生产具有改性糖基化重组糖蛋白的方法与流程
本申请要求于2014年3月17日提交的美国临时申请号61/954,337的权益,其全部内容以引用方式并入本文中。
背景技术:
糖基化(glycosylation)对糖蛋白的结构和功能至关重要。例如,认为糖基化可影响蛋白折叠(及由此的稳定性)和/或糖蛋白的生物活性。治疗性重组糖蛋白的需求,特别是单克隆抗体,在最近的二十年强劲增长。以前的研究显示,重组糖蛋白聚糖结构的微小差异可能影响糖蛋白的生物活性和药代动力学。例如,阿法达贝泊汀是具有两个额外的N-连接糖基化位点的重组人红细胞生成素(EPO)的高度糖基化的类似物。与内源或重组EPO相比,额外糖基化增加了糖类分子质量百分比,并且显著延长了阿法达贝泊汀的血清半衰期。此外,对于治疗性抗体,其功效主要依赖于抗体依赖性细胞毒性(ADCC),去除Fc部分的核心岩藻糖残基的化学-酶促和遗传方法已被开发,以增加由所述抗体诱导的ADCC效应的效力。
但是,目前可用的用于糖基化重塑的方法通常需要多种酶和/或多个步骤,导致制造糖工程化的重组蛋白成本高。
技术实现要素:
本发明是基于基因工程宿主动物细胞的开发,其能够生产糖蛋白,如具有包括去岩藻糖基化和单糖基化的改性糖基化的抗体。这样的宿主动物细胞被工程化以过量表达一种或多种岩藻糖苷酶、糖苷内切酶或二者。出乎意料的是,宿主动物细胞的细胞糖基化机制的改变没有导致与糖蛋白的合成和宿主细胞的生长相关的不利影响。
因此,本发明提供一种基因工程宿主动物细胞(例如,哺乳动物细胞),其过量表达岩藻糖苷酶,糖苷内切酶或二者,其中与野生型对应物相比,所述宿主动物细胞生产具有改性糖基化的糖蛋白。在一些实例中,岩藻糖苷酶可以是哺乳动物岩藻糖苷酶或细菌岩藻糖苷酶,例如,人FUCA1,人FUCA2,灰仓鼠(Cricetulus griseus)岩藻糖苷酶,α-L-1脑膜脓毒性金黄杆菌(Chryseobacterium meningosepticum),α-1,6-岩藻糖苷酶或细菌岩藻糖苷酶BF3242。可替代地或另外地,糖苷内切酶可以是Endo S酶,例如,包含SEQ ID NO:11所示氨基酸序列的酶。在一些实例中,基因工程化宿主动物细胞表达(i)人FUCA1,人FUCA2,灰仓鼠岩藻糖苷酶α-L-1,脑膜脓毒性金黄杆菌α-1,6-岩藻糖苷酶或细菌岩藻糖苷酶BF3242,和(ii)Endo S(如SEQ ID NO:11)。
本文中所描述的基因工程宿主动物细胞可以进一步表达糖蛋白,所述糖蛋白可以是外源性的(在相同类型的天然动物细胞中不表达)。实例包括:但不限于抗体、Fc融合蛋白、细胞因子、激素、生长因子或酶。
在一些实例中,基因工程宿主动物细胞是哺乳动物细胞,例如中国仓鼠卵巢(CHO)细胞,大鼠骨髓瘤细胞,幼仓鼠肾(BHK)细胞,杂交瘤细胞,拿马瓦(Namalwa)细胞,胚胎干细胞或受精卵。
本文还描述了用于生产具有改性糖基化模式(例如,去岩藻糖基化或单糖基化)的糖蛋白的方法,所述方法使用任何本文所述的基因工程宿主动物细胞。所述方法可以包括(i)提供表达(a)糖蛋白和(b)岩藻糖苷酶、糖苷内切酶或二者的宿主动物细胞;在允许用于生产糖蛋白和岩藻糖苷酶、糖苷内切酶或二者的条件下,培养所述宿主动物细胞;(ⅱ)收集所述宿主动物细胞或培养上清液以便分离糖蛋白,和任选地(iii)分离所述糖蛋白。所述方法可以进一步包括(ⅳ)分析所述糖蛋白的糖基化模式。
此外,本发明特征在于一种用于制备本文描述的任一基因工程动物细胞的方法。所述方法可以包括:(i)将一种或多种表达载体引入动物细胞,所述表达载体共同地编码岩藻糖苷酶、糖苷内切酶或二者,以及任选地(ii)将编码糖蛋白的表达载体引入所述动物细胞。所述方法可以进一步包括分选表达岩藻糖苷酶、糖苷内切酶、和糖蛋白的转化细胞。
在下面的描述中提出本发明中一或多个具体实施方式的细节。从以下几个具体实施方式的详细说明和图示以及所附的权利要求书,本发明的其它特征或优点将是显而易见的。
附图说明
图1为各种不同的N-聚糖的结构示意图,A:糖蛋白的典型N连接聚糖,B:去岩藻糖基化的N-聚糖,C:具有单N-乙酰葡糖胺(Nacetylglucosamine)还原糖(单糖基化)的N-聚糖。
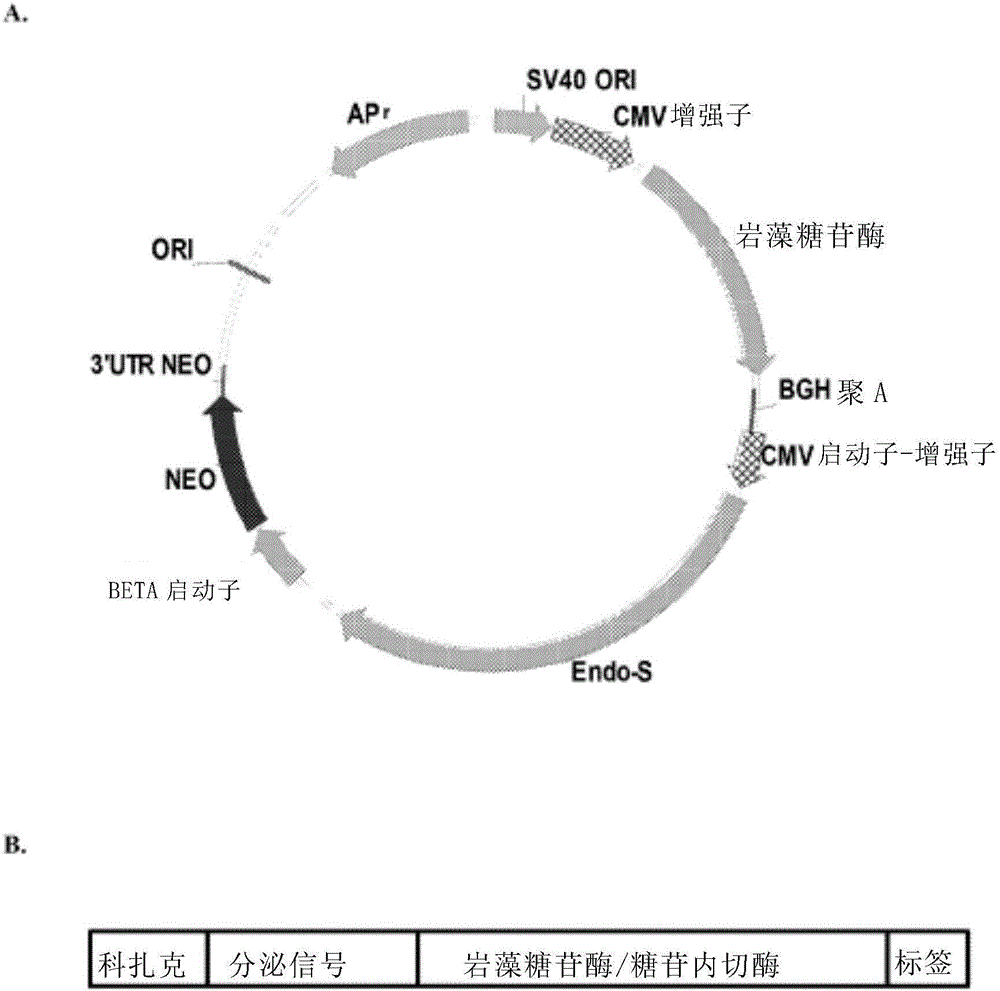
图2为用于生产岩藻糖苷酶的示例性表达载体的示意图,A:携带岩藻糖苷酶基因的示例性质粒的图谱,B:用于表达岩藻糖苷酶或糖苷内切酶S的示例性表达盒。
图3包括表示通过在工程化以表达岩藻糖苷酶和/或糖苷内切酶的宿主细胞内抗体的瞬时表达生产均匀去岩藻糖基化(afucosylated)单糖(GlcNAc)抗体h4B12的示意图,A:为生产均匀去岩藻糖基化单糖(GlcNAc)抗体的示意图,B:显示在工程化宿主细胞中产生抗体4B12糖基化的示意图,所述宿主细胞经工程化以表达人FUCA1,人FUCA2,灰仓鼠岩藻糖苷酶α-L-1,或脑膜脓毒性金黄杆菌(C.meningosepticum)α-1,6-岩藻糖苷酶,通过LC/MS/MS测定,C:为通过Western印迹检测到的CHO细胞内岩藻糖苷酶或糖苷内切酶的瞬时表达的示意图,D:表示在如上文所示的表达岩藻糖苷酶或糖苷内切酶的CHO细胞中生产抗体h4B12的图,通过LC/MS/MS测定,所述抗体具有均匀的无岩藻糖的单糖(GlcNAc)糖型。均匀N-聚糖是指糖蛋白例如抗体中N-聚糖(例如,去岩藻糖基化N-聚糖)相对于总N-聚糖的比率。
图4包括示出生产均匀去岩藻糖基化单糖(GlcNAc)抗体利妥昔单抗的示意图,通过在工程化以表达岩藻糖苷酶和/或糖苷内切酶的宿主细胞中瞬时表达所述抗体,A:表示在如上文所述的工程化以表达各种不同的岩藻糖苷酶或糖苷内切酶的宿主细胞中生产的抗体利妥昔单抗的糖基化,B:表示通过Western印迹测定,在如上文所述的CHO细胞中瞬时表达岩藻糖苷酶(左)或糖苷内切酶(右)。
具体实施方式
本文公开了基因工程宿主动物细胞例如哺乳动物细胞,其能够生产具有改性糖基化模式(例如改性N-糖基化模式如去岩藻糖基化N-聚糖或单糖聚糖)的糖蛋白(例如外源糖蛋白如抗体)。这种宿主动物细胞可以被工程化以过量表达岩藻糖苷酶,糖苷内切酶或二者。任选地,宿主动物细胞也可被改造以表达外源糖蛋白例如抗体。
图1中A表示野生型哺乳动物细胞中产生的糖蛋白的典型复杂N-聚糖的结构。这种复杂N-聚糖包含连接至糖基化位点的N-乙酰基葡萄糖胺(GlcNAc)残基,糖蛋白的天冬酰胺(Asn)残基,以及岩藻糖残基,其以α1,6键连接至所述Asn残基。所述基因工程宿主动物细胞能够产生糖蛋白(如内源或外源),所述糖蛋白具有改性N-聚糖,如去岩藻糖化N-聚糖,其中一个实施例显示于图1中B,以及单糖N-聚糖,其中仅GlcNAc残基连接至Asn糖基化位点(图1中C)。具有改性糖基化的糖蛋白是指糖蛋白携带至少一种聚糖例如N-聚糖,其结构上与所述基因工程宿主动物细胞的野生型对应物产生的糖蛋白的聚糖不同。去岩藻糖化聚糖是指不含α1,6岩藻糖残基或任何岩藻糖残基的任何聚糖。
A.岩藻糖苷酶
岩藻糖苷酶是一种能够分解岩藻糖的酶。这种酶从包含岩藻糖残基的聚糖切割岩藻糖残基。用于制备基因工程宿主动物细胞的岩藻糖苷酶可以是哺乳动物岩藻糖苷酶或细菌岩藻糖苷酶。在一些实施方式中,所述岩藻糖苷酶是野生型酶,如野生型细菌酶或野生型哺乳动物酶例如人类酶。多种示例性岩藻糖苷酶的氨基酸序列及其编码核苷酸序列提供如下(包括C端的His标签)。
人类岩藻糖苷酶FUCA1:
氨基酸序列(SEQ ID NO:1)
MRVPAQLLGLLLLWLPGARCQPPRRYTPDWPSLDSRPLPAWFDEAKFGVFIHWGVFSVPAWGSEWFWWHWQGEGRPQYQRFMRDNYPPGFSYADFGPQFTARFFHPEEWADLFQAAGAKYVVLTTKHHEGFTNWPSPVSWNWNSKDVGPHRDLVGELGTALRKRNIRYGLYHSLLEWFHPLYLLDKKNGFKTQHFVSAKTMPELYDLVNSYKPDLIWSDGEWECPDTYWNSTNFLSWLYNDSPVKDEVVVNDRWGQNCSCHHGGYYNCEDKFKPQSLPDHKWEMCTSIDKFSWGYRRDMALSDVTEESEIISELVQTVSLGGNYLLNIGPTKDGLIVPIFQERLLAVGKWLSINGEAIYASKPWRVQWEKNTTSVWYTSKGSAVYAIFLHWPENGVLNLESPITTSTTKITMLGIQGDLKWSTDPDKGLFISLPQLPPSAVPAEFAWTIKLTGVKHHHHHH
核苷酸序列(SEQ ID NO:2;密码子经优化)
atgagagtgcctgctcagctgctgggactgctgctgctgtggctgcctggtgctagatgccagccccctcggagatacacccctgactggccttccctggactccagacctctgcccgcttggtttgacgaggccaagttcggcgtgttcatccactggggcgtgttctccgtgcctgcctggggctctgagtggttctggtggcattggcagggcgagggcagacctcagtaccagcggttcatgcgggacaactacccccctggcttctcctacgccgacttcggccctcagttcaccgcccggttcttccaccctgaggaatgggccgatctgttccaggccgctggcgccaaatacgtggtgctgaccaccaagcaccacgagggcttcaccaactggccctcccccgtgtcctggaactggaactctaaggacgtgggcccccaccgggatctcgtgggagaactgggaaccgccctgcggaagcggaacatcagatacggcctgtaccactccctgctggaatggttccaccccctgtacctgctggacaagaagaacggcttcaagacccagcacttcgtgtccgccaagaccatgcccgagctgtacgacctcgtgaactcctacaagcccgacctgatttggagcgacggcgagtgggagtgccccgacacctattggaactccaccaactttctgtcctggctgtacaacgactcccctgtgaaggacgaggtggtcgtgaacgacagatggggccagaactgctcctgtcaccacggcggctactacaactgcgaggacaagttcaagccccagtccctgcccgaccacaagtgggagatgtgcacctctatcgacaagttctcctggggctaccggcgggacatggccctgtctgatgtgaccgaggaatccgagatcatctccgagctggtgcagaccgtgtccctgggcggcaactacctgctgaacatcggccctaccaaggacggcctgatcgtgcccatcttccaggaacggctgctggccgtgggcaagtggctgtctatcaacggcgaggccatctacgcctccaagccttggcgagtgcagtgggagaagaacaccacctccgtgtggtacacctccaagggctctgccgtgtacgccatcttcctgcactggcccgagaacggcgtgctgaacctggaatcccccatcaccacctctaccaccaagatcaccatgctgggcatccagggcgacctgaagtggtccaccgaccctgacaagggcctgttcatctccctgccccagctgcctccttccgctgtgcctgctgagttcgcctggaccatcaagctgaccggcgtgaagcaccaccaccatcaccattga
人类岩藻糖苷酶FUCA2:
氨基酸序列(SEQ ID NO:3)
MRVPAQLLGLLLLWLPGARCHSATRFDPTWESLDARQLPAWFDQAKFGIFIHWGVFSVPSFGSEWFWWYWQKEKIPKYVEFMKDNYPPSFKYEDFGPLFTAKFFNANQWADIFQASGAKYIVLTSKHHEGFTLWGSEYSWNWNAIDEGPKRDIVKELEVAIRNRTDLRFGLYYSLFEWFHPLFLEDESSSFHKRQFPVSKTLPELYELVNNYQPEVLWSDGDGGAPDQYWNSTGFLAWLYNESPVRGTVVTNDRWGAGSICKHGGFYTCSDRYNPGHLLPHKWENCMTIDKLSWGYRREAGISDYLTIEELVKQLVETVSCGGNLLMNIGPTLDGTISVVFEERLRQMGSWLKVNGEAIYETHTWRSQNDTVTPDVWYTSKPKEKLVYAIFLKWPTSGQLFLGHPKAILGATEVKLLGHGQPLNWISLEQNGIMVELPQLTIHQMPCKWGWALALTNVIHHHHHH
核苷酸序列(SEQ ID NO:4;密码子经优化)
atgagagtgcctgctcagctgctgggactgctgctgctgtggctgcctggcgctagatgccactccgccaccagattcgaccccacctgggagtctctggacgccagacagctgcccgcttggtttgaccaggccaagttcggcatcttcatccactggggcgtgttctccgtgcccagcttcggctctgagtggttctggtggtactggcagaaagagaagatccccaaatacgtggagttcatgaaggacaactacccccccagctttaagtacgaggacttcggccccctgttcaccgccaagttcttcaacgccaaccagtgggccgacatcttccaggcctctggcgccaagtacatcgtgctgacctccaagcaccacgagggcttcaccctgtggggctccgagtactcctggaactggaacgccatcgacgagggccccaagcgggacatcgtgaaagaactggaagtggccatccggaaccggaccgacctgagattcggcctgtactactccctgttcgagtggttccaccccctgtttctggaagatgagtcctccagcttccacaagcggcagttccccgtgtccaagaccctgcccgagctgtacgagctcgtgaacaactaccagcccgaggtgctgtggagtgacggggatggtggtgcccccgatcagtactggaactctaccggcttcctggcctggctgtacaacgagtctcctgtgcggggcaccgtcgtgaccaacgatagatggggcgctggctccatctgcaagcacggcggcttctacacctgttccgaccggtacaaccccggccatctgctgcctcacaagtgggagaactgcatgaccatcgacaagctgtcctggggctacagaagagaggccggcatctccgactacctgacaatcgaggaactcgtgaagcagctggtggaaaccgtgtcctgcggcggcaacctgctgatgaacatcggccctaccctggacggcaccatctccgtggtgttcgaggaacggctgcggcagatgggctcctggctgaaagtgaacggcgaggccatctacgagacacacacctggcggtcccagaacgacaccgtgacccctgacgtgtggtacaccagcaagcccaaagaaaagctggtgtatgccatcttcctgaagtggcctacctccggccagctgttcctgggccaccctaaggctatcctgggcgccaccgaagtgaaactgctgggccatggacagcccctgaactggatctccctggaacagaacggcatcatggtggaactgccccagctgaccatccatcagatgccctgcaaatggggctgggccctggccctgaccaacgtgatccaccatcaccaccaccactga
