用于高浓度淀粉液化的a-淀粉酶突变体及其编码基因和它们的应用的制作方法
本发明属于酶工程和基因工程领域,具体地,涉及一种用于高浓度淀粉液化的a-淀粉酶突变体及其编码基因和它们在高浓度淀粉液化中的应用。
背景技术:
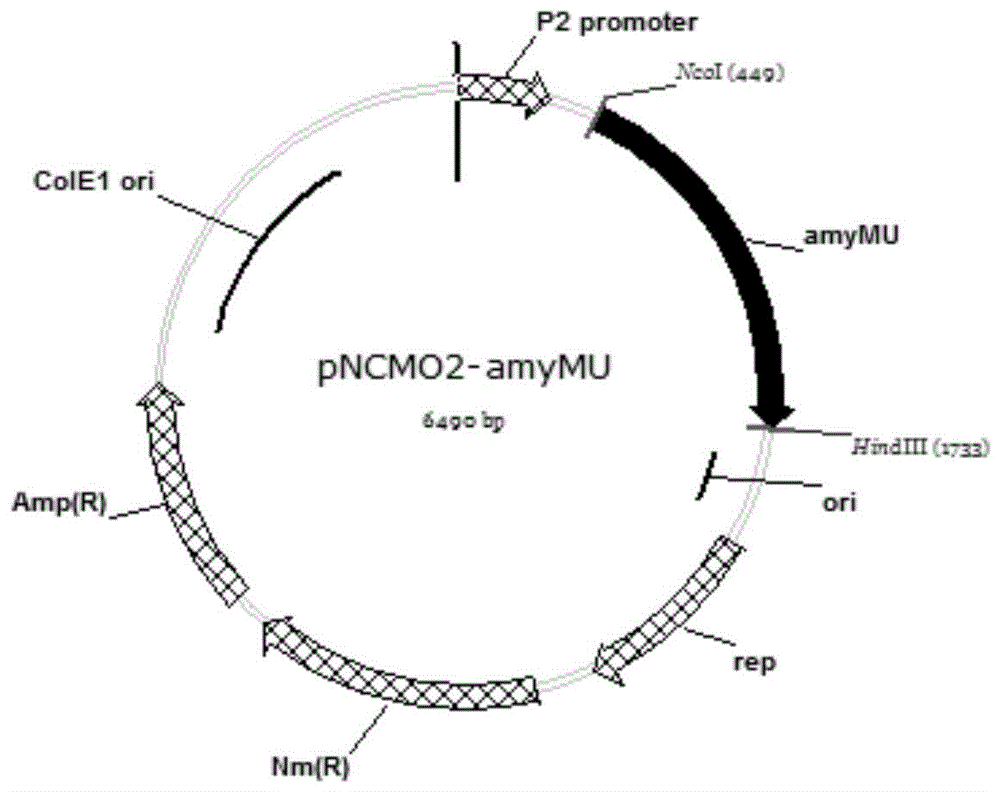
:淀粉是自然界中储量最为丰富的碳水化合物之一,也是极其重要的工业原料,然而淀粉需要初步处理之后才可以应用于糖类、氨基酸、酒精发酵等深加工行业中,淀粉初步处理首先将含有淀粉颗粒的乳浊液升温至60-70℃,使得淀粉颗粒吸水膨胀,形成糊状的液体(即糊化),糊化后的淀粉在淀粉酶的作用下被迅速降粘液化成短链的糊精(即液化),液化是淀粉水解中一个十分重要步骤,其中a-淀粉酶对淀粉液化效果具有决定性的作用。大规模工业化的淀粉液化工艺主要采用瞬间高温喷射液化,在此过程中,淀粉醪的温度可达105℃以上,这就要求所采用的淀粉酶具有良好的热稳定性,它在作用于淀粉浆溶液时可将淀粉浆溶液的粘稠度迅速降低。目前,工业上大规模生产中淀粉液化采用的a-淀粉酶主要为诺维信和杰能科开发的高温a-淀粉酶,该酶来源于地衣芽孢杆菌(b.licheniformis),经过蛋白质工程的改造该酶在95℃时的半衰期已达到达250min,然而该酶的活性和稳定性依赖于钙离子的存在,钙离子的存在会严重抑制以淀粉糖为原料制备高果糖浆中关键酶葡萄糖异构酶的活性。另一方面,随着淀粉糖生产企业进一步降低生产成本的需求,高浓度液化工艺逐渐推出,淀粉乳初始浓度由原来的25-30重量%逐步提升到35重量%以上,淀粉乳初始浓度升高时,淀粉糊化后粘度的增加使得液化控制变得困难,并且对淀粉酶的特性提出了新的需求,在高浓度液化工艺下a-淀粉酶需要耐高温、最适催化温度范围宽泛、性能稳定和催化效率高等特性以实现快速降粘、提高仪器运转效率、保障淀粉液化质量。而目前国内为实现高浓度液化,基本都是在液化工艺上的进行改进,如cn104520333a中公开了一种连续液化高浓度淀粉的方法,即在采用两阶段液化及多种降解淀粉的酶的复配工艺,该工艺操作步骤多,酶制剂用量繁琐;cn104293863a中公开了一种促进高浓度淀粉液化的预处理方法,采用中温α-淀粉酶复配耐高温α-淀粉酶的方法,但该方法降粘效果有限,而且还增加了酶制剂的成本;cn104911234a提供了与cn104293863a类似的分步液化高浓度玉米淀粉的方法,以40-65重量%的高浓度玉米淀粉乳为反应底物,采用中温α-淀粉酶和耐高温α-淀粉酶复配分步液化,然而酶制剂的用量是cn104293863a方法的6-370倍,才能得到合适糖化的液化液;此外,cn201610726308.3中公开了一种高浓度淀粉连续喷射液化的方法,该方法采用浓度40~50%的淀粉乳,以喷射液化完成后的液化液按照15-35重量%回流至喷射泵进料口,以料代水对喷射瞬间高温后的糊化液进行降粘。而在淀粉酶制剂方面,主要集中在对现在已有的中温淀粉酶和高温淀粉酶的耐高温型和催化活性进行改造,或开发新的耐高温淀粉酶,如专利cn107312763a、cn107312764a、cn107326020a和cn107345223a均是以来源于地衣芽孢杆菌(b.licheniformis)的a-淀粉酶为模板进行不同位点及少数氨基酸的突变获得a-淀粉酶突变体,该突变体可在80-110℃,ph值5.0-5.8,条件下实行很好的淀粉液化,其实施例采用的干基质量分数为32重量%的淀粉乳对a-淀粉酶突变体进行应用效果评价,同时淀粉乳的最高浓度也只是尝试到了37重量%,未进行高浓度淀粉(>40重量%)液化效果的测试。因此,可见目前还没有针对高浓度淀粉液化这一特定工艺需求开发的专用酶制剂。技术实现要素:本发明针对目前现有的商业化的a-淀粉酶催化活性具有钙离子依赖性,以及高浓度淀粉液化工艺对a-淀粉酶在耐高温、最适催化温度范围宽、性能稳定、催化效率高和迅速降粘等功能上的需求,提供一种a-淀粉酶突变体,其在高浓度淀粉液化工艺下具有耐高温、最适催化温度范围宽、性能稳定、催化效率高和迅速降粘的特点,且不具有钙离子依赖性,从而能够满足现代淀粉糖生产企业进一步降低生产成本的需求,以克服现有产品的不足。为了实现上述目的,第一方面,本发明提供了一种a-淀粉酶突变体,所述a-淀粉酶突变体具有seqidno:2所示的氨基酸序列;或具有在seqidno:2所示的氨基酸序列的基础上经过取代、缺失或添加一个或几个氨基酸且酶活性不变的由seqidno:2衍生的氨基酸序列。第二方面,本发明提供了一种能够编码第一方面所述的a-淀粉酶突变体的基因。第三方面,本发明提供了一种含有第二方面所述的基因的重组表达载体。第四方面,本发明提供了一种含有第三方面所述的重组表达载体的重组菌株。第五方面,本发明提供了一种制备a-淀粉酶突变体的方法,该方法包括以下步骤:(1)培养第三方面所述的重组菌株,使编码a-淀粉酶突变体的基因表达;(2)分离提纯所表达的a-淀粉酶突变体。第六方面,本发明提供了一种用于高浓度淀粉液化的酶制剂,该酶制剂含有第一方面所述的a-淀粉酶突变体作为活性成分。第七方面,本发明提供了一种第一方面所述的a-淀粉酶突变体、第二方面所述的基因、第三方面所述的重组表达载体、第四方面所述的重组菌株以及第六方面所述的酶制剂在高浓度淀粉液化中的应用。本发明的人工合成a-淀粉酶突变体可在ph4.5-6.0、温度60-110℃和无钙离子液化体系下,对高浓度淀粉乳初始浓度进行高效稳定的水解,达到高浓度淀粉液化工艺迅速降粘的要求。同时,减少钙离子的添加更有利于实现产品的下游加工应用。本发明的其它特征和优点将在随后的具体实施方式部分予以详细说明。附图说明附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:图1为原核穿梭质粒pncmo2-amymu载体示意图。具体实施方式以下对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。在本文中所披露的范围的端点和任何值都不限于该精确的范围或值,这些范围或值应当理解为包含接近这些范围或值的值。对于数值范围来说,各个范围的端点值之间、各个范围的端点值和单独的点值之间,以及单独的点值之间可以彼此组合而得到一个或多个新的数值范围,这些数值范围应被视为在本文中具体公开。在本发明中,在未作相反说明的情况下,使用的术语“酶活力”的大小即酶用量的多少,用酶活力单位表示,即酶单位(u),本发明中酶单位的定义是:在ph5.5、70℃条件下,1分钟将1g可溶淀粉完全液化所需要的酶量为一个酶活力单位。本文中使用的术语“基因重排”是指本发明为了获得a-淀粉酶突变体而通过将来源不同的a-淀粉酶的编码序列进行dnasel酶切pcr变性复性实现基因间同源性错配重组,形成融合基因的一种酶分子体外定向进化技术。而本文中使用的术语“目标基因”是指为了将靶基因导入、表达和/或敲除而依据本领域已知的方法设计得到的基因。在本发明中,amymu为编码本发明a-淀粉酶突变体的基因,其核苷酸序列可如seqidno.:1所示,其氨基酸序列可如seqidno.:2所示;bsta为编码来源于bacillusstearothermophilus的a-淀粉酶的基因,其多核苷酸序列可如seqidno.:3所示,其氨基酸序列如seqidno.:4所示;bla为编码来源于bacilluslicheniformis的a-淀粉酶的基因,其多核苷酸序列可如seqidno.:5所示,其氨基酸序列如seqidno.:6所示;tsa为编码来源于thermococcussiculi的a-淀粉酶的基因,其多核苷酸序列可如seqidno.:7所示,其氨基酸序列如seqidno.:8所示;baa为编码来源于bacillusamyloliquefaciens的a-淀粉酶的基因,其多核苷酸序列可如seqidno.:9所示,其氨基酸序列如seqidno.:10所示。第一方面,本发明提供一种a-淀粉酶突变体,所述a-淀粉酶突变体具有seqidno:2所示的氨基酸序列;或具有在seqidno:2所示的氨基酸序列的基础上经过取代、缺失或添加一个或几个氨基酸且酶活性不变的由seqidno:2衍生的氨基酸序列。seqidno:2malnngtmmqyfewylpndgqhwkrlqndsaylaehgitavwippaykgtsqadvydpydffdlgeyyqkgtvetrfgtkelqdaigslhsrnvqvygdvvlnhkagadewnpfvgdytwtdfsgvasgkytanyldfhpnevkccdegtfgdypdiahekswdqhwlwasdesyaaylrsigvdawrfdyvkgygawvikdwldwwggwavgeywdtnvdallnwaynsnakvfdfplyykmdeafdnknipalvdalrygqtvvsrdpfkavtfvanhdtdiiwnkypayafiltresgypqvfygdmygtkgdsqreipalkhkiepilkarkeyaygpqhdyidhpdvigwtregdssaaksglaalitdgpggakrmyvgrqnagetwhditgnrsdtvtitsdgwgefhvndgsvsiyvqk*其中,酶活性不变是指在相同的测定条件下,具有由seqidno:2衍生的氨基酸序列的a-淀粉酶的酶活力与具有seqidno:2所示的氨基酸序列的a-淀粉酶突变体的酶活力之间的百分比(相对活性)不低于95%(或96%,或97%,或98%,或99%,或100%)。组成蛋白质的20种氨基酸残基,按照侧链极性可以分成四类:1、非极性的氨基酸:丙氨酸(ala)、缬氨酸(val)、亮氨酸(leu)、异亮氨酸(ile)、甲硫氨酸(met)、苯丙氨酸(phe)、色氨酸(trp)和脯氨酸(pro);2、极性不带电荷的氨基酸:甘氨酸(gly)、丝氨酸(ser)、苏氨酸(thr)、半胱氨酸(cys)、天冬氨酸(asn)、谷氨酰胺(gln)和酪氨酸(tyr);3、带正电荷的氨基酸:精氨酸(arg)、赖氨酸(lys)和组氨酸(his);4、带负电荷的氨基酸:天冬氨酸(asp)和谷氨酸(glu)(参见“生物化学”(第二版)上册,沈同、王镜岩,第82-83页,高等教育出版社,1990年12月)。蛋白质中如果发生同属一个类别的氨基酸残基取代,例如由arg取代lys或由leu取代ile,所述残基在蛋白质结构域中所起的作用(比如提供正电荷或形成疏水囊袋结构的作用)没有改变,因此对蛋白质的立体结构并不会产生影响,因此仍然可以实现蛋白的功能。