基因表达数据的跨平台转换的制作方法
相关申请的交叉引用
本发明涉及于2014年10月17日提交的共同待决的美国临时申请no.62/065367,在此通过引用将其完整公开内容并入,如同其完整地在本文中被阐述。
本发明的实施例总体涉及基因表达数据的使用,并且具体涉及跨过不同谱分析平台使用基因表达数据。
背景技术:
基因表达的动态范围根据谱分析平台的选择而可能可观地变化。因此,预测性基因标志一般是平台特异性的。一般来说,由不同种类的平台生成的表达数据不能被直接组合用于计算分析,因此限制旧数据的使用并且妨碍新的谱分析技术的采用。更具体地,会难以将从极大量的旧微阵列研究得到的知识和见解转移到新平台(诸如下一代测序(ngs)系统)上。
已经提出许多方法来处理表达数据的跨平台兼容性。一种方法涉及将探测结果/读数映射到通用基因组目标,然后针对每个目标调用平台水平的表达(针对微阵列的rma和针对rna-seq的rpkm),并且最后应用分位数归一化,假设跨平台的表达分布仅在样本特异性比例因子上不同。另一方法涉及应用逐基因因子分析以利用预期最大化(em)算法从多个平台获得统一的表达测量结果。又一方法使用功能测量误差模型的系统来对基因表达测量结果进行建模,并且使用针对基因的子集的据称更可靠但是低通量qrt-pcr表达来对平台进行校准。然而,像因子分析一样,该模型仅可以对适合所有三个平台的表达范围适用,并且具有极限表达的基因被排除。又一方法涉及对与rna-seq数据中的探针区域交叠的读数的数量进行计数,使用经验贝叶斯方法估计探针区域表达,并且随后将修改的rma算法(即,没有背景修正步骤)应用在探针区域表达上以获得基因水平的表达。然而,该方法涉及关于映射的读数的更复杂的计算,并且在平台的选择方面(即针对输入的rna-seq和针对输出的rma)是硬性的。
考虑到这些现有方法的限制,将期望具有支持测量结果从一个基因表达平台到另一基因表达平台的转换的一般化方法。
技术实现要素:
提供此发明内容来以简化的形式介绍一些概念,这些概念在下文详细说明部分中被进一步描述。此发明内容并不旨在识别所要求保护的主题的关键特征或重要特征,也不旨在被用作确定所要求保护的主题的范围的辅助手段。
本发明的方面涉及一种数据驱动的通用的基于回归的架构,所述架构支持测量结果在宽动态范围内从一个平台到另一平台的转换,其可应用于但不限于基因表达,其中,选定的总结统计/特征值作为用于模型参数的预测指标。该架构包括初级模型训练和转换以及额外水平的分类回归和转换过程。
本发明的实施例消除了为了组合的分析的不必要的样本的重新谱分析,解决了向后兼容性问题,并且通过允许旧数据被容易地转换以便与来自更新平台的数据一起使用而促进新的谱分析技术的采用。此外,通过将输入数据转换到主要平台或通过针对替代性平台调整标签的参数,平台特异的基因标签能够扩展以便在来自多个平台的表达数据上使用。
根据本公开的一个方面,本发明的实施例涉及一种用于对基因表达数据进行转换的方法。在一些实施例中,所述方法包括构建使用样本表达数据来将基因表达数据从第一谱分析平台转换到第二谱分析平台的初级模型,使得经转换的数据的总体分布类似于所述第二平台的数据总体分布。
在一些实施例中,构建所述初级模型包括,识别在利用第一谱分析平台得到的核酸表达数据的第一集合与利用第二谱分析平台得到的核酸表达数据的第二集合之间的至少一个共同表达,其中,每个共同表达与所述第一集合和所述第二集合两者中都存在的样本相关联。在一些实施例中,构建所述模型包括,对所述至少一个共同表达执行回归分析,得到针对每个样本的回归参数的一个集合。在一些实施例中,构建所述模型包括,从所述第一谱分析平台选择预测所述至少一个集合回归参数的至少一个候选特征。在一些实施例中,构建所述模型包括,识别针对与所选择的所述至少一个候选特征中的每个相关联的逐样本的数据转换的初级模型。在一些实施例中,构建所述模型还包括,利用谱分析平台生成表达数据的至少一个集合,所述表达数据的至少一个集合是表达数据的所述第一集合和第二集合中的至少一个集合。
