控制装置、控制系统和控制方法与流程
本发明涉及控制数据取得装置组的控制装置、控制系统、和控制方法。
背景技术:
近年来,与人在相同空间中移动同时提供各种服务的服务机器人正在被广泛开发。这样的机器人中,有外观与人相近、通过用声音和手势进行交流而进行符合用户意图的服务的机器人。机器人为了正确地把握用户的意图,不仅需要把握用户发出的声音和手势,还需要把握用户和机器人所在的状况、和过去发生的事情。
例如,专利文献1公开了用公知的动作捕捉系统和红外线反射标记检测用户和机器人的位置或朝向,在移动至可以进行对话的位置关系(阵形)之后,开始会话的机器人。作为可以进行对话的位置关系的定义,具体地提出了多种用户与机器人的视野、距离等条件。
另外,例如,专利文献2公开了判别服务对象的方法。专利文献2通过用行动识别传感器选择服务对象候选,用机器人进行确认动作,来实现高精度的服务。
另外,例如,专利文献3公开了基于对机器人存在的环境用1种以上手段识别的结果检测目标(物体),保持关于目标的信息的方法。
另外,例如专利文献4公开了通过基于用在环境内设置的各种观测装置取得的对话对象(用户)的行动历史决定机器人的对话对象和行动,而进行展示会场中的展示对象物的指引和推荐的机器人。
现有技术文献
专利文献
专利文献1:日本特开2012-161851号公报
专利文献2:日本特开2008-142876号公报
专利文献3:wo2003/035334号公报
专利文献4:日本特开2005-131713号公报
技术实现要素:
发明要解决的课题
一般而言,对于服务机器人,要求提供指引、揽客、销售辅助、巡视等多种服务。应当提供的服务需要不是由机器人的采用者预先指定,而是与状况相应地适当选择并提供。此时,要求将通过对环境进行感测而得到的信息、关于用户的信息、过去的应对历史信息等作为数据库保存,在服务之间共享。
进而,强烈要求服务的种类在将来能够扩展。服务中共通的功能应当以服务开发者能够容易地使用的软件库等形式提供。上述专利文献1、专利文献2、专利文献3、专利文献4都没有规定适合提供多种服务的数据库系统的形式。
本发明目的在于构建并提供一种适合提供多种服务的数据库系统。
用于解决课题的方法
本申请中公开的发明的一个方面的控制系统,包括作为能够取得存在于空间内的对象物的位置和图像的1个以上数据取得装置的数据取得装置组、和控制上述数据取得装置组来执行对上述空间内或上述对象物的多个不同处理的控制装置。上述控制装置,包括执行关于上述多个不同处理的程序的处理器、存储上述程序的存储装置、和能够与上述数据取得装置组通信的通信接口,上述存储装置将因上述处理器执行上述多个不同处理中的任一个处理存储装置而产生的表示上述数据取得装置检测出第1对象物之后的关于第1对象物的一系列位置和图像的时序数据作为关于第1对象物的数据存储,上述处理器在上述多个不同处理的各处理中,执行:取得处理,从上述数据取得装置取得表示上述数据取得装置检测出第2对象物之后的关于上述第2对象物的一系列信息的时序数据作为关于第2对象物的数据;判断处理,基于上述存储装置中存储的关于上述第1对象物的数据中的关于上述第1对象物的信息、和用上述取得处理取得的关于第2对象物的数据中的关于上述第2对象物的信息,判断上述第1对象物与上述第2对象物的相同性;和保存处理,在由上述判断处理判断为具有相同性的情况下,将关于上述第2对象物的数据与关于上述第1对象物的数据关联地保存在上述存储装置中,在由上述判断处理判断为不具有相同性的情况下,将关于上述第2对象物的数据不与关于上述第1对象物的数据关联地保存在上述存储装置中。
发明的效果
根据本发明的代表性的实施方式,能够用多个不同处理协作而确定哪一个对象物何时存在于何处。上述以外的课题、结构和效果,将通过以下实施例的说明而说明。
附图说明
图1是表示本实施例的控制系统的使用例的说明图。
图2是表示控制系统的硬件结构例的框图。
图3是表示控制装置的硬件结构例的框图。
图4是表示机器人的硬件结构例的框图。
图5是表示现实世界db和时序db的存储内容例的说明图。
图6是表示人物像检测/识别程序进行的人物像检测/识别处理流程例的流程图。
图7是表示声音检测/识别程序进行的声音检测/识别处理流程例的流程图。
图8是表示人物鉴别程序进行的人物鉴别处理流程例的流程图。
图9是表示销售辅助时的现实世界db和时序db的更新例的说明图。
图10是表示指引时的现实世界db和时序db的更新例的说明图。
图11是表示指引时的现实世界db和时序db的更新例的说明图。
具体实施方式
<控制系统的使用例>
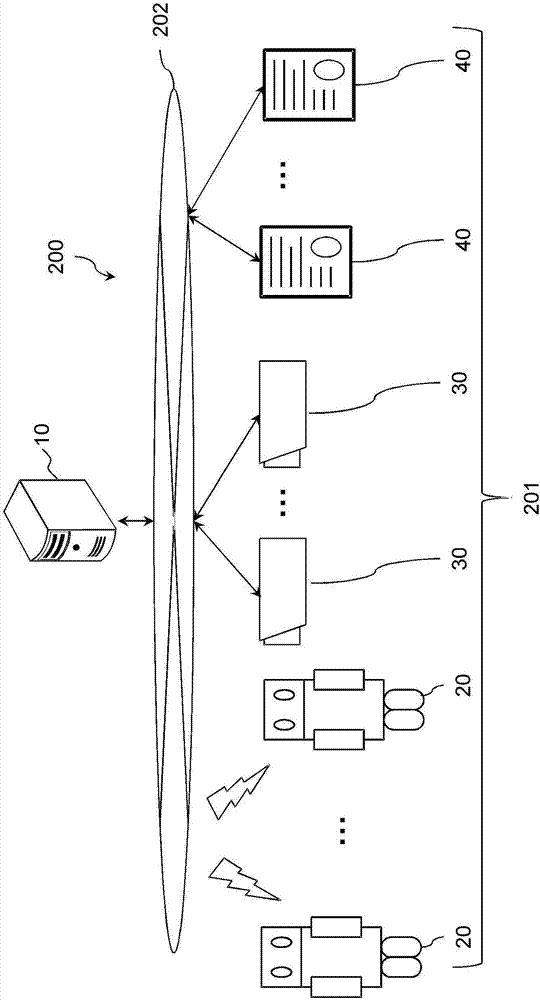
图1是表示本实施例的控制系统的使用例的说明图。空间1例如是商业设施这样的、人物h从出入口2进出场、人物h购买商品或者接受服务提供的空间。空间1被控制装置10控制。控制装置10对空间1中设置的数据处理装置进行控制。数据处理装置中,有移动式的数据处理装置、和固定式的数据处理装置。
移动式的数据处理装置是在空间1内移动的数据处理装置。移动式的数据处理装置,例如是自主地移动、与控制装置10通信的机器人20。机器人20是通过控制装置10的控制,取得空间1内的声音和图像并对控制装置10发送,从控制装置10接收人物h所需的声音和图像并输出的数据处理装置。机器人20可以用车轮行驶,也可以用多个脚步行或行驶。另外,机器人20也可以是如无人飞行器一般在空间1内飞行的数据处理装置。
固定式的数据处理装置是在空间1内固定的数据处理装置。固定式的数据处理装置例如是环境摄像机30或数字标牌40。环境摄像机30是通过控制装置10的控制,取得空间1内的图像并对控制装置10发送的数据处理装置。环境摄像机30例如是能够测量到被摄体的距离的三维摄像机。数字标牌40是通过控制装置10的控制,从控制装置10接收人所需的声音和图像并输出的数据处理装置。
