用于检测与有机磷农药相关的Ⅱ型糖尿病易感基因试剂盒的制作方法
本发明属于基因工程
技术领域:
,尤其涉及一种用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒。
背景技术:
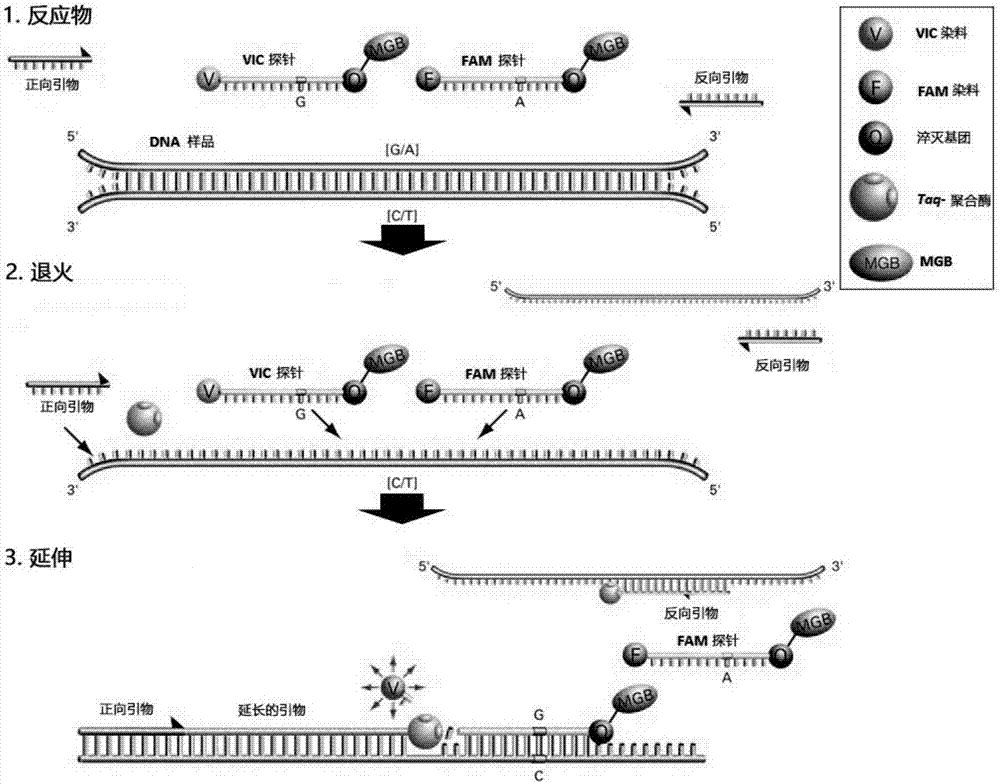
:糖尿病是是一种以高血糖为特征的代谢性疾病,最常见的一类是ⅱ型糖尿病(type2diabetesmellitus,t2dm),大约占糖尿病总数的90%左右。t2dm是一种极具异质性的代谢性疾病,病因及发病机理复杂。目前认为它是由遗传、环境、行为等多种危险因素共同参与和相互作用引起的多因子疾病。近年来,随着人类基因组计划的完成、高通量单核苷酸多态性(singlenucleotidepolymorphism,snp)检测生物芯片的建立以及全基因组关联研究(genome-wideassociationstudy,gwas)的开展,一系列t2dm相关易感基因被发现,并引起人们的关注。目前已经筛选出至少40个和t2dm相关的易感基因,主要包括:tcf7l2、pparg、kcnj11、cdkal1、oct1、cdkn2a/b、slc30a8、igf2bp2和fto等。易感基因对于发现一些以前未被发现的可能改变β细胞功能、胰岛素活动或其他代谢活动的生物学通路有很好的提示作用。有机磷作为一类高效、广谱的杀虫剂被广泛应用,在很大程度上提高了农作物的产量。但是有机磷农药具有较强的毒性,由此而造成的农产品有机磷农药残留量也越来越大,导致农民在接触、食用后造成有机磷的积累,对人体健康的危害也增加了。已有研究表明,长期微量接触有机磷农药会对机体造成损伤,会导致多器官、多系统的慢性损伤甚至危及生命。长期微量接触有机磷农药对哺乳动物的毒性除了抑制胆碱酯酶活性外,还会通过各种途径干扰哺乳动物糖代谢,诱发实验动物高血糖症,具有潜在的致糖尿病效应。糖尿病易感基因检测方法以往一般采用pcr-rflp(限制性片段长度多态性聚合酶链反应)、pcr-sbt(聚合酶链反应直接测序法)和pcr-ssp(序列特异引物引导的pcr反应)等。但是普遍存在操作时间长、步骤繁琐的缺点,不能满足现代医学实时检测的要求;需要有高度的特异性引物,优化的扩增条件,否则易出现假阳性或假阴性,造成结果模棱两可或误判;对特殊结构dna序列难以测序,容易导致漏检。因此,如何快速、准确检测与有机磷农药有关的ⅱ型糖尿病易感基因是糖尿病临床诊断的主要难题之一。针对传统的易感基因检测方法缺点,基于taqman探针的定量pcr技术是在普通pcr反应体系中加入荧光基团,根据等位基因产物,分别用两种荧光染料标记,只有完全匹配的探针才能扩增出各自对应的基因型,因此特异性强。可以在一次pcr反应中就完成对单个snp位点的基因型判定,故操作简便、耗时短、灵敏度高。因此将taqman探针和定量pcr法应用于与有机磷相关的ⅱ型糖尿病易感基因检测,有利于糖尿病的分子诊断。技术实现要素:针对现有技术存在的问题,本发明提供了一种用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒。本发明是这样实现的,一种用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒,所述用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒由pcr扩增引物和用于检测与有机磷农药相关的导致的ⅱ型糖尿病易感基因的特异性寡核苷酸探针组成;所述特异性寡核苷酸探针的核苷酸序列为seqidno:1~seqidno:14;所述pcr扩增引物,序列为seqidno:15~seqidno:28。进一步,所述ⅱ型糖尿病7个易感基因为:mthfr、capn10、lep、il1a、apoe、ctla4和apob基因。进一步,所述用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒还包括2×taqmanmastermix和pcr等级的水;进一步,所述特异性寡核苷酸探针5’端的荧光基团,野生型探针为vic,突变型探针为fam,3’端的淬灭基团为nfq。