一种基于Maxout神经元的深度双向LSTM声学模型的制作方法
本发明属于人工智能语音识别领域,主要涉及深度神经网络在语音声学模型中的应用。
背景技术:
深度神经网络(deepneuralnetwork,dnn)的研究与应用极大的推动了自动语音识别(automaticspeechrecognition,asr)技术的发展。在大词汇量连续语音识别(largevocabularycontinuousspeechrecognition,lvcsr)系统中,相比于传统的高斯混合模型-隐马尔科夫模型(gaussianmixturemodels-hiddenmarkovmodels,gmm-hmm)声学模型,基于dnn的声学模型表现出更好的优势。seidef等人将基于dnn-hmm声学模型用于switchboard电话转录任务,其字错误率(worderrorrate,wer)相对下降了33%。dnn-hmm声学模型的研究和扩展给asr技术带来了前所未有的发展。
以前的研究主要集中在用于处理固定长度输入窗的上下文声学特征的前馈神经网络上。然而实际的语音信号具有动态特性,dnn不能很好地表征语音帧之间的长时依赖特性。所以,像循环神经网络(recurrentneuralnetwork,rnn)这样的更强大的序列信号模型再次引起了研究者的关注。最近,rnn在提高语音识别率上的性能优越性已得到证明,rnn的隐含层中具有循环结构,可捕获到更长的时间动态特性。但是标准的rnn仍然受限于梯度消失和爆炸问题,因此提出长短时记忆(longshort-termmemory,lstm)rnn模型,该模型中的输入信号、循环信号和输出信号都由门信号控制,在一定程度上克服了这些问题。gravesa等人建立了基于lstmrnn的语音识别系统,在timit音素识别任务中取得了很好的成果。sakh等人将混合深度lstm-hmm语音识别系统通过帧级交叉熵(crossentropy,ce)训练和序列级鉴别训练获得更好的识别结果。此后,研究了许多lstm网络的变体,并针对多种asr任务进行了有效的实验验证。jaitlyn等人提出深度双向长短时记忆-隐马尔科夫模型(deepbidirectionallongshorttermmemory-hiddenmarkovmodels,dblstm-hmm)声学模型,并在timit和wsj语料库中验证了其识别性能。chenk等人提出在lvcsr中使用上下文敏感块-随时间反向传播(context-sensitive-chunkback-propagationthroughtime,csc-bptt)算法来训练dblstm声学模型。dblstm能够在模型内部存储某一帧的前后语音信息,训练被分类帧两侧的上下文声学特征。
在神经网络训练阶段,lstm可以通过标准rnn的基于梯度的算法进行训练,如实时循环学习(real-timerecurrentlearning,rtrl)、随时间反向传播(back-propagationthroughtime,bptt)以及其多种变体。但是,由于dblstm在每个时间步长上的双向依赖性,上述的训练算法不能直接应用于dblstm训练。因为在lvcsr中,dblstm不适合于低延迟识别,可能会导致整个语音识别的延迟。chenk等人提出一种csc-hmm训练算法,它将每个序列分解为多个具有上下文敏感的组块,并行处理这些组块,这样只是在一小段语音中延迟,而不是整个语句。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种解决rnn训练过程中梯度消失和爆炸问题,以及应用csc-hmm训练算法满足dblstm在每个时间步长上的双向依赖性的特点,实现更好是语音识别性能的基于maxout神经元的深度双向lstm声学模型。本发明的技术方案如下:
