基于高通量测序的鳓鱼SNP标记开发方法及应用与流程
本发明涉及分子生物学技术领域,尤其是涉及基于高通量测序的鳓鱼snp标记开发方法及应用。
技术背景
鳓鱼(ilishaelongate),属于鲱形目(clupeiformes),锯腹鳓科(pristigasteridae),鳓属(ilisha),为我国沿海广泛分布的暖水性中上层重要经济鱼类,渤海、黄海、东海、南海均有产出,产量最多的海域位于东海。鳓鱼以浮游生物为主,包括硅藻类、小型游泳动物(幼鱼)、桡足类、磷虾类、长尾类和糠虾类等,兼食底栖生物和小型游泳动物,同时又是多种高营养级鱼类的捕食对象,在海洋生态系统食物链中发挥着承上启下的重要作用。同时,鳓鱼含肉率高、肉质细嫩、味道鲜美、营养丰富,是我国传统名贵鱼类,鳓鱼的干制品,如广东的曹白鱼鲞、浙江的糟鲞已久负盛名;而且鳓鱼也是中国出口创汇的重要水产品之一。
近年来受过度捕捞、全球气候变化、环境污染和栖息地破坏等影响,使得鳓鱼野生群体数量大大减少,长此以往势必会对鳓鱼的遗传多样性和种质资源造成巨大破坏,产生难以估量的损失。由于其不仅是重要的渔业捕捞对象,还是海洋生态系统变动的关键指示种,在物质循环和能量流动中发挥不可替代的作用,鳓鱼资源的衰退不仅会造成其自身渔业产量的大幅减少,而且还会破坏整个沿海生态系统的物质能量循环网结构。因此,加强对鳓鱼资源的管理和保护刻不容缓。群体遗传学研究对于正确理解与种群适应性、持续性及种群动态相关的生态与进化过程至关重要,是制定有效保护和合理开发利用生物资源策略的基础。研究鳓鱼的种群遗传结构,阐明种群对本地环境的适应性机制,可为鳓鱼资源的合理开发利用和管理保护提供重要的科学指导,对衰退种质资源的补充和生态系统的健康发展都具有重要的科学意义。
单核苷酸多态性(singlenucleotidepolymorphism,snp)指的是某种生物不同个体dna序列中单个核苷酸点突变产生的多态性,包括置换、颠换、插入或缺失引起的多态现象。snp是由美国学者lander于1996年提出的继rflp、ssr的第三代新型分子标记技术,1998~2002年每年都召开“snps与复杂基因组”国际会议以探讨snps在复杂基因组中应用,随着pcr、分型检测、dna芯片等技术的不断发展,snp趋于高通量、自动化。近年来,分子标记技术逐渐成为研究水产动物遗传学的重要手段,snp作为第三代遗传标记,位点数量多、密度广、遗传多样性高以及自动化程度强,能够显示其他分子标记技术难以检测到的遗传信息多态性,故而,snp标记技术对于水产动物遗传学研究具有重要意义。
基于先进的简化基因组测序技术获得高密度的snp位点,可从全基因组层面查明中国沿海黄鲫种群的遗传多样性水平、种群遗传结构等重要群体遗传学参数,能够克服传统方法中依赖于单个或少数基因位点来评估海洋生物群体遗传和进化机制带来的不确定性和分辨率不高的问题,将为黄鲫的有效管理及合理保护提供背景知识,并有助于推动中国海洋鱼类群体基因组学研究向更深发展。
目前获取基因信息数据的方法主要有两种:基因分型和基因测序。基因分型主要是利用已知的单核苷酸多态性(snp)位点侧翼的碱基序列设计探针,并将探针固定在基因芯片上。当待测样本的dna与基因芯片上的探针序列互补杂交并通过扫描荧光信号来探知杂交,便可鉴定样本dna上这些探针位点(snp位点)的基因型。而基因测序是对目标dna进行碱基序列测定,并进行相关分析。