在一些实施例中,所述方法包括利用所述构建的初级模型转换所述样本表达数据。在一些实施例中,所述方法包括通过根据以下中的至少一个进行回归分析来构建分类模型:(a)经转换的样本表达数据中的至少一些和(b)共同表达中的至少一些。在一些实施例中,以下中的至少一项是基于表型数据或己知引入跨平台偏差的任何因子的:(a)对经转换的样本表达数据中的至少一些的选择和(b)对共同表达中的至少一些的选择。在一些实施例中,所述方法包括使用根据经转换的样本表达数据构建的所述分类模型来对经转换的样本表达数据进行转换并从其构建另一分类模型来对该过程进行迭代。在一些实施例中,所述方法包括通过以构建的分类模型的构建的顺序应用所述构建的分类模型而将表达数据的集合从所述第一谱分析平台转换到所述第二谱分析平台。
在一些实施例中,所述第一谱分析平台或所述第二谱分析平台选自包括但不限于以下项的组:agilentgeneexpressionmicroarrays、affymetrixgeneprofilingarraycgmpu133p2/humangenomeu133plus2.0/u133a2.0、illuminagenomeanalyzer/miseq/nextseq/hiseq、nanostringncountersprint/max/flex、以及oxfordnanoporeminion/promethion/gridion。在一些实施例中,所述至少一个共同表达通过以下中的至少一种来识别:匹配基因组位置、匹配外显子、匹配亚型(isoform)和匹配转录。在一些实施例中,所述至少一个候选特征选自包括以下项的组平均转录表达、平均归一化探针强度、检测到的基因的数量、每个样本的读数的总数量、每个外显子/基因/亚型的读数的平均数量、读数范围和每个样本的任何其他适当统计。在一些实施例中,所述模型中的每个选自包括以下项的组:线性模型、对数模型、分段线性模型和回归模型。
根据本公开的另一方面,本发明的实施例涉及一种用于对基因表达数据进行转换的装置。在一些实施例中,所述装置包括处理器。在一些实施例中,所述装置包括接口。在一些实施例中,所述装置包括可在所述处理器上运行的计算机可执行指令。在一些实施例中,所述计算机可执行指令在所述处理器上运行,以利用样本表达数据构建用于将基因表达数据从第一谱分析平台转换到第二谱分析平台的初级模型,使得所述转换的数据的总体分布类似于所述第二平台的数据总体分布。
在一些实施例中,用于构建所述初级模型的所述计算机可执行指令包括用于以下的计算机可执行指令:识别利用第一谱分析平台得到的核酸表达数据的第一集合与利用第二谱分析平台得到的核酸表达数据的第二集合之间的至少一个共同表达,每个共同表达与所述第一集合和第二集合两者中都存在的样本相关联。在一些实施例中,用于构建模型的所述计算机可执行指令包括用于以下的计算机可执行指令:对所述至少一个共同表达执行回归分析,得到针对每个样本的回归参数的一个集合。在一些实施例中,用于构建模型的所述计算机可执行指令包括用于以下的计算可执行指令:从所述第一谱分析平台选择预测所述至少一个集合回归参数的至少一个候选特征。在一些实施例中,用于构建模型的所述计算机可执行指令包括用于以下的计算可执行指令:识别与所选择的所述至少一个候选特征中的每个相关联的初级模型。
在一些实施例中,所述接口被配置为从谱分析平台接收表达数据的至少一个集合,所述表达数据的至少一个集合是表达数据所述第一集合和所述第二集合中的至少一个集合。