其中,在数据处理装置中,将能够取得图像和声音的机器人20、和能够取得图像的环境摄像机30称为数据取得装置。另外,在数据处理装置中,将能够输出图像和声音的机器人20和数字标牌40称为数据输出装置。
<控制系统的硬件结构例>
图2是表示控制系统的硬件结构例的框图。控制系统200是控制装置10、数据处理装置组201、遗失物管理系统1130经由lan(localareanetwork:局域网)、wan(wideareanetwork:广域网)、互联网等网络202可通信地连接的系统。遗失物管理系统1130是管理遗失物的图像、拾得日期时间、拾得场所、拾得者这些遗失物信息的系统。
<控制装置10的硬件结构例>
图3是表示控制装置10的硬件结构例的框图。控制装置10具有第1处理器301、第1存储装置302、第1通信if(interface)303、和将它们连接的总线304。第1处理器301将第1存储装置302的一部分作为工作区域对控制装置10进行控制。第1处理器301执行第1存储装置302中存储的程序,或者参考第1存储装置302中存储的模型,或者从现实世界db341和时序db342中读取或写入数据。
第1存储装置302例如是hdd(harddiskdrive)、闪存。第1存储装置302存储媒体处理程序310、现实世界db管理程序321、时序db管理程序322、综合控制程序323、媒体处理模型330、现实世界db341、和时序db342。
媒体处理程序310是执行媒体处理的程序。媒体处理是指用媒体处理程序310中包括的各种程序执行的处理。媒体处理程序310包括人物像检测/识别程序311、脸部检测/识别程序312、声音检测/识别程序313、人物鉴别程序314、和人物状态推定程序315。人物像检测/识别程序311是参考人物像检测/识别模型331检测人物像、识别检测出的人物像是怎样的人物的程序。脸部检测/识别程序312是参考脸部检测/识别模型332检测脸部、识别检测出的脸部是怎样的脸部的程序。声音检测/识别程序313是参考声音检测/识别模型333检测声音、识别检测出的声音是怎样的声音的程序。人物鉴别程序314是参考人物鉴别模型334鉴别人物的程序。人物状态推定程序315是参考人物状态推定模型335推定人物的状态的程序。
现实世界db管理程序321是管理现实世界db341的程序。时序db管理程序322是管理时序db342的程序。综合控制程序323是参考现实世界db341和时序db342、对数据处理装置进行控制的程序。例如,综合控制程序323是生成机器人20的动作指示并对机器人20发送的程序。
媒体处理模型330是媒体处理程序310中的媒体处理中使用的模型。媒体处理模型330包括人物像检测/识别模型331、脸部检测/识别模型332、声音检测/识别模型333、人物鉴别模型334、和人物状态推定模型335。
人物像检测/识别模型331是作为模板的各种人物像(例如体形、性别)的数据。脸部检测/识别模型332是表示作为模板的各种脸(例如脸的形状、发型、眼、耳、鼻、口的大小和形状)的数据。声音检测/识别模型333是表示作为模板的各种声音模型(例如与振幅对应的音位)和与声音对应的性别和年龄段的模型的数据。用声音模型得到声音识别结果,用性别和年龄段的模型得到说话者识别结果。
人物鉴别模型334是鉴别在某个空间的某个时间段确定的空间内人物像区域的时序数据和空间内声音区域的时序数据是否同一人物的模型。具体而言,例如人物鉴别模型334是空间内人物像区域的时序数据的阈值、与空间内声音区域的时序数据的阈值的组合。在某个空间的某个时间段确定的空间内人物像区域的时序数据和空间内声音区域的时序数据在各自的阈值以上的情况下,将空间内人物像区域的时序数据和空间内声音区域的时序数据鉴别为确定任一个人物的数据。
人物状态推定模型335是表示作为模板的人物的状态(例如站着的状态、坐着的状态)的数据。
现实世界db341是按索引管理关于现实世界、即空间1内的人物的信息的数据库。具体而言,例如现实世界db341按索引存储来自数据处理装置的输入图像和输入声音、人物像区域、空间内人物像区域、声音识别结果、说话者识别结果。时序db342是管理按索引管理的信息的时序数据的数据库。对于它们用图5在后文中叙述。
<机器人20的硬件结构例>
图4是表示机器人20的硬件结构例的框图。机器人20具有第2处理器401、第2存储装置402、第2通信if403、麦克风404、扬声器405、摄像机406、lidar(laserimagingdetectionandranging)407、移动装置408、和将它们连接的总线304。第2处理器401将第2存储装置402的一部分作为工作区域对机器人20进行控制。第2处理器401执行第2存储装置402中存储的程序。
第2存储装置402例如是hdd(harddiskdrive)、闪存。第2存储装置402存储控制程序421、网络发送接收程序422、声音输入输出程序423、图像输入程序424、lidar输入程序425、和移动程序426。
控制程序421是按照来自控制装置10的媒体处理程序310的行动指令,与第2存储装置402内的其他程序协作地对机器人20进行控制的程序。另外,控制程序421也起到人工智能的作用。
网络发送接收程序422是按照来自控制程序421的指令与控制装置10之间发送接收数据的程序。例如,网络发送接收程序422从第2通信if403经由网络202对控制装置10发送声音数据和图像数据、方向数据、距离数据等输入数据。另外,网络发送接收程序422从网络202经由第2通信if403接收来自控制装置10的行动指令和输出数据。
声音输入输出程序423是按照来自控制装置10的媒体处理程序310的声音输入指令,从麦克风404输入外部环境的声音并将其作为声音数据保存在第2存储装置402中,或者使用来自控制装置10的媒体处理程序310的声音数据从扬声器405输出声音的程序。