一种基于maxout神经元的深度双向lstm声学模型,其该模型包括:多个双向长短时记忆网络blstm层形成的多层dblstm深度双向长短时记忆网络、选择连接层、全连接层和隐马尔可夫模型,其中,所述多层dblstm深度双向长短时记忆网络用于语音识别的声学模型,所述选择连接层用于对多个双向长短时记忆网络blstm层的输出进行加权变换,所述全连接层用于对加权变换后的值进行非线性变换,最终得到隐马尔可夫模型所需的后验概率,所述隐马尔可夫模型用于得到语音识别概率;将语音特征输入多层dblstm网络进行非线性变换,得到具有上下文语音帧信息的特征矢量,多层dblstm网络采用csc-bptt上下文敏感块的随时间反向传播训练算法进行网络参数训练;多层blstm网络输出的数据采用选择连接层对其进行加权变换后再作为全连接层的输入;全连接层对输入数据进行变换,全连接层部分采用maxout单元代替原来的sigmoid单元,并且利用dropout正则化训练算法对其进行参数训练,再通过softmax输出层得到声学模型中hmm模型所需的后验概率;前端dblstm神经网络得到后验概率后,在经过hmm模型最终输出得到声学模型得分。
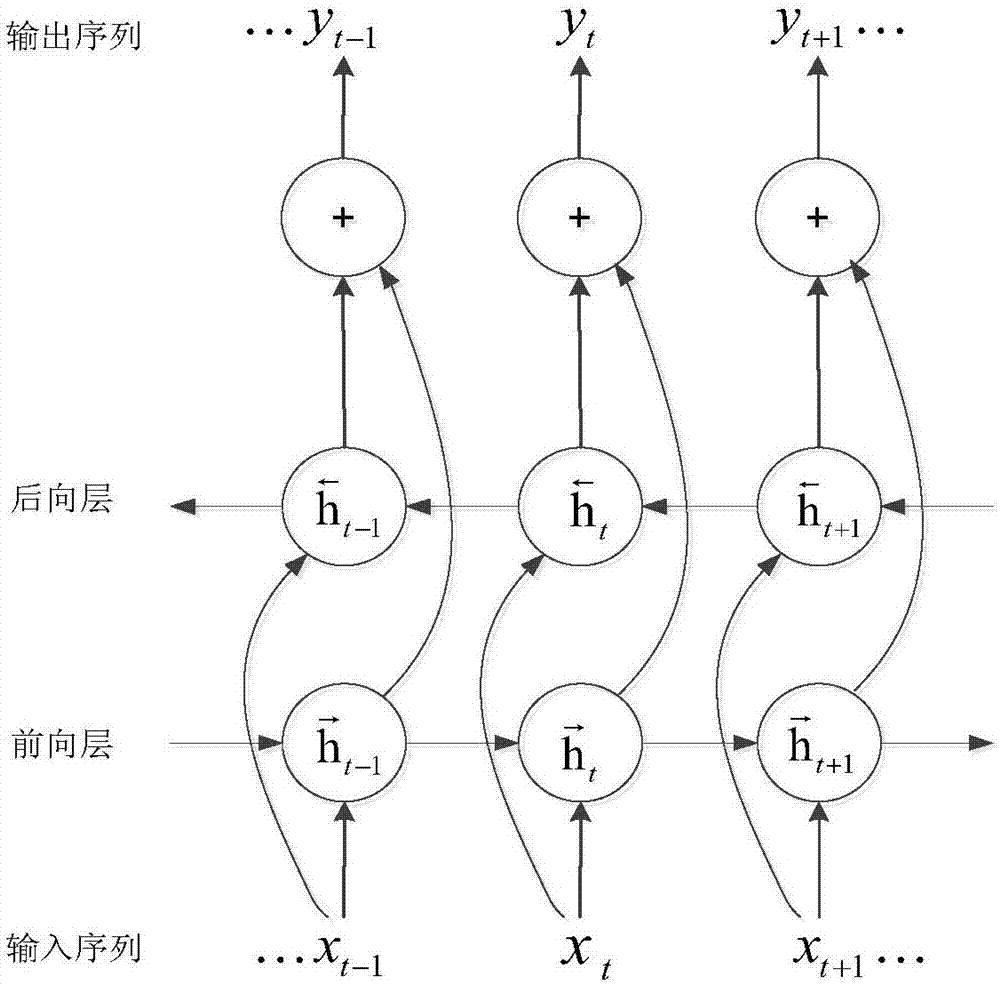
进一步的,所述dblstm网络通过两个单独的隐含层同时处理两个方向的信息,然后前馈到同一个输出层,dblstm网络中含有两个lstm层,一层从前到后迭代计算前向隐含层向量
by表示输出层的偏置向量,yt表示输出值,h表示输出层的激活函数,
进一步的,所述dblstm递归神经网络(深度双向长短时记忆递归神经网络)计算方法为:
首先,对于标准的rnn,给定一个输入序列x=(x1,x2,...,xt),通过t=1到t迭代计算出rnn隐含层的状态向量h=(h1,h2,...,ht)和输出向量y=(y1,y2,...,yt),即
ht=h(wxhxt+whhht-1+bh)
yt=whyht+by
其中,w代表各层间的权值矩阵;bh和by分别为隐含层和输出层的偏置向量;h为输出层的激活函数,wxh表示输如层和隐含层之间的权值矩阵,whh表示隐含层与隐含层之间的权值矩阵,why表示隐含层和输入层之间的权值矩阵。
lstm单元中,激活函数h通过下列公式实现:
it=σ(wxixt+whiht-1+wcict-1+bi)
ft=σ(wxfxt+whfht-1+wcfct-1+bf)
ct=ftct-1+ittanh(wxcxt+whcht-1+bc)
ot=σ(wxoxt+whoht-1+wcoct-1+bo)
ht=ottanh(ct)
其中,σ为标准sigmoid函数;i、f、o和c分别为输入门、遗忘门、输出门和内存单元;bi、bf、bo和bc分别为输入门、遗忘门、输出门和内存单元的偏置向量;w为各单元与门矢量之间的权值矩阵,如wxi为网络输入和输入门之间的权重矩阵。
进一步的,所述选择连接层的计算方法为:
该层是将dblstm最后一层blstm隐含层输出的两个矢量数据按照上述公式进行加权求和,最终得到一个矢量作为全连接层的输入信号。
进一步的,所述全连接层中maxout神经元的计算方法为:
在maxout神经网络中,每个maxout神经元由几个可选择的激活单元组成,maxout神经元的输出是选择其的激活单元单元组中最大值:
其中,
其中,
公式表明,当取最大值时maxout神经元的梯度为1,否则为0,这样在训练期间产生恒定的梯度,从而解决了梯度消失的问题。
进一步的,所述全连接层中dropout正则化训练算法计算方法为:
dropout正则化在训练阶段和测试阶段分别采用不同的正则化方法:
1)sgd训练阶段:将二值掩膜ml应用于原始激活单元,从而获得maxout神经元输出值:
其中,θ代表神经元进行的非线性变换,是向量的乘积,二值掩膜ml服从伯努利分布(1-r),r称为dropout率;
2)测试阶段:不需要省略激活神经元,但神经元激活值要按照1-r进行缩小用于补偿dropout训练。
进一步的,所述的dblstm网络的训练算法csc-bptt算法的计算过程为:
chunkbptt算法是将给定的每个序列分成多个特定长度nc的可能重叠chunk块,这些chunk共同组成一个较大的块batch,对于长度小于nc的chunk,添加空帧,在训练时每个chunk被当作独立的序列并行输入进行训练,从而更新网络参数;
csc-bptt算法是在chunkbptt算法的基础上进行改进的,上下文敏感块在固定数据帧nc的chunk左侧添加帧数为nl的数据作为上文信息,在chunk右侧添加帧数为nr的数据作为下文信息,将csc记为“nl-nc+nr”,整个序列被分为多个上下文敏感块,其中,第一个chunk的nl=0,最后一个chunk的nr=0;
在训练过程中,附加的上下文帧与chunk帧结合作为输入,生成chunk帧的输出,由于上下文帧本身并不产生输出,所以这些帧在训练期间不会产生错误信号,但chunk帧的错误信号仍会流经上下文帧用以获得相应的梯度值,从而更新网络参数。
本发明的优点及有益效果如下:
本发明模型包括:多个blstm层形成的dblstm网络、选择连接层、全连接层和隐马尔可夫(hmm)模型。dblstm在时域和空间域内都具有深层结构。它可以通过与线性循环连接的门信号来处理时域中的梯度消失的问题,但其并不能很好的解决空间域中梯度消失的问题。maxout神经元可以通过产生恒定梯度来解决此问题,因此考虑用maxout神经网络来增加dblstm的深度。除了用maxout网络加深网络深度,还将dropout正则化算法引入maxout网络中用于避免sgd训练过程中的过拟合现象。考虑到dropout正则化会损坏blstm所学习的长时记忆信息,所以只在全连接层的maxout网络中使用。由于dblstm网络在每个时间步长上的双向依赖性,不能直接使用一般的基于梯度的训练算法。目前适合dblstm网络的训练算法只有epoch-wisebptt和chunkbptt,但它们在训练时丢失了上下文的依赖信息,导致训练的模型性能降低。chenk等人提出用csc-bptt算法训练dblstm声学模型的方法已经在大词汇量连续语音识别系统中得到很好的验证。在训练过程中,附加的上下文帧与chunk帧结合作为输入,生成chunk帧的输出。由于上下文帧本身并不产生输出,所以这些帧在训练期间不会产生错误信号,但chunk帧的错误信号仍会流经上下文帧用以获得相应的梯度值,从而更新网络参数。
通过kaldi语音工具箱在switchboard语料库中进行评估实验。将该发明的dblstm-hmm声学模型与原来的dnn-hmm、rnn-hmm和lstm-hmm声学模型一起进行语音识别实验,在相同的语料库中,证明了本发明的声学模型的有效性。