灰仓鼠(中国仓鼠)岩藻糖苷酶FUCA2
氨基酸序列(SEQ ID NO:5)
MRVPAQLLGLLLLWLPGARCKSSRRYDPTWESLDRRPLPSWFDQAKFGIFIHWGVFSVPSFGSEWFWWYWQKEKRPKFVDFMNNNYPPGFKYEDFGVLFTAKFFNASQWADILQASGAKYLVLTSKHHEGFTLWGSEYSWNWNAVDEGPKRDIVKELKVAITKNTDLRFGLYYSLFEWFHPLFLEDKLSSFQKRQFPISKMLPELYELVNKYQPDILWTDGDGGAPDRYWNSTGFLAWLYNESPVRNTVVTNDRWGAGSICKHGGYYTCSDRYNPGHLLPHKWENCMTIDQFSWGYRREAVISDYLTIEELVKQLVETVACGGNLLMNIGPTLDGIIPVIFEERLRQMGMWLKVNGEAIYETQPWRSQNDTATPDVWYTYKPEEKIVYAIFLKWPVSRELFLEQPIGSLGETEVALLGEGKPLTWTSLKPNGIIVELPQLTLHQMPCKWGWTLALTNVTHHHHHH
核苷酸序列(SEQ ID NO:6;密码子经优化)
atgagagtgcctgctcagctgctgggactgctgctgctgtggctgcctggcgctagatgcaagtcctctcggagatacgaccccacctgggagtccctggacagaaggcctctgcccagttggttcgaccaggccaagttcggcatcttcatccactggggcgtgttctccgtgcccagcttcggctctgagtggttctggtggtactggcagaaagagaagcggcccaagttcgtggacttcatgaacaacaactacccccctggctttaagtacgaggacttcggcgtgctgttcaccgccaagttcttcaacgcctcccagtgggccgacatcctgcaggcttccggcgctaagtacctggtgctgacctccaagcaccacgagggctttaccctgtggggctccgagtactcctggaactggaacgccgtggacgagggccctaagcgggacatcgtgaaagaactgaaggtggccatcaccaagaacaccgacctgagattcggcctgtactactccctgttcgagtggttccaccccctgtttctggaagataagctgtccagcttccagaagcggcagttccccatctccaagatgctgcccgagctgtacgagctcgtgaacaagtaccagcctgacatcctgtggaccgacggggatggtggcgcccctgacagatactggaactctaccggcttcctggcctggctgtacaacgagtcccctgtgcggaacaccgtcgtgaccaacgacagatggggcgctggctccatctgcaagcacggcggctactacacctgttccgaccggtacaaccccggccatctgctgcctcacaagtgggagaactgcatgacaatcgaccagttctcctggggctaccggcgcgaggccgtgatctctgactacctgaccatcgaggaactcgtgaagcagctggtggaaaccgtggcctgtggcggcaacctgctgatgaacatcggccctaccctggacggcatcatccccgtgatcttcgaggaacggctgcggcagatgggcatgtggctgaaagtgaacggcgaggccatctacgagacacagccttggcggtcccagaacgacaccgccacacctgacgtgtggtacacctacaagcccgaagagaagatcgtgtacgccatcttcctgaagtggcccgtgtccagagagctgtttctggaacagcccatcggctccctgggcgagacagaagtggctctgctgggcgagggcaagcctctgacctggacctccctgaagcccaatggcatcatcgtggaactgccccagctgaccctgcaccagatgccctgtaaatggggctggaccctggccctgaccaacgtgacccaccaccaccatcaccactga
脑膜脓毒素金黄杆菌α1,6-岩藻糖苷酶
氨基酸序列(SEQ ID NO:7)
MRVPAQLLGLLLLWLPGARCHNVSEGYEKPADPLVVQNLEQWQDLKFGLFMHWGTYSQWGIVESWSLCPEDESWTQRKPEHGKSYNEYVKNYENLQTTFNPVQFNPQKWADATKKAGMKYVVFTTKHHDGFAMFDTKQSDYKITSSKTPFSKNPKADVAKEIFNTFRDNGFRIGAYFSKPDWHSDDYWWSYFPPKDRNVNYDPQKYPARWENFKKFTFNQLNEITSNYGKIDILWLDGGWVRPFHTIDPNIEWQRTIKVEQDIDMDKIGTMARKNQPGIIIVDRTVPGKWENYVTPEQAVPEHALSIPWESCITMGDSFSYVPNDNYKSSQKIIETLIRIISRGGNYLMNIAPGPNGDYDAVVYERLKEISGWMDKNQSAVFTTRALAPYHESDFYYTQSKDGKIVNVFHISEKSNYQAPSELSFSIPENINPKTVKVLGISSQIKWKKKGNKIHVQLPEERTKLNYSTVIQITQHHHHHH
核苷酸序列(SEQ ID NO:8;密码子经优化)
atgagagtgcctgctcagctgctgggactgctgctgctgtggctgcctggcgctagatgccacaatgtgtccgagggctacgagaagcccgccgaccctctggtggtgcagaacctggaacagtggcaggacctgaagttcggcctgttcatgcactggggcacctactcccagtggggcatcgtggaatcctggtccctgtgccctgaggacgagtcttggacccagcggaagcctgagcacggcaagtcctacaacgagtacgtgaagaactacgagaacctgcagaccaccttcaaccccgtgcagttcaacccccagaagtgggccgacgccaccaagaaagccggcatgaaatacgtggtgttcaccaccaagcaccacgacggcttcgccatgttcgacaccaagcagtccgactacaagatcacctcctccaagacccccttcagcaagaaccccaaggccgacgtggccaaagagattttcaacaccttccgggacaacggcttccggatcggcgcctacttctccaagcctgactggcactccgacgactactggtggtcctacttcccacccaaggaccggaacgtgaactacgaccctcagaaataccccgccagatgggagaacttcaagaagttcaccttcaatcagctgaacgagatcaccagcaactacggcaagatcgacatcctgtggctggacggcggatgggtgcgacccttccacaccatcgaccccaacatcgagtggcagcggaccatcaaggtggaacaggacatcgacatggacaagatcggcaccatggcccggaagaaccagcccggcatcatcatcgtggaccggaccgtgcctggcaagtgggagaattacgtgacccccgagcaggccgtgcctgagcatgccctgtctatcccttgggagtcctgtatcacaatgggcgacagcttctcctacgtgcccaacgacaactacaagtcctcccagaagatcatcgagacactgatcaggatcatctccagaggcggcaactacctgatgaatatcgcccctggccccaacggcgactacgacgctgtggtgtacgagcggctgaaagaaatctccggctggatggataagaaccagtccgccgtgtttaccacccgggctctggccccttaccacgagtccgacttctactacacccagtccaaggacggaaagatcgtgaacgtgttccacatctccgagaagtccaactaccaggccccctccgagctgtccttcagcatccccgagaacatcaaccccaagaccgtgaaggtgctgggcatctccagccagatcaagtggaagaagaagggcaacaagatccacgtgcagctgcccgaggaacggaccaagctgaactactccaccgtgatccagatcacccagcaccaccaccatcaccactga
细菌岩藻糖苷酶BF3242
氨基酸序列(SEQ ID NO:9)
MRVPAQLLGLLLLWLPGARCQQKYQPTEANLKARSEFQDNKFGIFLHWGLYAMLATGEWTMTNNNLNYKEYAKLAGGFYPSKFDADKWVAAIKASGAKYICFTTRHHEGFSMFDTKYSDYNIVKATPFKRDVVKELADACAKHGIKLHFYYSHIDWYREDAPQGRTGRRTGRPNPKGDWKSYYQFMNNQLTELLTNYGPIGAIWFDGWWDQDINPDFDWELPEQYALIHRLQPACLVGNNHHQTPFAGEDIQIFERDLPGENTAGLSGQSVSHLPLETCETMNGMWGYKITDQNYKSTKTLIHYLVKAAGKDANLLMNIGPQPDGELPEVAVQRLKEVGEWMSKYGETIYGTRGGLVAPHDWGVTTQKGNKLYVHILNLQDKALFLPIVDKKVKKAVVFADKTPVRFTKNKEGIVLELAKVPTDVDYVVELTIDHHHHHH
核苷酸序列(SEQ ID NO:10;密码子经优化)
atgagagtgcctgctcagctgctgggactgctgctgctgtggctgcctggtgctagatgccagcagaagtaccagcccaccgaggccaacctgaaggccagatccgagttccaggacaacaagttcggcatcttcctgcactggggcctgtacgccatgctggctactggcgagtggaccatgaccaacaacaacctgaactacaaagagtacgctaagctggctggcggcttctacccctccaagttcgacgccgacaaatgggtggccgccatcaaggcctctggcgccaagtacatctgcttcaccacccggcaccacgagggcttctccatgttcgacaccaagtactccgactacaacatcgtgaaggccacccccttcaagcgggacgtcgtgaaagagctggccgacgcctgcgctaagcacggcatcaagctgcacttctactactcccacatcgactggtacagagaggacgccccccagggcagaaccggcagaagaacaggcagacccaaccccaagggcgactggaagtcctactaccagtttatgaacaaccagctgaccgagctgctgaccaactacggccccatcggcgccatttggttcgacgggtggtgggaccaggacatcaaccccgacttcgactgggagctgcccgagcagtacgccctgatccacagactgcagcccgcctgtctcgtgggcaacaaccaccaccagaccccctttgccggcgaggacatccagattttcgagcgggatctgcccggcgagaacaccgctggactgtctggccagtccgtgtcccatctgcccctggaaacctgcgagacaatgaacggcatgtggggctacaagatcaccgaccagaactacaagtccaccaagacactgatccactacctcgtgaaagccgctggcaaggacgccaacctgctgatgaacatcggcccccagcctgacggcgagctgcctgaagtggctgtgcagcggctgaaagaagtgggagagtggatgtctaagtacggcgagactatctacggcaccagaggcggcctggtggcccctcatgattggggcgtgaccacccagaagggcaacaagctgtacgtgcacatcctgaacctgcaggacaaggccctgttcctgcccatcgtggacaagaaagtgaagaaagccgtggtgttcgccgacaagacccccgtgcggttcaccaagaacaaagagggcatcgtgctggaactggccaaggtgcccaccgacgtggactacgtggtggaactgaccatcgaccaccatcatcaccaccactga
在一些实施方式中,岩藻糖苷酶可为相较于上述提供示例性的岩藻糖苷酶(例如SEQ ID NO:1,SEQ ID NO:3,SEQ ID NO:5,SEQ ID NO:7或SEQ ID NO:9,以及本文所述的其它岩藻糖苷酶)任一者,具有至少85%(例如90%、93%、95%、96%、97%、98%或99%)序列相同性的酶(如野生型酶)。
两种氨基酸序列“百分比相同性”使用Karlin和Altschul Proc.Natl.Acad.Sci.USA 87:2264-68,1990的算法确定,其如Karlin和Altschul Proc.Natl.Acad.Sci.USA 90:5873-77,1993描述修正。这种算法被并入Altschul等人.J.Mol.Biol.215:403-10,1990中的NBLAST和XBLAST程序(版本2.0)。BLAST蛋白质搜索可以采用XBLAST程序进行,其中评分(score)为50、字长(wavelength)为3,以获取与本发明蛋白质分子同源的氨基酸序列。若二序列间存在间隙(gap),可使用Altschul等人,核酸研究(Nucleic Acids Res).25(17):3389-3402,1997所描述的Gapped BLAST。采用BLAST和Gapped BLAST程序时,可以使用各程序(例如BLAST和Gapped BLAST)默认的参数。
可用于构建基因工程宿主动物细胞的哺乳动物岩藻糖苷酶包括但不限于:以GenBank登录号NP_114409.2,XP_003811598.1,AAH03060.1,EHH53333.1,XP_001127152.1,XP_010360962.1,XP_006084558.1,XP_004263802.1,XP_007171384.1,XP_006075254.1,XP_010982011.1,NP_001004218.1和XP_010964137.1所披露的那些。
可用于构建基因工程宿主动物细胞的细菌糖苷酶包括但不限于:以GenBank登录号WP_008769537.1,WP_032568292.1,EYA08300.1,WP_005780841.1,EXY26528.1,WP_044654435.1,WP_029425671.1,WP_022470316.1,CDA84816.1,WP_004307183.1和WP_008025871.1所披露的那些。
B.糖苷内切酶
糖苷内切酶是指能够破坏聚糖中2个单糖间糖苷键的酶,从而从糖蛋白或糖酯中释放寡糖。本发明披露中使用的糖苷内切酶(例如野生型酶)包括糖苷内切酶D、糖苷内切酶F、糖苷内切酶F1、糖苷内切酶F2、糖苷内切酶H、和糖苷内切酶S。各亚属示例性糖苷内切酶列于下表:
其它适用的糖苷内切酶包括与本文所述的酶具有至少85%(如90%,95%,98%,或99%)序列相同性的那些。与上述所列的糖苷内切酶任一者具有高度序列同源性(如至少85%序列相同性)的酶被预期具有相同的生物活性。此类酶(例如野生型)可以使用以上所列酶之一从基因数据库例如GenBank中查询获得。
在一些实施方式中,本文所述的糖苷内切酶为Endo S酶。Endo S是一种糖苷内切酶,其特异性切割连接至原始IgG分子Fc结构域Asn糖基化位点的第一个GlcNAc残基的N-聚糖,产生单糖基化的IgG分子,即具有单一GlcNAc连接至Asn糖基化位点的IgG分子。氨基酸序列以及编码核苷酸序列提供如下:
Endo S氨基酸序列(SEQ ID NO:11)
MRVPAQLLGLLLLWLPGARCAQHDSLIRVKAEDKVVQTSPSVSAIDDLHYLSENSKKEFKEGLSKAGEVPEKLKDILSKAQQADKQAKVLAEMKVPEKIAMKPLKGPLYGGYFRTWHDKTSDPAEKDKVNSMGELPKEVDLAFVFHDWTKDYSLFWQELATKHVPTLNKQGTRVIRTIPWRFLAGGDHSGIAEDTQKYPNTPEGNKALAKAIVDEYVYKYNLDGLDVDIERDSIPKVNGKESNENIQRSIAVFEEIGKLIGPKGADKSRLFIMDSTYMADKNPLIERGAPYIDLLLVQVYGIQGEKGDWDPVARKPEKTMEERWESYSKYIRPEQYMVGFSFYEENAGSGNLWYDINERKDDHNPLNSEIAGTRAERYAKWQPKTGGVKGGIFSYAIDRDGVAHQPKKVSDDEKRTNKAIKDITDGIVKSDYKVSKALKKVMENDKSYELIDQKDFPDKALREAVIAQVGSRRGDLERFNGTLRLDNPDIKSLEGLNKLKKLAKLELIGLSQITKLDSSVLPENIKPTKDTLVSVLETYKNDDRKEEAKAIPQVALTISGLTGLKELNLAGFDRDSLAGIDAASLTSLEKVDLSKNKLDLAAGTENRQIFDVMLSTVSNRVGSNEQTVTFDHQKPTGHYPNTYGTTSLRLPVGEGKIDLQSQLLFGTVTNQGTLINSEADYKAYQEQLIAGRRFVDPGYAYKNFAVTYDAYKVRVTDSTLGVTDEKKLSTSKEETYKVEFFSPTNGTKPVHEAKVVVGAEKTMMVNLAAGATVIKSDSHENAKKVFDGAIEYNPLSFSSKTSITFEFKEPGLVKYWRFFNDITRKDDYIKEAKLEAFVGHLEDDSKVKDSLEKSTEWVTVSDYSGEAQEFSQPLDNISAKYWRVTVDTKGGRYSSPSLPELQILGYRLPLTHDYKDDDDK
Endo S核苷酸序列(SEQ ID NO:12;密码子经优化)
atgagagtgcctgctcagctgctgggcctgctgctgctgtggctgcctggtgctagatgcgcccagcacgactccctgatcagagtgaaggccgaggacaaggtggtgcagacctccccttccgtgtccgccatcgacgacctgcactacctgtccgagaactccaagaaagagttcaaagagggcctgtccaaggccggcgaggtgcccgaaaagctgaaggacatcctgagcaaggctcagcaggccgacaagcaggccaaggtgctggccgagatgaaggtgccagagaagatcgccatgaagcccctgaagggccctctgtacggcggctacttcagaacctggcacgacaagacctccgaccccgccgagaaggacaaagtgaactccatgggcgagctgcccaaagaggtggacctggccttcgtgttccacgactggaccaaggactactccctgttctggcaggaactggccaccaagcacgtgcccaccctgaacaagcagggcaccagagtgatccggacaatcccctggcggtttctggctggcggcgaccactctggaatcgccgaggatacccagaagtaccccaacacccccgagggcaacaaggccctggctaaggccatcgtggacgagtacgtgtacaagtacaacctggacggcctggacgtggacatcgagcgggactccatccctaaagtgaacggcaaagagtccaacgagaacatccagcggtctatcgccgtgttcgaggaaatcggcaagctgatcggccccaagggcgccgacaagtcccggctgttcatcatggactccacctacatggccgataagaaccccctgatcgagagaggcgccccttacatcgatctgctgctggtgcaggtgtacggcatccagggcgagaagggcgattgggaccctgtggcccggaagcctgaaaagaccatggaagagagatgggagtcctactccaagtacatccggcccgagcagtatatggtgggattcagcttctacgaggaaaacgccggctccggcaacctgtggtacgacatcaacgagcggaaggacgaccacaaccctctgaactccgagatcgccggcacccgggctgagagatacgctaagtggcagcccaagaccggcggagtgaagggcggcatcttctcctacgccatcgatagggatggcgtggcccaccagcctaagaaggtgtccgacgacgagaagcggaccaacaaggctatcaaggacatcaccgacggcatcgtgaagtccgactacaaggtgtccaaagccctgaagaaagtgatggaaaacgacaagagctacgagctgatcgaccagaaggacttccccgataaggccctgcgcgaggccgtgattgctcaagtgggctccagacggggcgacctggaaagattcaacggcaccctgcggctggacaaccccgacatcaagtccctggaaggcctgaacaaactgaagaagctggccaagctggaactgatcggactgtcccagatcacaaagctggactcctccgtgctgcctgagaacatcaagcccaccaaggacaccctggtgtccgtgctggaaacctacaagaacgacgaccggaaagaggaagccaaggccatccctcaggtggccctgaccatctctggcctgaccggcctgaaagagctgaatctggccggcttcgaccgggattccctggctggaatcgatgccgcctctctgacctccctggaaaaagtggacctgtctaagaacaagctggatctggctgccggcaccgagaaccggcagatcttcgacgtgatgctgtccaccgtgtccaacagagtgggcagcaacgagcagaccgtgaccttcgaccaccagaagcccaccggccactaccctaacacctacggcaccacctccctgagactgcctgtgggcgagggcaagatcgacctgcagtcccagctgctgttcggcaccgtgaccaaccagggcacactgatcaactccgaggccgattacaaggcctaccaggaacagctgatcgctgggcggagattcgtggaccctggctacgcttacaagaacttcgccgtgacctacgatgcctacaaagtgcgcgtgaccgactccaccctgggcgtgacagacgaaaagaagctgagcacctccaaagaagagacatacaaggtggaattcttctcccccaccaatggcaccaagcctgtgcatgaggctaaggtggtcgtgggcgccgagaaaaccatgatggtcaacctggccgctggcgccaccgtgatcaagtctgactctcacgagaatgccaaaaaggtgttcgacggcgccatcgagtacaatcctctgagcttctccagcaagaccagcatcaccttcgagtttaaagaacccggcctcgtgaaatactggcggttcttcaacgatatcacccgcaaggacgactacatcaaagaggctaagctggaagccttcgtgggccatctggaagatgactccaaagtgaaggactctctggaaaagtccaccgagtgggtcaccgtgtctgactactctggcgaggcccaggaattctcccagcccctggacaacatctccgccaagtattggagagtgaccgtggacaccaagggcggacggtacagctctcctagcctgcccgagctgcagatcctgggctacagactgcctctgacccacgactataaggacgacgacgacaaatga
一些实施方式中,本文所述Endo S酶可以是相较于SEQ ID NO:11具有至少85%(例如90%,93%,95%,96%,97%,98%,或99%)序列相同性的酶(例如野生型酶)。实例包括但不限于:GenBank登录号.EQB24254.1,WP_037584019.1,WP_012679043.1,和ADC53484.1所描述的那些。
C.基因工程宿主动物细胞
本文所述宿主动物细胞是基因工程化的,以过量表达一种或多种具有特异性聚糖-修饰活性的酶(例如糖苷酶或乙二醇转移酶)。基因工程宿主动物细胞是指携带外源(非原生)基因材料的动物细胞,这些外源基因编码本文所述的一种或多种岩藻糖苷酶和糖苷内切酶。过量表达酶的宿主细胞是指基因工程宿主细胞,所述基因工程宿主细胞表达酶的水平相较于该宿主细胞野生型对应物表达酶的水平高(例如20%,50%,80%,100%,2-倍,5-倍,10-倍,50-倍,100-倍,1,000-倍,104-倍,或105-倍),该宿主细胞野生型对应物即为未含有与基因工程宿主细胞相同基因改性的相同类型的细胞。在一些实施方式中,编码本文所述外源酶的基因可被导入到适用的母体动物细胞,以生产本文所述基因工程宿主动物细胞。外源酶是指不存在于用以制造工程化宿主动物细胞的母体细胞内的酶。
本文所述基因工程宿主动物细胞,相较于野生型对应物,能够生产具有改性糖基化的糖蛋白,其可以通过常规重组技术制备。一些情况下,可将强的启动子插入内源岩藻糖苷酶和/或糖苷内切酶基因上游,以增强其表达。其它情况下,可将编码一种或多种岩藻糖苷酶和/或糖苷内切酶的基因材料导入母体宿主细胞,以生产本文所述的基因工程宿主动物细胞。
利用本领域熟知的方法,可将编码岩藻糖苷酶或糖苷内切酶的基因插入适用的表达载体(例如病毒载体或非病毒载体)。Sambrook等人.,分子克隆(Molecular Cloning),实验手册(A Laboratory Mannual),第三版.,冷泉港实验室出版社。举例而言,基因与载体在合适的条件下可互相接触,用限制性内切酶在各分子上创造互补端,可互补配对,且以连接酶相连接。或者,可将合成的核酸连接物连接至基因末端。这些合成的连接物含有相对应于载体上特定限制位点的核酸序列。在一些实施方式中,岩藻糖苷酶或糖苷内切酶的基因包含于表达盒内,其包含一种或多种下述元件:科扎克序列以及信号肽序列,其位于酶的N末端,以及蛋白质标签(例如FLAG,His标签,包括几丁质结合蛋白(CBP)、麦芽糖结合蛋白(MBP)、和谷胱甘肽-S-转移酶(GST))。所述蛋白标签可以位于酶的N末端或者C末端。见例如图2中B。
此外,所述表达载体可包含,例如,下述部分或全部:选择性标记基因,例如新霉素基因,用于哺乳动物细胞筛选稳定或瞬时转染子;源于人类CMV立即早期基因的增强子/启动子序列,用于高水平转录;用于mRNA稳定性,源自SV40的转录终止和RNA加工信号(基因);SV40多瘤复制起始(序列)和ColE1,用于适度游离型复制;通用多克隆位点;以及T7与SP6RNA启动子,用于体外转录正义与反义RNA。合适的载体以及用于生产含转基因载体的方法为本领域公知且可及。Sambrook等人.,分子克隆,实验手册,第三版.,冷泉港实验室出版社。
若需用二种或二种以上酶构建本文所述的宿主动物细胞,例如二种或多种岩藻糖苷酶,二种或多种糖苷内切酶,或岩藻糖苷酶与糖苷内切酶组合,则编码二种或多种酶的基因可插入各自表达载体或插入到经设计以表达多种蛋白的共用表达载体。
用于生产岩藻糖苷酶和/或糖苷内切酶表达载体可导入适用的母体宿主细胞,包括但不限于:鼠骨髓瘤细胞(如NSO细胞)、中国仓鼠卵巢(CHO)细胞、人类胚胎肾细胞(如HEK293)、和人类视网膜母细胞瘤细胞(如PER.C6)。选择适用的宿主细胞系,其属于本领域技术人员公知范畴,将取决于高产率需求及生产具有所需性质产物的需求之间的平衡。
一些情况下,表达载体可经设计,以致它们能通过本领域公知方法,以同源或非同源重组并入细胞基因中。用于将表达载体转移至母宿主细胞的方法包括但不限于:病毒介导的基因转移、脂质体介导的转移、转化、转染和转导,例如,病毒介导的基因转移,如使用基于DNA病毒如腺病毒、腺相关病毒以及疱疹病毒的载体,以及基于反转录病毒的载体。基因转移模式的示例包括,如:裸DNA、CaPO4沉淀、DEAE葡聚糖、电穿孔、原生质体融合、脂转染、细胞显微注射以及病毒载体、佐剂辅助型DNA、基因枪、导管。在一个示例当中,使用病毒载体。为了增加非病毒载体至细胞的输送,核酸或蛋白可偶联结合至抗体或它的结合片段,其结合细胞表面抗原。也包含靶标抗体或其片段的脂质体可用于本文所述的方法。
本文所述“病毒载体”是指以重组方式生产的病毒或病毒颗粒,其包含待输送至宿主细胞的多核苷酸,不论体内、离体或体外。病毒载体的示例包括:反转录病毒载体例如慢病毒载体、腺病毒载体、腺相关病毒载体及其类似物。对于反转录病毒载体介导的基因转移方面,载体构建物是指包含反转录病毒基因组或其部分的多核苷酸,以及治疗性基因。
基因工程宿主动物细胞可包含使用为所导入的一种或多用基因组成型表达或诱导型表达所创建的表达盒。此表达盒可包括调节元件,如启动子、起始密码子、终止密码子及多腺苷化信号。所述元件能够可操作连接至编码感兴趣的表面蛋白的基因,如此,该基因在宿主细胞中可操作(例如表达)。
许多启动子可用于表达岩藻糖苷酶和/或糖苷内切酶(以及本文所述的任何外源糖蛋白)。可用于表达蛋白的启动子为本领域公知,包括但不限于:巨细胞病毒(CMV)中间早期启动子、病毒LTR如劳斯肉瘤(Rous sarcoma)病毒LTR、HIV-LTR、HTLV-1LTR、猿猴(simian)病毒40(SV40)早期启动子、大肠杆菌lac UV5启动子及单纯疱疹tk病毒启动子。
也可以使用调节性启动子。此类调节性启动子包括使用四环素抑制子(tetR)[Gossen,M.和Bujard,H.,Proc.Natl.Acad.Sci.USA 89:5547-5551(1992);Yao,F.等人,人类基因治疗,9:1939-1950(1998);Shockelt,P.等人,Proc.Natl.Acad.Sci.USA,92:6522-6526(1995)]的那些。其它系统包括FK506二聚体,使用雌二醇的VP16或p65,RU486,二酚米乐甾酮(diphenol murislerone)或雷帕霉素(rapamycin)。诱导性系统可向英杰(Invitrogen)、克隆泰克(Clontech)和阿瑞雅德(Ariad)购买。