图像输入程序424是按照来自控制装置10的媒体处理程序310的声音输入指令,用摄像机406拍摄外部环境,作为图像数据输入至第2存储装置402的程序。
lidar输入程序425是输入表示从lidar407得到的从机器人20来看的对象物的方向的方向数据和表示与机器人20之间的距离的距离数据的程序。
移动程序426是按照来自控制装置10的媒体处理程序310的行动指令,对移动装置408进行驱动控制,使机器人20移动至目的位置的程序。
第2通信if403是与控制装置10之间发送接收数据和指令的装置。第2通信if403接收来自控制装置10的数据和指令并保存在第2存储装置402中。另外,第2通信if403基于网络发送接收程序422的控制,对控制装置10发送第2存储装置402内的来自各种程序的数据。
麦克风404是输入机器人20的外部环境的声音的装置。麦克风404基于声音输入输出程序423的控制,将声音保存在第2存储装置402中。麦克风404例如构成为阵列状,也能够检测音源的方向。扬声器405是对外部环境输出来自控制装置10的声音数据的装置。扬声器405基于声音输入输出程序423的控制输出声音。
摄像机406是拍摄机器人20的外部环境的装置。摄像机406基于图像输入程序424的控制,将拍摄外部环境得到的图像数据保存在第2存储装置402中。
lidar407是通过对障碍物发射可见光等电磁波、测量其反射波,来测定至观测平面上的各方向的障碍物的距离的装置。本实施例中,作为一例,观测平面与地面平行,方向分辨率是1度。
移动装置408是使机器人20移动的机构。移动装置408例如是具有车轮的机构。另外,也可以是具有多个脚的步行/行驶机构。
<现实世界db341和时序db342>
图5是表示现实世界db341和时序db342的存储内容例的说明图。图5为了说明现实世界db341中存储的索引与时序db342中存储的时序数据的关联性,而在说明上以综合了现实世界db341和时序db342的状态进行说明。关于存储的数据的种类,如图5的图例所示。索引保存在现实世界db341中,时序数据和聚类结果(cluster)保存在时序db342中。聚类结果是时序数据的聚类结果。现实世界db341和时序db342中保存的数据,按数据处理装置的每个种类构成树结构。
第1树501是源自机器人20的树结构数据,第2树502是源自环境摄像机30的树结构数据。第1树501用机器人索引510作为根节点,用输入图像索引511、输入图像时序数据512、人物像区域索引513、人物像区域时序数据514、空间内人物像区域索引515、空间内人物像区域时序数据516、输入声音索引517、输入声音时序数据518、声音区间索引519、声音区间时序数据521、声音识别结果索引522、说话者识别结果索引523、空间内声音区域索引524、空间内声音区域时序数据525、聚类结果c作为中间节点。节点之间用链接连接。
机器人索引510是包括唯一地确定机器人20的机器人id的索引。机器人索引510也包括机器人20的本地坐标系中的位置数据和方向数据。
输入图像索引511是确定输入图像时序数据512的索引。输入图像索引511在输入了来自机器人20的输入图像时序数据512的情况下生成,与依次输入的输入图像时序数据512链接。
输入图像时序数据512是按时序输入的一系列输入图像数据。输入图像时序数据512的各输入图像数据中,包括在机器人20的本地坐标系中、从机器人20来看的根据该输入图像数据确定的对象物(例如人物)的位置数据和方向数据。
人物像区域索引513是确定人物像区域时序数据514的索引。人物像区域索引513在输入了来自机器人20的输入图像时序数据512的情况下生成,与依次生成的人物像区域时序数据514链接。
人物像区域时序数据514是按时序生成的一系列人物像区域数据。人物像区域数据是指表示包含从同一时刻的输入图像数据中检测出的人物的图像(人物像)的区域(例如矩形)的数据。人物像区域数据也包括同一时刻的输入图像数据的位置数据和方向数据。
空间内人物像区域索引515是确定空间内人物像区域时序数据516的索引。空间内人物像区域索引515在生成了人物像区域时序数据514的情况下生成,与依次生成的空间内人物像区域时序数据516链接。
空间内人物像区域时序数据516是按时序生成的一系列空间人物像区域数据。空间人物像区域数据是指将同一时刻的人物像区域数据的位置数据和方向数据变换至空间1的全局坐标系得到的人物像区域数据。
输入声音索引517是确定输入声音时序数据518的索引。输入声音索引517在输入了来自机器人20的输入声音时序数据518的情况下生成,与依次输入的输入声音时序数据518链接。
输入声音时序数据518是按时序输入的一系列输入声音数据。输入声音时序数据518的各输入声音数据中,包括在机器人20的本地坐标系中、从机器人20来看的根据该输入图像声音数据确定的对象物(例如人物h)的位置数据和方向数据。
声音区间索引519是确定声音区间时序数据521的索引。声音区间索引519在输入了来自机器人20的输入声音时序数据518的情况下生成,与依次输入的声音区间时序数据521链接。
声音区间时序数据521是与输入声音时序数据518对应的一系列声音区间数据。声音区间数据是指表示从声音的说话开始时刻到说话结束时刻的声音区间的数据。
声音识别结果索引522是包括关于每个声音区间的输入声音数据的声音识别结果的节点。关于声音识别结果,声音识别结果是指用声音检测/识别程序313检测和识别得到的信息。声音识别结果可以是每个声音区间的波形数据,也可以是将输入声音数据文本化得到的字符串数据。
说话者识别结果索引523是包括关于每个声音区间的输入声音数据的说话者识别结果的节点。说话者识别结果是确定用声音检测/识别程序313检测和识别得到的确定声音的说话者的信息。说话者识别结果的说话者,具体是指例如将用声音区间时序数据521确定的某个时间段的输入声音数据、与该时间段中的位置数据和方向数据组合得到的信息。