所述同属一个类别的氨基酸残基取代可以发生在上述a-淀粉酶突变体的任意一个氨基酸残基位置上。如前所述,本发明提供的a-淀粉酶突变体还可以进行修饰或突变,得到衍生的蛋白质。本发明所述“衍生的蛋白质”指与具有上述氨基酸序列的a-淀粉酶突变体具有氨基酸序列上的差异,也可以有不影响序列的修饰形式上的差异,或者兼而有之。这些蛋白包括天然或诱导的遗传变异体。所述诱导变异体可以通过各种技术得到,如辐射或诱变剂等产生的随机突变,也可以通过如定点突变法或其他已知分子生物学的技术。所述“衍生的蛋白质”还包括具有天然l型氨基酸的残基的类似物(如d型氨基酸),以及具有非天然存在的或合成的氨基酸(如β-氨基酸、γ-氨基酸等)的类似物。修饰(通常不改变一级结构,即不改变氨基酸序列)形式包括:体内或体外的蛋白的化学衍生形式如乙酰化或羧基化。修饰还包括糖基化,如那些在蛋白的合成和加工中或进一步加工步骤中进行糖基化修饰而产生的蛋白。这种修饰可以通过将蛋白暴露于进行糖基化的酶(如哺乳动物的糖基化酶或去糖基化酶)而完成。修饰形式还包括具有磷酸化氨基酸残基(如磷酸酪氨酸,磷酸丝氨酸,磷酸苏氨酸)的序列。还包括被修饰从而提高了其抗蛋白水解性能或优化了溶解性能的蛋白。为了方便纯化,还可以采用本领域常见的标签对a-淀粉酶突变体的氨基酸序列进行添加修饰,举例来说,可以通过在a-淀粉酶突变体的氨基酸序列的氨基末端和/或羧基末端连接下表1所示的标签(如poly-arg、poly-his、flag、strep-tagⅱ和c-myc中的至少一种)而获得。所述标签不会影响本发明的a-淀粉酶突变体的活性,在实际应用过程中,可以根据需求选择是否添加标签。表1标签残基数氨基酸序列poly-arg5-6(通常为5个)rrrrr(seqidno:11)poly-his2-10(通常为6个)hhhhhh(seqidno:12)flag8dykddddk(seqidno:13)strep-tagⅱ8wshpqfek(seqidno:14)c-myc10eqkliseedl(seqidno:15)上述a-淀粉酶突变体可以通过人工合成得到,也可以先合成其编码基因,再通过生物表达获得。第二方面,本发明还提供了能够编码上述a-淀粉酶突变体的基因。本领域公知,组成蛋白质的20种不同的氨基酸中,除met(atg)或trp(tgg)分别为单一密码子编码外,其他18种氨基酸分别由2-6个密码子编码(sambrook等,分子克隆,冷泉港实验室出版社,纽约,美国,第二版,1989,见950页附录d)。即由于遗传密码子的简并性,决定一个氨基酸的密码子大多不止一个,三联体密码子中第三个核苷酸的置换,往往不会改变氨基酸的组成,因此编码相同蛋白的基因的核苷酸序列可以不同。本领域人员根据公知的密码子表,从本发明公开的氨基酸序列,以及由所述氨基酸序列得到的a-淀粉酶突变体活性不变的氨基酸序列,完全可以推导出能够编码它们的基因的核苷酸序列,通过生物学方法(如pcr方法、突变方法)或化学合成方法得到所述核苷酸序列,因此该部分核苷酸序列都应该包括在本发明范围内。相反,利用本文公开的dna序列,也可以通过本领域公知的方法,例如sambrook等的方法(分子克隆,冷泉港实验室出版社,纽约,美国,第二版,1989)进行,通过修改本发明提供的核酸序列,得到与本发明所述a-淀粉酶突变体活性一致的氨基酸序列。优选地,所述基因具有seqidno:1所示的核苷酸序列。seqidno:1atggctcttaacaacggcacaatgatgcaatacttcgaatggtaccttcctaacgatggccaacattggaaacgtcttcaaaacgattctgcttaccttgctgaacatggcatcacagctgtttggatccctcctgcttacaaaggcacatctcaagctgatgtttacgatccttacgatttcttcgatcttggcgaatactaccaaaaaggcacagttgaaacacgtttcggcacaaaagaacttcaagatgctatcggctctcttcattctcgtaacgttcaagtttacggcgatgttgttcttaaccataaagctggcgctgatgaatggaaccctttcgttggcgattacacatggacagatttctctggcgttgcttctggcaaatacacagctaactaccttgatttccatcctaacgaagttaaatgctgcgatgaaggcacattcggcgattaccctgatatcgctcatgaaaaatcttgggatcaacattggctttgggcttctgatgaatcttacgctgcttaccttcgttctatcggcgttgatgcttggcgtttcgattacgttaaaggctacggcgcttgggttatcaaagattggcttgattggtggggcggctgggctgttggcgaatactgggatacaaacgttgatgctcttcttaactgggcttacaactctaacgctaaagttttcgatttccctctttactacaaaatggatgaagctttcgataacaaaaacatccctgctcttgttgatgctcttcgttacggccaaacagttgtttctcgtgatcctttcaaagctgttacattcgttgctaaccatgatacagatatcatctggaacaaataccctgcttacgctttcatccttacacgtgaatctggctaccctcaagttttctacggcgatatgtacggcacaaaaggcgattctcaacgtgaaatccctgctcttaaacataaaatcgaacctatccttaaagctcgtaaagaatacgcttacggccctcaacatgattacatcgatcatcctgatgttatcggctggacacgtgaaggcgattcttctgctgctaaatctggccttgctgctcttatcacagatggccctggcggcgctaaacgtatgtacgttggccgtcaaaacgctggcgaaacatggcatgatatcacaggcaaccgttctgatacagttacaatcacatctgatggctggggcgaattccatgttaacgatggctctgtttctatctacgttcaaaaa如上所述,相应地,所述核苷酸序列的5'端和/或3'端还可以连接有上表1所示的标签的编码序列。本发明提供的核苷酸序列通常可以用聚合酶链式反应(pcr)扩增法、重组法、或人工合成的方法获得。例如,本领域技术人员根据本发明所提供的核苷酸序列,可以很容易得到模板和引物,利用pcr进行扩增获得有关序列。根据本发明一种优选的实施方式,本发明提供的核苷酸序列可以通过基因重排的技术获得,根据本发明一种优选的实施方式,获得bsta、bla、tsa和baa基因片段,并以此作为模板,分别pcr扩增获得bsta、bla、tsa和baa基因片段,通过琼脂糖凝胶电泳和胶回收试剂盒纯化bsta、bla、tsa和baa基因片段,进行dnaase酶切反应,酶切后通过琼脂糖凝胶电泳将50-100bp的dna小片段进行胶回收,随后采用基因重组反应体系和反应条件进行bsta、bla、tsa和baa基因的体外重排,获得本发明的核苷酸序列。一旦获得了有关核苷酸序列,就可以用重组法大批量的获得有关氨基酸序列。通常将所得核苷酸序列克隆入载体,再转入基因工程菌中,然后通过常规的方法从增殖后的宿主细胞分离得到有关核苷酸序列。此外,还可用公知的人工化学合成的方法来合成有关核苷酸序列。第三方面,本发明提供的重组表达载体含有本发明提供的基因。重组表达载体中使用的“载体”可选用本领域已知的各种载体,如市售的各种质粒、粘粒、噬菌体及反转录病毒等,本发明优选pncmo2-amymu质粒,其示意图如图1所示。重组表达载体构建可采用能够在载体多克隆位点具有切割位点的各种核酸内切酶进行酶切获得线性质粒,与采用相同核酸内切酶切割的基因片段连接,获得重组质粒。第四方面,本发明提供的重组菌株含有本发明提供的重组表达载体。可以通过本领域常规的方法将所述重组表达载体转化、转导或者转染到宿主细胞(菌株)中,如氯化钙法化学转化、高压电击转化,优选电击转化。所述宿主细胞可以为原核细胞或真核细胞,优选为原核细胞,进一步优选为杆状菌,如大肠杆菌(escherichiacoli)或枯草芽孢杆菌(bacillussubtilis)。第五方面,本发明提供一种制备a-淀粉酶突变体的方法,该方法包括以下步骤:(1)培养如上所述的重组菌株,使编码a-淀粉酶突变体的基因表达;(2)分离提纯所表达的a-淀粉酶突变体。所述培养条件为常规的培养条件,当所述重组菌种为重组芽孢杆菌时,可以使用含有新霉素的tm培养基,于200rpm、32℃条件下培养82h以发酵表达重组蛋白,然后超声破碎细胞,再经过纯化即可得到a-淀粉酶突变体,具体方法为本领域技术人员的常规技术手段,在此不再赘述。第六方面,本发明提供了一种用于高浓度淀粉液化的酶制剂,该酶制剂含有本发明提供的a-淀粉酶突变体作为活性成分。根据本发明,以所述酶制剂的总重量为基准,所述a-淀粉酶突变体的含量可以为10-90重量%。所述酶制剂中还可以含有本领域技术人员公知的溶剂(如甘油、糖类和蛋白酶抑制剂等蛋白保护剂)等。第七方面,本发明还提供了如上所述的a-淀粉酶突变体、如上所述的基因、如上所述的重组表达载体、如上所述的重组菌株以及如上所述的高浓度淀粉液化的酶制剂在高浓度淀粉液化中的应用。本发明中,使用所述a-淀粉酶突变体液化高浓度淀粉的方法可以包括:将高浓度淀粉浆液与所述a-淀粉酶突变体接触,并按照本领域常规的淀粉液化方法进行液化。其中,所述高浓度淀粉优选为固含量在36重量%以上的淀粉乳;更优选为固含量36-65重量%的淀粉乳,进一步更优选为固含量36-48重量%的淀粉乳。此处需要说明的是,本发明提供的a-淀粉酶突变体不仅适用固含量在36重量%以上的淀粉乳的液化,而是相比于现有的a-淀粉酶,本发明提供的a-淀粉酶突变体在对36重量%以上的淀粉乳液化时,具有更优的效果,但对于固含量在36重量%以上的淀粉乳液化时,其效果也由于现有的a-淀粉酶。以下将通过实施例对本发明进行详细描述。