的高质量碱基占比(默认值可以适当定义,例如默认定义高质量碱基为测序质量>=20的碱基)。
f)统计每个基因组位置上,各个测序碱基对应reads的比对链方向信息。
3)各类全局背景错误率估计
a)单碱基替换的背景错误率估计:在一些实施方案中,可以基于适当的模型如二项分布模型,采用极大似然估计方法,计算单个样本中不同类型单碱基发生替换的背景水平。在一些实施方案中,若样本使用umi方法生成consensusreads,则使用相同方法估计单个样本的consensusreads中不同类型单碱基发生替换的背景水平。
b)序列偏向性背景错误率估计:在一些实施方案中,可以对具有不同上游序列的碱基位置进行分组,上游序列长度可以适当定义,例如默认定义的上游序列长度为2bp。在一些实施方案中,对于单个组别,基于适当的模型如二项分布模型,采用极大似然估计方法,计算单个样本中不同类型单碱基发生替换的背景水平。
c)碱基测序质量背景水平估计:在一些实施方案中,基于适当的模型如二项分布模型,采用极大似然估计方法,计算单个样本中低测序质量碱基的整体水平。在一些实施方案中,高质量碱基可以适当定义,例如默认定义高质量碱基为测序质量>=20的碱基,反之则为低测序质量碱基。
d)碱基位置变向性背景水平估计:在一些实施方案中,基于适当的模型如二项分布模型,采用极大似然估计方法,计算单个样本近末端碱基的整体水平。在一些实施方案中,碱基距离可以适当定义,例如默认定义近末端碱基为离reads任一端相距<=4bp的碱基,反之则为远末端碱基。
e)reads测序质量背景水平:在一些实施方案中,基于适当的模型如二项分布模型,采用极大似然估计方法,计算单个样本中低测序质量reads的整体水平。在一些实施方案中,测序质量reads可以适当定义,例如默认定义高测序质量reads中测序质量>=20的碱基比例不低于90%,反之则为低测序质量reads。
f)reads比对质量背景水平估计:在一些实施方案中,基于适当的模型如二项分布模型,采用极大似然估计方法,计算单个样本中低比对质量reads的整体水平。在一些实施方案中,高比对质量reads可以适当定义,例如默认定义高比对质量reads的mapq值为30,反之则为低比对质量reads。
4)snv的提取和特征值计算:在一些实施方案中,可以以分块为单位,结合参考基因组序列信息,提取块内每个基因组位置上非参考碱基作为候选的snv,计算所有snv的变异丰度、位点测序深度以及以下一种或多种特征值:
a)与全局单碱基替换的背景水平的差异显著性:在一些实施方案中,可以提取snv的变异丰度、位点测序深度以及单碱基替换的背景错误率估计值,结合二项分布,计算差异显著性p值,并转换为phred分值。
b)与全局序列偏向性背景水平的差异显著性:在一些实施方案中,可以提取snv的变异丰度、位点测序深度以及该碱基位置对应的序列偏向性背景错误率估计值,结合二项分布,计算差异显著性p值,并转换为phred分值。
c)与全局碱基测序质量背景水平的差异显著性:在一些实施方案中,可以提取snv的高/低测序质量碱基频数和碱基测序质量背景水平估计值,结合二项分布,计算差异显著性p值,并转换为phred分值。
d)与局部碱基测序质量背景水平的差异显著性:在一些实施方案中,可以提取snv的高/低测序质量碱基频数和该基因组位置上所有高/低测序质量碱基频数,结合二项分布,计算差异显著性p值,并转换为phred分值。
e)与全局碱基位置变向性背景水平的差异显著性:在一些实施方案中,可以提取snv的近/远末端碱基频数和碱基位置变向性背景水平估计值,结合二项分布,计算差异显著性p值,并转换为phred分值。
f)与局部碱基位置变向性背景水平的差异显著性:在一些实施方案中,可以提取snv的近/远末端碱基频数和该基因组位置上所有近/远末端碱基频数,结合二项分布,计算差异显著性p值,并转换为phred分值。
g)与全局reads测序质量背景水平的差异显著性:在一些实施方案中,可以提取snv的高/低质量reads数目和reads测序质量背景水平估计值,结合二项分布,计算差异显著性p值,并转换为phred分值。
h)与局部reads测序质量背景水平的差异显著性:在一些实施方案中,可以提取snv的高/低质量reads数目和该基因组位置上所有高/低质量reads数目,结合二项分布,计算差异显著性p值,并转换为phred分值。