在一些实施例中,所述装置还包括可在所述处理器上运行的用于以下的计算机可执行指令:利用所构建的初级模型转换所述样本表达数据。在一些实施例中,所述装置还包括可在所述处理器上运行的用于以下的计算机可执行指令:通过回归分析来从以下中的至少一个来构建分类模型:(a)经转换的样本表达数据中的至少一些和(b)共同表达中的至少一些。在一些实施例中,以下中的至少一个基于表型数据或已知引入跨平台偏差的任何其他因子:(a)对经转换的样本表达数据中的至少一些的选择和(b)对共同表达中的至少一些的选择。在一些实施例中,所述装置还包括可在所述处理器上运行的用于以下的计算机可执行指令:使用根据经转换的样本表达数据构建的所述分类模型来对经转换的样本表达数据进行转换并从其构建另一分类模型来对该过程进行迭代。在一些实施例中,所述装置还包括可在所述处理器上运行用于以下的计算机可执行指令:通过以所构建的分类模型构建的顺序应用所构建的分类模型而将表达数据的集合从所述第一谱分析平台转换到所述第二谱分析平台。
在一些实施例中,所述第一谱分析平台或所述第二谱分析平台选自包括但不限于以下项的组:agilentgeneexpressionmicroarrays、affymetrixgeneprofilingarraycgmpu133p2/humangenomeu133plus2.0/u133a2.0、illuminagenomeanalyzer/miseq/nextseq/hiseq、nanostringncountersprint/max/flex、以及oxfordnanoporeminion/promethion/gridion。
在一些实施例中,用于识别至少一个共同表达的所述计算机可执行指令包括用于以下的计算机可执行指令:通过以下中的至少一种来识别所述至少一个共同表达:匹配基因组位置、匹配外显子、匹配亚型和匹配转录。在一些实施例中,所述至少一个候选特征选自包括以下项的组:平均转录表达、平均归一化探针强度、检测到的基因的数量、每个样本的读数的数量、每个外显子/基因/亚型的读数的平均数量、读数范围和每个样本的任何其他适当统计。在一些实施例中,所述模型中的每个选自包括以下项的组:线性模型、对数模型、分段线性模型、以及回归模型。
根据对以下详细描述的阅读和对相关联的附图的查阅,以非限制性实施例为特征的这些及其他特征和优点将会是显而易见的。应理解,前述一般描述和以下详细描述两者都仅是解释性的,并不对要求保护的非限制性实施例进行限定。
附图说明
附图并非旨在按比例进行绘制。在附图中,在各个图中图示的每个完全相同或几乎完全相同的部件可以由相同数字来表示。为了清楚的目的,不是每个部件都在每个附图中进行标记。本发明的各种实施例现在将会参照附图以范例的方式进行描述,其中:
图1是用于将基因表达数据从第一平台转换到第二平台的过程的流程图;
图1是根据本发明的一个实施例的模型训练过程的流程图;
图2是根据本发明的一个实施例的初级模型构建过程的流程图;
图3是根据本发明的一个实施例的用于利用初级模型来转换样本数据的过程的流程图;
图4是根据本发明的一个实施例的分类回归过程的流程图;
图5是根据本发明的一个实施例的用于使用模型来转换额外数据的过程的流程图;
图6是根据本发明的一个实施例的发展并应用的多个转换模型的图示;
图7呈现了在本发明的一个实施例中发展的平均表达水平与回归参数之间的线性模型;
图8示出了针对每个样本的预测的分段线性模型;
图9分别示出了在(a)第一水平的逐样本转换之后以及(b)第二水平的逐基因转换之后转换的表达与原始的微阵列表达之间的关系;并且
图10呈现了根据本发明的用于基因表达数据的跨平台转换的装置的实施例的方框图。
具体实施方式
