用于治疗诊断应用的方法和试剂盒与流程
领域
本公开提供对模板化组装靶标的鉴定、富集和评估。
背景
药物研发的目标是递送对致病细胞,例如病毒感染的细胞、赘生性细胞、产生自身免疫应答的细胞以及其它失调或功能障碍细胞有特异性的有效生物治疗干预,而对相邻正常细胞或患者的整体健康状况无毒害风险。不幸的是,研发这些药剂极其困难。
已经出现的允许向致病细胞递送有效干预同时减轻对正常细胞的毒性的方法是使治疗剂靶向对致病细胞有特异性的分子标记物。靶向治疗剂已经在有限的病例中显示出非凡的临床结果,但由于缺乏靶向疗法的可接近标记物,目前在其可应用性上受到限制。发现许多致病细胞类型的蛋白质标记物是极其困难的,且常常是不可能的。
现有的核酸靶向疗法(如sirna)能够下调潜在危险基因的表达,但不能递送有效的细胞毒性或细胞抑制性干预,因此在消除危险细胞本身方面不是特别有效。
因此,需要研发高度靶向性治疗剂,而没有现有干预的不良功效和/或严重副作用。
概述
本公开涉及用于鉴定、富集和评估模板化组装靶标的方法和试剂盒。
一些实施方案涉及用于鉴定模板化组装靶标的方法,其包括合成第一群体的模板化组装反应物和第二群体的相应的模板化组装反应物,其中第一和第二群体的模板化组装反应物包含寡核苷酸序列;使两个群体的模板化组装反应物与靶核酸杂交;进行模板化组装反应,其中杂交的第一群体的模板化组装反应物和杂交的第二群体的相应的模板化组装反应物进行模板化组装;以及鉴定与进行了模板化组装的第一或第二群体的模板化组装反应物杂交的靶核酸,其中杂交的靶核酸为模板化组装靶标。
在一些实施方案中,合成第一和第二群体的模板化组装反应物可包括合成约5至约100个核苷酸长或约7至约30个核苷酸长的随机或基因特异性寡核苷酸序列。模板化组装反应物还可包括核酸酶抗性磷酸二酯主链或核酸酶抗性糖部分。模板化组装反应物可包括与所述寡核苷酸序列相邻的5'或3'引发位点。所述模板化组装反应物群体在相应群体上也可包括修饰,如5’-叠氮化物和3’-炔基;5’-炔和3’-叠氮基;及n-羟基琥珀酰亚胺和环辛炔。所述修饰可对选自无痕膦酚施陶丁格连接(tracelessphosphinophenolstaudingerligation)或无痕膦甲硫醇施陶丁格连接(tracelessphosphinomethanethiolstaudingerligation)的无痕施陶丁格连接(tracelessstaudingerligation)有特异性。模板化组装反应物也可包括间隔子或接头,例如至少6个碳原子。
在一些实施方案中,所述方法可包括在使模板化组装反应物群体与靶核酸杂交之前,获得靶核酸。在所述方法中还可包括从靶样品中分离核酸。
在一些实施方案中,靶样品可以是细胞群体、肿瘤、组织和器官中的至少一种。靶核酸也可保持其天然二级结构。所述靶核酸也可包括细胞核酸模板,例如已知致癌基因或肿瘤抑制因子、细胞周期调节子和介质、转录调节子和介质、翻译调节子和介质、端粒酶、细胞骨架组分和激酶的基因组或表达基因。
在一些实施方案中,使两个群体的模板化组装反应物与靶核酸杂交可包括去除未结合的模板化组装反应物。去除未结合的模板化组装反应物也可包括通过酶消化、超滤或凝胶尺寸排阻色谱法或其任何组合中的至少一种去除未结合的反应物。
在一些实施方案中,模板化组装反应可以是点击化学反应、施陶丁格还原、非无痕施陶丁格连接、无痕施陶丁格连接、无痕膦酚施陶丁格连接、无痕膦甲硫醇施陶丁格连接、天然化学连接和生物正交化学反应或其任何组合中的至少一种。
在一些实施方案中,鉴定所述靶核酸可包括去除未能进行模板化组装的所述杂交的第一群体的模板化组装反应物和所述杂交的第二群体的相应的模板化组装反应物。在所述鉴定中还可包括将反应的模板化组装反应物与未反应的模板化组装反应物微区室化和/或扩增杂交的靶核酸。另外,将杂交的靶核酸测序可用于鉴定靶核酸。
本公开还涉及用于鉴定至少包括第一和第二群体的模板化组装反应物的模板化组装靶标的模板化组装反应物文库,其中所述模板化组装反应物包括寡核苷酸序列和用于在模板化组装反应中反应的修饰。还公开了用于鉴定模板化组装靶标的试剂盒,其包括用于鉴定具有修饰为相应的模板化组装反应物的寡核苷酸序列的模板化组装靶标的寡核苷酸文库和试剂。另外,包括一对从空间引发的化学连接寡核苷酸(close)产物文库富集的模板化组装靶标,所述产物具有由于它们的空间接近性通过与细胞核酸模板杂交而化学连接的寡核苷酸。
本公开还涉及一种用于从空间引发的化学连接寡核苷酸(close)产物文库富集一对模板化组装靶标的方法,其包括:获得由于与细胞核酸靶标的空间接近性通过模板化组装而化学连接的寡核苷酸文库,扩增所述连接的寡核苷酸-细胞核酸靶标文库以及选择性富集连接的寡核苷酸-细胞核酸靶标,其中出于与所关注的异常细胞病理或与所述细胞核酸靶标不连续杂交的相关性对所述连接靶标进行选择。所述方法还可包括去除源自所关注的匹配的正常细胞的连接靶标。
还包括成对的从空间引发的化学连接寡核苷酸(close)产物文库富集的模板化组装靶标,所述产物包含由于它们的空间接近性通过与细胞核酸模板杂交而化学连接的寡核苷酸。close文库可由化学连接的寡核苷酸的短pcr产物双链体构成,例如来自化学连接产物的扩增文库或经重排的化学连接产物的扩增文库。所述寡核苷酸可在源自异常靶细胞的close文库中与源自正常细胞的close文库相比差异性富集。所述寡核苷酸对于差异性源自异常靶细胞而非所关注的匹配的正常细胞的连接靶标选择性富集。
本公开还涉及评估一对空间引发的化学连接寡核苷酸(close)产物的模板化组装的方法,其包括将该对close产物修饰为模板化组装反应物,将该对经修饰的close产物转染至所关注的异常靶细胞中,并且筛选该对经修饰的close产物的模板化组装。也可通过添加芘基,如芘马来酰亚胺,和/或在芘和马来酰亚胺之间包括间隔臂来修饰close产物。
附图简述
已将附图包括在本文中,使得以上叙述的本公开的特征、优点和目的将变得更清楚并且可以详细地理解。这些图形成了说明书的一部分。然而,值得注意的是,附图说明本公开的一些实施方案而不应视为对权利要求范围的限制。
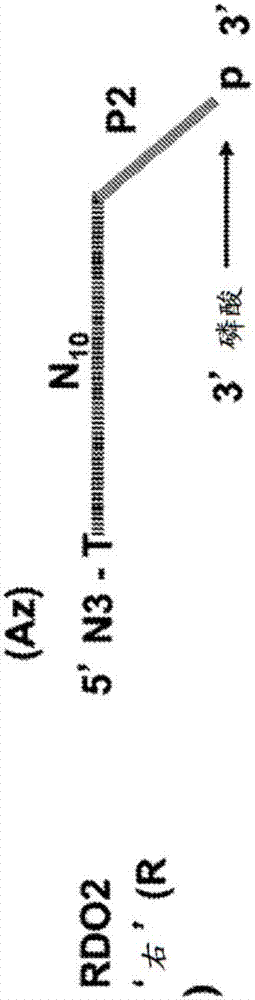
图1a、1b、1c和1d说明以下的示意构型:1a)随机十聚体寡核苷酸(rdo);p1:引物位点1;n10:随机十聚体序列段;me-c:5-甲基脱氧胞苷残基;ak:3’-末端炔,呈3’-炔丙基形式;1b)rdo2;p2:引物位点2;n10:随机十聚体序列段;az:5’-末端叠氮基;1c)和与引物位点互补的2’-o-甲基寡核苷酸杂交的rdo1(rdo1:p1c);p1:引物位点1;n10:随机十聚体序列段;ak:3’-末端炔,呈3’-炔丙基形式;和1d)和与引物位点互补的2’-o-甲基寡核苷酸杂交的rdo2(rdo2:p2c);p2:引物位点1;n10:随机十聚体序列段;az:5’-末端叠氮基;为方便起见,在close文库的上下文中将rdo1和rdo2称为“左”(l)和“右”(r)寡核苷酸。
图2示出了来自rdo群体的特异性寡核苷酸的经标记的5'和3'末端,在线性(连续)位点或不连续(构象决定的)位点上的代表性杂交介导的空间比对;s1和s2表示选自原始随机十聚体总群体的十聚体亚群。
图3a、3b和3c是代表性图,其示出了分别来自5’和3’标记的随机十聚体群体的特异性寡核苷酸之间的生产性和非生产性杂交;3a)生产性,来自5’-叠氮化物和3’-炔修饰群体两者;3b)非生产性,仅来自5’-叠氮化物修饰群体;及3c)非生产性,仅来自3’-炔修饰群体。
图4示出了与相等数量的相同模式(rnd1-rnd17)的随机寡核苷酸相比,close克隆(c1-c19)的代表性实例;cl1=tggatctctgc(seqidno:1),ttaaagtgacc(seqidno:2);cl2=tgagtgtgtgc(seqidno:3),tgcgcacactc(seqidno:4);cl3=acgggcccggc(seqidno:5),ttcgcgtccag(seqidno:6);cl4=tcttttacgcc(seqidno:7),tctgcccaggc(seqidno:8);cl5=acaccctcgcc(seqidno:9),taccttctccc(seqidno:10);cl6=tcacattcacc(seqidno:11),ttgtggatgtg(seqidno:12);cl8=ggcccttctac(seqidno:13),tcgtctgcggc(seqidno:14),cl9=ttcaatgggcc(seqidno:15),ttacccagtgc(seqidno:16);cl10=atcaaccctgc(seqidno:17),tgtattcgcca(seqidno:18);cl11=acgccgattgc(seqidno:19),tggcagtcggc(seqidno:20);cl12=acctaacagcc(seqidno:21),ttcatccgttc(seqidno:22);cl13=ttgaacgatcc(seqidno:23),taggtcgttca(seqidno:24);cl14=atagaaggggc(seqidno:25),ttaggccaaca(seqidno:26);cl15=ccaactgtagc(seqidno:27),taggcggttgg(seqidno:28);cl16=cccggcctccc(seqidno:29),ttcctagctgc(seqidno:30);cl17=aaaccgacagc(seqidno:31),tatgctgtcgg(seqidno:32);cl19=attcgcccccc(seqidno:33),tccgcttcggt(seqidno:34)。
图5示出了close文库从具有来自相应正常细胞的close文库的异常细胞来源的代表性消减;p1-p4表示不同的引发位点;s1和s2表示来自异常细胞,来自初始随机区域的选定十聚体序列段;s3和s4表示来自相应正常细胞,来自初始随机区域的选定十聚体序列段。
图6示出了通过用固相链霉亲和素选择和用过量游离生物素洗脱获得纯化脱硫生物素化‘上游’链(对应于原代close文库的链)的代表性程序。
图7示出了在相应正常细胞rna源上对close克隆的代表性选择,以富集正常细胞背景缺乏的close克隆;如本文所述制备脱硫生物素化顶链。
图8a和8b是对候选特异性close十聚体(a1和a2)的芘标记及激发荧光产生的代表性说明;7a)芘马来酰亚胺与3’-或5’-末端sh基团的化学偶联;及7b)来自杂交诱导的空间接近性的激基缔合物荧光。
图9说明了用于将特异性close克隆的相对水平量化为与源rna模板水平相关的代表性qpcr;上:通过杂交接近性选择的原代close克隆化学连接群体,描绘了cu(i)催化的三唑键联和两个特异性十聚体区域a1和a2;中:显示从互补序列到p2的第二周期延伸的特异性a1/a2克隆,及具有5’-氟和3’淬灭剂的退火qpcr探针;下:延伸完成(正如在中间图中一样),有链置换和探针消化以使氟不淬灭并允许荧光定量。
图10描绘具有特异性十聚体区域a1和a2的单个候选closee对的代表性数字pcr;在与靶rna杂交和cu(i)催化的化学连接后,化学连接的二聚体的数量近似于靶rna中模板分子的数量;通过用摩尔过量的引物和探针,及pcr相关的缓冲液和酶需求(taq1dna聚合酶;其它图解符号和荧光生成过程)进行区室化来制备连接产物用于数字pcr,在扩增后,带有连接的二聚体且匹配引物和具有靶二聚体的探针的区室产生荧光信号;因此,(+)信号区室的计数等于存在的二聚体的原始数量,并且又近似于模板分子的数量。
图11描绘对+/-dna酶处理的close/rna杂交的代表性凝胶评估;泳道1,close寡核苷酸+rna模板+dna酶;泳道2,close寡核苷酸+rna模板,无dna酶;泳道3,close寡核苷酸,无模板+dna酶;泳道4,close寡核苷酸,无模板和dna酶);结果显示不管是否存在模板都存在close寡核苷酸遗留物(泳道2和4),但只有在rna模板存在时,在dna酶处理后观察到条带(泳道1对比泳道3);切除泳道1中对应于预期大小的化学连接的close二聚体的条带(扩增的close寡核苷酸+rna模板+dna酶)并用原始引物重新扩增以增加有效产量。
图12描绘用于rna/未杂交的close寡核苷酸分离的peg试验的代表性凝胶分析(2%琼脂糖);泳道1-3:mu89rna加上经2’-o-甲基保护链退火的close寡核苷酸;泳道4-6:mu89rna加上无保护链的close寡核苷酸;泳道1和4:最终peg团块(2x沉淀);泳道2和5:第一peg上清液;及泳道3和6:第二peg上清液。
图13以代表性示意图形式描绘具有单一peg沉淀和dna酶步骤的close过程。
图14描绘代表性close位点命名规约;与模板上的不连续位点杂交的l-和r-close寡核苷酸,其经化学修饰的末端可以线性指向彼此(“内向”构型)或彼此相对(“外向”构型);一些构型可以加速效应子部分反应性,这取决于:1)l和r位点之间的距离(如上所述的n序列);2)n和侧翼序列的展曲性;及3)促进空间接近性的二级结构。
图15描绘二级结构环内的代表性不连续“内向”对比“外向”位点;如果杂交位点是在环内,则外向构型的末端可以在空间上聚集在一起,而常规内向取向活性较差。
图16描绘代表性不连续结构:试验“内向”对比“外向”构型;在所用条件下,不存在模板时未观察到明显的点击反应。
图17描绘“外向”点击对环形成的代表性依赖;此处“对照”序列具有促进环形成的g-c序列段,经非自互补序列置换,使得不能形成环;在所用条件下,不存在模板时未观察到明显的点击反应。
图18描绘图19中所用的茎环模板的代表性结构。
图19示出了与模板链上的不连续位点杂交后,点击反应的代表性示范;图18所示茎-环寡核苷酸的示意性描绘;条带显示点击-连接产物(20-聚体)的位置,可与模板链(30-聚体)区分开。
图20示出了野生型和突变hpv模板上退火的代表性芘标记的寡核苷酸pyeto.1和pyeto.2;对于野生型序列(hpv-1),寡核苷酸彼此位移一个碱基(盒式da残基),与其中它们直接并置的hpv-0模板不一样;对于hpv-2和hpv-3模板,位移分别为两个和三个da残基(盒式);taactgtcaaaagcca
ctgtgtcctgaagaaagcaaagacatctggacaaaaagc(seqidno:89);taactgtcaaaagccactgtgtcctgaagaaaagcaaagacatctggagaaaaagc(seqidno:35);taactgtcaaaagccactgtgtcctgaagaaaaagcaaagacatctggacaaaaagc(seqidno:90);taactgtcaaaagccactgtgtcctgaagaaaaaagcaaagacatctggacaaaaagc(seqidno:91);uccagaugucuuugc-芘(seqidno:36),芘-uuucuucaggacacag(seqidno:88)。
图21显示按等摩尔量计,特定模板上芘激基缔合物荧光的诱导;hpv-0、hpv-1、hpv-2、hpv-3;hpv-scr=来自hpv-0序列的随机乱序模板;nt=无模板。
图22将代表性close交叉软件原理描绘为流程图,显示了每个close克隆序列的加工途径。
图23描绘代表性close交叉软件原理。
图24描绘代表性close交叉软件原理:命中物实例;用特异性close克隆从close交叉软件中找到plxna3序列,其中close匹配物呈外向构型(在这种情况下,l-close匹配物比r-close匹配物更接近rna靶序列的5’末端);close序列用这些试验中所用的呈外向或内向构型的10-聚体点击寡核苷酸的标准互补序列置换;在所用条件下,不存在模板时未观察到明显的点击反应。
图25描绘当靶模板为效应子局部的摩尔过量时模板滴定效应的代表性示意图。
图26描绘模板滴度效应与芘荧光的代表性示范;taactgtcaaaagccactgtgtcctgaagaaaagcaaagacatctggacaaaaagc(seqidno:35);uccagaugucuuugc-芘(seqidno:36),芘-uuucuucaggacacag(seqidno:88)。
图27描绘用体外rna模板的模板滴度效应的代表性示范;mu89rna:点击寡核苷酸的指定摩尔比是基于假定约1500个碱基的平均rna尺寸;gaaauagaugguccagcuggacaagcagaa(seqidno:37);cttgtccagctggaccatct(seqidno:38)。
图28描绘代表性的靶向性close;表达易位的示意性实例,其中两个正常转录物有效地融合在一起;虽然只有一个可以作为线性连续序列靶向的可能的连接序列,,但是通过由较高级rna折叠和二级结构介导的空间接近性形成许多潜在的close位点。
图29描绘与生物素化底链去除组合的代表性不对称pcr。
图30描绘代表性的靶向性close原理;探针“拉出”具有杂交序列的close成员;这些可能但不一定包括连续的左和右close区段;因此可以借助于线性杂交探针发现不连续位点。
图31描述用作靶向性close探针的代表性bcr-abl区段(1338个碱基;seqidno:39);黑色文字:bcr序列;灰色文本:abl序列(gagttcaa/aagccctt处的连接点;seqidno:44);相关扩增引物的引发位点加有下划线。
图32a和32b分别描绘用于靶向性close的代表性凝胶纯化方法和用bcr-abl探针获得的克隆的实例,以及bcr-abl候选物的实例(凝胶图:泳道a:盒区,长单链探针与靶细胞全rna上连接的单链close二聚体杂交后,因而携带具有杂交序列的双链体close克隆;低分子条带,游离的过量close序列;泳道b:缺乏长探针分子的对照;盒区,与探针序列相同迁移率的凝胶对照区;低分子条带,游离的过量close序列);以及来自于获自2个周期的bcr-abl选择的k562rna的克隆的close克隆的两个实例;对于每一个而言,第一序列显示实际close22-聚体,具有灰色的插入ct二聚体(对于dbbc2-01=ataagcacctcttcaaggtctg;seqidno:40;对于dbbc2-08=tgacctgctcctcacccctcct;seqidno:41);这些链的反向互补序列(对于dbbc2-01=cagaccttgaagaggtgcttat;seqidno:42;对于dbbc2-08=aggaggggtgaggagcaggtca;seqidno:43)对应于bcr-abl探针的(+)链,或整个rna转录物;有下划线的黑体文字显示了bcr/abl匹配物,其坐标如下(从所编8703-碱基bcr-abl全长转录物;探针范围跨坐标2766-4103);n值对应于l和r匹配物最近端之间的距离。
图33a和33b描绘具有末端叠氮化物和环辛炔基的rdo的代表性示意构型;p1、p2:分别为引物位点1和2;n10:随机十聚体序列段;cot:3'-末端修饰的环炔;az:5'-末端叠氮基。
图34a和34b分别描绘由靶rna链的二级结构引起的杂交介导的空间接近性驱动的代表性“非天然”5’-5’(头对头,a)和3'-3'(尾对尾,b)化学连接;az,5'叠氮化物;cot,5'环辛炔。
图35描绘具有5'点击基团(叠氮化物、az和环炔、cot)、初始随机区(n1和n2)、pcr引物位点(p1和p2)和限制位点/引物区(a1和a2)的代表性单链寡核苷酸;s1和s2表示选自原始随机十聚体总群体的十聚体亚群;还显示了通过rna二级结构空间接近性杂交产生的头对头化学连接的点击产物。
图36a和36b描绘5'-5'点击反应性的可能5'结构;36a,提供炔基的5'己炔基修饰;36b,5'-叠氮基,其通过5'-氨基(从5'-羟基开始有6碳间隔子)与通过3碳间隔子与叠氮化物部分键联的n-羟基琥珀酰亚胺反应,随后在酰胺键上形成而提供。
图37显示双链5'-5'化学连接产物通过聚合酶延伸,随后用限制性内切核酸酶agei再次切割(s1和s2表示选自原始随机十聚体总群体的十聚体亚群)的代表性生成。
图38说明了并入5'-甲基-dctp并且使用区域a1的互补区段的代表性延伸;所得延伸双链体的半甲基化区域用灰色背景阴影表示;s1和s2表示选自原始随机十聚体总群体的十聚体亚群。
图39是将5'-5'化学连接的双链体产物分成体外微区室的代表性图;此处每个片段最初已经用限制酶e2(在指定实施方案中为agei)切割。
图40描绘了将未连接的5'-标记的双链体链代表性地分成微区室;此处5'-环炔修饰的链先前已经用限制酶e2(在指定实施方案中为agei)在a2区域中裂解。
图41显示代表性xmai切割(在指定实施方案中)和微区室内5'-5'键联的重新连接。
图42是微区室中xmai裂解的5'-5'键联产物(在指定实施方案中)的循环,直至达到不可逆且可扩增的重排终点的代表性图示。
图43是具有3'点击基团(叠氮化物和炔)、初始随机区(n1和n2)、pcr引物位点(p1和p2)和限制位点/引物区(a1和a2)的单链寡核苷酸的代表性图;s1和s2表示选自原始随机十聚体总群体的十聚体亚群;还显示了通过rna二级结构空间接近性杂交产生的尾对尾化学连接的点击产物。
图44a和44b描绘3'-3'点击反应性的代表性可能3'结构;44a)提供环炔基的3'修饰;44b)3'-叠氮基,其通过3'-氨基(与3'-羟基有6碳间隔子)与通过3碳间隔子与叠氮化物部分连接的n-羟基琥珀酰亚胺反应,随后在酰胺键联上形成而提供。
图45说明双链3'-3'化学连接产物通过聚合酶延伸,随后用限制性内切核酸酶agei再次切割的代表性生成;s1和s2表示选自原始随机十聚体总群体的十聚体亚群。