一些诱导性启动子的效果可随时间增加。在这种情况下,通过串联方式插入多重抑制子,如通过内部核糖体插入位点(internal ribosome entry site;IRES)将TetR连接至TetR,可以增加此类系统的效果。或者,可以于筛选所需功能前,等待至少3天。虽然可能发生某些沉默现象,可以通过使用适当数目细胞而最小化该现象,所述细胞数目较佳为至少1x104、更佳为至少1x105、又更佳为至少1x106、甚至更佳为至少1x107。可以通过公知方法增强所需蛋白表达,以增进所述系统的功效。例如,使用土拔鼠肝炎病毒转录后调控元件(Woodchuck Hepatitis Virus Posttranscriptional Regulatory Element;WPRE)。参见Loeb,V.E.,等人,人类基因治疗(Human Gene Therapy)10:2295-2305(1999);Zufferey,R.,等人,J.of Virol.73:2886-2892(1999);Donello,J.E.,等人,J.of Virol.72:5085-5092(1998).
用于实施本文所述方法的聚腺苷酸化信号的示例包括但不限于:人类I型胶原蛋白聚腺苷酸化信号、人类II型胶原蛋白聚腺苷酸化信号及SV40聚腺苷酸化信号。
包括可操作地连接至调控元件的岩藻糖苷酶基因和/或糖苷内切酶基因(以及本文所述的糖蛋白基因)的外源基因材料,可维持存在于细胞以作为功能胞质分子、功能游离分子或其可整合入细胞的染色体DNA。外源基因材料可导入细胞,其以质粒形式维持为独立基因材料。或者,可整合入染色体的线型DNA,可被导入细胞。当导入DNA至细胞内时,可加入促进DNA整合入染色体的试剂。适用于促进整合的DNA序列也可包括于DNA分子中。或者,可将RNA导入细胞。
可使用选择性标记监控本文所述宿主动物细胞对所需转入基因的摄取。这些标记基因可以受控于任何启动子或诱导性启动子。这些是本领域公知的,且包括改变细胞对刺激,如营养物、抗生素等的敏感性的基因。基因包括那些neo、puro、tk、多重抗药性(multiple drug resistance;MDR)等基因。其它基因表达可易于进行筛选的蛋白,如绿色荧光蛋白(GFP)、蓝色荧光蛋白(BFP)、荧光素酶及LacZ。
D.生产具有改性糖基化的糖蛋白
基因工程宿主动物细胞可用于生产具有改性糖基化模式的糖蛋白(如内源性或外源性)。一些具体实施方式中,用于生产上述基因工程宿主动物细胞的母宿主细胞已携带编码外源性糖蛋白的一或多个基因。在其它实施方式中,编码感兴趣糖蛋白的一个或多个基因可被导入基因工程宿主动物细胞,所述宿主动物细胞可由本领域公知或本文所述方法表达一种或多种岩藻糖苷酶和/或糖苷内切酶。
能产生感兴趣糖蛋白和一种或多种岩藻糖苷酶和/或糖苷内切酶两者的基因工程宿主动物细胞可于容许蛋白质表达的适当条件下培养。可收集细胞和/或培养基,可使用常规技术自细胞和/或培养基分离和纯化感兴趣的糖蛋白。可以常规技术如LC/MS/MS测定所生产的糖蛋白的糖基化模式,以确认糖基化改性。
一些实施例中,感兴趣的糖蛋白为抗体。示例性抗体包括但不限于:阿昔单抗(糖蛋白IIb/IIIa;心血管疾病),阿达木单抗(TNF-α;各种自身免疫性疾病,如类风湿性关节炎),阿仑单抗(CD52;慢性淋巴细胞白血病),巴利昔单抗(IL-2Rα受体(CD25);移植排斥),贝伐单抗(血管内皮生长因子A;各种癌症,如结肠直肠癌、非小细胞肺癌、胶质母细胞瘤、肾癌、湿性年龄相关性黄斑退化),卡妥索单抗,西妥昔单抗(EGF受体,各种癌症,如结肠直肠癌、头颈癌),赛妥珠单抗(如聚乙二醇结合赛妥珠单抗certolizumab pegol)(TNFα;克隆氏症,类风湿性关节炎),达利珠单抗(IL-2Rα受体(CD25);移植排斥),依库珠单抗(补体蛋白C5;阵发性睡眠性血红蛋白尿症(paroxysmal nocturnal hemoglobinuria)),依法利珠单抗(CD11a;牛皮癣),吉妥珠单抗(CD33;急性骨髓性白血病(如伴随卡里奇霉素(calicheamicin))),替伊莫单抗(ibritumomab tiuxetan)(CD20;非霍奇金淋巴瘤(如伴钇-90或铟-111)),英夫利昔单抗(TNF-α;各种自身免疫性疾病,如类风湿性关节炎),莫罗单抗-CD3(T细胞CD3受体;移植排斥),那他珠单抗(α-4(α4)整合素;多发性硬化症,克隆氏症),奥马珠单抗(IgE;过敏性哮喘),帕利珠单抗(RSV F蛋白表位;呼吸道融合病毒感染),帕尼单抗(EGF受体;癌症,如结肠直肠癌),兰尼单抗(血管内皮生长因子A;湿性年龄相关性黄斑退化),利妥昔单抗(CD20;非霍奇金淋巴瘤),托西莫单抗(CD20,非霍奇金淋巴瘤),曲妥珠单抗(ErbB2;乳腺癌)。
一些实施例中,感兴趣糖蛋白是细胞因子。示例包括但不限于:干扰素(如IFN-α、INF-β或INF-γ)、白介素(如IL-2,IL-3,IL-4,IL-5,IL-6,IL-7,IL-12),及集落刺激因子(如G-CSF、GM-CSF、M-CSF)。IFN可为如干扰素α2a或干扰素α2b。参见如Mott HR和Campbell ID.“四螺旋束生长因子及其受体:蛋白-蛋白相互作用(Four-helix bundle growth factors and their receptors:protein-protein interactions).”Curr Opin Struct Biol.1995 2月;5(1):114-21;Chaiken IM,Williams WV.“识别四螺旋束细胞因子结构-功能关系:重新模拟设计(Identifying structure-function relationships in four-helix bundle cytokines:towards de novo mimetics design).”Trends Biotechnol.1996,10月;14(10):369-75;Klaus W等人,“由异核核磁共振光谱学测定溶解状态中人类干扰素α-2a的三维高分辨率结构(The three-dimensional high resolution structure of human interferon alpha-2a determined by heteronuclear NMR spectroscopy in solution)”.J.Mol Biol.,274(4):661-75,1997,对于某些此类细胞因子的进一步讨论。
感兴趣的蛋白质可为细胞因子蛋白,其具有与一种或多种前述细胞因子类似的结构。例如,所述细胞因子可为IL-6类细胞因子例如白血病抑制因子(leukemia inhibitory factor;LIF)或抑瘤素M(oncostatin M)。一些实施方式中,所述细胞因子自然结合至包含GP130信号转导亚基的受体。其它感兴趣的四螺旋束蛋白包括生长激素(growth hormone;GH)、泌乳素(prolactin;PRL)及胎盘生乳素(placental lactogen)。一些具体实施方式中,靶标蛋白为红血球生成刺激剂,如(EPO),其也为四螺旋束细胞因子。一些具体实施方式中,红血球生成刺激剂为EPO变体,如阿法达贝泊汀,也称作新型红血球生成刺激蛋白(novel erythropoiesis stimulating protein;NESP),其被工程化以含有5条N-连接的糖链(比重组HuEPO多2条)。一些具体实施方式中,所述蛋白包含5个螺旋。例如,所述蛋白可为干扰素β,如干扰素β-1a或β-1b,其(如所理解)通常归类为四螺旋束细胞因子。一些具体实施方式中,靶标蛋白为IL-9,IL-10,IL-11,IL-13,或IL-15。参见如Hunter,CA,免疫学自然综述(Nature Reviews Immunology)5,521-531,2005,对特定细胞因子的探讨。还参见Paul,WE(编辑),基础免疫学(Fundamental Immunology),Lippincott Williams和Wilkins;第6版,2008。
此外,感兴趣的蛋白可以为用于治疗人体疾病或失调,经美国食品药品管理局(或对等法规机构如欧洲药物评审局)批准的蛋白。此类蛋白可为或可不为这样的蛋白,聚乙二醇化(PEGylated)形式已经经临床试验和/或上市许可。在某些情况下,所述感兴趣蛋白为Fc融合蛋白,包括但不限于:阿巴西普、依那西普、IL-2-Fc融合蛋白、CD80-Fc融合蛋白,及PDL1-1-Fc融合蛋白。
进一步地,感兴趣的蛋白可为神经营养因子,即促进神经谱系细胞(该词如本文所使用包括神经祖细胞、神经元、及神经胶质细胞,如星状胶质细胞、少突胶质细胞、小胶质细胞)存活、发育和/或功能的因子。例如,一些具体实施方式中,靶标蛋白为促进轴突生长的因子。一些具体实施方式中,所述蛋白为睫状神经营养因子(ciliary neurotrophic factor;CNTF,一种四螺旋束蛋白)或其类似物如阿索开(Axokine),其为人类睫状神经营养因子的修饰版本,其具有C端15个氨基酸截断以及2个氨基酸取代,其体外与体内试验的功效为CNTF的3至5倍,且具有改进的稳定性。
或者,感兴趣的蛋白可为酶,如代谢或其他生理过程中重要的酶。如本领域所知,酶或者其他蛋白质的缺乏可造成多种疾病。此类疾病包括与糖类代谢、氨基酸代谢、有机酸代谢、卟啉(porphyrin)代谢、嘌呤或嘧啶代谢、溶酶体储存失调、血液凝聚等缺陷相关的疾病。实例包括法布瑞症(Fabry disease)、高歇氏症(Gaucher disease)、庞贝氏症(Pompe disease)、腺苷脱胺酶缺失、天冬酰胺酶缺失、卟啉病(porphyria)、血友病以及遗传性血管水肿。一些具体实施方式中,蛋白为凝血或凝聚因子(如因子VII、VIIa、VIII或IX)。其他具体实施方式中,蛋白是一种酶,其在糖类代谢、氨基酸代谢、有机酸代谢、卟啉代谢、嘌呤或嘧啶代谢、和/或溶酶体储存中发挥作用,其中外源性注射所述酶可至少部分缓解疾病。
此外,感兴趣的蛋白可为激素,如胰岛素、生长激素、黄体生成素、卵泡刺激素、及促甲状腺激素。感兴趣的蛋白可为生长因子,包括但不限于:肾上腺髓质素(adrenomedullin;AM)、血管生成素(angiopoietin;Ang)、自分泌运动因子(autocrine motility factor)、骨形成蛋白(bone morphogenetic proteins;BMPS)、脑源神经营养因子(brain-derived neurotrophic factor;BDNF)、表皮生长因子(EGF)、红血球生成素(EPO)、成纤维细胞生长因子(fibroblast growth factor;FGF)、胶质源性神经营养因子(glial cell line-derived neurotrophic factor;GDNF)、粒细胞集落刺激因子(granulocyte colony-stimulating factor;G-CSF)、粒细胞巨噬细胞集落刺激因子(granulocyte macrophage colony-stimulating factor;GM-CSF)、生长分化因子-9(growth differentiation factor-9;GDF9)、愈合因子、肝细胞生长因子(HGF)、肝癌源性生长因子(hepatoma-derived growth factor;HDGF)、类胰岛素生长因子(IGF)、角质细胞生长因子(keratinocyte growth factor;KGF)、促移行因子(migration-stimulating factor;MSF)、肌肉生长抑制素(myostatin;GDF-8)、神经生长因子(NGF)与其他神经营养因子、血小板衍生生长因子(PDGF)、血小板生成素(TPO)、转化生长因子α(TGF-α)、转化生长因子β(TGF-β)、肿瘤坏死因子α(TNF-α)、血管内皮生长因子(VEGF)及胎盘生长因子(PGF)。
据信无需进一步详尽说明,本领域普通技术人员可根据前面描述,最大程度利用本发明。因此,下列具体实施方式应理解为仅具有说明性,而非以任何方式局限本发明。通过引用并入本文引用的所有出版物用于本文引用的主题或目的。
实施例
方法
i.构建用于生产岩藻糖苷酶或糖苷内切酶的表达载体
为了构建岩藻糖苷酶或糖苷内切酶的表达载体,以常规技术分离岩藻糖苷酶或糖苷内切酶基因,并基于仓鼠细胞的密码子使用,进行密码子优化。合成基因由GeneArt Corp制备,并在限制酶位点Bgl II/EcoR I插入到pcDNA3.1B(-)Myc-His载体(英杰,US)(图2中A)。α岩藻糖苷酶的表达盒,从5’到3’,包含科扎克序列、Igk前导序列、岩藻糖苷酶编码序列及His-标签编码序列。图2中B。糖苷内切酶表达盒,从5’到3’,包含科扎克序列、Igk前导序列、糖苷内切酶编码序列、及His-标签编码序列。图2中B。
ii.制备去岩藻糖基化抗体
抗体产生细胞株以0.3~3.0×106存活细胞/毫升的浓度维持于完全培养基,以8mM L-谷氨酰胺与抗结块剂1:100稀释补充的CD FortiCHOTM培养基(生命科技(Life Technologies),美国)。将细胞维持在含8%CO2培养箱中的振荡台,其设定为130-150rpm。
为了制备去岩藻糖基化抗体,利用FreeStyleMAX试剂(生命科技,美国)根据制造商的方案,以编码前述α-岩藻糖苷酶的表达载体转染前述抗体产生细胞。将转染细胞培养于含有4g/L葡萄糖的培养基,且每隔一天置换培养基。当细胞存活率降至70%时,收取细胞。收集澄清的培养上清液,并以蛋白A层析法纯化。
iii.分析抗体糖基化
根据本文所述方法制备的重组抗体是经过还原、烷基化、及于37℃25mM碳酸氢铵缓冲液(pH~8)存在下以胰酶隔夜分解。将PNG酶F溶液(3μL,罗氏(Roche))加至200μL经分解的样本,且将混合物于37℃下再孵育16小时。使用C18柱(沃特斯(Waters))从肽中分离释放出的聚糖。以乙腈洗脱Sep-Pak C18,之后以水清洗。将PNG酶F分解样本填入该柱,并以1%乙醇冲洗释放的聚糖,同时肽仍结合于Sep-Pak C18。释放的蛋白质寡糖首先用多孔性石墨碳管柱(PhyNexus)纯化,之后经全甲基化(permethylated)。所有质谱实验以Orbitrap Fusion Tribrid质谱仪进行,其经由直接输注至纳米电喷雾源(nano-electrospray source)内。
结果
1.生产具有单糖(GlcNAc)糖型的抗体h4B12、利妥昔单抗和奥马珠单抗
通过岩藻糖苷酶切割反应,可由前述二糖变体制备单糖的糖变体。由许多可得酶的检索及通过LC/MS/MS的乙二醇-肽分析显示,经过优化切割反应条件,使用α-1,6岩藻糖苷酶可达到有效去岩藻糖苷化,且较高的切割效率与较低的NF/N比例有关。或者,可依次结合两种反应酶以获得单糖的糖变体,所述两种酶包括糖苷内切酶(Endo S)和α-1,6-岩藻糖苷酶。所得的单-GlcNAc糖变体示于图3中A。
结果显示,Endo S移除大于90%本文所述的工程CHO细胞中产生的h4B12、利妥昔单抗和奥马珠单抗的重链的N-连接聚糖。关于表达各岩藻糖苷酶的CHO细胞中产生的h4B12抗体,五种不同类型的岩藻糖苷酶FUCA1、FUCA2、灰仓鼠岩藻糖苷酶α-L-1、脑膜脓毒性金黄杆菌α-1,6-岩藻糖苷酶以及BF3242的去岩藻糖基化能力分别为5.8%,9.1%,17.7%,11.5和68%。图3中B。酶表达以Western blot法检测,如图3中C所示。
2-去氧-2-氟L-岩藻糖是经氟化的岩藻糖类似物。其可以在宿主细胞内代谢,以产生基于底物的岩藻糖基转移酶抑制剂。当培养瞬时表达岩藻糖苷酶BF3242和Endo S的产生抗体的CHO细胞时,连接至CHO细胞产生的抗体的N-聚糖中,99.89%为单糖基化(GlcNAc-Ig-Fc)。图3中D。
CHO-35D6细胞,其产生利妥昔单抗,以表达载体稳定转染,以生产BF3242和Endo S。细胞于100~400g/ml G418存在下培养。因此,所产生的抗体含有17-19%的GlcNAc-Ig-Fc。图4中A。
酶表达以Western blot法检测,如图4中B所示。
在工程化以表达岩藻糖苷酶和Endo S两者的CHO细胞中所生产的奥马珠单抗中,观察到类似结果。
对于制备均一的聚糖型抗体中的转糖基化反应而言,这样的效率代表了至为重要的步骤。
其它实施方式
本说明书所揭示的所有特征可以任意组合结合。本说明书揭示的各特征可基于相同、等同或类似目的,以另一特征所替代。因此,除非另有明确指明,所揭示的各特征仅为一通用系列的等同或类似特征的实例。
由上述陈述,本领域普通技术人员可易于确定本发明的必要特征,且在不背离其精神及范畴之下,可进行本发明的各种变更及改进,以使其适应于各种不同的用途及条件。因此,其它实施方式也在权利要求范围内。