(1)实施例中所用的方法和设备下述实施例中所述实验方法和设备,如无特殊说明,均为常规方法(例如可利用下列著作中描述的标准程序来实施:sambrook等,molecularcloning:alaboratorymanual(第3版),coldspringharborlaboratorypress,coldspringharbor,n.y.,usa(2001);davis等,basicmethodsinmolecularbiology,elseviersciencepublishing,inc.,newyork,usa(1995);以及currentprotocolsincellbiology(cpcb)(juans.bonifacino等著,johnwileyandsons,inc.))和设备。下述实施例中所用的实验材料,如无特别说明,全部试剂购自oxoid公司。(2)实施例中所用的培养基、菌体和酶·lb固体培养基(lb平板):胰蛋白胨10g/l;酵母浸粉5g/l;琼脂15g/l;氯化钠20-100g/l;ph7.0;121℃灭菌15min。·soc培养基组份浓度:2%(w/v)tryptone;0.5%(w/v)yeastextract;0.05%(w/v)nacl;2.5mmkcl;10mmmgcl2;20mmglucose;121℃灭菌15min。·短小芽孢杆菌mt液体培养基:葡萄糖10g/l;牛肉浸粉5g/l;酵母粉2g/l;feso4.7h2o0.01g/l;mnso4.4h2o0.01g/l;znso4.7h2o0.01g/l;mgcl24g/l;121℃灭菌15min。(mt固体培养基则在mt液体的基础上添加琼脂15g/l)·突变体库筛选培养基(平板):胰蛋白胨10g/l;酵母浸粉5g/l;琼脂15g/l;2%可溶性淀粉;5mmedta;ph7.0,121℃灭菌15min。·短小芽孢杆菌种子培养基(sm液体):葡萄糖10g/l;酵母浸粉15g/l;feso4.7h2o0.01g/l;mnso4.4h2o0.01g/l;znso4.7h2o0.01g/l;121℃灭菌15min。·短小芽孢杆菌发酵培养基(tm液体):葡萄糖10g/l;牛肉浸粉5g/l;酵母粉2g/l;feso4.7h2o0.01g/l;mnso4.4h2o0.01g/l;znso4.7h2o0.01g/l;121℃灭菌15min。·大肠杆菌克隆与表达宿主细胞购自北京全式金生物技术有限公司;·电转化大肠杆菌trans109感受态购自北京全式金生物技术有限公司;·短小芽孢杆菌(brevibacilluschoshinensissp3)及表达质粒pncmo2以试剂盒形式购自takara;·双酶切试剂购自neb,常规试剂;·连接反应试剂购自neb,常规试剂。(3)序列·所用目标基因序列和引物均由金唯智公司合成;测序由上海生工生物工程有限公司完成。·使用的引物序列如表2所示:表2.引物序列引物名称序列(5’-3’)序列编号m13-rv-fgagcggataacaatttcacacaggseqidno.:16m13-47-rcgccagggttttcccagtcacgacseqidno.:17pnc-fcgcttgcaggattcggseqidno.:18pnc-dcaatgtaattgttccctacctgcseqidno.:19(4)反应体系和反应条件·双酶切反应体系和反应条件如下表3所示:表3.ncoi/hindiii双酶切反应体系和反应条件·连接反应体系和反应条件如下表4所示:表4.t4dna连接酶连接体系和反应条件·酶切反应体系和反应条件如下表5所示:表5dnaase酶切反应体系和条件·pcr反应体系和反应条件如下表6和表7所示:表6pcr反应条件表7pcr体系为15μl,各组分比例如下:dntp(10mm)1.0μl10×rtaqdna聚合酶buffer1.5μl上游引物(10μm)0.5μl下游引物(10μm)0.5μl菌落1μlrtaqdna聚合酶(5u/μl)0.5μlddh2o10.0μl·基因重组(dnashuffling)反应体系和反应条件如下表8和下表9所示:表8无引物pcr扩增表9接头引物pcr扩增(5)测定方法·淀粉乳粘度测定:取30g待测定的淀粉乳倒入rva粘度分析仪的样品罐中,设定程序如下:在60℃下保温1.5min,随后升温至95℃,升温所需时间为6min,在95℃下保温5.5min,随后降温至50℃,降温所需时间为2.5min,转速设定为250rpm,测量液化过程的粘度,取液化过程粘度曲线的最高峰值作为样品粘度评价指标,单位为cp。·淀粉酶活性检测及定义:淀粉酶酶活定义:在ph5.5、70℃条件下,1分钟将1g可溶淀粉完全液化所需要的酶量定义为1u。酶活测定:试管中配制10ml1重量%糊化淀粉溶液(1.0g可溶淀粉,加入25ml0.4mnaoh,60℃5min,冷却后加入25ml0.4mch3cooh,定容至100ml),70℃保温10min,加入1.0ml稀释后的酶液,70℃恒温水浴锅中加热10min,冷却后加入1ml1m盐酸终止反应,取1ml反应液加入预先装好10ml工作碘液(0.5gi2和5.0gki水中研磨,定容至1000ml)的试管,摇匀迅速在660nm波长下测定吸光值(od660),以不加酶液(加相同酶液体积的水)的相同反应液为对照记录其在660nm波长下测定吸光值(od0660),淀粉酶活性计算公式如下:酶活=[(od660-od0660)*100/od660*10]*酶的稀释倍数·样液de值的测定方法:(1)溶液配制(a)次甲基蓝指示液(10g/l):称取次甲基蓝1.0g,加水溶解并定容至100ml。(b)葡萄糖标准溶液(2g/l):称取100±2℃烘干至恒重的基准无水葡萄糖0.5000g(称准至0.0001g),加水溶解并定容至250ml。(c)费林溶液配制费林溶液i:称取硫酸铜(cuso4·5h2o)69.3g,加水溶解并定容至1000ml,贮于棕色瓶中;费林溶液ii:称取酒石酸钾钠(knac4h4o6·4h2o)346.0g和氢氧化钠100.0g,加水溶解并定容至1000ml,贮于橡胶塞玻璃瓶中。使用前若有沉淀,则吸取上层清夜使用;(2)标定:预滴定时,依次吸取费林溶液ii、费林溶液i各5.0ml于锥形瓶中,加水20ml,加入玻璃珠3粒,加入葡萄糖标准溶液24ml,摇匀锥形瓶中溶液,并将锥形瓶加热,控制溶液在120±15s内沸腾,并保持微沸,加入次甲基蓝指示液2滴,继续以葡萄糖标准溶液滴定,直至蓝色刚好消失为其终点,整个滴定操作应在3min内完成。正式滴定时,预加入比上述滴定消耗的葡萄糖标准溶液少1ml的葡萄糖标准溶液,做平行试验,记录消耗葡萄糖标准的总体积,取其算术平均值。根据式[1]计算费林溶液ii、i各5ml时消耗葡萄糖的质量:式中:rp:费林溶液ii、i各5ml时消耗葡萄糖的质量,g;m1:称取基准无水葡萄糖的量,g;v1:消耗葡萄糖标准溶液的总体积,ml。(3)测定样液中的de值(a)样液的制备称取一定量的样液,取样量以满足滴定为条件,每100ml样液中含有还原糖量125-200mg(称准至0.0001g)为宜,加热水溶解,并用水定容至250ml。(b)预滴定依次吸取费林溶液ii、费林溶液i各5.0ml于锥形瓶中,加水20ml,加入玻璃珠3粒,预加入部分样液,加热锥形瓶,控制溶液在120±15s内沸腾,并保持微沸,以每2秒1滴的速度滴加样液,至溶液蓝色即将消失时,加入次甲基蓝指示液2滴,再继续滴加样液直至蓝色刚好消失为其终点,记录消耗样液的总体积。(c)正式滴定依次吸取费林溶液ii、费林溶液i各5.0ml于锥形瓶内,加入比预滴定样液少1ml的样液于锥形瓶中,加热锥形瓶,控制溶液在120±15s内沸腾,并保持微沸状态,以每2秒1滴的速度滴加样液,至溶液蓝色即将消失时,加入次甲基蓝指示液2滴,再继续滴加样液直至蓝色刚好消失为其终点,整个滴定操作须在3min内完成,记录消耗样液的总体积,根据式[2]计算样液中的de值:式中:de值:样液中葡萄糖当量值,%;rp:费林溶液ii、i各5ml时消耗葡萄糖的质量,g;m2:取样量,g;v2:滴定时消耗样液的总体积,ml;dmc:样液中糖浆干物质(固形物)的含量,%。4、喷射液化方法:喷射口的温度为108℃维持在管内3-10分钟,蒸汽压力为0.6mpa,喷射液化后产物进行闪蒸,温度降至98℃,随后在95℃下保温2h,得到液化液。实施例1本实施例用于说明a-淀粉酶突变体库的建立委托金唯智公司进行基因合成基因bsta、bla、tsa和baa,其核苷酸序列分别如seqidno.:3、5、7、9所示,合成时各基因的5‘端插入ncoi酶切位点序列,3‘端插入hindiii酶切位点序列,合成后的序列均连接在puc57载体上。以以上序列作为模板,以m13-rv-f和m13-47-r为引物分别扩增获得bsta、bla、tsa和baa基因片段,通过1.2%琼脂糖凝胶电泳和胶回收试剂盒纯化bsta、bla、tsa和baa基因片段,进行dnaase酶切反应,酶切后通过2%琼脂糖凝胶电泳将50-100bp的dna小片段进行胶回收,随后采用基因重组反应体系和反应条件进行bsta、bla、tsa和baa基因的体外重排,以引物m13-rv-f和m13-47-r扩增重排后的基因,以2%琼脂糖凝胶电泳回收1500bp左右的基因重组片段,多次进行上述步骤获得10-20μg基因重组片段备用。上述获得的重组基因片段通过ncoi和hindiii双酶切后,以2%琼脂糖凝胶电泳回收酶切后的基因片段(需回收近5μg),连接至pncmo2穿梭载体上;参照t4dna连接酶连接体系和反应条件,分5批次且每批次并行进行10个体系的连接反应,获得750μl的连接产物;采用凝胶回收试剂盒对连接产物进行脱盐回收,回收产物采用100μl的ddh2o进行洗脱,获得约85μl脱盐连接产物。取5μl轻混入100μl的电转化感受态细胞trans109,进行电转化(电转条件:0.2cm电转化杯,200欧姆,25μfd,2.5千伏),电转化迅速加入900μl37℃预热好的soc培养基,按此方法将85μl脱盐连接产物全部转化完。将转化液置于37℃下培养1小时进行细胞复苏,复苏后每100μl左右涂布于含有100μg/ml氨苄青霉素的lb固体平板上,按此方法将转化液全部于lb固体平板上,将所有平板置于37℃下培养15小时;取出平板每个平板随机挑取10个转化子进行菌落pcr的鉴定(以pnc-f和pnc-d为上下游引物),其结果显示阳性转化子比率为80%左右。