图46说明了并入5'-甲基-dctp并且使用区域a2的互补区段的代表性延伸;所得延伸双链体的半甲基化区域用灰色背景阴影表示;s1和s2表示选自原始随机十聚体总群体的十聚体亚群。
图47是将3'-3'化学连接的双链体产物分成体外微区室的代表性图示;此处每个片段最初已经用限制酶e2(在指定实施方案中为agei)裂解。
图48图示将未连接的3'-点击标记的双链体链代表性地分成微区室;此处3'-炔修饰的链先前已经用限制酶e2(在指定实施方案中为agei)在a2区域中裂解。
图49是xmai切割(在指定实施方案中)和微区室内3'-3'键联的重新连接的代表性图。
图50显示微区室中xmai裂解的3'-3'连接产物(在指定实施方案中)的代表性循环,直至达到不可逆且可扩增的重排终点。
图51说明具有非聚合酶可读的5'-和3’-点击基团(分别为环炔和叠氮化物)、初始随机区(n1和n2)、pcr引物位点(p1和p2)和限制位点/引物区(a1和a2)的代表性单链寡核苷酸;s1和s2表示选自原始随机十聚体总群体的十聚体亚群;还显示了通过rna二级结构空间接近性杂交产生的头对尾化学连接(不可直接扩增)的点击产物。
图52a、52b、52c和52d是显示5'-3'点击反应性的可能的5'和3'结构的代表性图,其中不需要聚合酶通读;52a)代表性5'-环炔和5'-叠氮化物修饰;在不需要聚合酶通读时,一对5'和3'修饰的点击修饰寡核苷酸可以携带上述代表性修饰的任一环炔-叠氮化物组合:例如,一对寡核苷酸携带如图52a/c表示的5'和3'结构;52b)代表性5'-环炔和5'-叠氮化物修饰;在不需要聚合酶通读时,一对5'和3'修饰的点击修饰寡核苷酸可以携带上述代表性修饰的任一环炔-叠氮化物组合:例如,一对寡核苷酸携带如图52b/d表示的5'和3'结构;52c)代表性3'-环炔和3'-叠氮化物修饰;在不需要聚合酶通读时,一对5'和3'修饰的点击修饰寡核苷酸可以携带上述代表性修饰的任一环炔-叠氮化物组合:例如,一对寡核苷酸携带如图52a/c表示的5'和3'结构;及52d)代表性3'-环炔和3'-叠氮化物修饰;在不需要聚合酶通读时,一对5'和3'修饰的点击修饰寡核苷酸可以携带上述代表性修饰的任一环炔-叠氮化物组合:例如,一对寡核苷酸携带如图52b/d表示的5'和3'结构。
图53a和53b是具有非聚合酶可读的5'-和3'-点击基团,出于核酸酶抗性而被修饰的单链寡核苷酸区域的代表性图;用点状背景显示;53a)非修饰区域保留正常dna主链和碱基以允许限制酶裂解;3'位点通过三个经修饰的碱基延伸,主链经修饰;53b)非修饰区域保留正常dna主链和碱基以允许限制酶裂解;3'位点通过三个经修饰的碱基延伸,主链经修饰。
图54说明双链5'-3'化学连接产物通过聚合酶延伸,随后用限制性内切核酸酶agei再次切割的代表性生成;s1和s2表示选自原始随机十聚体总群体的十聚体亚群。
图55显示将5'-3'化学连接的双链体产物代表性分成体外微区室;此处每个片段最初已经用限制酶e2(在指定实施方案中为agei)裂解。
图56是将未连接的5'/3'点击标记的双链体链分成微区室的代表性说明;此处5'-叠氮化物修饰的链先前已经用限制酶e2(在指定实施方案中为agei)在a2区域中裂解。
图57是xmai切割(在指定实施方案中)和微区室内5'-3'键联的重新连接的代表性图。
图58显示微区室中xmai裂解(在指定实施方案中)的5'-3'连接产物的代表性循环,直至达到不可逆且可扩增的重排终点。
图59描绘体外区室化使得分子特异性重排成为可能,以扩增和鉴定特异性序列的能力的代表性测试;步骤1.验证模型:制备4x寡核苷酸,2个具有5'-叠氮化物,2个具有5'直链炔(可通过cu(i)介导的点击化学连接);每一个设计具有特异性标记物序列,并使得差异性扩增成为可能。
图60描绘5'-5'寡核苷酸连接的酶促重排过程的代表性示范;预定大小的产物仅在应用切割和重新连接时才形成;非常相似的重排使得3'-3'或“不可读的”5'-3'连接点的扩增成为可能。
图61描绘纯化的上部条带5'-5'化学连接加合物(来自切除的凝胶带)的代表性测试,与相应的未纯化材料的样品并排运行。
图62描绘代表性测试设计用于使可扩增产物与所有模型上部条带5'-5'加合物产物成为可能的酶(agei、xmai、t4dna连接酶)的用途。
图63描绘用于成功ivc的模型寡核苷酸检测系统的代表性原理;在这种情况下,双链化5'-5'加合物是用于在ivc中进行测试的预切agei,从而仅需xmai和连接酶来完成重排。
图64描绘代表性测试设计用于检测特异性重排的引物,无论是直接(单分子)还是特异性交叉;对于进行酶促重排的两种不同的5'-5'产物的混合物,特异性引物对必须能够唯一识别每种直接产物或特异性交叉产物。
图65描绘代表性测试具有预先形成的重排,无pcr诱导的伪交叉的重排定向引物的特异性;bh、fh=分别为直接重排bh和fh加合物;bh+fh重排=用同时存在的bh和fh产物进行重排过程(从而允许交叉重排);bh+fh混合物=bh和fh加合物重排单独进行,然后在pcr之前混合在一起;bh+fhage=bh和fh加合物仅用agei切割并在pcr前混合;co=无模板对照。
图66描绘体外区室化试验的代表性嵌套pcr结果;没有观察到可检测的交叉产物(垂直的白色箭头)。
图67描绘借助于循环和反向pcr,5'-3'连接的代表性close扩增;由于形成庞大的无痕产品,这应用直接通读是不可能的;这种方法的潜在问题是独立分子之间的交叉连接(而不是环化),这将使正确信息乱序;这可以通过在低浓度下进行连接步骤来最小化。
描述
本公开涉及用于鉴定、富集和评估模板化组装反应物的方法和试剂盒。
现将描述某些示例性实施方案以提供对本文公开的装置和方法的结构、功能、制造和使用的原理的全面理解。附图中说明了这些实施方案的一个或多个实例。本领域的技术人员将理解,本文具体描述并在附图中说明的装置和方法是非限制性示例性实施方案,并且本公开的范围仅由权利要求限定。结合一个示例性实施方案说明或描述的特征可以与任何其它实施方案的特征组合。此类修改和变化旨在被包括在本公开的范围内。
本文引用的所有出版物、专利和专利申请,无论是上文的还是下文的,均据此通过引用整体并入。如本说明书和所附权利要求中所用的,除非内容另外明确指出,否则单数形式“一个”、“一种”和“该(所述)”包括多个指示物。本公开中使用的术语遵循本领域普通技术人员普遍接受的标准定义。如果需要任何进一步的解释,下面进一步阐明了一些术语。
如本文中所用,术语“约”是指可以例如通过现实世界中的测量或处理程序;通过这些程序中的无意错误;通过组合物或试剂的制造、来源或纯度的差异等出现的数值量变化。通常,如本文中所用,术语“约”意指比规定值或规定值的范围大或小规定值的1/10,例如±10%。例如,约30%的浓度值可以指27%至33%的浓度。术语“约”还指本领域技术人员视为等效的变化,只要此类变化不涵盖现有技术实践的已知值。术语“约”之后的每个值或值的范围也旨在涵盖规定的绝对值或值的范围的实施方案。无论是否有术语“约”修饰,权利要求中列举的定量值都包括所列值的等效值,例如可以发生,但将被本领域技术人员视为等效的此类值在数值量上的变化。
短语“活性效应子结构”和“效应子结构”在本文中可互换使用,并且是指触发所需效应的模板化组装产物的活性部分。
如本文中所用,术语“碱基”是指含有嘌呤或嘧啶基团或人工类似物的分子,其通过watson-crick或hoogsteen键合相互作用与另一相应的碱基形成结合对。碱基还含有促进聚合物如寡聚物中的多个碱基共价连接在一起的基团。非限制性实例包括核苷酸、核苷、肽核酸残基或吗啉代残基。
如本文中所用,术语“结合”是指两个彼此靠近的分子之间的稳定相互作用。该术语包括物理相互作用,例如化学键(直接连接或通过中间结构连接),以及非物理相互作用和吸引力,例如静电吸引、氢键和范德华力/分散力。
如本文中所用,短语“生物偶联化学”是指在温和条件下将常见官能团连接在一起,有利于多部分化合物的模块化构建的化学合成策略和试剂。
如本文中所用,“空间引发的化学连接寡核苷酸”是指由于它们的空间接近性,已经通过与靶核酸模板杂交而化学连接的成对寡核苷酸。
如本文中所用,短语“效应子局部部分”是指模板化组装反应物的一部分,其有助于通过核酸模板化组装形成的产物中的效应子结构的化学结构。效应子局部部分可以是反应物的不同部分,或者可包括或由核酸识别部分和/或选择性反应部分的一部分或全部组成。
术语“接头”和“间隔子”在本文中可互换使用并且是指模板化组装反应物中与寡核苷酸序列相邻的分子。接头可以是附加寡核苷酸序列、肽、肽模拟物结构的非活性部分、药物的非活性部分或小于20kda的其它生物活性化合物。接头可由支链或非支链的共价键合分子链组成。
如本文中所用,短语“无痕生物正交化学”是指涉及选择性反应部分的反应,其中选择性反应部分的部分或整个结构保留在产物结构中。
如本文中所用,短语“核酸识别部分”是指利于与靶核酸的序列特异性结合的寡核苷酸。核酸识别部分的实例是与靶核酸结合的寡核苷酸序列。
术语“寡核苷酸序列”和“寡聚物”在本文中可互换使用并且是指由多个单元组成的分子,其中一些或全部单元是能够形成watson-crick或hoogsteen碱基配对相互作用,允许与双链体或多链体结构中的核酸的序列特异性结合的碱基。非限制性实例包括寡核苷酸、肽核酸寡聚物和吗啉代寡聚物。
如本文中所用,短语“致病细胞”可以指能够引起或促进患病或异常状况的细胞,例如感染病毒的细胞、肿瘤细胞和感染微生物的细胞,或产生诱导或介导包括但不限于变态反应、过敏反应、炎症和自身免疫性疾病的分子的细胞。
短语“药学上可接受的”在本文中使用时是指并非生物学或其他方面不可接受的物质,其可以并入组合物中并且施用给患者而不引起不可接受的生物学效应或以不可接受的方式与组合物的其它组分相互作用。
短语“药学上可接受的盐”意指由碱或酸制备的,可接受用于向患者例如哺乳动物施用的盐(例如,对于给定剂量方案具有可接受的哺乳动物安全性的盐)。
如本文中所用的术语“盐”可以包括源自药学上可接受的无机酸和碱的盐和源自药学上可接受的有机酸和碱的盐及其衍生物和变体。
如本文中所用的术语“样品”是指在可能发生核酸模板化组装时可向其中施用模板化组装反应物的任何体系。非限制性实例可包括活细胞、固定或保藏细胞、整个生物体、组织、肿瘤、裂解物或体外测定系统。
短语“选择性反应部分”是指例如通过与相应的模板化组装反应物的化学反应,使得产物的形成成为可能的模板化组装反应物的部分。例如,选择性反应部分可易与相应的选择性反应部分反应,但不易与天然生物分子反应。
短语“一组相应的反应物”或“相应的模板化组装反应物”在本文中称为模板化组装反应物,其聚集在单个靶模板上以参与模板组装反应。
在本文的任何实施方案中,“受试者”可为体外细胞,如培养物中的细胞,或活生物体中的体内细胞。在一些实施方案中,受试者可为微生物。在一些实施方案中,受试者可为源自或包含在从较大生物体获得的样品中的细胞。例如,受试者可为通过活检程序从生物体获得的样品中所含的细胞,并且可对其进行所述方法。在一些实施方案中,受试者可为从生物体获得的祖细胞的后代(通过细胞分裂)。受试者也可为哺乳动物。受试者的实例可包括但不限于人、马、猴、狗、猫、小鼠、大鼠、牛、猪、山羊和绵羊。在一些实施方案中,“受试者”通常为人患者。
如本文中所用,术语“超抗原”是指结合广泛亚类的表达特定可变(v)区的t细胞的抗原。
如本文中所用,短语“无痕生物正交化学”是指参与选择性反应部分的反应,其中通过从产物结构消除部分或全部选择性反应部分而形成天然存在的键,例如酰胺。
如本文中所用,短语“靶区室”是指含靶核酸,或与非靶区室不同量的靶核酸的细胞、病毒、组织、肿瘤、裂解物、其它生物结构、空间区域或样品。
短语“靶核酸序列”和“靶核酸”可互换使用并且是指旨在充当核酸模板化组装的模板的单元或核酸序列。
术语“模板化组装”、“模板化组装反应”和“核酸模板化组装”在本文中可互换使用并且是指在靶核酸上产物结构的合成,使得可以通过模板化组装反应物在与靶核酸结合时就近组装,促进产物形成。
如本文中所用,短语“模板化组装连接产物”是指通过一种或多种模板化组装反应物的相互作用、结合或反应形成的产物结构。
如本文中所用,短语“模板化组装反应物”是指以序列特异性方式结合靶核酸或在模板化组装反应期间参与产物形成的寡核苷酸序列。
本文还包括“衍生物”或“类似物”,如其盐、水合物、溶剂化物或已经经过化学修饰并保持相同生物活性或缺乏生物活性,和/或充当模板化组装反应物,或以与模板化组装反应物一致的方式起作用的能力的其它分子。
当存在一种或多种靶,如特异性核酸序列时,靶向模板组装产生所需的化学结构。公开的方法和试剂盒允许鉴定、分析或发现特异性遗传模板。所公开的方法和试剂盒还鉴定模板化组装所靶向的特异性核酸序列,以避免脱靶毒性并增强特异性反应性。公开的方法和试剂盒进一步富集和评估用于模板化组装的特异性核酸序列。通过鉴定靶细胞的独特核酸序列,定向干预可以集中在这些特定细胞上,例如通过自我破坏或其它细胞的免疫治疗性破坏,而不诱导对缺乏模板靶标的非靶细胞,如正常细胞的毒性。
模板化组装靶标的鉴定可包括用于合成模板化组装反应物,使所述模板化组装反应物与靶核酸杂交,进行模板化组装反应,以及鉴定与所述模板化组装反应物杂交的靶核酸的方法和试剂盒。
如本文中所用,短语“模板化组装反应物”是指以序列特异性方式结合靶核酸或在模板化组装反应期间参与产物形成的寡核苷酸序列。模板化组装反应物可包括核酸识别部分,如寡核苷酸序列。通过引用整体并入本文的美国申请第61/831,133号,公开了包括核酸识别部分、选择性反应部分和效应子局部部分以生成靶向治疗剂的靶向模板化组装反应物。在本公开中,模板化组装反应物不需要但仍可包括效应子局部部分。靶核酸的鉴定、分析或发现不需要产生效应功能,如美国申请第61/831,133号中所公开的,所以模板化组装反应物中包括至少核酸识别部分和选择性反应部分的存在。在一些实施方案中,公开了第一群体的模板化组装反应物和第二群体的相应的模板化组装反应物,其中所述第一群体包括与第二群体的不同的寡核苷酸序列或不同的寡核苷酸序列文库。在一些实施方案中,公开了第一群体的模板化组装反应物和第二群体的相应的模板化组装反应物,其中所述第一群体包括不同于第二群体的的特异性寡核苷酸序列或化学修饰。
寡核苷酸序列可以通过本领域已知的几种方法合成。基于核苷酸的寡核苷酸序列可以在溶液中或在固相上使用亚磷酰胺化学法合成。肽核酸也可以在溶液中或在固相上使用本领域已知的方法合成。也可使用各种吗啉代合成方法。任何上述类型的寡核苷酸序列也可以从各种商业来源完全合成获得。
寡核苷酸序列可以包括碱基对形成单元的序列,如核酸或核酸类似物。寡核苷酸序列可由多个单元组成,其中一些或全部单元是能够形成watson-crick或hoogsteen碱基配对相互作用,允许与双链体或多链体结构中的靶核酸的序列特异性结合的碱基。
短语“核酸”是本领域公知的。如本文中所用的“核酸”通常是指包含核苷酸的dna、rna或其衍生物或类似物的分子(即,链)。核苷酸包括例如dna中发现的天然存在的嘌呤或嘧啶碱基(例如,腺嘌呤“a”、鸟嘌呤“g”、胸腺嘧啶“t”或胞嘧啶“c”)或rna(例如,a、g、尿嘧啶“u”或c)。短语“核酸”或“rna分子”涵盖术语“寡核苷酸”和“多核苷酸”,各自作为“核酸”亚属。
寡核苷酸序列可以是dna核苷酸、rna核苷酸、硫代磷酸酯修饰的核苷酸、2'-o-烷基化rna核苷酸、卤代核苷酸、锁核酸核苷酸(lna)、肽核酸(pna)、吗啉代核酸类似物(吗啉代)、假尿苷核苷酸、黄嘌呤核苷酸、次黄嘌呤核苷酸、2'-脱氧肌苷核苷酸、能够形成碱基对的其它核酸类似物或其组合。在一些实施方案中,寡核苷酸序列包括核酸并且与mrna靶标杂交。
可以并入商购的衍生化碱基以引入官能团,包括但不限于胺、酰肼、硫醇、羧酸、异氰酸酯、醛,然后可以使用生物偶联化学的标准技术与其它部分上的活性官能团偶联,以促进完整模板化组装反应物的合成。
寡核苷酸序列也可并入特化单元,与专化单元相互反应或结合。例如,当使用模板化组装反应物,包括寡核苷酸序列时,在可能降解标准dna或rna(例如活细胞或裂解物)的核酸酶的存在下,可能需要向寡核苷酸序列中并入核酸酶-抗性碱基。一些非限制性实例可包括硫代磷酸酯碱基、2’-o-烷基化或2’-卤代rna碱基、锁核酸、肽核酸、吗啉代或包括这些中的至少一种的嵌合体。与依赖于rna酶h活性的反义探针不同,寡聚物的内部碱基不需要诱导靶rna转录物的rna酶h水解。因此,在寡核苷酸序列的任何位置都不需要rna酶h诱导的碱基。
可以将模板化组装反应物合成为包括为随机序列或基因特异性序列的寡核苷酸序列。在一些实施方案中,模板化组装反应物可通过基因特异性寡核苷酸序列结合靶核酸。寡核苷酸可为与一个或多个靶核酸互补的连续或非连续序列。短语“靶核酸序列”和“靶核酸”可互换使用并且是指旨在充当核酸模板化组装的靶标或模板的单元或核酸序列。
寡核苷酸序列可以通过与靶核酸上的杂交位点互补为基因特异性,允许与靶核酸的序列特异性结合。在一些实施方案中,寡核苷酸序列是与靶核酸互补的连续序列。在一些实施方案中,选择寡核苷酸序列,使其序列与已知存在于非靶核酸中的序列不相似。在一些实施方案中,寡核苷酸序列包括在靶核酸内发现的一个或多个突变,允许模板化组装反应物与靶核酸,而不是与不含突变的非靶核酸的特异性结合。在一些实施方案中,可以合成具有茎-环结构的寡核苷酸序列,可能改善与靶核酸的所需结合相互作用。
寡核苷酸序列也可为随机序列。随机寡核苷酸序列可包括任何上述碱基对形成单元或随机序列中的特化单元。
寡核苷酸序列可为约5至约100个核苷酸长。在一些实施方案中,随机或基因特异性序列可为约5至约100个核苷酸长。寡核苷酸序列可为5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99或100个核苷酸长度的任一种。在一些实施方案中,寡核苷酸序列可为约5至约30个核苷酸,约7至约25个核苷酸长,或约7至约15个核苷酸。
寡核苷酸序列,无论是随机的还是基因特异性的,都可以与寡核苷酸序列长度为约5至约100个碱基长度的任一值的靶核酸互补。在一些实施方案中,寡核苷酸序列可与寡核苷酸序列长度在长度约5至约50个碱基,长度约5至约40个碱基或长度约10至约30个碱基范围内的靶核酸互补。
寡核苷酸序列也可优化以提供化学性质。可基于化学性质,如互补序列的解链和退火温度选择寡核苷酸序列的长度。解链温度,tm,定义为按摄氏度计的温度,在该温度下指定寡核苷酸序列所有分子的50%杂交成双链,而50%作为单链存在。退火温度通常比解链温度低5c。
寡核苷酸序列的tm可以在使用模板化组装反应物的情况的温度低约10c至高约40c的范围内。例如,如果在37c下使用模板化组装反应物,则设计预期tm为27c至77c的寡核苷酸。在一些实施方案中,可在大约37c下使用模板化组装反应物,并且寡核苷酸序列的tm可设计为在约37c至约52c的范围内。
在一些实施方案中,可以设计寡核苷酸序列,使得结合靶核酸的tm基本上不同于结合相似非靶核酸的tm。例如,可以设计寡核苷酸序列,使得靶核酸上与之结合的杂交位点包括突变位点。在一些实施方案中,寡核苷酸序列与靶核酸结合的tm等于或高于使用模板化组装反应物的温度,而寡核苷酸序列与非靶核酸结合的tm低于使用模板化组装反应物的温度。然后寡核苷酸序列与突变靶序列,而不是与非靶非突变序列结合。
寡核苷酸序列的tm可以在使用模板化组装反应物的情况的温度低约10c至高约40c的范围内。例如,如果在37c下使用模板化组装反应物,则设计预期tm为27c至77c的寡核苷酸序列。在一些实施方案中,可在大约37c下使用模板化组装反应物,并且寡核苷酸序列的tm可设计为在约37c至约52c的范围内。
模板化组装反应物还可包括与寡核苷酸序列相邻的5'和/或3'引发位点。引发位点可直接侧接寡核苷酸序列或者可通过接头序列与寡核苷酸序列隔开。可包括本领域常用的引物序列。此类实例可包括但不限于m13、t3、t7、sp6、vf2、vr、其修饰形式、其互补序列及其反向序列。另外,还包括定制引物序列。
模板化组装反应物也可包括中间体,如接头或间隔子。接头可以是范围1至约50个核苷酸长的附加寡核苷酸序列。接头也可以是肽、肽模拟物结构的非活性部分、药物的非活性部分或小于20kda的其它生物活性化合物。接头可由支链或非支链的共价键合分子链组成。在一些实施方案中,接头是至少6个碳原子的间隔子。
模板化组装反应物还可包括与在模板化组装反应中会有反应性的寡核苷酸序列,如选择性反应部分相邻的修饰。对于模板化组装反应的此类修饰于美国申请第61/831,133号中公开,其通过引用整体并入本文。在一些实施方案中,所述修饰侧接寡核苷酸序列。如本文中所用,“侧翼序列”可以指直接,例如在寡核苷酸序列的1至5个碱基对中,或非常接近寡核苷酸序列,例如在5至20个碱基对中的区域。
所述修饰可以是生物惰性的。具体而言,一个寡核苷酸序列上的修饰可易与另一个寡核苷酸序列上的相应修饰相互作用,但不易与天然生物分子相互作用。这是为了确保在相应的模板化组装反应物组装时形成模板化组装反应。还避免在环境中发生的非特异性反应,并防止形成非预期的产物。
选择性反应部分、出于模板化组装反应中的反应性的修饰的实例,可包括添加生物正交反应性部分。生物正交反应性部分可以包括那些可以进行叠氮化物和炔之间的“点击”反应,叠氮化物和膦之间的无痕或非无痕施陶丁格反应以及硫酯与硫醇之间的天然化学连接反应的基团。另外,生物正交部分可以是叠氮化物、环辛炔、硝酮、降冰片烯、氧杂降冰片二烯、膦、二烷基膦、三烷基膦、膦硫醇、膦酚、环辛烯、氧化腈、硫酯、四嗪、异腈、四唑、四环烷及其衍生物。
在一些实施方案中,公开了第一群体的模板化组装反应物和第二群体的相应的模板化组装反应物。第一群体可包括一个修饰且第二群体可包括相应的修饰。例如,第一群体可以在模板化组装反应物上包括叠氮化物并且第二群体可以在模板化组装反应物上包括炔,使得第一和第二群体能够在点击反应中反应生成连接产物。