基因表达数据的跨平台兼容性是研究的关键和活跃的主题。管理和分析源于混合的平台的样本数据会是效率低的。例如,癌症基因组图谱(tcga)目前有五个不同的平台用于rna表达:agilentg4502a、affymetrixht-hg_u133a、hg-u133_plus_2、illuminaga、以及illuminahiseq2000,因此使得难以通过组合的分析利用数据的全部潜力。此外,基因表达的动态范围能够依据谱分析平台的选择而相当大地变化。
由于多年来基于在前技术生成的大量旧数据、现有平台的多样性和新平台的出现,提供跨各种平台的数据的兼容性能够是有利的。打破平台屏障意味着节省样本的重新谱分析的成本,以便执行组合的分析。它还能够解决向后兼容性问题,并且通过允许旧数据被容易地转换以便与来自更新平台的数据一起使用而促进新的谱分析技术的采用。具体地,极大资源已经花费在微阵列研究上,并且希望将来自这些研究的知识和见解转移到新平台(诸如下一代测序(ngs)技术)上。
本发明的实施例使用将表达数据从一个平台转换到另一平台的模型来促进基因表达数据的跨平台兼容性。这些实施例也能够在临床研究设置中跨临床研究人员可用的不同队列被应用,以便通过将输入数据转换到主平台或通过使标签的参数适应替代性平台而评估新的队列上的许多标签。
参照图1,根据本发明的用于对基因表达数据进行转换的方法的一个实施例以初级模型的构建(步骤100)开始,所述初级模型用于直接将表达数据从第一谱分析平台转换到第二谱分析平台而无需中间转换。所述初级模型然后可以用来将表达数据从第一平台转换到第二平台(步骤104)。
然而,在一些实施例中,模型构建过程可包括额外水平的迭代。在这些实施例中,额外的模型(例如,分类回归模型)可以根据经转换的表达数据来构建(步骤108)。该额外的模型反过来可以用来对额外的表达数据进行转换(步骤104)。可以通过额外的多轮分类模型构建(步骤108)并且应用那些分类模型以转换数据(步骤104)来对该过程进行迭代,所述表达数据然后可以用来构建额外的分类模型(步骤108)等。当多个分类模型被构建并且随后被用于转换表达数据时,所述模型以其构建的顺序被应用–即,被构建的第一模型是用来转换数据的第一模型,被构建的第二模型用来对第一模型转换的数据进行转换等。
初级模型的构建
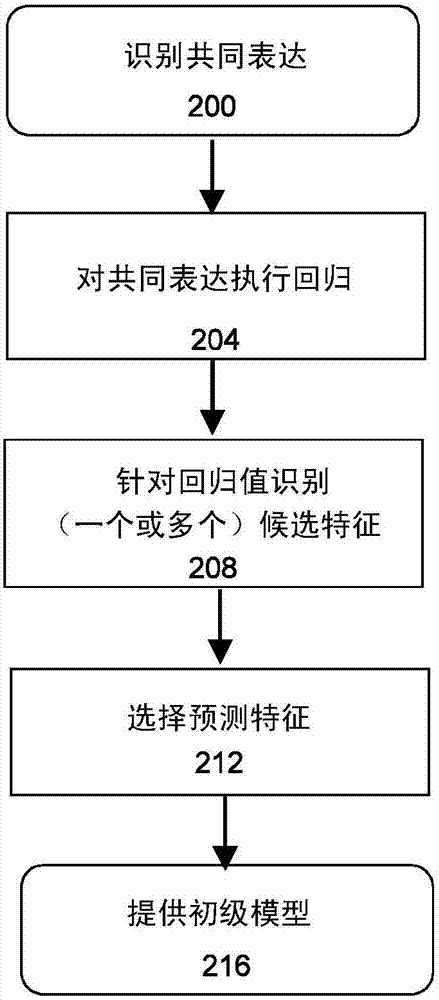
如在上面讨论的,本发明的实施例通常构建用于在平台之间转换数据集的初级模型(步骤100)。参照图2,模型训练过程开始于识别针对平台x的表达数据(即,xi={xgj}i,j=1…k,其中gj表示针对平台x的k个基因目标)与针对平台y的表达数据(yi={ygj}i,j=1…l,具有针对平台y的l个基因目标)之间的至少一个共同基因目标(步骤200)。
如果不存在两组目标之间的直接映射,则目标可以按其基因组位置而从一个集合被映射到另一集合。例如,如果源数据是rna-seq外显子表达而目的数据是微阵列基因表达,那么与微阵列探针集交叠的外显子能够被识别,并且在应用回归之前被总结为基因表达。
给定{si}i=1…n表示可用于构建用于将基因表达数据从平台x转换到平台y的模型的n个训练样本,对于每个样本si,使用在两个平台上检测到的表达在xi与yi之间执行回归(步骤204)。
用于回归过程的目标模型被先验地假设为由m个参数来定义。取决于观察到的来自源平台与目的平台的训练数据之间的关系,能够选择得到最小误差的任何回归模型,诸如非线性、对数、loess(局部回归)或变量带误差(errors-in-variables)(eiv)模型。此外,优化函数能够被应用以选择具有最小误差的模型。这种选择可以是人类操作者的决定,或它可以是自动或半自动过程的结果。在适当的模型被选择的情况下,回归过程的输出是n组参数ri={rk}i,k=1…m。