本发明的另一目的在于提供一种所述用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒的检测方法,所述用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒的检测方法包括以下步骤:步骤一,提取样本dna;步骤二,将目的基因、目的基因的扩增引物、探针按照确定比例混合;步骤三,通过荧光定量pcr仪进行实时荧光检测;步骤四,待测样本基因型判读。进一步,扩增体系为:2×taqmanmastermix10.0μl、基因组dna模板2μl(10~50ng/μl)、10pmol/μl上下游引物各0.9μl、10pmol/μl野生型和突变型探针各0.5μl,补充pcr等级的水至终体积20μl。进一步,扩增程序为:95℃10min,(92℃15s,60℃1min)×60个循环,72℃10min;pcr完成后使用abi公司7900ht型荧光定量pcr仪进行数据扫描,检测结果使用相应软件appliedbiosystemsautocallertmsoftware进行基因型判读。本发明的优点及积极效果为:1.高灵敏度、高通量、低成本。本发明的试剂盒采用taqman-实时定量荧光pcr方法来检测与有机磷农药有关的ⅱ型糖尿病易感基因,适用于检测人类全血、组织等全基因组dna样本,且只需10ng-20ng基因组dna,相比传统的pcr-ssp技术所需的50-100ng基因组dna,灵敏度更高;一次可同时进行至少96例样本的检测,平均每个反应管成本低廉。2.操作简便、耗时短。一次pcr反应就完成了扩增与测序两项内容,2-3h内即可完成实时定量pcr实验。3.易规模化应用。所设计的特异性探针针对dna点突变,结果准确度高,具有很好的应用市场和经济效益。4.安全、无污染。反应过程无需二次添加试剂,避免了二次污染的可能,所有反应试剂均安全、无毒。附图说明图1是本发明实施例提供的用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒的检测方法流程图。图2是本发明实施例提供的taqman探针检测原理示意图。图3是本发明实施例提供的有机磷农药有关的ii型糖尿病7个易感基因检测位点聚类结果示意图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。目前尚未见有关文献披露合适的与有机磷农药相关的ⅱ型糖尿病易感基因检测试剂盒。如何快速、准确地检测与有机磷农药相关的ⅱ型糖尿病易感基因突变是糖尿病临床诊断需要解决的问题。taqman-实时定量pcr法是在dna扩增反应中,加入荧光基团和淬灭基团,探针完整时,报告基团发射的荧光信号被淬灭基团吸收;pcr扩增时,taq酶的5’-3’外切酶活性将探针酶切降解,使荧光基团和淬灭基团分离,从而荧光监测系统可接收到荧光信号,即每扩增一条dna链,就有一个荧光分子形成,实现了荧光信号的累积与pcr产物的形成完全同步,具有灵敏度高、特异性强、操作简便、耗时短、高通量、无污染等特点。采用taqman-实时定量pcr技术,研究ⅱ型糖尿病基因易感性和有机磷农药之间的相关性,以此研究成果应用于ⅱ型糖尿病精准治疗和防控工作,为有机磷农药残留所致的ⅱ型糖尿病患者在易感基因筛查、早期诊断和精准治疗方面提供科学依据。下面结合附图对本发明的应用原理作详细的描述。本发明实施例提供的用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒由pcr扩增引物和用于检测与有机磷农药相关的导致的ⅱ型糖尿病易感基因的特异性寡核苷酸探针组成。本发明实施例的用于检测与有机磷农药相关的ⅱ型糖尿病7个易感基因为:mthfr、capn10、lep、il1a、apoe、ctla4和apob基因。本发明实施例的特异性寡核苷酸探针的核苷酸序列为seqidno:1~seqidno:14。本发明实施例的pcr扩增引物,序列为seqidno:15~seqidno:28。所述的与有机磷农药相关的ⅱ型糖尿病7个易感基因检测试剂盒还包括2×taqmanmastermix和pcr等级的h2o;所述特异性寡核苷酸探针5’端的荧光基团,野生型探针为vic,突变型探针为fam,3’端的淬灭基团为nfq。