出于模板化组装反应中的反应性的多种修改可与本文公开的方法和试剂盒一起使用,一些非限制性实例包括:
叠氮化物-炔“点击化学”:点击化学具高度选择性,因为在典型条件下,叠氮化物和炔都不与常见生物分子反应。r-n3形式的叠氮化物和r-c≡ch形式的末端炔或r-c≡c-r形式的内部炔易于相互反应以生成呈1,2,3-三唑形式的huisgen环式加成产物
基于叠氮化物的模板化组装反应物具有子结构:r-n3,其中r为化学接头、核酸识别部分或效应子局部部分。叠氮化物和叠氮化物衍生物可易于由商购试剂制备。
叠氮化物也可在效应子局部部分合成期间引入效应子局部部分中。在一些实施方案中,在效应子局部部分肽的合成期间使用标准肽合成方法,通过并入商购的叠氮化物衍生化标准氨基酸或氨基酸类似物,将叠氮基引入到由肽组成的效应子局部部分中。可用叠氮化物置换α-氨基使氨基酸衍生化,获得以下形式的结构:
其中r为标准氨基酸或非标准氨基酸类似物的侧链。
商购产品可以引入叠氮化物官能性作为氨基酸侧链,产生以下形式的结构:
其中a为标准氨基酸或非标准氨基酸类似物的侧链上的任何原子及其取代基。
通过重氮转移法将肽上的胺基转化为叠氮化物合成后,也可将叠氮化物引入效应子局部部分中。生物偶联化学法也可用于将商购衍生化叠氮化物连接到含有合适的反应基团的化学接头、核酸识别部分或效应子局部部分。
标准炔可以通过类似于叠氮化物并入的方法并入到模板化组装反应物中。炔官能化核苷酸类似物是可商购的,允许在核酸识别部分合成时直接并入炔基。类似地,可通过标准肽合成法将炔衍生化氨基酸类似物并入效应子局部部分中。另外,与生物偶联化学法相容的不同官能化炔可用于促进通过合适的官能团或侧基向其它部分并入炔。
叠氮化物激活的炔“点击化学”:标准叠氮化物-炔化学反应通常需要催化剂,如铜(i)。因为催化浓度的铜(i)对许多生物系统有毒,所以标准叠氮化物-炔化学反应在活细胞中的使用有限。基于活化炔的无铜点击化学体系避开了有毒催化剂。
活化炔常常呈环辛炔形式,其中并入到环辛基中向炔中引入了环应变
杂环原子或取代基可以引入环辛基环中的各个位置,这可以改变炔的反应性或在化合物中提供其它替代性化学性质。环上的各个位置也可以用作连接环辛炔与核酸模板化组装部分或接头的连接点。环或其取代基上的这些位置可以任选地用辅助基团进一步衍生化。
多种环辛炔是可商购的,包括适合与标准生物偶联化学方案一起使用的几种衍生形式。商购的环辛炔衍生化核苷酸可有助于促进在核酸识别部分合成期间方便地并入选择性反应部分
基于环辛炔-叠氮化物的生物正交化学法可产生通用结构的模板化组装产物:
另一实例:
叠氮化物-膦施陶丁格化学法:基于叠氮化物和膦或亚磷酸盐之间的快速反应,损失n2的施陶丁格还原,也表示生物正交反应。施陶丁格连接,其中在施陶丁格反应中在反应物间形成共价连接,适合用于核酸模板化组装中。非无痕和无痕形式的施陶丁格连接都允许在这些反应中形成的产物的化学结构上有多种选择。
非无痕施陶丁格连接:标准施陶丁格连接是叠氮化物与苯基取代的膦如三苯基膦之间的非无痕反应,其中膦上的亲电子阱取代基如甲酯与反应的氮杂-内鎓盐中间体重排,以生成通过氧化膦连接的连接产物。模板化组装反应物a和b形成的施陶丁格连接产物的实例可具有以下结构:
携带亲电子阱的苯基取代的膦也可容易地合成。衍生化形式是可商购的并且适于并入到模板化组装反应物中:
无痕施陶丁格连接:在一些实施方案中,能够进行无痕施陶丁格连接的膦可用作选择性反应部分。在无痕反应中,膦在氮杂-内鎓盐中间体重排期间用作离去基团,产生通常呈天然酰胺键形式的连接。能够进行无痕施陶丁格连接的化合物通常呈硫酯衍生化膦或酯衍生化膦的形式:
用于无痕施陶丁格连接的酯衍生化膦。
用于无痕施陶丁格连接的硫酯衍生化膦。
化学接头或辅助基团可以任选地作为取代基附接于上述结构中的r基团,为核酸识别部分提供连接点或向反应物引入附加官能性。
无痕膦酚施陶丁格连接:与非无痕施陶丁格苯基膦化合物相比,无痕膦酚上亲电子阱酯的取向相对于苯基是反向的。这使得无痕施陶丁格连接能够在与叠氮化物的反应中发生,在不含氧化膦的产物中产生天然酰胺键
如果合适的亲水性基团如叔胺附接到苯基膦上,则无痕施陶丁格连接可以在无有机共溶剂的水介质中进行。weisbord和marx(2010)的文章描述了水溶性膦酚的制备,其可以通过温和的steglich酯化,使用碳二亚胺如二环己基碳二亚胺(dcc)或n,n'-二异丙基碳二亚胺(dic)和酯活化剂如1-羟基苯并三唑(hobt)来负载含有羧酸(例如肽的c末端)的所需效应子局部部分。这种方法促进以下形式的模板化组装反应物的合成:
基于水溶性膦酚的无痕模板化组装反应物结构。
无痕膦甲硫醇施陶丁格连接:膦甲硫醇表示用于介导无痕施陶丁格连接反应的膦酚的替代物。一般而言,膦甲硫醇与膦酚相比在介导无痕施陶丁格连接反应中具有有利的反应动力学性质。美国申请2010/0048866和tam等人的文章(2007)描述了以下形式的水溶性膦甲硫醇的制备:
这些化合物可负载肽或呈活化酯形式的其它有效负载,以形成适于用作无痕生物正交反应基团的硫酯:
基于水溶性膦甲硫醇无痕施陶丁格生物正交化学的模板化组装反应物结构。
天然化学连接:天然化学连接是基于硫酯与带有硫醇和胺的化合物之间的反应的生物正交法。典型的天然化学连接在带有c端硫酯的肽与带有n端半胱氨酸的另一个肽之间,如下所见:
天然化学连接可用于介导无痕反应,生成含有内部半胱氨酸残基,或者如果利用非标准氨基酸,则含有含硫醇的残基的肽或肽模拟物。
n端半胱氨酸可通过标准氨基酸合成方法并入。末端硫酯可以通过本领域已知的几种方法生成,包括使用诸如二环己基碳二亚胺(dcc)的试剂将活化酯与硫醇缩合,或者通过使用“安全捕获”载体树脂在肽合成期间引入。
其它模板化组装反应部分:只要在复杂的生物环境中以高度选择性的方式有效介导反应,任何合适的生物正交反应化学法均可用于合成模板化组装反应物。最近开发的可能合适的替代生物正交化学法的非限制性实例是四嗪和各种烯烃如降冰片烯和反式环辛烯之间的反应,其有效地介导水性介质中的生物正交反应。
在一些实施方案中,模板化组装反应物还可以包括效应子局部部分,使得当一组相应的模板化组装反应物参与模板化组装反应时,可以产生活性效应子产物。效应子局部部分可以是活性效应子结构的一部分,使得当一组相应的模板化组装反应物参与模板化反应时,其效应子局部部分组合以在模板化组装连接产物中生成所需的活性效应子结构。因此,效应子局部部分有助于活性效应子结构的化学结构。效应子局部部分可以是模板化组装反应物的不同部分,或者可包括由核酸识别部分的一部分或全部和/或选择性反应部分的一部分或全部。短语“活性效应子结构”和“效应子结构”在本文中可互换使用,并且是指触发所需效应的模板组装产物的活性部分。
效应子局部部分不具有靶向活性或与活性效应子结构相关的相同水平的活性。在一些实施方案中,效应子局部结构与活性效应子结构相比基本上无活性。在一些实施方案中,单独的效应子局部部分可以具有独立活性,但使效应子局部部分结合一起产生它们单独不具有的活性。例如,结合两种不同抗体(各自结合效应子局部结构)的二价效应子结构,使得效应子适合例如用于诊断评估的夹心elisa中的检测。在一些实施方案中,效应子局部部分一起产生可以在模板化组装反应后检测到的信号,如荧光。
模板化组装靶标的鉴定可包括使模板化组装反应物与靶核酸杂交。
来自所关注来源的核酸,如dna或rna,可以与模板化组装反应物杂交以选择性地结合寡核苷酸序列。靶核酸能够根据标准watson-crick、hoogsteen或反向hoogsteen结合互补规则与寡核苷酸碱基配对时,为该寡核苷酸的“互补序列”或与之“互补”。
如本文中所用,术语“互补”和“互补序列”是指包含连续核苷酸或半连续核苷酸序列(例如,分子中不存在一个或多个核苷酸部分),即使并非所有核苷酸都与对应核苷酸碱基配对,也能够与可为连续、半连续或非连续核苷酸的靶核酸链或双链体杂交的寡核苷酸。在一些实施方案中,“互补”核酸包含其中约70%、约71%、约72%、约73%、约74%、约75%、约76%、约77%、约77%、约78%、约79%、约80%、约81%、约82%、约83%、约84%、约85%、约86%、约87%、约88%、约89%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%至约100%及其中可推论的任何范围的寡核苷酸序列能够在杂交期间与单链或双链靶核酸碱基配对的序列。在一些实施方案中,术语“互补”正如本领域普通技术人员将理解的那样,是指可在严格条件下与靶核酸链或双链体杂交的寡核苷酸。
在一些实施方案中,“部分互补的”核酸包含可在低严格度条件下与单链或双链核酸杂交的序列,或含有其中少于约70%的核苷酸序列能够在杂交期间与单链或双链核酸分子碱基配对的序列。
杂交之前,修饰为核酸模板反应物的寡核苷酸进行瞬时热变性步骤(2分钟/80℃)。将样品暴露于有益于通过互补寡核苷酸与可接近的靶核酸序列段杂交的条件。
任何核酸均可以是用于核酸模板化组装的可能靶核酸,条件是至少一些序列信息可用,足以直接或间接结合寡核苷酸。核酸识别部分单元的一些非限制性实例可包括寡核苷酸、肽核酸寡聚物和吗啉寡聚物。靶核酸序列或寡核苷酸的一些非限制性实例可包括mrna、基因组或细胞器dna、附加体或质粒dna、病毒dna或rna、mirna、rrna、snrna、trna或任何其它生物或人工核酸序列。
在一些实施方案中,靶核酸可在靶区室内存在,但在非靶区室内不存在。这个实施方案的实例包括致病或患病细胞中存在,但在健康细胞中不存在的核酸序列。如本文中所用,短语“致病细胞”可以指能够引起或促进患病或异常状况的细胞,例如感染病毒的细胞、肿瘤细胞和感染微生物的细胞。
含靶核酸的任何细胞、病毒、组织、空间区域、裂解物或样品的其它子组分可以提供靶核酸。含靶核酸的靶区室可以包括但不限于致病细胞、癌细胞、病毒、感染病毒或其它病原体的宿主细胞,或有助于自身免疫性的免疫系统的细胞,例如适应性或先天性免疫系统、移植排斥或过敏反应的细胞。在一些实施方案中,靶核酸可存在于病毒或感染病毒的细胞中,但在健康细胞中不存在。病毒的一些非限制性实例包括dna病毒、rna病毒或逆转录病毒。在一些实施方案中,靶核酸可存在于肿瘤或癌细胞中,但在健康细胞中不存在。癌症的一些非限制性实例可包括由致癌病毒,例如人乳头瘤病毒、爱泼斯坦-巴尔病毒(epstein-barrvirus)、乙型肝炎病毒、丙型肝炎病毒、人t淋巴细胞病毒、默克尔细胞多瘤病毒(merkelcellpolyomavirus)和卡波西肉瘤(kaposi'ssarcoma)相关疱疹病毒引起的癌症。在一些实施方案中,靶核酸可存在于感染物或微生物,或受感染物或微生物感染的细胞中,但在健康细胞中不存在。感染物或微生物的一些非限制性实例可包括病毒、细菌、真菌、原生生物、朊病毒或真核寄生物。
靶核酸序列也可以是基因,例如致癌基因、突变基因、致癌病毒基因、病毒核酸序列、微生物核酸序列、差异表达基因及其核酸基因产物的片段、部分或局部。
病毒特异性靶核酸的一些非限制性实例包括dna病毒、rna病毒或逆转录病毒中存在的序列。癌症特异性核酸的一些非限制性实例可包括源自致癌病毒,包括但不限于人乳头瘤病毒、爱泼斯坦-巴尔病毒、乙型肝炎病毒、丙型肝炎病毒、人t淋巴细胞病毒、默克尔细胞多瘤病毒和卡波西肉瘤相关疱疹病毒的序列。癌症特异性靶核酸的实例可包括突变致癌基因,如突变的ras、hras、kras、nras、braf、egfr、flt1、flt4、kdr、pdgfra、pdgfrb、abl1、pdgfb、myc、ccnd1、cdk2、cdk4或src基因;突变肿瘤抑制基因,如tp53、tp63、tp73、mdm1、mdm2、atm、rb1、rbl1、rbl2、pten、apc、dcc、wt1、irf1、cdk2ap1、cdkn1a、cdkn1b、cdkn2a、trim3、brca1或brca2基因;及在癌细胞中表达的基因,其中该基因可能未经突变或遗传改变,但在施用时在样品的健康细胞中不表达,如癌胚抗原。
靶核酸可以在使模板化组装反应物中的寡核苷酸与靶核酸杂交之前获得。靶核酸可进一步分离自靶样品,如细胞群体、肿瘤、组织或器官。靶核酸也可存在于全细胞裂解物而非分开或分离的其它细胞物质中。在一些实施方案中,在杂交之前保持靶核酸的天然二级结构。
在一些实施方案中,与非靶区室相比,靶核酸可按有差异的量或浓度存在于靶区室内。实例包括但不限于在癌细胞中以不同于健康细胞的水平表达的基因,如myc、端粒酶、her2或细胞周期依赖性激酶。在一些实施方案中,靶核酸序列可以是在靶区室内相对于非靶区室至少1.5x倍或2.0x倍差异性表达的基因。这些的一些实例可以包括但不限于与介导i型过敏反应相关的基因,对其而言靶rna分子含有免疫球蛋白ε重链序列;在t细胞亚群中表达的基因,例如特异性t细胞受体(tcr),其在特定主要组织相容性(mhc)蛋白如胰岛素原来源的肽和含有源自致糖尿病cd8+t细胞的α或β可变区序列的克隆特异性mrna的的情况下识别自身抗原;其生成可通过加剧炎症反应而具有不良结果的细胞因子,包括但不限于tnf-α、tnf-β、il-1、il-2、il-4、il-6、il-8、il-10、il-12、il-15、il-17、il-18、il-21、il-22、il-27、il-31、ifn-γ、osm和lif。
在一些实施方案中,靶核酸存在于靶区室和可接受的非靶区室亚类中,但不存在于不同或有差别的非靶区室亚类中。一些非限制性实例可包括在癌细胞中表达并限于健康细胞类别的基因,例如癌-睾丸抗原、存活素、前列腺特异性抗原、癌胚抗原(cea)、甲胎蛋白和其它癌胚蛋白。同样,面对严重的疾病,许多组织和器官对其它健康生活来说并不是必不可少的。例如,黑素细胞抗原如melan-a/mart-1和gp100在许多恶性黑素瘤以及正常黑素细胞上表达,并且靶向这些抗原的疗法可以破坏肿瘤和正常黑素细胞两者,导致白癜风,但主要肿瘤减少。同样,当这些组织的肿瘤出现时,生殖器官可经手术切除,如睾丸、卵巢和子宫,以及相关器官如乳腺和前列腺可被靶向,并且这些器官内正常组织的破坏可以是可耐受的疗法结果。此外,产生激素,如甲状腺素和胰岛素的一些细胞可以用相关的肽或蛋白质代替,从而允许潜在靶向在这些起源的肿瘤的存在下可能存在的正常细胞。
靶核酸也可包括先前未鉴定的新序列。在一些实施方案中,可以通过序列分析,如下一代测序、全转录组(rna-seq)或全基因组测序、微阵列分析、基因表达(sage)的连续分析来评估样品,以确定样品的基因组成。靶核酸序列可以鉴定为存在于靶区室中,但不存在于非靶区室中,或者与非靶区室相比在靶区室中以不同的量或浓度存在的那些。然后通过这种方法鉴定的序列可用作靶核酸。
模板化组装反应物的寡核苷酸序列可在具有不同严格度的杂交条件下杂交。短语“杂交条件”是指寡核苷酸将与其靶核酸杂交,通常是在核酸的复杂混合物,如全细胞裂解物中,但不与其它序列杂交的条件。杂交条件是序列依赖性的并且在不同情况下将会不同。较长的序列在较高的温度下特异性杂交。在tijssen,techniquesinbiochemistryandmolecularbiology--hybridisationwithnucleicprobes,“overviewofprinciplesofhybridizationandthestrategyofnucleicacidassays”(1993)中发现了对核酸杂交的广泛指导。通常,将杂交条件选择为比特定序列在限定的离子强度ph下的热熔点(tm)低约5-10c。tm是50%与靶标互补的寡核苷酸与靶核酸杂交平衡时的温度(在限定的离子强度、ph和核酸浓度下)(因为靶核酸过量存在,在tm下,50%探针在平衡时被占有)。
具有寡核苷酸序列的模板化组装反应物在杂交期间可超过靶核酸过量存在。在一些实施方案中,寡核苷酸可以比靶核酸以约10-100倍过量存在。寡核苷酸可以比靶核酸以约5x、10x、15x、20x、25x、30x、35x、40x、45x、50x、55x、60x、65x、70x、75x、80x、85x、90x、95x、100x、125x、150x、200x、300x或之间的任意数量过量存在。
虽然可容许比靶模板过量的具有寡核苷酸序列(效应子局部)的模板化组装反应物,但是相反的情况(过量的靶模板)可降低模板化组装效力。这种“模板滴定”效应表明模板水平的定量是非常有用的,和鉴定rna靶分子内的合适特异性位点一样。关于模板化组装的应用,极低水平的rna靶标也可能产生相反效果。因此,受稳态模板水平和其它因素(包括靶位点接近效率)影响,对于特定模板而言可能存在理想范围。
杂交条件可以是其中盐浓度低于约1.0m钠离子,在ph7.0至8.3下通常为约0.01至1.0m钠离子浓度(或其它盐)并且温度对于短探针(例如,10至50个核苷酸)而言为至少约30c而对于长寡核苷酸(例如,大于50个核苷酸)而言为至少约60c的条件。杂交条件也可以利用添加去稳定剂如甲酰胺实现。对于选择性或特异性杂交,阳性信号是本底的至少两倍,任选地为本底杂交的10倍。示例性杂交条件可以如下:50%甲酰胺、5xssc和1%sds,在42c下孵育,或5xssc、1%sds,在65c下孵育,在65c下于0.2xssc和0.1%sds中洗涤。此类杂交和洗涤步骤可进行,例如5、10、15、30、60、90或更多分钟。在一个示例性实施方案中,此类杂交和洗涤步骤可进行2-16小时的时间段。
也可在杂交之后去除过量的未结合的模板化组装反应物。可通过本领域常用的方法,例如但不限于酶消化、超滤或凝胶尺寸排阻色谱法去除未结合的模板化组装反应物。
杂交也可相继进行。在一些实施方案中,第一群体的模板化组装反应物与靶核酸杂交。可去除第一群体的过量的未结合的模板化组装反应物。然后第二群体的相应的模板化组装反应物可与已经与第一群体的杂交的靶核酸杂交。也可去除第二群体的过量的未结合的模板化组装反应物。
核酸模板化组装使两个或更多个模板化组装反应物接近以产生模板化组装连接产物。如本文中所用,短语“模板化组装连接产物”是指通过一种或多种模板化组装反应物的相互作用、结合或反应形成的产物结构。模板化组装连接产物可包括能够产生所需生物活性的活性效应子产物。通过单独的模板化组装反应物以位置和/或取向特异性方式,通过结合相互作用,例如与靶核酸的杂交和退火来组装而促进模板化组装连接产物形成。在单个靶模板上聚集在一起以参与模板化组装反应的模板化组装反应物在本文中被称为“一组相应的反应物”或“相应的模板化组装反应物”。一组相应的模板化组装反应物以序列特异性方式结合核酸靶模板的空间接近部分,并且彼此容易反应以生成包括活性效应子结构的模板化组装连接产物。
模板化组装反应可以是但不限于以下反应:点击化学反应、施陶丁格化学反应、非无痕施陶丁格连接、无痕施陶丁格连接、天然化学连接和其它模板组装反应。在一些实施方案中,模板化组装反应可以是无痕膦酚施陶丁格连接或无痕膦甲硫醇施陶丁格连接。在一些实施方案中,可进行点击反应。
模板化组装反应在美国申请第61/831,133号中进一步公开,其通过引用整体并入本文。
模板化组装后可去除过量的未结合的模板化组装反应物。可通过本领域常用的方法,例如但不限于酶消化、超滤或凝胶尺寸排阻色谱法去除未结合的模板化组装反应物。
鉴定靶核酸可包括以下的任一种或组合:扩增反应或未反应的模板化组装反应物;选择性裂解反应或未反应的模板化组装反应物;将反应的模板化组装反应物与未反应的模板化组装反应物微区室化;并且将来自模板化组装反应物的寡核苷酸测序。
可通过用与特定寡核苷酸携带的引发位点互补的引物扩增互补反应的模板化组装(close)反应物,进行靶核酸的鉴定。只有已经通过特异性模板化组装反应化学连接且形成三唑产物的模板化组装反应物对(分别来自每个单独修饰的群体)可能通过pcr,借助于反应物间产生的特异性键联扩增。
除了靶rna序列内连续的用于模板化组装的效应子局部位点外,非连续(不连续)靶位点也可能有效,条件是借助于折叠rna二级结构或其它高级结构排列使其空间接近。此类二级结构基序的非限制性实例包括茎环、环内的内部位点和假结。
来自模板化组装反应物的寡核苷酸可按空间接近方式与靶核酸杂交,然而不能促进可扩增模板化组装反应键联。这可能发生在杂交使非生物可扩增的5'-5'或3'-3'末端并置时,或者模板组装反应物的5'-和3'-修饰末端之间的模板组装反应产生尺寸或结构与聚合酶不相容的产物时。
也可进行反应的模板化组装反应物或已反应产物的选择性裂解。已反应产物超过未反应产物的限制性消化可以利用工程化为与寡核苷酸序列相邻的引物位点或接头序列的位点。还可用甲基化特异性酶区分已反应和未反应产物。在一些实施方案中,可以使用对5-甲基胞嘧啶半甲基化敏感的裂解酶。在一些实施方案中,可通过聚合酶延伸使已反应产物为双链。可以用识别引物位点或接头序列中的限制性位点的酶裂解所得双链体。
裂解的已反应产物也可经酶促连接以保留近侧杂交序列之间的键联信息并且能够进行扩增。
也可以使用体外区室化通过将未反应链隔绝到单独分离的区室内,防止其与可产生假扩增信号(并非由原始模板化组装反应产生的信号)的其它未反应链的连接或反应,将模板化组装反应键联依赖与未反应的模板化组装反应物分离。这些条件可以通过形成可以由任何适合的不混溶液体组合产生的乳液来实现。亲水溶剂形成微观或胶体尺寸的“水性”液滴。“液滴”在本文中也称为“微区室”。胶体中的水性液滴可以由适于形成乳液的任何亲水性材料形成,其中含有稳定形式的生化组分;并提供可以发生所述反应的环境。
可通过添加一种或多种表面活化剂(表面活性剂)使乳液稳定。这些表面活性剂被称为乳化剂,并且在亲水/疏水界面处起到防止(或至少延迟)分相的作用。许多疏水性液体如油和许多乳化剂可用于产生双相乳液;最新的汇编物列出了超过16,000种表面活性剂,其中许多用作乳化剂(ash,m.和ash,i.handbookofindustrialsurfactants.gowerpublishingltd:aldershot,hampshire,uk(1993);及schick,nonionicsurfactants.marceldekker:n.y.(1996))如山梨糖醇酐单油酸酯(spantm80;ici))和聚氧乙烯山梨糖醇酐单油酸酯(tweentm80;ici))。
