一种高辨识力的原油指纹谱构建及鉴别方法与流程
本发明涉及一种基于显微共焦拉曼光谱的高辨识力、低维指纹谱的构建以及鉴别方法,具体涉及一种新型的原油指纹谱构建方法,以及基于此指纹谱的溢油鉴别方法。
背景技术:
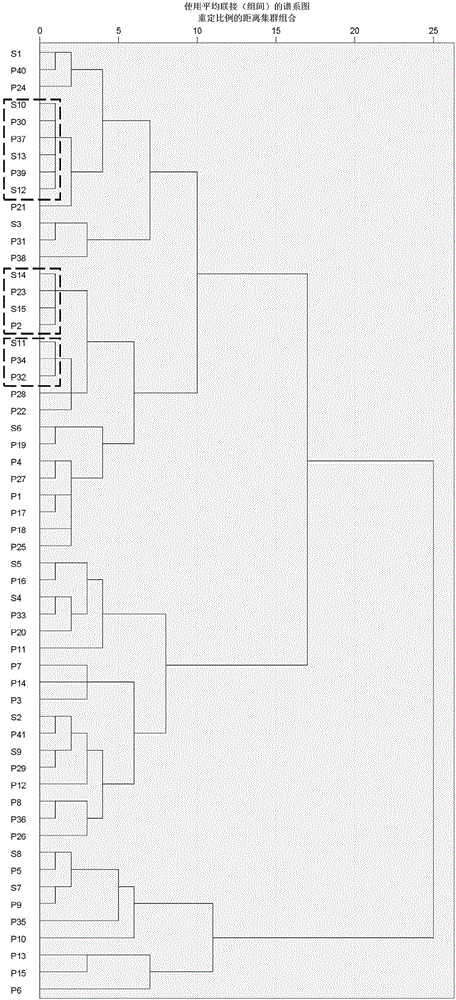
:在远洋石油运输及海洋油气开发中,溢油事故时有发生。根据溢油样与可疑溢油源的物理、化学指纹信息进行溯源鉴别,可为事故的责任认定和法律裁决提供可靠的科学依据,也是及时采取有效控制对策的重要前提。欧洲标准委员会(CEN)、美国材料与试验协会(ASTM)以及国际海事组织(IMO)已发布溢油鉴别标准和文件。在多年现场执法以及参考国外技术基础上,国家海洋局于1997年发布了《海面溢油鉴别系统规范》的行业标准(HY043-1997),将气相色谱法、红外光谱法和荧光光谱法作为溢油鉴别的三种基本方法。2007年,国家质量监督检验检疫总局和国家标准化管理委员会发布了《海面溢油鉴别系统规范》的国家推荐标准(GB/T21247-2007),提出逐级方式的溢油鉴别原则:“首先,进行可疑溢油源样品的筛选,将荧光光谱法或红外光谱法作为可选方法,先于气相色谱法进行初步筛选,排除掉明显不一致的可疑溢油样品;然后进行气相色谱和气相色谱/质谱分析,必要时辅以单分子烃稳定碳同位素分析,进行最终判别。所有样品在相同分析仪器、相同分析条件下进行。”对于海面溢油鉴别,不同的研究方法各有优势和不足。气相色谱/质谱法可分析溢油中的轻质组分,不适用于检测难挥发或热稳定性差的高沸点组分;荧光光谱的信号强度较高,但谱线的细节不够丰富;红外光谱可探测溢油中的有机官能团信息,但水会对其产生严重干扰;稳定同位素质谱可通过同位素丰度比来探究溢油的差异,但操作复杂且购置及运行成本较高。原油成分复杂且在自然环境中不易降解,对环境及生态安全造成严重威胁和破坏,海面溢油的流动性还可能导致越境污染。有关原油的鉴别是溢油鉴别研究中的难点和热点。为确保溢油鉴别的准确度和说服力,将多种方法联合使用以获取更丰富的油样信息是国际上普遍采用的策略。研发简便快捷且高准确度的原油鉴别新方法,与现行的《海面溢油鉴别系统规范》相互支持和补充,可显著提高鉴别效率和说服力,而且具有重要的现实意义。拉曼光谱具有测试简便快捷、样品用量小、无需预处理、样品无损伤、不受海水干扰等特点,在油样鉴别领域具有广泛的应用前景。使用拉曼光谱测定油样时,荧光跃迁和拉曼跃迁会同时被激发。通常,荧光信号强度较大,谱峰相对平滑;拉曼信号相对较弱,细节信息较为丰富。检测器采集的原始信号为光滑荧光信号与拉曼细节的叠加谱。原油组分复杂,不同组分的拉曼峰重叠严重,导致原本相互分离的谱峰变成连续的谱带。传统拉曼研究采用拟合方法进行荧光背底扣除,难免将原油样品的拉曼信号一并扣除,数据真实性会大打折扣。CN201310347484.2将同时包含荧光与拉曼信号的原始拉曼谱作为原油光谱指纹进行盲样鉴别。在指纹采集中不进行任何荧光背底扣除处理,将提取的光谱指纹数据转化为多维空间矢量,使用系统聚类分析对五种原油盲样的鉴别准确率为100%。这种方法避免了传统拉曼研究在扣除荧光背底时可能导致的不确定性,具有样品信息丰富的特点。需要指出的是,在提取的原始拉曼谱中有较大量的数据,并不能反映不同种类样品之间的差异,但对应的信号强度较大。CN201310347484.2未对光谱指纹中各数据变量的有效程度进行甄别,而是将采集的所有光谱数据全部用于盲样鉴别,使得不能体现样品差异的“低效”数据也参与系统聚类分析。这些“低效”数据不仅无助于提高鉴别辨识度,还会对有效数据造成干扰。当嫌疑油样种类较少或油样之间差异较大时,采用CN201310347484.2的方法进行溢油鉴别是可行的,且具有数据分析简便快捷的特点。