现有技术如授权公告号为cn105238859b的中国发明专利,公开了一种获取鸡全基因组高密度snp标记位点的方法,包括以下步骤:(1)预测用ecori与msei的双酶切鸡基因组所获得的酶切片段分布情况;(2)根据ecori与msei的酶切片段分布特点设计通用接头、条形码接头及pcr扩增引物;(3)构建简化基因组测序文库;(4)利用步骤(3)构建的文库进行上机测序;(5)根据测序结果获得snp标记位点;该发明获取每个snp标记位点的成本比传统芯片技术降低一个数量级,且方法技术稳定,重复性高。然而该发明测序程序较复杂,目标dna获取纯度低。
技术实现要素:
本发明的目的在于提供一种基于高通量测序的鳓鱼snp标记开发方法,该方法具有简单、高效、snp标记筛选获取效率高、重复性好、成本低等优点;采用该方法对鳓鱼snp标记开发,可用于研究鳓鱼的种群遗传结构,对阐明种群对本地环境的适应性机制,以及鳓鱼资源的合理开发利用和管理保护提供重要的科学指导,对衰退种质资源的补充和生态系统的健康发展都具有重要的科学意义。
本发明针对上述技术中提到的问题,采取的技术方案为:
基于高通量测序的鳓鱼snp标记开发方法,包括以下步骤:
提取基因组dna:提取用溶液包括提取液i和提取液ii;其中提取液i包括缓冲盐、非离子表面活性剂、以及中性盐的水溶液,其ph值为7.5-8.5;提取液ii包括缓冲盐和阳离子表面活性剂,其ph值为7.8-8.2;
具体步骤为:将鳓鱼肌肉或鳍条组织样品剪碎,置于提取液i,加入环状dna和甲壳质,冻融2-3次,离心,收集上清液后加入提取液ii,颠倒混匀后,离心产生白色沉淀,洗涤沉淀得dna样品,待用;
rad文库构建与高通量测序:采用限制性内切酶ecori对基因组dna进行酶切,向酶切片段中加入第一接头,将所得dna片段混池,打断,通过琼脂糖凝胶电泳回收350-550bp的dna片段,对所得dna片段进行末端平化,3’端加“a”,接着加入第二接头,第二接头为分叉的y型接头,可阻止未连接第一接头的片段扩增,得dna模板,通过桥式pcr扩增所制备的dna模板,成簇后应用illuminahiseq4000测序平台进行双端测序;该过程不受参考基因组的限制,可简化复杂基因组,能够在整个基因组内批量寻找snp位点,具有一致的扩增效率,有效地降低了建库成本和测序成本;
原始序列数据过滤:过滤掉原始测序数据中包含带adaptor信息、低质量碱基和未测出的碱基的readspair;原始测序数据中所包含的这些信息会对后续的信息分析造成很大的干扰,分析前将这些干扰信息去除掉,所得到的有效数据为后续数据的精确分析提供了保证;
snp信息位点检测与筛选:将过滤所得的readspair通过bwa软件与已发表的鳓鱼基因组草图进行比对,接着采用samtools0.1.19中的贝叶斯算法模型以最大reads深度为1000的参数设置进行snp的检测,过滤得鳓鱼snp标记位点;
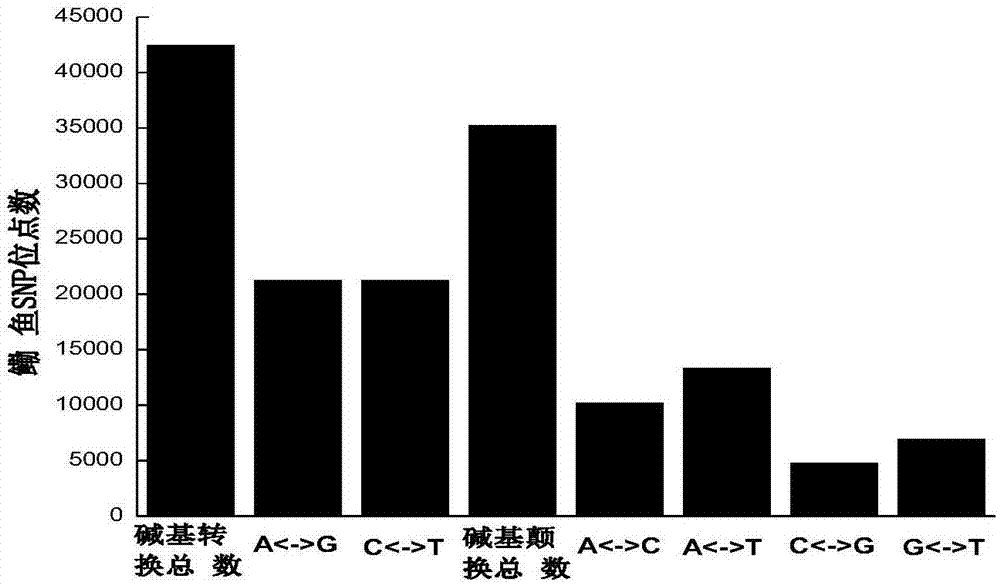
利用获得的鳓鱼snp标记位点对鳓鱼群体进行遗传学分析:本研究总共筛选出了77,634个高质量的多态snps,如图1,其中42,447个snp来自于碱基间的转换(a/g、c/t),35,187个snp来自于碱基间的颠换(a/c、a/t、c/g及g/t),也就是说,这些snp中54.70%是由碱基之间的转换产生的,45.30%是由碱基之间颠换产生的;同时,我们也发现a/g的数量最为丰富(27.50%),c/g的数量最少(6.16%)。