寡核苷酸的序列可以使用任何合适的测序方法测定并验证,包括但不限于化学降解(a.m.maxam和w.gilbert,methodsofenzymology,1980,65,499-560)、基质辅助激光解吸电离飞行时间(maldi-tof)质谱法(pieles等人,nucleicacidsres.,1993,21,3191-3196)、碱性磷酸酶和外切核酸酶消化后的质谱法(wu等人,anal.biochem.,2001,290,347-352),等等。
在一些实施方案中,可通过扩增已反应或未反应的模板化组装反应物并将来自已反应的模板化组装反应物的寡核苷酸测序来鉴定靶核酸。
还公开了富集模板化组装反应物的方法。富集可以用与病理、病态、所关注的异常细胞或特定细胞核酸靶标具有相关性的模板化组装靶标选择已反应的模板化组装反应物。
在一些实施方案中,从空间引发的化学连接寡核苷酸(close)产物文库富集一对模板化组装效应子包括获得由于与细胞核酸靶标的空间接近性通过模板化组装而化学连接的寡核苷酸文库,扩增连接的寡核苷酸-细胞核酸靶标文库,并且选择性富集连接的寡核苷酸-细胞核酸靶标,其中出于与所关注的异常细胞病理或与细胞核酸靶标不连续杂交的相关性对连接的靶标进行选择。
在一些实施方案中,可以对特定的靶rna富集已经与细胞rna靶源杂交的模板化组装效应子,其中这些是从先前的观察结果已知的。此类靶向富集可以在空间接近的close效应子的化学连接之后应用,并且在本文中被称为“靶向close”。所需靶向富集可以通过结合总细胞rna的close文库亚群和对应于所关注靶标的特异性核酸探针序列之间的杂交来实现。使close子文库和探针两者呈现为适当互补性的单链时,此类杂交是最有效的。
如本文中所用,“空间引发的化学连接寡核苷酸”是指由于由于它们的空间接近性,已经通过与靶核酸模板杂交而化学连接的成对寡核苷酸。
大的close集合被称为close文库,其可以呈原始、重排或扩增形式。原始close文库包括由空间激活反应引起的模板化组装反应的化学产物。扩增的close文库可直接从具有可读化学连接点的原始文库的pcr得到,或间接得到,其中如同用重排文库所实现的,pcr受引发位点操作允许。在一些实施方案中,close产物包括化学连接的寡核苷酸的短pcr产物双链体。可通过用与特定寡核苷酸携带的引发位点互补的引物扩增化学连接的寡核苷酸,进行close产物的扩增。只有已经通过模板化组装反应化学连接的寡核苷酸对(分别来自每个单独修饰的群体)可能通过pcr,借助于寡核苷酸之间产生的键联扩增。
模板化组装后还可去除过量的未结合的模板化组装反应物。可通过本领域常用的方法,例如但不限于用聚乙二醇8000(peg)连续沉淀、酶消化、超滤或凝胶尺寸排阻色谱法去除未结合的模板化组装反应物。
消减法也可用于富集close文库中连接的寡核苷酸对。来自close文库的源自靶细胞或组织的连接寡核苷酸对可富集超过源自不同细胞或组织的连接寡核苷酸对。在一些实施方案中,源自异常靶细胞的连接寡核苷酸对可富集超过源自正常细胞对应物的连接寡核苷酸对。在一些实施方案中,可通过从所关注的正常细胞去除连接靶标,富集来自所关注的异常细胞的连接靶标。可在源自异常靶细胞和正常细胞的连接寡核苷酸对的文库之间实现消减,其中在杂交之后通过固相链霉亲和素结合去除生物素化的正常序列。消减后剩余的连接寡核苷酸对可进一步加工用于鉴定。
还公开了评价用于模板化组装的一对空间引发的化学连接寡核苷酸(close)产物的方法。该对作为模板化组装反应物的close产物可修饰为易于和另一模板化组装反应物上的相应修饰相互作用,但将不易与天然生物分子相互作用。所述修饰可赋予在模板化组装反应中的反应性,例如在模板化组装反应中的选择性反应部分反应性。选择性反应部分的实例可包括添加生物正交反应部分。在一些实施方案中,可在close产物上添加芘基,如芘马来酰亚胺。
与上述类似,close产物还可包括5’和/或3’引发位点,和/或中间体,如接头或间隔子。close产物也可进一步加工用于如本文所述的鉴定。
在一些实施方案中,公开了用于鉴定模板化组装靶标的模板化组装反应物文库。该文库可包括模板化组装反应物。在一些实施方案中,该文库包括第一和第二群体的模板化组装反应物,其中模板化组装反应物包括寡核苷酸序列和用于在模板化组装反应中反应的修饰。
在一些实施方案中,文库可包括空间引发的化学连接寡核苷酸(close)产物。该文库还包括至少一对经富集为包括由于它们的空间接近性通过与细胞核酸模板杂交而化学连接的寡核苷酸的模板化组装靶标。close文库可包括化学连接产物的扩增文库及源自异常靶细胞与正常细胞相比富集的寡核苷酸。
本文描述的试剂盒可用于发现所关注细胞中的新模板位点。这些可以是靶rna模板的连续区段中的线性位点,相同靶模板中的不连续(构象激活)位点,或经由特异性细胞内形成的高级核酸或核蛋白复合物并置的单独模板内的位点。
对所关注细胞有特异性的模板位点可用本文描述的试剂盒和方法鉴定并且用作鉴定其它细胞大背景下所关注的此类细胞的存在的诊断标准。例如,在血液、尿液、腹水、脑脊髓液、支气管灌洗液、口腔洗液和痰、巴氏涂片、组织活检或器官、胆汁、粪便物或其它体液或部分的样品中。
在检测是基于荧光的实施方案中,试剂盒可包括模板化组装反应物,在模板化组装反应物例如芘激基缔合物和荧光检测试剂连接后产生荧光信号。在一些实施方案中,试剂盒可包括模板化组装反应物,在模板化组装反应物连接后催化酶促反应,及用于酶读数例如但不限于elisa的检测试剂。
可采用一组相应的模板化组装反应物和受试者的诊断试验评估。这种评估可用于确定一组特定的模板化组装反应物是否可以有能力在给定受试者中产生效应子结构。如果先前尚未使用模板化组装反应物,或者如果当前样品与先前样品明显不同,例如样品含有比先前样品水平低的靶核酸,则这可能有用。所述试剂盒和诊断法也可检测样品中靶核酸的存在或不存在或样品中靶核酸的丰度。所述试剂盒和诊断法也可用于确定核酸靶标对于模板化组装反应是否是可接近的,从而提供关于样品中核酸靶标的二级结构的信息。在一些实施方案中,可以测定模板化组装反应物用于鉴定靶核酸的能力。
所述试剂盒和诊断法可包括使相应的模板化组装反应物与一种样品或多种样品接触。还包括对通过成功的模板化组装反应产生的活性的方便体外读数的鉴定。此类读数可包括但不限于酶活性如夹心酶联免疫吸附剂和磷酸酶测定,磷光、免疫荧光、生物发光等可进行。
为了进行体外夹心式诊断评估测定,可以进行以下步骤。可从受试者获得样品以在体外测定。任选地,获得靶区室样品(例如,肿瘤活检)和非靶区室阴性对照(例如,健康组织的样品)。可在合适的缓冲液中裂解样品以释放核酸,这可促进易用性或增加测定的灵敏度。可向样品或裂解物施用模板化组装反应物。当存在靶核酸时,形成模板化组装连接产物。
然后连接产物可被固定的捕获分子结合。所述分子可以固定在容器如微量滴定板孔上,或基质如与测定培养基混合的琼脂糖珠或磁珠上。可以去除样品材料和非连接反应物并且可洗涤固定的复合物。对模板化组装连接产物的可接近部分有特异性的检测分子可以与固定的复合物一起孵育,并且可进行适当的检测读数。在一些实施方案中,检测分子、捕获分子或两者的特异性可选择性检测模板化组装连接产物上在进行模板化组装反应之前在任何模板化组装反应物上不存在的结构,使得可以捕获和/或检测模板化组装连接产物。例如,捕获分子的特异性选择性检测在起始模板化组装反应物中不存在的效应子产物结构,确保仅捕获和检测出模板化连接产物。
在一些实施方案中,检测分子的特异性可选择性检测一种模板化组装反应物上的结构,而捕获分子的特异性可选择性检测不同模板化组装反应物上的结构,使得模板化组装连接产物将包括两种结构并且因此被检测到。单一化合物上所含的多组模板化组装反应物可能与这个实施方案不相容。
为了更有效地理解本文公开的主题,下面提供了实施例。应当理解,这些实施例仅用于说明目的,而不应解释为以任何方式限制所要求保护的主题。
实施例:
实施例1:使用在带有预先附接的引物位点的寡核苷酸之间产生可扩增键联的模板化组装反应物文库,从样品中鉴定模板化组装靶序列或结构(实际实施例)
合成两个rdo群体。在基于亚磷酰胺的合成期间,由25:25:25:25da:dc:dg:dt比率构成随机区域。一个合成群体具有5’-碘-dt修饰用于随后化学转化为5’叠氮基,和pcr引物的3’-引发位点,其用经设计防止从这个末端不必要的聚合酶延伸的3’-磷酸基团加帽。另一个群体带有pcr引物的5’-引发位点和3’-5-甲基-c炔修饰(炔丙基)。图1a、1b、1c和1d中描绘了这些寡核苷酸的构型。
来自所关注的细胞来源的rna与随机寡核苷酸群体杂交。一种原理依赖于来自每个文库的特定成员与可接近的细胞rna序列段的杂交。来自两个文库的两个寡核苷酸都以足够的空间接近性退火为rna序列时,点击反应性是合适的。所引起的此类近侧链的化学连接允许其后续扩增和鉴定。杂交之前,经修饰的寡核苷酸进行瞬时热变性步骤(2分钟/80c),但是由于需要保留天然二级结构,这不适用于rna靶标。也可按等效方式筛选全细胞裂解物,其中使用蛋白酶和rna酶两种以便保护内源性天然折叠rna或核糖核蛋白结构。
rna可通过任何标准程序制备,包括但不限于,来自商业供应商的试剂盒如qiagen和norgen。
可制备呈温和条件下获得的全细胞质裂解物形式的rna。可实现此类条件,但不限于用20mmtrisph7.4、10mmnacl和3mmmgcl2的低渗缓冲液进行渗透性裂解的实例。细胞裂解应在用蛋白酶抑制剂与1mm苯甲磺酰氟的混合物(pmsf)保护蛋白质时,并且还在氧化不敏感型核糖核酸酶抑制剂,例如(但不限于)鼠rna酶抑制剂(newenglandbiolabs)的存在下进行。
同时用两个随机化学修饰的群体在相对于彼此按摩尔浓度计的50:50混合物中,通过假定1500个碱基的细胞rna的平均分子量计算,比存在的rna量10-100倍过量,并用1-10微克的起始rna进行rna-寡核苷酸杂交。杂交可进行2-16小时的时间段。可以在50mmtrisph7.5、10mmmgcl2、100mmnacl、1mm二硫赤藓糖醇和2.4个单位/ml的鼠rna酶抑制剂(newenglandbiolabs)中进行杂交。
当杂交步骤完成时,通过peg沉淀、超滤或凝胶尺寸排阻色谱法去除未结合的寡核苷酸。(只要条件利于dna:rna双链体存留,已经与细胞rna杂交的随机寡核苷酸将随rna共同纯化)。
在替代性程序中,通过用dna酶i处理而耗尽未结合的寡核苷酸,其中杂交的rna:dna双链体对dna酶i作用不敏感,并且通过用2’-o-甲基互补链双链体化来保护未杂交的引物位点p1和p2(图1c、图1d)。dna酶i处理可用作其它纯化方法的替代,或连同后续peg沉淀、超滤或凝胶尺寸排阻色谱法使用。
然后在50-100μl体积中进行cu(i)点击催化反应30-60分钟/25c。直至这个步骤完成,最好尽可能使用无rna酶的严格条件和合适的rna酶抑制剂,保持靶细胞rna的结构完整性。可用商业试剂盒,或用本领域已知的单独组分进行cu(i)-点击催化。可选地,可使用特异性螯合剂,包括但不限于化合物tbta、thpta、bttaa和bttes递送cu(i)组分(besanceney-webler等人,angewandtchemieinternationaledition,2011,50,8051-8056)。
在cu(i)催化的点击反应完成之后,为制剂脱盐以去除铜离子,最方便的是使用小的一次性离心柱(biorad或pierce)。
然后用匹配选自原始随机群体的特异性寡核苷酸所携带的引发位点的引物进行pcr。只有已经化学连接的寡核苷酸对(分别来自每个单独修饰的群体)可能通过这种pcr方法,借助于所用特异性5’-叠氮化物/3’-炔寡核苷酸所产生的“生物相容性”三唑键联扩增(图2)。可通过连续位点或通过靶rna折叠并置的位点促进此类连接(图2)。产品仅可由已经以正确取向与靶模板退火的close寡核苷酸形成(图3a、3b、3c)。
实施例2:close文库的高容量测序和差异性生物信息学分析(预示性实施例)
为了方便起见本文用首字母缩写词close(指示空间引发的化学连接寡核苷酸)指由于它们的空间接近性已经通过与细胞rna模板的杂交而化学连接的任何成对的寡核苷酸。大的close集合被称为close文库,其可以呈原始、重排或扩增形式。
原始close文库含有由空间激活反应直接引起的点击化学反应的化学产物。因此扩增的close文库直接从具有可读化学连接点的原始文库的pcr得到,或间接得到,其中pcr已变得受引发位点操作允许,如同用重排文库所实现的。
任何扩增的close文库(直接或间接的)都是所用pcr引物和引发位点所限定的化学连接寡核苷酸和最初连接的空间相邻的寡核苷酸对的短双链体的大集合。
来自所关注的异常细胞与其正常对应物的扩增close文库可直接进行测序和生物信息学分析。更集中的方法采用差异性消减杂交来缩小候选物的范围。
从凝胶上切除对应于原始close文库的pcr扩增产物的条带并克隆。
在close克隆的一些实施方案中,借助于由用taqdna聚合酶扩增产生的1-碱基5’da悬突克隆切除的条带。将此类5’da-close片段克隆到具有单碱基5’dt悬突的质粒载体中。在合适的大肠杆菌(e.coli)宿主中分离大量质粒克隆作为小型制剂,并将其用来自close插入物上游和下游的引物进行常规的自动化测序,放置在足够距离处,使得完成close插入物的通读。
测序的close克隆一致地呈预期构型,其中(+)链22-聚体二聚体(对应于原始单链寡核苷酸)(从l-到r-,图1a、1b、1c和1d)为5’n10-ct-n10。将一系列任意选择的close克隆序列与一组随机产生的相同模式的序列做比较(图4)。close系列具有明显高于在纯随机基础上预计的gc含量,表明基于杂交的选择程序利于由更高gc水平所赋予的更高稳定性。
在close克隆的一些实施方案中,制备切除条带用于根据illumina方案进行下一代测序。在close克隆的一些实施方案中,制备切除条带用于根据其它下一代测序方案进行下一代测序,包括但不限于焦磷酸测序、abisolid测序、helicos、nanopore测序和iontorrent测序方案。
当来自异常细胞来源的大量close克隆已经测序时,谨慎的做法是根据它们的分化状态和细胞表达表型、基因型和多态性分布,将积累的序列数据与来自正常细胞的相应数据进行比较,尽可能严格地与异常细胞靶标匹配。这种分析对应于硅片消减法。
通过与用于来自异常细胞的所关注的的close文库的方法对应,从经扩增的close文库的序列close克隆的匹配的正常细胞获得序列数据。
将来自所关注的异常细胞和匹配的正常细胞的多组close序列数据进行生物信息学分析。每个close序列的(+)链可定义为被ct二核苷酸隔开的两个十聚体序列段,对应于(扩增后)原始寡核苷酸所带有的3’-(5-甲基)-dc-炔丙基和5’-dt-叠氮基之间的化学连接点。
排除候选close克隆的选择标准包括:未能找到任一个十聚体序列段和所关注细胞的表达或基因组序列之间的任何显著匹配。“显著性”在此定义为任一序列段至少70%匹配。
来自所关注的异常细胞来源的close序列对将按它们从克隆close文库的随机挑选(通过常规克隆和测序)中出现的频率来分级。
使用频率分级标准作为程序指南,将针对来自相应正常来源的close对筛选来自异常细胞来源的close对。鉴定出与正常细胞来源匹配时,将来自异常细胞的匹配close对从进一步分析中排除。
将异常close序列对标记为受特别关注的其它标准是:1)构成close对的任一个或两个十聚体序列匹配与所关注的异常细胞的病理有潜在相关性的序列,或2)将close对匹配鉴定为在相同rna链上或在独立rna链上不连续出现时。
记录的肿瘤细胞的潜在关注的序列包括但不限于已知致癌基因或肿瘤抑制因子、细胞周期调节子和介质、转录调节子和介质、翻译调节子和介质、端粒酶、细胞骨架组分和激酶的基因组或表达基因。
实施例3:利用close文库通过物理close文库消减来鉴定对所关注的细胞有特异性的序列或结构(预示性实施例)
可在源自异常靶细胞和正常细胞的连接寡核苷酸对的文库之间实现消减,其中在杂交之后通过固相链霉亲和素结合去除生物素化的正常序列。
根据本文公开的方案获得的扩增close文库源自所关注的异常细胞。
选择尽可能与所关注的异常细胞的相同谱系和分化状态密切匹配的正常细胞。非限制性实例包括:黑素瘤细胞、正常黑素细胞、b淋巴瘤、正常b细胞、t淋巴瘤和正常t细胞。
从所关注的匹配的正常细胞获得close文库。除使用初始寡核苷酸中的不同引发位点(p3、p4)外,以与相应异常细胞相同的方式制备此类文库(图5)。同样,用于最终扩增步骤中的引物应带有5’-生物素基团,使得扩增的close产物本身在两条链上经生物素化(图5)。
由pcr反应获得时,正常和异常close文库两者经苯酚萃取并用0.3m乙酸钠和2.5体积的乙醇沉淀,用70%乙醇洗涤,干燥并重新溶于20μlte中。然后将正常的生物素化扩增close文库与来自异常细胞的其对应物非生物素化文库,按正常:异常close产物10:1的比率混合。使混合文库在95℃下变性10分钟,然后缓慢冷却至室温。
然后用过量的固相链霉亲和素处理重新杂交的产物以固定和去除所有生物素化链。在非限制性实施方案中,固相链霉亲和素可以是链霉亲和素磁珠或链霉亲和素-琼脂糖。所用任何固相链霉亲和素基质的结合能力应是生物素化寡核苷酸总摩尔数至少10倍过量。
然后将固相链霉亲和素基质与未结合的非生物素化剩余物分离,剩余物由来自异常细胞close文库,尚未与来自相应正常细胞文库的生物素化寡核苷酸杂交的寡核苷酸构成。在使用链霉亲和素磁珠的实施方案中,磁力分离器完成固相链霉亲和素的下拉。在使用链霉亲和素-琼脂糖的分离实施方案中,通过以5000g/10分钟离心来分离固相链霉亲和素。
然后使用对来自所关注的异常细胞来源的close文库有特异性的引物扩增可溶相材料的样品(图5)。然后使再次扩增的富集close文库进行针对原始正常细胞close文库的第二个消减循环。然后使再次扩增的富集close文库进行针对原始正常细胞close文库的第三个消减循环。然后使再次扩增的富集close文库进行序列分析。
实施例4:利用close文库通过rna选择来鉴定对所关注的细胞有特异性的序列或结构(预示性实施例)
可选地,可通过交叉杂交对(在源自异常细胞本身的群体内)与正常细胞rna来源的结合来选择限于异常细胞的寡核苷酸对。
根据本文的方案获得的扩增close文库源自所关注的异常细胞。
close文库再次扩增,其中引物p1带有5’-脱硫生物素修饰,而引物p2未经修饰(图6)。使半脱硫生物素化的扩增close文库在95℃/10分钟下变性,然后用过量的固相链霉亲和素基质孵育。用tris缓冲盐水洗涤固相链霉亲和素基三次,然后用5mm游离生物素洗脱结合的脱硫生物素链(图6)。为洗脱物脱盐并通过凝胶尺寸排阻色谱法去除过量的游离生物素。
脱硫生物素链对应于与得自与异常rna的原始杂交的原始close文库相同的意义。选择与所关注的异常细胞匹配的正常细胞。从正常细胞来源分离全rna制剂。
使游离的脱硫生物素链变性(80℃/5分钟)并使其与细胞rna制剂杂交和用于原始close文库本身与异常细胞来源的rna杂交相同的时间段。在添加变性close文库之前,rna制剂未热处理。通过假定1500个碱基的细胞rna的平均分子量计算,rna制剂比脱硫生物素链2倍摩尔过量。图7中描绘了这个过程。
通过凝胶尺寸排阻色谱法将杂交的rna-close文库成员与未结合的close文库成员分离。未结合的close文库样品在如以上所公开的相同条件下再次扩增和加工,产生脱硫生物素链的扩增选定群体(图7)。
游离脱硫生物素链在如以上所公开的相同条件下与相同的正常rna靶标杂交。通过凝胶尺寸排阻色谱法将杂交的rna-close文库成员与未结合的close文库成员分离。
在一些实施方案中,用正常(非生物素化)引物再次扩增未结合的close文库的样品,以形成选定双链体链的扩增群体。在一些实施方案中,未结合的close文库的样品在如以上所公开的相同条件下再次扩增和加工,产生脱硫生物素链的扩增次级选定群体。与相同的正常细胞rna靶标杂交之后,选择未结合的脱硫生物素链,然后用正常(非生物素化)引物再次扩增,以形成选定双链体链的扩增次级群体。然后使扩增的未结合的close文库进行序列分析。
实施例5:通过芘激基缔合物荧光对close来源的序列或结构候选物进行评估:确认分子接近性并量化拷贝数,及优化十聚体组成部分(预示性实施例)
应以容许集中于具有驱动高水平模板化组装的最大潜力的特定候选物的这种方式,确认通过以上公开的方法(或其任何组合)鉴定的close候选物,或独立来源的位点的任何候选物对的活性和效率。分子接近性的独立量度是芘分子之间的激基缔合物荧光的引发。
应用以上公开的方法(或其任何组合)之后,close对候选物的每个十聚体组成部分将具有鉴定的可与之杂交的细胞模板。基于通过应用close技术鉴定的已知模板,如它们所靶向杂交的模板的互补序列所指示的那样,在至少一部分情况下,可用于延伸十聚体对中的任一个或两个。延伸可通过热双链体稳定化帮助细胞内模板化。也评估此类延伸和优化的候选物。
一起构成close对的单独十聚体序列独立地重新合成并用芘基标记(图8a和8b)。通过将末端硫醇基并入合成的dna中(视情况而定在5’-或3’-末端处,在每种情况下作为可还原的二硫化物)并且随后使-sh基团与芘马来酰亚胺反应,实现芘标记。
可选地,可通过在芘和马来酰亚胺部分之间具有间隔臂的芘马来酰亚胺,包括但不限于芘-4-马来酰亚胺添加芘基。芘添加位点基于最初使用的close方法的类型。对于用以上一些方法鉴定的close对,芘修饰附接在与分别用于原始叠氮化物和炔修饰相同的5’-和3’-末端(图1a-1d)。由于用以上一些方法鉴定的close对包含十聚体序列段之间的侧翼序列,所以这些种类的对用附接到准确原始序列的芘基或没有原始侧翼序列的十聚体序列段进行评估。