给定针对每个样本si的回归参数ri,从由平台x生成的能够为针对回归参数的良好预测指标的数据中选择候选特征f(步骤208)。例如,如果平台x是微阵列平台,则候选f可以包括平均表达、平均归一化探针强度等。如果平台x是rna-seq平台,则候选f可以包括平均表达、检测到的基因的数量、读数的总数量、读数范围等。关于回归模型的选择,候选特征f的识别可以由人类操作者或由自动或半自动过程来执行。
不一定仅从源数据提取预测特征。有时来自目标数据的特征可以在预测回归参数时具有良好性能。在一些实施例中,这样的目标平台特征也可以被包括在模型中,并且例如被分配有用于转换过程的训练数据中的特征的平均值。
已经从平台x识别可能的候选特征f(步骤208),实际上预测回归参数ri的那些特征fk必须从该组可能的候选特征f被识别(步骤212)。在一个实施例中,预测特征可以借助于例如逐步回归或其他自动、手动、或半自动方法来识别。如果目标是要针对单个参数而非子集选择单个预测特征,则与参数具有最高相关的特征能够被选择。
模型构建过程的输出包括所识别的预测特征fk和其对应的用于预测针对每个样本的si的回归模型参数ri的模型γk(步骤216)。
在一些实施例中,针对具体平台(例如,针对平台x的xi,针对平台y的yi等)的具有适当归一化的表达数据在识别共同表达(步骤200)之前针对训练样本{si}(未示出)被生成。
初级模型转换
一旦初级模型已经被产生,它就可以用来将随后的样本从平台x转换到平台y。对于以下讨论来说假设存在针对新样本pn的在平台x上生成的数据。该数据包括表达谱zn和在上面关于图2讨论的预测特征{fk}k=1,…,m的多组预测特征值{vk}n。
参照图3,与pn相关联的新数据的转换开始于预测特征值{vk}n代入其相应模型{γk}得到针对si的回归模型参数rn(步骤300)。
预测的回归模型参数rn能够被应用于预定的回归模型(步骤304),使得表达谱能够估计为针对样本pn的
分类模型构建和转换
在一些实施例中,初级模型可以足以在谱分析平台之间转换表达数据。如在上面讨论的,在其他实施例中,额外水平的分类建模和转换可以用来在平台之间转换数据。
具体地,如果存在引入额外的跨平台差异的一个或多个因子,那么可以执行对与所述因子相关的额外水平的回归,其中来自之前水平的回归的转换的数据充当到下一水平的回归的输入。
例如,假设在在定义明确的类别
参照图4,分类建模过程开始于接收来自初级模型或来自之前水平的分类建模的经转换的数据(步骤400)。其次,对所有接收的经转换的值执行按类别分层的回归(步骤404)。对于每个类别,显著改善准确性(例如,均方根误差)的那些模型被识别并且被保留(步骤408)。那些模型的识别针对能够提供转换的数据的准确性的类别中的每个产生额外的多组回归参数{qm}l(步骤412)。
参照图5,与pn相关联的经转换的数据的进一步转换开始于回归参数{qm}l代入其相应的回归模型(步骤500)。这些模型然后能够用于针对样本pn在第l级的转换处将表达谱估计为
在图4和5中示出的训练数据的分类建模和转换的这种过程能够针对多个独立因子进行重复以提高转换准确性。结果是依赖于顺序的回归模型的“栈”,其中初级逐样本回归在底部处而针对每个类别因子的额外层在彼此之上。图6呈现了针对o个独立因子的这种布置的一个范例。应当注意,当应用转换模型的栈时,被应用的模型的顺序必须与模型构建过程中遵循的构建的顺序相同。
示例性实施例
根据一个实施例,提供了用于使用具有在相应平台中的每个上生成的数据的545个tcga样本将基因表达数据(以log2标尺)从affymetrixgenechiphthumangenomeu133arrayplatset(rma)转换到illuminahiseq1000rna-seq(rsem)的系统和方法。一些逐样本统计在表1中针对两个平台进行总结。每个样本的平均相关性为0.713,并且总的来说更高的表达示出更强的相关性。