空间内声音区域索引524是确定空间内声音区域时序数据525的索引。空间内声音区域索引524在生成了声音区间时序数据521的情况下生成,与依次生成的空间内声音区域时序数据525链接。
空间内声音区域时序数据525是按时序生成的一系列空间内声音区域数据。空间内声音区域数据是指将对应的声音区间数据中的位置数据和方向数据变换至空间1的全局坐标系得到的声音区间数据。
聚类结果c是对空间内人物像区域时序数据516和空间内声音区域时序数据525在某个时间段中聚类得到的结果。
第2树502用环境摄像机索引520作为根节点,用输入图像索引511、输入图像时序数据512、人物像区域索引513、人物像区域时序数据514、空间内人物像区域索引515、空间内人物像区域时序数据516、聚类结果作为中间节点。节点之间用链接连接。环境摄像机索引520是包括唯一地确定环境摄像机30的环境摄像机id的索引。环境摄像机索引520包括环境摄像机30的本地坐标系中的位置数据和方向数据。另外,关于各中间节点,在第1树501的说明中,将“机器人20”置换为“环境摄像机30”即可,所以省略。
<媒体处理程序310进行的处理流程例>
接着,说明媒体处理程序310进行的处理流程例。
图6是表示人物像检测/识别程序311进行的人物像检测/识别处理流程例的流程图。第1处理器301等待数据处理装置d(以下称为“装置d”)的输入图像i(步骤s601:no),取得了装置d的输入图像i的情况下(步骤s601:yes),如果不存在[装置d,输入图像时序数据512<i>,“输入图像”]的条目,则在现实世界db341中创建该条目(步骤s602)。即,第1处理器301创建与根节点即装置索引链接的输入图像索引511。关于装置索引,如果数据处理装置是机器人20则是指机器人索引510,如果数据处理装置是环境摄像机30则是指环境摄像机索引520。
接着,第1处理器301在时序db342中,对于输入图像时序数据512<i>的当前时刻t追加输入图像i(步骤s603)。然后,第1处理器301使用人物像检测/识别模型331,从输入图像i中检测与人物像检测/识别模型331匹配的人物像区域a(步骤s604)。
接着,第1处理器301在现实世界db341中,如果不存在[输入图像时序数据512<i>,人物像区域时序数据514<a>,“人物像区域”]的条目,则创建该条目(步骤s605)。即,第1处理器301创建与输入图像时序数据512<i>链接的人物像区域索引513。然后,第1处理器301在时序db342中,对人物像区域时序数据514<a>的当前时刻t追加步骤s604中检测出的人物像区域a(步骤s606)。
接着,第1处理器301根据人物像区域a计算空间内人物像区域a'(步骤s607)。即,将本地坐标系的人物像区域a的位置数据和方向数据变换为全局坐标系的人物像区域a的位置数据和方向数据。其中,本地坐标系的人物像区域a的位置数据和方向数据,由装置d的本地坐标系的人物的位置数据和方向数据、和从lidar407得到的装置d至人物的距离和方向决定。
接着,第1处理器301在现实世界db341中,如果不存在[人物像区域a,空间内人物像区域时序数据516<a'>,“空间内人物像区域”]的条目,则创建该条目(步骤s608)。即,第1处理器301创建与人物像区域时序数据514<a>链接的人物像区域索引513。然后,第1处理器301在时序db342中,对空间内人物像区域时序数据516<a'>的当前时刻t追加步骤s607中计算得到的空间内人物像区域a'(步骤s608)。然后,返回步骤s601。
图7是表示声音检测/识别程序313进行的声音检测/识别处理流程例的流程图。第1处理器301等待装置d的输入声音s(步骤s701:no),取得了装置d的输入声音s的情况下(步骤s701:yes),如果不存在[装置d,输入声音时序数据518<s>,“输入声音”]的条目,则在现实世界db341中创建该条目(步骤s702)。即,第1处理器301创建与根节点即装置索引链接的输入声音索引517。
接着,第1处理器301在时序db342中,对输入声音时序数据518<s>的当前时刻t追加输入声音s(步骤s703)。然后,第1处理器301使用声音检测/识别模型333,从输入声音s中检测与声音检测/识别模型333匹配的声音的声音区间r(步骤s704)。
接着,第1处理器301在现实世界db341中,如果不存在[装置d,声音区间时序数据521<r>,“声音区间”]的条目,则创建该条目(步骤s705)。即,第1处理器301创建与声音区间时序数据521<r>链接的声音区间索引519。然后,第1处理器301在时序db342中,对声音区间时序数据521<r>的当前时刻t追加步骤s704中检测出的声音区间r(步骤s706)。
接着,第1处理器301基于装置d的位置数据和方向数据,根据声音区间r计算空间内声音区域p(步骤s707)。即,第1处理器301将本地坐标系的声音区间r的位置数据和方向数据变换为全局坐标系的声音区间r的位置数据和方向数据。其中,本地坐标系的声音区间r的位置数据和方向数据,由装置d的本地坐标系的人物的位置数据和方向数据、和从lidar得到的装置d至人物的距离和方向决定。
接着,第1处理器301在现实世界db341中,如果不存在[装置d,空间内声音区域时序数据525<p>,“空间内声音区域”]的条目,则创建该条目(步骤s708)。即,第1处理器301创建与空间内声音区域时序数据525<p>链接的空间内声音区域索引524。然后,第1处理器301在时序db342中,对空间内声音区域时序数据525<p>的当前时刻t追加步骤s707中计算得到的空间内声音区域p(步骤s709)。