作为优选,环状dna为高纯度的细菌质粒dna;可根据需要选用不同大小的环状dna,只要所加环状dna与所构建的目标dna文库能够有效分离即可;环状dna和甲壳质的特殊存在,一方面能够促进鳓鱼组织细胞中水分子与非离子表面活性剂结合,发生水合作用,从而对鳓鱼组织细胞蛋白质表层的水化膜构成破坏,致使蛋白质易于聚集形成沉淀,同时由于其存在能够降低提取液i的介电常数,增加被提取鳓鱼组织细胞中相反电荷基团之间的吸引力,促进了蛋白质分子的聚集和沉淀,有效提高了鳓鱼组织细胞蛋白质的脱除率,提高了被提取组织dna的纯度,降低了dna片段的损失和浪费,减少了获取成本;另一方面,当样品中混有大量微生物(或其他异种生物)基因组污染,环状dna和甲壳质具有识别污染并破坏其结构的功效,使得提取目标dna可不受干扰地进行后续的建库和测序,因而snp标记筛选准确度高、获取效率高。
作为优选,缓冲盐选自tris-hcl、磷酸钠、磷酸氢二钠和磷酸二氢钠中的至少一种,浓度为100-200mm。
作为优选,非离子表面活性剂为c12~c18的脂肪醇醚硫酸铵或脂肪醇醚硫酸钠。
作为优选,阳离子表面活性剂为阳离子聚丙烯酰胺,其浓度为0.1-5ppm。
作为优选,中性盐为氯化钠或氯化钾,浓度为100-200mm。
作为优选,提取基因组dna过程中,冷冻的温度为-196至-20℃,融化的温度为40-70℃。
作为优选,rad文库构建及测序中酶切反应体系为40-50μl,其中含有1-2μl10×nebbuffer,0.5-0.8μl内切酶,0.5-0.8μl基因组dna,其余为双蒸水。该条件下,内切酶稳定性好,不易失活,且所获得的dna片段纯度高,为后续步骤提供了充足的dna片段。
作为优选,rad文库构建与高通量测序中桥式pcr扩增所用的上游引物序列为:5’-acggatactgaccaccgt-3’,下游引物序列为:5’-caagcacgcctacatacgc-3’;上下游引物长度适当,与模板的序列紧密互补,引物与引物之间难以形成稳定的二聚体和发夹结构,在错配位点的引发效率极低。
作为优选,rad文库构建与高通量测序中桥式pcr扩增条件为:90-100℃变性10s,55-70℃退火30s,50-80℃延伸30s,进行15-20个循环,最后50-80℃延伸5min。该条件下,靶序列变性彻底,其不影响聚合酶的活性,引物延伸完全,能够达到有效的扩增量,且非特异性扩增少。
基于高通量测序的鳓鱼snp标记开发方法的应用,可利用鳓鱼snp标记研究鳓鱼的种群遗传结构,对阐明种群对本地环境的适应性机制,以及鳓鱼资源的合理开发利用和管理保护提供重要的科学指导,对衰退种质资源的补充和生态系统的健康发展都具有重要的科学意义。
与现有技术相比,本发明的优点在于:1)本发明克服了标记数目的匮乏对鳓鱼群体遗传结构精确分析的限制,snp标记筛选准确度高、获取效率高,无需纯化步骤,降低了dna片段的损失和浪费,减少了获取成本;2)本发明在配置pcr扩增体系过程中加入甲壳质流体,能够有效提高pcr扩增效果,同时降低实验成本。
附图说明
图1是本发明获得的鳓鱼snp标记位点图。
具体实施方式
下面通过实施例对本发明方案作进一步说明:
实施例1:
一种基于高通量测序的鳓鱼snp标记开发方法,包括以下步骤:
提取基因组dna:将鳓鱼肌肉或鳍条组织样品剪碎,置于提取液i:70ml浓度为120mm的tris-hcl和磷酸氢二钠,0.3g脂肪醇醚硫酸铵,30ml浓度为120mm的氯化钠溶液;加入0.5μg质粒dna和0.1μg甲壳质,冻融2-3次,冷冻的温度为-166℃,融化的温度为50℃,离心,收集上清液后加入提取液ii:10ml浓度为100mm的tris-hcl和磷酸氢二钠和30ml浓度为0.5ppm的阳离子聚丙烯酰胺,颠倒混匀后,离心产生白色沉淀,洗涤沉淀得dna样品,待用;环状dna和甲壳质的特殊存在,一方面能够促进鳓鱼组织细胞中水分子