序列表
<110> 泉盛生物科技公司
<120> 生产具有可控多糖形式的重组蛋白的方法
<130> F0720.70001WO00
<150> US 61/954,337
<151> 2014-03-17
<160> 12
<170> PatentIn version 3.5
<210> 1
<211> 461
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 1
Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp Leu Pro
1 5 10 15
Gly Ala Arg Cys Gln Pro Pro Arg Arg Tyr Thr Pro Asp Trp Pro Ser
20 25 30
Leu Asp Ser Arg Pro Leu Pro Ala Trp Phe Asp Glu Ala Lys Phe Gly
35 40 45
Val Phe Ile His Trp Gly Val Phe Ser Val Pro Ala Trp Gly Ser Glu
50 55 60
Trp Phe Trp Trp His Trp Gln Gly Glu Gly Arg Pro Gln Tyr Gln Arg
65 70 75 80
Phe Met Arg Asp Asn Tyr Pro Pro Gly Phe Ser Tyr Ala Asp Phe Gly
85 90 95
Pro Gln Phe Thr Ala Arg Phe Phe His Pro Glu Glu Trp Ala Asp Leu
100 105 110
Phe Gln Ala Ala Gly Ala Lys Tyr Val Val Leu Thr Thr Lys His His
115 120 125
Glu Gly Phe Thr Asn Trp Pro Ser Pro Val Ser Trp Asn Trp Asn Ser
130 135 140
Lys Asp Val Gly Pro His Arg Asp Leu Val Gly Glu Leu Gly Thr Ala
145 150 155 160
Leu Arg Lys Arg Asn Ile Arg Tyr Gly Leu Tyr His Ser Leu Leu Glu
165 170 175
Trp Phe His Pro Leu Tyr Leu Leu Asp Lys Lys Asn Gly Phe Lys Thr
180 185 190
Gln His Phe Val Ser Ala Lys Thr Met Pro Glu Leu Tyr Asp Leu Val
195 200 205
Asn Ser Tyr Lys Pro Asp Leu Ile Trp Ser Asp Gly Glu Trp Glu Cys
210 215 220
Pro Asp Thr Tyr Trp Asn Ser Thr Asn Phe Leu Ser Trp Leu Tyr Asn
225 230 235 240
Asp Ser Pro Val Lys Asp Glu Val Val Val Asn Asp Arg Trp Gly Gln
245 250 255
Asn Cys Ser Cys His His Gly Gly Tyr Tyr Asn Cys Glu Asp Lys Phe
260 265 270
Lys Pro Gln Ser Leu Pro Asp His Lys Trp Glu Met Cys Thr Ser Ile
275 280 285
Asp Lys Phe Ser Trp Gly Tyr Arg Arg Asp Met Ala Leu Ser Asp Val
290 295 300
Thr Glu Glu Ser Glu Ile Ile Ser Glu Leu Val Gln Thr Val Ser Leu
305 310 315 320
Gly Gly Asn Tyr Leu Leu Asn Ile Gly Pro Thr Lys Asp Gly Leu Ile
325 330 335
Val Pro Ile Phe Gln Glu Arg Leu Leu Ala Val Gly Lys Trp Leu Ser
340 345 350
Ile Asn Gly Glu Ala Ile Tyr Ala Ser Lys Pro Trp Arg Val Gln Trp
355 360 365
Glu Lys Asn Thr Thr Ser Val Trp Tyr Thr Ser Lys Gly Ser Ala Val
370 375 380
Tyr Ala Ile Phe Leu His Trp Pro Glu Asn Gly Val Leu Asn Leu Glu
385 390 395 400
Ser Pro Ile Thr Thr Ser Thr Thr Lys Ile Thr Met Leu Gly Ile Gln
405 410 415
Gly Asp Leu Lys Trp Ser Thr Asp Pro Asp Lys Gly Leu Phe Ile Ser
420 425 430
Leu Pro Gln Leu Pro Pro Ser Ala Val Pro Ala Glu Phe Ala Trp Thr
435 440 445
Ile Lys Leu Thr Gly Val Lys His His His His His His
450 455 460
<210> 2
<211> 1386
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 2
atgagagtgc ctgctcagct gctgggactg ctgctgctgt ggctgcctgg tgctagatgc 60
cagccccctc ggagatacac ccctgactgg ccttccctgg actccagacc tctgcccgct 120
tggtttgacg aggccaagtt cggcgtgttc atccactggg gcgtgttctc cgtgcctgcc 180
tggggctctg agtggttctg gtggcattgg cagggcgagg gcagacctca gtaccagcgg 240
ttcatgcggg acaactaccc ccctggcttc tcctacgccg acttcggccc tcagttcacc 300
gcccggttct tccaccctga ggaatgggcc gatctgttcc aggccgctgg cgccaaatac 360
gtggtgctga ccaccaagca ccacgagggc ttcaccaact ggccctcccc cgtgtcctgg 420
aactggaact ctaaggacgt gggcccccac cgggatctcg tgggagaact gggaaccgcc 480
ctgcggaagc ggaacatcag atacggcctg taccactccc tgctggaatg gttccacccc 540
ctgtacctgc tggacaagaa gaacggcttc aagacccagc acttcgtgtc cgccaagacc 600
atgcccgagc tgtacgacct cgtgaactcc tacaagcccg acctgatttg gagcgacggc 660
gagtgggagt gccccgacac ctattggaac tccaccaact ttctgtcctg gctgtacaac 720
gactcccctg tgaaggacga ggtggtcgtg aacgacagat ggggccagaa ctgctcctgt 780
caccacggcg gctactacaa ctgcgaggac aagttcaagc cccagtccct gcccgaccac 840
aagtgggaga tgtgcacctc tatcgacaag ttctcctggg gctaccggcg ggacatggcc 900
ctgtctgatg tgaccgagga atccgagatc atctccgagc tggtgcagac cgtgtccctg 960
ggcggcaact acctgctgaa catcggccct accaaggacg gcctgatcgt gcccatcttc 1020
caggaacggc tgctggccgt gggcaagtgg ctgtctatca acggcgaggc catctacgcc 1080
tccaagcctt ggcgagtgca gtgggagaag aacaccacct ccgtgtggta cacctccaag 1140
ggctctgccg tgtacgccat cttcctgcac tggcccgaga acggcgtgct gaacctggaa 1200
tcccccatca ccacctctac caccaagatc accatgctgg gcatccaggg cgacctgaag 1260
tggtccaccg accctgacaa gggcctgttc atctccctgc cccagctgcc tccttccgct 1320
gtgcctgctg agttcgcctg gaccatcaag ctgaccggcg tgaagcacca ccaccatcac 1380
cattga 1386
<210> 3
<211> 465
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 3
Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp Leu Pro
1 5 10 15
Gly Ala Arg Cys His Ser Ala Thr Arg Phe Asp Pro Thr Trp Glu Ser
20 25 30
Leu Asp Ala Arg Gln Leu Pro Ala Trp Phe Asp Gln Ala Lys Phe Gly
35 40 45
Ile Phe Ile His Trp Gly Val Phe Ser Val Pro Ser Phe Gly Ser Glu
50 55 60
Trp Phe Trp Trp Tyr Trp Gln Lys Glu Lys Ile Pro Lys Tyr Val Glu
65 70 75 80
Phe Met Lys Asp Asn Tyr Pro Pro Ser Phe Lys Tyr Glu Asp Phe Gly
85 90 95
Pro Leu Phe Thr Ala Lys Phe Phe Asn Ala Asn Gln Trp Ala Asp Ile
100 105 110
Phe Gln Ala Ser Gly Ala Lys Tyr Ile Val Leu Thr Ser Lys His His
115 120 125
Glu Gly Phe Thr Leu Trp Gly Ser Glu Tyr Ser Trp Asn Trp Asn Ala
130 135 140
Ile Asp Glu Gly Pro Lys Arg Asp Ile Val Lys Glu Leu Glu Val Ala
145 150 155 160
Ile Arg Asn Arg Thr Asp Leu Arg Phe Gly Leu Tyr Tyr Ser Leu Phe
165 170 175
Glu Trp Phe His Pro Leu Phe Leu Glu Asp Glu Ser Ser Ser Phe His
180 185 190
Lys Arg Gln Phe Pro Val Ser Lys Thr Leu Pro Glu Leu Tyr Glu Leu
195 200 205
Val Asn Asn Tyr Gln Pro Glu Val Leu Trp Ser Asp Gly Asp Gly Gly
210 215 220
Ala Pro Asp Gln Tyr Trp Asn Ser Thr Gly Phe Leu Ala Trp Leu Tyr
225 230 235 240
Asn Glu Ser Pro Val Arg Gly Thr Val Val Thr Asn Asp Arg Trp Gly
245 250 255
Ala Gly Ser Ile Cys Lys His Gly Gly Phe Tyr Thr Cys Ser Asp Arg
260 265 270
Tyr Asn Pro Gly His Leu Leu Pro His Lys Trp Glu Asn Cys Met Thr
275 280 285
Ile Asp Lys Leu Ser Trp Gly Tyr Arg Arg Glu Ala Gly Ile Ser Asp
290 295 300
Tyr Leu Thr Ile Glu Glu Leu Val Lys Gln Leu Val Glu Thr Val Ser
305 310 315 320
Cys Gly Gly Asn Leu Leu Met Asn Ile Gly Pro Thr Leu Asp Gly Thr
325 330 335
Ile Ser Val Val Phe Glu Glu Arg Leu Arg Gln Met Gly Ser Trp Leu
340 345 350
Lys Val Asn Gly Glu Ala Ile Tyr Glu Thr His Thr Trp Arg Ser Gln
355 360 365
Asn Asp Thr Val Thr Pro Asp Val Trp Tyr Thr Ser Lys Pro Lys Glu
370 375 380
Lys Leu Val Tyr Ala Ile Phe Leu Lys Trp Pro Thr Ser Gly Gln Leu
385 390 395 400
Phe Leu Gly His Pro Lys Ala Ile Leu Gly Ala Thr Glu Val Lys Leu
405 410 415
Leu Gly His Gly Gln Pro Leu Asn Trp Ile Ser Leu Glu Gln Asn Gly
420 425 430
Ile Met Val Glu Leu Pro Gln Leu Thr Ile His Gln Met Pro Cys Lys
435 440 445
Trp Gly Trp Ala Leu Ala Leu Thr Asn Val Ile His His His His His
450 455 460
His
465
<210> 4
<211> 1398
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 4
atgagagtgc ctgctcagct gctgggactg ctgctgctgt ggctgcctgg cgctagatgc 60
cactccgcca ccagattcga ccccacctgg gagtctctgg acgccagaca gctgcccgct 120
tggtttgacc aggccaagtt cggcatcttc atccactggg gcgtgttctc cgtgcccagc 180
ttcggctctg agtggttctg gtggtactgg cagaaagaga agatccccaa atacgtggag 240
ttcatgaagg acaactaccc ccccagcttt aagtacgagg acttcggccc cctgttcacc 300
gccaagttct tcaacgccaa ccagtgggcc gacatcttcc aggcctctgg cgccaagtac 360
atcgtgctga cctccaagca ccacgagggc ttcaccctgt ggggctccga gtactcctgg 420