然而,当嫌疑油样种类较多或相似度较高时,这种方法的辨识力尚显不足,针对不同油样之间的指纹差异也不够直观和明显。技术实现要素:针对现有方法的不足,提出一种新型的原油指纹构建、表征及鉴别方法。将样品的光谱特征差异“浓缩”为3-5个变量,构建出新型的特征指纹谱,使得油样差异的表征更为直观明显,指纹比对更为简单便捷,而且对于油样的指纹辨识度更强。本发明所述的新型指纹谱构建及鉴别方法可为现行的《海面溢油鉴别系统规范》提供有力的技术支撑,显著提高溢油鉴别的效率、准确度和说服力。本发明所述的指纹谱构建及鉴别方法在艺术品、文物、珠宝、刑侦物证的无损鉴定,道地药材、海产品的产地鉴别、医学诊断等领域也有广泛的应用前景。本发明所述的具有高辨识力的原油指纹谱构建及鉴别方法,其包括以下步骤:(1)对标样和待鉴别的盲样分别采集平行样品(每种不少于4个),使用可见光作为激发光源的拉曼光谱仪,在相同的条件下采集包含荧光及拉曼信息的特征光谱数据。本领域技术人员可知,在样品采集时,对已知种类的标样和待鉴别的盲样分别采集越多的平行样品,则更能验证结果的准确性,本发明实施例中选择10个以上的平行样品进行试验,准确性更高。(2)基于全部标样数据,采用逐步判别法对不同波数处的强度变量作为优选变量组,剔除对判别不重要的变量,仅保留判别能力强的变量进行筛选;基于优选变量组对应的强度数据,依据“同类离差最小,类间离差最大”的原则构建出典则判别函数组。求算出各典则判别函数对方差的贡献率。(3)根据(4)和/或(5)的鉴别结果,得出盲样鉴别结论,其中:(4)基于典则判别函数组,将优选出变量组所对应的强度数据投影至新的低维空间,使得不同类油样的之间特征差异“浓缩”至低维度。将每种标样及盲样的所有平行样品在新的低维空间中投影坐标的均值,作为该种样品的重心坐标。通过对低维空间中标样及盲样重心坐标的系统聚类分析,进行盲样鉴别;(5)基于累积方差贡献率最显著的前三维、前四维、前五维的重心坐标,分别绘制出柱状堆栈图,作为各标样及盲样在三、四、五维空间的“浓缩”指纹谱。通过直接比对盲样与标样的“浓缩”指纹谱,进行盲样鉴别。为了便于利用鉴别人员的直观洞察力,即为了可视化,将其降到合理的低维度;本发明实施例显示,基于方差贡献最显著的三、四、五维空间的“浓缩”指纹谱,应可满足绝大多数的鉴别要求。显然,也可绘制更高维数的指纹谱进行鉴别,但在鉴别实践中的必要性可能不大。对于上文步骤(3)而言,优选的情况下,本领域技术人员可以根据(4)和/或(5)的鉴别结果的一致性,得出准确率高、说服力强的鉴别结论。最优选的情况下,还可以参考Fisher判别法所得出的结论,三种方法相互印证,其鉴别结论的准确度更高且说服力更强,其中:所述的Fisher判别法是对每种盲样的所有平行样品逐一地进行鉴别。对于上文所述的技术方案,优选的情况下,所述采集荧光及拉曼信息的条件为:激发光波长为532、514.5、488、457.9或632.8nm,滤光片设置为0.1%,孔径及狭缝分别为500μm和200μm,物镜10×,检测范围为50-6000cm-1或200-6000cm-1,测定样品的拉曼位移-强度谱,所有光谱数据均不进行任何荧光背景扣除处理。对所有光谱数据进行标准化处理,使得所有谱图的强度最大值相同,最小值也相同。然后,基于标准化后的数据进行鉴别分析。对于上文所述的技术方案,优选的情况下,采用逐步判别法剔除对判别不重要的变量时,使用的判别方法为Wilk’slambda,未解释方差,马哈拉诺比斯距离,最小F值或Rao’sV。最优选为Wilk’slambda法。对于上文所述的技术方案,优选的情况下,采用逐步判别法剔除对判别不重要的变量时,判别标准为统计量F的值。当F大于F进入时,保留该变量;当F值小于F删除时,剔除该变量。其中,F进入大于F删除,F进入为5.84-1.84,F删除为4.72-0.72。