同时每个平板上加入1mllb液体培养基并用涂布棒将平板上的菌落洗脱下来,将所有平板上的菌落洗脱下来,采用质粒提取试剂盒提取洗脱下来菌液中的质粒,共提取获得质粒100μl(共计2μg)。参照takara短小芽孢杆菌试剂盒的操作说明,短小芽孢杆菌感受态细胞为试剂盒提供的,采用试剂盒提供的ntp转化的方法,每个感受态细胞转入5μl质粒(约100ng),共转化20支短小芽孢杆菌,将转化复苏后的转化液3000rpm、4℃条件下离心,收集菌体,将菌体涂布至含有10μg/ml新霉素的mt培养基中,37℃过夜培养并计算菌落数,建立a-淀粉酶突变体库。多次重复上述工作,以便结合后期筛选具有较大的a-淀粉酶突变体库才能获得目标突变体(本发明建立的突变体库库容为2×106)。实施例2本实施例用于说明a-淀粉酶突变体的筛选及异源表达将上述建立的a-淀粉酶突变体库(生长在mt培养基平板上的菌落),用qpix450挑克隆机器采用类似平板影印的方式,将mt培养基平板上的菌落转移到含有10μg/ml新霉素的突变体库筛选平板上,37℃过夜培养后放入4℃冰箱放置两天,取出后挑选具有明显水解透明圈的单菌落为第一轮筛选的无ca2+依赖型的a-淀粉酶突变体(共计获得456个)。将所有第一轮筛选获得的突变体接种到含有10μg/ml新霉素的sm培养基中(48孔深孔板培养),将接种好的培养基置于200rpm、32℃条件下培养12h作为种子液;吸取培养好的种子液,以5%的接种量接种至含有10μg/ml新霉素的tm培养基中(48孔深孔板培养),于200rpm、32℃条件下培养82h以发酵表达重组蛋白,培养后48孔深孔板在4000rpm、4℃条件下离心,收集发酵上清液即为突变体粗酶液。在48孔板中每孔加入200μl1%糊化淀粉溶液,70℃保温10min,加入20μl的突变体粗酶液(与培养孔板一一对应),制备平行孔板5个,分别置于90℃、95℃、100℃、105℃、110℃恒温水浴锅中加热10min,冷却后每孔加入20μl1m盐酸终止反应,取20μl反应液加入预先装好200μl工作碘液的48孔板中,摇匀迅速在660nm波长下测定吸光值(od660),以上工作采用贝克曼的移液工作站进行第二轮耐高温a-淀粉酶突变体的筛选,经过以上多次筛选共获得8个突变体100℃下具有较高活性,其中2个在105℃下仍具有相等活性,将其分别命名为amymu1和amymu2。将amymu1和amymu2a-淀粉酶突变体的重组短小芽孢杆菌单克隆接种至20ml含有10μg/ml新霉素的sm培养基中,将接种好的培养基至于200rpm、32℃条件下培养12h做为种子液;吸取培养好的种子液,以5%的接种量接种至300ml(1l摇瓶)含有10μg/ml新霉素的tm培养基中,于200rpm、32℃条件下培养82h以发酵表达重组蛋白,同时以不含抗生素的相同培养基及培养方法培养没有表达外源基因的短小芽孢杆菌为空白对照,培养结束后4000rpm、4℃条件下离心,收集发酵上清液作为粗酶液备用。实施例3本实施例用于说明a-淀粉酶突变体的酶学特性及稳定性(1)酶活力测试取上述粗酶液进行sds-page分析,突变体amymu1和amymu2分子量分别为52kd和47kd;对上述粗酶液进行酶活检测,突变体amymu1和amymu2酶活分别为52u/ml和60u/ml。(2)突变体催化反应最适ph检测分别将突变体amymu1和amymu2(每个反应酶量均为0.05u)与不同ph(3-7)配制的1%糊化淀粉进行反应,按照酶活测定方法检测,使用的不同ph(3-7)缓冲液为:0.1mol/l甘氨酸-盐酸缓冲液(ph3.0);0.1mol/l醋酸缓冲液(ph4.0—5.0);0.1mol/l磷酸钾缓冲液(ph6.0—7.0);每隔0.5ph值设定一个反应条件,以酶活最高的ph值点设定为相对活性为100%,其余酶活低于最高点的均按照该位点酶活除以最高点酶活乘以100%记为该ph值点的相对活性,结果见表10。表10:不同突变体最适催化反应ph由表10可见,突变体amymu1催化反应的有效ph值范围为5.0-7.0,最适ph值范围为5.5-6.5;突变体amymu2催化反应的有效ph值范围为4.5-7.0,最适ph值范围为5.0-6.0;突变体amymu2比amymu1更适合在酸性环境下的催化反应而且有效的ph值范围较宽泛。(3)突变体不同ph值下的稳定性检测将突变体amymu1和amymu2(每个反应酶量均为0.1u)与50mm的不同ph(4.5、5.0、5.5、6.0)缓冲液1:1混合,25℃放置,分别在不同时间间隔取样,按照酶活测定方法检测,以零时刻的酶活作为100%算出不同ph放置时间下的剩余酶活力,检测突变体amymu1和amymu2的酸碱稳定性,结果见表11。表11:突变体在不同ph值下的稳定性由表11可见,突变体amymu2在酸性环境下的稳定性明显强于amymu1,amymu2在ph4.5下放置3小时仍能有50%以上的催化活性,当然突变体amymu1和amymu2在越偏中性的环境其稳定性越好,说明本发明的a-淀粉酶突变体均具有很好的耐酸性。(4)突变体催化反应最适温度检测突变体amymu1和amymu2(每个反应酶量均为0.05u)与ph为6.0的1%糊化淀粉分别在不同温度(50-120℃)下反应,以酶活最高的温度设定为相对活性为100%,其余酶活低于最高点的均按照该位点酶活除以最高点酶活乘以100%记为该温度下的相对活性,结果见表12。表12:不同突变体最适催化反应温度温度℃5060708090100110120amymu152%64%80%91%100%81%45%23%amymu263%79%86%94%100%90%87%41%由表12可见,突变体amymu1和amymu2最适催化温度均为90℃左右,突变体amymu2催化反应的有效温度范围为60-110℃,突变体amymu1催化反应的有效温度范围为70-100℃;说明本发明的a-淀粉酶突变体属于高温酶,具有很好高温催化性能;其中突变体amymu2同时还兼具有非常宽泛的有效催化温度,当温度为50℃时仍具有63%的催化活性,而温度高达110℃时具有近90%的催化活性。(5)突变体不同温度下的稳定性检测首先将突变体amymu1和amymu2的粗酶液均调节为20u/ml,amymu1和amymu2各取1ml分别放于90℃、100℃、110℃水浴中保温180min,分别在不同时间间隔取样2.5μl,按照酶活测定方法检测,以零时刻的酶活作为100%算出不同温度放置时间下的剩余酶活力,检测突变体amymu1和amymu2的温度稳定性,结果见表13。表13:突变体在不同温度下的稳定性由表13可见,突变体amymu2在90℃保温180min仍具有50%以上的活性,在110℃保温40min具有60%以上的活性,表现出较好的高温耐受性,相比下突变体amymu1耐温性较差,90℃保温60min就不到50%的活性。根据上述对突变体amymu1和amymu2酶学特性及稳定性的分析,本发明最终确定突变体amymu2为本发明权利要求的a-淀粉酶突变体(seqidno:2),将其命名为amymu,本发明的a-淀粉酶突变体amymu催化反应的有效ph值范围为4.5-7.0,最适ph值范围为5.0-6.0,最适催化温度均为90℃左右,有效温度范围为60-110℃,有效催化温度范围非常宽,可同时实行中温淀粉酶和高温淀粉酶的催化功效,具有非常好的耐酸性和热稳定性。实施例4本实施例用于说明本发明提供的a-淀粉酶突变体(amymu)的应用(1)a-淀粉酶突变体amymu对不同浓度玉米淀粉乳的液化和降粘效果测试测试条件:以烘干玉米淀粉作为原料,在60℃的调浆罐中配制干基质量分数分别为36wt%、38wt%、40wt%、42wt%、44wt%、46wt%、48wt%、50wt%的淀粉乳,用8m盐酸将ph调节至5.5。向所述调浆罐中加入20u/g淀粉的a-淀粉酶突变体amymu粗酶液,混合后在60℃保温0.5h,然后反应体系升温进行喷射液化得到液化液,液化液进行de值和黏度检测,同时观察样品蛋白絮凝情况,结果见表14。表14:不同玉米淀粉浓度下amymu液化效果结果显示,a-淀粉酶突变体amymu可应用于不同浓度淀粉乳的液化工艺,有效液化浓度为36-48wt%;在淀粉乳浓度高达48wt%,本发明的a-淀粉酶突变体amymu仍能正常液化,并达到液化工艺的需求,同时蛋白质絮凝状态明显,漂浮在液化液上,高温时淀粉乳粘度降幅效果十分明显,降粘效果达到高浓度淀粉液化工艺条件,用101号150mm直径滤纸过滤,过滤速度为每4min滤出42ml;说明本发明的a-淀粉酶突变体amymu非常适合于高浓度淀粉液化工艺使用。(2)不同a-淀粉酶对高浓度淀粉液化效果测试测试条件:本发明a-淀粉酶突变体amymu、liquozymesupre(购自novozymes)、superliq3.0t(购自南京百斯杰),以烘干玉米淀粉作为原料,在60℃的调浆罐中配制干基质量分数分别为38wt%的淀粉乳,用8m盐酸将ph调节至5.5。向所述调浆罐中加入20u/g淀粉的不同a-淀粉酶,混合后在60℃保温0.5h,然后反应体系升温进行喷射液化得到液化液,液化液进行de值和黏度检测,同时观察样品蛋白絮凝情况,结果见表15。表15:不同a-淀粉酶对高浓度淀粉液化效果a-淀粉酶突变体amymuliquozymesupresuperliq3.0tde值(%)22.419.719.6黏度(cp)53421230712048结果可见,在相同的液化工艺条件下,本发明的a-淀粉酶突变体amymu与目前的商业淀粉酶液化效果相当,且蛋白絮凝状态均较好,说明本发明的a-淀粉酶突变体amymu可应用于淀粉糖行业的液化工艺段;另外,本发明的a-淀粉酶突变体amymu在该液化工艺条件下,其淀粉乳的降粘效果明显优于商业淀粉酶,说明本发明的a-淀粉酶突变体amymu更适合于在高浓度淀粉液化工艺中使用。(3)不同液化工艺对高浓度淀粉液化效果测试测试条件:(a)一步液化:以烘干玉米淀粉作为原料,在60℃的调浆罐中配制干基质量分数分别为44wt%的淀粉乳,用8m盐酸将ph调节至5.5;向所述调浆罐中加入20u/g淀粉的a-淀粉酶突变体amymu,混合后在60℃保温0.5h,然后反应体系升温进行喷射液化得到液化液,液化液进行de值和黏度检测,同时观察样品蛋白絮凝情况。