评估芘修饰的close十聚体在与互补dna模板体外杂交后的荧光变化(图8a和8b)。用荧光分光光度计,使用具有不同程度序列错配的对照模板序列测量激基缔合物和单体(e/m)发射光谱之间的比率。激发波长为335nm,单体峰发射波长为375-410nm,激基缔合物发射峰为480nm。
对于细胞内筛选,在具有核酸酶抗性磷酸二酯主链或糖部分的close十聚体的类似物上进行芘修饰。这些包括但不限于2’-o-甲基-核苷酸和硫代磷酸酯核苷酸。
将核酸酶修饰且经芘标记的close十聚体转染至所关注的异常靶细胞中,并且也转染至缺乏准确靶模板的匹配的正常对应物对照细胞中。通过荧光显微镜术评估对应于激基缔合物形成的荧光,并通过分光荧光测定法量化。
激基缔合物阳性信号确认了close寡核苷酸对的空间接近性,并且还借助于其相对信号强度,提供相对转录水平。作为可接近性和模板拷贝数的组合的信号强度从而提供了对配备有效应子局部结构的不同close十聚体之间的相对潜在模板化组装水平的度量。
实施例6:通过qpcr扩增对close来源的序列或结构候选物进行评估:确认分子接近性并量化拷贝数,及优化十聚体组成部分(预示性实施例)
可确认close候选物或独立来源的位点的任何候选物对的效率,并通过点击连接和qpcr评估其靶模板的相对丰度。另外,针对每个候选物对的优化可应用如上所述的相同方法。已经从close文库获得十聚体对时,也可按相同方式评估基于已知靶模板序列的延伸。
用一组替代的引物位点(p1和p2,如图1a-1d)重新合成单独的特定close候选物。在发起倍增的一些实施方案中,对于每个(p1.1/p2.1;p1.1/p2.2;p1.3/p2.3;p1.4/p2.4;和p1.5/p2.5)用不同引物位点合成一组多达五个的独立候选close十聚寡核苷酸。
用rna制剂或含有rna和核糖核蛋白的细胞质裂解物独立地孵育每对单独的close候选物,并且在杂交后去除过量的寡核苷酸。每种制剂在保护免受rna酶的条件下用cu(i)催化进行点击化学连接,然后脱盐。在cu(i)点击介导的连接和脱盐后,用rna酶a、rna酶1f和rna酶iii处理制剂。
然后如图9所描绘和如kono等人,mol.cancerres.,2006,4,779-792所描述,制剂样品进行定量pcr(qpcr)。qpcr探针长度为15-20个碱基,并且与引物p1区的一部分、一个十聚体的整体、与所有close克隆互补的桥接ct二核苷酸和第二十聚体的多达5个碱基互补(图9的s2)。通过也赋予探针特异性)的选定十聚体区)的碱基组成测定特异性探针长度,使得探针-靶标双链体的tm在标准盐条件下为至少62c。每个探针配备有5’-氟和3’-淬灭剂,使得可通过标准taqman化学法量化荧光。
附接的5’-氟可以是但不限于famtm、tamratm、cy5tm、cy3tm、hextm、joetm或roxtm。附接的3’-淬灭剂可以是但不限于bhq1tm、bhq2tm、
设置初始杂交特异性候选close对用于倍增。在倍增实验中,同时添加多达五对单独的特异性close十聚体,以与上述rna或全细胞裂解物靶标杂交。
如上所述处理倍增制剂。倍增组的化学连接的特异性close对在单次测定中用于qpcr,其中由每种情况下对应于特异性十聚体区域的单独探针,并且通过使用连接的对特异性探针-淬灭剂组合来定义每个close对本身。在倍增测定中每个单独靶标的相对水平源自每种情况下的特异性荧光标记物,并且与正常管家基因对照的相应水平相关。
实施例7:通过数字pcr扩增对close来源的候选序列或结构进行评估:确认分子接近性并量化拷贝数,及优化十聚体组成部分(预示性实施例)
可确认close候选物或独立来源的位点的任何候选物对的效率,并通过点击连接和数字pcr评估其靶模板的绝对丰度。如上所述,由于模板滴定的可能性,期望测定靶转录物表达水平。另外,针对每个候选物对的优化可应用如本文所述的相同方法。已经从close文库获得十聚体对时,也可按相同方式评估基于已知靶模板序列(如本文所述)的延伸。
用一组替代的引物位点(p1和p2,如图1a-1d)重新合成单独的特定close候选物。在发起倍增的一些实施方案中,对于每个(p1.1/p2.1;p1.1/p2.2;p1.3/p2.3;p1.4/p2.4;和p1.5/p2.5)用不同引物位点合成一组多达五个的独立候选close十聚寡核苷酸。
每种制剂在保护免受rna酶的条件下用cu(i)催化进行点击化学连接,脱盐并用rna酶处理。然后将每个特定情况下单独得到的制剂样品在分子上分隔到不同区室内,连同taqdna聚合酶、dntp、含1.5mm氯化镁的标准pcr缓冲液、同源引物和用于每个靶向配对十聚体的荧光量化的特异性双标记探针一起用于数字pcr(图10)。
在一些实施方案中,用于数字pcr的组分的分子分隔借助于微区室完成,通过应用可商购的技术来实现,包括但不限于bio-rad和raindancetechnologies分别作为qx100和raindrop系统销售的那些。在一些实施方案中,用于数字pcr的组分的分子分隔通过微流体腔室完成,通过应用可商购的技术来实现,包括但不限于fluidigm销售的那些(biomarksystem)。
分隔的靶标、引物、探针和其它扩增组分的每种制剂进行热扩增,使得在靶标扩增发生时产生特异性荧光信号,其中信号提供对活性区室的数字化量度,并且转而提供对其所涵盖的单独靶分子的量化。区室加工、荧光测量和后续靶标数量的计数是根据生产商的规格和说明进行的。
设置初始杂交特异性close对用于倍增。在倍增实验中,同时添加多达五对单独的特异性close十聚体,以与上述rna或全细胞裂解物靶标杂交。如上所述进行杂交样品和倍增close寡核苷酸的加工。
将含有倍增的化学连接close十聚体对(通过杂交选择)的组合样品分为单独的测定,用于通过数字pcr扩增和分析进行每项特异性靶标测定。不同的靶标用唯一的引物组合和唯一的氟探针标记来指定。
倍增是在杂交水平上进行的,但数字pcr分析是在1-plex水平上进行的。
通过倍增数字pcr分析含有倍增的化学连接close十聚体对(通过杂交选择)的组合样品,其中除以上指定的组分以外,每个特异性引物对(对每个close靶标定义的)和每个荧光标记探针也存在。
每个数字区室含多个引物和探针,但其中每个区室内的特异性是通过引物和探针与每种情况下存在的单个close化学连接的靶分子之间的测序匹配产生的。
根据生产商对以上指定的仪器的规格和说明,如上所述进行数字pcr扩增和分析,具有同时分析多个可依靠其单独的发射波长来区分的荧光信号的附加特征。
在杂交水平和数字pcr分析水平上进行倍增。
实施例8:用于去除未杂交的close寡聚物的dna酶处理,及后续克隆和测序(实际实施例)
叠氮化物和炔修饰的close文库与细胞rna靶标(mu89)在32c下杂交16小时。在20μl具有200pmol的各close文库(先前与2'-o-me互补寡核苷酸退火为它们的引发位点区域)中,用20μgmu89rna或无模板对照进行孵育。所有组分在孵育之前混合,无预热步骤。
杂交后,每份样品在28c下经+/-dna酶处理4小时,接着进行苯酚萃取、脱盐(bio-radp6离心柱于10mmtrisph7.4中)和沉淀。粒化、洗涤和干燥之后,使每份样品进行标准的thpta点击反应。
简言之,按以下顺序添加制备以下组分的预混物:20μl于0.155mnacl中的70mmtris(3羟丙基三唑基甲基)胺(thpta)、4μl于0.155mnacl中的500mm抗坏血酸钠、2μl于0.155mnacl中的100mmcuso4,然后向每根管添加2.6μl的这种预混物用于点击反应,使得最终体积为50μl于x1磷酸盐缓冲盐水中。管在0c下(于冰上)孵育30分钟,然后在25c下孵育2小时。在孵育期结束时,通过如上所述的bio-radp6柱使管内容物脱盐,并且用匹配close寡核苷酸引发位点的引物使各0.5μl(1/100)进行pcr扩增。pcr循环使用递减扩增策略,最终温度为60c,并且在最终递减温度下循环22次。
在15%丙烯酰胺凝胶上分析产物(图11;泳道1,close寡核苷酸+rna模板+dna酶;泳道2,close寡核苷酸+rna模板,无dna酶;泳道3,close寡核苷酸,无模板+dna酶;泳道4,close寡核苷酸,无模板且无dna酶)。结果显示不管是否存在模板都存在close寡核苷酸遗留物(泳道2和4),但只有在rna模板存在时,在dna酶处理后观察到条带(泳道1对比泳道3)。切除泳道1中对应于预期大小的化学连接的close二聚体的条带(扩增的close寡核苷酸+rna模板+dna酶)并用原始引物重新扩增以增加有效产量。
产物用pgem-teasy载体系统(promega)克隆并且用克隆片段插入点上游和下游的引物对单独的质粒克隆测序。经由blast搜索将序列与人转录组做比较。分析的31种克隆中,许多显示与特异性细胞rna匹配,区域内≥16/20的碱基对应于每个单体close寡核苷酸的两个十聚体随机区域。
用对每个候选rna靶标有特异性的引物,通过pcr测试原始mu89黑素瘤细胞源中候选细胞rna的表达。以下rna在mu89中表达并且呈现为初始候选物用于进一步close分析:nol9、otub1(转录变体2)、brca2、mapkapk2和alpk1(转录变体1和2)。
close寡聚物:
1)trt-ak:catctccacctccataacccannnnnnnnnncme–炔丙基(seqidno:45);
2)azc-trt-n2:叠氮化物-dtnnnnnnnnnnaggtgataggtggaggtggta-p(seqidno:46);
用于扩增连接的close寡聚物的引物:
1)trz.f:catctccacctccataac(seqidno:47);
2)trz.r-n2:taccacctccacctatcacct(seqidno:48);
具有2’-o-甲基主链的保护寡核苷酸:
1)trzfco-2om:uggguuauggagguggagaug(seqidno:49);
2)trzr-n2-2om:uaccaccuccaccuaucaccu(seqidno:50);
实施例9:通过连续peg沉淀去除未杂交的close寡核苷酸的方案(实际实施例)
3.2%聚乙二醇8000(peg),在2mnacl的存在下,用于去除几乎所有未杂交的close寡核苷酸。简言之,将黑素瘤细胞系mu89rna(9.0μg;通过qiagenrnaeasy方案制备)与200pmol用等摩尔量的2’-o-me引物位点保护链预先退火(参见实施例8)的close寡核苷酸(各200pmol的寡核苷酸trt-ak和az-trt-n2(参见实施例8),或200pmol无任何保护链预先退火的相同close寡核苷酸混合。每种制剂(50μl最终体积)由50mmtrisph8.3、2.5mmedta、2mnacl、40个单位的鼠rna酶抑制剂(promega)构成,由40%peg原液添加3.2%peg(4μl)作为最终组成部分。于冰上30分钟后,在微量离心机以最大速度将管离心10分钟(≥14krpm)。小心地取出所得上清液并保留,并将团粒重新溶于含相同缓冲液、盐、rna酶抑制剂和peg浓缩物的新鲜溶液中(50μl)。再于冰上30分钟后,如之前那样将管离心,取出上清液并保留,并将最终团粒重新溶于50μlte中。
在2%琼脂糖凝胶上测试最终团粒及第一和第二上清液的样品(5μl,各自的1/10)(图12)。结果显示(未杂交的)寡核苷酸的巨大优势与mu89rna分离并在第一上清液中发现。
实施例10:通过单一peg沉淀和dna酶i处理去除未杂交的close寡核苷酸的方案(实际实施例)
在close加工的另一个实施方案中,单一peg沉淀和dna酶i处理的组合对于去除大部分未杂交的close寡核苷酸是有效的。对于这种方案,必须通过与互补的2'-o-甲基链杂交来保护close寡核苷酸的引发位点免受dna酶i攻击(如实施例8)。使用与实施例9相同的盐和缓冲液条件,使与靶细胞rna(如实施例1中详述的那样进行,最常在30c下)的杂交进行用3.2%peg沉淀。在这之后,使用与实施例8相同的条件进行点击反应(总是使用经相同处理但不含点击试剂的样品的平行对照),随后脱盐。然后,在28c下于x1rqdna酶i缓冲液(promega)中进行dna酶i处理4小时。然后苯酚萃取样品,用20μg糖原/0.3m乙酸钠/3体积乙醇沉淀,团粒化,用1ml70%乙醇洗涤,干燥并于25μlte缓冲液中复原,然后进行pcr分析(如实施例8)。所有处理是在0.6个单位/ml的鼠核糖核酸酶抑制剂(newenglandbiolabs)的存在下进行的,直至dna酶i处理结束。这个过程作为整体在图13中有示意性描绘。获得的结果与图11相当,从而peg/dna酶处理的组合在去除未杂交的close寡核苷酸中是有效的。
实施例11:不同形式的不连续close位点的限定和分析(实际实施例)
当就原始靶rna序列来说这些是不连续的时,应用close方法需要对特异性潜在位点的某些限定。l-和r-close寡核苷酸(图1),由连续杂交位点或靶序列中近侧空间的但不连续的位点形成了具有插入ct序列的22-聚体(图14)。对于后者,沿着模板杂交l-和r-close寡核苷酸的定位对于可以产生位点空间接近性的二级结构种类显著。在本文中,closel-和r-寡核苷酸带有彼此相向的效应子3’和5’末端的排列(连续位点的常规取向)称为“内向”构型;相反取向(效应子3’和5’末端彼此背离)称为“外向”构型(图14)。在许多情况下外向构型将不能促进反应性,因为效应子官能团不指向彼此。然而,在某些二级结构的情况下靶位点的定位可利于外向优于内向构型。这是当在足够大小的靶模板环中存在杂交位点时的情况(图15),其中内向而不是外向取向在空间上分离。这最初是用模型效应子局部(带有炔和叠氮化物点击基团)和设计为通过自互补的内部区域呈现环结构的更长的寡核苷酸测试的。在形成的所得环结构中,这些寡核苷酸具有点击寡聚物的互补位点,呈外向(“环-外向型1”)或内向(“环-内向型1”)构型排列。点击寡核苷酸(5’-叠氮化物和3’-线性炔标记的链各50pmol)和环状模板(50pmol)最初在25μlx1m缓冲液(10mmtrisph7.5、10mmmgcl2、50mmnacl、1mm二硫赤藓糖醇)中通过在80c下加热2分钟并冷却至室温来退火。
然后使来自每次退火(20pmol)的十(10)μl用thpta或在缺乏点击催化剂的等效缓冲液中进行cu(i)点击催化。按以下顺序添加制备以下组分的预混物:20μl于0.155mnacl中的70mmtris(3羟丙基三唑基甲基)胺(thpta);4μl于0.155mnacl中的500mm抗坏血酸钠;和2μl于0.155mnacl中的100mmcuso4。然后向每根管添加2.6μl的这种预混物用于点击反应,使得最终体积为50μl于x1磷酸盐缓冲盐水中。
管在0c下(于冰上)孵育30分钟,然后在25c下孵育2小时。在孵育期结束时,通过如上所述的bio-radp6柱使管内容物脱盐,并且用20μg糖原(sigma)沉淀。离心后,用70%乙醇洗涤团粒,干燥并重新溶于5μlte中。每一种(1μl)的样品在15%尿素变性凝胶上运行并且用sybr-金染色。结果显示了在线性模板上模板化产生的预期点击化学连接产物(图16;泳道2,相对于无点击对照的泳道1)。用环-外向型1看到相应的点击条带(图16;泳道4),但用环-内向型1看到的极少(图16;泳道6),这支持最初的预测。另外的实验表明,外向构型点击活性通过对照寡核苷酸依赖于环二级结构,其中自互补区被最低限度自我相互作用的序列置换。以与上述相同的方式进行退火和点击反应之后,凝胶结果显示了来自具有自互补环的外向构型的点击产物条带(泳道4,图17),但是当去除自互补性时没有产物(泳道6,图17)。就点击互补位点相对于自互补区域的定位来说,图17中的环状寡核苷酸(环-外向型2)不同于图16中所用的(环-外向型1):环-外向型1,点击互补位点距自互补区域1个碱基;环-外向型2,这增加到5个碱基。然而,仍然观察到外向型-点击活性。
图16的寡核苷酸序列:
5’-叠氮化物寡聚物:叠氮化物-tggaccatct(点击寡聚物-1)(seqidno:51);
3’-炔寡聚物:pcttgtccagcme-炔丙基(点击寡聚物-2)(seqidno:52);
线性模板:gaaatagatggtcca|gctggacaagcagaa(seqidno:53);
呈外向构型的具有点击寡核苷酸1和2的互补位点的成环模板(‘环-外向型1’;62-聚体):
gcgcgcgcgctgctggacaagtccttttttccttttttcctagatggtccatgcgcgcgcgc(seqidno:54);
呈内向构型的具有点击寡核苷酸1和2的互补位点的成环模板(‘环-内向型1’;62-聚体):
gcgcgcgcgctagatggtccatccttttttccttttttcctgctggacaagtgcgcgcgcgc(seqidno:55);
图17的寡核苷酸序列:
5’-叠氮化物和3’-炔寡巨物,及线性模板:如同图16。
呈外向构型的具有点击寡核苷酸1和2的互补位点的成环模板(‘环-外向型2’;60-聚体):
gcgcgcgcgctccttgctggacaagttttccttttagatggtccattcctgcgcgcgcgc(seqidno:56)
无自互补区域的环-外向型2的对照寡核苷酸(‘对照-外向型2’;60-聚体):
acggactgcttccttgctggacaagttttccttttagatggtccattccttcatcaaacc(seqidno:57)
加下划线的序列显示了其自互补性使成环成为可能的gc区。黑体序列显示与以上点击寡核苷酸1和2互补的位点。agatggtcca:与点击寡聚物1(seqidno:58)互补;gctggacaag:与点击寡聚物2(seqidno:59)互补。
实施例12:通过茎环与空间接近但非连续的杂交位点的体外点击反应(实际实施例)
进行另外的试验,通过在靶模板中形成茎环致使与点击-标记寡核苷酸(模型效应子局部)互补的位点在空间上接近,使得杂交位点在环本身的外部。设计用于体外点击反应的模板序列,使得连同缺乏此类结构的适当对照序列一起,将在室温下形成茎环结构,其中点击寡核苷酸呈内向构型杂交(图18)。
点击寡核苷酸(5’-叠氮化物和3’-线性炔标记的链各50pmol)和各种模板(50pmol)最初在25μlx1m缓冲液(10mmtrisph7.5、10mmmgcl2、50mmnacl、1mm二硫赤藓糖醇)中通过在80c下加热2分钟并冷却至室温来退火。
然后使来自每次退火(20pmol)的十(10)μl用thpta或在缺乏点击催化剂的等效缓冲液中进行cu(i)点击催化。然后以与实施例11相同的方式进行点击反应。每一种(1μl)的样品在15%尿素变性凝胶上运行并且用sybr-金染色(图19)。
经化学修饰的寡核苷酸由trilink(5’-叠氮化物寡聚物)或universityofwisconsinbiotechnologyfacility(3’-炔寡聚物)制备。
图19的寡核苷酸序列:
5’-叠氮化物寡聚物:叠氮化物-tggaccatct(点击寡聚物-1)(seqidno:51);
3’-炔点击寡聚物:pcttgtccagcme-炔丙基(点击寡聚物-2)(seqidno:52);
线性模板:gaaatagatggtcca|gctggacaagcagaa(seqidno:60);
相邻茎部:agatggtccagtcggcgcgcctcgaaaacgaggcgcgccgacgctggacaag(seqidno:61);
茎部-x1系统空位:
agatggtccatgtcggcgcgcctcgaaaacgaggcgcgccgactgctggacaag(seqidno:62);
乱序的茎部:
agatggtccagcccccaggccgcatacgacggctagggagcggctggacaag(seqidno:63)。
加下划线的序列显示了其自互补性使茎环形成成为可能的区域。黑体序列显示与以上点击寡核苷酸1和2互补的位点。agatggtcca:与点击寡聚物1互补(seqidno:58);gctggacaag:与点击寡聚物2互补(seqidno:59)。
实施例13:通过特异性模板定向杂交产生的芘激基缔合物活性(实际实施例)
芘激基缔合物荧光可用于证明靶模板上close寡核苷酸的分子接近性,并因此用作验证候选靶标的手段。使用以下用于证明在人乳头瘤病毒(hpv)rna模板的dna拷贝上的芘标记的寡核苷酸的特异性的方案。具有2’o-甲基主链的芘寡核苷酸:
pyeto.1:5’-芘-(c6)-uuucuucaggacacag(seqidno:64);
pyeto.2:uccagaugucuuugc-(c6)-芘-3’(seqidno:65);
混合1nmolhpv模板(10μl)和各1nmol的pyeto.1/pyeto.2(各2μl)于100μl的x1“p缓冲液”中(用作10μl的x10原液:200mmtrisph7.4、250mmnacl和50mmmgcl2)并且最终达到100μl。为管准备100μl的pyeto.1/pyeto.2寡核苷酸和以下模板的混合物(图20):hpv-0、hpv-1、hpv-2、hpv-3、hpv-scr(随机乱序的hpv模板)和无模板。图21显示野生型和突变hpv模板上退火的pyeto.1和to.2。
各自在80c下加热2分钟,并使其在室温下冷却。将管简单离心并将内容物按1:2稀释系列添加到每个黑色96孔板中(各自最终为50μl)。以用于荧光测量的tecan分光光度计装置和becton-dickinson96孔黑色侧面板进行读数。(对335nm激发/480nm发射设置读数,具有仪器优化的荧光设置)。