表1–具有在affymetrix微阵列和illuminarna-seq平台两者上生成的表达数据的tcga样本的总结统计
通过针对每个样本生成rna-seq与微阵列表达的散点图,能够看出它们的关系能够由分段线性模型合适地近似。在使用r编程语言的示例性实施方式中,线性回归的‘lm’函数和‘分段’包的‘分段’函数被应用于断点(xb)估计。这得到在估计的断点之前和之后针对线性模型四个回归参数{m1,c1,m2,c2}:y1=m1x1+c1,对于x≤xb,以及y2=m2x2+c2,对于x>xb。在下面的表2中总结了回归的分段线性模型的总结统计。
表2–回归的分段线性模型的总结统计。
接下来,生成用于预测四个回归模型参数的候选特征的小的集合,并且能够确定平均表达水平可行的单线性预测指标,其中具有r=-0.55对于m1和r=0.74对于c2的中等的强相关性,但是r=-0.27对于c1和r=0.19对于m2的更小相关性,其具有小的方差0.04。图7(a)斜率1、7(b)截距1、7(c)斜率2和7(d)截距2中示出了平均表达水平与四个回归参数之间的线性模型。
使用平均表达水平作为预测指标,能够预测针对每个样本的分段线性模型。图8(a)和8(b)示出了针对两个样本的基于直接回归和预测方法的分段线性模型,即,针对两个tcga样本的利用回归模型和预测模型的跨平台散点图。
如所图示的,对于中到高微阵列表达,预测的rna-seq表达具有均方根误差erms=1.4,其非常接近基于通过直接回归得到的估计的值的1.39的均方根误差。为了进一步改善准确性,额外水平的回归和转换能够被应用在使用如上面描述的分类方法跨所有样本通过基因进行分层的经初级转换的值上。图9(a)和9(b)示出了针对一个样本分别在第一水平的逐样本转换和第二水平的逐基因转换之后的经转换的表达与原始的微阵列表达之间的关系。
参照图10,图示了根据本发明的一个实施例的用于对基因表达数据进行转换的系统的示意表示1000。系统1000包括用于接收样本表达数据1004的接收器1002、被配置为存储接收的样本表达数据1004的存储器1006、和处理器1008。
处理器1008被配置为如上所述地建立初级模型和分类模型,用于将基因表达数据从第一谱分析平台转换到第二谱分析平台,使得经转换的数据的总体分布类似于第二平台的数据总体分布。
应用
本发明的实施例可以被扩展到从由多个平台测量的数据来计算统一的表达。例如,所有数据都可以利用例如eiv回归模型被转换到一个特定平台,并且然后针对每个目标将经转换的值利用加权平均进行组合,所述加权平均使用与相应源平台的估计的噪声方差成反比的权重。
虽然本发明的以上实施例关于对基因组平台执行的测量结果进行描述,但是相同的过程和程序能够被应用于生理建模、成像、个人连续健康数据以及其他。
尽管本发明的以上实施例关于基因表达数据进行描述,但是本文中描述的过程和程序可应用于解决跨任何数字读数的不同平台或解析流水线的兼容性问题。例如,甲基化水平、蛋白表达或甚至传感器测量结果由于底层系统的固有差别而具有结构差异。
等价方案、定义等
尽管本文中描述和图示了本发明的多个实施方式,但本领域普通技术人员可容易地想到用于执行本文中描述的功能以及/或获得本文中描述的结果和/或一个或多个优点的众多其它装置和/或结构,并且这样的变化和/或修改中的每个均被认为落在本发明的范围内。更一般而言,本领域技术人员可容易地理解本文中描述的所有参数、尺寸、材料和配置均旨在作为示例性的,且实际的参数、尺寸、材料和/或配置将取决于本发明的教导所用于的具体应用。本领域技术人员使用不超过常规的试验就可认识或能够确定与本文中描述的本发明的具体实施方式的许多等同方案。因此,应理解上述实施方式仅作为示例来介绍的,并且,在所附权利要求和其等同方案的范围内,可与具体描述和要求保护的不同地来实践本发明。本发明被指向本文中描述的每个单个特征、系统、物品、材料、部件和/或方法。另外,如果这样的特征、系统、物品、材料、部件和/或方法相互不矛盾的话,两个或更多这样的特征、系统、物品、材料、部件和/或方法的任意组合被包括在本发明的范围内。
