靶向敲除TNFα基因的sgRNA和敲除TNFα基因的猪胚胎成纤维细胞系及其应用的制作方法
本发明涉及基因工程技术领域,尤其涉及靶向敲除tnfα基因的sgrna和敲除tnfα基因的猪胚胎成纤维细胞系及其应用。
背景技术:
crispr-cas系统是在大多数古生菌和多数细菌中存在的一种用于抵抗外源病毒或dna入侵的获得性免疫系统。ii型rispr-cas9系统是目前改造最成功、应用最广泛的,主要是通过一段短的rna序列与dna靶点序列按照碱基互补原则形成双链后,结合cas9蛋白在dna靶位点诱导形成双链断裂损伤,损伤修复时可以在基因组靶位点引入特殊的基因突变。crispr-cas9系统具有设计简单,打靶效率高及能在靶位点形成多种突变的优点,目前已广泛应用于基因功能及转基因动物等的研究中。
肿瘤坏死因子tnfα(tumornecrosisfactoralpha)是一种促炎细胞因子,能参与正常炎症反应和免疫反应。近年的研究发现tnfα还能通过作用于生长激素/胰岛素样生长因子轴,来抑制机体生长和导致肌肉蛋白降解,可能在肌肉发育方面起负调控作用。目前对tnfα基因的研究大部分是利用抑制剂发掘其在人和小鼠中的作用,对猪源tnfα功能研究鲜有报道,而且药物阻断的特异性和有效性的很难保障,不能很好的解释基因功能,也存在一定的安全风险。
目前现有技术的抑制剂、沉默、敲低、干扰等方法特异性不强、沉默不彻底或者无法沉默tnfα基因表达,因此有必要研制一种能实现沉默彻底且能长期稳定体外培养的猪tnfα基因缺失细胞株,期望通过tnfα基因缺失成纤维细胞株制备转基因猪,为免疫和炎症反应的研究提供疾病模型,同时为深入挖掘tnfα基因在猪肌肉发育方面的调控作用研究提供基础。
技术实现要素:
为了至少解决现有技术存在的一种问题,本发明提供一种靶向敲除tnfα基因的sgrna和敲除tnfα基因的猪胚胎成纤维细胞系及其应用。
第一方面,本发明提供一种靶向敲除tnfα基因的sgrna,所述sgrna靶点序列如seqidno:1所示。
本发明进一步提供编码所述sgrna的dna分子。
本发明进一步提供含有所述sgrna的生物材料,所述生物材料为载体、表达盒或转基因细胞中的一种或多种。
例如,可以将所述sgrna通过酶切连接至载体px330上,具体方法为:
在tnfα基因的第一外显子上的靶点序列(seqidno:1)的5'端加上bbsi的酶切位点caccg,构成序列seqidno:2,并人工合成其互补序列seqidno:3,将互补序列seqidno:2和seqidno:3退火所形成的双链dna分子,与经过bbsi酶切的px330载体连接,从而构建表达载体px330-tnfα。
第二方面,本发明提供一种敲除了tnfα基因的细胞系的构建方法,包括:
利用crispr-cas9系统敲除所述细胞系的tnfα基因,所述crispr-cas9系统使用的sgrna靶点序列包括如seqidno:1所示的序列。
进一步地,所述利用crispr-cas9系统敲除所述细胞系的tnfα基因中使用px330载体。
进一步地,所述细胞系为猪胚胎成纤维细胞系。
作为一种优选的实施方式,本发明提供一种猪胚胎成纤维细胞系的构建方法,包括:
s1、培养猪胚胎成纤维细胞至70~90%汇合度时,将含有表达载体px330-tnfα的混合液转染进猪胚胎成纤维细胞中并培养;
s2、待细胞数目长满后提取细胞基因组dna并进行pcr鉴定;
s3、将pcr产物测序,测序结果与野生型参考序列比对,确定突变体;
进一步地,所述步骤s2中pcr鉴定所用的上游引物、下游引物分别如seqidno:5和seqidno:6所示。
本发明进一步提供所述构建方法构建得到的猪胚胎成纤维细胞系在建立免疫和炎症反应的疾病研究模型中的应用。
本发明进一步提供所述猪胚胎成纤维细胞系在在转基因猪制备中的应用。
本发明具备如下有益效果:
1、本发明首次得到tnfα基因敲除的猪胚胎成纤维细胞系,利用crispr-cas9系统从猪胚胎成纤维细胞中敲除tnfα基因,有效改进了抑制剂、沉默、敲低、干扰等方法特异性不强、沉默不彻底或者无法沉默基因表达的缺点,敲除效果更加彻底,适用于对tnfα缺失的猪胚胎成纤维细胞进行更加深入的研究,填补国内外相关技术的空白,具有较大的应用研究价值。
2、本发明通过向猪胚胎成纤维细胞转染px330-tnfα载体达到tnfα基因敲除的目的,可提高基因敲除效率和特异性。crispr-cas9基因编辑技术可在不引入任何外源基因的情况下进行基因修饰,获得的6个不同编辑类型的基因敲除细胞系可作为体细胞核移植的供体,给转基因猪的制备提供更多的可能性,为免疫和炎症反应的研究提供疾病模型,同时为深入挖掘tnfα基因在猪肌肉发育发面的调控作用研究提供基础。
附图说明
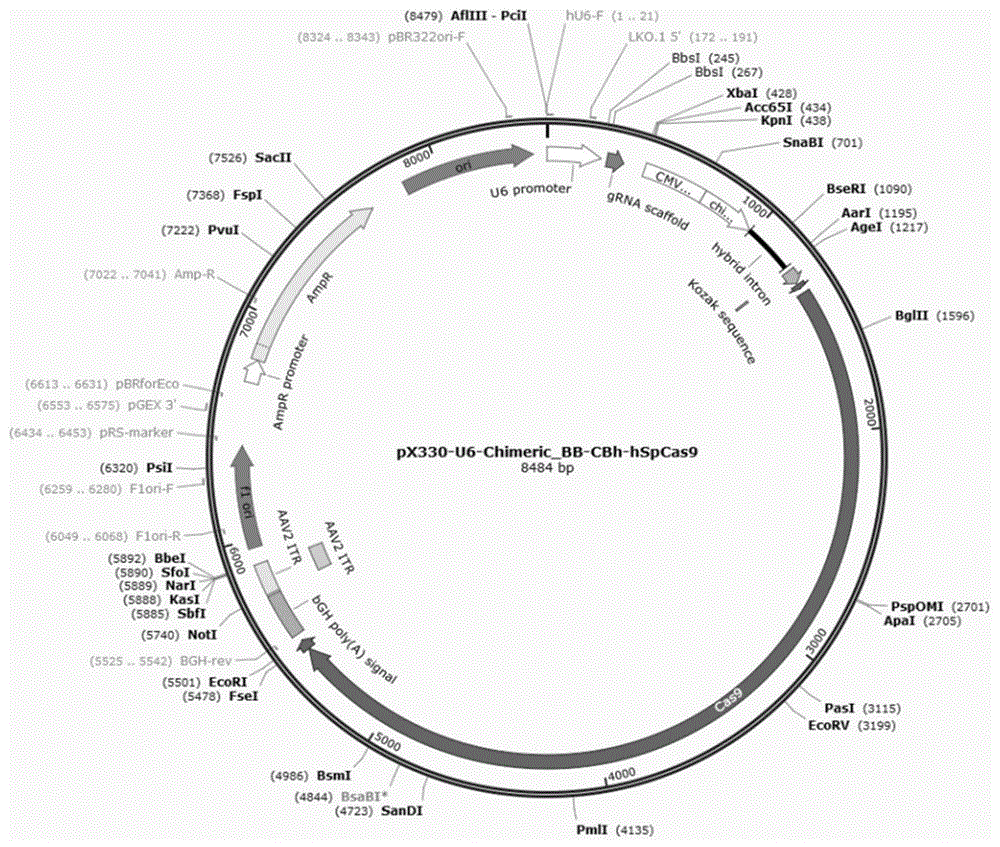
图1为本发明实施例1提供的px330载体骨架图;
图2为本发明实施例1提供的px330-tnfα重组载体测序序列比对结果;
图3为本发明实施例1提供的电转前的猪胚胎成纤维细胞;
图4为本发明实施例1提供的重组表达载体靶向切割效率检测,箭头标注的为切割位点;
图5为本发明实施例2提供的突变型细胞clone9-1的碱基序列及对应氨基酸序列的比对分析;其中碱基序列比对中框出的为靶点序列,氨基酸序列比对中星号为终止密码子;
图6为本发明实施例2提供的突变型细胞clone9-2c3的碱基序列及对应氨基酸序列的比对分析;其中碱基序列比对中框出的为靶点序列,氨基酸序列比对中星号为终止密码子;
图7为本发明实施例2提供的突变型细胞clone9-1c3的碱基序列及对应氨基酸序列的比对分析;其中碱基序列比对中框出的为靶点序列,氨基酸序列比对中星号为终止密码子;
图8为本发明实施例2提供的突变型细胞clone9-2d1的碱基序列及对应氨基酸序列的比对分析;其中碱基序列比对中框出的为靶点序列,氨基酸序列比对中星号为终止密码子;
图9为本发明实施例2提供的突变型细胞clone9-e8的碱基序列及对应氨基酸序列的比对分析;其中碱基序列比对中框出的为靶点序列,氨基酸序列比对中星号为终止密码子;
图10为本发明实施例2提供的突变型细胞clone9-f8的碱基序列及对应氨基酸序列的比对分析;其中碱基序列比对中框出的为靶点序列,氨基酸序列比对中星号为终止密码子。
具体实施方式
实施例1靶向tnfα基因的crispr-cas9打靶载体的构建及检测
1、tnfα基因sgrna的序列设计
从ncbi网站下载猪tnfα基因序列(登录号nc_010449.5),利用网站http://crispr.mit.edu/在该基因的第一外显子上设计敲除靶位点,共设计了10个靶点,根据pcr测序峰图筛选出套峰最高的sgrna即为编辑效率高的sgrna,最终优选出的sgrna靶点序列为:gcgctcgccaagaaggccg(如seqidno:1所示),根据bbsi限制性内切酶在sgrna的两端设计酶切位点,在sgrna的5'端加上caccg构成oligo1,序列如seqidno:2所示;反向互补序列的5'端加上aaac,3'端加上c构成oligo2,序列如seqidno:3所示,最后将设计好的序列送至生物公司合成。
2、px330质粒表达载体的构建
(1)px330载体骨架如图1所示。按照表1配制酶切体系,配制完成以后将体系置于37℃的水浴锅中酶切4~5h。酶切结束后进行1%琼脂糖凝胶电泳,根据tiangen胶回收试剂盒回收纯化含粘性末端的酶切产物。
表1-px330酶切体系试剂配制表
(2)按照表2的实际用量配制oligo退火体系,置于pcr仪中。设置pcr仪程序,首先37℃孵育30min使oligo的5'端磷酸化,然后95℃变性5min,最后以5℃/min的速度降温至25℃,即可得到退火产物双链dna分子。
表2-oligo退火体系
(3)取1μl退火产物,加入199μlddh2o,稀释混匀。