与非离子表面活性剂结合,发生水合作用,从而对鳓鱼组织细胞蛋白质表层的水化膜构成破坏,致使蛋白质易于聚集形成沉淀,同时由于其存在能够降低提取液i的介电常数,增加被提取鳓鱼组织细胞中相反电荷基团之间的吸引力,促进了蛋白质分子的聚集和沉淀,有效提高了鳓鱼组织细胞蛋白质的脱除率,提高了被提取组织dna的纯度,降低了dna片段的损失和浪费,减少了获取成本;另一方面,当样品中混有大量微生物(或其他异种生物)基因组污染,环状dna和甲壳质具有识别污染并破坏其结构的功效,使得提取目标dna可不受干扰地进行后续的建库和测序,因而snp标记筛选准确度高、获取效率高;
rad文库构建与高通量测序:将提取的基因组dna保存在超纯水中,稀释浓度在25ng/μl以上,dna的总质量大于1μg,采用限制性内切酶ecori对基因组dna进行酶切,酶切反应体系为50μl(2μl10×nebbuffer,0.5μl内切酶,0.5μl基因组dna,其余为双蒸水),酶切反应条件为:36℃反应9min,然后71℃反应18min,向酶切片段中加入第一接头(可与ecori酶切dna缺口互补),将所得片段混池,随机打断到一定的片段(平均片段长度约600bp),通过琼脂糖凝胶电泳回收300bp-450bp的dna片段,末端平化后加3’daoverhang,接着加入第二接头,第二接头含有3’dtoverhang,可以与随机打断的3’daoverhang互补结合,从而形成pcr富集扩增前的dna模板,接着通过桥式pcr扩增所制备的dna模板,桥式pcr扩增所用的上游引物序列为:5’-acggatactgaccaccgt-3’,下游引物序列为:5’-caagcacgcctacatacgc-3’,成簇后应用illuminahiseq4000测序平台进行双端测序,其中,第一接头包含4个部分:ecori限制性内切酶酶切末端,用以对样品进行追踪的6bpbarcode序列(每个barcode序列之间至少存在2个碱基的差异以避免由于测序误差造成的样品归属偏差),与illumina测序引物结合的互补序列以及与pcr扩增前引物结合的序列;第二接头为局部双链分叉y型dna,可实现选择性的扩增同时含有第一接头和第二接头的dna;
上述pcr扩增条件为:90℃变性10s,55℃退火30s,50℃延伸30s,进行15个循环,最后50℃延伸5min;该条件下,靶序列变性彻底,其不影响聚合酶的活性,引物延伸完全,能够达到有效的扩增量,且非特异性扩增少;
原始序列数据过滤:dna文库通过illuminahiseq4000平台进行测序,测序得到的原始测序序列为原始数据,原始测序数据中会包含带接头(adaptor)信息、低质量碱基和未测出的碱基(以n表示)的readspair,然而这些信息会对后续的信息分析造成很大的干扰,分析前需将这些干扰信息去除掉,最终得到的数据即为有效数据,此外,在获得有效数据后,需要进一步去除由于pcr复制导致的重复reads(duplication)并对数据的质量得分(q20,q30)及gc含量分布进行评估,以保证后续数据分析的要求,过滤的标准为:过滤掉含有接头序列的readspair;当单端测序read中n碱基(n表示测序无法确定的碱基信息)的含量超过10%时,去除此对双末端reads;当单端测序read中含有的低质量(phredscore≤5)碱基数超过该条read长度的50%时,去除此对双末端readspair;过滤掉由于pcr扩增产生的重复序列;