优选的F上限和F下限分别为3.84,2.71。有关Wilk’slambda以及统计量F值的计算说明如下:为总离差平方和;为组间离差平方和;为组内离差平方和;Wilk’slambda=SSE/SST;MSA=SSA/(m-1),为平均组间离差平方和;MSE=SSA/(n-m),为平均组内离差平方和;F=MSA/MSE;其中,n为总样本量,m为控制变量的水平数,Xik为第i个水平下第k个样本值,ni为控制变量第i个水平的样本量,为第i个水平下的均值,为观测量均值。对于上文所述的技术方案,优选的情况下,采用最近邻元素法,以幂次为4的闵可夫斯基距离(q=4)或切比雪夫距离为判据,对低维空间中标样及盲样的重心坐标进行系统聚类分析。其中,优选判据为切比雪夫距离。有关闵可夫斯基距离及切比雪夫距离的定义说明如下:设第i个样品的重心为P维空间的点Yi,其坐标为(Yi1,Yi2,Yi3,…,Yip)(i=1,2,3,…,n),则第i个样品的重心Yi与第j个样品的重心Yj之间闵可夫斯基距离定义为:dij(q)=[Σk=1p|Yik-Yjk|q]1/q]]>其中i,j=1,2,3,…n;q为正整数。闵可夫斯基距离的幂次(q)为正无穷时,dij(∞)=max1≤k≤p|Yik-Yjk|,为切比雪夫距离。对于上文所述的技术方案,优选的情况下,优选出的强度变量所对应的波数,按照重要性程度,取前200个排序,本发明实施例中优选出的强度变量对应的波数组如表2所示。有益效果1.采用逐步判别法,从荧光及拉曼信号均显著的特征光谱数据中,剔除对油样鉴别不重要的数据,仅保留判别能力强的优选变量组,使得样品辨识度更高。2.采用典则判别函数使判别能力强的优选变量组投影至低维空间,将油样的主要特征差异“浓缩”至累积方差贡献率最为显著的3-5个维度变量,进一步突出了不同油样之间的特征差异。3.将累积方差贡献率最为显著的前三、前四、前五维空间的重心坐标作为指纹数据,绘制成柱状堆栈图,更为直观地反映出不同油样之间的指纹特征差异,使得指纹比对更为简单便捷,提高了盲样鉴别效率。4.当嫌疑油样种类较多(40余种)或原始谱相似时,基于新型指纹的谱图比对、聚类分析、Fisher判别的盲样鉴别准确率均为100%,三种方法相互印证,准确度高且说服力强。附图说明图1.采集的41种原油标样的原始光谱图。图2.采用幂次为4的闵可夫斯基距离对原始光谱数据系统聚类分析的树状图。图3.采用切比雪夫距离对原始光谱数据系统聚类分析的树状图。图4.采用幂次为4的闵可夫斯基距离对低维数据(F上限=3.84,F下限=2.71)系统聚类分析的树状图。图5.采用切比雪夫距离对低维数据(F上限=3.84,F下限=2.71)系统聚类分析的树状图。图6.基于前三个低维重心坐标绘制的标样及盲样的柱形堆栈指纹谱(F上限=3.84,F下限=2.71)。图7.基于前四个低维重心坐标绘制的标样及盲样的柱形堆栈指纹谱(F上限=3.84,F下限=2.71)。图8.基于前五个低维重心坐标绘制的标样及盲样的柱形堆栈指纹谱(F上限=3.84,F下限=2.71)。图9.采用幂次为4的闵可夫斯基距离对低维数据(F上限=1.84,F下限=0.71)系统聚类分析的树状图。图10.采用切比雪夫距离对低维数据(F上限=1.84,F下限=0.71)系统聚类分析的树状图。图11.基于前五个低维重心坐标绘制的标样及盲样的柱形堆栈指纹谱(F上限=1.84,F下限=0.71)。图12.采用幂次为4的闵可夫斯基距离对低维数据(F上限=5.84,F下限=4.71)系统聚类分析的树状图。图13.采用切比雪夫距离对低维数据(F上限=5.84,F下限=4.71)系统聚类分析的树状图。图14.基于前五个低维重心坐标绘制的标样及盲样的柱形堆栈指纹谱(F上限=5.84,F下限=4.71)。