(b)分步液化:以烘干玉米淀粉作为原料,在50℃的调浆罐中配制干基质量分数分别为32wt%的淀粉乳,用8m盐酸将ph调节至6.0;向所述调浆罐中加入20u/g淀粉的中温α-淀粉酶(购自购自南京百斯杰),混合后在55℃保温1h得到第一淀粉乳;向所述第一淀粉乳中搅拌加入玉米淀粉,得到干基质量分数为44wt%的第二淀粉乳,向所述调浆罐中加入20u/g淀粉的高温α-淀粉酶(superliq3.0t购自购自南京百斯杰),混合后在55℃保温0.5h以上,然后反应体系升温进行喷射液化得到液化液,液化液进行de值和黏度检测,同时观察样品蛋白絮凝情况。结果见表16。表16:不同液化工艺对高浓度淀粉液化效果液化工艺一步液化分步液化淀粉酶突变体amymu中温α-淀粉酶+superliq3.0tde值(%)19.420.3黏度(cp)71207031结果可见,在44wt%的高浓度淀粉液化中,仅采用本发明的a-淀粉酶突变体amymu一种酶的一步液化工艺就可以达到采用中温和高温淀粉酶的分步液化效果,而且蛋白质絮凝正常;说明本发明的a-淀粉酶突变体amymu不仅适合于高浓度淀粉液化工艺使用,同时可行使中温和高温淀粉酶的功效,在高浓液化中达到复合使用中温和高温淀粉酶的液化效果,一步高浓液化工艺还可实现工艺简单、降低生产成本、提高淀粉糖行业的工作效率。以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。sequencelisting<110>中粮集团有限公司吉林中粮生化有限公司<120>用于高浓度淀粉液化的a-淀粉酶突变体及其编码基因和它们的应用<130>快i56030cof<160>19<170>patentinversion3.3<210>1<211>1281<212>dna<213>a-淀粉酶突变体核苷酸序列<400>1atggctcttaacaacggcacaatgatgcaatacttcgaatggtaccttcctaacgatggc60caacattggaaacgtcttcaaaacgattctgcttaccttgctgaacatggcatcacagct120gtttggatccctcctgcttacaaaggcacatctcaagctgatgtttacgatccttacgat180ttcttcgatcttggcgaatactaccaaaaaggcacagttgaaacacgtttcggcacaaaa240gaacttcaagatgctatcggctctcttcattctcgtaacgttcaagtttacggcgatgtt300gttcttaaccataaagctggcgctgatgaatggaaccctttcgttggcgattacacatgg360acagatttctctggcgttgcttctggcaaatacacagctaactaccttgatttccatcct420aacgaagttaaatgctgcgatgaaggcacattcggcgattaccctgatatcgctcatgaa480aaatcttgggatcaacattggctttgggcttctgatgaatcttacgctgcttaccttcgt540tctatcggcgttgatgcttggcgtttcgattacgttaaaggctacggcgcttgggttatc600aaagattggcttgattggtggggcggctgggctgttggcgaatactgggatacaaacgtt660gatgctcttcttaactgggcttacaactctaacgctaaagttttcgatttccctctttac720tacaaaatggatgaagctttcgataacaaaaacatccctgctcttgttgatgctcttcgt780tacggccaaacagttgtttctcgtgatcctttcaaagctgttacattcgttgctaaccat840gatacagatatcatctggaacaaataccctgcttacgctttcatccttacacgtgaatct900ggctaccctcaagttttctacggcgatatgtacggcacaaaaggcgattctcaacgtgaa960atccctgctcttaaacataaaatcgaacctatccttaaagctcgtaaagaatacgcttac1020ggccctcaacatgattacatcgatcatcctgatgttatcggctggacacgtgaaggcgat1080tcttctgctgctaaatctggccttgctgctcttatcacagatggccctggcggcgctaaa1140cgtatgtacgttggccgtcaaaacgctggcgaaacatggcatgatatcacaggcaaccgt1200tctgatacagttacaatcacatctgatggctggggcgaattccatgttaacgatggctct1260gtttctatctacgttcaaaaa1281<210>2<211>427<212>prt<213>a-淀粉酶突变体氨基酸序列<400>2metalaleuasnasnglythrmetmetglntyrpheglutrptyrleu151015proasnaspglyglnhistrplysargleuglnasnaspseralatyr202530leualagluhisglyilethralavaltrpileproproalatyrlys354045glythrserglnalaaspvaltyraspprotyraspphepheaspleu505560glyglutyrtyrglnlysglythrvalgluthrargpheglythrlys65707580gluleuglnaspalaileglyserleuhisserargasnvalglnval859095tyrglyaspvalvalleuasnhislysalaglyalaaspglutrpasn100105110prophevalglyasptyrthrtrpthrasppheserglyvalalaser115120125glylystyrthralaasntyrleuaspphehisproasngluvallys130135140cyscysaspgluglythrpheglyasptyrproaspilealahisglu145150155160lyssertrpaspglnhistrpleutrpalaseraspglusertyrala165170175alatyrleuargserileglyvalaspalatrpargpheasptyrval180185190lysglytyrglyalatrpvalilelysasptrpleuasptrptrpgly195200205glytrpalavalglyglutyrtrpaspthrasnvalaspalaleuleu210215220asntrpalatyrasnserasnalalysvalpheasppheproleutyr225230235240tyrlysmetaspglualapheaspasnlysasnileproalaleuval245250255aspalaleuargtyrglyglnthrvalvalserargaspprophelys260265270alavalthrphevalalaasnhisaspthraspileiletrpasnlys275280285tyrproalatyralapheileleuthrarggluserglytyrprogln290295300valphetyrglyaspmettyrglythrlysglyaspserglnargglu305310315320ileproalaleulyshislysilegluproileleulysalaarglys325330335glutyralatyrglyproglnhisasptyrileasphisproaspval340345350ileglytrpthrarggluglyaspserseralaalalysserglyleu355360365alaalaleuilethraspglyproglyglyalalysargmettyrval370375380glyargglnasnalaglygluthrtrphisaspilethrglyasnarg385390395400seraspthrvalthrilethrseraspglytrpglygluphehisval405410415asnaspglyservalseriletyrvalglnlys420425<210>3<211>1581<212>dna<213>b.stearothermophilusa-淀粉酶核苷酸序列<400>3atgcttttctgccctacaggccaacctgctaaagctgctgctcctttcaacggcacaatg60atgcaatacttcgaatggtaccttcctgatgatggcacactttggacaaaagttgctaac120gaagctaacaacctttcttctcttggcatcacagctctttggcttcctcctgcttacaaa180ggcacatctcgttctgatgttggctacggcgtttacgatctttacgatcttggcgaattc240aaccaaaaaggcacagttcgtacaaaatacggcacaaaagctcaataccttcaagctatc300caagctgctcatgctgctggcatgcaagtttacgctgatgttgttttcgatcataaaggc360ggcgctgatggcacagaatgggttgatgctgttgaagttaacccttctgatcgtaaccaa420gaaatctctggcacataccaaatccaagcttggacaaaattcgatttccctggccgtggc480aacacatactcttctttcaaatggcgttggtaccatttcgatggcgttgattgggatgaa540tctcgtaaactttctcgtatctacaaattccgtggcatcggcaaagcttgggattgggaa600gttgatacagaaaacggcaactacgattaccttatgtacgctgatcttgatatggatcat660cctgaagttgttacagaacttaaaaactggggcaaatggtacgttaacacaacaaacatc720gatggcttccgtcttgatgctgttaaacatatcaaattctctttcttccctgattggctt780tcttacgttcgttctcaaacaggcaaacctcttttcacagttggcgaatactggtcttac840gatatcaacaaacttcataactacatcacaaaaacaaacggcacaatgtctcttttcgat900gctcctcttcataacaaattctacacagcttctaaatctggcggcgctttcgatatgcgt960acacttatgacaaacacacttatgaaagatcaacctacacttgctgttacattcgttgat1020aaccatgatacagaacctggccaagctcttcaatcttgggttgatccttggttcaaacct1080cttgcttacgctttcatccttacacgtcaagaaggctaccctggcgttttctacggcgat1140tactacggcatccctcaatacaacatcccttctcttaaatctaaaatcgatcctcttctt1200atcgctcgtcgtgattacgcttacggcacacaacatgattaccttgatcattctgatatc1260atcggctggacacgtgaaggcgttacagaaaaacctggctctggccttgctgctcttatc1320acagatggccctggcggctctaaatggatgtacgttggcaaacaacatgctggcaaagtt1380ttctacgatcttacaggcaaccgttctgatacagttacaatcacatctgatggctggggc1440gaattcaaagttaacggcggctctgtttctgtttgggttcctcgtaaaacaacagtttct1500acaatcacacgtcctatcacaacacgtccttggacaggcgaattcgttcgttggacagaa1560cctcgtcttgttgcttggcct1581<210>4<211>526<212>prt<213>b.stearothermophilusa-淀粉酶氨基酸序列<400>4leuphecysprothrglyglnproalalysalaalaalapropheasn151015glythrmetmetglntyrpheglutrptyrleuproaspaspglythr202530leutrpthrlysvalalaasnglualaasnasnleuserserleugly354045ilethralaleutrpleuproproalatyrlysglythrserargser505560aspvalglytyrglyvaltyraspleutyraspleuglyglupheasn65707580glnlysglythrvalargthrlystyrglythrlysalaglntyrleu859095glnalaileglnalaalahisalaalaglymetglnvaltyralaasp100105110valvalpheasphislysglyglyalaaspglythrglutrpvalasp115120125alavalgluvalasnproseraspargasnglngluileserglythr130135140tyrglnileglnalatrpthrlyspheasppheproglyargglyasn145150155160thrtyrserserphelystrpargtrptyrhispheaspglyvalasp165170175trpaspgluserarglysleuserargiletyrlyspheargglyile180185190glylysalatrpasptrpgluvalaspthrgluasnglyasntyrasp195200205tyrleumettyralaaspleuaspmetasphisprogluvalvalthr210215220gluleulysasntrpglylystrptyrvalasnthrthrasnileasp225230235240glypheargleuaspalavallyshisilelyspheserphephepro245250255asptrpleusertyrvalargserglnthrglylysproleuphethr260265270valglyglutyrtrpsertyraspileasnlysleuhisasntyrile275280285thrlysthrasnglythrmetserleupheaspalaproleuhisasn290295300lysphetyrthralaserlysserglyglyalapheaspmetargthr305310315320leumetthrasnthrleumetlysaspglnprothrleualavalthr325330335phevalaspasnhisaspthrgluproglyglnalaleuglnsertrp340345350valaspprotrpphelysproleualatyralapheileleuthrarg355360365glngluglytyrproglyvalphetyrglyasptyrtyrglyilepro370375380glntyrasnileproserleulysserlysileaspproleuleuile385390395400alaargargasptyralatyrglythrglnhisasptyrleuasphis405410415seraspileileglytrpthrarggluglyvalthrglulysprogly420425430serglyleualaalaleuilethraspglyproglyglyserlystrp435440445mettyrvalglylysglnhisalaglylysvalphetyraspleuthr450455460glyasnargseraspthrvalthrilethrseraspglytrpglyglu465470475480phelysvalasnglyglyservalservaltrpvalproarglysthr485490495thrvalserthrilethrargproilethrthrargprotrpthrgly500505510gluphevalargtrpthrgluproargleuvalalatrppro515520525<210>5<211>1452<212>dna<213>b.licheniformisa-淀粉酶核苷酸序列<400>5gctgctaaccttaacggcacacttatgcaatacttcgaatggtacatgcctaacgatggc60caacattggaaacgtcttcaaaacgattctgcttaccttgctgaacatggcatcacagct120gtttggatccctcctgcttacaaaggcacatctcaagctgatgttggctacggcgcttac180gatctttacgatcttggcgaattccatcaaaaaggcacagttcgtacaaaatacggcaca240aaaggcgaacttcaatctgctatcaaatctcttcattctcgtgatatcaacgtttacggc300gatgttgttatcaaccataaaggcggcgctgatgctacagaagatgttacagctgttgaa360gttgatcctgctgatcgtaaccgtgttatctctggcgaacatcttatcaaagcttggaca420catttccatttccctggccgtggctctacatactctgatttcaaatggcattggtaccat480ttcgatggcacagattgggatgaatctcgtaaacttaaccgtatctacaaattccaaggc540aaagcttgggattgggaagtttctaacgaaaacggcaactacgattaccttatgtacgct600gatatcgattacgatcatcctgatgttgctgctgaaatcaaacgttggggcacatggtac660gctaacgaacttcaacttgatggcttccgtcttgatgctgttaaacatatcaaattctct720ttccttcgtgattgggttaaccatgttcgtgaaaaaacaggcaaagaaatgttcacagtt780gctgaatactggcaaaacgatcttggcgctcttgaaaactaccttaacaaaacaaacttc840aaccattctgttttcgatgttcctcttcattaccaattccatgctgcttctacacaaggc900ggcggctacgatatgcgtaaacttcttaacggcacagttgtttctaaacatcctcttaaa960tctgttacattcgttgataaccatgatacacaacctggccaatctcttgaatctacagtt1020caaacatggttcaaacctcttgcttacgctttcatccttacacgtgaatctggctaccct1080caagttttctacggcgatatgtacggcacaaaaggcgattctcaacgtgaaatccctgct1140cttaaacataaaatcgaacctatccttaaagctcgtaaacaatacgcttacggcgctcaa1200catgattacttcgatcatcatgatatcgttggctggacacgtgaaggcgattcttctgtt1260gctaactctggccttgctgctcttatcacagatggccctggcggcgctaaacgtatgtac1320gttggccgtcaaaacgctggcgaaacatggcatgatatcacaggcaaccgttctgaacct1380gttgttatcaactctgaaggctggggcgaattccatgttaacggcggctctgtttctatc1440