snp信息位点检测与筛选:将过滤所得的readspair通过bwa软件与已发表的鳓鱼基因组草图进行比对,接着采用samtools0.1.19中的贝叶斯算法模型以最大reads深度为1000的参数设置进行snp的检测,最后对检测到的snp位点按照以下的标准进行过滤:snp的质量值不低于30(q30);snp的reads支持数不低于10;snp的个体覆盖度不低于80%;最小等位基因频率(maf)不低于5%;仅保留双等位基因位点;每个群体杂合度ho≤0.5;近交系数-0.3≤fis≤0.3;通过深度、覆盖度等参数过滤后,共得到77,634个snp位点;
群体遗传学分析:本研究总共筛选出了77,634个高质量的多态snps,如图1,其中42,447个snp来自于碱基间的转换(a/g、c/t),35,187个snp来自于碱基间的颠换(a/c、a/t、c/g及g/t),也就是说,这些snp中54.70%是由碱基之间的转换产生的,45.30%是由碱基之间颠换产生的;同时,我们也发现a/g的数量最为丰富(27.50%),c/g的数量最少(6.16%);这些位点可用于研究鳓鱼的种群遗传结构,对阐明种群对本地环境的适应性机制,以及鳓鱼资源的合理开发利用和管理保护提供重要的科学指导,对衰退种质资源的补充和生态系统的健康发展都具有重要的科学意义。
实施例2:
一种基于高通量测序的鳓鱼snp标记开发方法,包括以下步骤:
提取基因组dna:将鳓鱼肌肉或鳍条组织样品剪碎,置于提取液i:70ml浓度为150mm的tris-hcl和磷酸氢二钠,0.5g脂肪醇醚硫酸铵,30ml浓度为130mm的氯化钠溶液;加入0.5μg质粒dna和0.1μg甲壳质,冻融2-3次,冷冻的温度为-166℃,融化的温度为50℃,离心,收集上清液后加入提取液ii:10ml浓度为100mm的tris-hcl和磷酸氢二钠和30ml浓度为1.6ppm的阳离子聚丙烯酰胺,颠倒混匀后,离心产生白色沉淀,洗涤沉淀得dna样品,待用;
rad文库构建与高通量测序:将提取的基因组dna保存在超纯水中,稀释浓度在25ng/μl以上,dna的总质量大于1μg,采用限制性内切酶ecori对基因组dna进行酶切,酶切反应体系为50μl(2μl10×nebbuffer,0.5μl内切酶,0.5μl基因组dna,其余为双蒸水),酶切反应条件为:38℃反应12min,然后73℃反应25min,向酶切片段中加入第一接头(可与ecori酶切dna缺口互补),将所得片段混池,随机打断到一定的片段(平均片段长度约600bp),通过琼脂糖凝胶电泳回收300bp-450bp的dna片段,末端平化后加3’daoverhang,接着加入第二接头,第二接头含有3’dtoverhang,可以与随机打断的3’daoverhang互补结合,从而形成pcr富集扩增前的dna模板,接着通过桥式pcr扩增所制备的dna模板,桥式pcr扩增所用的上游引物序列为:5’-acggatactgaccaccgt-3’,下游引物序列为:5’-caagcacgcctacatacgc-3’,成簇后应用illuminahiseq4000测序平台进行双端测序,其中,第一接头包含4个部分:ecori限制性内切酶酶切末端,用以对样品进行追踪的6bpbarcode序列(每个barcode序列之间至少存在2个碱基的差异以避免由于测序误差造成的样品归属偏差),与illumina测序引物结合的互补序列以及与pcr扩增前引物结合的序列;第二接头为局部双链分叉y型dna,可实现选择性的扩增同时含有第一接头和第二接头的dna;
上述pcr扩增条件为:98℃变性10s,65℃退火30s,72℃延伸30s,进行18个循环,最后72℃延伸5min;