(4)配置退火产物与酶切后px330质粒的连接体系,按照表3配置连接体系,于16℃连接过夜。
表3-连接体系
(5)将重组载体转化进dh5α大肠杆菌感受态细胞中,混匀后冰浴30min,然后42℃热激转化90s,再冰浴2min,加入37℃温育好的无菌lb培养基(1%胰蛋白胨、0.5%酵母提取物、1%氯化钠)950μl,在37℃,180rpm/min的条件下震荡培养1h,取100μl菌液均匀涂布在氨苄青霉素抗性固体lb培养基(含100μg/ml的氨苄青霉素)上,37℃培养箱过夜倒置培养12~16h。
(6)测序:取单菌落,在1ml含100μg/ml氨苄青霉素的液体lb培养基中培养,150rpm摇菌至浑浊,菌液送往测序公司,测序使用u6启动子的正向引物,其序列为:5'-gagggcctatttcccatgattcc-3'(如seqidno:4所示)。
(7)保菌:测序结果如图2所示,将连接正确的菌落挑选出来,命名为px330-tnfα,扩大培养,然后加入20%的硝酸甘油,在-80℃冰箱中保存。
3、打靶效率检测
待六孔板中猪胚胎成纤维细胞生长至70%~90%的汇合度时(如图3所示),进行电穿孔转染,转染体系为150μl电击液和6μg表达载体px330-tnfα,电转程序为a024。转染后的细胞培养48h后,收集细胞提取基因组,进行pcr扩增,将得到的474bp产物送公司测序,以检测打靶效率。pcr鉴定所用的上游引物、下游引物分别如seqidno:5和seqidno:6所示。pcr扩增使用20ul反应体系:10μl2×powertaqpcrmastermix,8μlddh2o,上下游引物各0.5μl,dna模板1μl;pcr反应条件:94℃预变性5min;30个循环:94℃变性30s,60℃退火30s,72℃延伸30s;最后72℃终延伸5min。
测序结果如图4所示,px330-tnfα质粒能在猪胚胎成纤维细胞基因组的靶位点附近发生切割,具有较高活性,可用于后续实验。
实施例2tnfα基因敲除猪胚胎成纤维细胞系的构建及基因组鉴定
1、阳性单克隆细胞的筛选
(1)待猪胚胎成纤维细胞生长至70%~90%的汇合度时,配制含有150μl电击液、6μg表达载体px330-tnfα和3μgg418抗性质粒的混合液,使用a024程序进行电转。
(2)转染6h后换成含10%胎牛血清生长培养基,24h后消化分盘,将6孔板中的细胞传代至10~20个10cm培养皿中,添加600μg/ml的g418进行筛选,每4~5天换液一次,大概换2次即可得到单克隆细胞团。
(3)挑选形态规则且状态良好的单克隆细胞,用克隆环转移至48孔板中继续培养。
(4)待细胞数目足够多后,转至24孔板培养,再长满后,一部分细胞继续传代至12孔板长满后冻存,另一部分细胞提取基因组dna。
2、阳性单克隆细胞的鉴定
(1)以细胞提取基因组dna为模板进行pcr。pcr鉴定所用的上游引物、下游引物分别如seqidno:5和seqidno:6所示。pcr扩增使用20ul反应体系:10μl2×powertaqpcrmastermix,8μlddh2o,上下游引物各0.5μl,dna模板1μl;pcr反应条件:94℃预变性5min;30个循环:94℃变性30s,60℃退火30s,72℃延伸30s;最后72℃终延伸5min。
(2)将474bp的pcr产物测序,测序结果与野生型pcr参考序列(如seqidno:7所示)比对,确定有6个单克隆在第一外显子上的靶位点附近发生了非三倍数的碱基indel,导致阅读框移码突变,或出现提前终止密码子的突变,则可判断为tnfα基因敲除,具体突变序列鉴定分析如图5-图10所示,其中突变型clone9-1:缺失2bp;clone9-2c3:替换6bp,插入2bp;clone9-1c3:缺失5bp;clone9-2d1:缺失8bp;clone9-e8:缺失26bp;clone9-f8:插入1bp。