tacgttcaacgt1452<210>6<211>484<212>prt<213>b.licheniformisa-淀粉酶氨基酸序列<400>6alaalaasnleuasnglythrleumetglntyrpheglutrptyrmet151015proasnaspglyglnhistrplysargleuglnasnaspseralatyr202530leualagluhisglyilethralavaltrpileproproalatyrlys354045glythrserglnalaaspvalglytyrglyalatyraspleutyrasp505560leuglygluphehisglnlysglythrvalargthrlystyrglythr65707580lysglygluleuglnseralailelysserleuhisserargaspile859095asnvaltyrglyaspvalvalileasnhislysglyglyalaaspala100105110thrgluaspvalthralavalgluvalaspproalaaspargasnarg115120125valileserglygluhisleuilelysalatrpthrhisphehisphe130135140proglyargglyserthrtyrseraspphelystrphistrptyrhis145150155160pheaspglythrasptrpaspgluserarglysleuasnargiletyr165170175lyspheglnglylysalatrpasptrpgluvalserasngluasngly180185190asntyrasptyrleumettyralaaspileasptyrasphisproasp195200205valalaalagluilelysargtrpglythrtrptyralaasngluleu210215220glnleuaspglypheargleuaspalavallyshisilelyspheser225230235240pheleuargasptrpvalasnhisvalargglulysthrglylysglu245250255metphethrvalalaglutyrtrpglnasnaspleuglyalaleuglu260265270asntyrleuasnlysthrasnpheasnhisservalpheaspvalpro275280285leuhistyrglnphehisalaalaserthrglnglyglyglytyrasp290295300metarglysleuleuasnglythrvalvalserlyshisproleulys305310315320servalthrphevalaspasnhisaspthrglnproglyglnserleu325330335gluserthrvalglnthrtrpphelysproleualatyralapheile340345350leuthrarggluserglytyrproglnvalphetyrglyaspmettyr355360365glythrlysglyaspserglnarggluileproalaleulyshislys370375380ilegluproileleulysalaarglysglntyralatyrglyalagln385390395400hisasptyrpheasphishisaspilevalglytrpthrargglugly405410415aspserservalalaasnserglyleualaalaleuilethraspgly420425430proglyglyalalysargmettyrvalglyargglnasnalaglyglu435440445thrtrphisaspilethrglyasnargsergluprovalvalileasn450455460sergluglytrpglygluphehisvalasnglyglyservalserile465470475480tyrvalglnarg<210>7<211>1308<212>dna<213>thermococcussiculia-淀粉酶核苷酸序列<400>7atggctaaataccttgaacttgaagaaggcggcgttatcatgcaagctttctactgggat60gttcctggcggcggcatctggtgggatacaatccgttctaaaatccctgattggtacgat120gctggcatctctgctatctggatccctcctgcttctaaaggcatgtctggcggctactct180atgggctacgatccttacgatttcttcgatcttggcgaatactaccaaaaaggcacagtt240gaaacacgtttcggctctaaagaagaacttgttaacatgatcaacacagctcatgcttac300ggcatcaaagttatcgctgatatcgttatcaaccatcgtgctggcggcgatcgtgaatgg360aaccctttcgttggcgattacacatggacagatttctctggcgttgcttctggcaaatac420acagctaactaccttgatttccatcctaacgaagttaaatgctgcgatgaaggcacattc480ggcgattaccctgatatcgctcatgaaaaatcttgggatcaacattggctttgggcttct540gatgaatcttacgctgcttaccttcgttctatcggcgttgatgcttggcgtttcgattac600gttaaaggctacggcgcttgggttatcaaagattggcttgattggtggggcggctgggct660gttggcgaatactgggatacaaacgttgatgctcttcttaactgggcttacaactctaac720gctaaagttttcgatttccctctttactacaaaatggatgaagctttcgataacaaaaac780atccctgctcttgttgatgctcttcgttacggccaaacagttgtttctcgtgatcctttc840aaagctgttacattcgttgctaaccatgatacagatatcatctggaacaaataccctgct900tacgctttcatccttacatacgaaggccaacctgttatcttctaccgtgattacgaagaa960tggcttaacaaagatcgtcttaaaaaccttatctggatccatgatcatcttgctggcggc1020tctacatctatcgtttactacgattctgatgaacttatcttcgttcgtaacggctacggc1080gatcgtcctggccttatcacatacatcaaccttggctcttctaaagctggccgttgggtt1140tacgttcctaaattcgctggctcttgcatccatgaatacacaggcaaccttggcggctgg1200gttgataaatgggttgattctggcggctgggtttaccttgaagctcctgctcatgatcct1260gctaacggccaatacggctactctgtttggtcttactgcggcgttggc1308<210>8<211>435<212>prt<213>thermococcussiculia-淀粉酶氨基酸序列<400>8alalystyrleugluleuglugluglyglyvalilemetglnalaphe151015tyrtrpaspvalproglyglyglyiletrptrpaspthrileargser202530lysileproasptrptyraspalaglyileseralailetrpilepro354045proalaserlysglymetserglyglytyrsermetglytyrasppro505560tyraspphepheaspleuglyglutyrtyrglnlysglythrvalglu65707580thrargpheglyserlysglugluleuvalasnmetileasnthrala859095hisalatyrglyilelysvalilealaaspilevalileasnhisarg100105110alaglyglyaspargglutrpasnprophevalglyasptyrthrtrp115120125thrasppheserglyvalalaserglylystyrthralaasntyrleu130135140aspphehisproasngluvallyscyscysaspgluglythrphegly145150155160asptyrproaspilealahisglulyssertrpaspglnhistrpleu165170175trpalaseraspglusertyralaalatyrleuargserileglyval180185190aspalatrpargpheasptyrvallysglytyrglyalatrpvalile195200205lysasptrpleuasptrptrpglyglytrpalavalglyglutyrtrp210215220aspthrasnvalaspalaleuleuasntrpalatyrasnserasnala225230235240lysvalpheasppheproleutyrtyrlysmetaspglualapheasp245250255asnlysasnileproalaleuvalaspalaleuargtyrglyglnthr260265270valvalserargaspprophelysalavalthrphevalalaasnhis275280285aspthraspileiletrpasnlystyrproalatyralapheileleu290295300thrtyrgluglyglnprovalilephetyrargasptyrgluglutrp305310315320leuasnlysaspargleulysasnleuiletrpilehisasphisleu325330335alaglyglyserthrserilevaltyrtyraspseraspgluleuile340345350phevalargasnglytyrglyaspargproglyleuilethrtyrile355360365asnleuglyserserlysalaglyargtrpvaltyrvalprolysphe370375380alaglysercysilehisglutyrthrglyasnleuglyglytrpval385390395400asplystrpvalaspserglyglytrpvaltyrleuglualaproala405410415hisaspproalaasnglyglntyrglytyrservaltrpsertyrcys420425430glyvalgly435<210>9<211>1452<212>dna<213>b.amyloliquefaciensa-淀粉酶核苷酸序列<400>9atggttaacggcacacttatgcaatacttcgaatggtacacacctaacgatggccaacat60tggaaacgtcttcaaaacgatgctgaacatctttctgatatcggcatcacagctgtttgg120atccctcctgcttacaaaggcctttctcaatctgataacggctacggcccttacgatctt180tacgatcttggcgaattccaacaaaaaggcacagttcgtacaaaatacggcacaaaatct240gaacttcaagatgctatcggctctcttcattctcgtaacgttcaagtttacggcgatgtt300gttcttaaccataaagctggcgctgatgctacagaagatgttacagctgttgaagttaac360cctgctaaccgtaaccaagttacatctgaagaataccaaatcaaagcttggacagatttc420cgtttccctggccgtggcaacacatactctgatttcaaatggcattggtaccatttcgat480ggcgctgattgggatgaatctcgtaaaatctctcgtatcttcaaattccgtggcgaaggc540aaagcttgggattgggaagtttcttctgaaaacggcaactacgattaccttatgtacgct600gatgttgattacgatcatcctgatgttgttgctgaaacaaaaaaatggggcatctggtac660gctaacgaactttctcttgatggcttccgtatcgatgctgctaaacatatcaaattctct720ttccttcgtgattgggttcaagctgttcgtcaagctacaggcaaagaaatgttcacagtt780gctgaatactggcaaaacaacgctggcaaacttgaaaactaccttaacaaaacatctttc840aaccaatctgttttcgatgttcctcttcatttcaaccttcaagctgcttcttctcaaggc900ggcggctacgatatgcgtcgtcttcttgatggcacagttgtttctcgtcatcctgaaaaa960gctgttacattcgttgaaaaccatgatacacaacctggccaatctcttgaatctacagtt1020caaacatggttcaaacctcttgcttacgctttcatccttacacgtgaatctggctaccct1080caagttttctacggcgatatgtacggcacaaaaggcacatctcctaaagaaatcccttct1140cttaaagataacatcgaacctatccttaaagctcgtaaagaatacgcttacggccctcaa1200catgattacatcgatcatcctgatgttatcggctggacacgtgaaggcgattcttctgct1260gctaaatctggccttgctgctcttatcacagatggccctggcggctctaaacgtatgtac1320gctggccttaaaaacgctggcgaaacatggtacgatatcacaggcaaccgttctgataca1380gttaaaatcggctctgatggctggggcgaattccatgttaacgatggctctgtttctatc1440tacgttcaaaaa1452<210>10<211>483<212>prt<213>b.amyloliquefaciensa-淀粉酶氨基酸序列<400>10valasnglythrleumetglntyrpheglutrptyrthrproasnasp151015glyglnhistrplysargleuglnasnaspalagluhisleuserasp202530ileglyilethralavaltrpileproproalatyrlysglyleuser354045glnseraspasnglytyrglyprotyraspleutyraspleuglyglu505560pheglnglnlysglythrvalargthrlystyrglythrlysserglu65707580leuglnaspalaileglyserleuhisserargasnvalglnvaltyr859095glyaspvalvalleuasnhislysalaglyalaaspalathrgluasp100105110valthralavalgluvalasnproalaasnargasnglnvalthrser115120125gluglutyrglnilelysalatrpthrasppheargpheproglyarg130135140glyasnthrtyrseraspphelystrphistrptyrhispheaspgly145150155160alaasptrpaspgluserarglysileserargilephelysphearg165170175glygluglylysalatrpasptrpgluvalsersergluasnglyasn180185190tyrasptyrleumettyralaaspvalasptyrasphisproaspval195200205valalagluthrlyslystrpglyiletrptyralaasngluleuser210215220leuaspglypheargileaspalaalalyshisilelyspheserphe225230235240leuargasptrpvalglnalavalargglnalathrglylysglumet245250255phethrvalalaglutyrtrpglnasnasnalaglylysleugluasn260265270tyrleuasnlysthrserpheasnglnservalpheaspvalproleu275280285hispheasnleuglnalaalaserserglnglyglyglytyraspmet290295300argargleuleuaspglythrvalvalserarghisproglulysala305310315320valthrphevalgluasnhisaspthrglnproglyglnserleuglu325330335serthrvalglnthrtrpphelysproleualatyralapheileleu340345350thrarggluserglytyrproglnvalphetyrglyaspmettyrgly355360365thrlysglythrserprolysgluileproserleulysaspasnile370375380gluproileleulysalaarglysglutyralatyrglyproglnhis385390395400asptyrileasphisproaspvalileglytrpthrarggluglyasp405410415serseralaalalysserglyleualaalaleuilethraspglypro420425430glyglyserlysargmettyralaglyleulysasnalaglygluthr435440445trptyraspilethrglyasnargseraspthrvallysileglyser450455460aspglytrpglygluphehisvalasnaspglyservalseriletyr465470475480valglnlys<210>11<211>5<212>prt<213>poly-arg标签<400>11argargargargarg15<210>12<211>6<212>prt<213>poly-his标签<400>12hishishishishishis15<210>13<211>8<212>prt<213>flag标签<400>13asptyrlysaspaspaspasplys15<210>14<211>8<212>prt<213>strep-tagⅱ标签<400>14trpserhisproglnpheglulys15<210>15<211>10<212>prt<213>c-myc标签<400>15gluglnlysleuileserglugluaspleu1510<210>16<211>24<212>dna<213>m13-rv-f<400>16gagcggataacaatttcacacagg24<210>17<211>24<212>dna<213>m13-47-r<400>17cgccagggttttcccagtcacgac24<210>18<211>16<212>dna<213>pnc-f<400>18cgcttgcaggattcgg16<210>19<211>23<212>dna<213>pnc-d<400>19caatgtaattgttccctacctgc23当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1