具体实施方式下述非限制性实施例可以使本领域的普通技术人员更全面地理解本发明,但不以任何方式限制本发明。实施例1本实施例使用41种原油标样,分别来自中国石化北京石油化工科学研究院、中国石化抚顺石油化工研究院,中国石油大学(北京)重质油实验室。从中随机选取15种原油作为盲样。每种标样各采集20个平行样品,每种盲样各采集10个平行样品。标样及盲样的编号分别以字母P和S开头,如表1。表1.不同种类的原油标样(41种)以及盲样(15种)产地及编号说明采用HoribaJYXploRA显微共焦拉曼光谱仪采集每个油样的光谱指纹。检测范围为50-6000cm-1,滤光片设置为0.1%,孔径及狭缝分别为500μm和200μm,光栅为1200T,物镜10×,CCD检测器温度为-51℃,曝光时间1s,每个谱图累加30次。所有样品采用相同的测试条件,光谱数据不进行任何荧光背景扣除处理。对每个光谱数据进行标准化处理,将最大值设为10000,最小值设为0。然后,采用将标准化后的数据进行以下鉴别分析。将每种标样及盲样的平行样品数据各自求均值,作为该样品的均值谱。图1为采集的41种原油标样的均值谱,同时包含样品的荧光及拉曼特征。每个谱线均由2915个横坐标不同的点组成。可以看出,有些谱图相似度较高,发生部分重叠。当油样种类较多时,通过谱图直接比对进行盲样鉴别的难度较大。拉曼光谱是由一系列横、纵坐标分别为波数和强度的点所组成的。在相同条件下,采集的拉曼谱是由相同个数的点组成的,而且不同拉曼谱中这些点的横坐标也一一对应。本发明所述的方法中,组成每个原始拉曼谱的点的个数均为2915。因此,每个拉曼谱可转化为一个2915维空间中的矢量。其中,拉曼光谱中每一点的横坐标(波数)对应2915维空间中的一个维度,每个点的纵坐标(强度)分别对应于该矢量在相应维度中的投影坐标。图2为采用SPSS软件,使用最近邻元素法,以幂次为4的闵可夫斯基距离为判据对原始均值谱数据进行系统聚类分析的树状图。如图2中的虚线框所示,S10,S13,S12三个盲样与P30,P37,P39三个标样聚为一类,未能区分;S14,P23,S15,P2聚为一类,未能区分;S11,P34,P32聚为一类,未能区分。其余10种盲样各自与相对应的标样聚为一类,得到了准确鉴别。图3为采用最近邻元素法,以切比雪夫距离为判据对原始均值谱数据进行系统聚类分析的树状图。如图中虚线框所示,S13,S12与P39聚为一类,未能区分;S11,P34,P32聚为一类,未能区分。其余12种盲样得到了准确鉴别。图2及图3表明,采用切比雪夫距离为判据的辨识力优于幂次为4的闵可夫斯基距离,但这两种聚类分析中均有部分盲样未能得到有效辨识。这是由于未对光谱指纹中各数据变量的有效程度进行甄别,而是将采集的所有光谱数据全部用于盲样鉴别,使得不能体现样品差异的数据也参与系统聚类分析,对鉴别造成干扰,导致对一些样品的辨识力不足。针对以上问题,采用SPSS软件,使用逐步判别法从原始光谱数据剔除对判别不重要的强度变量。使用的判别方法为Wilk’slambda法,判别标准为统计量F的值。表2是优选出的前200个变量所对应的波数(保留两位小数),按照重要性程度依次排序。表2.采用逐步判别法优选出的前200个强度变量对应的波数组当F值大于F上限=3.84时,保留该变量;当F值小于F下限=2.71时,剔除该变量。通过此步骤,原始谱的2915维数据中有2832维数据被剔除,仅保留73维判别能力强的变量。这些被保留的变量对应于表2中序号为1至73的波数组。然后,依据“同类离差最小,类间离差最大”原则,建立典则判别函数组。将相应的标样及盲样数据分别代入判别函数组,使其分别投影至新的低维(40维)空间。图4为采用最近邻元素法,以幂次为4的闵可夫斯基距离为判据对投影至低维空间中的标样及盲样重心坐标进行系统聚类分析的树状图。