aactggaacg ccatcgacga gggccccaag cgggacatcg tgaaagaact ggaagtggcc 480
atccggaacc ggaccgacct gagattcggc ctgtactact ccctgttcga gtggttccac 540
cccctgtttc tggaagatga gtcctccagc ttccacaagc ggcagttccc cgtgtccaag 600
accctgcccg agctgtacga gctcgtgaac aactaccagc ccgaggtgct gtggagtgac 660
ggggatggtg gtgcccccga tcagtactgg aactctaccg gcttcctggc ctggctgtac 720
aacgagtctc ctgtgcgggg caccgtcgtg accaacgata gatggggcgc tggctccatc 780
tgcaagcacg gcggcttcta cacctgttcc gaccggtaca accccggcca tctgctgcct 840
cacaagtggg agaactgcat gaccatcgac aagctgtcct ggggctacag aagagaggcc 900
ggcatctccg actacctgac aatcgaggaa ctcgtgaagc agctggtgga aaccgtgtcc 960
tgcggcggca acctgctgat gaacatcggc cctaccctgg acggcaccat ctccgtggtg 1020
ttcgaggaac ggctgcggca gatgggctcc tggctgaaag tgaacggcga ggccatctac 1080
gagacacaca cctggcggtc ccagaacgac accgtgaccc ctgacgtgtg gtacaccagc 1140
aagcccaaag aaaagctggt gtatgccatc ttcctgaagt ggcctacctc cggccagctg 1200
ttcctgggcc accctaaggc tatcctgggc gccaccgaag tgaaactgct gggccatgga 1260
cagcccctga actggatctc cctggaacag aacggcatca tggtggaact gccccagctg 1320
accatccatc agatgccctg caaatggggc tgggccctgg ccctgaccaa cgtgatccac 1380
catcaccacc accactga 1398
<210> 5
<211> 465
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 5
Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp Leu Pro
1 5 10 15
Gly Ala Arg Cys Lys Ser Ser Arg Arg Tyr Asp Pro Thr Trp Glu Ser
20 25 30
Leu Asp Arg Arg Pro Leu Pro Ser Trp Phe Asp Gln Ala Lys Phe Gly
35 40 45
Ile Phe Ile His Trp Gly Val Phe Ser Val Pro Ser Phe Gly Ser Glu
50 55 60
Trp Phe Trp Trp Tyr Trp Gln Lys Glu Lys Arg Pro Lys Phe Val Asp
65 70 75 80
Phe Met Asn Asn Asn Tyr Pro Pro Gly Phe Lys Tyr Glu Asp Phe Gly
85 90 95
Val Leu Phe Thr Ala Lys Phe Phe Asn Ala Ser Gln Trp Ala Asp Ile
100 105 110
Leu Gln Ala Ser Gly Ala Lys Tyr Leu Val Leu Thr Ser Lys His His
115 120 125
Glu Gly Phe Thr Leu Trp Gly Ser Glu Tyr Ser Trp Asn Trp Asn Ala
130 135 140
Val Asp Glu Gly Pro Lys Arg Asp Ile Val Lys Glu Leu Lys Val Ala
145 150 155 160
Ile Thr Lys Asn Thr Asp Leu Arg Phe Gly Leu Tyr Tyr Ser Leu Phe
165 170 175
Glu Trp Phe His Pro Leu Phe Leu Glu Asp Lys Leu Ser Ser Phe Gln
180 185 190
Lys Arg Gln Phe Pro Ile Ser Lys Met Leu Pro Glu Leu Tyr Glu Leu
195 200 205
Val Asn Lys Tyr Gln Pro Asp Ile Leu Trp Thr Asp Gly Asp Gly Gly
210 215 220
Ala Pro Asp Arg Tyr Trp Asn Ser Thr Gly Phe Leu Ala Trp Leu Tyr
225 230 235 240
Asn Glu Ser Pro Val Arg Asn Thr Val Val Thr Asn Asp Arg Trp Gly
245 250 255
Ala Gly Ser Ile Cys Lys His Gly Gly Tyr Tyr Thr Cys Ser Asp Arg
260 265 270
Tyr Asn Pro Gly His Leu Leu Pro His Lys Trp Glu Asn Cys Met Thr
275 280 285
Ile Asp Gln Phe Ser Trp Gly Tyr Arg Arg Glu Ala Val Ile Ser Asp
290 295 300
Tyr Leu Thr Ile Glu Glu Leu Val Lys Gln Leu Val Glu Thr Val Ala
305 310 315 320
Cys Gly Gly Asn Leu Leu Met Asn Ile Gly Pro Thr Leu Asp Gly Ile
325 330 335
Ile Pro Val Ile Phe Glu Glu Arg Leu Arg Gln Met Gly Met Trp Leu
340 345 350
Lys Val Asn Gly Glu Ala Ile Tyr Glu Thr Gln Pro Trp Arg Ser Gln
355 360 365
Asn Asp Thr Ala Thr Pro Asp Val Trp Tyr Thr Tyr Lys Pro Glu Glu
370 375 380
Lys Ile Val Tyr Ala Ile Phe Leu Lys Trp Pro Val Ser Arg Glu Leu
385 390 395 400
Phe Leu Glu Gln Pro Ile Gly Ser Leu Gly Glu Thr Glu Val Ala Leu
405 410 415
Leu Gly Glu Gly Lys Pro Leu Thr Trp Thr Ser Leu Lys Pro Asn Gly
420 425 430
Ile Ile Val Glu Leu Pro Gln Leu Thr Leu His Gln Met Pro Cys Lys
435 440 445
Trp Gly Trp Thr Leu Ala Leu Thr Asn Val Thr His His His His His
450 455 460
His
465
<210> 6
<211> 1398
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 6
atgagagtgc ctgctcagct gctgggactg ctgctgctgt ggctgcctgg cgctagatgc 60
aagtcctctc ggagatacga ccccacctgg gagtccctgg acagaaggcc tctgcccagt 120
tggttcgacc aggccaagtt cggcatcttc atccactggg gcgtgttctc cgtgcccagc 180
ttcggctctg agtggttctg gtggtactgg cagaaagaga agcggcccaa gttcgtggac 240
ttcatgaaca acaactaccc ccctggcttt aagtacgagg acttcggcgt gctgttcacc 300
gccaagttct tcaacgcctc ccagtgggcc gacatcctgc aggcttccgg cgctaagtac 360
ctggtgctga cctccaagca ccacgagggc tttaccctgt ggggctccga gtactcctgg 420
aactggaacg ccgtggacga gggccctaag cgggacatcg tgaaagaact gaaggtggcc 480
atcaccaaga acaccgacct gagattcggc ctgtactact ccctgttcga gtggttccac 540
cccctgtttc tggaagataa gctgtccagc ttccagaagc ggcagttccc catctccaag 600
atgctgcccg agctgtacga gctcgtgaac aagtaccagc ctgacatcct gtggaccgac 660
ggggatggtg gcgcccctga cagatactgg aactctaccg gcttcctggc ctggctgtac 720
aacgagtccc ctgtgcggaa caccgtcgtg accaacgaca gatggggcgc tggctccatc 780
tgcaagcacg gcggctacta cacctgttcc gaccggtaca accccggcca tctgctgcct 840
cacaagtggg agaactgcat gacaatcgac cagttctcct ggggctaccg gcgcgaggcc 900
gtgatctctg actacctgac catcgaggaa ctcgtgaagc agctggtgga aaccgtggcc 960
tgtggcggca acctgctgat gaacatcggc cctaccctgg acggcatcat ccccgtgatc 1020
ttcgaggaac ggctgcggca gatgggcatg tggctgaaag tgaacggcga ggccatctac 1080
gagacacagc cttggcggtc ccagaacgac accgccacac ctgacgtgtg gtacacctac 1140
aagcccgaag agaagatcgt gtacgccatc ttcctgaagt ggcccgtgtc cagagagctg 1200
tttctggaac agcccatcgg ctccctgggc gagacagaag tggctctgct gggcgagggc 1260
aagcctctga cctggacctc cctgaagccc aatggcatca tcgtggaact gccccagctg 1320
accctgcacc agatgccctg taaatggggc tggaccctgg ccctgaccaa cgtgacccac 1380
caccaccatc accactga 1398
<210> 7
<211> 481
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 7
Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp Leu Pro
1 5 10 15
Gly Ala Arg Cys His Asn Val Ser Glu Gly Tyr Glu Lys Pro Ala Asp
20 25 30
Pro Leu Val Val Gln Asn Leu Glu Gln Trp Gln Asp Leu Lys Phe Gly
35 40 45
Leu Phe Met His Trp Gly Thr Tyr Ser Gln Trp Gly Ile Val Glu Ser
50 55 60
Trp Ser Leu Cys Pro Glu Asp Glu Ser Trp Thr Gln Arg Lys Pro Glu
65 70 75 80
His Gly Lys Ser Tyr Asn Glu Tyr Val Lys Asn Tyr Glu Asn Leu Gln
85 90 95
Thr Thr Phe Asn Pro Val Gln Phe Asn Pro Gln Lys Trp Ala Asp Ala
100 105 110
Thr Lys Lys Ala Gly Met Lys Tyr Val Val Phe Thr Thr Lys His His
115 120 125
Asp Gly Phe Ala Met Phe Asp Thr Lys Gln Ser Asp Tyr Lys Ile Thr
130 135 140
Ser Ser Lys Thr Pro Phe Ser Lys Asn Pro Lys Ala Asp Val Ala Lys
145 150 155 160
Glu Ile Phe Asn Thr Phe Arg Asp Asn Gly Phe Arg Ile Gly Ala Tyr
165 170 175
Phe Ser Lys Pro Asp Trp His Ser Asp Asp Tyr Trp Trp Ser Tyr Phe
180 185 190
Pro Pro Lys Asp Arg Asn Val Asn Tyr Asp Pro Gln Lys Tyr Pro Ala
195 200 205
Arg Trp Glu Asn Phe Lys Lys Phe Thr Phe Asn Gln Leu Asn Glu Ile
210 215 220
Thr Ser Asn Tyr Gly Lys Ile Asp Ile Leu Trp Leu Asp Gly Gly Trp
225 230 235 240
Val Arg Pro Phe His Thr Ile Asp Pro Asn Ile Glu Trp Gln Arg Thr
245 250 255
Ile Lys Val Glu Gln Asp Ile Asp Met Asp Lys Ile Gly Thr Met Ala
260 265 270
Arg Lys Asn Gln Pro Gly Ile Ile Ile Val Asp Arg Thr Val Pro Gly
275 280 285
Lys Trp Glu Asn Tyr Val Thr Pro Glu Gln Ala Val Pro Glu His Ala
290 295 300
Leu Ser Ile Pro Trp Glu Ser Cys Ile Thr Met Gly Asp Ser Phe Ser
305 310 315 320
Tyr Val Pro Asn Asp Asn Tyr Lys Ser Ser Gln Lys Ile Ile Glu Thr
325 330 335
Leu Ile Arg Ile Ile Ser Arg Gly Gly Asn Tyr Leu Met Asn Ile Ala
340 345 350
Pro Gly Pro Asn Gly Asp Tyr Asp Ala Val Val Tyr Glu Arg Leu Lys