接着,第1处理器301在现实世界db341中,使用声音检测/识别模型333,按每个声音区间r创建与声音检测/识别模型333匹配的声音识别结果v(步骤s710)。然后,第1处理器301在现实世界db341中,如果不存在[声音区间r,声音识别结果v,“声音识别结果”]的条目,则创建该条目(步骤s711)。即,第1处理器301生成与声音区间时序数据521<r>链接的声音识别结果索引522。然后,第1处理器301将步骤s710中创建的每个声音区间r的声音识别结果v与声音识别结果索引522关联。
同样地,第1处理器301在现实世界db341中,使用声音检测/识别模型333,按每个声音区间r创建与声音检测/识别模型333匹配的说话者识别结果w(步骤s712)。然后,第1处理器301在现实世界db341中,如果不存在[声音区间r,说话者识别结果w,“说话者识别结果”]的条目,则创建该条目(步骤s713)。即,第1处理器301创建与声音区间时序数据521<r>链接的说话者识别结果索引523。然后,第1处理器301将步骤s712中创建的每个声音区间r的说话者识别结果w与声音识别结果索引522关联。然后,返回步骤s701。
图8是表示人物鉴别程序314进行的人物鉴别处理流程例的流程图。首先,第1处理器301等待在时序db342中追加空间内人物像区域时序数据516<a'>或空间内声音区域时序数据525<p>(步骤s801:no)。在已追加的情况下(步骤s801:yes),第1处理器301收集包括与追加的数据相同时刻t的空间内人物像区域时序数据516和空间内声音区域时序数据525(步骤s802)。然后,第1处理器301使用人物鉴别模型334,用收集的时序数据鉴别人物(步骤s803)。在不能鉴别的情况下(步骤s804:no),返回步骤s801。在能够鉴别的情况下(步骤s804:yes),第1处理器301基于时刻t前后的位置数据对收集的时序数据进行聚类(步骤s805)。由此,按某一时间段的某个位置的收集时序数据生成聚类结果。
接着,第1处理器301执行步骤s806~s812,删除聚类结果内的其他人的时序数据。具体而言,例如第1处理器301判断步骤s805中生成的聚类结果组中是否存在未选择的聚类结果c(步骤s806)。在存在未选择的聚类结果c的情况下(步骤s806:yes),第1处理器301选择1个未选择的聚类结果c(步骤s807)。然后,第1处理器301判断是否存在属于选择聚类结果c的未选择的数据<x>(步骤s808)。数据<x>是选择聚类结果c内的时序数据中的某一时刻的数据。
在存在未选择的数据<x>的情况下(步骤s808:yes),第1处理器301选择未选择的数据<x>(步骤s809)。然后,第1处理器301在现实世界db341中,如果不存在[聚类数据c,数据<x>,“人物鉴别”]的条目,则创建。即,第1处理器301如果未创建人物鉴别索引则创建,对聚类结果c关联选择数据<x>和人物鉴别索引。如果已创建人物鉴别索引,则第1处理器301对选择聚类结果c的人物鉴别索引关联选择数据<x>。
然后,第1处理器301在现实世界db341中,如果存在选择聚类结果c以外的[聚类结果c',数据<x>,“人物鉴别”]的条目,则对该条目设定删除标志(步骤s811),返回步骤s808。在步骤s808中,在不存在未选择的数据<x>的情况下(步骤s808:no),返回步骤s806。在步骤s806中,在不存在未选择的聚类结果c的情况下(步骤s806:no),第1处理器301将聚类结果组的各聚类结果中设定了删除标志的条目删除(步骤s812),返回步骤s801。由此,各聚类结果成为表示用某一时间段的某个位置的收集时序数据确定的1个人物的数据。
另外,关于脸部检测/识别程序312的处理并未图示,但第1处理器301从图6的步骤s604中检测出的人物像区域a中,使用脸部检测/识别模型332检测脸部,识别是何种类型的脸。脸部识别结果保存在人物像区域a中。另外,关于人物状态推定程序315的处理并未图示,但第1处理器301从图6的步骤s604中检测出的人物像区域a中,使用人物状态推定模型335推定人物像区域a内的人物的状态。人物状态推定结果保存在人物像区域a中。
<控制系统200的应用例>
接着,用图9~图11说明控制系统200的应用例。图9~图11中,控制系统200在参考并更新现实世界db341和时序db342的同时执行销售辅助(图9)、指引(图10)、和监视(图11)这3个任务。销售辅助是控制装置10使机器人20执行在空间1内机器人20靠近人物并推荐商品的处理的处理。指引是控制装置10使机器人20执行在空间1内人物靠近了机器人20的情况下机器人20与该人物的要求相应地提供信息的处理的处理。也可以不是机器人20,而是数字标牌40。监视是控制装置10使机器人20执行在空间1内机器人20监视可疑人物的处理的处理。也可以不是机器人20,而是环境摄像机30。
这3个任务用综合控制程序323执行。本例中,销售辅助(图9)、指引(图10)、和监视(图11)同时并行地执行。但是,例如也可以按销售辅助(图9)、指引(图10)、和监视(图11)的顺序时序地执行。图9~图11表示图5所示的现实世界db341和时序db342的具体的存储内容例,但一同记载了索引和时序数据。另外,图9~图11中,为了方便而说明了以机器人20和环境摄像机30为动作主体的处理,但实质上控制装置10使机器人20和环境摄像机30执行处理。
<销售辅助>
图9是表示销售辅助中的现实世界db341和时序db342的更新例的说明图。在步骤s901中,环境摄像机30拍摄人物h取得图像911,从取得的图像911中检测包括人物像的人物区域912。另外,环境摄像机30测定从环境摄像机30到人物h的距离及其方向。控制装置10参考地图db920,根据环境摄像机30预先保持的自身位置913、和测定得到的距离和方向,计算人物区域912的位置即人物位置914。地图db920存储以全局坐标系为基准的空间1的地图数据。人物位置914是变换至空间1的全局坐标系的位置数据。