该模型为解决lstm训练过程中常出现的梯度消失和爆炸问题,将dblstm神经网络与maxout神经元和dropout正则化算法相结合提出一种改进的dblstm-hmm声学模型结构,并且为适应dblstm对每个时间步长的双向依赖性,提出采用csc-bptt算法训练模型中多层blstm网络。该模型在一定程度上减少了dblstm模型的训练时间,并提高了语音识别率。
附图说明
图1是本发明优选实施例的单个lstm单元结构图。
图2dblstm网络结构图;
图3maxout神经网络结构图;
图4基于maxout神经元的dblstm网络结构图;
图5上下文敏感块示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
本发明如图1所示为单个lstm单元结构图,其与标准rnn不同。对于标准的rnn,给定一个输入序列x=(x1,x2,...,xt),可以通过t=1到t迭代计算出rnn隐含层的状态向量h=(h1,h2,...,ht)和输出向量y=(y1,y2,...,yt),即
ht=h(wxhxt+whhht-1+bh)
yt=whyht+by
其中,w代表各层间的权值矩阵;bh和by分别为隐含层和输出层的偏置向量;h为输出层的激活函数。
一般的rnn通常会出现梯度消失的问题,所以其对长时序列特征建模的效果并不好。lstm通过构建内存单元对序列信息进行建模,可以解决此类问题。在lstm单元中,激活函数h通过下列公式实现:
it=σ(wxixt+whiht-1+wcict-1+bi)
ft=σ(wxfxt+whfht-1+wcfct-1+bf)
ct=ftct-1+ittanh(wxcxt+whcht-1+bc)
ot=σ(wxoxt+whoht-1+wcoct-1+bo)
ht=ottanh(ct)
其中,σ为标准sigmoid函数;i、f、o和c分别为输入门、遗忘门、输出门和内存单元;bi、bf、bo和bc分别为输入门、遗忘门、输出门和内存单元的偏置向量;w为各单元与门矢量之间的权值矩阵,如wxi为网络输入和输入门之间的权重矩阵。
如图2所示为dblstm网络结构图。dblstm网络通过两个单独的隐含层同时处理两个方向的信息,然后前馈到同一个输出层。dblstm网络中含有两个lstm层,一层从前到后迭代计算前向隐含层向量
如图3所示为maxout神经网络结构图。在深度神经网络的应用中,sigmoid神经元具有平滑性和梯度计算简单等特点,因此广泛应用于多种神经网络中。但其仍然存在一个缺点:在随机梯度下降(stochasticgradientdescent,sgd)训练算法中,sigmoid神经元可能会导致训练过程中梯度消失。这是因为当输入值较大(不在零附近)时,sigmoid函数的梯度值通常趋向于非常小,甚至消失。当网络较深时,这个问题尤为严重,使得这个过程对超参数调整特别敏感。maxout神经元通过在sgd训练期间产生恒定的梯度来有效地处理梯度消失的问题。maxout网络收敛速度快,泛化能力强,比整流线性单元(rectifiedlinrarunits,relu)网络和sigmoid网络更容易优化。
在maxout神经网络中,每个maxout神经元又由几个可选择的激活单元组成,maxout神经元的输出是选择其单元组中最大值:
其中,
其中,
在sgd训练过程中,maxout神经元的梯度计算为:
当取最大值时maxout神经元的梯度为1,否则为0。这样在训练期间产生恒定的梯度,从而解决了梯度消失的问题。