原始序列数据过滤:dna文库通过illuminahiseq4000平台进行测序,测序得到的原始测序序列为原始数据,原始测序数据中会包含带接头(adaptor)信息、低质量碱基和未测出的碱基(以n表示)的readspair,然而这些信息会对后续的信息分析造成很大的干扰,分析前需将这些干扰信息去除掉,最终得到的数据即为有效数据,此外,在获得有效数据后,需要进一步去除由于pcr复制导致的重复reads(duplication)并对数据的质量得分(q20,q30)及gc含量分布进行评估,以保证后续数据分析的要求,过滤的标准为:过滤掉含有接头序列的readspair;当单端测序read中n碱基(n表示测序无法确定的碱基信息)的含量超过10%时,去除此对双末端reads;当单端测序read中含有的低质量(phredscore≤5)碱基数超过该条read长度的50%时,去除此对双末端readspair;过滤掉由于pcr扩增产生的重复序列;
snp信息位点检测与筛选:将过滤所得的readspair通过bwa软件与已发表的鳓鱼基因组草图进行比对,接着采用samtools0.1.19中的贝叶斯算法模型以最大reads深度为1000的参数设置进行snp的检测,最后对检测到的snp位点按照以下的标准进行过滤:snp的质量值不低于30(q30);snp的reads支持数不低于10;snp的个体覆盖度不低于80%;最小等位基因频率(maf)不低于5%;仅保留双等位基因位点;每个群体杂合度ho≤0.5;近交系数-0.3≤fis≤0.3;通过深度、覆盖度等参数过滤后,共得到77,634个snp位点;
群体遗传学分析:本研究总共筛选出了77,634个高质量的多态snps,如图1,其中42,447个snp来自于碱基间的转换(a/g、c/t),35,187个snp来自于碱基间的颠换(a/c、a/t、c/g及g/t),也就是说,这些snp中54.70%是由碱基之间的转换产生的,45.30%是由碱基之间颠换产生的;同时,我们也发现a/g的数量最为丰富(27.50%),c/g的数量最少(6.16%);这些位点可用于研究鳓鱼的种群遗传结构,对阐明种群对本地环境的适应性机制,以及鳓鱼资源的合理开发利用和管理保护提供重要的科学指导,对衰退种质资源的补充和生态系统的健康发展都具有重要的科学意义。
实施例3:
rad文库构建与高通量测序过程中,在pcr扩增体系过程中加入甲壳质流体,甲壳质的质量百分比为0.16%,溶剂为l-氨基酸乙酯;其余部分和实施例2完全一致;甲壳质流体的特殊存在,对dna具有极强的吸附力,能够提高pcr成功率,同时甲壳质流体是由许多微小球体组成,可以包裹反应体系,使pcr扩增反应在一个个微小的独立空间完成,从而提高pcr扩增的反应敏感度,使反应更加充分,提高微量dna的pcr扩增效果;此外,甲壳质流体能提高反应体系的沸点使体系缓冲液不易蒸发,降低了pcr扩增过程中试剂的用量,从而降低了实验成本。
对比例1:
提取基因组dna过程中不加入环状dna和甲壳质,其余部分和实施例2完全一致;最终过滤筛选得52730个高质量的多态snps,这说明加入环状dna和甲壳质能有效提高提取dna的完整度,有利于获得鳓鱼全基因组信息,提高snp标记筛选准确度和获取率。
本发明操作步骤中的常规操作为本领域技术人员所熟知,在此不进行赘述。
以上所述的实施例对本发明的技术方案进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充或类似方式替代等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!