对于基于激基缔合物的激发和发射波长,并且仅对特异性模板观察到荧光。(在乱序和非模板对照中没有信号)。虽然所有hpv模板都引发激基缔合物荧光,但在5’和3’-标记的寡核苷酸之间偏移2个碱基时观察到最佳结果。参见图21。
实施例14:通过close交叉软件分析close候选物(实际实施例)
为了利于对close克隆的鉴定,开发了软件(“close交叉分析”),以连同可通过国家生物技术信息中心获得的免费在线blast(基本局部比对搜索工具)软件一起工作。特别需要这种新型软件用于鉴定单个模板上的非连续close命中物,对其而言单独的blast不太适合。基本策略涉及为了blast搜索人rna-seq数据库的目的而单独处理close二聚体的每个测序的l-和r-11-聚体。(这与rna模板定向化学连接之前,每个l-和r-close寡核苷酸杂交的实际情形类似)。很明显,当用任意11-聚体序列在人转录组序列间进行搜索时,预期会有大量的随机完全匹配(平均每4.106个碱基将会发现一个随机的11-聚体),并且如果将严格性降至低于完全匹配,则会产生更多。(实际上,close连接可容忍每个寡聚物许多错配)。将这些第一序列设置为最多提供20,000个命中物,这实际上涵盖等于或大于8/11匹配的命中物。然后扫描这些单独命中物列表(作为xml文件)中的常用rna-seq文件条目;从而找到因其与特定l和r-close克隆序列的命中物匹配而交叉的文件。此后,该程序在链型的基础上进行筛选。在这种情况下只有“+/-”命中物是相关的,并且因此排除其它的。(输入close序列默认为“+”取向;因为寻求靶rna中的互补杂交序列,所以强制“-”取向命中物)。然后在两个水平上进行命中物分级:组合l和r搜索的匹配分数(优选匹配最多22个),和另外基于“n值”的等级,其中n=最靠近靶标5'末端的close匹配序列的5'末端和最远离靶标5'端的close匹配序列的3'末端之间的距离。虽然原则上rna折叠可以使就初级序列而言非常远的位点接近,但推断低n值(接近度更近)可能具有更高的频率。(对于完全连续位点而言,n=0)。作为流程图的代表软件在图22中有描绘,并且在图23中也有说明。
进一步检查close软件交叉文件命中物的实例。从得自mu89黑素瘤细胞rna的扩增close二聚体文库看,一种候选物是来自基因plxna3的转录物。在这种情况下,closel-和r-位点呈外向构型,并且n值仅为24个碱基。为了进一步研究,将相同plxna3序列(作为单链dna)作为模型模板在体外进行测试,除了用与用于实施例11和12的相同修饰点击寡核苷酸10-聚体置换plxna3内的close位点外。将这些呈外向和内向构型置于源自plxna3的侧翼序列中。使此类模板与10-聚体点击寡聚物退火,并且随后用和不用如同实施例1的点击催化试剂处理(图24)。结果显示在任一取向上发生点击反应。因此,观察到的呈外向构型的close杂交与模型模板的点击反应性相容。
图24的寡核苷酸序列:
5’-叠氮化物寡聚物:叠氮化物-tggaccatct(点击寡聚物-1)(seqidno:51);
3’-炔点击寡聚物:pcttgtccagcme-炔丙基(点击寡聚物-2)(seqidno:52);
线性模板:gaaatagatggtccagctggacaagcagaa(seqidno:60);
plxa3-外向模型:
ttctggctggacaagtcaagaacccgcagttcgtgttcgagatggtccagaaca(seqidno:66);
plxa3-内向模型:
ttctgagatggtccatcaagaacccgcagttcgtgttcggctggacaaggaaca(seqidno:67)。
黑体序列显示与以上点击寡核苷酸1和2互补的位点。agatggtcca:与点击寡聚物1(seqidno:58)互补;gctggacaag:与点击寡聚物2(seqidno:59)互补。加下划线的序列对应于plxna3close命中物的n区。
实施例15:用模型效应子局部对模板滴定效应的证明(实际实施例)
过量靶模板对双分子效应子局部组装的影响可以由先验性推理推断出(图25),源于预计在过量靶模板上效应子局部的隔离和稀释,降低两个效应子局部在同一模板上伴随着伴发的定向模板装配而配对的频率。这最初是使用芘荧光(实施例5和13)作为与寡核苷酸模板上紧密连接的位点杂交的寡核苷酸之间的空间接近性的读数来测试的。将不同量的模板hpv-1(野生型;图20)与恒定的各1nmol的芘标记的效应子寡核苷酸(pye-to.1、pye-to.2;图14)混合,进行5分钟/80c加热并冷却至室温,然后用tecan分光光度计读取荧光(如同实施例13)。结果显示出在1:1摩尔比下的荧光峰,接着是直到监测结束的线性下降(图26;8倍效应子摩尔过量)。
在替代性试验中,使用点击标记寡核苷酸之间的模板化体外反应性。在这种情况下,rna寡核苷酸用作模板,因为高浓度的模板除非除去,否则会干扰凝胶带测定读数,并且rna链易于通过碱水解去除。这种情况下使用的模板寡核苷酸是与先前使用的(实施例11和12)相同线性dna模板的rna形式。如同先前所用(实施例11和12)的点击标记效应子各在50pmol下使用,并且与不同量的带有互补序列的rna模板混合,最初于25μlx1m缓冲液(10mmtrisph7.5、10mmmgcl2、50mmnacl、1mm二硫赤藓糖醇)中退火。在70c下加热样品1分钟,冷却至室温,并且用和不用点击催化试剂以与实施例11相同的方式处理,接着进行脱盐。然后除对照样品外全部于75μl中用0.2mnaoh处理20分钟/70c,用1.2m乙酸(13.5μl)和1mtris(3.8μl)中和达到100μl的最终体积。然后用20μg糖原和0.3m乙酸钠使样品经乙醇沉淀(3体积)。团粒化并用70%乙醇洗涤后,使样品重新溶于5μlte中。这些制剂各1μl在98c下于98%甲酰胺、10mmedta中变性5分钟,并且在15%变性尿素凝胶上运行。凝胶分析显示在没有碱水解时,rna模板可见并且在促进标记寡核苷酸之间的点击反应性上已经有效(图27)。在这项实验中,包括mu89rna作为特异性对照,并且未发现模板化效应子组装。用rna寡核苷酸作为模板也可明确证明滴定效应。此处最佳点击产物形成发生在10:1模板:效应子比率下,但在100:1模板:效应子比率下几乎不存在。这种总体趋势在后续试验中可再现。
值得注意的是,虽然基于荧光的测定在等摩尔水平下产生峰值活性(图26),但rna模板化组装在更高的模板水平下得到改善,至少多达10:1摩尔比(图27)。这种明显的差异很可能归因于各自模板的性质。在基于芘的测定中,dna模板几乎没有形成二级结构的倾向,而rna模板可以形成小的茎环(图27)。而且,rna双链体具有比同源dna螺旋增加的热稳定性。因此,dna寡核苷酸效应子与rna模板的退火与rna链本身的内部退火竞争,导致对模板的需求增加超过等摩尔浓度以获得最佳结果。即使如此,当rna模板水平足够高时,滴定效应显而易见,严重限制了产物的数量。总的来说,理论滴定效应(图25)可以用实际的实验系统明确地证明,但除了效应子/模板比率本身之外,其它因素也可以影响模板水平产生相反效果的点。
转而,这些结果证实,测量候选close靶标的表达水平是重要的辅助实验目标(实施例6和7)。
图27的寡核苷酸序列:
5’-叠氮化物寡聚物:叠氮化物-tggaccatct(点击寡聚物-1)(seqidno:51);
3’-炔点击寡聚物:pcttgtccagcme-炔丙基(点击寡聚物-2)(seqidno:52);
线性rna模板:gaaauagauggucca|gcuggacaagcagaa(seqidno:68);
黑体序列显示与以上点击寡核苷酸1和2互补的位点。agauggucca:与点击寡聚物1互补(seqidno:69);gcuggacaag:与点击寡聚物2互补(seqidno:70)。
实施例16:用bcr-abl靶标进行的靶标定向性close分析(实际实施例)
与一般close方法相反,靶标定向性close集中于已知的肿瘤特异性转录物。表达的肿瘤特异性易位是这种定向形式的close技术的良好模型,其中跨越融合接合点的两个区段对应于正常转录物。在这种情况下,肿瘤特异性线性连续易位的定义限于接合序列本身。相反,转录物(其通常非常大)的折叠具有产生易位所特有的多个不连续位点的潜力(在图28中示意性显示)。可以通过close分析找到术语中的这些位点,用作模板化组装靶标。
bcr-abl易位转录物长期以来被称为慢性骨髓性白血病和某些其它转化状态的标记物和驱动因子(通过融合bcr-abl激酶的表达)。在用于本实施例的实验工作中的白血病细胞系k562中强烈表达。
使用来自k562细胞的全细胞rna进行如同实施例1的close分析,并且在杂交后,根据实施例10中描述的方案去除未杂交的close寡核苷酸。然后使用扩增的close化学连接的二聚体(在全局k562rna上模板化)制备对应于和原始close文库寡核苷酸相同意义的单链。为了实现这一点,用比也经生物素化的底链10倍过量的顶(所需)链进行不对称pcr。在这些条件下扩增循环35次后,去除链霉亲和素磁珠上所有带有底链的产物(不管是完整的双链体还是经下游引物退火的单链或部分延伸产物)。图29中示出了这种方法及其实用性。
因而与原始细胞定义的rna靶标相同意义的单链探针是必需的。虽然原始close杂交受到rna折叠影响(因此使得就一级碱基序列而言分离的位点能够并置),但是不需要为靶标定向性close捕获概括此类结构。虽然l-和r-close位点可与不连续位点杂交,但所有需要的是l-或r-区域与捕获探针结合(图30)。使用整个天然转录序列也不是必需的。在bcr-abl的情况下,认为跨越转录物断裂点区域是必不可少的,因为与bcr和abl两者结合的close克隆是建立完全肿瘤特异性所必需的,并且使用极长探针(在各种同种型中,一些>8kb)选择bcr或abl限制性close克隆的概率增加。因此使用跨越断裂点的1338个碱基的dna探针(1338探针)(图31)。
为了致使呈正确意义上的单链,由反向转录的k562rna扩增1338-探针,底链经生物素化。使产物与链霉亲和素磁珠结合后,通过用0.1m氢氧化钠/5mmedta变性(20秒),随后用20μg糖原/0.3m乙酸钠进行快速乙醇沉淀而获得所需的顶链。团粒化并用70%乙醇洗涤后,干燥单链探针并在te缓冲液中复原。
1338-探针和原始k562rna选择的close产物的单链在30c下杂交6小时,之后必需分离未结合的close级分。在这种情况下有几种选择。一种非限制性的方法是使用琼脂糖凝胶,包括pippinprep装置(sagescience)。这在图32a中示意性示出。这种凝胶体系中的分离受到close二聚寡核苷酸和探针序列之间的大尺寸差异促进。探针和杂交的close链共同迁移;在条带切除和核酸洗脱后,可通过sybr-金染色鉴定其迁移率。可以包括来自缺乏杂交探针的close产物的具有与探针相同迁移率的模拟条带作为对照(图32a)。
再次扩增与探针共同迁移的close产物,并且如上所述用于制备单链材料。这使得靶标定向性close循环能够随着第一轮close选定的单链产物与相同探针的杂交进行,随着每次循环运行可实现特异性杂交序列的逐渐富集。至少两个循环后,可以克隆close产物并进行如上所述的序列分析。
这两个这种循环后的结果显示,22个测序的克隆中,50%显示与bcr和abl序列匹配(其余显示与bcr或abl而非两者匹配)。图32a中还示出了对于l-和r-序列而言≥8/11匹配的克隆的实例。注意因为探针是整个转录物的小部分,并且l/r位点可能已经与后者的不连续区段杂交,因此不一定是两种都会与探针序列匹配的情况。然而,出于同样原因,必要的验证要求是至少一个匹配的close序列落在探针的边界内。列举的满足这种条件的候选物实施例(图32b)在接合序列上是不连续的,并且展示出如上所定义的外向构型。
实施例17:通过加工非天然5’–5’键联以允许扩增化学连接对,从样品中鉴定模板化组装靶序列或结构(预示性实施例)
合成具有5'-叠氮基或5'-环炔基的寡核苷酸的单独群体,其带有具有特定侧翼序列的随机序列段(描绘于图33a和33b中)。折叠的rna靶结构可以促进5'-5'或3'-3'末端之间的接近(图34a和34b),使得点击反应性能够产生非天然链键联(对于5'-5'示出;图35)。侧翼序列构成每个寡核苷酸一端的引发位点(p1和p2),而另一端是较短的区域(“适应位点”;a1和a2;图35),以使得酶促重排和二聚体扩增成为可能。每个适应位点含有单独限制酶(图35的e1和e2)的识别位点,其中每种酶的识别位点是不同的,但是在用每种酶进行双链体裂解之后产生的悬突与连接相互相容。在e1和e2裂解产生的dna末端连接后,所得连接的e1-e2产物不能被任一种酶裂解。将引物位点设计为排除为e1和e2选择的识别序列。
因为任何形式的5'-5'化学键联都不可被任何核酸聚合酶直接读取,所以5'-叠氮基或5'-环炔基与上述寡核苷酸的化学连接方式不是至关重要的,条件是活性叠氮基或炔基与末端5'核酸部分之间的稳定化学键合的位点通过至少6个碳原子的间隔臂或间隔基团桥接(图36a和36b)。在一些实施方案中,叠氮基通过与n-羟基琥珀酰亚胺反应与核酸5’末端连接,并且炔基通过附接的己烷基连接。
以上构型的5’-叠氮化物和5’-环炔修饰的寡核苷酸的单独群体与来自所关注的细胞的全rna制剂,或可选地全细胞rna-蛋白制剂杂交。用每种寡核苷酸群体在相对于彼此按摩尔浓度计的50:50混合物中,通过假定1500个碱基的细胞rna的平均分子量计算,比存在的rna量10-100倍过量,并用1-10微克的起始rna进行杂交。杂交可进行2-16小时的时间段。
杂交后,进行5’-叠氮化物和应变5’环炔部分之间接近性诱导的自发性反应,去除过量寡核苷酸和脱盐。然后用rna酶a和rna酶1处理制剂。所得制剂包括因缺乏空间接近性而不能反应的过量无变化的寡核苷酸链,以及少数所需的5'-5'已反应产物。
致使全部所得寡核苷酸链为双链。这可以通过与引发位点1(p1)和适应位点2(a2)互补的引物实现,并且各自用全部四种脱氧核苷三磷酸和大肠杆菌dna聚合酶i的klenow片段延伸,使得每条新链延伸至5'-5'接合点(图37)。
当实现延伸双链体的定向裂解时,不期望随机区域中的序列通过用于裂解的酶的限制性位点的偶然出现而被裂解。鉴于此,替代性实施方案使用由5-甲基-脱氧胞苷三磷酸、脱氧腺苷三磷酸、脱氧鸟苷三磷酸和胸苷三磷酸组成的脱氧核苷三磷酸混合物,使得在随机区的互补序列中产生用于5-甲基胞嘧啶的半甲基化双链体。因此使用对5-甲基胞嘧啶半甲基化敏感的裂解酶。同样,因为在发生裂解的适应区域a1和a2中应防止半甲基化,所以在延伸反应之前使与区域a1互补的5'-磷酸化链与模板退火。(通过由它的非甲基化互补链引发形式来保持适应区域a2未甲基化;图38)。因为在引物延伸期间区域a1的互补链不应置换,所以使用非链置换聚合酶,例如t4dna聚合酶(图38)。区域a1的5'-磷酸化互补序列和新延伸的链之间所产生的缺口用t4dna连接酶封闭(图38)。
然后用识别限制性位点e2的酶裂解所得到的延伸双链体(图37)。在一些实施方案中,酶e2特异性对应于识别序列accggt的agei以产生四碱基悬突5’-ccgg。
在后续步骤中,利用以下条件:a)在能够进行扩增的连接介导的重排过程中保持近侧杂交序列之间的键联信息;b)保持裂解序列相对于彼此呈高浓度的微环境,从而驱动它们的连接;和c)将未反应的链隔绝到单独分离的区室内,防止它们连接介导的重组,这会产生虚假扩增信号(不是由近侧模板化驱动的原始点击反应产生的信号)。这些条件可通过体外区室化实现。
通过使油包水微区室涵盖来自未反应寡核苷酸和5'-5'点击连接二聚体的群体的单个分子来实现体外区室化,如同致使其为双链,并用对应于位点e2的酶裂解。如davidson等人,2009所述(图39),在精确控制搅拌的条件下,由试剂级矿物油和洗涤剂,添加所需的内部组分,形成微区室。在油包水微区室形成期间,以下组分过量存在,使得每个区室将接收相同的缓冲组合物(50mm醋酸钾、20mmtris-乙酸盐,ph7.9/25c,包括1mmatp和10mm醋酸镁离子),以及蛋白质t4dna连接酶和蛋白质限制酶识别位点e1的至少一个拷贝。因为微区室大大超过存在的分子种类,平均只有一个连接分子并入每个区室内(图39)。同样,使未连接的片段也分隔到微区室内(图40)。在一些实施方案中,e1限制酶是xmai,其识别序列cccggg以产生与agei相容的四碱基悬突5’-ccgg。连接来自agei和xmai裂解的悬突后,所得序列是两种酶都不能裂解的accggg。
在37c下孵育微区室2小时,然后在20c下孵育2小时。在带有单个5'-5'化学连接的二聚体的每个区室中,用xmai裂解之后是与另一个xmai悬突的后续连接(与原始裂解相反)或与相同区室内存在的单个agei末端存在相同的连接(图41)。xmai-xmai再连接可被xmai裂解,但agei-xmai连接不能,因此不可避免地成为每个微区室内的主要种类(图42)。寡核苷酸最初未化学连接成二聚体(图39)的区室不能参与这种再连接/再切割循环。
然后通过用乙醚处理来破坏微区室。可依靠上述重排方法扩增通过在rna模板上的空间接近性选择的来自原始随机群体的特定寡核苷酸对。
实施例18:通过加工非天然3’-3’键联以允许扩增化学连接配对,从样品中鉴定模板化组装靶序列或结构(预示性实施例)
合成具有3'-叠氮基或3'-环炔基的寡核苷酸的单独群体,其带有具有特定侧翼序列的随机序列段(描绘于图43中)。
因为任何形式的3'-3'化学连接都不可被任何核酸聚合酶直接读取,所以3'-叠氮基或3'-环炔基与上述寡核苷酸的化学键联方式不是至关重要的,条件是活性叠氮基或环炔基与末端3'核酸部分之间的稳定化学键合的位点通过至少6个碳原子的间隔臂或间隔基团桥接(图44a和44b)。在一些实施方案中,叠氮基通过与n-羟基琥珀酰亚胺反应与核酸3’末端连接,并且环炔基通过附接的己烷基连接。
以上构型的3’-叠氮化物和3’-环炔修饰的寡核苷酸的单独群体与来自所关注的细胞的全rna制剂,或可选地全细胞rna-蛋白制剂杂交。用每种寡核苷酸群体在相对于彼此按摩尔浓度计的50:50混合物中,通过假定1500个碱基的细胞rna的平均分子量计算,比存在的rna量10-100倍过量,并用1-10微克的起始rna进行杂交。杂交可进行2-16小时的时间段。
杂交后,进行5’-叠氮化物和应变5’环炔部分之间接近性诱导的自发性反应,去除过量寡核苷酸和脱盐。所得制剂包括因缺乏空间接近性而不能反应的过量无变化的寡核苷酸链,以及少数所需的3'-3'已反应产物。
致使全部所得寡核苷酸链为双链。这可以通过与引发位点2(p2)和适应位点1(a1)互补的引物实现,并且各自以全部四种脱氧核苷三磷酸和大肠杆菌dna聚合酶i的klenow片段延伸,使得每条新链延伸至3'-3'接合点(图45)。
当实现延伸双链体的定向裂解时,不期望随机区域中的序列通过用于裂解的酶的限制性位点的偶然出现而被裂解。鉴于此,替代性实施方案使用由5-甲基-脱氧胞苷三磷酸、脱氧腺苷三磷酸、脱氧鸟苷三磷酸和胸苷三磷酸组成的脱氧核苷三磷酸混合物,使得在随机区的互补序列中产生用于5-甲基胞嘧啶的半甲基化双链体。在一些实施方案中,因此使用对5-甲基胞嘧啶半甲基化敏感的裂解酶。同样,因为在发生裂解的适应区域a1和a2中应防止半甲基化,所以在延伸反应之前使与区域a2互补的5'-磷酸化链与模板退火。(通过由其非甲基化互补链引发来保持适应区域a1未甲基化;图16)。因为在引物延伸期间区域a1的互补链不应置换,所以应使用非链置换聚合酶,例如t4dna聚合酶(图16)。区域a1的5'-磷酸化互补序列和新延伸的链之间所产生的缺口用t4dna连接酶封闭(图46)。
然后用识别限制性位点e2的酶裂解所得到的延伸双链体。在一些实施方案中,酶e2特异性对应于识别序列accggt的agei以产生四碱基悬突5’-ccgg。
在后续步骤中,利用以下条件:a)在能够进行扩增的连接介导的重排过程中保持近侧杂交序列之间的键联信息;b)保持裂解序列相对于彼此呈高浓度的微环境,从而驱动它们的连接;和c)将未反应的链隔绝到单独分离的区室内,防止它们连接介导的重组,这会产生虚假扩增信号(不是由近侧模板化驱动的原始点击反应产生的信号)。这些条件可通过体外区室化实现。
通过使油包水微区室涵盖来自未反应寡核苷酸和3'-3'点击连接二聚体的群体的单个分子来实现体外区室化,如同致使其为双链,并用对应于位点e2的酶裂解。如davidson等人2009所述(图47),在精确控制搅拌的条件下,由试剂级矿物油和洗涤剂,添加所需的内部组分,形成微区室。在油包水微区室形成期间,以下组分过量存在,使得每个区室将接收相同的缓冲组合物(50mm醋酸钾、20mmtris-乙酸盐,ph7.9/25c,包括1mmatp和10mm醋酸镁离子),以及蛋白质t4dna连接酶和蛋白质限制酶识别位点e1的至少一个拷贝。因为微区室大大超过存在的分子种类,平均只有一个连接分子并入每个区室内(图47)。同样,使未连接的片段也分隔到微区室内(图48)。在这个非限制性实例中,e1限制酶是xmai,其识别序列cccggg以产生与agei相容的四碱基悬突5’-ccgg。连接来自agei和xmai裂解的悬突后,所得序列是两种酶都不能裂解的accggg。
在37c下孵育微区室2小时,然后在20c下孵育2小时。在带有单个3'-3'化学连接的二聚体的每个区室中,用xmai裂解之后是与另一个xmai悬突的后续连接(与原始裂解相反)或与相同区室内存在的单个agei末端存在相同的连接(图49)。xmai-xmai再连接可被xmai裂解,但agei-xmai连接不能,因此不可避免地成为每个微区室内的主要种类(图50)。寡核苷酸最初未化学连接成二聚体(图48)的区室不能参与这种再连接/再切割循环。