图中,15种盲样分别与相应的标样聚为一类,表明全部得到准确鉴别。图5为采用最近邻元素法,以切比雪夫距离为判据对投影至低维空间中的标样及盲样重心坐标进行系统聚类分析的树状图。图中,15种盲样分别与相应的标样聚为一类,表明全部得到准确鉴别。图4及图5表明,通过剔除光谱数据中不重要的变量,并投影至低维空间后,系统聚类分析对盲样的辨识力显著提高。表3给出了各判别函数对方差的贡献率。可以看出,对方差的贡献最显著的前三,前四,前五个判别函数的累计方差贡献率为90.741,95.973,97.555%,表明使用前三维、前四维、前五维的坐标已可较全面地反映不同种类样品之间的特征差异。表3.不同典则判别函数对方差贡献率(F上限=3.84,F下限=2.71)将每种标样的所有平行样品在新的低维空间中的坐标均值,作为该种标样的重心坐标。类似地,将每种盲样的所有平行样品在新的低维空间中的坐标均值,作为该种盲样的重心坐标。将方差贡献最显著的前三维、前四维、前五维重心坐标,绘制成柱状堆栈图,作为各标样在三、四、五维空间的指纹谱。图6是基于每种标样和盲样前三维重心坐标,绘制成的柱状堆栈图。图7是基于每种标样和盲样前四维重心坐标,绘制成的柱状堆栈图。图8是基于每种标样和盲样前五维重心坐标,绘制成的柱状堆栈图。在图6,7,8中,41种原油标样之间的特征差别均非常明显,根据盲样和标样的指纹谱的直接比对,很容易实现15种盲样的准确鉴别。采用Fisher判别法对15种盲样中的所有平行样品数据,逐一进行判别分析。结果显示,共计150个盲样的指纹鉴别全部正确。综上,基于新型指纹的谱图比对、系统聚类分析、Fisher判别的盲样鉴别准确率均为100%。实施例2采用SPSS软件,使用逐步判别法从原始光谱数据剔除对判别不重要的强度变量。使用的判别方法为Wilk’slambda法,判别标准为统计量F的值。当F值大于F上限=1.84时,保留该变量;当F值小于F下限=0.71时,剔除该变量。通过此步骤,原始谱的2915维变量中有2558维被剔除,保留357维判别能力强的变量。然后,依据“同类离差最小,类间离差最大”原则,建立典则判别函数组。将相应的标样及盲样数据分别代入判别函数组,使其分别投影至新的低维(40维)空间。图9是采用最近邻元素法,以幂次为4的闵可夫斯基距离为判据对投影至低维空间中的标样及盲样重心坐标进行系统聚类分析的树状图。15种盲样分别与相应的标样聚为一类,表明全部得到准确鉴别。图10是采用最近邻元素法,以切比雪夫距离为判据对投影至低维空间中的标样及盲样重心坐标进行系统聚类分析的树状图。15种盲样分别与相应的标样聚为一类,表明全部得到准确鉴别。表4给出了不同典则判别函数的方差贡献率(F上限=1.84,F下限=0.71)。可以看出,对方差的贡献最显著的前三,前四,前五个判别函数的累计方差贡献率为88.024,94.719,96.457%,表明使用前三维、前四维、前五维的坐标可较全面地反映不同种类样品之间的特征差异。表4.不同典则判别函数对方差贡献率(F上限=1.84,F下限=0.71)将每种标样的所有平行样品在新的低维空间中的坐标均值,作为该种标样的重心坐标。类似地,将每种盲样的所有平行样品在新的低维空间中的坐标均值,作为该种盲样的重心坐标。图11是基于每种标样和盲样前五维重心坐标,绘制成的柱状堆栈图。图中,41种原油标样之间的特征差别均非常明显,根据盲样和标样的指纹谱的直接比对,很容易实现15种盲样的准确鉴别。采用Fisher判别法对15种盲样中的所有平行样品数据,逐一进行判别分析。结果显示,150个盲样的指纹鉴别全部正确。综上,基于新型指纹的谱图比对、系统聚类分析、Fisher判别的盲样鉴别准确率均为100%。实施例3采用SPSS软件,使用逐步判别法从原始光谱数据剔除对判别不重要的强度变量。