步骤s902在步骤s901中人物位置914的一定时间内的时序数据的各位置数据在允许范围内的情况下执行。在步骤s902中,机器人20向由环境摄像机30确定的人物位置914移动靠近。此时,机器人20例如通过使用lrf(laserrangefinder:激光测距仪)和地图db920进行的扫描匹配而在更新空间1的全局坐标系中的自身位置921的同时移动。机器人20用摄像机406拍摄存在于人物位置914的人物h取得图像922,从取得的图像922中检测包括人物像的人物区域923。另外,机器人20用lidar407测定从摄像机406到人物h的距离及其方向,参考地图db920,根据机器人20的当前的自身位置921、和测定得到的距离和方向,计算人物区域923的位置即人物位置924。人物位置924是变换至空间1的全局坐标系的位置数据。另外,机器人20根据图像922识别脸部区域925。
步骤s903在步骤s902结束时执行。在步骤s903中,控制装置10判断步骤s901中确定的人物位置914的时序数据与步骤s902中确定的人物位置924的时序数据在同一时间段内是否相似。相似性例如根据两个时序数据的欧几里得距离判断。例如,如果欧几里得距离在阈值以下则相似。在相似的情况下,同一时间段内在人物位置914和人物位置924存在的人物h是同一人物h,控制装置10保存为人物931。人物931与人物区域912、923、脸部区域925链接。由此,确定某一时间段存在的人物h和脸部。
步骤s904在步骤s903结束时执行。在步骤s904中,机器人20位于人物931(确定的人物h)附近。机器人20用麦克风404检测周边声音941,根据用麦克风404检测出的音源的方向和当前的自身位置921,计算发出声音的位置即声音位置942a、942b。声音位置942a、942b是变换至空间1的全局坐标系的位置数据。
另外,机器人20判断步骤s902中确定的人物位置924的时序数据与声音位置942a的时序数据在同一时间段内是否相似。相似性例如根据两个时序数据的欧几里得距离判断。例如,如果欧几里得距离在阈值以下则相似。相似的情况下,同一时间段内在人物位置924和声音位置942a存在的人物h是同一人物。从而,机器人20取得周边声音941中在声音位置942a说话的声音943a的识别结果944a,将该声音943a与人物931关联。然后,控制装置10将与人物931关联的这些数据保存在以唯一确定该人物h的识别符即个人945为索引的个人db946中。对于声音位置942b也同样地处理,由此,机器人20取得声音943b和识别结果944b,将该声音943b与人物931关联。然后,控制装置10将与人物931关联的这些数据保存在以个人945为索引的个人db946中。
另外,在步骤s904中,假设声音位置942a、942b是同一人物931的声音位置,但存在多个人物h在机器人20附近对话的情况。例如,人物ha移动至收银台前的情况下,存在作为顾客的人物ha与作为店员的人物hb对话的情况。对人物ha、hb分别确认人物931。从而,例如控制装置10将声音位置942a、声音943a、识别结果944a(例如:“我想试穿商品x”)与人物ha的人物931关联,将识别结果944a保存在以唯一确定该人物ha的识别符即个人945为索引的个人db946中。同样地,控制装置10将声音位置942b、声音943b、识别结果944b(例如:试衣间在那边。)与人物hb的人物931关联,将识别结果944b保存在以唯一确定该人物ha的识别符即个人945为索引的个人db946中。
另外,也可以使控制装置10能够与作为店员的人物hb的便携终端(未图示)通信。例如,该情况下,作为顾客的人物ha的声音位置942a的时序数据与作为店员的人物hb的声音位置942b的时序数据在同一时间段内相似。从而,控制装置10将人物ha确定为人物hb的对话对象,将人物ha、hb的各个人db946内的数据传输至人物hb的便携终端。由此,作为店员的人物hb能够确认何时何处与谁进行了怎样的会话。另外,因为能够参考人物ha的个人db946,所以也能够确认人物ha在空间1内的时序的移动轨迹。从而,人物hb能够确定人物ha的喜好而有助于销售。
另外,人物hb也可以将人物ha的个人信息输入便携终端,更新个人db946。由此,此后控制装置能够确认用个人db946确定的人物hb是怎样的人物h。
<指引>
图10是表示指引中的现实世界db341和时序db342的更新例的说明图。对于与图9相同的数据附加相同符号并省略其说明。在销售辅助中,由机器人20靠近人物h,但在指引中,机器人20检测靠近机器人20的人物h并进行指引。
在步骤s1001中,机器人20用lidar407检测靠近的对象物。另外,机器人20例如通过使用lrf和地图db920进行的扫描匹配而在更新空间1的全局坐标系中的自身位置1011的同时移动。机器人20用摄像机406拍摄靠近的对象物取得图像1012,从取得的图像1012中检测包括人物像的人物区域1013。另外,机器人20用lidar407测定从摄像机406到人物h的距离及其方向。控制装置10参考地图db920,根据机器人20的当前的自身位置1011、和测定得到的距离和方向,计算人物区域1013的位置即人物位置1014。人物位置1014是变换至空间1的全局坐标系的位置数据。另外,机器人20从图像1012中识别脸部区域1015。
步骤s1002在步骤s1001中人物位置1014的一定时间内的时序数据的各位置数据在允许范围内的情况下执行。在步骤s1002中,机器人20用麦克风404检测周边声音1021,根据用麦克风404检测出的音源的方向和当前的自身位置1011,计算发出声音的位置即声音位置1022a、1022b。声音位置1022a、1022b是变换至空间1的全局坐标系的位置数据。