然后通过用乙醚处理来破坏微区室。可依靠上述重排方法扩增通过在rna模板上的空间接近性选择的来自原始随机群体的特定寡核苷酸对。
实施例19:寡核苷酸对之间的化学连接与直接聚合酶通读不相容时,通过加工5’–3’键联从样品中鉴定模板化组装靶序列或结构(预示性实施例)
在一些情况下,筛选无法通过聚合酶直接通读的5'-3'近侧键联可能是有用的或甚至是必要的。在这种情况下,至少有两个主要因素是起作用的:1)如果使用预先活化的点击反应物(例如,如同应变环辛烯一样),则避免了对cu(i)催化的需要;和2)预先活化的点击反应物可用于活细胞中的筛选,当存在对cu(i)催化的需求时,这是困难或不可能的。
合成具有5'-和3'-点击基团的寡核苷酸的单独群体。可以使用群体的任一组(5’-环炔加上3’-叠氮化物)或(5’-叠氮化物加上3’-环炔),因为对聚合酶通读没有要求。所有寡核苷酸均带有具有特定侧翼序列的随机序列段(描述于图51中)。侧翼序列构成每个寡核苷酸一端的引发位点(p1和p2),而另一端是较短的区域(“适应位点”;a1和a2),以使得酶促重排和二聚体扩增成为可能。每个适应位点含有单独限制酶(图51的e1和e2)的识别位点,其中每种酶的识别位点是不同的,但是在用每种酶进行双链体裂解之后产生的悬突与连接相互相容。在e1和e2裂解产生的dna末端连接后,所得连接的e1-e2产物不能被任一种酶裂解。将引物位点设计为排除为e1和e2选择的识别序列。
因为在实施例4中,对5'-3'化学连接可被任何核酸聚合酶直接读取没有要求,所以叠氮基或环炔基与上述寡核苷酸的化学键联方式不是至关重要的,条件是活性叠氮基或炔基与末端核酸部分之间的稳定化学键合的位点通过至少6个碳原子的间隔臂或间隔基团桥接(图52a、52b、52c和52d)。在一些实施方案中,叠氮化物部分通过与n-羟基琥珀酰亚胺的反应与核酸5’末端或3’末端连接,并且炔部分呈附接的环炔基的形式与核酸5’末端或3’末端连接。
以上构型的叠氮化物和炔修饰的寡核苷酸的单独群体与来自所关注的细胞的全rna制剂,或可选地全细胞rna-蛋白制剂杂交。用每种寡核苷酸群体在相对于彼此按摩尔浓度计的50:50混合物中,通过假定1500个碱基的细胞rna的平均分子量计算,比存在的rna量10-100倍过量,并用1-10微克的起始rna进行杂交。杂交可进行2-16小时的时间段。
由于紧密接近叠氮化物的应变炔基之间的反应性加速,直接产生了点击反应性,排除了对cu(i)催化的需要。
鉴于避免了cu(i)催化需求,可将标记的寡核苷酸群体引入活细胞中,用于细胞内杂交。除非需要限制酶裂解以便实现容许扩增的所需重排时,合成具有核酸酶抗性磷酸二酯主链或糖部分的杂交寡核苷酸(图53a和53b)。所有寡核苷酸末端(包括经点击基团加帽的那些)由经修饰区段组成。当这些构成了含有限制位点的a1和a2区域(图51)时,具有正常碱基和主链的a1和a2区域随经修饰的主链延伸3个碱基,以阻止核酸外切攻击。这些寡核苷酸的经修饰区段包括但不限于2’-o-甲基-核苷酸和硫代磷酸酯核苷酸。
在一些实施方案中,通过可商购的转染试剂,包括但不限于lipofectamine和fugene,将部分核酸酶抗性寡核苷酸引入所关注的靶细胞中。
杂交之后,就用核糖核酸酶处理而言,如同实施例2一样,进行所述方法。在使用细胞内筛选的实施方案中,破坏细胞并进行用rna酶和蛋白酶的处理。蛋白酶处理包括但不限于蛋白酶k。处理后,通过尺寸排阻色谱法为制剂排空低分子量产物。
所得制剂包括因缺乏空间接近性而不能反应的过量无变化的寡核苷酸链,以及所需的5'-3'已反应产物。致使全部所得寡核苷酸链为双链。这可以通过与适应位点1(a1)和适应位点2(a2)互补的引物实现,并且各自用全部四种脱氧核苷三磷酸和大肠杆菌dna聚合酶i的klenow片段延伸,使得每条新链从5'-3'接合点延伸或延伸至5'-3'接合点(图54)。
在将经修饰的核酸用于细胞内筛选时,修改引物延伸程序。核糖部分修饰为2’-o-甲基衍生物,使用如上所述的相同a1和a2引物,可将逆转录酶用于代替klenow片段用于延伸目的。
当实现延伸双链体的定向裂解时,不期望随机区域中的序列通过用于裂解的酶的限制性位点的偶然出现而被裂解。鉴于此,使用由5-甲基-脱氧胞苷三磷酸、脱氧腺苷三磷酸、脱氧鸟苷三磷酸和胸苷三磷酸组成的脱氧核苷三磷酸混合物,使得在随机区的互补序列中产生用于5-甲基胞嘧啶的半甲基化双链体。在一些实施方案中,因此使用对5-甲基胞嘧啶半甲基化敏感的裂解酶。(通过由非甲基化互补链引发来保持适应区域a1和a2未甲基化;图54)。
然后用识别限制性位点e2的酶裂解所得到的延伸双链体。在这个非限制性实例中,酶e2特异性对应于识别序列accggt的agei以产生四碱基悬突5’-ccgg。
在后续步骤中,利用以下条件:a)在能够进行扩增的连接介导的重排过程中保持近侧杂交序列之间的键联信息;b)保持裂解序列相对于彼此呈高浓度的微环境,从而驱动它们的连接;和c)将未反应的链隔绝到单独分离的区室内,防止它们连接介导的重组,这会产生虚假扩增信号(不是由近侧模板化驱动的原始点击反应产生的信号)。这些条件可通过体外区室化实现。
通过使油包水微区室涵盖来自未反应寡核苷酸和5'-3'点击连接二聚体的群体的单个分子来实现体外区室化,如同致使其为双链,并用对应于位点e2的酶裂解。如davidson等人2009所述(图55),在精确控制搅拌的条件下,由试剂级矿物油和洗涤剂,添加所需的内部组分,形成微区室。在油包水微区室形成期间,以下组分过量存在,使得每个区室将接收相同的缓冲组合物(50mm醋酸钾、20mmtris-乙酸盐,ph7.9/25c,包括1mmatp和10mm醋酸镁离子),以及蛋白质t4dna连接酶和蛋白质限制酶识别位点e1的至少一个拷贝。因为微区室大大超过存在的分子种类,平均只有一个连接分子并入每个区室内(图55)。同样,使未连接的片段也分隔到微区室内(图56)。在一些实施方案中,e1限制酶是xmai,其识别序列cccggg以产生与agei相容的四碱基悬突5’-ccgg。连接来自agei和xmai裂解的悬突后,所得序列是两种酶都不能裂解的accggg(图57)。
在37c下孵育微区室2小时,然后在20c下孵育2小时。在带有单个5'-3'化学连接的二聚体的每个区室中,用xmai裂解之后是与另一个xmai悬突的后续连接(与原始裂解相反)或与相同区室内存在的单个agei末端存在相同的连接。xmai-xmai再连接可被xmai裂解,但agei-xmai连接不能,因此不可避免地成为每个微区室内的主要种类(图58)。具有未反应的寡核苷酸的区室与其它潜在可连接的分子分隔开(图56)。
然后通过用乙醚处理来破坏微区室。可依靠上述重排方法扩增通过在rna模板上的空间接近性选择的来自原始随机群体的特定寡核苷酸对。
在实施例19的另一个实施方案中,与微区室的“连通”可通过纳米液滴实现,如miller等人,naturemethods,2006,3,561-570)所述。
实施例20:用模型系统验证体外区室化对close重排过程的遏制(实际实施例)
期望验证酶促重排过程和体外区室化遏制单分子重排的能力,以便保存每个close二聚体中体现的信息。实现这一点最有效的方式是用序列致使其相互可区别的特定点击-标记寡核苷酸。
实施例20的寡核苷酸序列(a-d):
a.5’叠氮化物-ctccataacccatggacatgtaccggtgatcc(seqidno:71)
b.5’己炔基–gatccccgggctatgtctagaggagaaggaga(seqidno:72)
c.5’叠氮化物-ctccataacccaaggatcctcaccggtgatcc(seqidno:73)
d.5’-己炔基–gatccccgggtaccgagcataggagaaggaga(seqidno:74)
其中“叠氮化物”指示经由n-羟基琥珀酰亚胺中间体偶联的叠氮基,并且“己炔基”指示通过6-碳线性间隔子与dna载体分开的炔。加下划线的序列指示限制位点:a,ncoi;b,xbai;c,bamhi;d,asp718i。黑体序列对应于实施例17、18和19中随机化的区域。序列ctccataaccca(seqidno:75)和aggagaaggaga(seqidno:76):分别是用于扩增的截短正向(有义)和反向(反义)引物位点。
模型寡核苷酸a-d可通过限制位点消化(如双链体)或通过用对每种寡核苷酸有特异性的延伸引物进行pcr扩增来进行相互区分。
在模型的第一阶段,寡核苷酸a-d的所有四种可能的叠氮化物-炔组合以高浓度(10pmol/μl;50μl体积)混合,并如同实施例1进行未模板化催化剂辅助的点击反应,同样在反应后脱盐。当在变性丙烯酰胺凝胶上测试反应时,可重复地观察到双相点击特异性条带图案:在较高表观分子量(是单体分子量的大致两倍)下的“上部”条带,以及迁移率比原始条带略低的“下部”条带(图59)。通过从制备凝胶切除而纯化上部和下部条带,免于泳道饱和的多个泳道(图59)破碎并且使寡核苷酸扩散出来,接着是其沉淀和复原。
此时,认为有必要测试任一或两种条带是否可以进行容许扩增的酶促重排过程(实施例17、18和19)。虽然在游离溶液中进行这个过程并未保存来自每个点击分子的信息,但酶需求是不变的,并且这种情况下的成功也验证了重排过程本身。最初用klenowdna聚合酶i片段、dntp和合适的引物致使上部和下部条带的样品均为双链:
致使模型或实际5’-5’文库寡核苷酸为双链的引物:
e1-ext:ggatcaccggt(seqidno:77)
trz.r:gcctctaagtctccttctcct(seqidno:78)
然后用或不用xmai和agei,并依次用或不用t4dna连接酶处理双链制剂。此后,用引物trz.f(catctccacctccataaccca)(seqidno:79)和trz.r(同上)扩增样品,并在非变性丙烯酰胺凝胶上运行。从上部和下部制剂观察到预期大小(68bp)的条带,但只有在限制酶消化和连接之后,充分支持计划的重排过程(图60)。得出的结论是,上部和下部条带都是可重排的5'-5'加合物,其中较快迁移的下部条带最有可能是自我折叠的变性抗性形式。为了继续模型过程,使用上部条带。虽然产量明显低于下部条带,但是上部条带更容易从未反应的单体中分解出来。
因此,显示四种可能的5'-5'加合物的样品(图59)在变性凝胶上是基本上纯的(图61)。同上用klenow酶使这些的样品(1pmol)延伸,然后用xmai/agei测试并用t4dna连接酶重新连接。除了单独地每种加合物之外,重排试验中还包括加合物与异源组成部分寡核苷酸的两种混合物。这些是加合物bh+fh(分别对应于原始寡核苷酸a/b和c/d的5’-5’连接)和加合物dh+hh(分别对应于原始寡核苷酸a/d和c/b的5’-5’连接)。酶处理后,所有加合物制剂显示出可扩增材料(用与图60相同的方法和引物),但不用酶什么也观察不到(图62)。
此后,可能使用模型寡核苷酸检测系统评估ivc使得分子特异性重排成为可能,而不会丢失来自非天然化学连接的close信息的成功。图63中示意性地描绘了这种系统的原理。在均相溶液中或通过成功的微区室化,保持特定5'-5'加合物分离时,只有一种可能的重排产物是可能的。然而,如果混合相同构型的不同加合物(或者如果ivc不足),则在连接步骤期间会发生不同加合物间的交叉,这会破坏特定5’-5’close寡核苷酸内所含的信息。如果可以设计对每种原始寡核苷酸序列(a-d)有特异性的pcr引物,则用各种引物组合的扩增模式会直接报告加合物重排的状态。
为原始点击-标记寡核苷酸a-d设计具有所需特异性的引物。此处特异性引物对旨在仅扩增特定的直接(单分子)重排或特定的交叉产物。例如,对于bh加合物而言,在重排后,所需引物将仅扩增b-a序列,并且同样地对于bh加合物而言,正确的引物应仅特异性扩增d-c序列。当bh和fh加合物混合时,可以形成两种可能的交叉产物:b-c和d-a,对其而言特异性引物组合也是理想的。注意在此类混合物中,将能够形成“直接”产物以及交叉产物。
bh和fh加合物的制剂在使它们为双链之后使用,并且进行agei/xmai/dna连接酶处理以便重排。这些是在高灵敏度下作为单加合物和作为混合物(bh+fh加合物)进行的。发现(图64),设计为对bh和fh加合物的直接重排有特异性的引物对是令人满意的(仅由同源重排,或由bh+fh混合物看到产物)。在两个可能的交叉引物对中,一个(对于b-c交叉而言)显示出低但可检测的交叉特异性(显示具有(单独的bh)的产物,但另一个交叉引物对(d-a)似乎具有高度特异性(图64)。因此进一步使用这个引物对,因为任一对都足以证明交叉的存在或不存在。
用于重排和交叉试验的寡核苷酸序列:这些是‘通用引物trz.f和trz.r(同上)的延伸,其会扩增a-d重排物的任一组合。
对直接bh重排有特异性的引物:
trz.f+te:cacctccataacccatggaca(seqidno:80)
trz.r+ce:ctaagtctccttctcctctagaca(seqidno:81)
对直接fh重排有特异性的引物:
trz.f+ae:ccacctccataacccaaggat(seqidno:82)
trz.r+ae:tctaagtctccttctcctatgct(seqidno:83)
对bh-fh交叉重排#1有特异性的引物(b-c):
trz.f+te/trz.r+ae(同上)。
对bh-fh交叉重排#2有特异性的引物(d-a):
trz.f+ae/trz.r+ce(同上)。
黑体序列对应于超过trz.f和trz.r的3’末端的延伸。
还需要进行附加对照,其中单独重排的bh和fh加合物的样品在pcr之前单独混合(这不同于bh和fh加合物在重排过程本身之前混合的反应,其中促进交叉,如图64所示)。该第二对照组通过假pcr效应测试在该系统是否可以发生交叉。发现(图65)未发生此类pcr诱导的交叉效应。
确认了引物特异性,可以继续进行使用模型寡核苷酸测试体外区室化。此处,用agei预先切割的双链体的5’-5’加合物(实施例17,图39)和xmai/t4dna连接酶/缓冲液/1mmatp与必需的油和表面活性剂混合以形成乳液。(用agei预先切割简化了乳液混合物中内含物的酶需求)。最初显示,在1mmatp存在下,xmai和t4dna连接酶两者在1xcutsmart缓冲液(newenglandbiolabs)中有活性,因此在混合期间用于形成乳液。当最初存在预先切割的bh和fh加合物时,如果乳化和区室化成功,则在允许在乳液本身中进行重排之后应该不可检测出交叉产物。
除省去triton-x100以外,通过davidson等人,currentprotocolsinmolecularbiology,2009,24.6.1-24.6.12的方法制备乳液混合物。总是使用用于分配粘性流体的正位移移液器(gilson),按以下方式产生乳液本身:乳液混合物对应于950μl矿物油(分子生物学级,sigma)、45μlspan-80(sigma)和5μl吐温-80(tween-80)(sigma)。于具有1mmatp、含xmai和t4dna连接酶的x1cutsmart缓冲液中制备50μlagei预先切割的加合物(按预定量)或对照的混合物。(在乳液形成之前仅立即添加酶,并于冰上在0c下保持所有制剂冷却。)将乳液混合物置于13ml管中(17x95mm;vwrscientific)并在添加9.5x9.5mm离心柱(fisherscientific)之前冷却并且在13ml管中混合,装在含冰烧瓶中,并且用corningpc-410d搅拌器在1150rpm下离心2分钟。此后,将冷却的加合物/缓冲液/酶混合物(50μl)缓慢地添加(10x5μl等分试样)到离心乳液的上面,之后再继续离心10分钟。在一些试验中,这之后是附加超声处理步骤以匀化微液滴尺寸。使用五轮三秒中等强度的超声猝发,管在猝发间期冷却。然后小心地将乳液转移到2ml管中,并在30c下孵育1小时;在25c下孵育4小时。同上,制备50μl体积的对照反应物,但未进行乳化过程。孵育期结束时,用乙醚破坏乳液。最初向每根管添加500μltris缓冲盐水(包括非乳化对照,然后保持在冰上),然后使用以下萃取程序:1x0.5ml乙醚;2x1.0ml乙醚;1x0.5ml乙醚,每次离心2分钟/13,000rpm以分相。然后用40μg糖原/0.3m乙酸钠/3体积乙醇沉淀所有水相(包括非乳化对照)中的物质,用70%乙醇洗涤、干燥并在10μlte中复原。
以作为“高浓度”的各5.109个分子的bh和fh加合物(用agei预先切割)和作为“低浓度”的各108个分子的输入,各自在有和无乳液介导的区室化的酶促重排条件下进行试验。
为增强检测灵敏度,使用嵌套式引物策略进行产物后乳化分析。使用一组各自在以上重排特异性引物5’的第一轮引物:
trz.f+t:catctccacctccataacccat(trz.f+te上游,序列同上)(seqidno:84)
trz.r+c:gcctctaagtctccttctcctc(trz.r+ce上游,序列同上)(seqidno:85)
trz.f+a:catctccacctccataacccaa(trz.f+ae上游,序列同上)(seqidno:86)
trz.r+a:gcctctaagtctccttctccta(trz.r+ae上游,序列同上)(seqidno:87)
图66中示出了此类实验的结果。正如所料,即使用低浓度加合物,在没有区室化的情况下,也观察到bh和fh重排产物,以及交叉条带(泳道l-ct,图66)。进行了离心和超声处理以便乳化的高浓度加合物也显示出清晰的交叉条带(泳道h-sc,图66)。然而,低浓度加合物混合物,无论是仅进行了离心还是离心加超声处理以便乳化,都仅显示出直接bh和fh重排产物条带,没有交叉的证据。
得出的结论是:
1)模型系统是体外微区室中遏制重排过程的有效试验;
2)大量的加合物混合物可以使ivc过程饱和,允许未区室化物质存留并且发生交叉;并且
3)ivc可含适量(108个分子或更少)的加合物混合物并且可以检测到分子特异性重排。
实施例21:通过环化和反向pcr扩增close5’-3’连接克隆(预示性实施例)
在不可扩增的5’-3’close接合(但不是5’-5’或3’-3’)的情况下,除微区室化外还存在替代性策略。此处接合的close单链的5’-和3’-末端是规定序列,由此各自的互补寡核苷酸可以退火,并且因此提供用于自我连接目的的5’-悬突。(具有末端规定序列的close克隆足够长,以发生自我环化)。酶促环化后,引物p1和p2(图67)使得反向扩增成为可能,包括随机化区域内所含的信息(各close克隆的特异性序列)。
环化必须在低浓度下进行,以将与所需分子内环化相反的分子间连接的可能性降到最低。
除本文描述的那些外,对所述主题的各种修改从前面的描述看对本领域的技术人员将显而易见。此类修改也旨在属于所附权利要求书的范围内。本申请中引用的每个参考文献(包括但不限于期刊论文、美国和非美国专利、专利申请公开、国际专利申请公开、基因库登录号等)通过引用整体并入本文。
序列表
<110>邓恩·伊恩(dunn,ian)
马修·劳勒(lawler,matthew)
<120>用于治疗诊断应用的方法和试剂盒
<130>140763.00302wo
<150>62/086,658
<151>2014-12-02
<150>62/086,661
<151>2014-12-02
<160>91
<170>patentin2.1版
<210>1
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>1
tggatctctgc11
<210>2
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>2
ttaaagtgacc11
<210>3
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>3
tgagtgtgtgc11
<210>4
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>4
tgcgcacactc11
<210>5
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>5
acgggcccggc11
<210>6
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>6
ttcgcgtccag11
<210>7
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>7
tcttttacgcc11
<210>8
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>8
tctgcccaggc11
<210>9
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>9
acaccctcgcc11
<210>10
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>10
taccttctccc11
<210>11
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>11
tcacattcacc11
<210>12
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>12
ttgtggatgtg11
<210>13