i)与全局reads比对质量背景水平的差异显著性:在一些实施方案中,可以提取snv的高/低比对质量reads数目和reads比对质量背景水平估计值,结合二项分布,计算差异显著性p值,并转换为phred分值。
j)与局部reads比对质量背景水平的差异显著性:在一些实施方案中,可以提取snv的高/低比对质量reads数目和该基因组位置上所有高/低比对质量reads数目,结合二项分布,计算差异显著性p值,并转换为phred分值。
k)与局部链偏向性背景水平的差异显著性:在一些实施方案中,可以提取snv的正/负链reads数目和该基因组位置所有正/负链reads的背景水平,结合二项分布,计算差异显著性p值,并转换为phred分值。
l)与基线数据噪点水平的差异显著性:在一些实施方案中,可以提取snv的变异丰度、位点测序深度以及该snv在基线数据集中的背景水平,结合二项分布,计算差异显著性p值,并转换为phred分值。
5)snv过滤:在一些实施方案中,可以结合训练数据集,设定针对每个特征的合适阈值。在一些实施方案中,可以对于每个snv变异,逐一判断该变异的各项特征值是否符合设定的阈值要求。若符合,则保留;若不符合,则滤除。
各特征值对应的过滤器阈值可以结合使用的样本类型,实验试剂,测序平台,测序深度和读长,根据实际训练数据集来训练参数。
表二indel检测的过滤器
步骤s7,针对癌症相关的可用药indel位点突变采取了独立的补救措施,对mapq过滤器中热点变异区间回溯热点变异indel位点。
步骤s8,合并snv和indel变异列表。
步骤s9,对多个连续点突变位点(mnv)和复杂indel变异进行校正,现有软件通常将其分开检测为多个变异,我们将其整合为一个复杂变异。示例图3示。在一些实施方案中,具体方法可以如下进行:对mnv识别判断连续位置in-cis的snv并进行合并校正;示例变异见图3a示。对复杂indel识别分为2个步骤:a)针对reads的比对到参考基因组序列的部分进行indel扫描,扫描过程中若发现单个reads上存在多个indel或snv位点,并且相邻indel或snv位点距离不超多8bp时,则将其合并或一个complexindel;b)针对reads的softclipped部分的碱基序列,先进行长度判断,当该部分序列长度不低于8bp时,开启针对softclipped序列的局部重比对。重比对过程使用动态规划方法完成,默认搜索该部分序列在其上下游各50bp范围内的最优比对位置。若最优比对位置与参考基因组序列的一致性不低于99%,则认为局部重比对成功。基于重比对后的结果,进行indel提取。示例变异见图3b示。
步骤s10,变异命名标准化。严格遵守hgvs命名标准,将规则采用程序脚本实现。
步骤s11,变异roi过滤,针对产品的目标检测范围对变异位点进行过滤。
步骤s12,变异临信息注释和功能重要性过滤,具体过滤标准如下:
1)去除dbsnp144中标记为commonsnp的变异
2)去除esp6500中,maf>=0.015的变异
3)去除1000g中,maf>=0.015的变异
4)除外显子边界2bp范围内的同义突变外,其余位置的同义突变均剔除
5)内含子边界2bp范围内的变异保留,其余内含子区域变异剔除
6)tert启动子区域内的变异会被保留
7)对于wbc样本中,特定的药物代谢相关snp位点,会被救回并
步骤13,输出该患者变异列表以及对应的变异注释信息。
在一些实施方案中,针对indel过滤器可以包括下述一个或多个步骤:
1)目标区域分块:对提供的目标区域文件进行分块。在一些实施方案中,若存在多个目标区域,则可以一行存储一个。在一些实施方案中,块大小可以进行适当设置,例如可以默认最大不超过300bp。若单个目标区域不足300bp,则不进行分块。在一些实施方案中,也可自行设计块大小,例如范围为:100bp、200bp、300bp、400bp、500bp……直至染色体长度。
2)目标区域内的遍历:以块为单位,对块内所有reads进行indel遍历。在一些实施方案中,indel遍历过程可以包括3个阶段:
a)针对reads的比对到参考基因组序列的部分进行indel扫描,扫描过程中若发现单个reads上存在多个indel或snv位点,并且相邻indel或snv位点距离不超多适当长度如8bp时,则将其合并或一个complexindel。
b)针对reads的softclipped部分的碱基序列,先进行长度判断,当该部分序列长度不低于适当长度如8bp时,开启针对softclipped序列的局部重比对。在一些实施方案中,重比对过程使用动态归还方法完成,默认搜索该部分序列在其上下游适当长度如各50bp范围内的最优比对位置。若最优比对位置与参考基因组序列的一致性不低于适当值如99%,则认为局部重比对成功。基于重比对后的结果,进行indel提取。
c)完成上述两项后,以块为单位进行结果汇总,记录不同indel,并提取以下一种或多种信息:
i)统计每个indel支持的reads数。在一些实施方案中,若样本使用umi方法生成consensusreads,则额外统计每个indel支持的consensusreads数。
ii)统计每个indel支持的reads的比对质量。
iii)统计每个indel支持的reads的比对链方向信息。
iv)统计每个indel的形式,分析indel发生位置及其下游适当范围如100bp范围内,是否序列存在str区域,并判断该indel是否为str区域的repeatunit。
3)各类全局背景错误率估计
a)indel的背景错误率估计:在一些实施方案中,可以基于适当的模型如二项分布模型,采用极大似然估计方法,计算单个样本中不同类型单碱基发生indel的背景水平。在一些实施方案中,若样本使用umi方法生成consensusreads,则使用相同方法估计单个样本的consensusreads中不同类型单碱基发生替换的背景水平
b)reads比对质量背景水平估计:在一些实施方案中,可以基于适当的模型如二项分布模型,采用极大似然估计方法,计算单个样本中低比对质量reads的整体水平。在一些实施方案中,默认值可以适当定义,例如默认定义高比对质量reads的mapq值为30,反之则为低比对质量reads。
c)str区域内replicationslippage的背景水平估计:在一些实施方案中,可以对具有unit长度和repeatunit个数的str区域进行分组。在一些实施方案中,对于单个组别,可以基于适当的模型如二项分布模型,采用极大似然估计方法,计算单个样本中str区域内不同indel发生的背景水平。
4)indel的特征值计算:在一些实施方案中,可以以分块为单位,结合参考基因组序列信息,提取块内提取出的indel的变异丰度、位点测序深度以及以下特征值:
a)与全局indel的背景水平的差异显著性:在一些实施方案中,可以提取indel的变异丰度、位点测序深度以及indel的背景错误率估计值,结合二项分布,计算差异显著性p值,并转换为phred分值。
b)与str区域内replicationslippage的背景水平的差异显著性:在一些实施方案中,可以提取indel的变异丰度、位点测序深度以及该碱基位置对应的str区域内replicationslippage的背景错误率估计值,结合二项分布,计算差异显著性p值,并转换为phred分值。
c)与全局reads比对质量背景水平的差异显著性:在一些实施方案中,可以提取indel的高/低比对质量reads数目和reads比对质量背景水平估计值,结合二项分布,计算差异显著性p值,并转换为phred分值。
d)与局部链偏向性背景水平的差异显著性:在一些实施方案中,可以提取indel的正/负链reads数目和该基因组位置所有正/负链reads的背景水平,结合二项分布,计算差异显著性p值,并转换为phred分值。
e)与基线数据噪点水平的差异显著性:在一些实施方案中,可以提取indel的变异丰度、位点测序深度以及该snv在基线数据集中的背景水平,结合二项分布,计算差异显著性p值,并转换为phred分值。
5)indel过滤:在一些实施方案中,可以结合训练数据集,设定针对每个特征的合适阈值。在一些实施方案中,对于每个indel变异,逐一判断该变异的各项特征值是否符合设定的阈值要求。若符合,则保留;若不符合,则滤除。
各特征值对应的过滤器阈值可以结合使用的样本类型,实验试剂,测序平台,测序深度和读长等,根据实际训练数据集来训练参数。