maxout神经元虽然很好的解决了dnn训练时梯度消失的问题,但有时也会出现过拟合现象。相关研究表明[25],dropout正则化是避免过拟合的一种有效的方法,且其也有利于神经网络模型平均。文献[26],首次将dropout正则化方法应用到lvcsr任务中,并取得很好的效果。
dropout正则化在训练阶段和测试阶段分别采用不同的正则化方法:
sgd训练阶段:将二值掩膜ml应用与原始激活单元,从而获得maxout神经元输出值:
其中,θ代表神经元进行的非线性变换,如sigmoid和maxout函数,是向量的乘积,二值掩膜ml服从伯努利分布(1-r),r称为dropout率。低dropout率能保留更多的有用信息,而较高的dropout率可实现更高的正则化,因此选择一个合适的dropout率尤为重要。
测试阶段:不需要省略激活神经元,但神经元激活值要按照1-r进行缩小用于补偿dropout训练。
如图4所示为基于maxout神经元的dblstm网络结构图。dblstm在时域和空间域内都具有深层结构。它可以通过与线性循环连接的门信号来处理时域中的梯度消失的问题,但其并不能很好的解决空间域中梯度消失的问题。maxout神经元可以通过产生恒定梯度来解决此问题,因此考虑用maxout神经网络来增加dblstm的深度。结合上述研究,提出一种dblstm与maxout神经网络组合的深度混合声学模型。在图4中blstm作为底层可以对语音信号的长时依赖信息建模。选择连接层将多层blstm网络输出的数据按照公式(10)变换后再输入后面隐含层网络。具有maxout神经元的全连接层利用dropout正则化算法进行训练,可以得到更好的dblstm模型平均。最后加入softmax层作为整个神经网络的输出。
除了用maxout网络加深网络深度,还将dropout正则化算法引入maxout网络中用于避免sgd训练过程中的过拟合现象。考虑到dropout正则化会损坏blstm所学习的长时记忆信息,所以只在全连接层的maxout网络中使用。
如图5所示为csc-bptt训练算法中的上下文敏感块示意图。csc-bptt算法是在chunkbptt算法的基础上进行改进的。在固定数据帧nc的chunk左侧添加帧数为nl的数据作为上文信息,在chunk右侧添加帧数为nr的数据作为下文信息。为了方便,将csc记为“nl-nc+nr”。整个序列被分为多个上下文敏感块,其中,第一个chunk的nl=0,最后一个chunk的nr=0。在训练过程中,附加的上下文帧与chunk帧结合作为输入,生成chunk帧的输出。由于上下文帧本身并不产生输出,所以这些帧在训练期间不会产生错误信号,但chunk帧的错误信号仍会流经上下文帧用以获得相应的梯度值,从而更新网络参数。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!
- SPNP‑IX在制备Kv4.2通道工具试剂中的应用的制造方法与工艺
- SPNP‑IX在制备Kv4.3通道工具试剂中的应用的制造方法与工艺
- SPNP‑27在制备Nav1.5通道抑制剂中的应用的制造方法与工艺
- SPNP‑27在制备Nav1.3通道抑制剂中的应用的制造方法与工艺
- 一种多肽在制备Nav1.3钠通道工具试剂中的应用的制造方法与工艺
- SPKP‑XI在制备Kv4.2通道抑制剂中的应用的制造方法与工艺
- 基于水凝胶溶胀特性的可控自变形神经微电极的制造方法与工艺
- SPKP‑XI在制备Kv4.1钾通道抑制剂中的应用的制造方法与工艺
- 小驳骨提取物作为神经保护剂的应用的制造方法与工艺
- 巴戟天低聚果糖提取物在制备防治阿尔茨海默症药物、保健品或食品中的应用的制造方法与工艺