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>13
ggcccttctac11
<210>14
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>14
tcgtctgcggc11
<210>15
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>15
ttcaatgggcc11
<210>16
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>16
ttacccagtgc11
<210>17
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>17
atcaaccctgc11
<210>18
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>18
tgtattcgcca11
<210>19
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>19
acgccgattgc11
<210>20
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>20
tggcagtcggc11
<210>21
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>21
acctaacagcc11
<210>22
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>22
ttcatccgttc11
<210>23
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>23
ttgaacgatcc11
<210>24
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>24
taggtcgttca11
<210>25
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>25
atagaaggggc11
<210>26
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>26
ttaggccaaca11
<210>27
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>27
ccaactgtagc11
<210>28
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>28
taggcggttgg11
<210>29
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>29
cccggcctccc11
<210>30
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>30
ttcctagctgc11
<210>31
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>31
aaaccgacagc11
<210>32
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>32
tatgctgtcgg11
<210>33
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>33
attcgcccccc11
<210>34
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>34
tccgcttcggt11
<210>35
<211>56
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>35
taactgtcaaaagccactgtgtcctgaagaaaagcaaagacatctggacaaaaagc56
<210>36
<211>15
<212>rna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>36
uccagaugucuuugc15
<210>37
<211>30
<212>rna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>37
gaaauagaugguccagcuggacaagcagaa30
<210>38
<211>20
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>38
cttgtccagctggaccatct20
<210>39
<211>20
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>39
aagctgcgccacgtcttcctgttcaccgacctgcttctctgcaccaagct50
caagaagcagagcggaggcaaaacgcagcagtatgactgcaaatggtaca100
ttccgctcacggatctcagcttccagatggtggatgaactggaggcagtg150
cccaacatccccctggtgcccgatgaggagctggacgctttgaagatcaa200
gatctcccagatcaagaatgacatccagagagagaagagggcgaacaagg250
gcagcaaggctacggagaggctgaagaagaagctgtcggagcaggagtca300
ctgctgctgcttatgtctcccagcatggccttcagggtgcacagccgcaa350
cggcaagagttacacgttcctgatctcctctgactatgagcgtgcagagt400
ggagggagaacatccgggagcagcagaagaagtgtttcagaagcttctcc450
ctgacatccgtggagctgcagatgctgaccaactcgtgtgtgaaactcca500
gactgtccacagcattccgctgaccatcaataaggaagatgatgagtctc550
cggggctctatgggtttctgaatgtcatcgtccactcagccactggattt600
aagcagagttcaaaagcccttcagcggccagtagcatctgactttgagcc650
tcagggtctgagtgaagccgctcgttggaactccaaggaaaaccttctcg700
ctggacccagtgaaaatgaccccaaccttttcgttgcactgtatgatttt750
gtggccagtggagataacactctaagcataactaaaggtgaaaagctccg800
ggtcttaggctataatcacaatggggaatggtgtgaagcccaaaccaaaa850
atggccaaggctgggtcccaagcaactacatcacgccagtcaacagtctg900
gagaaacactcctggtaccatgggcctgtgtcccgcaatgccgctgagta950
tctgctgagcagcgggatcaatggcagcttcttggtgcgtgagagtgaga1000
gcagtcctggccagaggtccatctcgctgagatacgaagggagggtgtac1050
cattacaggatcaacactgcttctgatggcaagctctacgtctcctccga1100
gagccgcttcaacaccctggccgagttggttcatcatcattcaacggtgg1150
ccgacgggctcatcaccacgctccattatccagccccaaagcgcaacaag1200
cccactgtctatggtgtgtcccccaactacgacaagtgggagatggaacg1250
cacggacatcaccatgaagcacaagctgggcgggggccagtacggggagg1300
tgtacgagggcgtgtggaagaaatacagcctgacggtg1338
<210>40
<211>22
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>40
ataagcacctcttcaaggtctg22
<210>41
<211>22
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>41
tgacctgctcctcacccctcct22
<210>42
<211>22
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>42
cagaccttgaagaggtgcttat22
<210>43
<211>22
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>43
aggaggggtgaggagcaggtca22
<210>44
<211>16
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>44
gagttcaaaagccctt16
<210>45
<211>32
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<220>
<221>misc_feature
<222>(22)..(31)
<223>n为任何核苷酸
<400>45
catctccacctccataacccannnnnnnnnnc32
<210>46
<211>31
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<220>
<221>misc_feature
<222>(1)..(10)
<223>n为任何核苷酸
<400>46
nnnnnnnnnnaggtgataggtggaggtggta31
<210>47
<211>18
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>47
catctccacctccataac18
<210>48
<211>21
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>48
taccacctccacctatcacct21
<210>49
<211>21
<212>rna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>49
uggguuauggagguggagaug21
<210>50
<211>21
<212>rna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>50
uaccaccuccaccuaucaccu21
<210>51
<211>10
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>51
tggaccatct10
<210>52
<211>10
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>52
cttgtccagc10
<210>53
<211>30
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>53
gaaatagatggtccagctggacaagcagaa30
<210>54
<211>62
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>54
gcgcgcgcgctgctggacaagtccttttttccttttttcctagatggtcc50
atgcgcgcgcgc62
<210>55
<211>62
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>55
gcgcgcgcgctagatggtccatccttttttccttttttcctgctggacaa50
gtgcgcgcgcgc62
<210>56
<211>60
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>56
gcgcgcgcgctccttgctggacaagttttccttttagatggtccattcct50
gcgcgcgcgc60
<210>57
<211>60
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>57
acggactgcttccttgctggacaagttttccttttagatggtccattcct50
tcatcaaacc60
<210>58
<211>10
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>58
agatggtcca10
<210>59
<211>10
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>59
gctggacaag10
<210>60
<211>30
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>60
gaaatagatggtccagctggacaagcagaa30
<210>61
<211>52
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>61
agatggtccagtcggcgcgcctcgaaaacgaggcgcgccgacgctggaca50
ag52
<210>62
<211>54
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>62
agatggtccatgtcggcgcgcctcgaaaacgaggcgcgccgactgctgga50
caag54
<210>63
<211>52
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>63
agatggtccagcccccaggccgcatacgacggctagggagcggctggaca50
ag52
<210>64
<211>16
<212>rna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>64
uuucuucaggacacag16
<210>65
<211>15
<212>rna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>65
uccagaugucuuugc15
<210>66
<211>54
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>66
ttctggctggacaagtcaagaacccgcagttcgtgttcgagatggtccag50
aaca54
<210>67
<211>54
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>67
ttctgagatggtccatcaagaacccgcagttcgtgttcggctggacaagg50
aaca54
<210>68
<211>30
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>68
gaaauagaugguccagcuggacaagcagaa30
<210>69
<211>10
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>69
agauggucca10
<210>70
<211>10
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>70
gcuggacaag10
<210>71
<211>32
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>71
ctccataacccatggacatgtaccggtgatcc32
<210>72
<211>32
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>72
gatccccgggctatgtctagaggagaaggaga32
<210>73
<211>32
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>73
ctccataacccaaggatcctcaccggtgatcc32
<210>74
<211>32
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>74
gatccccgggtaccgagcataggagaaggaga32
<210>75
<211>12
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>75
ctccataaccca12
<210>76
<211>12
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>76
aggagaaggaga12
<210>77
<211>11
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>77
ggatcaccggt11
<210>78
<211>21
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>78
gcctctaagtctccttctcct21
<210>79
<211>21
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>79
catctccacctccataaccca21
<210>80
<211>21
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>80
cacctccataacccatggaca21
<210>81
<211>24
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>81
ctaagtctccttctcctctagaca24
<210>82
<211>21
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>82
ccacctccataacccaaggat21
<210>83
<211>23
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>83
tctaagtctccttctcctatgct23
<210>84
<211>22
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>84
catctccacctccataacccat22
<210>85
<211>22
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>85
gcctctaagtctccttctcctc22
<210>86
<211>22
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>86
catctccacctccataacccaa22
<210>87
<211>22
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>87
gcctctaagtctccttctccta22
<210>88
<211>16
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>88
uuucuucaggacacag16
<210>89
<211>55
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>89
taactgtcaaaagccactgtgtcctgaagaaagcaaagacatctggacaa50
aaagc55
<210>90
<211>57
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>90
taactgtcaaaagccactgtgtcctgaagaaaaagcaaagacatctggac50
aaaaagc57
<210>91
<211>58
<212>dna
<213>人工序列
<220>
<223>人工序列描述:合成的
<400>91
taactgtcaaaagccactgtgtcctgaagaaaaaagcaaagacatctgga50
caaaaagc58
- 还没有人留言评论。精彩留言会获得点赞!