综上所述,本发明首次得到tnfα基因敲除的猪胚胎成纤维细胞系,利用crispr-cas9系统从猪胚胎成纤维细胞中敲除tnfα基因,有效改进了抑制剂、沉默、敲低、干扰等方法特异性不强、沉默不彻底或者无法沉默基因表达的缺点,敲除效果更加彻底,适用于对tnfα缺失的猪胚胎成纤维细胞进行更加深入的研究,填补国内外相关技术的空白,具有较大的应用研究价值。
本发明通过向猪胚胎成纤维细胞转染px330-tnfα载体达到tnfα基因敲除的目的,可提高基因敲除效率和特异性。crispr-cas9基因编辑技术可在不引入任何外源基因的情况下进行基因修饰,获得的6个不同编辑类型的基因敲除细胞系可作为体细胞核移植的供体,为转基因猪的制备提供更多的可能性,其后代不含任何外源dna,可以为免疫和炎症反应的研究提供疾病模型,同时为深入挖掘tnfα基因在猪肌肉发育发面的调控作用研究提供基础。
虽然,上文中已经用一般性说明及具体实施方案对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
序列表
<110>中国农业大学
<120>靶向敲除tnfα基因的sgrna和敲除tnfα基因的猪胚胎成纤维细胞系及其应用
<130>khp201113831.0
<160>7
<170>siposequencelisting1.0
<210>1
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>1
gcgctcgccaagaaggccg19
<210>2
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>2
caccggcgctcgccaagaaggccg24
<210>3
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>3
aaaccggccttcttggcgagcgcc24
<210>4
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>4
gagggcctatttcccatgattcc23
<210>5
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>5
tcagaagacacacccccgaa20
<210>6
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>6
tccttctctctctcccccca20
<210>7
<211>474
<212>dna
<213>人工序列(artificialsequence)
<400>7
tcagaagacacacccccgaacaggcagccggacgactctctccctctcacacgctgcccc60
ggggcgccaccatctcccagctggacctgagcccctctgaaaaagacaccatgagcactg120
agagcatgatccgagacgtggagctggcggaggaggcgctcgccaagaaggccgggggcc180
cccagggctccaggaggtgcctgtgcctcagcctcttctccttcctcctggtcgcaggag240
ccaccacgctcttctgcctactgcacttcgaggttatcggcccccagaaggaagaggtga300
gcgcctggccagccttggctcattctcccacccggagagaaatggggaagaaagagggcc360
agagacgagctgggggaaagaagtgtgctgatggggagtgtggggaggaaatcatggaga420
aagatggggaggcagaaggagacgtggagagagatggggggagagagagaagga474
- 还没有人留言评论。精彩留言会获得点赞!