355 360 365
Glu Ile Ser Gly Trp Met Asp Lys Asn Gln Ser Ala Val Phe Thr Thr
370 375 380
Arg Ala Leu Ala Pro Tyr His Glu Ser Asp Phe Tyr Tyr Thr Gln Ser
385 390 395 400
Lys Asp Gly Lys Ile Val Asn Val Phe His Ile Ser Glu Lys Ser Asn
405 410 415
Tyr Gln Ala Pro Ser Glu Leu Ser Phe Ser Ile Pro Glu Asn Ile Asn
420 425 430
Pro Lys Thr Val Lys Val Leu Gly Ile Ser Ser Gln Ile Lys Trp Lys
435 440 445
Lys Lys Gly Asn Lys Ile His Val Gln Leu Pro Glu Glu Arg Thr Lys
450 455 460
Leu Asn Tyr Ser Thr Val Ile Gln Ile Thr Gln His His His His His
465 470 475 480
His
<210> 8
<211> 1446
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 8
atgagagtgc ctgctcagct gctgggactg ctgctgctgt ggctgcctgg cgctagatgc 60
cacaatgtgt ccgagggcta cgagaagccc gccgaccctc tggtggtgca gaacctggaa 120
cagtggcagg acctgaagtt cggcctgttc atgcactggg gcacctactc ccagtggggc 180
atcgtggaat cctggtccct gtgccctgag gacgagtctt ggacccagcg gaagcctgag 240
cacggcaagt cctacaacga gtacgtgaag aactacgaga acctgcagac caccttcaac 300
cccgtgcagt tcaaccccca gaagtgggcc gacgccacca agaaagccgg catgaaatac 360
gtggtgttca ccaccaagca ccacgacggc ttcgccatgt tcgacaccaa gcagtccgac 420
tacaagatca cctcctccaa gacccccttc agcaagaacc ccaaggccga cgtggccaaa 480
gagattttca acaccttccg ggacaacggc ttccggatcg gcgcctactt ctccaagcct 540
gactggcact ccgacgacta ctggtggtcc tacttcccac ccaaggaccg gaacgtgaac 600
tacgaccctc agaaataccc cgccagatgg gagaacttca agaagttcac cttcaatcag 660
ctgaacgaga tcaccagcaa ctacggcaag atcgacatcc tgtggctgga cggcggatgg 720
gtgcgaccct tccacaccat cgaccccaac atcgagtggc agcggaccat caaggtggaa 780
caggacatcg acatggacaa gatcggcacc atggcccgga agaaccagcc cggcatcatc 840
atcgtggacc ggaccgtgcc tggcaagtgg gagaattacg tgacccccga gcaggccgtg 900
cctgagcatg ccctgtctat cccttgggag tcctgtatca caatgggcga cagcttctcc 960
tacgtgccca acgacaacta caagtcctcc cagaagatca tcgagacact gatcaggatc 1020
atctccagag gcggcaacta cctgatgaat atcgcccctg gccccaacgg cgactacgac 1080
gctgtggtgt acgagcggct gaaagaaatc tccggctgga tggataagaa ccagtccgcc 1140
gtgtttacca cccgggctct ggccccttac cacgagtccg acttctacta cacccagtcc 1200
aaggacggaa agatcgtgaa cgtgttccac atctccgaga agtccaacta ccaggccccc 1260
tccgagctgt ccttcagcat ccccgagaac atcaacccca agaccgtgaa ggtgctgggc 1320
atctccagcc agatcaagtg gaagaagaag ggcaacaaga tccacgtgca gctgcccgag 1380
gaacggacca agctgaacta ctccaccgtg atccagatca cccagcacca ccaccatcac 1440
cactga 1446
<210> 9
<211> 440
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 9
Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp Leu Pro
1 5 10 15
Gly Ala Arg Cys Gln Gln Lys Tyr Gln Pro Thr Glu Ala Asn Leu Lys
20 25 30
Ala Arg Ser Glu Phe Gln Asp Asn Lys Phe Gly Ile Phe Leu His Trp
35 40 45
Gly Leu Tyr Ala Met Leu Ala Thr Gly Glu Trp Thr Met Thr Asn Asn
50 55 60
Asn Leu Asn Tyr Lys Glu Tyr Ala Lys Leu Ala Gly Gly Phe Tyr Pro
65 70 75 80
Ser Lys Phe Asp Ala Asp Lys Trp Val Ala Ala Ile Lys Ala Ser Gly
85 90 95
Ala Lys Tyr Ile Cys Phe Thr Thr Arg His His Glu Gly Phe Ser Met
100 105 110
Phe Asp Thr Lys Tyr Ser Asp Tyr Asn Ile Val Lys Ala Thr Pro Phe
115 120 125
Lys Arg Asp Val Val Lys Glu Leu Ala Asp Ala Cys Ala Lys His Gly
130 135 140
Ile Lys Leu His Phe Tyr Tyr Ser His Ile Asp Trp Tyr Arg Glu Asp
145 150 155 160
Ala Pro Gln Gly Arg Thr Gly Arg Arg Thr Gly Arg Pro Asn Pro Lys
165 170 175
Gly Asp Trp Lys Ser Tyr Tyr Gln Phe Met Asn Asn Gln Leu Thr Glu
180 185 190
Leu Leu Thr Asn Tyr Gly Pro Ile Gly Ala Ile Trp Phe Asp Gly Trp
195 200 205
Trp Asp Gln Asp Ile Asn Pro Asp Phe Asp Trp Glu Leu Pro Glu Gln
210 215 220
Tyr Ala Leu Ile His Arg Leu Gln Pro Ala Cys Leu Val Gly Asn Asn
225 230 235 240
His His Gln Thr Pro Phe Ala Gly Glu Asp Ile Gln Ile Phe Glu Arg
245 250 255
Asp Leu Pro Gly Glu Asn Thr Ala Gly Leu Ser Gly Gln Ser Val Ser
260 265 270
His Leu Pro Leu Glu Thr Cys Glu Thr Met Asn Gly Met Trp Gly Tyr
275 280 285
Lys Ile Thr Asp Gln Asn Tyr Lys Ser Thr Lys Thr Leu Ile His Tyr
290 295 300
Leu Val Lys Ala Ala Gly Lys Asp Ala Asn Leu Leu Met Asn Ile Gly
305 310 315 320
Pro Gln Pro Asp Gly Glu Leu Pro Glu Val Ala Val Gln Arg Leu Lys
325 330 335
Glu Val Gly Glu Trp Met Ser Lys Tyr Gly Glu Thr Ile Tyr Gly Thr
340 345 350
Arg Gly Gly Leu Val Ala Pro His Asp Trp Gly Val Thr Thr Gln Lys
355 360 365
Gly Asn Lys Leu Tyr Val His Ile Leu Asn Leu Gln Asp Lys Ala Leu
370 375 380
Phe Leu Pro Ile Val Asp Lys Lys Val Lys Lys Ala Val Val Phe Ala
385 390 395 400
Asp Lys Thr Pro Val Arg Phe Thr Lys Asn Lys Glu Gly Ile Val Leu
405 410 415
Glu Leu Ala Lys Val Pro Thr Asp Val Asp Tyr Val Val Glu Leu Thr
420 425 430
Ile Asp His His His His His His
435 440
<210> 10
<211> 1323
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 10
atgagagtgc ctgctcagct gctgggactg ctgctgctgt ggctgcctgg tgctagatgc 60
cagcagaagt accagcccac cgaggccaac ctgaaggcca gatccgagtt ccaggacaac 120
aagttcggca tcttcctgca ctggggcctg tacgccatgc tggctactgg cgagtggacc 180
atgaccaaca acaacctgaa ctacaaagag tacgctaagc tggctggcgg cttctacccc 240
tccaagttcg acgccgacaa atgggtggcc gccatcaagg cctctggcgc caagtacatc 300
tgcttcacca cccggcacca cgagggcttc tccatgttcg acaccaagta ctccgactac 360
aacatcgtga aggccacccc cttcaagcgg gacgtcgtga aagagctggc cgacgcctgc 420
gctaagcacg gcatcaagct gcacttctac tactcccaca tcgactggta cagagaggac 480
gccccccagg gcagaaccgg cagaagaaca ggcagaccca accccaaggg cgactggaag 540
tcctactacc agtttatgaa caaccagctg accgagctgc tgaccaacta cggccccatc 600
ggcgccattt ggttcgacgg gtggtgggac caggacatca accccgactt cgactgggag 660
ctgcccgagc agtacgccct gatccacaga ctgcagcccg cctgtctcgt gggcaacaac 720
caccaccaga ccccctttgc cggcgaggac atccagattt tcgagcggga tctgcccggc 780
gagaacaccg ctggactgtc tggccagtcc gtgtcccatc tgcccctgga aacctgcgag 840
acaatgaacg gcatgtgggg ctacaagatc accgaccaga actacaagtc caccaagaca 900
ctgatccact acctcgtgaa agccgctggc aaggacgcca acctgctgat gaacatcggc 960
ccccagcctg acggcgagct gcctgaagtg gctgtgcagc ggctgaaaga agtgggagag 1020
tggatgtcta agtacggcga gactatctac ggcaccagag gcggcctggt ggcccctcat 1080
gattggggcg tgaccaccca gaagggcaac aagctgtacg tgcacatcct gaacctgcag 1140
gacaaggccc tgttcctgcc catcgtggac aagaaagtga agaaagccgt ggtgttcgcc 1200
gacaagaccc ccgtgcggtt caccaagaac aaagagggca tcgtgctgga actggccaag 1260
gtgcccaccg acgtggacta cgtggtggaa ctgaccatcg accaccatca tcaccaccac 1320
tga 1323
<210> 11
<211> 920
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 11
Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp Leu Pro
1 5 10 15
Gly Ala Arg Cys Ala Gln His Asp Ser Leu Ile Arg Val Lys Ala Glu
20 25 30
Asp Lys Val Val Gln Thr Ser Pro Ser Val Ser Ala Ile Asp Asp Leu
35 40 45
His Tyr Leu Ser Glu Asn Ser Lys Lys Glu Phe Lys Glu Gly Leu Ser
50 55 60
Lys Ala Gly Glu Val Pro Glu Lys Leu Lys Asp Ile Leu Ser Lys Ala
65 70 75 80
Gln Gln Ala Asp Lys Gln Ala Lys Val Leu Ala Glu Met Lys Val Pro
85 90 95
Glu Lys Ile Ala Met Lys Pro Leu Lys Gly Pro Leu Tyr Gly Gly Tyr
100 105 110
Phe Arg Thr Trp His Asp Lys Thr Ser Asp Pro Ala Glu Lys Asp Lys
115 120 125
Val Asn Ser Met Gly Glu Leu Pro Lys Glu Val Asp Leu Ala Phe Val
130 135 140
Phe His Asp Trp Thr Lys Asp Tyr Ser Leu Phe Trp Gln Glu Leu Ala
145 150 155 160