本发明支持单个样本变异检测,也支持癌组织和对照血液和癌旁样本的配对检测。针对配对检测样本,将增加区分体细胞变异和胚系变异的步骤,具体方法如图4示。对体细胞/胚系变异过滤采用以下标准:
1)体细胞变异
a)对标记为hotspot的变异直接输出,不考虑是否其他过滤。
b)滤除40bp或以上的indel
c)滤除germline变异
2)胚系变异
a)滤除40bp或以上的indel
b)只输出germline基因列表范围内的变异。
本发明方法检测性能评估数据如下表三至表四示:
评估数据来源于思路迪临床检测的肿瘤患者组织样本以及对应的血液或癌旁对照样本(获得患者知情同意书并通过伦理委员会批准,患者姓名等临床信息都已隐去)。分析突变位点包括靶向捕获panel覆盖的适当的基因如381个基因全外显子区域以及内含子两个碱基可变剪切位点(见表五)。在一些实施方案中,本发明的测序流程包括:文库构建随机首先将至少200ng的基因组dna打断成主带集中于170bp长的dna片段,随后进行dna片段末端修复,在片段的3’段加上“a”,然后连接文库接头,进行pcr,构建出初始杂交文库。将构建的初始杂交文库与381基因panel进行杂交,富集目的片段,洗脱后进行pcr扩增,得到最终的杂交文库。最后,使用illuminanextseq500测序仪pe75的测序长度上机测序,得到每个肿瘤组织样品的下机数据至少1gb,对照样本下机数据至少300mb。实验过程中的主要试剂见表六。具体实验方案一般根据制造商推荐的流程进行。
表三体细胞变异性能评估结果
备注:旧流程指的是使用公共软件mutect,varscan,pindel组合预测得到的并集的结果。tpr:truepredictionrate;ppv:positivepredictionrate。
表四体细胞热点变异性能评估结果
备注:旧流程指的是使用公共软件mutect,varscan,pindel组合预测得到的并集的结果。tpr:truepredictionrate;ppv:positivepredictionrate。
图5展示了示例硬件装置500的框图。硬件装置500包括处理器506。处理器506可以是单一处理单元或者是多个处理单元,用于执行本文描述的流程。装置500还可以包括接收信号的输入单元502、以及提供信号的输出单元504。输入单元502和输出单元504可以布置为单一或分离的单元。此外,装置500可以包括具有非易失性或易失性存储器形式的至少一个可读存储介质508,例如eeprom、闪存、和/或硬盘驱动器。可读存储介质508包括计算机程序510,该计算机程序510包括代码/计算机可读指令,其在由装置500中的处理器506执行时使得硬件装置500可以执行例如本文描述的流程及其变形。计算机程序510可配置为具有例如计算机程序模块510a,模块510b,模块510c架构的计算机程序代码,用于执行本文描述的步骤。在一些实施方案中,代码中的至少一项可以至少部分地实现为硬件电路。处理器可以是单个cpu,也可以包括两个或更多个处理单元。计算机程序可以由连接到处理器的计算机程序产品来承载。计算机程序产品可以包括其上存储有计算机程序的计算机可读介质。例如,计算机程序产品可以是闪存、随机存取存储器(ram)、只读存储器(rom)、eeprom,且上述计算机程序模块可以用ue内的存储器的形式被分布到不同计算机程序产品中。这些计算机程序指令可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,从而这些指令在由该处理器执行时可以创建用于实现这些功能/操作的装置。另外,本文描述的方案可以采取存储有指令的计算机可读介质上的计算机程序产品的形式,该计算机程序产品可供指令执行系统使用或者结合指令执行系统使用。
总结来说,本发明提供了一套肿瘤ngs测序数据突变检测分析方法以及配套装置,相对于常规mutect+varscan+pindel流程在性能上有较大的提升,能够实现临检变异分析的自动判读。同时本发明提供了一种噪点过滤的分析流程框架,能广泛适用于各种样本,包括例如ffpe、ctdna和wbc样本。
表五靶向捕获panel覆盖的381个基因列表
表六实验主要试剂
- 还没有人留言评论。精彩留言会获得点赞!