另外,机器人20判断步骤s1001确定的人物位置1014的时序数据与声音1022a的时序数据在同一时间段内是否相似。相似性例如根据两个时序数据的欧几里得距离判断。例如,如果欧几里得距离在阈值以下则相似。相似的情况下,同一时间段内在人物位置1014和声音位置1022a存在的人物h是同一人物h。从而,机器人20取得周边声音1021中在声音位置1022a说话的声音1023a的识别结果1024a,将该声音1023a与人物931关联。然后,控制装置10将与人物931关联的这些数据保存在以唯一确定该人物h的识别符即个人945为索引的个人db946中。对于声音位置1022b也同样地处理,由此,机器人20取得声音1023b和识别结果1024b,将该声音1023b与人物931关联。然后,控制装置10将与人物931关联的这些数据保存在以个人945为索引的个人db946中。
步骤s1003在步骤s1002之后执行。机器人20判断步骤s1001中确定的人物位置1014的时序数据与声音位置1022a的时序数据在同一时间段内是否相似。相似性例如根据两个时序数据的欧几里得距离判断。例如,如果欧几里得距离在阈值以下则相似。相似的情况下,同一时间段内在人物位置1014和声音位置1022a存在的人物h是同一人物。从而,机器人20取得周边声音1021中在声音位置1022a说话的声音1023a的识别结果1024a,将该声音1023a与人物931关联。然后,控制装置10将与人物931关联的这些数据保存在以个人945为索引的个人db946中。对于声音位置1022b也同样地处理,由此,机器人20取得声音1023b和识别结果1024b,将该声音1023b与人物931关联。然后,控制装置10将与人物931关联的这些数据保存在以个人945为索引的个人db946中。
该情况下,用人物931确定的人物h靠近机器人20并与机器人20对话,所以声音1023a、1023b的识别结果1024a、1024b是人物h说话的声音。另外,机器人20在人物h靠近至自身位置1011的规定距离以内的情况下,说出“请问您有什么事?”。例如,如果声音1023a的识别结果1024a是“ww在哪里?”,则机器人20说出“我带您去ww吧。”。如果下一个声音1023b的识别结果1024b是“拜托了”,则机器人20说出“那么请跟我来。”。
另外,在移动中,机器人20也可以从个人db组中使用本次确定的人物931的个人db946内的数据,进行与该人物931的喜好相应的对话和信息提供。例如,机器人20也可以参考个人db946内的识别结果944a、944b,确定关键字,从将关键字与话题关联的闲聊db(未图示)中,使用与确定的关键字对应的话题,与人物h对话。闲聊db可以存储在机器人20中,也可以存储在控制装置10中。另外,机器人20也可以从网络202搜索对应的话题。
<监视>
图11是表示指引中的现实世界db341和时序db342的更新例的说明图。对于与图9和图10相同的数据附加相同符号并省略其说明。在监视中,机器人20和环境摄像机30对空间1内进行监视。
在步骤s1101中,环境摄像机30在自身位置1111拍摄外部环境取得图像1112。控制装置10检测图像1112与从同一位置拍摄的过去的图像的差区域1113。另外,环境摄像机30测定从自身位置1111到差区域1113的距离及其方向。控制装置10参考地图db920,根据环境摄像机30预先保持的自身位置1111、和测定得到的距离和方向,计算差区域1113的位置即差位置1114。地图db920存储以全局坐标系为基准的空间1的地图数据。差位置1114是变换至空间1的全局坐标系的位置数据。然后,控制装置10识别差区域1113内的物体并作为物体识别结果1115输出。
步骤s1102与步骤s1101同时并行地执行。在步骤s1102中,机器人20在空间1内巡逻,例如通过使用lrf(laserrangefinder)和地图db920进行的扫描匹配而在更新空间1的全局坐标系中的自身位置1121的同时移动。机器人20在自身位置1121拍摄外部环境取得图像1122。控制装置10检测图像1122与从同一位置拍摄的过去的图像的差区域1123。另外,机器人20测定从当前的自身位置1121到差区域1123的距离及其方向。控制装置10参考地图db920,根据当前的自身位置1121、和测定得到的距离和方向,计算差区域1123的位置即差位置1124。地图db920存储以全局坐标系为基准的空间1的地图数据。差位置1124是变换至空间1的全局坐标系的位置数据。然后,控制装置10识别差区域1123内的物体并作为物体识别结果1125输出。
步骤s1103是使用步骤s1101的物体识别结果1115或步骤s1102的物体识别结果1125,与过去累积的数据对照的处理。例如,控制装置10参考人物db组,如果存在与物体识别结果1115或物体识别结果1125一致的人物931,则检测出存在用人物931确定的人物h。另外,控制装置10访问与控制装置10可通信地连接的遗失物管理系统1130,如果存在与物体识别结果1115或物体识别结果1125一致的遗失物的图像,则判断为物体识别结果1115或物体识别结果1125是遗失物。
如以上说明,本实施例的控制装置10控制能够取得空间1内存在的对象物(例如人物和物品)的位置和图像的数据取得装置组(机器人20和环境摄像机30),执行例如上述销售辅助(图9)、指引(图10)、和监视(图11)这3个任务作为对于空间1内或对象物的多个不同处理。
第1存储装置302通过第1处理器301执行多个不同处理中的任一个处理,而将表示数据取得装置检测出第1对象物(例如人物ha)后的第1对象物的一系列位置和图像的时序数据作为关于第1对象物的数据(例如关于人物ha的个人db946)存储。第1处理器301在多个不同处理的各处理中,执行取得处理、判断处理、和保存处理。
取得处理是第1处理器301从数据取得装置取得表示数据取得装置检测出第2对象物(某个人物h)后的第2对象物的一系列信息(例如位置和图像)的时序数据作为关于第2对象物的数据的处理。取得处理例如相当于人物像检测/识别程序311。
判断处理是第1处理器301基于第1存储装置302中存储的关于第1对象物的数据中的关于第1对象物的信息(例如第1对象物的图像)、和用取得处理取得的关于第2对象物的信息(例如关于第2对象物的数据中的第2对象物的图像),判断第1对象物与第2对象物的相同性的处理。判断处理例如相当于人物鉴别程序314。
保存处理是在由判断处理判断为具有相同性的情况下,将关于第2对象物的数据与关于第1对象物的数据关联地保存在第1存储装置302(现实世界db341和时序db342)中,在由判断处理判断为不具有相同性的情况下,将关于第2对象物的数据不与关于第1对象物的数据关联地保存在第1存储装置302中的处理。
由此,能够将多个不同处理的任一个处理(例如销售辅助)中得到的关于第1对象物的数据、与其他处理(例如指引)中得到的关于第2对象物的数据关联。由此,多个不同处理中能够协作地确定哪个对象物何时存在于何处。
另外,第1存储装置302通过第1处理器301执行任一个处理,而将表示特定的数据取得装置(机器人20)检测出第3对象物之后的第3对象物的一系列位置、图像、和来自第3对象物的声音的时序数据作为关于第3对象物的数据存储。该情况下,第1处理器301在多个不同处理中的控制特定的数据取得装置的处理中,执行取得处理、判断处理、和保存处理。
在取得处理中,第1处理器301从上述特定的数据取得装置取得表示特定的数据取得装置检测出第4对象物之后的第4对象物的一系列位置、图像和来自上述第4对象物的声音的时序数据作为关于第4对象物的数据。
另外,在判断处理中,第1处理器301基于第1存储装置302中存储的关于第3对象物的数据中的第3对象物的图像、和用取得处理取得的关于第4对象物的数据中的第4对象物的图像,判断第3对象物与第4对象物的相同性。
另外,在保存处理中,第1处理器301在由判断处理判断为具有相同性的情况下,将关于第4对象物的数据与关于第3对象物的数据关联地保存在第1存储装置302中,在由判断处理判断为不具有相同性的情况下,将关于第4对象物的数据不与关于第3对象物的数据关联地保存在第1存储装置302中。
由此,能够将多个不同处理的任一个处理(例如销售辅助)中得到的关于第3对象物的数据、与其他处理(例如指引)中得到的关于第4对象物的数据关联。由此,多个不同处理中能够协作地确定哪个对象物何时在何处发出了声音。
另外,通过执行取得处理、判断处理、和保存处理,也可以将第4对象物与不包括声音的时序数据的第1对象物关联。同样地,通过执行取得处理、判断处理、和保存处理,也可以将第2对象物与包括声音的时序数据的第3对象物关联。
另外,第1处理器301在多个不同处理中的控制特定的数据取得装置的处理中,基于第4对象物的图像的特征,执行识别第4对象物是人物的识别处理。识别处理例如相当于人物像检测/识别程序311和脸部检测/识别程序312。由此,确定对象物是人物。
另外,第1处理器301在多个不同处理中的控制特测定的数据取得装置的处理中,执行取得处理、识别处理、和发送处理。在取得处理中,第1处理器301从特定的数据取得装置取得表示特定的数据取得装置检测出存在于第4对象物的规定距离以内的第5对象物之后的第5对象物的一系列位置、图像和来自第5对象物的声音的时序数据作为关于第5对象物的数据。第5对象物例如是与第4对象物(人物ha)对话的店员hb。在识别处理中,第1处理器301基于第5对象物的图像的特征,识别第5对象物是人物。在发送处理中,第1处理器301对第5对象物的终端发送第5对象物存在于第4对象物的规定距离以内的时间段中的关于第4对象物的数据。
由此,作为店员的人物hb能够确认何时何处与谁进行了怎样的会话。另外,因为能够参考人物ha的个人db946,所以也能够确认人物ha在空间1内的时序的移动轨迹。从而,人物hb能够确定人物ha的喜好而有助于销售。
另外,第1处理器301在多个不同处理中的控制特定的数据取得装置的处理中,在取得处理中,取得来自终端的输入信息,在保存处理中,将输入信息与关于第4对象物的数据关联地保存。
另外,特定的数据取得装置是能够在空间1内移动的机器人20,第1处理器301在多个不同处理中的控制特定的数据取得装置的处理中,在特定的数据取得装置检测出人物靠近的情况下,执行取得处理。由此,能够对靠近机器人20的人物执行上述指引的任务。
另外,特定的数据取得装置是能够在空间1内移动的机器人20,第1处理器301在多个不同处理中的控制特定的数据取得装置的处理中,在特定的数据取得装置检测出人物的情况下使其向人物移动,执行取得处理。由此,能够由机器人20靠近人物并执行上述销售辅助的任务。
另外,本发明不限定于上述实施例,包括在附加的权利要求书的主旨内的各种变形例和同等结构。例如,上述实施例是为了易于理解地说明本发明而详细说明的,本发明并不限定于必须具备说明的全部结构。另外,可以将某个实施例的结构的一部分置换为其他实施例的结构。另外,也可以在某个实施例的结构上添加其他实施例的结构。另外,对于各实施例的结构的一部分,可以追加、删除、置换其他结构。
另外,上述各结构、功能、处理部、处理单元等的一部分或全部,例如可以通过集成电路设计等而用硬件实现,也可以通过处理器解释、执行实现各功能的程序而用软件实现。
实现各功能的程序、表、文件等信息,能够保存在存储器、硬盘、ssd(solidstatedrive)等存储装置、或者ic(integratedcircuit)卡、sd卡、dvd(digitalversatiledisc)等记录介质中。
另外,控制线和信息线示出了认为说明上必要的,并不一定示出了实现上必要的全部的控制线和信息线。实际上也可以认为几乎全部结构都相互连接。
附图标记说明
10控制装置
20机器人
30环境摄像机
200控制系统
201数据处理装置组
301第1处理器
302第1存储装置
310媒体处理程序
323综合控制程序
341现实世界db
342时序db。
- 还没有人留言评论。精彩留言会获得点赞!