除非明确地作出相反指示,否则在本说明书和权利要求中所用的词语“一”和“一个”应被理解为指的是“至少一个”。
在本说明书和权利要求中所用的短语“和/或”应被理解为指的是如此结合的元素“之一或两者”,即在一些情况下元素结合存在而在其它情况下分离存在。除非明确地作出相反指示,否则除了具体由“和/或”分句标识出的元素之外,其它元素可以可选地存在,而无论与这些具体标识出的元素有无关联。因此,作为一个非限制性示例,对“a和/或b”而言,当与比如“包括”的开放式语言结合起来使用时,在一种实施方式中可指的a而没有b(可选地包括除b以外的元素);在另一实施例中,指的b而没有a(可选地包括除a以外的元素);在又一实施例中,指的a和b这两者(可选地包括其它元素);等。
在本说明书和权利要求中所用的“或”应被理解为与以上定义的“和/或”具有相同的含义。例如,当在列举中分隔项目时,“或”或“和/或”应解读为包含的,即,包括多个元素或元素列举中的至少一个,但还可包括多于一个,并且可选地包括额外的未列举的项目。只有明确作出相反指示的术语,比如“仅一个”或“确切地一个”(或,当用于权利要求中时的“由……组成”),将指称包含多个元素或元素列举中的确切地一个元素。总体而言,对本文中所用的术语“或”而言,当被用在比如“其一”、“之一”、“仅一个”或“确切地一个”的排他术语后面时,应仅仅解读为指示排他的选择(即“一个或另一个,而不是两者都”)。对“主要由……组成”而言,当在权利要求中使用时,应具有其在专利法范围内使用时的常规含义。
在本说明书和权利要求中所用的引用一种或多种元素的列举的短语“至少一个”应理解为指的是从元素列举中的任意一种或多种元素中选择至少一个元素,但不一定包括在元素列举中具体列出的每一元素的至少一个,并且不排除元素列表中的元素的任意组合。该定义还允许可以任选地存在不同于短语“至少一个”所引用的元素列举中的被具体标识出的元素的其它元素,而无论其与这些具体标识出的元素有无关联。因此,作为一个非限制性示例,对“a和b中的至少一个”(或等同地,“a或b中的至少一个”,或等同地“a和/或b中的至少一个”)而言,在一个实施例中可以是指至少一个(任选地包含多于一个)a而没有b存在(并且任选地包括不同于b的元素);在另一实施例中可以是指至少一个(任选地包含多于一个)b而没有a存在(并且任选地包括不同于a的元素);在又一实施例中,是指至少一个(任选地包括多于一个)a,以及至少一个(并且任选地包括多于一个)b(并且任选地包括其它元素);等。
在权利要求中,以及在上述说明书中,所有比如“包含”、“包括”、“承载”、“具有”、“含有”、“涉及”、“持有”等的过渡词均应被理解为开放式的,即应被理解为指的是包括但不限于。
只有“由……组成”和“主要由……组成”等过渡词会分别是封闭式或半封闭连接词,与美国专利局专利审查程序指南第2111.03节中所阐述。
在权利要求中使用诸如“第一”、“第二”、“第三”等序数术语来修饰权利要求要素本身并不暗示一个权利要求要素具有优于另一权利要求要素的任何优先性、在先性或顺序或执行方法的动作的时间顺序,而仅用作区分具有某一名称的一个权利要求要素与具有同一名称(除了序数术语的使用)的另一要素以区分权利要求要素的标志。
还应当理解,除非明确指示相反情形,在本文中要求保护的包括多于一个步骤或动作的任何方法中,该方法的步骤或动作的顺序不一定受限于该方法所列举的步骤或动作的顺序。
- 还没有人留言评论。精彩留言会获得点赞!