使用的判别方法为Wilk’slambda法,判别标准为统计量F的值。当F值大于F上限=5.84时,保留该变量;当F值小于F下限=4.71时,剔除该变量。通过此步骤,原始谱的2915维变量中有2870维被剔除,保留45维判别能力强的变量。这些被保留的变量对应于表2中序号为1至45的波数组。然后,依据“同类离差最小,类间离差最大”原则,建立典则判别函数组。将相应的标样及盲样数据分别代入判别函数组,使其分别投影至新的低维(40维)空间。图12是采用最近邻元素法,以幂次为4的闵可夫斯基距离为判据对投影至低维空间中的标样及盲样重心坐标进行系统聚类分析的树状图。15种盲样分别与相应的标样聚为一类,表明全部得到准确鉴别。图13是采用最近邻元素法,以切比雪夫距离为判据对投影至低维空间中的标样及盲样重心坐标进行系统聚类分析的树状图。15种盲样分别与相应的标样聚为一类,表明全部得到准确鉴别。表5给出了不同典则判别函数的方差贡献率(F上限=5.84,F下限=4.71)。可以看出,对方差的贡献最显著的前三,前四,前五个判别函数的累计方差贡献率为90.653,96.251,97.779%,表明使用前三维、前四维、前五维的坐标已可较全面地反映不同种类样品之间的特征差异。表5.不同典则判别函数对方差贡献率(F上限=5.84,F下限=4.71)典则判别函数方差百分比累积方差%典则判别函数方差百分比累积方差%174.57674.576210.00499.98429.35383.928220.00399.98736.72590.653230.00399.99045.59896.251240.00299.99251.52897.779250.00299.99360.86998.648260.00199.99570.34598.993270.00199.99680.27199.264280.00199.99790.18099.445290.00199.998100.15099.594300.00199.998110.14899.742310.00099.999120.07299.814320.00099.999130.06299.875330.00099.999140.03099.905340.000100.000150.02199.926350.000100.000160.01899.944360.000100.000170.01299.956370.000100.000180.01299.968380.000100.000190.00899.976390.000100.000200.00499.981400.000100.000将每种标样的所有平行样品在新的低维空间中的坐标均值,作为该种标样的重心坐标。类似地,将每种盲样的所有平行样品在新的低维空间中的坐标均值,作为该种盲样的重心坐标。图14是基于每种标样和盲样前五维重心坐标,绘制成的柱状堆栈图。图中,41种原油标样之间的特征差别均非常明显,根据盲样和标样的指纹谱的直接比对,很容易实现15种盲样的准确鉴别。综上,基于新型指纹的谱图比对、系统聚类分析、Fisher判别的盲样鉴别准确率均为100%。以上实施例表明,通过剔除原始光谱指纹中不重要变量以及典则判别函数投影变换,本发明构建的新型指纹谱对不同油样差别的表征比原始光谱指纹更为明显和直观,而且对油品的辨识力显著增强,盲样鉴别更为便捷且准确度非常高。本发明所述的新型指纹谱构建及鉴别方法可与现行的《海面溢油鉴别系统规范》提供有力的技术支撑,显著提高溢油鉴别的效率、准确度和说服力。本发明所述的新型指纹谱构建及鉴别方法在艺术品、文物、珠宝、刑侦物证的无损鉴定,道地药材、海产品的产地鉴别、医学疾病诊断等领域也有广泛的应用前景。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1