Thr Lys His Val Pro Thr Leu Asn Lys Gln Gly Thr Arg Val Ile Arg
165 170 175
Thr Ile Pro Trp Arg Phe Leu Ala Gly Gly Asp His Ser Gly Ile Ala
180 185 190
Glu Asp Thr Gln Lys Tyr Pro Asn Thr Pro Glu Gly Asn Lys Ala Leu
195 200 205
Ala Lys Ala Ile Val Asp Glu Tyr Val Tyr Lys Tyr Asn Leu Asp Gly
210 215 220
Leu Asp Val Asp Ile Glu Arg Asp Ser Ile Pro Lys Val Asn Gly Lys
225 230 235 240
Glu Ser Asn Glu Asn Ile Gln Arg Ser Ile Ala Val Phe Glu Glu Ile
245 250 255
Gly Lys Leu Ile Gly Pro Lys Gly Ala Asp Lys Ser Arg Leu Phe Ile
260 265 270
Met Asp Ser Thr Tyr Met Ala Asp Lys Asn Pro Leu Ile Glu Arg Gly
275 280 285
Ala Pro Tyr Ile Asp Leu Leu Leu Val Gln Val Tyr Gly Ile Gln Gly
290 295 300
Glu Lys Gly Asp Trp Asp Pro Val Ala Arg Lys Pro Glu Lys Thr Met
305 310 315 320
Glu Glu Arg Trp Glu Ser Tyr Ser Lys Tyr Ile Arg Pro Glu Gln Tyr
325 330 335
Met Val Gly Phe Ser Phe Tyr Glu Glu Asn Ala Gly Ser Gly Asn Leu
340 345 350
Trp Tyr Asp Ile Asn Glu Arg Lys Asp Asp His Asn Pro Leu Asn Ser
355 360 365
Glu Ile Ala Gly Thr Arg Ala Glu Arg Tyr Ala Lys Trp Gln Pro Lys
370 375 380
Thr Gly Gly Val Lys Gly Gly Ile Phe Ser Tyr Ala Ile Asp Arg Asp
385 390 395 400
Gly Val Ala His Gln Pro Lys Lys Val Ser Asp Asp Glu Lys Arg Thr
405 410 415
Asn Lys Ala Ile Lys Asp Ile Thr Asp Gly Ile Val Lys Ser Asp Tyr
420 425 430
Lys Val Ser Lys Ala Leu Lys Lys Val Met Glu Asn Asp Lys Ser Tyr
435 440 445
Glu Leu Ile Asp Gln Lys Asp Phe Pro Asp Lys Ala Leu Arg Glu Ala
450 455 460
Val Ile Ala Gln Val Gly Ser Arg Arg Gly Asp Leu Glu Arg Phe Asn
465 470 475 480
Gly Thr Leu Arg Leu Asp Asn Pro Asp Ile Lys Ser Leu Glu Gly Leu
485 490 495
Asn Lys Leu Lys Lys Leu Ala Lys Leu Glu Leu Ile Gly Leu Ser Gln
500 505 510
Ile Thr Lys Leu Asp Ser Ser Val Leu Pro Glu Asn Ile Lys Pro Thr
515 520 525
Lys Asp Thr Leu Val Ser Val Leu Glu Thr Tyr Lys Asn Asp Asp Arg
530 535 540
Lys Glu Glu Ala Lys Ala Ile Pro Gln Val Ala Leu Thr Ile Ser Gly
545 550 555 560
Leu Thr Gly Leu Lys Glu Leu Asn Leu Ala Gly Phe Asp Arg Asp Ser
565 570 575
Leu Ala Gly Ile Asp Ala Ala Ser Leu Thr Ser Leu Glu Lys Val Asp
580 585 590
Leu Ser Lys Asn Lys Leu Asp Leu Ala Ala Gly Thr Glu Asn Arg Gln
595 600 605
Ile Phe Asp Val Met Leu Ser Thr Val Ser Asn Arg Val Gly Ser Asn
610 615 620
Glu Gln Thr Val Thr Phe Asp His Gln Lys Pro Thr Gly His Tyr Pro
625 630 635 640
Asn Thr Tyr Gly Thr Thr Ser Leu Arg Leu Pro Val Gly Glu Gly Lys
645 650 655
Ile Asp Leu Gln Ser Gln Leu Leu Phe Gly Thr Val Thr Asn Gln Gly
660 665 670
Thr Leu Ile Asn Ser Glu Ala Asp Tyr Lys Ala Tyr Gln Glu Gln Leu
675 680 685
Ile Ala Gly Arg Arg Phe Val Asp Pro Gly Tyr Ala Tyr Lys Asn Phe
690 695 700
Ala Val Thr Tyr Asp Ala Tyr Lys Val Arg Val Thr Asp Ser Thr Leu
705 710 715 720
Gly Val Thr Asp Glu Lys Lys Leu Ser Thr Ser Lys Glu Glu Thr Tyr
725 730 735
Lys Val Glu Phe Phe Ser Pro Thr Asn Gly Thr Lys Pro Val His Glu
740 745 750
Ala Lys Val Val Val Gly Ala Glu Lys Thr Met Met Val Asn Leu Ala
755 760 765
Ala Gly Ala Thr Val Ile Lys Ser Asp Ser His Glu Asn Ala Lys Lys
770 775 780
Val Phe Asp Gly Ala Ile Glu Tyr Asn Pro Leu Ser Phe Ser Ser Lys
785 790 795 800
Thr Ser Ile Thr Phe Glu Phe Lys Glu Pro Gly Leu Val Lys Tyr Trp
805 810 815
Arg Phe Phe Asn Asp Ile Thr Arg Lys Asp Asp Tyr Ile Lys Glu Ala
820 825 830
Lys Leu Glu Ala Phe Val Gly His Leu Glu Asp Asp Ser Lys Val Lys
835 840 845
Asp Ser Leu Glu Lys Ser Thr Glu Trp Val Thr Val Ser Asp Tyr Ser
850 855 860
Gly Glu Ala Gln Glu Phe Ser Gln Pro Leu Asp Asn Ile Ser Ala Lys
865 870 875 880
Tyr Trp Arg Val Thr Val Asp Thr Lys Gly Gly Arg Tyr Ser Ser Pro
885 890 895
Ser Leu Pro Glu Leu Gln Ile Leu Gly Tyr Arg Leu Pro Leu Thr His
900 905 910
Asp Tyr Lys Asp Asp Asp Asp Lys
915 920
<210> 12
<211> 2763
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 12
atgagagtgc ctgctcagct gctgggcctg ctgctgctgt ggctgcctgg tgctagatgc 60
gcccagcacg actccctgat cagagtgaag gccgaggaca aggtggtgca gacctcccct 120
tccgtgtccg ccatcgacga cctgcactac ctgtccgaga actccaagaa agagttcaaa 180
gagggcctgt ccaaggccgg cgaggtgccc gaaaagctga aggacatcct gagcaaggct 240
cagcaggccg acaagcaggc caaggtgctg gccgagatga aggtgccaga gaagatcgcc 300
atgaagcccc tgaagggccc tctgtacggc ggctacttca gaacctggca cgacaagacc 360
tccgaccccg ccgagaagga caaagtgaac tccatgggcg agctgcccaa agaggtggac 420
ctggccttcg tgttccacga ctggaccaag gactactccc tgttctggca ggaactggcc 480
accaagcacg tgcccaccct gaacaagcag ggcaccagag tgatccggac aatcccctgg 540
cggtttctgg ctggcggcga ccactctgga atcgccgagg atacccagaa gtaccccaac 600
acccccgagg gcaacaaggc cctggctaag gccatcgtgg acgagtacgt gtacaagtac 660
aacctggacg gcctggacgt ggacatcgag cgggactcca tccctaaagt gaacggcaaa 720
gagtccaacg agaacatcca gcggtctatc gccgtgttcg aggaaatcgg caagctgatc 780
ggccccaagg gcgccgacaa gtcccggctg ttcatcatgg actccaccta catggccgat 840
aagaaccccc tgatcgagag aggcgcccct tacatcgatc tgctgctggt gcaggtgtac 900
ggcatccagg gcgagaaggg cgattgggac cctgtggccc ggaagcctga aaagaccatg 960
gaagagagat gggagtccta ctccaagtac atccggcccg agcagtatat ggtgggattc 1020
agcttctacg aggaaaacgc cggctccggc aacctgtggt acgacatcaa cgagcggaag 1080
gacgaccaca accctctgaa ctccgagatc gccggcaccc gggctgagag atacgctaag 1140
tggcagccca agaccggcgg agtgaagggc ggcatcttct cctacgccat cgatagggat 1200
ggcgtggccc accagcctaa gaaggtgtcc gacgacgaga agcggaccaa caaggctatc 1260
aaggacatca ccgacggcat cgtgaagtcc gactacaagg tgtccaaagc cctgaagaaa 1320
gtgatggaaa acgacaagag ctacgagctg atcgaccaga aggacttccc cgataaggcc 1380
ctgcgcgagg ccgtgattgc tcaagtgggc tccagacggg gcgacctgga aagattcaac 1440
ggcaccctgc ggctggacaa ccccgacatc aagtccctgg aaggcctgaa caaactgaag 1500
aagctggcca agctggaact gatcggactg tcccagatca caaagctgga ctcctccgtg 1560
ctgcctgaga acatcaagcc caccaaggac accctggtgt ccgtgctgga aacctacaag 1620
aacgacgacc ggaaagagga agccaaggcc atccctcagg tggccctgac catctctggc 1680
ctgaccggcc tgaaagagct gaatctggcc ggcttcgacc gggattccct ggctggaatc 1740
gatgccgcct ctctgacctc cctggaaaaa gtggacctgt ctaagaacaa gctggatctg 1800
gctgccggca ccgagaaccg gcagatcttc gacgtgatgc tgtccaccgt gtccaacaga 1860
gtgggcagca acgagcagac cgtgaccttc gaccaccaga agcccaccgg ccactaccct 1920
aacacctacg gcaccacctc cctgagactg cctgtgggcg agggcaagat cgacctgcag 1980
tcccagctgc tgttcggcac cgtgaccaac cagggcacac tgatcaactc cgaggccgat 2040
tacaaggcct accaggaaca gctgatcgct gggcggagat tcgtggaccc tggctacgct 2100
tacaagaact tcgccgtgac ctacgatgcc tacaaagtgc gcgtgaccga ctccaccctg 2160
ggcgtgacag acgaaaagaa gctgagcacc tccaaagaag agacatacaa ggtggaattc 2220
ttctccccca ccaatggcac caagcctgtg catgaggcta aggtggtcgt gggcgccgag 2280
aaaaccatga tggtcaacct ggccgctggc gccaccgtga tcaagtctga ctctcacgag 2340
aatgccaaaa aggtgttcga cggcgccatc gagtacaatc ctctgagctt ctccagcaag 2400
accagcatca ccttcgagtt taaagaaccc ggcctcgtga aatactggcg gttcttcaac 2460
gatatcaccc gcaaggacga ctacatcaaa gaggctaagc tggaagcctt cgtgggccat 2520
ctggaagatg actccaaagt gaaggactct ctggaaaagt ccaccgagtg ggtcaccgtg 2580
tctgactact ctggcgaggc ccaggaattc tcccagcccc tggacaacat ctccgccaag 2640
tattggagag tgaccgtgga caccaagggc ggacggtaca gctctcctag cctgcccgag 2700
ctgcagatcc tgggctacag actgcctctg acccacgact ataaggacga cgacgacaaa 2760
tga 2763
- 还没有人留言评论。精彩留言会获得点赞!