如图1所示,本发明实施例提供的用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒的检测方法包括以下步骤:s101:提取样本dna;s102:将目的基因、目的基因的扩增引物、探针按照确定比例混合;s103:通过荧光定量pcr仪进行实时荧光检测;s104:待测样本基因型判读。在本发明的优选实施例中:扩增体系为:2×taqmanmastermix10.0μl、基因组dna模板2μl(10~50ng/μl)、10pmol/μl上下游引物各0.9μl、10pmol/μl野生型和突变型探针各0.5μl,补充pcr等级的水至终体积20μl。在本发明的优选实施例中:扩增程序为:95℃10min,(92℃15s,60℃1min)×60个循环,72℃10min;pcr完成后使用abi公司7900ht型荧光定量pcr仪进行数据扫描,检测结果使用相应软件appliedbiosystemsautocallertmsoftware进行基因型判读。本发明实施例的试剂盒的用途是:针对的基因为与有机磷农药相关的ⅱ型糖尿病7个易感基因。本发明通过对与有机磷农药有关的ii型糖尿病易感基因位点进行筛选,设计相关探针,经过反复试验和验证,得到了一组杂交特异性高准确度好的探针,探针序列如下。表1特异性寡核苷酸探针序列基因名称探针序号野生型探针序列mthfr15'-vic-atgaaatcggctcccgc-nfq-3'capn1035'-vic-aagtaaggcgtttgaag-nfq-3'lep55'-vic-cagcgccagcggttgcaa-nfq-3'il1a75'-vic-ccaggcaacaccattgaa-nfq-3'apoe95'-vic-cggccgcacacgtcct-nfq-3'ctla4115'-vic-aacctggctaccaggacct-nfq-3'apob135'-vic-tgtatcttctagggtctct-nfq-3'基因名称探针序号突变型探针序列mthfr25'-fam-atgaaatcgactcccgc-nfq-3'capn1045'-fam-aagtaaggcatttgaag-nfq-3'lep65'-fam-cagcgccaacggttgcaa-nfq-3'il1a85'-fam-ccaggcaacatcattgaa-nfq-3'apoe105'-fam-cggccgcgcacgtcct-nfq-3'ctla4125'-fam-aacctggctgccaggacc-nfq-3'apob145'-fam-tgtatcttctagagtctct-nfq-3'与有机磷农药有关的ii型糖尿病易感基因位点pcr扩增引物序列如下。表24个易感基因突变位点的引物序列基因名称位点引物序号正向引物序列5'-3'mthfrrs180113315gcacttgaaggagaaggtgtctcapn10rs379226717gcgctcacgcttgctleprs779903919gcaagttgtgatcgggccgctatil1ars180058721gccacaggaattataaaagctgagaapoers42935823agaccatgaaggagttgaaggcctctla4rs92616925aaggctcagctgaacctggapobrs69327ggctcacatgaaggccaaattc基因名称位点引物序号反向引物序列5'-3'mthfrrs180113316cctcaaagaaaagctgcgtgatgcapn10rs379226718cctcaccaagtcaaggcttagcleprs779903920ggcacagcccagcagcaaatcil1ars180058722cccgggaggtatgcgtaagapoers42935824cacctgctccttcacctcgtctla4rs92616926gctgaaacaaatgaaaccapobrs69328agttcctgctgaatgtccatttgat下面结合实施例对本发明的应用原理作进一步的描述。实施例1:本发明的实施例筛选与有机磷农药长期接触人群,根据ⅱ型糖尿病易感基因,采用meta分析方法,对每个易感基因进行分类统计,计算or值,统计出与有机磷农药长期接触相关的易感基因位点。以mthfr的rs1801133基因位点为例,统计有机磷农药长期接触易感人群组与对照组、未有接触史易感人群与对照组的数据,经reviewmanager5软件分析,结果显示,该位点or值为2.03,大于1,因此该位点为有机磷农药长期接触易感人群的危险因素。本发明实施例中的用于检测与有机磷有关的2型糖尿病易感基因的特异性寡核苷酸探针,该探针的核苷酸序列如seqidno:1~14所示,扩增引物如seqidno:15~28所示,委托上海某公司合成。实施例2:1.dna样本的提取及稀释按常规方法获得用乙二胺四乙酸(edta)抗凝的真空采血管采集静脉血后进行基因组dna提取,血液基因组dna提取试剂盒为上海联吉医学检验所有限公司自建试剂盒,用pcr等级水稀释样品至10~50ng/μl。2.样本检测扩增体系为:2×taqmanmastermix10.0μl、基因组dna模板2μl(10~50ng/μl)、10pmol/μl上下游引物各0.9μl、10pmol/μl野生型和突变型探针各0.5μl,补充pcr等级的水至终体积20μl。扩增程序为:95℃10min,(92℃15s,60℃1min)×60个循环,72℃10min;pcr完成后使用abi公司7900ht型荧光定量pcr仪进行数据扫描,检测结果使用相应软件appliedbiosystemsautocallertmsoftware进行基因型判读。3.检测结果图3-ⅰ中基因为mthfr,genotype11即对应图3中ⅰ的genotype列的11,对应显示在报告中的基因型是gg,genotype11:4表示,检测结果为gg的样本数为4个;genotype12:3表示,检测结果为ag的样本数为3个;genotype22:2表示,检测结果为aa的样本数为2个。图3-ⅱ中基因为capn10,genotype11:0表示,检测结果为aa的样本数为0个;genotype12:2表示,检测结果为ag的样本数为2个;genotype22:4表示,检测结果为gg的样本数为4个。图3-ⅲ中基因为lep,genotype11:5表示,检测结果为aa的样本数为5个;genotype12:1表示,检测结果为ag的样本数为1个;genotype22:1表示,检测结果为gg的样本数为1个。图3-ⅳ中基因为il1a,genotype11:1表示,检测结果为aa的样本数为1个;genotype12:1表示,检测结果为ag的样本数为1个;genotype22:3表示,检测结果为gg的样本数为3个;ntc:1代表1个阴性对照样本。图3-ⅴ中基因为apoe,genotype11:0表示,检测结果为gg的样本数为0个;genotype12:4表示,检测结果为ag的样本数为4个;genotype22:16表示,检测结果为aa的样本数为16个。图3-ⅵ中基因为ctla4,genotype11:0表示,检测结果为aa的样本数为0个;genotype12:4表示,检测结果为ag的样本数为4个;genotype22:16表示,检测结果为gg的样本数为16个。图3-ⅶ中基因为apob,genotype11:0表示,检测结果为aa的样本数为0个;genotype12:2表示,检测结果为ag的样本数为2个;genotype22:6表示,检测结果为gg的样本数为6个。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。<110>徐州工程学院<120>用于检测与有机磷农药相关的ⅱ型糖尿病易感基因试剂盒<160>29<210>1<211>17<212>dna<213>人工序列(artificialsequence)<400>1atgaaatcggctcccgc<210>2<211>17<212>dna<213>人工序列(artificialsequence)<400>2atgaaatcgactcccgc<210>3<211>17<212>dna<213>人工序列(artificialsequence)<400>3aagtaaggcgtttgaag<210>4<211>17<212>dna<213>人工序列(artificialsequence)<400>4aagtaaggcatttgaag<210>5<211>18<212>dna<213>人工序列(artificialsequence)<400>5cagcgccagcggttgcaa<210>6<211>18<212>dna<213>人工序列(artificialsequence)<400>6cagcgccaacggttgcaa<210>7<211>18<212>dna<213>人工序列(artificialsequence)<400>7ccaggcaacaccattgaa<210>8<211>18<212>dna<213>人工序列(artificialsequence)<400>8ccaggcaacatcattgaa<210>9<211>16<212>dna<213>人工序列(artificialsequence)<400>9cggccgcacacgtcct<210>10<211>16<212>dna<213>人工序列(artificialsequence)<400>10cggccgcgcacgtcct<210>11<211>19<212>dna<213>人工序列(artificialsequence)<400>11aacctggctaccaggacct<210>12<211>18<212>dna<213>人工序列(artificialsequence)<400>12aacctggctgccaggacc<210>13<211>19<212>dna<213>人工序列(artificialsequence)<400>13tgtatcttctagggtctct<210>14<211>19<212>dna<213>人工序列(artificialsequence)<400>14tgtatcttctagagtctct<210>15<211>22<212>dna<213>人工序列(artificialsequence)<400>15gcacttgaaggagaaggtgtct<210>16<211>23<212>dna<213>人工序列(artificialsequence)<400>16cctcaaagaaaagctgcgtgatg<210>17<211>15<212>dna<213>人工序列(artificialsequence)<400>17gcgctcacgcttgct<210>18<211>22<212>dna<213>人工序列(artificialsequence)<400>18cctcaccaagtcaaggcttagc<210>19<211>23<212>dna<213>人工序列(artificialsequence)<400>19gcaagttgtgatcgggccgctat<210>20<211>21<212>dna<213>人工序列(artificialsequence)<400>20ggcacagcccagcagcaaatc<210>21<211>25<212>dna<213>人工序列(artificialsequence)<400>21gccacaggaattataaaagctgaga<210>22<211>19<212>dna<213>人工序列(artificialsequence)<400>22cccgggaggtatgcgtaag<210>23<211>24<212>dna<213>人工序列(artificialsequence)<400>23agaccatgaaggagttgaaggcct<210>24<211>20<212>dna<213>人工序列(artificialsequence)<400>24cacctgctccttcacctcgt<210>25<211>19<212>dna<213>人工序列(artificialsequence)<400>25aaggctcagctgaacctgg<210>26<211>18<212>dna<213>人工序列(artificialsequence)<400>26gctgaaacaaatgaaacc<210>27<211>22<212>dna<213>人工序列(artificialsequence)<400>27ggctcacatgaaggccaaattc<210>28<211>25<212>dna<213>人工序列(artificialsequence)<400>28agttcctgctgaatgtccatttgat<210>29<211>30<212>dna<213>人工序列(artificialsequence)<400>29tgtatcttctagagtctctc当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1